
Abstract
Haplotyping of human chromosomes is a prerequisite for cataloguing the full repertoire of genetic variation. We present a microfluidics-based, linked-read sequencing technology that can phase and haplotype germline and cancer genomes using nanograms of input DNA. This high-throughput platform prepares barcoded libraries for short-read sequencing and computationally reconstructs long-range haplotype and structural variant information. We generate haplotype blocks in a nuclear trio that are concordant with expected inheritance patterns and phase a set of structural variants. We also resolve the structure of the EML4-ALK gene fusion in the NCI-H2228 cancer cell line using phased exome sequencing. Finally, we assign genetic aberrations to specific megabase-scale haplotypes generated from whole-genome sequencing of a primary colorectal adenocarcinoma. This approach resolves haplotype information using up to 100 times less genomic DNA than some methods and enables the accurate detection of structural variants.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
Receive 12 print issues and online access
$209.00 per year
only $17.42 per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others

Accession codes
References
Kitzman, J.O. et al. Haplotype-resolved genome sequencing of a Gujarati Indian individual. Nat. Biotechnol. 29, 59–63 (2011).
Adey, A. et al. The haplotype-resolved genome and epigenome of the aneuploid HeLa cancer cell line. Nature 500, 207–211 (2013).
1000 Genomes Project Consortium. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012).
Suk, E.K. et al. A comprehensively molecular haplotype-resolved genome of a European individual. Genome Res. 21, 1672–1685 (2011).
Duitama, J. et al. Fosmid-based whole genome haplotyping of a HapMap trio child: evaluation of Single Individual Haplotyping techniques. Nucleic Acids Res. 40, 2041–2053 (2012).
Peters, B.A. et al. Accurate whole-genome sequencing and haplotyping from 10 to 20 human cells. Nature 487, 190–195 (2012).
Kaper, F. et al. Whole-genome haplotyping by dilution, amplification, and sequencing. Proc. Natl. Acad. Sci. USA 110, 5552–5557 (2013).
Selvaraj, S., R Dixon, J., Bansal, V. & Ren, B. Whole-genome haplotype reconstruction using proximity-ligation and shotgun sequencing. Nat. Biotechnol. 31, 1111–1118 (2013).
Amini, S. et al. Haplotype-resolved whole-genome sequencing by contiguity-preserving transposition and combinatorial indexing. Nat. Genet. 46, 1343–1349 (2014).
Pendleton, M. et al. Assembly and diploid architecture of an individual human genome via single-molecule technologies. Nat. Methods 12, 780–786 (2015).
Abate, A.R., Chen, C.H., Agresti, J.J. & Weitz, D.A. Beating Poisson encapsulation statistics using close-packed ordering. Lab Chip 9, 2628–2631 (2009).
Kuleshov, V. et al. Whole-genome haplotyping using long reads and statistical methods. Nat. Biotechnol. 32, 261–266 (2014).
Li, H. & Durbin, R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics 26, 589–595 (2010).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–1303 (2010).
Cleary, J.G. et al. Joint variant and de novo mutation identification on pedigrees from high-throughput sequencing data. J. Comput. Biol. 21, 405–419 (2014).
Kidd, J.M. et al. Mapping and sequencing of structural variation from eight human genomes. Nature 453, 56–64 (2008).
Layer, R.M., Chiang, C., Quinlan, A.R. & Hall, I.M. LUMPY: a probabilistic framework for structural variant discovery. Genome Biol. 15, R84 (2014).
Mills, R.E. et al. 1000 Genomes Project. Mapping copy number variation by population-scale genome sequencing. Nature 470, 59–65 (2011).
Hopmans, E.S. et al. A programmable method for massively parallel targeted sequencing. Nucleic Acids Res. 42, e88 (2014).
Myllykangas, S., Buenrostro, J.D., Natsoulis, G., Bell, J.M. & Ji, H.P. Efficient targeted resequencing of human germline and cancer genomes by oligonucleotide-selective sequencing. Nat. Biotechnol. 29, 1024–1027 (2011).
Schrider, D.R. et al. Gene copy-number polymorphism caused by retrotransposition in humans. PLoS Genet. 9, e1003242 (2013).
Frampton, G.M. et al. Development and validation of a clinical cancer genomic profiling test based on massively parallel DNA sequencing. Nat. Biotechnol. 31, 1023–1031 (2013).
Lipson, D. et al. Identification of new ALK and RET gene fusions from colorectal and lung cancer biopsies. Nat. Med. 18, 382–384 (2012).
Choi, Y.L. et al. Identification of novel isoforms of the EML4-ALK transforming gene in non-small cell lung cancer. Cancer Res. 68, 4971–4976 (2008).
Koivunen, J.P. et al. EML4-ALK fusion gene and efficacy of an ALK kinase inhibitor in lung cancer. Clin. Cancer Res. 14, 4275–4283 (2008).
Soda, M. et al. Identification of the transforming EML4-ALK fusion gene in non-small-cell lung cancer. Nature 448, 561–566 (2007).
Jung, Y. et al. Discovery of ALK-PTPN3 gene fusion from human non-small cell lung carcinoma cell line using next-generation RNA sequencing. Genes Chromosom. Cancer 51, 590–597 (2012).
Kircher, M. et al. A general framework for estimating the relative pathogenicity of human genetic variants. Nat. Genet. 46, 310–315 (2014).
Cancer Genome Atlas Network. Comprehensive molecular characterization of human colon and rectal cancer. Nature 487, 330–337 (2012).
Chen, K. et al. BreakDancer: an algorithm for high-resolution mapping of genomic structural variation. Nat. Methods 6, 677–681 (2009).
Shen, J.J. & Zhang, N.R. Change-point model on nonhomogeneous Poisson processes with application in copy number profiling by next-generation DNA sequencing. Ann. Appl. Stat. 6, 476–496 (2012).
Fearon, E.R. & Vogelstein, B. A genetic model for colorectal tumorigenesis. Cell 61, 759–767 (1990).
Vogelstein, B. et al. Genetic alterations during colorectal-tumor development. N. Engl. J. Med. 319, 525–532 (1988).
Klein, A.M. et al. Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells. Cell 161, 1187–1201 (2015).
Macosko, E.Z. et al. Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets. Cell 161, 1202–1214 (2015).
Borgström, E. et al. Phasing of single DNA molecules by massively parallel barcoding. Nat. Commun. 6, 7173 (2015).
de Vree, P.J. et al. Targeted sequencing by proximity ligation for comprehensive variant detection and local haplotyping. Nat. Biotechnol. 32, 1019–1025 (2014).
Regan, J.F. et al. A rapid molecular approach for chromosomal phasing. PLoS ONE 10, e0118270 (2015).
Roach, J.C. et al. Chromosomal haplotypes by genetic phasing of human families. Am. J. Hum. Genet. 89, 382–397 (2011).
Kent, W.J. BLAT—the BLAST-like alignment tool. Genome Res. 12, 656–664 (2002).
Acknowledgements
This work was supported by US National Institutes of Health grants NHGRI P01HG000205 (to B.T.L., E.S.H., S.M.G., J.M.B. and H.P.J.), NCI R33CA174575 (to J.M.B., S. Greer and H.P.J.) and NHGRI R01HG006137 (to H.P.J.). The American Cancer Society provided additional support to S. Greer and H.P.J. (Research Scholar grant, RSG-13-297-01-TBG). H.P.J. also received support from the Doris Duke Clinical Foundation, the Clayville Foundation, the Seiler Foundation and the Howard Hughes Medical Institute.
Author information
Authors and Affiliations
Contributions
B.T.L., M.S.-L., M.J., J.M.B., C.M.H., S.K.-P., L. Merrill, R.B., A.J.M., Y.L., A.D.P., A.J.L., P.H., L.G., K.B., P.P., E.S.H., C.W., K.M.G., S.S., K.D.N., B.J.H. and H.P.J. designed the experiments. B.T.L., J.M.B., C.M.H., L. Merrill, J.M.T., P.A.M., P.W.W., R.B., A.J.M., Y.L., P.B., A.D.P., A.J.L., P.M., G.M.V., L. Montesclaros, M.L., L.G., D.E.B., K.B., P.P., E.S.H., C.W., J.P.D., I.W., H.S.O, J.Y.L., Z.W.B., K.M.G, G.P.M., Z.W.B., F.M., N.O.K., J.A.B., S.G., C.B., A.N.F., A.C. and B.J.H. conducted the experiments. D.A.M., R.B., A.J.M., S.W.S., S.K., J.A.B., A.K., K.D.N. and B.J.H. designed the instrument. M.S.-L., M.J., C.M.H., P.W.W., R.B., A.J.M., Y.L., A.D.P., A.J.L., P.H., L. Merrill, L.G., K.P.B., P.P., S.K., J.P.D., J.A.B., K.D.N. and B.J.H. designed reagents for phasing. B.T.L, J.M.B., E.S.H. and H.P.J. designed reagents for targeted sequencing analysis. G.X.Y.Z., M.S.-L., S.K.-P., P.M., G.K.L., D.L.S., W.H.H., R.T.W., S.S. and K.D.N. wrote the haplotype analysis algorithms. J.M.B. and S.M.G. wrote the analysis algorithms for short-read sequencing analysis. M.S.-L., P.J.M, A.W., G.K.L., D.L.S., W.H.H. and R.T.W. wrote the analysis software. G.X.Y.Z., B.T.L., M.S.-L., M.J., J.M.B., C.M.H., S.K.P., J.M.T., R.B., A.J.M., Y.L., P.B., P.M., P.H., L. Merrill, M.L., A.W., K.B., P.P., S.K., J.P.D., I.W., H.S.O., S.M.G., S. Greer, J.Y.L., Z.W.B., K.M.G., W.H.H., G.P.M., Z.W.B., F.M., J.A.B., S. Gauby, C.B., A.N.F., W.H.H., A.C., S.S., K.D.N., B.J.H. and H.P.J. analyzed the data. G.X.Y.Z., B.T.L., M.S.-L., M.J., S. Greer, B.J.H. and H.P.J. wrote the manuscript. H.P.J. oversaw the overall genetic experiments and analysis.
Corresponding authors
Ethics declarations
Competing interests
G.X.Y.Z., M.S.-L., M.J., C.M.H., S.K.-P., D.A.M., L. Merrill, J.M.T., P.A.M., P.W.W., R.B., A.J.M., Y.L., P.B., A.D.P., A.J.L., P.M., G.M.V., P.H., L. Montesclaros, M.L., L.G., A.W., D.E.B., S.W.S., K.P.B., P.P., S.K., G.K.L., D.S., J.P.D., I.W., H.S.O., J.Y.L., Z.W.B., K.M.G., W.H.H., G.P.M., Z.W.B., F.M., N.O.K., R.W., J.A.B., S. Gauby, A.K., C.B., A.N.F., A.C., S.S., K.D.N. and B.J.H. are employees of 10X Genomics.
Integrated supplementary information
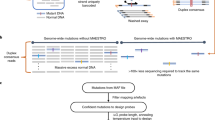
Supplementary Figure 1 Barcode sequencing library and analysis software workflow.
(a) Barcoded primers are used to initiate primer extension in each droplet, which is then followed by (b) pooling of droplets, end-repair, and ligation of P7 sequencing adaptor. The library is completed by (c) sample indexing PCR and (d) sequencing on Illumina sequencers. (e) The barcode pipeline builds upon accepted aligners such as BWA and previously called variants or from variant callers such as Freebayes and GATK. It uses linked-reads to enable phasing and structural variant calling. The results are produced in standard file formats such as BAM, VCF, and BEDPE.
Supplementary Figure 2 Sequencing and phasing performance of NA12878 trio.
(a) Number of reads corresponding to each barcoded oligonucleotide is plotted against its rank to illustrate the uniformity of counts over 100,000 barcodes. (b) Pulse-field gel electrophoresis of the trio input DNA. NA12878 DNA was run on a separate gel from NA12877 and NA12882, along with 5 kb and 8-48 kb ladders to estimate the size of input DNA. (c) Gap size distribution of GemCode NA12878 WGS sample. (d) Coverage vs. GC fraction of barcode libraries from NA12878 WGS sample. The relative coverage, normalized by the median, is plotted against GC fraction brackets, spanning from 29% to 60%. (e) Cumulative distribution function of phase block length of NA12878 trio exome samples. (f) Phasing accuracy of the nuclear trio exome data.
Supplementary Figure 3 Comparison between barcoded and standard TruSeq libraries.
Coverage distributions of NA12878 from (a) phased library from 1ng of genomic DNA, (b) standard TruSeq library from 100 ng of genomic DNA. (c) Coverage statistics between NA12878 phased barcoded library versus a standard Illumina TruSeq library.
Supplementary Figure 4 Barcode overlap of structural variants.
We generated non-overlapping window size of 100 kb to visualize structural alterations with uniquely mapping, non-duplicated reads. (a) Schematics of barcode overlap in reference (WT), deletion, inversion and tandem duplication. Matrix view of representative barcode overlap patterns for (b) reference, (c) deletion, (d) inversion and (e) tandem duplication events. Barcode overlap of heterozygous (f) inversion and (g) inversion and tandem duplication events in NA12878.
Supplementary Figure 5 Barcode count analysis of eight deletion candidates in linked-read WGS data from NA12878.
(a) Barcode counts in regions of five high-scoring deletions. (b) Barcode counts in the interval covering of three low-scoring deletions.
Supplementary Figure 6 Validation of genomic deletions with targeted sequencing.
We used a targeted sequencing approach called Oligonucleotide Selective-Sequencing (OS-Seq) for validating breakpoints of the deletions. Four out of five of the high-ranked candidates had a minimum of 450 reads aligning beyond the opposite breakpoint and at least 90 reads covering the breakpoint. The remaining high scoring deletion was found to have added sequence complexity that was observed in the targeted sequencing data. An example of a high scoring deletion that was validated is shown. (a) Ribbon plot displaying the location of reads mapped to breakpoints of a high-scoring deletion. Left, position of reads mapped to the left breakpoint, where red represents probes mapping to 5’ end of the breakpoint (using coordinates at the bottom of the plot), and blue represents probes mapping to the 3’ end of the breakpoint (using coordinates at the top of the plot). Right, position of reads mapped to the right breakpoint. The y-axis indicates the index of the reads. Pink line represents the mappability of the reads, where 1 indicates unique mapping, and 0 indicates mapping to multiple places in the genome. Because the deletion is heterozygous, reads colored in red on the left plot represent reads from the wild type allele, and reads colored in blue on the left plot represents reads from the deleted haplotype. The asterisks and arrows denote locations of primer probes, their direction of capture, and their typical capture distance. (b) Validation of breakpoint structure by soft-clipped read counting. Read 1s are grouped based on primer probe (read 2) identity. Soft-clipped reads supporting the breakpoint structure are tallied based on each breakpoint’s start and end location, and are reported as reads mapping “across” the breakpoint in Supplemental Table 6. (c) IGV screenshots of read alignment from a high-scoring deletion by left and right breakpoints, and Haplotype 1 and Haplotype 2. The deletion involves Haplotype 2 is shown by missing reads from left and right breakpoints of the haplotype. (d) IGV screenshots of read alignment from a low-scoring deletion by left and right breakpoints, and Haplotype 1 and Haplotype 2. Reads are missing from the right breakpoint of both Haplotype 1 and Haplotype 2, suggesting that reads cannot be properly mapped to the breakpoint, and the breakpoint is not accurate.
Supplementary Figure 7 ALK gene fusions in NA12878 exome and NCI-H2228 WGS data.
Heatmap of barcode overlap of (a) EML4-ALK and (b) ALK-PTPN3 in NA12878 exome (a negative control). Barcode overlap of (c) EML4-ALK and (d) ALK-PTPN3 in NCI-H2228 WGS. (e) RT-PCR data of EML4-ALK and ALK-PTPN3 transcripts in NA12878 and NCI-H2228.
Supplementary information
Supplementary Text and Figures
Supplementary Figures 1–7 (PDF 1570 kb)
Supplementary Information
Supplementary Tables 1–6, Supplementary Tables 8–13 and Supplementary Notes 1 and 2 (PDF 1939 kb)
Rights and permissions
About this article

Cite this article
Zheng, G., Lau, B., Schnall-Levin, M. et al. Haplotyping germline and cancer genomes with high-throughput linked-read sequencing. Nat Biotechnol 34, 303–311 (2016). https://doi.org/10.1038/nbt.3432
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/nbt.3432
This article is cited by
-
Heteromultivalency enables enhanced detection of nucleic acid mutations
Nature Chemistry (2024)
-
Chromosome-scale genome assembly of Lepus oiostolus (Lepus, Leporidae)
Scientific Data (2024)
-
Next-Generation Sequencing in Medicinal Plants: Recent Progress, Opportunities, and Challenges
Journal of Plant Growth Regulation (2024)
-
The effect of hyperthyroidism on cognitive function, neuroinflammation, and necroptosis in APP/PS1 mice
Journal of Translational Medicine (2023)
-
Pairwise comparative analysis of six haplotype assembly methods based on users’ experience
BMC Genomic Data (2023)
