
Abstract
We report evidence of a deep interplay between cross-correlations hierarchical properties and multifractality of New York Stock Exchange daily stock returns. The degree of multifractality displayed by different stocks is found to be positively correlated to their depth in the hierarchy of cross-correlations. We propose a dynamical model that reproduces this observation along with an array of other empirical properties. The structure of this model is such that the hierarchical structure of heterogeneous risks plays a crucial role in the time evolution of the correlation matrix, providing an interpretation to the mechanism behind the interplay between cross-correlation and multifractality in financial markets, where the degree of multifractality of stocks is associated to their hierarchical positioning in the cross-correlation structure. Empirical observations reported in this paper present a new perspective towards the merging of univariate multi scaling and multivariate cross-correlation properties of financial time series.
Similar content being viewed by others
Introduction
Financial markets dynamics is driven by forces that show their signatures ubiquitously through the complex behaviour of the price historical time series1. A major challenge is to seek connections between different aspects of complexity and to come up with some common mechanism able to explain these aspects coherently. There are two main elements that define the complexity of financial time series: the first is multifractality2,3,4, which is associated to the behavior of each single variable and the way it scales in time; the second is the structure of dependency between time series5, associated with the collective behavior of the whole set of variables. So far, these two manifestation of complexity have been investigated separately. In this paper we point out that -in fact- they are related and we propose a model that can reproduce the observed relationship.
In spite of their intrinsic complexity, prices show remarkable regularities, which are commonly referred to as stylised facts6,7,8. These empirical features are somehow the footprint of some underlying layout which distinguishes prices from purely random processes. Indeed, researchers have been progressively stranding away from the hypothesis of Brownian motion, originally proposed by Bachelier in 19009, as a realistic model for the price evolution and more complex dynamics along with more refined models and mechanisms have been proposed over the past twenty years10. For instance, prices increments at low frequencies (intra-day to weekly) are known to show non-Gaussian behaviour and other distributions, for example Student-t with degrees of freedom in the range [3, 5] have been shown to better fit financial returns11. Another ubiquitous property not exhibited by random noise is the presence of persistence in the price increments, responsible for a phenomenon which is commonly referred to as volatility clustering12,13. Volatility tends to cluster particularly over turbulent periods, where large fluctuations are observed more frequently than in tranquil market periods. Both fat tails and time persistence are captured by a more general behaviour widely observed in financial markets across different asset classes: multifractality. Multifractality is a measure of the complexity of the process, but at the same time it reflects its regularities, mirroring some of the most relevant stylised facts. Many studies have investigated the multifractal behaviour of financial time series14,15,16,17,18,19,20 and several models have been proposed in order to explain its phenomenology21,22,23,24,25.
Further to the complex and regular properties of the single prices, financial markets also exhibit distinctive cross-dependency patterns, which are well captured in the framework of network theory26,27,28. The complex dependency structure of a multivariate dataset can be mapped into a structure of nested hierarchies of correlations through clustering methods29,30,31 which extract a hierarchy of nested clusters of stocks. The hierarchical organisation provides a very useful display of the hidden dependency patterns governing a set of stocks: it reveals which prices are more strongly correlated with respect to the rest of the market and it has been shown to match the intuition of explaining market moves in terms of few hierarchical factors32.
In this article we investigate the interplay between two measures of complexity in the stock prices time series, namely their multifractality and their hierarchical order measured through a clustering algorithm. The first measure reflects properties of the single time series and, as repeatedly shown in many works34,35, is influenced by two main factors: (a) a broad unconditional distribution of the process increments and (b) the long-range non-linear time dependence of the increments. The second deals with the complex cross correlation structure of a multivariate set of time series and therefore necessarily reflects some forms of interaction between stock prices. Here we show that these two measures of complexity, associated with the irregularities present in the prices, are remarkably intertwined and show cogent correlations, especially for certain classes of stocks belonging to specific sectors of the market and to the set of clusters which best express the corresponding sectors. Starting from these observations, we postulate the existence of a hierarchical structure of risks which can be deemed responsible for both stock multivariate dependency structure and univariate multifractal behaviour. We then construct a model that reproduces these empirical observations, built on the hypothesis that a complex hierarchy of risk factors affects the stocks heterogeneously. We show that a simple assumption of nested multiplicative risks can explain the observed correlations between multifractality and hierarchical order, hence providing new insights into the underlying mechanism governing financial markets.
Among different clustering algorithms, in this paper we consider the DBHT, a new deterministic clustering technique which has been shown to outperform many other methods33.The hierarchical organisation generated by the DBHT can be visualised by means of a dendrogram. The reason for choosing the DBHT clustering algorithm among many that return the hierarchical trees of stocks is because this is the only one which, together with hierarchy, uniquely defines clusters and therefore provides a way to identify inter-cluster as well as intra-clusters hierarchy33. While the intra-cluster hierarchy reveals the dependence between the different clusters, the inter-cluster hierarchy provides additional information about the nested organisation of stocks inside each cluster. We will refer to the junctions in the dendrograms as dendrogram nodes (or simply nodes) and to the hierarchical structure above (under) the cluster level as super (sub)-cluster hierarchy respectively.
The hierarchical structure produced by the DBHT provides a natural way to associate with each stock a hierarchical order, that is the number of nodes above each stock along the path from the stock at the bottom of the dendrogram to the top of the dendrogram. We will denote with n the generic order and with ni the hierarchical order of a specific stock i, where i = 1, …, N. In other words, ni measures how deep down the hierarchical tree lies a certain stock i. A schematic hierarchical structure is given in Figure 1. The hierarchical tree Γi is defined to be the set of nodes along the simple path Γi from the stock to the top of the dendrogram, i.e. Γi = {am:m ∈ γi}, where we denote by γi the set of positive numbers identifying the nodes above stock i. Note that there's only one such simple path for each stock i. Then the hierarchical order is defined as the cardinality of Γi, ni = card(Γi). In the example reproduced in Figure 1, for the stock labeled by i, we have γi = {1, 2, 4, 5, 8, 10}, Γi = {a1, a2, a4, a5, a8, a10}, i.e. the set of nodes denoted by the red dots and ni = 6.

Example of hierarchical structure.
The path highlighted in red is Γi, while the thick red bullets are the nodes am, m ∈ γi, which correspond to the risks stock i is exposed to. Note that the risk a1 is common to all stocks, while other risks affect groups of stocks only. The dashed branches of the dendrogram indicate an arbitrary hierarchy.
In this paper we conjecture that the hierarchical order ni can be actually viewed as a measure of the riskiness of stock i, because of its positive dependence with multifractality. This entails that the cross-correlation properties of the multivariate dataset are somehow entangled with the stylised facts displayed by the univariate time series. In particular the hierarchical structure of correlation provides likewise a snapshot of the hierarchy of risks in the market. To the best of our knowledge, up to now no attempt to uncover this kind of underlying structure has been made in the literature.
Results
Cluster detection and sectors
We have considered daily stock prices comprising the 342 most capitalised stocks continuously traded in the NYSE in the period 2-01-1997 to 31-12-2012. Data have been provided by Bloomberg. The dataset includes stocks from 9 different market sectors, according to the Bloomberg classification. The taxonomy of the stocks in the respective sectors is given in the Supplementary Material (SM), where we also report details on the clusters detected through DBHT clustering algorithm. We have also performed the clustering by means of a different clustering procedure, namely the Single Linkage Cluster Analysis (SLCA)36, whose comparison with DBHT we report in SM. In particular, in Figure S1 in SM we report the two hierarchical structures obtained with DBHT and SLCA: comparing the two one can appreciate how the SLCA returns a range of hierarchical orders n ∈ [2, 115] of the stocks much larger than the one obtained through the DBHT, n ∈ [5, 19]. With such a wide range of variability of n it is nearly impossible to distinguish the effect of cross-correlation on multifractality and, this is a reason why, we chose the DBHT as the clustering algorithm to perform the analysis. Moreover, as already mentioned in the introduction, the DBHT identifies clusters uniquely from topological constraints, whereas the SLCA only provides the hierarchical organisation33.
Correlation between multifractality and hierarchical order
We have looked at the correlation between the hierarchical order and the multifractal properties of the stocks. As an indicator of degree of multifractality we have considered, as in previous studies37,38, the quantity

where H(q) for q = 1, 2 is the generalised Hurst exponent computed from the linear scaling of the empirical q-moments (see Methods Section for more details). We have removed from the analysis all stocks whose multifractality cannot be statistically distinguished from zero, which correspond to weak multifractal behaviour and hence would not be relevant in this context. The benchmark value for multifractal stocks has been set to ΔH(1, 2) > 0.015 (see Methods). We plot in Figure 2 the mean value 〈ΔH(1, 2)〉 with standard error  (with s the standard deviation on the mean) for each observed hierarchical order on all stocks analysed (see Methods for details). We observe a positive dependence between the two variables up to n = 14, with correlation coefficient 0.8, followed by some noisier flat trend. The positive correlation between 〈ΔH(1, 2)〉 and n is also confirmed by performing a t-test on the correlation coefficient validated with p-value p = 0.002. All stocks with hierarchical order in the range [5, 14] (which accounts for 90% of all stocks) exhibit multifractal properties increasing along with their depth in the hierarchy of correlations. On the other hand, the apparent saturation observed for orders larger than 14 suggests that the hierarchical structure of cross-correlations may be responsible for the multifractal properties of the stocks only up to a certain order. Let us note in particular that the number of stocks found with hierarchical order n > 14 is too small to allow any robust statistical conclusion, which is also the reason why standard errors in Figure 2 are very large for n > 14.
(with s the standard deviation on the mean) for each observed hierarchical order on all stocks analysed (see Methods for details). We observe a positive dependence between the two variables up to n = 14, with correlation coefficient 0.8, followed by some noisier flat trend. The positive correlation between 〈ΔH(1, 2)〉 and n is also confirmed by performing a t-test on the correlation coefficient validated with p-value p = 0.002. All stocks with hierarchical order in the range [5, 14] (which accounts for 90% of all stocks) exhibit multifractal properties increasing along with their depth in the hierarchy of correlations. On the other hand, the apparent saturation observed for orders larger than 14 suggests that the hierarchical structure of cross-correlations may be responsible for the multifractal properties of the stocks only up to a certain order. Let us note in particular that the number of stocks found with hierarchical order n > 14 is too small to allow any robust statistical conclusion, which is also the reason why standard errors in Figure 2 are very large for n > 14.

Demonstration that multifractality and hierarchical order are positively correlated.
(Color online) We plot in blue circles with error bars the multifractal indicator 〈ΔH(1, 2)〉 averaged over the stocks sharing the same hierarchical order, against the hierarchical order n. The blue solid line is the linear fit over the averages, while the orange horizontal dashed line marks the limit up to which the increasing trend is observed. The error bars are the standard errors computed as  , where s is the standard deviation over the stocks having same hierarchical order.
, where s is the standard deviation over the stocks having same hierarchical order.
The positive correlation between 〈ΔH(1, 2)〉 and n has been also observed by considering single stocks rather than the average for each fixed n: we show in Figure 3 ΔH(1, 2) as a function of n for single stocks and the fits obtained when one considers the single stocks instead of the averages for each hierarchical order. By limiting the fitting region to the range of orders n ∈ [5, 14], we found a correlation coefficient between the two variables ΔH(1, 2) and n of 0.19, validated with p-Value p = 0.001. By comparing the two plots of Figures 2 and 3 one can note how the averages are much more correlated to the hierarchical order than the single points. Also, from Figure 3 one can see that only a small percentage of stocks shows hierarchical order above 14: thus limiting the fitting to n ≤ 14 gives a more robust statistical validity of the linear trend.

Demonstration that multifractality and hierarchical order are positively correlated on single stocks.
We plot in black dots the multifractal indicator 〈ΔH(1, 2)〉 against the hierarchical order n. The blue solid line marks the linear fit over all hierarchical order in5,20, whereas the orange solid line marks the fit on all stocks such that n ∈ [5, 14].
We have investigated this relationship for other markets as well, namely: London Stock Exchange (LSE), Tokyo Stock Exchange (TSE) and Hong Kong Stock Exchange (HKSE). Results and details are reported in Sections 2–3 of the SM. The interdependence between multifractality and hierarchical cross-correlation order has been confirmed on data from LSE (see Figure S4). The two Asian markets show a much wider range of hierarchical order due to the appearance of one very large hub in the correlation network, which includes most of the stocks. This hub biases the evaluation of the proper hierarchical order. However, by detrending the time series we can remove the large hubs and, at least for TSE data and only for the small hierarchical orders, retrieve a similar behaviour to that observed in Figure 2 (see Figure S6). As explained in detail in the SM though, detrending the series seriously affects the scaling properties of the data and the overall trend in the plots 〈ΔH(1, 2)〉 vs n is fundamentally flat. Nonetheless we mention (and report in Figure S5) that without detrending the series the positive dependence between ΔH(1, 2) and n is observed (for small n) in both TSE and HKSE data.
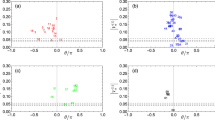
We have also detected the same positive dependence between hierarchical order and multifractality on specific market sectors and on clusters found through DBHT clustering algorithm. We show in the top of Figure 4 plots of the multifractality indicator versus the hierarchical order computed on stocks belonging to Financial and Industrial sectors. The black dots are values for single stocks whereas the red squares are the average multifractal indicators for each order. Both sets of stocks show a very well defined positive correlation between the hierarchical order n and the multifractality indicator ΔH(1, 2), which is evident from the positive trend recovered in both examples.

Correlation between multifractality and hierarchical order in single sectors and clusters.
We plot in black dots ΔH(1, 2) against the hierarchical order n for stocks in the Financial (top left) and Industrial (top right) sectors and cluster 2 (bottom left) and cluster 3 (bottom right). In all plots the blue line is the best fit of the dots, while the red squares are the averages of ΔH(1, 2) for each fixed order. The correlation coefficients and p-values are respectively: (0.48,0.0007) top left; (0.61,0.05) top right; (0.30,0.03) bottom left; (0.24,0.11) bottom right.
In Figure 4 we also report the trends observed on two of the largest clusters found through the DBHT, namely clusters 2 and 3. These clusters are found to be those better expressing Financial and Industrial sectors: the Financial sector has large components in clusters 2, 4 and 6, whereas a large component of stocks from the Industrial sector is found in cluster 3 (see Table 2 in the SM for full details). All stocks belonging to the largest clusters and the corresponding sectors that better match the clusters show a tendency to pair high multifractality with depth in the hierarchy of correlations (for other examples see SM, where we also report the results of the significance tests). The positive correlation between multifractality and n has been validated via the t-test already performed for the entire set of stocks shown in Figures 2 and 3: for the plots in Figure 4 we found for correlation and p-value (clockwise from top left plot): (0.48,0.0007), (0.61,0.05), (0.30,0.03) and (0.24,0.11). These results confirm the statistical significance of the trends observed. Moreover, the positive trends have been also observed when restricting the attention on sub clusters, i.e. groups of stocks below the cluster level in the hierarchy. More details about the analysis on sub clusters is reported in the SM. We also report in the SM a bootstrap study which retains only the stocks whose hierarchical order is validated after resampling with replacement the empirical time series. We find that the most robust hierarchical orders show even neater correlation with the corresponding multifractality indicators and this further analysis helps reinforcing the significance of the trends shown in Figure 4.
Although in all cases shown multifractality is found to depend on the hierarchical order, this dependence is likely to be non-linear. Let us consider for example the stocks in cluster 2: the trend is clearly increasing for n ∈ [9, 14], then there is some oscillation around somewhat less than the value of multifractality attained for n = 14 similarly to what observed on the complete set of stocks in Figure 2.
The correlation between multifractality and hierarchical order has been also detected dynamically in time. We have performed DBHT clustering in time on 50 overlapping time windows of length 752 days. The hierarchical structure evolves significantly in time revealing time varying topological properties of the dendrograms. In particular we tracked the number of clusters  observed on the time window t. This gives a measure of how compact the hierarchy is: a large number of clusters corresponds to a hierarchy sprawled horizontally, while a small number of clusters corresponds to a hierarchical tree narrow and deep and therefore compact. The observed behaviour of
observed on the time window t. This gives a measure of how compact the hierarchy is: a large number of clusters corresponds to a hierarchy sprawled horizontally, while a small number of clusters corresponds to a hierarchical tree narrow and deep and therefore compact. The observed behaviour of  is reported in the left plot in Figure 5. We observed a systematic decrease of
is reported in the left plot in Figure 5. We observed a systematic decrease of  with time, with the trend being steeper in the period preceding the 2007–2008 financial crisis. Hence, the overall contraction of the market already reported in other studies39,40,41 corresponds to a contraction of the hierarchy, which reflects the fact that the market tends to show less heterogeneity in correlations. Note that to the shrinkage of the hierarchical structure corresponds an increase of the average correlation 〈ρ〉t in the market, as shown in the right plot in Figure 5. Remarkably, the increasing coalescence of the hierarchical structure is followed through by an increase in both average multifractality 〈ΔH(1, 2)〉t and average hierarchical order 〈n〉t, whose behaviours in time are reported in Figure 6. The increase in multifractality can be explained through the exposure of the prices to a larger set of risks, which seem to be well captured by the increase in the average hierarchical order.
with time, with the trend being steeper in the period preceding the 2007–2008 financial crisis. Hence, the overall contraction of the market already reported in other studies39,40,41 corresponds to a contraction of the hierarchy, which reflects the fact that the market tends to show less heterogeneity in correlations. Note that to the shrinkage of the hierarchical structure corresponds an increase of the average correlation 〈ρ〉t in the market, as shown in the right plot in Figure 5. Remarkably, the increasing coalescence of the hierarchical structure is followed through by an increase in both average multifractality 〈ΔH(1, 2)〉t and average hierarchical order 〈n〉t, whose behaviours in time are reported in Figure 6. The increase in multifractality can be explained through the exposure of the prices to a larger set of risks, which seem to be well captured by the increase in the average hierarchical order.

Coalescence of the hierarchy in time and dynamical correlation.
(Left) The number of cluster  as a function of time is plotted in time in blue empty circles. The dashed red line is the best fit over the entire time period 2-01-1997 to 31-12-2012, while the magenta line is the fit over the shorter period preceding the 2007/2008 financial crisis September 2002 through November 2007. Standard errors on the circles are not reported as too small to be visible. (Right) Dynamical evolution of the average correlation (thick dots) in the same time period. The dashed coloured lines represent the 2.5%, 25%, 75%, 97.5%-quantiles, taken from the distribution of all the observed correlation coefficients.
as a function of time is plotted in time in blue empty circles. The dashed red line is the best fit over the entire time period 2-01-1997 to 31-12-2012, while the magenta line is the fit over the shorter period preceding the 2007/2008 financial crisis September 2002 through November 2007. Standard errors on the circles are not reported as too small to be visible. (Right) Dynamical evolution of the average correlation (thick dots) in the same time period. The dashed coloured lines represent the 2.5%, 25%, 75%, 97.5%-quantiles, taken from the distribution of all the observed correlation coefficients.

Average multifractality and hierarchical order in time.
(Left) The blue diamonds are values of the average multifractality over 50 overlapping time windows. The dashed green line is the best fit over the entire time period 2-01-1997 to 31-12-2012, while the blue line is the fit over the shorter period preceding the 2007/2008 financial crisis, September 2002 through November 2007. (Right) The red circles are values of the average hierarchical order over 50 overlapping time windows. The dashed green line is the best fit over the entire time period 2-01-1997 to 31-12-2012, while the blue line is the fit over the shorter period preceding the 2007/2008 financial crisis, September 2002 through November 2007. In both plots the error bars are the standard mean error on the mean  , with s the standard deviation.
, with s the standard deviation.
The observed trends strongly suggest a deep interplay between the cross dependence patterns of the market and the multifractal properties of the stock prices. A natural interpretation is then to consider the hierarchical order as the number of different risks affecting each stock together with all other stocks sharing the same hierarchical structure. These observations give in fact a new insight into the mechanism responsible for the heterogeneity of multifractality in stock prices. Backed up by numerous empirical studies which have confirmed the prominent role of the fat tailed nature of the distribution of returns as the main source of observed multifractality34,35,42,43, the observations presented here point in the direction of a mechanism of price formation where the measured multifractal behaviour emerges from the collective action of many different risks, which are in turn captured in the market hierarchical structure. The combined action of many risks has the effect of swelling the tails of the returns distribution, triggering an increase in the measured degree of multifractality20.
A multivariate dynamical hierarchical model
In order to explain the mechanism underlying the observed link between multifractality and correlation hierarchy we introduce a dynamical hierarchical model (DHM), whose main novelty with respect to standard multivariate models5 lies in the introduction of a perturbation term on the correlation matrix associated to its hierarchical structure. We model returns of stock i as

where  is a stationary multivariate Gaussian random variable, i.e.
is a stationary multivariate Gaussian random variable, i.e.  with Σ the covariance matrix and σi,t is a volatility factor. Differently from usual multivariate models, σi,t is not common to all stocks but depends explicitly on the hierarchical structure of the market. We suppose there is a volatility factor xt common to all stocks and then a latent hierarchical structure of risks am with m = 1, …, N − 1, associated with the nodes of the dendrogram. The process xt is chosen as a stationary log-normal stochastic process autocorrelated in time, with the autocovariance function decaying as a power law, i.e. Cov(xtxt+h) ~ h−1, in line with a sweeping amount of studies on multi fractals in finance22,23. For the arbitrary stock i with hierarchical path Γi = {am, m ∈ γi} we define the volatility factor as
with Σ the covariance matrix and σi,t is a volatility factor. Differently from usual multivariate models, σi,t is not common to all stocks but depends explicitly on the hierarchical structure of the market. We suppose there is a volatility factor xt common to all stocks and then a latent hierarchical structure of risks am with m = 1, …, N − 1, associated with the nodes of the dendrogram. The process xt is chosen as a stationary log-normal stochastic process autocorrelated in time, with the autocovariance function decaying as a power law, i.e. Cov(xtxt+h) ~ h−1, in line with a sweeping amount of studies on multi fractals in finance22,23. For the arbitrary stock i with hierarchical path Γi = {am, m ∈ γi} we define the volatility factor as

where Km are Bernoulli random variables with probabilities pm associated to the nodes am along the hierarchical tree Γi. Returns therefore take the form  , where
, where  . It is worth remarking that the hierarchical term
. It is worth remarking that the hierarchical term  introduces a richer structure of dependence, where the topology of the risk organisation plays a crucial role in creating heterogeneous dependence that cannot be accounted for by standard multivariate models. The correlation matrix ρ of this model has entries
introduces a richer structure of dependence, where the topology of the risk organisation plays a crucial role in creating heterogeneous dependence that cannot be accounted for by standard multivariate models. The correlation matrix ρ of this model has entries  , where (see SM for proof)
, where (see SM for proof)

In the last equation p denotes the set of probabilities involved in the relevant dendrogram, ζ1(p) = p(e − 1) + 1 and ζ2(p) = p(e2 − 1) + 1. ρij is therefore factorized into two contributions: the correlation coefficient of the multivariate random vector  and the hierarchical factor
and the hierarchical factor  . Although the expression of the perturbation factor
. Although the expression of the perturbation factor  may look rather daunting, it has a very simple interpretation. In both limit cases where the probabilities associated with the risks are all zero or all one, one has
may look rather daunting, it has a very simple interpretation. In both limit cases where the probabilities associated with the risks are all zero or all one, one has  , which corresponds to the hierarchy effect being turned off. For all other possible values of the probabilities one has
, which corresponds to the hierarchy effect being turned off. For all other possible values of the probabilities one has  . The correlation coefficient ρij is therefore shrunk by a highly diversified hierarchical structure but increases when the hierarchy coalesces, which is exactly what has been observed empirically and reported in Figure 5. Note that both cases pm = 0, ∀m = 1, …, N − 1 and pm = 1, ∀m = 1, …, N − 1 correspond to the absence of a diversified hierarchical structure: in the first case indeed all nodes are switched off, leaving only the common factor to contribute to the volatility, in the second case all risks are active with probability one and thus there is no diversification in the hierarchical configurations of each stock. We show in the left plot in Figure 7 the distribution of measured correlations on a multivariate synthetic DHM with probabilities pm, m = 1, … N − 1 uniformly distributed in the range [0.1, 0.4] compared to a multivariate log-normal model, which is recovered from the DHM when all pm's are one. One can see how the distribution in the case of
. The correlation coefficient ρij is therefore shrunk by a highly diversified hierarchical structure but increases when the hierarchy coalesces, which is exactly what has been observed empirically and reported in Figure 5. Note that both cases pm = 0, ∀m = 1, …, N − 1 and pm = 1, ∀m = 1, …, N − 1 correspond to the absence of a diversified hierarchical structure: in the first case indeed all nodes are switched off, leaving only the common factor to contribute to the volatility, in the second case all risks are active with probability one and thus there is no diversification in the hierarchical configurations of each stock. We show in the left plot in Figure 7 the distribution of measured correlations on a multivariate synthetic DHM with probabilities pm, m = 1, … N − 1 uniformly distributed in the range [0.1, 0.4] compared to a multivariate log-normal model, which is recovered from the DHM when all pm's are one. One can see how the distribution in the case of  is more skewed to the left. Increasing the values of the probabilities progressively shifts the median to the right (see SM). The limit
is more skewed to the left. Increasing the values of the probabilities progressively shifts the median to the right (see SM). The limit  corresponds to the case where the market is dominated by one single risk and the multi-branched hierarchical structure disappears. This scenario corresponds to the single factor log-normal volatility multivariate model, to which the DHM reduces when the correlation increases. The conjecture of this underlying hierarchical structure becomes even more appealing on account of a recent study44 about the inadequacy of elliptical distributions to describe the stock returns dependency structure. The authors have shown that the single factor volatility seems to work quite well when the correlation coefficient between two stocks is large, but performs poorly for small correlations. Their observations fit well in the framework of our model, where the hierarchical factor is needed to explain small correlation. A comparison between multivariate log-normally distributed synthetic time series (yellow dots), synthetic DHM time series (green dots) and empirical data (magenta dots) is reported in the right plot in Figure 7, where we also plot the theoretical relation expected to hold between linear correlation and Kendall's τ for the class of elliptical distributions, τ = 2/π arcsin ρ45. We can see that, while the multivariate log-normal model cannot fully explain the real stocks departing from the theoretical relation, the DHM allows for a much broader dispersion and thus can better explain the empirical observations. The width of the dispersion about the theoretical relation depends on the probabilities pm and the green cloud of dots collapses onto the yellow one in the limit pm → 1 or pm → 0, m = 1, …, N − 1.
corresponds to the case where the market is dominated by one single risk and the multi-branched hierarchical structure disappears. This scenario corresponds to the single factor log-normal volatility multivariate model, to which the DHM reduces when the correlation increases. The conjecture of this underlying hierarchical structure becomes even more appealing on account of a recent study44 about the inadequacy of elliptical distributions to describe the stock returns dependency structure. The authors have shown that the single factor volatility seems to work quite well when the correlation coefficient between two stocks is large, but performs poorly for small correlations. Their observations fit well in the framework of our model, where the hierarchical factor is needed to explain small correlation. A comparison between multivariate log-normally distributed synthetic time series (yellow dots), synthetic DHM time series (green dots) and empirical data (magenta dots) is reported in the right plot in Figure 7, where we also plot the theoretical relation expected to hold between linear correlation and Kendall's τ for the class of elliptical distributions, τ = 2/π arcsin ρ45. We can see that, while the multivariate log-normal model cannot fully explain the real stocks departing from the theoretical relation, the DHM allows for a much broader dispersion and thus can better explain the empirical observations. The width of the dispersion about the theoretical relation depends on the probabilities pm and the green cloud of dots collapses onto the yellow one in the limit pm → 1 or pm → 0, m = 1, …, N − 1.

Modification in the correlation structure by means of the hierarchical model.
(Left) We plot in blue bars the histogram of the observed pair correlations on 342 DHM simulated time series, with hierarchical structure extracted from empirical data. The dashed red line is the histogram observed on a multivariate log-normal model, corresponding to the absence of any hierarchical structure. (Right) We plot Kendall τ against linear correlation ρ for multivariate log-normally distributed synthetic time series (yellow dots), synthetic DHM time series (green dots) and empirical data (magenta dots), compared with the theoretical relation expected for elliptically distributed random variables (red thick line).
Overall one can say that the DHM allows for time varying correlation and different correlation regimes are ascribed to a time varying structural organisation of risks in the market. The non-stationary nature of correlations46,47 is a very relevant issue in quantitative finance and any sound portfolio strategy should take this feature into account48.
Further to the time varying correlation patterns, the DHM is also capable of reproducing the observed correlation between hierarchical order and multifractality. The intuitive idea behind the mechanism is that high multifractality of the signals is dominated by large fluctuations rather than by a complex time dependence structure. Hence, although the time correlation structure of the common volatility factor stays the same, the upsurge in the number of observed extreme events can trigger multifractality to increase dramatically. As an example, we illustrate the properties of the model on a restricted multivariate data set of 25 stocks, whose hierarchical structure retrieved via DBHT are reported in the SM. The hierarchical order n is found to vary in the range [3, 8]. The behaviour of the average 〈ΔH(1, 2)〉 as function of the hierarchical order is shown in Figure 8 for 1000 simulations of DHM with the same hierarchical structure. We observe clearly that deeper stocks tend to have larger multifractality, as a result of the coordinate action of the many risks. Conversely, stocks with small hierarchical order show smaller multifractality in comparison. The model also reproduces time varying multifractality along with a varying hierarchical structure. We consider a two-regime hierarchical structure extracted from empirical data by means of DBHT over two different time windows, labelled T1 and T2 respectively. We fix T1 = T2 = 2013 days, corresponding to half the length of the empirical time series of returns. The two corresponding hierarchies are labelled  and
and  . We plot in Figure 9 the q-quantiles
. We plot in Figure 9 the q-quantiles  and
and  for q = {2.5%, 50%, 97.5%} of the distribution of ΔH(1, 2) measured on the simulated DHM time series with hierarchies
for q = {2.5%, 50%, 97.5%} of the distribution of ΔH(1, 2) measured on the simulated DHM time series with hierarchies  in the first tranche and
in the first tranche and  in the second. Comparing the hierarchical orders of the stocks in both tranches, we plot in different colours the quantiles on the two different time windows, both for stocks whose hierarchical order increases (left) and those whose hierarchical order decreases (right). We observe a systematic shift of the distribution of ΔH(1, 2) towards larger values for those stocks whose hierarchical order increases and a shift towards smaller values for those whose hierarchical order decreases. This confirms further that the underlying structure of risks can be a good candidate to explain empirical observations presented above as well as empirical observations of time-varying multifractality38.
in the second. Comparing the hierarchical orders of the stocks in both tranches, we plot in different colours the quantiles on the two different time windows, both for stocks whose hierarchical order increases (left) and those whose hierarchical order decreases (right). We observe a systematic shift of the distribution of ΔH(1, 2) towards larger values for those stocks whose hierarchical order increases and a shift towards smaller values for those whose hierarchical order decreases. This confirms further that the underlying structure of risks can be a good candidate to explain empirical observations presented above as well as empirical observations of time-varying multifractality38.

Demonstration that DHM time series with higher hierarchical order show larger multifractality.
We plot in squares the average values of ΔH(1, 2) for each hierarchical order ni. The averages are computed over 1000 realisations of DHM simulations with the hierarchical structure extracted from empirical data and probabilities initialised randomly with values ranging in [0, 1]. The error bars are standard deviations over the observed ΔH(1, 2) for each hierarchical order. The blue line is the best fit on all the simulated stocks.

Time varying multifractality with two-regime hierarchical structure.
(Left) The plot shows the q-quantiles  and
and  for q = {2.5%, 50%, 97.5%} for the 10 DHM simulated time series whose hierarchical order
for q = {2.5%, 50%, 97.5%} for the 10 DHM simulated time series whose hierarchical order  . Red lines correspond to p-quantiles in T1 while black lines to p-quantiles in T2. (Right) The q-quantiles
. Red lines correspond to p-quantiles in T1 while black lines to p-quantiles in T2. (Right) The q-quantiles  and
and  for q = {2.5%, 50%, 97.5%} for the 11 DHM simulated time series whose hierarchical order
for q = {2.5%, 50%, 97.5%} for the 11 DHM simulated time series whose hierarchical order  . Blue lines correspond to q-quantiles in T1 while orange lines to q-quantiles in T2. The probabilities of the risks are initialised to values ranging in [0.4, 0.6].
. Blue lines correspond to q-quantiles in T1 while orange lines to q-quantiles in T2. The probabilities of the risks are initialised to values ranging in [0.4, 0.6].
Let us also mention that this model is capable of reproducing all the relevant statistical properties of asset returns. The autocorrelation function of the square returns simulated with probabilities in the range [0, 1] is found to decay as a power law with the lag h, specifically  with β ∈ [0.3, 0.6], in line with what observed on financial time series8. The model also reproduces tails thicker than those accounted for by a simple log-normal volatility model49: the common volatility factor is in fact not sufficient to explain the values of the tail exponents α of financial returns probability distributions, which, as discussed for example in11, are found to be in the range [1, 5]. The hierarchical structure instead can produce such small values of α (particularly α < 2) thanks to the combined action of the many hierarchical risks. The risks associated with the internal nodes increase sensibly the excess kurtosis, which, particularly for probabilities in the range [0.5, 1], assumes values comparable to those observed on empirical data.
with β ∈ [0.3, 0.6], in line with what observed on financial time series8. The model also reproduces tails thicker than those accounted for by a simple log-normal volatility model49: the common volatility factor is in fact not sufficient to explain the values of the tail exponents α of financial returns probability distributions, which, as discussed for example in11, are found to be in the range [1, 5]. The hierarchical structure instead can produce such small values of α (particularly α < 2) thanks to the combined action of the many hierarchical risks. The risks associated with the internal nodes increase sensibly the excess kurtosis, which, particularly for probabilities in the range [0.5, 1], assumes values comparable to those observed on empirical data.
Discussion
We have shown that multifractality in financial markets is not independent from the hierarchical order measured through a correlation based clustering algorithm. We have detected that, within a reasonably large range of hierarchical orders, stocks deeper in the hierarchy of correlations are also those showing higher degree of multifractality. This result holds globally on the average multifractality measured on the entire market as well as locally for all major market sectors and the corresponding clusters detected by the DBHT clustering algorithm. This main empirical result has been also verified on a dataset from a different western market while it is less evident in markets showing very large hubs of correlated stocks (see example of the Japanese and Hong Kong market in SM). We have also shown that to the contraction of the market typically unfolding before a financial crisis corresponds a shrinkage of the hierarchical structure and an average increase of multifractality. Starting from these observations we have proposed a model which incorporates explicitly a time varying hierarchical structure of risks into the volatility factor. The presence of the hierarchical factor in the volatility results in a perturbation to the correlation structure of the multivariate time series which is shown to include also the empirical observations not accounted for by a standard multivariate model with one common volatility factor only. The latter is recovered in the limit of no hierarchy of risks, which corresponds to a very compact market where one single risk is enough to explain all correlations. The model has been shown to faithfully reproduce the correlation between multifractality and hierarchical order thus providing a new mechanism to explain the source of heterogeneity and time dependence of multifractality in financial markets, already reported in previous works37,38.
The relevance of the observations presented in this paper lays in the identification of a possible underlying mechanism where cross-correlation and univariate time series properties are merged together in a unified framework.
An interesting outlook is to devise a method to identify the underlying structure of risks conjectured in this paper in order to come up with a reliable calibration scheme which could be further used to develop portfolio strategies or asset allocation based on a perturbed correlation matrix.
Methods
Multifractality measure
The multifractality proxy ΔH(1, 2) is estimated via the generalised Hurst exponent (GHE) method4. The GHE H(q) is estimated from the scaling of the empirical q-moments  , where we denote rt,ℓ = log pt+ℓ − log pt the log-return at time t and scale ℓ, with pt the asset price at time t. The exponent H(q) is then estimated as average of several linear fits of the relation log M(q, ℓ) ~ qH(q) log ℓ with scale τ ∈ [1, ℓmax] and ℓmax varied in the range [5, 19]. We have considered as significantly multifractal only those stocks showing ΔH(1, 2) > 0.015. This value has been chosen as the 95% probability value of ΔH(1, 2) on uniscaling processes. To obtain it we have simulated 1000 realisations of fractional Brownian motion with Hurst parameter H randomly chosen in the range [0.1, 0.9] and then computed the value of ΔH(1, 2) corresponding to (two side) 95% probability. In our data base of 342 stocks we found 72 stocks excluded as weakly multifractal.
, where we denote rt,ℓ = log pt+ℓ − log pt the log-return at time t and scale ℓ, with pt the asset price at time t. The exponent H(q) is then estimated as average of several linear fits of the relation log M(q, ℓ) ~ qH(q) log ℓ with scale τ ∈ [1, ℓmax] and ℓmax varied in the range [5, 19]. We have considered as significantly multifractal only those stocks showing ΔH(1, 2) > 0.015. This value has been chosen as the 95% probability value of ΔH(1, 2) on uniscaling processes. To obtain it we have simulated 1000 realisations of fractional Brownian motion with Hurst parameter H randomly chosen in the range [0.1, 0.9] and then computed the value of ΔH(1, 2) corresponding to (two side) 95% probability. In our data base of 342 stocks we found 72 stocks excluded as weakly multifractal.
The average values of ΔH(1, 2) for each different order  reported in Figures 2 and 4 have been computed as
reported in Figures 2 and 4 have been computed as  , where
, where  is the number of stocks with order
is the number of stocks with order  . Likewise the standard deviation is computed as
. Likewise the standard deviation is computed as  .
.
Dependency measure and DBHT
The clustering is performed on the weighted graph associated with the correlation matrix of the empirical time series, whose entries are computed via the weighted Pearson estimator50. We have implemented, in order to reduce the impact of remote events on present correlations, exponential weights  such that wt > 0 and
such that wt > 0 and  . The parameter θ has been set to θ = Δt/3 according to criteria previously established50. This corresponds to θ = 1342 for the entire time window and θ = 250 for the moving windows of 752 days.
. The parameter θ has been set to θ = Δt/3 according to criteria previously established50. This corresponds to θ = 1342 for the entire time window and θ = 250 for the moving windows of 752 days.
Model simulation
The DHM time series have been simulated multiplying a multivariate Gaussian random vector  with location parameter μ = 0 and covariance matrix Σ times the volatility factor σt. The covariance matrix Σ has been chosen to be the covariance matrix of the real data. The volatility factor σt has been simulated multiplying a time correlated log-normal process xt times a hierarchical factor
with location parameter μ = 0 and covariance matrix Σ times the volatility factor σt. The covariance matrix Σ has been chosen to be the covariance matrix of the real data. The volatility factor σt has been simulated multiplying a time correlated log-normal process xt times a hierarchical factor  , whose components match the hierarchy detected through DBHT. The process xt has been simulated as
, whose components match the hierarchy detected through DBHT. The process xt has been simulated as  , with
, with  . The autocorrelation function of ξt has been chosen, according to the cascade picture in23, as
. The autocorrelation function of ξt has been chosen, according to the cascade picture in23, as  , where λ and T are two parameters, which, in all simulations reported in this paper, have been set to λ = 0.2 and T = 800. Other values have also been extensively tested, showing negligible effects on multifractality properties compared to the hierarchical factor. We have initialised the probabilities of the dendrogram nodes to random values uniformly drawn in different ranges, always checking that the choice would not bias the outcome of the simulation. In the multi-regime simulations, we have first computed the covariance matrices of the data
, where λ and T are two parameters, which, in all simulations reported in this paper, have been set to λ = 0.2 and T = 800. Other values have also been extensively tested, showing negligible effects on multifractality properties compared to the hierarchical factor. We have initialised the probabilities of the dendrogram nodes to random values uniformly drawn in different ranges, always checking that the choice would not bias the outcome of the simulation. In the multi-regime simulations, we have first computed the covariance matrices of the data  on different time windows T1, …, Td and then performed DBHT on each time window. The different hierarchical structures
on different time windows T1, …, Td and then performed DBHT on each time window. The different hierarchical structures  recovered have been plugged into the model, keeping both
recovered have been plugged into the model, keeping both  and xt stationary on all the different tranches.
and xt stationary on all the different tranches.
References
Dacorogna, M. An Introduction to High-Frequency Finance., (Acad. Pr. 2001).
Mandelbrot, B. Fractals and Scaling in Finance: Discontinuity, Concentration, Risk., (Spr. Ver. 1997).
Di Matteo, T., Aste, T. & Dacorogna, M. Long-term memories of developed and emerging markets: Using the scaling analysis to characterize their stage of development. J. Bank. & Fin. 29(4), 827–851 (2005).
Di Matteo, T. Multi-scaling in finance. Quant. Fin. 7(1), 21–36 (2007).
McNeil, A., Frey, R. & Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools., (Prin. Univ. Pr. 2005).
Mantegna, R. & Stanley, H. E. An Introduction to Econophysics: Correlations and Complexity in Finance., (Cam. Univ. Pr. 2000).
Chakraborti, A., Toke, I. M., Patriarca, M. & Abergel, F. Econophysics review: I. empirical facts. Quant. Fin. 11(7), 991–1012 (2011).
Cont, R. Empirical properties of asset returns: stylized facts and statistical issues. Quant. Fin., 1, 223–236 (2001).
Bachelier, L. Théorie de la Spéculation., (Gauthier-Villars 1900).
Malevergne, Y. & Sornette, D. Extreme Financial Risks: From Dependence to Risk Management., (Spr. Ver. 2006).
Bouchaud, J.-P. & Potters, M. Theory of Financial Risk and Derivative Pricing: From Statistical Physics to Risk Management., (Cam. Univ. Pr. 2003).
Mandelbrot, B. The variation of certain speculative prices. The J. of Bus. 36(4), 394–419 (1963).
Miccichè, S. Empirical relationship between stocks' cross-correlation and stocks' volatility clustering. J. of Stat. Mech. 2013(05), P05015 (2013).
Di Matteo, T., Aste, T. & Dacorogna, M. Scaling behaviors in differently developed markets. Phys. A 324(1), 183–188 (2003).
Barunik, J. & Kristoufek, L. On hurst exponent estimation under heavy-tailed distributions. Phys. A 389(18), 3844–3855 (2010).
Liu, R., Di Matteo, T. & Lux, T. True and apparent scaling: The proximity of the markov-switching multifractal model to long-range dependence. Phys. A 383(1), 35–42 (2007).
Liu, R., Di Matteo, T. & Lux, T. Multifractality and long-range dependence of asset returns: The scaling behaviour of the markov-switching multifractal model with lognormal volatility components. Adv. in Comp. Syst. 11(5), 669–684 (2008).
Lux, T. Detecting multifractal properties in asset returns: The failure of the “scaling estimator”. Int. J. of Mod. Phys. C 15(04), 481–491 (2004).
Lux, T. The markov-switching multifractal model of asset returns. J. of Bus. & Econ. Stat. 26(2), 194–210 (2008).
Bouchaud, J.-P., Potters, M. & Meyer, M. Apparent multifractality in financial time series. The Eur. Phys. J. B 13(3), 595–599 (2000).
Ding, Z., Granger, C. & Engle, R. A long memory property of stock market returns and a new model. J. of Emp. Fin. 1(1), 83–106 (1993).
Calvet, L. & Fisher, A. Multifractality in asset returns: theory and evidence. Rev. of Econ. and Stat. 84(3), 381–406 (2002).
Bacry, E., Delour, J. & Muzy, J.-F. Multifractal random walk. Phys. Rev. E 64(2), 026103 (2001).
Eisler, Z. & Kertesz, J. Multifractal model of asset returns with leverage effect. Phys. A 343, 603–622 (2004).
Filimonov, V. & Sornette, D. Self-excited multifractal dynamics. Europhys. Lett. 94(4), 46003 (2011).
Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology, (Ox. Univ. Pr. 2007).
Di Matteo, T., Pozzi, F. & Aste, T. The use of dynamical networks to detect the hierarchical organization of financial market sectors. The Eur. Phys. J. B 73(1), 3–11 (2010).
Aste, T. & Di Matteo, T. Dynamical networks from correlations. Phys. A 370(1), 156–161 (2006).
Mantegna, R. Hierarchical structure in financial markets. The Eur. Phys. J. B 11(1), 193–197 (1999).
Tumminello, M., Aste, T., Di Matteo, T. & Mantegna, R. A tool for filtering information in complex systems. Proc. Nat. Ac. Sci. 102(30), 10421 (2005).
Tumminello, M., Lillo, F. & Mantegna, R. Correlation, hierarchies and networks in financial markets. J. of Econ. Behav. & Org. 75(1), 40–58 (2010).
Tumminello, M., Lillo, F. & Mantegna, R. Hierarchically nested factor model from multivariate data. Europhys. Lett. 78, 30006 (2007).
Song, W. M., Di Matteo, T. & Aste, T. Hierarchical information clustering by means of topologically embedded graphs. PloS One 7(3), e31929 (2012).
Zhou, W.-X. The components of empirical multifractality in financial returns. Europhys. Lett. 88(2), 28004 (2009).
Kantelhardt, J., Zschiegner, S., Koscielny-Bunde, E., Havlin, S., Bunde, A. & Stanley, H. E. Multifractal detrended fluctuation analysis of nonstationary time series. Phys. A 316(1), 87–114 (2002).
Gower, J. C. & Ross, G. Minimum spanning trees and single linkage cluster analysis. Appl. stat. 54–64 (1969).
Morales, R., Di Matteo, T., Gramatica, R. & Aste, T. Dynamical generalized hurst exponent as a tool to monitor unstable periods in financial time series. Phys. A 391, 3180–3189 (2012).
Morales, R., Di Matteo, T. & Aste, T. Non-stationary multifractality in stock returns. Phys. A 392, 6470–6483 (2013).
Onnela, J.-P., Chakraborti, A., Kaski, K. & Kertesz, J. Dynamic asset trees and black monday. Phys. A 324(1), 247–252 (2003).
Aste, T., Shaw, W. & Di Matteo, T. Correlation structure and dynamics in volatile markets. New J. of Phys. 12, 085009 (2010).
Onnela, J. P., Chakraborti, A., Kaski, K., Kertesz, J. & Kanto, A. Dynamics of market correlations: Taxonomy and portfolio analysis. Phys. Rev. E 68(5), 056110 (2003).
Barunik, J., Aste, T., Di Matteo, T. & Liu, R. Understanding the source of multifractality in financial markets. Phys. A 391, 4234–4251 (2012).
Morales, R. PhD thesis., (2014).
Chicheportiche, R. & Bouchaud, J. P. The joint distribution of stock returns is not elliptical. Int. J. of Theor. and Appl. Fin. 15, 03 (2012).
Lindskog, F., McNeil, A. & Schmock, U. Kendall's tau for elliptical distributions. 111, in Credit Risk-Measurement, Evaluation and Management. Phys. Ver. 157 (2003).
Tóth, B. & Kertész, J. Increasing market efficiency: Evolution of cross-correlations of stock returns. Phys. A 360(2), 505–515 (2006).
Münnix, M., Shimada, T., Schäfer, R., Seligman, F., Guhr, T. & Stanley, H. E. Identifying states of a financial market. Sci. Rep. 2, 644 (2012).
Livan, G., Inoue, J. I. & Scalas, E. On the non-stationarity of financial time series: impact on optimal portfolio selection. J. of Stat. Mech. 2012(07), P07025 (2012).
Bacry, E., Kozhemyak, A. & Muzy, J. F. Continuous cascade models for asset returns. J. of Econ. Dyn. and Cont. 32(1), 156–199 (2008).
Pozzi, F., Di Matteo, T. & Aste, T. Exponential smoothing weighted correlations. The Eur. Phys. J. B 85, 175 (2012).
Acknowledgements
The authors wish to thank Jean-Philippe Bouchaud and N. Musmeci for helpful discussions. TDM wishes to thank the COST Action TD1210 for partially supporting this work. Support of the Economic and Social Research Council (ESRC) in funding the Systemic Risk Centre is acknowledged by TA (ES/K002309/1).
Author information
Authors and Affiliations
Contributions
R.M., T.D.M. and T.A. all contributed equally to the manuscript writing the paper, revising it and preparing figures and tables.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Supplementary Information
Supporting Information
Rights and permissions
This work is licensed under a Creative Commons Attribution 3.0 Unported License. The images in this article are included in the article's Creative Commons license, unless indicated otherwise in the image credit; if the image is not included under the Creative Commons license, users will need to obtain permission from the license holder in order to reproduce the image. To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/
About this article
Cite this article
Morales, R., Di Matteo, T. & Aste, T. Dependency structure and scaling properties of financial time series are related. Sci Rep 4, 4589 (2014). https://doi.org/10.1038/srep04589
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep04589
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
