
Abstract
Pedotransfer function (PTF) approach is a convenient way for estimating difficult-to-measure soil properties from basic soil data. Typically, PTFs are developed using a large number of samples collected from small (regional) areas for training and testing a predictive model. National soil legacy databases offer an opportunity to provide soil data for developing PTFs although legacy data are sparsely distributed covering large areas. Here, we examined the Indian soil legacy (ISL) database to select a comprehensive training dataset for estimating cation exchange capacity (CEC) as a test case in the PTF approach. Geostatistical and correlation analyses showed that legacy data entail diverse spatial and correlation structure needed in building robust PTFs. Through non-linear correlation measures and intelligent predictive algorithms, we developed a methodology to extract an efficient training dataset from the ISL data for estimating CEC with high prediction accuracy. The selected training data had comparable spatial variation and nonlinearity in parameters for training and test datasets. Thus, we identified specific indicators for constructing robust PTFs from legacy data. Our results open a new avenue to use large volume of existing soil legacy data for developing region-specific PTFs without the need for collecting new soil data.
Similar content being viewed by others

Introduction
Soil information systems are increasingly used in developing ecosystem-scale understanding of critical zone processes and ecosystem services1,2. More recently, a greater role is attributed to large-scale soil data for realizing the sustainable development goals of food security, water management, and other health threats3. Comprehensive databases have been used to develop pedotransfer functions (PTF) for critical soils parameters such as soil hydraulic properties (UNSODA4, HYPRES5), soil organic carbon (SOC) contents (LUCAS6), and geochemical parameters (GEMAS7). Similarly, soil survey efforts have led to the creation of large repositories of legacy soil databases in many countries. Recently, legacy data for 196,498 geo-referenced locations covering 173 countries have been pooled to create a global soil information system under the umbrella of Global Soil Partnership8. Interestingly, much of legacy soil data remain largely underutilized9.
Although PTFs are attractive, their reliability depends on the amount (data size) and structure of the input parameters10,11. For instance, datasets with a few soil samples may be sufficient to develop reliable PTFs for relatively small geographical areas12. However, in large and heterogeneous landscape with high spatial soil variability13, PTF performance is influenced by the size and spread of soil sampling locations14. It is generally argued that PTFs should not be extrapolated beyond the geographical region or soil type from which they are developed15,16,17,18,19. Such a proposition has led to the creation of several region-specific and PTF-specific soil databases in countries and continents4,5,6,7. Ideally, the similarities or differences between the calibration and validation data and the underlying correlation structure should be considered as key determinants for the efficacy of a developed PTF20,21 rather than their geographical origin. Such a hypothesis has not been tested with experimental data to our knowledge. Specifically, what constitute key components of a training dataset and how to generate such a dataset are not clearly defined.
Spatial variability in soils is complex and soil properties generally do not follow spatial stationarity rules22. Moreover, many soil properties in samples collected from large areas show inherent non-linearities14. Legacy soil data also carry information on both spatial variability and non-linearity23. In addition, the size and volume of data available in many legacy soil databases are large24. Thus, legacy data may serve as a rich data source for developing region-specific PTFs if key features of a training dataset are well-defined and a methodology to extract such a dataset from legacy data is developed. Importantly, such a methodology will save time and effort needed in creating new datasets for developing region-specific PTFs.
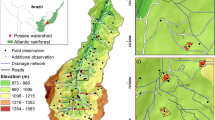
Therefore, the overall objective of this study was to examine if the large-scale legacy soil databases may be used for obtaining training data to calibrate PTFs. The specific objective was to examine how correlation structure, spatial variability, and non-linearity in training and test datasets influence PTF performance. To test these objectives, we selected the soil survey data collected by the National Bureau of Soil Survey and Land Use Planning (NBSS&LUP), Nagpur, India (hereinafter, referred to as Indian Soil Legacy or ISL database) as the legacy data source. We used the ISL database (shown with black dots in Fig. 1) for developing multiple training datasets for calibrating PTFs. Over the last decade, we also developed soil databases for the states of Odisha and West Bengal (shown with green dots in Fig. 1) as a part of building a spectral library for eastern Indian soils25,26. These two regional soil databases were used as independent test datasets; hereinafter, these databases are referred to as West Bengal test data (WBT database) and Odisha test data (ODT database). Because cation exchange capacity (CEC) data were available in all the three datasets and it is an important soil function parameter27, we selected CEC as a candidate for developing PTFs from legacy database. Both linear and non-linear modelling approaches such as multiple linear regression (MLR), ridge regression (RR), support vector regression (SVR), random forest (RF), and extreme gradient boosting (XGB) were examined to develop robust PTF for CEC. The XGB approach is an efficient machine learning algorithm28 and has not been used for developing PTFs in soil literature.

Map of India with the sampling locations for the Indian soil legacy data. Nine soil location datasets (WB250 to WB2250) were obtained by drawing circles with indicated radii of 250–2,250 km from the centre point (88.901°E and 23.126°N) located within the West Bengal state(right panel). Eight soil location datasets (OD250 to OD2250) were obtained by drawing circles with indicated radii of 250–2000 km from the centre point (85.584°E and 21.088°N) located within the Odisha state (left panel). The sampling locations for the West Bengal (WBT) and Odisha test data (ODT) collected by the Soil Physics laboratory at the Indian Institute of Technology Kharagpur, India is shown as green dots.
Indian soil legacy database (training data)
The ISL database contained soil data for 4,190 soil horizons representing 1,092 georeferenced soil profile locations (Fig. 1) distributed over 11 Indian states: Andhra Pradesh29, Bihar30, Rajasthan31, West Bengal32, Madhya Pradesh33, Odisha34, Maharashtra35, Telangana29, Chhattisgarh33, Gujarat36, and Kerala37. These 11 states together occupy1.94 million km2 area and account for 59% of total geographical area of India. The soil sampling locations encompass four major cratonic provinces of India: Singhbhum in eastern India, Bastar in central India, Dharwar in southern India, and Aravalli–Bundelkhand in western India38. While granite-gneisses dominate Singhbhum craton, Dharwar and Aravalli–Bundelkhand are majorly basaltic in nature. Prevailing high rainfall and high temperature with granitic parent material in the eastern Indian regions have led to the formation of moderate to strongly weathered soils25 with the dominance of kaolinitic clays with different intergrades of smectites39. In contrast, basaltic parent material and low rainfall in the western Indian states have led to the formation of black cotton soils with vermicullitic and illitic clays in the Dharwar region40 while the deserts in the far western Rajasthan have very weakly developed soil profiles41. Thus, the ISL dataset has a wide variation in clay mineralogy and resulting CEC values and serves as rich pool of soil data for calibrating PTFs albeit the size of the dataset is still small compared to the total geographical area from which it is developed.
West Bengal and Odisha database (test data)
Similar to variations in the ISL dataset, soils samples in the WBT and ODT datasets also encompass large variability because of contrasting geomorphological conditions. The WBT sampling locations were distributed in the whole of West Bengal state while the ODT sampling locations were distributed mostly along the four river systems (Subarnarekha, Brahmani, Baitarani and Mahanadi) of northern Odisha. Soils of West Bengal are classified into five soil chrono-associations42: Ganga Floodplain (age: 0.5 ka), Bhagirathi Plain and Old Ganga Plain (age: 1–1.5 ka), Barind Tract (Lower Level) and Damodar Deltaic Plain (age: 3–4 ka), Bhagirathi-Ajay Plain and Ajay-Silai Plain (age: 5–6 ka), and Upland with Red Soils (age: 350–1,000 ka). Such detailed geomorphological studies are not available for ODT samples. Nevertheless, there is a large variation in elevations in northern part of Odisha because of the presence of both plain and mountainous landscape. The elevation at the sampling locations of WBT database ranged from 3 to 156 m above the mean sea level (MSL) whereas those of ODT samples ranged from 1 to 589 m above MSL (the elevation map for the two states is provided in the Supplementary Document as Fig. S1). The parent material in the ODT samples are primarily of Archean and Proterozoic age43. Soils of both these sites show moderate to high weathering intensities with slightly higher silica to sesquioxide molar ratios and lower K2O contents for the ODT than WBT sampling locations25. They majorly represent Alfisols, Inceptisols, and Entisols with limited samples categorized under the Ultisol and Oxisol soil orders40 (USDA soil classification). With differing landforms and similar weathering stages, these two soil datasets may be treated as independent test data for examining the performance of developed PTFs.
Selection of training data from large-scale soil legacy database
Locational similarity
We used a series of preliminary modelling to identify an appropriate subset of training data from the ISL database. First, we used the ISL data from West Bengal and Odisha state as training datasets because of their similarity with the test datasets (WBT and ODT) in terms of geographical origin. Although we had 438 soil records in West Bengal and 432 soil records for the Odisha subset of ISL data, resulting PTFs failed to perform well for estimating the CEC values in both the test datasets. We also used the environmental covariates (i.e., elevation, average precipitation, and average temperature) for both these states as predictors of CEC along with the clay content, SOC content, and pH values; resulting PTFs under-predicted the CEC values for the respective test datasets. These results suggested that the local soil legacy data alone are inadequate for developing robust PTFs contradicting the long-standing notion that the training and test datasets for PTFs should be drawn from the same geographical region16,17,18. To test this observation further, we used the k-mean clustering approach to divide the entire ISL database into distinct (similar) clusters based on clay content, pH, and SOC triplets. Resulting PTFs developed with these clusters and their combinations did not describe the variability in CEC values in test datasets. Clustering approach created training datasets that had soil locations randomly scattered over the entire study area (covering all the 11 states). Consequently, the clusters and their combinations lacked inherent spatial correlation for the predictor and response soil properties. Moreover, local pedogenetic environment is known to influence soil characteristics (clay and SOC contents) linked to cation exchange behaviour. For instance, the eastern Indian soils have a high weathering intensity25 leading into dominantly kaolinitic clay mineralogy, which would impart characteristically low CEC values. Therefore, we concluded that locational similarity between training and test datasets should form an important criterion in developing PTFs in addition to other features in training datasets. To explore the later, we examined the ISL data beyond the geographical origin of test datasets and examined the variability and nonlinearity in soil properties, which may contribute to the performance of a local PTF.
Spatial structure in training and test data
For selecting training data beyond locational similarity with test data, we examined spatial structures in the ISL and test datasets. The geometric extent (maximum width of a spatial data) for test datasets were more or less similar. For instance, a circle with a radius of 237 km could enclose sampling locations in the WBT samples around the centre point of 88.901°E and 23.126°N located within the West Bengal. Similarly, the sampling locations in ODT samples could be enclosed with a radius of 242 km around the centre point of 85.584°E and 21.088°N located within Odisha. As Fig. 1 shows, all the sampling locations of legacy and test data may be enclosed within a circle of radius 2,250 km. Thus, the geometric extent in our study varies from 250 × 2 = 500 km for the test datasets to 2,250 × 2 = 4,500 km in the ISL dataset. Because both support and spacing for the dataset could not be varied, we chose to examine the spatial structure in the ISL dataset from geometric consideration by incrementally changing geometric extent from a radius of 250–2,250 km as shown by the concentric circles enclosing various sampling locations. Thus, we obtained 9 training datasets for West Bengal-centric data and 8 datasets for Odisha-centric data. The increment of 250 km was chosen for simplicity because the sampling locations in the test datasets could be enclosed by circles with radii of 237 km and 242 km for West Bengal and Odisha, respectively. Because the total number of soil records in the ISL database was small (1,092 profiles with 4,190 soil layers) and our test samples (N = 402) were collected from top 20 cm soil depth, we calibrated PTFs by selecting training data by dividing ISL dataset into surface and whole profile soil datasets. Details of resulting 34 training datasets are presented in the method section.
Before analysing spatial structure and nonlinearity in soil parameters, we estimated the mean and the coefficients of variation (CV) values for CEC, pH, clay and SOC contents in all the datasets (Table 1). In general, average values for these soil properties for the surface datasets were significantly different from those of the whole profile datasets (t-test at 5% significance level). Similarly, the average values for different soil properties were significantly different across two test datasets except for clay contents. The average clay contents and pH values in both test samples were lower than those for ISL datasets; opposite trend was observed for SOC contents. Both test datasets showed similar CEC values with the averages of 17.82 cmolc kg−1 for WBT samples and 20.5 cmolc kg−1 for ODT samples. These CEC values are indicative of mixed clay mineralogy. Indeed, the presence of kaolinite, illite, and smectites clays in the ratio of 9:28:49 in alluvial soils and in 60:21:6 for red and laterite soils have been reported in West Bengal soils39. The training datasets showed a slightly wide variation in CEC with averages ranging from 11.91to 21.9 cmolc kg−1. Larger CEC values for both test datasets than their local ISL training data (i.e., WB250 and OD250) suggest that the PTF derived with the regional training datasets may not always capture the variability in test data. The CV values for clay contents in the WBT and ODT samples were higher than those of the ISL location datasets; the opposite trend may be seen for the SOC and CEC values. Variations in all the four soil parameters are shown using box plots in Supplementary Document (Fig. S2).
Spatial variability in test data
The WBT dataset resulted in a linear semivariogram for CEC with nugget = 32.13, sill = 52.38, and range = 24.45 km while the ODT data showed a pure nugget variogram (nugget = 105.18). We repeated the semivariogram analyses by removing trend in the CEC data for the WBT samples and results showed a pure nugget effect similar to the ODT dataset. With no spatial structure, CEC values in test datasets may be considered as randomly distributed over the testing areas.
Spatial variability in training data
Similar to test datasets, we removed trends from all the 34 training datasets before fitting semivariograms. In general, a spherical model was fitted to the residuals of CEC, clay, and pH values while an exponential model was fitted to the residuals of SOC values. The range values for the semivariograms fitted to each of the soil properties for each of the training datasets are plotted as a function of the radius of the training dataset (Fig. 2). Figure 2 shows that training datasets have range values of about 1,250 km for CEC, 1,000 km clay, and about 1,500 km for pH and SOC values. With the range parameter varying from 1,000–1,500 km, one would expect to have spatially correlated response and predictor variable even if we use the entire ISL database as the training dataset. Semivariograms obtained for West Bengal centric training datasets of surface soils and Odisha centric training datasets for whole profile soils are shown for illustration as Supplementary Material (Fig. S3).

Ranges (km) for the theoretical semivariograms fitted to cation exchange capacity (CEC), clay, pH and soil organic carbon (SOC) for each West Bengal (WB) centric and Odisha (OD) centric location datasets vs. the radii (km) for each of these location datasets.
Correlation structure among predictor and response variables
To examine the nature of relationships between CEC and its predictors in the ISL training datasets, we fitted generalized additive models (GAM) to predict CEC from clay content, pH, and SOC content. Spline-fitted pH, clay and SOC contents for the 9 West Bengal-centric and 8 Odisha-centric training datasets are presented in the Supplementary Documents (Fig. S4). The smoothing splines and their effective degrees of freedom (df) show that clay content had a stronger nonlinear relationship with CEC values for the whole profile soil samples than for surface soil samples. For surface soil samples, the extent of nonlinearity for clay contents was highest in the WB2000 (df = 8.45) and OD2000 (df = 8.34). The pH values had almost linear variations with CEC for surface soil samples up to 1,000 km radius in the West Bengal-centric and 500 km radius in the Odisha-centric datasets. Similarly, the SOC values had linear relationship with the CEC values in WB250, WB500, WB 750, and WB1250 calibration datasets for the surface soil group whereas WB1000, WB1500, WB1750, WB2000, and WB2250 datasets showed nonlinearity. For the whole profile soil samples, the SOC values showed linear relationship with the CEC values for WB250 and WB500 location dataset whereas nonlinear relationship was observed for the remaining location training datasets (Fig. S3). All the Odisha-centric training datasets showed nonlinearity for SOC values in both surface and whole profile soil groups. Interestingly, the observed the partial residuals for SOC for both Odisha and West Bengal training dataset compared to pH and clay content data (Fig. S4) suggested that SOC may not be a strongly contributing variable to CEC although model performance significantly changed when SOC was excluded in the PTF development (t-test at 1% significance level). This may be expected because the SOC contents for the ISL datasets are inherently low. The GAM analyses indicated that the extent of nonlinearity generally increases with the increase in the spatial extent of the soil datasets suggesting that a linear PTF model may be developed with soils belonging to the 250–750 km radius, however, as the spatial extent increases, a nonlinear modelling algorithm should be followed.
With linear and nonlinear relationships between CEC and its predictors, the Pearson correlation coefficient (σ) and distance correlation coefficient (dCor) were estimated to quantify the extent of correlation between CEC and its predictor variables. Figure 3 shows the σ vs. dCor values for nine West Bengal-centric whole profile training datasets as an example; all the 238 different correlation coefficients are listed in Table S6 (Supplementary Material). In general, Fig. 3 shows that both the σ and dCor values for clay contents were higher than for the other predictor variables, pH and SOC content, because of the close relationship between clay types and CEC. Soil reaction appeared to be the next important predictor variable. With typically low SOC contents in Indian soils, the correlation coefficients between CEC and SOC contents were lowest in magnitude in all the training datasets. An important observation in Fig. 3 is that an increase in the contributing sampling area (from 250 to 2,250 km) altered the correlation coefficients for the individual predictors and CEC in different ways. The dCor values for clay content showed a general decreasing trend while the Pearson correlation coefficients first increased and then decreased with the increase in geometric extent (Fig. 3a). In contrast, both the coefficients for soil pH reached a minimum value at about 500 km and thereafter sharply increased before reaching a plateau at about 1,250 km (Fig. 3b). Soil organic carbon contents showed yet different trend by reaching a minimum value at about 500 km and a maximum value at about 1,750 km (Fig. 3c). When all the three variables were considered together, the dCor value showed a clear peak at 1,750 km (Fig. 3d) suggesting that three contributing predictor variables of clay, pH and SOC triplets for the datasets enclosed in a radius of 1,750 km will show maximum correlation with the CEC values compared to other training datasets. Similar results were observed for the remaining three datasets: High dCor values were reached for the datasets enclosed with 2000 km radius for the West Bengal- and Odisha-centric surface soil samples and with 1,500 km radius samples for Odisha-centric whole profile samples. Interestingly, the training datasets showing the highest dCor coefficient between CEC and SOC contents were identical to those showing the highest dCor coefficient between CEC and all the predictors combined. This clearly suggests that SOC content is a key parameter for estimating CECs in addition to clay contents. Thus, Fig. 3 shows that WB1750, WB2000, OD1500, and OD2000 may serve as the best training datasets. It may be noted that the consideration of calibration (training) data from regions enclosed within radii of 1,500 to 2000 km include soil samples developed from basaltic rocks that favours the formation of expanding clays, which may serve as a reason behind high dCor values in these training datasets. Moreover, the geostatistical analysis of the predictor and response soil properties show that even for radii beyond 1,500 km, the properties show spatial similarity.

Pearsons correlation coefficient and distance correlation coefficient values between cation exchange capacity (CEC) and clay content (clay), CEC and pH , CEC and soil organic carbon content (SOC), and CEC and clay, pH, SOC combined for the West Bengal centric legacy location datasets for the whole profile soil samples.
PTFs for CEC from legacy data
Five different modelling approaches were used for 9 West Bengal-centric and 8 Odisha-centric ISL datasets and model performances were tested on WBT and ODT datasets. With separate surface and whole profile data treated as separate datasets, these modelling efforts led to having a total of 170 sets of R2 and RMSE values along with estimated bias (Tables 2 and 3). In general, the performance of the MLR- and RR-based PTFs decreased with the increase in the geographical extent of the training dataset because of the increase in the nonlinear relationship among response and predictor soil properties. Performance of the linear regression model in training datasets with small spatial extent may have resulted from the linearity in SOC and pH values observed for WB250, WB500, and WB750 datasets through GAM analyses. The effect of linearity on model performance may also be observed with generally lower R2 statistics for Odisha-centric than West Bengal-centric training datasets—GAM analyses suggested that relationships among predictor variables for CEC were more nonlinear and weaker for the Odisha-centric than West Bengal-centric training datasets. For the SVR approach, CEC values for the test datasets were over-predicted even when a genetic algorithm was used for tuning model parameters. The predictions by RF and XGB were almost similar; however, the boosting approach worked better than the bagging approach leading to superior performance of the XGB approach among all the five modelling algorithms used. Table 2 shows that the maximum validation (test) RMSE values of 7.13 cmolc kg−1 and 7.04 cmolckg−1 were observed in WB2000 surface and WB1750 whole profile training datasets, respectively. Similarly, the training datasets OD2000 (which is basically the entire ISL surface database) and OD1500 of the whole profile soil group provided the best prediction of CEC values for the ODT dataset with RMSEs of 8.46 cmolc kg−1 and 8.90 cmolc kg−1, respectively. Observed vs. predicted CEC values by the best PTFs trained on the best ISL training datasets are shown as supplementary Figure S5. Similar error values for predicting CEC using a single data source for subsampling calibration and validation datasets have been reported in the literature. For example, an RMSE value of 6.58 cmolc kg−1 was reported44. Therefore, we can conclude that we achieved a good prediction of CEC values for our independent test datasets. From the correlation structure between the response and predictor soil properties that we obtained, we chose the maximum ρ values. Interestingly, maximum ρ values were observed for CEC and clay contents in all the four training datasets (ρ = 0.83 in WB500 surface soils, ρ = 0.83 in WB250 whole profile soils, ρ = 0.84 in OD250 surface soils, and ρ = 0.80 in OD 250 whole profile soils). The RMSE values obtained for the prediction of CEC values using the datasets showing maximum ρ values and using MLR modelling approach were plotted in Fig. 4. In the same graph, we plotted the values of the minimum RMSE vs. the corresponding dCor values for the best training datasets (WB1750, WB2000, OD1500 and OD2000). No trend is observed for the ρ and RMSE values, however, a clear decreasing trend in the RMSE values with the increase in maximum dCor suggests that model performance is strongly controlled by parameter nonlinearity in the calibration (training) and validation (test) datasets.

Maximum Pearsons correlation coefficients (ρ) vs. the minimum root mean squared error (RMSE) values for the PTFs tested on the West Bengal and Odisha test datasets trained on the specific training datasets that showed the maximum ρ. The figure also plots the maximum distance correlation coefficients (dCor) vs. the minimum root mean squared error (RMSE) values for the PTFs tested on the West Bengal and Odisha test datasets trained on the specific training datasets that showed the maximum dCor values.
Discussion
Soil properties, soil functions, and PTFs are influenced by inherent nonlinearity of processes, spatial variability of soil parameters45, and diverse agro-climatic conditions. Collected from large areas, legacy data contain information on all these three attributes. Therefore, a carefully-selected subset of legacy data is sufficient to develop a robust regional PTF and, hence, identification of this subset is the key step in PTF analysis. With a series of modelling studies, we observed that the best training dataset had three critical attributes: (a) locational similarity between the training and test datasets, (b) the presence of spatial correlations for each of the predictor and response soil properties, and (c) the presence of a strong correlation between the predictor and response soil property. Indeed, PTFs developed with the legacy soil data belonging to the same location as that of the test data alone failed to predict the CEC values calling for additional features in training datasets. Combining soils randomly from multiple locations to develop a robust PTF might not work, because we observed that creating clusters from legacy data with locations spreading all over the country and creating PTF combining those clusters failed to predict the CEC for the test datasets. This also may be the reason that limits us to develop a PTF model using combined continental- and country-level legacy soil data. Indeed, we repeated our analysis by selecting training datasets around a centre point on roughly at the centre of the country (21.145°N, 79.088°E). Training datasets distributed with as wide as 1,000 km extent from such an India-centric centre point and the efficient XGB algorithm resulted in the R2 values of 0.30 (RMSE = 9.08) for WBT and 0.29 (RMSE = 9.33) for the ODT datasets. Such a result suggests that both training and test datasets should not only share locational similarity (as evident from clustering analysis), the predictor and response variables in the training datasets should have similar spatial structure. This requirement stems from the argument that the set of rules relating a response soil property with predictor properties may not become too much diverse if each soil property is spatially-correlated with itself. If such spatial dependency criterion is ignored, there may be chance of including sampling pairs having lag distance beyond range, where diversity may exist but the set of statistical rules relating predictor and response soil properties may differ reducing the performance of resulting PTFs. Therefore, a spatial correlation for the predictor and response soil properties forms the second criterion for an ideal training dataset. The third criterion results from the requirement for strong correlation structure between the predictor and response soil properties in a training dataset—both linear and nonlinear as may be inherent with specific soil properties. From the correlation structure analysed in our study, we observed that a nonlinear correlation coefficient is required to capture the inherent relationship among predictor and response soil properties. The final requirement pertains to the use of an intelligent predictive algorithm that exploits the three features of locational similarity in test and training datasets, spatial similarity among predictor and response variables, and inherent nonlinearity in soil parameters. We observed that the XGB algorithm showed best learning capability among all the predictive modelling approaches. Recently, it has also been shown that transfer rules learnt by the more general global models developed with the continental data on soil spectra were transferred to a local domain to generalize a soil spectral model46. A similar learning of the XGB model when trained on soils belonging to a wider geographical area as compared to the local soil samples might have helped in better performance of the developed PTFs in this study. These results are combined to build a scheme for choosing the training dataset from the legacy soil database in Fig. 5.The developed workflow may be used for deriving training datasets from legacy soil data. Specifically, the proposed criteria may be used to develop region-specific PTFs from legacy soil data in countries with a wide range in environmental and edaphic factors without collecting new soil data.

Scheme followed to utilize the legacy soil data to obtain region-specific robust pedotransfer functions for difficult-to-measure soil properties; GAM: general additive model, dCor: distance correlation, CEC: cation exchange capacity, SOC: soil organic carbon content.
Methods
M1-collection and compilation of test dataset
The test datasets were generated in our laboratory as a part of building spectral library of soils for the eastern Indian states of West Bengal and Odisha during the last decade. We refer to these two state-wise databases as West Bengal Test (WBT) and Odisha Test (ODT) databases. The database consisted of surface soil samples available for 102 locations across West Bengal state and 300 locations across Odisha state, respectively (Fig. 1). For both the datasets, soil samples were collected mostly from agricultural fields cultivated with rice (Oryza sativa L.) crop. Collected samples were air‐dried and passed through a 2‐mm sieve before analysing them in laboratory to determine different soil properties. SOC contents for the processed soil samples were estimated using the chromic acid digestion method47, and particle size distribution was determined using the pipette method48. Soil pH was measured on a 1:2.5 soil:water suspension49. The CEC was determined by the ammonium saturation method at pH 7.050. It may be noted that the ISL database also has soil data from both West Bengal and Odisha states. However, the sampling locations of those soil series are different from the sampling locations of soil samples present in the WBT and ODT databases (Fig. 1). Thus, the WBT and ODT databases serve as independent test datasets in our study.
M2-selection of training datasets
Because we had only 4,190 records in the whole ISL dataset compared to the large region over which ISL data was developed, we chose to test our approach on ODT and WBT datasets separately. This provided two instances of model validation. To realize separate sets of training data for ODT and WBT test datasets, we considered generating both West Bengal-centric and Odisha-centric training datasets. We observed that the WBT data may be enclosed in a circle of radius 237 km with the centre located at 88.901°E latitude and 23.126°N longitude; similarly, the ODT data may be enclosed in a circle of radius 242 km with the centre located at 85.584°E latitude and 21.088°N longitude. For simplicity, we considered 250 km as the radius of the circle (instead of 237 or 242 km) located around the selected centre points for both the test data regions (Fig. 1). The ISL datasets located within these circles may be assumed to serve as local training data (i.e., having similar geographical origin as those of the respective test datasets). The furthest point along western India stretched about 2,250 km from the WBT and 2000 km from the ODT centre points. We arbitrarily divided these stretches of 2,250 km into concentric rings by drawing circles of radii 250, 500, 750, 1,000, 1,250, 1,500, 1,750, 2000, and 2,250 km and divided the ISL database into multiple location datasets. For example, the sampling points falling within 500 km from the centre point of 88.901°E and 23.126°N are considered location dataset corresponding to 500 km and so on. We refer to West Bengal-centric datasets as WB250, WB500, WB750,…, and WB2250. The number of soil samples belonging to each of these nine location datasets are 62, 199, 328, 418, 544, 643, 812, 1,000, and 1,092, respectively, when only surface soils of the ISL database is considered. When the whole soil profile is considered, the numbers of soils belonging to each of these location datasets are: 301, 909, 1,470, 1,820, 2,271, 2,617, 3,106, 3,810, and 4,190, respectively. Similarly, we obtained eight Odisha-centric location datasets (OD250, OD500, OD750,…, and OD2000). The number of soil samples belonging to each of these eight location datasets are 73, 287, 466, 571, 696, 884, 1,030, and 1,092, respectively when only surface samples of the ISL database is considered. When the whole soil profile is considered, the numbers of soils belonging to each of these location datasets are: 339, 1,280, 2014, 2,395, 2,797, 3,438, 4,028, and 4,190, respectively. Details of these location datasets (soil orders and agro-ecological zones to which these location datasets belong) are provided as Supplementary Documents (Table S7). Spatial analysis of data for visualization and sub-setting it in to different concentric zones were conducted with ArcGIS®(ESRI).
M3-geostatistical analysis
We examined the spatial structure in all the training datasets and the test datasets for all the soil properties involved in the PTF development. For the whole soil profile data, weighted-average of the profile soil data was considered for each location for estimating the semivariograms. Different theoretical semivariogram functions were fitted to each of those experimental semivariograms to obtain the range, nugget, and sill values. These parameters provided an average measure of dissimilarity for a property as a function of separation distance. Best-fitted theoretical semivariogram models were chosen based on weighted least-square fitting where weights (wi) for each lag class were proportional to number of data pairs and inversely proportional to lag distance. As the soil samples were collected from wide geographical areas, we removed stationarity in the datasets before fitting the semivariogram models. A trend surface model was fitted to detrend the observed data using least-squared approach. The residuals (= difference between observed and modelled soil parameter) were then used to estimate semivariograms. All geostatistical analyses were carried out using the lattice and gstat packages in R programming environment51.
M4-dependency measurements
A generalized additive modelling (GAM) approach52 was also used to examine the marginal relationship between CEC values and the predictor variable(s) such pH, clay and SOC contents. The basic idea in GAM is to fit a function on each of the predictors to capture relationships between the response and the predictor variables. The effective degrees of freedom of the smoothing spline fitted to each of the predictor variables is an indication of the underlying nonlinearity between the predictors and the response variable. A penalized smoothing spline approach was used to choose the effective degrees of freedom for the smoothing splines for this study using mgcv package in R programming environment51.
We used both linear and non-linear correlation measures for quantitatively assess the extent of correlation among different soil parameters. The Pearson correlation coefficient (ρ) describing linear correlation between two parameters is given as:
where x and y are two random variables and n is the number of variables. Similarly, the distance correlation53 (dCor) is a nonlinear dependency measure based on distribution or density functions and is given as:
where x and y are two random vectors. The distance covariance (dcov) function in Eq. (2) is estimated as:
where ϕx(t) and ϕy(s) are the respective characteristic functions of the random vectors x and y, ϕx,y(t, s) is the joint characteristic function of x and y, and dx and dy are the dimensions of x and y, respectively. The weight function w(t, s) is given by
with \( c_{d} = \pi^{{\left( {1 + d} \right)/2}} /\left\{ {\left( {1 + d} \right)/2} \right\}\) .The dCor value between two variables is zero if and only if the two variables are independent53.
M5-regression and data-mining approaches
Five different regression algorithms were used to develop PTFs for CEC: multiple linear regression (MLR), ridge regression (RR), support vector regression (SVR), random forests (RF), and extreme gradient boosting (XGB). We have considered an RBF kernel function and used genetic algorithm (GA) to optimize regularization parameter C, bandwidth of RBF kernel σ2 and radius of a tube loss function ɛ for the SVR model. Steps followed for optimizing SVR using GA is already reported54. For the RF-based model development, the number of trees in the forest (N_estimators) and the depth of each tree in the forest (max_depth) were tuned based on leave-one-out cross validation of the training dataset. For the XGB-based models, we tuned the learning rate, the maximum tree depth, fraction of observation to be randomly sampled, and fraction of column to be randomly sampled for each tree using a leave-one-out cross validation of the training datasets. We used xgboost, e1071, randomForest, glmnet library functions in R programming environment51 to implement the above modelling approaches. Details for each of these five modelling approaches are provided as Supplementary Document.
M6-model accuracy
The accuracy of the models was adjudged using the coefficient of determination (R2), root-mean-squared error (RMSE), and bias values estimated as:
where N is the number of samples, Yiis the observed value of the CEC, f(x)i is the predicted value of CEC values.
References
Greiner, L., Keller, A., Grêt-Regamey, A. & Papritz, A. Soil function assessment: review of methods for quantifying the contributions of soils to ecosystem services. Land Use Policy 69, 224–237 (2017).
Banwart, S. A., Nikolaidis, N. P., Zhu, Y. G., Peacock, C. L. & Sparks, D. L. Soil functions: connecting earth’s critical zone. Annu. Rev. Earth Pl. Sc. 47, 333–359 (2019).
Keesstra, S. D. et al. The significance of soils and soil science towards realization of the United Nations Sustainable Development Goals. Soil 2, 111–128 (2016).
Nemes, A., Schaap, M. G., Leij, F. J. & Wösten, J. H. M. Description of the unsaturated soil hydraulic database UNSODA version 2.0. J. Hydrol. 251(3–4), 151–162 (2001).
Wösten, J. H. M. The HYPRES database of hydraulic properties of European soils. Adv. Geo Ecol. 32, 135–143 (2000).
Orgiazzi, A., Ballabio, C., Panagos, P., Jones, A. & Fernández-Ugalde, O. LUCAS Soil, the largest expandable soil dataset for Europe: a review. Eur. J. Soil Sci. 69(1), 140–153 (2018).
Reimann, C. et al. GEMAS: Establishing geochemical background and threshold for 53 chemical elements in European agricultural soil. Appl. Geochem. 88, 302–318 (2018).
Batjes, N. H., Ribeiro, E. & Van Oostrum, A. Standardised soil profile data to support global mapping and modelling (WoSIS snapshot 2019). Earth Syst. Sci. Data. 12, 299–320 (2020).
Filippi, P., Minasny, B., Cattle, S. R. & Bishop, T. F. A. Monitoring and modeling soil change: the influence of human activity and climatic shifts on aspects of soil spatiotemporally. Adv. Agron. 139, 153–214 (2016).
Ghehi, N. G. et al. Nonparametric techniques for predicting soil bulk density of tropical rainforest top soils in Rwanda. Soil Sci. Soc. Am. J. 76, 1172–1183 (2012).
Haghverdi, A., Cornelis, W. M. & Ghahraman, B. A. Pseudo-continuous neural network approach for developing water retention pedotransfer functions with limited data. J. Hydrol. 442, 46–54 (2012).
Aimrun, W. & Amin, M. S. M. Pedo-transfer function for saturated hydraulic conductivity of lowland paddy soils. Paddy Water Environ. 7(3), 217–225 (2009).
Savvides, A., Corstanje, R., Baxter, S. J., Rawlins, B. G. & Lark, R. M. The relationship between diffuse spectral reflectance of the soil and its cation exchange capacity is scale-dependent. Geoderma 154(3–4), 353–358 (2010).
Akpa, S. I. C., Ugbaje, S. U., Bishop, T. F. A. & Odeh, I. O. Enhancing pedotransfer functions with environmental data for estimating bulk density and effective cation exchange capacity in a data-sparse situation. Soil Use Manage 32(4), 644–658 (2016).
McBratney, A. B., Minasny, B., Cattle, S. R. & Vervoort, R. W. From pedotransfer functions to soil inference systems. Geoderma 109(1–2), 41–73 (2002).
Minasny, B., McBratney, A. B. & Bristow, K. L. Comparison of different approaches to the development of pedotransfer functions for water-retention curves. Geoderma 93(3–4), 225–253 (1999).
Hodnett, M. G. & Tomasella, J. Marked differences between van Genuchten soil water-retention parameters for temperate and tropical soils: a new water-retention pedo-transfer functions developed for tropical soils. Geoderma 108(3–4), 155–180 (2002).
Santra, P. & Das, B. S. Pedotransfer functions for soil hydraulic properties developed from a hilly watershed of Eastern India. Geoderma 146(3–4), 439–448 (2008).
Santra, P. et al. Pedotransfer functions to estimate soil water content at field capacity and permanent wilting point in hot Arid Western India. J. Earth Syst. Sci. 127(3), 35 (2018).
Nemes, A. Why do they keep rejecting my manuscript—do’s and don’ts and new horizons in pedotransfer studies. Agrokémiaéstalajtan 64(2), 361–371 (2015).
Looy, V. et al. Pedotransfer functions in Earth system science: challenges and perspectives. Rev. Geophys. 55(4), 1199–1256 (2017).
McBratney, A. B. & Minasny, B. Spacebender . Spat Stat. 4, 57–67 (2013).
Schillaci, C., Acutis, M., Vesely, F. & Saia, S. A simple pipeline for the assessment of legacy soil datasets: An example and test with soil organic carbon from a highly variable area. CATENA 175, 110–122 (2019).
Batjes, N. H. et al. WoSIS: providing standardised soil profile data for the world. Earth Syst. Sci. Data 9, 1–14 (2017).
Mohanty, B., Gupta, A. & Das, B. S. Estimation of weathering indices using spectral reflectance over visible to mid-infrared region. Geoderma 266, 111–119 (2016).
Vasava, H. B., Gupta, A., Arora, R. & Das, B. S. Assessment of soil texture from spectral reflectance data of bulk soil samples and their dry-sieved aggregate size fractions. Geoderma 337, 914–926 (2019).
Lal, R. Biochar and soil carbon sequestration. Agricultural and environmental applications of biochar: advances and barriers (SSSA Spec. Pub. 63), 175–198 (2016).
Chen, T., He, T., Benesty, M., Khotilovich, V. &Tang, Y. Xgboost: extreme gradient boosting. R Package Ver. 0.4–2, 1–4 (2015).
Reddy, R. S., Budihal, S. L., Kumar, S. C. R. & Naidu, L.G. K. Benchmark soils of Andhra Pradesh (NBSS Publ. No. 128, NBSS&LUP, Nagpur, 2005).
Sahoo, A. K., Sarkar, D. & Gajbhiye, K. S. Soil Series of Bihar (NBSS Publ. No. 98, NBSS&LUP, Nagpur, 2002).
Shyampura, R. L., Singh, S. K., Singh, R. S., Jain, B. L. & Gajbhiye, K. S. Soil Series of Rajasthan (NBSS Publ. No. 95, NBSS&LUP, Nagpur, 2002).
Nayak D. C., Sarkar D. & Velayutham M. Soil series of West Bengal (NBSS Publ. No. 89, NBSS&LUP, Nagpur, 2001).
Tamgadge, D. B., Gajbhiye, K. S., Velayutham, M. & Kaushal, G. S. Soil Series of Madhya Pradesh(NBSS Publ. No. 78, NBSS&LUP, Nagpur, 1999).
Sarkar, D., Sah, K. D., Sahoo, A. K., & Gajbhiye, K. S. Soil Series of Orissa (NBSS Publ. No. 119, NBSS&LUP, Nagpur, 254p.2005).
Challa, O., Gajbhiye, K. S., & Velayutham, M. Soil Series of Maharashtra (NBSS Publ. No. 79, NBSS&LUP, Nagpur, 1999).
Sharma, J. P. Soil Series of Gujarat, NBSS Publ. No. 120 (NBSS&LUP, Nagpur, 2006).
NBSS&LUP Staff. Soil Series of Kerala (NBSS Publ. No. 136, NBSS&LUP, Nagpur, 2006).
De, S. et al. Sedimentation history of the Paleoproterozoic Singhbhum Group of rocks, eastern India and its implications. Earth-Sci. Rev. 163, 141–161 (2016).
Ghosh, S. K., Sahu, S. S. & Das, S. C. Clay mineralogy of alluvial, red and lateritic soil profiles from West Bengal. Proc. Ind. Natl. Sci. Acad. 40, 200–208 (1974).
Bhattacharyya, T., et al. Soils of India: historical perspective, classification and recent advances. Curr. Sci. 1308–1323 (2013).
Singh, S. K., Baser, B. L. & Shyampura, R. L. Chemical composition and charge behaviour of smectites in Vertisols of Rajasthan. J. Ind. Soc. Soil Sci. 50(1), 106–111 (2002).
Singh, L. P., Parkash, B. & Singhvi, A. K. Evolution of the lower Gangetic Plain landforms and soils in West Bengal, India. CATENA 33(2), 75–104 (1998).
Bandopadhyay, P. C., Eriksson, P. G. & Roberts, R. J. A verticpaleosol at the Archean-Proterozoic contact from the Singhbhum-Orissa craton, eastern India. Precambrian Res. 177(3–4), 277–290 (2010).
Bayat, H., Davatgar, N. & Jalali, M. Prediction of CEC using fractal parameters by artificial neural networks. Int. Agrophys. 28(2), 143–152 (2014).
Nielson, D. R. & Wendroth, O. Spatial and temporal statistics: sampling field soils and their vegetation. GeoEcol. textbook, ISBN 3-923381-46-6, US-ISBN 1-593262-59-0 (2003).
Padarian, J., Minasny, B. & McBratney, A. B. Transfer learning to localise a continental soil vis-NIR calibration model. Geoderma 340, 279–288 (2019).
Walkley, A. & Black, I. A. An examination of the Degtjareff method for determining soil organic matter, and a proposed modification of the chromic acid titration method. Soil Sci. 37(1), 29–38 (1934).
Gee, G. W., & Bauder, J. W. Particle-size analysis. Methods of soil analysis: Part 1—Physical and mineralogical methods, (methods of soil an1), 383–411 (1986).
Hendershot, W. H., Lalande, H., & Duquette, M. Soil reaction and exchangeable acidity. Soil Sampl. Methods Anal., 2 (1993).
Soil Survey Staff. Soil Survey Manual. U.S. Department of Agriculture Handbook No. 18 U.S. Government Printing Office, Washington, DC, 437–1036 (1993).
R Core Team. R: A language and environment for statistical computing. R Foundation forStatistical Computing, Vienna, Austria. ISBN 3-900051-07-0. https://www.R-project.org/ (2013).
Hastie, T. J. & Tibshirani, R. J. Generalized additive models. Monogr. Stat. Appl. Probab. 43, 335 (1990).
Székely, G. J., Rizzo, M. L. & Bakirov, N. K. Measuring and testing dependence by correlation of distances. Ann. Stat. 35(6), 2769–2794 (2007).
Sajan, K. S., Kumar, V. & Tyagi, B. Genetic algorithm based support vector machine for on-line voltage stability monitoring. Int. J. Elec. Power 73, 200–208 (2015).
Acknowledgements
We thankfully acknowledge the National Bureau of Soil Survey and Land Use Planning, Nagpur for providing soil survey data in the public domain (https://krishikosh.egranth.ac.in/) in form of Soil Series Publications.
Author information
Authors and Affiliations
Contributions
P.C.: Implemented all algorithms. Wrote major portion of the manuscript. Prepared all tables and Figures. Developed the idea of correlation structures. B.S.D.: Conceived the basic idea behind this manuscript. Wrote portions of the manuscript and edited the manuscript. H.B.V.: Collected test soil samples and measured all the basic soil properties except cation exchange capacity. Provided GIS support during data analysis including correcting locational mismatches in Legacy data. N.P.: Measured Cation Exchange Capacity in the test data. P.S.: Conducted geostatistical analysis and wrote the geostatistical description in the result section.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chakraborty, P., Das, B.S., Vasava, H.B. et al. Spatial structure, parameter nonlinearity, and intelligent algorithms in constructing pedotransfer functions from large-scale soil legacy data. Sci Rep 10, 15050 (2020). https://doi.org/10.1038/s41598-020-72018-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-72018-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
