
Abstract
The problem of gender bias is highly prevalent and well known. In this paper, we have analysed the portrayal of gender roles in English movies, a medium that effectively influences society in shaping people’s beliefs and opinions. First, we gathered scripts of films from different genres and derived sentiments and emotions using natural language processing techniques. Afterwards, we converted the scripts into embeddings, i.e., a way of representing text in the form of vectors. With a thorough investigation, we found specific patterns in male and female characters’ personality traits in movies that align with societal stereotypes. Furthermore, we used mathematical and machine learning techniques and found some biases wherein men are shown to be more dominant and envious than women, whereas women have more joyful roles in movies. In our work, we introduce, to the best of our knowledge, a novel technique to convert dialogues into an array of emotions by combining it with Plutchik’s wheel of emotions. Our study aims to encourage reflections on gender equality in the domain of film and facilitate other researchers in analysing movies automatically instead of using manual approaches.
Similar content being viewed by others


Introduction
As the movie industry is one of the influential branches of the media reaching billions of viewers worldwide, they play a great role in shaping the beliefs and opinions of people (Sparks, 2015). Since blockbuster films are those that make money by giving the audience what they want, like, or expect, thus the portrayal of gender roles in blockbuster movies has a direct influence on viewers, possibly reinforcing or contributing to societal gender stereotypes (Ward and Grower, 2020). Thus, in our work, we aim to study and analyse gender bias based on emotions expressed by male and female characters in movies using different Natural Language Processing (NLP) techniques. For this purpose, we chose around thirty blockbuster English movies from IMDb (IMDb, 2019) and performed a comparative analysis of the characters. The study is mainly based on the statistical distribution of male and female characters over a certain period and the sentiment and emotions expressed in their dialogues. Through our work, we are trying to present an approach to understanding and promoting studies on the highly prevalent issue of gender inequality in movies. Furthermore, our analysis allows us to help address the global problem of gender inequality and bring positive social change using NLP.
Related works
Several studies have emerged in the past two decades that attempt to assess the gender gap between men and women in various fields (Lariviére et al., 2013; Lauzen, 2019; Wagner et al., 2015).
Many studies have utilised the Bechdel Test (Bechdel, 1986) to evaluate gender bias in movies. Kagan et al. (Kagan et al., 2020) in their studies presented 15,540 movie social networks where their findings showed a gender gap in almost all genres of the film industry. However, they also found that all aspects of women’s roles in movies show a trend of improvement over the years with a constant rise in the centrality of female characters and the number of movies that pass the Bechdel test.
Xu et al. (Xu et al., 2019) in their analysis of 7226 books, 6087 film synopsis, and 1109 film scripts, identified the constructed emotional dependence of female characters on male characters, also called the Cinderella complex, where women depend on men for a happy and fulfilling life. They used the word embedding techniques with word vectors trained on the Google News dataset to construct a happiness vector for automatically calculating the happiness score for every word in the document. The happiness vector contains words such as success, succeed, luck, fortune, happy, glad, joy, and smile for positive and failure, fail, unfortunate, unhappy, sad, sorrow, and tear for negative sentiment. Their analysis of female and male characters showed that female’s word vector is oriented toward romance, whereas men’s toward adventure. Their studies showed how such narratives embed stereotypical gender roles into moral tales and institutionalise gender inequality through these cultural products.
Similarly, Yu et al. (Yu et al., 2017) analysed the emotion represented in Korean thriller movie scripts. The authors performed manual emotion annotation on movie scenes based on eight emotion types defined by Plutchik (Plutchik, 1988). Further, they used the Python-based NLTK VADERSentiment tool to analyse the sentiment of the same script and compared the results obtained with manual tagging. Their result showed that the emotions of anger and fear were most matched, whereas the emotion of surprise, anticipation, and disgust had a lower matching score.
Anikina (Anikina, 2017) in her work performed manual annotation on movie dialogues based on Plutchik’s emotion wheel. The author used machine learning classifiers (fastText, OpenNLP and SVM) to train on different datasets and implemented rule-based NRC emotion lexicon classifiers to detect the emotions. The study compared the results obtained from NRC Lexicon with manually annotated data to find the accuracy. The study highlighted how the unavailability of annotated resources on movie script domain affected the training process as the data from different domains had to be used and also discussed the limitations of used classifiers in performing multi-label emotion classification.
Similarly, the Bechdel test mostly focuses on assessing the fairness of female representation by three rules, which fails even for female oriented movies (Coyle, 2018; Florio, 2019; Waletzko, 2015) and also does not address stereotypes. In this study, we address the limitations of the Bechdel test by expanding our work to examine the stereotypes by employing both sentiment analysis and the analysis of the embedded emotions. Moreover, in previous studies, stereotypes are generally only analysed using word embedding techniques by creating word vectors. In our work, we are not only relying on the word vectors but also analysing the sentiment and emotions embedded with those words for better representation of our results and hence expanding the work beyond just the positive-negative affect dimension. Further, we present a novel approach to converting dialogues into an array of emotions by combining it with Plutchik’s wheel of emotions.
Methods
In this section, we present the workflow of our approaches, as presented in Fig. 1. A brief description of the three modules is as follows. More detailed information on each module is provided in sections ‘Data processing module, Emotion recognition module, Analysis module’, respectively.

(1) data processing module, (2) emotion detection module, and (3) analysis module.
Data processing module
In this module, we convert the scripts of movies from PDF into a machine-readable format. Movie scripts are first converted from PDF into HTML using online tools. Then we process the HTML and separate scenarios and dialogues of each character.
Emotion recognition module
This module looks at every character’s prevalent positive and negative sentiments using Stanza (Qi et al., 2020), a Python natural language analysis package. Next, we run NRCLex (Mohammad and Turney, 2013)—a rule-based model for emotion detection trained on 27,000 manually annotated common words and phrases. From this step, we get the “emotion scores" for eight primary emotions: fear, anger, trust, surprise, sadness, disgust, joy, and anticipation. Finally, with the help of Plutchik’s wheel of emotions, which describes how emotions are related, we compute 24 secondary emotions. In this module, we convert sentences into embeddings. An embedding is a learned numerical representation of sentences in the form of a vector, where similar sentences will have a similar representation.
Analysis module
In the last module, we perform empirical analysis, statistical methods such as Mann–Whitney U-test, and machine learning techniques, namely clustering and classification, to determine if gender bias exists in the collection of scenarios. The way we determine if bias exists is explained in each section, For example, after running the Mann–Whitney U-test, if we get different U-scores for female and male populations with a significant P-value, we could be certain that they are written differently. Our approach is modular, and modules are loosely coupled and highly cohesive.
Data processing module
In this section, we present the first module of this study, i.e., the data processing module. This module includes data collection and data processing steps.
Data collection
To ensure the global reach of the movies and their impact on society, we opted only for the top-rated movies of all time listed on IMDB. We downloaded scripts of 34 movies from different genres, namely romance, fantasy, fiction, drama, and action, spread over the years ranging from 1972 to 2021. We considered several parameters while choosing the scripts: the accessibility of the scripts, the compatibility of the script’s format with our data processing module, and overall how popular the movie was. Initially, we started with a list of the top 1000 popular movies of all time on IMDB and grouped them into five chunks. We then randomly selected ten movies from each chunk. In the case of series such as Harry Potter, all of the movies were kept. Afterwards, we dropped the movies whose script was not freely available, or the quality of the available manuscript was not suitable to be processed by our module. The final dataset was capped at 34. The year distribution of the movies is presented in Fig. 2. In total, we collected 26,279 dialogues and 457 characters, out of which 118 are female characters, and 339 are male.

Bar graph showing the distribution of the selected movies based on their published year.
Data processing
Movie scripts are technical documents created by screenwriters and serve as an essential reference for filmmakers. Blocks of text divided into scene headers, scene descriptions, speakers, and utterances are parts of a standard movie script. The critical point is the different indentations used for every block. The typical format of scripts is shown in Fig. 3.

The way movie scripts are typically composed.
We converted these scripts into a processed set of scenarios and dialogues where individual characters’ information is extracted and exploited using the information about indentation. We would refer to them as character dictionaries for the rest of this paper. We first converted PDF files into HTML format and used BeautifulSoup (Richardson, 2007)—a Python library for pulling data out of HTML—and regex to create character dictionaries. In the HTML files, the style attribute of every element has a property named ‘left’ and ‘top’, which indicates the value of the starting pixel from the left, i.e., indentation and dialogue sequence, respectively. We have stored the processed version of scripts in JSON format, i.e., attribute-value pairs, where the attribute is the name of the character and the value is the list of dialogues.
In the next step, we created a database from the character dictionaries by further processing the data. Screenwriters sometimes add extra text to the character’s name, such as (V.O.), (O.S.), etc., suggesting a voice-over or off-screen dialogue. First, we processed such terms and deleted this extra information because it is irrelevant to our study. Then, we tagged each character with their respective genders.
Furthermore, we added the movie’s name and the year it was released into the database for visualisation and analysis purposes. Finally, we dropped the characters with less than five dialogues since they did not contribute to our results in a meaningful way. Performing all these steps, we generated a final database, which was also manually validated to ensure its correctness.
Emotion recognition module
In this section, we present the second module of this study, i.e., the emotion recognition module. This module includes finding sentiments and emotions for each character.
Sentiment analysis
We first used the Stanza package (Qi et al., 2020) to find the sentiment of every dialogue. Stanza is a Python natural language analysis package that supports sentiment analysis on raw text from diverse sources as input. It produces annotations without having to annotate or tokenize the text manually. It is built with a highly accurate CNN classifier pipeline trained on 112 datasets, enabling efficient training and evaluation of annotated data. The reason for using Stanza is that it is built on top of the PyTorch library (Paszke et al., 2019), which gives a high-speed performance on GPU-enabled machines and has better accuracy than other under-optimised models. Stanza classified each dialogue as positive, negative, or neutral. However, more than 70% of the conversations organised by Stanza were neutral. Therefore, Stanza did not provide much information about the bias in male or female characters.
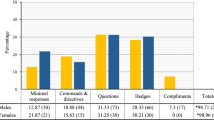
These results prompted us to check the validity of the Stanza model, for which we used the trivial approach of manually annotating the data ourselves and then comparing the result with the Stanza model. To reduce the bias, the same data were manually annotated by two different people, and 179 dialogues spoken by Harry in the Harry Potter series were chosen randomly. After comparing the accuracy of the model with human evaluation, we acquire the following accuracy scores shown in Table 1.
Emotion detection
By looking at the results of Stanza, we came to know that the overall outlook of positivity and negativity was not drastically different. But, generally, the emotions conveyed by humans are much more complex than only positive and negative. Therefore, for deeper analysis, we ran NRCLex on every dialogue. NRCLex takes a string, i.e., dialogue, as input and returns the emotion scores for the primary eight emotions. Those primary emotions can also be grouped into positive and negative, as suggested by Robert Plutchik. The model classifies joy, anticipation, trust, and surprise as positive emotions and anger, fear, sadness, and disgust as negative emotions. Comparison of genders based on positive vs. negative emotions represented in Fig. 4.

Bar graph showing the distribution of positive and negative emotion scores obtained after sentiment analysis.
By running NRCLex, we converted every dialogue into an embedding of eight dimensions. Each dimension represents one primary emotion, and its value is a floating-point number showing the likelihood of that sentence conveying that emotion. A sentence could be conveying multiple emotions with varying intensities (Ward and Grower, 2020). It’s a probability distribution. Therefore, the embedding or vector sums up to one.
Furthermore, we analysed these primary emotions based on Plutchik’s emotion wheel as shown in Fig. 5. Psychologist Robert Plutchik proposes it through his famous “wheel of emotions” (Mohsin and Beltiukov, 2019). The model shows the intensities of different emotions and how they are interconnected. We use this model as a reference to create complex emotions.

Wheel of emotion showing the interconnection between different emotions.
We computed 24 secondary emotions by averaging the scores of two primary emotions, e.g., envy was derived by taking an average score of sadness and anger. Lastly, we augmented this new information with the previous database and converted every dialogue into a vector of dimension 32. Since there are eight primary emotions and 24 secondary emotions based on Plutchik’s wheel of emotion (Mohsin and Beltiukov, 2019). The list of emotions are; anger, joy, anticipation, surprise, trust, delight, sadness, disgust, hope, curiosity, despair, confined, envy, cynicism, pride, love, submission, shame, awe, disapproval, remorse, aggression, anxiety, outrage, fear, dominance, guilt, sentimentality, optimism, pessimism, contempt, and morbidness.
Analysis module
In this section, we present the third module of this study, i.e., the analysis module. This module describes major trends in the data and how characters are written.
Clustering
Clustering is the process of splitting a population or set of data points into many groups so that data points in the same group are more similar than data points in other groups (Thomas, 2022). To put it another way, the goal is to separate groups with similar characteristics and assign them to clusters.
In our final database, we averaged the emotion scores of characters based on all of their dialogues. This new database has a size of 457 x 32, where 457 is the total number of characters. In our database, the ratio of male and female characters is roughly 3:1, i.e., for every female character, there are three male characters. The idea behind applying clustering is that if there is no bias in how male and female characters are written, the clusters made should also follow more or less the same ratio as there is in the data.
We use both k-means clustering and hierarchical clustering. First of all, we used the elbow method on the sum of squared distances to find the optimal number of clusters, which turned out to be seven. For Agglomerative clustering, we use euclidean distance and ward’s linkage, a method for hierarchical clustering. The results of clustering are discussed in section ‘Clustering’.
Results
This section discusses the findings of our analysis using Empirical, Machine Learning, and statistical techniques.
Gender distribution over the years
We have compared the ratio of male and female distribution over the years based on the number of their presence and based on the number of their dialogues. Figure 6 shows grouped total number of characters over the last 20 years. During the years 2000–2004, only 15.1% of characters were females however, during 2015–2019, this percentage increased to 43.9%. It is observed that with the evolution of time, gender distribution is getting more or less balanced.

Gender distribution over the years based on the number of dialogues and the number of their presence in movies.
Mann–Whitney U-test
Based on NRCLex, we have extracted the emotions expressed by male and female characters from their dialogues in all the movies. The obtained emotion score was within the range of 0-1. For detailed analysis, we performed the Mann–Whitney U-test—a form of inferential statistic used to see if there is a significant difference between two groups’ means—on all 32 emotions in the two gender groups. We choose the Mann–Whitney U-test because it is non-parametric and robust against non-normality, and our data is not normal. Through this comparison, we found some notable differences in the distribution of some emotions. The analysis showed that male and female characters exhibit most emotions like anger, aggressiveness, despair, envy, outrage, and love very differently from one another. Male characters have higher values for emotions like anger and aggressiveness. On the other hand, female characters have higher values for emotions such as joy. These results are in line with the gender stereotypes in our society. Women are perceived to be more loving and caring, whereas men are supposed to be more aggressive and powerful.
The U1, U2, and P-value scores of some emotions are shown in Table 2.
Visualising data
Box plots comparison of female vs. male on average emotion scores is shown in Fig. 7. Female plots are shown in blue colour, and the male plot is shown in red colour. According to our results, it is observed that male characters have higher scores on the emotions such as aggressiveness and dominance, and female characters have higher scores on emotions such as joy.

a Aggressiveness, b Anger, c Anxiety, d Dominance.
We have used the t-SNE dimensionality reduction technique to visualise the characters’ data. It calculates a similarity measure based on the distance between points and maintains the global structure. In other words, it converts some N-dimensional data into k-dimensional data, where k < N and x1, x2, …, xK are the new axes for the data. In the visualisation shown in Fig. 8, male characters are represented as blue and female characters as red. It is observed that most females are crowded at the centre, whereas the males are clustered sparsely. This uneven distribution shows a pattern in which characters are primarily written in movies. With the exception of two, most female characters exhibit more or less the same emotions, implying they are written in the same way. In contrast, male characters in the film exhibit a range of emotions and have much more diverse personality traits showing a difference in how they are written.

Gender-wise clustering of characters based on their emotions.
Dialogues analysis
In order to analyse the variations in the dialogues spoken by male and female characters, we performed a sentence-level analysis, which involved extracting the most commonly used words by both genders.
We plotted a word cloud of the words spoken by male and female characters. A word cloud is a graphic depiction of a text’s most commonly occurring terms. Each word’s size in a word cloud reflects how frequently it appears in the text. The word cloud will give us insight into the common themes of words the characters use more often. In Fig. 9, the word clouds, matching nouns used by male and female characters were excluded in order to trace the unique differences between each gender. In this illustration, we notice that the female characters’ dialogues commonly included the nouns: kitchen, fashion, dress, skirt, sweetheart, and madam; meanwhile, the male characters used the nouns: time, business, war, world, man, and home. These results imply that female characters are shown to be more inclined towards their clothes and household chores. This is also in line with other studies on gender roles (Collins, 2011). In comparison, male characters are shown as more ambitious and concerned with business and the world. These results correlate with social stereotypes of gender (Yu et al., 2022) in our society.

a Female, b Male.
Clustering
For further analysis to find out if there is an implicit bias between the traits of male and female characters, we have clustered characters together into seven smaller groups. The clusters are formed based on the similarity between characters, and we can safely say that the groups represent the type or nature of the characters in general. Therefore, characters with similar traits will be grouped and of somewhat the same category. The overall ratio of male and female characters in our database is 3:1. And if there were no bias in how the characters are written, the proportion of male and female characters would be similar in the clusters. However, we employed two different techniques to cluster them, and in both of them, there was an uneven ratio of genders in the smaller groups, as shown in Fig. 10. Some groups even have a balance of around 6:1, which implies high bias in writing those kinds of characters.

a Hierarchical clustering, b Clustering with k-means.
Conclusion
Pop culture plays a significant role in shaping societal perceptions and attitudes towards gender roles. Through various forms of media such as television, film, music, and social media, pop culture presents images and storylines that can reinforce or challenge traditional gender roles. On the other hand, pop culture can also challenge these stereotypes by featuring strong and complex female characters or depicting men in traditionally feminine roles. Pop culture can also influence how individuals understand and perform their own gender, by providing examples of gender expression and behaviours.
In this study, we have analysed gender representation in a collection of movies and how gender distribution changed over time. Compared to previous works, we rely not only on word vectors but create new embeddings by analysing the emotions associated with these words. We looked into how stereotypes are presented via emotions, making the results more intuitive. Furthermore, we highlighted the hidden bias by using clustering and other ML techniques. The result of this study suggests that although over years the women portrayal have greatly improved, underneath the surface, implicit biases exist. Our clustering results indicate that while the male characters enjoy a variety of emotions when they are portrayed, women are clustered together following the same emotional pattern.
This insight is strengthened by our sentiment analysis of the characters. We found that different kinds of positive emotions are associated with different genders. Those emotions reflect the stereotypes that exist in our society. For example, men are shown to be more dominant and envious than women, and women are shown to be more optimistic and joyful.
The result also indicates that the script writers and the movie producers should be aware of these available biases. There should be a conscious effort to question the portrayal of the characters to make sure the individuality of the characters, independent of their gender, is respected.
We believe that the implicit gender biases are not only available in the movie industry but in a plethora of other cultural products. As a future research direction, it would be interesting to investigate other areas, for example music and conceptual art industry.
Data availability
The datasets generated during and/or analysed during the current study are available in the following github repository: https://github.com/melihkurtaran/DIE_Gender_Equality_in_Movies.
References
Anikina T (2017) Sentiment and Emotion Movie Script (Doctoral dissertation, Saarland University) p. 102
Bechdel A (1986) Dykes to watch out for: The rule. Off Our Backs, 16, 27
Collins RL (2011) Content analysis of gender roles in media: where are we now and where should we go? Sex Role 64:290–298
Coyle J (2018) Time’s Up study concludes ’female-led’ films do better than male ones at the box office. URL https://www.usatoday.com/story/life/2018/12/11/times-up-study-female-led-films-outperform-males-box-office/2279801002/
Florio A (2019) 25 movies that don’t pass the bechdel test but are still worth watching (2019). URL https://www.bustle.com/entertainment/feminist-movies-fail-bechdel-test
IMDb Press room-imdb (2019) URL www.imdb.com/pressroom/?ref_=helpms_ih_gi_whatsimdb
Kagan D, Chesney T, Fire M (2020) Using data science to understand the film industry’s gender gap. Palgrave Commun 6:1–16. https://doi.org/10.1057/s41599-020-0436-1
Lariviére V et al. (2013) Bibliometrics: global gender disparities in science. Nature 504:211–213. https://doi.org/10.1038/504211a
Lauzen MM (2019) Boxed in 2018–19: women on screen and behind the scenes in television. The Center for the Study of Women in Television and Film, San Diego State University
Mohammad SM, Turney PD (2013) Crowdsourcing a word-emotion association lexicon. Comput Intell 29:436–465
Mohsin MA, Beltiukov A (2019) Summarizing emotions from text using plutchik’s wheel of emotions. In: 7th Scientific Conference on Information Technologies for Intelligent Decision Making Support (ITIDS 2019), Atlantis Press, pp 291–294
Paszke A et al. (2019) PyTorch: an imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems, vol 32. Curran Associates, Inc. URL https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf
Plutchik R (1988) The nature of emotions: Clinical implications. In: Emotions and psychopathology. Springer, pp. 1–20
Qi P et al. (2020) Stanza: A python natural language processing toolkit for many human languages. arXiv preprint arXiv:2003.07082, pp 101–108
Richardson L (2007) Beautiful soup documentation. p. 84. URL https://readthedocs.org/projects/beautiful-soup-4/downloads/pdf/latest
Sparks G (2015) Media effects research: a basic overview. Boston, MA: Wadsworth
Thomas M (2022) Wisemonkeys ∣ K-means use cases (2022). URL https://wisemonkeys.info/blogs/K-means-use-cases
Wagner C et al. (2015) It’s a Man’s wikipedia? Assessing gender inequality in an online encyclopedia. Proc Int AAAI Conf WebSoc Media 9:454–463. https://ojs.aaai.org/index.php/ICWSM/article/view/14628
Waletzko A (2015) Why the bechdel test fails feminism. URL https://www.huffpost.com/entry/why-the-bechdel-test-fails-feminism_b_7139510
Ward L, Grower P (2020) Media and the development of gender role stereotypes. Ann Rev Dev Psychol 2:177–199
Xu H et al. (2019) The Cinderella Complex: Word embeddings reveal gender stereotypes in movies and books. PLoS ONE 14:e0225,385. https://doi.org/10.1371/journal.pone.0225385. publisher: Public Library of Science
Yu HY, Kim MH, Bae BC (2017) Emotion and sentiment analysis from a film script: a case study. J Digit Content Soc 18:6
Yu Y, Hao Y, Dhillon P (2022) Unpacking gender stereotypes in film dialogue. In: Social Informatics: 13th International Conference, SocInfo 2022, Glasgow, UK, October 19–21, Proceedings. Springer-Verlag. pp. 398–405
Zhou D, Zhang X, Zhou Y, Zhao Q, Geng X (2016) Emotion distribution learning from texts. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. pp. 638–647
Acknowledgements
The work has been partially supported by the EMJMD master’s programme in Engineering of Data-Intensive Intelligent Software Systems (EDISS—European Union’s Education, Audiovisual and Culture Executive Agency grant number 619819).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Haris, M.J., Upreti, A., Kurtaran, M. et al. Identifying gender bias in blockbuster movies through the lens of machine learning. Humanit Soc Sci Commun 10, 94 (2023). https://doi.org/10.1057/s41599-023-01576-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-023-01576-3
