
Abstract
We study evolutionary game dynamics on structured populations in which individuals take part in several layers of networks of interactions simultaneously. This multiplex of interdependent networks accounts for the different kind of social ties each individual has. By coupling the evolutionary dynamics of a Prisoner's Dilemma game in each of the networks, we show that the resilience of cooperative behaviors for extremely large values of the temptation to defect is enhanced by the multiplex structure. Furthermore, this resilience is intrinsically related to a non-trivial organization of cooperation across the network layers, thus providing a new way out for cooperation to survive in structured populations.
Similar content being viewed by others

Introduction
The understanding of the emergence of cooperative behavior in human and animal societies1,2 as well as in other contexts (e.g., the formation of multicellular organisms or their organs3) is a major challenge in science. Interdisciplinary physicists have paid attention to this problem because of the underlying nonlinear and stochastic nature of the interactions among the entities involved4,5,6. The mathematical setting that has led to many deep insights about this problem is evolutionary game theory7,8,9, that allows to formulate in quantitative terms the most important prototypical social interactions, such as conflicts and/or dilemmas10. Scientists have unraveled that a key issue to ascertain the evolution of cooperation is the network of relationships11,12,13 among the intervening agents. This drive us to evolutionary game theory on graphs, one of the most intriguing dynamical processes on networks and one that is currently receiving a lot of attention14,15,16,17,18,19,20,21.
As network science evolves22,23,24,25, new questions about the capital problem of the emergence of cooperation arise. The empirical resolution of the structure and time evolution of social ties has been simultaneously improved. These advances has been largely facilitated by the explosion of data about mobile communication28,29, web-based social platforms26,27 and even the monitoring of face-to-face human interactions30,31. Thus, although the network perspective has offered a novel way out for cooperation to survive in social systems32,33,34,35, the latter advances on the characterization of social systems demand more work to unveil the influence that social patterns have on the evolution of cooperation. Particularly important in the description of social systems are those structures that account for multiple types of links and time-evolution of links, commonly known as multiplex36,37,38.
Social systems are shown as a superposition or projection of a number of interdependent complex social networks, where nodes represent individuals and links account for different kind of social ties such as those stablished with family relatives, friends, work collaborators, etc. In our daily life we experience this social splitting by distinguishing our behavior within each of the social layers we belong to. However, the influence that the multiplex nature of social interactions has on the evolution of cooperation is still an open question, being recently tackled39 within a framework consisting in two coupled networks. Besides, on more general grounds, it has been recently shown that the interdependent structure can influence dramatically the functioning of complex systems in the context of percolation40,41,42,43,44 and cascade failures41,45. Thus, it is necessary to study how the interplay among such multiple interdependent social networks affects the onset of large scale human behavior, in particular the emergence of cooperation in multiplexes.
In this report, we address the problem of the emergence of cooperation in multiplexes. We will use tools of complex networks and evolutionary game theory to shed light on the emergence of cooperation in populations of individuals participating simultaneously in several networks in which a Prisoner's Dilemma game is played. Our results show that a mutiplex structure enhances the resilience of cooperation to defection. Moreover, we show that this latter enhancement relies on a nontrivial organization of the cooperative behavior across the network layers.
Let us first describe the multiplex backbone in which the evolutionary game is implemented. We consider a set of m interdependent networks each of them containing the same number N nodes and L links. Each individual is represented by one node in each of the m networks layers while its neighbors are (in principle) different for each of the layers (see Fig. 1). In this way we define a set of m adjacency matrices {Al} (with l = 1, …, m) so that  when individuals i and j are connected within network l whereas
when individuals i and j are connected within network l whereas  otherwise. Thus, a given individual, say i, is connected to
otherwise. Thus, a given individual, say i, is connected to  other individuals within network layer l. In our case we will consider that each of the layers is an Erdös-Rényi (ER) random graph characterized by an average degree 〈k〉 = 2L/N. In this way, the probability that an individual is connected to k individual in a given layer is given by the Poisson distribution: P(k) = 〈k〉k exp(−k)/k.
other individuals within network layer l. In our case we will consider that each of the layers is an Erdös-Rényi (ER) random graph characterized by an average degree 〈k〉 = 2L/N. In this way, the probability that an individual is connected to k individual in a given layer is given by the Poisson distribution: P(k) = 〈k〉k exp(−k)/k.

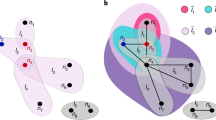
Schematic representation of a multiplex network.
The multiplex is made of N = 5 nodes embedded within m = 3 interdependent networks (or layers) each one containing L = 3 links.
Having introduced the multiplex composed by the set of m interdependent networks we now focus on the formulation of the evolutionary dynamics. Each of the individuals, say i, adopts a given strategy  for playing with its neighbors in network l at time step t. This strategy can be cooperation
for playing with its neighbors in network l at time step t. This strategy can be cooperation  or defection
or defection  . Then, at each time step, each individual plays a Prisoner's Dilemma (PD) game with its neighbors in network l. For each of the
. Then, at each time step, each individual plays a Prisoner's Dilemma (PD) game with its neighbors in network l. For each of the  PD games played within network layer l an individual i facing a cooperator neighbor will collect a payoff 1 or b > 1 when playing as cooperator or as defector respectively. On the contrary if i faces a defector it will not collect any payoff regardless of its strategy. This is the weak version of the PD game which makes use of a single parameter b accounting for the temptation of playing as defector. After round t of the PD game, an individual has played once with its
PD games played within network layer l an individual i facing a cooperator neighbor will collect a payoff 1 or b > 1 when playing as cooperator or as defector respectively. On the contrary if i faces a defector it will not collect any payoff regardless of its strategy. This is the weak version of the PD game which makes use of a single parameter b accounting for the temptation of playing as defector. After round t of the PD game, an individual has played once with its  neighbors in layer l thus collecting an overall payoff
neighbors in layer l thus collecting an overall payoff  . Obviously, the net payoff of a player i is the sum of all the payoffs collected in each of the m network layers,
. Obviously, the net payoff of a player i is the sum of all the payoffs collected in each of the m network layers,  , achieved by using a set of strategies
, achieved by using a set of strategies  .
.
Once the PD is played, all the players update their strategies simultaneously, i.e., we consider synchronous updates. The update process makes use of the replicator-like rule that works as follows. Each of the players, say i, chooses a layer, say l, at random among the m possible networks and a neighbor j (also randomly) among its  acquaintances. Then it compares their total payoffs, Pi(t) and Pj(t), obtained in the last round of the game. If Pi(t) > Pj(t) nothing happens and i will use the same strategy within the network layer l in the next round of the PD game, si(t + 1) = si(t). However, when Pj(t) > Pi(t) agent i will take the strategy of j at layer l with a probability proportional to their payoff difference:
acquaintances. Then it compares their total payoffs, Pi(t) and Pj(t), obtained in the last round of the game. If Pi(t) > Pj(t) nothing happens and i will use the same strategy within the network layer l in the next round of the PD game, si(t + 1) = si(t). However, when Pj(t) > Pi(t) agent i will take the strategy of j at layer l with a probability proportional to their payoff difference:

where  . Note that the update process entangles the evolutionary dynamics of the network layers as the choice of what strategy will be used in a given layer during the next round of the game depends on the overall payoffs, not only on the payoffs obtained in the particular layer. Although other entanglements are also possible to make the evolutionary dynamics of the m networks interdependent, the one used in this work relies on the social nature of layers' interdependency. While two neighbors within a given layer know the strategies used by each other in the layer, they are unaware of their opponent's strategies in the remaining networks, so they have to assume that the total benefit or success achieved by their layer's acquaintances is the outcome of using the observed strategy in each of the m networks of the multiplex.
. Note that the update process entangles the evolutionary dynamics of the network layers as the choice of what strategy will be used in a given layer during the next round of the game depends on the overall payoffs, not only on the payoffs obtained in the particular layer. Although other entanglements are also possible to make the evolutionary dynamics of the m networks interdependent, the one used in this work relies on the social nature of layers' interdependency. While two neighbors within a given layer know the strategies used by each other in the layer, they are unaware of their opponent's strategies in the remaining networks, so they have to assume that the total benefit or success achieved by their layer's acquaintances is the outcome of using the observed strategy in each of the m networks of the multiplex.
Following the above evolutionary rules we let evolve the states of each individual in each of the layers and compute the instantaneous level of cooperation cl(t) in each layer l and in the whole multiplex c(t) as:

Results
In Fig. 2 we plot the average fraction of cooperators 〈c〉 (see Methods) versus b for different values of the number m of layers and two values of the layers' average degree 〈k〉 = 3 and 20. Note that the case m = 1 corresponds to the absence of layers' interdependency. While for low values of the temptation b the average level of cooperation on the multiplex decreases with the number m of layers, it increases with m for higher values of b, so that the decrease of cooperation with b becomes progressively slower as the number of layers in the multiplex increases. Importantly, the resilience of cooperation observed for large values of the temptation to defect is not restricted to the weak version of the PD game; we have checked that our results qualitatively remain unaltered when two defectors playing get a positive payoff, i.e., when defection is a strict best response to itself.

Cooperation diagrams of multinetworks.
Average level of cooperation 〈c〉 as a function of the temptation to defect b for several multinetworks with different number of layers m. In panel A the network layers are ER graphs with 〈k〉 = 3 (sparse graphs) while in panel B we have 〈k〉 = 20. In both cases N = 250 nodes. As can be observed, the resilience of cooperation increases remarkably as the number of layers m grows. Finally, panel C shows the curves 〈c〉(b) for ER graphs with 〈k〉 = 3 (as in panel A) for m = 2 and m = 10 and different network sizes N = 100, 200 and 400.
The possibility that agents adopt different strategies in different layers is crucial for the resilience of cooperation in multiplexes, as revealed in Fig. 3, where we show the average cooperation level achieved in the multiplex when agents use homogeneous strategies ( independent of l), i.e., the same strategy in the m layers. Indeed, for homogeneous strategists' populations the cooperation decays dramatically with b, the faster the larger the value of m. This can be easily understood as follows: The situation when agents use homogeneous strategies is equivalent to consider the standard evolutionary game dynamics on a network whose set of links is the union of the set of layer's links (with weights assigned to them whenever two agents are neighbors in more than one layer in the multiplex). This network has (approximately) an average degree of m〈k〉, which for large values of m approaches a well-mixed population, where cooperation extinguishes quickly.
independent of l), i.e., the same strategy in the m layers. Indeed, for homogeneous strategists' populations the cooperation decays dramatically with b, the faster the larger the value of m. This can be easily understood as follows: The situation when agents use homogeneous strategies is equivalent to consider the standard evolutionary game dynamics on a network whose set of links is the union of the set of layer's links (with weights assigned to them whenever two agents are neighbors in more than one layer in the multiplex). This network has (approximately) an average degree of m〈k〉, which for large values of m approaches a well-mixed population, where cooperation extinguishes quickly.

Comparison with the cooperation diagrams of null models.
Average degree of cooperation 〈c〉 as a function of b (solid line with filled circles) for m = 3 (A), 6 (B), 10 (C) and 20 (D). In each panel we show the case of a simplex (m = 1) network, the evolution 〈c〉(b) for homogeneous strategists' populations corresponding to each value of m (Homo.) and the curve 〈c〉(b) corresponding to the mean-field assumption for the coupling between layers (M.F.). Each multiplex network has N = 250 nodes while the interdependent layers are ER graphs with 〈k〉 = 3.
The survival of cooperation in multiplexes is supported by the network structure inside the multiplex layers, i.e. on network reciprocity46. One can easily prove that if the layers are assumed to be well-mixed (fully connected), then the only surviving strategy of the evolutionary dynamics is to defect in all the layers. To characterize the degree of heterogeneity of the surviving strategies on the multiplex, let us consider the fraction xi(t) of layers where agent i plays as a cooperator at time t:

that, after averaging over the observation time interval T (see above) defines the variable x, whose probability density P(x) as a function of b is shown in Fig. 4. One should remark that P(x) exhibits a well defined maximum for each value of b, along with a relatively small width around it. In other words, for each value of b there is a truly characteristic value of the fraction x of layers where a randomly chosen agent behaves cooperatively. On the contrary, the layer's cooperation level  possess a rather wide distribution density, as shown in Fig 5. In a given multiplex realization and for a given value of the temptation parameter b, layers with quite dispersed cooperation levels coexist, so that there is no truly characteristic value for the layer's cooperation. In other words, the cooperative components [whose number is typically m⋅xmax, where xmax is the location of the maximum of P(x)] of the agents' set of strategies
possess a rather wide distribution density, as shown in Fig 5. In a given multiplex realization and for a given value of the temptation parameter b, layers with quite dispersed cooperation levels coexist, so that there is no truly characteristic value for the layer's cooperation. In other words, the cooperative components [whose number is typically m⋅xmax, where xmax is the location of the maximum of P(x)] of the agents' set of strategies  are not uniformly distributed on the multiplex layers.
are not uniformly distributed on the multiplex layers.

Evolution of the degree of cooperation of individuals across layers.
Each contour plot shows the evolution of the probability P(x) of finding an individual playing as cooperator in a fraction x of the network layers as b increases. In A m = 15 while for B m = 20. In both cases the networks have N = 250 nodes while each layer is an ER graph with 〈k〉 = 3. Observe that the resilience of cooperation is intrinsically due to the fact that individuals play different strategies across the different layers (no homogeneous strategists appear until defection dominates at very high values of b). For each value of b there is a well defined maximum for P(x).

Histograms of layers' cooperation level.
The panels show the probability of finding a level of cooperation cl in a randomly chosen layer of the multiplex. The results are obtained from a multiplex of m = 20 layers and four different values of the temptation parameter b = 1.0, 1.2, 1.4 and 1.6 from panels A to D. 50 realizations of the multiplex were employed.
The above findings suggest the failure of “mean-field-like” theoretical explanations of the observed behavior based on the absence of correlations. As an example, consider a layer l and let us assume that the payoff an agent receives from the games played on the rest of layers is normally distributed according to the hypothesis that it has 〈k〉 neighbors on each layer and that agents use the cooperative strategy in each layer with a probability x, independently of each other. One can compute easily the mean and the variance of this payoff distribution, as a function of x, m and b (see Methods). For self-consistency, one can assign to x the value cl(t) of the instantaneous cooperation in the considered layer and then proceed to run the evolutionary game dynamics on the layer with payoffs given by the sum of the payoff obtained in the layer plus a payoff taken from this “mean-field-like” distribution. The results obtained from this approach are shown in Fig. 3. The only feature of the behavior observed in the multiplex that seems to be slightly captured, but only qualitatively, by this approach is the tendency when m increases to the decrease of cooperation for low values of b and its increase for high values of b. The building up of correlations in the distribution over the multiplex layers of the fraction of cooperative strategies appears to be an essential ingredient for the observed enhancement of cooperation in multiplexes.
Discussion
Summing up, we have incorporated the multiplex character of social interactions into the formulation of evolutionary games in structured populations. By considering a Prisoner's Dilemma game we have shown that cooperation is able to resist under extremely adverse conditions, for which the usual simplex formulation, i.e. the network approach, fails. In a nutshell, the addition of network layers has two effects. On one hand the level of cooperation for low values of the temptation to defect appears to decrease. However, the enhancement of the cooperation resilience shows up when temptation is further increased. It is in the region of large temptation when the interdependency of network layers outperform, regarding the average level of cooperation, the behavior found in simplex networks reaching values of b > 3 for which even scale-free networks fail to sustain cooperation34,35.
The observed resilience of multiplex networks is sustained in the segregation of cooperative and defective strategies across the multiple network layers contained in the multiplex. Moreover, we have shown that this segregation is non-trivial by comparing with mean-field approaches producing no cooperation. Thus, our results point out a complementary mechanism to the so-called network reciprocity, paving the way to the study of more complex and realistic multiplex architectures and alternative dynamical couplings between the networks embedded in them. Let us note, that we have made use of network layers with a regular (Erdös-Rényi) topology in order to avoid spurious effects, such as the degree heterogeneity, that may contribute to the enhancement of cooperation. However, the study of multiplex topologies incorporating the interdependency of scale-free layers seems a promising continuation of the results presented here.
Methods
Numerical and statistical details of the simulations
In our simulations we start from a configuration in which a player i in layer l cooperates or defects with equal probability. Then, we run the evolutionary dynamics for a transient time t0 of typically t0 = 2×104 generations. After this transient period we further iterate the evolutionary dynamics over a time interval T of typically 105 generations. It is during this latter window when we compute the quantities of interest such as the average cooperation level in a given layer l,  :
:

or the average cooperation in the whole multiplex  :
:

The values shown in each plot represent the average of the above quantities over a number of realizations, typically 50. After this latter average we obtain the final average level of cooperation 〈c〉 for each value of the temptation parameter b.
Mean-field calculation
The mean-field assumption for the coupling of layers assumes that there is no correlation between the strategies used by an individual in each of the m layers. To this aim, we consider a network (single layer) in which an individual plays a PD game with his neighbors receiving a payoff. In addition we add to this latter payoff a quantity mimicking the payoff obtained in the rest of (m − 1) layers. This additional payoff is randomly assigned after each round of the game from a normal distribution whose precise form depends on the number of cooperators in the system.
To compute the mean and variance of the normal distribution at work, we first consider that all the nodes in the network are connected to 〈k〉 neighbors in each of the network layers. In this way, the possible payoffs of a given individual i in one of the network layers l are  . Considering now that players use the cooperative strategy in each layer with probability x, independently of each other and that the multiplex is composed of m network layers we can assign compute the probability
. Considering now that players use the cooperative strategy in each layer with probability x, independently of each other and that the multiplex is composed of m network layers we can assign compute the probability  that player i obtain a payoff
that player i obtain a payoff  in layer l. In our case, we fix 〈k〉 = 3 so that there are 7 possible payoffs whose probabilities read:
in layer l. In our case, we fix 〈k〉 = 3 so that there are 7 possible payoffs whose probabilities read:







With these expressions one can easily compute the expected value for the payoff obtained by an individual i in a layer l given the value of x as:

while the variance of the above expected value reads:

Given the values of x and b, equations (6) and (7) allow us to compute the normal distribution and assign the additional payoffs a player receives from the other (m − 1) layers. For self-consistency, at each time step, the value of x is re-computed from the fraction of cooperators in the system, i.e. cl(t), in the considered layer.
References
Pennisi, E. How did cooperative behavior evolve? Science 309, 93 (2005).
Pennisi, E. On the origin of cooperation? Science 325, 1196–1199 (2009).
Maynard-Smith, J. & Szathmary, E. The Major Transitions in Evolution (Freeman, Oxford, UK, 1995).
Castellano, C., Marsili, M. & Vespignani, A. Nonequilibrium Phase Transition in a Model for Social Influence. Phys. Rev. Lett. 85, 3536–3539 (2000).
Klemm, K., Eguíluz, V. M., Toral, R. & San Miguel, M. Global culture: A noise induced transition in finite systems. Phys. Rev. E 67, 045101(R) (2003).
Helbing, D., Treiber, M. & Saam, N. J. Analytical Investigation of. Innovation Dynamics Considering Stochasticity in the Evaluation of Fitness. Phys. Rev. E 71, 067101 (2005).
Maynard-Smith, J. Evolution and the Theory of Games (Cambridge Univ. Press, Cambridge, UK, 1982).
Gintis, H. Game theory evolving (Princeton University Press, Princeton, NJ, 2009).
Nowak, M. A. Evolutionary dynamics: exploring the equations of life (The Belknap Press of Harvard University Press, Cambridge, MA, 2006)
Kollock, P. Social dilemmas: the anatomy of cooperation. Annu. Rev. Sociol. 24, 183–214 (1998).
Wellman, B. & Berkowitz, S. D. Social Structures: A Network Approach (Cambridge Univ. Press, Cambridge, 1988).
Wasserman, S. & Faust, K. Social Network Analysis (Cambridge Univ. Press, Cambridge, 1994).
Jackson, M. O. Social and economic networks (Princeton Univ. Press, Princeton, NJ, 2008).
Szabó, G. & Fáth, G. Evolutionary games on graphs. Phys. Rep. 447, 97–216 (2007).
Szolnoki, A., Perc, M. & Danku, Z. Towards effective payoffs in the prisoner's dilemma game on scale-free networks. Physica A 387, 2075–2082 (2008).
Lozano, S., Arenas, A. & Sánchez, A. Mesoscopic structure conditions the emergence of cooperation on social networks. PLoS ONE 3, e1892 (2008).
Roca, C. P., Cuesta, J. & Sánchez, A. Evolutionary game theory: temporal and spatial effects beyond replicator dynamics. Phys. Life Rev. 6, 208–249 (2009).
Perc, M. & Szolnoki, A. Coevolutionary games - A mini review. BioSystems 99, 109–125 (2010).
Santos, F. C., Santos, M. D. & Pacheco, J. M. Social diversity promotes the emergence of cooperation in public goods games. Nature 454, 213–216 (2008).
Gómez-Gardeñes, J., Romance, M., Criado, R., Vilone, D. & Sánchez, A. Evolutionary games defined at the network mesoscale: The Public Goods game. Chaos 21, 016113 (2011).
Wang, Z., Szolnoki, A. & Perc, M. If players are sparse social dilemmas are too: Importance of percolation for evolution of cooperation. Sci. Rep. 2, 369 (2012).
Albert, R. & Barabási, A.-L. Statistical mechanics of complex networks. Rev. Mod. Phys. 74, 47–97 (2002).
Newman, M. E. J. The Structure and Function of Complex Networks. SIAM Rev. 45, 167–256 (2003).
Boccaletti, S., Latora, V., Moreno, Y., Chavez, M. & Hwang, D.-U. Complex Networks: Structure and Dynamics. Phys. Rep. 424, 175–308 (2006).
Dorogovtsev, S. N., Goltsev, A. V. & Mendes, J. F. F. Critical phenomena in complex networks. Rev Mod. Phys. 80, 1275–1335 (2008).
Ahn, Y., Han, S., Kwak, H., Moon, S. & Jeong, H. Analysis of topological characteristics of huge on-line social networking services. Proceedings of the 16th International Conference on World Wide Web (2007).
Leskovec, J., Huttenlocher, D. & Kleinberg, J. Predicting positive and negative links in online social networks. ACM WWW International conference on World Wide Web (2010).
Onnela, J.-P., Saramaki, J., Hyvonen, J., Szabó, G., Lazer, D., Kaski, K., Kertesz, J. & Barabási, A.-L. Structure and tie strengths in mobile communication networks. Proc. Nat. Acad. Sci. U.S.A. 104, 7332–7336 (2007).
González, M. C., Hidalgo, C. A. & Barabási, A.-L. Understanding individual human mobility patterns. Nature 453, 779–782 (2008).
Zhao, K., Stehlé, J., Bianconi, G. & Barrat, A. Social network dynamics of face-to-face interactions. Phys. Rev. E 83, 056109 (2011).
Isella, L., Stehlé, J., Barrat, A., Cattuto, C., Pinton, J.-F. & Van den Broeck, W. What's in a crowd? Analysis of face-to-face behavioral networks. J. Theor. Biol. 271, 166–180 (2011).
Santos, F. C. & Pacheco, J. M. Scale-Free Networks Provide a Unifying Framework for the Emergence of Cooperation. Phys. Rev. Lett. 95, 098104 (2005).
Santos, F. C., Pacheco, J. M. & Lenaerts, T. Evolutionary dynamics of social dilemmas in structured heterogeneous populations. Proc. Natl. Acad. Sci. U.S.A. 103, 3490–3494 (2006).
Gómez-Gardeñes, J., Campillo, M., Floría, L. M. & Moreno, Y. Dynamical Organization of Cooperation in Complex Topologies. Phys. Rev. Lett. 98, 108103 (2007).
Poncela, J., Gómez-Gardeñes, J., Floría, L. M. & Moreno, Y. Natural Selection of cooperation and degree hierarchy in heterogeneous populations. J. Theor. Biol. 253, 296–301 (2008).
Kurant, M. & Thiran, P. Layered Complex Networks. Phys. Rev. Lett. 96, 138701 (2006).
Mucha, P. J., Richardson, T., Macon, K., Porter, M. A. & Onnela, J.-P. Community structure in time-dependent, multiscale and multiplex networks. .Science 328, 876–878 (2010).
Szell, M., Lambiotte, R. & Thurner, S. Multi-relational Organization of Large-scale Social Networks in an Online World. Proc. Natl. Acad. Sci. U.S.A. 107, 13636–13641 (2010).
Wang, Z., Szolnoki, A. & Perc, M. Evolution of public cooperation on interdependent networks: The impact of biased utility functions. .EPL 97, 48001 (2012).
Buldyrev, S. V., Parshani, R., Paul, G., Stanley, H. E. & Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028 (2010).
Parshani, R., Buldyrev, S. & Havlin, S. Critical effect of dependency groups on the function of networks. Proc. Natl. Acad. Sci. U.S.A. 108, 1007–1010 (2011).
Gao, J., Buldyrev, S. V., Stanley, H. E. & Havlin, S. Networks formed from interdependent networks. Nature Phys. 8, 40–48 (2012).
Lee, K.-M., Kim, J. Y., Cho, W.-K., Goh, K.-I. & Kim, I.-M. Correlated multiplexity and connectivity of multiplex random networks. New J. Phys. 14, 033027 (2012).
Brummitt, C. D., D'Souza, R. M. & Leicht, E. A. Suppressing casades of load in interdependent networks. Proc. Natl. Acad. Sci. U.S.A. 109, E680–E689 (2012).
Brummitt, C. D., Lee, K.-M. & Goh, K.-I. Multiplexity-facilitated cascades in networks. Phys. Rev. E 85, 045102(R) (2012).
Floría, L. M., Gracia-Lázaro, C., Gómez-Gardeñes, J. & Moreno, Y. Social Network Reciprocity as a Phase Transition in Evolutionary Cooperation. Phys. Rev. E 79, 026106 (2009).
Acknowledgements
The Authors acknowledge support from the Spanish DGICYT under projects FIS2009-13364-C02-01, FIS2009-13730-C02-02, MTM2009-13848, FIS2010-18639 and FIS2011-25167 (cofinanced by FEDER funds) by the Comunidad de Aragón (Project No. FMI22/10) and by Generalitat de Catalunya 2009-SGR-838. J.G.G. is supported by MICINN through the Ramón y Cajal program.
Author information
Authors and Affiliations
Contributions
J.G.G., L.M.F. and A.A. devised the model and designed the study. J.G.G. and I.R. carried out the numerical simulations. J.G.G. and L.M.F. analyzed the data and prepared the figures. J.G.G., L.M.F. and A.A. wrote the main text of the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareALike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/3.0/
About this article
Cite this article
Gómez-Gardeñes, J., Reinares, I., Arenas, A. et al. Evolution of Cooperation in Multiplex Networks. Sci Rep 2, 620 (2012). https://doi.org/10.1038/srep00620
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep00620
This article is cited by
-
Evolutionary games on multilayer networks: coordination and equilibrium selection
Scientific Reports (2023)
-
Evolution of prosocial behaviours in multilayer populations
Nature Human Behaviour (2022)
-
A tensor-based formulation of hetero-functional graph theory
Scientific Reports (2022)
-
An improved efficient routing strategy on two-layer networks
Pramana (2022)
-
Dynamics of resilience–equity interactions in resource-based communities
Communications Earth & Environment (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
