
Abstract
Precise genome-editing platforms are versatile tools for generating specific, site-directed DNA insertions, deletions, and substitutions. The continuous enhancement of these tools has led to a revolution in the life sciences, which promises to deliver novel therapies for genetic disease. Precise genome-editing can be traced back to the 1950s with the discovery of DNA’s double-helix and, after 70 years of development, has evolved from crude in vitro applications to a wide range of sophisticated capabilities, including in vivo applications. Nonetheless, precise genome-editing faces constraints such as modest efficiency, delivery challenges, and off-target effects. In this review, we explore precise genome-editing, with a focus on introduction of the landmark events in its history, various platforms, delivery systems, and applications. First, we discuss the landmark events in the history of precise genome-editing. Second, we describe the current state of precise genome-editing strategies and explain how these techniques offer unprecedented precision and versatility for modifying the human genome. Third, we introduce the current delivery systems used to deploy precise genome-editing components through DNA, RNA, and RNPs. Finally, we summarize the current applications of precise genome-editing in labeling endogenous genes, screening genetic variants, molecular recording, generating disease models, and gene therapy, including ex vivo therapy and in vivo therapy, and discuss potential future advances.
Similar content being viewed by others
Introduction
Among the approximately 25,000 annotated genes in the human genome, over 3000 mutations have been identified in connection with diseases, and ongoing research is revealing additional genetic variations relevant to various disorders.1 Thus, a primary goal of biomedical research is to identify, characterize, and correct these mutations, in order to cure disease. The rapid progress in the diagnosis of genetic diseases has been driven by the decreasing costs of genome sequencing, advancements in computational techniques for comparing human genome sequences,2 and the expanded utilization of high-throughput genomic screening.3,4,5 Nevertheless, the scarcity of treatments, let alone cures, for genetic diseases, has led to an increasing gap between diagnostic capabilities and therapeutic options.6 This emphasizes a pressing need for the development of effective treatments. The prospect of mitigating or rectifying disease-causing mutations is an enticing objective with the potential to save and enhance countless lives, while the recent emergence of precise genome-editing technology provides a pathway to making the dream a reality.
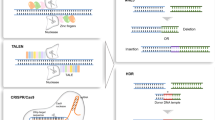
An ideal gene-editing technology should be able to transform a target DNA sequence into any other desired sequence while achieving high on-target editing rates (efficiency), and minimal off-target edits (specificity).7 The life sciences have long aspired to create gene-editing tools that possess exceptional efficiency, adaptability, product purity, and precision in targeting specific genetic sequences. In the nearly 70 years since the discovery of DNA’s double-helix structure,8,9,10 scientists have employed a variety of methods for genome modification, including homologous recombination,11,12,13 the Cre/LoxP system,14,15,16 zinc-finger nucleases (ZFNs),17,18,19 transcription activator-like effector nucleases (TALENs),20,21,22 and the CRISPR/Cas system and CRISPR/Cas-derived base editors (BEs) and prime editors (PEs)23,24,25,26,27 (Fig. 1). This continuous improvement and diversification of genome-editing technologies suggests that widespread correction of genetic disease via precise genome-editing is only a matter of time, and that progress towards this goal is rapidly accelerating.

Timeline of the development of precise genome-editing tools. Key milestones in precise genome-editing are indicated. HR Homologous recombination, ZFNs Zinc-finger nucleases, TALENs Transcription activator-like effector nucleases, HITI Homology-independent targeted integration, CAST CRISPR-associated transposase. This figure was produced using BioRender.com
This review seeks to offer a comprehensive overview of precise genome-editing modalities and their underlying mechanisms. We briefly introduce the history of precise gene editing in human disease, ranging from the earliest experiments to the development of modern techniques. Next, we discuss a variety of modern precise genome-editing strategies, highlighting the limitations and challenges of each. Lastly, we focus on therapeutic applications of precise gene editing in human disease.
History events of precise genome-editing in human disease
The concept of utilizing gene editing for the purpose of disease treatment or trait modification can be traced back to as early as the 1950s, coinciding with the momentous uncover of DNA’s double-helix structure by Watson and Crick.28 In the subsequent 1960s, scientists discovered restriction endonucleases, which specifically recognize short stretches of nucleotides in DNA and create double-strand DNA breaks (DSBs) at or near the recognition locus (also known as a restriction site).29,30,31 This discovery of restriction enzymes would prove to be pivotal to the development of recombinant DNA techniques when, in 1972, Paul Berg used restriction enzymes to create the first recombinant DNA molecule, marking the birth of genetic engineering.8,32 In the 1980s, bacteriophage P1 Cre recombinase was discovered,33 and scientists soon developed mechanisms to control recombinase activity, namely through the strategic insertion of 34-nucleotide DNA sequences called “loxP” sites (locus of crossing, P1), which Cre will recognize and facilitate site-specific recombination between, resulting in the removal of intervening DNA.34,35,36,37 By the 1990s, researchers had started using the Cre/loxP system to engineer genomic modifications in mice.38,39 These ventures in genetic engineering were facilitated by the discovery that DNA sequences could be inserted into the specific loci of mammalian cells via homologous recombination (HR).40,41,42 This gene targeting technology was subsequently used on mouse embryonic stem (ES) cells which in turn were used to generate large numbers of genetically modified mouse strains.43,44,45,46,47,48 However, these efforts were hindered by the very low frequency of natural HR between exogenous donor DNA and target DNA.49
In the 1980s, scientists identified the potential to engineer zinc-finger proteins, allowing them to selectively bind to specific DNA sequences and opening the door to the design of customized DNA-binding proteins.50,51,52,53 The next stage in the evolution of this technology came in the late 1990s when researchers developed ZFNs capable of introducing DSBs in a sequence-specific manner. This was achieved by fusing engineered zinc-finger domains to the FokI endonuclease domain.54 Subsequently, ZFNs were used to produce targeted genome edits in various model organisms, including human cell lines.55,56,57,58,59 The utilization of ZFNs to induce a DSB at the target site substantially increased the efficiency of HR, with cellular success rates reported to be as high as 20%,60 thus greatly promoting the widespread application of gene editing. This approach of homology-directed repair (HDR) of DSBs would later become standard practice for several different genome-editing modalities. Despite the successes of ZFNs, their design and production are time-consuming, laborious, and expensive, and these factors prevented widespread adoption. In 2009, researchers discovered transcription activator-like effectors (TALEs), which, similar to zinc-finger proteins, can specifically bind to DNA sequences.61,62 In 2011, scientists engineered TALEs that fused to the nonspecific FokI cleavage domain (TALENs), allowing for the introduction of targeted DSBs in human cells with high efficiency.63 TALENs show multiple advantages over engineered ZFNs, including an easier design process, and their potential ability to be targeted to a wider range of sequences.64 However, this approach still suffers from the complexities associated with needing to engineer a new protein for each target.
This barrier to progress in the gene editing field would not be surmounted until 2012 when Doudna, Charpentier, et al.23 developed CRISPR/Cas9 gene editing systems. Unlike ZFNs and TALENs, which both specifically bind to DNA through complex engineered proteins, the CRISPR/Cas9 system relies on the specific binding of an engineered single guide RNA (sgRNA) with homology to the target DNA. These easily programmable sgRNAs bind to Cas9 and guide the Cas9 nuclease to the DNA target site, where a DSB is created. Following this discovery, Feng et al.24 and Church et al.65 employed the CRISPR/Cas9 system to achieve accurate cleavage at endogenous genomic loci in human and mouse cells. The advent of the CRISPR/Cas9 system significantly streamlined genome-editing, resulting in rapid adoption. Common simple use cases include inactivating gene function by introducing small, partially random insertions and deletions (indels), which are formed during the repair of DSBs. As with ZFNs and TALENs, precise editing can be achieved via HDR when a donor template is provided along with the guide RNA and Cas9 nuclease. However, HDR is typically restricted to dividing cells due to overlaps in the cellular machinery required for cell cycle progression and HDR.62,66,67,68 To bypass this limitation, in 2016, Belmonte et al.69 developed Cas9-mediated homology-independent targeted integration (HITI), enabling efficient DNA knock-in in both dividing and non-dividing cells in vitro, and notably, in vivo. While HITI can achieve robust insertion efficiencies, indel frequencies are relatively high at the junctions between the insertion and native locus, as well as at targets where insertion fails.70 In comparison, HDR typically results in low indel rates at positions flanking the insertion, while indels are commonly found at target sites where HDR fails.71,72 In addition to these limitations, all of the precise editing techniques discussed above involve the creation of DNA breaks which can trigger strong DNA damage responses, which may impact cell phenotypes.73,74
In 2016 and 2017, Liu et al.25,26 developed BEs, which are capable of chemically converting one DNA nucleotide to another at a target locus. This was achieved by fusing a nuclease-dead mutant Cas9 (dCas9) protein to a cytidine or an adenosine deaminase enzyme. The fusion protein retains the ability to be programmed with a sgRNA, but does not induce DSBs; instead, the editing complex mediates the direct conversion of C•G to T•A or A•T to G•C. This system demonstrated gene editing efficiencies up to 55%, with minimal off-target edits.26 However, this exciting technology is not without limitations. While BEs have the capacity to induce transition mutations, converting purine to purine (A to G) or pyrimidine to pyrimidine (C to T), they currently cannot perform the eight transversion mutations (purine to pyrimidine) and cannot perform targeted deletions or insertions. In 2019, Liu et al.27 further modified CRISPR/Cas9 and developed the PE system, allowing for precise modifications to DNA sequences at a specific locus through the fusion of dCas9 or nickase Cas9 with an engineered reverse transcriptase, guided by a PE guide RNA (pegRNA) specifying the target site and desired edit. This system can perform targeted insertions, deletions, and any type of point mutation, without requiring DSBs or donor DNA templates.27 During the same time period, Zhang et al.75 and Sternberg et al.76 characterized a CRISPR-associated transposase (CAST) that utilizes Tn7-like transposase subunits and type V-K or type I-F CRISPR effectors, enabling RNA-guided DNA transposition with unidirectional insertion of DNA segments at specific loci. Work by Kleinstiver et al.77 and Sternberg et al.78 would later demonstrate that CASTs could be engineered to precisely integrate large DNA sequences in human cells with improved integration product purity and genome-wide specificity. After nearly seventy years of development, these diverse systems showcase the rapidly evolving nature of precise genome-editing, as well as the ever-expanding number of use cases, and substantial improvements in editing efficiency and specificity (Fig. 1).
Overview of precise genome-editing strategies
Currently, precise genome-editing is achieved using various molecular tools and techniques that activate DNA repair pathways. These techniques can be roughly divided into DSB and non-DSB mediated repair mechanisms. DSBs primarily contribute to precise genome-editing via the HDR DNA repair pathway, while a variety of genome-editing modalities utilize non-DSB DNA repair pathways (Table 1).
HDR-mediated precise genome-editing
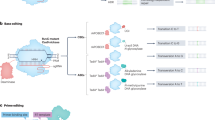
Early methods of HR-based precise genome-editing involved the introduction of exogenous double-stranded DNA template into cells. Recombination between the target locus and the template would occasionally occur, resulting in precise editing, which was successfully used to generate knock-in cell lines and gene-modified mice. However, the frequency of HR between exogenous donor DNA and target DNA in the absence of a DSB is very low,49 and this shortcoming precluded the use of the approach in therapeutics. However, in the presence of both an exogenous donor template and a DSB in the target locus, HR efficiency can be improved by many orders of magnitude.57,79 This HDR-mediated approach to genome-editing is dependent on efficient introduction of nuclease for target-specific dsDNA cleavage. Currently, the most widely used site-specific nucleases include ZFNs, TALENs, and CRISPR/Cas9 (Fig. 2).

Precise genome-editing with site specific nucleases. ZFNs create double-strand breaks (DSBs) using the FokI restriction enzyme paired with specific zinc-finger DNA-binding domains. TALENs induce DSBs using the FokI restriction enzyme in conjunction with specific TALE DNA-binding domains. Cas9 nuclease, targeted by guide RNAs, creates DSBs using two distinct domains of nuclease. Genome-editing utilizing nucleases relies on two primary DNA repair pathways. The first pathway consists of end-joining mechanisms, which can be divided into classical nonhomologous end-joining (c-NHEJ), which can be used to produce targeted semi-random indels, and homology-independent target integration (HITI), which can be used to insert an exogenous sequence at a desired genomic target in the absence of homology arms. The second major repair mechanism is homology-directed repair (HDR), which primarily occurs in dividing cells, and can be used to create precise targeted edits via a single-strand or double-strand DNA donor template. ZFNs Zinc-finger nucleases, TALENs Transcription activator-like effector nucleases. This figure was produced using BioRender.com
ZFNs-mediated HDR
ZFNs are chimeric proteins formed by linking the endonuclease domain of the bacterial FokI restriction enzyme with an array of site-specific DNA-binding domains, sourced from zinc-finger–containing transcription factors.54 The zinc-finger protein, possessing DNA-binding specificity, was initially identified in 1985 within transcription factor IIIa in Xenopus oocytes.52 An individual zinc-finger domain, consisting of approximately 30 amino acids, recognizes a 3 base pair (bp) DNA sequence.80 When arranged in tandem, these zinc-finger domains can potentially adhere to a longer DNA sequence 9 to 18 bp in length.81 By leveraging an 18 bp DNA sequence, specificity could be attained within an immense 68 billion-bp DNA pool. Thus, this breakthrough enabled the precise targeting of specific sequences within the human genome, marking a significant advancement.82,83
Since the FokI nuclease necessitates dimerization for DNA cleavage, ZFNs are structured as a pair that identifies two sequences bordering the target site—one on the forward strand and another on the reverse strand. When the ZFNs bind on both sides of the site, the FokI domains within the pair dimerize, leading to DNA cleavage at the target site. This process results in the creation of a DSB with 5’ overhangs.18,84 These DSBs can be used in combination with exogenous or endogenous donor templates to achieve precise genome-editing via the HDR pathway. Given the modular design of ZFNs, it’s possible to fine-tune the zinc-finger and nuclease domains independently. This capability empowers scientists to create new modular combinations, optimizing their affinity and specificity for applications in genome engineering.85
Nevertheless, ZFNs as first-generation gene editing tools have limitations. Assembling zinc-finger domains to bind an extended DNA sequence is a challenging task. The complexity of this process has hindered the dissemination of the approach beyond a small, specialized field.86 An additional drawback lies in the restricted target site selection, as the existing ZFN components can only address sites occurring at approximately 200 bp intervals in a random DNA sequence.87 This may present challenges for targeting particular sites, thus limiting the technique’s potential as a therapeutic tool.87
TALENs-mediated HDR
TALENs are also chimeric site-specific nucleases, in which an engineered array of TALE-specific DNA binding domains are fused with FokI endonuclease.63,88 TALEs, derived from plant pathogenic bacteria of the Xanthomonas genus, consist of repetitive sequences with 10 to 30 tandem arrays, enabling them to bind and identify extended DNA sequences.61,89 Each repeat comprises 33–35 amino acids, and specificity for one of the four DNA base pairs is determined by two adjacent amino acids, known as the repeat-variable di-residue.90,91,92 Thus, each repeat corresponds precisely to a base pair within the target DNA sequence. TALENs, akin to ZFNs, have the capability to induce DSBs at a specific target locus, facilitating precise genome-editing through the HDR pathway.
In comparison with ZFNs, TALENs have several potential advantages. First, recognizing individual bases with TALE–DNA binding repeats provides more design flexibility compared to triplet-confined zinc-finger proteins. TALENs can be rapidly designed and assembled in as little as two days and can be produced in large quantities, reaching into the hundreds at once.64,93,94 Second, the TALE repeat array can be easily extended to any desired length, in contrast to engineered ZFNs, which typically bind sequences of 9 to 18 bp.87 Additionally, TALENs offer more flexibility in selecting target sites, as theoretically, numerous TALEN pairs can be designed for each base pair within any arbitrary DNA sequence.94 Nonetheless, widespread TALEN adoption faces multiple challenges, one of which is the repetitive structure of TALENs, which may hinder their efficient packaging and delivery using certain viral vectors.95 Another commonly agreed limitation with TALE arrays is that TALE binding sites need to be initiated with a thymine base in order to achieve maximal binding.96
CRISPR/Cas-mediated HDR
The classical CRISPR/Cas system, which was first developed as a gene-editing tool in 2012,23 employs the Cas9 endonuclease. CRISPR/Cas9 system has two components: an engineered sgRNA derived from the mature tracrRNA:crRNA complex, which forms base pairs with target DNA, and the Cas9 endonuclease, which cuts the target dsDNA to create DSBs.23 The sgRNAs have two key features: a 20 bp sequence at the 5’ end that determines the target DNA site via Watson-Crick base-pairing, and the remaining 3’ sequence that recruits Cas9. After being guided to the target DNA sequence by the sgRNA, Cas9 recognizes the protospacer adjacent motif (PAM), an NGG sequence motif adjacent to the target, and subsequently, uses its RuvC and HNH domains to cleave the two single-strand DNA (ssDNA) sequences, forming a DSB.28 The HNH domain of Cas9 cleaves the DNA strand complementary to the sgRNA, and the RuvC domain cleaves the remaining strand, leading to a blunt-ended break, although DSBs with 5’ overhangs have also been proposed.97,98
Unlike ZFNs and TALENs, which demand protein recoding with substantial DNA segments (ranging from 500 to 1500 bp) for each unique target location, CRISPR-Cas9 offers great adaptability, as targeting is achieved by simply modifying the 20 bp protospacer sequence in the sgRNA. This is often accomplished via single-step cloning of the 20 bp segment into a plasmid encoding the sgRNA.65 Another potential benefit of CRISPR-Cas9 is its capability for multiplexing—utilizing multiple sgRNAs concurrently to target numerous sites simultaneously within the same cell, which is particularly valuable for assessing genetic interactions, and when generating an extensive array of vectors for targeting numerous sites or even entire genome-wide libraries.99,100,101,102 Thus CRISPR/Cas9-mediated HDR has been widely applied in various cultured cell lines,103,104,105,106 mice,107,108,109 pig,110,111 rabbit,112,113 and zebrafish.114
Nevertheless, A clear disadvantage of CRISPR/Cas9 is off-target nuclease activity, which can lead to serious adverse effects. To address this deficiency, one strategy involves utilizing a modified Cas9 variant capable of inducing a single-strand nick in the target DNA, as opposed to a DSB. By employing a pair of these “nickase” CRISPR-Cas9 complexes, each with binding sites on opposite DNA strands flanking the target site, allows for the generation of an outcome similar to a DSB with 5’ overhangs.115,116,117 Since a DSB is only formed when both distinct sgRNA/Cas9 complexes act at the same target, off-target activity is much less likely to result in a DSB. In another similar approach, fusion of dCas9 with the catalytic domain of Fok1 has been employed to enhance the precision of DSB creation.118,119 The catalytic domain of the Fok1 nuclease is only active when it forms a homodimer. Consequently, the synchronized recruitment of two Fok1 catalytic domain monomers to adjacent DNA sites is crucial for efficient and precise DNA cleavage in human cells, leading to minimal off-target editing efficiency for these systems.118,119 In addition to these nuclease-focused optimizations, engineering approaches for sgRNA, such as truncation or chemical modification, have demonstrated the ability to decrease off-target editing efficiency by up to three orders of magnitude while preserving high levels of on-target editing.120,121 Another challenge of utilizing the CRISPR/Cas9 system is the size of the Cas9 protein. The cDNA that encodes classical S. pyogenes Cas9 (spCas9) is approximately 4.2 kilobases (kb) in size, slightly larger than a TALEN or ZFN. This makes spCas9 challenging to deliver via commonly used viral vectors, such as adeno-associated virus (AAV), which has a cargo size limited to less than 4.7 kb.122 To address this shortness, novel Cas variants have been developed, such as S. aureus Cas9 (saCas9),123 Cas12a,124 Cas12e,125 Cas12f,126,127 Cas12j,128,129 and Cas12n.130 These new Cas variants usually have a small molecular weight. For instance, Cas12f is one of the most compact Cas variants, consisting of ~400–700 amino acids. Several groups have developed a series of Cas12f proteins, which showed efficient gene editing.131,132,133 This size reduction makes it possible to package the Cas nuclease, a guide RNA, and a donor template for HDR all within a single AAV vector.
The Mechanism of HR
DSBs can undergo repair through the endogenous repair machinery, involving either the non-homologous end joining (NHEJ) or HDR pathways. NHEJ introduces semi-random indels; however, when a donor DNA template, either double-stranded or single-stranded, is available and possesses homology to the adjacent sequences surrounding the DSBs, the HDR pathway may be taken, resulting in a DSB repair that follows the base sequence of the donor template, and thus achieving a precise edit. The most common form of HDR is HR, which includes two sub-pathways of double-strand break repair (DSBR) and synthesis-dependent strand annealing (SDSA).134,135
The initial process of HR involves the resection of a DSB to provide long 3’ single-stranded DNA overhangs. The Mre1, Rad50, and Nbs1 proteins form a three-subunit Mre1-Rad50-Nbs1(MRN) complex that recognizes and binds to the DSB ends through facilitated diffusion. The MRN complex recruits and activates the ataxia-telangiectasia mutated (ATM) protein kinase.136,137 Activated ATM can phosphorylate the C-terminal binding protein interacting protein (CtIP),138 which then interacts with breast cancer-associated protein 1 (BRCA1) to form a BRCA1/MRN/CtIP complex.139 The complex is then involved in 5’ end cleavage near the DSB site to expose long 3’ ssDNA overhangs.140,141,142 The overhangs are then recognized and bound by the replication protein A (RPA), which protects and stabilizes them.143 Subsequently, RAD51 interacts with BRCA2 to form a presynaptic nucleoprotein filament complex which replaces RPA on the ssDNA and searches for endogenous or exogenous homologous DNA.144,145
An intermediate displacement loop (D-loop) is formed when one of the long 3’ ssDNA overhangs invade the double stranded donor template. Next, DNA polymerase δ (Poly δ) uses the 3’ end of the invading strand to prime the synthesis of a new strand.146,147,148 In DSBR, after one strand invasion and new DNA synthesis, the second 3’ ssDNA overhangs will be captured to form two intermediates with Holliday junctions (HJs).149 These are accompanied by gap-filling DNA synthesis and ligation.150 Finally, the resolution of HJs is processed to generate either non-crossover or crossover products.151 Alternatively, in SDSA, the invaded template strand dissociates from the D-loop during new DNA synthesis.152 The newly synthesized ssDNA pairs with the complementary ssDNA strand at the opposite end of the DSBs, and the resulting ends are extended through gap-filling DNA synthesis and ligated, generating only non-crossover products.151 Since HDR utilizes donor templates for guiding repair, it can be harnessed to achieve precise DNA editing. However, the activation of the key protein ATM in the HDR pathway is cell cycle-dependent.153 Therefore, HDR is restricted in the S/G2 phases of the dividing cells.
Although HDR-mediated precise genome-editing has tremendous use cases and potential in biology and medicine, there are still limitations and challenges that need to be addressed. First, HDR is a less efficient DNA repair pathway than NHEJ.79,154,155,156 Even with recent advancements, current approaches for rectifying point mutations through HDR in therapeutically relevant settings still suffer from inefficiency.28 The efficiency of HDR repair depends on several factors, such as the NHEJ and HDR pathways, the length of the donor template, and the location of the target site. Moreover, achieving efficient delivery of the donor template to target cells or organisms poses a challenge, particularly for certain cell types. Second, the availability of the cellular machinery involved in HDR is typically limited to the S and G2 phases of the cell cycle.157,158 The cell cycle dependence of HDR can limit the efficiency of genome-editing, particularly in cells with a short S/G2 phase or in vivo applications, which often involve cells with low proliferation rates. Intriguingly, we and other teams have found that postmitotic cells can also repair DSBs through HDR when donor templates are delivered via AAV.72,159,160 More importantly, we found that HDR efficiency in postmitotic cells is considerable and can be comparable with mitotic cells.72 These findings broaden the potential applications of HDR, although further research is required to comprehensively elucidate the mechanisms involved in AAV-mediated HDR in non-dividing cells. A third limitation of HDR-mediated precise genome-editing is the requirement for DSBs, which are associated with undesired outcomes. Nuclease-induced DSBs can lead to various genomic alterations, including large deletions, retrotransposon insertions, chromosomal translocations, chromothripsis, and activation of p53, potentially resulting in the formation of oncogenic cells.161,162,163,164,165,166,167,168 Furthermore, the delivery of nuclease reagents to target cells or tissues is a crucial step for successful genome-editing. Delivery efficiency depends on the cell or tissue type, the delivery method used, and the stability of the reagents in vivo. For example, in select cell lines, the delivery of RNPs can generate higher concentrations of nuclear Cas9/gRNA complex, and higher editing efficiencies, than is achieved through the delivery of plasmids or viral vectors.169 Unfortunately, the delivery of components in vivo remains challenging for many tissues.
Efforts have been made to enhance the efficiency of HDR-mediated precise genome-editing, aiming to address the associated challenges and limitations. These strategies include inhibition of the NHEJ DNA repair pathway,79,170,171 activation of the HDR DNA repair pathway,172,173,174,175,176 modification of the DNA donor templates,72,160,177,178,179 and delivery of nuclease reagents.180,181,182 While the primary emphasis is on improving the accuracy and effectiveness of DSB-mediated editing, these challenges encourage the exploration of alternative strategies for precise genome-editing.
Non HDR-mediated precise genome-editing
Non HDR-mediated precise genome-editing uses a diversity of DNA repair mechanisms. These strategies include site-specific recombinase systems, HITI, BEs, PEs, and CAST (Fig. 3).

Strategies of non HDR-mediated precise genome-editing. a Cre/loxP system, consisting of Cre recombinase and loxP sites, facilitates DNA recombination through excision (removing a DNA segment between loxP sites in the same orientation), inversion (flipping a segment between loxP sites in opposite orientations), and translocation exchanging segments between two loxP sites in the same orientation on different DNA strands. b Base editing involves the introduction of C•G-to-T•A or C•G-to-G•C point mutations using cytosine base editors (CBEs), which employ Cas9 nickase or dCas9 fused to cytidine deaminase. Additionally, A•T-to-C•G point mutations can be reversed through adenine base editors (ABEs), utilizing a fusion of dCas9 or Cas9 nickase and evolved TadA* deoxyadenosine deaminase. c Prime editors comprise a Cas9 nickase domain fused to a reverse transcriptase domain. A prime editing guide RNA (pegRNA), engineered for specificity, directs the prime editor to its target on genomic DNA, including the desired edit within an extension. Following nicking the PAM-containing strand, the freed genomic DNA 3’ end engages in a primer–template complex with the pegRNA extension. Subsequently, the reverse transcriptase domain copies the template from the pegRNA extension into the genomic DNA directly, facilitating the addition of point mutations, small deletions, or small insertions at the target locus. d CAST combines Cas proteins with transposase-associated components. Transposase proteins (Tns) bind to transposon DNA, while Cas proteins are guided to the target locus in a PAM-dependent, RNA-directed manner. This localization facilitates transposon DNA integration at the target site, with each Cas-transposase complex having a specific guide RNA length and a preferred integration distance 3’ of the PAM. This figure was produced using BioRender.com
Site-specific recombinase system
The classical site-specific recombinase system is Cre/loxP, which is widely employed for introducing conditional changes to transgenes and integrating DNA cassettes into eukaryotic chromosomes.15,16,183,184 The Cre/loxP system consists of two components: a Cre recombinase and specific 34 bp sequences known as loxP sites (Fig. 3a). Cre, a 38 kDa bacterial enzyme derived from P1 bacteriophage, has the ability to recognize and cut loxP sites.185 The loxP sequence consists of two recombinase-binding elements, each spanning 13 bp, arranged as near-perfect inverted repeats on opposing sides of an uneven 8 bp crossover region, which plays a critical role in establishing the orientation of loxP sites.186,187 Cre initiates the recombination event by binding to the 13 bp inverted repeat regions at the loxP sites. This action facilitates the formation of synaptic complexes, which consist of four Cre molecules that bridge two loxP sites oriented in the same direction.188 Subsequently, the Cre complex facilitates the exchange of DNA strands between the two sites, occurring within an asymmetrical 8 bp central spacer sequence.189 The asymmetrical central spacer serves as a template that unequivocally dictates the ultimate orientation of the DNA product, ensuring that the chromosomal rearrangements resulting from Cre-mediated recombination are entirely foreseeable.189,190 Hence, depending on how the loxP sites are oriented, Cre-mediated recombination can achieve excision (deletions), inversions, or translocations (Fig. 3a).191 In addition to the Cre/loxP system, various recombinase systems, such as Flp/FRT,34 Dre/rox,192 and Vika/vox193 have been developed as precise genome-editing tools.
Since site-specific recombinases mediate highly efficient and controlled DNA recombination, these systems have found widespread use in creating genetically engineered mouse models.194,195,196 However, they also have significant drawbacks. First, this recombination system cannot be used to precisely correct mutations, or to insert exogenous DNA sequences, and therefore cannot be used for gene therapy. Another drawback is that the target recognition site, such as loxP and rox, must be initially inserted into the genome, usually through techniques based on HR. Hence, the process is costly and time-consuming, and these challenges are exacerbated when aiming for more complex models involving multiple alleles.197
HITI
HITI is a NHEJ-based targeted gene knock-in method, which requires a site-specific nuclease such as Cas9 for DSB creation (Fig. 2). During NHEJ-mediated DSB repair, an exogenously supplied donor sequence gets inserted into the break site.198,199 In the HITI approach, the donor plasmids are designed without homology arms, preventing DSBs from being repaired via the HDR pathway. Instead, the donor DNA is designed to contain Cas9 cleavage sites flanking the donor sequence.69 Cas9 subsequently induces DSBs in both the genomic target sequence and the donor plasmid, resulting in blunt ends for both the target and donor sequences. The linearized donor DNA plasmid is then utilized for repair via the NHEJ pathway, facilitating its integration into the DSB site.69 Upon successful integration of the donor DNA into the genome in the desired orientation, it disrupts the Cas9 target sequence, thereby preventing subsequent Cas9 cleavage. In cases where the genomic DSB is repaired through error-free NHEJ without the insertion of donor DNA, the Cas9 target sequence remains intact, leading to a second round of Cas9 cleavag.200 As NHEJ is active throughout the cell cycle, it is noteworthy that even non-dividing cells retain their NHEJ capabilities. Therefore, HITI-mediated precise genome-editing can be used in terminally differentiated and post-mitotic cells, such as cardiomyocytes of the heart, or neurons of the brain. Indeed, HITI has been widely used for both in vitro and in vivo precise genome-editing, including gene therapy,69,201,202 and cell tracking.199,203,204 Nevertheless, HITI still has several major barriers to further adoption. A significant hurdle lies in the efficiency of current HITI methodologies. While HITI can integrate DNA at specified target sites in numerous non-dividing tissues, its efficiency often falls below 5%.200 Additionally, HITI can only be applied for the insertion of exogenous DNA at a target locus, but cannot be used for DNA substitution, which is necessary for correction of many mutations.200 Consequently, the range of genetic anomalies that HITI technology can address remains restricted. Furthermore, as discussed above, HITI also involves the creation of DSBs and off-target effects which may result in adverse consequences for genome stability.
BEs
BEs are capable of accurately introducing specific point mutations without requiring DSBs, DNA templates, or reliance on HDR.25,26,205 BEs consist of a CRISPR-Cas nuclease that has been rendered catalytically inactive, such that it only acts as a genome targeting module. These nuclease components are linked with a ssDNA deaminase enzyme and, in certain circumstances, associated with proteins that modulate DNA repair mechanisms (Fig. 3b).25,26 The categories of BEs are cytosine BEs (CBEs), which enable the alteration of C•G-to-T•A base pairs,25 adenine BEs (ABEs), which facilitate the conversion of A•T-to-G•C base pairs,26 and recently developed C-to-G BEs (CGBEs), which cause C•G-to-G•C base transversions (Fig. 3b).206,207,208 In BEs, the catalytically deficient Cas nuclease precisely positions an ssDNA deaminase enzyme at a specified genomic target sequence. When Cas binds, the sgRNA spacer pairs with the target DNA strand, causing the displacement of the genomic DNA strand containing the PAM and forming a ssDNA R-loop.209,210 CBEs employ cytidine deaminases to change cytosine bases found in the R-loop into uracils, which are then recognized by polymerases as thymine.25,211 ABEs utilize engineered TadA* deoxyadenosine deaminases to convert adenosine bases within the R-loop into inosines, which are recognized by polymerases as guanines.26 CGBEs function similarly to CBEs but promote the substitution of deaminated cytosine with guanine in the R-loop, although typically with lower efficiencies and product purities in comparison to CBEs and ABEs.206,207,208 Effective modification of target nucleotides situated within the R-loop depends on the successful interactions between the deaminase enzyme and the substrate nucleotides. This interaction within the R-loop defines the “base editing activity window”, as it is crucial for achieving efficient base editing results. In situations involving typical CBEs and ABEs employing Cas9, this activity window generally encompasses positions 4 to 8 within the protospacer (with the first nucleotide of the protospacer designated as position 1 and the PAM found at positions 21–23).25,26
Compared to Cas nucleases, BEs demonstrate significantly higher efficiency, generate few indel byproducts, and result in considerably fewer unintended effects associated with DSBs in direct side-by-side assessments.161,163,168,212,213,214 Thus, BEs have been widely applied in diverse cell types and organisms to introduce or reverse transition point mutations.215,216,217,218,219,220,221,222 Nevertheless, several limitations of BEs should be addressed. First, BEs typically deaminate nucleotides within a limited 4–5 nucleotide (nt) window, and this can lead to “bystander editing”, where adjacent C or A nucleotides near the target C or A may also undergo conversion.25,26 When BEs are used to modify the coding sequence, the changes typically lead to synonymous mutations within the usual base editing activity window, mainly because transition mutations often don’t affect the genetic code. Second, the effectiveness of BEs is constrained by the Cas domain’s targeting scope, which necessitates the existence of a PAM sequence at a particular distance range (usually 13 to 17 nucleotides) from the target base. Third, it’s worth noting that certain BEs may lead to off-target mutations in both DNA and RNA.223,224,225 Although engineering endeavors have alleviated numerous of these limitations.226,227,228,229,230,231 Additionally, current BEs are capable of inducing only 6 out of the 12 potential categories of point mutations, which means that the majority of transversions, and numerous other types of DNA edits, including insertions and deletions, remain beyond the scope of BEs.25,26,206
PEs
PEs are chimeric proteins formed by combining a Cas9 nickase domain, which is a deactivated HNH nuclease, with a laboratory-evolved Moloney murine leukemia virus reverse transcriptase (MMLV-RT) domain (Fig. 3c).27 The PEs are directed to the editing site using an engineered pegRNA, which includes the Cas9-binding spacer sequence, and a reverse transcriptase (RT) template that carries the intended modification and a primer binding site (PBS).27 Upon binding of the PE to the target site, the Cas9 nickase generates a cut in the non-target DNA strand, revealing a 3’ ssDNA segment that forms a hybrid with the PBS. This hybridized structure allows the associated RT to elongate the nicked 3’ ssDNA through the RT template (Fig. 3c). This RT activity leads to the formation of two redundant ssDNA flaps: a 5’ flap containing the original unedited sequence and a 3’ flap with the edited sequence. Although the thermodynamically favored pairing of the fully complementary 5’ flap with the unedited strand is anticipated, its vulnerability to excision by endogenous structure-specific endonucleases frequently leads to the hybridization of the edited 3’ flap, producing a heteroduplex. Eventually, the resolution of the heteroduplex involves ligation and DNA mismatch repair mechanisms, which replicate information from the edited strand to the unedited strand, ensuring the enduring integration of the desired modification. The PE system comprises three characterized versions. PE1 involves the fusion of the Cas9 nickase with the regular MMLV-RT. In PE2, the conventional MMLV-RT is replaced with an engineered pentamutant MMLV RT, resulting in a 3-fold enhancement in editing efficiency. Lastly, PE3 combines the PE2 fusion protein with pegRNA and an extra sgRNA that directs the nicking of the non-edited strand, leading to an additional 3- to 4-fold increase in editing efficiency.27
PEs present a distinctive array of benefits for precise genome-editing. In contrast to BEs that can only create 6 specific types of point mutations, PEs can generate all 12 varieties of single- or multi-base substitutions, small insertions, small deletions, and combinations of these modifications.27 Furthermore, PE has the capability to modify bases located at a considerable distance (at least 33 bp) from the initial nick created by the prime editing. Consequently, PE offers increased adaptability in contrast to base editing, as it does not require the existence of a PAM sequence near the targeted editing site. Compared to HDR, which mainly workes in the S/G2 phase of mitotic and meiotic cells, PE can be employed in non-dividing cells, which is necessary for many in vivo applications. Additionally, PE typically results in significantly fewer indel byproducts, and notably, it infrequently causes alterations in DNA at unintended off-target genomic sites. Based on these advantages, PEs have been proven to facilitate precise gene modifications in a range of cell types,232,233,234,235 organoids,236,237 zebrafish,235 mice,238,239,240,241,242 and plants.243,244,245,246 Nonetheless, the technology is still in its nascent phase, and there are several challenges that need to be addressed for the technology to fully realize its potential. First, the challenge of low editing efficiency is a critical issue, with efficiency often falling below 20% in cell lines and diminishing further in primary cells.247 Many endeavors have focused on effector proteins,248,249 pegRNAs,250,251 DNA repair pathways,248,252 and chromatin accessibility253,254 to improve the efficiency. Moreover, successfully delivering prime-editing reagents into the desired target cells is still an obstacle. The substantial size of the length PE hinders its integration into a single AAV vector, posing a significant challenge to its safe in vivo delivery.
CAST
Transposases are self-contained enzymatic systems responsible for incorporating or removing DNA segments in the genome.255 They function by identifying and removing the left-end (LE) and right-end (RE) motifs that flank the transposable element.256 The transposable element is subsequently integrated into new non-homologous sites.255 As a consequence of transposition, duplications of the transposon’s end sequences arise from the repair of ssDNA gaps formed during the integration of the transposon into the genome.257 Recent computational examination of bacterial genomes revealed the presence of CRISPR loci containing Cas genes, CRISPR RNA array elements, and transposase-specific genes.258,259,260 This finding implied the possibility of RNA-guided transposition in bacteria.261,262 Subsequent investigations effectively recreated simplified RNA-guided transposition utilizing type I-F and type V-K CRISPR-associated transposase (CAST) systems, leading to the targeted integration of substantial DNA fragments within bacterial genomes.75,76,263
The type I-F CAST system comprises three key elements: transposase operon, CRISPR-Cas-associated machinery, and the donor LE–cargo–RE transposase DNA substrate (Fig. 3d). The primary distinction between the type I-F and type V-K systems lies in their CRISPR–Cas-associated components. The type I-F system relies on the CRISPR-associated complex for antiviral defense (CASCADE) lacking the Cas3 nuclease–helicase, whereas the type V-K system CASCADE utilizes Cas12k effectors with naturally inactivated nuclease domains.264 In the type I-F system, transposition cargo insertions take place approximately 47–51 bp downstream from the end of the protospacer (Fig. 3d), and the optimal cargo size is determined to be around 775 bp.76 In comparison, insertions for type V-F occur predominantly between 60 and 66 bp downstream of the PAM sequence (Fig. 3d), enabling the integration of cargo DNA segments 500 bp to 10 kb.75 Comparative studies indicate that the type I-F system exhibits higher efficiency and purity of products compared to the type V-K system.265,266 Moreover, the type I-F system did not consistently yield detectable off-target effects throughout the E. coli genome, while off-target transposition of type V-K was detected at multiple loci.267 While the original type I-F and type V-K CAST systems were initially confined to bacterial applications, recent investigations have demonstrated the potential of engineered versions of both type I-F and V-K systems for facilitating transposon-mediated integration in human cells.77,78 CASTs show promise for precise genome-editing, although further engineering endeavors will be needed to improve the efficiency of integration.
Delivery of precise genome-editing reagents
Efficient and safe and delivery of precise genome-editing components to target tissues is a critical prerequisite for the success of genome-editing procedures. Typically, genome-editing delivery strategies are categorized into DNAs, RNAs, and proteins, including ribonucleoproteins (RNPs) (Fig. 4).

Delivery strategies for precise genome-editing reagents. Precise genome-editing components encompass a variety of forms, including DNA, RNA, and protein complexes such as ribonucleoproteins (RNPs). DNA is commonly delivered through microinjection or electroporation of plasmids, as well as viral vectors such as lentivirus, adeno-associated virus (AAV), and adenovirus (AdV). RNA can be introduced through microinjection or electroporation of RNPs, or via carriers like lipid nanoparticles (LNPs) and virus-like particles (VLPs). Proteins, specifically RNPs, are typically delivered through microinjection or electroporation, or using carriers like LNPs and VLPs. This figure was produced using BioRender.com
Delivery via DNA
The strategy for delivering DNA components via vectors such as plasmid or recombinant virus is widely used in vitro and in vivo due to simplicity (Fig. 4). In numerous cultured mammalian cell lines, high editing efficiencies can be attained by transiently transfecting cells with lipids or using electroporation to introduce genome-editing plasmids, including those for HDR, HITI, BEs, and PEs.27,56,77,104,268,269,270,271 While plasmid-based delivery offers convenience, one main limitation of plasmid delivery is that transfection efficiency varies by cell type and is generally limited to in vitro applications.272,273 An additional limitation is that delivering DNA increases the potential for non-specific DNA recombination with the genome.274,275,276,277 In comparison to plasmid vectors, utilizing viruses to transport DNA encoding genome-editing represents a promising delivery approach for in vivo research and therapeutic applications. The utilization of non-integrating vectors like AAV, adenoviral (AdV) vectors, or herpes simplex virus (HSV) minimizes the risk of integration of foreign DNA into the host genome. Nevertheless, infection with AdV and HSV-1 may trigger inflammatory reactions,278 while AAV is considered to be both non-pathogenic and non-inflammatory.279
Interestingly, the AAV genome is initially ssDNA and gets converted to dsDNA only after arriving in the host cell nucleus.280 AAV has high transduction efficiency in both mitotic and postmitotic cells, has an attractive safety profile, and the capability to specifically transduce a range of tissues via different serotypes.122,280 As a result, AAV is an ideal vector for genome-editing reagents delivering, which can be used for both in vivo and in vitro experiments. However, AAV is constrained by its capacity to package DNA cargo, limited to approximately 4.7 kb in length, rendering it insufficient for packaging larger genome-editing reagents, such as the Cas-mediated HDR Cas protein and donor template components (>5 kb), HITI (>5 kb), BE (~6 kb), PE (~7 kb), and CAST (>6 kb). Multiple groups have used dual AAV systems to circumvent this limitation. There are two types of dual AAV systems: in one system the first AAV carries the Cas nuclease, while the second AAV carries the HDR donor or HITI donor template respectively.69,72,281,282,283,284,285,286 In the second type of dual AAV delivery system large single gene editing components, such as BEs and PEs, are split between two AAV vectors, and each half is fused to a trans-splicing intein.109,216,240,242,287,288,289,290,291,292,293 Upon co-infection with these split AAVs, the large cargo protein is reassembled through a process of trans protein splicing. While this approach holds potential, the requirement for successful production and delivery of two different AAVs adds complexity and requires fine-tuning to ensure effective delivery of genome-editing reagents in living organisms.7
Delivery via RNA
RNA-based delivery of genome-editing components has several promising features, including smaller molecular structures, rapid onset, and mitigation of off-target effects that are caused by persistent expression of Cas proteins.294,295 The delivery of genome editors in the form of mRNA is currently a widely pursued strategy. Delivering of mRNA encoding the genome-editing reagents can be achieved via various approaches, such as microinjection or electroporation, and by using non-viral vectors such as lipid nanoparticles (LNP) and newly developed virus like particles (VLPs) (Fig. 4). Microinjection or electroporation of genome editor RNAs can effectively facilitate precise genome-editing in a variety of settings, including cultured cell lines,248,250,296 primary human T cells,297 mouse embryos,274 mouse zygotes,298 and human stem cells,299,300 and often exhibits higher efficiency than plasmid transfection. Nonetheless, it’s worth noting that electroporation, while effective for gene editing, has been associated with negative impacts on cell viability, as the stress imposed on cells during the process can lead to alterations in gene expression profiles, potentially diminishing their proliferative capacity and modifying cellular functions.301 LNP technology stands as an effective method for delivering genome-editing RNAs, offering key benefits such as biodegradability, excellent biocompatibility, structural flexibility, low toxicity and immunogenicity, and high delivery efficiency and robust RNA protection against degradation.302,303,304,305,306,307 Multiple groups have used LNPs to deliver genome-editing RNAs, such as Cas-mediated HDR components and BEs for both in vitro and in vivo applications.180,308,309,310 Finally, VLPs, homologs of the retroviral capsid protein which are capable of binding and trafficking RNA, are an emerging approach with potential for enabling precise and effective intracellular delivery of cargo mRNAs in mammalian cells,311,312,313 but have not yet been utilized for genome-editing.
Delivery via RNPs
RNPs-based delivery is a simple method that offers precise control over nuclease dosage without signal amplification.314 RNPs delivery streamlines the genome-editing process by bypassing the need for transcription and translation processes. As a result, RNPs delivery initiates genome-editing almost immediately, typically within about 3 h, and undergoes rapid degradation, usually occurring within approximately 24 h. In contrast, plasmid delivery has a longer onset time, usually taking more than 8 h to commence genome-editing, and its effects persist for several days.315 Moreover, RNP transfection avoids DNA integration, and minimizes the risk of off-target effects.315 Delivery of RNPs for precise genome-editing can be achieved using direct microinjection or electroporation, LNPs, and VLPs (Fig. 4). Microinjection or electroporation of RNPs containing precise genome-editing components, including HDR, HITI, BEs, and PEs, have demonstrated efficient editing results in diverse cell types, including cultured cell lines,248 human stem cells,178,316 primary human T cell,182,235 human embryos,317 fibroblasts,315 and iPSCs.315 Utilizing LNPs to deliver RNPs has successfully facilitated precise genome-editing via HDR and BE, both in vitro and in vivo.169,276,318,319 VLPs, comprising viral proteins capable of infecting cells but devoid of viral genetic material, serve as effective carriers for RNP cargoes. They harness the efficiency and tissue-targeting benefits of viral delivery while mitigating the risks, such as viral genome integration and the extended presence of the editing agent.320 Several groups have successfully achieved precise genome-editing by using VLPs to deliver editing components such as Cas9, donor templates, BEs, and PEs in vitro or in vivo.321,322,323,324,325 Although successful delivery of RNPs can improve gene editing, current RNPs delivery strategies are inefficiency compared to DNA and mRNA delivery.
Applications of precise genome-editing
Labeling endogenous genes
The spatial and temporal specificity of gene expression governs the structure and function of higher organisms. Each organ-specific cell type has a unique gene expression profile. Disruption of this expression profile will cause abnormal structure and function of organs, which manifests as disease. Similarly, the interior of eukaryotic cells is segregated by membranes into different organelles. Their structures and functions are highly specialized, and different proteins are precisely localized to ensure the normal structure and function of the organelle. Therefore, changes in cellular functions are often accompanied or caused by changes in subcellular localization of proteins.326 As a result, precisely mapping the subcellular localization of proteins is critical to understanding their roles in cellular processes.
Conventionally, approaches including immunostaining and overexpression of proteins fused with epitope tags or fluorescent proteins have been widely used to study protein subcellular localization. However, these methods have significant limitations. Firstly, immunostaining commonly encounters challenges due to the absence of specific antibodies against the target protein. Moreover, immunostaining often can’t distinguish between WT and mutant proteins, particularly if the mutant protein has only a small point mutation or indel. However, even small mutations can change protein subcellular localization.327,328 Overexpression of tagged proteins has similar limitations, one being that the cell’s protein targeting mechanisms can be overwhelmed by high levels of exogenous protein, resulting in a subcellular localization profile that dramatically differs from that of the endogenous protein.329,330 For example, fluorophore tags at high intracellular concentrations can cause expressed proteins to assemble into a complex, which may result in ectopic cellular localization.331 Thus, overexpressed fusion proteins often show diffuse localizations, while natively expressed proteins display more nuanced staining patterns.331
To address these problems, precise gene editing can be employed to insert epitope tags or fluorescent proteins at endogenous loci both in vivo within somatic tissues and in vitro. Early versions of this approach were based on natural HR and were used to generate knock-in mice featuring proteins fused to epitope tags or fluorescent proteins.332 However, generating mice by natural HR is costly and time-consuming. HDR, which employs systems such as CRISPR/Cas9, can efficiently insert epitope tags or fluorescent proteins, to label endogenous genes in vitro and in vivo.72,160,177,333,334 For instance, our team performed CRISPR/Cas9-mediated HDR through systemic injection of an AAV9 vector carrying donor template to Cas9-expressing mice. We successfully integrated the red fluorescent protein mScarlet into the endogenous TTN and PLN loci, creating fusion proteins which allowed for visualization of their localization.72 Additionally, HITI and PEs have also been employed to tag endogenous genes.27,69,203,248,335 For example, Belmonte et al.69 utilized the HITI approach to integrate sequence coding for fluorescent proteins into endogenous genes, both in cultured cells and, significantly, in living organisms. Similarly, Liu et al.248 employed PEs to introduce epitope tags into native genomic sites, achieving insertion rates of up to 70% in cell culture.
In addition to labeling normal proteins, precise genome-editing can also be employed to both create and determine the localization of mutant proteins, which can give important clues as to the mechanisms by which mutant proteins cause disease. However, this approach is limited by the need to create both the mutation and the epitope tag insertion at the same time with the same donor DNA, thus necessitating that the mutation be located in close proximity to the N or C-terminus. In addition to mutations close to the native termini, frameshifting mutations that result in a nearby premature stop codon can also be created and tagged in this manner. One important caveat of this approach is that some loss of function may occur from targeted alleles that undergo NHEJ instead of HDR or HITI. PEs may avoid this issue but are limited by modest insertion lengths. While NHEJ alleles will not be tagged, disruption of their function by indels may influence the localization of a tagged allele. These confounding effects can typically be mitigated by designing sgRNAs to cut in a nearby intron or untranslated region (UTR) rather than targeting the coding sequence.
Screening genetic variants
Creating genetic perturbations and evaluating their outcomes through functional characterization or enrichment stands as a commonly employed technique for unraveling biological pathways and mechanisms. CRISPR/Cas screening-based genetic perturbations have revolutionized the field of functional genomics, offering researchers unprecedented control and precision in manipulating the genome for a deeper understanding of gene function and regulation. To date, most CRISPR screens have relied on imprecise indel formation to create loss-of-function perturbations, however, precise genome-editing can be employed to create specific variants, which can then be functionally screened.
Multiple groups have successfully achieved functional screens through precise genome-editing tools, such as HDR,177,336,337,338 BEs,339,340,341,342,343,344 and PEs.345,346 For example, Shendure et al.337 utilized CRISPR/Cas9-mediated HDR to precisely edit exon 18 of BRCA1. They employed a diverse library of donor templates to replace a 6 bp genomic region with every conceivable hexamers or the entire exon with all potential single nucleotide variants. This approach allowed them to assess substantial impacts on transcript abundance, which could be attributed to nonsense-mediated decay and the influence of exotic splicing elements. In another pioneering study, Doench et al.339 used BEs in pooled screens to assay variants at endogenous loci in mammalian cells. Initially, they evaluated the effectiveness of BEs in positive and negative selection screens, accurately identifying established loss-of-function mutations in BRCA1 and BRCA2. Next, they screened BH3 mimetics and PARP inhibitors, pinpointing specific point mutations associated with drug sensitivity or resistance. Finally, they constructed a library of sgRNAs designed to induce 52,034 ClinVar variants in 3584 genes. Through screens conducted under cellular stress conditions, they identified loss-of-function variants in multiple DNA damage repair genes. In a final example, Cohn et al.345 developed a high-throughput variant classification method by adapting PEs and combining it with a strategy that allows for haploidization of any locus, thereby streamlining the interpretation of genetic variants. They applied this strategy to evaluate the functionality of genetic variants with unknown significance within NPC1, a gene associated with the lysosomal storage disorder Niemann–Pick disease type C1.
Despite these successes, significant limitations remain. Cas nuclease-mediated HDR exhibits restricted efficiency and reduced product purity across various cell types. BEs are constrained to C•G-to-T•A and A•T-to-G•C transition edits, and the outcomes of PEs are determined through sequencing the edited locus, limiting mutagenesis to a specific gene. Nevertheless, we anticipate that continued progress in integrating precise genome-editing systems into genetic screening workflows will streamline the discovery and characterization of novel gene variants and accelerate dissection of complex genetic pathways.
Molecular recording
Capturing and preserving a record of cellular events through modifications to genomic DNA sequences offers a means of non-invasive surveillance, which is useful for studying intricate biological systems. In molecular recording, specific genetic elements are engineered to respond to environmental signals or cellular events, leading to changes in the DNA sequence that can be deciphered through sequencing. In contrast to Cas9-mediated NHEJ, precise genome-editing has the capability to produce specific base sequences which encode digital information. This unique feature makes it feasible to effectively record the type, duration, and sequence of cellular signals over time.
Several teams have successfully recorded molecular events using BEs347,348,349,350 and PEs.351 For example, Lu et al.350 utilized BEs to create a platform for manipulating and assessing cellular processes, known as DOMINO (DNA-based Ordered Memory and Iteration Network Operator). This platform allows for the direct connection of stimulus-dependent base editing to a phenotypic readout. In one configuration of the system, two guide RNAs expressed from conditional promoters are required to activate a third guide RNA, which results in expression of a genomically integrated GFP gene. In this way, the platform allows for construction of programmable AND/OR logic circuits controlling the expression of genetically encodable readouts. In another example of molecular recording, Shendure et al.351 created the DNA typewriter system, a sequential approach for writing information into a tandem array of truncated PE target sites. These target sites are strategically designed to allow editing of only one site at a time. To transcribe activity directional manner, short PE-mediated insertions encode the cellular signal being recorded and finalize the protospacer sequence of the adjacent target site. This conversion of the adjacent site into a viable prime editing target facilitates the next recording event. The system was utilized for encoding text messages and reconstructing cellular lineages, illustrating the potential of prime editing molecular recorders in applications for biotechnology research.
While these results are promising, the field remains at a nascent stage. One key concern is that these tools may introduce unintended mutations or alterations in the genome, leading to unpredictable outcomes, such as compromised reliability and accuracy of the recorded information.351 Balancing the benefits of molecular recording with the need for minimizing unintended consequences and improving the sophistication and capacity of recording systems will remain active areas of development.
Generating disease models
Mutations that alter amino acids or nucleotides are often found in the genomes of patients with genetic diseases and are widely used in the simulation of human diseases in various model systems. Researchers utilize two key tools to mimic human disease: transgenic animals involve the random insertion of a foreign gene into an animal’s genetic material, and gene edited animals, where specific genes are either disabled or modified.352 In contrast to transgenic disease models, where the incorporation of foreign genes and their regulatory elements can pose a risk of disrupting host genes, potentially leading to cancer or other dysfunction,353,354,355,356,357,358 the precise alterations created in gene-edited animals are less likely to have unintended consequences. Early animal models were generated by introducing edited embryonic stem (ES) cells into blastocysts, a process often relying on inefficient natural HR.359,360 By using higher efficiency methods such as HDR, BEs, and PEs, this process has been dramatically accelerated.
Multiple research teams have successfully employed HDR, EBs, and PEs strategies to efficiently produce various disease models, including edited mice,234,238,361,362,363,364 rats,363 pigs,365 zebrafish,221,235 and Drosophila.366 For example, when Gruber et al.361 utilized CRISPR/Cas9-mediated HDR to generate MplS504N mutant mice, 2 of 16 founder mice harbored the mutation and displayed the anticipated myeloproliferative neoplasms (MPNs) phenotype. Similarly, ABE9 was employed by Li et al.363 to achieve specific A-to-G conversions in mouse and rat embryos, efficiently creating disease models, with an impressive efficiency rate of up to 62.41%. Finally, Kim et al.234 harnessed enhanced prime editing to produce mutant mice, achieving editing frequencies as high as 47%.
Gene therapy
Traditional treatments for genetic disease perform poorly, providing only limited relief of clinical symptoms in many cases. Hence, effective, and safe gene therapy methods are urgently needed to achieve a radical cure for genetic diseases. Thus far two methods of gene therapy have been widely used: first, viral delivery of an exogenous wildtype gene to replace the defective endogenous gene367,368,369,370,371,372 and second, use of RNA interference (RNAi)373,374,375,376 to degrade target mRNA and suppress the expression of defective genes. These methods, however, have limitations. For example, delivery of therapeutic genes by viral vectors might introduce new mutations during the process of virus entry into the body, resulting in dysregulation of endogenous gene expression,377 and non-integrating viral vectors can be lost over time,378,379 while RNAi may suffer from modest inhibitory effects and poor specificity.380,381
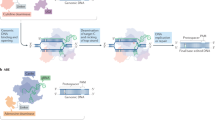
Given their ability to create specific, site-directed DNA insertions, deletions, and substitutions, precise genome editors have garnered significant interest in the biomedical research community. This interest stems from the potential to correct genetic mutations associated with human illnesses. Precise genome-editing-mediated gene therapy can be performed ex vivo or in vivo (Fig. 5). In ex vivo gene therapy, the target cells are removed from the patient and cultured in vitro, where the mutant gene can be corrected via genome-editing. Subsequently, these edited cells are expanded to produce enough cells expressing the corrected gene, and finally returned to the patient (Fig. 5a). For in vivo gene therapy, the genome-editing elements necessary for genome-editing are directly introduced to the body via RNPs, LNP, or viral vectors, to make systemic or target somatic cell genome edits (Fig. 5b).1 Currently, various precise genome-editing strategies have been extensively employed in gene therapy for a variety of tumors and genetic disease, many of which have entered clinical trials (Tables 2 and 3).

Ex vivo and in vivo precise genome-editing therapy. a In ex vivo editing therapy, cells are harvested from the patient, modified, and subsequently reintroduced. b For in vivo systemic therapy (on the left), universal delivery agents are employed, capable of targeting a broad range of tissue types. For targeted in vivo therapy (on the right), targeted intervention can be accomplished by directly injecting viral vectors into the affected tissue or through systemic administration of vectors with an innate affinity for particular tissues, such as the heart, liver, or skeletal muscle. This figure was produced using BioRender.com
Ex vivo gene therapy
Ex vivo gene therapy has multiple advantages. First, this type of gene therapy allows the target cells to be easily manipulated via various elements (such as RNPs, mRNA, DNA, and proteins) through various delivery systems, including viral vectors, electroporation, lipid nanoparticles, cell-penetrating peptides, and carbon nanowires.382,383,384,385,386,387,388 This broad selection of delivery options often translates to high gene editing efficiencies.382,389 Second, ex vivo therapy is well-targeted, since only the targeted cells are present at the time of editing.390 Moreover, ex vivo therapy can trigger a smaller immune response in comparison to in vivo therapy since there are no gene-editing elements directly introduced into the body.390,391 Third, non-specific edits that result in harmful phenotypes can be screened out prior to the cells being returned to the patient, thus resulting in a much more attractive safety profile for this approach.
Precise genome editors have been successfully applied for ex vivo gene therapy to fix mutations associated with various genetic diseases of the blood system. Kohn et al.392, Tisdale et al.393, Porteus et al.394 and Liu et al.386,395 employed HDR, BEs, and PEs to correct the HBB gene in hematopoietic stem cells (HSCs) as a treatment for Sickle cell disease (SCD). These approaches yielded therapeutic-level gene correction with efficiency ranging from 30% to 80%. Subsequent transplantation of these modified human HSCs into immunodeficient mice resulted in a significant reduction in hypoxia-induced sickling of bone marrow reticulocytes, suggesting enduring and effective genome-editing. Miccio et al.396 Bauer et al.397 and Bauer et al.398 utilized ABE8e to specifically target the prevalent HBB mutation IVS1-110 (G > A), BCL11A enhancer, or both the BCL11A enhancer and HBG promoters in hematopoietic stem and progenitor cells (HSPCs) from β-thalassemia patients, achieving gene editing efficiencies of up to 80%. Long-lasting therapeutic modifications were achieved in self-renewing repopulating HSCs, as evidenced by assessments in both primary and secondary recipients. Furthermore, the durable therapeutic editing extended to self-renewing repopulating human HSCs, as evidenced in primary and secondary recipient assays. In another case of successful therapeutic gene editing, Malech et al.399,400 achieved insertion of the wild-type CYBB gene into the AAVS1 locus or corrected the mutant CYBB gene in CD34+ HSPCs obtained from patients with the X-linked chronic granulomatous disease (X-CGD) using HDR strategies. This HDR-mediated CYBB insertion or correction resulted in efficient restoration of CYBB expression and increased NADPH oxidase activity. In a final example, transplant of gene-repaired X-CGD HSPCs into C-CGD model mice led to successful engraftment and the generation of functional mature human myeloid and lymphoid cells. In addition, precise genome-editing, including HDR and HITI, can also be applied for chimeric antigen receptor (CAR)-T cell therapy. Previously, CARs were typically delivered to T cells via γ-retroviral transduction, or other randomly integrating vectors.401,402,403 However, the use of these vectors comes with potential drawbacks, including clonal expansion, variegated transgene expression, oncogenic transformation, and transcriptional silencing.404,405,406 In contrast, HDR and HITI enable efficient sequence-specific insertion of CARs, which avoids the above limitations. This approach was demonstrated by Sadelain et al.407 Bao et al.408 Hunag et al.409 and Feldman et al.202 who achieved highly efficient and precise gene targeting of CAR-T cells using HDR or HITI, resulting in enhanced T cell potency both in vitro and in vivo.
Although the advantages of ex vivo gene therapy are notable, limitations also should be considered. First, the target cells of ex vivo therapy must be able to survive outside the body for a long period of time, which is problematic for many fully differentiated cell types. As a consequence, ex vivo gene therapy is primarily constrained to tissues containing adult stem cells, such as the hematopoietic systems.1 A second major limitation of ex vivo therapy is that when cells cultured in vitro are transplanted back into the patient, the transplantation efficiency is often poor, which reduces the effectiveness of the treatment.1
In vivo gene therapy
Compared with ex vivo gene therapy, in vivo gene therapies have several advantages. First, in vivo therapies may be more suitable for treating cell types that cannot be readily cultured and expanded ex vivo. Second, in vivo therapies can be more cost effective since slow and labor-intensive culture processes are avoided. Third, in vivo therapies can simultaneously target a variety of tissue types, making it possible to treat diseases that affect multiple organ systems.
In vivo gene therapies based on precise genome-editing have been employed to directly correct disease-causing mutations or to precisely insert a therapeutic transgene at an endogenous locus linked to a variety of genetic disorders in humans associated with Duchenne Muscular Dystrophy (DMD),284,287 Spinal Muscular Atrophy (SMA),410 Hypertrophic Cardiomyopathy (HCM),411,412 Ornithine Transcarbamylase Deficiency (OTCD),282,413 Familial Hypercholesterolemia (FH),283 Fabry disease,414 Adrenoleukodystrophy (ALD),286 Phenylketonuria,109,240 Type I tyrosinemia,310,415,416,417,418 Hutchinson-Gilford Progeria Syndrome (HGPS),419 and inherited retinal disease.417,420,421,422 For instance, in a mouse model of OTCD, Wilson et al.282,414 corrected a mutant OTC gene or inserted a codon-optimized human OTC (hOTCco) transgene at the mutant OTC locus via delivery of CRISPR/Cas9-mediated HDR components with a dual AAV system. These two approaches resulted in a reversal of the mutation in 6.7% to 20.1% of hepatocytes and improved the survival of mice exposed to a high-protein diet, which typically worsens the disease. Gersbach et al.284 employed an AAV-based HITI method to correct the expression of full-length dystrophin in a DMD mouse model. This led to the successful correction of full-length dystrophin expression in both skeletal and cardiac muscle, effectively alleviating the disease symptoms. Schwank et al.109 corrected the PAH point mutation linked to phenylketonuria in mice using an intein-split base editing approach delivered by dual AAVs. This approach led to mRNA PAH correction rates reaching as high as 63%, restoration of PAH enzyme activity, and the reversal of the light fur phenotype in PAHenu2 mice. Sontheimer et al.418 addressed a FAH transversion mutation in a mouse model of tyrosinemia type I through the delivery of PEs via AAV and hydrodynamic tail-vein injection. These interventions resulted in the recovery of weight in the mice, with editing efficiencies in the liver reaching approximately 11.5% from AAV delivery and 1.3% from hydrodynamic injection.
In addition to genetic diseases, in vivo precise genome-editing also has been used in non-genetic disease, such as cardiovascular disease. PCSK9 is predominantly found in the liver and functions as an inhibitor of the LDL receptor.423 Inhibiting PCSK9 disrupts its binding to the LDL receptor, leading to a reduction in blood LDL levels, offering a potential treatment avenue for atherosclerotic cardiovascular disease.424 Liu et al.425 Kathiresan et al.426 and Schwank et al.427 used base editing to knockdown PCSK9 in mice and nonhuman primate models, resulting in substantial reductions of PCSK9 and LDL cholesterol levels, with approximately 90% and 60% reductions observed in mice and nonhuman primates, respectively. A second cardiovascular application relates to CaMKIIδ, which plays a pivotal role in regulating cardiac signaling and function.428 Nevertheless, prolonged CaMKIIδ overactivity is associated with various cardiac diseases in both humans and mice, such as hypertrophy, ischemia/reperfusion (IR) injury, arrhythmias, and heart failure.429 Olson et al.430 employed BEs to eliminate the oxidative activation sites of CaMKIIδ. Editing CaMKIIδ in mice during an episode of IR rescued cardiac function, even after substantial damage.
Although advances in precise genome-editing in vivo gene therapy provide examples of various therapeutic strategies, the low efficiency and the immune response caused by viral vectors should be considered. Another challenge is that the sustained expression of in vivo genome-editing reagents, such as Cas9, may increase off-target effects and genotoxicity. Thus, spatiotemporal control of CRISPR/Cas9 expression is particularly important.431
Discussion and perspectives on future directions
Precise genome-editing can be achieved through a variety of distinct tools that introduce precise changes to the DNA sequence of cells or organisms. The capability to precisely manipulate the genome with precision has numerous direct applications in basic science research, disease modeling, and medicine. However, despite significant recent progress, low efficiency remains a major barrier to further adoption. BEs are less affected by this issue, demonstrating high in vivo editing efficiency, but unfortunately, BEs are limited to C•G-to-T•A and A•T-to-G•C transition edits. In addition to BEs, recent advances have significantly improved the efficiency of other precise genome-editing approaches, such as HDR and PEs, both in vitro and in vivo. While early results are promising, the efficiency of these gene editing approaches needs to be improved to enable broad development of effective gene therapies. A second major challenge of precise genome-editing is off-target mutations, particularly in systems based on CRISPR/Cas9, such as HDR, HITI, BEs, and PEs. Newly developed Cas variants with lower rates of off-target editing have been reported, such as a new subtype of Cas12f, enAsCas12f, which showed lower off-target effects than Cas9.133 However, the efficiency of these new Cas variants in targeting DNA needs additional improvement. Furthermore, delivery of precise genome-editing reagents to target cells or tissues is a crucial step for successful genome-editing. The delivery efficiency depends on the cell or tissue type, the delivery method used, and the stability of the reagents in vivo. For example, delivery of RNPs can be more efficient than delivery of plasmids or viral vectors.169 Unfortunately, delivery of components to many tissues in vivo remains challenging, and will require considerable additional vector engineering efforts.
The ongoing refinement of existing editing tools will focus on improving efficiency and specificity, while expanding targeting capabilities and optimizing delivery systems will also drive the field forward. Ultimately, these improvements will enable more sophisticated applications, including the development of novel therapies.
References
Cox, D. B. T., Platt, R. J. & Zhang, F. Therapeutic genome editing: prospects and challenges. Nat. Med. 21, 121–131 (2015).
Craig Venter, J. et al. The sequence of the human genome. Science 291, 1304–1351 (2001).
Metzker, M. L. Sequencing technologies - the next generation. Nat. Rev. Genet. 11, 31–46 (2010).
Valouev, A. et al. A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning. Genome Res. 18, 1051–1063 (2008).
Margulies, M. et al. Genome sequencing in microfabricated high-density picolitre reactors. Nature 437, 376–380 (2005).
Doudna, J. A. The promise and challenge of therapeutic genome editing. Nature 578, 229–236 (2020).
Chen, P. J. & Liu, D. R. Prime editing for precise and highly versatile genome manipulation. Nat. Rev. Genet. 24, 161–177 (2023).
Jackson, D. A., Symons, R. H. & Berg, P. Biochemical method for inserting new genetic information into DNA of Simian Virus 40: circular SV40 DNA molecules containing lambda phage genes and the galactose operon of Escherichia coli. Proc. Natl. Acad. Sci. USA 69, 2904–2909 (1972).
Cohen, S. N., Chang, A. C. Y., Boyer, H. W. & Helling, R. B. Construction of biologically functional bacterial plasmids in vitro. Proc. Natl. Acad. Sci. USA 70, 3240–3244 (1973).
Berg, P. et al. Letter: potential biohazards of recombinant DNA molecules. Science 185, 303 (1974).
Yang, X. W., Model, P. & Heintz, N. Homologous recombination based modification in Escherichia coli and germline transmission in transgenic mice of a bacterial artificial chromosome. Nat. Biotechnol. 15, 859–865 (1997).
Muyrers, J. P. P., Zhang, Y. & Stewart, A. F. Techniques: recombinogenic engineering—new options for cloning and manipulating DNA. Trends Biochem. Sci. 26, 325–331 (2001).
Baudin, A., Ozier-kalogeropoulos, O., Denouel, A., Lacroute, F. & Cullin, C. A simple and efficient method for direct gene deletion in Saccharomyces cerevisiae. Nucleic Acids Res. 21, 3329–3330 (1993).
Pu, W. et al. Genetic targeting of organ-specific blood vessels. Circ. Res. 123, 86–99 (2018).
Branda, C. S. & Dymecki, S. M. Talking about a revolution: the impact of site-specific recombinases on genetic analyses in mice. Dev. Cell 6, 7–28 (2004).
Gilbertson, L. Cre-lox recombination: Cre-ative tools for plant biotechnology. Trends Biotechnol. 21, 550–555 (2003).
Carroll, D. Genome engineering with zinc-finger nucleases. Genetics 188, 773–782 (2011).
Urnov, F. D., Rebar, E. J., Holmes, M. C., Zhang, H. S. & Gregory, P. D. Genome editing with engineered zinc finger nucleases. Nat. Rev. Genet. 11, 636–646 (2010).
Rahman, S. H., Maeder, M. L., Joung, J. K. & Cathomen, T. Zinc-finger nucleases for somatic gene therapy: the next frontier. Hum. Gene Ther. 22, 925–933 (2011).
Joung, J. K. & Sander, J. D. TALENs: a widely applicable technology for targeted genome editing. Nat. Rev. Mol. Cell Biol. 14, 49–55 (2013).
Chen, K. & Gao, C. TALENs: customizable molecular DNA scissors for genome engineering of plants. J. Genet. Genom. 40, 271–279 (2013).
Sun, N. & Zhao, H. Transcription activator-like effector nucleases (TALENs): a highly efficient and versatile tool for genome editing. Biotechnol. Bioeng. 110, 1811–1821 (2013).
Jinek, M. et al. A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science 337, 816–821 (2012).
Cong, L. et al. Multiplex genome engineering using CRISPR/Cas systems. Science 339, 819–823 (2013).
Komor, A. C., Kim, Y. B., Packer, M. S., Zuris, J. A. & Liu, D. R. Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage. Nature 533, 420–424 (2016).
Gaudelli, N. M. et al. Programmable base editing of A•T to G•C in genomic DNA without DNA cleavage. Nature 551, 464–471 (2017).
Anzalone, A. V. et al. Search-and-replace genome editing without double-strand breaks or donor DNA. Nature 576, 149–157 (2019).
Doudna, J. A. & Charpentier, E. Genome editing. The new frontier of genome engineering with CRISPR-Cas9. Science 346, 1258096 (2014).
Dussoix, D. & Arber, W. Host specificity of DNA produced by Escherichia coli. II. Control over acceptance of DNA from infecting phage lambda. J. Mol. Biol. 5, 37–49 (1962).
Arber, W. & Dussoix, D. Host specificity of DNA produced by Escherichia coli. I. Host controlled modification of bacteriophage lambda. J. Mol. Biol. 5, 18–36 (1962).
Loenen, W. A. M., Dryden, D. T. F., Raleigh, E. A., Wilson, G. G. & Murrayy, N. E. Highlights of the DNA cutters: a short history of the restriction enzymes. Nucleic Acids Res. 42, 3–19 (2014).
Morrow, J. F. & Berg, P. Cleavage of Simian virus 40 DNA at a unique site by a bacterial restriction enzyme. Proc. Natl. Acad. Sci. USA 69, 3365–3369 (1972).
Sternberg, N. & Hamilton, D. Bacteriophage P1 site-specific recombination. I. Recombination between loxP sites. J. Mol. Biol. 150, 467–486 (1981).
Broach, J. R., Guarascio, V. R. & Jayaram, M. Recombination within the yeast plasmid 2mu circle is site-specific. Cell 29, 227–234 (1982).
Hoess, R. H., Ziese, M. & Sternberg, N. P1 site-specific recombination: nucleotide sequence of the recombining sites. Proc. Natl. Acad. Sci. USA 79, 3398–3402 (1982).
Abremski, K., Hoess, R. & Sternberg, N. Studies on the properties of P1 site-specific recombination: evidence for topologically unlinked products following recombination. Cell 32, 1301–1311 (1983).
Abremski, K. & Hoess, R. Bacteriophage P1 site-specific recombination. Purification and properties of the Cre recombinase protein. J. Biol. Chem. 259, 1509–1514 (1984).
Lakso, M. et al. Targeted oncogene activation by site-specific recombination in transgenic mice. Proc. Natl. Acad. Sci. USA 89, 6232–6236 (1992).
Gu, H., Zou, Y. R. & Rajewsky, K. Independent control of immunoglobulin switch recombination at individual switch regions evidenced through Cre-loxP-mediated gene targeting. Cell 73, 1155–1164 (1993).
Smithies, O., Gregg, R. G., Boggs, S. S., Koralewski, M. A. & Kucherlapati, R. S. Insertion of DNA sequences into the human chromosomal β-globin locus by homologous recombination. Nature 317, 230–234 (1985).
Thomas, K. R., Folger, K. R. & Capecchi, M. R. High frequency targeting of genes to specific sites in the mammalian genome. Cell 44, 419–428 (1986).
Capecchi, M. R. Gene targeting in mice: functional analysis of the mammalian genome for the twenty-first century. Nat. Rev. Genet. 6, 507–512 (2005).
Joyner, A. L., Skarnes, W. C. & Rossant, J. Production of a mutation in mouse En-2 gene by homologous recombination in embryonic stem cells. Nature 338, 153–156 (1989).
Zijlstra, M., Li, E., Sajjadi, F., Subramani, S. & Jaenisch, R. Germ-line transmission of a disrupted beta 2-microglobulin gene produced by homologous recombination in embryonic stem cells. Nature 342, 435–438 (1989).
Schwartzberg, P. L., Goff, S. P. & Robertson, E. J. Germ-line transmission of a c-abl mutation produced by targeted gene disruption in ES cells. Science 246, 799–803 (1989).
DeChiara, T. M., Efstratiadis, A. & Robertsen, E. J. A growth-deficiency phenotype in heterozygous mice carrying an insulin-like growth factor II gene disrupted by targeting. Nature 345, 78–80 (1990).
Koller, B. H., Marrack, P., Kappler, J. W. & Smithies, O. Normal development of mice deficient in beta 2M, MHC class I proteins, and CD8+ T cells. Science 248, 1227–1230 (1990).
Thomas, K. R. & Capecchi, M. R. Targeted disruption of the murine int-1 proto-oncogene resulting in severe abnormalities in midbrain and cerebellar development. Nature 346, 847–850 (1990).
Ding, Y. et al. Increasing the homologous recombination efficiency of eukaryotic microorganisms for enhanced genome engineering. Appl. Microbiol. Biotechnol. 103, 4313–4324 (2019).
Miller, J., McLachlan, A. D. & Klug, A. Repetitive zinc-binding domains in the protein transcription factor IIIA from Xenopus oocytes. EMBO J. 4, 1609–1614 (1985).
Frankel, A. D., Berg, J. M. & Pabo, C. O. Metal-dependent folding of a single zinc finger from transcription factor IIIA. Proc. Natl. Acad. Sci. USA 84, 4841–4845 (1987).
Diakun, G. P., Fairall, L. & Klug, A. EXAFS study of the zinc-binding sites in the protein transcription factor IIIA. Nature 324, 698–699 (1986).
Klug, A. The discovery of zinc fingers and their development for practical applications in gene regulation and genome manipulation. Q Rev. Biophys. 43, 1–21 (2010).
Kim, Y.-G., Cha, J. & Chandrasegaran, S. Hybrid restriction enzymes: zinc finger fusions to Fok I cleavage domain. Proc. Natl. Acad. Sci. USA 93, 1156–1160 (1996).
Bibikova, M., Beumer, K., Trautman, J. K. & Carroll, D. Enhancing gene targeting with designed zinc finger nucleases. Science 300, 764 (2003).
Porteus, M. H. & Baltimore, D. Chimeric nucleases stimulate gene targeting in human cells. Science 300, 763 (2003).
Hockemeyer, D. et al. Efficient targeting of expressed and silent genes in human ESCs and iPSCs using zinc-finger nucleases. Nat. Biotechnol. 27, 851–857 (2009).
Hockemeyer, D. et al. Genetic engineering of human pluripotent cells using TALE nucleases. Nat. Biotechnol. 29, 731–734 (2011).
Perez-Pinera, P., Ousterout, D. G., Brown, M. T. & Gersbach, C. A. Gene targeting to the ROSA26 locus directed by engineered zinc finger nucleases. Nucleic Acids Res. 40, 3741–3752 (2012).
Urnov, F. D. et al. Highly efficient endogenous human gene correction using designed zinc-finger nucleases. Nature 435, 646–651 (2005).
Boch, J. et al. Breaking the code of DNA binding specificity of TAL-type III effectors. Science 326, 1509–1512 (2009).
Boch, J. & Bonas, U. Xanthomonas AvrBs3 family-type III effectors: discovery and function. Annu. Rev. Phytopathol. 48, 419–436 (2010).
Miller, J. C. et al. A TALE nuclease architecture for efficient genome editing. Nat. Biotechnol. 29, 143–150 (2011).
Cermak, T. et al. Efficient design and assembly of custom TALEN and other TAL effector-based constructs for DNA targeting. Nucleic Acids Res. 39, e82 (2011).
Mali, P. et al. RNA-guided human genome engineering via Cas9. Science 339, 823–826 (2013).
Orthwein, A. et al. A mechanism for the suppression of homologous recombination in G1 cells. Nature 528, 422–426 (2015).
Escribano-Díaz, C. et al. A cell cycle-dependent regulatory circuit composed of 53BP1-RIF1 and BRCA1-CtIP controls DNA repair pathway choice. Mol. Cell 49, 872–883 (2013).
Aylon, Y. & Kupiec, M. Cell cycle-dependent regulation of double-strand break repair: a role for the CDK. Cell Cycle 4, 258–260 (2005).
Suzuki, K. et al. In vivo genome editing via CRISPR/Cas9 mediated homology-independent targeted integration. Nature 540, 144–149 (2016).
Willems, J. et al. ORANGE: a CRISPR/Cas9-based genome editing toolbox for epitope tagging of endogenous proteins in neurons. PLoS Biol. 18, e3000665 (2020).
Hilton, I. B. & Gersbach, C. A. Enabling functional genomics with genome engineering. Genome Res. 25, 1442–1455 (2015).
Zheng, Y. et al. Efficient in vivo homology-directed repair within cardiomyocytes. Circulation 145, 787–789 (2022).
Hussmann, J. A. et al. Mapping the genetic landscape of DNA double-strand break repair. Cell 184, 5653–5669.e25 (2021).
Ciccia, A. & Elledge, S. J. The DNA damage response: making it safe to play with knives. Mol. Cell 40, 179–204 (2010).
Strecker, J. et al. RNA-guided DNA insertion with CRISPR-associated transposases. Science 365, 48–53 (2019).
Klompe, S. E., Vo, P. L. H., Halpin-Healy, T. S. & Sternberg, S. H. Transposon-encoded CRISPR-Cas systems direct RNA-guided DNA integration. Nature 571, 219–225 (2019).
Tou, C. J., Orr, B. & Kleinstiver, B. P. Precise cut-and-paste DNA insertion using engineered type V-K CRISPR-associated transposases. Nat. Biotechnol. 41, 968–979 (2023).
Lampe, G. D. et al. Targeted DNA integration in human cells without double-strand breaks using CRISPR-associated transposases. Nat. Biotechnol. 42, 87–98 (2023).
Maruyama, T. et al. Increasing the efficiency of precise genome editing with CRISPR-Cas9 by inhibition of nonhomologous end joining. Nat. Biotechnol. 33, 538–542 (2015).
Beerli, R. R. & Barbas, C. F. Engineering polydactyl zinc-finger transcription factors. Nat. Biotechnol. 20, 135–141 (2002).
Liu, Q., Segal, D. J., Ghiara, J. B. & Barbas, C. F. Design of polydactyl zinc-finger proteins for unique addressing within complex genomes. Proc. Natl. Acad. Sci. USA 94, 5525–5530 (1997).
Beerli, R. R., Segal, D. J., Dreier, B. & Barbas, C. F. Toward controlling gene expression at will: specific regulation of the erbB-2/HER-2 promoter by using polydactyl zinc finger proteins constructed from modular building blocks. Proc. Natl. Acad. Sci. USA 95, 14628–14633 (1998).
Beerli, R. R., Dreier, B. & Barbas, C. F. Positive and negative regulation of endogenous genes by designed transcription factors. Proc. Natl. Acad. Sci. USA 97, 1495–1500 (2000).
Smith, J. et al. Requirements for double-strand cleavage by chimeric restriction enzymes with zinc finger DNA-recognition domains. Nucleic Acids Res. 28, 3361–3369 (2000).
Li, H. et al. Applications of genome editing technology in the targeted therapy of human diseases: mechanisms, advances and prospects. Signal Transduct. Target Ther. 5, 1 (2020).
Ramirez, C. L. et al. Unexpected failure rates for modular assembly of engineered zinc fingers. Nat. Methods 5, 374–375 (2008).
Gupta, R. M. & Musunuru, K. Expanding the genetic editing tool kit: ZFNs, TALENs, and CRISPR-Cas9. J. Clin. Investig. 124, 4154–4161 (2014).
Bogdanove, A. J. & Voytas, D. F. TAL effectors: customizable proteins for DNA targeting. Science 333, 1843–1846 (2011).
Moscou, M. J. & Bogdanove, A. J. A simple cipher governs DNA recognition by TAL effectors. Science 326, 1501 (2009).
Morbitzer, R., Römer, P., Boch, J. & Lahaye, T. Regulation of selected genome loci using de novo-engineered transcription activator-like effector (TALE)-type transcription factors. Proc. Natl. Acad. Sci. USA 107, 21617–21622 (2010).
Streubel, J., Blücher, C., Landgraf, A. & Boch, J. TAL effector RVD specificities and efficiencies. Nat. Biotechnol. 30, 593–595 (2012).
Cong, L., Zhou, R., Kuo, Y. C., Cunniff, M. & Zhang, F. Comprehensive interrogation of natural TALE DNA-binding modules and transcriptional repressor domains. Nat. Commun. 3, 968 (2012).
Kim, Y. et al. A library of TAL effector nucleases spanning the human genome. Nat. Biotechnol. 31, 251–258 (2013).
Reyon, D. et al. FLASH assembly of TALENs for high-throughput genome editing. Nat. Biotechnol. 30, 460–465 (2012).
Holkers, M. et al. Differential integrity of TALE nuclease genes following adenoviral and lentiviral vector gene transfer into human cells. Nucleic Acids Res. 41, e63 (2013).
Gaj, T., Gersbach, C. A. & Barbas, C. F. ZFN, TALEN, and CRISPR/Cas-based methods for genome engineering. Trends Biotechnol. 31, 397–405 (2013).
Shou, J., Li, J., Liu, Y. & Wu, Q. Precise and predictable CRISPR chromosomal rearrangements reveal principles of Cas9-mediated nucleotide insertion. Mol. Cell 71, 498–509 (2018).
Shi, X. et al. Cas9 has no exonuclease activity resulting in staggered cleavage with overhangs and predictable di-and tri-nucleotide CRISPR insertions without template donor. Cell Discov. 5, 1–4 (2019).
Wang, T., Wei, J. J., Sabatini, D. M. & Lander, E. S. Genetic screens in human cells using the CRISPR-Cas9 system. Science 343, 80–84 (2014).
Shalem, O. et al. Genome-scale CRISPR-Cas9 knockout screening in human cells. Science 343, 84–87 (2014).
Koike-Yusa, H., Li, Y., Tan, E. P., Velasco-Herrera, M. D. C. & Yusa, K. Genome-wide recessive genetic screening in mammalian cells with a lentiviral CRISPR-guide RNA library. Nat. Biotechnol. 32, 267–273 (2014).
Zhou, Y. et al. High-throughput screening of a CRISPR/Cas9 library for functional genomics in human cells. Nature 509, 487–491 (2014).
Zhang, J.-P. et al. Efficient precise knockin with a double cut HDR donor after CRISPR/Cas9-mediated double-stranded DNA cleavage. Genome Biol. 18, 1–18 (2017).
Paquet, D. et al. Efficient introduction of specific homozygous and heterozygous mutations using CRISPR/Cas9. Nature 533, 125–129 (2016).
Ran, F. A. et al. Genome engineering using the CRISPR-Cas9 system. Nat. Protoc. 8, 2281–2308 (2013).
Fu, Y. W. et al. Dynamics and competition of CRISPR-Cas9 ribonucleoproteins and AAV donor-mediated NHEJ, MMEJ and HDR editing. Nucleic Acids Res. 49, 969–985 (2021).
Ibraheim, R. et al. Self-inactivating, all-in-one AAV vectors for precision Cas9 genome editing via homology-directed repair in vivo. Nat. Commun. 12, 6267 (2021).
Lee, K. et al. Nanoparticle delivery of Cas9 ribonucleoprotein and donor DNA in vivo induces homology-directed DNA repair. Nat. Biomed. Eng. 1, 889–901 (2017).
Villiger, L. et al. Treatment of a metabolic liver disease by in vivo genome base editing in adult mice. Nat. Med. 24, 1519–1525 (2018).
Ryu, J., Prather, R. S. & Lee, K. Use of gene-editing technology to introduce targeted modifications in pigs. J. Anim. Sci. Biotechnol. 9, 5 (2018).
Tan, W. et al. Efficient nonmeiotic allele introgression in livestock using custom endonucleases. Proc. Natl. Acad. Sci. USA 110, 16526–16531 (2013).
Song, Y. et al. Functional validation of the albinism-associated tyrosinase T373K SNP by CRISPR/Cas9-mediated homology-directed repair (HDR) in rabbits. EBioMedicine 36, 517–525 (2018).
Jeon, I. S. et al. Role of RS-1 derivatives in homology-directed repair at the human genome ATG5 locus. Arch. Pharm. Res. 43, 639–645 (2020).
Bai, H. et al. CRISPR/Cas9-mediated precise genome modification by a long ssDNA template in zebrafish. BMC Genom. 21, 67 (2020).
Ran, F. A. et al. Double nicking by RNA-guided CRISPR Cas9 for enhanced genome editing specificity. Cell 154, 1380–1389 (2013).
Mali, P. et al. CAS9 transcriptional activators for target specificity screening and paired nickases for cooperative genome engineering. Nat. Biotechnol. 31, 833–838 (2013).
Cho, S. W. et al. Analysis of off-target effects of CRISPR/Cas-derived RNA-guided endonucleases and nickases. Genome Res. 24, 132–141 (2014).
Guilinger, J. P., Thompson, D. B. & Liu, D. R. Fusion of catalytically inactive Cas9 to FokI nuclease improves the specificity of genome modification. Nat. Biotechnol. 32, 577–582 (2014).
Tsai, S. Q. et al. Dimeric CRISPR RNA-guided FokI nucleases for highly specific genome editing. Nat. Biotechnol. 32, 569–576 (2014).
Cromwell, C. R. et al. Incorporation of bridged nucleic acids into CRISPR RNAs improves Cas9 endonuclease specificity. Nat. Commun. 9, 1448 (2018).
Hu, W. X. et al. ExsgRNA: reduce off-target efficiency by on-target mismatched sgRNA. Brief. Bioinform 23, bbac183 (2022).
Wang, D., Tai, P. W. L. & Gao, G. Adeno-associated virus vector as a platform for gene therapy delivery. Nat. Rev. Drug Discov. 18, 358–378 (2019).
Ran, F. A. et al. In vivo genome editing using Staphylococcus aureus Cas9. Nature 520, 186–191 (2015).
Chen, J. S. et al. CRISPR-Cas12a target binding unleashes indiscriminate single-stranded DNase activity. Science 360, 436–439 (2018).
Tsuchida, C. A. et al. Chimeric CRISPR-CasX enzymes and guide RNAs for improved genome editing activity. Mol. Cell 82, 1199–1209.e6 (2022).
Karvelis, T. et al. PAM recognition by miniature CRISPR-Cas12f nucleases triggers programmable double-stranded DNA target cleavage. Nucleic Acids Res. 48, 5016–5023 (2020).
Takeda, S. N. et al. Structure of the miniature type V-F CRISPR-Cas effector enzyme. Mol. Cell 81, 558–570.e3 (2021).
Carabias, A. et al. Structure of the mini-RNA-guided endonuclease CRISPR-Cas12j3. Nat. Commun. 12, 4476 (2021).
Pausch, P. et al. DNA interference states of the hypercompact CRISPR-CasΦ effector. Nat. Struct. Mol. Biol. 28, 652–661 (2021).
Chen, W. et al. Cas12n nucleases, early evolutionary intermediates of type V CRISPR, comprise a distinct family of miniature genome editors. Mol. Cell 83, 2768–2780.e6 (2023).
Kim, D. Y. et al. Efficient CRISPR editing with a hypercompact Cas12f1 and engineered guide RNAs delivered by adeno-associated virus. Nat. Biotechnol. 40, 94–102 (2022).
Kong, X. et al. Engineered CRISPR-OsCas12f1 and RhCas12f1 with robust activities and expanded target range for genome editing. Nat. Commun. 14, 2046 (2023).
Wu, T. et al. An engineered hypercompact CRISPR-Cas12f system with boosted gene-editing activity. Nat. Chem. Biol. 19, 1384–1393 (2023).
Sung, P. & Klein, H. Mechanism of homologous recombination: mediators and helicases take on regulatory functions. Nat. Rev. Mol. Cell Biol. 7, 739–750 (2006).
San Filippo, J., Sung, P. & Klein, H. Mechanism of eukaryotic homologous recombination. Annu. Rev. Biochem. 77, 229–257 (2008).
Paull, T. T. Mechanisms of ATM Activation. Annu. Rev. Biochem. 84, 711–738 (2015).
Williams, R. S. et al. Nbs1 flexibly tethers Ctp1 and Mre11-Rad50 to coordinate DNA double-strand break processing and repair. Cell 139, 87–99 (2009).
Yu, X. & Chen, J. DNA damage-induced cell cycle checkpoint control requires CtIP, a phosphorylation-dependent binding partner of BRCA1 C-terminal domains. Mol. Cell Biol. 24, 9478–9486 (2004).
Chen, L., Nievera, C. J., Lee, A. Y.-L. & Wu, X. Cell cycle-dependent complex formation of BRCA1· CtIP· MRN is important for DNA double-strand break repair. J. Biol. Chem. 283, 7713–7720 (2008).
Zhu, Z., Chung, W.-H., Shim, E. Y., Lee, S. E. & Ira, G. Sgs1 helicase and two nucleases Dna2 and Exo1 resect DNA double-strand break ends. Cell 134, 981–994 (2008).
Sartori, A. A. et al. Human CtIP promotes DNA end resection. Nature 450, 509–514 (2007).
Garcia, V., Phelps, S. E. L., Gray, S. & Neale, M. J. Bidirectional resection of DNA double-strand breaks by Mre11 and Exo1. Nature 479, 241–244 (2011).
Chen, R. & Wold, M. S. Replication protein A: single-stranded DNA’s first responder: dynamic DNA-interactions allow replication protein A to direct single-strand DNA intermediates into different pathways for synthesis or repair. Bioessays 36, 1156–1161 (2014).
Renkawitz, J., Lademann, C. A., Kalocsay, M. & Jentsch, S. Monitoring homology search during DNA double-strand break repair in vivo. Mol. Cell 50, 261–272 (2013).
Yang, H., Li, Q., Fan, J., Holloman, W. K. & Pavletich, N. P. The BRCA2 homologue Brh2 nucleates RAD51 filament formation at a dsDNA–ssDNA junction. Nature 433, 653–657 (2005).
Pomerantz, R. T., Kurth, I., Goodman, M. F. & O’Donnell, M. E. Preferential D-loop extension by a translesion DNA polymerase underlies error-prone recombination. Nat. Struct. Mol. Biol. 20, 748–755 (2013).
Roy, U. & Greene, E. C. Demystifying the D-loop during DNA recombination. Nature 586, 677–678 (2020).
Miyabe, I. et al. Polymerase δ replicates both strands after homologous recombination-dependent fork restart. Nat. Struct. Mol. Biol. 22, 932–938 (2015).
Snowden, T., Acharya, S., Butz, C., Berardini, M. & Fishel, R. hMSH4-hMSH5 recognizes Holliday Junctions and forms a meiosis-specific sliding clamp that embraces homologous chromosomes. Mol. Cell 15, 437–451 (2004).
Punatar, R. S., Martin, M. J., Wyatt, H. D. M., Chan, Y. W. & West, S. C. Resolution of single and double Holliday junction recombination intermediates by GEN1. Proc. Natl. Acad. Sci. USA 114, 443–450 (2017).
Li, X. & Heyer, W. D. Homologous recombination in DNA repair and DNA damage tolerance. Cell Res. 18, 99–113 (2008).
Li, X., Stith, C. M., Burgers, P. M. & Heyer, W.-D. PCNA is required for initiation of recombination-associated DNA synthesis by DNA polymerase δ. Mol. Cell 36, 704–713 (2009).
Jin, M. H. & Oh, D. Y. ATM in DNA repair in cancer. Pharm. Ther. 203, 107391 (2019).
Pannunzio, N. R., Watanabe, G., Lieber, M. R. & Nonhomologous, D. N. A. end-joining for repair of DNA double-strand breaks. J. Biol. Chem. 293, 10512–10523 (2018).
Mao, Z., Bozzella, M., Seluanov, A. & Gorbunova, V. Comparison of nonhomologous end joining and homologous recombination in human cells. DNA Repair 7, 1765–1771 (2008).
Chang, H. H. Y., Pannunzio, N. R., Adachi, N. & Lieber, M. R. Non-homologous DNA end joining and alternative pathways to double-strand break repair. Nat. Rev. Mol. Cell Biol. 18, 495–506 (2017).
Yeh, C. D., Richardson, C. D. & Corn, J. E. Advances in genome editing through control of DNA repair pathways. Nat. Cell Biol. 21, 1468–1478 (2019).
Yang, H. et al. One-step generation of mice carrying reporter and conditional alleles by CRISPR/Cas-mediated genome engineering. Cell 154, 1370–1379 (2013).
Ishizu, T. et al. Targeted genome replacement via homology-directed repair in non-dividing cardiomyocytes. Sci. Rep. 7, 9396 (2017).
Nishiyama, J., Mikuni, T. & Yasuda, R. Virus-mediated genome editing via homology-directed repair in mitotic and postmitotic cells in mammalian brain. Neuron 96, 755–768 (2017).
Kosicki, M., Tomberg, K. & Bradley, A. Repair of double-strand breaks induced by CRISPR-Cas9 leads to large deletions and complex rearrangements. Nat. Biotechnol. 36, 765–771 (2018).
Cullot, G. et al. CRISPR-Cas9 genome editing induces megabase-scale chromosomal truncations. Nat. Commun. 10, 1136 (2019).
Alanis-Lobato, G. et al. Frequent loss of heterozygosity in CRISPR-Cas9-edited early human embryos. Proc. Natl. Acad. Sci. USA 118, e2004832117 (2021).
Leibowitz, M. L. et al. Chromothripsis as an on-target consequence of CRISPR-Cas9 genome editing. Nat. Genet. 53, 895–905 (2021).
Tao, J., Wang, Q., Mendez-Dorantes, C., Burns, K. H. & Chiarle, R. Frequency and mechanisms of LINE-1 retrotransposon insertions at CRISPR/Cas9 sites. Nat. Commun. 13, 3685 (2022).
Ihry, R. J. et al. p53 inhibits CRISPR-Cas9 engineering in human pluripotent stem cells. Nat. Med. 24, 939–946 (2018).
Haapaniemi, E., Botla, S., Persson, J., Schmierer, B. & Taipale, J. CRISPR-Cas9 genome editing induces a p53-mediated DNA damage response. Nat. Med. 24, 927–930 (2018).
Enache, O. M. et al. Cas9 activates the p53 pathway and selects for p53-inactivating mutations. Nat. Genet. 52, 662–668 (2020).
Wei, T., Cheng, Q., Min, Y. L., Olson, E. N. & Siegwart, D. J. Systemic nanoparticle delivery of CRISPR-Cas9 ribonucleoproteins for effective tissue specific genome editing. Nat. Commun. 11, 3232 (2020).
Canny, M. D. et al. Inhibition of 53BP1 favors homology-dependent DNA repair and increases CRISPR-Cas9 genome-editing efficiency. Nat. Biotechnol. 36, 95–102 (2018).
Weber, T. et al. Increasing the efficiency of homology-directed repair for CRISPR-Cas9-induced precise gene editing in mammalian cells. Nat. Biotechnol. 33, 543–548 (2015).
Jayathilaka, K. et al. A chemical compound that stimulates the human homologous recombination protein RAD51. Proc. Natl. Acad. Sci. USA 105, 15848–15853 (2008).
Song, J. et al. RS-1 enhances CRISPR/Cas9-and TALEN-mediated knock-in efficiency. Nat. Commun. 7, 10548 (2016).
Pinder, J., Salsman, J. & Dellaire, G. Nuclear domain ‘knock-in’screen for the evaluation and identification of small molecule enhancers of CRISPR-based genome editing. Nucleic Acids Res. 43, 9379–9392 (2015).
Huang, J. et al. RAD18 transmits DNA damage signalling to elicit homologous recombination repair. Nat. Cell Biol. 11, 592–603 (2009).
Nambiar, T. S. et al. Stimulation of CRISPR-mediated homology-directed repair by an engineered RAD18 variant. Nat. Commun. 10, 3395 (2019).
Sharon, E. et al. Functional genetic variants revealed by massively parallel precise genome editing. Cell 175, 544–557 (2018).
Martin, R. M. et al. Highly efficient and marker-free genome editing of human pluripotent stem cells by CRISPR-Cas9 RNP and AAV6 donor-mediated homologous recombination. Cell Stem Cell 24, 821–828 (2019).
Shy, B. R. et al. High-yield genome engineering in primary cells using a hybrid ssDNA repair template and small-molecule cocktails. Nat. Biotechnol. 41, 521–531 (2023).
Yin, H. et al. Therapeutic genome editing by combined viral and non-viral delivery of CRISPR system components in vivo. Nat. Biotechnol. 34, 328–333 (2016).
Richardson, C. D. et al. CRISPR-Cas9 genome editing in human cells occurs via the Fanconi anemia pathway. Nat. Genet. 50, 1132–1139 (2018).
Schumann, K. et al. Generation of knock-in primary human T cells using Cas9 ribonucleoproteins. Proc. Natl. Acad. Sci. USA 112, 10437–10442 (2015).
Kos, C. H. Cre/loxP system for generating tissue-specific knockout mouse models. Nutr. Rev. 62, 243–246 (2004).
Lanza, A. M., Dyess, T. J. & Alper, H. S. Using the Cre/lox system for targeted integration into the human genome: loxFAS-loxP pairing and delayed introduction of Cre DNA improve gene swapping efficiency. Biotechnol. J. 7, 898–908 (2012).
Marshall Stark, W., Boocock, M. R. & Sherratt, D. J. Catalysis by site-specific recombinases. Trends Genet. 8, 432–439 (1992).
Ringrose, L. et al. Comparative kinetic analysis of FLP and cre recombinases: mathematical models for DNA binding and recombination. J. Mol. Biol. 284, 363–384 (1998).
Rüfer, A., Neuenschwander, P. F. & Sauer, B. Analysis of Cre-loxP interaction by surface plasmon resonance: Influence of spermidine on cooperativity. Anal. Biochem. 308, 90–99 (2002).
Van Duyne, G. D. Cre recombinase. Microbiol. Spectr. 3, MDNA3-2014 (2015).
Hoess, R. H., Wierzbicki, A. & Abremski, K. The role of the loxP spacer region in P1 site-specific recombination. Nucleic Acids Res. 14, 2287–2300 (1986).
Lee, G. & Saito, I. Role of nucleotide sequences of loxP spacer region in Cre-mediated recombination. Gene 216, 55–65 (1998).
Meinke, G., Bohm, A., Hauber, J., Pisabarro, M. T. & Buchholz, F. Cre recombinase and other tyrosine recombinases. Chem. Rev. 116, 12785–12820 (2016).
Sauer, B. & McDermott, J. DNA recombination with a heterospecific Cre homolog identified from comparison of the pac-c1 regions of P1-related phages. Nucleic Acids Res. 32, 6086–6095 (2004).
Karimova, M. et al. Vika/vox, a novel efficient and specific Cre/loxP-like site-specific recombination system. Nucleic Acids Res. 41, e37 (2013).
Nalbandian, A., Llewellyn, K. J., Nguyen, C., Monuki, E. S. & Kimonis, V. E. Targeted excision of VCP R155H mutation by Cre-LoxP technology as a promising therapeutic strategy for valosin-containing protein disease. Hum. Gene Ther. Methods 26, 13–24 (2015).
Yu, M., Owens, D. M., Ghosh, S. & Farber, D. L. Conditional PDK1 ablation promotes epidermal and T-Cell-mediated dysfunctions leading to inflammatory skin disease. J. Investig. Dermatol. 135, 2688–2696 (2015).
Lin, C. Y. et al. Healing of massive segmental femoral bone defects in minipigs by allogenic ASCs engineered with FLPo/Frt-based baculovirus vectors. Biomaterials 50, 98–106 (2015).
Huang, J. et al. Generation and comparison of CRISPR-Cas9 and Cre-mediated genetically engineered mouse models of sarcoma. Nat. Commun. 8, 15999 (2017).
Cristea, S. et al. In vivo cleavage of transgene donors promotes nuclease-mediated targeted integration. Biotechnol. Bioeng. 110, 871–880 (2013).
Maresca, M., Lin, V. G., Guo, N. & Yang, Y. Obligate ligation-gated recombination (ObLiGaRe): custom-designed nuclease-mediated targeted integration through nonhomologous end joining. Genome Res. 23, 539–546 (2013).
Suzuki, K. & Izpisua Belmonte, J. C. In vivo genome editing via the HITI method as a tool for gene therapy. J. Hum. Genet. 63, 157–164 (2018).
Tornabene, P. et al. Therapeutic homology-independent targeted integration in retina and liver. Nat. Commun. 13, 1963 (2022).
Balke-Want, H. et al. Homology-independent targeted insertion (HITI) enables guided CAR knock-in and efficient clinical scale CAR-T cell manufacturing. Mol. Cancer 22, 100 (2023).
Kelly, J. J. et al. Safe harbor-targeted CRISPR-Cas9 homology-independent targeted integration for multimodality reporter gene-based cell tracking. Sci. Adv. 7, eabc3791 (2021).
Auer, T. O., Duroure, K., De Cian, A., Concordet, J. P. & Del Bene, F. Highly efficient CRISPR/Cas9-mediated knock-in in zebrafish by homology-independent DNA repair. Genome Res. 24, 142–153 (2014).
Komor, A. C., Badran, A. H. & Liu, D. R. CRISPR-based technologies for the manipulation of eukaryotic genomes. Cell 168, 20–36 (2017).
Kurt, I. C. et al. CRISPR C-to-G base editors for inducing targeted DNA transversions in human cells. Nat. Biotechnol. 39, 41–46 (2021).
Zhao, D. et al. Glycosylase base editors enable C-to-A and C-to-G base changes. Nat. Biotechnol. 39, 35–40 (2021).
Chen, L. et al. Programmable C:G to G:C genome editing with CRISPR-Cas9-directed base excision repair proteins. Nat. Commun. 12, 1384 (2021).
Jiang, F. & Doudna, J. A. CRISPR-Cas9 structures and mechanisms. Annu Rev. Biophys. 46, 505–529 (2017).
Nishimasu, H. et al. Crystal structure of Cas9 in complex with guide RNA and target DNA. Cell 156, 935–949 (2014).
Komor, A. C. et al. Improved base excision repair inhibition and bacteriophage Mu Gam protein yields C:G-to-T:A base editors with higher efficiency and product purity. Sci. Adv. 3, eaao4774 (2017).
Hu, P. et al. Regulatory basis for reproductive flexibility in a meningitis-causing fungal pathogen. Nat. Commun. 13, 7938 (2022).
Ferrari, S. et al. Efficient gene editing of human long-term hematopoietic stem cells validated by clonal tracking. Nat. Biotechnol. 38, 1298–1308 (2020).
Song, Y. et al. Large-fragment deletions induced by Cas9 cleavage while not in the BEs system. Mol. Ther. Nucleic Acids 21, 523–526 (2020).
Rees, H. A. & Liu, D. R. Base editing: precision chemistry on the genome and transcriptome of living cells. Nat. Rev. Genet. 19, 770–788 (2018).
Levy, J. M. et al. Cytosine and adenine base editing of the brain, liver, retina, heart and skeletal muscle of mice via adeno-associated viruses. Nat. Biomed. Eng. 4, 97–110 (2020).
Liu, Z. et al. Highly efficient RNA-guided base editing in rabbit. Nat. Commun. 9, 2717 (2018).
Yang, B., Yang, L. & Chen, J. Development and application of base editors. CRISPR J. 2, 91–104 (2019).
Molla, K. A. & Yang, Y. CRISPR/Cas-mediated base editing: technical considerations and practical applications. Trends Biotechnol. 37, 1121–1142 (2019).
Zafra, M. P. et al. Optimized base editors enable efficient editing in cells, organoids and mice. Nat. Biotechnol. 36, 888–896 (2018).
Zhang, Y. et al. Programmable base editing of zebrafish genome using a modified CRISPR-Cas9 system. Nat. Commun. 8, 118 (2017).
Li, Q. et al. CRISPR-Cas9-mediated base-editing screening in mice identifies DND1 amino acids that are critical for primordial germ cell development. Nat. Cell Biol. 20, 1315–1325 (2018).
Jin, S. et al. Cytosine, but not adenine, base editors induce genome-wide off-target mutations in rice. Science 364, 292–295 (2019).
Zuo, E. et al. Cytosine base editor generates substantial off-target single-nucleotide variants in mouse embryos. Science 364, 289–292 (2019).
Grünewald, J. et al. Transcriptome-wide off-target RNA editing induced by CRISPR-guided DNA base editors. Nature 569, 433–437 (2019).
Miller, S. M. et al. Continuous evolution of SpCas9 variants compatible with non-G PAMs. Nat. Biotechnol. 38, 471–481 (2020).
Kim, Y. B. et al. Increasing the genome-targeting scope and precision of base editing with engineered Cas9-cytidine deaminase fusions. Nat. Biotechnol. 35, 371–376 (2017).
Huang, T. P. et al. Circularly permuted and PAM-modified Cas9 variants broaden the targeting scope of base editors. Nat. Biotechnol. 37, 626–631 (2019).
Walton, R. T., Christie, K. A., Whittaker, M. N. & Kleinstiver, B. P. Unconstrained genome targeting with near-PAMless engineered CRISPR-Cas9 variants. Science 368, 290–296 (2020).
Rees, H. A., Wilson, C., Doman, J. L. & Liu, D. R. Analysis and minimization of cellular RNA editing by DNA adenine base editors. Sci. Adv. 5, eaax5717 (2019).
Grünewald, J. et al. CRISPR DNA base editors with reduced RNA off-target and self-editing activities. Nat. Biotechnol. 37, 1041–1048 (2019).
Sürün, D. et al. Efficient generation and correction of mutations in human iPS cells utilizing mRNAs of CRISPR base editors and prime editors. Genes 11, 511 (2020).
Adikusuma, F. et al. Optimized nickase- and nuclease-based prime editing in human and mouse cells. Nucleic Acids Res. 49, 10785–10795 (2021).
Park, S. J. et al. Targeted mutagenesis in mouse cells and embryos using an enhanced prime editor. Genome Biol. 22, 170 (2021).
Petri, K. et al. CRISPR prime editing with ribonucleoprotein complexes in zebrafish and primary human cells. Nat. Biotechnol. 40, 189–193 (2022).
Schene, I. F. et al. Prime editing for functional repair in patient-derived disease models. Nat. Commun. 11, 5352 (2020).
Geurts, M. H. et al. Evaluating CRISPR-based prime editing for cancer modeling and CFTR repair in organoids. Life Sci. Alliance 4, e202000940 (2021).
Gao, P. et al. Prime editing in mice reveals the essentiality of a single base in driving tissue-specific gene expression. Genome Biol. 22, 83 (2021).
Zheng, C. et al. A flexible split prime editor using truncated reverse transcriptase improves dual-AAV delivery in mouse liver. Mol. Ther. 30, 1343–1351 (2022).
Böck, D. et al. In vivo prime editing of a metabolic liver disease in mice. Sci. Transl. Med. 14, eabl9238 (2022).
Liu, P. et al. Improved prime editors enable pathogenic allele correction and cancer modelling in adult mice. Nat. Commun. 12, 2121 (2021).
Davis, J. R. et al. Efficient prime editing in mouse brain, liver and heart with dual AAVs. Nat. Biotechnol. https://doi.org/10.1038/S41587-023-01758-Z (2023).
Jiang, Y. Y. et al. Prime editing efficiently generates W542L and S621I double mutations in two ALS genes in maize. Genome Biol. 21, 257 (2020).
Lin, Q. et al. Prime genome editing in rice and wheat. Nat. Biotechnol. 38, 582–585 (2020).
Lu, Y. et al. Precise genome modification in tomato using an improved prime editing system. Plant Biotechnol. J. 19, 415–417 (2021).
Lin, Q. et al. High-efficiency prime editing with optimized, paired pegRNAs in plants. Nat. Biotechnol. 39, 923–927 (2021).
Kim, H. K. et al. Predicting the efficiency of prime editing guide RNAs in human cells. Nat. Biotechnol. 39, 198–206 (2021).
Chen, P. J. et al. Enhanced prime editing systems by manipulating cellular determinants of editing outcomes. Cell 184, 5635–5652.e29 (2021).
Velimirovic, M. et al. Peptide fusion improves prime editing efficiency. Nat. Commun. 13, 3512 (2022).
Nelson, J. W. et al. Engineered pegRNAs improve prime editing efficiency. Nat. Biotechnol. 40, 402–410 (2022).
Benjamin, A. S., Zhang, L. Q., Qiu, C., Stocker, A. A. & Kording, K. P. Efficient neural codes naturally emerge through gradient descent learning. Nat. Commun. 13, 7972 (2022).
Ferreira da Silva, J. et al. Prime editing efficiency and fidelity are enhanced in the absence of mismatch repair. Nat. Commun. 13, 760 (2022).
Jain, M. S. et al. MultiMAP: dimensionality reduction and integration of multimodal data. Genome Biol. 22, 346 (2021).
Liu, N. et al. HDAC inhibitors improve CRISPR-Cas9 mediated prime editing and base editing. Mol. Ther. Nucleic Acids 29, 36–46 (2022).
Rebollo, R., Romanish, M. T. & Mager, D. L. Transposable elements: an abundant and natural source of regulatory sequences for host genes. Annu. Rev. Genet. 46, 21–42 (2012).
Munoz-Lopez, M. & Garcia-Perez, J. DNA transposons: nature and applications in genomics. Curr. Genom. 11, 115–128 (2010).
Hickman, A. B. & Dyda, F. DNA transposition at work. Chem. Rev. 116, 12758–12784 (2016).
Peters, J. E., Makarova, K. S., Shmakov, S. & Koonin, E. V. Recruitment of CRISPR-Cas systems by Tn7-like transposons. Proc. Natl. Acad. Sci. USA 114, E7358–E7366 (2017).
Makarova, K. S. et al. An updated evolutionary classification of CRISPR-Cas systems. Nat. Rev. Microbiol. 13, 722–736 (2015).
Shmakov, S. et al. Diversity and evolution of class 2 CRISPR-Cas systems. Nat. Rev. Microbiol. 15, 169–182 (2017).
Koonin, E. V. & Makarova, K. S. Mobile genetic elements and evolution of CRISPR-Cas Systems: all the way there and back. Genome Biol. Evol. 9, 2812–2825 (2017).
Faure, G. et al. CRISPR-Cas in mobile genetic elements: counter-defence and beyond. Nat. Rev. Microbiol. 17, 513–525 (2019).
Schmitz, M., Querques, I., Oberli, S., Chanez, C. & Jinek, M. Structural basis for the assembly of the type V CRISPR-associated transposon complex. Cell 185, 4999–5010.e17 (2022).
Saito, M. et al. Dual modes of CRISPR-associated transposon homing. Cell 184, 2441–2453.e18 (2021).
Rubin, B. E. et al. Species- and site-specific genome editing in complex bacterial communities. Nat. Microbiol 7, 34–47 (2022).
Vo, P. L. H. et al. CRISPR RNA-guided integrases for high-efficiency, multiplexed bacterial genome engineering. Nat. Biotechnol. 39, 480–489 (2021).
Anzalone, A. V., Koblan, L. W. & Liu, D. R. Genome editing with CRISPR-Cas nucleases, base editors, transposases and prime editors. Nat. Biotechnol. 38, 824–844 (2020).
Osborn, M. J. et al. TALEN-based gene correction for epidermolysis bullosa. Mol. Ther. 21, 1151–1159 (2013).
Mariyanna, L. et al. Excision of HIV-1 proviral DNA by recombinant cell permeable tre-recombinase. PLoS One 7, e31576 (2012).
Li, X. et al. Base editing with a Cpf1-cytidine deaminase fusion. Nat. Biotechnol. 36, 324–327 (2018).
Bodles-Brakhop, A. M., Heller, R. & Draghia-Akli, R. Electroporation for the delivery of DNA-based vaccines and immunotherapeutics: current clinical developments. Mol. Ther. 17, 585–592 (2009).
Li, L., Hu, S. & Chen, X. Non-viral delivery systems for CRISPR/Cas9-based genome editing: challenges and opportunities. Biomaterials 171, 207–218 (2018).
Wallen, M., Aqil, F., Spencer, W. & Gupta, R. C. Exosomes as an emerging plasmid delivery vehicle for gene therapy. Pharmaceutics 15, 1832 (2023).
Kim, K. et al. Highly efficient RNA-guided base editing in mouse embryos. Nat. Biotechnol. 35, 435–437 (2017).
Rees, H. A. et al. Improving the DNA specificity and applicability of base editing through protein engineering and protein delivery. Nat. Commun. 8, 15790 (2017).
Zuris, J. A. et al. Cationic lipid-mediated delivery of proteins enables efficient protein-based genome editing in vitro and in vivo. Nat. Biotechnol. 33, 73–80 (2015).
Wang, M. et al. Efficient delivery of genome-editing proteins using bioreducible lipid nanoparticles. Proc. Natl. Acad. Sci. USA 113, 2868–2873 (2016).
Thomas, C. E., Ehrhardt, A. & Kay, M. A. Progress and problems with the use of viral vectors for gene therapy. Nat. Rev. Genet. 4, 346–358 (2003).
Miao, C. H. et al. Nonrandom transduction of recombinant adeno-associated virus vectors in mouse hepatocytes in vivo: cell cycling does not influence hepatocyte transduction. J. Virol. 74, 3793–3803 (2000).
Li, C. & Samulski, R. J. Engineering adeno-associated virus vectors for gene therapy. Nat. Rev. Genet. 21, 255–272 (2020).
De Caneva, A. et al. Coupling AAV-mediated promoterless gene targeting to SaCas9 nuclease to efficiently correct liver metabolic diseases. JCI Insight 4, e128863 (2019).
Yang, Y. et al. A dual AAV system enables the Cas9-mediated correction of a metabolic liver disease in newborn mice. Nat. Biotechnol. 34, 334–338 (2016).
Zhao, H. et al. In vivo AAV-CRISPR/Cas9-mediated gene editing ameliorates atherosclerosis in familial hypercholesterolemia. Circulation 141, 67–79 (2020).
Pickar-Oliver, A. et al. Full-length dystrophin restoration via targeted exon integration by AAV-CRISPR in a humanized mouse model of Duchenne muscular dystrophy. Mol. Ther. 29, 3243–3257 (2021).
Abifadel, M. & Boileau, C. Genetic and molecular architecture of familial hypercholesterolemia. J. Intern. Med. 293, 144–165 (2023).
Hong, S. A. et al. In vivo gene editing via homology-independent targeted integration for adrenoleukodystrophy treatment. Mol. Ther. 30, 119–129 (2022).
Chemello, F. et al. Precise correction of Duchenne muscular dystrophy exon deletion mutations by base and prime editing. Sci. Adv. 7, eabg4910 (2021).
Ryu, S. M. et al. Adenine base editing in mouse embryos and an adult mouse model of Duchenne muscular dystrophy. Nat. Biotechnol. 36, 536–539 (2018).
Chew, W. L. et al. A multifunctional AAV-CRISPR-Cas9 and its host response. Nat. Methods 13, 868–874 (2016).
Lim, C. K. W. et al. Treatment of a mouse model of ALS by In Vivo Base Editing. Mol. Ther. 28, 1177–1189 (2020).
Gao, Z. et al. A truncated reverse transcriptase enhances prime editing by split AAV vectors. Mol. Ther. 30, 2942–2951 (2022).
Zhi, S. et al. Dual-AAV delivering split prime editor system for in vivo genome editing. Mol. Ther. 30, 283–294 (2022).
Xu, L. et al. Efficient precise in vivo base editing in adult dystrophic mice. Nat. Commun. 12, 3719 (2021).
Popovitz, J. et al. Gene editing therapeutics based on mRNA delivery. Adv. Drug Deliv. Rev. 200, 115026 (2023).
Yao, S., He, Z. & Chen, C. CRISPR/Cas9-mediated genome editing of epigenetic factors for cancer therapy. Hum. Gene Ther. 26, 463–471 (2015).
Van Den Plas, D. et al. Efficient removal of LoxP-flanked genes by electroporation of Cre-recombinase mRNA. Biochem. Biophys. Res. Commun. 305, 10–15 (2003).
Hendel, A. et al. Chemically modified guide RNAs enhance CRISPR-Cas genome editing in human primary cells. Nat. Biotechnol. 33, 985–989 (2015).
Liang, P. et al. Effective gene editing by high-fidelity base editor 2 in mouse zygotes. Protein Cell 8, 601–611 (2017).
Wang, J. et al. Homology-driven genome editing in hematopoietic stem and progenitor cells using ZFN mRNA and AAV6 donors. Nat. Biotechnol. 33, 1256–1263 (2015).
Li, H. et al. Highly efficient generation of isogenic pluripotent stem cell models using prime editing. Elife 11, e79208 (2022).
Kavanagh, H. et al. A novel non-viral delivery method that enables efficient engineering of primary human T cells for ex vivo cell therapy applications. Cytotherapy 23, 852–860 (2021).
Maestro, S., Weber, N. D., Zabaleta, N., Aldabe, R. & Gonzalez-Aseguinolaza, G. Novel vectors and approaches for gene therapy in liver diseases. JHEP Rep. 3, 100300 (2021).
Houseley, J. & Tollervey, D. The many pathways of RNA degradation. Cell 136, 763–776 (2009).
Finn, J. D. et al. A single administration of CRISPR/Cas9 lipid nanoparticles achieves robust and persistent in vivo genome editing. Cell Rep. 22, 2227–2235 (2018).
Kowalski, P. S., Rudra, A., Miao, L. & Anderson, D. G. Delivering the messenger: advances in technologies for therapeutic mRNA Delivery. Mol. Ther. 27, 710–728 (2019).
Rosenblum, D. et al. CRISPR-Cas9 genome editing using targeted lipid nanoparticles for cancer therapy. Sci. Adv. 6, eabc9450 (2020).
Zong, Y., Lin, Y., Wei, T. & Cheng, Q. Lipid Nanoparticle (LNP) Enables mRNA delivery for cancer therapy. Adv. Mater. 35, e2303261 (2023).
Conway, A. et al. Non-viral delivery of zinc finger nuclease mRNA enables highly efficient in vivo genome editing of multiple therapeutic gene targets. Mol. Ther. 27, 866–877 (2019).
Jiang, T. et al. Chemical modifications of adenine base editor mRNA and guide RNA expand its application scope. Nat. Commun. 11, 1979 (2020).
Song, C. Q. et al. Adenine base editing in an adult mouse model of tyrosinaemia. Nat. Biomed. Eng. 4, 125–130 (2020).
Ashley, J. et al. Retrovirus-like Gag Protein Arc1 Binds RNA and traffics across synaptic boutons. Cell 172, 262–274.e11 (2018).
Segel, M. et al. Mammalian retrovirus-like protein PEG10 packages its own mRNA and can be pseudotyped for mRNA delivery. Science 373, 882–889 (2021).
Pandya, N. J. et al. Secreted retrovirus-like GAG-domain-containing protein PEG10 is regulated by UBE3A and is involved in Angelman syndrome pathophysiology. Cell Rep. Med. 2, 100360 (2021).
Liu, J. et al. Efficient delivery of nuclease proteins for genome editing in human stem cells and primary cells. Nat. Protoc. 10, 1842–1859 (2015).
Kim, S., Kim, D., Cho, S. W., Kim, J. & Kim, J. S. Highly efficient RNA-guided genome editing in human cells via delivery of purified Cas9 ribonucleoproteins. Genome Res. 24, 1012–1019 (2014).
Bloomer, H., Smith, R. H., Hakami, W. & Larochelle, A. Genome editing in human hematopoietic stem and progenitor cells via CRISPR-Cas9-mediated homology-independent targeted integration. Mol. Ther. 29, 1611–1624 (2021).
Miao, D., Giassetti, M. I., Ciccarelli, M., Lopez-Biladeau, B. & Oatley, J. M. Simplified pipelines for genetic engineering of mammalian embryos by CRISPR-Cas9 electroporation†. Biol. Reprod. 101, 177–187 (2019).
Yeh, W. H., Chiang, H., Rees, H. A., Edge, A. S. B. & Liu, D. R. In vivo base editing of post-mitotic sensory cells. Nat. Commun. 9, 2184 (2018).
Mirjalili Mohanna, S. Z. et al. LNP-mediated delivery of CRISPR RNP for wide-spread in vivo genome editing in mouse cornea. J. Control Release 350, 401–413 (2022).
Bai, B. et al. Virus-like particles of SARS-like coronavirus formed by membrane proteins from different origins demonstrate stimulating activity in human dendritic cells. PLoS One 3, e2685 (2008).
Banskota, S. et al. Engineered virus-like particles for efficient in vivo delivery of therapeutic proteins. Cell 185, 250–265.e16 (2022).
Lyu, P. et al. Adenine base editor ribonucleoproteins delivered by lentivirus-like particles show high on-target base editing and undetectable RNA off-target activities. CRISPR J. 4, 69–81 (2021).
Hamilton, J. R. et al. Targeted delivery of CRISPR-Cas9 and transgenes enables complex immune cell engineering. Cell Rep. 35, 109207 (2021).
Mangeot, P. E. et al. Genome editing in primary cells and in vivo using viral-derived Nanoblades loaded with Cas9-sgRNA ribonucleoproteins. Nat. Commun. 10, 45 (2019).
Raguram, A., Banskota, S. & Liu, D. R. Therapeutic in vivo delivery of gene editing agents. Cell 185, 2806–2827 (2022).
Itzhak, D. N., Tyanova, S., Cox, J. & Borner, G. H. H. Global, quantitative and dynamic mapping of protein subcellular localization. Elife 5, e16950 (2016).
Karakikes, I. et al. Correction of human phospholamban R14del mutation associated with cardiomyopathy using targeted nucleases and combination therapy. Nat. Commun. 6, 6955 (2015).
Haghighi, K. et al. A mutation in the human phospholamban gene, deleting arginine 14, results in lethal, hereditary cardiomyopathy. Proc. Natl. Acad. Sci. USA 103, 1388–1393 (2006).
Gibson, T. J., Seiler, M. & Veitia, R. A. The transience of transient overexpression. Nat. Methods 10, 715–721 (2013).
Schwinn, M. K., Steffen, L. S., Zimmerman, K., Wood, K. V. & Machleidt, T. A simple and scalable strategy for analysis of endogenous protein dynamics. Sci. Rep. 10, 8953 (2020).
Rizzo, M. A., Davidson, M. W. & Piston, D. W. Fluorescent protein tracking and detection: applications using fluorescent proteins in living cells. Cold Spring Harb. Protoc. 2009, pdb.top64 (2009).
Yang, J. et al. Neuronal release of proBDNF. Nat. Neurosci. 12, 113–115 (2009).
Mikuni, T., Nishiyama, J., Sun, Y., Kamasawa, N. & Yasuda, R. High-throughput, high-resolution mapping of protein localization in mammalian brain by in vivo genome editing. Cell 165, 1803–1817 (2016).
Nozawa, K. et al. Cellular and subcellular localization of endogenous neuroligin-1 in the cerebellum. Cerebellum 17, 709–721 (2018).
Yarnall, M. T. N. et al. Drag-and-drop genome insertion of large sequences without double-strand DNA cleavage using CRISPR-directed integrases. Nat. Biotechnol. 41, 500–512 (2023).
Garst, A. D. et al. Genome-wide mapping of mutations at single-nucleotide resolution for protein, metabolic and genome engineering. Nat. Biotechnol. 35, 48–55 (2017).
Findlay, G. M., Boyle, E. A., Hause, R. J., Klein, J. C. & Shendure, J. Saturation editing of genomic regions by multiplex homology-directed repair. Nature 513, 120–123 (2014).
Findlay, G. M. et al. Accurate classification of BRCA1 variants with saturation genome editing. Nature 562, 217–222 (2018).
Hanna, R. E. et al. Massively parallel assessment of human variants with base editor screens. Cell 184, 1064–1080.e20 (2021).
Cuella-Martin, R. et al. Functional interrogation of DNA damage response variants with base editing screens. Cell 184, 1081–1097.e19 (2021).
Coelho, M. A. et al. Base editing screens map mutations affecting interferon-γ signaling in cancer. Cancer Cell 41, 288–303.e6 (2023).
Kim, Y. et al. High-throughput functional evaluation of human cancer-associated mutations using base editors. Nat. Biotechnol. 40, 874–884 (2022).
Martin-Rufino, J. D. et al. Massively parallel base editing to map variant effects in human hematopoiesis. Cell 186, 2456–2474.e24 (2023).
Sánchez-Rivera, F. J. et al. Base editing sensor libraries for high-throughput engineering and functional analysis of cancer-associated single nucleotide variants. Nat. Biotechnol. 40, 862–873 (2022).
Erwood, S. et al. Saturation variant interpretation using CRISPR prime editing. Nat. Biotechnol. 40, 885–895 (2022).
Mathis, N. et al. Predicting prime editing efficiency and product purity by deep learning. Nat. Biotechnol. 41, 1151–1159 (2023).
Tang, W. & Liu, D. R. Rewritable multi-event analog recording in bacterial and mammalian cells. Science 360, eaap8992 (2018).
Farzadfard, F. & Lu, T. K. Emerging applications for DNA writers and molecular recorders. Science 361, 870–875 (2018).
Tang, W., Hu, J. H. & Liu, D. R. Aptazyme-embedded guide RNAs enable ligand-responsive genome editing and transcriptional activation. Nat. Commun. 8, 15939 (2017).
Farzadfard, F. et al. Single-nucleotide-resolution computing and memory in living cells. Mol. Cell 75, 769–780.e4 (2019).
Choi, J. et al. A time-resolved, multi-symbol molecular recorder via sequential genome editing. Nature 608, 98–107 (2022).
Bowers, B. J. Applications of transgenic and knockout mice in alcohol research. Alcohol Res. Health 24, 175–184 (2000).
Ittner, L. M. & Götz, J. Pronuclear injection for the production of transgenic mice. Nat. Protoc. 2, 1206–1215 (2007).
Williams, A. et al. Position effect variegation and imprinting of transgenes in lymphocytes. Nucleic Acids Res. 36, 2320–2329 (2008).
Gao, Q. et al. Telomeric transgenes are silenced in adult mouse tissues and embryo fibroblasts but are expressed in embryonic stem cells. Stem Cells 25, 3085–3092 (2007).
Pedram, M. et al. Telomere position effect and silencing of transgenes near telomeres in the mouse. Mol. Cell Biol. 26, 1865–1878 (2006).
Milot, E. et al. Heterochromatin effects on the frequency and duration of LCR-mediated gene transcription. Cell 87, 105–114 (1996).
Tasic, B. et al. Site-specific integrase-mediated transgenesis in mice via pronuclear injection. Proc. Natl. Acad. Sci. USA 108, 7902–7907 (2011).
Soriano, P. Gene targeting in ES cells. Annu Rev. Neurosci. 18, 1–18 (1995).
Hickman-Davis, J. M. & Davis, I. C. Transgenic mice. Paediatr. Respir. Rev. 7, 49–53 (2006).
Adriaanse, F. R. S. et al. A CRISPR/Cas9 engineered MplS504N mouse model recapitulates human myelofibrosis. Leukemia 36, 2535–2538 (2022).
Platt, R. J. et al. CRISPR-Cas9 knockin mice for genome editing and cancer modeling. Cell 159, 440–455 (2014).
Chen, L. et al. Engineering a precise adenine base editor with minimal bystander editing. Nat. Chem. Biol. 19, 101–110 (2023).
Liu, Y. et al. Efficient generation of mouse models with the prime editing system. Cell Discov. 6, 27 (2020).
Yan, S. et al. Cas9-mediated replacement of expanded CAG repeats in a pig model of Huntington’s disease. Nat. Biomed. Eng. 7, 629–646 (2023).
Bosch, J. A., Birchak, G. & Perrimon, N. Precise genome engineering in Drosophila using prime editing. Proc. Natl. Acad. Sci. USA 118, e2021996118 (2021).
Büning, H. Gene therapy enters the pharma market: the short story of a long journey. EMBO Mol. Med. 5, 1–3 (2013).
Ylä-Herttuala, S. Endgame: glybera finally recommended for approval as the first gene therapy drug in the European union. Mol. Ther. 20, 1831–1832 (2012).
Aiuti, A., Roncarolo, M. G. & Naldini, L. Gene therapy for ADA-SCID, the first marketing approval of an ex vivo gene therapy in Europe: paving the road for the next generation of advanced therapy medicinal products. EMBO Mol. Med. 9, 737–740 (2017).
Maude, S. L. et al. Tisagenlecleucel in Children and Young Adults with B-Cell Lymphoblastic Leukemia. N. Engl. J. Med. 378, 439–448 (2018).
Maude, S. L. et al. Chimeric antigen receptor T cells for sustained remissions in leukemia. N. Engl. J. Med. 371, 1507–1517 (2014).
Thompson, A. A. et al. Gene therapy in patients with transfusion-dependent β-Thalassemia. N. Engl. J. Med. 378, 1479–1493 (2018).
Martier, R. et al. Targeting RNA-mediated toxicity in C9orf72 ALS and/or FTD by RNAi-based gene therapy. Mol. Ther. Nucleic Acids 16, 26–37 (2019).
Evers, M. M. et al. AAV5-miHTT gene therapy demonstrates broad distribution and strong human mutant huntingtin lowering in a huntington’s disease minipig model. Mol. Ther. 26, 2163–2177 (2018).
Kleinman, M. E. et al. Sequence- and target-independent angiogenesis suppression by siRNA via TLR3. Nature 452, 591–597 (2008).
DeVincenzo, J. et al. A randomized, double-blind, placebo-controlled study of an RNAi-based therapy directed against respiratory syncytial virus. Proc. Natl. Acad. Sci. USA 107, 8800–8805 (2010).
Pavel-Dinu, M. et al. Gene correction for SCID-X1 in long-term hematopoietic stem cells. Nat. Commun. 10, 1634 (2019).
Wang, J. et al. Existence of transient functional double-stranded DNA intermediates during recombinant AAV transduction. Proc. Natl. Acad. Sci. USA 104, 13104–13109 (2007).
Le Hir, M. et al. AAV genome loss from dystrophic mouse muscles during AAV-U7 snRNA-mediated exon-skipping therapy. Mol. Ther. 21, 1551–1558 (2013).
Castanotto, D. & Rossi, J. J. The promises and pitfalls of RNA-interference-based therapeutics. Nature 457, 426–433 (2009).
Tiemann, K. & Rossi, J. J. RNAi-based therapeutics-current status, challenges and prospects. EMBO Mol. Med. 1, 142–151 (2009).
Song, X. et al. Delivery of CRISPR/Cas systems for cancer gene therapy and immunotherapy. Adv. Drug Deliv. Rev. 168, 158–180 (2021).
Dever, D. P. et al. CRISPR/Cas9 β-globin gene targeting in human haematopoietic stem cells. Nature 539, 384–389 (2016).
Kohn, D. B. et al. Autologous ex vivo lentiviral gene therapy for adenosine deaminase deficiency. N. Engl. J. Med. 384, 2002–2013 (2021).
DeWitt, M. A. et al. Selection-free genome editing of the sickle mutation in human adult hematopoietic stem/progenitor cells. Sci. Transl. Med. 8, 360ra134 (2016).
Everette, K. A. et al. Ex vivo prime editing of patient haematopoietic stem cells rescues sickle-cell disease phenotypes after engraftment in mice. Nat. Biomed. Eng. 7, 616–628 (2023).
Song, S. et al. Inhibition of IRF5 hyperactivation protects from lupus onset and severity. J. Clin. Investig. 130, 6700–6717 (2020).
Prominski, A., Li, P., Miao, B. A. & Tian, B. Nanoenabled bioelectrical modulation. Acc. Mater. Res. 2, 895–906 (2021).
Zhang, X., Wang, L., Liu, M. & Li, D. CRISPR/Cas9 system: a powerful technology for in vivo and ex vivo gene therapy. Sci. China Life Sci. 60, 468–475 (2017).
Rosanwo, T. O. & Bauer, D. E. Editing outside the body: ex vivo gene-modification for β-hemoglobinopathy cellular therapy. Mol. Ther. 29, 3163–3178 (2021).
Abraham, A. A. & Tisdale, J. F. Gene therapy for sickle cell disease: moving from the bench to the bedside. Blood 138, 932–941 (2021).
Hoban, M. D. et al. Correction of the sickle cell disease mutation in human hematopoietic stem/progenitor cells. Blood 125, 2597–2604 (2015).
Uchida, N. et al. Preclinical evaluation for engraftment of CD34+ cells gene-edited at the sickle cell disease locus in xenograft mouse and non-human primate models. Cell Rep. Med. 2, 100247 (2021).
Wilkinson, A. C. et al. Cas9-AAV6 gene correction of beta-globin in autologous HSCs improves sickle cell disease erythropoiesis in mice. Nat. Commun. 12, 686 (2021).
Newby, G. A. et al. Base editing of haematopoietic stem cells rescues sickle cell disease in mice. Nature 595, 295–302 (2021).
Hardouin, G. et al. Adenine base editor-mediated correction of the common and severe IVS1-110 (G>A) β-thalassemia mutation. Blood 141, 1169–1179 (2023).
Zeng, J. et al. Therapeutic base editing of human hematopoietic stem cells. Nat. Med. 26, 535–541 (2020).
Liao, J. et al. Therapeutic adenine base editing of human hematopoietic stem cells. Nat. Commun. 14, 207 (2023).
De Ravin, S. S. et al. CRISPR-Cas9 gene repair of hematopoietic stem cells from patients with X-linked chronic granulomatous disease. Sci. Transl. Med. 9, eaah3480 (2017).
De Ravin, S. S. et al. Targeted gene addition in human CD34(+) hematopoietic cells for correction of X-linked chronic granulomatous disease. Nat. Biotechnol. 34, 424–429 (2016).
Evgin, L. et al. Oncolytic virus-mediated expansion of dual-specific CAR T cells improves efficacy against solid tumors in mice. Sci. Transl. Med. 14, eabn2231 (2022).
Poorebrahim, M. et al. Production of CAR T-cells by GMP-grade lentiviral vectors: latest advances and future prospects. Crit. Rev. Clin. Lab Sci. 56, 393–419 (2019).
Huang, R. et al. Recent advances in CAR-T cell engineering. J. Hematol. Oncol. 13, 86 (2020).
Michieletto, D., Lusic, M., Marenduzzo, D. & Orlandini, E. Physical principles of retroviral integration in the human genome. Nat. Commun. 10, 575 (2019).
de Sousa Russo-Carbolante, E. M. et al. Integration pattern of HIV-1 based lentiviral vector carrying recombinant coagulation factor VIII in Sk-Hep and 293T cells. Biotechnol. Lett. 33, 23–31 (2011).
Tao, J., Zhou, X. & Jiang, Z. cGAS-cGAMP-STING: The three musketeers of cytosolic DNA sensing and signaling. IUBMB Life 68, 858–870 (2016).
Eyquem, J. et al. Targeting a CAR to the TRAC locus with CRISPR/Cas9 enhances tumour rejection. Nature 543, 113–117 (2017).
Chang, Y. et al. CAR-neutrophil mediated delivery of tumor-microenvironment responsive nanodrugs for glioblastoma chemo-immunotherapy. Nat. Commun. 14, 2266 (2023).
Zhang, J. et al. Non-viral, specifically targeted CAR-T cells achieve high safety and efficacy in B-NHL. Nature 609, 369–374 (2022).
Arbab, M. et al. Base editing rescue of spinal muscular atrophy in cells and in mice. Science 380, eadg6518 (2023).
Reichart, D. et al. Efficient in vivo genome editing prevents hypertrophic cardiomyopathy in mice. Nat. Med. 29, 412–421 (2023).
Chai, A. C. et al. Base editing correction of hypertrophic cardiomyopathy in human cardiomyocytes and humanized mice. Nat. Med. 29, 401–411 (2023).
Wang, L. et al. A mutation-independent CRISPR-Cas9-mediated gene targeting approach to treat a murine model of ornithine transcarbamylase deficiency. Sci. Adv. 6, eaax5701 (2020).
Pagant, S. et al. ZFN-mediated in vivo gene editing in hepatocytes leads to supraphysiologic α-Gal A activity and effective substrate reduction in Fabry mice. Mol. Ther. 29, 3230–3242 (2021).
Yin, H. et al. Genome editing with Cas9 in adult mice corrects a disease mutation and phenotype. Nat. Biotechnol. 32, 551–553 (2014).
Jiang, T., Zhang, X. O., Weng, Z. & Xue, W. Deletion and replacement of long genomic sequences using prime editing. Nat. Biotechnol. 40, 227–234 (2022).
Jang, H. et al. Application of prime editing to the correction of mutations and phenotypes in adult mice with liver and eye diseases. Nat. Biomed. Eng. 6, 181–194 (2022).
Liu, B. et al. A split prime editor with untethered reverse transcriptase and circular RNA template. Nat. Biotechnol. 40, 1388–1393 (2022).
Koblan, L. W. et al. In vivo base editing rescues Hutchinson-Gilford progeria syndrome in mice. Nature 589, 608–614 (2021).
She, K. et al. Dual-AAV split prime editor corrects the mutation and phenotype in mice with inherited retinal degeneration. Signal Transduct. Target Ther. 8, 57 (2023).
Suh, S. et al. Restoration of visual function in adult mice with an inherited retinal disease via adenine base editing. Nat. Biomed. Eng. 5, 169–178 (2021).
Choi, E. H. et al. In vivo base editing rescues cone photoreceptors in a mouse model of early-onset inherited retinal degeneration. Nat. Commun. 13, 1830 (2022).
Sahng, W. P., Moon, Y. A. & Horton, J. D. Post-transcriptional regulation of low density lipoprotein receptor protein by proprotein convertase subtilisin/kexin type 9a in mouse liver. J. Biol. Chem. 279, 50630–50638 (2004).
Stein, E. A. et al. Effect of a monoclonal antibody to PCSK9, REGN727/SAR236553, to reduce low-density lipoprotein cholesterol in patients with heterozygous familial hypercholesterolaemia on stable statin dose with or without ezetimibe therapy: a phase 2 randomised controlled trial. Lancet 380, 29–36 (2012).
Davis, J. R. et al. Efficient in vivo base editing via single adeno-associated viruses with size-optimized genomes encoding compact adenine base editors. Nat. Biomed. Eng. 6, 1272–1283 (2022).
Musunuru, K. et al. In vivo CRISPR base editing of PCSK9 durably lowers cholesterol in primates. Nature 593, 429–434 (2021).
Rothgangl, T. et al. In vivo adenine base editing of PCSK9 in macaques reduces LDL cholesterol levels. Nat. Biotechnol. 39, 949–957 (2021).
Beckendorf, J., van den Hoogenhof, M. M. G. & Backs, J. Physiological and unappreciated roles of CaMKII in the heart. Basic Res. Cardiol. 113, 29 (2018).
Neef, S. et al. CaMKII-dependent diastolic SR Ca2+ leak and elevated diastolic Ca2+ levels in right atrial myocardium of patients with atrial fibrillation. Circ. Res. 106, 1134–1144 (2010).
Lebek, S. et al. Ablation of CaMKIIδ oxidation by CRISPR-Cas9 base editing as a therapy for cardiac disease. Science 379, 179–185 (2023).
Zhuo, C. et al. Spatiotemporal control of CRISPR/Cas9 gene editing. Signal Transduct. Target Ther. 6, 238 (2021).
Acknowledgements
This work was supported by the National Science Foundation of China (Grant numbers 82200265, 82070324, 82270249), and the USA National Institutes of Health (Grant numbers R00HL143194, R21HD108460).
Author information
Authors and Affiliations
Contributions
Y.Z. and Y.L. contributed equally to this work; the conception and design of the study: Y.Z. and Y. L.; Y.Z. created the figures; K.Z. reviewed the manuscript. T.L. collected and prepared the related papers; manuscript review and corresponding author: N-J. V., Y.H. All authors have read and approved the article.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zheng, Y., Li, Y., Zhou, K. et al. Precise genome-editing in human diseases: mechanisms, strategies and applications. Sig Transduct Target Ther 9, 47 (2024). https://doi.org/10.1038/s41392-024-01750-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41392-024-01750-2
