
Abstract
Despite the fundamental contribution of the gut microbiota to host physiology, the extent of its variation in genetically-identical animals used in research is not known. We report significant divergence in both the composition and metabolism of gut microbiota in genetically-identical adult C57BL/6 mice housed in separate controlled units within a single commercial production facility. The reported divergence in gut microbiota has the potential to confound experimental studies using mammalian models.
Similar content being viewed by others


Introduction
Researchers using animal models are becoming increasingly aware of possible influences of the gut microbiota on physiology. Murine models have been used to demonstrate relationships between the gut microbiota and obesity1, metabolic disease2, cardiovascular health3, nervous system development4, diabetes5 and immune function6, hepatic function7, inflammatory bowel conditions8 and carcinogenesis9, highlighting the potential impact that differences in the microbiome of mice from different animal facilities could have on research. However, most researchers assume that genetically-identical mice derived from a single supplier will have an equivalent microbiome. To test this assumption we studied the faecal microbiome and metabolome of genetically-identical C57BL/6 mice housed in four separate controlled units within a single facility of a commercial supplier of animals for research. Faecal samples were collected at eight weeks of age from twenty mice, with five mice sampled in each of four barrier rooms. These mice were separated by no more than ten generations.
Methods
Murine faecal samples
Faeces were collected from eight week old C57BL/6 at the Charles River commercial facility (Margate, UK) under commercial licence, with all mice kept in accordance with protocols approved by The Animal Health and Welfare Board for England. Samples were collected from 20 mice, housed in four separate barrier rooms within the facility, fed the same chow (a VRF1 diet, SDS). The five mice sampled in each room were housed in separate cages. The five mice from each of the four rooms were taken from separate cages i.e. no two mice came from the same cage. Mice in this study were handled by individuals wearing gloves for cage cleaning purposes on a weekly basis. Mice were not housed exclusively with litter mates, with 27 individuals housed per room. Samples consisted of individual faecal pellets taken from individual mice. After collection, pellets were placed into separate collection tubes and frozen prior to analysis.
Microbiota
Nucleic acid extractions were carried out using a combination of physical disruption and phenol/chloroform extraction methods, described previously10. 16S rRNA gene universal Bacterial primers 27F-519R (27F 5′-AGRGTTTGATCMTGGCTCAG, 519R 5′-GTNTTACNGCGGCKGCTG) were used in a single-step 30 cycle PCR using HotStarTaq Plus Master Mix Kit (Qiagen, Valencia, CA) performed under the following conditions: 94oC for 5 minutes, followed by 28 cycles of: 94oC for 30 seconds, 53oC for 40 seconds and 72oC for 1 minute. Amplification was followed by a final elongation step at 72oC for 5 minutes. Following PCR, all amplicon products from different samples were mixed in equal concentrations and purified using Agencourt Ampure beads (Agencourt Bioscience Corporation, MA, USA). Samples were sequenced utilizing Roche 454 FLX titanium instruments and reagents following manufacturer's guidelines. A total of 165,934 16S rRNA gene sequences were obtained from the 20 faecal sample extracts. Following curation, an average of 4,356 sequences was obtained for each of the samples. For analysis of alpha and beta diversity, samples were normalised to 2,179 sequences per sample.
Sequence data analysis was carried out. Here, the Q25 sequence data derived from the sequencing process was processed using standard analysis pipeline processes (MR DNA, Shallowater, USA). Sequences were depleted of barcodes and primers then short sequences <200 bp removed, as were sequences with ambiguous base calls removed and sequences with homopolymer runs exceeding 6 bp, sequences were denoised and chimeras removed11,12,13,14,15,16,17. Operational taxonomic units were defined after removal of singleton sequences, clustering at 3% divergence (97% similarity). Final OTUs were taxonomically classified using BLASTn against a curated databased derived from GreenGenes, NCBI and RDP databases18. Normalized and de-noised files were then rarefied and run through QIIME19 to generate alpha and beta diversity data. Additional statistical analyses were performed with NCSS2007 (NCSS, UT) and XLstat 2012 (Addinsoft, NY).
A range of diversity and richness measures were used to assess changes in microbiota composition, including taxa richness, Chao1, Shannon index, Simpson index 1-D20. Analysis of microbiota diversity was performed using PAST - Palaeontological Statistics, version 3.01, a program available from the University of Oslo website link (http://folk.uio.no/ohammer/past).
1H NMR metabolomics
Portions of mouse faeces of approximately 0.02 g were resuspended by vortexing in 500 μl of phosphate buffered saline. Particulate matter was pelleted by centrifugation at 13,000 × g for 10 min and supernatant transferred to a fresh microfuge tube. Centrifugation was repeated, with pelleted material again discarded. Supernatant was frozen by immersion in liquid nitrogen, lyophilised at −58°C overnight and re-suspended in 500 μl D2O. 1H NMR spectra of three replicates were acquired at 400 MHz on a Bruker Avance spectrometer (Bruker, Coventry, UK) equipped with a 5 mm QNP probe using a zgesgp pulse sequence incorporating water suppression via excitation sculpting with gradients. The 1H 90 degree pulse was 9.75 μs. The spectral width was 20 ppm. Free induction decays were multiplied with an exponential function corresponding to a line broadening of 0.3 Hz. The spectra were Fourier transformed and calibrated to a 2,2,3,3,-D4-3-(Trimethylsilyl) propionic acid (TSP) reference signal at 0 ppm. Phase correction was performed manually and automatic baseline correction was applied. To help in the assignment of the metabolite resonances, J-resolved 2D correlation was performed with pre-saturation during relaxation delay using gradients (J-Res, Bruker). Pre-processing and orthogonal projection to latent structures discriminant analysis (OPLS-DA) were carried out with software that was developed in our laboratory for a previous study21 using the python programming language with numpy and scipy for calculations and matplotlib for visualization. The nonlinear iterative partial least-squares (NIPALS) algorithm22 was used for OPLS-DA analysis. Regions above 8.5 ppm and below 0.45 ppm were excluded because of noise content. The water peak and TSP reference signal were also excluded. Spectra were bucketed using 0.005 ppm bin size leaving 1588 data points per spectrum. These spectra were normalized23,24 and auto-scaled (variance of every data point normalized to 1). Cross-validation was performed where 75% of the samples were used as a training set and the remaining 25% as a test set, ensuring that the number of samples in the test set was proportional to the total number of samples from each class and that at least one sample from each class was present in the test set. To choose the number of components for the model, a leave-one-out cross-validation was carried out on the samples in the training set and the F1 used to choose the number of components, with the additional constraint to use a maximum of 8 components. A double cross-validation was repeated 2000 times with randomly chosen samples in the training and test set to prevent bias due to the choice of training or test set. This led to 4 × 2000 models. Finally, this procedure was repeated with randomly generated class assignments to provide a reference value for Q2. The chosen number of components minus one was then used as an OPLS filter and a PLS-DA analysis with two components was carried out on the filtered data to yield one predictive and one orthogonal component. In the back-scaled loadings analysis, peaks that allow the models to distinguish between classes were assigned by comparing chemical shift values and multiplicities from J-resolved NMR spectra to values from the BMRB25 and HMDB26.
Results & Discussion
Analysis of the bacterial identities derived from 16S ribosomal RNA gene sequencing revealed the faecal microbiota to be dominated by the phyla Bacteroidetes and Firmicutes, (62.4 ± 22.4 (SD)% and 34.7 ± 23.9%, respectively) although marked variation was observed in phylum relative abundance between individual animals (Fig. S1). Further, microbiota alpha diversity, as assessed by rarefaction and Chao1 richness estimate, OTU richness and Shannon Index were significantly lower for mice of one room group (room 4) compared with mice from other room groups (Table S1) (Kruskall-Wallis controlled multiple pair-wise comparison, p < 0.001).
Analysis of microbiota at the genus level identified the twenty genera with the highest mean relative abundance (Table S2), which were broadly in keeping with those reported in the murine gut previously27. The most commonly numerically dominant genus was Prevotella, (39.0 ± 20.2% of sequences), a genus associated with a long term carbohydrate-rich diet in humans28. Again however, significant differences in the microbiota were identified between room groups (controlled ANOVA tests, p < 0.05) (Table S3). Coprococcus, Ruminococcus and Anaerotruncus were significantly higher in room 1 samples, Pedobacter was significantly higher in room 2 samples, Novispirillum was significantly higher in room 3 samples and Prevotella was significantly higher in room 4 samples. Samples from rooms 2 and 3 groups had significantly higher abundance of Parabacteroides and Sphingobacterium than samples from rooms 1 and 4.
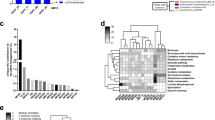
Hierarchal cluster analysis based upon the predominant genera indicates divergence in the composition of the microbiota into three clusters (Fig. 1). Cluster I comprised samples from all animals from room 3 and additional animals from rooms 1 and 2, cluster II comprised all animals from room 4 and cluster III included all of the remaining animals from rooms 1 and 2. Notably is the absence, or very low abundance, in room group 4 of a number of genera including Sutterella, Sphingobacterium, Novispirillum and Porphyromonas. Overall therefore, the bacterial microbiota showed marked divergence that was in cases linked to room occupancy, with these compositional differences resolving into three clusters.

Heat map analysis of the predominant genera identified in this study.
A hierarchal cluster diagram was constructed using Ward's minimum variance clustering and Manhattan distances. Room group 1 and room group 2 exhibit some co-clustering indicating differences within the groups. The heatmap describes the relative percentage in each sample of the associated genera with a legend provided in the upper left of the figure.
Whilst all mice received the same standard diet, the differences in constituency of their microbiota indicated a potential for distinct metabolomic characteristics. The major constituent of mouse chow, carbohydrates, are fermented in the colon to short chain fatty acids (SCFA), primarily acetate, butyrate, lactate and propionate29,30. Whilst SCFAs are just one class of compounds, they are important in shaping the microbial community and preventing the growth of pathogens31,32. Moreover, SCFA levels impact on the host and are known to be important in relation to nutrition, adipose tissue deposition, immunity and cancer amongst other conditions30,33. Different SCFAs have been associated with effects on specific physiological processes34, with the type of SCFAs varying between bacterial genera35. To test for a functionally-distinct signal, we performed a metabolomic analysis of the faecal material.
1H NMR spectroscopy was performed on buffered saline extracts from the same faecal samples used for microbiota sequencing. We hypothesised that there would be differences when comparing the metabolome of faeces from mice whose faecal microbiota were distinct. Analysis involved a series of pairwise orthogonal partial least squares discriminant analysis (OPLS-DA) tests using classes suggested by clustering according to microbiota (Fig. 2), room occupancy or dominant phyla. Scores plots for each of three pairwise comparisons show that there are substantial differences in the metabolomes extracted from faeces of mice assigned to each cluster (Fig. 2 - left panels). Q2 obtained for each test performed were compared with a reference value for Q2, obtained after repeating cross-validation with randomly generated class assignments (Table 1). As shown, Q2 scores for the metabolomic data pairwise analysis performed when separated according to these clusters were >0.50 which is an accepted threshold for a “good” model36,37. As such, we observed clear metabolomic differences in the murine faecal samples based on clusters as defined by the composition of the bacteria present. Further, microbiota data were used to assess the relative contribution of Bacteroidetes, Firmicutes and Proteobacteria to each of the samples tested. Here, Q2 scores were all >0.41. Significant differences were also identified in the metabolome of faeces from mice housed in different room groups with Q2 scores all >0.67 (room 2 vs. room 3).

OPLS-DA scores plots (left panels) and back-scaled loadings plots (right panels) for comparisons between the murine faecal metabolomes as clustered according to microbiota data composition.
Resonances with high variance and high weight are highlighted in red. The distinguishing metabolites that could be unambiguously assigned are annotated in each back-scaled loadings plot. Q2 values for the cross-validated OPLS-DA comparisons are provided in Table 1.
Next, we identified the key drivers of the differences in the metabolomic data by generating back-scaled loadings plots and assigning resonances with high variance and high weight, indicated by greater intensity and yellow/red color respectively (Fig. 2 – right panels). Notably, Clusters I and II were distinguished by the greater abundance of a number of amino acids in the faecal metabolomes of mice in Cluster II whereas the faecal metabolomes of mice from Cluster III were distinguished from those in Cluster I and II on the basis of short chain fatty acids which were more abundant in Cluster III. At the outset of this study, we hypothesised that there would be minimal differences between the gut microbiota as sampled in the context of genetically identical mice. However, significant differences were observed in the taxa detected, their relative abundance and overall bacterial diversity. This variation in the faecal microbiota was linked, at least in part, to the barrier room in which the mice were housed. Assessment of the metabolome associated with these animals showed that microbiota and metabolome findings were largely consistent.
Murine models are used in biomedical research to address almost every aspect of human health. To avoid potentially confounding differences in genetic backgrounds, mice are taken from inbred populations with the rationale being that the resulting homogeneity provides a uniform “platform” for study. By far the most common genetic background for mice used as models of human disease is the strain C57BL/6, as used here. When purchased for research, individual C57BL/6 mice are commonly considered to be equivalent. Increasingly however, the potential of the gastrointestinal microbiota to influence the host in relation to health and a wide range of clinical syndromes is being recognised38. In this light, the differences identified in microbiota here require further consideration. Given the potential impact of the gut microbiota on so many important physiological processes, the degree to which it is conserved between individual animals used in biological research is arguably as important as their genetic uniformity. Further, variation in gut microbiota composition is likely to be even higher in less well controlled experimental facilities and to be exacerbated when mice are moved between facilities, experience changes in diet and are exposed to animals with different microbiota. The divergence in gut microbiota composition, as reflected in faecal bacteria, strongly suggests that efforts must be made to ensure uniformity of intestinal microbiota in animals used in research.
References
Bäckhed, F. Changes in intestinal microflora in obesity: cause or consequence? J. Pediatr. Gastroenterol. Nutr. 48 Suppl 2, S56–7 (2009).
Vijay-Kumar, M. et al. Metabolic syndrome and altered gut microbiota in mice lacking Toll-like receptor 5. Science 328, 228–31 (2010).
Stepankova, R. et al. Absence of microbiota (germ-free conditions) accelerates the atherosclerosis in ApoE-deficient mice fed standard low cholesterol diet. J. Atheroscler. Thromb. 17, 796–804 (2010).
Diaz Heijtz, R. et al. Normal gut microbiota modulates brain development and behavior. Proc. Natl. Acad. Sci. U S A 108, 3047–52 (2011).
Cani, P. D. et al. Changes in gut microbiota control metabolic endotoxemia-induced inflammation in high-fat diet-induced obesity and diabetes in mice. Diabetes 57, 1470–81 (2008).
Claus, S. P. et al. Colonization-induced host-gut microbial metabolic interaction. MBio 2, e00271-10; 10.1128/mBio.00271-10 (2011).
Björkholm, B. et al. Intestinal microbiota regulate xenobiotic metabolism in the liver. PLoS One 4, e6958; 10.1371/journal.pone.0006958 (2009).
Frank, D. N. et al. Molecular-phylogenetic characterization of microbial community imbalances in human inflammatory bowel diseases. Proc. Natl. Acad. Sci. U S A. 104, 13780–5 (2007).
Lee, S. H. et al. ERK activation drives intestinal tumorigenesis in Apc(min/+) mice. Nat. Med. 16, 665–70 (2010).
Rogers, G. B. et al. A Novel Microbiota Stratification System Predicts Future xacerbations in Bronchiectasis. Ann. Am. Thorac. Soc. Epub ahead of print; DOI:10.1513/AnnalsATS.201310-335OC (2014).
Dowd, S. E. et al. Evaluation of the bacterial diversity in the feces of cattle using 16S rDNA bacterial tag-encoded FLX amplicon pyrosequencing (bTEFAP). BMC Microbiol. 8, 125 (2008).
Dowd, S. E., Sun, Y., Wolcott, R. D., Domingo, A. & Carroll, J. A. Bacterial tag-encoded FLX amplicon pyrosequencing (bTEFAP) for microbiome studies: bacterial diversity in the ileum of newly weaned Salmonella-infected pigs. Foodborne Pathog. Dis. 5, 459–72 (2008).
Edgar, R. C. Search and clustering orders of magnitude faster than BLAST. Bioinformatics 26, 2460–1 (2010).
Capone, K. A., Dowd, S. E., Stamatas, G. N. & Nikolovski, J. Diversity of the human skin microbiome early in life. J. Invest. Dermatol. 131, 2026–32 (2011).
Dowd, S. E. et al. Survey of fungi and yeast in polymicrobial infections in chronic wounds. J. Wound Care 20, 40–7 (2011).
Eren, A. M. et al. Exploring the diversity of Gardnerella vaginalis in the genitourinary tract microbiota of monogamous couples through subtle nucleotide variation. PLoS One 6, e26732; 10.1371/journal.pone.0026732 (2011).
Swanson, K. S. et al. Phylogenetic and gene-centric metagenomics of the canine intestinal microbiome reveals similarities with humans and mice. ISME J. 5, 639–49 (2011).
DeSantis, T. Z. et al. Greengenes, a chimera-checked 16S rRNA gene database and workbench compatible with ARB. Appl. Environ. Microbiol. 72, 5069–72 (2006).
Caporaso, J. G. et al. QIIME allows analysis of high-throughput community sequencing data. Nat. Methods 7, 335–6 (2010).
Haegeman, B. et al. Robust estimation of microbial diversity in theory and in practice. ISME J. 7, 1092–101 (2013).
Vermeer, L. S., Fruhwirth, G. O., Pandya, P., Ng, T. & Mason, A. J. NMR metabolomics of MTLn3E breast cancer cells identifies a role for CXCR4 in lipid and choline regulation. J. Proteome Res. 11, 2996–3003 (2012).
Andersson, M. A comparison of nine PLS1 algorithms. J. Chemometrics 23, 518–529 (2009).
Kozlowska, J. et al. The impact of Pseudomonal growth on cystic fibrosis airway secretion composition in a metabolomic investigation. Metabolomics. 9, 1262–1273 (2013).
Dieterle, F., Ross, A., Schlotterbeck, G. & Senn, H. Probabilistic quotient normalization as robust method to account for dilution of complex biological mixtures. Application in 1H NMR metabonomics. Anal. Chem. 78, 4281–90 (2006).
Ulrich, E. L. et al. BioMagResBank. Nucleic Acids Res. 36, D402–8 (2008). Wishart, D. S. Computational approaches to metabolomics. Methods Mol. Biol. 593, 283–313 (2010).
Wishart, D. S. Computational approaches to metabolomics. Methods Mol. Biol. 593, 283–313. (2010).
Linnenbrink, M. et al. The role of biogeography in shaping diversity of the intestinal microbiota in house mice. Mol. Ecol. 22, 1904–16 (2013).
Wu, G. D. et al. Linking long-term dietary patterns with gut microbial enterotypes. Science 334, 105–8 (2011).
Roberfroid, M. et al. Prebiotic effects: metabolic and health benefits. Br. J. Nutr. 104 Suppl 2, S1–63 (2010).
Delzenne, N. M. & Cani, P. D. Interaction between obesity and the gut microbiota: relevance in nutrition. Annu. Rev. Nutr. 31, 15–31 (2011).
Blaut, M. Relationship of prebiotics and food to intestinal microflora. Eur. J. Nutr. 41 Suppl 1, I11–6 (2002).
Duncan, S. H., Louis, P., Thomson, J. M. & Flint, H. J. The role of pH in determining the species composition of the human colonic microbiota. Environ. Microbiol. 11, 2112–22 (2009).
Maslowski, K. M. et al. Regulation of inflammatory responses by gut microbiota and chemoattractant receptor GPR43. Nature 461, 1282–6 (2009).
Xiong, Y. et al. Short-chain fatty acids stimulate leptin production in adipocytes through the G protein-coupled receptor GPR41. Proc. Natl. Acad. Sci. U S A. 101, 1045–50. (2004).
Hague, A. et al. Sodium butyrate induces apoptosis in human colonic tumour cell lines in a p53-independent pathway: implications for the possible role of dietary fibre in the prevention of large-bowel cancer. Int. J. Cancer 55, 498–505 (1993).
Szymanska, E., Saccenti, E., Smilde, A. K. & Westerhuis, J. A. Double-check: validation of diagnostic statistics for PLS-DA models in metabolomics studies. Metabolomics 8, S3–S16 (2012).
Westerhuis, J. A. et al. Assessment of PLSDA cross validation. Metabolomics 4, 81–9 (2008).
Shanahan, F. The colonic microbiota in health and disease. Curr. Opin. Gastroenterol. 29, 49–54 (2013).
Author information
Authors and Affiliations
Contributions
G.B.R., K.D.B., A.J.M. and M.M. wrote the main manuscript text and prepared all figures. S.E.D. and G.B.R. prepared figure 1 A.J.M. prepared figure 2. J.Ko. performed 1H NMR, J.Ke. K.M. and M.F. were responsibility for animal housing and sample collection and S.E.D. performed 16S rRNA gene sequencing. All authors approved the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Supplementary Information
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International License. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder in order to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/4.0/
About this article

Cite this article
Rogers, G., Kozlowska, J., Keeble, J. et al. Functional divergence in gastrointestinal microbiota in physically-separated genetically identical mice. Sci Rep 4, 5437 (2014). https://doi.org/10.1038/srep05437
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep05437
This article is cited by
-
Zebrafish: an efficient vertebrate model for understanding role of gut microbiota
Molecular Medicine (2022)
-
Temporospatial shifts within commercial laboratory mouse gut microbiota impact experimental reproducibility
BMC Biology (2020)
-
Diet induced obesity is independent of metabolic endotoxemia and TLR4 signalling, but markedly increases hypothalamic expression of the acute phase protein, SerpinA3N
Scientific Reports (2018)
-
The composition of the zebrafish intestinal microbial community varies across development
The ISME Journal (2016)
-
Cross-fostering immediately after birth induces a permanent microbiota shift that is shaped by the nursing mother
Microbiome (2015)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
