
Abstract
Much of quantitative genetics is based on the ‘infinitesimal model’, under which selection has a negligible effect on the genetic variance. This is typically justified by assuming a very large number of loci with additive effects. However, it applies even when genes interact, provided that the number of loci is large enough that selection on each of them is weak relative to random drift. In the long term, directional selection will change allele frequencies, but even then, the effects of epistasis on the ultimate change in trait mean due to selection may be modest. Stabilising selection can maintain many traits close to their optima, even when the underlying alleles are weakly selected. However, the number of traits that can be optimised is apparently limited to ~4Ne by the ‘drift load’, and this is hard to reconcile with the apparent complexity of many organisms. Just as for the mutation load, this limit can be evaded by a particular form of negative epistasis. A more robust limit is set by the variance in reproductive success. This suggests that selection accumulates information most efficiently in the infinitesimal regime, when selection on individual alleles is weak, and comparable with random drift. A review of evidence on selection strength suggests that although most variance in fitness may be because of alleles with large Nes, substantial amounts of adaptation may be because of alleles in the infinitesimal regime, in which epistasis has modest effects.
Similar content being viewed by others


Introduction
The relation between an organism’s DNA sequence and its fitness is extremely complex, being mediated by gene expression, physiology, development and behaviour, all in interaction with the environment. Population and quantitative genetics use simple and abstract models to explain the evolutionary consequences of this relationship—a bold undertaking. Many have questioned whether this approach can account for the complexities of gene interaction (that is, of epistasis), and have suggested that properly incorporating epistasis will radically change our ability to determine the causes of quantitative variation, and our understanding of evolution (Carlborg and Haley, 2004; Carter et al., 2005; Huang et al., 2012; Hansen, 2013; Nelson et al., 2013).
In fact, classical quantitative and population genetics do allow for an arbitrary relation between genotype and phenotype, and for evolution across a ‘rugged fitness landscape’. Phenotypic traits (including fitness) depend on interactions among sets of alleles, as well as on the marginal effects of individual alleles. Remarkably, the variance associated with sets of one, two or more genes can be estimated from correlations of the trait between relatives, without any need to know the detailed genetic basis of trait variation (Fisher, 1918; Lynch and Walsh, 1998). Within this framework, epistasis has two distinct roles. First, it generates nonrandom associations among alleles (that is, linkage disequilibria). However, in a sexual population these are broken up by recombination, and hence have no long-term consequence. More important, epistasis makes the marginal (that is, additive) effects of alleles depend on the current genetic background. Thus, even though the immediate response of allele frequencies to selection is due to the additive component of genetic variance, these additive effects may change over time. Indeed, an amino acid that is benign in one species may be lethal when in the genetic background of even a closely related species (Kondrashov et al., 2002).
Fisher and Wright developed methods that can describe arbitrary epistasis: the analysis of variance (Fisher, 1918), leading to the ‘Fundamental Theorem of Natural Selection’ (Fisher, 1930), and selection gradients on the ‘adaptive landscape’ (Wright, 1931). In both models, the response of allele frequencies to selection is primarily because of the additive effects of individual alleles: nonadditive variance does not contribute directly to long-term evolution. However, Fisher and Wright held very different views on the evolutionary significance of epistasis (Provine, 1988). Wright (1931) argued that gene interactions lead to multiple ‘adaptive peaks’, and that progressive evolution is limited by the difficulty of crossing between these. In contrast, Fisher (1930) held that because environments fluctuate, and because evolution occurs in a space of extremely high dimension, there can be a continuing response to selection without the need ever to cross a fitness valley in opposition to selection.
In the following, I bring together theoretical results that show that the evolution of complex traits can be described by an ‘infinitesimal model’ that is not sensitive to the detailed way in which genes interact. Epistasis has surprisingly little effect on the response to either directional or stabilising selection, even when substantial fractions of the genetic variance are because of gene interactions, and the underlying fitness landscape is rugged. This leads to robust limits to the number of traits that can be kept close to an intermediate optimum, and suggests that selection is most efficient in the infinitesimal regime, when it is comparable with the strength of random drift on individual alleles.
The infinitesimal model
Practical quantitative genetics depends on the infinitesimal model, under which the components of genetic variance remain approximately constant despite selection. Defined at the individual level, in its simplest form this model states that two parents produce offspring whose breeding values are normally distributed around the mean breeding value of the parents, with variance independent of these parental values. This definition extends to the whole pedigree, such that the distribution of descendants is multivariate normal, with a covariance that is independent of the ancestral values. This implies that selection of specific individuals as parents only affects the offspring means and not their covariance (Lange, 1978; Bulmer, 1980).
This standard infinitesimal model can be justified as the limit of an additive model, when the number of loci tends to infinity (Fisher, 1918; Bulmer, 1980). However, the model extends to allow for substantial epistasis (Barton et al., 2016; Paixao and Barton, 2016). The key assumption is that phenotypes occupy a narrow range, relative to the range of multilocus genotypes that are possible, given the standing variation. This is consistent with the basic observation that artificial selection can shift the mean phenotype far outside its original range, within a few tens of generations, and implies that very many genotypes are consistent with any specific trait value; recombination between these different genotypes generates new variation. Thus, knowing the trait value gives little information about individual genotype, and hence hardly influences the distribution of allele frequencies. Therefore, selection on a trait that depends on very many loci hardly perturbs the variance components away from their neutral evolution.
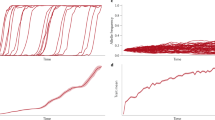
This is illustrated by Figure 1 which includes strong epistatic interactions, so that most of the additive variance is due to epistatic coefficients; as is typical, the epistatic variance is much smaller than the additive component (lower pair of curves at right). Selection rapidly changes the mean, by ~11 genetic s.d. over 100 generations, However, the variance components are only modestly changed from their neutral evolution: the additive component is reduced by 25%, and the nonadditive component by 31%, after 100 generations (compare dashed and solid lines at right).

The effect of selection on the mean and variance components in the presence of epistasis. Directional selection, β=0.2 (solid line) is contrasted with the neutral case (dashed line); shaded areas indicate ±1 s.d. The left panel shows the change in mean from its initial value and the right panel shows the additive variance, VA, and the additive × additive variance, VA A (lower pair of curves). Only the genic components of variance are shown; random linkage disequilibria make no appreciable difference on average. There are M=3000 loci, and N=100 haploid individuals. Alleles are given equal main effects but random sign  . Sparse pairwise epistasis is represented by choosing a fraction 1/M of pairwise interactions, ωι j, from a normal distribution with s.d.
. Sparse pairwise epistasis is represented by choosing a fraction 1/M of pairwise interactions, ωι j, from a normal distribution with s.d.  . The trait is now defined as z=δ.γ+δ.ω.δT, where δ=±(1/2). Initial allele frequencies are drawn from a U-shaped β-distribution, mean p̄=0.2 and variance 0.2 p̄q̄. Individuals are produced by Wright–Fisher sampling from parents chosen with probability proportional to W=eβ z. For each example, three sets of allelic and epistatic effects are drawn and for each of those, three populations are evolved; this gives 9 replicates in all.
. The trait is now defined as z=δ.γ+δ.ω.δT, where δ=±(1/2). Initial allele frequencies are drawn from a U-shaped β-distribution, mean p̄=0.2 and variance 0.2 p̄q̄. Individuals are produced by Wright–Fisher sampling from parents chosen with probability proportional to W=eβ z. For each example, three sets of allelic and epistatic effects are drawn and for each of those, three populations are evolved; this gives 9 replicates in all.
To account for epistasis, the basic infinitesimal model must be extended, such that individual trait values are represented by components due to sets of one, two or more loci. However, the distribution of these components among offspring follows rules that depend only on the components of genetic variance, and not on the values of the parents (Figure 2). The infinitesimal model can apply even when much of the genotypic variance is due to epistatic interaction. The covariance between relatives is given by the rules of classical quantitative genetics, and just as in the additive case, these covariances depend only on the components of genetic variance in the base population. Allele frequencies may change substantially as a result of random drift: the crucial assumption is that selection on the phenotype causes only a small perturbation away from neutrality. The cumulative effects of these small perturbations change the genetic components of the trait mean significantly, but not the variance components themselves.

The mean and variance of offspring plotted against components of the parents’ trait values. Top left: additive component of offspring, AO, against the mean of the parents’ additive component, AP. The line represents AO=AP. Top right: the same, but for the additive × additive components. The line shows a linear regression. Bottom left: additive variance among offspring, VA,O against the mean additive components of the parents, AP. Bottom right: additive × additive variance of offspring against the mean additive × additive component of the parents. Lines in the bottom row show quadratic regressions. The example shows a nonadditive trait under selection β=0.2, with M=3000 loci and N=100 haploid individuals, as in Figure 1. At generation 20, 200 pairs of minimally related parents (F=0.165) were chosen, and 1000 offspring were generated for each pair. For each offspring, the components of trait value were calculated relative to the allele frequencies, p, in the base population. Defining genotype by X=0, 1, these components are A=ζ.(α+(ω+ωT).(p−1/2)), AA=ζ.ω.ζT, where ζ=X−p.
Though only a few examples are shown here, the infinitesimal model applies very widely. Nevertheless, it clearly does not apply to all forms of epistasis: systematically positive or negative interactions, such as might be produced by a scale change, would cause offspring distributions to be non-Gaussian, and to be centred away from the mean of the parents. The key point in this section, however, is that random epistatic interactions are consistent with an infinitesimal limit, in which the response to selection on quantitative traits can be predicted from classical quantitative genetics. The complications of epistasis are entirely absorbed into a few variance components that are hardly perturbed by selection.
The overall sign of epistasis has received much attention: systematically negative epistasis would give an advantage to sex and recombination, and would allow a higher mutation rate without leading to excessive load (Kondrashov, 1988). However, invoking systematic epistasis raises the question of why the effects of interactions between alleles should be biased with respect to the marginal effects of these alleles on fitness. This might be a side effect of how organisms are built, which might in turn be because of past selection for (say) robustness to environmental or genetic perturbation. There is a close analogy here with the evolution of dominance. The immediate cause of dominance may be that losing function from one copy of a gene causes little fitness loss, whereas losing both is strongly deleterious. However, this raises the question of why organisms should typically have excess capacity; that redundancy may itself be because of selection for robustness against environmental fluctuations (Wright, 1929; Bourguet, 1999).
Directional selection
This extension of the infinitesimal model immediately leads to a remarkably general expression for the effect of epistasis on the limits to directional selection on standing variation (Paixao and Barton, 2016). (Note that here, I use directional selection to refer to an exponential relation between fitness and trait; other forms of selection—for example, truncation selection—will select on the variance as well as the mean). Under the infinitesimal model, the additive variance, VA, decreases by a factor (1−1/(2Ne)) per generation, whereas the mean increases by βVA, where β is the selection gradient. Therefore, the total change in mean sums to 2Neβ which is just 2Ne times the change in the first generation (V0A being the initial additive variance). Robertson (1960) showed that this result can be derived by considering the slight increase in fixation probability of favourable alleles because of selection—a derivation that makes clear that the infinitesimal model implicitly assumes selection on individual alleles, s, to be weaker than drift (that is, Nes<<1).
The same argument applies with epistasis: classical quantitative genetics gives expressions for the conversion of epistatic variance into additive variance because of the changes in additive effects of alleles as the genetic background changes (Hill et al., 2006). The total response to directional selection β of a haploid population is Neβ, V0G which only depends on the total initial genotypic variance V0G. Because the change in mean in the first generation, β, is proportional only to the additive component of the genetic variance, the response to selection is slower in the presence of epistasis (for a given total variance, V0G). It is remarkable that the ultimate change in trait mean, which may take the phenotype far beyond its initial range, can be predicted simply from the components of variation in the original population.
Epistatic variance makes a bigger contribution to the ultimate response of a diploid population: the increase in mean is  , where V0A(k) is the initial kth order variance component. However, it is still unlikely that higher-order variance components can be substantial, for two reasons. First, for biallelic loci with allele frequencies p, q, VA(k) is proportional to (2pq)k, and as the product of allele frequencies pq is less than one-fourth, we expect 2k−1 VA(k) to decrease with k, especially when the contributing alleles are rare (Maki-Tanila and Hill, 2014). Second, for the additive variance to be much smaller than epistatic variance, the marginal effects of alleles must be small—as, for example, for variation in fitness components that is maintained by balancing selection. However, such special situations are sensitive to allele frequency, and any change in allele frequencies will generate additive variance. In addition, balancing selection is likely to act on a small number of loci with relatively large effect that would be rapidly fixed by strong directional selection (an exception is where recessive lethals increase a selected trait when heterozygous; see, for example, Yoo, 1980). Such extreme cases cannot be common, as artificially selected traits usually do not revert when selection is relaxed (Weber, 1996).
, where V0A(k) is the initial kth order variance component. However, it is still unlikely that higher-order variance components can be substantial, for two reasons. First, for biallelic loci with allele frequencies p, q, VA(k) is proportional to (2pq)k, and as the product of allele frequencies pq is less than one-fourth, we expect 2k−1 VA(k) to decrease with k, especially when the contributing alleles are rare (Maki-Tanila and Hill, 2014). Second, for the additive variance to be much smaller than epistatic variance, the marginal effects of alleles must be small—as, for example, for variation in fitness components that is maintained by balancing selection. However, such special situations are sensitive to allele frequency, and any change in allele frequencies will generate additive variance. In addition, balancing selection is likely to act on a small number of loci with relatively large effect that would be rapidly fixed by strong directional selection (an exception is where recessive lethals increase a selected trait when heterozygous; see, for example, Yoo, 1980). Such extreme cases cannot be common, as artificially selected traits usually do not revert when selection is relaxed (Weber, 1996).
Epistatic variance makes a relatively larger contribution to selection response in diploids than in haploids, as represented by the factor 2k−1 in the above formula. This is because an allele has twice the effect in a homozygote as in a heterozygote, and hence the ultimate effect of interaction among a set of k alleles is greater by a factor 2k, compared with their effect when segregating as heterozygotes. We have ignored dominance here, but note that rare recessives can inflate additive variance when they become common, and that this ‘conversion’ of dominance to additive variance may be much larger than the conversion of epistatic variance (Hill et al., 2006). However, there must still be a systematic bias towards favourable effects of rare recessives to increase the expected selection response.
The connection between the components of initial standing variation and the ultimate selection response is very general: it applies for any form of epistasis, provided that interactions are not strongly biased with respect to the selected trait, and provided that genetic variance is dissipated primarily by sampling drift rather than by selection. It applies even when the fitness landscape is ‘rugged’, so that large populations would be trapped at local ‘adaptive peaks’. This is simply because when selection on individual alleles is weak relative to drift, populations can readily cross between such peaks. As I argue in the following, selection is, in some sense, most efficient in this ‘infinitesimal’ regime.
How does epistasis affect the response to directional selection in the opposite case of a very large population? Now, the initial variance components are not directly relevant, because very rare alleles, which initially make hardly any contribution to the variance components, can increase to determine the ultimate response. Nevertheless, we can compare the total change in mean with that what would be achieved under the corresponding additive model, in which the effects of alleles on the original genetic background remain constant. Of course, if epistasis is systematically positive, there will be an accelerating response, and a much larger total change than with the original additive effects; conversely, systematically negative epistasis leads to a smaller selection response (Hansen, 2013).
If epistatic interactions are random with respect to the marginal effects on the trait, and if the optimal genotype is the same under the epistatic and the corresponding additive models, then epistasis has no expected effect (Paixao and Barton, 2016). However, if epistasis is sufficiently strong, the marginal effects of alleles will change sign as allele frequencies change, so that a different optimal genotype will be reached. Now, epistasis does increase the expected response, even when interactions are random with respect to fitness. The magnitude of this effect can be predicted if interactions among different sets of genes are independent of each other, and matches simulations of random pairwise epistasis well. Overall, however, the effect of epistasis on selection response is modest (Paixao and Barton, 2016; Figure 3).

The effective dimension of trait variation in short versus long term. Left: the fraction of variance explained by the largest 1, 2, …, eigenvectors for 10, 100, 1000 traits (black, blue, red, top to bottom), measured in the final generation. Right: the same, but for a population that contains all mutations that fixed over 50 000 generations (that is, an F2 between the ancestral and derived population). An additive infinite sites model was simulated, with free recombination, stabilising selection exp(−|z|2/(2Vs)), Vs=100, N=100 haploid individuals, and mutation rate U=0.1 per genome per generation. Mutations have magnitude |α| drawn from an exponential with mean 1 with random direction. In these simulations, the variance of each trait mean around the optimum is close to the predicted Vs/(2N)=0.5, causing a loss of fitness 1/(4N)=0.0025 per trait. A full colour version of this figure is available at the Heredity journal online.
These arguments apply to the initial response to selection because of standing variation. Over longer timescales (>50 generations, say; Hill, 1982), mutation makes a significant contribution, increasing additive variance by VAm per generation. Under the standard infinitesimal model, the additive variance approaches an equilibrium between mutation and random drift of 2NeVAm, and the mean will change under directional selection in proportion to this variance. In the short term, mutation generates negligible epistatic variance, unless mutations have large effect, as it introduces alleles at low frequency (Hill and Rasbash, 1986). However, epistasis makes additive effects conditional on genotype, so that the effect of new mutations may change with the mean. In the long term, the genetic variance will evolve unpredictably, as new alleles introduced by mutation become common enough to interact with each other. Nevertheless, as mutational variance is ubiquitous (Houle et al., 1996; Lynch and Walsh, 1998), an indefinite response to directional selection is expected.
When multiple traits are selected, the mean changes in proportion to the additive genetic covariance matrix (termed the ‘G matrix’) that in turn is proportional to the mutational covariance in the infinitesimal limit. The G matrix has received much attention on the grounds that it constrains adaptation. However, artificial selection has proved successful even when deliberately applied to trait combinations that show minimal variance (see, for example, Weber et al., 1999; Hill and Kirkpatrick, 2010; Marchini et al., 2014): as long as there is some additive variance in the direction of selection, selection can change the mean. Of course, the G matrix has very high dimension, and some directions may have zero variance (that is, there may be some zero eigenvalues). Even then, however, the G matrix does not necessarily constrain adaptation in the long term: it inevitably changes as new mutations arise, with effects in different directions. Imagine that traits may be influenced by a very large number of sites, n, of which only a much smaller number, 1<< ns<< n, are segregating at any one time; any allele potentially has random effects on all k traits. At any time, G will have dimension ns, but as alleles are lost or fixed, in the long run adaptation can occur through the whole space of dimension n >> ns. Thus, evolution is constrained by the total number of sites that could affect the traits, and not by the number segregating at any particular time. Therefore, observation of the G matrix at any one time would not inform us about constraint on long-term evolution. This is illustrated in Figure 3. The left panel shows that in any one generation, most variance is explained by <50 dimensions, regardless of the number of traits under stabilising selection. In contrast, the right panel shows that over 50 000 generations, variance is spread over a number of dimensions proportional to the number of traits. Thus, each trait is kept close to the optimum, regardless of how many traits are being selected.
Stabilising selection
Variation of the mean
How does epistasis affect the precision of adaptation to an intermediate optimum? As with directional selection, there are general constraints on adaptation that are insensitive to gene interaction—even when the underlying adaptive landscape supports many local fitness peaks.
First, consider how accurately selection can keep the population mean near to some optimum. Assume that fitness falls away from the optimum as a Gaussian function,  , of the individual trait value. Then, the mean moves towards the optimum at a rate
, of the individual trait value. Then, the mean moves towards the optimum at a rate  , and fluctuates because of random sampling, with variance.
, and fluctuates because of random sampling, with variance.  When very many loci affect the trait, the genetic variance evolves slowly, and hence VA can be taken as constant. Therefore, the variance of the mean around the optimum is
When very many loci affect the trait, the genetic variance evolves slowly, and hence VA can be taken as constant. Therefore, the variance of the mean around the optimum is  , and the loss of fitness due to this variation is 1/(4Ne) (Lande, 1976). The argument extends to multiple loci, predicting a loss of mean fitness of 1/(4Ne) per trait. This seems to set a strong constraint on the number of traits that can be kept near their optima, despite random drift. Crucially, the argument applies even if there is epistatic variance for the trait: both the change in mean due to selection and the variance of fluctuations depend on the additive component of variance that cancels from the final expression.
, and the loss of fitness due to this variation is 1/(4Ne) (Lande, 1976). The argument extends to multiple loci, predicting a loss of mean fitness of 1/(4Ne) per trait. This seems to set a strong constraint on the number of traits that can be kept near their optima, despite random drift. Crucially, the argument applies even if there is epistatic variance for the trait: both the change in mean due to selection and the variance of fluctuations depend on the additive component of variance that cancels from the final expression.
This argument for the precision of phenotypic adaptation applies to quantitative traits, and is independent of the strength of selection on individual alleles. Kondrashov (1995) has made a related argument for the loss of fitness because of the random fixation of deleterious alleles for which Nes~1, and Lynch and Hagner (2015) have argued that adaptation is limited by the requirement that selection on each allele be stronger than drift (that is, Nes ≳1). However, Charlesworth (2013a, 2013b), points out that these arguments do not apply to polygenic traits under stabilising selection: a trait can be kept near its optimum even when it depends on very many sites, such that the selection on each is much weaker than random drift. Indeed, this is the assumption on which the infinitesimal model is based (Robertson, 1960). Nevertheless, random drift does limit the effectiveness of selection, regardless of Nes on individual alleles. Taken at face value, the ‘drift load’ seems to limit the number of independently selected traits to ~4Ne.
The same result can be derived in a more concrete way by using stationary distribution of Wright (1938) for allele frequencies:

This assumes (as throughout this paper) linkage equilibrium, biallelic loci and mutation at rates μ and ν to alleles P and Q, respectively. Z is a normalising constant. Mean fitness only depends on the mean and total genetic variance of the trait, VG. We can therefore average over allele frequencies, conditional on these, obtaining the joint distribution of the mean and genetic variance:

where ψN* is the neutral distribution of {z̄,VG} (Barton, 1989). We can go further, and find the stationary distribution of the trait mean by integrating out the genetic variance:

where ψN** (z̄) is the distribution of the mean in the absence of any selection on the mean, but including selection against the variance. By assuming that the variance of the mean when selection on the mean is relaxed is much larger than the variance of the adaptive landscape, W̄ (that is,  ), we immediately find that
), we immediately find that  , just as derived above by a purely phenotypic argument. Again, we have made no specific assumptions about the relation between genotype and phenotype: the load due to random fluctuations of the mean away from the optimum is independent of the genetic variance and its components.
, just as derived above by a purely phenotypic argument. Again, we have made no specific assumptions about the relation between genotype and phenotype: the load due to random fluctuations of the mean away from the optimum is independent of the genetic variance and its components.
Variance around the mean
Adaptation depends on individuals being close to the optimum, not just on the population mean being close. Specifically, under Gaussian stabilising selection the loss of fitness due to genetic variance around the population mean is ~VG/(2Vs). To find VG and its components, so as to understand how epistasis affects the genetic load, we must make assumptions about the maintenance and genetic basis of trait variation. When mutation rates per locus are low, the alleles that contribute genetic variance are rare, and hence the effects of new mutations are larger than the genetic s.d. at each locus. Though there has been considerable debate, the consensus is that this is typically the case (Turelli, 1984; Johnson and Barton, 2005). Rare alleles evolve approximately independently of each other, and hence rather than considering a continuum of alleles, we can assume two alleles per locus.
There has been much debate recently over what fraction of variance in complex traits is due to rare versus common alleles (see, for example, Robinson et al., 2014). This is a different question, which asks whether an individual allele that contributes variance is typically at (say) 0.1, 1 or 20%. In contrast, theoretical results on maintenance of variation depend on the distribution of effects at a locus, the question being whether there is typically a common ‘wild type’, with variation being because of one or more rare alleles, or instead, many alleles with a continuous distribution of effects. Under the ‘continuum-of-alleles’ model, every allele is rare.
The classical model for the maintenance of trait variation through a balance between mutation and stabilising selection assumes low mutation rates and additive effects, and goes back to Fisher (1930) and Wright (1935). In an infinite population, assuming that the mean is at the optimum, and that selection is stronger than mutation, the equilibrium genetic variance is VG=VA=2UVs, where U=2 Σiμi is the genomic mutation rate. The loss of fitness because of mutation is therefore just U, consistent with Haldane's Principle (Haldane, 1927).
Although trait variance is entirely additive under this model, there is strong epistasis for fitness: an allele that increases the trait is favoured only if the trait is below the optimum. Many combinations of alleles can come close to the optimum, and hence there are very many stable equilibria. If alleles have equal effects, equilibria may deviate from the optimum, and have substantially inflated genetic variance, well above the simple prediction VA=2UVs (Figure 4, top). Thus, it would seem that the rugged fitness landscape generated by epistasis for fitness impedes adaptation by inflating variance around the optimum. Such trapping of populations at inferior local optima motivated the ‘shifting balance’ theory of evolution of Wright (1931).

Adaptation on a rugged landscape. Each panel plots the genetic variance against the trait mean for an additive trait under stabilising selection towards an optimum at zero; fitness is exp (−Sz2/2), with S=0.005. There are 100 loci each with two alleles and symmetric mutation μ=0.0005. Populations are evolved for 104 generations from an initial β distribution with variance Fpq, with F=0.5, p=0.1, 0.5, 0.9 (black, blue, grey). Large dots show the final state for an infinitely large population (100 replicates), whereas small dots show results for a diploid population of N=3 × 104 individuals. The upper panel is for equal effects (γ=1) and the lower panel for unequal effects, drawn from an exponential distribution with mean γ=1. A full colour version of this figure is available at the Heredity journal online.
This simple model of equal allelic effects and an infinite population is misleading, however. When allelic effects are broadly distributed, there are still many alternative equilibria, but these have more similar properties, with mean close to the optimum and a genetic variance that is close to the naive prediction, 2UVs (Vladar and Barton, 2014; Figure 4, bottom). Here, the genomic mutation rate, U, is summed over an effective number of loci that have effects higher than a critical value of  ; thus, the genetic variance is lower, to the extent that some loci have effects below this threshold (Figure 4). Moreover, in a finite population, populations can readily shift between adaptive peaks, provided that Nes for individual alleles is not too large; as we have seen, relatively strong drift at individual loci is compatible with precise adaptation of the mean. Thus, we can use simple quantitative genetic models, even when there is strong underlying epistasis for fitness, and a rugged fitness landscape.
; thus, the genetic variance is lower, to the extent that some loci have effects below this threshold (Figure 4). Moreover, in a finite population, populations can readily shift between adaptive peaks, provided that Nes for individual alleles is not too large; as we have seen, relatively strong drift at individual loci is compatible with precise adaptation of the mean. Thus, we can use simple quantitative genetic models, even when there is strong underlying epistasis for fitness, and a rugged fitness landscape.
Epistasis allows the genetic variance to evolve
With a strictly additive trait, the mutational variance is fixed, and the genetic variance maintained around any particular ‘adaptive peak’ is the same. In contrast, if there is epistasis for the trait, this gives a flexibility to the genetic system that allows the evolution of robustness to mutation (Wilke et al., 2001; Hermisson et al., 2003; Jones et al., 2007). Allelic effects now depend on the genetic background, and we may expect that under stabilising selection, they will evolve to lower values. This will lead to a reduction in both the additive variance generated by mutation, Vm, and the standing additive variance, and hence will increase fitness. However, epistasis itself generates additional nonadditive variance, and hence it is not obvious how the overall fitness will be affected by epistasis. We explore this issue in the following paragraphs, where we consider stabilising selection on a trait with an arbitrary genetic basis.
First, consider very low mutation rates (4Neμ≪1) so that populations are near fixation for a single genotype. The stationary distribution is proportional to W̄2Ne, and will simply be concentrated around those genotypes that most closely match the optimum. As the mutation rate increases, the distribution will still be concentrated around these genotypes that are associated with higher mean fitness, but selection now favours lower trait variance as well as proximity of the mean to the optimum. Alleles with effect that outweighs mutation reduce mean fitness by an amount equal to the mutation rate, independent of their marginal effect, and hence at first one might think that only the distance of the predominant genotype to the optimum matters, and not the effects of variance away from that genotype. However, under stabilising selection Vs, alleles with marginal effect smaller than  are held at intermediate frequency by mutation, causing a smaller load, and are hence more probable under the stationary distribution (Vladar and Barton, 2014). In addition, the load decreases below the mutation rate in the presence of negative epistasis (Kimura and Maruyama, 1966). For these two reasons, populations tend to evolve towards genotypes with smaller additive effects, and as a result, the mutational variance Vm decreases.
are held at intermediate frequency by mutation, causing a smaller load, and are hence more probable under the stationary distribution (Vladar and Barton, 2014). In addition, the load decreases below the mutation rate in the presence of negative epistasis (Kimura and Maruyama, 1966). For these two reasons, populations tend to evolve towards genotypes with smaller additive effects, and as a result, the mutational variance Vm decreases.
Figure 5 illustrates these points, using deterministic simulations of the model of sparse pairwise epistasis from Figures 1 and 2. As mutation rates increase, variance around the optimum increases, and allelic effects evolve so as to reduce the additive variance (top panel, middle line). However, epistatic variance increases with μ2, and predominates for high mutation rates (top panel, lower line). In this example, these two effects compensate precisely, so that the total genotypic variance is indistinguishable from that in an additive model with the same initial allelic effects (top panel, upper line). The lower panel shows the variance of allelic effects, which is proportional to Vm. When mutation rates are low, these increase slightly over time (lower panel, left), but with high mutation rates, allelic effects decrease (lower panel, right). Despite the evolution of some robustness, epistasis does not increase mean fitness overall, but may have consequences for further adaptation if the optimum shifts.

Evolution of the additive variance under stabilising selection in the presence of epistasis. Top: variance components are plotted against the mutation rate, μ, for the epistatic model (solid lines show the mean, and grey areas the s.d.). The upper line shows the total genotypic variance, VG, that is the sum of additive and nonadditive components (middle, lower lines). This is compared with the variance, V*A, under the corresponding additive model, starting from the same allele frequencies and the same additive effects; this is indistinguishable from VG (upper line). The (small) s.d. among 10 replicates is indicated. Bottom: the variance of additive effects at the beginning and end; this is proportional to the mutational variance V*m. Fitness is 1−z2/(2Vs), Vs=5. The trait, z, is the sum of exponentially distributed main effects plus random pairwise interactions. There are M=1000 biallelic loci, but otherwise parameters are as in Figures 1 and 2. A single realisation of the genetic architecture is used with 10 replicates for each mutation rate starting from allele frequencies drawn from a β-distribution with mean=0.2 and variance 0.2. Simulations are deterministic and run for 50 000 generations. Linkage equilibrium is imposed, so that only allele frequencies are followed.
Hermisson et al. (2003) studied a similar model of pairwise epistasis, but allowing a continuum of allelic effects. Their deterministic analysis showed that epistatic selection necessarily acts to decrease the additive variance, but that the mutational variance may nevertheless increase. Loci with higher mutation rates are under stronger selection to reduce additive effects, but loci with lower mutation rates may become less buffered. Thus, ‘canalization’ does not necessarily evolve in such models of random pairwise epistasis. Jones et al. (2007) consider a different model, involving multiple traits, and analysing a modifier that alters the genetic correlation. Such modifiers allow the evolution of strong correlations that reduce the net genetic covariance and hence increase mean fitness under stabilising selection. Overall, it is not clear how readily epistasis can allow evolution of robustness that increases mean fitness, and that can therefore be considered an adaptation for robustness. This depends on the nature of epistasis that is allowed: random pairwise interactions or interactions that systematically modify robustness.
Limits to selection
Mean fitness
Is the number of degrees of freedom that can be optimised by selection inevitably limited by the effective population size? Just as for the mutation load in a sexual population (Kimura and Maruyama, 1966; Kondrashov, 1988), negative epistasis for fitness can greatly reduce the ‘drift load’. To understand how this apparently general limit can be evaded, consider a simple model in which fitness depends only on the Euclidean distance, r, from an optimum. This is similar to Fisher’s ‘geometric model’ (Fisher, 1930; Orr, 2000), except that we consider populations of individuals, rather than an adaptive walk between fixed states. The distance, r, can be treated as a quantitative trait with an approximately normal distribution within populations. Crucially, we expect that when there are very many degrees of freedom, individuals will almost all be a substantial distance away from the optimum, even if in widely different directions. The stationary distribution of r under the influence of selection, mutation and random drift depends on how selection eliminates the least fit individuals. Figure 6 compares quadratic stabilising selection with truncation selection, the most extreme form of negative epistasis. With quadratic selection, the loss of fitness due to mutation and random drift increases in proportion to the number of traits: any number of traits can be kept close to the optimum, but at the cost of a decreasing mean fitness. With truncation selection, the load also increases with the number of selected traits, but is an order of magnitude smaller (Figure 6). This is essentially the same argument as made by Kondrashov (1988) for the mutation load in a sexual population.

Comparison between quadratic and truncation selection on the deviation from a multitrait optimum. The left panel shows the distribution of distance from the optimum, r, for n=3, 10, 30, 100 traits (left to right), under quadratic stabilising selection; the upper curve shows the fitness, exp(−(S/2) r2). The right panel shows the same, but for truncation selection in which only individuals with r<2 reproduce. Simulations are of 100 haploid individuals, each with 100 unlinked loci; alleles have continuously distributed vectors of effects. The trait is the sum of effects of each locus. Mutation rate is 0.001 per locus, and adds a random Gaussian with s.d. σ=0.1 for each trait. Results are averaged over generations 4000 to 20 000. Under quadratic stabilising selection, the reduction in mean fitnesses is 0.014, 0.046, 0.127 and 0.318 for 3,…, 100 traits. In contrast, under truncation selection the loss of mean fitness (that is, the fraction of offspring with r>2) are 0.00247, 0.00642 and 0.0269 for 3, 10, 30 traits. With 100 traits under truncation selection, the population does not equilibrate: loci fix deleterious alleles, leading to a decline in fitness through Muller’s Ratchet.
As more generally for these kinds of ‘load’ argument, one can ask why selection should act in this special way, systematically to reduce the load (Kimura, 1983), and whether it in fact does so. Note that if population size were to change, then the load would remain low only if there were a steep gradient of mean fitness with respect to r2, at the current value. Evasion of the load requires some kind of frequency dependence (for example, because of competition), such that the steep gradient in mean fitness coincides with the position of the population.
Information gain as a measure of the effect of selection
The genetic variance in fitness may pose a more robust constraint on the effectiveness of selection, as it is a quantity that can be measured on an actual population, and is clearly limited by reproductive capacity. We can ask, for a given variance in fitness, how many alleles can be substituted, how far the trait mean can be changed and how many traits can be kept close to their optimum. To make these questions precise, we need a common measure that applies to both discrete genes and continuous traits.
The increase in mean fitness is not a satisfactory measure for several reasons. Absolute fitness must remain close to 1 if the population is to survive. The component of fitness increase due to selection on allele frequencies is, according to the ‘Fundamental Theorem’ of Fisher (1930), precisely equal to the additive genetic variance in fitness, leading to a circular argument; in any case, the increase in mean fitness because of selection does not necessarily reflect progressive change. More fundamentally, fitness differences are the forces that drive adaptation and should not be used to measure its outcome.
An obvious measure, which generalises to both discrete and continuous variation, is the mutual information of the actual probability distribution, ψ, compared with the neutral distribution in the absence of selection on the mean, ψN (Mustonen and Lässig, 2010). This is also termed the Kullback–Leibler divergence of the selected from the neutral distribution:

Here, H is the log probability of a given state, relative to its probability in the absence of selection. ℐ is a measure of information that can also be thought of as a negative entropy; Iwasa (1988) and Barton and Vladar (2009) define entropy as SH=−ℐ. Here, we choose to include the effect of mutation in the baseline distribution, ψN, whereas Iwasa (1988) and Barton and Vladar (2009) kept it separate.
This information gain, ℐ, measures the degree to which the distribution of states of the population is concentrated around a particular state. In itself, ℐ is independent of whether the evolved states are more or less fit, though we expect selection to tend to pick out fit states. Rather, it is a measure of the improbability of the actual outcomes in the absence of selection. If the population is certain to be in some particular state, then ℐ is minus the log probability of that state being reached by neutral evolution.
This information measure applies to quantitative traits as well as to discrete alleles. If the trait follows a normal distribution, then the state of the population is described by its mean and variance (z̄, Vg), and ℐ measures the change in the distribution of these variables because of selection. For simplicity, assume that the distribution of the variance is not affected by selection (that is, the infinitesimal limit), and further assume that the trait mean follows a Gaussian, with expectations  and variance v, vN under selection and in its absence. Then:
and variance v, vN under selection and in its absence. Then:

The first term depends only on the factor by which selection has changed the variance of the mean; it is always positive, and increases as 1/2 log [vN/v] for v≪vN. The second term is also positive, and is proportional to the squared change in expected mean caused by selection relative to the neutral variance, vN.
The gain in information because of selection can be calculated from the distribution of allele frequencies or from the distribution of trait means and variances. What is the relation between these two versions? At a stationary state, Wright’s distribution is simply the product of the neutral distribution, and W̄2Ne (Equation (1–3)). Therefore, ℐ is the same, whether measured from allele frequencies or from the distribution of the quantitative traits that determine fitness. This is a consequence of the fact that the distribution of allele frequencies conditional on mean fitness is independent of selection under Wright’s distribution. When the population is not drawn from a stationary distribution, the equivalence of the two measures of ℐ is not exact. However, because the distribution of allele frequencies remains close to the stationary form even when rapidly evolving (Barton and Vladar, 2009), the measures are likely to be close to each other. (Note that throughout this section, we have ignored linkage disequilibrium; this will be valid when selection is weak relative to recombination).
Information gain for a given variance in fitness
The simplest example is the substitution of a single allele under constant directional selection; we will see that this readily generalises to the change in mean of a quantitative trait under directional selection. Here, I show that for a given fitness variance, the information gain is maximised when selection is weak relative to random drift.
Suppose that the allele starts in enough copies to evolve deterministically (Nes p0>>1). Then, it is certain to fix under selection, compared with a neutral probability of fixation p0. The ultimate gain in information is therefore log (1/p0). This was first pointed out by Kimura (1961), who showed that it equals the ‘cost of selection’ of Haldane (1957)—the total loss of mean fitness because of slowly fixing a favourable allele by selection rather than immediately establishing the fittest allele. Kimura (1961) argued that this cost limits the rate of adaptation, and estimated a maximum gain of 108 bits on the vertebrate lineage since the Cambrian.
However, as with other such arguments from the genetic load, it can be alleviated if there is negative epistasis—or in the most extreme case, truncation selection. Suppose that in every generation, the fittest fraction θ is selected. Then, every rare allele will increase by a factor 1/θ, and will quickly rise to high frequency; in a sexual population, recombination then combines these alleles to assemble the fittest genotype. (With asexual reproduction, different favourable alleles compete, and the ‘cost of selection’ is not alleviated by epistasis; Worden, 1995. To a lesser extent, linkage disequilibrium will also reduce mean fitness). With truncation selection, or similar schemes with negative epistasis, the rate of adaptation is limited by the variance in reproductive success, rather than by the mean fitness, relative to the optimal genotype.
In the simplest case, of constant selection on a single allele, the total variance in fitness during a substitution is  for p0<<1. Thus, the gain in information for a given fitness variance is greatest when selection is weak. However, when selection is so weak that drift becomes significant, favourable alleles may be lost, and the information gain decreases below log (1/p0). Appendix A shows that the expected information gain per fitness variance is maximised in the infinitesimal limit, tending to Ne/2 as Nes–>0.
for p0<<1. Thus, the gain in information for a given fitness variance is greatest when selection is weak. However, when selection is so weak that drift becomes significant, favourable alleles may be lost, and the information gain decreases below log (1/p0). Appendix A shows that the expected information gain per fitness variance is maximised in the infinitesimal limit, tending to Ne/2 as Nes–>0.
This argument extends to directional selection on an additive trait; with a selection gradient β, an allele with effect γ on the trait experiences selection s=βγ. This scenario is essentially that considered by Robertson (1960): individual alleles evolve almost neutrally, but overall there is an excess of favourable over unfavourable substitutions. The overall ratio of ℐ/VW(a) will be a mixture across strongly and weakly selected substitutions. Starting from a poorly adapted state, the mean fitness will increase in proportion to the variance in fitness, but ℐ will increase more slowly, as weakly selected variants start to contribute to adaptation. Ultimately, the trait mean, and hence the mean fitness, will increase as a result of more strongly selected alleles, yet the net change in allele frequencies, as measured by ℐ, may be because of much more weakly selected alleles.
Watkins (2002) gives a similar argument, justifying information as a measure of adaptation, and showing that the amount of information that can be maintained in a balance between mutation and truncation selection is much greater when a wide range of genotypes are fit than when specific genotypes are selected. This advantage only exists under sexual reproduction; Peck and Waxman (2010) lay out this argument in more detail.
The same result can be derived more directly by considering the quantitative trait under the infinitesimal model. With a selection gradient β, the variance in fitness is β2 Vg. The variance of the trait mean, v, increases as a result of random drift, but independent of directional selection; thus, v=vN in Equation (5), and  . The additive variance decreases by a factor (1−1/(2Ne)) per generation (assuming diploidy), whereas the variance of the mean increases by
. The additive variance decreases by a factor (1−1/(2Ne)) per generation (assuming diploidy), whereas the variance of the mean increases by  . Therefore, v=vN=1/Ne. The expected mean increases by
. Therefore, v=vN=1/Ne. The expected mean increases by  in each generation or
in each generation or  . Therefore,
. Therefore,  , where
, where  is the total fitness variance, summed over the whole time course. We see that the rate of information gain per generation is just (Ne/2) times the additive fitness variance, exactly as found by considering individual alleles. This is higher by a factor ~Ne than the limit set by the ‘cost of selection’ (Kimura, 1961).
is the total fitness variance, summed over the whole time course. We see that the rate of information gain per generation is just (Ne/2) times the additive fitness variance, exactly as found by considering individual alleles. This is higher by a factor ~Ne than the limit set by the ‘cost of selection’ (Kimura, 1961).
How does epistasis affect this argument? At the level of individual substitutions, the problem seems very difficult, as the fixation probability depends on a marginal selection that changes through time as the genetic background changes. However, in the infinitesimal limit, we can take the variance components to be constant. The same argument carries through, except that the rate of information gain because of selection on the trait mean depends on the additive variance, whereas the genetic variance in fitness includes epistatic components. Therefore, epistasis reduces the information gain under directional selection. This argument is close to that made by Paixao and Barton (2016), in their extension of the selection limit of Robertson (1960).
A general bound on the rate of accumulation of information
It is hard to find results for stochastic processes that are far from their stationary state; even in physics, progress has been surprisingly recent. A remarkably general result, which applies to complete histories of dynamical systems, was derived by Jarzynski (2001) and Crooks (1998, 2000). Mustonen and Lässig (2010) apply this relation to population genetics to show a very general relation between the net response to selection, measured by the ‘fitness flux’, Φ, and the concentration of populations into states that would be highly improbable in the absence of selection, as measured by H:

for a haploid population. The expectation is over all paths between arbitrary start and end points. (There is a pervasive factor of two error in Mustonen and Lässig (2010) that is corrected here; Appendix B). This equation applies with epistasis: the selection coefficients si are then the marginal selection on each allele, and depend on the changing genetic background.
Because  , this implies that:
, this implies that:

(Mustonen and Lässig, 2010, Equation (5)). In the special case where selection can be described by a constant adaptive landscape (that is, if genotype fitnesses are fixed), the fitness flux is equal to the log mean fitness: Φ=log(W̄). If we also assume that the neutral process is constant, Equation (7) then corresponds to the result of Iwasa (1988), which defined a ‘free fitness’ that never decreases. Thus, Mustonen and Lässig (2010) have generalised the analysis of Iwasa (1988) to allow for fluctuating adaptive landscapes, and for cases where the dynamics cannot be described by any potential function.
The fitness flux, Φ, is the net increase in fitness that would occur if changes in genotypic fitness over time were ignored. It measures the extent to which allele frequencies change in the direction favoured by selection, and corresponds to the total work done on a physical system (that is, to the integral of force times displacement). We can understand the fitness flux by separating the change in allele frequency into components due to selection, mutation and drift. The change due to selection on allele frequencies is Δspi=si pi qi, which contributes  to the fitness flux in haploids. This is just the partial change in mean fitness identified by the Fundamental Theorem of Fisher (1930), and is equal to the additive genetic variance in fitness in a haploid population, VW(a). Changes in allele frequency due to mutation and drift also contribute to the fitness flux. These do not depend directly on the effects of the allele on fitness, but if the population is well adapted, we expect them typically to make a negative contribution to the fitness flux. Mutation and drift are expected to interfere with selection, and to reduce the fitness of a well-adapted population.
to the fitness flux in haploids. This is just the partial change in mean fitness identified by the Fundamental Theorem of Fisher (1930), and is equal to the additive genetic variance in fitness in a haploid population, VW(a). Changes in allele frequency due to mutation and drift also contribute to the fitness flux. These do not depend directly on the effects of the allele on fitness, but if the population is well adapted, we expect them typically to make a negative contribution to the fitness flux. Mutation and drift are expected to interfere with selection, and to reduce the fitness of a well-adapted population.
The fitness flux is not a practicably observable quantity: it is the sum over the selection on, and the change in frequency of, every allele. However, if the variance in fitness is generally larger than the fitness flux, that sets a more useful bound on the rate of gain of information:

This is not an exact result: if a population is initially in an unusually maladapted state, then mutation or drift may tend to increase fitness, in which case the fitness flux would be larger than the variance in fitness. However, to the extent that populations are well adapted, so that forces other than selection tend to degrade fitness, the product of population size and additive variance in fitness sets an upper bound to the rate at which selection can accumulate information, regardless of the degree of epistasis or fluctuations in selection.
Figure 7 shows an example in which selection on one of two alleles is either increased abruptly to a constant value (left), or gradually (right); the inequality (8) holds in both cases. With an abrupt increase, the distribution moves to a new stationary state, leading to an increase in information, and a larger increase in total fitness flux (red and blue curves, respectively). The total fitness variance is always higher than the fitness flux, and continues to increase even after a stationary state has been reached. If selection increases gradually (right), the increase in information approaches the fitness flux; these two become equal if selection changes sufficiently slowly (Mustonen and Lässig, 2010). The total fitness variance is always higher and continues to increase.

Each plot shows the increase in information, the fitness flux multiplied by 2N, and the cumulative variance in fitness, multiplied by 2N (red: ΔH, blue: 2N Φ, black: 2N V). Initially, the population is in the stationary state, with μ=0.0025 and a haploid population of N=50. The left plot shows an abrupt increase in selection to s=0.05, whereas the right plot shows a linear increase from s=0 to s=0.05 over 10 000 generations. In both examples, the increase in information (red) is smaller than the fitness flux (blue) that in turn is smaller than the cumulative variance in fitness (black). However, the increase in information is closer to the upper bound set by fitness flux when selection increases gradually. Numerical values are calculated using the Wright–Fisher transition matrix. A full colour version of this figure is available at the Heredity journal online.
The previous section showed that the increase in mean of an additive trait under directional selection leads to an increase in information equal to Ne/2 times the total variance in fitness; this holds for both haploid and diploid populations. The inequality (8) necessarily still holds, but the fitness flux no longer approaches the increase in information as selection is changed gradually. This is because neither the distribution under selection nor the neutral distribution with which it is compared are stationary: the variance in mean keeps increasing.
Discussion
Epistasis in the infinitesimal limit
The argument set out here is that though the mapping from genotype to phenotype is complex, with strong interactions between many genes, the evolution of complex traits may nevertheless be approximated by just a few parameters, using an extension to the infinitesimal model. This approximation requires three assumptions: that many genes affect each trait; that the range of trait variation is narrow relative to what is possible in the current population; and that interactions are not systematically biased with respect to the direction of selection. Then, trait evolution depends on just a few variance components that are hardly influenced by selection, at least assuming free recombination. On this view, the complexities of epistasis are limited in two ways: (1) they are absorbed into a few variance components, and (2), of these, the additive component typically dominates.
Epistasis can sustain multiple ‘adaptive peaks’ that can trap populations in suboptimal states. However, when selection on each allele is comparable to drift (that is, Nes≲1), random fluctuations allow populations to evolve more or less freely across rugged landscapes. Crucially, multiple traits can still be kept close to their optima, even when drift dominates selection on individual alleles (Kimura, 1965; Charlesworth, 2013a, 2013b). In this infinitesimal regime, epistasis does influence the response to directional and stabilising selection, but its effects are limited by the typically modest magnitude of the nonadditive variance. Specifically, the effective population size limits the total response to both directional and stabilising selection: a selection gradient, β, causes a total change Neβ for haploids (Robertson, 1960; Paixao and Barton, 2016), whilst random drift causes a variance of the mean around the optimum Vs/(2Ne), hence reducing mean fitness by 1/(4Ne).
In principle, quantitative trait locus mapping, and genome-wide association studies allow us to identify interactions between alleles as well as their marginal (that is, additive) effects. However, estimates of epistatic interactions are hard to validate. More important for the argument here, strong interactions among loci may have little effect in aggregate. This point is illustrated by the contrasting analyses of Weber et al. (1999) of the same cross between populations of Drosophila selected for different wing shape. A model of 11 interacting loci with strong interactions fit best, yet because these interactions varied in sign, the overall data fit closely to an additive infinitesimal model.
Though classical quantitative genetics allows epistasis and dominance to be described by higher-order variance components, which remain approximately constant in the infinitesimal limit, the simpler additive model is often adequate. For example, a large meta-analysis of twin studies in humans found 69% of cases to be consistent with additivity (Polderman et al., 2015). There are strong theoretical arguments that even when the underlying genes interact strongly, most variance is additive (Hill et al., 2008). In particular, deleterious mutations are rare, and rare alleles necessarily contribute mostly additive variance. Huang et al. (2012) argue that there is widespread epistasis for behavioural traits in Drosophila. However, their estimates are for variance among inbred lines, rather than an outcrossed population, which amplifies nonadditive variance. Variation in estimated allelic effects across backgrounds may also be because of statistical error rather than epistasis (Maki-Tanila and Hill, 2014, pp 363–364).
The infinitesimal limit depends implicitly on selection being weak relative to random drift (that is, Nes≲1). This is plausible for artificially selected populations of a few hundred individuals that are selected for up to a hundred generations (Hill and Kirkpatrick, 2010). Indeed, the review of Weber and Diggins (1990) of laboratory selection experiments found the selection response over 50 generations to be remarkably close to the infinitesimal prediction of Robertson (1960). However, the strength of selection relative to drift in natural populations remains obscure—despite intense debate during the last decades of the previous century, and despite the present abundance of sequence data (Kimura, 1983; Hey, 1999). The following section briefly summarises the various lines of evidence on the strength of selection on traits and on the underlying alleles.
The strength of selection relative to drift
First, consider selection on traits. Direct estimates of directional and stabilising selection, made by correlating trait values with fitness components, typically give strong values. The survey of Kingsolver and Diamond (2011) of 143 studies found an average directional selection gradient of 0.08 on survival, 0.19 on fecundity and 0.17 on mating success, standardised relative to phenotypic s.d. Stabilising selection is also typically strong but, surprisingly, is as often negative (that is, disruptive) as positive. Larger studies gave systematically smaller estimates, suggesting that publication bias may inflate estimates (Kingsolver et al., 2001). In addition, long-term studies find that trait means often remain constant, despite high heritability and strong directional selection (see, for example Kruuk et al., 2002). Nevertheless, despite these difficulties, traits do typically seem to be associated with strong fitness differences. This seems paradoxical: it is hardly conceivable that all traits are strongly selected. Possibly, measured traits are correlated with a small number of strongly selected traits, such as body size (Barton, 1990). The problem can be stated more precisely by considering the matrix of stabilising selection on the multivariate phenotype: the leading eigenvalues of this matrix may be large, yet the bulk of eigenvalues may be far smaller (Walsh and Blows, 2009). Long-term stability of the phenotype implies that there must be some net stabilising selection, but this is in practice impossible to measure directly and might be very weak for the great majority of degrees of freedom.
How strong is the selection on the alleles responsible for trait variation? It is difficult to identify such alleles, let alone directly measure their effect on fitness. However, several indirect approaches can be used. If genetic variation is maintained by a balance between mutation and selection, then the strength of selection against deleterious mutations can be estimated from the ratio between the rate of increase of additive variance due to mutation and the standing genetic variance, VAm/Vg. This suggests selection coefficients of s~10−3 or more, estimates being remarkably consistent across diverse traits and species (Lynch and Walsh, 1998; Johnson and Barton, 2005). Decades of classical work on Drosophila has applied essentially this approach to fitness components such as female fecundity and larval viability. Charlesworth (2014) reviews this work, and concludes that the selection on the mutations that sustain fitness variance is relatively strong, averaging a few percent. The difference between estimates for quantitative traits in general and fitness components is to be expected: if alleles have a random vector of effects on traits, the mean selection against alleles contributing to fitness variance will be stronger than that on arbitrary traits. Charlesworth (2014) also concludes that genomic mutation rates are not high enough to explain observed levels of fitness variance, suggesting a substantial component contributed by balancing selection.
The distribution of fitness effects of deleterious mutations can also be estimated by comparing the frequencies of putatively selected alleles with a neutral baseline. This approach is sensitive to demography, though that is to some extent controlled by the comparison between neutral and selected variants within the same population. In a Rwandan population of Drosophila melanogaster, thought to have a stable history, a broadly log-normal distribution was estimated, with mean selection s~10−3 against non-synonymous mutations (Kousathanas and Keightley, 2013; Charlesworth, 2014). This low value appears inconsistent with estimates from Vm/Vg for fitness components of a few percent. However, the estimates can be reconciled if some of the mutation load is due to a different class of mutations that are strongly selected—for example, transposable elements (Charlesworth, 2014). In any case, selection coefficients of s~10−3 are strong relative to random drift, in all but the sparsest species: for example, Ne for the D. melanogaster example above was estimated from synonymous diversity as ~7 × 105, so that Nes~680.
These indirect estimates, whether based on Vm/Vg or on the allele frequency spectrum, give the selection against deleterious mutations. Positive selection can be detected from an excess of nonsynonymous divergence relative to polymorphism (McDonald and Kreitman, 1991), or from the reduction in diversity around a selective sweep (Maynard Smith and Haigh, 1974). The former method does not give an estimate of selection strength, whereas reduced diversity may be because of deleterious mutations (‘background selection’) as well as positive selection. However, diversity is lower in regions of reduced recombination, and it is also lower around nonsynonymous substitutions. Elyashiv et al. (2016) use these patterns of diversity and divergence in D. melanogaster to fit a model that includes the distribution of fitness effects of both deleterious mutations and adaptive substitutions. They find that both processes substantially reduce neutral diversity across the genome. The estimated selection on deleterious mutations is ~10−1.5, similar to the values estimated from Vm/Vg; however, the estimated mutation rate is excessive, suggesting that the patterns attributed to background selection may be partly because of other forms of linked selection. The reduction in diversity around nonsynonymous substitutions leads to estimates of positive selection: a small fraction of substitutions are driven by moderately strong selection (~10−3.5), whereas the bulk are estimated to be under much weaker selection (~10−6–10−5.5).
Such indirect estimates of selection, based on the effects of linked selection across the genome, are at best tentative; indeed, previous estimates spanned many orders of magnitude (Sella et al., 2009). There is a consensus that although selection against nonsynonymous mutations spans a wide range, it is on average much stronger than drift. However, the majority of sites under constraint are noncoding, and likely to be under much weaker purifying selection than amino-acid changes. Although most fitness variance may be because of mutations with effects on fitness much stronger than drift (including most amino-acid substitutions and transposable element insertions), most of the functional genome might be maintained by much weaker selection. Similarly, although we know many examples of adaptation due to strong selection on major alleles, and whereas most of the fitness variance associated with adaptation may be because of alleles for which selection is much stronger than random drift, it might still be that most substitutions are under much weaker selection, and have been strongly influenced by drift. In that case, many substitutions may be of deleterious alleles, or may compensate for previous maladaptive substitutions. Indeed, in the infinitesimal limit, there can be rapid and precise adaptation of multiple traits through imperceptible shifts in allele frequency distribution that could not be detected by any of the indirect methods just discussed. This may be the case for most recent adaptation in humans (Hernandez et al., 2011).
How many degrees of freedom can be maintained despite random drift?
Regardless of the strength of selection on each allele, there is a robust limit to the number of traits that can be kept close to their optima: for every degree of freedom, fluctuations in the mean reduce mean fitness by ~1/(4Ne), which would seem to limit the number of degrees of freedom to of order effective population size. As with other such arguments from genetic load, this limit can be evaded by a specific form of epistasis that ensures that the loss of mean fitness relative to the optimum is much smaller than expected from the marginal effect of additional small deviations (Figure 6). In the absence of evidence that this is the case, or theoretical arguments that it should evolve, this drift load should be taken seriously.
It is important to realise that this constraint does not depend on the amount of variation within the population. Although it can be derived by considering a genetically variable quantitative trait, it can also be derived from the stationary distribution of genotype frequencies (Equation (3)) that in turn depends on the ratio between fixation probabilities of deleterious versus favourable alleles. Therefore, the number of evolvable degrees of freedom may be much larger than the number of segregating alleles, which depends on the mutation rate as well as population size: in the long term, populations can explore a space of much higher dimension than that determined by the currently segregating alleles (Figure 3). In the very long term, there can be qualitative changes in what is possible (most obviously, following ‘major transitions’ in genetic organisation; Szathmáry and Maynard Smith, 1995); over such long time-spans, the idea of a stationary distribution makes little sense.
An organism is described by an essentially infinite number of variables. Clearly, the genome of a multicellular organism does not specify the precise change in morphology and physiological activity through development and across environments. This is most obvious if we consider the extraordinary complexity of connections in the brain, but even a single-celled organism has a highly complex intracellular structure and biochemical activity that may respond to a variety of environmental stimuli. Rather than specifying this complexity directly, the genome regulates gene expression that in turn influences the organism’s change through time in response to changing conditions. However, though we cannot regard the genome as directly specifying the organism, neither can we regard it as simply triggering an invariant program that is determined largely by the cellular machinery: very many features of the organism can evolve, and indeed must do so if the species is to adapt to new conditions. The number of degrees of freedom that can be optimised lies somewhere between the extremes of precise and detailed specification versus triggering an invariant program. It is intriguing that the size of the functional genome (as measured by the amount of constrained sequence or the number of coding genes) varies rather little between organisms with apparently very different complexities.
To make the question more concrete, we can focus on gene expression. An initial estimate for the number of degrees of freedom would then be the number of genes, ∼2 × 104 for a typical multicellular eukaryote such as human or Drosophila. Clearly, gene expression must be maintained at an appropriate level in response to multiple stimuli, including the concentration of transcription factors expressed during development, biochemical feedbacks and environmental signals. In eukaryotes, the expression of alternative splice variants must also be regulated. Thus, ‘expression’ of a single gene is itself a complex multivariate trait that we might guess involves at least 10 and possibly many more degrees of freedom. Of course, sets of genes tend to be coexpressed, but to the extent that they each have their own promoter that can evolve independently, we must still consider every gene as having its own independent degrees of freedom. Overall, this line of argument suggest at least 105 degrees of freedom.
Previous discussions have given far smaller estimates for the effective number of dimensions. Kirkpatrick (2009) shows that most trait variance may be concentrated along a few axes, so that the effective number of dimensions (defined by the distribution of eigenvalues) is small. Martin and Lenormand (2006, Table 2) estimate the effective number of dimensions in which mutations act, based on the distribution of fitness effects and assuming Fisher’s geometric model. Their meta-analysis, which gives very small values (~1) for the effective number of dimensions, seems dubious, because it relies on the predicted form for the distribution of fitness effects under restrictive assumptions, and because high mutation rates for quantitative traits and large numbers of estimated quantitative trait loci imply extensive pleiotropy (Johnson and Barton, 2005). In any case, the drift load depends on the total number of dimensions rather than on an ‘effective dimensionality’ that is weighted towards axes with large effect. (Martin (2014) refers to this total as the number of ‘optimised traits’).
What happens to a population that decreases in size? The success of domestication shows that populations of just a few hundred can adapt well to radically new conditions (Hill and Kirkpatrick, 2010). However, over longer timescales, it would seem that a substantial and possibly catastrophic fitness decline must ensue, as random drift fixes slightly deleterious mutations (Kondrashov, 1995; Lynch and Hagner, 2015), and moves trait means away from their optima. Charlesworth (2013a) has criticised such arguments on the grounds that compensatory mutations prevent decline, and that stabilising selection can be effective even when individual alleles are dominated by drift. However, as argued above, small populations should ultimately be unable to maintain more than ~4Ne traits close to their optima. Decline is expected to be slow. Immediately after population size falls, genetic variation will decrease, but even in the most extreme case, will fix a genotype that is ~ s.d. from the optimum, and hence not far outside the initial range of phenotypic variation. Decline continues more slowly, as new mutations are fixed that take the mean ever further from the optimum. A new equilibrium is reached when the marginal selection becomes strong enough to make fixation of deleterious mutations unlikely (Figure 6). Thus, functional complexity will only be lost over the timescale of molecular evolution.
s.d. from the optimum, and hence not far outside the initial range of phenotypic variation. Decline continues more slowly, as new mutations are fixed that take the mean ever further from the optimum. A new equilibrium is reached when the marginal selection becomes strong enough to make fixation of deleterious mutations unlikely (Figure 6). Thus, functional complexity will only be lost over the timescale of molecular evolution.
Summary
Since long before there was any understanding of genetics, we have known that artificial selection is remarkably effective; indeed, this was one of Darwin’s strongest arguments that natural selection is responsible for complex adaptation. The analysis of variance introduced by Fisher (1918) describes an arbitrarily complicated relation between genotype and phenotype via a series of variance components, yet the additive component almost always explains the bulk of variance, and allows accurate predictions for the response to selection.
Our understanding of the underlying genetic complexity, first through classical genetics and later through molecular biology, seems incompatible with this simple view, and supported the long-standing argument that epistasis constrains evolution (Wright, 1931; Wolf, 2000; Hansen, 2013). Specifically, it is argued that epistasis makes the marginal effects of alleles unpredictable, so that selection becomes ineffective. If epistasis is strong enough that allelic effects change sign, then populations may be trapped at suboptimal ‘adaptive peaks’. Related arguments for constraints on selection are that pleiotropic allelic effects, and tradeoffs between different fitness components, prevent response to selection. From the quantitative genetic viewpoint, these are all arguments that there may be no additive variance for selected traits—and are most obviously countered by the observation that there is almost always ample heritable variance, much of it additive. It is impossible to reject the possibility that the additive genetic variation occupies a space of limited dimension, so that there is indeed no additive variance in some directions. However, although the dimensionality that can be explored by any one population is limited by the number of segregating alleles, the space that can, in the longer term, be explored by mutation may be much larger.
Many of these arguments are supported by models of a few interacting loci under strong selection that typically do lead to a rugged fitness landscape on which selection is ineffective. Here, I have argued that if traits depend on very large numbers of loci, so that alleles are influenced by drift as well as selection, then epistasis is no longer a constraint: populations can escape local adaptive peaks, and traits evolve under the infinitesimal model in which the additive variance is not eroded by selection.
In the long term, epistasis obviously matters: separate populations inevitably diverge, accumulate different gene combinations and eventually become incompatible with each other, even if traits are under the same selection. The relation between fitness and traits may also be complex, with multiple peaks that reflect interactions between traits. My argument is not that epistasis is irrelevant to evolution, but rather that it does not significantly constrain the way populations respond to selection on complex traits. Populations typically contain abundant additive variance that allows them to follow a moving optimum in a high-dimensional trait space.
Though gene interactions may not prevent adaptation of multiple traits, population size sets a fundamental constraint that applies independently of the nature of epistasis. The change in mean because of directional selection on standing variation is proportional to Ne, regardless of epistasis (Robertson, 1960; Paixao and Barton, 2016); a similar argument applies when mutation sustains a continued response that we again expect to be proportional to Ne in the infinitesimal limit. The number of traits that can be optimised by stabilising selection seems limited to ~4Ne by the loss of mean fitness associated with fluctuations of each trait. If this limit could be somehow evaded, a more robust limit is set by the variance in fitness that is required to accumulate information. However, this more fundamental limit is proportional to Ne VW(a) per generation, the product of effective size and additive variance in fitness, which leaves ample scope for the evolution of complexity. Perhaps most important, such selection is most efficient (that is, maximises the gain in information per fitness variance) under the infinitesimal regime.
Data archiving
The code used to generate the figures is available from the Dryad Digital Repository: http://dx.doi.org/10.5061/dryad.s5s7r.
References
Barton NH . (1989). The divergence of a polygenic system under stabilising selection, mutation and drift. Genet Res 54: 59–77.
Barton NH . (1990). Pleiotropic models of quantitative variation. Genetics 124: 773–782.
Barton NH, Etheridge AM, Veber A . (2016) . The infinitesimal model http://biorxiv.org/content/early/2016/02/15/039768.
Barton NH, Vladar HP . (2009). Statistical mechanics and the evolution of polygenic quantitative traits. Genetics 181: 997–1011.
Bourguet D . (1999). The evolution of dominance. Heredity 83: 1–4.
Bulmer MG . (1980) The Mathematical Theory of Quantitative Genetics. Oxford University Press: Oxford.
Carlborg Ö, Haley CS . (2004). Epistasis: too often neglected in complex trait studies? Nat Rev Genet 5: 618–625.
Carter AJR, Hermisson J, Hansen TF . (2005). The role of epistatic gene interactions in the response to selection and the evolution of evolvability. Theor Popul Biol 68: 179–196.
Charlesworth B . (2013a). Why we are not dead one hundred times over. Evolution 67: 3354–3361.
Charlesworth B . (2013b). Stabilizing selection, purifying selection, and mutational bias in finite populations. Genetics 194: 955–971.
Charlesworth B . (2014). The causes of natural variation in fitness– evidence from studies of Drosophila populations. Proc Natl Acad Sci USA 112: 1662–1669.
Crooks GE . (1998). Non-equilibrium measurements of free energy differences for microscopically reversible Markovian systems. Phys Rev E 61: 2361–2366.
Crooks GE . (2000). Path - ensemble averages in systems driven far from equilibrium. Phys Rev E 61: 2361–2366.
Elyashiv E, Sattath S, Hu TT, Strutsovsky A, McVicker G, Andolfatto P et al. (2016). A genomic map of the effects of linked selection in Drosophila. PLoS Genet 12 ((8)): e1006130.
Ewens WJ . (2004) Mathematical Population Genetics I: Theoretical Introduction. Springer: Verlag, Berlin.
Fisher RA . (1918). The correlation between relatives on the supposition of Mendelian inheritance. Proc R Soc Edinburgh 52: 399–433.
Fisher RA . (1930) The Genetical Theory of Natural Selection. Oxford University Press: Oxford.
Haldane JBS . (1927). A mathematical theory of natural and artificial selection V Selection and mutation. Proc Camb Phil Soc 26: 220–230.
Haldane JBS . (1957). The cost of natural selection. J Genet 55: 511–524.
Hansen TF . (2013). Why epistasis is important for selection and adaptation. Evolution 67: 3501–3511.
Hermisson J, Hansen TF, Wagner GP . (2003). Epistasis in polygenic traits and the evolution of genetic architecture under stabilizing selection. Am Nat 161: 708–734.
Hernandez RD, Kelley JL, Elyashiv E, Melton C, Auton A, McVean G et al. (2011). Classic selective sweeps were rare in recent human evolution. Science 331: 920–924.
Hey J . (1999). The neutralist, the fly, and the selectionist. Trends Ecol Evol 14: 35–37.
Hill WG . (1982). Rates of change in quantitative traits from fixation of new mutations. Proc Natl Acad Sci USA 79: 142–145.
Hill WG, Barton NH, Turelli M . (2006). Prediction of effects of genetic drift on variance components under a general model of epistasis. Theor Popul Biol 70: 56–62.
Hill WG, Goddard ME, Visscher PM . (2008). Data and theory point to mainly additive genetic variance for complex traits. PLOS Genet 4: e1000008.
Hill WG, Kirkpatrick M . (2010). What animal breeding has taught us about evolution. Annu Rev Ecol Evol Syst 41: 1–19.
Hill WG, Rasbash J . (1986). Models of long-term artificial selection in finite population with recurrent mutation. Genet Res 48: 125–131.
Houle D, Moriwaka B, Lynch M . (1996). Comparing mutational variabilities. Genetics 143: 1467–1483.
Huang W, Richards S, Carbone MA, Zhu D, Anholt R, Ayroles JF et al. (2012). Epistasis dominates the genetic architecture of Drosophila quantitative traits. Proc Natl Acad Sci USA 109: 15553–15559.
Iwasa Y . (1988). Free fitness that always increases in evolution. J Theor Biol 135: 265–282.
Jarzynski C . (2001). How does a system respond when driven away from thermal equilibrium? Proc Natl Acad Sci USA 98: 3636–3638.
Johnson T, Barton NH . (2005). Theoretical models of selection and mutation on quantitative traits. Phil Trans R Soc Lond B 360: 1411–1425.
Jones AG, Arnold SJ, Bürger R . (2007). The mutation matrix and the evolution of evolvability. Evolution 61: 727–745.
Kimura M . (1961). Natural selection as the process of accumulating genetic information in adaptive evolution. Genet Res 2: 127–140.
Kimura M . (1965). A stochastic model concerning the maintenance of genetic variability in quantitative characters. Proc Natl Acad Sci USA 54: 731–736.
Kimura M . (1983) The Neutral Theory of Molecular Evolution. Cambridge University Press: Cambridge, UK.
Kimura M, Maruyama T . (1966). The mutation load with epistatic interactions in fitness. Genetics 54: 1337–1351.
Kingsolver JG, Diamond SE . (2011). Phenotypic selection in natural populations: what limits directional selection. Am Nat 177: 346–357.
Kingsolver JG, Hoekstra HE, Hoekstra JM, Berrigan D, Vignieri SN, Hill CE et al. (2001). The strength of phenotypic selection in natural populations. Am Nat 157: 245–261.
Kirkpatrick M . (2009). Patterns of quantitative genetic variation in multiple dimensions. Genetica 136: 271–284.
Kondrashov AS . (1988). Deleterious mutations and the evolution of sexual reproduction. Nature 336: 435–440.
Kondrashov AS . (1995). Contamination of the genome by very slightly deleterious mutations: why have we not died 100 times over. J Theor Biol 175: 583–594.
Kondrashov AS, Sunyaev S, Kondrashov FA . (2002). Dobzhansky–Muller incompatibilities in protein evolution. Proc Natl Acad Sci USA 99: 14878–14883.
Kousathanas A, Keightley PD . (2013). A comparison of models to infer the distribution of fitness effects of new mutations. Genetics 193: 1197–1208.
Kruuk LEB, Slate J, Pemberton JM, Brotherstone S, Guiness FE, Clutton-Brock T . (2002). Antler size in red deer: heritability and selection but no evolution. Evolution 56: 1683–1695.
Lande R . (1976). Natural selection and random genetic drift in phenotypic evolution. Evolution 30: 314–334.
Lange K . (1978). Central limit theorems for pedigrees. J Math Biol 6: 59–66.
Lynch M, Hagner K . (2015). Evolutionary meandering of intermolecular interactions along the drift barrier. Proc Natl Acad Sci USA 112: E30–E38.
Lynch M, Walsh JB . (1998) Genetics and Analysis of Quantitative Traits. Sinauer Press: Sunderland, MA.
Maki-Tanila A, Hill WG . (2014). Influence of gene interaction on complex trait variation with multilocus models. Genetics 198: 355–367.
Marchini M, Sparrow LM, Cosman MN, Dowhanik A, Krueger CB, Hallgrimsson B et al. (2014). Impacts of genetic correlation on the independent evolution of body mass and skeletal size in mammals. BMC Evol Biol 14: 258.
Martin G . (2014). Fisher’s geometrical model emerges as a property of complex integrated phenotypic networks. Genetics 197: 237–255.
Martin G, Lenormand T . (2006). A general multivariate extension of Fisher's geometrical model and he distribution of mutation fitness effects across species. Evolution 60: 893–907.
Maynard Smith J, Haigh J . (1974). The hitch-hiking effect of a favourable gene. Genet Res 23: 23–35.
McDonald JH, Kreitman M . (1991). Adaptive protein evolution at the Adh locus in Drosophila. Nature 351: 652–654.
Mustonen V, Lässig M . (2010). Fitness flux and ubiquity of adaptive evolution. Proc Natl Acad Sci USA 107: 4248–4253.
Nelson RM, Pettersson ME, Carlborg Ö . (2013). A century after Fisher: time for a new paradigm in quantitative genetics. Trends Genet 29: 669–676.
Orr HA . (2000). Adaptation and the cost of complexity. Evolution 54: 13–20.
Paixao T, Barton NH . (2016). The effect of gene interactions on the long-term response to selection. Proc Natl Acad Sci USA 113: 4422–4427.
Peck JR, Waxman D . (2010). Is life impossible? Information, sex and the origin of complex organisms. Evolution 64: 3300–3309.
Polderman TJC, Benyamin B, de Leeuw CA, Sullivan PF, van Bochoven A, Visscher PM et al. (2015). Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nat Genet 47: 702–709.
Provine W . (1988) Sewall Wright and Evolutionary Biology. University of Chicago Press: Chicago, IL, USA.
Robertson A . (1960). A theory of limits in artificial selection. Proc R Soc Lond B 153: 234–249.
Robinson MR, Wray NR, Visscher PM . (2014). Explaining additional genetic variation in complex traits. Trends Genet 30: 124–132.
Sella G, Petrov DA, Przeworski M, Andolfatto P . (2009). Pervasive natural selection in the Drosophila genome? PLoS Genet 5: e1000495.
Szathmáry E, Maynard Smith J . (1995). The major evolutionary transitions. Nature 374: 227–232.
Turelli M . (1984). Heritable genetic variation via mutation-selection balance: Lerch’s Zeta meets the abdominal bristle. Theor Popul Biol 25: 1–56.
Vladar HP, Barton NH . (2014). Stability and response of polygenic traits to stabilizing selection and mutation. Genetics 197: 749–767.
Walsh B, Blows MW . (2009). Abundant genetic variation+strong selection=multivariate genetic constraints: a geometric view of adaptation. Annu Rev Ecol Evol Syst 40: 41–59.
Watkins CJCH . (2002). The channel capacity of evolution: ultimate limits on the amount of information maintainable in the genome. Proc Third Intern Conf Bioinf Genome Reg Struct 2: 58–60.
Weber KE . (1996). Large genetic change at small fitness cost in large populations of Drosophila melanogaster selected for wind tunnel flight: rethinking fitness surfaces. Genetics 144: 205–213.
Weber KE, Diggins LT . (1990). Increased selection response in larger populations II Selection for ethanol vapor resistance in Drosophila melanogaster at two population sizes. Genetics 125: 585–597.
Weber KE, Eisman R, Morey L, Patty A, Sparks J, Tausek M et al. (1999). An analysis of polygenes affecting wing shape on chromosome 3 in Drosophila melanogaster. Genetics 153: 773–786.
Wilke C, Wang JL, Ofria C, Lenski RE, Adami C . (2001). Evolution of digital organisms at high mutation rates leads to survival of the flattest. Nature 412: 331–333.
Wolf JB . (2000) Epistasis and the Evolutionary Process. Oxford University Press: Oxford, UK.
Worden RP . (1995). A speed limit for evolution. J Theor Biol 176: 137–152.
Wright S . (1929). The evolution of dominance. Am Nat 63: 558–561.
Wright S . (1931). Evolution in Mendelian populations. Genetics 16: 97–159.
Wright S . (1935). The analysis of variance and the correlation between relatives with respect to deviations from an optimum. J Genet 30: 243–256.
Wright S . (1938). The distribution of gene frequencies under irreversible mutation. Proc Natl Acad Sci USA 24: 253–259.
Yoo BH . (1980). Long-term selection for a quantitative character in large replicate populations of Drosophila melanogaster. I. Response to selection. Genet Res 35: 1–17.
Acknowledgements
I am grateful to Tiago Paixao, Bill Hill, and an anonymous reviewer for their helpful comments and for support from the European Research Council Advanced Grant 250152.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author declares no conflict of interest.
Appendices
Appendix A
Information gain and fitness variance
One locus, two alleles, no mutation
Suppose that a locus is initially at p0, and is then subject to constant selection s. It will ultimately fix one or other allele, with probabilities  for the two alleles. The neutral probabilities are just ψN[0]=q0,ψN[1]=p0:
for the two alleles. The neutral probabilities are just ψN[0]=q0,ψN[1]=p0:

where α=4Nes p0.
The corresponding total variance in diploid fitness is  , taking the integral over the whole time course to loss or fixation. To find this, we find t(x;p0), the expected time spent at x, given an initial frequency p. From Ewens (2004, 5.52–5.55), setting h=1/2, α=4Nes, the unconditional values are (5.48):
, taking the integral over the whole time course to loss or fixation. To find this, we find t(x;p0), the expected time spent at x, given an initial frequency p. From Ewens (2004, 5.52–5.55), setting h=1/2, α=4Nes, the unconditional values are (5.48):

The expected total heterozygosity is therefore:

For small p, this tends to  , that itself tends to 16Np0 for small α. Thus, a single neutral mutation, initially at p0=1/N contributes
, that itself tends to 16Np0 for small α. Thus, a single neutral mutation, initially at p0=1/N contributes  on its way to loss or fixation.
on its way to loss or fixation.
Figure 8 (right) shows the scaled ratio between the information gain and the expected total fitness variance. This is maximised at 1/16 in the infinitesimal limit, independent of p0, when α=4Nes–>0. Rescaling, we find that ℐ/VW(a)=Ne/2.

The gain in information, ℐ, and the expected total heterozygosity,  , plotted against initial allele frequency, p0 (left and middle respectively). The right plot shows the ratio between the information gain and the expected total fitness variance. Selection strength is 4Nes=α=0.125, 0.25,…, 8 (black…red). In the limit α→0, the scaled ratio tends to 1/16, independent of p0. A full colour version of this figure is available at the Heredity journal online.
, plotted against initial allele frequency, p0 (left and middle respectively). The right plot shows the ratio between the information gain and the expected total fitness variance. Selection strength is 4Nes=α=0.125, 0.25,…, 8 (black…red). In the limit α→0, the scaled ratio tends to 1/16, independent of p0. A full colour version of this figure is available at the Heredity journal online.
Appendix B
Minor errors in Mustonen and Lässig (2010)
Note that there is a pervasive factor of two error in Mustonen and Lässig (2010). Their Equation (2), which corresponds to Wright’s stationary distribution (Equation 1), should include a factor of 2 in the exponent. This is not due to the assumption of haploidy versus diploidy: Wright’s formula is the same in both cases, with the factor of 2 in the number of genes compensating a factor of 2 in the definitions of mean fitness. The factor of 2 in Wright’s formula arises from the factor of 1/2 in the stochastic term of the diffusion equation that is missing from Mustonen and Lässig (2010, Equation (S20)).
There is also a sign error in Ω in Equation (S74).
Rights and permissions
About this article

Cite this article
Barton, N. How does epistasis influence the response to selection?. Heredity 118, 96–109 (2017). https://doi.org/10.1038/hdy.2016.109
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/hdy.2016.109
This article is cited by
-
Pleiotropy, epistasis and the genetic architecture of quantitative traits
Nature Reviews Genetics (2024)
-
Gene-poor Y-chromosomes substantially impact male trait heritabilities and may help shape sexually dimorphic evolution
Heredity (2023)
-
Thinking outside Earth’s box—how might heredity and evolution differ on other worlds?
Evolution: Education and Outreach (2022)
-
The long-term effects of genomic selection: 1. Response to selection, additive genetic variance, and genetic architecture
Genetics Selection Evolution (2022)
-
In defence of doing sums in genetics
Heredity (2019)
