
Abstract
Collisions at high-energy particle colliders are a traditionally fruitful source of exotic particle discoveries. Finding these rare particles requires solving difficult signal-versus-background classification problems, hence machine-learning approaches are often used. Standard approaches have relied on ‘shallow’ machine-learning models that have a limited capacity to learn complex nonlinear functions of the inputs, and rely on a painstaking search through manually constructed nonlinear features. Progress on this problem has slowed, as a variety of techniques have shown equivalent performance. Recent advances in the field of deep learning make it possible to learn more complex functions and better discriminate between signal and background classes. Here, using benchmark data sets, we show that deep-learning methods need no manually constructed inputs and yet improve the classification metric by as much as 8% over the best current approaches. This demonstrates that deep-learning approaches can improve the power of collider searches for exotic particles.
Similar content being viewed by others



Introduction
The field of high-energy physics is devoted to the study of the elementary constituents of matter. By investigating the structure of matter and the laws that govern its interactions, this field strives to discover the fundamental properties of the physical universe. The primary tools of experimental high-energy physicists are modern accelerators, which collide protons and/or antiprotons to create exotic particles that occur only at extremely high-energy densities. Observing these particles and measuring their properties may yield critical insights about the very nature of matter1. Such discoveries require powerful statistical methods, and machine-learning tools have a critical role. Given the limited quantity and expensive nature of the data, improvements in analytical tools directly boost particle discovery potential.
To discover a new particle, physicists must isolate a subspace of their high-dimensional data in which the hypothesis of a new particle or force gives a significantly different prediction than the null hypothesis, allowing for an effective statistical test. For this reason, the critical element of the search for new particles and forces in high-energy physics is the computation of the relative likelihood, the ratio of the sample likelihood functions in the two considered hypotheses, shown by Neyman and Pearson2 to be the optimal discriminating quantity. Often this relative likelihood function cannot be expressed analytically, so simulated collision data generated with Monte Carlo methods are used as a basis for approximation of the likelihood function. The high dimensionality of data, referred to as the feature space, makes it intractable to generate enough simulated collisions to describe the relative likelihood in the full feature space, and machine-learning tools are used for dimensionality reduction. Machine-learning classifiers such as neural networks provide a powerful way to solve this learning problem.
The relative likelihood function is a complicated function in a high-dimensional space. Although any function can theoretically be represented by a ‘shallow’ classifier, such as a neural network with a single hidden layer3, an intractable number of hidden units may be required. Circuit complexity theory tells us that deep neural networks (DN) have the potential to compute complex functions much more efficiently (fewer hidden units), but in practice they are notoriously difficult to train due to the vanishing gradient problem4,5; the adjustments to the weights in the early layers of a DN rapidly approach zero during training. A common approach is to combine shallow classifiers with high-level features that are derived manually from the raw features. These are generally nonlinear functions of the input features that capture physical insights about the data. Although helpful, this approach is labour-intensive and not necessarily optimal; a robust machine-learning method would obviate the need for this additional step and capture all of the available classification power directly from the raw data.
Recent successes in deep learning—for example, neural networks with multiple hidden layers—have come from alleviating the gradient diffusion problem by a combination of factors, including: (1) speeding up the stochastic gradient descent algorithm with graphics processors; (2) using much larger training sets; (3) using new learning algorithms, including randomized algorithms such as dropout6,7; and (4) pre-training the initial layers of the network with unsupervised learning methods such as autoencoders8,9. This second approach attempts to learn a useful layered representation of the data without having to backpropagate through a DN; standard gradient descent is only used at the end to fine-tune the network. With these methods, it is becoming common to train DNs of five or more layers. These advances in deep learning could have a significant impact on applications in high-energy physics. Construction and operation of the particle accelerators is extremely expensive, so any additional classification power extracted from the collision data is very valuable.
In this paper, we show that the current techniques used in high-energy physics fail to capture all of the available information, even when boosted by manually constructed physics-inspired features. This effectively reduces the power of the collider to discover new particles. We demonstrate that recent developments in deep-learning tools can overcome these failings, providing significant boosts even without manual assistance.
Results
Particle collisions
The vast majority of particle collisions do not produce exotic particles. For example, though the Large Hadron Collider (LHC) produces approximately 1011 collisions per hour, approximately 300 of these collisions result in a Higgs boson, on average. Therefore, good data analysis depends on distinguishing collisions which produce particles of interest (signal) from those producing other particles (background).
Even when interesting particles are produced, detecting them poses considerable challenges. They are too small to be directly observed and decay almost immediately into other particles. Though new particles cannot be directly observed, the lighter stable particles to which they decay, called decay products, can be observed. Multiple layers of detectors surround the point of collision for this purpose. As each decay product pass through these detectors, it interacts with them in a way that allows its direction and momentum to be measured.
Observable decay products include electrically-charged leptons (electrons or muons, denoted ℓ), and particle jets (collimated streams of particles originating from quarks or gluons, denoted j). In the case of jets we attempt to distinguish between jets from heavy quarks (b) and jets from gluons or low-mass quarks; jets consistent with b-quarks receive a b-quark tag. For each object, the momentum is determined by three measurements: the momentum transverse to the beam direction (pT), and two angles, θ (polar) and ϕ (azimuthal). For convenience, at hadron colliders, such as Tevatron and LHC, the pseudorapidity, defined as η=−ln(tan(θ/2)) is used instead of the polar angle θ. Finally, an important quantity is the amount of momentum carried away by the invisible particles. This cannot be directly measured, but can be inferred in the plane transverse to the beam by requiring conservation of momentum. The initial state has zero momentum transverse to the beam axis, therefore any imbalance of transverse momentum (denoted  ) in the final state must be due to production of invisible particles such as neutrinos (ν) or exotic particles. The momentum imbalance in the longitudinal direction along the beam cannot be measured at hadron colliders, as the initial state momentum of the quarks is not known.
) in the final state must be due to production of invisible particles such as neutrinos (ν) or exotic particles. The momentum imbalance in the longitudinal direction along the beam cannot be measured at hadron colliders, as the initial state momentum of the quarks is not known.
Benchmark case for Higgs bosons
The first benchmark classification task is to distinguish between a signal process where new theoretical Higgs bosons (HIGGS) are produced, and a background process with the identical decay products but distinct kinematic features. This benchmark task was recently considered by experiments at the LHC10 and the Tevatron colliders11.
The signal process is the fusion of two gluons into a heavy electrically neutral Higgs boson (gg→H0), which decays to a heavy electrically-charged Higgs bosons (H±) and a W boson. The H± boson subsequently decays to a second W boson and the light Higgs boson, h0, which has recently been observed by the ATLAS12 and CMS13 experiments. The light Higgs boson decays predominantly to a pair of bottom quarks, giving the process:

which leads to  , see Fig. 1. The background process, which mimics
, see Fig. 1. The background process, which mimics  without the Higgs boson intermediate state, is the production of a pair of top quarks, each of which decay to Wb, also giving
without the Higgs boson intermediate state, is the production of a pair of top quarks, each of which decay to Wb, also giving  , see Fig. 1.
, see Fig. 1.

(a) Diagram describing the signal process involving new exotic Higgs bosons H0 and H±. (b) Diagram describing the background process involving top quarks (t). In both cases, the resulting particles are two W bosons and two b-quarks.
Simulated events are generated with the MadGraph5 (ref. 14) event generator assuming 8 TeV collisions of protons as at the latest run of the Large Hadron Collider, with showering and hadronization performed by PYTHIA15 and detector response simulated by DELPHES16. For the benchmark case here,  and
and  has been assumed.
has been assumed.
We focus on the semi-leptonic decay mode, in which one W boson decays to a lepton and neutrino (ℓν) and the other decays to a pair of jets (jj), giving decay products ℓν bjjb. We consider events which satisfy the requirements:
-
Exactly one electron or muon, with pT>20 GeV and |η|<2.5;
-
at least four jets, each with pT>20 GeV and |η|<2.5;
-
b-tags on at least two of the jets, indicating that they are likely due to b-quarks rather than gluons or lighter quarks.
Events which satisfy the requirements above are naturally described by a simple set of features which represent the basic measurements made by the particle detector: the momentum of each observed particle. In addition, we reconstruct the missing transverse momentum in the event and have b-tagging information for each jet. Together, these twenty-one features comprise our low-level feature set. Figure 2 shows the distribution of a subset of these kinematic features for signal and background processes.

Distributions in  events for simulated signal (black) and background (red) benchmark events. Shown are the distributions of transverse momenta (pT) of each observed particle (a–e) as well as the imbalance of momentum in the final state (f). Momentum angular information for each observed particle is also available to the network, but is not shown, as the one-dimensional projections have little information.
events for simulated signal (black) and background (red) benchmark events. Shown are the distributions of transverse momenta (pT) of each observed particle (a–e) as well as the imbalance of momentum in the final state (f). Momentum angular information for each observed particle is also available to the network, but is not shown, as the one-dimensional projections have little information.
The low-level features show some distinguishing characteristics, but our knowledge of the different intermediate states of the two processes allows us to construct other features which better capture the differences. As the difference in the two hypotheses lies mostly in the existence of new intermediate Higgs boson states, we can distinguish between the two hypotheses by attempting to identify whether the intermediate state existed. This is done by reconstructing its characteristic invariant mass; if a particle A decays into particles B and C, the invariant mass of particle A (mA) can be reconstructed as:

where E is the energy and p is the three-dimensional momentum of the particle. Similarly, the invariant mass of more than two particles can be defined as the modulus of the particles’ Lorentz four-vector sum. In the signal hypothesis we expect that:
-
W→ℓν gives a peak in the mℓν distribution at the known W boson mass, mW,
-
W→jj gives a peak in the mjj distribution at mW,
-
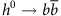 gives a peak in the
gives a peak in the 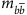 distribution at the known Higgs boson mass,
distribution at the known Higgs boson mass, 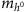 ,
, -
H±→Wh0 gives a peak in the
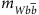 distribution at the assumed H± mass,
distribution at the assumed H± mass, 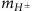 ,
, -
H0→W H± gives a peak in the
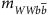 distribution at the assumed H0 mass, at
distribution at the assumed H0 mass, at 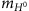 ,
,
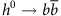 gives a peak in the
gives a peak in the 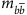 distribution at the known Higgs boson mass,
distribution at the known Higgs boson mass, 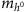 ,
,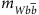 distribution at the assumed H± mass,
distribution at the assumed H± mass, 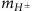 ,
,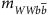 distribution at the assumed H0 mass, at
distribution at the assumed H0 mass, at 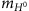 ,
,Note that the leptonic W boson is reconstructed by combining the lepton with the neutrino, whose transverse momentum is deduced from the imbalance of momentum in the final state objects and whose rapidity is set to give mℓν closest to mW=80.4 GeV.
Whereas in the case of the  background we expect that:
background we expect that:
-
W→ℓν gives a peak in mℓν at mW,
-
W→jj gives a peak in mjj at mW,
-
t→Wb gives a peak in mjℓν and mjbb at mt.
See Fig. 3 for distributions of these high-level features for both signal and background processes. Clearly these contain more discrimination power than the low-level features.

Distributions in simulation of invariant mass calculations in  events for simulated signal (black) and background (red) events.
events for simulated signal (black) and background (red) events.
We have published a data set containing 11 million simulated collision events for benchmarking machine-learning classification algorithms on this task, which can be found in the UCI Machine Learning Repository at archive.ics.uci.edu/ml/datasets/HIGGS.
Benchmark case for supersymmetry particles
The second benchmark classification task is to distinguish between a process where new supersymmetric particles (SUSY) are produced, leading to a final state, in which some particles are detectable and others are invisible to the experimental apparatus, and a background process with the same detectable particles but fewer invisible particles and distinct kinematic features. This benchmark problem is currently of great interest to the field of high-energy physics, and there is a vigorous effort in the literature17,18,19,20 to build high-level features which can aid in the classification task.
The signal process is the production of electrically-charged supersymmetric particles (χ±), which decay to W bosons and an electrically neutral supersymmetric particle χ0, which is invisible to the detector. The W bosons decay to charged leptons l and invisible neutrinos ν, see Fig. 4. The final state in the detector is therefore two charged leptons (ℓℓ) and missing momentum carried off by the invisible particles (χ0χ0νν). The background process is the production of pairs of W bosons, which decay to charged leptons l and invisible neutrinos ν, see Fig. 4. The visible portion of the signal and background final states both contain two leptons (ℓℓ) and large amounts of missing momentum due to the invisible particles. The classification task requires distinguishing between these two processes using the measurements of the charged lepton momenta and the missing transverse momentum.

Example diagrams describing the signal process involving hypothetical supersymmetric particles χ± and χ0 along with charged leptons ℓ± and neutrinos ν (a) and the background process involving W bosons (b). In both cases, the resulting observed particles are two charged leptons, as neutrinos and χ0 escape undetected.
As above, simulated events are generated with the MadGraph (ref. 14) event generator assuming 8 TeV collisions of protons as at the latest run of the Large Hadron Collider, with showering and hadronization performed by PYTHIA15 and detector response simulated by DELPHES16. The masses are set to  and
and  .
.
We focus on the fully leptonic decay mode, in which both W bosons decay to charged leptons and neutrinos, ℓνℓν. We consider events which satisfy the requirements:
-
Exactly two electrons or muons, each with pT>20 GeV and |η|<2.5;
-
at least 20 GeV of missing transverse momentum.
As above, the basic detector response is used to measure the momentum of each visible particle, in this case the charged leptons. In addition, there may be particle jets induced by radiative processes. A critical quantity is the missing transverse momentum,  . Figure 5 gives distributions of low-level features for signal and background processes.
. Figure 5 gives distributions of low-level features for signal and background processes.

Distribution of low-level features in simulated samples for the SUSY signal (black) and background (red) benchmark processes.
The search for supersymmetric particles is a central piece of the scientific mission of the Large Hadron Collider. The strategy we applied to the Higgs boson benchmark, of reconstructing the invariant mass of the intermediate state, is not feasible here, as there is too much information carried away by the escaping neutrinos (two neutrinos in this case, compared with one for the Higgs case). Instead, a great deal of intellectual energy has been spent in attempting to devise features that give additional classification power. These include high-level features such as:
-
Axial
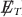 T: missing transverse energy along the vector defined by the charged leptons,
T: missing transverse energy along the vector defined by the charged leptons, -
stransverse mass MT2: estimating the mass of particles produced in pairs and decaying semi-invisibly17,18,
-
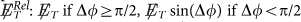 , where Δϕ is the minimum angle between
, where Δϕ is the minimum angle between 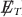 and a jet or lepton,
and a jet or lepton, -
razor quantities β,R and MR (ref. 19),
-
super-razor quantities βR+1, cos(θR+1), Δ
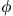 Rβ,
Rβ, 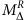 ,
, 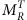 , and
, and 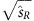 (ref. 20).
(ref. 20).
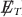 T: missing transverse energy along the vector defined by the charged leptons,
T: missing transverse energy along the vector defined by the charged leptons,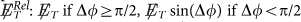 , where Δϕ is the minimum angle between
, where Δϕ is the minimum angle between 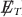 and a jet or lepton,
and a jet or lepton,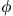 Rβ,
Rβ, 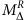 ,
, 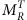 , and
, and 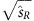 (ref.
(ref. See Fig. 6 for distributions of these high-level features for both signal and background processes.

Distribution of high-level features in simulated samples for the SUSY signal (black) and background (red) benchmark processes.
A data set containing five million simulated collision events is available for download at archive.ics.uci.edu/ml/datasets/SUSY.
Current approach
Standard techniques in high-energy physics data analyses include feed-forward neural networks with a single hidden layer and boosted decision trees. We use the widely-used TMVA package21, which provides a standardized implementation of common multivariate learning techniques and an excellent performance baseline.
Deep learning
We explored the use of DNs as a practical tool for applications in high-energy physics. Hyper-parameters were chosen using a subset of the HIGGS data consisting of 2.6 million training examples and 100,000 validation examples. Due to computational costs, this optimization was not thorough, but included combinations of the pre-training methods, network architectures, initial learning rates and regularization methods shown in Supplementary Table 3. We selected a five-layer neural network with 300 hidden units in each layer, a learning rate of 0.05, and a weight decay coefficient of 1 × 10−5. Pre-training, extra hidden units and additional hidden layers significantly increased training time without noticeably increasing performance. To facilitate comparison, shallow neural networks were trained with the same hyper-parameters and the same number of units per hidden layer. Additional training details are provided in the Methods section below.
The hyper-parameter optimization was performed using the full set of HIGGS features. To investigate whether the neural networks were able to learn the discriminative information contained in the high-level features, we trained separate classifiers for each of the three feature sets described above: low-level, high-level and combined feature sets. For the SUSY benchmark, the networks were trained with the same hyper-parameters chosen for the HIGGS, as the data sets have similar characteristics and the hyper-parameter search is computationally expensive.
Performance
Classifiers were tested on 500,000 simulated examples generated from the same Monte Carlo procedures as the training sets. We produced receiver operating characteristic curves to illustrate the performance of the classifiers. Our primary metric for comparison is the area under the receiver operating characteristic curve (AUC), with larger AUC values indicating higher classification accuracy across a range of threshold choices.
This metric is insightful, as it is directly connected to classification accuracy, which is the quantity optimized for in training. In practice, physicists may be interested in other metrics, such as signal efficiency at some fixed background rejection or discovery significance as calculated by P-value in the null hypothesis. We choose AUC as it is a standard in machine learning, and is closely correlated with the other metrics. In addition, we calculate discovery significance—the standard metric in high-energy physics—to demonstrate that small increases in AUC can represent significant enhancement in discovery significance.
Note, however, that in some applications the determining factor in the sensitivity to new exotic particles is determined not only by the discriminating power of the selection, but by the uncertainties in the background model itself. Some portions of the background model may be better understood than others, so that some simulated background collisions have larger associated systematic uncertainties than other collisions. This can transform the problem into one of reinforcement learning, where per-collision truth labels no longer indicate the ideal network output target. This is beyond the scope of this study, but see refs 22, 23 for stochastic optimizaton strategies for such problems.
Figure 7 and Table 1 show the signal efficiency and background rejection for varying thresholds on the output of the neural network (NN) or boosted decision tree (BDT).

For the Higgs benchmark, comparison of background rejection versus signal efficiency for the traditional learning method (a) and the deep learning method (b) using the low (lo)-level features, the high (hi)-level features and the complete set of features.
A shallow NN or BDT trained using only the low-level features performs significantly worse than one trained with only the high-level features. This implies that the shallow NN and BDT are not succeeding in independently discovering the discriminating power of the high-level features. This is a well-known problem with shallow-learning methods, and motivates the calculation of high-level features.
Methods trained with only the high-level features, however, have a weaker performance than those trained with the full suite of features, which suggests that despite the insight represented by the high-level features, they do not capture all the information contained in the low-level features. The deep-learning techniques show nearly equivalent performance using the low-level features and the complete features, suggesting that they are automatically discovering the insight contained in the high-level features. Finally, the deep-learning technique finds additional separation power beyond what is contained in the high-level features, demonstrated by the superior performance of the DN with low-level features to the traditional network using high-level features. These results demonstrate the advantage to using deep-learning techniques for this type of problem.
The internal representation of an NN is notoriously difficult to reverse engineer. To gain some insight into the mechanism by which the DN is improving upon the discrimination in the high-level physics features, we compare the distribution of simulated events selected by a minimum threshold on the NN or DN output chosen to give equivalent rejection of 90% of the background events. Figure 8 shows events selected by such thresholds in a mixture of 50% signal and 50% background collisions compared with pure distributions of signal and background. The NN preferentially selects events with values of the features close to the characteristic signal values and away from background-dominated values. The DN, which has a higher efficiency for the equivalent rejection, selects events near the same signal values, but also retains events away from the signal-dominated region. The likely explanation is that the DN has discovered the same signal-rich region identified by the physics features, but has in addition found avenues to carve into the background-dominated region.

Distribution of events for two rescaled input features: (a) mWbb and (b) mWWbb. Shown are pure signal and background distributions, as well as events which pass a threshold requirement which gives a background rejection (rej) of 90% for a deep network with 21 low-level inputs (DN21) and a shallow network with seven high-level inputs (NN7).
In the case of the SUSY benchmark, the DNs again perform better than the shallow networks. The improvement is less dramatic, though statistically significant.
An additional boost in performance is obtained by using the dropout5,6 training algorithm, in which we stochastically drop neurons in the top hidden layer with 50% probability during training. For DNs trained with dropout, we achieve an AUC of 0.88 on both the low-level and complete feature sets. Table 2, Supplementary Figs 10 and 11 compare the performance of shallow and DNs for each of the three sets of input features.
In this SUSY case, neither the high-level features nor the DN finds dramatic gains over the shallow network of low-level features. The power of the DN to automatically find nonlinear features reveals something about the nature of the classification problem in this case: it suggests that there may be little gain from further attempts to manually construct high-level features.
Analysis
To highlight the advantage of DNs over shallow networks with a similar number of parameters, we performed a thorough hyper-parameter optimization for the class of single-layer neural networks over the hyper-parameters specified in Supplementary Table 4 on the HIGGS benchmark. The largest shallow network had 300,001 parameters, slightly more than the 279,901 parameters in the largest DN, but these additional hidden units did very little to increase performance over a shallow network with only 30,001 parameters. Supplementary Table 5 compares the performance of the best shallow networks of each size with DNs of varying depth.
Although the primary advantage of DNs is their ability to automatically learn high-level features from the data, one can imagine facilitating this process by pre-training a neural network to compute a particular set of high-level features. As a proof of concept, we demonstrate how DNs can be trained to compute the high-level HIGGS features with a high degree of accuracy (Supplementary Table 6). Note that such a network could be used as a module within a larger neural network classifier.
Discussion
It is widely accepted in experimental high-energy physics that machine-learning techniques can provide powerful boosts to searches for exotic particles. Until now, physicists have reluctantly accepted the limitations of the shallow networks employed to date; in an attempt to circumvent these limitations, physicists manually construct helpful nonlinear feature combinations to guide the shallow networks.
Our analysis shows that recent advances in deep-learning techniques may lift these limitations by automatically discovering powerful nonlinear feature combinations and providing better discrimination power than current classifiers—even when aided by manually constructed features. This appears to be the first such demonstration in a semi-realistic case.
We suspect that the novel environment of high-energy physics, with high volumes of relatively low-dimensional data containing rare signals hiding under enormous backgrounds, can inspire new developments in machine-learning tools. Beyond these simple benchmarks, deep-learning methods may be able to tackle thornier problems with multiple backgrounds, or lower-level tasks such as identifying the decay products from the high-dimensional raw detector output.
Methods
Neural network training
In training the neural networks, the following hyper-parameters were predetermined without optimization. Hidden units all used the tanh activation function. Weights were initialized from a normal distribution with zero mean and standard deviation 0.1 in the first layer, 0.001 in the output layer and 0.05 in all other hidden layers. Gradient computations were made on mini-batches of size 100. A momentum term increased linearly over the first 200 epochs from 0.9–0.99, at which point it remained constant. The learning rate decayed by a factor of 1.0000002 every batch update until it reached a minimum of 10−6. Training ended when the momentum had reached its maximum value and the minimum error on the validation set (500,000 examples) had not decreased by more than a factor of 0.00001 over 10 epochs. This early stopping prevented overfitting and resulted in each neural network being trained for 200–1,000 epochs.
Autoencoder pre-training was performed by training a stack of single-hidden-layer autoencoder networks as in ref. 9, then fine-tuning the full network using the class labels. Each autoencoder in the stack used tanh hidden units and linear outputs, and was trained with the same initialization scheme, learning algorithm and stopping parameters as in the fine-tuning stage. When training with dropout, we increased the learning rate decay factor to 1.0000003, and only ended training when the momentum had reached its maximum value and the error on the validation set had not decreased for 40 epochs.
Data sets
The data sets were nearly balanced, with 53% positive examples in the HIGGS data set and 46% positive examples in the SUSY data set. Input features were standardized over the entire training/test set with mean 0 and s.d. 1, except for those features with values strictly >0—these we scaled so that the mean value was 1.
Computation
Computations were performed using machines with 16 Intel Xeon cores, an NVIDIA Tesla C2070 graphics processor and 64 GB memory. All neural networks were trained using the GPU-accelerated Theano and Pylearn2 software libraries24,25. Our code is available at https://github.com/uci-igb/higgs-susy.
Additional information
How to cite this article: Baldi, P. et al. Searching for exotic particles in high-energy physics with deep learning. Nat. Commun. 5:4308 doi: 10.1038/ncomms5308 (2014).
References
Dawson, S. et al. Higgs Working Group Report of the Snowmass 2013 Community Planning Study, Preprint at http://arxiv.org/abs/1310.8361 (2013).
Neyman, J. & Pearson, E. On the problem of the most efficient tests of statistical hypotheses. Phil. Trans. R. Soc. Lond. A 231, 694–706 (1933).
Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 2, 359366 (1989).
Hochreiter, S. Recurrent neural net learning and vanishing gradient. Int. J. Uncertain. Fuzz. 6, 107–116 (1998).
Bengio, Y., Simard, P. & Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166 (1994).
Hinton, G., Srivastava, N., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. Preprint at http://arxiv.org/abs/1207.0580 (2012).
Baldi, P. & Sadowski, P. The dropout learning algorithm. Artif. Intell. 210, 78–122 (2014).
Hinton, G. E., Osindero, S. & Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554 (2006).
Bengio, Y. et al. in:Advances in Neural Information Processing Systems 19 MIT Press (2007).
Aad, G. et al. Search for a Multi-Higgs Boson Cascade in events with the ATLAS detector in pp collisions at s=8 TeV. Phys. Rev. D 89, 032002 (2014).
Aaltonen, T. et al. Search for a two-Higgs-boson doublet using a simplified model in collisions at =1.96 TeV. Phys. Rev. Lett. 110, 121801 (2013).
ATLAS Collaboration. Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B716, 1–29 (2012).
CMS Collaboration. Observation of a new boson at a mass of 125 GeV with the CMS experiment at the LHC. Phys. Lett. B716, 30–61 (2012).
Alwall, J. et al. MadGraph 5: going beyond. J. High Energy Phys. 1106, 128 (2011).
Sjostrand, T. et al. PYTHIA 6.4 physics and manual. J. High Energy Phys. 05, 026 (2006).
Ovyn, S., Rouby, X. & Lemaitre, V. DELPHES, a framework for fast simulation of a generic collider experiment. Preprint at http://arxiv.org/abs/0903.2225 (2009).
Cheng, H.-C. & Han, Z. Minimal Kinematic Constraints and m(T2). J. High Energy Phys. 0812, 063 (2008).
Barr, A., Lester, C. & Stephens, P. m(T2): The Truth behind the glamour. J. Phys. G29, 2343–2363 (2003).
Rogan, C. Kinematical variables towards new dynamics at the LHC. Preprint at http://arxiv.org/abs/1006.2727 (2010).
Buckley, M. R., Lykken, J. D., Rogan, C. & Spiropulu, M. Super-Razor and Searches for Sleptons and Charginos at the LHC (2013).
Hocker, A. et al. TMVA—Toolkit for Multivariate Data Analysis. PoS ACAT, 040 (2007).
Whiteson, S. & Whiteson, D. In IAAI 2007: Proceedings of the Nineteenth Annual Innovative Applications of Artificial Intelligence Conference1819–1825 (2007).
Aaltonen, T. et al. Measurement of the top quark mass with dilepton events selected using neuroevolution at CDF. Phys. Rev. Lett. 102, 152001 (2009).
Bergstra, J. et al. Theano: a CPU and GPU math expression compiler. In: Proceedings of the Python for Scientific Computing Conference (SciPy) (Austin, TX, 2010).
Goodfellow, I. J. et al. Pylearn2: a machine learning research library. Preprint at http://arxiv.org/abs/1308.4214 (2013).
Acknowledgements
We are grateful to Kyle Cranmer, Chris Hays, Chase Shimmin, Davide Gerbaudo, Bo Jayatilaka, Jahred Adelman and Shimon Whiteson for their insightful comments. We wish to acknowledge a hardware grant from NVIDIA.
Author information
Authors and Affiliations
Contributions
P.B. conceived the idea of applying deep-learning methods to high-energy physics and particle detection. D.W. chose the benchmarks and generated the data and structured the problem. P.B. and P.S. designed the architectures and the algorithms. P.S. implemented the code and performed the experiments. All authors analysed the results and contributed to writing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Information
Supplementary Figures 1-3 and Supplementary Tables 1-4 (PDF 746 kb)
Rights and permissions
About this article

Cite this article
Baldi, P., Sadowski, P. & Whiteson, D. Searching for exotic particles in high-energy physics with deep learning. Nat Commun 5, 4308 (2014). https://doi.org/10.1038/ncomms5308
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms5308
This article is cited by
-
A systematic evaluation of machine learning on serverless infrastructure
The VLDB Journal (2024)
-
Deterministic subsampling for logistic regression with massive data
Computational Statistics (2024)
-
A fast DBSCAN algorithm using a bi-directional HNSW index structure for big data
International Journal of Machine Learning and Cybernetics (2024)
-
Stochastic projective splitting
Computational Optimization and Applications (2024)
-
Artificial intelligence for improved fitting of trajectories of elementary particles in dense materials immersed in a magnetic field
Communications Physics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
