
Abstract
Carbon offsets are widely promoted as a strategy to lower the cost of emission reductions, but recent findings suggest that offsets may not causally reduce emissions by the amount claimed. In a compliance market, offsets increase net emissions if they do not reflect real emission reductions beyond the baseline scenario. Few studies have examined the additionality of forest carbon offsets within California’s U.S. Forest Projects compliance offset protocol, one of the largest forest offset programs in the world. Here we examine additionality in California’s offset protocol. Since 2012, most of California’s offset credits (84%) have been awarded to improved forest management projects. Using a database of improved forest management project characteristics, locations, and remotely sensed forest disturbance data indicative of management activity, we find that projects have been primarily allocated to forests with high carbon stocks (127% higher than regional averages) and low historical disturbance (28% less disturbance than regional averages since 1985). A matching and panel regression analysis failed to show additionality, as project creation did not significantly lower disturbance rates 3 and 5 years after project implementation relative to similar non-project lands. These results indicate that California’s forest offset protocol may contribute to an increasingly large carbon debt.
Similar content being viewed by others


Introduction
Mitigating greenhouse gas (GHG) emissions and the risks associated with climate change are among the most pressing challenges society faces today1. Central to reaching climate change-related targets is reducing the amount of carbon dioxide (CO2; carbon, hereafter) in the atmosphere2,3, and GHG emissions trading programs have become the policy of choice for many governments4. Carbon offsetting has gained popularity as a tool to reduce the cost of compliance with voluntary and government-mandated emissions reduction targets globally5. Concerns, however, have been raised about the effectiveness of offsets5,6,7,8,9,10,11. Ideally, when carbon emissions are offset, the offset project should mitigate or reduce emissions or remove carbon from the atmosphere equal to the emissions being offset. Where emission reductions are required by law (i.e., a compliance market), if the amount of carbon mitigated, reduced, or removed by an offset project is less than the amount that the offset entitles its purchaser to emit, carbon offsetting can lead to higher overall emissions, reduced incentives to develop lower-emissions technologies, and increased warming12,13. Therefore, the effectiveness of offset policies hinges on the offset protocol’s ability to ensure equivalence and additionality.
Improved forest management (IFM), which supports greater sequestration and storage of carbon, can be an impactful and cost-effective strategy to reduce atmospheric carbon concentration level2,14,15,16. For IFM offset projects to be additional, land enrolled should be part of a harvest management plan or otherwise not managed optimally for carbon sequestration; after project establishment, harvest should be delayed, or the forest managed in a way to sustain or increase carbon stocks. Failure to develop protocols that ensure additionality in IFM projects can lead to over-crediting and associated carbon debt12,13,17.
Under its cap-and-trade system, California began compliance offset protocols in 2012. The California Air Resources Board (ARB) issues offset credits worth one metric tonne of CO2-equivalent emissions to registered projects in the United States that reduce, mitigate, or sequester GHG. The California Code of Regulations requires additionality by stating that to reduce atmospheric carbon, GHG reductions through offsets must be “real, additional, quantifiable, permanent, verifiable, and enforceable”18. IFM projects are the backbone of the policy, with 85.5% of credits allocated by California’s cap-and-trade system being awarded to US forest offset projects to date—nearly all of which (98.6%) were awarded to IFM projects19. Haya10,20 estimates that for the compliance period between 2021 and 2030, offsets could represent more than 50% of the reductions attributable to the cap-and-trade program. Despite these legal requirements and the importance of IFM projects to California’s climate goals, growing empirical evidence suggests that offsets in this program are not accurately credited for baselines, additionality, and leakage, leading to over-crediting, and non-additional due to asymmetric information and adverse selection12,17,21,22,23,24.
Here we empirically examine the additionality of forest offset projects at this early stage in the program by quantifying the impacts of forest offset projects on forest disturbance associated with carbon emissions. While the additionality of forest offset projects is determined by emission reductions over the 100-year project lifespan, and optimal management may require early management decisions resulting in disturbance to facilitate improved long-term forest management, we propose that additionality measured over the short term can serve as an early indicator of policy effectiveness.
To do this, we focused on three main questions: (1) To what extent do IFM projects exhibit characteristics—such as size, location, ownership class, credits received, and baseline carbon stocks—commonly associated with lower long-term disturbance? (2) Do pre-project disturbance rates on IFM projects suggest that enrolled forests were at a lower risk of harvest than non-enrolled forests, even without credits? (3) After projects are established, is forest disturbance reduced relative to comparable lands—that is, do projects show clear signs of additionality?
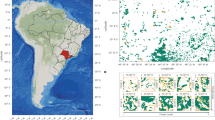
We explore heterogeneity across geographies for each question as timber patterns and disturbance risks vary by region. We utilize Supersections, sub-state delineations based on similar ecosystem types and equivalent to the EPA’s Ecoregions Level III designations25,26,27. ARB uses Supersections to establish whether a project’s baseline aboveground carbon stocking is above or below the average in a similar region (Fig. 1)25,28. Here we use the same direct comparison method—we calculate historical forest disturbance rates within Supersection and project bounds and compare them directly to one another to evaluate disturbance rates on project lands. Because different landowner types may have divergent management goals17, we also explore heterogeneity across landowner types by using a forest landowner classification stratum developed by the US Forest Service to group projects29,30 (see Supplementary Table 1 for a complete description of each landowner type). Groups include corporate timber interests, families, Native American Tribes, timber investment management organizations (TIMO) and real estate investment trusts (REIT), and an aggregate group labeled ‘other,’ which comprises primarily of non-governmental organizations (NGOs) and land trusts.

a Yellow shading represents locations and boundaries of offset projects relative to blue shading, which represents locations and boundaries of Supersections. b Progressively darker red shading represents greater numbers of offset projects located within each Supersection. c Progressively darker red shading represents greater total area of land (hectares) offset within each Supersection. d Progressively darker red shading represents higher mean baseline carbon stocking of total offset project land relative to its respective Supersection.
We examine 136 IFM projects that have been developed in 31 states and 40 Supersections, for which we were able to obtain spatial project boundaries, with a primary focus on 90 of those projects, which have been issued ARB credits, located in 24 states and 31 Supersections (see Supplementary Table 2 for a summary of all 117 ARB-credited compliance IFM projects to date; see Supplementary Table 3 for comparisons between credited and non-credited projects included in this study across regions). The basis of our analysis is our two unique datasets and the ability to observe forest disturbance before and after project establishment. To create the first dataset, we collected, combined, cleaned, and harmonized disparate boundary files for IFM compliance projects, creating the most complete dataset possible of ARB compliance IFM project boundaries31,32,33. To create the second dataset, we used time series satellite data from the Landsat archive and a well-established algorithm for detecting forest disturbance (LandTrendr) to map forest disturbances caused by management activity in all represented Supersections and projects between 1985 and 202034,35,36,37. Our dataset distinguishes natural disturbances from harvests so that we can focus on the role of forest management in offsets. We distinguish this difference by using predictive modeling, omitting disturbances such as wildfires38, considering spatial and temporal patterns indicative of forest management, and extending the timeframe of commonly used forest change datasets, providing sufficient temporal resolution to understand harvest risk39. Together, these two datasets provide sufficient temporal and spatial heterogeneity to apply statistical matching and panel regression techniques to evaluate if the projects show signs of additionality.
Results and discussion
Participating IFM forest offset projects
The 90 credited projects included in this analysis were primarily located on forestlands owned by three ownership types: ‘other,’ comprising mainly NGOs (34.4% of projects), corporate (23.3% of projects), and TIMO/REIT (18.9% of projects) (Table 1). While there were fewer Tribal projects (15.6% of projects), they were substantially larger than projects owned by other ownership classes: on average, they were 32,220 ha, compared to the next largest, TIMO/REIT projects, with an average size of 24,230 ha; ‘other’ projects with an average size of 16,454 ha; and corporate projects with an average size of 11,297 ha. Projects on family forestlands were less common—only 7.8% of projects—and smaller in size than other project types, with an average size of 2092 ha.
While projects owned by corporate and ‘other’ interests were most common, the highest percentage of credits in California’s program has been allocated to Tribal projects (47.9% of all credits) and TIMO/REIT projects (23.7% of credits) due in part to their larger size. The projects included in this analysis have been issued 140.8 million credits—76.8% of the total 183.3 million credits that ARB has issued across all compliance IFM projects as of 2020 (Supplementary Table 2)28.
On average, across ownership classes, projects were stocked at carbon levels that were 127% of Common Practice values, which is the average standing live carbon of forests within the project’s Supersection and Assessment Area. Family-owned forestlands had the highest average stocking level above Common Practice at 145%, followed by Tribal forestlands at 139.5%, corporate forestlands at 128.9%, and ‘other’ forestlands at 123.2%, TIMO/REIT projects had the lowest aboveground carbon stocking at 115.5% of Common Practice. The minimum stocking level above Common Practice for TIMO/REIT, Tribal, and family projects was 100%. Across corporate, Tribal, family, and ‘other’ projects, eight reported carbon levels above 200% of Common Practice, with the highest being 256.1%.
Comparing forest disturbance rates
Using our remotely sensed dataset of forest management-related disturbances between 1985 and 2020, we calculated the total annual disturbed area and disturbance rate over the time series for project areas and Supersections. Results were further explored across landowner types and at the coarsest EPA Ecoregion level (Level I) to explore whether ownership type is associated with different baseline disturbance rates (Fig. 2; Supplementary Table 3).

Annual disturbance is reported between 1986 and 2020. Darker green dotted and solid lines represent annual disturbance on offset project land compared to lighter green dotted and solid lines representing annual disturbance on Supersection land.
Rates of management-related disturbance were relatively low throughout the United States. Overall, about 0.2% of forested pixels in our dataset were disturbed annually, likely due to forest harvest. Annual disturbance rates in projects were statistically lower overall than in Supersections; on average, 0.16% of project land was disturbed each year compared to 0.22% of Supersection land. Not only were average disturbance rates across the 35-year time series lower for project land compared to Supersection land, but this pattern of lower disturbance on project land was also observed for almost all individual years of the time series (Fig. 2). Projects experienced less annual disturbance than Supersections for 31 of the 35 years included in our analysis. There was, however, heterogeneity within individual projects and their respective Supersections. Using pairwise Wilcoxon rank-sum tests to compare each project/respective Supersection pair, 71% of projects (64 of 90) had lower annual rates of disturbance than their respective Supersection, 21% of which (19 of 90 projects) had significantly lower annual rates of disturbance than their Supersection (p < 0.001). 12% of projects (11 of 90) had significantly higher rates (p < 0.001).
Comparing mean annual disturbance rates by ownership class for all Supersections and all projects in the analysis, disturbance rates were significantly higher in Supersections than projects (p < 0.001) on TIMO/REIT, corporate, and family-owned forestlands. TIMO/REIT-owned forestlands had the largest discrepancy in annual disturbance rate between Supersections (0.43%) and projects (0.17%). There was also a large difference in annual disturbance rates for corporate-owned forestlands between Supersections (0.35%) and projects (0.14%). Tribal lands experienced the lowest annual rates of disturbance for both projects and Supersections, with the project rate (0.17%) higher than the Supersection rate (0.1%; p < 0.001). No significant difference was found between ‘other’ projects and their respective Supersections.
Disturbance after project establishment
To estimate the impact of project establishment on disturbance rates, we used pre-regression matching and linear probability models. We utilized matching to create a dataset comprising comparable control and treatment observations to minimize selection bias due to the non-random locations and characteristics of projects40,41. We matched points created from individual project and non-project forest pixels within Supersections (Supplementary Fig. 2, Supplementary Table 5), then combined all data from the Supersections. We used this dataset in a difference-in-differences regression framework and modeled our results for (1) three years before and after project designation and (2) five years before and after project designation. We specified two models: a fixed effects linear probability model and a random effects logit model (Table 2; Supplementary Tables 6–9). Standard errors were clustered at the Supersection level (see Methods for further details).
In this statistical framework, we seek to identify the impact of the policy based on differences in trends between project and non-project areas before and after treatment. The key identifying assumption of the model is that overall trends in forest disturbance mirror each other in project and Supersection areas before project enrollment. While it’s difficult to test statistically, Fig. 2 supports the use of the difference-in-differences approach, as trends in project and non-project areas are similar over time. A strength of the difference-in-difference approach is that the results are not biased by unobservable time-invariant confounders that might impact forest harvests such as land use history, stable landcover preferences, and stable regional attitudes toward forest harvesting. We note, however, that results may be biased if time-variant unobservable variables are correlated with treatment selection and forest disturbance, or if time-invariant variables interact with time-varying ones. For example, these models would be biased if a generational change took place in land ownership shifted landowner attitudes as the land was enrolled as a project. While we have seen little evidence that such shifts are happening at the program scale, we cannot completely rule out such a scenario. Likewise, standard errors in the model can be biased if inter-project covariances differ between project and disturbance pixels.
Our panel regression results fail to support the presence of additionality at this early stage in California’s forest carbon offset program. When data is pooled across land ownership types, we do not find a statistically significant impact of project establishment for either timeframe at normal levels of significance (Fig. 3). Indeed, the only ownership class where we see a consistent negative statistically significant impact of project establishment is the TIMO/REIT class. As an ownership group, these projects appear to be additional at this early stage. In addition, project establishment is associated with increased forest harvest for ‘other’ projects.

For each ownership class, rates for matched data are compared between all projects and all Supersections five years before and after project commencement (lighter green and darker green, respectively).
Implications for climate change policy
California’s offset program has enrolled IFM projects that have experienced low disturbance rates over the past 35 years. As such, projects have much higher levels of aboveground carbon stocking than their respective Supersection averages. If these carbon-rich forests were threatened with harvest, they might be suitable choices for offsetting. Our findings from the matching and panel regression models, however, fail to find that that offsets were threatened by forest harvest in the absence of the program, and are therefore non-additional in the short term. Because California’s U.S. Forest Projects offsets can be used for regulatory compliance, unless the management of offsets changes in the future, the policy may be creating a carbon debt and lead to increased carbon in the atmosphere relative to the state’s cap-and-trade targets.
The incentive structure of the protocol is reflected in these results, which issues credits by comparing a project’s baseline against Common Practice values. Highly stocked forests are issued large amounts of credits, and developers are paid immediately for existing carbon stocks. Baseline setting in this way rewards landowners for past decisions not to harvest. However, these may be the very landowners and locations that are also unlikely to harvest in the future. In this way, California’s program fails to properly incentivize additionality and potentially suffers from strong adverse selection. This is reflected in our results, where we cannot statistically document decreases in forest harvest patterns three and five years after project establishment for the program by any landowner type except TIMO/REIT.
At this early stage in California’s program, we suggest strengthening protocols to ensure additionality. This will require the program to reconsider how it establishes baselines and business-as-usual scenarios. Data on past forest harvests, both inside and outside of project areas, can be used to provide compelling and credible baselines and is available at sufficiently high temporal and spatial resolutions for all areas covered by the California program. We suggest the policy make better use of these data sources to develop more credible baselines from which to measure additionality.
While our results suggest limited additionality, and we believe our findings are explained by the incentives provided by California’s policy, we stress that this is an early assessment of a program that requires forests to maintain carbon stocks for 100 years. Optimal carbon management over the project period may require early management actions that result in forest disturbance but lead to greater carbon over the course of the project, yet the current protocol appears to create a disincentive for this type of management32. There is a chance that the positive coefficients for forest disturbance for ‘other’ forestlands identify early management that may lead to longer-term sequestration. Further research at the level of individual project forest management plans will help clarify if this is the case.
California has developed ambitious climate change-related targets, policies, and programs, and the outcomes of these decisions are likely to influence the development of offset programs elsewhere. For this reason, California’s offset program must serve the overall goal it was designed to aid in achieving. Current incentives encourage the offsetting of carbon-rich forests but do not sufficiently address additionality. We suggest that strong reforms are needed for California’s offset program to be a world-leading standard.
Methods
Overview of the california compliance offset program
The California Compliance Offset Program began in 2012 to reach target emissions reduction goals set by the 2008 AB 32 Scoping Plan42. In this program, the California Air Resources Board (ARB) calculates and allocates a specific number of offset credits to qualifying projects that reduce or sequester GHG under ARB-approved protocols. Offset credits are a “tradable compliance instrument… that represent verified GHG reductions or removal enhancements of one metric ton of [carbon dioxide equivalent] CO2e” and are required to be “real, additional, quantifiable, permanent, verifiable, and enforceable”28. To comply with mandatory emission reductions, businesses are permitted to purchase these offset credits to substitute a maximum of 8% of their reductions from 2012–2020, 4% from 2021–2025, and 6% from 2026–2030.
ARB recognizes four different types of forestry offset projects: land reforestation, avoided conversion, improved forest management, and urban forestry. To register an IFM offset project, landowners must have their land evaluated to assure that improvements will occur, commit to the agreement for 100 years, and monitor and report project data throughout the project’s lifetime. The number of offset credits awarded to an individual project is determined by comparing overall carbon stocking on project land to baseline carbon stocking in the Supersection in which the project is located (the ‘Common Practice’ statistic, estimated using data made available by the US Forest Service Forest Inventory and Analysis (FIA) National Program). Our research focuses only on IFM projects, which make up 84% of all offset credits.
Offset boundaries, supersections, and landowners
IFM offset projects were included in this analysis if they met three criteria: (1) they were compliance projects and not Early Action (where credits were awarded to entities reducing emissions before compliance was required); (2) they were listed on an ARB-designated registry; (3) their boundary GIS data was uploaded or otherwise made available. ARB tasks much of the oversight of projects to three registries: Verified Carbon Standard (now Verra California Offset Project Registry, or VCSOPR), the Climate Action Reserve, and the American Carbon Registry. When this data was collected, many projects were listed across all three registries that did not satisfy the requirement of boundary file upload. Once collected, all files were converted to shapefiles and processed to equal-area conic projection. Geometries were checked for validity, and geometrical errors were repaired if present. The study area included the boundaries for each project and the boundaries of the 40 Supersections in which they were located. Supersections are equivalent to the EPA’s sub-state Ecoregions Level III designations25,28. For projects that intersected multiple Supersections, the primary and secondary Supersections, in terms of the percentage of the project’s area contained, were included.
We stratified our analysis across five land ownership types: corporate, TIMO/REIT, Tribal, family, and ‘other’ owners (primarily land trusts and NGOs), all of whom may have different management objectives. For example, corporate forest owners typically have predictable forest management goals to maximize profit from timber harvest. In contrast, non-industrial private forest owners (Tribal, family, and ‘other’ owners) may be motivated by alternative goals in addition to, or instead of, financial gain, such as ecosystem services43. Forest owner types and definitions for the US were sourced from the US Forest Service29.
Identifying forest disturbance from 1985-2020 with remote sensing
We created forest disturbance maps indicative of management activities such as clearcutting and selective harvest from 1985 to 2020. We conducted the analysis for each project and Supersection using Google’s Earth Engine platform and the LandTrendr algorithm36,37,44,45 (see Supplementary Fig. 1 for remote sensing analysis and validation process diagram). LandTrendr (Landsat-based detection of trends in disturbance and recovery) has been used in many forest change analyses and was utilized in this work for several reasons. First, LandTrendr is an effective tool for analyzing forest harvest-related disturbances across diverse landscapes37. Second, it is optimized to detect forest disturbance related to forest management activities like harvesting, e.g., clearcutting, selective harvesting, and thinning, by allowing parameter customization to identify specific types of forest management36. Lastly, LandTrendr is effective at large-scale analyses in Google’s Earth Engine platform, which provides the computational power to conduct time series at the national scale needed for this analysis37.
For each project and Supersection, the Landsat archive—US Geological Survey (USGS) Surface Reflectance Tier 1 data34,35—accessed via GEE, was used to create annual composite images for each year between 1984 and 2020 inclusive. Data from 1984 was ultimately omitted from analyses due to the non-uniform availability of imagery. Imagery from all available Landsat sensors was considered in creating the composites, including Landsat 5 Thematic Mapper (TM), Landsat 7 Enhanced Thematic Mapper + (ETM + ), and Landsat 8 Operational Land Imager (OLI). The archive was filtered for all images that overlapped the bounds of the project or assessed Supersection. Images were then filtered to those acquired within a peak growing season time range from mid-June to mid-September between 1985 and 2020.
A harmonization function was deployed to prepare images in the filtered collection for processing by correcting for discrepancies across images acquired from different Landsat sensors46. Clouds, cloud shadows, water, snow/ice, primary and secondary roads, water bodies, and fire activity areas were masked out.
Annual medoid composites were made with the processed and filtered image collection by selecting the images for each year with spectral values most similar to the median spectral values of the series37. Areas of forest with less than 30% canopy cover were masked out from the composites with the following process: first, a baseline forest cover image was generated using the Global Forest Watch forest cover layer from 2000 as an initial reference point39. The layer was filtered to include only areas with canopy cover greater than or equal to 30%. A random sample of points was generated within the forested areas, and then the points were then used to sample the Landsat composite image we created for the year 2000. A supervised random forest classification was conducted to classify forest cover areas in the 1985 composite image using the collected training data from 200047. Areas classified in 1985 as non-forest or forest with less than 30% canopy cover were masked out in every subsequent annual image of the time series. These steps were done for each project and Supersection individually.
Annual composite images were clipped to project or Supersection extents. The Normalized Burn Ratio (NBR) spectral index48,49 was used as the input for LandTrendr, which has been utilized in many studies using LandTrendr to detect forest disturbance50,51 and is an exceptionally reliable metric compared to other commonly used indices52. The LandTrendr algorithm was applied, and the magnitude of change was calculated per pixel. For each pixel time series, if there was more than one disturbance detected, only the greatest magnitude disturbance was ultimately considered. Finally, pixels were clustered into minimum mapping units of 10 pixels using a 10-pixel sieve50,53 to resolve noise ( < 10 disturbed pixels surrounded by non-disturbance) and small, isolated areas of under-threshold disturbance ( < 10 non-disturbed pixels surrounded by disturbance).
Validation of landtrendr analysis
To validate the LandTrendr analysis results, a stratified random sample of 3,114 points was generated based on the area proportions of the disturbed/non-disturbed map to manually confirm or reject each of the three classes within both Supersection and project lands: (1) non-forested areas; (2) forested areas that were not disturbed; and (3) forest areas that were disturbed54. We then split this number of validation points in half, sampling half from project land and half from non-project Supersection land. Each point was also assigned a five-year time period from 1985 to 2020. The classification was manually confirmed or rejected using imagery from that five-year period in Google Earth Pro. If imagery was not available, a new random point was assigned with the same parameters55.
Each of the three validation classes ultimately had 1038 total points sampled. 92% of points classified as non-forest were manually confirmed as non-forest; 89% of points classified as non-disturbed forest were manually confirmed as non-disturbed forest, and 86% of points classified as disturbed forest were manually confirmed as disturbed forest. To further validate our results, the total area of pixels that experienced a disturbance in the LandTrendr analysis was compared with the total disturbance areas reported in the Global Forest Watch (GFW) dataset, developed by Hansen et al.39. Several metrics were calculated and compared because of the temporal and processing differences between our study and GFW data. First, the total forest disturbances detected in the LandTrendr outputs between 1986 and 2020 were calculated at the Supersection level. The same was done for the GFW data for all available data at the time of writing, 2000–2020. Because we masked out certain types of disturbances that could be present in the GFW dataset, such as wildfires, we also applied the same masks to omit them from the GFW data before summarizing it at the Supersection level. We calculated a second metric for the LandTrendr output dataset that summarized disturbances detected within the same period GFW data was available. An important aspect of the LandTrendr model we used was a parameter that returned only one disturbance event per observation. For the second GFW summary, we masked out any points that had experienced a disturbance before 2000 in the LandTrendr output. This was done because we could be certain that those areas would not experience a disturbance if only the years 2000–2020 were isolated. On average, Supersections experienced 2723 km2 and 1985 km2 of forest disturbance in the second LandTrendr and GFW summaries, respectively (Supplementary Table 4).
Comparing disturbance rates over time between projects and supersections
To test the difference in forest disturbance rates between projects and Supersections, we calculated disturbance rates for overall project land and overall Supersection land. Disturbance rates were calculated using a random sample of the full dataset. We calculated the disturbance rate over time for a total of 35 time steps, starting with the rate of change from 1985 to 1986 and ending with the rate of change from 2019 to 2020. The matching procedure was done using the full dataset and produced 5,997,312 data points split equally between project and non-project Supersection points. The full unmatched dataset was then randomly sampled to equal the sample size of the matched dataset. Using this randomly sampled dataset, we then averaged the disturbance rate for all projects and compared it to the average disturbance rate for all Supersections. We performed pairwise Wilcoxon tests as a non-parametric alternative to paired t-tests to evaluate significant differences in disturbance rates between projects and Supersections56.
Statistical signals of project commencement on forest disturbance
To estimate the effect of project commencement on forest disturbance, we combine matching methods with a difference-in-difference panel regression. Past research has shown that combining matching and difference-in-difference estimators provides stronger estimates than matching alone40. In these methods, matching is first used to build comparison treatment and control datasets. Where Supersections cover vast areas, this ensures that project points and non-project points have similar harvest likelihoods. The points resulting from the matching analysis were then used as input for the difference-in-differences regression models. The use of difference-in-difference regression then accounts for time-invariant unobservable variables that may influence both treatment and outcome.
Approach
To match points between project land and non-project Supersection land, we calculated and compiled several variables known to be spatial determinants of forest harvesting, including slope, aspect, elevation, distance to roads, distance to mills, and landcover type57. The TIGER US Census Roads dataset was used to calculate the distance to roads, and the US Wood-Using Mill Locations dataset to calculate the distance to mills. We used a nearest-neighbor matching method and a logistic regression method of measuring distance with the MatchIt package in R58. A 0.2 caliper value and a random matching order were used58. We matched points individually within Supersections and then combined Supersection data to create the panel used in the difference-in-differences model. The balance between matched and non-matched observations was interrogated by comparing the standardized mean difference between matched and unmatched data (Supplementary Fig. 2; Supplementary Table 5).
We used a difference-in-differences panel model approach to estimate the impact of offset project commencement on the matched dataset. We chose difference-in-differences models because they effectively isolate policy impacts from other factors54,55. Specifically, we estimated the model:
here \({Disturbance}\) is equal to one if a human-caused disturbance is observed at point i in year t, and equal to zero otherwise. \({{Project}}_{i}\) identifies if a point is part of a project (1) or not (0). \({{After}}_{{it}}\) indicates if azx time period is before (0) or after (1) project commencement. The interaction term \({{Project}}_{{it}}* {{After}}_{{it}}\), identifies observations that are both projects and in time periods after the project has commenced versus observations that are either not projects or projects before commencement. The other variables refer to static and time-varying co-variants that impact forest harvest. The error term can be segregated into a unit-specific error term \({p}_{i}\) and an observation-specific error term \({e}_{{it}}.\)
We used two models to estimate this formula. First, we used a fixed effects linear probability model with standard errors clustered at the Supersection level. In this model, all time-invariant variables in the regression equation fall out of the estimator. Second, we used a random effects logit model with standard errors clustered at the Supersection level. The two models have trade-offs. The random effects model more accurately reflects the dependent variable’s binomial nature, while the linear probability model allows for the inclusion of fixed effects40. In addition, while unobserved spatial-auto correlation may decrease standard errors in the linear probability model, it can actually bias coefficient estimates in the logit model. We estimated the impact of the policy three years and five years pre- and post-implementation to isolate policy effects. Both logit and linear probability models were conducted in Stata using the xtlogit and xtreg commands.
Model limitations
As with any statistical model, our model may be biased if key identifying assumptions are not met. The concern of most consequence in this work is the possibility of an unobservable covariate that varies with time and impacts forest disturbance, as well as enrollment in California’s offset program. While it is impossible to list all potential unobserved covariates, we directly address four of the most important potential unobserved variables and provide evidence for why we do not think they are driving our results.
Variation in co-benefits of standing forests to landowners
If landowners vary in their preferences for other co-benefits of standing forests or in their ability to financially benefit from such co-benefits (e.g., some locations might have stronger forest-related tourism potential because of differences in geological/natural features, or geographic access to existing tourism flows), they could be more likely to enroll and less likely to harvest in the absence of enrollment. In this scenario, our estimates could be biased toward showing a greater impact. Given that we find a null impact, our results suggest that even if this unobservable variable existed, it would not qualitatively impact our main findings.
Family situation of landowners
Landowners’ family situations may impact their need or preference for deriving income from their land via credits, where those who need income may be less likely to harvest and more likely to enroll in California’s offset program. Because we include pre-treatment harvest levels, we would only expect the family situation of the landowner to impact our result if the landowner’s situation were to change at the same time as the treatment (i.e., if it changes before the pre-treatment period, it should be accounted for). While we cannot completely rule this situation out, it is unlikely that such an effect is driving the overall results here, given the relatively small amount of offset land owned by families (0.9% of the total project hectares for the 90 credited projects included in this analysis, and 0.8% when all 117 credited projects to date are considered—see Supplementary Table 2).
Maturity of forests and relationship to harvest probability
There is no nationwide dataset on forest age at the scale of the data used here. Older forest stocks are typically (although not always) more valuable than younger ones and may be more likely to be harvested. For example, if a forest has a typical harvest rotation of 30 or 40 years, trees younger than this are less likely to be harvested than trees older than this. If forestlands with younger stocks are systematically enrolled in a project because they cannot generate revenue through harvesting, and forestlands with older stocks systematically harvest more, our estimates would be biased toward showing a greater impact of the program. However, our estimates show a null effect of the program for the program overall and for all but one ownership class. This suggests that even if our results are biased by this unobservable, the null effect estimated in the model will still hold.
Maturity of forests and relationship to carbon payments
Older forests typically contain more carbon than younger forests59. Given that the California program pays landowners for carbon stocks above Common Practice levels, there is an economic incentive to enroll older forests in the program. Likewise, the incentive to harvest also increases as forests mature. If there were a systematic enrollment of older forests over younger forests in California’s offset program, our model estimates would be biased downward as the likelihood of forest harvest increases with age. In this case, a time-variant unobservable would be biasing our model.
While we cannot completely rule this out, this is unlikely for two reasons. First, the dataset used is based on forested areas in 1984 and remained forested until the pre-treatment period. Given that the earliest projects enrolled in the program in 2012, the five-year pre-treatment observation means the observations were forested in 2007. This suggests that the youngest stands in our dataset were at least 30 years old (23 years of observation (1984–2007) plus roughly seven years to be classified as forest in 1984). This suggests that by the end of our sample, the youngest forests were ~40 years of age. We believe that most forests in our dataset were of age to be merchantable timber by the end of our dataset. If this is the case, a landowner enrolling old forests in the program faces an economic trade-off between enrolling for credits or harvesting for revenue. Most economic models of improved forest management suggest that break-even prices for delaying harvest is over $50 and credits in the California market have stayed below $20 a ton, so we suggest this outcome is unlikely13,60,61,62.
Second, given that nearly all the forests in our sample are of harvestable age, it is unclear if older stands are more or less likely to be harvested. Relatively younger stands suggest a history of past forest harvest, meaning that the property may be managed for timber. If this is the case, the probability of harvest without the program may be higher than for older forests with little to no management history. If very old forests with very high carbon stocks are not part of active management, and this management continues, our results will be biased the other way, and the takeaways from our model will stay the same. That is, selection into very old forests may imply selection into non-managed forests, where harvesting is unlikely.
Data availability
All data used in this study are publicly available online. Boundary files for IFM compliance projects are available through the Verra California Offset Project Registry31 at https://registry.verra.org/, the Climate Action Reserve32 at https://thereserve2.apx.com/myModule/rpt/myrpt.asp?r=111, and the American Carbon Registry33 at https://acr2.apx.com/myModule/rpt/myrpt.asp?r=111. Data utilized to estimate the Common Practice statistic comes from project listing documents, which are available on the three registries’ websites as well. California Air Resources Board utilizes data from the USFS FIA National Program to calculate Common Practice values, which is available at https://apps.fs.usda.gov/DATIM/Default.aspx. Supersection26,27 shapefiles are available from the ARB US Forest Projects website at https://ww3.arb.ca.gov/cc/capandtrade/protocols/usforest/2015/ak.se.sc.Supersection.shp.5.4.15.zip (Alaska) and https://ww3.arb.ca.gov/cc/capandtrade/protocols/usforest/2015/super.section.shapefiles5.4.15.zip (continental US). Datasets utilized to create maps of forest disturbance are available as follows: US Geological Survey (USGS) Surface Reflectance Tier 1 data and Landsat Archive34,35 at https://www.usgs.gov/core-science-systems/nli/landsat/landsat-data-access; European Commission’s Joint Research Centre Global Surface Water Mapping Layers, v1.263 at https://global-surface-water.appspot.com/download; MODIS Burned Area Monthly Global 500 m38 at https://lpdaac.usgs.gov/products/mcd64a1v006/; and Global Forest Watch39 forest cover layer at https://data.globalforestwatch.org/. Datasets used for variable creation included the GRIDMET Drought: CONUS Drought Indices (PDSI)64 at https://www.northwestknowledge.net/metdata/data/; US Wood-Using Mill Locations - 200565 at https://www.srs.fs.usda.gov/econ/data/mills/; and TIGER: US Census Roads66 at https://www.census.gov/programs-surveys/geography/guidance/tiger-data-products-guide.html. Forest ownership in the conterminous United States29 is available through the US Forest Service Research Data Archive at https://www.fs.usda.gov/rds/archive/Catalog/RDS-2020-0044.
Code availability
The code developed for the processing and analysis of data and to generate figures and tables in this analysis is available from the corresponding author upon reasonable request.
References
IPCC. Summary for Policymakers. In Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 3–32 (Cambridge Univ. Press, 2021). https://doi.org/10.1017/9781009157896.001.
Griscom, B. W. et al. Natural climate solutions. Proc. Natl. Acad. Sci. 114, 11645–11650 (2017).
Lewis, S. L., Wheeler, C. E., Mitchard, E. T. A. & Koch, A. Restoring natural forests is the best way to remove atmospheric carbon. Nature 568, 25–28 (2019).
State and Trends of Carbon Pricing 2021. https://doi.org/10.1596/978-1-4648-1728-1 (2021)
Editorial Board. Net-zero carbon pledges must be meaningful to avert climate disaster. Nature 592, 8 (2021). https://doi.org/10.1038/d41586-021-00864-9.
Coffield, S. R. et al. Using remote sensing to quantify the additional climate benefits of California Forest Carbon Offset Projects. Glob. Chang. Biol. 28, 6789–6806 (2022).
Lang, S., Blum, M. & Leipold, S. What future for the voluntary carbon offset market after Paris? An explorative study based on the Discursive Agency Approach. Clim. Policy 19, 414–426 (2019).
Watt, R. The fantasy of carbon offsetting. Env. Polit. 00, 1–20 (2021).
Spash, C. L. The brave new world of carbon trading. New Political Econ. 15, 169–195 (2010).
Haya, B. et al. Managing uncertainty in carbon offsets: insights from California’s standardized approach. Clim. Policy 20, 1112–1126 (2020).
Haya, B. Carbon Offsetting: An Efficient Way to Reduce Emissions or to Avoid Reducing Emissions? An Investigation and Analysis of Offsetting Design and Practice in India and China [(Doctoral dissertation) Energy & Resources Group, University of California]. https://escholarship.org/content/qt7jk7v95t/qt7jk7v95t.pdf (2020)
Badgley, G. et al. Systematic over‐crediting in California’s forest carbon offsets program. Glob. Chang. Biol. https://doi.org/10.1111/gcb.15943 (2021)
Van Kooten, G. C. & Johnston, C. M. T. The economics of forest carbon offsets. Annu. Rev. Resour. Econ. 8, 227–246 (2016).
Harper, A. B. et al. Land-use emissions play a critical role in land-based mitigation for Paris climate targets. Nat. Commun. 9 (2018).
Seddon, N. et al. Global recognition of the importance of nature-based solutions to the impacts of climate change. Glob. Sustain. 3 (2020).
Fargione, J. E. et al. Natural climate solutions for the United States. Sci. Adv. 11, 1–15 (2018).
Ruseva, T. et al. Additionality and permanence standards in California’s Forest Offset Protocol: A review of project and program level implications. J. Environ. Manag. 198, 277–288 (2017).
California Code of Regulations (CCR), title 17, section 95970.
California Air Resources Board. ARB Offset Credit Issuance Table. https://ww3.arb.ca.gov/cc/capandtrade/offsets/issuance/arboc_issuance.xlsx (2022).
Haya, B. The Size of California’s Carbon Offset Program. http://bhaya.berkeley.edu/docs/FACTSHEET-the-size-of-CAs-offset-program-Haya.pdf (2018).
Haya, B. The California Air Resources Board’s U.S. Forest Offset Protocol Underestimates Leakage. https://gspp.berkeley.edu/assets/uploads/research/pdf/Policy_Brief-US_Forest_Projects-Leakage-Haya_4.pdf (2019).
Burke, P. J. Undermined by adverse selection: Australia’s direct action abatement subsidies. Econ. Papers 35, 216–229 (2016).
Joppa, L. N. & Pfaff, A. High and far: biases in the location of protected areas. PLoS ONE 4, 1–6 (2009).
Millard-Ball, A. The trouble with voluntary emissions trading: Uncertainty and adverse selection in sectoral crediting programs. J. Environ. Econ. Manag. 65, 40–55 (2013).
US Environmental Protection Agency (EPA). Ecoregions of North America (EPA, 2015).
California Air Resources Board. Alaska Supersection. https://ww3.arb.ca.gov/cc/capandtrade/protocols/usforest/2015/ak.se.sc.Supersection.shp.5.4.15.zip (2022).
California Air Resources Board. Continental US Supersections ARB US Forest Projects. https://ww3.arb.ca.gov/cc/capandtrade/protocols/usforest/2015/super.section.shapefiles5.4.15.zip (2022).
California Air Resources Board & California Environmental Protection Agency Air Resources Board. Compliance Offset Protocol U.S. Forest Projects. https://ww2.arb.ca.gov/sites/default/files/classic//cc/capandtrade/protocols/usforest/forestprotocol2015.pdf (2015).
Sass, E. M., Butler, B. J. & Markowski-Lindsay, M. A. Forest ownership in the conterminous United States circa 2017: distribution of eight ownership types—geospatial dataset. Fort Collins, CO For. Serv. Res. Data Arch. https://doi.org/10.2737/RDS-2020-0044 (2020).
Hewes, J. H., Butler, B. J. & Liknes, G. C. Forest ownership in the conterminous United States circa 2014: distribution of seven ownership types—geospatial dataset. Fort Collins, CO For. Serv. Res. Data Arch. (2017).
Verra. California Offset Project Registry. https://registry.verra.org/ (2022).
Climate Action Reserve. https://thereserve2.apx.com/myModule/rpt/myrpt.asp?r=111 (2022).
American Carbon Registry. https://acr2.apx.com/myModule/rpt/myrpt.asp?r=111 (2022).
Masek, J. G. et al. A Landsat surface reflectance dataset for North America, 1990-2000. IEEE Geosci. Remote Sens. Lett. 3, 68–72 (2006).
Vermote, E., Justice, C., Claverie, M. & Franch, B. Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sens. Environ. 185 (2016).
Kennedy, R. E., Yang, Z. & Cohen, W. B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 114, 2897–2910 (2010).
Kennedy, R. E. et al. Implementation of the LandTrendr algorithm on Google Earth Engine. Remote Sens. 10, 1–10 (2018).
NASA LP DAAC, USGS EROS Center. MODIS Burned Area Monthly Global 500m. https://lpdaac.usgs.gov/products/mcd64a1v006/.
Hansen, M. C. et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 342, 850–853 (2013).
Jones, K. W. & Lewis, D. J. Estimating the counterfactual impact of conservation programs on land cover outcomes: The role of matching and panel regression techniques. PLoS ONE 10, 1–22 (2015).
Herbert, C., Haya, B. K., Stephens, S. L. & Butsic, V. Managing nature-based solutions in fire-prone ecosystems: Competing management objectives in California forests evaluated at a landscape scale. Front. For. Glob. Change 5, 957189 (2022).
California Assembly Bill No. 32-Global Warming Solutions Act of 2006. 38500–38599. http://www.arb.ca.gov/cc/docs/ab32text.pdf (2006).
Kelly, E. C., Gold, G. J. & Di Tommaso, J. The willingness of non-industrial private forest owners to enter California’s carbon offset market. Environ. Manag. 60, 882–895 (2017).
Google Developers. ee.Algorithms.TemporalSegmentation.LandTrendr. Google Earth Engine (GEE) (2020).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 202, 18–27 (2017).
Roy, D. P. et al. Characterization of Landsat-7 to Landsat-8 reflective wavelength and normalized difference vegetation index continuity. Remote Sens. Environ. 185, 57–70 (2016).
Schultz, M., Verbesselt, J., Herold, M. & Avitabile, V. Assessing error sources for Landsat time series analysis for tropical test sites in Viet Nam and Ethiopia. Earth Resources and Environmental Remote Sensing/GIS Applications IV, 23–25 September, 2013, Dresden, Germany (2013).
Key, C. H. & Benson, N. C. Landscape assessment: ground measure of severity, the composite burn index; and remote sensing of severity, the normalized burn ratio. FIREMON: Fire effects monitoring and inventory system. Gen. Tech. Report. RMRS-GTR-164-CD: LAI-15 file:///C:/Users/jcronan.000/Documents/UW/JFSP_ASF/ASF_Info_LibraryKey&Benson_2006_CBI.FIREMON-2367368725/Key&Benson_2006_CBI.FIREMON.pdf (2006).
Miller, J. D. & Thode, A. E. Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR). Remote Sens. Environ. 109, 66–80 (2007).
Kennedy, R. E. et al. Spatial and temporal patterns of forest disturbance and regrowth within the area of the Northwest Forest Plan. Remote Sens. Environ. 122, 117–133 (2012).
White, J. C., Wulder, M. A., Hermosilla, T., Coops, N. C. & Hobart, G. W. A nationwide annual characterization of 25 years of forest disturbance and recovery for Canada using Landsat time series. Remote Sens. Environ. 194, 303–321 (2017).
Cohen, W. B., Yang, Z., Healey, S. P., Kennedy, R. E. & Gorelick, N. A LandTrendr Multispectral Ensemble for Forest Disturbance Detection. Remote Sens. Environ. 205, 11–13 (2017).
Soto-Berelov, M. & Hislop, S. Approaches used for pixel based time series analysis of Landsat data Literature Review A Monitoring and Forecasting Framework for the Sustainable Management of SE Australian Forests at the Large Area Scale. Project vol. 4104 https://www.crcsi.com.au/assets/Program-4/Agriculture/4.104-LandFor/Project4-104-LandFor-LitRevTimeSeriesV1-1.pdf (2016).
Olofsson, P. et al. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 148, 42–57 (2014).
Bruggeman, D., Meyfroidt, P. & Lambin, E. F. Forest cover changes in Bhutan: Revisiting the forest transition. Appl. Geogr. 67, 49–66 (2016).
Hollander, M., Wolfe, D. A. & Chicken, E. Nonparametric statistical methods. Nonparametric Statistical Methods. https://doi.org/10.1002/9781119196037 (2015)
Pokharel, R., Grala, R. K., Grebner, D. L. & Cooke, W. H. Mill willingness to use logging residues to produce electricity: a spatial logistic regression approach. For. Sci. 65, 277–288 (2019).
Ho, D. E., Imai, K., King, G. & Stuart, E. A. Matching as nonparametric pre-processing for reducing model dependence in parametric causal inference. Polit. Anal. 15, 199–236 (2007).
Pregitzer, K. S. & Eugenie, S. E. Carbon cycling and storage in world forests: biome patterns related to forest age. Glob. Chang. Biol. 10.12, 2052–2077 (2004).
Hope, E. S. et al. A financial analysis of four carbon offset accounting protocols for a representative afforestation project (southern Ontario, Canada). Can. J. For. Res. 51.7, 1015–1028 (2021).
Kerchner, C. D. & William, S. K. California’s regulatory forest carbon market: Viability for northeast landowners. For. Policy Econ. 50, 70–81 (2015).
Nepal, P., Robert, K. G. & Donald, L. G. Financial feasibility of increasing carbon sequestration in harvested wood products in Mississippi. For. Policy Econ. 14.1, 99–106 (2012).
European Commission’s Joint Research Centre. Global Surface Water Mapping Layers, v1.2. https://global-surface-water.appspot.com/download.
Abatzoglou, J. T. Development of gridded surface meteorological data for ecological applications and modelling. Int. J. Climatol. 33, 121–131 (2013).
Prestemon, J. et al. U.S. wood-using mill locations – 2005. https://www.srs.fs.usda.gov/econ/data/mills/ (2008).
United States Census Bureau. TIGER: US Census Road. https://www.census.gov/programs-surveys/geography/guidance/tiger-data-products-guide.html (2016).
Author information
Authors and Affiliations
Contributions
J.S. led the analysis with extensive and consistent contributions from C.N., M.P., M.B., and B.K.H. at various stages of the work, and from V.B. throughout. Jared Stapp and Van Butsic contributed equally to the conceptual design of the analysis. J.S., V.B., C.N., M.P., M.B., and B.K.H. all contributed to the organization, writing, and refinement of the manuscript, as well as expertise and feedback throughout the work. J.S. compiled and processed datasets, conducted the remote sensing analysis, wrote the code, and made the visualizations. J.S. and Van Butsic co-designed the statistical analyses.
Corresponding author
Ethics declarations
Competing interests
The authors declare the following competing interests: at the time of publication, Jared Stapp, Matthew Potts, Matthias Baumann, and Van Butsic were employed by Carbon Direct Inc. Christoph Nolte and Barbara K. Haya declare no competing interests.
Peer review
Peer review information
Communications Earth & Environment thanks Lilli Kaarakka, Guangyu Wang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editors: Nadine Mengis and Clare Davis. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Stapp, J., Nolte, C., Potts, M. et al. Little evidence of management change in California’s forest offset program. Commun Earth Environ 4, 331 (2023). https://doi.org/10.1038/s43247-023-00984-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43247-023-00984-2
This article is cited by
-
Australian human-induced native forest regeneration carbon offset projects have limited impact on changes in woody vegetation cover and carbon removals
Communications Earth & Environment (2024)
-
Pervasive over-crediting from cookstove offset methodologies
Nature Sustainability (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
