
Abstract
Quantum annealing provides a way of solving optimization problems by encoding them as Ising spin models which are implemented using physical qubits. The solution of the optimization problem then corresponds to the ground state of the system. Quantum tunneling is harnessed to enable the system to move to the ground state in a potentially high non-convex energy landscape. A major difficulty in encoding optimization problems in physical quantum annealing devices is the fact that many real world optimization problems require interactions of higher connectivity, as well as multi-body terms beyond the limitations of the physical hardware. In this work we address the question of how to implement multi-body interactions using hardware which natively only provides two-body interactions. The main result is an efficient circuit design of such multi-body terms using superconducting flux qubits in which effective N-body interactions are implemented using N ancilla qubits and only two inductive couplers. It is then shown how this circuit can be used as the unit cell of a scalable architecture by applying it to a recently proposed embedding technique for constructing an architecture of logical qubits with arbitrary connectivity using physical qubits which have nearest-neighbor four-body interactions. It is further shown that this design is robust to non-linear effects in the coupling loops, as well as mismatches in some of the circuit parameters.
Similar content being viewed by others

Introduction
Solving machine learning and optimization problems by casting them as an Ising spin glass, and then using a physical device to take advantage of quantum fluctuations has been a subject of much recent interest.1,2,3,4,5,6,7,8,9 This interest is due in a large part to demonstration of the underlying principles of quantum annealing in condensed matter systems10 and the more recent development of a programmable annealing device by D-Wave Systems Inc.11, 12
Although the niobium superconducting quantum interference device (SQUIDs) which are the basic building blocks of the D-Wave annealer display limited coherence, it has been used to demonstrate that quantum tunneling is an exploitable resource in a computational setting.13 Furthermore the development of annealers using aluminum SQUIDs with orders-of-magnitude longer coherence lifetimes14 may enable further improvements in the computational performance of future quantum annealers.
Mapping real-world problems, or indeed problems with a similar difficulty to interesting real-world problems, to a programmable annealer is a major practical challenge.15, 16 It is known, for example, that even though finding the ground state of the native so-called Chimera graph of the D-Wave device is non-deterministic polynomial time (NP)-hard, typical randomly generated instances on this graph are actually easy to solve by simulated annealing type algorithms.17 Because it is non-planar, minor embedding can be used to map a fully connected graph to the Chimera, although at a significant overhead.7, 18
The NP-completeness of finding the ground state of an arbitrary (two-body) Ising spin glass and therefore a Chimera graph guarantees that any NP-complete problem can be mapped to finding the ground state of a Hamiltonian which is a subgraph of a Chimera with polynomial overhead. For examples of how this can be done in practice, see ref. 19,20,21,22. However, there is no indication that this approach is optimal. For problems which require higher order interactions a mapping must be found from a Higher Order Binary Optimization to a Quadratic Unconstrained Binary Optimization problem.20 Typically this is done iteratively, with an N-body interaction being reduced to a two-body interaction using a complete graph on N logical bits and (N−2) ancilla bits.23 This necessitates (N−1) (2N−3) two-body couplers.
In this letter, and a related work24 we examine an alternative architecture, in which higher order problems can be expressed natively by coupling logical qubits to a group of ancillae. This letter focuses on native circuit implementations of this architecture, while ref. 24 examines how the same principles can be applied within the Chimera architecture.
Implementing a single logical clause using the methods of ref. 19, 20, would require the construction of a penalty function (up to an unimportant energy offset) on a set of logical qubits, where the penalty is 0 if the clause is satisfied and greater than or equal to a penalty weight g if the clause is violated. In the ideal case g should be infinite, but in practice its maximal value is limited by the hardware.
This function gives a generally different penalty to all “wrong” answers (i.e., the ones which violate the clause). Hence the ground state of sums of more than one of these penalty functions (i.e., a sum of multiple penalty functions on overlapping subsets of bits) is meaningful if there exists a solution which violates zero or only one of the clauses. In the 3-SAT example in ref. 19, this kind of superposition is acceptable because the problem is cast as a decision problem of whether a state exists which satisfies all of the penalties. However under a simple generalization of the problem to max-3-SAT, where we ask what is the choice which violates the least number of the constraints, this kind of superposition no longer yields a valid expression of the problem.
Our proposal on the other hand is to construct a function which reproduces the spectrum of a high order penalty term, which is equal to zero if the clause is satisfied and exactly equal to the penalty weight g if the clause is violated. Because all states which violate the clause are penalized equally, the ground state of a sum of an arbitrary number of such terms will in fact be the state which violates the smallest number of clauses, regardless of how many can be simultaneously satisfied. In general it may also be interesting to penalize different violations differently, (i.e., weighted max-k-SAT) but in a controlled way; our method also supports this.
As an example of how these techniques can be used, we explicitly show how to construct superconducting circuits which realize the fully connected architecture recently proposed in ref. 25 as an alternative to the Chimera graph with minor embedding. We show that this architecture allows us an additional freedom in choosing the annealing path which is not a feature in the current D-Wave device architecture. While a recent numerical study26 has cast doubt on whether this method of embedding problems will perform better than the method proposed in ref. 18, it does still have some novel features such as a greater richness of potential decoding methods.
For simplicity, and because it is what is required for the architecture in ref. 25, we will restrict ourselves to discussing how to reproduce the classical spectrum of multi-body operators of the form \({{\cal H}_N} = {{\it{J}}_N}\sigma _1^z \ldots \sigma _N^z\). Such multi-body terms are important for many applications. For example, it is known that spin glasses undergo a transition in complexity when moving from two-body couplings to multi-body terms of order 3 and higher.27,28,29 In this transition the number of extrema of the energy landscape growths from a polynomial to an exponential function in the number of spins, where at the same time a banded structure in energy appears for saddle points of various orders.28 The latter has various implications for example for energy landscapes of deep neural networks which are related to spin glasses and where the order of the multi-body term of the spin glass is given by the depth of the network.30, 31 This transition is in terms of the typical energy landscape structure. The fact that the 2-local Ising model is universal in the sense of being able to simulate classical Hamiltonians32 means that it could mimic the landscape of any Hamiltonian.
Results
As discussed above, in many foreseeable applications for adiabatic quantum computation, one needs implementations of interactions with multi-body terms. These interactions are of the type
However, the architecture used in quantum annealing devices generally only allows for two-body interactions, leading to Hamiltonians of the form
where the first sum is taken over all adjacent qubits in the connectivity graph of the architecture.
We now describe a construction which reproduces the low-energy spectrum of Eq. (1) using a Hamiltonian with two-body interactions of the form of Eq. (2) including additional ancilla qubits. This is first done on a theoretical level. In the next section we present an efficient circuit design of this construction.
The Hamiltonian which reproduces the spectrum of the N-body term in Eq. (1) constitutes N logical qubits which are fully connected and an additional N ancilla qubits which are connected to all logical qubits but not amongst each other. This is illustrated in Fig. 1 for the case of N = 4. The reason behind this construction will become apparently below. However, we can already deduce that if this construction is to reproduce the low energy spectrum of Eq. (1), then by symmetry the logical qubits must all have equal magnetic fields, h, as well as equal two-body couplings, J, amongst each other. The same is true for the two-body couplings between the logical qubits and the ancillas, here denoted by J a. This leads to the following Hamiltonian

Graph showing the connectivity of the Hamiltonian Eq. (3) for N = 4. The green vertices represent the logical qubits while the red vertices represent the ancillas. The logical qubits are fully connected amongst themselves with two-body couplings, represented as edges, of strength J (black). Each ancilla is connected to every logical qubit with two-body couplings of strength J a (blue)
This construction relies on symmetry to effectively count the number of logical bits in the up orientation. By symmetry, the effect of the logical bits on the ancillas only depends on the number of logical bits in this orientation and not on their arrangement. What is left to do is to pick ancilla fields such that they have a different unique ground state configuration depending on this number, and that the energy of each of these configurations is the same. Once this is accomplished, the coupling can be realized by adding additional fields to the ancillas which we will denote by q i ≠ 0. The condition that each number of logical bits in the up orientation corresponds to a single ancilla configuration can be accomplished (assuming J a > 0) by choosing \(h_i^a = - {J^a}\left( {2i - N} \right) + {q_i}\) with 0 < q i < J a . The yet to be defined term q i determines an effective energy landscape depending only on the number of logical bits which are up. To match the energy landscape of (1), one should choose
with any q 0 which satisfies |J N | ≪ q 0 < J a and |J N | ≪ J a−q 0 < J a. The Hamiltonian (Eq. (3)) with coupling assignments (Eq. (4)), up to an overall constant energy offset, precisely reproduces the low energy spectrum of the Hamiltonian (Eq. (1)). For more details on this construction, see Appendix 1. This is assured for the part of the spectrum with \(\left| {{{\cal H}_N}} \right| \ll {J^a}\). Once \(\left| {{{\cal H}_N}} \right| \sim {J^a}\) the ancillae will no longer be in their corresponding ground state and the construction breaks down. Thus the range of the spectrum which can be reproduced using the above construction depends on the maximal coupling strength of the quantum annealing device in question. Note that the strongest field which needs to be applied for a coupler on N spins is \(h_N^a \approx N{J^a} - {q_0}\).
If one only cares that the ground state is correct, and does not want to sample over a thermal distribution, than the conditions on the strength of |J N | which can be supported can be relaxed to |J N | < q 0 < J a and |J N | < J a−q 0 < J a. In the case where thermal sampling is desired, exactly how much less than min (J a−q 0, q 0) |J N | has to be dependent on both the temperature of the sampling and the accuracy desired. The probability of a coupler having its ancillae in an excited state will in this case be roughly proportional to exp (−min(j a−q 0, q 0)/T).
The above construction can be used for example to minor embed multi-body terms in already existing architectures such as the one produced by D-wave Systems Inc., as we show in a related work on message decoding problems on the D-wave device.24 In this case the fully connected graph shown in Fig. 1 must be obtained from a minor embedding18 in the Chimera graph. This is done using strong minor embedding couplings of strength J m to “identify” qubits. This introduces a third energy scale into the problem and one must ensure that |J N | ≪ J a≪ J m.
Circuit for implementing of the multi-body interactions—In the previous section we presented an implementation which reproduces the low energy spectrum of multi-body terms using a system which only has two-body interactions. While it is possible to use minor embedding techniques to implement the above construction in already existing architectures such as D-wave, it can be used to design a purpose-built circuit for multi-body terms. As we will show below, the fact that both logical qubits as well as ancillae have all couplings of the same strength permits a very efficient circuit implementation.
In particular, in this section we present a circuit implementation of a unit cell consisting of four logical qubits coupled through a four-body interaction. In the following section we then show how to use the unit cell to build a scalable architecture.
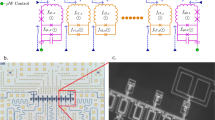
To implement the fully connected graph between the logical qubits, as well as the coupling between the logical qubits and the ancillae, we first inductively couple all of the qubits, both logical and ancilla, to a large loop. We demonstrate later that this arrangement produces the desired graph up to the relevant order in perturbation theory. This loop is the outer loop in Fig. 2. This coupler however also produces unwanted coupling terms between the ancillae. To cancel these off, we must add an additional loop (the inner loop in Fig. 2) which can be biased with equal magnitude and opposite sign as the outer coupling loop to cancel the undesirable coupling between the ancillas.

Drawing of the circuit which implements the low energy spectrum of a four-body coupler. The 4-logical qubits appear as the 4 (green) circuits on the perimeter, with a large loop (gray) coupling them together. Further in is a set of 4 ancilla qubits (red), which in turn themselves are coupled by an inner most loop (gray), which counteract the couplings induced from the outer loop. Note that the qubits are compound-compound Josephson junction circuits, while the couplers are simply compound
The circuit design shown in Fig. 2 requires that more than two qubits can be coupled using the same rf-SQUID coupler design as presented in ref. 33. We demonstrate that to the same relevant order as used in the expansion in that paper, a group of qubits all inductively coupled to the same superconducting circuit realizes a fully connected two-body graph of couplers between all of the qubits. Following,33 the energy for such a circuit with a coupler c and n qubits including Josephson and magnetic terms is
where \({\it{\vec \phi }}\) is a vector of the junction phases, \({{\it{\vec \phi }}^x}\) is the phase introduced by an external flux. The inductance matrix \({\Bbb L}\) is given by,
This expression can easily be inverted to obtain the term \({{\Bbb L}^{ - 1}}\) in the above expression up to O (M 2). Following,33 we choose the bias fluxes such that,
where \(\phi _c^{\left( 0 \right)}\) is the phase difference of the coupler due to its self induced flux, as explained in ref. 33. It is now worth noting that if we choose any pair of qubits i ≠ j and separate out only terms in Eq. (5) which contain φ i and/or φ j , these equations will be identical to those found in ref. 33. These equations can therefore be solved independently in exactly the same way that was done in that paper resulting in,
which is exactly the formula of a set of couplings realizing a fully connected graph between all of the qubits. These couplings are collectively tuneable through the function \(F\left( {\phi _c^x} \right)\) whose exact form is not important for our purposes, but is identical to the one found in ref. 33. They cannot however be addressed individually. For our design we desire all L 1 = L 2 = … = L and M 1c = M 2c = … = M. However, as we will show, it is possible to tune for some types of imperfections in these values for a real device.
Effect of higher order mutual inductance terms– While our calculations to demonstrate that this device will work are based on the truncation of the potential energy at O(M 2), in real devices one may want to make the coupling strong enough that these terms are not completely negligible. Fortunately, due to the high symmetry of our construction, spurious couplings between the logical qubits, or the ancillas, or combinations of the two must be symmetric under permutations of the logical bits, which is the exact same symmetry as the effective coupling which the device realizes. Moreover, the effect of non-linear couplings from higher orders in M being included is effectively fixed with respect to the fields which are used to control the effective multi-body coupling, so a calibration at one coupling value will remain valid even if a different Hamiltonian is implemented. In a real device the effects of these spurious couplings need only to be measured once with appropriate compensating fields applied.
Because, for J a > 0 the logical states will all have the same energy, no compensation fields are necessary to deal with higher order (in M/L) terms arising from the outer coupling loop. The same cannot be said for the inner coupling loop however.
We now make the qualitative discussion in the previous two parargraphs quantitaitive by examining the effect of order M 3 terms on the four-body circuit numerically. We will restrict ourselves to discussion of terms involving three distinct mutual inductances, based on the fact that terms associated with (M ic )2 M jc will come in as one and two body terms because they only involve interactions between qubit pairs which can easilty be compensated. The remaining term will be proportional to \({E^{\left( 3 \right)}}\mathop {\sum}\nolimits_{i \ne j \ne k} {\sigma _i^z\sigma _j^z\sigma _k^z} \), where |E (3)| ∝ M 3 is the energy scale associated with three body terms. We now determine how strong such terms can be without causing the coupler to fail. We define failure as the case when a ‘spurious’ state (i.e., one in which the total magnetization of the logical and ancilla qubits is not zero) has a lower energy than the highest energy non-spurious state. Assuming that E (3) and the energy scale associated with the two body terms E (2) have the same sign, through numerical matrix analysis, we find that these higher order terms can be tolerated as long as \(\left| {\frac{{{E^{(3)}}}}{{{E^{(2)}}}}} \right|\) ≲ 8.33% if J a > 0, |J N | = 0.25 J a and |q 0| = 0.5 J a, or \(\left| {\frac{{{E^{(3)}}}}{{{E^{(2)}}}}} \right|\) ≲ 16.7% if |J N | ≪ J a. If the system can somehow be engineered such that \(\frac{{{E^{\left( 3 \right)}}}}{{{E^{(2)}}}}\) < 0, than this number jumps to 37.5% in the case where |J N | = 0.25 J a and 50% if |J N | ≪ J a. In either case, the numerical values that we have extracted demonstrate that even if the terms at the next highest perturbative order are non-negligible, or in fact relatively strong, they can be removed by applying compensating fields.
Robustness to process variability of mutual inductance– Our realization of a multi-qubit fully connected effective two-body graph is based on an experimentally proven design for a single coupler.33 For this reason many of the design problems have already been solved.34 One issue which will affect our design differently is mismatches in the inductive couplings between the qubits and the loops. For a single coupler between two qubits it is not important for the mutual inductances to be matched since the coupling strength is simply proportional to a product of the mutual inductances between the two qubits and the coupler. For our designs on the other hand, mismatches in the mutual inductances on the outer coupling loop will lead to different coupling strengths which can be viewed as effective spurious couplings between the logical bits and/or ancillae.
Let us first consider the effect of mismatches in mutual inductances involving the ancilla qubits. The effect of these will be two-fold. Firstly, mismatched inductances will lead to imperfect cancellation of the couplings between the ancillae. If these spurious couplings are weak, they will not affect which ancillae are flipped, and just add a predictable (i.e., independent of which exact logical bits are up) energy penalty in exactly the same way as the ancilla fields which are used to enforce the effective couplers. Secondly, mismatches in these couplings will mean that the couplings between each ancilla and the logical qubits will be different (although identical for a given ancilla). Again, if the mismatches are small these can be corrected for with a slight modification to the ancilla fields.
We have shown above that small mismatches in the mutual inductances between the ancilla and the coupling loops are rather benign and can be easily corrected for. Let us now consider mismatches in the inductances between the logical bits and the outer coupling loops. These will lead firstly to effective couplings between logical bits and secondly to mismatches in the couplings between logical bits and ancillae. The former will introduce a term of the form \(\mathop {\sum}\nolimits_i {\frac{{\Delta {M_i}}}{{{M_i}}}} {J^a}\sigma _i^z\mathop {\sum}\nolimits_{j \ne i} {\sigma _j^z} \) while the second of these terms will be of the form \(\mathop {\sum}\nolimits_i {\frac{{\Delta {M_i}}}{{{M_i}}}} {J^a}\sigma _i^z\mathop {\sum}\nolimits_j {\sigma _{j,a}^z} \). If we assume that the mismatches in the mutual inductances are small enough that they do not change the order in which the ancillae flip, then the ancillae states just represent a count of the logical spins which are up and the second of these terms can be written as \( - \mathop {\sum}\nolimits_i {\frac{{\Delta {M_i}}}{{{M_i}}}} {J^a}{\rm{sgn}}\left( {{J_a}} \right)\sigma _i^z\left( {\mathop {\sum}\nolimits_{j \ne i} {\sigma _{j,a}^z + \sigma _i^z} } \right)\). Therefore, as long as J a > 0, the effect of such mismatches will only be to introduce an irrelevant constant energy offset. We can therefore conclude that if the coupling J N is anti-ferromagnetic, then via adjustment of the local fields on the ancillae, all mutual inductance mismatches below a certain threshold can be corrected for with existing controls.
This correction threshold is the point at which the order which the ancillae flip deviates from the case where the inductances are all matched. While finding the exact value of mutual inductance mismatches at which this happens depends on the specific errors in a detailed way, we can make simple arguments to find lower bounds for this threshold. We first note that the maximum energy shift of any state caused by a mispecification on the mutual inductance between an ancilla and the inner loop cannot be more than \(\frac{{\Delta M_{a,i}^{inner}}}{{M_{a,i}^{inner}}}{J^a}\left( {N - 1} \right)\). Similarly for coupling with the outer loop, the energy shift cannot be more than \(\frac{{\Delta {M_{(a),i}}}}{{M_{(a),i}^{inner}}}{J^a}\left( {2N - 1} \right)\). In addition to these shifts, the spectrum will be modified by correction terms which must be added to the Hamiltonian. Each of these corrections must also be smaller than the maximum energy shift. Furthermore, due to symmetry, all logical states are affected in the same way by any mismatch involving the outer coupling loop, therefore only mismatches on the inner loop will require corrective modification of the fields. By summing up all possible shifts and corrections, and comparing to the minimum energy difference between a state where the ancillae correctly map the configuration of the logical spins and states where they do not, we conclude that mutual inductance mismatches will certainly be correctable as long as
Where \(\left\{ {\left| {\frac{{\Delta M}}{M}} \right|} \right\}\) indicates the set of all mutual inductance mismatches. While simple, this bound is not necessarily tight—there may be many cases where this bound is not met, and yet it is still feasible to correct for inductance mismatches. This nevertheless demonstrates that for the four-body device, errors of at least \(\left| {\frac{{\Delta M}}{M}} \right|\) ≲ 0.63% can be tolerated if we choose |q 0| = \(\frac{1}{2}\)|J a | and |J| N ≪ J a.
As Fig. 3 illustrates, this bound is overly pessimistic. This figure shows the modeled yield rate as a function of the normalized standard deviation in mutual inductance between the coupling loops and the qubits and ancillae for a four-body coupler circuit with |q 0| = 0.5 |J a |. Here yield is defined as the fraction of modeled circuits for which correction by tuning of the ancilla local fields allows the implementation of Hamiltonian (Eq. (1)) to be successfully implemented. Failure in this case is defined as a spurious state (i.e., one in which the total magnetization is non-zero, see Table 1) occurring at lower energy than any non-spurious state. We assume that mutual inductance errors follow independent Gaussian distributions. We find that for |J N | ≪ J a, the circuit will almost always be correctable even if the standard deviation in M is as large as around 5%. For |J N | = 0.25J a, it will almost always work if the standard deviation in M is as large as around 2.5%. Of all 10,000 instances of mismatch rates tested, the lowest values of \(\frac{{{\sigma _M}}}{M}\) where failure was observed (i.e., a spurious state had a lower energy than a non-spurious state) were 0.0420 for |J N | ≪ J a and 0.0193 for |J N | = 0.25 J a.

Yield rates for four-body coupling circuits with |q 0| = \(\frac{1}{2}\)|J a | vs. deviation of M, \(\frac{{{\sigma _M}}}{M}\). The blue curve is for |J N | ≪ J a while the brown is for |J N | = 0.25 J a
In practice the largest source of uncertainty in the mutual inductance occurs at the design stage since finite element methods typically are accurate to around 10%. Fabrication of test structures enable this uncertainty to be corrected to around 1%.35 Furthermore if necessary the mutual inductance can be adaptively corrected by applying a flux to a SQUID loop between the qubits or ancillae on one hand and the coupling loops on the other, following the approach of ref. 34.
The requirements on the ancilla are much less strict than those on the logical qubits. They do not need to be read out at the end of the annealing run. Furthermore, there is no reason to which the ancillae need to be run on the same annealing schedule as the logical qubits. This presents a significant advantage in that the annealing schedule in this architecture naturally breaks down into a path in a space defined by two parameters. Adjusting the annealing parameter (i.e., the ratio between the longitudinal and transverse fields) on the ancillas adjusts how strongly the multi-body constraints are enforced. The annealing parameter on the logical bits on the other hand acts analogously to the way it does in the standard two-body transverse field Ising model.
This natural breakdown into two independent annealing parameters allows for several interesting possibilities. For one this provides a natural testbed for an optimizable annealing schedule. Secondly, by introducing a control element which acts non-deterministically, a device could be designed which anneals on a different schedule each run. If a pathological region (for example one with a very small gap) exists in the annealing trajectory space, such a protocol may be able to avoid this region during some of the runs, thereby increasing the robustness of the annealing algorithm. A quantitative analysis of such two-parameter annealing schedules goes beyond the scope of this paper and would be a rich area for further analysis.
The techniques we propose here could be used to construct an effective three-body coupler with three ancillae. This can be done more efficiently however using a gadget proposed independently in ref. 24, 36 which also has symmetry under permutation of the logical bits. Because the circuit implementation of this simpler design for three bit couplers only differs slightly from the general design, we reserve discussion of this to Section 2 of the Supplemental Material.
Applications to construct a scalable architecture—We now show how our above circuit design can be used to construct a scalable architecture using a recently proposed embedding techniques25 which maps M logical qubits with full connectivity to K = M (M−1)/2 physical qubits which have four-body nearest neighbor interactions (see Fig. 4a). More concretely, in ref. 25 a model with two-body interactions but arbitrary connectivity is considered
where qubits are on a fully connected graph and we have left out the magnetic fields for simplicity. We see that we have M (M−1)/2 degrees of freedom in the assignment of the couplings J ij . In the embedding proposed in ref. 25 the system is mapped to a system with K = M (M−1)/2 physical qubits \(\tilde \sigma _i^z\) arranged in a pattern as shown in Fig. 4a, where the K original couplings J ij map on the K magnetic fields \({\tilde b_i}\) of the physical qubits. The original qubits are associated with M four-body interactions, shown as plaquette in Fig. 4a. The resulting Hamiltonian is

a Schematically illustration of the embedding technique proposed in ref. 25 Shown is an embedding for M = 3 logical qubits whose interactions are mapped onto K = 6 physical qubits (green circles). Besides the six physical qubits encoding the interactions, there are an additional two physical qubits which enforce the boundary condition. The physical qubits are coupled using four-body interactions as illustrated by the plaquette (red squares). b A physical circuit implementation of the above embedding using our circuit design of a four-body term as presented in the previous section. The four qubits surrounding the four-body circuit are extended to couple to neighboring four-body circuits. This presents a concrete circuit design for a scalable quantum annealing architecture using superconducting qubits
In Fig. 4b we illustrate how such an architecture can be physically implemented using our circuit design of a four-body term. The resulting architecture is scalable in the sense that adding a new logical qubit simply amounts to adding a new row at the bottom. The final row is also used for readout of the values of the logical qubits as explained in ref. 25.
Combining the embedding proposed in ref. 25 with the circuit design for four-body interactions between rf-SQUIDs as described in the previous sections provides a concrete implementation for a scalable architecture allowing for two-body interactions of arbitrary connectivity. Interactions between rf-SQUIDs are mediated by the simple circuit design described above which involves at maximum couplings between five loops.
One major concern with rf-SQUID systems is the presence of noise which couples inductively into the system. The primary goal of the architecture proposed in ref. 25, is not to reduce such noise, but rather to provide an alternative method of embedding problems to the traditional minor embedding approach.7, 18 Fortunately however, most improvements in fabrication and other techniques which would benefit devices with architectures which require minor embedding to map highly connected graphs would also benefit systems where problems are embedded using the methods of ref. 25.
Whether a circuit implementation using the architecture proposed here is more or less noisy than ones using other rf-SQUID architectures is likely to depend on details of the physical implementation. In particular, in designing the value of the circulating current in the rf SQUID qubit annealer there is a trade-off between coupling and coherence. Smaller values of circulating current lead to longer coherence lifetimes (due to the lower flux noise) and will require higher values of qubit-coupler mutual inductance which will in turn be less susceptible to process variability. One advantage of our method however is that all of the qubit circuits are planar, which may lead to a relatively simpler fabrication process, and therefore more flexibility in terms of making modifications to reduce noise.
Discussion
Overcoming the physical limitations on connectivity and multi-body interactions of the underlying Ising spin system in hardware implementations of quantum annealing devices is a major challenge. In this work we present a method of effectively implementing a Hamiltonian with multi-body terms by reproducing its low energy spectrum using a Hamiltonian which only involves two-body interactions and a number of ancilla qubits. While this construction can be used as a minor-embedding technique for existing quantum annealing architectures (as we explore in a related work)24, the major result of this work is an efficient circuit design of the construction using superconducting flux qubits, as well as calculations which demonstrate that this circuit is robust to realistic design imperfections. Having the possibility of inductively coupling a number of qubits with all-to-all couplings of equal strength using a single coupling loop enables us to implement the multi-body terms using a very efficient circuit design. In the last section we show concretely how this circuit can be used as a unit cell for a scalable architecture using a recent embedding technique25 which encodes logical qubits of arbitrary connectivity using physical qubits with nearest-neighbor four-body interactions.
As a final remark, let us mention that here we have focused on circuit based implementations of multi-body terms in the z-basis, i.e., \(\sigma _1^z \ldots \sigma _N^z\). This is natural, since the optimization problem is encoded in the z-basis. However, one can in principle also consider similar constructions in the basis of the transverse magnetic field, i.e., \(\sigma _1^x \ldots \sigma _N^x\), thereby enabling implementation of non-stoquastic Hamiltonians37 involving multi-body terms. We leave such an analysis for future work.
Note added—After a preprint of this letter appeared on arXiv, a related paper36 was released which proposes an implementation of multi-body terms using Transmon qubits. Further, a revision of ref. 38 was released which added an abstract construction of multi-body terms using a chaining of three-body terms. While no physical implementation is discussed in this paper, the abstract formalism relates to that of ref. 36 and could be implemented in a similar manner.
Methods
Calculations were first performed by hand and then verified by a simple Matlab scripts containing less than 150 lines of code in total, including subroutines. For the yield calculations, we generated error Hamiltonians H error with independent Gaussianly distributed couplings corresponding to mis-specifications of each mutual inductance. We then examined the eigenstates of H tot = H Coupler + \(\frac{{{\sigma _M}}}{M}\) H error and found the value of \(\frac{{{\sigma _M}}}{M}\) where spurious state energies crossed logical state energies. Note that this technique ignores higher order interaction terms from these mismatches, which would have an effect of order \({\left( {\frac{{{\sigma _M}}}{M}} \right)^2}\). A similar technique is used to calculate the strength of higher order terms which can be compensated. While our code could be quickly and easily reproduced by anyone with basic proficiency in programming, it is also available from the authors upon request.
Data availability
All relevant data are available from the corresponding author upon request without restrictions.
Code availability
All computer code used in this manuscript is available from the corresponding author upon request without restrictions.
References
O’Gorman, B. et al. Bayesian network structure learning using quantum annealing. Eur. Phys. J. Spec. Top. 224, 163 (2015).
Neven, H. et al. Image recognition with an adiabatic quantum computer I. Mapping to quadratic unconstrained binary optimization. Preprint at arXiv:0804.4457 (2008).
Santra, S. et al. Max 2-SAT with up to 108 qubits. New. J. Phys. 16, 045006 (2014).
Hen, I. & Young, A. P. Solving the graph-isomorphism problem with a quantum annealer. Phys. Rev. A 86, 042310 (2012).
Perdomo-Ortiz, A. et al. Finding low-energy conformations of lattice protein models by quantum annealing. Sci. Rep. 2, 571 (2012).
Boixo, S. et al. Evidence for quantum annealing with more than one hundred qubits. Nat. Phys. 10, 218–224 (2014).
Venturelli, D. et al. Quantum optimization of fully-connected spin glasses. Phys. Rev. X 5, 031040, Preprint at arXiv:1406.7553 (2015).
Rieffel, E. et al. A case study in programming a quantum annealer for hard operational planning problems. Quantum Inf. Process. 14, 1–36 (2015).
Chancellor, N., Szoke, S., Vinci, W., Aeppli, G. & Warburton, P. Maximum-entropy inference with a programmable annealer. Sci. Rep. 6, 22318 (2016).
Brooke, J., Bitko, D., Rosenbaum, T. F. & Aeppli, G. Quantum annealing of a disordered magnet. Science 284, 779–781 (1999).
Johnson, W. M. et al. Quantum annealing with manufactured spins. Nature 473, 194 (2011).
Harris, R. et al. Experimental investigation of an eight-qubit unit cell in a superconducting optimization processor. Phys. Rev. B 82, 024511 (2010).
Denchev, V. S. et al. What is the Computational Value of Finite Range Tunneling?. Phys. Rev. X 6, 031015 (2016).
Yan, F. et al. The flux qubit revisited to enhance coherence and reproducibility. Nat. Comms. 7, 12964 (2016).
Hen, I. et al., Probing for quantum speedup in spin glass problems with planted solutions. Preprint at arXiv:1502.01663 (2015).
Katzgraber, H. G., Hamze, F., Zhu, Z., Ochoa, A. J. & Munoz-Bauza, H. Seeking quantum speedup through spin glasses: the good, the bad, and the ugly. Phys. Rev. X 5, 031026 (2015).
Katzgraber, H. G., Hamze, F. & Andrist, R. S. Glassy Chimeras could be blind to quantum speedup: designing better benchmarks for quantum annealing machines. Phys. Rev. X 4, 021008 (2014).
Choi, V. Minor-embedding in adiabatic quantum computation: II. Minor-universal graph design. Quantum Inf. Process. 10, 43353 (2011).
Choi, V. Adiabatic quantum algorithms for the NP-complete maximum-weight independent set, Exact Cover and 3SAT Problems. Preprint at arXiv:1004.2226 (2004).
Bian, Z. et. al. Discrete optimization using quantum annealing on sparse Ising models. Front. Phys. 2, 00056 (2014).
Biamonte, J. D. Nonperturbative k-body to two-body commuting conversion Hamiltonians and embedding problem instances into Ising spins. Phys. Rev. A 77, 052331 (2008).
Whitfield, J. D., Faccin, M. & Biamonte, J. D. Ground-state spin logic. Europhys. Lett. 99, 57004 (2012).
Perdomo-Ortiz, A. et al. Construction of model Hamiltonians for adiabatic quantum computation and its application to finding low-energy conformations of lattice protein models. Phys. Rev. A 78, 012320 (2008).
Chancellor, N., Zohren, S., Warburton, P., Benjamin, S. & Roberts, S. A direct mapping of Max k-SAT and high order parity checks to a Chimera graph. Sci. Rep. 6, 37107 (2016).
Lechner, W., Huke, P. and Zoller, P. A quantum annealing architecture with all-to-all connectivity from local interactions 1, e1500838 (2015).
Albash, T. Vinci, W. Lidar, D. A. Simulated quantum annealing with two all-to-all connectivity schemes. Preprint at arXiv:1603.03755 (2016).
Sherrington, D. Physics and complexity: an introduction. In Proc. Mathematics and Statistics. Managing Complexity, Reducing Perplexity (eds. Delitala M. and Ajmone Marsan G.), 67, 119–129 (Springer, 2014).
Auffinger A., Ben Arous G. and Cerny, J. Random matrices and complexity of spin glasses. Preprint at arXiv:1003.1129 (2010).
Thomas, C. K. & Katzgraber, H. G. Optimizing glassy p-spin models. Phys. Rev. E 83, 046709 (2011).
Choromanska, A., Henaff, M., Mathieu, M., Ben Arous, G., LeCun, Y. The loss surfaces of multilayer networks. Preprint at arXiv:1412.0233 (2014).
Sagun, L., Guney, V. U., Ben Arous, G. and LeCun, Y. Explorations on high dimensional landscapes. Preprint at arXiv:1412.6615 (2014).
De las Cuevas, G. & Cubitt, T. S. Simple universal models capture all classical spin physics. Science 351, 6278 (2016).
van den Brink, A. M., Berkley, A. J. & Yalowsky, M. Mediated tunable coupling of flux qubits. New. J. Phys. 7, 230 (2005).
Harris, R. et. al. Compound Josephson-junction coupler for flux qubits with minimal crosstalk. Phys. Rev. B 80, 052506 (2009).
Tolpygo, S. K. et al. Inductance of circuit structures for MIT LL superconductor electronics fabrication process with 8 Niobium Layers. IEEE Trans. Appl. Supercond. 25, 3, 11000905 (2015).
Leib, M., Zoller, P. and Lechner, W., A Transmon quantum annealer: decomposing many-body ising constraints into pair interactions. Preprint at arXiv:1604.02359 (2016).
Bravyi, S. et al. The complexity of Stoquastic Local Hamiltonian problems. Quant. Inf. Comp. 8, 0361 (2008).
Rocchetto, A., Benjamin, S. C. and Li, Y., Stabilisers as a design tool for new forms of Lechner-Hauke-Zoller Annealer. Preprint at arXiv:1603.08554 (2016).
Acknowledgements
The authors would like to thank Simon Benjamin and Stephen Roberts for discussions. N.C. and P.A.W. were supported by EPSRC (Grant refs: EP/K004506/1 and EP/H005544/1) and Lockheed Martin. S.Z. acknowledges support by Nokia Technologies, Lockheed Martin, and the University of Oxford through the Quantum Optimization and Machine Learning (QuOpaL) Project.
Author information
Authors and Affiliations
Contributions
The authors all contributed to the development of the idea, and all wrote the paper together. S.Z. created the diagrammatic figures, while N.C. produced all numerical data and created the yield rate figure.
Corresponding author
Ethics declarations
Competing interests
The authors have jointly filed for a (UK) patent for the coupler design described in this document.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chancellor, N., Zohren, S. & Warburton, P.A. Circuit design for multi-body interactions in superconducting quantum annealing systems with applications to a scalable architecture. npj Quantum Inf 3, 21 (2017). https://doi.org/10.1038/s41534-017-0022-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-017-0022-6
This article is cited by
-
Short-depth QAOA circuits and quantum annealing on higher-order ising models
npj Quantum Information (2024)
-
Forecasting Election Polls with Spin Systems
SN Computer Science (2022)
-
High-accuracy Ising machine using Kerr-nonlinear parametric oscillators with local four-body interactions
npj Quantum Information (2021)
-
Automated design of superconducting circuits and its application to 4-local couplers
npj Quantum Information (2021)
-
Benchmarking the quantum approximate optimization algorithm
Quantum Information Processing (2020)
