
Abstract
Objective
Develop and validate a resiliency score to predict survival and survival without neonatal morbidity in preterm neonates <32 weeks of gestation using machine learning.
Study design
Models using maternal, perinatal, and neonatal variables were developed using LASSO method in a population based Californian administrative dataset. Outcomes were survival and survival without severe neonatal morbidity. Discrimination was assessed in the derivation and an external dataset from a tertiary care center.
Results
Discrimination in the internal validation dataset was excellent with a c-statistic of 0.895 (95% CI 0.882–0.908) for survival and 0.867 (95% CI 0.857–0.877) for survival without severe neonatal morbidity, respectively. Discrimination remained high in the external validation dataset (c-statistic 0.817, CI 0.741–0.893 and 0.804, CI 0.770–0.837, respectively).
Conclusion
Our successfully predicts survival and survival without major morbidity in preterm babies born at <32 weeks. This score can be used to adjust for multiple variables across administrative datasets.
Similar content being viewed by others
Introduction
In infants born preterm, gestational age (GA) is the best indicator of maturity and is a strong driver of survival and other health and neurodevelopmental outcomes [1]. Several other predictors influence outcomes in this vulnerable patient population. In their landmark paper, Tyson and colleagues showed that consideration of birth weight, sex, antenatal steroid administration, and multiple gestation improved prediction of survival of extremely low gestational age infants [2]. Several prediction models have subsequently been developed to predict mortality and morbidity in very preterm neonates including a variety of maternal, antenatal, and postnatal candidate predictors with variable predictive performance [3, 4].
Risk assessment and outcome prediction in extremely preterm neonates is important for multiple reasons. Understanding an infant’s range of potential outcomes can inform counseling and medical decision making, both antenatally when making shared decisions around the provision of intensive care at delivery as well as postnatally if complications develop [5]. Another important goal of prediction models includes their use in benchmarking and comparing performance across centers to guide continuous quality improvement in care practices [6]. Finally, prediction models can help ensure that both care practices and outcomes are observed to be equitable in order to reduce the impact of discrimination and structural racism [7].
It has been shown that race/ethnicity as well as certain sociodemographic factors are associated with a variety of long-term outcomes in very preterm neonates [8, 9]. Some of the previously described prediction models include race/ethnicity and/or sociodemographic factors [4]. This approach, however, assumes that the models are performing equally across all racial, ethnic, and sociodemographic groups, which should not be assumed. It may also limit our ability to adequately address risk and resiliency specifically in communities most in need.
Interestingly, all currently existing survival and major morbidity prediction models for infants born preterm have defined their prediction around “risk factors.” Such an approach may encourage a focus by care providers on deficits rather than on strengths that may foster better outcomes. Resilience can be conceptualized as a positive adaptation to an experienced adversity. This concept may deepen our understanding of the variation in outcomes after the adverse experience of preterm birth [10,11,12]. Focusing on resilience rather than risk in predictive modeling may shift our framework from identifying deficits to promotive factors [10]. This frameshift has also been prioritized by families experiencing preterm birth.
The goal of this study was to develop a prediction model for survival without major morbidity in preterm infants born at <32 weeks using a resiliency frame. Machine learning was used to build a resiliency score with a focus on maternal, perinatal, and neonatal factors known at the time of birth. The model was externally validated. Performance was assessed across race/ethnic and sociodemographic subgroups to ensure validity across diverse populations.
Methods
Our primary dataset was drawn from all California live born infants between 2011 and 2017. Birth and death certificates (up to 12 months of age) from California Vital Statistics were linked to the database maintained by the California Office of Statewide Health Planning and Development (OSHPD). This dataset was randomly divided into a training dataset (2/3 of the data) and an internal validation dataset (1/3 of the data). We also externally validated the model using a retrospective cohort derived from the Iowa Perinatal Health Research Collaborative (IPHRC) database.
The primary OSHPD dataset included detailed information on maternal and infant characteristics from hospital discharge records from one year prior to birth to one year of age. The data included diagnosis and procedure codes based on the International Classification of Diseases, 9th and 10th Revision, clinical modification (ICD-CM). GA was determined by best obstetric estimate from ultrasound and/or last menstrual period. This dataset has been used in multiple studies examining birth and neonatal outcomes [13,14,15,16,17]. All linked singleton liveborn infants with GA < 32 weeks without major congenital or chromosomal anomalies were included in this study (ICD-9 and 10 codes used to define major congenital or chromosomal anomalies are listed in Supplemental Table 1).
The primary outcome was survival to 1 year of age (determined by death certificate or death as the hospital discharge status). The secondary outcome was a composite of survival without any major neonatal morbidity. Major neonatal morbidity was determined from ICD-9 and ICD-10 CM codes. These included bronchopulmonary dysplasia (BPD, ICD-9 770.7, ICD-10 P27.1), necrotizing enterocolitis (NEC, ICD-9 777.5, ICD-10 P77), intraventricular hemorrhage > grade II (IVH, ICD-9 772.13 and 772.14, ICD-10 P52.2), periventricular leukomalacia (PVL, ICD-9 779.7, ICD-10 P91.2), and retinopathy of prematurity (ROP) > stage 2. To define ROP > stage 2 we used diagnostic or procedure codes (ICD-9 362.25-7 or 14.2, 14.5, 14.7 14.9, ICD-10 H35.14-6 or any procedure code for surgery on retina or choroid plexus).
The data was randomly divided into a training and validation dataset as described above. The model was developed using the training sample only. Maternal, perinatal, and neonatal covariates that have been significantly associated with neonatal outcomes in prior studies were considered for inclusion in the model (Supplemental Table 2).
We fit a logistic regression model to the outcomes. Due to the large number of potential covariates, the model was built using the least absolute shrinkage and selection operator (LASSO). The LASSO is a logistic regression method that is able to accommodate large numbers of predictors in a statistically principled way to reduce model complexity and avoid over-fitting the prediction model. It involves penalizing the absolute size of the regression coefficients with the consequence that regression coefficients are reduced in absolute size and variables that do not strongly predict the outcome have the coefficients set to zero, eliminating them from the model. Cross-validation (within the training data) was used to select the optimal weighting parameter (lambda) and thus the final model. The resiliency score for a specific observation consists of the sum of all the beta coefficients based on the state of the observed covariates. In order to convert the resiliency score to a survival probability, the constant of the model is added to the score and the following formula can be used: survival probability = e(constant + resiliency score)/(1 + e(constant + resiliency score)).
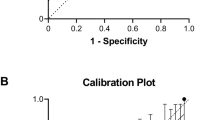
Discrimination was assessed in the internal and external validation samples by calculating c-statistics and receiver operator characteristic curves (ROCs) for the resiliency score and both of our outcomes. Calibration was assessed in the primary dataset by dividing the validation sample into deciles based on the resiliency score values and comparing predicted and observed survival and survival without major morbidity rates for each decile of the validation sample.
For each subject we calculated the predicted outcome probabilities based on the model. We then stratified the sample by gestational age and found the smallest and the largest observed predicted outcome probability in this group. We then stratified the sample by race/ethnicity, insurance status, and maternal education to assess the resiliency score performance in different race/ethnic and sociodemographic groups. For that purpose, we calculated the observed outcome probability and the predicted outcome probability for each subgroup. The predicted outcome probability was calculated by finding the mean value of all predicted outcome probabilities in the respective subgroup.
We also performed external validation in a retrospective cohort derived from the Iowa Perinatal Health Research Collaborative (IPHRC) database, a resource composed of linked maternal and newborn electronic health record (EHR) data for deliveries occurring at a single tertiary care unit. EHR data within this database were provided by the Institute for Clinical and Translational Science (ICTS) Bioinformatics Core at the University of Iowa. The validation dataset included 1347 deliveries at <32 weeks gestation born between January 1, 2012 and December 31, 2019. We excluded 261 deliveries that were missing either the maternal or delivery medical record, 4 newborns transferred out of the facility during the first day of life, 13 fetal demises, 294 twin or higher order multiples, 13 infants born to mothers already included in the dataset with a previous pregnancy, and 86 newborns with a major congenital anomaly as defined in Supplemental Table 3.
The primary and secondary outcomes were defined in the same manner as in the derivation dataset. Maternal, perinatal, and neonatal characteristics were defined by ICD9 and ICD10 codes as outlined above (Supplemental Table 2) examining infant codes up to 365 days after birth and maternal codes between 280 days before delivery through 42 days after delivery. Maternal body mass index (BMI) was derived either directly from a reported BMI in the EMR or by calculating BMI using weight and height, using the earliest recorded BMI or height and weight during the antenatal period. Mode of delivery was recorded directly from the medical record. Resiliency scores for survival and survival without major morbidity were calculated for the Iowa population using the coefficients from the model developed in the California dataset and AUCs were calculated to assess discrimination in the validation dataset.
All analyses were performed by using STATA version 16.1 (Stata Statistical Software: Release 16. College Station, TX: StataCorp LP). The use of the OSHPD database was approved by the Committee for the Protection of Human Subjects within the California Health and Human Services Agency, the use of the Iowa dataset was approved for a waiver of consent by the University of Iowa Institutional Review Board (IRB number: 202007280).
We utilized California’s Office of Statewide Health Planning and Development database (OSHPD). The data use agreement with the OSHPD prohibits distribution of any patient-level data; thus, the data used for this study are not made publicly available. Data can be requested from OSHPD (https://www.oshpd.ca.gov/HID/HIRC/index.html) by qualified researchers for a fee. Similarly, the data use agreement of the Iowa clinical database does not allow to share patient level data. All other analytic methods and study materials are available upon reasonable request from the corresponding author.
Results
We identified 21,483 preterm infants born alive <32 weeks of gestation in California from 2011–2017. Mortality in the entire dataset was 13.5% (2896/21483), 18.1% survived with neonatal morbidity (3884/21483) and 68.4% survived without morbidity (14,703/21,483). The training dataset consists of 14,322 infants and the validation dataset of 7161 infants, respectively. Maternal, perinatal, and neonatal characteristics for the training dataset are shown in Table 1.
After applying the LASSO method for survival, the cross validated lambda was 0.00075. Supplemental Fig. 1a shows the cross-validation plot. Out of the 30 covariates, 29 were retained in the model: …maternal age, maternal BMI, sex, gestational age and z-score for BW, vaginal delivery, absence of preeclampsia, hypertension, diabetes, smoking, drug abuse, infection, abruption, uterine rupture or PPROM, oligohydramnios, or polyhydramnios. The only factor not included in the model is “no preterm labor.” Similarly, after applying the LASSO method for survival without severe morbidity, the cross validated lambda was 0.00032. Supplemental Fig. 1b shows the cross-validation plot. All 30 covariates were retained in the final model. Table 2 shows the beta coefficient for each covariate or covariate level from the LASSO model for survival and survival without severe morbidity. Covariate categories with a listed value of 0 are the reference category. Covariates or covariate categories with a negative beta coefficient reduce the resiliency score and are negatively associated with the specified outcomes, while covariates or covariate categories with a positive beta coefficient are positively associated with survival or survival without severe morbidity.
Discrimination of the model in the internal validation dataset was excellent with a c-statistic of 0.895 (95% CI 0.882–0.908) for survival and 0.867 (95% CI 0.857–0.877) for survival without severe neonatal morbidity, respectively (Supplemental Fig. 2). Calibration of both models was also excellent with very similar observed and predicted rates for both outcomes (Supplemental Table 4).
The strong predictive value of GA can be seen in the wide range of values for the beta coefficients for GA categories: for survival, the beta coefficient is −0.968 for GA of 22 weeks and +0.608 for GA of 31 weeks, and for survival without major neonatal morbidity, the beta coefficient for GA of 22 weeks is −0.773 while it is +1.0 for GA of 31 weeks. However, the other covariates also contribute significantly to the model. Supplemental Table 5 and Fig. 1 show the relative importance of all the other covariates by presenting the smallest and largest outcome range based on the model stratified by each week of GA.

The boxplots for observed predicted probability for survival and survival without morbidity by gestational age.
Supplemental Table 6 shows the observed and expected outcome probabilities for racial and ethnic groups as well as for groups defined by different sociodemographic factors. The observed and expected outcome probabilities closely approximate each other for each of these subgroups.
With regards to external validation, the baseline characteristics of the Iowa dataset are presented in Table 3. Mortality in this dataset was 5.6% (38/676); 46.9% (317/676) survived with neonatal morbidity and 47.5% (321/676) survived without morbidity. However, the proportion of survived with neonatal morbidity dropped to 4.3% (29/676) when BPD was excluded from the neonatal morbidity definition. Discrimination of the model in the external validation dataset remained excellent with a c-statistic of 0.817 (95% CI 0.741-0.893) for survival and 0.804 (95% CI 0.770-0.837) for survival without severe neonatal morbidity, respectively. Calibration in the external validation dataset is shown in Table 4 for the morbidity definition including and excluding BPD.
Discussion
Using maternal, perinatal, and neonatal predictors readily available in most administrative databases at the time of birth, we built a model based on resiliency score with excellent discrimination and calibration to predict survival and survival without neonatal morbidity in neonates <32 weeks of gestational age. This prediction model performed well in an external validation cohort. While gestational age had the strongest influence on the resiliency score, the other included predictors increased the predictive ability of the model. The resiliency score performed well in all race/ethnic and sociodemographic subgroups.
A wide variety of predictive models for survival and survival without severe morbidity after preterm birth have been developed [2,3,4, 18]. Some of these models are parsimonious and others incorporate a wide variety of predictors. Like previous models, the main driver for successful prediction in our model is GA at birth, as can be clearly seen by the variability of the beta coefficients. Importantly, despite GA being the strongest predictor of survival and survival without severe morbidity, other factors contribute and should not be ignored. In our prediction model, we show how outcome predictions vary widely for the same GA based on other predictors, validating the importance of these factors. For example, a neonate born at 23 weeks with the highest resiliency score, or most favorable covariates, had a predicted survival chance of 66.7%, while the neonate born at the same GA with the lowest resiliency score, or least favorable covariates, had a predicted chance of survival of 0.5%.
Our model adds to the existing literature on neonatal outcome prediction in a few novel ways. First, we used machine learning, more specifically the LASSO method, to develop our model. The main benefit of the LASSO method compared to traditional logistic regression is the ability of the LASSO method to select relevant variables. It is superior to forward or backward selection often used in logistic regression and avoids overfitting by shrinking the coefficients [19]. Second, the main advantage of this score is that it incorporates many variables that are available in the different administrative datasets available. This score can be used to adjust for several important maternal and neonatal factors and may make comparison between databases more streamlined.
The focus of our model on resilience or promotive factors, rather than risks or maladaptive factors, is a frameshift from previous algorithms focused on risk. Preterm birth has increasingly been understood to be an adverse event biologically for the infant, after which both adaptive and maladaptive processes can occur to render an infant resilient or at risk [10, 12] There have been previous studies focused specifically on resiliency of preterm infants, but these have focused on longer term outcomes at transition to home or in early school age, rather than in the immediate neonatal hospitalization [11, 20]. Additionally, caregivers of preterm infants have increasingly called for the use of strength-based frameworks, such as the use of hope and resilience, both for antenatal counseling and in understanding long term prognosis of their infants [21]. For our model to fit the needs of caregivers and bedside clinicians as critical stakeholders in the outcomes, we chose this specific frameshift from risk to resilience. We would like to acknowledge though that resiliency is just the opposite of risk, and survival is just the opposite of mortality. If we were to develop a traditional risk score, the results with regards to discrimination and calibration would have been the same.
We intentionally did not include race/ethnicity or socioeconomic risk factors in our model. There is increasing recognition that inclusion of race and ethnicity into prediction algorithms might lead to bias and can exacerbate health care disparities [22]. For example, the calculator for successful vaginal birth after cesarean section (VBAC) included race/ethnicity. A Hispanic or Black woman with the same medical characteristics as a white woman had a much lower predicted success rate for VBAC [23]. In this example, if providers are influenced by concerns over perceived risk, they may be less likely to offer a trial of labor to women with low VBAC scores, and the race-based correction in the VBAC calculator may exacerbate racial disparities [23]. It is important to recognize that race and ethnicity reflect social constructs rather than a biological truth wherein biological definitions of race have been challenged by findings of greater genetic variation within rather than between groups based on skin color [24]. Several recent studies highlight the importance of minimizing racial bias in prediction models [25, 26]. Similarly, socioeconomic factors have been shown to be associated with poor clinical outcomes [27]. However, this association is often mediated through medical risk factors and predictors as well as structural discrimination; as such, we elected to not include those into the model. We present model performance in different race/ethnic and socioeconomic groups and found that it performed well across groups. This is an important finding and will allow this scoring to be used across subpopulations thereby minimizing biased approaches to care in different race/ethnic and socioeconomic groups.
A significant strength of this study is the use of an external validation dataset. While our internal validation avoided overfitting of the model, the external validation shows that this model can discriminate well in other populations. The calibration in the Iowa dataset identified interesting issues. BPD has historically been a complicated morbidity to capture accurately in administrative datasets based on differing definitions. The BPD ICD9 and 10 codes are used significantly more often in the Iowa dataset compared to California due to local definitions of BPD, leading to different rates of neonatal morbidity in the two cohorts. This led to overestimation of survival without neonatal morbidity in the calibration table. After excluding BPD from the morbidity definition, the neonatal morbidity is extremely low in the Iowa cohort at just 4.3%, and therefore, the model underestimates the survival without major morbidity. The truth is somewhere in between as some of the infants in this cohort will have long-term pulmonary morbidity. This example shows the importance of understanding local context and the potential need to recalibrate the model if it is used across different populations or with variable definitions of important outcomes.
As the above paragraph illustrates, one of the main weaknesses of this study is that it relies on ICD9 and ICD10 codes, which can lead to misclassification. BPD has historically been a complicated morbidity to capture accurately in administrative datasets. Coders with limited medical knowledge often determine that diagnosis leading to an overestimation in certain datasets. For example, BPD is often used as a diagnosis for any infant with respiratory distress and prolonged respiratory support. Additionally, the score can only be used in datasets with the available variables which might reduce its potential for broad application.
Our model using resiliency score is shown here to successfully predict survival and survival without major morbidity in preterm babies born at <32 weeks. In addition, it can be used across different epidemiological settings and race/ethnic and sociodemographic subpopulations. A resiliency score can be used and be helpful in clinical settings and in antenatal and postnatal counseling with a focus on protection rather than risk.
Data availability
The data use agreement with the OSHPD prohibits distribution of any patient-level data; thus, the data used for this study are not made publicly available. Data can be requested from OSHPD (https://www.oshpd.ca.gov/HID/HIRC/index.html) by qualified researchers for a fee. Similarly, the data use agreement of the Iowa clinical database does not allow to share patient level data. All other analytic methods and study materials are available upon reasonable request from the corresponding author.
References
Higgins RD, Delivoria-Papadopoulos M, Raju TNK. Executive Summary of the Workshop on the Border of Viability. Pediatrics. 2005;115:1392–6.
Tyson JE, Parikh NA, Langer J, Green C, Higgins RD, Network NI of CH and HDNR. Intensive Care for Extreme Prematurity — Moving beyond Gestational Age. N. Engl J Med. 2008;358:1672–81.
Ambalavanan N, Carlo WA, Bobashev G, Mathias E, Liu B, Poole K, et al. Prediction of Death for Extremely Low Birth Weight Neonates. Pediatrics. 2005;116:1367–73.
Pollack MM, Koch MA, Bartel DA, Rapoport I, Dhanireddy R, El-Mohandes AAE, et al. A Comparison of Neonatal Mortality Risk Prediction Models in Very Low Birth Weight Infants. Pediatrics. 2000;105:1051–7.
Lemyre B, Daboval T, Dunn S, Kekewich M, Jones G, Wang D, et al. Shared decision making for infants born at the threshold of viability: a prognosis-based guideline. J Perinatol. 2016;36:503–9.
Haumont D, Modi N, Saugstad OD, Antetere R, NguyenBa C, Turner M, et al. Evaluating preterm care across Europe using the eNewborn European Network database. Pediatr Res. 2020;88:484–95.
Pabayo R, Ehntholt A, Davis K, Liu SY, Muennig P, Cook DM. Structural Racism and Odds for Infant Mortality Among Infants Born in the United States 2010. J Racial Ethn Heal Disparities. 2019;6:1095–106.
Calling S, Li X, Sundquist J, Sundquist K. Socioeconomic inequalities and infant mortality of 46 470 preterm infants born in Sweden between 1992 and 2006. Paediatr Perinat Ep. 2011;25:357–65.
Travers CP, Carlo WA, McDonald SA, Das A, Ambalavanan N, Bell EF, et al. Racial/Ethnic Disparities Among Extremely Preterm Infants in the United States From 2002 to 2016. Jama Netw Open. 2020;3:e206757.
Masten AS. Ordinary Magic. Am Psychol. 2001;56:227–38.
Poehlmann-Tynan J, Gerstein ED, Burnson C, Weymouth L, Bolt DM, Maleck S, et al. Risk and resilience in preterm children at age 6. Dev Psychopathol. 2014;27:843–58.
Luthar SS, Cicchetti D, Becker B. The Construct of Resilience: A Critical Evaluation and Guidelines for Future Work. Child Dev. 2000;71:543–62.
Baer RJ, Chambers CD, Jones KL, Shew SB, MacKenzie TC, Shaw GM, et al. Maternal factors associated with the occurrence of gastroschisis. Am J Med Genet A. 2015;167:1534–41.
Jelliffe-Pawlowski LL, Norton ME, Baer RJ, Santos N, Rutherford GW. Gestational dating by metabolic profile at birth: a California cohort study. Am J Obstet Gynecol. 2016;214:511.e1–511.e13.
Stey A, Barnert ES, Tseng C-H, Keeler E, Needleman J, Leng M, et al. Outcomes and Costs of Surgical Treatments of Necrotizing Enterocolitis. Pediatrics. 2015;135:e1190–e1197.
Gage S, Kan P, Lee HC, Gould JB, Stevenson DK, Shaw GM, et al. Maternal Asthma, Preterm Birth, and Risk of Bronchopulmonary Dysplasia. J Pediatrics. 2015;167:875–880.e1.
Jelliffe-Pawlowski LL, Norton ME, Shaw GM, Baer RJ, Flessel MC, Goldman S, et al. Risk of critical congenital heart defects by nuchal translucency norms. Am J Obstet Gynecol. 2015;212:518.e1–518.e10.
Laughon MM, Langer JC, Bose CL, Smith PB, Ambalavanan N, Kennedy KA, et al. Prediction of Bronchopulmonary Dysplasia by Postnatal Age in Extremely Premature Infants. Am J Resp Crit Care. 2011;183:1715–22.
Kim SM, Kim Y, Jeong K, Jeong H, Kim J. Logistic LASSO regression for the diagnosis of breast cancer using clinical demographic data and the BI-RADS lexicon for ultrasonography. Ultrasonography. 2018;37:36–42.
Treyvaud K, Inder TE, Lee KJ, Northam EA, Doyle LW, Anderson PJ. Can the home environment promote resilience for children born very preterm in the context of social and medical risk? J Exp Child Psychol. 2012;112:326–37.
Lemmon ME, Huffstetler H, Barks MC, Kirby C, Katz M, Ubel PA, et al. Neurologic Outcome After Prematurity: Perspectives of Parents and Clinicians. Pediatrics. 2019;144:e20183819.
Vyas DA, Eisenstein LG, Jones DS. Hidden in Plain Sight — Reconsidering the Use of Race Correction in Clinical Algorithms. N Engl J Med. 2020;383:874–82.
Vyas DA, Jones DS, Meadows AR, Diouf K, Nour NM, Schantz-Dunn J. Challenging the Use of Race in the Vaginal Birth after Cesarean Section Calculator. Women’s Heal Issues. 2019;29:201–4.
Mallick S, Li H, Lipson M, Mathieson I, Gymrek M, Racimo F, et al. The Simons Genome Diversity Project: 300 genomes from 142 diverse populations. Nature. 2016;538:201–6.
Park Y, Hu J, Singh M, Sylla I, Dankwa-Mullan I, Koski E, et al. Comparison of Methods to Reduce Bias From Clinical Prediction Models of Postpartum Depression. Jama Netw Open. 2021;4:e213909.
Obermeyer Z, Powers B, Vogeli C, Mullainathan S. Dissecting racial bias in an algorithm used to manage the health of populations. Science. 2019;366:447–53.
Owens-Young J, Bell CN. Structural Racial Inequities in Socioeconomic Status, Urban-Rural Classification, and Infant Mortality in US Counties. Ethn Dis. 2020;30:389–98.
Acknowledgements
We thank the Institute of Clinical and Translational Science at the University of Iowa for their support in developing the IPHRC dataset (UL1TR002537). We also thank Nancy Weathers at the University of Iowa for project management support.
Funding
This research was supported by a grant from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (R01 HD102381). The content is solely the responsibility of the authors and does not necessarily represent the official views of the Eunice Kennedy Shriver National Institute of Child Health and Human Development or the National Institutes of Health.
Author information
Authors and Affiliations
Contributions
MS and KR conceptualized and designed the study, performed data analysis, drafted the initial manuscript, and reviewed and revised the manuscript. RB conceptualized the study, assisted with data analysis, reviewed and revised the manuscript. JC assisted with study design and reviewed and revised the manuscript. SO conceptualized the study, assisted with data analysis, reviewed and revised the manuscript. CMC conceptualized and assisted with study design, offering expertise in analytic plan, reviewed and revised the manuscript. LJ assisted with study design, critically reviewed the manuscript for important intellectual content, and reviewed and revised the manuscript. ER participated in conceptualization and study design including the analytic plan and assisted in drafting and revising the manuscript. All authors approved the final manuscript as submitted and agree to be accountable for all aspects of the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Steurer, M.A., Ryckman, K.K., Baer, R.J. et al. Developing a resiliency model for survival without major morbidity in preterm infants. J Perinatol 43, 452–457 (2023). https://doi.org/10.1038/s41372-022-01521-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41372-022-01521-3
