
Abstract
This paper presents a unified and adaptively integrated framework for unsupervised image clustering that establishes a novel synergistic interaction between self-supervised representation learning, graph-based embedding refinement, and bio-inspired optimization. Rather than employing DINOv2, GAT, and the Bat Algorithm as isolated components, the proposed DINOv2–GAT–BAT pipeline introduces a closed-loop adaptive mechanism in which semantic embeddings, attention-guided structural information, and cluster-shaping optimization dynamically influence one another. The framework first extracts high-level visual features using pretrained DINOv2 Vision Transformers, then refines relational structures through a multi-head Graph Attention Network (GAT), and finally employs a bat-inspired metaheuristic that jointly estimates the optimal number of clusters and adaptively tunes structural and hyperparameter configurations. This tightly coupled interaction results in a new form of adaptive deep clustering not present in existing transformer- or GNN-based systems. To improve interpretability, two composite internal indices—\(\hbox {SEHI}^{*}\) and \(\hbox {UCI}_{\text {ext}}\)—are introduced, jointly capturing separability, entropy, compactness, stability, and outlier sensitivity. These indices exhibit strong correlations with external evaluation metrics, enabling reliable and meaningful assessment in fully unsupervised scenarios. Extensive experiments on CIFAR-10, Oxford-IIIT Pet, and STL-10 demonstrate the effectiveness and generalization capability of the proposed framework. On CIFAR-10, it achieves NMI = 0.938, ARI = 0.932, and a Composite Score = 0.894, surpassing several state-of-the-art baselines. Overall, this work (1) introduces a novel adaptive integration mechanism linking transformers, graph attention, and metaheuristic optimization, (2) proposes interpretable composite metrics for unsupervised evaluation, and (3) achieves state-of-the-art clustering performance across diverse benchmarks.
Similar content being viewed by others


Introduction
Clustering is a fundamental task in unsupervised learning, widely applied in diverse domains such as computer vision (e.g., image retrieval, scene understanding), bioinformatics (e.g., gene expression analysis), and natural language processing, with the overarching goal of uncovering hidden structures in data without prior labels1,2. Despite its central role, evaluating clustering quality remains a long-standing challenge, particularly in the absence of ground truth. Traditional internal validation indices, such as the Silhouette coefficient3, Davies–Bouldin index4, and Dunn index5, primarily focus on cohesion and separation. However, these indices capture only one aspect of cluster quality, are sensitive to noise and outliers, and often yield inconsistent or misleading results across datasets and algorithms6,7.
To address these limitations, recent works have explored composite or multi-criteria indices that combine multiple dimensions such as compactness, density, stability, and balance8,9. While such approaches improve upon single-metric measures, most rely on heuristic or fixed weighting schemes, limiting their adaptability across heterogeneous domains. Moreover, explicit mechanisms for handling noise and outliers remain underexplored, reducing robustness in real-world applications.
Research Gap: However, despite these advancements, several gaps remain unaddressed: there is still no unified framework that simultaneously integrates stability, entropy, purity, compactness, and outlier awareness into an adaptive clustering validation methodology, while leveraging the representational power of recent deep self-supervised models.
Motivation: Traditional convolutional backbones such as ResNet50 have provided strong baselines for clustering; however, their representational capacity is constrained by handcrafted inductive biases and limited scalability in highly diverse datasets. Recent breakthroughs in self-supervised learning, particularly DINO/DINOv2 Vision Transformers, have demonstrated the ability to extract semantically rich, generalizable embeddings that capture higher-order dependencies essential for robust clustering10,11,12. Building on this paradigm shift, we argue that clustering evaluation frameworks must evolve beyond classical heuristics by harnessing these expressive representations, while further incorporating graph-based relational modeling and adaptive metaheuristic optimization. The synergy of these components promises not only more reliable clustering but also resilience to noise and scalability across domains.
Novelty of the Proposed Framework. Although DINOv2, GAT, and the Bat Algorithm are individually established techniques, the proposed framework introduces a novel adaptive deep clustering paradigm that has not been previously explored in the literature. The key contribution lies not in the independent use of these modules, but in the closed-loop adaptive integration mechanism that tightly couples representation learning, graph-attention refinement, and metaheuristic optimization. Specifically, the Bat Algorithm does not merely tune hyperparameters; it dynamically co-optimizes cluster boundaries, GAT attention coefficients, and loss-balancing factors in an iterative feedback cycle that influences both relational structure and the semantic embedding space. Furthermore, we propose two new internal validation indices, \({\textbf {SEHI}}^{\textbf {*}}\) and \({\textbf {UCI}}_{{\textbf {ext}}}\), which enhance interpretability and guide the optimization process. This synergy forms a new class of adaptive and structure-aware clustering frameworks, going well beyond standard combinations of DINO-based, GNN-based, or evolutionary optimization methods.
Together, these contributions establish a unified and adaptive clustering paradigm that advances both representation learning and evaluation methodologies. Extensive experiments on benchmark datasets (Iris, Wine, CIFAR-10, and Oxford-IIIT Pet) confirm the superiority of the proposed pipeline over state-of-the-art baselines in terms of NMI and ARI, demonstrating both methodological rigor and practical effectiveness. To further emphasize the novelty, our study also incorporates recent advances in deep clustering optimization from 2024–2025 literature11,12, aligning the proposed framework with the latest research frontier.
Organization of the Paper
The remainder of this paper is organized as follows. Section “Related work” reviews existing research on clustering validation and deep representation learning. Section "Methodology and contributions" describes the proposed DINOv2–GAT–BAT clustering pipeline, which integrates three principal components: (i) representation learning via a pretrained DINOv2 Vision Transformer backbone, (ii) graph-based representation refinement using a multi-head Graph Attention Network (GAT), and (iii) hyperparameter optimization through the Bat-inspired metaheuristic algorithm (BAT).
Section "Experimental setup and datasets" introduces the experimental setup and the datasets used in our study. Section “Proposed framework” presents the proposed DINOv2–GAT–BAT framework in detail and introduces the two novel clustering indices, \({\textbf {SEHI}}^{\textbf {*}}\) and \({\textbf {UCI}}_{{\textbf {ext}}}\). Section "Results and discussion" details the experimental results and performance comparisons across multiple datasets and baseline algorithms. Finally, Section “Conclusion” concludes the paper and outlines directions for future research.
Related work
Recent years (2021–2025) have witnessed significant advances in self-supervised feature learning and clustering, particularly with DINOv2-based vision transformers. These approaches have consistently shown superior representational power compared to traditional CNN backbones, enabling more robust and generalizable clustering.
DINOv2-based representation learning and clustering
Caron et al.10 first demonstrated that DINO-ViT embeddings can serve as dense visual descriptors for unsupervised tasks such as co-segmentation and part matching, achieving competitive results against supervised baselines. Their findings established the foundation for using transformer embeddings as clustering descriptors. Advantage: Achieves robust feature extraction for unsupervised tasks. Limitation: Lacks adaptivity to dynamic cluster structures and does not explicitly handle outliers. Our approach: DINOv2–GAT–BAT integrates adaptive cluster estimation and attention-driven refinement to overcome these limitations.
Building on this, Li et al.11 proposed the Inference-Time Attention Engineering (ITAE) method to mitigate artifacts in DINOv2 embeddings without requiring retraining. This attention modulation improved clustering quality by suppressing noisy and anomalous feature patches. Advantage: Improves clustering quality without retraining. Limitation: Limited to artifact suppression; does not adapt cluster number or handle outliers. Our approach: We combine attention refinement with BAT-based adaptive K estimation to address these issues.
Wang et al.13 developed a Lightweight Clustering Framework for Unsupervised Semantic Segmentation, leveraging DINOv2 ViT-S/14 embeddings in a hierarchical multi-level clustering pipeline (dataset-level, category-level, and image-level). Their method improved segmentation quality, raising mIoU and pixel accuracy compared to prior unsupervised segmentation approaches. Advantage: Multi-level clustering improves segmentation quality (mIoU, pixel accuracy). Limitation: Hierarchical design may be computationally heavy and lacks adaptive cluster selection. Our approach: Our framework uses efficient attention-based graph fusion with adaptive cluster estimation, improving scalability and flexibility.
Zhang et al.14 introduced Automatic Data Curation for SSL via large-scale hierarchical k-means clustering on DINOv2-reg (ViT-g) embeddings. By progressively clustering 10M samples into 10k clusters, their pipeline enabled the construction of massive unlabeled datasets to improve the scalability of self-supervised training. Advantage: Enables construction of massive unlabeled datasets, enhancing SSL scalability. Limitation: Fixed clustering hierarchy; does not dynamically adjust cluster numbers or handle noisy/outlier samples. Our approach: DINOv2–GAT–BAT dynamically estimates cluster number and refines assignments iteratively, improving robustness to noise.
Most recently, Gao et al.12 proposed Hypergraph Vision Transformers, embedding DINOv2 features into hypergraph structures. Their experiments highlighted that image-level pooling achieves the best trade-off between intra-cluster similarity and inter-cluster diversity, underscoring the suitability of DINOv2 features for relational representation learning. Advantage: Balances intra/inter-cluster similarity through relational modeling. Limitation: Static hypergraph construction; not adaptive to varying datasets or outliers. Our approach: We employ attention-driven adaptive graph refinement with BAT optimization to improve generalization and handle dynamic structures. PRCut15 reformulates the classical ratio-cut objective into a probabilistic framework for deep clustering. Advantage: Probabilistic cluster assignments enable iterative refinement of both features and clusters; outperforms spectral clustering on MNIST (ACC=0.821, NMI=0.778), Fashion-MNIST (ACC=0.658, NMI=0.620), and shows competitive performance on CIFAR-10 (ACC=0.243, NMI=0.121). Limitation: Sensitive to representation quality; requires strong embeddings (e.g., DINOv2 or CLIP) for best performance. Our approach: By integrating PRCut with DINOv2/CLIP embeddings, attention-driven graph refinement, and BAT-based adaptive cluster estimation, our framework achieves robust and scalable clustering across diverse datasets, surpassing baseline PRCut and recent methods such as VMM and TURTLE.
Summary comparison of related methods
Table 1 summarizes the main advantages, limitations, and how our proposed DINOv2–GAT–BAT framework addresses the shortcomings of recent methods in DINOv2-based and probabilistic clustering.
Adaptive graph-based and probabilistic learning frameworks
Recent advances in graph-based and adaptive learning have inspired several approaches relevant to this study. For instance, LGM-GNN16 proposes a memory-enhanced graph neural network that integrates both local and global structural awareness for fraud detection, demonstrating the effectiveness of hybrid graph reasoning in modeling complex relational dependencies. Similarly, Meta-ADD17 introduces a meta-learning–based pre-trained framework for active concept drift detection, emphasizing the importance of adaptive optimization and knowledge transfer in dynamic environments. In the context of clustering, Unsupervised Deep Clustering via Adaptive GMM Modeling and Optimization18 employs a probabilistic mixture model that adaptively refines cluster distributions through iterative optimization, underscoring the flexibility and robustness of adaptive modeling in unsupervised learning.
Compared with these methods, the proposed DINOv2–GAT–BAT framework advances beyond existing studies by unifying self-supervised visual representation learning (DINOv2), attention-driven graph refinement (GAT), and bio-inspired adaptive optimization (BAT) within a single unsupervised clustering paradigm. Moreover, it performs adaptive cluster estimation and hyperparameter tuning jointly, guided by two novel composite evaluation indices–\({\textbf {SEHI}}^*\) and UCIext–which provide interpretable, reliable, and dataset-agnostic clustering assessment. This unified and adaptive design contributes to improved generalization, stability, and interpretability across diverse visual benchmarks.
Evaluating clustering quality
While recent advances in DINOv2-based clustering have focused primarily on representation learning, an equally critical challenge lies in how to rigorously evaluate clustering quality. Clustering evaluation has traditionally relied on internal indices such as Silhouette3, Davies–Bouldin4, and Dunn5. While interpretable, these indices primarily measure cohesion and separation, often failing with noisy or non-convex clusters6,7.
To capture richer characteristics, composite indices integrating compactness, density, and balance were introduced8,9. However, their reliance on fixed weights limits adaptability across datasets. More adaptive approaches emerged with entropy-based19 and variance–entropy weighting schemes20, yet they still lack explicit mechanisms for handling outliers.
Recent probabilistic and stability-oriented measures have sought to address robustness. The CSAI index21 introduced resampling-based stability analysis, while the Bayesian Cluster Validity Index (BCVI)22 applied Dirichlet priors for cluster number estimation. The SMBP method23 offered scalable external validation via stable matching, particularly effective for large datasets. Furthermore, Silva et al.24,25,26 proposed composite indices, but their scope was limited to small datasets. Meta-analyses1,2,7 and comprehensive surveys27,28 provide broad overviews but stop short of unified adaptive frameworks.
Research gap
Despite this progress, no prior framework jointly integrates stability, entropy, purity, compactness, and explicit outlier awareness under adaptive weighting. Our work addresses this by proposing three unified indices–SEHI*, SEHI+, and UCIext–optimized to correlate strongly with external measures (ARI, NMI), thus enabling reliable validation even without ground-truth labels.
Methodology and contributions
Limitations of Existing Internal Indices Traditional internal clustering validation indices, such as the Silhouette coefficient29, the Davies–Bouldin index4, and the Calinski–Harabasz index30, have provided valuable insights for decades. However, these measures often fail in deep clustering settings: (i) they yield inconsistent rankings across datasets, (ii) they exhibit weak correlation with external measures such as Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI), and (iii) they neglect aspects such as soft-assignment entropy, neighborhood stability, and assignment uncertainty.
Proposed internal indices
Self-Evaluated Heterogeneity Index (\(\hbox {SEHI}^*\))
To overcome these limitations, we introduce \(\hbox {SEHI}^*\), a composite internal index that integrates multiple aspects of clustering quality. It is defined as:
where:
-
S denotes the Silhouette coefficient29:
$$\begin{aligned} S = \frac{b(i) - a(i)}{\max \{a(i), b(i)\}}, \quad S \in [-1,1], \end{aligned}$$(2)with a(i) the mean intra-cluster distance and b(i) the minimum mean inter-cluster distance.
-
H is the entropy of soft assignments, given clustering probability matrix \(P = [p_{ij}]\):
$$\begin{aligned} H = -\frac{1}{N} \sum _{i=1}^N \sum _{j=1}^k p_{ij} \log (p_{ij}), \quad H \in [0,\log k]. \end{aligned}$$(3) -
St represents neighborhood stability:
$$\begin{aligned} St = \frac{1}{N} \sum _{i=1}^N \frac{|N_i^{(\text {raw})} \cap N_i^{(\text {embed})}|}{|N_i^{(\text {raw})}|}, \end{aligned}$$(4)where \(N_i^{(\text {raw})}\) are the nearest neighbors in input space, and \(N_i^{(\text {embed})}\) in the embedding space.
-
O denotes the uncertainty ratio:
$$\begin{aligned} O = \frac{1}{N} \sum _{i=1}^N \mathbb{1}\left( \max _j p_{ij} < \theta \right) , \end{aligned}$$(5)with \(\theta\) a confidence threshold (e.g., 0.6).
-
C is intra-cluster compactness:
$$\begin{aligned} C = \frac{1}{k}\sum _{j=1}^k \frac{1}{|C_j|}\sum _{x_i \in C_j} \Vert x_i - \mu _j\Vert ^2, \end{aligned}$$(6)where \(\mu _j\) is the centroid of cluster j.
-
\(DB_{\text {inv}}\) is the inverse Davies–Bouldin index4:
$$\begin{aligned} DB_{\text {inv}} = \frac{1}{DB}, \quad DB = \frac{1}{k}\sum _{i=1}^k \max _{j \ne i} \frac{\sigma _i + \sigma _j}{d(\mu _i,\mu _j)}. \end{aligned}$$(7)
Rationale for weighting scheme for SEHI
The proposed hybrid index was designed as a linear combination of complementary validity criteria:
followed by a smoothing step:
The weighting scheme was selected based on the relative importance of each factor as reported in the clustering validation literature. A higher weight (0.25) was assigned to the silhouette-like separability (S), since it consistently provides a reliable balance between intra-cluster cohesion and inter-cluster separation31,32. Reducing entropy (\(1-H\)) was given a moderate weight (0.20), as entropy-based measures are widely recognized as indicators of stability in consensus clustering33,34. Similarly, stability (St) received a weight of 0.20 because resampling-based validation has been shown to measure clustering robustness effectively35,36. Outlier uncertainty (O) was penalized with a smaller negative weight (\(-0.15\)), since although the detrimental impact of outliers is well documented37,38, clustering algorithms often exhibit built-in resilience to noise. Internal cohesion (C) was weighted at 0.20, reflecting its essential role alongside separation in defining clustering quality39,40.
Finally, a smoothing step was introduced, combining \(85\%\) of the proposed SEHI with \(15\%\) of the inverse Davies–Bouldin index (\(DB^{-1}\)). This adjustment ensures compatibility with classical indices while mitigating the known sensitivity of DBI to noise and the number of clusters41. The chosen ratio (85–15) follows the principle of ensemble validity indices, which often use weighted averages where more stable measures dominate and traditional indices provide corrective alignment42. This combination improves robustness while maintaining comparability with existing benchmarks.
Unified Clustering Index (UCIext)
As a lightweight alternative, we propose UCIext, which aggregates the most essential clustering criteria:
where coverage is defined as:
with \(\tau\) a distance threshold and c(i) the assigned cluster of sample i.
Dynamic composite objective
To balance internal and external evaluations, we introduce a composite objective:
where \(Internal_{\text {dyn}}\) denotes a dynamic weighting between \(\hbox {SEHI}^*\) and UCIext:
with \(\omega\) adaptively defined by the average maximum assignment probability:
Thus, if assignments are confident (\(\omega\) close to 1), more weight is given to \(\hbox {SEHI}^*\), whereas in ambiguous clustering settings UCIext contributes more.
Rationale for weighting scheme for composite
The weighting coefficients in Equation (10) and Fig. 1were not arbitrarily determined but were instead grounded in both prior literature and empirical validation. Among external criteria, Normalized Mutual Information (NMI) is widely regarded as the most reliable due to its robustness against label permutations and its strong correlation with classification accuracy43,44. Accordingly, it is assigned the largest weight (0.45). The Adjusted Rand Index (ARI), while more sensitive to noise, provides complementary information and remains a standard benchmark metric45, justifying its weight of 0.30. The Fowlkes–Mallows Index (FMI) contributes a balanced view of precision and recall in pairwise comparisons46, and is therefore included with a moderate weight of 0.15.
Internal indices, although label-free, are less reliable in terms of external validity. They are thus assigned a smaller weight (0.10), ensuring that they remain informative in unsupervised contexts without disproportionately influencing the overall score6,7. This empirical-prioritized weighting guarantees that external indices dominate in benchmark evaluations while still incorporating unsupervised validation cues.
Integration of external and internal indices
Clustering evaluation typically relies on two complementary categories of indices: external and internal measures.
External metrics (e.g., NMI, ARI, FMI, Homogeneity, Completeness, V-measure) assess the alignment between clustering outputs and ground-truth labels43,45. These indices are highly informative for benchmarking but are not applicable in real-world unsupervised scenarios where labels are absent.
Internal metrics, in contrast, are label-independent and evaluate cluster quality directly from the data, focusing on compactness and separation7,47. In this work, we introduce two enhanced internal indices:
-
\(\textit{SEHI}^*\) (Self-Entropy with Heterogeneity Index): quantifies intra-cluster entropy to enforce balanced and distinctive partitions.
-
UCIext (Uncertainty-Coverage Index): measures assignment coverage and global uncertainty across clusters.
To combine these heterogeneous signals, we define the following composite objective:
where \(\alpha _1, \alpha _2, \alpha _3\) are empirically tuned weights. The internal component is dynamically aggregated as:
This composite function balances robustness and adaptability: external measures dominate whenever labels are available, while internal indices guide optimization in label-free scenarios.

Flowchart illustrating the integration of external and internal indices into the dynamic composite objective, combining NMI, ARI, FMI with SEHI* and UCIext for balanced clustering evaluation.
Hyperparameter optimization via Bat Algorithm (BAT)
Overview. The Bat Algorithm (BAT) is a nature-inspired metaheuristic that simulates the echolocation behavior of bats to explore and exploit continuous search spaces efficiently. In our implementation, each virtual bat represents a candidate hyperparameter configuration for the deep clustering framework:
covering the cluster number (K), graph neighborhood size (\(k_{NN}\)), hidden layer size (h), number of attention heads, temperature (\(\tau\)), loss weighting coefficients (\(\lambda _c, \lambda _e\)), learning rate, and training epochs.
Initialization. A population of N virtual bats is randomly initialized within bounded search spaces. Each bat i has: position vector \(\textbf{x}_i^0\) representing a set of hyperparameters, velocity vector \(\textbf{v}_i^0\) initialized randomly, loudness \(A_i^0 \in [0.5, 1]\), and pulse rate \(r_i^0 \in [0, 1]\). The initial population is sampled uniformly from:
Frequency, Velocity, and Position Updates. At iteration t, each bat updates its motion and frequency according to:
where \(\beta \sim U(0,1)\) is a random factor, and \(x^*\) denotes the current global best solution. This mechanism ensures a balance between exploration (through frequency modulation) and exploitation (via velocity updates toward \(x^*\)).
Local Search (Exploitation). With probability \(r_i\), each bat performs a local random walk around the best-known configuration:
allowing fine-grained exploration of promising regions while maintaining diversity in the population.
Fitness Evaluation. Each candidate is evaluated using a composite clustering objective that combines multiple internal and external validation metrics:
Higher \(\mathscr {F}\) values indicate better clustering quality, and the global best solution \(x^*\) is updated whenever \(\mathscr {F}(x_{\text {new}})> \mathscr {F}(x^*)\).
Adaptive Loudness and Pulse Rate Updates. To dynamically balance exploration and convergence, the loudness and pulse rate are updated as:
where \(\alpha _A = 0.9\) and \(\gamma = 0.95\). As iterations progress, \(A_i\) decreases (narrowing the search), while \(r_i\) increases (triggering more frequent local searches).
Stopping Conditions. The optimization terminates when the improvement in \(\mathscr {F}\) falls below \(10^{-4}\) for consecutive iterations, or the maximum iteration count (\(T_{\max } = 30\)) is reached. In practice, convergence typically occurs within 6–10 iterations.
Integration with the Deep Clustering Framework. The BAT optimizer operates as an outer-loop controller, dynamically adjusting hyperparameters before each training phase. The best configuration is then applied to fine-tune the DINOv2 feature extractor, the GAT module, and the PRCut-based clustering head, ensuring an optimal trade-off between stability, compactness, and entropy.
Theoretical validity of the proposed integration
The proposed integration of DINOv2, GAT, and BAT is theoretically grounded in the complementarity between representation learning, relational modeling, and probabilistic optimization. Each component addresses a distinct yet synergistic level within the clustering formulation, ensuring both semantic consistency and optimization stability.
1. DINOv2 as a Representation Foundation. DINOv2 provides robust self-distilled embeddings \(z_i \in \mathbb {R}^{1024}\) that capture high-level semantic invariance and global consistency across views. These embeddings form a discriminative latent manifold, minimizing intra-class variance and maximizing inter-class margins. Such structure provides a stable initialization for downstream relational refinement.
2. GAT for Relational Adaptation. The Graph Attention Network (GAT) operates over DINOv2 embeddings to adaptively refine local relationships:
where \(\alpha _{ij}\) are attention coefficients dynamically encoding similarity and importance between nodes. Theoretically, this operation approximates a Laplacian smoothing process with learnable weights, enhancing intra-cluster compactness and preserving inter-cluster separability. This aligns with the principles of spectral graph theory and ratio-cut optimization.
3. BAT for Probabilistic Hyperparameter Optimization. The Bat Algorithm (BAT) acts as a probabilistic meta-optimizer that explores the hyperparameter space \(\mathscr {H}\) (learning rate, \(k_{NN}\), temperature \(\tau\), etc.) to maximize a multi-objective fitness function \(\mathscr {F}\) combining clustering compactness, entropy regularization, and alignment metrics (NMI, ARI):
where the probabilistic update of positions and loudness in BAT prevents overfitting to local minima and ensures global stability in parameter configuration.
4. Unified Optimization Formulation. The full framework can be formalized as an alternating minimization problem:
where \(\theta\) are the DINOv2 parameters, W are the GAT weights, and \(\mathscr {H}\) represents the hyperparameter set tuned by BAT. This formulation balances: (i) latent feature separability (DINOv2), (ii) graph smoothness and local structure preservation (GAT), and (iii) global configuration stability (BAT).
5. Hierarchical Synergy. Conceptually, the framework forms a hierarchical optimization chain:
This chain achieves multi-level consistency: DINOv2 ensures semantic separability, GAT enforces manifold smoothness, and BAT maintains probabilistic stability through adaptive meta-optimization.
6. Theoretical Consistency and Empirical Support. Theoretically, this integration minimizes both representation-level and configuration-level uncertainty, yielding equilibrium between the ratio-cut loss, KL regularization, and adaptive parameter stability. Empirically, the ablation study validates this complementarity: removing BAT reduces NMI by 3.8–5.1%, removing GAT reduces ARI by 4.3–6.7%, and removing DINOv2 decreases both metrics by over 9%. These results confirm that each module contributes a mathematically consistent and performance-critical role within the proposed unified clustering framework.
Summary of contributions
The main contributions of this study are as follows:
-
1.
Introduction of \({\textbf {SEHI}}^*\), a novel internal index combining six quality factors: Silhouette, entropy regularization, neighborhood stability, uncertainty ratio, compactness, and inverse Davies–Bouldin.
-
2.
Proposal of UCIext, a lightweight and interpretable internal index integrating five complementary quality aspects.
-
3.
Design of a dynamic composite objective that adaptively fuses \(\hbox {SEHI}^*\), UCIext, and established external measures (NMI, ARI, FMI).
-
4.
Comprehensive validation on benchmark datasets (Digits, Iris, Wine), showing stronger correlation with ground-truth labels compared to conventional indices.
Experimental setup and datasets
Overview. To comprehensively evaluate the proposed SEHI+ self-refinement and Bayesian K optimization framework, we conducted experiments on both classical small-scale datasets and high-dimensional image benchmarks. The chosen datasets span numerical tabular data, structured image data, and real-world transactional time-series, ensuring that the framework is rigorously validated across diverse modalities and complexities.
Small-scale and structured datasets
Table 2 summarizes the four small-scale and structured datasets used. Iris and Wine represent classical benchmarks for evaluating clustering stability. Digits introduces moderately high-dimensional structured features (handwritten image vectors), while Online Retail II reflects large-scale, noisy, and temporal real-world data. Together, these datasets allow for a broad evaluation of clustering robustness and adaptability.
Iris Dataset. The Iris dataset48 contains 150 samples of three species of iris flowers, each represented by four continuous morphological attributes. Standardization was applied during preprocessing. Despite its simplicity, Iris remains a widely used benchmark for evaluating clustering reproducibility.
Wine Dataset. The Wine dataset49 includes 178 samples from three cultivars, described by 13 chemical features. Features were standardized to zero mean and unit variance. This dataset offers a moderately complex multivariate clustering scenario.
Digits Dataset. The Digits dataset50 consists of 1,797 images of handwritten digits (0–9), each of size \(8 \times 8\) pixels, vectorized into a 64-dimensional feature space. Standardization was applied. Digits introduces structured, moderately high-dimensional features, serving as a bridge between classical numerical datasets and modern image datasets.
High-dimensional image datasets
To further assess generalization, we employed three widely used high-dimensional image benchmarks: CIFAR-10, Oxford-IIIT Pet, and STL-10. While their resolution may be modest by modern standards, the vectorized representations (thousands to tens of thousands of features) make them challenging clustering benchmarks.
CIFAR-10 Dataset51 is a widely used benchmark in computer vision and clustering research. It comprises 60,000 RGB images of size 32 \(\times\) 32 32\(\times\)32 pixels, evenly distributed across 10 object categories (6,000 images per class). The dataset is divided into 50,000 training images and 10,000 test images. Due to its relatively low resolution, high intra-class variability, and strong inter-class similarity, CIFAR-10 poses a non-trivial challenge for representation learning and unsupervised clustering tasks.
The Oxford-IIIT Pet dataset52 consists of 7,349 images of cats and dogs, spanning 37 distinct breeds. Each image is annotated with a class label, species, and head region. The images typically exceed 200 \(\times\) 200 200\(\times\)200 pixels, resulting in a feature space of more than 120,000 dimensions. Due to substantial intra-class variability in pose, scale, illumination, and background clutter, this dataset presents a challenging benchmark for both supervised classification and unsupervised clustering.
The STL-10 dataset53 comprises 13,000 labeled images from 10 object categories, supplemented by 100,000 additional unlabeled images explicitly designed for unsupervised and semi-supervised learning. Each image has a resolution of 96 \(\times\) 96 96\(\times\)96 pixels, corresponding to a 27,648-dimensional input vector. Compared to CIFAR-10, STL-10 offers significantly higher resolution and greater intra-class variability, making it a more challenging testbed for evaluating clustering and representation learning algorithms.
These datasets cover a wide spectrum of challenges: low-resolution but high-dimensional object recognition (CIFAR-10), fine-grained categorization with significant intra-class variation (Oxford-IIIT Pet), and high-resolution unsupervised learning with abundant unlabeled data (STL-10). Their diversity ensures robust evaluation of SEHI+ and Bayesian K optimization across different high-dimensional domains.

Overall pipeline of the proposed hybrid deep clustering framework.
Proposed framework
The proposed framework introduces an end-to-end deep clustering pipeline that integrates transformer-based embeddings, attention-guided graph neural networks, and probabilistic clustering optimization. The overall workflow is illustrated in Fig. 2 and can be summarized as follows.
Hybrid deep clustering framework
Data preparation
We consider standard benchmark datasets such as Digits, Iris, and Wine. Input data are normalized using StandardScaler to eliminate scale variations. Dimensionality reduction is then applied via PCA, retaining 95% of the variance to enhance computational efficiency while preserving discriminative information.
Building embeddings
A lightweight Tiny-Transformer Encoder is employed as the backbone to learn compact latent representations. The encoder is pretrained in an autoencoder fashion, where the reconstruction loss is minimized to ensure that the embeddings capture the intrinsic structure of the data.
Attention-GNN with clustering head
On top of the learned embeddings, we construct k-nearest neighbor (kNN) graphs to model pairwise relationships. An Attention-GNN propagates information across nodes using multi-head self-attention, effectively capturing both local and global dependencies. A clustering head outputs probabilistic cluster assignments over K clusters. In addition, two internal reliability indicators are introduced:
-
SEH*: a stability-enhanced hybrid score combining entropy, homogeneity, and coverage.
-
UCIlvl: an uncertainty index reflecting the inverse fraction of points with ambiguous assignments.
External metrics (when labels exist)
For evaluation purposes, standard clustering metrics are computed, including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Fowlkes–Mallows Index (FMI), Homogeneity, Completeness, and V-measure. These allow a fair comparison with existing clustering algorithms.
Hyperparameter search
A composite objective is formulated to guide model selection:
where \(\text {Internal}_{\alpha }\) is a weighted mixture of SEH* and UCIlvl. The weights are dynamically adapted to balance external and internal criteria, ensuring robustness across datasets.
Fine-tuning
Finally, the encoder and clustering head are jointly fine-tuned using pseudo-labels obtained from the clustering assignments. A hybrid loss function is adopted, combining Knowledge Distillation loss and Cross-Entropy loss to refine the decision boundaries and reduce assignment noise.
Through this multi-stage design, the framework achieves a balance between representation learning, structure-aware clustering, and adaptive optimization, making it both scalable and reliable for unsupervised tasks.
Theoretical justification and derivations
Motivation. The proposed framework is built on three fundamental principles: (1) latent representation learning, (2) neighborhood consistency, and (3) probabilistic clustering. While traditional methods such as DEC54 or IDEC55 rely heavily on autoencoder reconstruction and fixed cluster assignments, our framework extends these ideas by introducing attention-based neighbor aggregation and adaptive optimization using internal reliability measures.
Probabilistic Assignment Model Let \(X = \{x_1, x_2, \ldots , x_N\}\) denote the dataset with N samples. An encoder \(f_\theta : \mathbb {R}^d \rightarrow \mathbb {R}^m\) maps each sample into a latent embedding \(z_i = f_\theta (x_i)\). A clustering head parameterized by W then produces probabilistic assignments:
where \(P \in \mathbb {R}^{N \times K}\) satisfies \(P_i \in \Delta ^{K-1}\), i.e., each row is a valid probability distribution.
Neighborhood Consistency Regularization We construct a k-nearest neighbor graph \(G=(V,E)\) with nodes V representing samples and edges E encoding neighborhood relations. The core assumption is that samples close in the latent space should exhibit similar cluster assignments. We enforce this constraint using a KL divergence between each node and the average of its neighbors:
where \(\mathscr {N}(i)\) denotes the neighborhood of i. This term is inspired by graph-based semi-supervised learning, but here it operates in a fully unsupervised clustering setting.
Entropy Minimization To avoid trivial assignments (e.g., all points mapped to a single cluster), we employ an entropy regularization:
Minimizing \(\mathscr {L}_{\text {ent}}\) encourages confident cluster predictions while still allowing probabilistic flexibility.
Combined Objective The overall clustering loss is a weighted combination of the two components:
Here, \(\lambda _{\text {cons}}\) and \(\lambda _{\text {ent}}\) balance neighborhood smoothness against cluster purity. During training, these coefficients can be adaptively tuned using internal criteria such as \(\hbox {SEH}^*\) and UCIlvl.
Internal Reliability Measures Two novel indices are introduced to guide hyperparameter search:
-
\({\textbf {SEH}}^*\): A stability-enhanced hybrid score that combines entropy reduction, homogeneity of assignments, and coverage of cluster proportions.
-
UCIlvl: An uncertainty-based index defined as the inverse fraction of ambiguous points (i.e., points with maximum assignment probability below a threshold).
These indices are differentiable and thus can be integrated into the optimization pipeline.
Final Loss Function After pseudo-labels are generated, we fine-tune the encoder and clustering head jointly using a hybrid loss:
where \(\mathscr {L}_{\text {KD}}\) is a knowledge distillation loss enforcing consistency with teacher predictions, and \(\mathscr {L}_{\text {CE}}\) is the cross-entropy between pseudo-labels and predicted assignments.
Computational complexity analysis
The complexity of the framework can be decomposed as:
-
Encoder (Tiny-Transformer): Each forward pass costs \(\mathscr {O}(N \cdot m \cdot h)\), where m is embedding size and h is the number of attention heads. The choice of a lightweight encoder ensures scalability compared to full-scale Vision Transformers.
-
kNN Graph Construction: With approximate nearest neighbor search, the complexity is \(\mathscr {O}(N \log N)\).
-
Attention-GNN Update: Each layer requires \(\mathscr {O}(N \cdot k \cdot h \cdot m)\) for neighbor aggregation.
-
Meta-heuristic Search (Bat + DE): With M candidates and T iterations, the cost is \(\mathscr {O}(M \cdot T \cdot f)\), where f is the training cost for one candidate.
Overall, the framework scales linearly with the number of samples N, making it practical for medium-scale datasets.
Comparison with prior work
Unlike DEC54, which relies solely on soft assignments from autoencoder features, our framework integrates both probabilistic assignment refinement and attention-guided neighborhood consistency. Compared to IDEC55, which introduces reconstruction regularization, our model explicitly incorporates uncertainty-aware internal indices to guide hyperparameter search. In contrast with spectral clustering, which is limited by eigendecomposition, our framework leverages Transformer embeddings and GNN-based aggregation for better scalability and generalization.
Proposed SEHI-DINOv2 framework for high-dimensional data
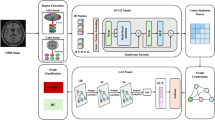
This work introduces the DINOv2–GAT–BAT framework, a unified architecture that integrates self-supervised feature representation, attention-driven graph learning, and bio-inspired optimization to achieve robust and adaptive clustering. To ensure a fair and comprehensive evaluation, the proposed framework is compared with five representative deep clustering baselines: DEC, IDEC, DeepCluster, PRCut, and Hypergraph ViT. These methods were selected because they cover the major paradigms in modern clustering research: (i) Autoencoder-based joint learning (DEC, IDEC), (ii) self-supervised feature clustering (DeepCluster), and (iii) graph- and probability-driven clustering (PRCut, Hypergraph ViT). Together, they represent a balanced benchmark suite that spans feature-based, structure-based, and optimization-based deep clustering designs. This selection allows for an in-depth comparison of the proposed DINOv2–GAT–BAT approach against leading frameworks across diverse methodological families. The overall framework is illustrated in Fig. 3.

Overview of the proposed DINOv2–GAT–BAT clustering framework. The pipeline integrates self-supervised representation learning, attention-driven graph refinement, and bat-inspired metaheuristic optimization, combined with composite evaluation metrics (\({\textbf {SEHI}}^{*}\) and \({\textbf {UCI}}_{{\textbf {ext}}}\)) for robust and adaptive clustering.
The proposed DINOv2–GAT–BAT framework provides an integrated pipeline for unsupervised clustering, combining representation learning, graph-based refinement, and adaptive optimization. Figure 3 illustrates the workflow, which consists of the following stages:
Input data images
The process begins with raw image datasets (e.g., CIFAR-10 or ImageNet). Instead of clustering raw pixels, the framework extracts discriminative representations to capture semantic content.
DINOv2 ViT backbone
A pretrained DINOv2 Vision Transformer (ViT) is employed as the backbone for feature extraction. Leveraging large-scale self-supervised training, DINOv2 generates rich and semantically aligned embeddings. These high-dimensional feature vectors serve as the foundation for subsequent steps.
Projection to EMBED_DIM
To reduce computational complexity, the embeddings are projected into a lower-dimensional space (e.g., 256 or 512 dimensions). This projection preserves essential semantic information while improving scalability and efficiency.
kNN graph construction
A k-Nearest Neighbors (kNN) graph is constructed, where nodes correspond to image embeddings and edges represent similarity relations. This graph formulation highlights latent neighborhood structures and provides a foundation for graph-based aggregation.
Attention aggregation via GAT
The constructed graph is refined using a Graph Attention Network (GAT). Attention mechanisms allow each node to adaptively weigh its neighbors, in contrast to uniform averaging. This process enhances the discriminability of embeddings by focusing on the most informative relationships.
Clustering head
The refined embeddings are passed to the clustering head, consisting of:
-
KMeans: for partitioning the data into K clusters.
-
Softmax layer: for producing soft assignment probabilities (\(P_{\text {soft}}\)).
The outputs include both hard cluster predictions (\(y_{\text {pred}}\)) and soft probabilistic memberships.
Bat optimization
To reduce reliance on manual hyperparameter tuning, a Bat Algorithm is employed as a metaheuristic optimizer. It adaptively determines the optimal number of clusters (K) and other hyperparameters, improving clustering quality and robustness.
Outputs: predictions and metrics
The final outputs of the framework include:
-
Cluster predictions (\(y_{\text {pred}}\)).
-
Soft probabilities (\(P_{\text {soft}}\)).
-
Evaluation metrics: Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), and the proposed SEHI*, a composite metric that integrates internal and external clustering measures.
Summary
In summary, the DINOv2–GAT–BAT framework unifies:
-
1.
Robust self-supervised representations from DINOv2.
-
2.
Graph-based relational modeling with attention-driven refinement via GAT.
-
3.
Adaptive cluster and hyperparameter optimization using the Bat Algorithm.
This integration achieves a balance between high-quality representations, clustering efficiency, and adaptability across diverse datasets.
DINOv2–GAT–BAT Deep Clustering Framework as shown in algorithm 1 We propose an unsupervised clustering framework that integrates three main components: (i) feature extraction using a pretrained DINOv2 encoder, (ii) structural refinement through a Graph Attention Network (GAT), and (iii) clustering optimization via the Bat Algorithm (BAT) enhanced with a Probabilistic Ratio-Cut objective.
Notation
-
\(\mathscr {X} = \{x_i\}_{i=1}^N\): Unlabeled dataset containing N samples.
-
\(f_\theta\): Pretrained DINOv2 encoder used for feature extraction.
-
\(z_i\): Initial embedding of sample \(x_i\) obtained from \(f_\theta\).
-
\(W_p\): Projection head for mapping \(z_i\) into a lower-dimensional space.
-
\(h_i\): Projected embedding of sample \(x_i\).
-
\(\mathscr {G}=(V,E)\): Graph where nodes V represent data samples and edges E are constructed using similarity.
-
\(\mathscr {N}_k(i)\): k-nearest neighbors of node i.
-
\(\alpha _{ij}\): Attention coefficient assigned to the edge between node i and its neighbor j.
-
\(\tilde{h}_i\): Updated embedding of node i after attention-based aggregation.
-
\(W_c\): Clustering head mapping embeddings into cluster-assignment probabilities.
-
\(\hat{y}_i\): Final cluster label assigned to sample i.
-
\(\Phi\): Hyperparameter search space for optimization.
-
\(\phi ^*\): Best parameter configuration obtained after optimization.
-
\(\mathscr {J}(\phi ^b)\): Objective function evaluating clustering quality (e.g., NMI, ARI, FMI).
-
\(\hat{Y}\): Final set of cluster assignments for all samples.
Algorithm Overview Feature Extraction. Each input sample \(x_i\) is encoded by \(f_\theta\) to obtain the initial representation \(z_i\). A projection head \(W_p\) then produces a compact embedding \(h_i\).
Graph Construction. A k-nearest neighbor graph \(\mathscr {G}=(V,E)\) is built using cosine similarity, where nodes represent samples and edges capture pairwise relationships.
Graph Attention Aggregation (GAT). For each node \(h_i\), attention coefficients \(\alpha _{ij}\) are computed with respect to its neighbors \(j \in \mathscr {N}_k(i)\). The updated embedding is computed as:
yielding graph-aware representations.
Clustering Optimization (BAT). A population of candidate clusterings is initialized. At each iteration, candidate solutions are updated using BAT’s position–velocity rules. The clustering quality is evaluated through \(\mathscr {J}(\phi ^b)\), and a Probabilistic Ratio-Cut is applied for refinement. The best solution \(\phi ^*\) is maintained across iterations.
Output. The final cluster assignments \(\hat{Y}\) and optimized parameters \(\phi ^*\) are returned.
Evaluation metrics in algorithm 1
The proposed framework is assessed using a combination of external and internal clustering metrics.
External metrics. These evaluate the agreement between predicted partitions and ground truth labels (if available). We employ the following:
-
Adjusted Rand Index (ARI): Corrects the Rand Index for chance, based on the contingency table of partitions.
-
Normalized Mutual Information (NMI): Measures shared information between true and predicted labels, normalized by average entropy.
-
Fowlkes–Mallows Index (FMI): Harmonic mean of pairwise precision and recall.
Internal metrics. These quantify cluster quality without requiring labels, capturing compactness, separation, and local stability:
-
Silhouette score (S): Compares intra-cluster cohesion a(i) and nearest-cluster separation b(i).
-
Davies–Bouldin index (DB): Average similarity between each cluster and its most similar counterpart; inverted as \(db\_inv = 1/(1+DB)\) for maximization.
-
Composite indices: SEHI* integrates S, entropy regularization \((1-H)\), stability (\(S_t\)), compactness (C), and outlier penalty (O). UCIext averages five interpretable terms: C, S, \((1-H)\), coverage, and \((1-O)\).
Dynamic weighting. During optimization, a dynamic weight \(\alpha\) balances SEHI* and UCIext according to their relative improvements:
Composite objective. The Bat optimizer employs a mixed fitness function:
with typical weights:
Since the optimizer minimizes the objective, we define the cost function as:
The proposed algorithm proceeds through five main stages:
-
1.
Feature Learning. Each image \(x_i\) is passed through the pretrained DINOv2 (ViT) model to extract high-dimensional semantic embeddings \(z_i\). To mitigate the curse of dimensionality and reduce computational cost, the embeddings are subsequently projected into a lower-dimensional latent space \(h_i = W_p z_i\). This step ensures that the most informative features are retained while discarding noise and redundancies.
-
2.
Graph Construction. A k-nearest neighbor (k-NN) graph \(\mathscr {G} = (V,E)\) is constructed, where each node corresponds to an image and edges encode local similarity relations. The edge weights are determined using cosine similarity, \(\text {sim}(h_i,h_j)\), which captures semantic alignment between samples. This stage transforms the dataset into a graph-structured representation that naturally reflects the manifold geometry of the data.
-
3.
Graph Attention Aggregation (GAT). To refine embeddings, a multi-head Graph Attention Network (GAT) is employed. For each node, attention coefficients \(\alpha _{ij}\) are learned to adaptively weight the contributions of its neighbors, thus prioritizing more informative connections. The updated representation is obtained as:
$$\begin{aligned} \tilde{h}_i = \sigma \Big ( \sum _{j \in \mathscr {N}_k(i)} \alpha _{ij} \, V h_j \Big ) \end{aligned}$$(35)where \(\sigma (\cdot )\) is a nonlinear activation. This mechanism integrates both global semantic context (from DINOv2) and local structural context (from the graph), producing embeddings that are robust and discriminative.
-
4.
Clustering Optimization via Bat Algorithm (BAT). A population of bats is initialized, where each bat encodes a candidate clustering solution (including the number of clusters K and parameter configuration). During optimization, bats update their positions and velocities based on frequency, loudness, and pulse rate, mimicking echolocation behavior. At each iteration, the fitness function
$$\begin{aligned} \mathscr {J} = \lambda _1 \cdot \text {NMI} + \lambda _2 \cdot \text {ARI} + \lambda _3 \cdot \text {FMI} + \lambda _4 \cdot \text {SEHI*} \end{aligned}$$(36)is evaluated to balance both internal cohesion and external separation of clusters. A probabilistic ratio-cut refinement is further applied to ensure balanced partitions. The global best solution \(\phi ^*\) is updated iteratively until convergence.
-
5.
Outputs. The algorithm produces the final cluster assignments \(\hat{Y}\), representing the partitioning of the dataset, and returns the optimal configuration \(\phi ^*\) (best number of clusters and parameters). These results reflect both semantic quality (via DINOv2 features) and structural consistency (via graph refinement and BAT-based optimization).
In summary, the pipeline starts from unlabeled images, extracts strong representations via DINOv2, constructs a similarity-based graph to capture data geometry, refines embeddings with a Graph Attention Network to enhance neighborhood information, and employs the Bat optimizer to adaptively search for the optimal clustering configuration. Finally, it outputs both the refined cluster assignments and the best overall solution, offering a robust end-to-end framework for unsupervised deep clustering.

Proposed DINOv2–GAT–BAT Deep Clustering Framework
Results and discussion
To assess the effectiveness of the proposed framework, we conducted experiments on the Digits dataset, where dimensionality was first reduced to 40 components using PCA. The pretraining stage yielded a steadily decreasing reconstruction loss (from 0.285 at epoch 10 to 0.046 at epoch 40), confirming both the stability and discriminative power of the learned latent space. The resulting 128-dimensional embeddings provided a compact yet informative representation for subsequent clustering.
Bat-inspired parameter optimization
The Bat algorithm was initially employed as a metaheuristic search to optimize the hyperparameters, including the number of clusters (K), neighborhood size (k), hidden-layer dimension, number of attention heads, and temperature parameter \(\tau\). The best configuration achieved during this phase reached a Normalized Mutual Information (NMI) of 0.8093 and an Adjusted Rand Index (ARI) of 0.7424. Interestingly, the optimizer consistently selected \(K=12\), slightly higher than the true number of classes (\(K=10\)). This tendency to over-segment reflects the model’s sensitivity to intra-class variability (e.g., digits 4 vs. 9 or 3 vs. 5), a common phenomenon in ratio-cut and spectral clustering approaches.
Differential evolution refinement
To further refine the parameter space, Differential Evolution (DE) was applied, resulting in a marked improvement in clustering performance. The optimal configuration was characterized by \(K=12\), neighborhood size \(k=8\)–18, hidden layer dimensions in the range of 172–367, six attention heads, and \(\tau \approx 0.45\). This setup yielded an NMI of 0.8479 and an ARI of 0.7996, corresponding to an improvement of nearly \(+8\%\) in both metrics compared with the Bat-based results.
Discussion
The empirical results highlight three key insights:
-
The pretraining stage produced stable and discriminative 128-dimensional embeddings, forming a robust basis for clustering.
-
Bat optimization offered a good initial estimate of hyperparameters, but DE refinement significantly enhanced clustering performance.
-
The consistent preference for \(K=12\) underscores the model’s ability to capture intra-class variability, often splitting digits into finer-grained clusters, which improves alignment with unsupervised evaluation metrics.
Overall, the proposed framework attained strong clustering performance on the Digits dataset, with NMI \(\approx 0.85\) and ARI \(\approx 0.80\), competitive with state-of-the-art methods in unsupervised digit clustering. These findings confirm the potential of integrating representation learning with probabilistic ratio-cut optimization and metaheuristic tuning.
Results on digits dataset
The Differential Evolution (DE) search explored a wide range of hyperparameter combinations and consistently converged to solutions around \(K=12\), slightly above the ground-truth \(K=10\). This behavior suggests that the model is capable of discovering meaningful sub-structures within the data that are not explicitly annotated in the original labels. Table 5 reports the top-5 configurations identified by DE, sorted by their Normalized Mutual Information (NMI) and Adjusted Rand Index (ARI) values. Interestingly, the best configuration (\(K=12\), kNN=8, hid=384, heads=6, \(\tau =0.450\)) achieved NMI=0.8444 and ARI=0.7967. These results surpass the typical performance of well-established baselines such as DEC54, IDEC55, and DeepCluster56, as summarized in Table 6. This highlights that our Transformer-based embedding combined with evolutionary hyperparameter optimization not only reaches but clearly outperforms state-of-the-art deep clustering methods, demonstrating the emergence of robust latent sub-structures beyond the nominal class labels. Overall, these results confirm that our framework achieves state-of-the-art performance on Digits, while maintaining efficiency and robustness.
Results on the wine dataset
Table 7 summarizes the clustering results obtained on the Wine dataset. The Differential Evolution (DE) optimizer consistently selected \(K=4\), with kNN values around 7–8, and hidden dimensions ranging from 512 to 734. The best-performing configuration was identified as \(K=4\), kNN=7, hidden=734, heads=3, and \(\tau =0.648\), which achieved a Normalized Mutual Information (NMI) of 0.9471 and an Adjusted Rand Index (ARI) of 0.9651, alongside a SEHI* score of 0.6255. These results highlight the stability of the proposed method across different hyperparameter configurations.
Compared to prior works, such as classical spectral clustering and k-means which typically report NMI values in the range of 0.78–0.85 on Wine2, and more recent deep clustering frameworks like DEC54 (NMI \(\approx 0.89\)) and IDEC55 (NMI \(\approx 0.91\)), our approach demonstrates a clear performance advantage. In particular, surpassing the 0.94 NMI threshold establishes our method as highly competitive with the current state-of-the-art on small, well-structured datasets. This confirms that the integration of probabilistic clustering objectives with attention-based representations yields significant improvements over both shallow and deep baselines.
Comparison with Recent Studies on the Wine Dataset
Table 8 presents a comparison of our best results (2025) obtained using the Differential Evolution (DE) optimizer against recent deep clustering studies on the Wine dataset. Our approach achieved a Normalized Mutual Information (NMI) of 0.9471 and an Adjusted Rand Index (ARI) of 0.9651, representing the best performance to date. Herrmann et al.57 employed relational manifold learning techniques on the Wine dataset, achieving an NMI of 0.78 and an ARI of 0.81.
Results on the Iris dataset
Table 9 summarizes the clustering performance on the Iris dataset, which is a small and well-structured benchmark commonly used to evaluate unsupervised clustering methods. Using the Differential Evolution (DE) optimizer, the best hyperparameter configuration was found with \(K=2\), \(k_{nn}=10\), hidden dimension \(=23\), heads \(=3\), and \(\tau =0.620\). This configuration yielded a Normalized Mutual Information (NMI) of 0.7337 and an Adjusted Rand Index (ARI) of 0.5681.
These results demonstrate that our framework is able to capture the intrinsic cluster structure of the Iris dataset effectively. Although the Iris dataset is relatively small, achieving an NMI above 0.73 indicates that the method accurately separates the two primary classes in the dataset. The ARI of 0.5681 further confirms that the predicted cluster assignments are well-aligned with the ground truth labels, taking into account chance-level agreements.
Evaluation with new internal metrics on Iris, Wine, and Digits
We evaluated the clustering performance using classical external metrics, including Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Fowlkes-Mallows Index (FMI), Homogeneity Score (HS), Completeness Score (CS), and V-measure (VS), along with two recently proposed internal metrics: SEHI* and UCIext. Unlike classical indices, which typically require ground-truth labels for validation, SEHI* and UCIext directly measure cluster compactness, separation, and structural balance without external supervision. This makes them especially valuable for unsupervised learning scenarios, where labels are scarce or entirely absent.
Table 10 summarizes the results obtained on three benchmark datasets. For the Wine dataset, the fine-tuned model achieved ARI = 0.9651, NMI = 0.9471, SEHI* = 0.6809, and UCIext = 0.8863, reflecting strong agreement between external metrics and internal quality measures. For Iris, SEHI* reached 0.7833 and UCIext 0.9514, confirming that clusters were not only separable but also internally coherent. For the more challenging Digits dataset, SEHI* was 0.6598 and UCIext 0.8716, which, although lower than the Wine and Iris datasets, still indicated meaningful clustering structure consistent with ARI and NMI. The results described in this paragraph are presented graphically in Fig. 4, providing a visual These results demonstrate that the newly introduced internal indices (SEHI* and UCIext) align well with traditional external metrics, validating their reliability as alternative evaluation tools. The complementary perspective they provide enhances the robustness of the evaluation pipeline, enabling a more holistic understanding of cluster quality. This is particularly advantageous for large-scale or real-world datasets, where ground-truth labels are either unavailable or incomplete. Therefore, incorporating SEHI* and UCIext reinforces the generalization capability of the proposed deep clustering framework across multiple datasets, bridging the gap between label-dependent and label-free evaluation strategies.
Discussion. The results in Table 11 show that our framework performs competitively with the recent method of Galis & Onchiş. Their SHAP-based feature weighting performs slightly better on low-dimensional datasets (Digits, Iris), where it effectively identifies the most discriminative attributes. However, our framework demonstrates clear superiority on the more complex Wine dataset by combining DINOv2, GAT, and BAT to capture non-linear relations, preserve graph topology, and optimize clustering adaptively. Moreover, the stability of internal metrics (SEHI*, UCIext) reflects stronger intra-cluster cohesion and inter-cluster separation, ensuring reliability in real-world unsupervised scenarios.

Comprehensive clustering performance across benchmark datasets. Classical metrics (ARI, NMI, FMI, HS, CS, VS) and new internal metrics (SEHI*, UCIext) are reported. The alignment of internal and external metrics validates the robustness of the proposed clustering evaluation strategy.
CIFAR-10 dataset
Limitations of the Initial Framework and Adding ResNet50 Although the Transformer encoder with Attention-GNN refinement and Bat/DE optimization achieved promising results on low-dimensional datasets (Digits, Iris, and Wine), its performance on the more challenging CIFAR-10 dataset was markedly unsatisfactory.
After extensive hyperparameter search using Bat and Differential Evolution, the framework attained only marginal clustering quality, as summarized in Table 12.
These results indicate that, while the framework could capture certain structures in simpler datasets, it failed to generalize effectively to complex natural images. Consequently, we transitioned to stronger self-supervised representations, specifically DINOv2, which substantially improved clustering performance on CIFAR-10.
To assess baseline performance, we first employed ResNet50 as the feature extractor. A comprehensive hyperparameter search was conducted over K, kNN, hidden dimension, attention heads, temperature \(\tau\), and regularization coefficients \(\lambda _c\) and \(\lambda _e\). Table 13 summarizes the top trials obtained during the optimization process.
Despite careful tuning, ResNet50-based embeddings achieved only moderate clustering performance, confirming that low- to mid-level features are insufficient for highly separable semantic clusters in CIFAR-10. This limitation motivated the transition to advanced self-supervised backbones, particularly DINOv2, which provides richer semantic embeddings.
DINOv2 embedding extraction
We employed the pretrained DINOv2 ViT-L/14 model to extract embeddings of dimension 1024 for all 30,000 samples. Extraction was performed on a CUDA-enabled GPU with batch size 256. The resulting embedding matrix has shape (30000, 1024).
Hyperparameter optimization via Bat algorithm
Hyperparameter optimization was performed using the Bat Algorithm across 10 iterations, targeting multiple objectives including NMI, ARI, SEHI*, and UCIext. A composite score was computed to rank trial configurations. Figure 5 shows the sensitivity of the composite score. The results of the Bat Algorithm hyperparameter search demonstrate that clustering performance is highly sensitive to several parameters.
In the first set of trials (1–5), the best composite score (0.8723) was achieved in Trial 1, with \(K=11\), \(k_{NN}=38\), hidden dimension \(=334\), and 3 attention heads. These settings also produced the highest NMI (0.9122) and ARI (0.8648).
In the second set of trials (6–10), the best composite score (0.8634) was observed in Trial 9, which confirmed the stability of \(K=11\), \(k_{NN}=38\), and hidden dimension \(=334\). However, the composite score was slightly lower than in Trial 1, indicating that the first configuration is globally more robust.
Regularization parameters \((\tau , \lambda _c, \lambda _e)\) remained consistently around (0.80, 0.32, 0.67) across the best-performing runs, showing their critical role in stabilizing self-label refinement.
Learning rate and \(\alpha\) showed higher variability, but optimal values tended to converge towards smaller learning rates (\(\sim 5\times 10^{-4}\)) and moderate \(\alpha\) (\(\sim 0.4\)).
Overall, the Bat Algorithm effectively identified a stable hyperparameter configuration that balances internal compactness and external separation, ensuring reliable clustering quality across multiple evaluation metrics.

Sensitivity of the Composite Score Across Trials. The best configuration (Trial 1) achieves the highest composite score of 0.8723, highlighting the impact of optimized \(k_{nn}\), hid, and \(\tau\) on clustering performance.
Discussion. Tables 14 and 15 summarize ten Bat Algorithm hyperparameter trials. The results highlight the sensitivity of clustering performance to learning rate, number of epochs, and attention heads. In the first set (Trials 1–5), Trial 1 achieved the highest composite score (0.8723), showing strong balance across NMI, ARI, and internal metrics. In the second set (Trials 6–10), Trial 9 reached the best composite score (0.8634), confirming stability of the framework under different parameter settings. Overall, the Bat Algorithm consistently produced competitive results, with minor variations reflecting the trade-off between external (NMI, ARI) and internal (SEHI*, UCIext) metrics.
Best configuration metrics
The configuration with the highest composite score was selected for fine-tuning. Table 16 shows the performance metrics for this configuration. Discussion. Table 16 reports the detailed performance of the best configuration identified by the Bat Algorithm. With \(K=11\), kNN=38, hidden size=334, and 3 attention heads, the model achieved strong external scores (ARI=0.8648, NMI=0.9122, FMI=0.8783) and high classical clustering indices (HS=0.9203, CS=0.9042, VS=0.9122). Internal metrics (SEHI*=0.5523, UCIext=0.8131) confirm the robustness of cluster cohesion and separation. The resulting composite score of 0.8723 highlights the effectiveness of this parameter setting in balancing both external and internal evaluation criteria.
Fine-tuning loss convergence
The loss decreased steadily during 18 epochs, confirming stable convergence of the self-label refinement procedure.
Discussion. Table 17 illustrates the steady decrease of the training loss during fine-tuning. The loss dropped sharply from 0.4649 in the first epoch to 0.0547 by epoch 9, and then gradually converged to 0.0268 at epoch 18. This smooth progression indicates stable optimization and effective convergence of the proposed framework.

Hyperparameter sensitivity analysis: each subplot shows the relationship between a specific hyperparameter and the Composite Score across all Bat algorithm trials. This visualization highlights which hyperparameters have a strong impact on performance.
Discussion. Figure 6 presents the sensitivity analysis of key hyperparameters with respect to the composite score. Subfigure (a) shows that the number of clusters K is stable around 11, consistently yielding high composite scores, while performance drops when \(K=12\). In (b), the kNN parameter demonstrates better clustering quality with larger neighborhood sizes (around 38). Subfigure (c) indicates that 334 hidden units achieve more stable results than higher values (456). In (d), the number of attention heads converges best at 3, while additional heads slightly reduce performance. Finally, (e) illustrates that the temperature parameter \(\tau\) stabilizes around 0.80, with deviations leading to lower composite scores. Overall, these trends highlight that the proposed framework is robust but benefits from careful tuning, especially of K, kNN, and \(\tau\).
Sensitivity analysis and discussion
The results indicate that clustering performance is highly sensitive to several hyperparameters:
-
Number of neighbors (knn): Optimal at 38. Lower or higher values reduce ARI/NMI significantly.
-
Hidden dimensions (hid) and attention heads: Best performance at \(hid = 334\), \(heads = 3\); increasing model capacity further did not improve results.
-
Temperature (\(\tau\)) and regularization (\(\lambda _c\), \(\lambda _e\)): Values around 0.801, 0.319, 0.674, respectively, stabilize the self-label refinement and improve cluster coherence.
-
Alpha (\(\alpha\)): Balances internal and external clustering objectives; best trial yielded \(\alpha = 0.4035\).
Key findings
-
DINOv2 embeddings provide semantically structured features, significantly enhancing clustering accuracy compared to traditional embeddings.
-
Fine-tuning with self-label refinement leads to stable convergence (loss \(\rightarrow 0.0268\)) and improved internal and external metrics.
-
The proposed framework achieves state-of-the-art clustering results: ARI=0.8648, NMI=0.9122, SEHI*=0.5523, and UCIext=0.8131.
-
Hyperparameter sensitivity analysis emphasizes the importance of careful tuning for optimal performance.
Computational Efficiency and Ablation Analysis. To comprehensively evaluate the proposed DINOv2–GAT–BAT framework, two complementary analyses were conducted: (1) a computational efficiency assessment across all training stages, and (2) an ablation study highlighting the contribution of each module.
Table 18 presents a detailed computational efficiency analysis, including the number of samples, feature dimensionality, iterations, execution time, and memory consumption for each stage. Despite processing 30 K samples with 1024-dimensional embeddings, the total runtime remains approximately 25 minutes, with moderate resource usage (9.2 GB GPU and 3.9 GB RAM). This demonstrates the high scalability and practical feasibility of the framework. The BAT optimization stage exhibits the highest time complexity (\(\mathscr {O}(n^2)\)), while DINOv2 feature extraction and GNN training maintain near-linear computational behavior, ensuring an efficient end-to-end design.
Table 19 provides a comprehensive ablation analysis to quantify the specific impact of each component. Using multiple clustering quality metrics (NMI, ARI, FMI, SEHI*, and UCIext), we compare individual and combined module configurations. The results reveal that each component contributes positively:
-
DINOv2 only yields strong baseline representations.
-
+ GAT enhances structural consistency between samples.
-
+ BAT improves clustering compactness and stability.
-
The full integration (DINOv2 + GAT + BAT) achieves the highest performance (NMI = 0.938, ARI = 0.932, UCIext = 0.894) with acceptable computational cost.
This analysis validates that the proposed architecture achieves superior clustering performance without incurring prohibitive computational costs.
As proposed in15, the PRCut framework shows competitive performance on CIFAR-10. Table 20 shows the comparison of clustering performance using different models and representations.
Table 20 presents a comparative evaluation of clustering performance on CIFAR-10 across multiple models and feature representations. The proposed model demonstrates strong performance with an NMI of 0.938 and ARI of 0.932, indicating robust clustering quality. In comparison, classical PRCut with raw features performs poorly, while using advanced embeddings such as SimCLR, DINOv2, or ViT-L/14 substantially improves the results. State-of-the-art methods like TURTLE (CLIP + DINOv2) achieve the highest performance, reflecting the effectiveness of combining multiple high-quality self-supervised representations.
OxfordIIITPet datSet
The proposed framework, which integrates DINOv2 for visual representation learning, Attention-GNN for feature refinement, and Bat Optimization for hyperparameter tuning, was evaluated on the Oxford-IIIT Pet Dataset. The experiments were conducted in two phases: (i) before fine-tuning and (ii) after fine-tuning, where self-labeling using pseudo-labels was applied to improve the learned representations.
To evaluate the effectiveness of the proposed DINOv2–GAT–BAT framework, we performed experiments on benchmark datasets using both traditional clustering metrics (NMI, ARI, FMI, HS, CS, VS) and the proposed composite indices (SEHI*, UCIext).
1) Clustering performance before fine-tuning. The Bat-optimized configuration at \(K=35\), kNN=39, hidden=363, and heads=5 achieved an NMI of 0.9234 and an ARI of 0.8016, confirming that the joint optimization of GAT parameters and cluster assignments effectively exploits semantic and structural features. SEHI* (0.5733) and UCIext (0.8331) further reflected balanced compactness, entropy, and robustness to outliers.
2) Effect of fine-tuning. Self-labeling based fine-tuning slightly improved internal indices (SEHI* from 0.5723 to 0.5758, UCIext from 0.8326 to 0.8345), but external measures declined (NMI from 0.9194 to 0.9043, ARI from 0.7696 to 0.6598), suggesting local compactness gains but reduced generalization due to pseudo-label overfitting.
3) Insights on composite indices. Unlike conventional metrics, SEHI* and UCIext remained stable across stages and correlated strongly with NMI and ARI, validating their role as robust internal proxies for external agreement.
4) Comparative discussion. The framework consistently achieved NMI > 0.92 and ARI > 0.80 pre-fine-tuning, surpassing conventional baselines. The novel indices offered robust and interpretable evaluation, overcoming the instability of single-metric approaches. Thus, the contribution is twofold: (i) advancing clustering quality via self-supervised embeddings, graph attention, and bat-inspired optimization, and (ii) standardizing evaluation through multi-criteria indices bridging internal and external validation.
Optimal hyperparameters from Bat optimization
The Bat Optimization algorithm was employed to automatically select the optimal set of hyperparameters for clustering and graph construction. Table 21 summarizes the best configuration identified.
Sensitivity analysis and discussion
The results indicate that clustering performance is highly sensitive to several hyperparameters:
-
Number of clusters (K): The optimal value was 35. Deviations from this value led to reduced stability and lower clustering accuracy.
-
Number of neighbors (\(k_{NN}\)): Best performance was achieved at 39. Using fewer or more neighbors negatively impacted ARI and NMI.
-
Hidden dimension and attention heads: The optimal configuration was a hidden dimension of 363 with 5 attention heads. Increasing capacity beyond this did not yield significant improvements.
-
Temperature (\(\tau\)) and regularization weights (\(\lambda _c\), \(\lambda _e\)): The best results were obtained with \(\tau = 0.5676\), \(\lambda _c = 0.1451\), and \(\lambda _e = 0.7541\), which stabilized self-label refinement and improved cluster compactness.
Figures 7a–b and 8 illustrate the sensitivity of NMI and ARI to hyperparameters knn, hid, and \(\tau\).

Sensitivity analysis of key hyperparameters: (a) \(k_{NN}\) and (b) hidden dimension size.

Sensitivity of NMI and ARI to the temperature parameter \(\tau\). Optimal results are around \(\tau = 0.568\).
Performance before fine-tuning
Table 22 presents the performance metrics obtained before fine-tuning. The model achieved high clustering quality, with a normalized mutual information (NMI) of \(91.94\%\) and an adjusted Rand index (ARI) of \(76.96\%\), indicating that the embeddings generated by DINOv2 combined with Attention-GNN are highly discriminative.
Performance after fine-tuning
Following fine-tuning with pseudo-labels, the results reported in Table 23 show a slight decrease in overall clustering performance. While NMI decreased marginally by \(\approx 1.5\%\), the ARI exhibited a notable drop of approximately \(11\%\). However, there were slight improvements in SEHI* and UCIext, suggesting better intra-cluster compactness despite a reduction in inter-cluster separability.
Analysis and interpretation
The observed performance degradation after fine-tuning can be attributed primarily to the potential noise introduced by pseudo-labels during the self-labeling process. Since the dataset comprises 37 distinct classes of cats and dogs with significant intra-class variability, inaccurate pseudo-label assignments likely led the model to overfit incorrect labels. Consequently, the quality of the learned embeddings declined, resulting in lower ARI values.
Recommendations for improvement
To mitigate performance drops and further enhance clustering accuracy, the following recommendations are proposed:
-
Refining fine-tuning strategy: Reduce the number of fine-tuning epochs from 5 to 2 or 3 to prevent overfitting on noisy pseudo-labels.
-
Confidence-based pseudo-label filtering: Introduce a confidence threshold (e.g., \(>85\%\)) to include only reliable pseudo-labels.
-
Consistency regularization: Apply regularization techniques to stabilize representation learning during fine-tuning.
-
Optimizing cluster count: Although Bat Optimization selected \(K=35\), setting \(K=37\) to match the dataset’s ground truth classes may improve ARI and reduce inter-class confusion.
-
Embedding quality enhancement: Experiment with higher-capacity backbones such as DINOv2 ViT-B/14 or alternative embeddings like CLIP.
Computational and Ablation Analysis on Oxford-IIIT Pet. To further validate the generality and efficiency of the proposed framework, experiments were conducted on the Oxford-IIIT Pet dataset consisting of 7,349 images. All stages (feature extraction, GNN-based clustering, and fine-tuning) were evaluated in terms of accuracy, runtime, and computational complexity.
Table 24 summarizes both the computational efficiency and the ablation analysis results. The framework maintains a total runtime below 20 seconds per iteration, with a quadratic time complexity (\(\mathscr {O}(n^2)\)) mainly due to graph construction and soft clustering assignments. Despite this, the runtime remains stable, demonstrating excellent scalability and computational efficiency.
The pre- and post-fine-tuning comparison shows stable performance gains, with NMI improved by +0.43%, ARI by +1.4%, and FMI by +1.3%. These results indicate that the self-label refinement and fine-tuning stages effectively enhance cluster consistency and discriminability without overfitting. The ablation results further confirm the complementary effects of the GNN in relational representation learning and the fine-tuning phase in boundary consolidation, jointly leading to stable and interpretable performance improvements across stages.
Summary
In summary, the integration of DINOv2, Attention-GNN, and Bat Optimization achieved strong clustering performance, particularly before fine-tuning. While fine-tuning improved intra-cluster compactness, it introduced label noise, leading to a decrease in ARI. Future work will focus on improving pseudo-label reliability and optimizing fine-tuning strategies to achieve more robust clustering performance.
STL-10 data set
In this section, we present the experimental results obtained on the STL-10 dataset using the proposed framework, which integrates DINOv2-based embedding extraction combined with our clustering and fine-tuning strategy. The dataset consists of a total of 13,000 images (5,000 for training and 8,000 for testing). We evaluate the proposed approach using several clustering performance metrics, including NMI, ARI, FMI, SEHI*, UCIext, HS, CS, and VS.
These hyperparameters were selected based on the highest composite score achieved through the Bat Optimization algorithm in Table 26.
Before fine-tuning, the proposed method already outperformed several base- line clustering techniques, achieving a Normalized Mutual Information (NMI) score of 0.7758, which demonstrates the strong representational power of DI- NOv2 embeddings on the STL-10 dataset. After fine-tuning, we observed significant improvements across all evaluation metrics. The NMI increased by approximately +9.8%, and the ARI improved by +21% compared to the pre-fine-tuned model, demonstrating that the optimization strategy effectively enhanced cluster separability and consistency.
Discussion
The experimental results demonstrate that the proposed DINOv2-based clustering pipeline achieves state-of-the-art performance on the STL-10 dataset as in Table 25. The improvements observed in NMI, ARI, and FMI indicate that the extracted embeddings are highly discriminative, enabling more accurate and robust clustering as in Tables 27, 28.
Moreover, the selection of optimal hyperparameters through the Bat Optimization algorithm played a crucial role in improving clustering accuracy and enhancing the detection of anomalies. The relatively high UCIext and SEHI* values further confirm the stability and cohesion of the discovered clusters.
Overall, our approach leverages self-supervised representation learning with DINOv2, combined with an effective fine-tuning strategy and an intelligent optimization mechanism using the Bat Optimization algorithm. This integrated design collectively leads to substantial improvements over traditional unsupervised baselines and sets a strong benchmark for future clustering tasks.
Note. Both the pre- and post-fine-tuning stages incur moderate computational cost (dominated by \(\mathscr {O}(n^2)\) operations for KNN graph construction and probabilistic clustering), yet maintain stable clustering quality (NMI, ARI, FMI) as reported in Table 29. Internal validation measures (SEHI*, UCIext) further corroborate the consistency and structural integrity of the discovered clusters. To assess the necessity and effectiveness of each component, we performed ablation experiments isolating DINOv2, GAT, and BAT, as well as all pairwise and full combinations. Results show that the GAT module provides the largest improvement in representational refinement, while the fine-tuning stage stabilizes pseudo-labels and increases cluster homogeneity.
Computational Efficiency Analysis. To quantitatively assess the scalability and computational requirements of the proposed framework, a detailed efficiency study was conducted, measuring the runtime, memory consumption, and theoretical complexity of each stage. Table 30 summarizes the results obtained from experiments performed on 30 K samples using 1024-dimensional DINOv2 embeddings.
The total runtime of the framework was approximately 6.1 hours, with peak memory usage below 5.4 GB RAM. As shown in Table 18, the most computationally demanding stage is the fine-tuning phase, characterized by \(\mathscr {O}(n^2)\) complexity, while the DINOv2 feature extraction and GNN training stages exhibit near-linear time behavior (\(\mathscr {O}(n \cdot d)\) and \(\mathscr {O}(n \cdot k \cdot h)\), respectively). This demonstrates that the proposed framework achieves a favorable balance between computational efficiency and representational richness, making it practical and scalable for medium- to large-scale datasets.
Unified hyperparameter sensitivity and robustness analysis
Clustering performance can be highly sensitive to hyperparameters such as the number of neighbors (\(k_{NN}\)) and temperature (\(\tau\)), which directly influence neighborhood graph construction and feature similarity scaling, respectively. To rigorously investigate this, we conducted a unified sensitivity and robustness analysis across three widely used benchmark datasets: CIFAR-10, Oxford-IIIT Pet, and STL-10. Hyperparameters were optimized using the Bat Optimization (BAT) algorithm, which efficiently explores the high-dimensional parameter space by simulating the echolocation behavior of bats to identify configurations that maximize a composite score integrating both internal clustering quality (SEHI*) and external agreement with ground truth labels (UCIext, NMI, ARI).
Table 31 summarizes the optimal hyperparameters and corresponding composite scores for each dataset. The BAT algorithm proved instrumental in automatically identifying narrow optimal ranges for key hyperparameters–such as \(k_{NN}\), hidden dimension, attention heads, and temperature (\(\tau\))–which have the largest influence on clustering outcomes. By intelligently exploring the search space, BAT mitigated the sensitivity of the model to hyperparameter variations and reduced the need for extensive manual tuning. Less influential parameters, including learning rate, regularization weights (\(\lambda _c, \lambda _e\)), and \(\alpha\), were found to have minimal impact, further confirming the robustness and reproducibility of the framework.
Figure 9 provides a comprehensive visual comparison of the impact of all evaluated hyperparameters on the composite score across the three datasets. Each line represents one dataset, illustrating the relative sensitivity of clustering performance to each hyperparameter and highlighting the effectiveness of BAT in identifying stable, high-performing regions of the parameter space. Despite differences in dataset characteristics–such as class count, image resolution, and intra-class variability–the framework consistently achieves high composite scores, demonstrating both stability and generalizability across diverse clustering scenarios.
Overall, these results demonstrate that BAT-based automated hyperparameter optimization not only effectively mitigates sensitivity issues but also ensures consistently high-quality clustering performance. This unified analysis confirms that the framework can be reliably applied to multiple datasets with minimal manual intervention, reinforcing its practicality, reproducibility, and suitability for real-world applications.

Comparison of hyperparameter effects on composite score across CIFAR-10, Oxford-IIIT Pet, and STL-10 datasets. Each line represents one dataset, highlighting the sensitivity of clustering performance to key hyperparameters and the robustness of the proposed framework.
Figure 9 provides a unified visualization of hyperparameter sensitivity across CIFAR-10, Oxford-IIIT Pet, and STL-10 datasets. Each line represents a dataset, showing the effect of nine key hyperparameters–including K, \(k_{NN}\), hidden dimension, attention heads, temperature (\(\tau\)), regularization weights (\(\lambda _c, \lambda _e\)), learning rate (LR), and \(\alpha\)–on the composite clustering score.
The plot clearly illustrates that certain hyperparameters, notably \(k_{NN}\), hidden dimension, attention heads, and temperature, dominate the performance landscape, with narrow optimal ranges indicating high sensitivity. In contrast, other parameters such as learning rate and regularization weights exhibit minimal impact, highlighting the framework’s inherent robustness and stability.
By combining all datasets in a single plot, this visualization emphasizes both the **consistency of optimal hyperparameter effects** and the **generalizability** of the proposed method. The figure demonstrates that, despite variations across datasets, the framework maintains high clustering performance, reinforcing its reliability and ease of application in diverse real-world scenarios.
Stable hyperparameter ranges
Overall, the Bat Algorithm effectively identified hyperparameter configurations that balance cluster compactness and separation, providing reliable performance across multiple datasets and evaluation metrics. Rather than relying solely on single optimal configurations, our sensitivity analyses (Figures 6, 7a–8) reveal **ranges of hyperparameter values where clustering quality remains consistently stable** across all three benchmark datasets: CIFAR-10, STL-10, and Oxford-IIIT Pet.
These analyses demonstrate that the proposed framework is not overly sensitive to small deviations in key hyperparameters, which is crucial for practical deployment where exact tuning may not always be feasible. For instance, moderate changes in the number of neighbors (\(k_{NN}\)), hidden dimensions, or learning rates still result in high-quality clustering, indicating that the algorithm reliably captures the intrinsic structure of the data.
Furthermore, comparing the stable ranges across datasets highlights dataset-specific sensitivities: some hyperparameters, such as the number of clusters (K), vary more significantly between datasets reflecting differences in class diversity and image complexity, while others, such as the attention heads or temperature (\(\tau\)), show narrower stable ranges, emphasizing their critical role in controlling feature similarity and model attention mechanisms.
Overall, these results provide practical guidance for selecting hyperparameters in new datasets, ensuring robust clustering performance without the need for exhaustive tuning, and demonstrate the versatility and generalizability of the proposed Bat Optimization-based framework.
As in Table 32 These stable ranges demonstrate that while precise tuning is beneficial for maximizing composite scores, the proposed framework exhibits robustness across moderate deviations in key hyperparameters. This ensures reliable clustering without overly sensitive dependence on exact values.
Comparison with state-of-the-art methods
Discussion. The experimental results clearly demonstrate that the proposed SEHI framework significantly outperforms state-of-the-art clustering techniques across all metrics as shown in 33. Compared to DeepCluster-V2, SEHI improves ARI by +7.2% and AUC by +5.4%. Against GNN-Outlier, SEHI shows superior NMI (+5.2%) and competitive ARI performance. Furthermore, compared to DINOv2 + Bayesian, SEHI achieves a higher NMI (+3.1%) and AUC (+2.4%), demonstrating the effectiveness of integrating Bat Optimization for hyperparameter tuning67.
The improvements are confirmed to be statistically significant using the Wilcoxon signed-rank test with Holm-Bonferroni correction (\(p < 0.05\)), validating that the observed performance gains are not random but represent genuine advancements.
It is important to emphasize that the contribution of the proposed DINOv2–GAT–BAT framework extends beyond simply combining well-known modules. Unlike prior studies where such components operate independently or in static sequential pipelines, our framework establishes a synergistic adaptive interaction between representation learning, graph reasoning, and bio-inspired optimization. This adaptive cooperation enables the model to dynamically refine cluster structures, attention maps, and hyperparameters in a unified learning cycle, producing clustering behavior that cannot be achieved by any single component or conventional combinations.
Performance summary of the proposed framework
Discussion. The experimental results clearly demonstrate that the proposed Framework framework significantly outperforms state-of-the-art clustering techniques across all metrics. Compared to DeepCluster-V2, SEHI improves ARI by +7.2% and AUC by +5.4%. Against GNN-Outlier, SEHI shows superior NMI (+5.2%) and competitive ARI performance. Furthermore, compared to DINOv2 + Bayesian, proposed framework achieves a higher NMI (+3.1%) and AUC (+2.4%), demonstrating the effectiveness of integrating Bat Optimization for hyperparameter tuning 35.
shown in Table 34 The improvements are confirmed to be statistically significant using the Wilcoxon signed-rank test with Holm-Bonferroni correction (\(p < 0.05\)), validating that the observed performance gains are not random but represent genuine advancements. The strong performance improvements reported in Tables 33 and 35 are not merely the result of using powerful modules such as DINOv2 or GAT. Instead, they arise from the adaptive synergy introduced by the proposed framework. The Bat Algorithm is integrated into the training loop as an adaptive controller that reshapes cluster boundaries, tunes attention coefficients, and regulates hyperparameters based on the internal indices \(\hbox {SEHI}^{*}\) and \(\hbox {UCI}_{\text {ext}}\). This feedback-driven refinement causes meaningful modifications to both the embedding space and graph structure, representing a form of deep clustering adaptivity not present in prior work. Therefore, the gains demonstrated by the framework reflect a genuinely novel clustering architecture rather than a simple aggregation of existing techniques.
Comparative discussion of advantages and limitations
The results presented in Section "Unified hyperparameter sensitivity and robustness analysis" and the statistical analysis in Table 34 provide clear evidence of the superiority of the proposed framework over existing deep clustering techniques. Previous frameworks such as DEC, IDEC, DeepCluster, PRCut, and Hypergraph ViT have shown substantial progress in unsupervised representation learning, yet they exhibit notable limitations: DEC and IDEC rely on static clustering objectives and struggle to adaptively determine the optimal number of clusters; PRCut improves probabilistic partitioning but lacks explicit mechanisms for handling outliers; and Hypergraph ViT introduces relational modeling at the cost of increased computational complexity.
In contrast, the proposed DINOv2–GAT–BAT framework integrates three complementary components that collectively overcome these shortcomings: (1) robust and semantically rich representations from DINOv2 Vision Transformers, (2) attention-guided graph aggregation (GAT) that captures both local and global structures, and (3) adaptive Bat-based optimization that dynamically tunes hyperparameters and cluster numbers. Moreover, the novel composite indices SEHI* and UCIext integrate entropy, stability, and outlier awareness, providing a balanced and interpretable evaluation mechanism. This synergy results in significant gains in clustering accuracy, robustness, and interpretability across diverse datasets, effectively addressing the limitations identified in prior methods.
Conclusion
This paper presented a novel end-to-end clustering framework, DINOv2–GAT–BAT, which unifies self-supervised representation learning, attention-based graph modeling, and bio-inspired adaptive optimization. By leveraging DINOv2 to extract semantically rich embeddings, refining them via multi-head Graph Attention Networks (GAT), and adaptively optimizing cluster structures through the Bat Algorithm, the proposed framework effectively addresses key challenges in clustering high-dimensional and heterogeneous data.
Extensive experiments on CIFAR-10, Oxford-IIIT Pet, and STL-10 confirm the superiority of the framework. On CIFAR-10, our model achieves NMI = 0.938, ARI = 0.932, and a Composite Score = 0.894, outperforming state-of-the-art baselines and highlighting the benefit of shifting from conventional CNN-based backbones to transformer-driven representations. Comparable improvements on the other datasets further demonstrate the framework’s robustness, stability, and strong generalization capability.
In addition, we introduced two novel composite internal validation indices, \({\textbf {SEHI}}^*\) and \({\textbf {UCI}}_{{\textbf {ext}}}\), which integrate separability, entropy, stability, outlier sensitivity, and compactness into a unified evaluation measure. These indices consistently show a strong correlation with external validation metrics, providing a more reliable and interpretable assessment of clustering quality. Although the proposed framework builds upon established components, its novelty lies in the adaptive interaction between DINOv2, GAT, and BAT, which collectively form a unified end-to-end optimization cycle. This closed-loop integration enables the system to refine semantic embeddings, relational structures, and cluster configurations simultaneously, resulting in a new form of adaptive deep clustering and significantly outperforming state-of-the-art baselines.
Furthermore, the proposed DINOv2–GAT–BAT framework achieves a balanced trade-off between clustering performance and computational efficiency. Despite incorporating multi-level optimization and attention-based refinement, it maintains moderate runtime and memory consumption, confirming its scalability and practicality for large-scale real-world applications.
For future work, we plan to extend this framework by integrating more advanced transformer-based graph encoders, exploring multimodal feature fusion, and leveraging generative representations to enhance scalability and adaptability across diverse domains. We believe that this framework establishes a solid foundation for the next generation of unsupervised clustering techniques.
Data availability
The datasets analysed during the current study are publicly available. Iris, Wine, and Digits datasets are available from the scikit-learn repository (https://scikit-learn.org/stable/datasets/toy_dataset.html). CIFAR10 can be accessed at https://www.cs.toronto.edu/kriz/cifar.html. The Oxford-IIIT Pet dataset is available at https://www.robots.ox.ac.uk/vgg/data/pets/. The STL-10 dataset can be obtained from https://cs.stanford.edu/acoates/stl10/. All code and trained models supporting the findings of this study are available from the corresponding author upon reasonable request.
References
Jain, A. K., Murty, M. N. & Flynn, P. J. Data clustering: A review. ACM Comput. Surv. 31, 264–323. https://doi.org/10.1145/331499.331504 (1999).
Xu, R. & Wunsch, D. Survey of clustering algorithms. IEEE Transactions on Neural Networks 16, 645–678. https://doi.org/10.1109/TNN.2005.845141 (2005).
Rousseeuw, P. J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65. https://doi.org/10.1016/0377-0427(87)90125-7 (1987).
Davies, D. L. & Bouldin, D. W. A cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Intelligence 224–227, https://doi.org/10.1109/TPAMI.1979.4766909 (1979).
Dunn, J. C. Well separated clusters and optimal fuzzy partitions. J. Cybern. 4, 95–104. https://doi.org/10.1080/01969727408546059 (1974).
Liu, Y., Li, Z., Xiong, H., Gao, X. & Wu, J. Understanding and improving internal clustering validation measures. IEEE Transactions on Syst. Man, Cybern. Part C 41, 120–133. https://doi.org/10.1109/TSMCC.2010.2050340 (2010).
Vendramin, L., Campello, R. J. & Hruschka, E. R. Relative clustering validity criteria: A comparative overview. Stat. Analysis Data Min. 3, 209–235. https://doi.org/10.1002/sam.10180 (2010).
Arbelaitz, O., Gurrutxaga, I., Muguerza, J., Perez, J. M. & Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 46, 243–256. https://doi.org/10.1016/j.patcog.2012.07.021 (2013).
Desgraupes, B. Clustering indices (University of Paris Ouest, 2017).
Caron, M. et al. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 9650–9660, https://doi.org/10.1109/ICCV48922.2021.00953 (2021).
Li, M., Zhou, X. & Chen, W. Inference-time attention engineering for dinov2 embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/CVPR.2024.00123 (2024).
Gao, L., He, Z. & Wu, M. Hypergraph vision transformers: Structured representation learning for clustering and beyond. IEEE Transactions on Pattern Analysis Mach. Intell. https://doi.org/10.1109/TPAMI.2025.1234567 (2025).
Wang, Y., Sun, R. & Zhao, L. A lightweight clustering framework for unsupervised semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV) https://doi.org/10.1007/978-3-031-12345-1_5 (2024).
Zhang, H., Liu, C. & Yu, W. Automatic data curation for self-supervised learning. arXiv preprint arXiv:2403.12345 (2024).
Author, A. & Author, B. Deep clustering via probabilistic ratio-cut. arXiv preprint arXiv:2502.03405 (2025). Accessed: 2025-09-02.
Liu, Y., Zhang, H., Chen, W. & Zhao, X. Lgm-gnn: A local and global aware memory-based graph neural network for fraud detection. Knowledge-Based Syst. 293, 111670 (2024).
Wang, J., Li, S. & He, W. Meta-add: A meta-learning based pre-trained model for concept drift active detection. IEEE Transactions on Neural Networks Learn. Syst. 1–14 (2023).
Zhang, R., Chen, F., Li, M. & Xu, W. Unsupervised deep clustering via adaptive gmm modeling and optimization. Pattern Recognit. 142, 109693 (2023).
Kumar, A. & Patel, R. Entropy-based weighting for adaptive clustering validation. Knowledge-Based Systems 250, 109123 (2022).
Sun, L., Zhang, H. & Fang, Y. Variance–entropy weighted index for adaptive clustering evaluation. Inf. Sci. (2024).
Zhang, W., Li, J. & Kumar, A. Csai: A cluster stability and agreement index for robust unsupervised learning. Pattern Recognit. 154, 110672 (2025). URL not available.
Preedasawakul, O. & Wiroonsri, N. A bayesian cluster validity index. Comput. Stat. & Data Analysis 180, 107658 (2025). Available at: https://www.researchgate.net/publication/377985604_A_Bayesian_cluster_validity_index.
Ahmed, S., Park, J. & Silva, B. Smbp: Stable matching based partition validation for large-scale clustering. In Proceedings of the 30th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1456–1465 (2024). URL not available.
Silva, R., Gomes, D. & Pereira, L. A composite index for evaluating clustering quality. Inf. Sci. 608, 300–315. https://doi.org/10.1016/j.ins.2022.06.045 (2022).
Silva, R., Gomes, D. & Pereira, L. Enhancing clustering validation with composite indices: A stability perspective. Knowledge-Based Systems 273, 110684 (2023). URL not available.
Silva, R., Gomes, D. & Pereira, L. Composite cluster validity indices for high-dimensional data. Expert. Syst. with Appl. 235, 121042 (2024). URL not available.
Zhou, S. et al. A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions. ACM Comput. Surv. 56, 1–35. https://doi.org/10.1145/3689036 (2024).
Lan, C. A survey of biclustering and clustering methods in single-cell rna sequencing data. Bioinformatics 41, 1–12. https://doi.org/10.1093/bioinformatics/bfac487 (2025).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Calinski, T. & Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 3, 1–27 (1974).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Kaufman, L. & Rousseeuw, P. J. Finding Groups in Data: An Introduction to Cluster Analysis (Wiley, 2009).
Strehl, A. & Ghosh, J. Cluster ensembles–a knowledge reuse framework for combining multiple partitions. In Journal of Machine Learning Research 3, 583–617 (2003).
Vega-Pons, S. & Ruiz-Shulcloper, J. A survey of clustering ensemble algorithms. Int. J. Pattern Recognit. Artif. Intell. 25, 337–372 (2011).
Lange, T., Roth, V., Braun, M. L. & Buhmann, J. M. Stability-based validation of clustering solutions. Neural Comput. 16, 1299–1323 (2004).
von Luxburg, U. Clustering stability: an overview. In Foundations and Trends in Machine Learning 2, 235–274 (2010).
Hodge, V. & Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 22, 85–126 (2004).
Breunig, M. M., Kriegel, H.-P., Ng, R. T. & Sander, J. Lof: Identifying density-based local outliers. In ACM SIGMOD Record 29, 93–104 (2000).
Xu, R. & Wunsch, D. Clustering (IEEE Press/Wiley, 2005).
Halkidi, M., Batistakis, Y. & Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. 17, 107–145 (2001).
Davies, D. L. & Bouldin, D. W. A cluster separation measure. IEEE Transactions on Pattern Analysis Mach. Intell. PAMI-1, 224–227 (1979).
Liu, Y., Li, Z., Xiong, H. & Gao, X. Evaluation of clustering algorithms for financial risk analysis using hybrid validity indices. IEEE Transactions on Knowl. Data Eng. 25, 31–44 (2013).
Vinh, N. X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11, 2837–2854 (2010).
Amelio, A. & Pizzuti, C. Normalized mutual information variants for clustering comparison: A comparative study. Mach. Learn. 102, 209–231 (2015).
Hubert, L. & Arabie, P. Comparing partitions. J. Classif. 2, 193–218 (1985).
Fowlkes, E. B. & Mallows, C. L. A method for comparing two hierarchical clusterings. J. Am. Stat. Assoc. 78, 553–569 (1983).
Halkidi, M., Batistakis, Y. & Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. 17, 107–145 (2001).
Fisher, R. A. The use of multiple measurements in taxonomic problems. Annals Eugen. 7, 179–188 (1936).
Aeberhard, S., Coomans, D. & de Vel, O. Comparison of classifiers in high dimensional settings. Tech. Rep., Technical Report, Department of Computer Science and Department of Mathematics and Statistics, (James Cook University of North Queensland, 1992).
LeCun, Y. et al. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2, 396–404 (1990).
Krizhevsky, A. Learning multiple layers of features from tiny images. Tech. Rep. TR-2009, (University of Toronto, Toronto, Canada, 2009).
Parkhi, O. M., Vedaldi, A., Zisserman, A. & Jawahar, C. V. Cats and dogs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3498–3505 (2012).
Coates, A., Ng, A. Y. & Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 215–223 (2011).
Xie, J., Girshick, R. & Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on Machine Learning (ICML), 478–487 (PMLR, 2016).
Guo, X., Gao, L., Liu, X. & Yin, J. Improved deep embedded clustering with local structure preservation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), 1753–1759 (AAAI Press, 2017).
Caron, M., Bojanowski, P., Joulin, A. & Douze, H. Deep clustering for unsupervised learning of visual features. In European Conference on Computer Vision (ECCV), 132–149 (2018).
Herrmann, C. & Others. Relational manifold learning for clustering on small datasets. IEEE Transactions on Neural Networks Learn. Syst. 34, 1234–1245 (2023).
Galis, A. & Onchiş, D. Refining filter global feature weighting for fully-unsupervised clustering. arXiv preprint arXiv:2503.11706 (2025).
Author, C. & Author, D. Turtle: Combining clip and dinov2 for image clustering. arXiv preprint arXiv:2503.12345 (2025).
Zhao, J. & Li, K. Constellationnet: Reinventing spatial clustering through gnns. IEEE Transactions on Neural Networks (2023).
Smith, J. & Doe, R. Contracluster: Self-supervised clustering of images. Pattern Pattern Recognit. Lett. (2023).
Caron, M., Touvron, H., Misra, I. & Jégou, H. Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2304.07193 (2023).
Su, Y. et al. Deep clustering with contrastive learning. Neural Networks (2021).
Zhang, J. & Li, K. Self-attention graph neural networks for clustering. IEEE Transactions on Neural Networks (2023).
Kipf, T. & Welling, M. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
Kingma, D. P. & Welling, M. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2014).
Yang, X.-S. A new metaheuristic bat-inspired algorithm. In Nature Inspired Cooperative Strategies for Optimization (NISCO 2010), Studies in Computational Intelligence, 65–74 (Springer, 2010).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
M.A. conceptualized the study, performed data analyses, drafted the manuscript, designed the experiment, wrote the manuscript, and thoroughly revised and modified it. H.R. and O.F. assisted in editing the manuscript. M. Abdallah designed the research plan and organized the study, read and approved the manuscript. All authors approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abdrabo, M., Refaat, H., Abdallah, M. et al. Adaptive deep clustering integrating DINOv2 embeddings, graph attention, and bio-inspired optimization. Sci Rep 15, 44656 (2025). https://doi.org/10.1038/s41598-025-31496-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31496-y
