









« Prev Next »

Protein Structure
Proteins are the end products of the decoding process that starts with the information in cellular DNA. As workhorses of the cell, proteins compose structural and motor elements in the cell, and they serve as the catalysts for virtually every biochemical reaction that occurs in living things. This incredible array of functions derives from a startlingly simple code that specifies a hugely diverse set of structures.
In fact, each gene in cellular DNA contains the code for a unique protein structure. Not only are these proteins assembled with different amino acid sequences, but they also are held together by different bonds and folded into a variety of three-dimensional structures. The folded shape, or conformation, depends directly on the linear amino acid sequence of the protein.
What Are Proteins Made Of?
The building blocks of proteins are amino acids, which are small organic molecules that consist of an alpha (central) carbon atom linked to an amino group, a carboxyl group, a hydrogen atom, and a variable component called a side chain (see below). Within a protein, multiple amino acids are linked together by peptide bonds, thereby forming a long chain. Peptide bonds are formed by a biochemical reaction that extracts a water molecule as it joins the amino group of one amino acid to the carboxyl group of a neighboring amino acid. The linear sequence of amino acids within a protein is considered the primary structure of the protein.
Proteins are built from a set of only twenty amino acids, each of which has a unique side chain. The side chains of amino acids have different chemistries. The largest group of amino acids have nonpolar side chains. Several other amino acids have side chains with positive or negative charges, while others have polar but uncharged side chains. The chemistry of amino acid side chains is critical to protein structure because these side chains can bond with one another to hold a length of protein in a certain shape or conformation. Charged amino acid side chains can form ionic bonds, and polar amino acids are capable of forming hydrogen bonds. Hydrophobic side chains interact with each other via weak van der Waals interactions. The vast majority of bonds formed by these side chains are noncovalent. In fact, cysteines are the only amino acids capable of forming covalent bonds, which they do with their particular side chains. Because of side chain interactions, the sequence and location of amino acids in a particular protein guides where the bends and folds occur in that protein (Figure 1).
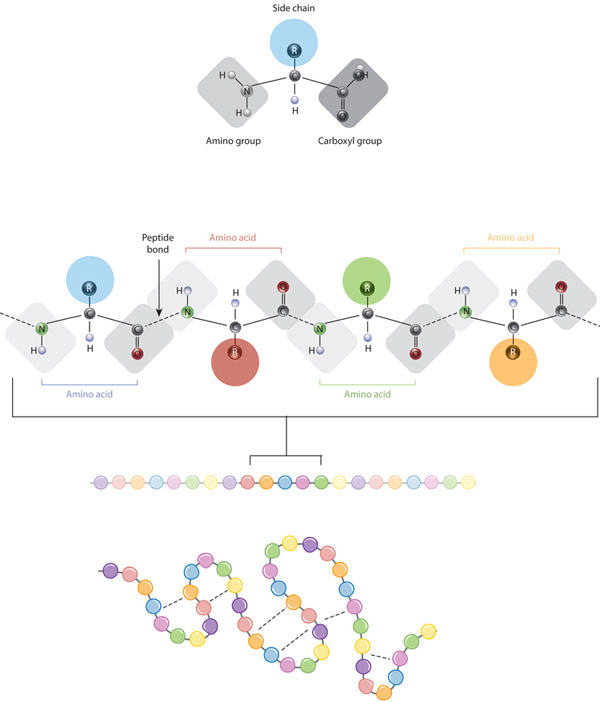
Figure 1: The relationship between amino acid side chains and protein conformation
The defining feature of an amino acid is its side chain (at top, blue circle; below, all colored circles). When connected together by a series of peptide bonds, amino acids form a polypeptide, another word for protein. The polypeptide will then fold into a specific conformation depending on the interactions (dashed lines) between its amino acid side chains.
© 2010 Nature Education All rights reserved. 
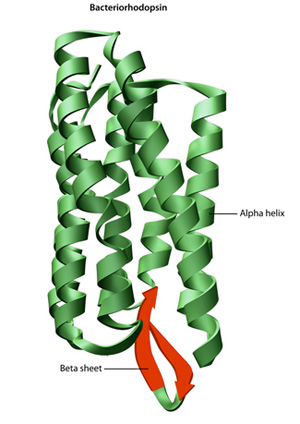
Figure 2: The structure of the protein bacteriorhodopsin
Bacteriorhodopsin is a membrane protein in bacteria that acts as a proton pump. Its conformation is essential to its function. The overall structure of the protein includes both alpha helices (green) and beta sheets (red).
© 2010 Nature Education All rights reserved.
The final shape adopted by a newly synthesized protein is typically the most energetically favorable one. As proteins fold, they test a variety of conformations before reaching their final form, which is unique and compact. Folded proteins are stabilized by thousands of noncovalent bonds between amino acids. In addition, chemical forces between a protein and its immediate environment contribute to protein shape and stability. For example, the proteins that are dissolved in the cell cytoplasm have hydrophilic (water-loving) chemical groups on their surfaces, whereas their hydrophobic (water-averse) elements tend to be tucked inside. In contrast, the proteins that are inserted into the cell membranes display some hydrophobic chemical groups on their surface, specifically in those regions where the protein surface is exposed to membrane lipids. It is important to note, however, that fully folded proteins are not frozen into shape. Rather, the atoms within these proteins remain capable of making small movements.
Even though proteins are considered macromolecules, they are too small to visualize, even with a microscope. So, scientists must use indirect methods to figure out what they look like and how they are folded. The most common method used to study protein structures is X-ray crystallography. With this method, solid crystals of purified protein are placed in an X-ray beam, and the pattern of deflected X rays is used to predict the positions of the thousands of atoms within the protein crystal.
How Do Proteins Arrive at Their Final Shapes?
In theory, once their constituent amino acids are strung together, proteins attain their final shapes without any energy input. In reality, however, the cytoplasm is a crowded place, filled with many other macromolecules capable of interacting with a partially folded protein. Inappropriate associations with nearby proteins can interfere with proper folding and cause large aggregates of proteins to form in cells. Cells therefore rely on so-called chaperone proteins to prevent these inappropriate associations with unintended folding partners.
Chaperone proteins surround a protein during the folding process, sequestering the protein until folding is complete. For example, in bacteria, multiple molecules of the chaperone GroEL form a hollow chamber around proteins that are in the process of folding. Molecules of a second chaperone, GroES, then form a lid over the chamber. Eukaryotes use different families of chaperone proteins, although they function in similar ways.
Chaperone proteins are abundant in cells. These chaperones use energy from ATP to bind and release polypeptides as they go through the folding process. Chaperones also assist in the refolding of proteins in cells. Folded proteins are actually fragile structures, which can easily denature, or unfold. Although many thousands of bonds hold proteins together, most of the bonds are noncovalent and fairly weak. Even under normal circumstances, a portion of all cellular proteins are unfolded. Increasing body temperature by only a few degrees can significantly increase the rate of unfolding. When this happens, repairing existing proteins using chaperones is much more efficient than synthesizing new ones. Interestingly, cells synthesize additional chaperone proteins in response to "heat shock."
What Are Protein Families?
All proteins bind to other molecules in order to complete their tasks, and the precise function of a protein depends on the way its exposed surfaces interact with those molecules. Proteins with related shapes tend to interact with certain molecules in similar ways, and these proteins are therefore considered a protein family. The proteins within a particular family tend to perform similar functions within the cell.
Proteins from the same family also often have long stretches of similar amino acid sequences within their primary structure. These stretches have been conserved through evolution and are vital to the catalytic function of the protein. For example, cell receptor proteins contain different amino acid sequences at their binding sites, which receive chemical signals from outside the cell, but they are more similar in amino acid sequences that interact with common intracellular signaling proteins. Protein families may have many members, and they likely evolved from ancient gene duplications. These duplications led to modifications of protein functions and expanded the functional repertoire of organisms over time.
Conclusion
Proteins are built as chains of amino acids, which
then fold into unique three-dimensional shapes. Bonding within protein
molecules helps stabilize their structure, and the final folded forms of
proteins are well-adapted for their functions.
eBooks
This page appears in the following eBook











