
Abstract
Understanding the relation between patterns of human mobility and the scaling of dynamical features of urban environments is a great importance for today's society. Although recent advancements have shed light on the characteristics of individual mobility, the role and importance of emerging human collective phenomena across time and space are still unclear. In this Article, we show by using two independent data-analysis techniques that the traffic in London is a combination of intertwined clusters, spanning the whole city and effectively behaving as a single correlated unit. This is due to algebraically decaying spatio-temporal correlations, that are akin to those shown by systems near a critical point. We describe these correlations in terms of Taylor's law for fluctuations and interpret them as the emerging result of an underlying spatial synchronisation. Finally, our results provide the first evidence for a large-scale spatial human system reaching a self-organized critical state.
Similar content being viewed by others

Introduction
Since their appearance, cities have been one of the main catalysts of human economical, social and cultural development. In recent years, the formation and internal dynamics of urban environments1 have been progressively regarded as the outcome of multilayered interactions of economic, infrastructural and social factors: a network of networks2 very much akin to highly structured, biological organisms and also sharing similar vulnerabilities3. In this analogy, transportation networks naturally identify with circulatory systems, supporting the urban ecosystem through enhanced mobility of people and goods4,5,6. Thus, in order to guarantee its smooth functioning, it is extremely important to be able to correctly describe and predict traffic dynamics at the metropolitan scale.
In the eighty years since Greenshields's seminal paper on the Fundamental Diagram7, the relation between traffic density and flow, great leaps have been taken toward the understanding of the complicated non-linear phenomena that precede and follow the break down of free flow giving way to a variety of different congested states: stop-and-go waves, wide moving jams and extended jams8,9.
Alongside traffic flow theory, the impact of different travel behaviours and traffic control schemes have been studied in depth10, for example in connection with the effect of pre-travel and real time travel information and variable travel demands11,12, real and perceived information uncertainty13,14 and its cognitive cost15, inequality among drivers16 or different user responses to travel information17.
More recently, attention shifted to the information feedback effects of advanced traffic control systems18,19,20 and the most promising (non equilibrium assignment) routing methods based on decentralised collection and projection of real-time information21,22,23, usually inspired by swarm or ant colony methods24. All of these methods focus on devising the best strategy to collect traffic information and forecast traffic conditions in order to minimise travel times.
Data-driven studies on urban traffic at the city level are instead less common, due to the inherent technical difficulties in recording and managing large quantities of traffic data. Although recently this tendency has reversed due to increased availability of data for large urban areas, a macroscopic description of traffic in dense complex environments like modern world cities is still an open problem, warranting approaches inspired by a combination of traffic flow theory and statistical mechanics. The emblematic example is the current discussion about the existence and definition of a meaningful Macroscopic Fundamental Diagram (MFD), the relation between urban traffic density and resulting flow at the city level. Various proposals for a well-defined state space for urban networks27,28,29,30,31 have been put forth, revolving on the identification of “reservoirs”, spatial units exhibiting uniform traffic distributions and properties.
The approach to congestion management based on perimeter control and reservoirs has been shown to be effective. Here we approach the topic of macroscopic urban traffic from a complementary point of view: instead of looking for the optimal partition of the sensors given the constraints of uniform traffic features and spatial proximity, we ask whether the system itself displays such a partition when we focus on the dynamical features of the traffic time-series.
In this regard, London offers an unique opportunity. Because of its history, it is characterised by a complex multi-core topology that cannot be easily reproduced by standard models of geometrical, or spatial, growing networks32,33. It displays very broad distributions of road lengths and capacities in addition to broad distributions of degrees and centralities of the dual graph33. All these features make it a particularly challenging and non-trivial testbed for studying large-scale traffic behaviour.
In this article, we analyze an extensive dataset of London's traffic through the goggles of two recently proposed methodologies of hierarchical topological clustering, called Partition Decoupling Method (PDM)34 and Spatial community detection35 and show that the attempt to self-consistently extract robust “traffic spatial units” highlights instead a rich, multilayered community organization.
The first layer of the PDM results represents the typical behaviour of sensors and identifies similarity classes on the network that are in general spatially extended and mutually overlapping. Hence, defining spatially separated regions from the dynamics alone encounters a fundamental obstacle in the correlations within the traffic network. This is confirmed by the second layer, which describes the fluctuations around the expected behaviour. At this level, the communities found (with one significant exception) span the whole network, implying system-wide fluctuations and strong effects over long ranges (up to 12 km).
An independent analysis based on a spatial, data-driven, modularity approach35 closely reproduces the results of the second layer of the PDM method and also provides a key for interpretation: the spatial correlation function of the fluctuations decays as a power-law over more than 12 km, covering the whole city.
In addition to the algebraically decaying spatial correlation function, we found 1/f power spectra over all sensors, which is the typical sign of long memory effects. The joint presence of long range temporal and spatial correlations in the network are typical indicators of critical systems. Moreover, as it is the internal dynamics of the system that drives it in this critical state, it is said to be in a self-organised critical state. Although the precise origin of self-organised criticality has been much debated since the introduction of the topic, it is seen as an “emerging collective phenomena”. The term collective is used because the spatially large correlation lengths of systems near the critical point (in a standard phase transition) imply that a macroscopic part of the system is involved; and it is emerging because in critical systems the large-scale coordination and the long-time memory (1/f) appear as a macroscopic manifestation of interactions at the microscopic level (which in this case corresponds to the single street level). In our case,the relationship between the scaling exponent of the correlation function and the Hurst exponent of the ensemble fluctuation scaling strongly suggests that the critical state is brought about by an underlying spatial synchronization, which in this particular case can be understood as the interaction between queues in the network and is consistent with biological examples of synchronization across large distances (e.g. forest masting)36,37 and with the marginal synchronization predicted for non-conserved systems38.
Results
Partition decoupling method
The Partition Decoupling Method (PDM) is a topological clustering technique proposed by Leibon et al.34 (see Methods) and successfully applied to the analysis of a section of the equities market34 and of gene expressions55. Through recursive clustering and “scrubbing” steps, the method allows to progressively uncover finer features in the data and finally yields a multi-layered community structure, where each layer encodes qualitatively different information in contrast to standard hierarchical clustering methods. For our dataset, the PDM yields two layers before stopping.
First layer
The first-layer characteristic vector of a community l represents the expected flow at given time on the sensors belonging to community l. In the same way, using the community assignment of sensors, we can also obtain a characteristic occupancy vector for each community. These two vectors together allow us to define a MFD for each community.
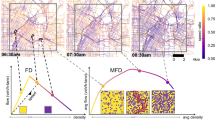
The partition for the first layer contains 15 communities (Figure 1). The sizes of the communities range between 1% to about 20% of the total number of sensors. We found different spatial patterns for communities: some (e.g. panels a, b and c of Figure 1) are composed by sensors distributed in spatially contiguous portions of the network, identifying particular regions as for example in the north-west and the south-east areas of London; others on the contrary appear to be scattered across the whole urban network. In addition, communities are often largely spatially overlapping. The uncovered modules therefore are not independent units that partition the traffic network in spatial areas, or reservoirs, as one might perhaps have expected. On the contrary, through the correlation of the timeseries, these units define classes of sensors sharing similar traffic features. Because the latter are also influenced by the position in the urban network (e.g. the centre of London versus peripheral suburban areas), these classes in some cases show localization in particular areas of the network. Moreover, the spatial overlap of the communities is consistent with this picture: the traffic measured by sensors belonging to a given region is the product of the superposition of the region and of the sensor's specific collocation (on a side road, on a high flow street). This can be seen by looking at the differences between the characteristic series of the communities. The MFD provides a graphical representation of the state space of traffic flow, characterizing its congestion or free flow behaviour. The bottom panel of Figure 1 shows the traffic flow as a function of density for each of the characteristic series, highlighting the differences between the activity patterns of the classes of sensors identified through the PDM.

Spatial localization and functional classes of sensors: first PDM layer.
The top panel displays the communities found for the first layer of the PDM analysis. In the bottom panel, the Fundamental Diagram (relation between traffic density and flow) of the characteristic series of each community is shown, with the same colour code as the spatial visualization. Communities are seen to emerge from two effects: spatial proximity (e.g., sensors in the north-east portion of Central London) and the dynamical properties of the traffic on the sensor (e.g., sensor near a junction as opposed to on a high-flow link). The groups of localized and spatially overlapping communities (e.g., {a, b, c}, {f, g, h}) in fact display markedly different behaviours in the relationship between the density and flow, as shown by the Fundamental Diagrams. Therefore, spatially constrained uniform traffic regions cannot be consistently defined. The value of s over each community picture represents the fraction of nodes belonging to each community. Note in particular that the largest one, community  , spatially extends over the whole network and is characterized by extremely low flows for all densities, clearly identifying network spots with major congestion issues.
, spatially extends over the whole network and is characterized by extremely low flows for all densities, clearly identifying network spots with major congestion issues.
Second layer
Using the characteristic series of the first layer to scrub the data, one can look for second order effects in the correlation of traffic flow (Figure 2). Note that, by construction, the second layer is effectively probing the structure of the fluctuations in the traffic flow. The PDM returns four communities: three, containing 97% of the sensors, span the whole network, implying that fluctuations in London are correlated over the whole city. The fourth clearly identifies the Vauxhall-Park Lane corridor, one of the major routes that crosses London in the North-South direction, suggesting a special role for this area, which is dominated by its internal fluctuations.

Correlation of traffic fluctuations: second PDM layer.
The communities on the second PDM layer are obtained by studying the correlation patterns of the detrended traffic flows. The characteristic series of the first layer are used for the detrending as detailed in the Methods section. Interestingly, communities a, b and d are characterized by a large heterogeneity in terms of number of sensors, spatial distribution and spatial overlap. Therefore, fluctuations show unexpected large-scale coordination across the catchment area. Against these pervasive fluctuations, community c emerges as a particular case: it identifies very well an important north-south corridor across Central London, where fluctuations are strong enough to emerge against the background.
Spatial modularity and temporal correlations
The results of the spatial modularity optimization (see Methods) support this interpretation. Spatial modularity returns a larger number of communities (78), which, when ranked by their size s, scale as a power law sν with exponent ν = 1.09 ± 0.01 (adj-R2 = 0.97). The largest one contains 70% of the sensors and is akin to the three large communities found by the PDM second layer, spreading over the whole network, while the remaining ones are small and localized (see Figure S.8 in the SI). Moreover, we find that the second largest community also identifies -although with additional noise- the same North-South corridor found by the PDM. The closeness of the results of the partitions given by the PDM second layer and the Spatial modularity is quantified by the distance between the two partitions measured by the Normalised Variation of Information59: 0.37. This figure reflects the difference in number of communities together with the similarities of the most important ones. In addition, to confirm that the structure unveiled by the Spatial modularity is genuinely caused by spatio-temporal synchronisation as argued below, we performed N = 100 randomisation of the sensor's position, while keeping their time-series the same. This gives a z-score of 35 for the modularity value found with the original positions, showing that the spatial organisation of the system is crucial (see SI for more details). The Spatial modularity, in addition to reproducing the most important results of the PDM, provides also a key to interpret the origin of the spatial overlap of communities and the power law shape of the spectra. In fact, Spatial modularity is a way of taking into account the spatial constraints of the system in the community detection. In the spatial null model, the fundamental element is the deterrence function f, defined in Eq. (5). In general, f measures the expected strength of a link between nodes at a given spatial distance. So, the optimal partition will cluster together nodes that are more similar or more interacting than expected at a certain distance. In our case, the links are (same time) correlations and therefore the deterrence function is the two-point correlation function at zero lag, C(r, τ = 0), in other words, it is the expected correlation between two sensors separated by a physical distance r. We find two regimes separated by a characteristic sensor distance r0 ~ 200 m (Figure S.11 in the SI). The case r < r0 typically corresponds to sensors on the same road and the coarse-graining of our data does not allow us to identify the functional shape conclusively. Nonetheless there appears to be a steep –faster than algebraic– decay up to r0. For r ≥ r0 instead, C(r, τ = 0) displays a clear power-law decay r−β with β = −0.26 ± 0.01 (adj-R2 = 0.98) up to about 12 km (Figure 3). We repeated the measure in the case of lagged correlations (τ = 30 mins) and found that the functional form remains a power law with the same exponent. These results suggest the presence of two mechanisms: one that is responsible for the internal unidimensional link dynamics, where correlations decrease rapidly (possibly exponentially) in space and a second that emerges at the network level, as the outcome of the different interacting flows. The crossover distance r0 between the two regimes corresponds to the emergence of a large connected component for the spatial network (see SI). Therefore, the power law correlations are a feature of traffic at the network level, that is lost at the level of a single road segment or similarly sized areas of the city.

Spatial correlations of traffic fluctuations.
The correlation functions C(r,τ) for delay τ = 0 (blue) and τ = 30 min (gray) decay algebraically as a function of the spatial distance r. The measured slope is β = −0.26 ± 0.01 implying a very slow decay of correlations for distances larger than 100 m).The plot for τ = 30 min has been lowered for visibility, since the the two curves overlap.
Long-range correlations usually emerge in systems with local interactions in the vicinity of a critical point39, that is near a (second-order) phase transition. When this happens, the whole system behaves as one dynamical module, where the underlying topological structure and details of the interaction determine the precise critical behaviour (the universality class). The large spanning community found in the community detection is then just the representation of this phenomenon. What is less clear, however, is how algebraic correlations can emerge for lengths r > r0.
This concept of phase transition and criticality for traffic is not new. A number of works in traffic flow theory investigated the properties of the transition from free flow to synchronized flow to congested flow on road segments8,40. In order for the continuous approximation to stand, sizable lengths of road were needed. The same holds for most of the phenomena predicted (and observed) in traffic flow, e.g. stop and go waves, wide moving jams, jam fronts propagation26.
In a dense urban environment, on the contrary, the situation is more complicated: due to the spatial constraints and richer infrastructure, the road segment flow dynamics does not dominate anymore, the concept of continuous flow density breaks down and most of the dynamics is in the queues, the street network topology and the traffic control. These elements are endogenous to the network as a whole, but not to the single link traffic variables. Nagel43 proposed that the interaction between the traffic and some traffic control strategies might result into a critical state46. This state would maximize throughput, but also minimize predictability. Indeed it would be characterized by power-law spatial correlations, fluctuations on all scales and usually long memory effects, encoded in the 1/f spectra of the observables in the system.
In Nagel's case, the control parameter was the network density and the order parameter the individual travel time43. At the point of maximum flow in the Fundamental Diagram, the travel time started increasing and a divergence of the error on the estimated travel time for individual cars was observed. These divergences are a general feature of (second-order) critical systems and result in fluctuations of all amplitudes on all scales near and at the critical point. Due to the nature of our dataset, it is not possible to measure the individual travel times. Despite that, we can probe memory effects in the network looking at the spectra of the occupancy and flow timeseries. Figure 4 shows the power spectra for the detrended flow and occupancy data, averaged over the sensors. Both show a peak, corresponding to a daily period (ωday = 10−5 Hz) and an underlying clear power law dependency with exponents  and
and  respectively.
respectively.

Power spectra of traffic variables.
Flow (purple) and occupancy (green) present very clear power-law scaling behaviour with exponent  and
and  respectively. The long-range memory effects span a wide range of temporal scales, persisting over weeks. The observable peak at
respectively. The long-range memory effects span a wide range of temporal scales, persisting over weeks. The observable peak at  corresponds to the daily correlations. The occupancy data have been lowered for visibility.
corresponds to the daily correlations. The occupancy data have been lowered for visibility.
Scaling in power spectra of traffic flow was observed in a number of different traffic situations25,47,48 and related to the existence of a self-organized maximum through-put state for unidimensional flows on long streets (with infinite length or periodic boundaries), where jams of all sizes appear producing a fractal landscape of densities. We see here that this feature survives also in urban flow, despite the finiteness of urban road segments and the presence of network infrastructure and traffic control.
Finally, power-law spatial correlations and 1/f spectra are the typical indicators of self-organized criticality. This means then that London, as a large spatial interacting system, displays a system spanning coherent state and in this sense it resembles a critical system.
Origins of correlations
The traditional way to study the critical features of a system is through its critical exponents. However, due to the poor resolution of the data and the non-uniform distribution of the sensors, it is very hard to devise a reliable renormalisation scheme on our dataset49. An alternative path is to look at the scaling of fluctuations (FS), also known as Taylor's law37,50, that has found wide application across different fields, from biology to infrastructure science.
It states that the fluctuations of a positive extensive quantity scale as a power law of the average value the quantity itself, with the value of the scaling exponent encoding information about the underlying processes. In particular, it is possible to define also an ensemble fluctuations as follows. Consider a system composed by many elements, indexed by i and equipped with a positive quantity fi, that -in our case- will be the sensors and their corresponding flows (i, fi(t)). Let us assume further that each element can be grouped according to some other quantity, usually referred to as the size S of the element due to the seminal paper by Taylor50, which treated the crop yield of fields of different sizes. In our case, we associate to each sensor i its average traffic occupancy <oi> and denote the ensemble average over sensors with similar occupancy o as37:

where Mo is the number of sensors with average occupancy equal to o. The variation inside each class is then given simply by:

and finally FS is written as

The ensemble fluctuations exponent αE is usually found in the interval 1/2 < αE < 1. For the sensors' data, αE = 0.87 ± 0.02 (adj-R2 = 0.95) (see Figure 5). The value of αE is usually found between the two extreme values 1/2 and 1, which correspond to fluctuations dominated by random internal dynamics and by external forcing respectively. The measured αE then implies that the network traffic dynamic is not dominated by either, but rather emerges from a combination of the two. More importantly, it provides us with new insights into the nature of the critical properties we observe. In fact, it is known36 that for complex systems whose components display long-range correlations of the form  , where HV is the Hurst exponent51, one has that HV = α. For the spatial correlations, we measured the exponent β = 0.26 ± 0.01, hence a predicted Hurst exponent HV = 0.87 ± 0.03, which is compatible with the measured scaling exponent.
, where HV is the Hurst exponent51, one has that HV = α. For the spatial correlations, we measured the exponent β = 0.26 ± 0.01, hence a predicted Hurst exponent HV = 0.87 ± 0.03, which is compatible with the measured scaling exponent.

Ensemble Fluctuation Scaling of traffic variables.
Collecting sensors in classes based on their average occupancy, the variation of the expected flow within each class scales algebraically with exponent αE = 0.87 ± 0.02, which is compatible with an underlying synchronization mechanism of the traffic flow.
The relations just used were first formulated in the context of ecological models, in particular the Sataka-Iwase model of trees masting36 after the observation of large scale synchronization of forests across thousands of kilometers. However, since they involve only the form of the correlation function and the properties of the fluctuation scaling can be used in a more general context. In this framework α = 1 would correspond to perfect synchronization and α = 1/2 to random fluctuations. For our dataset, the results indicate the presence of strong, yet partial spatial synchronization that spans the whole system and is the driving mechanism behind the scale-free fluctuations observed through the power spectra and the correlation function.
Discussion
Recent approaches to the control of the macroscopic dynamics of traffic in urban networks28,29,52 pivot on the identification of network reservoirs, or modules, characterized by uniform traffic conditions. These modules are very important because they allow the definition of a meaningful MFD for the whole unit, which in turn allow to devise control strategies for the whole network in terms of units, reducing significantly the complexity of the control problem. However, we find that the detection of modules directly on the correlation network of London's traffic highlight the presence of spatially overlapping traffic communities. Moreover, the MFDs obtained for communities of the first PDM layer show different internal dynamical properties.
Often modules identified through similar activity patterns and thus reciprocal correlations are considered functional units of a system, because they are thought to represent structures which evolve coherently, e.g. market sectors in studies of correlations of stock options' prices34 or separated regions in traffic on information and urban networks41. We prefer however to refer to these units as activity units since in our system it is not clear what function a given module would execute. Moreover, in order for a function to be performed, modules do not necessarily need to correlate their activity but rather coordinate to achieve a given goal42. The emerging community structure can be understood in terms of the temporal and spatial scale-free character of traffic flow fluctuations: the spatial overlap of communities is a consequence of the system being correlated over long distances. Hence, at the dynamical level London is best described as a composition of spatially entangled and dynamically diverse traffic profiles, displaying collective fluctuations.
The analysis of the ensemble fluctuation scaling showed that the origin of the latter lies in an underlying spatial synchronization, which can be thought of as a large scale coordination between queues. Due to the limitations of the dataset, it was not possible to investigate whether this criticality provides the best throughput (as suggested by Nagel43) or rather represents a danger, e.g. when significant congestion occurs, e.g. as result of accidents or failures near important or central bottlenecks. Although reducing drastically the density provides a natural solution, this does not seem likely to happen. Therefore whether the synchronisation is advantageous or not, any attempt at traffic control should take into account the possibility that such long range effects might arise.
In a large multicentric city like London, a large number of demand-side factors, including household activity generation, scheduling and allocation44,45 and mode and time of day choice, are likely to underly the aggregate traffic dynamics. While all these factors strongly contribute to the expected traffic patterns across the network, our analysis focused on the correlation structure of the fluctuations and therefore conveys information about how traffic at different locations coevolves. In this perspective, it is natural to expect that traffic control systems could be the cause of the appearance of the long range effects, especially in the presence of global traffic control schemes which could centrally create such fluctuations. Despite not having detailed information about London's current traffic control scheme, a few considerations on the traffic control's role can be made on a theoretical basis. London's Urban Traffic Control divides the city in four spatially separated regions for which the SCOOT system optimizes traffic signals. If the traffic control had a significant impact on the correlation structure of the network, it would be reasonable to expect that the community detection would highlight this. Instead, we found no trace of such regions in the correlation patterns of fluctuations, making an active role of traffic control in the large scale coordination less likely. Moreover, power-law spatially correlated fluctuations and long memory have been previously observed in simulations of simple lattice gas models53, where no control was present and the dynamics consisted only in repulsive interactions between particles on adjacent sites. Hence, it is possible that system-spanning fluctuations emerge from the queueing and spill-over effects between links across the city, independently of the traffic control.
Finally, it would be of great interest to perform the same type of analysis in different cities (e.g., Manhattan, for its grid structure, or Sao Paolo for its extreme density of cars), as this would allow to explore the phase diagram of urban traffic as a function of the street organisation and density of cars in order to determine the optimal city layout to minimize traffic problems.
Methods
Dataset
The dataset contains traffic flow records measured using 3256 inductive loop detectors operated by Transport for London and which form part of the SCOOT dynamic traffic control system54. The detectors are located mostly in the Central London area but also with some sensors as far as Tottenham to the north, Brixton to the south, Stamford to the east and Chiswick to the west. The area covered is roughly a square with a side of 15 km and the data refers to one month of continuous measures (September 2009). Each sensor is able to measure the number of passing vehicles (flow) and the fraction of time the sensor spends covered (occupancy, a good proxy for traffic density).
In this work, we approach the dataset from a statistical mechanics perspective, focusing on the graph of correlations between traffic flows as measured by the detectors. We will therefore study the correlation matrix obtained from the traffic timeseries as the weighted adjacency matrix of the correlation graph.
Partition decoupling method
The algorithm needs two inputs: a vector of data (e.g., coordinates in a high dimensional space or a time series) for each node and a similarity measure. We applied the method to the sensors' flow data using Pearson correlation coefficient as similarity measure. The output is a list of layers, each defined by a partition  . Each layer describes the finer structure of the data after having accounted (scrubbed) the effects of the previous ones. Starting from the actual data (the first layer, α = 1), we obtain for each community l = 1, …, m in partition
. Each layer describes the finer structure of the data after having accounted (scrubbed) the effects of the previous ones. Starting from the actual data (the first layer, α = 1), we obtain for each community l = 1, …, m in partition  a characteristic vector
a characteristic vector  , constructed by averaging over the vectors associated to the nodes belonging to l. The PDM then proceeds to the next layer (α = 1). This means removing the effect of the previous layer (α = 2) by writing the original timeseries as a combination of characteristic vectors of layer 1 plus a residual. The residual is then used as the basis for a new clustering detection, yielding the second layer partition
, constructed by averaging over the vectors associated to the nodes belonging to l. The PDM then proceeds to the next layer (α = 1). This means removing the effect of the previous layer (α = 2) by writing the original timeseries as a combination of characteristic vectors of layer 1 plus a residual. The residual is then used as the basis for a new clustering detection, yielding the second layer partition  . The method continues until it obtains residuals which cannot be distinguished from a random Gaussian model built from a randomization of the data itself, making the PDM self-contained and parameter-free.
. The method continues until it obtains residuals which cannot be distinguished from a random Gaussian model built from a randomization of the data itself, making the PDM self-contained and parameter-free.
As a note to the reader, we observe that different layers convey very different information. In particular, for traffic data the first layer communities will represent set of sensors sharing similar expected flows. This is therefore related to the position of the sensors in the network and spatially close sensors are likely to display strongly correlated flows. The second layer communities instead represents how fluctuations of traffic on top of the expected values correlate across the network. Section S1.1 of the SI provides further details on the PDM.
Spatial modularity
As we see in the Results section, it is interesting to compare the results of the PDM for the fluctuations of traffic (the second layer) with those of a different community detection algorithm where the dependency on the distance between sensors is explicit. The standard formulation of the Newman-Girvan (NG) modularity function56:

where  is a summation over pairs of nodes i and j belonging to the same community C of a partition
is a summation over pairs of nodes i and j belonging to the same community C of a partition  and therefore counts links between nodes within the same community. si is the strength of a node and 2m the total strength of the network. Optimising modularity thus groups together nodes that have more in common than what is expected by the null-model Pi,j. NG modularity depends strongly on the assumptions made for the null model used in the optimisation. In the present work, we adopt a variation of the standard NG modularity null-model, which introduces spatial constraints in a data-driven way. The original spatial null-model35 was based on a of the variation of the gravity model57:
and therefore counts links between nodes within the same community. si is the strength of a node and 2m the total strength of the network. Optimising modularity thus groups together nodes that have more in common than what is expected by the null-model Pi,j. NG modularity depends strongly on the assumptions made for the null model used in the optimisation. In the present work, we adopt a variation of the standard NG modularity null-model, which introduces spatial constraints in a data-driven way. The original spatial null-model35 was based on a of the variation of the gravity model57:

where f, the deterrence function, can be any (generally decreasing) function of the distance dij between i and j and Ni is an attribute of node i that plays a role similar to the mass. In its original formulation, the deterrence function was calculated from the flows between the nodes constituting the network. In the present work, the data do not provide flows of vehicles between sensors, but occupancy time-series (see data section) from which we calculated correlations matrices. Using correlation automatically renormalise the relative importance of the nodes for our purpose, so the mass term in the null-model can be set to 1 for all nodes. The null-model then reduces to the deterrence function which gives the average correlation between sensors as a function of their distance:

where Ωi,j is the correlation between two sensor's time series for a given time delay. The deterrence function is determined directly from the data and does not require a fit to some functional form57, thus making the method independent from external hypothesis. The modularity function has been optimized using the KL spectral tripartitioning method58. Section S1.2 of the SI provides further details on spatial modularity optimization.
References
Bettencourt, L. M. A., Lobo, J., Helbing, D., Kuhnert, C. & West, G. B. Growth, innovation, scaling and the pace of life in cities. Proc. Nat. Acad. Sci. USA 104(17), 7301–7306 (2007).
Gao, J., Buldyrev, S. V., Stanley, H. E. & Havlin, S. Networks formed from interdependent networks. Nat. Phys. 8, 40–48 (2011).
Buldyrev, S. V., Parshani, R., Paul, G., Stanley, H. E. & Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028 (2010).
Samaniego, H. & Moses, M. E. Cities as Organisms: Allometric Scaling of Urban Road Networks. J. Transp. Land Use 1, 21–39 (2008).
González, M. C., Hidalgo, C. A. & Barabási, A. L. Understanding individual human mobility patterns. Nature 453, 779–782 (2008).
Roth, C., Kang, S. M., Batty, M. & Barthélemy, M. Structure of Urban Movements: Polycentric Activity and Entangled Hierarchical Flows. PloS One 6 (1), e15923 (2011).
Greenshields, B. A study of traffic capacity. Highway Research Board (1935).
Kerner, B. & Rehborn, H. Experimental features and characteristics of traffic jams. Phys. Rev. E 53, 1297–1300 (1996).
Helbing, D. Verkehrsdynamik. Springer (1997).
Peeta, S. & Ziliaskopoulos, A. K. Foundations of dynamic traffic assignment: The past, the present and the future. Networks and Spatial Economics 1 (3), 233–265 (2001).
De Palma, A. & Fosgerau, M. Dynamic and Static congestion models: A review. Cahier de recherche, Ecole Polytechnique, CNRS (2010).
Ben-Akiva, M. E., Koutsopoulos, H. N., Mishalani, R. G. & Yang, Q. Simulation Laboratory for Evaluating Dynamic Traffic Management Systems. Journal of Transportation Engineering 123 (4), 283–289 (1997).
Wang, X. & Khattak, A. Role of travel information in supporting travel decision adaption: exploring spatial patterns. Transportmetrica, 1–19 (2011).
Gao, S., Frejinger, E. & Ben-Akiva, M. E. Adaptive route choices in risky traffic networks: A prospect theory approach. Transp. Res. Part C 18(5), 727–740 (2010).
Gao, S., Frejinger, E. & Ben-Akiva, M. E. Cognitive cost in route choice with real-time information: An exploratory analysis. In Transp. Res. Part a-Policy and Practice, Univ Massachusetts, Amherst, MA 01003 USA (2011).
Yang, H. Multiple equilibrium behaviors and advanced traveler information systems with endogenous market penetration. Transp. Res. Part B: Methodological 32(3), 205–218 (1998).
Bierlaire, M., Thémans, M. & Axhausen, K. W. Analysis of driver's response to real-time information in Switzerland. European Transport 34, 21–41 (2006).
Wang, Q.-X., Wang, B.-H., Zheng, W.-C., Yin, C.-Y. & Zhou, T. Advanced information feedback in intelligent traffic systems. Physical Review E 72(6), (2005).
Dong, C. F., Ma, X. & Wang, B. H. Weighted congestion coefficient feedback in intelligent transportation systems. Physics Letters A 374(11–12), 1326–1331 (2010).
Chen, B. & Cheng, H. H. A Review of the Applications of Agent Technology in Traffic and Transportation Systems. IEEE Transactions on Intelligent Transportation Systems 11(2), 485–497 (2010).
Claes, R., Holvoet, T. & Weyns, D. A decentralized approach for anticipatory vehicle routing using delegate multiagent systems. IEEE Transactions on Intelligent Transportation Systems 99 (2011).
Weyns, D., Holvoet, T. & Helleboogh, A. Anticipatory vehicle routing using delegate multiagent systems. Intelligent Transportation Systems Conference, 2007. ITSC 2007. IEEE, 87–93 (2007).
Narzt, W. et al. Self-Organization in Traffic Networks by Digital Pheromones. Intelligent Transportation Systems Conference, 2007. ITSC 2007. IEEE, 490–495 (2007).
Teodorovic, D. Swarm intelligence systems for transportation engineering: Principles and applications. Transp. Res. Part C: Emerging Technologies 16(6), 651–667 (2008).
Musha, T. & Higuchi, H. The 1/f fluctuation of a traffic current on an expressway. Jap. J. App. Phys. 15, 1271–1275 (1976).
Helbing, D. & Huberman, B. A. Coherent moving states in highway traffic. Nature 396, 738–740 (1998).
Helbing, D. Derivation of a fundamental diagram for urban traffic flow. Eur. Phys. J. B 70(2), 229–241 (2009).
Daganzo, C. F. & Geroliminis, N. An analytical approximation for the macroscopic fundamental diagram of urban traffic. Trans. Res. B 42(9), 771–781 (2008).
Geroliminis, N. & Daganzo, C. F. Existence of urban-scale macroscopic fundamental diagrams: Some experimental findings. Trans. Res. Part B 42(9), 759–770 (2008).
Daganzo, C. F., Gayah, V. V. & Gonzales, E. J. Macroscopic relations of urban traffic variables: Bifurcations, multivaluedness and instability. Trans. Res. B 45(1), 278–288 (2011).
Mazloumian, A., Geroliminis, N. & Helbing, D. The spatial variability of vehicle densities as determinant of urban network capacity. Phil. Trans. Roy. Soc. A 368(1928), 4627–4647 (2010).
Crucitti, P., Latora, V. & Porta, S. Centrality in networks of urban streets. Chaos 16, 015113 (2006).
Masucci, A. P., Smith, D., Crooks, A. & Batty, M. Random planar graphs and the london street network. Eur. Phys. J. B 71, 259–271 (2009).
Leibon, G., Pauls, S., Rockmore, D. & Savell, R. Topological structures in the equities market network. Proc. Nat. Acad. Sci. USA 105(52), 20589–20594 (2008).
Expert, P., Evans, T. S., Blondel, V. & Lambiotte, R. Uncovering space-independent communities in spatial networks. Proc. Nat. Acad. Sci. USA 108, 7663 (2011).
Satake, A. & Iwasa, Y. Pollen Coupling of Forest Trees: Forming Synchronized and Periodic Reproduction out of Chaos. J. Theo. Bio. 203(21), 63–84 (2000).
Eisler, Z., Bartos, I. & Kertész, J. Fluctuation scaling in complex systems: Taylor's law and beyond. Adv. Phys. 57(1), 89–142 (2008).
Middleton, A. & Tang, C. Self-organized criticality in nonconserved systems. Phys. Rev. Lett. 74(5), 742–745 (1995).
Ben Avraham, D. & Havlin, S. Diffusion and Reactions in Fractals and Disordered Systems, Cambridge Nonlinear Science Series. Cambridge University Press (2000).
Gao, K., Jiang, R., Wang, B. & Wu, Q. Discontinuous transition from free flow to synchronized flow induced by short-range interaction between vehicles in a three-phase traffic flow model. Phys. A 388(15–16), 3233–3243 (2009).
Zeng, H.-L., Guo, Y.-D., Zhu, C.-P., Mitrović, M. & Tadić, B. Congestion patterns of traffic studied on Nanjing city dual graph. IEEE Digital Signal Processing, 16th International Conference 1–8 (2009).
Simon, H. The architecture of complexity. Proc. Am. Phil. Soc. 106 (6), 467–482 (1962).
Nagel, K. & Paczuski, M. Emergent traffic jams. Phys. Rev. E 51(4), 2909–2918 (1995).
Oppenheim, N. Urban Travel Demand Modeling: from Individual Choices to General Equilibrium. John Wiley and Sons (1995).
Ortuzar, J. & Willumsen, L. G. Modelling Transport. Wyley and Sons (1994).
Jensen, H. J. Self-Organized Criticality: Emergent Complex Behavior in Physical and Biological Systems, Cambridge Lecture Notes in Physics, Cambridge University Press (1998).
Choi, M. Y. & Lee, H. Y. Traffic flow and 1/f fluctuations. Phys. Rev. E 52(6), 5979–5984 (1995).
Zhang, X. & Hu, G. 1/f noise in a two-lane highway traffic model. Phys. Rev. E 52(5), 4664–4668 (1995).
Song, C., Gallos, L. K., Havlin, S. & Makse, H. A. How to calculate the fractal dimension of a complex network: the box covering algorithm. J. Stat. Mech. 3, P03006 (2007).
Taylor, L. R. Aggregation, Variance and the Mean. Nature 189, 732–735 (1976).
Smith, H. An empirical law describing heterogeneity in the yields of agricultural crops. J. Agric. Sci. 28, 1–23 (1938).
Daganzo, C. F. Urban gridlock: Macroscopic modeling and mitigation approaches.Trans. Res. B 41(1), 49–62 (2007).
Fiig, T. & Jensen, H. Diffusive Description of Lattice-Gas Models. J. Stat. Phys. 71(3–4), 653–682 (1993).
Hunt, P., Robertson, D., Bretherton, R. & Winton, R. Scoot - a traffic responsive method of coordinating signals. Transport Road Research Laboratory (1981).
Braun, R., Leibon, G., Pauls, S. & Rockmore, D. Partition decoupling for multi-gene analysis of gene expression profiling data. BMC Bioinf. 12, 497 (2011).
Newman, M. Modularity and community structure in networks. Proc. Nat. Acad. Sci. USA 103(23), 8577–8582 (2006).
Erlander, S. & Stewart, N. F. The gravity model in transportation analysis: theory and extensions. VSP International Science Publishers (1990).
Richardson, T., Mucha, P. J. & Porter, M. A. Spectral tripartitioning of networks. Phys. Rev. E 80(3), 036111 (2009).
Meila, M. Comparing Clusterings by the Variation of Information. Learning Theory and Kernel Machines, 173–187 (2003).
Acknowledgements
The authors acknowledge Transport for London for the permission to use the traffic sensor data and Imperial College London's High Performance Computing cluster for computational support. G.P. acknowledges technical assistance and helpful discussions with Dr Rajesh Krishnan of the Centre for Transport Studies, Imperial College London. G.P. is supported by the TOPDRIM project funded by the Future and Emerging Technologies program of the European Commission under Contract IST-318121. P.E. is supported by the MRC Grant U.1200.04.007.00001.01.
Author information
Authors and Affiliations
Contributions
GP and PE performed the analysis, wrote the manuscript and prepared the figures. All authors designed the research and reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Electronic supplementary material
Supplementary Information
Supplementary Materials
Rights and permissions
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/
About this article
Cite this article
Petri, G., Expert, P., Jensen, H. et al. Entangled communities and spatial synchronization lead to criticality in urban traffic. Sci Rep 3, 1798 (2013). https://doi.org/10.1038/srep01798
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep01798
This article is cited by
-
Measuring accessibility to public services and infrastructure criticality for disasters risk management
Scientific Reports (2023)
-
Spatiotemporal dynamics of traffic bottlenecks yields an early signal of heavy congestions
Nature Communications (2023)
-
Perceiving spatiotemporal traffic anomalies from sparse representation-modeled city dynamics
Personal and Ubiquitous Computing (2023)
-
Connecting Hodge and Sakaguchi-Kuramoto through a mathematical framework for coupled oscillators on simplicial complexes
Communications Physics (2022)
-
Spatiotemporal behaviors of the ridership of a public transportation system during an epidemic outbreak: case of MERS in Seoul
Journal of the Korean Physical Society (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
