
Abstract
Colorectal cancer (CRC) is a leading cause of cancer-related death worldwide, and has a strong heritable basis. We report a genome-wide association analysis of 34,627 CRC cases and 71,379 controls of European ancestry that identifies SNPs at 31 new CRC risk loci. We also identify eight independent risk SNPs at the new and previously reported European CRC loci, and a further nine CRC SNPs at loci previously only identified in Asian populations. We use in situ promoter capture Hi-C (CHi-C), gene expression, and in silico annotation methods to identify likely target genes of CRC SNPs. Whilst these new SNP associations implicate target genes that are enriched for known CRC pathways such as Wnt and BMP, they also highlight novel pathways with no prior links to colorectal tumourigenesis. These findings provide further insight into CRC susceptibility and enhance the prospects of applying genetic risk scores to personalised screening and prevention.
Similar content being viewed by others

Introduction
Many colorectal cancers (CRC) develop in genetically susceptible individuals1 and genome-wide association studies (GWAS) of CRC have thus far reported 43 SNPs mapping to 40 risk loci in European populations2,3. In Asians, 18 SNPs mapping to 16 risk loci have been identified4,5, a number of which overlap with those reported in Europeans. Collectively across ethnicities GWAS has provided evidence for 53 unique CRC susceptibility loci. While much of the heritable risk of CRC remains unexplained, statistical modelling indicates that further common risk variants remain to be discovered6.
To gain a more comprehensive insight into CRC aetiology, we conducted a GWAS meta-analysis that includes additional, unreported datasets. We examine the possible gene regulatory mechanisms underlying all GWAS risk loci by analysing in situ promoter Capture Hi-C (CHi-C) to characterise chromatin interactions between predisposition loci and target genes, examine gene expression data and integrate these data with chromatin immunoprecipitation-sequencing (ChIP-seq) data. Finally, we quantify the contribution of the loci identified in this study, together with previously identified loci to the heritable risk of CRC and estimate the sample sizes required to explain the remaining heritability.
Results
Association analysis
Thus far, studies have identified 61 SNPs that are associated with CRC risk in European and Asian populations (Supplementary Data 1). To identify additional CRC risk loci, we conducted five new CRC GWAS, followed by a meta-analysis with 10 published GWAS totalling 34,627 cases and 71,379 controls of European ancestry under the auspices of the COGENT (COlorectal cancer GENeTics) consortium7 (Fig. 1, Supplementary Data 2). Following established quality control measures for each dataset8 (Supplementary Data 3), the genotypes of over 10 million SNPs in each study were imputed, primarily using 1000 Genomes and UK10K data as reference (see Methods). After filtering out SNPs with a minor allele frequency <0.5% and imputation quality score <0.8, we assessed associations between CRC status and SNP genotype in each study using logistic regression. Risk estimates were combined through an inverse-variance weighted fixed-effects meta-analysis. We found little evidence of genomic inflation in any of the GWAS datasets (individual λGC values 1.01–1.11; meta-analysis λ1000 = 1.01, Supplementary Figure 1).

Study design
Excluding flanking regions of 500 kb around each previously identified CRC risk SNP, we identified 623 SNPs associated with CRC at genome-wide significance (logistic regression, P < 5 × 10−8). After implementing a stepwise model selection, these SNPs were resolved into 31 novel risk loci, with 27 exhibiting Bayesian False Discovery Probabilities (BFDPs)9 <0.1 (Table 1, Fig. 2, Supplementary Figure 2). The association at 20q13.13 (rs6066825) had only been previously identified as significant in a multi-ethnic study10. Two new associations (rs3131043 and rs9271770) were identified within the 6p21.33 major histocompatibility (MHC) region, with rs3131043 located 470 kb 5′ of HLA-C, and rs9271770 located between HLA-DRB1 and HLA-DQA1. Imputation of the MHC region using SNP2HLA11 provided no evidence for additional MHC risk loci.

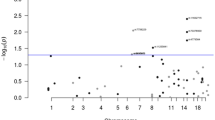
Manhattan plot showing all loci containing genetic risk variants independently associated with colorectal cancer risk at P < 5 × 10−8 in European populations. SNPs on the left of the plot are new SNPs identified in this study, and SNPs on the right were identified in previous studies and replicated at genome-wide significance in this study. The 79 risk SNPs consisted of 31 previously reported SNPs, 39 new risk SNPs, and nine SNPs previously identified in Asian but not in European populations (denoted in dark gold). Dotted lines indicate SNPs that were identified as independent through conditional analysis. Square brackets indicate the position of the sentinel SNP relative to nearest genes (“gene1-[]-gene2” for intergenic SNPs, “[gene]” for intragenic SNPs). The distance from the sentinel SNP to each gene is proportional to the number of dashes. The red line indicates the genome-wide significance threshold. The x-axis represents the −log10P-values of the SNPs, and the y-axis represents the chromosomal positions
We confirmed 28 of the 40 risk loci for CRC published as genome-wide significant in Europeans (i.e. P < 5 × 10−8) (Supplementary Data 1). For four previously reported risk loci2,12,13,14, we observed associations that were just below genome-wide significance (3q26.2, rs10936599, P = 1.41 × 10−7; 12p13.32, rs3217810, P = 1.09 × 10−6; 16q22.1, rs9929218, P = 4.96 × 10−7; 16q24.1, rs2696839, 1.28 × 10−6). In contrast, there was limited support in our current study for eight of the associations previously reported by others2,10,15,16,17 (2q32.3, rs11903757, P = 0.23; 3p14.1, rs812481, P = 0.44; 4q22.2, rs1370821, P = 3.41 × 10−5; 4q26, rs3987, P = 0.10; 4q32.2, rs35509282, P = 0.24; 10q11.23, rs10994860, P = 3.65 × 10−4; 12q24.22, rs73208120, P = 0.03; 20q11.22, rs2295444, P = 0.03), all having a BFDP >0.99 (Supplementary Data 1). Of the 16 reported Asian-specific loci4,5, nine harboured genome-wide significant signals in the current study (all BFDP <0.06), albeit sometimes at SNPs with low r2 but high D′ with the original SNP in Europeans, consistent with differences in allele frequencies in the different populations (Supplementary Data 1). Conditioning on the reported Asian SNPs, five of the nine European risk SNPs were independent of the Asian SNP (Pconditional < 5 × 10−8, Supplementary Data 4). We found no evidence of association signals at the remaining previously reported Asian SNPs.
Next, we performed an analysis conditioned on the sentinel SNP (r2 < 0.1 and Pconditional < 5 × 10−8; Table 2) to search for further independent signals at these new and previously reported risk loci. We confirmed the presence of previously reported dual signals at 14q22.2, 15q13.3 and 20p12.318. For the new risk loci, an additional independent signal was identified at 5p15.3. In addition, a further seven signals were found at five previously reported risk loci: 11q13.4, 12p13.32, 15q13.3, 16q24.1, 20q13.13. Two of these signals were at the 15q13.3 locus, of which one was 5′ of GREM1 and the other intronic to FMN1. A further two signals were proximal and distal of 20q13.13. At 12p13.32 and 16q24.1, genome-wide associations marked by rs12818766 and rs899244, respectively, were shown. These were independent of the previously reported associations2,14 at rs3217810 and rs2696839 (pairwise r2 = 0.0).
In total, we identified 39 new independent SNPs associated with CRC susceptibility at genome-wide significance in Europeans. Together with the nine associations previously identified in Asian populations, and the 31 previously identified SNPs that were confirmed here, this brought the number of identified CRC association signals in Europeans to 79. Several of these risk loci map to regions previously identified in other cancers. In particular, three regions harbour susceptibility loci for multiple cancers19, specifically 5p15.33 (TERT-CLPTM1L), 9p21.3 (CDKN2A) and 20q13.33 (RTEL1) (Supplementary Data 5).
Functional annotation and biological inference of risk loci
To the extent that they have been deciphered, most GWAS risk loci map to non-coding regions of the genome influencing gene regulation19. Consistent with this, we found evidence that the CRC risk SNPs mapped to regions enriched for active enhancer marks (H3K4me1 and H3K27ac) in colonic crypts (permutation test, P = 0.034 and 0.033, respectively) and colorectal tumours (P = 4.2 × 10−3 and 4.0 × 10−5) (Supplementary Figure 3). To determine whether the CRC SNPs overlapped with active regulatory regions in a cell-type specific manner20, we analysed the H3K4me3, H3K27ac, H3K4me1, H3K27me3, H3K9ac, H3K9me3 and H3K36me3 chromatin marks across multiple cell types from the NIH Roadmap Epigenomics project21. Colonic and rectal mucosa cells showed the strongest enrichment of risk SNPs at active enhancer and promoter regions (H3K4me3, H3K4me1 and H3K27ac marks, P < 5 × 10−4) (Supplementary Figure 3).
Given our observation that the risk loci map to putative regulatory regions, we examined both histone modifications and transcription factor (TF) binding sites in LoVo and HT29 CRC cells across the risk SNPs. Using variant set enrichment22, we identified regions of strong LD (defined as r2 > 0.8 and D′ > 0.8) with each risk SNP and determined the overlap with ChIP-seq data from the Systems Biology of Colorectal cancer (SYSCOL) study and inhouse-generated histone data. We identified an over-representation of binding for MYC, ETS2, cohesin loading factor NIPBL and cohesin-related proteins RAD21, SMC1A and SMC3 (Supplementary Figure 4). About 87% (69/79) of the risk SNPs were predicted to disrupt binding motifs of specific TFs, notably CTCF, SOX and FOX, with 35% located within TF binding peaks from LoVo, HT29 or ENCODE ChIP-seq data (Supplementary Data 6).
The upstream mechanisms by which predisposition SNPs influence disease risk is often through effects on cis-regulatory transcriptional networks, specifically through chromatin-looping interactions that are fundamental for regulation of gene expression. Therefore, to link regulatory regions containing risk SNPs to promoters of candidate target genes, we applied in situ promoter capture Hi-C (CHi-C) data in LoVo and HT29 cells (Supplementary Data 9). About 38% of the risk SNPs mapped to regions that showed statistically significant chromatin-looping interactions with the promoters of respective target genes. Notably, as well as confirming the interaction between rs6983267 and MYC at 8q24.21 (Supplementary Figure 2), the looping interaction from an active enhancer region at 10q25.2 implicates TCF7L2 as the target gene of rs12255141 variation (Fig. 3). TCF7L2 (previously known as TCF4) is a key transcription factor in the Wnt pathway and plays an important role in the development and progression of CRC23. Intriguingly, TCF7L2 has been shown to bind to a MYC enhancer containing rs698326724 and to a GREM1 enhancer near rs1696968125. Based on ChromHMM, this region is annotated as a promoter in HCT116 cells, but not in normal colonic and rectal mucosa. Additionally this locus has been implicated in lung cancer26 and low-grade glioma27. Similarly, the 9p21.3 chromatin interaction provides evidence to support CDKN2B as the target gene for rs1412834 variation, a region of somatic loss.

Regional plots of exemplar colorectal cancer risk loci. In the main panel, −log10P-values (y-axis) of the SNPs are shown according to their chromosomal positions (x-axis). The colour intensity of each symbol reflects the extent of LD with the top SNP: white (r2 = 0) through to dark red (r2 = 1.0), with r2 estimated from EUR 1000 Genomes data. Genetic recombination rates (cM/Mb) are shown with a light blue line. Physical positions are based on GRCh37 of the human genome. Where available, the upper panel shows Hi-C contacts from HT29 or LoVo. The lower panel shows the chromatin state segmentation track from the Roadmap Epigenomics project (colonic mucosa, rectal mucosa, sigmoid colon), and HCT116. Also shown are the relative positions of genes and transcripts mapping to each region of association. a rs12255141 (10q25.2); b rs12979278 (19q13); c rs2735940 (5p15); d rs7398375 (12q13.3)
We sought to gain further insight into the target genes at each locus, and hence the biological mechanisms for the associations, by performing expression quantitative trait locus (eQTL) analysis in colorectal tissue. We analysed inhouse eQTL data generated from samples of normal colonic mucosa (INTERMPHEN study, n = 131 patients) and GTEx data from transverse colon (n = 246). For the previously identified risk loci, there were eQTLs for rs4546885 and LAMC1 (1q25.3), rs13020391 and lnc-RNA RP11–378A13.1 (2q35), and rs3087967 and COLCA1, COLCA2 and C11orf53 (11q23.1). Amongst the eQTL associations at the new risk loci, pre-eminent eQTLs were rs9831861 and SFMBT1 (3p21.1), rs12427600 and SMAD9 (13q13.3), and rs12979278 and FUT2 and MAMSTR (19q13.33) (Supplementary Data 7). However, while multiple nominally significant cis-eQTLs were present, nearly half of all loci had no evidence of cis-eQTLs in the sample sets used.
In addition to eQTL analysis, we performed Summary-data-based Mendelian Randomization (SMR) analysis28 as a more stringent test for causal differences in gene transcription (Supplementary Data 8). There was support for the 11q23.1 locus SNP influencing CRC risk through differential expression of one or more of COLCA1, COLCA2 and C11orf53 transcripts (PSMR < 10−10). There was also evidence that the 3p21.1 and 19q13.33 SNPs acted through SFMBT1 and FUT2, respectively, (PSMR < 10−5), as well as the 6p21.31 SNP acted through class II HLA expression (PSMR < 5 × 10−4).
Based on genetic fine-mapping and functional annotation, our data indicated several candidate target genes with functions previously unconnected to colorectal tumourigenesis (Supplementary Data 9). The SFMBT1 protein (3p21.1) acts as a histone reader and a component of a transcriptional repressor complex29. TNS3 at 7p12.3 encodes the focal adhesion protein TENSIN3, to which the intestinal stem cell marker protein Musashi1 has been reported to bind. Tns3-null mice exhibit impaired intestinal epithelial development, probably because of defects in Rho GTPase signalling and cell adhesion30. LRP1 (12q13.3, LDL receptor-related protein 1) (Fig. 3) may be involved in Wnt-signalling31, although its role in the intestines has not previously been conclusively demonstrated. FUT2 at 19q13.33 encodes fucosyltransferase II. Variation at this locus is associated with differential interactions with intestinal bacteria and viruses. Our data thus provide evidence for a role of the microbiome in CRC risk32. PTPN1 (20q13.13), also known as PTP1B, encodes a non-receptor tyrosine phosphatase involved in regulating JAK-signalling, IR, c-Src, CTNNB1, and EGFR.
We annotated all risk loci with five types of functional data: (i) presence of a CHi-C contact linking to a gene promoter, (ii) presence of an association from eQTL, (iii) presence of a regulatory state, (iv) evidence of TF binding, and (v) presence of a nonsynonymous coding change (Supplementary Data 9). Collectively this analysis suggested three primary candidate disease mechanisms across a number of risk loci: firstly, genes linked to BMP/TGF-β signalling (e.g. GREM1, BMP2, BMP4, SMAD7, SMAD9); secondly, genes with roles either directly or indirectly linked to MYC (e.g. MYC, TCF7L2); and thirdly genes with roles in maintenance of chromosome integrity (e.g. TERT, RTEL1) and DNA repair (e.g. POLD3) (Supplementary Figure 5).
Pathway gene set enrichment analyses33 revealed several growth or development related pathways were enriched, notably TGF-β signalling and immune response pathways (Supplementary Figure 6, Supplementary Data 10). Other cancer-related themes included apoptosis and leukocyte differentiation pathways. We used Data-driven Expression-Prioritized Integration for Complex Traits (DEPICT)34 to predict gene targets based on gene functions that are shared across genome-wide significant risk loci, as well as those associated at P < 10−5 as advocated to mitigate against type II error. Tissue-specificity with respect to colonic tissue was evident (permutation test, P < 5 × 10−3) and among the protein-coding genes predicted, there was enrichment for TGF-β and PI3K-signalling pathways, and abnormal intestinal crypt gene sub-networks (P < 10−5; Supplementary Data 11).
Contribution of risk SNPs to heritability
Using Linkage Disequilibrium Adjusted Kinships (LDAK)35 in conjunction with the GWAS data generated on unselected CRC cases (i.e. COIN, CORSA, Croatia, DACHS, FIN, SCOT, Scotland1, SOCCS/LBC, SOCCS/GS, UKBB, VQ58 studies) we estimated that the heritability of CRC attributable to all common variation is 0.29 (95% confidence interval: 0.24–0.35). To estimate the sample size required to explain a greater proportion of the GWAS heritability, we implemented a likelihood-based approach using association statistics in combination with LD information to model the effect-size distribution36, which was best represented by a three-component model (mixture of two normal distributions). Under this model, to identify SNPs explaining 80% of the GWAS heritability, it is likely to require effective sample sizes in excess of 300,000 if solely based on GWAS associations (Supplementary Figure 7).
After adjusting for winner’s curse37, the 79 SNPs thus far shown to be associated with CRC susceptibility in Europeans explain 11% of the 2.2-fold familial relative risk (FRR)38, whilst all common genetic variants identifiable through GWAS could explain 73% of the FRR. Thus, the identified susceptibility SNPs collectively account for approximately 15% of the FRR of CRC that can be explained by common genetic variation. We incorporated the newly identified SNPs into risk prediction models for CRC and derived a polygenic risk score (PRS) based on a total of 79 GWAS significant risk variants. Individuals in the top 1% have a 2.6-fold increased risk of CRC compared with the population average (Supplementary Figure 8). Risk re-classification using this PRS offers the prospect of optimising prevention programmes for CRC in the population, for example through targeting screening6, and also preventative interventions. The identification of further risk loci through the analysis of even larger GWAS is likely to improve the performance of any PRS model.
Co-heritability with non-cancer traits
We implemented cross-trait LD score regression39 to investigate co-heritability globally between CRC and 41 traits with publicly available GWAS summary statistics data. None of the genetic correlations remained significant after Bonferroni correction (two-sided Z-test, P-threshold: 0.05/41 = 1.2 × 10−3). However, nominally significant positive associations with CRC risk (Supplementary Data 12) included insulin resistance, comprising raised fasting insulin, glucose and HbA1c (positive), hyperlipidaemia, comprising raised total cholesterol and low-density lipoprotein cholesterol, and ulcerative colitis, all of which are traits or diseases previously reported in observational epidemiological studies to be associated with CRC risk40,41.
Discussion
Here we report a comprehensive analysis that sheds new light on the molecular basis of genetic risk for a common cancer, and greatly increases the number of known CRC risk SNPs. To identify the most credible target genes at each site, we have performed detailed annotation using public databases, and have also acquired our own disease-specific data from ChIP-seq, promoter capture Hi-C and gene expression analyses.
Given that there remains significant missing common heritability for CRC, additional GWAS meta-analyses are likely to lead to discovery of more risk loci. Such an assertion is directly supported a contemporaneous study42, which has reported the identification of 40 independent signals; 30 novel loci and 10 conditionally independent association signals at previously and newly identified CRC risk loci. Of these, 18 were replicated in our analysis, with an additional five exhibiting an independent signal present at the same locus (Supplementary Data 13).
Overall, our findings provide new insights into the biological basis of CRC, not only confirming the importance of established gene networks, but also providing evidence that point to a role for the gut microbiome in CRC causation, and identifying several functional mechanisms previously unsuspected of any involvement in colorectal tumourigenesis. Several of the gene pathways identified through GWAS may provide potential novel targets for chemoprevention and chemotherapeutic intervention.
Methods
Ethics
Collection of patient samples and associated clinico-pathological information was undertaken with written informed consent and relevant ethical review board approval at respective study centres in accordance with the tenets of the Declaration of Helsinki. Specifically: (i) UK National Cancer Research Network Multi-Research Ethics Committee (02/0/097 [NSCCG], 01/0/5) [SOCCS], 05/S1401/89 [GS:SFHS], LREC/1998/4/183 [LBC1921], 2003/2/29 [LBC1936], 17/SC/0079 [CORGI] and 07/S0703/136 [SCOT]); (ii) The research activities of UK Biobank were approved by the North West Multi-centre Research Ethics Committee (11/NW/0382) in relation to the process of participant invitation, assessment and follow-up procedures. Additionally, ethics approvals from the National Information Governance Board for Health & Social Care in England and Wales and approval from the Community Health Index Advisory Group in Scotland were also obtained to gain access to the information that would allow the invitation of participants. This study did not need to re-contact the participants, and no separate ethics approval was required according to the Ethics and Governance Framework (EGF) of UK Biobank; (iii) South East Ethics Committee MREC (03/1/014); (iv) Written informed consent was obtained from all participants of CORSA. The study was approved by the ethical review committee of the Medical University of Vienna (MUW, EK Nr. 703/2010) and the “Ethikkommission Burgenland” (KRAGES, 33/2010) and (v) Finnish National Supervisory Authority for Welfare and Health, National Institute for Health and Welfare (THL/151/5.05.00/2017), the Ethics Committee of the Hospital District of Helsinki and Uusimaa (HUS/408/13/03/03/09).
The diagnosis of colorectal cancer (ICD-9 153, 154; ICD-10 C18.9, C19, C20) was established in all cases in accordance with World Health Organization guidelines.
Primary GWAS
We analysed data from five primary GWAS (Supplementary Data 2 and Supplementary Data 3):
-
(1)
The NSCCG-OncoArray GWAS comprised 6240 cases ascertained through the National Study of Colorectal Cancer Genetics (NSCCG)43 and 1041 cases collected through the CORGI consortium, genotyped using the Illumina OncoArray. Patients were selected for having a family history of CRC (at least one first-degree relative) or age of diagnosis below 58. Controls were also genotyped using the OncoArray and comprised (i) 3031 cancer-free men recruited by the PRACTICAL Consortium—the UK Genetic Prostate Cancer Study (UKGPCS) (age <65 years), a study conducted through the Royal Marsden NHS Foundation Trust and SEARCH (Study of Epidemiology & Risk Factors in Cancer), recruited via GP practices in East Anglia (2003–2009) and (ii) 4,488 cancer-free women across the UK, recruited via the Breast Cancer Association Consortium (BCAC).
-
(2)
The SCOT GWAS comprised 3076 cases from the Short Course Oncology Treatment (SCOT) trial—a study of adjuvant chemotherapy in colorectal cancer by the CACTUS and OCTO groups44. Controls comprised 4349 cancer-free individuals from The Heinz Nixdorf Recall study45. Both cases and controls were genotyped using the Illumina Global Screening Array.
-
(3)
SOCCS/Generation Scotland (SOCCS/GS) comprised 4772 cases from the Study of Colorectal Cancer in Scotland (SOCCS)12,13 and 12,158 controls including 2221 population-based controls from SOCCS and additional 9937 population controls without prior history of colorectal cancer from Generation Scotland-Scottish Family Health Study (GS:SFHS)46.
-
(4)
SOCCS/Lothian Birth Cohort (SOCCS/LBC) GWAS comprised 1037 cases from the Study of Colorectal Cancer in Scotland (SOCCS)47 and 1522 population-based controls without prior history of malignant tumours from the Lothian Birth Cohorts (LBC) of 1921 and 193648.
-
(5)
UK Biobank (UKBB) GWAS comprised 6360 cases and 25,440 population-based control individuals. UK Biobank is a large cohort study with more than 500,000 individuals recruited. Biological samples of these participants were genotyped using the custom-designed Affymetrix UK BiLEVE Axiom array on an initial 50,000 participants and Affymetrix UK Biobank Axiom array on the remaining 450,000 participants. The two arrays had over 95% common content. Genotyping was done at the Affymetrix Research Services Laboratory in Santa Clara, California, USA. Details on genotyping and quality control were previously reported49. Self-reported cases of cancers of bowel, colon or rectum, if not confirmed by the ICD9 or ICD10 codes were excluded from the analysis. Healthy control individuals without history of cancer and/or colorectal adenoma were included in the analysis after matching one case to four controls by age, gender, date of blood draw, ethnicity and region of residence (two first letters of postal code).
Published GWAS
We made use of 10 previously published GWAS (Supplementary Data 2): (1) UK1 (CORGI study) comprised 940 cases with colorectal neoplasia and 965 controls12; (2) Scotland1 (COGS study) included 1012 CRC cases and 1012 controls12; (3) VQ58 comprised 1800 cases from the UK-based VICTOR and QUASAR2 adjuvant chemotherapy clinical trials and 2690 population control genotypes from the Wellcome Trust Case Control Consortium 2 (WTCCC2) 1958 birth cohort50; (4) CCFR1 comprised 1290 familial CRC cases and 1055 controls from the Colon Cancer Family Registry (CCFR)15; (5) CCFR2 included a further 796 cases from the CCFR and 2236 controls from the Cancer Genetic Markers of Susceptibility (CGEMS) studies of breast and prostate cancer51,52; (6) COIN was based on 2244 CRC cases ascertained through two independent Medical Research Council clinical trials of advanced/metastatic CRC (COIN and COIN-B)53 and controls comprised 2162 individuals from the UK Blood Service Control Group genotyped as part of the WTCCC2; (7) Finnish GWAS (FIN)3 was based on 1172 CRC cases and 8266 cancer-free controls ascertained through FINRISK, Health 2000, Finnish Twin Cohort and Helsinki Birth Cohort Studies; (8) CORSA (COloRectal cancer Study of Austria) a molecular epidemiological study of 978 cases and 855 colonoscopy-negative controls54; (9) DACHS (Darmkrebs: Chancen der Verhütung durch Screening)55 based on 1105 cases and 700 controls and (10) Croatia consisted of 764 cases and 460 population-based controls56.
The VQ58, UK1 and Scotland1 GWAS were genotyped using Illumina Hap300, Hap240S, Hap370, Hap550 or Omni2.5 M arrays. 1958BC genotyping was performed as part of the WTCCC2 study on Hap1.2M-Duo Custom arrays. The CCFR samples were genotyped using Illumina Hap1M, Hap1M-Duo or Omni-express arrays. CGEMS samples were genotyped using Illumina Hap300 and Hap240 or Hap550 arrays. The COIN cases were genotyped using Affymetrix Axiom Arrays and the Blood Service controls were genotyped using Affymetrix 6.0 arrays. FIN cases were genotyped using Illumina HumanOmni 2.5M8v1 and controls using Illumina HumanHap 670k and 610k arrays. DACHS study samples were genotyped using the Illumina OncoArray, CORSA study sampels were genotyped on the Affymetrix Axiom Genome-Wide CEU 1 Array, and Croatia study samples were genotyped on Illumina OmniExpressExome BeadChip 8v1.1 or 8v1.3.
Quality control
Standard quality control (QC) measures were applied to each GWAS8. Specifically, individuals with low SNP call rate (<95%) as well as individuals evaluated to be of non-European ancestry (using the HapMap version 2 CEU, JPT/CHB and YRI populations as a reference) were excluded (Supplementary Figure 9). For apparent first-degree relative pairs, we excluded the control from a case-control pair; otherwise, we excluded the individual with the lower call rate. SNPs with a call rate <95% were excluded as were those with a MAF <0.5% or displaying significant deviation from Hardy–Weinberg equilibrium (P < 10−5). QC details are provided in Supplementary Data 3. All genotype analyses were performed using PLINK v1.957.
Imputation and statistical analysis
Prediction of the untyped SNPs was carried out using SHAPEIT v2.83758 and IMPUTE v2.3.259. The CCFR1, CCFR2, COIN, CORSA, Croatia, NSCCG-OncoArray, SCOT, Scotland1, SOCCS/GS, SOCCS/LBC, UK1 and VQ58 samples used a merged reference panel using data from 1000 Genomes Project (phase 1, December 2013 release) and UK10K (April 2014 release). Imputation of UKBB was based on data from 1000 Genomes Project (phase 3), UK10K and Haplotype Reference Consortium. The FIN and DACHS GWAS were imputed using a reference panel comprised of 1000 Genomes Projects Project with an additional population matched reference panel: 3882 Sequencing Initiative Suomi (SISu) haplotypes for the FIN study, and 3000 sequenced CRC cases for the DACHS study. We imposed predefined thresholds for imputation quality to retain potential risk variants with MAF >0.5% for validation. Poorly imputed SNPs defined by an information measure <0.80 were excluded. Tests of association between imputed SNPs and CRC were performed under an additive genetic model in SNPTEST v2.5.260. Principal components were added to adjust for population stratification where required (i.e. DACHS, FIN, NSCCG-OncoArray, SCOT and UKBB).
To determine whether specific coding variants within HLA genes contributed to the diverse association signals, we imputed the classical HLA alleles (A, B, C, DQA1, DQB1 and DRB1) and coding variants across the HLA region using SNP2HLA11. The imputation was based on a reference panel from the Type 1 Diabetes Genetics Consortium (T1DGC) consisting of genotype data from 5225 individuals of European descent with genotyping data of 8961 common SNPs and indel polymorphisms across the HLA region, and four digit genotyping data of the HLA class I and II molecules. For the X chromosome, genotypes were phased and imputed as for the autosomal chromosome, with the inclusion of the “chrX” flag. X chromosome association analysis was performed in SNPTEST using a maximum likelihood model, assuming complete inactivation of one allele in females and equal effect-size between males and females.
The adequacy of the case-control matching and possibility of differential genotyping of cases and controls was evaluated using a Q–Q plot of test statistics in individual studies (Supplementary Figure 1). Meta-analyses were performed using the fixed-effects inverse-variance method using META v1.761. Cochran’s Q-statistic to test for heterogeneity and the I2 statistic to quantify the proportion of the total variation due to heterogeneity were calculated. A Q–Q plot of the meta-analysis test statistics was also performed (Supplementary Figure 1). None of the studies showed evidence of genomic inflation, where λGC values for the CCFR1, CCFR2, COIN, CORSA, Croatia, DACHS, FIN, NSCCG-OncoArray, SCOT, Scotland1, SOCCS/GS, SOCCS/LBC, UKBB, UK1 and VQ58 studies were 1.03, 1.08, 1.09, 1.11, 1.01, 1.01, 1.09, 1.10, 1.08, 1.02, 1.09, 1.04, 1.05, 1.02 and 1.06, respectively. Estimates were calculated using the regression method, as implemented in GenABEL.
Definition of known and new risk loci
We sought to identify all associations for CRC previously reported at a significance level P < 5 × 10−8 by referencing the NHGRI-EBI Catalog of published genome-wide association studies, and a literature search for the years 1998–2018 using PubMed (performed January 2018). Additional articles were ascertained through references cited in primary publications. Where multiple studies reported associations in the same region, we only considered the first reported genome-wide significant association. New loci were identified based on SNPs at P < 5 × 10−8 using the meta-analysis summary statistics, with LD correlations from a reference panel of the European 1000 Genomes Project samples combined with UK10K. We only included one SNP per 500 kb interval. To measure the probability of the hits being false positives, the Bayesian False-Discovery Probability (BFDP)9 was calculated based on a plausible OR of 1.2 (based on the 95th percentile of the meta-analysis OR values) and a prior probability of association of 10−5. A conditional analysis was performed using Genome-wide Complex Trait Analysis (GCTA)62, conditioning on the new and known SNPs, and SNPs with Pconditioned < 5 × 10−8 and r2 > 0.1 were clumped using PLINK. The NSCCG-Oncoarray data were used to provide the LD reference data.
Fidelity of imputation
The reliability of imputation of the novel risk SNPs identified (all with an IMPUTE2 r2 > 0.8) was assessed for 51 SNPs (comprising all new signals not directly genotyped) by examining the concordance between imputed and whole-genome sequenced genotypes in a subset of 201 samples from the CORGI and NSCCG studies. More than 98% concordance was found between the directly sequenced and imputed SNPs (Supplementary Data 14).
eQTL analysis
In the INTERMPHEN study, biopsies of normal colorectal mucosa (trios of rectum, proximal colon and distal colon) were obtained from 131 UK individuals with self-reported European ancestry without CRC. Genotyping was performed using the Illumina Infinium Human Core Exome array, with quality control and imputation as above. RNA-seq was performed and data analysed as per the GTEx Project pipeline v7 using the 1000 Genomes and UK10K data as reference. Gene-level expression quantification was based on the GENCODE 19 annotation, collapsed to a single transcript model for each gene using a custom isoform procedure. Gene-level quantification (read counts and TPM values) was performed with RNA-SeQC v1.1.8. Gene expression was normalised using the TMM algorithm, implemented in edgeR, with inverse normal transformation, based on gene expression thresholds of >0.1 Transcripts Per Million (TPM) in ≥20% of samples and ≥6 reads in ≥20% of samples. cis-eQTL mapping was performed separately for proximal colon, distal colon and rectum samples using FastQTL. Principal components for the SNP data and additional covariate factors were identified using Probabilistic Estimation of Expression Residuals (PEER). P-values were generated for each variant-gene pair testing alternative hypothesis that the slope of a linear regression model between genotype and expression deviates from 0. The mapping window was defined as 1 Mb either side of the transcription start site. Beta distribution-adjusted empirical P-values from FastQTL were used to calculate Q-values, and FDR threshold of ≤0.05 was applied to identify genes with a significant eQTL. The normalised effect size of the eQTLs was defined as the slope of the linear regression, and computed as the effect of the alternative allele relative to the reference allele in the human genome reference GRCh37/hg19). MetaTissue was used to generate a “pan-colonic” eQTL measure from the three individual RNA-seq datasets per patient.
To supplement this analysis, we performed SMR analysis28 including all eQTLs with nominally significant associations (P < 0.05). We additionally examined for heterogeneity using the heterogeneity in dependent instruments (HEIDI) test, where PHEIDI < 0.05 were considered as reflective of heterogeneity and were excluded.
Promoter capture Hi-C
In situ promoter capture Hi-C (CHi-C) on LoVo and HT29 cell lines was performed as previously described63. Hi-C and CHi-C libraries were sequenced using HiSeq 2000 (Illumina). Reads were aligned to the GRCh37 build using bowtie2 v2.2.6 and identification of valid di-tags was performed using HiCUP v0.5.9. To declare significant contacts, HiCUP output was processed using CHiCAGO v1.1.8. For each cell line, data from three independent biological replicates were combined to obtain a definitive set of contacts. As advocated, interactions with a score ≥5.0 were considered to be statistically significant64.
Chromatin state annotation
Colorectal cancer risk loci and SNPs in LD (r2 > 0.8) were annotated for putative functional effect based upon ChIP-seq H3K4me1 (C15410194), H3K9me3 (C15410193), H3K27me3 (C15410195) and H3K36me3 (C15410192) for LoVo, and H3K4me1 and H3K9me3 for HT29. ChIP libraries were sequenced using HiSeq 2000 (Illumina) with 100 bp single-ended reads. Generated raw reads were filtered for quality (Phred33 ≥ 30) and length (n ≥ 32), and adapter sequences were removed using Trimmomatic v0.22. Reads passing filters were then aligned to the human reference (hg19) using BWA v0.6.1. Peak calls are obtained using MACS2 v 2.0.10.07132012.
Histone mark and transcription factor enrichment analysis
ChIP-seq data from colon crypt and tumour samples was obtained for H3K27ac and H3K4me165. Multiple samples of the same tissue type or tumour stage were merged together. Additional ChIP-seq data from the Roadmap Epigenomics project21 was obtained for H3K4me3, H3K27ac, H3K4me1, H3K27me3, H3K9ac, H3K9me3 and H3K36me3 marks in up to 114 tissues. Overlap enrichment analysis of CRC risk SNPs with these peaks was performed using EPIGWAS, as described by Trynka et al.20. Briefly, we evaluated if CRC risk SNPs and SNPs in LD (r2 > 0.8) with the sentinel SNP, were enriched at ChIP-seq peaks in tissues by a permutation procedure with 105 iterations.
To examine enrichment in specific TF binding across risk loci, we adapted the variant set enrichment method of Cowper-Sal lari et al.22. Briefly, for each risk locus, a region of strong LD (defined as r2 > 0.8 and D′ > 0.8) was determined, and these SNPs were termed the associated variant set (AVS). ChIP-seq uniform peak data were obtained for LoVo and HT29 cell lines (198 and 29 experiments, respectively)66 and the above described histone marks. For each of these marks, the overlap of the SNPs in the AVS and the binding sites was determined to produce a mapping tally. A null distribution was produced by randomly selecting SNPs with the same characteristics as the risk-associated SNPs, and the null mapping tally calculated. This process was repeated 105 times, and P-values calculated as the proportion of permutations where the null mapping tally was greater or equal to the AVS mapping tally. An enrichment score was calculated by normalising the tallies to the median of the null distribution. Thus, the enrichment score is the number of standard deviations of the AVS mapping tally from the median of the null distribution tallies.
Functional annotation
For the integrated functional annotation of risk loci, LD blocks were defined as all SNPs in r2 > 0.8 with the sentinel SNP. Risk loci were then annotated with five types of functional data: (i) presence of a CHi-C contact linking to a gene promoter, (ii) presence of an association from eQTL, (iii) presence of a regulatory state, (iv) evidence of TF binding, and (v) presence of a nonsynonymous coding change. Candidate causal genes were then assigned to CRC risk loci using the target genes implicated in annotation tracks (i), (ii), (iiii) and (iv). If the data supported multiple gene candidates, the gene with the highest number of individual functional data points was considered as the candidate. Where multiple genes had the same number of data points, all genes were listed. Direct nonsynonymous coding variants were allocated additional weighting. Competing mechanisms for the same gene (e.g. both coding and promoter variants) were allowed for. Finally, if no evidence was provided by these criteria, if the lead SNP was intronic we assigned candidacy on this basis, or if intergenic the nearest gene neighbour. Chromatin data were obtained from HaploReg v4 and regulatory regions from Ensembl.
Regional plots were created using visPIG67, using the data described above. We used ChromHMM to integrate DNAse, H3K4me3, H3K4me1, H3K27ac, Pol2 and CTCF states from the CRC cell line HCT116 using a multivariate Hidden Markov Model68. Chromatin annotation tracks for colonic mucosa (E075), rectal mucosa (E101) and sigmoid colon (E106) were obtained from the Roadmap Epigenomics project21, using the core 15-state model data based on H3K4me3, H3K4me1, H3K36me3, H3K27me3 and H3K9me3 marks.
Transcription factor binding disruption analysis
To determine if the risk variants or their proxies were disrupting motif binding sites, we used the motifbreakR package69. This tool predicts the effects of variants on TF binding motifs, using position probability matrices to determine the likelihood of observing a particular nucleotide at a specific position within a TF binding site. We tested the SNPs by estimating their effects on over 2,800 binding motifs as characterised by ENCODE, FactorBook, HOCOMOCO and HOMER. Scores were calculated using the relative entropy algorithm.
Heritability analysis
We used LDAK35 to estimate the polygenic variance (i.e. heritability) ascribable to SNPs from summary statistic data for the GWAS datasets which were based on unselected cases (i.e. CORSA, COIN, Croatia, DACHS, FIN, SCOT, Scotland1, SOCCS/GS, SOCCS/LBC, UKBB and VQ58). SNP-specific expected heritability, adjusted for LD, MAF and genotype certainty, was calculated from the UK10K and 1000 Genomes data. Individuals were excluded if they were closely related, had divergent ancestry from CEU, or had a call rate <0.99. SNPs were excluded if they showed deviation from HWE with P < 1 × 10−5, genotype yield <95%, MAF <1%, SNP imputation score <0.99, and the absence of the SNP in the GWAS summary statistic data. This resulted in a total 6,024,731 SNPs used to estimate the heritability of CRC.
To estimate the sample size required to detect a given proportion of the GWAS heritability we implemented a likelihood-based approach to model the effect-size distribution36, using association statistics from the meta-analysis, and LD information from individuals of European ancestry in the 1000 Genomes Project Phase 3. LD values were based on an r2 threshold of 0.1 and a window size of 1MB. The goodness of fit of the observed distribution of P-values against the expected from a two-component model (single normal distribution) and a three-component model (mixture of two normal distributions) were assessed, and a better fit was observed for the latter model. The percentage of GWAS heritability explained for a projected sample size was determined using this model, based on power calculations for the discovery of genome-wide significant SNPs. The genetic variance explained was calculated as the proportion of total GWAS heritability explained by SNPs reaching genome-wide significance at a given sample size. The 95% confidence intervals were determined using 105 simulations.
Cross-trait genetic correlation
LD score regression39 was used to determine if any traits were correlated with CRC risk. GWAS summary data were obtained for allergy, asthma, coronary artery disease, fatty acids, lipids (total cholesterol, high density lipoprotein, low-density lipoprotein, triglycerides), auto-immune diseases (Crohn’s disease, rheumatoid arthritis, atopic dermatitis, celiac disease, multiple sclerosis, primary biliary cirrhosis, inflammatory bowel disease, ulcerative colitis, systemic lupus erythematosus), anthropometric measures (BMI, height, body fat), glucose sensitivity (fasting glucose, fasting insulin, HbA1c), childhood measures (birth weight, birth length, childhood obesity, childhood BMI), eGFR and type 2 diabetes. All data were obtained for European populations. Summary statistics were reformatted to be consistent, and constrained to HapMap3 SNPs as these have been found to generally impute well. LD Scores were determined using 1000 Genomes European data.
Familial risk explained by risk SNPs
Under a multiplicative model, the contribution of risk SNPs to the familial risk of CRC was calculated from \(\mathop {\sum }\limits_k \frac{{{\mathrm{log\lambda }}_k}}{{\log {\mathrm{\lambda }}_0}}\), where λ0 is the familial risk to first-degree relatives of CRC cases, assumed to be 2.238, and λk is the familial relative risk associated with SNP k, calculated as \({\mathrm{\lambda }}_k = \frac{{p_kr_k^2 + q_k}}{{\left( {p_kr_k + q_k} \right)^2}}\), where pk is the risk allele frequency for SNP k, qk = 1−pk, and rk is the estimated per-allele OR from the meta-analysis70. The OR estimates were adjusted for the winner’s curse using the FDR Inverse Quantile Transformation (FIQT) method37. We constructed a PRS including all 79 CRC risk SNPs discovered or validated by this GWAS in the risk-score modelling. The distribution of risk on an RR scale in the population is assumed to be log-normal with arbitrary population mean μ set to -σ2/2 and variance \(\sigma ^2 = 2\mathop {\sum }\limits_k p_k(1 - p_k)\beta ^2\) where β and p correspond to the log odds ratio and the risk allele frequency, respectively, for SNP k. The distribution of PRS among cases is right-shifted by σ2 so that the overall mean PRS is 1.071. The risk distribution was also performed assuming all common variation, using \(\sigma ^2 = \log (\lambda _{{\mathrm{sib}}}^2)\), where λsib = 1.79, as determined using the heritability estimate from GCTA.
Pathway analysis
SNPs were assigned to genes as described in the functional annotation section. The genes that mapped to genome-wide significant CRC risk SNPs were analysed using InBio Map, a manually curated database of protein-protein interactions.
Gene set enrichment was calculated using GenGen. Enrichment scores were calculated using the meta-analysis results and were based on 103 permutations on the χ2 values between SNPs. Pathway definitions were obtained from the Bader Lab33, University of Toronto, July 2018 release. This data contained pathway information from Gene Ontology (GO), Reactome, HumanCyc, MSigdb C2 (curated dataset), NCI Pathway, NetPath and PANTHER for a total of 7269 pathways. GO annotations that were inferred computationally were excluded. To avoid biasing the results, the meta-analysis SNPs were pruned to only those with an r2 < 0.1 and a distance greater than 500 kb. Pathways were visualised using Cytoscape v3.6.1, together with the EnrichmentMap v3.1.0 and AutoAnnotate v1.2 plugins. Only pathways with an FDR <0.05 and edges with a similarity coefficient (number of shared genes between pathways) >0.55 were displayed.
URLs
Bader Lab pathway data: http://download.baderlab.org/EM_Genesets/July_01_2018/Human/symbol/
FastQTL: https://github.com/francois-a/fastqtl
GTEx: https://www.gtexportal.org/home/
InBioMap: https://www.intomics.com/inbio/map/#home
LD scores: https://data.broadinstitute.org/alkesgroup/LDSCORE/
NHGRI-EBI GWAS Catalog: https://www.ebi.ac.uk/gwas/
PredictDB: http://predictdb.org/
Roadmap Epigenomics data: https://egg2.wustl.edu/roadmap/web_portal/chr_state_learning.html
SYSCOL: http://syscol-project.eu/
UK Biobank: http://www.ukbiobank.ac.uk/scientists-3/genetic-data/
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The SCOT data can be requested through the TransSCOT committee according to the ethical permissions obtained as part of the clinical trial approval. The PRACTICAL and BCAC consortium control data are available through the respective Data Access Coordination Committees (http://practical.icr.ac.uk and http://bcac.ccge.medschl.cam.ac.uk/) and the Heinz Nixdorf Recall Study control data can be requested through https://www.uni-due.de/recall-studie/die-studien/hnr/. UK Biobank data can be obtained through http://www.ukbiobank.ac.uk/. The Colon Cancer Family Registry data can be obtained through http://coloncfr.org/.
Finnish cohort samples can be requested from THL Biobank https://thl.fi/en/web/thl-biobank. Hi-C, CHi-C, and histone ChIPseq sequencing data have been deposited in the European Genome-phenome Archive (EGA) under the accession code EGAS00001001946. The remaining data are contained within the Supplementary Files or available from the authors upon reasonable request.
Code availability
All bioinformatics and statistical analysis tools used are open source.
References
Graff, R. E. et al. Familial risk and heritability of colorectal cancer in the nordic twin study of cancer. Clin. Gastroenterol. Hepatol. 15, 1256–1264 (2017).
Schmit, S. L. et al. Novel common genetic susceptibility loci for colorectal cancer. J. Natl. Cancer Inst. 111, 146–157 (2018).
Orlando, G. et al. Variation at 2q35 (PNKD and TMBIM1) influences colorectal cancer risk and identifies a pleiotropic effect with inflammatory bowel disease. Hum. Mol. Genet 25, 2349–2359 (2016).
Tanikawa, C. et al. GWAS identifies two novel colorectal cancer loci at 16q24.1 and 20q13.12. Carcinogenesis 39, 652–660 (2018).
Zeng, C. et al. Identification of susceptibility loci and genes for colorectal cancer risk. Gastroenterology 150, 1633–1645 (2016).
Frampton, M. J. et al. Implications of polygenic risk for personalised colorectal cancer screening. Ann. Oncol. 27, 429–434 (2016).
Tomlinson, I. P. et al. COGENT (COlorectal cancer GENeTics): an international consortium to study the role of polymorphic variation on the risk of colorectal cancer. Br. J. Cancer 102, 447–454 (2010).
Anderson, C. A. et al. Data quality control in genetic case-control association studies. Nat. Protoc. 5, 1564–1573 (2010).
Wakefield, J. A Bayesian measure of the probability of false discovery in genetic epidemiology studies. Am. J. Hum. Genet 81, 208–227 (2007).
Schumacher, F. R. et al. Genome-wide association study of colorectal cancer identifies six new susceptibility loci. Nat. Commun. 6, 7138 (2015).
Jia, X. et al. Imputing amino acid polymorphisms in human leukocyte antigens. PLoS ONE 8, e64683 (2013).
Houlston, R. S. et al. Meta-analysis of three genome-wide association studies identifies susceptibility loci for colorectal cancer at 1q41, 3q26.2, 12q13.13 and 20q13.33. Nat. Genet. 42, 973–977 (2010).
Cogent Study et al. Meta-analysis of genome-wide association data identifies four new susceptibility loci for colorectal cancer. Nat. Genet. 40, 1426–1435 (2008).
Whiffin, N. et al. Identification of susceptibility loci for colorectal cancer in a genome-wide meta-analysis. Hum. Mol. Genet. 23, 4729–4737 (2014).
Peters, U. et al. Meta-analysis of new genome-wide association studies of colorectal cancer risk. Hum. Genet. 131, 217–234 (2012).
Real, L. M. et al. A colorectal cancer susceptibility new variant at 4q26 in the Spanish population identified by genome-wide association analysis. PLoS ONE 9, e101178 (2014).
Schmit, S. L. et al. A novel colorectal cancer risk locus at 4q32.2 identified from an international genome-wide association study. Carcinogenesis 35, 2512–2519 (2014).
Tomlinson, I. P. et al. Multiple common susceptibility variants near BMP pathway loci GREM1, BMP4, and BMP2 explain part of the missing heritability of colorectal cancer. PLoS Genet. 7, e1002105 (2011).
Sud, A., Kinnersley, B. & Houlston, R. S. Genome-wide association studies of cancer: current insights and future perspectives. Nat. Rev. Cancer 17, 692–704 (2017).
Trynka, G. et al. Chromatin marks identify critical cell types for fine mapping complex trait variants. Nat. Genet. 45, 124–130 (2013).
Roadmap Epigenomics Consortium. et al. Integrative analysis of 111 reference human epigenomes. Nature 518, 317–330 (2015).
Cowper-Sal lari, R. et al. Breast cancer risk-associated SNPs modulate the affinity of chromatin for FOXA1 and alter gene expression. Nat. Genet. 44, 1191–1198 (2012).
Bienz, M. & Clevers, H. Linking colorectal cancer to Wnt signaling. Cell 103, 311–320 (2000).
Tuupanen, S. et al. The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nat. Genet. 41, 885–890 (2009).
Lewis, A. et al. A polymorphic enhancer near GREM1 influences bowel cancer risk through differential CDX2 and TCF7L2 binding. Cell Rep. 8, 983–990 (2014).
Lan, Q. et al. Genome-wide association analysis identifies new lung cancer susceptibility loci in never-smoking women in Asia. Nat. Genet. 44, 1330–1335 (2012).
Kinnersley, B. et al. Genome-wide association study identifies multiple susceptibility loci for glioma. Nat. Commun. 6, 8559 (2015).
Zhu, Z. et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat. Genet. 48, 481–487 (2016).
Wu, S., Trievel, R. C. & Rice, J. C. Human SFMBT is a transcriptional repressor protein that selectively binds the N-terminal tail of histone H3. FEBS Lett. 581, 3289–3296 (2007).
Munoz, J. et al. The Lgr5 intestinal stem cell signature: robust expression of proposed quiescent ‘ + 4’ cell markers. EMBO J. 31, 3079–3091 (2012).
Westendorf, J. J., Kahler, R. A. & Schroeder, T. M. Wnt signaling in osteoblasts and bone diseases. Gene 341, 19–39 (2004).
Wacklin, P. et al. Faecal microbiota composition in adults is associated with the FUT2 gene determining the secretor status. PLoS ONE 9, e94863 (2014).
Merico, D., Isserlin, R., Stueker, O., Emili, A. & Bader, G. D. Enrichment map: a network-based method for gene-set enrichment visualization and interpretation. PLoS ONE 5, e13984 (2010).
Pers, T. H. et al. Biological interpretation of genome-wide association studies using predicted gene functions. Nat. Commun. 6, 5890 (2015).
Speed, D. et al. Reevaluation of SNP heritability in complex human traits. Nat. Genet. 49, 986–992 (2017).
Zhang, Y., Qi, G., Park, J. H. & Chatterjee, N. Estimation of complex effect-size distributions using summary-level statistics from genome-wide association studies across 32 complex traits. Nat. Genet. 50, 1318–1326 (2018).
Bigdeli, T. B. et al. A simple yet accurate correction for winner’s curse can predict signals discovered in much larger genome scans. Bioinformatics 32, 2598–2603 (2016).
Johns, L. E. & Houlston, R. S. A systematic review and meta-analysis of familial colorectal cancer risk. Am. J. Gastroenterol. 96, 2992–3003 (2001).
Bulik-Sullivan, B. et al. An atlas of genetic correlations across human diseases and traits. Nat. Genet. 47, 1236–1241 (2015).
Eaden, J. A., Abrams, K. R. & Mayberry, J. F. The risk of colorectal cancer in ulcerative colitis: a meta-analysis. Gut 48, 526–535 (2001).
Shikata, K., Ninomiya, T. & Kiyohara, Y. Diabetes mellitus and cancer risk: review of the epidemiological evidence. Cancer Sci. 104, 9–14 (2013).
Huyghe, J. R. et al. Discovery of common and rare genetic risk variants for colorectal cancer. Nat. Genet. 51, 76–87 (2019).
Penegar, S. et al. National study of colorectal cancer genetics. Br. J. Cancer 97, 1305–1309 (2007).
Paul, J. et al. SCOT: Short Course Oncology Therapy—a comparison of 12 and 24 weeks of adjuvant chemotherapy in colorectal cancer. J. Clin. Oncol. 29, e14145–e14145 (2011).
Schmermund, A. et al. Assessment of clinically silent atherosclerotic disease and established and novel risk factors for predicting myocardial infarction and cardiac death in healthy middle-aged subjects: rationale and design of the Heinz Nixdorf RECALL Study. Risk Factors, Evaluation of Coronary Calcium and Lifestyle. Am. Heart J. 144, 212–218 (2002).
Smith, B. H. et al. Cohort Profile: Generation Scotland: Scottish Family Health Study (GS:SFHS). The study, its participants and their potential for genetic research on health and illness. Int J. Epidemiol. 42, 689–700 (2013).
Theodoratou, E. et al. Dietary vitamin B6 intake and the risk of colorectal cancer. Cancer Epidemiol. Biomark. Prev. 17, 171–182 (2008).
Deary, I. J., Gow, A. J., Pattie, A. & Starr, J. M. Cohort profile: the Lothian Birth Cohorts of 1921 and 1936. Int J. Epidemiol. 41, 1576–1584 (2012).
Bycroft, C. et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018).
Power, C. & Elliott, J. Cohort profile: 1958 British birth cohort (National Child Development Study). Int J. Epidemiol. 35, 34–41 (2006).
Hunter, D. J. et al. A genome-wide association study identifies alleles in FGFR2 associated with risk of sporadic postmenopausal breast cancer. Nat. Genet 39, 870–874 (2007).
Yeager, M. et al. Genome-wide association study of prostate cancer identifies a second risk locus at 8q24. Nat. Genet. 39, 645–649 (2007).
Al-Tassan, N. A. et al. A new GWAS and meta-analysis with 1000Genomes imputation identifies novel risk variants for colorectal cancer. Sci. Rep. 5, 10442 (2015).
Hofer, P. et al. Bayesian and frequentist analysis of an Austrian genome-wide association study of colorectal cancer and advanced adenomas. Oncotarget 8, 98623–98634 (2017).
Weigl, K. et al. Strongly enhanced colorectal cancer risk stratification by combining family history and genetic risk score. Clin. Epidemiol. 10, 143–152 (2018).
He, Y. et al. Exploring causality in the association between circulating 25-hydroxyvitamin D and colorectal cancer risk: a large Mendelian randomisation study. BMC Med. 16, 142 (2018).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Delaneau, O., Marchini, J. & Zagury, J. F. A linear complexity phasing method for thousands of genomes. Nat. Methods 9, 179–181 (2011).
Howie, B. N., Donnelly, P. & Marchini, J. A flexible and accurate genotype imputation method for the next generation of genome-wide association studies. PLoS Genet. 5, e1000529 (2009).
Marchini, J., Howie, B., Myers, S., McVean, G. & Donnelly, P. A new multipoint method for genome-wide association studies by imputation of genotypes. Nat. Genet. 39, 906–913 (2007).
Liu, J. Z. et al. Meta-analysis and imputation refines the association of 15q25 with smoking quantity. Nat. Genet. 42, 436–440 (2010).
Yang, J., Lee, S. H., Goddard, M. E. & Visscher, P. M. GCTA: a tool for genome-wide complex trait analysis. Am. J. Hum. Genet. 88, 76–82 (2011).
Orlando, G., Kinnersley, B. & Houlston, R. S. Capture Hi-C library generation and analysis to detect chromatin interactions. Curr. Protoc. Hum. Genet. 98, e63 (2018).
Cairns, J. et al. CHiCAGO: robust detection of DNA looping interactions in Capture Hi-C data. . Genome Biol. 17, 127 (2016).
Cohen, A. J. et al. Hotspots of aberrant enhancer activity punctuate the colorectal cancer epigenome. Nat. Commun. 8, 14400 (2017).
Yan, J. et al. Transcription factor binding in human cells occurs in dense clusters formed around cohesin anchor sites. Cell 154, 801–813 (2013).
Scales, M., Jager, R., Migliorini, G., Houlston, R. S. & Henrion, M. Y. visPIG--a web tool for producing multi-region, multi-track, multi-scale plots of genetic data. PLoS ONE 9, e107497 (2014).
Jager, R. et al. Capture Hi-C identifies the chromatin interactome of colorectal cancer risk loci. Nat. Commun. 6, 6178 (2015).
Coetzee, S. G., Coetzee, G. A. & Hazelett, D. J. motifbreakR: an R/Bioconductor package for predicting variant effects at transcription factor binding sites. Bioinformatics 31, 3847–3849 (2015).
Schumacher, F. R. et al. Association analyses of more than 140,000 men identify 63 new prostate cancer susceptibility loci. Nat. Genet. 50, 928–936 (2018).
Pharoah, P. D., Antoniou, A. C., Easton, D. F. & Ponder, B. A. Polygenes, risk prediction, and targeted prevention of breast cancer. N. Engl. J. Med. 358, 2796–2803 (2008).
Acknowledgements
At the Institute of Cancer Research, this work was supported by Cancer Research UK (C1298/A25514). Additional support was provided by the National Cancer Research Network. In Edinburgh, the work was supported by Programme Grant funding from Cancer Research UK (C348/A12076) and by funding for the infrastructure and staffing of the Edinburgh CRUK Cancer Research Centre. In Birmingham, funding was provided by Cancer Research UK (C6199/A16459). We are grateful to many colleagues within UK Clinical Genetics Departments (for CORGI) and to many collaborators who participated in the VICTOR, QUASAR2 and SCOT trials.
We also thank colleagues from the UK National Cancer Research Network (for NSCCG). Support from the European Union [FP7/207–2013, grant 258236] and FP7 collaborative project SYSCOL and COST Action in the UK is also acknowledged [BM1206]. The COIN and COIN-B trials were funded by Cancer Research UK and the Medical Research Council and were conducted with the support of the National Institute of Health Research Cancer Research Network. COIN and COIN-B translational studies were supported by the Bobby Moore Fund from Cancer Research UK, Tenovus, the Kidani Trust, Cancer Research Wales and the National Institute for Social Care and Health Research Cancer Genetics Biomedical Research Unit (2011–2014).
We thank the High-Throughput Genomics Group at the Wellcome Trust Centre for Human Genetics (funded by Wellcome Trust grant reference 090532/Z/09/Z) and the Edinburgh Clinical Research Facility (ECRF) Genetics Core, Western General Hospital, Edinburgh, for the generation of genotyping data.
We thank the Lothian Birth Cohorts’ members, investigators, research associates, and other team members. We thank the Edinburgh Clinical Research Facility (ECRF) Genetics Core, Western General Hospital, Edinburgh, for genotyping. Lothian Birth Cohorts’ data collection is supported by the Disconnected Mind project (funded by Age UK), and the Biotechnology and Biological Sciences Research Council (BBSRC, for genotyping; BB/F019394/1) and undertaken within the University of Edinburgh Centre for Cognitive Ageing and Cognitive Epidemiology (funded by the BBSRC and Medical Research Council RC as part of the LLHW [MR/K026992/1]). ET was supported by Cancer Research UK CDF (C31250/A22804). This research has been conducted using the UK Biobank Resource under Application Number 7441.
Generation Scotland received core support from the Chief Scientist Office of the Scottish Government Health Directorates [CZD/16/6] and the Scottish Funding Council [HR03006]. Genotyping of the GS:SFHS samples was carried out by the Genetics Core Laboratory at the Clinical Research Facility, University of Edinburgh and was funded by the Medical Research Council UK and the Wellcome Trust (Wellcome Trust Strategic Award “STratifying Resilience and Depression Longitudinally” (STRADL) [104036/Z/14/Z]).
CFR was supported by a Marie Sklodowska-Curie Intra-European Fellowship Action and received considerable help from many staff in the Department of Endoscopy at the John Radcliffe Hospital in Oxford.
In Finland, this work was supported by grants from the Academy of Finland [Finnish Center of Excellence Program 2012–2017, 250345 and 2018–2025, 312041], the Jane and Aatos Erkko Foundation, the Finnish Cancer Society [personal grant to K.P.], the European Research Council [ERC; 268648], the Sigrid Juselius Foundation, SYSCOL, the Nordic Information for Action eScience Center (NIASC), the Nordic Center of Excellence financed by NordForsk [project 62721, personal grant to K.P.] and State Research Funding of Kuopio University Hospital [B1401]. We acknowledge the computational resources provided by the ELIXIR node, hosted at the CSC–IT Center for Science, Finland, and funded by the Academy of Finland [grants 271642 and 263164], the Ministry of Education and Culture, Finland. V.S. was supported by the Finnish Academy [grant number 139635] and the Finnish Foundation for Cardiovascular Research. J.-P.M. was funded by The Finnish Cancer Foundation and The Jane and Aatos Erkko Foundation. Sample collection and genotyping in the Finnish Twin Cohort has been supported by the Wellcome Trust Sanger Institute, ENGAGE—European Network for Genetic and Genomic Epidemiology, FP7-HEALTH-F4–2007; [grant agreement number 201413], the National Institute of Alcohol Abuse and Alcoholism [grants AA-12502 and AA-00145; to R.J.R. and K02AA018755 to D.M.D.] and the Academy of Finland [grants 100499, 205585, 265240 and 263278 to J.K.].
The work of the Colon Cancer Family Registry (CCFR) was supported by the National Cancer Institute (NCI) of the National Institutes of Health (NIH) under Award number U01 CA167551. The CCFR Illumina GWAS was supported by the NCI/NIH under Award Numbers U01 CA122839 and R01 CA143237 to G.C. The content of this manuscript does not necessarily reflect the views or policies of the NCI or any of the collaborating centres in the CCFR, nor does mention of trade names, commercial products, or organizations imply endorsement by the US Government or the CCFR.
The CORSA study was funded by FFG BRIDGE (grant 829675, to A.G.), the “Herzfelder’sche Familienstiftung” (grant to A.G.) and was supported by COST Action BM1206. We kindly thank all individuals who agreed to participate in the CORSA study. Furthermore, we thank all cooperating physicians and students and the Biobank Graz of the Medical University of Graz.
The DACHS study was supported by grants from the German Research Council (Deutsche Forschungsgemeinschaft, BR 1704/6–1, BR 1704/6–3, BR 1704/6–4, BR 1704/6–6 and CH 117/1–1), and the German Federal Ministry of Education and Research (01KH0404, 01ER0814, 01ER0815 and 01ER1505A, 01ER1505B). We thank all participants and cooperating clinicians, and Ute Handte-Daub, Ansgar Brandhorst, Muhabbet Celik and Ursula Eilber for excellent technical assistance.
The Croatian study was supported through the 10,001 Dalmatians Project, and institutional support of University Hospital for Tumours, Sestre milosrdnice University Hospital Center.
James East and Simon Leedham were funded by the National Institute for Health Research (NIHR) Oxford Biomedical Research Centre (BRC). The views expressed not necessarily those of the NHS, the NIHR or the Department of Health.
We acknowledge use of genotype data from the British 1958 Birth Cohort DNA collection, which was funded by the Medical Research Council Grant G0000934 and the Wellcome Trust Grant 068545/Z/02. A full list of the investigators who contributed to the generation of the data is available from http://www.wtccc.org.uk.
The BCAC study would not have been possible without the contributions of the following: Manjeet K. Bolla, Qin Wang, Kyriaki Michailidou and Joe Dennis. BCAC is funded by Cancer Research UK (C1287/A10118, C1287/A16563). For the BBCS study, we thank Eileen Williams, Elaine Ryder-Mills, Kara Sargus. The BBCS is funded by Cancer Research UK and Breast Cancer Now and acknowledges NHS funding to the National Institute of Health Research (NIHR) Biomedical Research Centre (BRC) and the National Cancer Research Network (NCRN). We thank the participants and the investigators of EPIC (European Prospective Investigation into Cancer and Nutrition). The coordination of EPIC is financially supported by the European Commission (DG-SANCO) and the International Agency for Research on Cancer. The national cohorts are supported by: Ligue Contre le Cancer, Institut Gustave Roussy, Mutuelle Générale de l’Education Nationale, Institut National de la Santé et de la Recherche Médicale (INSERM) (France); German Cancer Aid, German Cancer Research Center (DKFZ), Federal Ministry of Education and Research (BMBF) (Germany); the Hellenic Health Foundation, the Stavros Niarchos Foundation (Greece); Associazione Italiana per la Ricerca sul Cancro-AIRC-Italy and National Research Council (Italy); Dutch Ministry of Public Health, Welfare and Sports (VWS), Netherlands Cancer Registry (NKR), LK Research Funds, Dutch Prevention Funds, Dutch ZON (Zorg Onderzoek Nederland), World Cancer Research Fund (WCRF), Statistics Netherlands (The Netherlands); Health Research Fund (FIS), PI13/00061 to Granada, PI13/01162 to EPIC-Murcia, Regional Governments of Andalucía, Asturias, Basque Country, Murcia and Navarra, ISCIII RETIC (RD06/0020) (Spain); Cancer Research UK (14136 to EPIC-Norfolk; C570/A16491 and C8221/A19170 to EPIC-Oxford), Medical Research Council (1000143 to EPIC-Norfolk, MR/M012190/1 to EPIC-Oxford) (United Kingdom). We thank the SEARCH and EPIC teams, which were funded by a programme grant from Cancer Research UK (C490/A10124) and supported by the UK NIHR BRC at the University of Cambridge. We thank Breast Cancer Now and the Institute of Cancer Research (ICR) for support and funding of the UKBGS, and the study participants, study staff, and the doctors, nurses and other health-care providers and health information sources who have contributed to the study.
Genotyping of the PRACTICAL consortium OncoArray was funded by the US National Institutes of Health (NIH) [U19 CA 148537 for ELucidating Loci Involved in Prostate cancer SuscEptibility (ELLIPSE) project and X01HG007492 to the Center for Inherited Disease Research (CIDR) under contract number HHSN268201200008I]. Additional analytic support was provided by NIH NCI U01 CA188392 (PI: Schumacher). The PRACTICAL consortium was supported by Cancer Research UK Grants C5047/A7357, C1287/A10118, C1287/A16563, C5047/A3354, C5047/A10692, C16913/A6135, European Commission’s Seventh Framework Programme grant agreement n° 223175 (HEALTH-F2–2009–223175), and The National Institute of Health (NIH) Cancer Post-Cancer GWAS initiative grant: No. 1 U19 CA 148537–01 (the GAME-ON initiative). We would also like to thank the following for funding support: The Institute of Cancer Research and The Everyman Campaign, The Prostate Cancer Research Foundation, Prostate Research Campaign UK (now Prostate Action), The Orchid Cancer Appeal, The National Cancer Research Network UK, The National Cancer Research Institute (NCRI) UK. We are grateful for support of NIHR funding to the NIHR Biomedical Research Centre at The Institute of Cancer Research and The Royal Marsden NHS Foundation Trust, the Spanish Instituto de Salud Carlos III (ISCIII) an initiative of the Spanish Ministry of Economy and Innovation (Spain), and the Xunta de Galicia (Spain).
The APBC BioResource, which forms part of the PRACTICAL consortium, consists of the following members: Wayne Tilley, Gail Risbridger, Renea Taylor, Lisa Horvath, Vanessa Hayes, Lisa Butler, Trina Yeadon, Allison Eckert, Anne-Maree Haynes, Melissa Papargiris.
We are grateful for the provision of public data from the GTEx consortium.
Finally, the authors gratefully acknowledge the participation of patients, their families, and controls in the relevant studies.
Author information
Authors and Affiliations
Consortia
Contributions
Study concept and design: R.S.H., I.T. and M.G.D. Patient recruitment: S.P. and L.M. Sample preparation and genotyping: A.Holroyd., P.B. Primary data analysis: P.J.L., M.T., C.F.-R. and J.F.-T. Additional analysis: J.Studd., G.O., A.Sud., S.F., V.S., C.P., S.Briggs., L.M., E.Jaeger., A.S.-O., J.E. and S.L. Provided sample data: E.T., P.V.-S., L.Z., A.C., H.C., C.H., S.H., I.J.D., J.Starr., R.A., E.Johnstone., H.W., L.G., M.P., D.K., R.Kerr., T.M., R.Kaplan., N.A.-T., J.P.C., K.P., L.A.A., U.A.H., T.C., T.T., J.K., E.K., A.-P.S., J.G.E., H.R., P.K., E.P., P.J., V.S., S.R., A.P., L.R.-S., A.L., J.B., J.-P.M., D.D.B., A.-K.W., J.H., M.E.J., N.M.L., P.A.N., S.G., D.D., G.C., P.Hoffmann., M.M.N., K.-H.J., D.F.E., P.D.P.P., J.Peto., F.C., A.Swerdlow., R.A.E., Z.K.-J., K.M., N.P., PRACTICAL Consortium, A.Harkin., K.A., J.M., J.Paul., T.I., M.S., K.B., J.C.-C., M.H., H.B., I.K., P.M., P.Hofer., S.Brezina. and A.G. Writing manuscript: R.S.H., I.T., M.G.D and P.J.L. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
D.K. is a founder and shareholder of Oxford Cancer Biomarkers. V.S. has participated in a conference trip sponsored by Novo Nordisk and received an honorarium from the same source for participating in an advisory board meeting. The remaining authors declare no competing interests.
Additional information
Journal peer review information: Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional members from the Prostate Cancer Association Group to Investigate Cancer Associated Alterations in the Genome (PRACTICAL) consortium are listed below.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Law, P.J., Timofeeva, M., Fernandez-Rozadilla, C. et al. Association analyses identify 31 new risk loci for colorectal cancer susceptibility. Nat Commun 10, 2154 (2019). https://doi.org/10.1038/s41467-019-09775-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-019-09775-w
This article is cited by
-
Genome-wide polygenic risk scores for colorectal cancer have implications for risk-based screening
British Journal of Cancer (2024)
-
Prioritization of risk genes in colorectal cancer by integrative analysis of multi-omics data and gene networks
Science China Life Sciences (2024)
-
Germline genetic regulation of the colorectal tumor immune microenvironment
BMC Genomics (2024)
-
Genetic risk impacts the association of menopausal hormone therapy with colorectal cancer risk
British Journal of Cancer (2024)
-
Fine-mapping analysis including over 254,000 East Asian and European descendants identifies 136 putative colorectal cancer susceptibility genes
Nature Communications (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
