
Abstract
In this work, we present the CAS Landslide Dataset, a large-scale and multisensor dataset for deep learning-based landslide detection, developed by the Artificial Intelligence Group at the Institute of Mountain Hazards and Environment, Chinese Academy of Sciences (CAS). The dataset aims to address the challenges encountered in landslide recognition. With the increase in landslide occurrences due to climate change and earthquakes, there is a growing need for a precise and comprehensive dataset to support fast and efficient landslide recognition. In contrast to existing datasets with dataset size, coverage, sensor type and resolution limitations, the CAS Landslide Dataset comprises 20,865 images, integrating satellite and unmanned aerial vehicle data from nine regions. To ensure reliability and applicability, we establish a robust methodology to evaluate the dataset quality. We propose the use of the Landslide Dataset as a benchmark for the construction of landslide identification models and to facilitate the development of deep learning techniques. Researchers can leverage this dataset to obtain enhanced prediction, monitoring, and analysis capabilities, thereby advancing automated landslide detection.
Similar content being viewed by others
Background & Summary
Landslides, which are significant natural hazards, pose a formidable challenge in mountainous regions worldwide1,2. The escalating effects of climate change, population growth, and urbanization have amplified the frequency and severity of landslides3,4,5,6. To effectively mitigate the risks associated with landslides, it is crucial to obtain a precise and comprehensive landslide inventory map that accurately records the occurrences and characteristics of landslides7,8. With the development of deep learning techniques, the leveraging of convolutional neural networks to assist in the generation of landslide inventory maps has emerged as the current trend. However, existing landslide datasets for deep learning exhibit several limitations that hinder the advancement of landslide identification research9,10. First, in terms of size, most datasets are relatively small, containing only a limited number of samples, with the largest publicly available deep learning landslide dataset consisting of 3799 images and the smallest dataset comprising only 59 images. This paucity of data restricts the ability to build robust and generalizable models. Second, the quality of the data may be questionable, as many models rely on datasets that are not publicly available or subject to review. These datasets often suffer from a low spatial resolution, rendering them unable to capture fine-grained features of landslides. Furthermore, the sampling of landslides is severely inadequate, which poses challenges for models to effectively learn the diversity of landslide occurrences. This undersampling issue is manifested in several ways: a limited coverage in terms of data from various areas, restricted sampling devices, and inadequate number of samples covering diverse landslide triggers, such as rainfall, earthquakes, and volcanic eruptions. These sample size, data quality, and diversity limitations collectively impede the development and applicability of landslide identification models. Moreover, the absence of benchmark datasets hinders comparative evaluations of landslide identification models, limiting ability of researchers to assess their strengths, weaknesses, and potential improvements11,12,13,14,15,16. Addressing this gap, we present the CAS Landslide Dataset, a comprehensive collection of 20,865 RGB images derived from nine distinct regions. This dataset combines imagery from unmanned aerial vehicles (UAVs) and satellites (SAT), providing diverse terrain and environmental conditions for training and evaluating landslide identification models. In the dataset creation process, we employed a rigorous quality assessment method to ensure the data integrity. Through experimental validation, we unequivocally demonstrated the effectiveness of this method. Additionally, through comparative analysis with currently available deep learning landslide datasets, we demonstrated the advantages of the CAS Landslide Dataset in terms of quantity, quality, and generalizability. These findings verified the potential of the CAS Landslide Dataset as a standardized reference dataset for training and benchmarking landslide models developed by other researchers. In other words, our dataset could serve as a standardized dataset for other researchers to train and compare the performance levels of various models. By leveraging the diversity and comprehensiveness of this dataset, researchers can develop more precise and potent models for accurately identifying landslides, thereby enhancing disaster management and risk mitigation strategies. The openly accessible CAS Landslide Dataset, with its broad geographical coverage, could enable the scientific community to advance the understanding of landslide mechanisms and contribute to reducing the impact of landslides on humans. In Table 1, we provide representative samples and corresponding labels extracted from each subdataset within the dataset. Each row corresponds to one sample, showcasing an image and the associated label from the respective subdataset.
Methods
Study areas
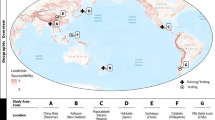
Our focus is on creating a standardized landslide dataset for deep learning, encompassing a diverse range of terrains, climate conditions, and vegetation cover levels, and incorporating data derived from various sources, such as UAV and satellite imagery. A location map of the study areas is shown in Fig. 1 below.

Location map of the study areas.
Data acquisition
The majority of our satellite imagery is sourced from various publicly available datasets provided by different organizations and can be accessed through the Google Earth Engine (GEE) platform17. These include Sentinel-2A/B (SEN2)18,19 and Landsat20. Our UAV imagery is sourced from collaborative partners and can be accessed through instructions provided later. To assist users in identifying our study areas, georeferenced shapefiles (shp files) delineating each research region were incorporated in the dataset. The images of Tiburon Peninsula (Sentinel), Moxitaidi (SAT), and Wenchuan originate from Google Earth Engine. Their utilization necessitates due adherence to the stipulations outlined in the Google Earth Engine (GEE) terms and conditions, as specified by the guidelines21. The imagery of the Tiburon Peninsula (Planet) was sourced from Planet’s Education and Research Program22.The imagery of Palu, Lombok were sourced from Digital Globe Open data Program23,24.Hokkaido Iburi-Tobu is sourced from Geospatial information Authority of Japan25. The imagery of Mengdong was procured through legitimate authorization from Beijing Lanyu Fangyuan Technology Co., Ltd. For those seeking access to the raw data, it is advised to directly engage with the aforementioned company and follow the purchasing guidelines outlined on their official website26. The imagery of Longxi River (SAT) was procured through legitimate authorization China Centre for Resources Satellite Data and Application27. Furthermore, the UAV images of the Longxi River, Jiuzhai Valley, and Luding were provided by the Sichuan Geomatics Center, an essential collaborative partner of the institutions of the authors of this work. Others wishing to repeat the work or perform similar studies may approach the Sichuan Geomatics Center28 or access their database29. For information regarding the source and capture time of the subdataset, please refer to Table 2 below.
Label creation
With reference to the disclosed landslide interpretations from previous work30,31,32,33,34, in conjunction with the acquired imagery, we created labels using QGIS version 3.32.3 and LabelMe software. QGIS was utilized for its comprehensive geospatial analysis capabilities, allowing for the precise analysis of landslide-related geographic information. LabelMe, however, was employed for our dataset due to its user-friendly interface and high suitability for semantic segmentation tasks. These tools were chosen based on their capabilities and suitability for accurately interpreting landslide features within the given context.
We used the following standards to ensure the accuracy and quality of the labels:
-
Reference Data:
We referred to existing landslide inventories and published sources to cross-verify our results and ensure alignment with recognized landslide interpretations.
-
Expert Input:
Our production process involved collaboration with domain experts and geologists, whose expertise in landslide identification and analysis contributed to the generation of accurate and consistent results.
-
Quality Control Measures:
We implemented stringent quality control procedures, including cross-verification of the results by multiple team members and resolution of discrepancies through discussion and consensus.
Building the dataset
We cropped the images into the 512 × 512 size TIFF format, and the label files, which contain interpretations of landslides corresponding to each image, were created in the same format. Specifically, the workflow for creating the dataset is shown in Fig. 2.

Workflow for Building the Dataset.
When creating the dataset, we encountered various challenges, as indicated in Table 3 below: insufficient content in cropped images (image boundary)35,36,37, low proportion of target objects (label pixel proportion)37,38,39, target obstruction by cloud cover (cloud)40,41, and discontinuity in the image content due to image stitching (seam)42,43,44. The incorporation of problematic data exhibiting these issues into the training dataset could result in increased computational costs because more invalid data must be processed. This could also cause model accuracy reduction, as the model may overfit the invalid data and yield biased predictions on the valid data. In contrast, excluding problematic data could decrease the computational costs and improve the model accuracy to some extent45,46,47,48,49. However, the resulting model must still resolve these problematic data during actual detection, which could significantly compromise the accuracy due to the model’s lack of experience with such data, yielding a less robust model. To address these data-related challenges that arise during image cropping and labelling, we devised a rigorous screening and filtering scheme. Specifically, we first used automated metrics to identify and quantify issues such as the image boundary, target size, and occlusion percentage. Images failing to meet certain thresholds were flagged. We then manually inspected the flagged images to make the final rejection or retention decision. For example, after iterative screening of the initial SAT dataset, we filtered out approximately 1,245 problematic images, which is approximately 14% of the initial dataset. This process allowed us to create a refined dataset, as evidenced by the 1% increase in the validation accuracy over models trained on the unfiltered dataset. The experimental results in this section are detailed in the Validation of Dataset Quality Control section below.
-
Image boundary
Due to the size of remote sensing (RS) images, which often exceeds the processing capacity of neural networks in terms of resolution and storage space, preprocessing operations such as cropping and scaling are typically needed before inputting the images into the neural network for training50,51. In the cropping process, we encountered the issue of boundary filling. Boundary filling refers to areas in the RS images that do not cover actual objects and are typically filled with white pixels or a fixed value. To maintain the integrity of the original image information while minimizing the negative impact of excessive white pixels on the model during training, we established a threshold. Data with a proportion of filled pixels exceeding 30% were excluded, ensuring that only the most relevant and informative data were used for training purposes.
-
Label pixel proportion
Within the context of landslide detection in RS images, one frequently encounters the small-sample detection problem. The proportion of pixels representing landslide areas in the satellite images of the region is relatively low. This poses a challenge when constructing the dataset, as individual images may contain only a minute fraction of landslides. Even for human observers, identifying landslide areas becomes arduous under such circumstances. Consequently, model training can be adversely affected. To address this issue, we established a threshold to exclude data in which the proportion of labelled pixels in a single image falls below 0.1%. As such, we ensured that the dataset primarily consists of images with a more notable representation of landslide areas, enabling more effective model training.
-
Cloud
Earthquakes and rainfall events are the primary natural hazards that can trigger landslides in mountainous areas, often resulting in extensive cloud cover in postevent satellite images. Mitigating the impact of clouds on landslide identification poses a persistent challenge in this domain. To enhance the model robustness while reducing the interference of excessive poor-quality image data during training, we opted to exclude satellite image instances in which the proportion of cloud pixels exceeds 80% and the clarity of landslide pixels is compromised. This strategic decision enabled us to incorporate only high-quality image data and enhance the model effectiveness in accurately detecting landslides triggered by earthquakes and rainfall events.
-
Seam
Imaging artefacts referred to as seams denote the observed discrepancies in brightness, colour, or texture between satellite images captured at different times or locations. These artefacts stem from variations in camera angles, lighting conditions, or ground changes during image acquisition. This issue is more prevalent in historical images and satellite images depicting underdeveloped regions. To curate our dataset effectively, we carefully excluded low-quality images exhibiting severe misalignment and blurred representations of landslide regions. This careful selection process ensured that our dataset contained pertinent information while mitigating the adverse impact of image artefacts, ultimately enhancing the robustness and accuracy of our model in landslide detection.
-
Manual inspection
After applying the automated and manual filtering procedures as detailed earlier, we conducted a meticulous visual inspection of both the retained and excluded datasets. This involved overlaying the labels onto the images and conducting a careful visual assessment to ensure the accuracy of the labels in relation to the actual features in the images. Specifically, we examined whether the labels accurately covered the corresponding landslides in the images. This thorough visual examination was crucial to validate the integrity and reliability of our dataset, thus enhancing the accuracy and quality of the data.
Model
To assess the performance and the usability of our dataset in semantic labelling tasks, we selected several deep learning models, including three renowned models commonly used in landslide identification and a deep learning network previously proposed to reinforce landslide recognition. Specifically, these models are an FCN52, U-net53, DeeplabV3+54, and MFFENet55.
Data Records
The CAS Landslide Dataset has been uploaded in Zenodo56. It is designed to be open and accessible to all landslide researchers and professionals. The data associated with this work can be accessed from the repository, which contains a project file labelled CAS Landslide Dataset, along with a README file, a study areas shp file and 16 zip files representing the different subdatasets. Each subdataset consists of three subfolders: img, label, and mask. It is important to note that in our mask files, landslide areas are labelled as 1, while non-landslide areas are labelled as 0.
Each subdataset within the dataset consists of three folders: img, label, and mask. All data within the dataset are in TIFF format and have a resolution of 512 × 512 pixels. To provide an overview of the key parameters of the dataset, they are compiled in Table 4, which is included and uploaded alongside the dataset.
Technical Validation
For training purposes, the DeepLabV3+, U-net, and MFFENet models utilize ResNet50 as the underlying backbone network, and FCN utilizes VGG16 as the backbone network. In regard to the model parameter settings, our implementation utilized PyTorch as the framework, employing the SGD optimizer with a learning rate of 0.01, a momentum of 0.9, and a weight decay of 0.0005. Given that landslide identification entails a task with imbalanced data samples, we utilized the Dice loss as our loss function. Notably, the model was trained on one NVIDIA Tesla V100-SXM2 32 GB video card.
Landslide extraction from remote sensing imagery is commonly approached as a task of semantic segmentation, wherein the aim is to precisely categorize pixels into two distinct classes: foreground and background. Within this framework, the assessment of segmentation performance entails the quantification of the intersecting region, denoting the count of veritable positive (TP) pixels, and the amalgamation, signifying the cumulative sum of TP, false positive (FP), and false negative (FN) pixels. Concretely, TP corresponds to accurately identified landslide pixels, FP denotes erroneously classified landslide pixels (belong to the non-landslide), and FN represents erroneously classified non-landslide pixels (belong to the landslide). We utilize six typical metrics: namely, precision, recall, F1 score, IoU, mIoU and Overall accuracy (OA). More specifically, precision reflects the false alarm rate, recall reflects the miss alarm rate of the model. Whereas F1 takes both indices into account; therefore, a larger score indicates a better model. loU represents the overlap rate of the change class on the detection map and the ground truth. MIoU is the average IoU across all classes. It calculates the IoU for each class and then takes the mean over all classes. MIoU provides a comprehensive measure of the detection performance across categories. OA (Overall Accuracy) is the overall accuracy of pixel classification. It reflects the proportion of all samples that are correctly classified. A higher OA indicates more accurate classification results. These six metrics can be calculated as follows:
Precision:
Recall:
F1 score:
IoU:
mIoU:
OA:
TP: True Positives
TN: True Negatives
FP: False Positives
FN: False Negatives
n: Number of Classes
Validation of the CAS landslide dataset
The CAS Landslide Dataset was primarily built using UAV and SAT imagery data obtained from 9 distinct regions. To validate the quality of the dataset, we followed the approach proposed by Géron A. and randomly split each subdataset into training and validation sets at a 7:3 ratio57. Next, we conducted model training on the carefully filtered dataset, which includes data from UAV, SAT, and combined UAV and SAT sources. The results for our datasets are listed in Table 5.
In our three datasets, the FCN and Unet models attained commendable scores, with mIoU values ranging from 72% to 78% and F1 scores ranging from 82% to 87%. The intricate network models, namely, DeepLabv3+ and MFFENet, yielded impressive outcomes, exhibiting an mIoU value ranging from 82% to 90% and an F1 score ranging from 89% to 94%. These findings accentuate the robustness and potential of our datasets. Upon horizontal comparison of the three datasets, it became apparent that the UAV dataset yielded the highest scores across all models. In contrast, the satellite dataset yielded the lowest scores, suggesting that its quality may not be on par with the UAV dataset. This discrepancy in the model performance could be attributed to the lower quality of satellite imagery than that of UAV imagery. Significantly, when considering the comprehensive unification of UAV and satellite datasets, the models achieved favourable scores. This demonstrates the robustness of our dataset in the domain of unmanned aerial vehicles and satellite imagery while providing valuable data support for landslide recognition employing multisensor images. Furthermore, it facilitates the production of subsequent large datasets and the training of significant models.
Validation of dataset quality control
In this section of the experiment, the quality control methods mentioned in the Building the dataset section are validated. The original SAT dataset used originates from an unfiltered SAT dataset, while the SAT dataset is consistent with the one used in the Validation of the CAS Landslide Dataset section, which is the dataset screened and ultimately published. The experimental results are presented in Table 6 below. The analysis of the datasets to be released and the original version revealed substantial disparities in their performance. The SAT dataset outperformed the original dataset across multiple vital metrics, including precision (74.275% vs. 72.365%), recall (89.187% vs. 88.382%), IoU (68.137% vs. 66.275%), F1 score (89.675% vs. 88.759%), mIoU (82.397% vs. 81.233%), and overall accuracy (96.881% vs. 96.457%). These outcomes indicate that the SAT dataset provides more precise and dependable labels, resulting in a superior segmentation performance. We eliminated a total of 1245 images, yet the model performance was actually improved. Specifically, the IoU metric, directly associated with landslide identification, increased by 1.862%, while the F1 score increased by 0.916%. This demonstrates the overall effectiveness of our screening method, resulting in not only computational savings but also accuracy enhancement.
Comparative experiment of the published landslide datasets for deep learning
To showcase the exceptional quality and robustness of our dataset, we compared it with previously published datasets. We carefully selected a validation set comprising 2119 images of UAV and satellite data from the region of Moxitaidi, while the remaining data were categorized into UAV and satellite classes and reconstituted as a training set. We obtained the RGB data from the Bijie Landslide Dataset58,59, which is a high-precision aerial imagery and interpretation dataset of landslide and debris flow disasters in Sichuan and surrounding areas (Sichuan and Surrounding Areas Landslide Dataset)60, HR-GLDD, which is a globally distributed high-resolution landslide dataset61,62, and Landslide4Sense63. To ensure consistency during training, we standardized the image to a resolution of 512 × 512 pixels. Table 7 presents our experimental results.
The data presented in this table reveals unexpected findings. Notably, the dataset encompassing Sichuan and its surrounding areas, despite comprising only 59 data samples, significantly outperforms the Bijie dataset, HR-GLDD and the dataset of the AI4RS group and provides a performance that approaches that of our SAT dataset in the Moxitaidi detection task. In comparison to the three other publicly available datasets, our dataset exhibits superior performance in terms of IoU, F1 score, and mIoU. These results highlight its exceptional capability in accurately identifying landslides within the designated task area. The exceptional training outcomes of the dataset for Sichuan and its surrounding areas can be attributed to several factors. First, the training set covers a geographically similar area to the verification set, both situated in Sichuan province, China. Second, the aerial images in the training set exhibit a commendable level of quality. Among the three datasets created the SAT+UAV dataset is notable, exhibiting impressive results that show the robustness of utilizing multisource data when managing unknown images. Moreover, a comparison between the UAV and SAT datasets reveals a positive correlation between the quality of the training set and the ability to identify landslides. Interestingly, despite the inferior quality of the SAT dataset in prior baseline analysis, this experiment yields results on par with those obtained with the superior Sichuan and Surrounding Areas Landslide Dataset. This suggests that the limitations of the satellite dataset primarily stem from the quality of the images themselves. It is imperative to emphasize that, for the datasets involved in this comparison, we solely employed RGB optical images for training, without incorporating additional data such as DEM data to aid in the training process. Despite containing a total of 1785 images, it is worth noting that the HR-GLDD dataset primarily consists of 1119 images allocated to the training set, while the remaining images are divided into test and verification sets.
Usage Notes
The CAS Landslide Dataset offers ultrahigh-resolution, multimodal, and diverse scenarios encompassing various terrains, climates, and vegetation changes. However, it is crucial to acknowledge its limitations. Specifically, the quantity of our dataset for deep learning tasks is still relatively small, and there are significant regional differences among certain subdatasets. These differences should be considered when training and utilizing the CAS Landslide Dataset to account for their potential impact on results. Furthermore, it is important to consider the limitations of the dataset, such as the spatial resolution ranging from 0.2–5 m and the data derived from SAT and UAV sources when interpreting results and evaluating the performance of the CAS Landslide Dataset.
Code availability
The code for cropping, generating dataset labels is publicly available: https://github.com/Aizu0/CAS-Landslide-Dataset-production-code.
References
Guzzetti, F. et al. Landslide inventory maps: New tools for an old problem. Earth-Science Reviews 112, 42–66, https://doi.org/10.1016/j.earscirev.2012.02.001 (2012).
Ouyang, C. et al. Insights from the failure and dynamic characteristics of two sequential landslides at Baige village along the Jinsha River, China. Landslides 16, 1397–1414 (2019).
Liu, J., Wu, Y. & Gao, X. Increase in occurrence of large glacier-related landslides in the high mountains of Asia. Scientific Reports 11, 1635, https://doi.org/10.1038/s41598-021-81212-9 (2021).
Gariano, S. L. & Guzzetti, F. Landslides in a changing climate. Earth-Science Reviews 162, 227–252, https://doi.org/10.1016/j.earscirev.2016.08.011 (2016).
Wang, F. et al. Climate change: Strategies for mitigation and adaptation. The Innovation Geoscience 1, 100015, https://doi.org/10.59717/j.xinn-geo.2023.100015 (2023).
Wei, K. et al. Reflections on the catastrophic 2020 Yangtze River Basin flooding in southern China. The Innovation 1 (2020).
Kirschbaum, D. B., Adler, R., Hong, Y., Hill, S. & Lerner-Lam, A. A global landslide catalog for hazard applications: method, results, and limitations. Natural Hazards 52, 561–575, https://doi.org/10.1007/s11069-009-9401-4 (2010).
Van Den Eeckhaut, M. & Francisco, H. D. D. Landslide inventories in Europe and policy recommendations for their interoperability and harmonisation-A JRC contribution to the EU-FP7 SafeLand project. (2012).
Zhao, C. & Lu, Z. Remote Sensing of Landslides—A Review. Remote Sensing 10, https://doi.org/10.3390/rs10020279 (2018).
Handwerger, A. L. et al. Generating landslide density heatmaps for rapid detection using open-access satellite radar data in Google Earth Engine. Nat. Hazards Earth Syst. Sci. 22, 753–773, https://doi.org/10.5194/nhess-22-753-2022 (2022).
Mohan, A., Singh, A. K., Kumar, B. & Dwivedi, R. Review on remote sensing methods for landslide detection using machine and deep learning. Transactions on Emerging Telecommunications Technologies 32, e3998, https://doi.org/10.1002/ett.3998 (2021).
Tehrani, F. S., Calvello, M., Liu, Z., Zhang, L. & Lacasse, S. Machine learning and landslide studies: recent advances and applications. Natural Hazards 114, 1197–1245, https://doi.org/10.1007/s11069-022-05423-7 (2022).
Korup, O. & Stolle, A. Landslide prediction from machine learning. Geology Today 30, 26–33, https://doi.org/10.1111/gto.12034 (2014).
Ma, Z., Mei, G. & Piccialli, F. Machine learning for landslides prevention: a survey. Neural Computing and Applications 33, 10881–10907, https://doi.org/10.1007/s00521-020-05529-8 (2021).
Ghorbanzadeh, O., Xu, Y., Ghamisi, P., Kopp, M. & Kreil, D. Landslide4Sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection. IEEE Transactions on Geoscience and Remote Sensing 60, 1–17, https://doi.org/10.1109/TGRS.2022.3215209 (2022).
Bui, D. T., Tsangaratos, P., Nguyen, V.-T., Liem, N. V. & Trinh, P. T. Comparing the prediction performance of a Deep Learning Neural Network model with conventional machine learning models in landslide susceptibility assessment. CATENA 188, 104426, https://doi.org/10.1016/j.catena.2019.104426 (2020).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote sensing of Environment 202, 18–27 (2017).
Drusch, M. et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote sensing of Environment 120, 25–36 (2012).
Online, S. SENTINEL-2 products, https://sentinel.esa.int/web/sentinel/missions/sentinel-2/data-products.
Center, U. E. R. O. a. S. E. Landsat products Data Citation, https://www.usgs.gov/centers/eros/data-citation/.
Google. Google geo guidelines, https://www.google.com/permissions/geoguidelines/.
Planet Lab. Planet education and research program, https://www.planet.com/markets/education-and-research/.
Program, D. G. O. D. Satellite images of Palu and Donggala, Sulawesi, Indonesia. https://www.digitalglobe.com/opendata/indonesia-earthquake-tsunami/ (2021).
Program, D. G. O. D. Satellite images of Indonesian island of Lombok https://www.maxar.com/open-data/indonesia-earthquake (2018).
Japan, G. I. A. O. Hokkaido Iburi-Tobu earthquake https://www.gsi.go.jp/BOUSAI/H30-hokkaidoiburi-east-earthquake-index.html (2018).
Beijing Lanyu Fangyuan Technology Co. Ordering process webpage http://kosmos-imagemall.com/.
CRESDA. China Centre for Resources Satellite Data and Application, https://data.cresda.cn/#/2dMap.
Sichuan Basic Geographic Information Center of the Ministry of Natural Resources. Sichuan Geomatics Center, https://www.webmap.cn/tempStore.do?method=siteTabView&storeId=25&tabId=839&sss=3.
National Catalogue Service For Geographic Information. Sichuan Geomatics Center, https://www.webmap.cn/mapDataAction.do?method=forw&resType=8.
Yang, H. et al. Rainfall-induced landslides and debris flows in Mengdong Town, Yunnan Province, China. Landslides 17, 931–941, https://doi.org/10.1007/s10346-019-01336-y (2020).
Zhao, B. et al. Preliminary analysis of some characteristics of coseismic landslides induced by the Hokkaido Iburi-Tobu earthquake (September 5, 2018), Japan. CATENA 189, 104502, https://doi.org/10.1016/j.catena.2020.104502 (2020).
Zhao, B., Liao, H. & Su, L. Landslides triggered by the 2018 Lombok earthquake sequence, Indonesia. CATENA 207, 105676, https://doi.org/10.1016/j.catena.2021.105676 (2021).
Zhao, B., Wang, Y., Li, W., Lu, H. & Li, Z. Evaluation of factors controlling the spatial and size distributions of landslides, 2021 Nippes earthquake, Haiti. Geomorphology 415, 108419, https://doi.org/10.1016/j.geomorph.2022.108419 (2022).
Zhao, B. et al. Insights into the mobility characteristics of seismic earthflows related to the Palu and Eastern Iburi earthquakes. Geomorphology 391, 107886, https://doi.org/10.1016/j.geomorph.2021.107886 (2021).
Qian, X. et al. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sensing 12 (2020).
Juan, L. & Oubong, G. in 2010 2nd International Conference on Image Processing Theory, Tools and Applications. 495–499.
Zhu, X. X. et al. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geoscience and Remote Sensing Magazine 5, 8–36, https://doi.org/10.1109/MGRS.2017.2762307 (2017).
Chen, J., Sun, J., Li, Y. & Hou, C. Object detection in remote sensing images based on deep transfer learning. Multimedia Tools and Applications 81, 12093–12109, https://doi.org/10.1007/s11042-021-10833-z (2022).
Jia, X. in 2017 29th Chinese Control And Decision Conference (CCDC). 4730–4735.
Xie, F., Shi, M., Shi, Z., Yin, J. & Zhao, D. Multilevel Cloud Detection in Remote Sensing Images Based on Deep Learning. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 10, 3631–3640, https://doi.org/10.1109/JSTARS.2017.2686488 (2017).
Shao, Z., Pan, Y., Diao, C. & Cai, J. Cloud Detection in Remote Sensing Images Based on Multiscale Features-Convolutional Neural Network. IEEE Transactions on Geoscience and Remote Sensing 57, 4062–4076, https://doi.org/10.1109/TGRS.2018.2889677 (2019).
Zhu, J. & Kelly, T. Seamless Satellite-image Synthesis. Computer Graphics Forum 40, 193–204, https://doi.org/10.1111/cgf.14413 (2021).
Markovitz, O. & Segal, M. in 2021 17th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob). 351–356.
Gudavalli, C. R., E.;Nataraj, L.;Chandrasekaran, S.;Manjunath, B. S.;Ieee. in 2022 IEEE/CVF Conference on computer vision and pattern recognition workshops, CVPRW 2022 1–11 (2022).
Zhuang, F. et al. A Comprehensive Survey on Transfer Learning. Proceedings of the IEEE 109, 43–76, https://doi.org/10.1109/JPROC.2020.3004555 (2021).
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K. Q. & Ieee. in 30TH IEEE conference on computer vision and pattern recognition (CVPR 2017) 2261–2269 (2017).
Yao, C., Luo, X., Zhao, Y., Zeng, W. & Chen, X. in 2017 3rd IEEE International Conference on Computer and Communications (ICCC). 1947–1955.
Mehmood, M., Shahzad, A., Zafar, B., Shabbir, A. & Ali, N. Remote Sensing Image Classification: A Comprehensive Review and Applications. Mathematical Problems in Engineering 2022, 5880959, https://doi.org/10.1155/2022/5880959 (2022).
Wang, C., Xin, C. & Xu, Z. A novel deep metric learning model for imbalanced fault diagnosis and toward open-set classification. Knowledge-Based Systems 220, 106925, https://doi.org/10.1016/j.knosys.2021.106925 (2021).
Fan, J., Han, M. & Wang, J. Single point iterative weighted fuzzy C-means clustering algorithm for remote sensing image segmentation. Pattern Recognition 42, 2527–2540, https://doi.org/10.1016/j.patcog.2009.04.013 (2009).
Li, Y., Zhang, H., Xue, X., Jiang, Y. & Shen, Q. Deep learning for remote sensing image classification: A survey. WIREs Data Mining and Knowledge Discovery 8, e1264, https://doi.org/10.1002/widm.1264 (2018).
Long, J., Shelhamer, E., Darrell, T. & Ieee in 2015 IEEE conference on computer vision and pattern recognition (CVPR) 3431–3440 (2015).
Ronneberger, O., Fischer, P. & Brox, T. in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. (eds Navab, N., Hornegger, J., Wells, W. M. & Frangi, A. F.) 234–241 (Springer International Publishing).
Chen, L. C. E., Zhu, Y. K., Papandreou, G., Schroff, F. & Adam, H. in Computer vision - ECCV 2018, PT VII Vol. 11211 833–851 (2018).
Xu, Q. et al. MFFENet and ADANet: a robust deep transfer learning method and its application in high precision and fast cross-scene recognition of earthquake-induced landslides. Landslides 19, 1617–1647, https://doi.org/10.1007/s10346-022-01847-1 (2022).
Xu, Y. et al. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Zenodo https://doi.org/10.5281/zenodo.10294997 (2023).
Géron, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow. (“O’Reilly Media, Inc.”, 2022).
Ji, S., Yu, D., Shen, C., Li, W. & Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 17, 1337–1352, https://doi.org/10.1007/s10346-020-01353-2 (2020).
Ji, S. P., Yu, D. W., Shen, C. Y., Li, W. L. & Xu, Q. Bijie Landslide Dataset, http://gpcv.whu.edu.cn/data/ (2020).
Zeng, C., Cao, Z., Su, F., Zeng, Z. & Yu, C. High-precision aerial imagery and interpretation dataset of landslide and debris flow disaster in Sichuan and surrounding areas. Science Data Bank https://doi.org/10.11922/sciencedb.j00001.00222 (2021).
Meena, S. R. et al. HR-GLDD: a globally distributed dataset using generalized deep learning (DL) for rapid landslide mapping on high-resolution (HR) satellite imagery. Earth Syst. Sci. Data 15, 3283–3298, https://doi.org/10.5194/essd-15-3283-2023 (2023).
Meena, S. R. et al. HR-GLDD: A globally distributed high resolution landslide dataset. Zenodo https://doi.org/10.5281/zenodo.7189381 (2022).
Ghorbanzadeh, O., Xu, Y., Ghamisi, P., Kopp, M. & Kreil, D. LandSlide4Sense, https://www.iarai.ac.at/landslide4sense/ (2022).
Acknowledgements
This research is funded by the Strategic Priority Research Program of CAS (Grant No. XDA23090303), the NSFC (Grant No. 42022054), the Sichuan Science and Technology Program (Grant No. 2022YFS0543, 2022YFG0140) and the Youth Innovation Promotion Association (Grant No. Y201970). Thanks for the raw data sharing from Sichuan Geomatics Center and Dr. Fenghuan Su.
Author information
Authors and Affiliations
Contributions
Yulin Xu collected the image data and Bo Zhao provided landslide interpretation data in Palu, Lombok, Tiburon Peninsula, Hokkaido Iburi-Tobu area. Yulin Xu and Yutao Luo made labels and the dataset. Chaojun Ouyang contributed to conceptualization. Yulin Xu, Chaojun Ouyang, Qingsong Xu provided methodology support. Chaojun Ouyang and Qingsong Xu contributed to reviewing. Dongpo Wang and Bo Zhao assisted in writing review and editing. Yutao Luo checked all extracted data. Yulin Xu completed the experiment, analyzed the results, and wrote the first draft. Chaojun Ouyang and Dongpo Wang took charge of the Supervision. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, Y., Ouyang, C., Xu, Q. et al. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Sci Data 11, 12 (2024). https://doi.org/10.1038/s41597-023-02847-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02847-z
