
Abstract
Internal and external factors regulating the past composition of plant communities are difficult to identify in palaeo-vegetation records. Here, we develop an index of relative entropy of community assembly, which applies to changes in the composition of a community over time, measuring disorder in its assembly relative to disassembly. Historical periods of relatively ordered assembly (negative index values) are characteristic of a community undergoing endogenous self-organisation, in contrast to relatively disordered assembly (positive values) characterising periods of exogenous abiotic forcing. We quantified the relative entropy index for a 22,000-year time-series of tundra vegetation obtained in the Polar Urals, based on sedimentary DNA. We find it most positive during the Late Pleistocene characterized by persistent taxa, and most negative during the post-glacial Holocene characterized by more ephemeral floras. Changes in relative entropy coincide with changes in regional temperature as reconstructed from stable oxygen composition of an Arctic ice-core. Our results suggest that temperature strongly influenced community assembly in the Polar Urals until about 9000 years before present, after which endogenous community self-organization prevailed through to the present. We conclude that time-series of community composition can reveal changes in the balance between internal and external influences on taxonomic turnover and resulting diversity.
Similar content being viewed by others

Introduction
The late-Quaternary paleo-record of changing floristic composition provides partial analogues that may inform projections of future responses of communities to externally imposed drivers, such as rapid climate change1,2. Interest has focused particularly on the transition from the Last Glacial Maximum, ca. 20,000 years before present (yr BP), to interglacial conditions, which involved rapid, large-magnitude changes in temperature and moisture. At a global scale, plant community composition can be explained by relatively well-known bioclimatic relationships. It is possible, for example, to simulate past continental-scale vegetation composition using climate data and compare results with observed paleo-data3. Conversely, elements of past climate variation, typically temperature and moisture variables, can be reconstructed using a variety of approaches4,5,6. Time series of plant paleodata have also provided information on other aspects of vegetation dynamics: biodiversity7, the occurrence of tipping points8, and shifts in dominant traits and functionality9. In particular, rates of change provide a concise index of temporal changes in diversity that can be driven by exogenous or endogenous processes10. Separating these drivers objectively in past community dynamics is a challenge: typically, the importance of facilitation, competition, dispersal and other endogenous factors in regulating the assembly of paleo communities is only inferred or ignored altogether.
Empirical paleodata further serve to assess the performance of ecological niche models11,12, and to inform simulations of taxa responses to projected future change13. Most simulations use climate envelopes to define taxa distributions, despite the known limitation that they model only abiotic controls over taxa presence and not the interaction of abiotic with biotic influences on ecological niches14. Forecasts of climate-change impacts from niche models consequently risk under-estimating the dynamic role of endogenous drivers (cf. dynamic vegetation models, which; however; require knowledge of taxon-specific ecologies15,16). In reality, climate change may disrupt the relationship between exogenous drivers of community dynamics, such as temperature or precipitation, and endogenous drivers, such as competition or facilitation, altering the patterns of accumulation or loss of taxa from a community. By ignoring the potential for interspecific competition and facilitation to regulate community assembly, climate-envelope models risk under- or overestimating community stability and resilience to chains of extinctions17,18. Indeed, a recent sedaDNA study identified adaptation to light and soil disturbance as important for post-glacial arrival in N Fennoscandia19. Here we address the issue of distinguishing endogenous from exogenous drivers without knowledge of taxon-specific drivers, by quantifying entropy in the assembly of communities relative to entropy in their disassembly.
A composite index of relative entropy of community assembly: RECA
Information theory quantifies uncertainty of outcome as entropy. A time-series of community composition has sequential values of entropy in the continuity of its taxa through time, which are determined by uncertainties in the outcome of taxon incidences from one sequential sample to the next. For each value of this directional entropy, the associated accumulation or loss of taxa results in a compositional entropy, which is determined by uncertainty in predicting the taxon of a randomly sampled individual in the timestep. Directional entropy is characterised by departure from perfectly nested or blocked incidence of taxa towards random changes in composition through time, measurable with a variation on the nestedness matrix based on overlap and decreasing fill (NODF20). The resulting compositional entropy is independently characterised by Shannon α-entropy21. Here we refer to these two metrics as, respectively ‘disorder’, quantifying degree of randomness in change through time, and ‘diversity’, reflecting the common application of Shannon α-entropy as the Shannon-Weiner index of α-diversity. For an alternative to diversity, we consider ‘richness’, given by the number of identified taxa in the dataset (listed in Supplementary Table 1). The Methods section details construction of these metrics, and demonstrates the independence of the disorder metric from richness, making it a more suitable measure of dissimilarity between samples than unmodified NODF or β-metrics, which inherently correlate with α-metrics22.
With disorder and diversity free to vary independently, their detrended fluctuations may or may not align with each other. Within the time series, periods during which the two detrended metrics fluctuate in opposite phase are indicated by negative correlations between them. The negative correlation denotes a period in which ordered assembly alternates with more disordered disassembly: taxa that enter the community have a stronger tendency to stay in, relative to the tendency of taxa that exit to stay out. With regard to taxon richness, were all taxa to have equal abundance, a negative disorder-diversity correlation would result from ordered increases and disordered decreases in richness.
Conversely, same-phase fluctuations in the detrended disorder and diversity produce a positive correlation, which defines a period in which disordered assembly alternates with more ordered disassembly: taxa that enter the community have a weaker tendency to stay in, relative to the tendency of taxa that exit to stay out. In this case, the richness of equal-abundance taxa would show disordered increases and ordered decreases.
The correlation of disorder with diversity (or richness) has a coefficient ranging between −1.0 and +1.0, covering the full spectrum of entropy in community assembly relative to the entropy of disassembly, from most ordered to most disordered. We use the Pearson product-moment correlation coefficient to index this relative entropy of community assembly, henceforth referred to as ‘RECA’. Its value informs on the influence of exogenous versus endogenous drivers of community change (Table 1). A period with negative RECA has more ordered community assembly than disassembly, which is characteristic of emergent processes of mutual competition and facilitation in ecological successions, and niche construction insofar as taxonomic composition influences community function23,24. Its disordered losses likewise characterise the consequences of diversity collapse in communities that are tightly structured into dominance hierarchies by competitive asymmetries25,26. A negative RECA thus expresses the expected self-organisation under endogenous drivers.
Conversely, a period with positive RECA has predictable sequences of losses, characteristic of regional extinctions or extinction cascades, which have been linked to the onset of adverse climatic conditions, or any conditions outside the envelope of variability in which the community has developed27,28. Unpredictable gains likewise characterise zero-sum dynamics of neutral-niche communities in which self-organisation plays a negligible role compared to exogenous drivers29. The positive RECA thus expresses the expected impacts of exogenous drivers.
This type of articulation of disorder with resulting diversity has signalled early warning of approaching lake eutrophication events on decadal scales, when applied to time-series of algae (diatom) and zoobenthos (chironomid) communities26. It has potential as a universal tool for analysing the construction of past communities, even in the absence of detailed information linking fossil taxa to their functional traits and ecologies, as is often the case with deep-time paleo sequences. If an entropy diagnostic is able to infer drivers of observed community changes in late-Quaternary paleo-records, it would have important applications to defining the climate envelopes of taxa informed by niche models13. The predictive value of niche models depends on distinguishing the realised from the fundamental niche11, which requires accounting for endogenous processes.
Here we apply the method to a late-Quaternary vegetation record for which we have relatively complete knowledge of both the ecology of plant taxa and climate trends since the Last Glacial Maximum (LGM). Our dataset is a floristically rich record of sedaDNA from 23,727 to 1,322 yr BP, extracted from sediments of the largest and deepest lake in the Polar Ural Mountains, northern Russia (Bolshoye Shchuchye30,31). Our aim is to test for the presence of millennial-scale periods of exogenous or endogenous regulation of community composition, and to interpret switches between them in relation to changing environmental influences on past communities. In common with many empirical time series, the Bolshoye Shchuchye dataset has a long-term trend in the time interval between consecutive samples, in this case from shorter to longer over time due to an initially high sedimentation rate from glacial in-wash. We address this issue by merging closely-spaced samples, using a procedure detailed in the methods, to result in a RECA time series extending back to 20,000 yr BP.
Results
Disorder and diversity trends on millennial scales
Time series of disorder and diversity of terrestrial plants show temporal fluctuations within long-term trends (Fig. 1). Although the disorder calculation requires a wider time window for later than for earlier samples (longer horizontal red lines in Fig. 1), even after sample mergers, this does not induce detectable autocorrelation in the 1st differences used to detrend the time series for quantification of RECA (Supplementary Fig. 1). We further explore the potential for an influence of sample interval on richness using a simulation of incidence matrices detailed in the Methods. Disorder declines markedly from ca. 18,500 yr BP, during rising diversity, which increases until the end of the Bølling-Allerød (ca. 12,900 yr BP), superimposed by a cyclic pattern of lesser falls and greater rises. Diversity reaches its highest sustained values during the period of transition from glacial to interglacial conditions, with pronounced peaks at ca. 13,000 and 10,000 yr BP interrupted by a trough at 11,400 yr BP, coinciding with the lowest disorder. After ca. 10,000 yr BP, diversity drops to its Holocene minimum at 8,800 yr BP, during a time of maximal Holocene disorder. Four upward spikes of diversity in the last 8,700 yr are each present in a single sample. Generally in the Holocene, diversity values are higher than those of the glacial period and similar to those of the late-glacial period. The time series of richness varies between 12 and 71 taxa per timestep, with no notable differences from the patterns for diversity.

Disorder (red-continuous) describes directional entropy: uncertainty in the outcome of sequential turnover; diversity (blue-dashed) describes compositional entropy: uncertainty in predicting the taxon of a randomly sampled individual from the timestep. Each horizontal red line stretches back through the 10 time steps used for calculation of that disorder value. At any time point on the x axis, the diversity is the value that results from the given disorder at that time point. Dotted vertical lines delimit the end of the LGM at 17,500 yr BP, the Bølling-Allerød period at 14,700–12,900 yr BP, the Younger Dryas at 12,900–11,500 yr BP, and the 8.2-k event at 8200 yr BP.
Evidence of the contributions to these patterns by different taxa comes from partitioning the dataset into functional groups (Fig. 2, incidence plot). Grass and forb communities of the Pleistocene gave way with rising temperature to shrub-tundra communities. Woody vegetation started to diversify with a moister climate during the Bølling-Allerød, exemplified by the establishment of Betula at 13,300 yr BP. The start of the Holocene at 11,500 yr BP marked the establishment of the woody taxa Vaccinium, Empetrum, Picea and Larix, with Alnus and Arctostaphylos coming in by 10,300 yr BP. This time coincided also with a marked change in the composition of graminoids and forbs, and the replacement of arctic-alpine with boreal taxa, including ferns (Fig. 2, Supplementary Fig. 2). Coniferous trees disappeared shortly after 5000 yr BP (Fig. 2 and Table 1). The four Holocene diversity spikes, at 8664, 7004, 4943 and 2034 yr BP, contain from 1.5 to 3.5 times the richness of forbs either side of the spike (14 to 30 more taxa), from 1.7 to 5.0 times the richness of bryophytes (2 to 6 more taxa), from 1.5 to 6.0 times the diversity of graminoids (1 to 5 more taxa), and from 0.9 to 1.1 times the diversity of trees and shrubs (−1 to 1 more taxa). These brief inflations of diversity, particularly in bryophytes and forbs, are poorly understood; they may relate to transitory changes in dominant source areas, for example if exceptional runoff delivered high volumes of material from upper elevations of the catchment.

The top plot shows incidences of contributing taxa, arranged from most to least incident in each of five functional groups (names in Supplementary Table 1; four diversity spikes indicated by vertical red dotted lines). The graph plots RECA as the sequential correlation of detrended disorder with diversity (continuous purple trace, and dashed trace after interpolation across the four diversity spike years), and of detrended disorder with richness (underlain continuous pink trace). For any x-axis date, the value of the trace is the RECA coefficient for the 10-sample window up to that date. RECA ranges between −1.0 (ordered assembly) and +1.0 (disordered assembly), characteristic of endogenous vs. exogenous drivers respectively. Horizontal dotted lines show values of RECA = 0 and ±0.5, for testing deviations of the trace values from random expectation. Regional temperature variation through time is represented by isotopic changes in the GRIP ice core (light blue, 22 time-point moving average in dark blue).
RECA switches between positive and negative on millennial-scales
The disorder and diversity values at each timestep were detrended by 1st differencing (i.e., using the quantity remaining after subtracting the value in the previous timestep: Methods). The resulting 1st differences of diversity switched sign more rapidly than random expectation, in contrast to 1st differences of disorder (autocorrelation p < 0.05 and p > 0.05, respectively, Methods). A total of 91 sequential correlations of disorder with diversity 1st differences during the 20,000-year sequence encompass only seven switches in the sign of the RECA coefficient, and prolonged periods at RECA > +0.5 (10 samples, 11,380 to 9077 yr BP) and at RECA < −0.5 (12 samples, 7536 to 3872 yr BP, Fig. 2).
We ranked the empirical RECA pattern amongst 10,000 patterns obtained from each of two randomisation procedures for disorder and diversity 1st differences (detailed in the Methods): (i) shuffling the temporal order of each empirical sequence, which removes autocorrelation structure; (ii) shifting each empirical sequence forwards or backwards in time, which retains the empirical autocorrelation structure. Less than 3% of randomised RECA time series combined as few or fewer sign switches with as many or more consecutive samples of such strongly positive (shuffling: p = 0.0175, shifting: p = 0.0287) or negative (shuffling: p = 0.0062, shifting: p = 0.0028) RECA coefficients. The time series of RECA calculated on richness combined 7 sign switches with a maximum of 5 consecutive samples at RECA > +0.5 (10,120 to 9077 yr BP; shuffling / shifting p = 0.0537 / 0.0356), and 17 at RECA < −0.5 (7426 to 2468 yr BP; shuffling / shifting p = 0.0012 / 0.0058). From these statistics we infer that the slow undulations in RECA and long Holocene period of strongly negative RECA are consistent with non-random influences on the state of RECA in the community (Fig. 2), with negligible direct influence on RECA patterns by autocorrelation in diversity 1st differences.
We tested whether the strongly negative RECA sustained over much of the Holocene was influenced by the four spikes in diversity during this period. For each spike, we replaced the recorded abundance of each taxon with abundance interpolated from the preceding and the following sample. This interpolation combines the same 7 RECA sign switches with a less prolonged period at RECA < −0.5 (9 consecutive samples, 7536 to 4943 yr BP, shuffling / shifting p = 0.0230 / 0.0087). The 10-sample window used for calculating each disorder value and each RECA correlation coefficient was subjected to sensitivity analyses. Compared to windows of 7, 9, 11 and 13 samples, the 10-sample window for disorder returned the smallest absolute difference in RECA between time-series with and without the four Holocene diversity spikes; for correlation, all five windows sizes had similarly small absolute differences in RECA with and without diversity spikes (Supplementary Figs. 3 and 4).
Distinctiveness of taxonomic groups varies with RECA
The LGM period until 17,500 yr BP contained the fewest taxa in the time series (Fig. 1, Fig. 2 incidence plot), with 18 bryophytes (0-4 per sample), 13 graminoids (1–6 per sample), 65 forbs (2–21 per sample), and 7 woody taxa (1–3 per sample). From about 21,000 yr BP, general diversity, largely driven by forb diversity, began a rising trend continuing to the onset of the Younger Dryas (12,900 yr BP); this is associated with declining disorder from a high of 50% at 19,321 yr BP (Fig. 1).
From the end of the LGM onwards, community composition changed detectably in distinctiveness between the periods of positive and negative RECA shown in Fig. 2. Principal components analyses (Fig. 3) reveal an evolution in composition from one switch in the sign of RECA to the next and, independently, a detectable difference in the representation of persistent and ephemeral taxa between positive and negative RECA. Sample scores in the first two dimensions of PCA space reveal the shifts in composition between periods, illustrated in Fig. 3a by the groupings of scores by colour on the PCA plot.

Plots show sample scores across periods cycling between negative and positive RECA. Samples with consecutive negative RECA (40 circles) span periods 17,499–16,493 (yellow), 15,746–15,035 (gold), 12,234–11,678 (green), 8406–1322 (olive) yr BP; samples with consecutive positive RECA (30 triangles) span intervening periods: 16,350–55,896 (gold) 14,930–12,395 (green), 11,559-8,664 (olive) yr BP. Four samples with diversity spikes (marked by crosses) use interpolated compositions. a PCA space for all 155 taxa present since 17,499 shows relative factor loadings in red (labelling the largest per quartile), with percent variance explained by each principal component in the axis label; a permutation test gives the probability of no difference in mean score magnitudes between negative and positive RECA, within respectively continuous and dashed convex polygons. b–d Inverse relations of score vector length to RECA for all taxa combined, forbs, and woody vegetation; e, f no such relation.
Sample scores reveal a trend in distinctiveness of floristic composition from positive through to negative RECA, illustrated in Fig. 3b–d for all taxa combined, forbs and woody vegetation, where larger-magnitude vectors tend to associate with negative RECA (negative correlations, p < 0.01). A score lying close to the origin indicates a sample containing only the most frequently present taxa; a score extending further from the origin indicates the presence of additional taxa or an assemblage of unusual taxa. The vector length of PCA scores thus functions as a measure of distinctiveness. The analysis shows a paucity of long-vectored (distinctive) samples with strongly positive RECA, and of short-vectored samples with strongly negative RECA, for forbs and woody vegetation, and for pooled taxa (Fig. 3 correlations). For these groups, negative RECA associates with high distinctiveness, also illustrated by the larger convex polygon around samples with negative than positive RECA (Fig. 3 top-left PCA plot; Supplementary Fig. 5). These relationships are independent of, or not fully explained by, partial correlations of RECA with richness (Supplementary Fig. 6). The bryophytes and graminoids show no trend in RECA with either distinctiveness (Fig. 3) or richness, and less apparent grouping by period (Supplementary Figs. 5 and 6).
RECA tracks regional temperature change
The GRIP ice core provides a reasonable reconstruction of variation in regional temperature (detailed in the Methods). It shows a series of strong climatic shifts marking the transition from the full-glacial period to the establishment of the Holocene interglacial. Within this dynamic period, rising RECA associates with warming limbs of the GRIP ice core record, and falling RECA with cooling limbs. The period from 16,500 to 9500 y BP has a positive association of RECA to δ 18O-ml−1 (inferred regional temperature) that is strongest in the changes over time, with an 80-yr lag in its response. Temperature explains 66% of the variation in RECA, with only 51 of 10,000 randomised time series of disorder and diversity 1st differences achieving at least as high a positive association (Fig. 4a). The lagged correlation shows change in RECA tracking temperature change most strongly during the Bølling-Allerød, Younger Dryas and start of the Holocene (compared to earlier in the Pleistocene, Fig. 4a, b). Regional temperature also has a strong influence on RECA calculated from the (alternative) disorder-richness correlation (Fig. 4b). Rising values of RECA follow pronounced and rapid warmings associated with the onset of Bølling-Allerød and of the Holocene. In the early Holocene, the rapid drop in RECA from its most positive to most negative, as regional temperature stabilises at its Holocene high, associates with the beginning of a sustained period of negative association of change in RECA with change in temperature (Fig. 4c, d).

RECA is modelled with diversity in left-hand plots, and with richness in right-hand plots. a, b Late Pleistocene to early-Holocene with 80-yr lag in response, with observations from 16,500 to 14,700 yr BP showing as circles, Bølling-Allerød showing as squares, Younger Dryas as triangles, and Holocene as diamonds; c, d Holocene associations with 240-yr lag in response. For each plot, changes over time (1st differences) are calculated on the 6th minus the 1st sample, and the 7th minus the 2nd sample, etc. Line shows least-squares regression. Inset statistics are Pearson correlation coefficient r, coefficient of determination r2, probability p of at least as strong a positive or negative association in 10,000 simulations of randomly shuffled 1st differences in disorder and diversity, sample size n.
The pronounced rise in RECA from 18,000 to 16,000 yr BP (Fig. 2) coincides with sharply rising diversity over the same period (Fig. 1), with the establishment of forbs, sedges and bryophytes, many new to the record. The period from 15,000 to 14,000 yr BP shows a second rise into positive RECA indicating disruptive exogenous influences during increasingly rapidly warming temperature, which peaks at the warmest period of the late Pleistocene, in the Bølling-Allerød. A subsequent decline in RECA is associated with declining temperatures moving into the Younger Dryas, to a minimum of both RECA and temperature at ca. 12,200 yr BP. The Younger Dryas ends with sharp rises in both temperature and RECA (Fig. 2), associated with dipping diversity from a high peak at 12,900 yr BP to a deep but brief trough at 11,400 yr BP (Fig. 1).
The largest change in RECA occurs after its steep rise out of the Younger Dryas, with a plunge from most strongly positive to most strongly negative RECA during the warming period of the early Holocene, between 9500 and 7000 yr BP (Fig. 2). The lowest-entropy regime lasts from ca. 7800 yr BP for 3000 to 6500 years (with the lower value based on interpolated diversity spikes). It corresponds with the establishment of trees around the lake, principally Betula, Larix, and Picea (Supplementary Table 1), and with spikes in diversity (Fig. 1). These patterns suggest a prolonged period of strong and stable coexistence, perhaps with capacity for rapid proliferations of taxa if the diversity spikes are not artefacts of in-wash from major flood events.
Discussion
Our principal findings are that (i) relative entropy of community assembly tracks regional temperature during the late Pleistocene until it switches into opposition with temperature throughout much of the post-glacial Holocene, and (ii) post-glacial periods of low relative entropy align with the most distinctive plant community compositions of the record.
The composite index of relative entropy of community assembly (RECA) presents an informative view of past plant assemblages. This emergent property of the palaeo-dataset provides insight into the temporal trajectory of arrivals and departures of taxa to and from vegetation at the site and, by inference, on community stability, interactions among taxa, and the main influences on community organization. The index detects several downward shifts that are consistent with niche construction and endogenous organization. In contrast, sharp upward peaks suggest disruption of communities, which could be driven by rapid environmental change. The changes in RECA are usually abrupt in both directions and are followed by sequences of values of the same sign.
Environmental drivers of disturbance in the study site can be climate-related or related to geomorphic or hydrologic features of the catchment. Although the GRIP record reflects proximal temperature changes over Greenland, the major fluctuations, particularly the warm Bølling-Allerød, cold Younger Dryas and the rapid temperature rise at the onset of the Holocene, are recorded widely in physical and biological proxies across the North Atlantic sector and into arctic Russia as far as the Urals31. A similar pattern of late-glacial climate fluctuations affected the flora and vegetation at Lake Bolshoye Shchuchye, as seen in both pollen and sedaDNA records32. Prior to the major warming at the onset of Bølling-Allerød, the long cold period ca. 23,000 to 14,600 yr BP also saw temperatures fluctuate, although at relatively low amplitude33. Locally, mountain glacier retreat began at 18,700 yr BP and glaciers were absent by 14,350 yr BP; there is evidence for increasing moisture from at least 16,000 yr BP, prior to initial shrub expansion ca. 15,000 yr BP34.
The oldest part of the record, dominated by an arctic-alpine flora, shows RECA dropping from strongly positive into strongly negative between ca. 20,000 yr BP and 18,000 yr BP. From ca 15,500 yr BP until the early Holocene there is a strong tendency to track the late-glacial regional climate curve, with an extended rise in RECA to a peak at the onset of the Bølling-Allerød suggesting turnover of community structure. The Bølling-Allerød peak and the later rise and peak in RECA at the start of the Holocene are both consistent with disruption of communities at times of rapid climate warming; each is followed by a subsequent drop into negative RECA consistent with endogenous reorganisation, with a trough of RECA in the Younger Dryas, and a sustained and prolonged low during the Holocene (RECA < −0.5). In each case, the major downward trajectories into negative RECA are consistent with niche construction phases: the first as an adjustment to cool-climate conditions and the second to warm conditions. The earlier oscillations are of similar magnitude; while they echo minor changes in the GRIP record, other drivers may have dominated then, such as catchment-scale responses to the onset of mountain glacier retreat towards complete deglaciation, influencing local climate and soil development processes.
The largest change in RECA occurs when the Younger Dryas gives way to the Holocene, at a time of sequential arrival of Holocene taxa, and at the same time an overall loss of taxa as evidenced by decreasing diversity both in sedaDNA (Fig. 1) and in pollen33. This sequence from 9500 to 8500 yr BP of dramatically falling RECA during sustained high regional temperature describes a large-scale readjustment to the onset of interglacial conditions, lasting ca. 2000 yr to 7500 yr BP. The high RECA that characterises the first 2000 yr of the Holocene may reflect differential rates of taxon migrations and soil development. The subsequent crash in RECA likely coincides with woody shrubs and trees starting to exert competitive dominance; this would regulate community structure for the next 4500 yr, until the retreat of the trees.
The distinctive plant community composition of the Holocene (Fig. 3) reflects the highest period of plant diversity in the record. This is driven partly by the establishment of new tree and shrub taxa plus the development of a boreal-forest field layer, and is likely associated with substantial changes in the functioning of the ecosystem. The long period of negative RECA in the early and mid-Holocene reflects the cumulative effects of ordered assembly and disordered disassembly, filling niche dimensions. The establishment of woody taxa brought a three-dimensional habitat structure to the terrestrial ecosystem surrounding the lake, with associated competition for light and moisture amongst herbaceous taxa30. A similar stabilizing effect of the establishment of forest was seen in Fennoscandia32. The plant community switched strongly away from regulation by exogenous drivers to sustained self-organisation, which strengthened competitive asymmetries associated with shading and facilitative interactions associated with Holocene soil formation35.
The current and projected rates and amplitudes of climate change are higher than those experienced in the tundra during the last 20,000 years. There is much interest in the likely responses of vegetation to such climate warming, particularly concerning leading and trailing migration fronts as taxa find their climate space36,37. Our observation of rapidly increasing RECA coinciding with two major increases in temperature raises the possibility that global warming might force a state change towards exogenous regulation of community structure, for the first time in ca. 9000 years at this site. The previous temperature rises, however, at the start of the Bølling-Allerød and the start of the Holocene, were both periods of cold-adapted taxa confronting warming conditions. The future will see warm-adapted taxa confronting warming and more extreme weather, conditions possibly without precedent in their evolutionary history throughout the Pleistocene. We might expect that the forbs dominating in the late Pleistocene, which now grow at high elevations near the site, will experience a period of rising RECA, which may, for example, leave them exposed to the establishment of warm-adapted, in-migrating taxa, including invasives.
Methods
Laboratory analysis of millennial-scale trends in community composition
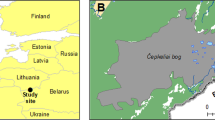
We analysed a 22,400-yr (23,727 to 1,322 yr BP) time series of incidence and abundance of vascular plant taxa from Lake Bolshoye Shchuchye in the Polar Urals (67° 53’ N, 66° 19’ E, 180 m altitude31) based on DNA from sediments (sedaDNA30). The lake has remained unglaciated since prior to the LGM (ca.25,000-17,500 yr BP), although local mountain glaciers were present in the upper elevations of the catchment at this time. The age model for the 25-m sediment core (core no. 506-48) was created by varve counting to 19,000 yr BP and from calibrated radiocarbon accelerator mass spectrometry (AMS) dates on terrestrial plant macrofossils31,34. The region has a cold continental modern climate (mean summer temperature ca. 7 °C)38. The lake and its catchment currently lie just beyond the modern boreal-forest limit, with low-arctic shrub tundra at lower elevation and arctic-alpine forb-dominated tundra and fellfield vegetation at higher elevation. The core is unusual in that these lake sediments record the sedaDNA of a large and topographically diverse catchment, sampling a range of communities in current arctic-alpine and shrub-tundra vegetation zones.
In common with all analyses of plant taxa in time series, we assume that artefacts of sampling have negligible influence on patterns in the data. Artefacts may arise when rare taxa appear sporadically in the record despite a constant presence in the environment. For this reason, modelling studies that use pollen data tend to focus on woody plants and other taxa that are reliable producers of abundant pollen. A shift from non-forest to forest biomes can skew pollen data, when abundant pollen of anemophilous woody taxa displaces rare pollen of entomophilous taxa from the pollen sum39. We minimise these issues by using a dataset of sedimentary ancient DNA, which is not prone to the anemophilous pollen issue and which represents taxa growing within the lake catchment, thus also avoiding the issue of long-distance transport and deposition of pollen from beyond the catchment40. An accompanying pollen dataset provides complementary taxonomic information but suffers from the biases described above, which may partly explain identification of 45 fewer taxa than in the sedaDNA dataset41.
DNA extraction, PCR amplification and sequencing followed standard protocols42. DNA was extracted from 153 sediment subsamples and 35 negative extraction and PCR controls within the dedicated ancient DNA facility at the Arctic University Museum of Norway. Each sample and negative control were independently amplified in eight PCR replicates, to improve the chance of detecting taxa with low quantities of template in the DNA extracts43. Next-generation sequence data were filtered using the OBITools software package44 following the protocol and criteria defined by Alsos et al.40. Taxonomic assignments were performed by matching sequences firstly to a local taxonomic reference library45,46,47, and secondly to a reference library generated after running the ecoPCR software package on the global EMBL database (release r117). In order to minimise erroneous taxonomic assignments, taxa were retained only if their match to a sequence in the reference library exceeded 98%. We further removed sequences that displayed higher average DNA reads in the negative extraction or PCR controls than lake sediment samples. Sequences assigned to taxa not present in northern Russia today were checked against the NCBI BLAST database (http://www.ncbi.nlm.nih.gov/blast/, accessed 2019) for multiple or alternative taxonomic assignments. Further details of the molecular methods are given in ref. 30.
We indexed relative abundance of taxa from the eight PCR replicates. For example, a taxon detected in four of eight replicates was assigned a relative abundance of 0.5. This is a more conservative quantification than proportion of reads, which are widely used partly due to most studies having few replicates19. It has the advantage of avoiding swamping by some taxa, usually willow growing on river and lake banks in northern regions including this study19,30. Highly abundant taxa usually occur in all repeats, whereas rare taxa may occur in only one repeat. The approach thereby uses the total sedaDNA assemblage while distinguishing abundant from rare members48. This index was used for calculating taxon diversity, as a comparator to taxon richness. In practice, outcomes of analyses differed very little between diversity and richness. The final DNA dataset comprised a matrix of 162 plant taxa occurring at one or more of 153 time points, with 6 to 71 taxa at any one time point (Supplementary Table 1 and ref. 49). The taxa include 30 bryophyte taxa (up to 11 per time point), 17 graminoids (up to 8 per time point), 101 forbs (up to 44 per time point), and 14 trees and shrubs (up to 10 per time point).
In order to account for a shorter interval between consecutive samples early in the dataset (due to higher sedimentation rates), we merged closely-spaced samples to ensure that none were separated by less than 100 years. The procedure for merging contiguous samples attempted to minimise the number of mergers needed to achieve the threshold. This required four steps: 1. Identify the sample with the smallest time interval to the next sample; 2. Count the number of mergers with neighbouring samples either later or earlier in the dataset required to achieve a sample interval of at least 100 years; 3. Merge forwards or backwards to achieve the minimum sample interval with the fewest mergers; 4. Repeat, until removal of all sample intervals <100 years. The merger of a set of contiguous samples involved pooling their taxa to include all presences across the merged set, summing the reads. Diversity, richness, disorder and RECA were all then calculated on the pooled sets as if each set was a single sample. The merged dataset had 110 samples, with 12 to 71 taxa per sample. Supplementary Fig. 7 plots the change in sample intervals, showing that they all influence samples >17,000 yr BP and all but one >18,200 yr BP. The remaining variation in sample intervals correlated only weakly with 1st differences in richness (r = −0.221 and −0.134 with and without Holocene diversity spikes), suggesting little direct influence of interval on the (dis)assembly of taxa. Any inflation of diversity caused by summing reads has negligible impact on RECA, evidenced in a low magnitude of difference in RECA values caused by calculating them on richness instead of diversity (Fig. 2).
Disorder and diversity
Disorder was measured at each sampled time point by quantifying randomness in compositional changes during the preceding period. This quantification was achieved with a specific application of the function ‘nestednodf([matrix], order = FALSE)’50 in R package ‘vegan’51. This function reports the NODF nestedness metric based on overlap and decreasing fill, which measures nestedness across rows and columns of a sample × taxon incidence matrix of presences (scoring ‘1’) and absences (‘0’). Here, the argument ‘order = FALSE’ stipulates no sorting of rows and columns, thereby retaining the sequential structure of samples. The NODF metric takes values on a scale from perfect nestedness at 100%, towards complete randomness at 50%; values below 50% indicate a segregation of taxa into discrete blocks or a chequerboard of incidence20. We converted this parameter into a measure of disorder equal to 100-NODF for values of NODF ≥ 50, or equal to NODF for values of NODF < 50. This ‘disorder’ metric thereby takes values on a scale from 0, indicating perfectly nested or blocked incidence, to 50, indicating completely random incidence. For each 10-sample incidence matrix, taxa were sorted left to right from most to least prevalent within the matrix. Disorder was then calculated both with samples in time sequence of oldest to youngest bottom to top and in reverse time, retaining the smallest of the two values. This procedure ensured an equal weighting of disorder on both assembly and disassembly. For the Bolshoye Shchuchye dataset, comparison of the disorder metric to NODF revealed that all departures of disorder from perfect randomness were explained by nestedness (NODF > 50%) from 19,900 yr BP until the present; imperfect randomness in earlier time periods was explained by taxa segregating into discrete blocks (NODF < 50%). Supplementary Fig. 2 illustrates examples of incidence matrices with high and low disorder, taken from the Bolshoye Shchuchye time series at contrasting time periods in the behaviour of the RECA metric.
Diversity was quantified at each sampled time point by Shannon α-entropy21 \(=-{\sum }_{i}^{S}{p}_{i}\,{{{{\mathrm{ln}}}}}\,{p}_{i}\), where pi is the proportional abundance of taxon i in a community of S taxa, with abundance given by the number of PCR replicates (from 0 to 8) reporting incidence of the taxon. The use of natural logarithms gives the metric units of ‘nats’, the natural unit of information. Shannon α-entropy quantifies the uncertainty in predicting the taxon of a randomly sampled individual from the dataset of all individuals of all taxa present at that timestep. For any set of S equally-abundant taxa, its exponent equals S. We additionally considered richness S as an alternative to diversity. Each value of diversity (or richness) is obtained at the youngest time point of a corresponding 10-sample window used to calculate disorder. It thus quantifies the α-diversity (or richness) resulting from the preceding disorder.
We tested the null expectation of independence between richness and disorder, and also between richness and β-metric values. For simulated time series of randomly allocated presences and absences amongst 162 taxa across 110 dated samples (equal in total richness and length to the Bolshoye Shchuchye dataset), Shannon β-entropy and the turnover component of Sorensen β both correlated negatively with richness and also matrix fill. In contrast, the disorder metric showed no correlation with either richness or matrix fill (coefficients in Supplementary Table 2a). Whereas the NODF metric, from which we derive the disorder metric, has a strongly positive correlation with matrix fill20, the inherent independence of disorder from richness and fill validates our subsequent correlation of these two variables to obtain biologically interesting insights from the RECA metric. An alternative randomisation that shuffles the empirical allocation of presences in samples for each taxon in turn (thereby matching empirical persistence), also returns a negligible correlation of disorder with richness (Supplementary Table 2b).
We tested for trends over time in disorder and diversity. Each time series was analysed for autoregressive integrated moving average with R function arima(p, d, q), in which p is the autoregressive order, d the degree of differencing, and q the moving-average order. The best-fitting models were arima(0, 1, 0) for disorder, arima(0, 1, 1) with drift for richness, and arima(0, 1, 1) with drift for diversity. Given the d = 1 degree of differencing for all three parameters, subsequent analyses were run on detrended time series constructed from 1st differences (Fig. 5). Each 1st difference is the difference of the parameter at the given time point from its value at the preceding time point.

1st differences in the observed sequences of disorder (red continuous) and diversity (blue dashed), Bolshoye Shchuchye DNA replicates from 22,258 to 1,423 yr BP (left to right). Dotted lines and shading at far right show 10-step forecasts with 95% CI (only indicative in time because of uneven temporal spacing), using best fitting arima(0, 0, 0) for disorder, and arima(0, 0, 1) for diversity. The average time between changes in the sign of 1st differences is 508 years for disorder (41 switches) and 298 years for diversity (70 switches), lying respectively within and below 95% CL at 353 and 521 years either side of the average 417 years for both disorder and diversity. from 10,000 randomisations by shuffling the temporal sequences.
The moving window used to calculate the time-series of disorder does not induce autocorrelation in its sequence of 1st differences (Pearson coefficient = +0.08, t97 = 0.82, p = 0.42, consistent with its autoregressive order of zero. Both first and last halves of the sequence have negligible autocorrelation (p > 0.3, Supplementary Fig. 1), despite a widening through time in the interval between consecutive samples and hence also widening of the time window used to calculate disorder (caused by higher sedimentation rate lower in the core). Moreover, the average time elapsed between each sign change in 1st differences is 508 years, not detectably higher than random expectation of 417 years. This expected value was calculated from the mean of 10,000 simulations of the time series, each independently randomising the order of observed values. In contrast, the time series of 1st differences in diversity shows negative autocorrelation (Pearson coefficient = −0.56, t97 = −6.67, p < 0.001, Supplementary Fig. 1). It has an average time between sign changes of 298 years, shorter than the lower 95% CL of 353 years for 10,000 randomisations of its time series (Fig. 5). The time series of 1st differences in richness likewise tends to switch sign at a higher frequency than random expectation.
Relative entropy of community assembly: RECA
The results section describes the millennial-scale evolution of RECA, measured in sequential correlations of detrended disorder with detrended diversity (or richness). We used a 10-sample window for each calculated value of disorder, and for each calculated coefficient of Pearson product-moment correlation on 1st differences of disorder and diversity (or richness). This yielded 91 RECA coefficients from windows averaging 1,918 yr for each of the disorder-diversity and disorder-richness correlations.
The choice of a 10-sample incidence matrix for calculating each disorder value represents a compromise between the need for sufficient replicates to minimise the influence of any one sample, and the need to draw each sample set from a sufficiently narrow time window to minimise carry-over effects between climatic periods. Likewise, the choice of 10 pairs of disorder-diversity values for each sequential correlation coefficient of RECA necessitated the same trade-off between sampling replication and temporal precision. We tested the efficacy of these choices with sensitivity analyses described in the Results, and with a simulation model of incidence matrices, which we describe here.
Modelling RECA time series with simulated incidence matrices
The simulation model created an incidence matrix of equivalent size to the Bolshoye Shchuchye dataset, of 162 taxa in a temporal sequence of 110 samples. From youngest to oldest samples top to bottom, it generated alternating periods of relatively low and high disorder, during alternating periods of community assembly and disassembly (model protocol detailed in Supplementary Methods, with R code). Level of disorder was regulated by sorting taxa left to right from most to least prevalent across samples within each period. Within-period (dis)assembly was simulated by sorting samples on richness. We explored a range of input settings for this simulation, for the purpose of testing the following expectations of RECA as a useful metric for explaining biogeographic processes:
-
1.
Alternating periods of low-disorder assembly and high-disorder disassembly yield a sequence of negative RECA, whereas alternating periods of low-disorder disassembly and high-disorder assembly yield a sequence of positive RECA. This expectation underpins the interpretation of endogenous and exogenous drivers of community assembly and disassembly summarised in Table 1. It may or may not be distinguishable from the null expectation of independently varying disorder and diversity described in the previous section.
-
2.
The magnitude of RECA is robust to a long-term trend through time in the empirical dataset, of rising diversity (Fig. 1 blue line, richness increasing by a factor of 2 from oldest to youngest samples), and hence also of matrix fill (increasing by a factor of 1.4). This trend associates with, and may be to a greater or lesser extent caused by, increasing time intervals over which taxa accumulate between consecutive samples (Fig. 1, lengthening red horizontal lines with time).
-
3.
Simulation of incidence matrices can guide selection of the sizes of sample windows used for empirical RECA calculations, to best inform underlying relationships of (dis)order to (dis)assembly. A simulation with input parameter values that match the empirical dataset should facilitate exploration of sampling influences on the observed patterns of RECA.
The simulation was initially given input parameter values that matched those in the empirical dataset (detailed in the model protocol). Sequential samples were set to alternate between disordered assembly and ordered disassembly for the oldest period of the dataset, and to alternate between disordered disassembly and ordered assembly during the youngest period. The single-sample switching between assembly and disassembly matched the rapid switching in the empirical dataset (Fig. 5, 1st differences in diversity). With this characterisation, relatively ordered disassembly sustains RECA > +0.5, whilst relatively ordered assembly sustains RECA < −0.5 (Fig. 6 main plot). Reversing the instruction on orderliness reverses the sequence of high and low RECA (Fig. 6, inset). In both cases, the pull to high-magnitude RECA was noticeably stronger at higher fill and richness (Fig. 6, younger half compared to older half), yet not enough to obscure the relationships. Removing these trends from the input parameters restored symmetry in RECA magnitudes by reducing variability between runs (Supplementary Fig. 8). This difference indicates that more confidence can be ascribed to empirical RECA in the younger half of the Bolshoye Shchuchye dataset, which has higher average richness, than the older half with lower richness.

Main plot shows consecutive samples alternating between disordered assembly and ordered disassembly in the older half, then alternating between disordered disassembly and ordered assembly in the younger half. Disorder was calculated using 10-sample incidence matrices, with fill increasing by a factor of 1.4 on average from oldest to youngest sample to an average final fill of 0.4, and richness increasing by a factor of 2 over the 110 samples to a final average of 40 taxa. Each RECA value was calculated on 10 disorder-richness pairs. Each trace shows one of 50 replicate time series of RECA, with the final replicate in yellow and the median in red. Inset shows the same plot with reversed instruction for (dis)ordered (dis)assembly in each half of the time series.
We used the simulation to explore the influence on RECA of alternative sizes of sample window for calculating disorder. For the parameter settings that yielded Fig. 6 using a 10-sample window, alternative windows of 7-, 9-, 11- and 13-samples gave a constantly weakly negative RECA score from oldest to youngest sample, with no half-way switch, and higher variation in the RECA time series amongst runs (Supplementary Fig. 9). These outcomes suggest a principled method of selecting the most informative sampling window for measuring disorder and RECA on empirical data: the window that yields the lowest variation in simulation runs on the empirical parameter settings. For example, were the empirical data to suggest a slower switching between assembly and disassembly (i.e., a lower frequency of sign switches in diversity 1st differences than in Fig. 5), this could be modelled by an incidence matrix of disordered (dis)assembly progressing across two sample intervals instead of one. Running the model with this parameter setting then yields a variation amongst runs that is lower with a 12-sample window for the disorder calculation than with either a 10- or a 14-sample window (Supplementary Fig. 10), reflecting the 3-sample periodicity of cycling between assembly and disassembly.
Null expectation of RECA time series
We ranked the empirical RECA pattern amongst 10,000 patterns obtained from each of two randomisation procedures on the 100-sample sequences of disorder and diversity 1st differences. The first procedure randomly shuffled the temporal order of each empirical sequence. Simulated sequences thereby contained all observed values of the variable, in randomised order. The second procedure shifted the empirical sequences in their time order of samples through all 10,000 permutations of start samples. This was achieved by giving each simulated sequence empirical values from sample x through to sample 100 in time order, followed by sample 1 through to sample x−1 in time order, for x = 1, 2, .. 100. For both procedures, RECA was calculated on sequential correlations of the simulated time series using the same 10-sample window as for the observed set. The 10,000 replicate RECA time series provide the null expectation of RECA characteristics, for the shuffle procedure given independent change in disorder and diversity from one sample to the next, and for the shift procedure given the empirical autocorrelation structure. In combination, these two procedures allowed us to test whether autocorrelation has a role in shaping the observed RECA pattern. If the observed autocorrelation in diversity 1st differences (Supplementary Fig. 1) contributes substantially to the observed pattern in RECA (Fig. 2), the pattern should have a lower ranking (higher p-value for Type-1 error) in the ‘shift’ permutations than in the ‘shuffle’ randomisations. Both randomisation procedures assume equally spaced samples through time, which is rarely achievable in palaeo time series, and not achieved here despite merging earlier samples to minimise differences in sample intervals. However, accumulation of more taxa during larger sample intervals appears to have limited influence on RECA patterns, based on the simulation of incidence matrices with Bolshoye Shchuchye characteristics described in the previous section.
Interpretation of taxonomic representation through time
Incidences of plant taxa in functional groups were analysed in relation to periods of positive and negative RECA using principal components analysis, with R function prcomp(). Analyses were run on the incidence of taxa ordered from most to least frequent, across samples ordered by date. Sample scores were centred at the origin of PCA space. Scores were not scaled, meaning that they expressed the data variance which provides a measure of distinctiveness, as described in the Results.
Interpretation of RECA with respect to climatic periods
The evolution of climate in the Polar Urals from the LGM to present is likely to reflect to some degree the major changes observed in the North Atlantic region. The GRIP oxygen-isotope record52 (72° 35’ N, 37° 38’ W) tracks the temperature of central Greenland53, with a δ 18O-ml−1 temperature coefficient of 0.63‰ per °C54. It can be viewed as a reference framework for expected climate variations, with the caveat that regional features will have mediated the climatology of the Polar Urals, particularly in the earlier portion of the record. Regional influences include the height and extent of the Scandinavian Ice Sheet and its effect on westerly circulation, the extent of sea-ice in the Kara Sea, the initial presence and subsequent demise of a local mountain glacier in the lake catchment, and the interplay of increasing summer insolation with continentality. Pollen data from Bolshoye Shchuchye41 indicate a late-glacial tripartite pattern: a rapid change from herbaceous to woody vegetation ca 14,000 yr BP, a brief reversion to herbaceous dominance, and then a major shift to woody dominance ca. 11,500 yr BP. We take this pattern of vegetation change to reflect the Bølling-Allerød warm period (14,700–12,900 yr BP), followed by cooling into the Younger Dryas (12,900–11,500 yr BP33) and subsequent Holocene warming.
The time series of RECA, represented by sequential correlations on 1st differences of disorder and diversity, was compared with the main changes of late-Quaternary climate, using the GRIP record as a template for the timing of changes after the end of the LGM, but without assuming equivalency in amplitudes between Greenland and the Northern Urals.
For the period 20,182 to 1322 yr BP, for which we have 87 RECA calculations, the GRIP ice core has 2915 dated records of δ 18O-ml−1. We therefore calculated its moving average across 2915/87 = 33 records to equilibrate the average temporal resolution of the two datasets. Each coefficient of observed correlation between moving-average δ 18O-ml−1 and corresponding RECA was assigned a probability of chance occurrence in randomly generated data. Chance occurrence was modelled by the distribution of coefficients for the same correlation calculated on 10,000 simulated time series of RECA, each generated from randomly shuffled 1st differences in disorder and diversity. By comparing the observed coefficient to quantiles of the distribution of coefficients for random time series, this significance test avoids the risk of overmatching that can otherwise result from comparisons of independently generated time series.
Data availability
The raw reads along with primers used are within the DRYAD database at https://doi.org/10.5061/dryad.jdfn2z378. The final dataset used in our analyses is given in Supplementary Table 1.
References
Barnosky, A. D. et al. Merging paleobiology with conservation biology to guide the future of terrestrial ecosystems. Science 355, eaah4787 (2017).
Nolan, C. et al. Past and future global transformation of terrestrial ecosystems under climate change. Science 361, 920–923 (2018).
Kaplan, J. O. et al. Climate change and Arctic ecosystems: 2. Modeling, paleodata – model comparisons, and future projections. J. Geophys. Res., [Atmos.] 108, 8171 (2003). https://doi.org/10.1029/2002JD002559.
Bartlein, P. J. et al. Pollen-based continental climate reconstructions at 6 and 21 ka: a global synthesis. Clim. Dyn. 37, 775–802 (2011).
Väliranta, M. et al. Plant macrofossil evidence for an early onset of the Holocene summer thermal maximum in northernmost Europe. Nat. Commun. 6, 6809 (2015).
Marsicek, J., Shuman, B. N., Bartlein, P. J., Shafer, S. L. & Brewer, S. Reconciling divergent trends and millennial variations in Holocene temperatures. Nature 554, 92–96 (2018).
Birks, H. J. B. et al. Does pollen-assemblage richness reflect floristic richness? A review of recent developments and future challenges. Rev. Palaeobot. Palynol. 228, 1–25 (2016).
Williams, J. W., Shuman, B. & Bartlein, P. J. Rapid responses of the prairie-forest ecotone to early Holocene aridity in mid-continental North America. Global Planet. Change 66, 195–207 (2009).
Barboni, D., Harrison, S. P. & Bartlein, P. J. Relationships between plant traits and climate in the Mediterranean region: A pollen data analysis. J. Vege. Sci. 15, 635–646 (2004).
Mottl, O. et al. Rate-of-change analysis in paleoecology revisited: A new approach. Rev. Palaeobot. Palynol. 293, 104483 (2021).
Worth, J. R. P., Williamson, G. J., Sakaguchi, S., Nevill, P. G. & Jordan, G. J. Environmental niche modelling fails to predict Last Glacial Maximum refugia: niche shifts, microrefugia or incorrect palaeoclimate estimates? Global Ecol. Biogeog. 23, 1186–1197 (2014).
Sanin, C. & Anderson, R. P. A framework for simultaneous tests of abiotic, biotic, and historical drivers of taxa distributions: empirical tests for North American wood warblers based on climate and pollen. Am. Nat. 192, E48–E61 (2018).
Nogués-Bravo, D. et al. Amplified plant turnover in response to climate change forecast by Late Quaternary records. Nat. Clim. Change 6, 1115–1119 (2016).
Elith, J. & Leathwick, J. R. Taxa distribution models: ecological explanation and prediction across space and time. Annu. Rev. Ecol. Evol. Syst. 40, 677–697 (2009).
Miller, P. A. et al. Exploring climatic and biotic controls on Holocene vegetation change in Fennoscandia. J. Ecol. 96, 247–259 (2008).
Yu, J. J., Berry, P., Guillod, B. P. & Hickler, T. Climate change impacts on the future of forests in Great Britain. Front. Env. Sci. 9, 640530 (2021). https://doi.org/10.3389/fenvs.2021.640530.
Elith, J., Kearney, M. & Phillips, S. The art of modelling range-shifting species. Meth. Ecol. Evol. 1, 330–342 (2010).
Dawson, T. P., Jackson, S. T., House, J. I., Prentice, I. C. & Mace, G. M. Beyond predictions: biodiversity conservation in a changing climate. Science 332, 53–58 (2011).
Alsos, I. G. et al. Postglacial species arrival and diversity buildup of northern ecosystems took millennia. Sci. Adv. 8, eabo7434 (2022).
Almeida-Neto, M., Guimarães, P., Guimarães, P. R. Jr, Loyola, R. D. & Ulrich, W. A consistent metric for nestedness analysis in ecological systems: reconciling concept and measurement. Oikos 117, 1227–1239 (2008).
Jost, L. Partitioning diversity into independent alpha and beta components. Ecology 88, 2427–2439 (2007).
Ricotta, C. & Pavoine, S. A multiple-site dissimilarity measure for species presence/absence data and its relationship with nestedness and turnover. Ecol. Indic. 54, 203–206 (2015).
Vandermeer, J. et al. Increased competition may promote taxa coexistence. Proc. Natl. Acad. Sci. 99, 8731–8736 (2002).
Rae, D. A., Armbruster, W. S., Edwards, M. E. & Svengård-Barre, M. Influence of microclimate and taxa interactions on the composition of plant and invertebrate communities in alpine northern Norway. Acta Oecol. 29, 266–282 (2006).
Tilman, D. Competition and biodiversity in spatially structured habitats. Ecology 75, 2–16 (1994).
Doncaster, C. P. et al. Early warning of critical transitions in biodiversity from compositional disorder. Ecology 97, 3079–3090 (2016).
Folke, C. et al. Regime shifts, resilience, and biodiversity in ecosystem management. Ann. Rev. Ecol. Evol. System. 35, 557–581 (2004).
Fischer, J. & Lindenmayer, D. B. Landscape modification and habitat fragmentation: a synthesis. Global Ecol. Biogeogr. 16, 265–280 (2007).
Hubbell, S. P. The Unified Neutral Theory of Biodiversity and Biogeography (Princeton Univ. Press, Princeton, 2001).
Clarke, C. L. et al. Persistence of arctic-alpine flora during 24,000 years of environmental change in the Polar Urals. Sci. Rep. 9, 19613 (2019). https://doi.org/10.1038/s41598-019-55989-9.
Svendsen, J. I. et al. Glacial and environmental changes during the last 60,000 years in the Polar Ural Mountains, Arctic Russia, inferred from a high resolution lake record and observations from adjacent areas. Boreas 48, 407–431 (2019).
Bjune, A. E. et al. Rapid climate changes during the Lateglacial and the early Holocene as seen from plant community dynamics in the Polar Urals, Russia. J. Quat. Sci. 37, 805–817 (2021).
Rasmussen, S. O., Bigler, M., Blockley, S. & Blunier, T. A stratigraphic framework for abrupt climatic changes during the Last Glacial period based on three synchronized Greenland ice-core records: refining and extending the INTIMATE event stratigraphy. Quat. Sci. Rev. 106, 14–28 (2014).
Regnéll, C., Haflidason, H., Mangerud, J. & Svendsen, J. I. Glacial and climate history of the last 24 000 years in the Polar Ural Mountains, Arctic Russia, inferred from partly varved lake sediments. Boreas 48, 432–443 (2018).
Wesser, S. D. & Armbruster, W. S. Species distribution controls across a forest-steppe transition: a causal model and experimental test. Ecol. Monogr. 61, 323–342 (1991).
Niskanen, A. K. J., Niittynen, P., Aalto, J., Väre, H. & Luoto, M. Lost at high latitudes: Arctic and endemic plants under threat as climate warms. Divers. Distrib. 25, 809–821 (2019).
MacDougall, A. S. et al. Comparison of the distribution and phenology of Arctic Mountain plants between the early 20th and 21st centuries. Global Change Biol. 27, 5070–5083 (2021).
Seppa, H. Pollen analysis – principles. In: Elias, S. A., Mock, C.J. (Eds.) Encyclopedia of Quaternary Science, 2nd Edition (Elsevier, Amsterdam, 2013), pp 794-804.
Parducci, L. et al. Ancient plant DNA in lake sediments. New Phytol. 214, 924–942 (2017).
Alsos, I. G. et al. Plant DNA metabarcoding of lake sediments: how does it represent the contemporary vegetation. Plos One 13, e0195403 (2018).
Clarke, C. L. et al. A 24,000-year ancient DNA and pollen record from the Polar Urals reveals temporal dynamics of arctic and boreal plant communities. Quat. Sci. Rev. 247, 106564 (2020). https://doi.org/10.1016/j.quascirev.2020.106564.
Alsos, I. G. et al. Sedimentary ancient DNA from Lake Skartjørna, Svalbard: Assessing the resilience of arctic flora to Holocene climate change. Holocene 26, 627–642 (2016).
Rijal, D. P. et al. Sedimentary ancient DNA shows terrestrial plant richness continuously increased over the Holocene in northern Fennoscandia. Sci. Adv. 7, eabf9557 (2021).
Boyer, F. et al. OBITOOLS: a unix-inspired software package for DNA metabarcoding. Mol. Ecol. Res. 16, 176–182 (2016).
Sønstebø, J. H. et al. Using next-generation sequencing for molecular reconstruction of past Arctic vegetation and climate. Mol. Ecol. Resour. 10, 1009–1018 (2010).
Willerslev, E. et al. Fifty thousand years of Arctic vegetation and megafaunal diet. Nature 506, 47–51 (2014).
Soininen, E. M. et al. Highly overlapping diet in two sympatric lemming species during winter revealed by DNA metabarcoding. Plos One 10, e0115335 (2015).
Ficetola, G. F. et al. Replication levels, false presences and the estimation of the presence/absence from eDNA metabarcoding data. Mol. Ecol. Res. 15, 543–556 (2014).
Clarke, C. L. et al. Persistence of arctic-alpine flora during 24,000 years of environmental change in the Polar Urals. Dryad, Dataset https://doi.org/10.5061/dryad.jdfn2z378 (2019).
Oksanen, J. & Carvalho, G. Nestedness indices for communities of islands or patches. R Documentation (2013). https://cran.r-project.org/web/packages/vegan/.
Oksanen, J., et al. _vegan: Community Ecology Package_. R package version 2.6-2, https://github.com/vegandevs/vegan (2022).
Grootes, P. M. & Stuiver, M. GISP2 Oxygen Isotope Data. PANGAEA, https://doi.org/10.1594/PANGAEA.56094 (1999).
Grootes, P. M., Stuiver, M., White, J. W. C., Johnson, S. & Jouzel, J. Comparison of oxygen isotope records from the GISP2 and GRIP Greenland ice cores. Nature 366, 552–554 (1993).
Dansgard, W., Johnsen, S. J., Clausen, H. B. & Gundestrup, N. Stable isotope glaciology. Meddelelelser om Grønland 197, 1–53 (1973).
Acknowledgements
This study was jointly supported by the Norwegian Research Council through the multinational research projects AfterIce (grant no. 213692/ F20 and 230617/ E10 to I.G. Alsos) and ECOGEN (grant no. 250963/F20 to I.G. Alsos), with a PhD studentship for C. L. Clarke provided by the UK Natural Environment Research Council (grant no. NE/L002531/1). The lake-sediment core sequence was obtained and subsequently dated via the Climate History along the Arctic Seaboard of Eurasia project (CHASE, grant. no. NRC 255415 led by J.-I. Svendsen and H. Haflidison). We thank M. K. Føreid Merkel and A.-E. Fedøy for providing assistance during sampling of the sediment cores. We thank S. Armbruster, G. A. Breed, J. A. Dearing, and D. Ehrich for commenting on earlier drafts, and G. Simpson and two anonymous reviewers for insightful and constructive criticism.
Author information
Authors and Affiliations
Contributions
C.P.D. conceived the idea, designed and conducted the statistical analyses, and wrote the first draft. C.L.C. conducted sedaDNA laboratory analyses; C.L.C., I.G.A. and M.E.E. created the dataset used here. M.E.E., and I.G.A. contributed to design of statistical analyses. All authors contributed to writing the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Earth & Environment thanks Gavin Leslie Simpson, Sara Hotchkiss and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editor: Aliénor Lavergne. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Doncaster, C.P., Edwards, M.E., Clarke, C.L. et al. The drivers of plant community composition have shifted from external to internal processes over the past 20,000 years. Commun Earth Environ 4, 171 (2023). https://doi.org/10.1038/s43247-023-00834-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43247-023-00834-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
