
Abstract
Alzheimer’s Disease (AD) is a progressive neurodegenerative disease and the leading cause of dementia. Early diagnosis is critical for patients to benefit from potential intervention and treatment. The retina has emerged as a plausible diagnostic site for AD detection owing to its anatomical connection with the brain. However, existing AI models for this purpose have yet to provide a rational explanation behind their decisions and have not been able to infer the stage of the disease’s progression. Along this direction, we propose a novel model-agnostic explainable-AI framework, called Granu\(\underline{la}\)r Neuron-le\(\underline{v}\)el Expl\(\underline{a}\)iner (LAVA), an interpretation prototype that probes into intermediate layers of the Convolutional Neural Network (CNN) models to directly assess the continuum of AD from the retinal imaging without the need for longitudinal or clinical evaluations. This innovative approach aims to validate retinal vasculature as a biomarker and diagnostic modality for evaluating Alzheimer’s Disease. Leveraged UK Biobank cognitive tests and vascular morphological features demonstrate significant promise and effectiveness of LAVA in identifying AD stages across the progression continuum.
Similar content being viewed by others

Introduction
Alzheimer’s disease is the leading cause of dementia. The number of people aged 65 and older with AD in the United States is estimated to be around 6.5 million, which is expected to grow to 13.8 million by 20501. AD is a progressive disease that can be broadly characterized into preclinical, prodromal mild cognitive impairment (MCI due to AD), mild AD, moderate AD, and severe AD based on the presence of clinical biomarkers and cognitive symptoms2,3. Early screening and diagnosis of AD are essential to alter the disease trajectory.
Pathological changes to the retina have been associated with early-stage neurodegenerative diseases4,5,6. Retinal screening presents a non-invasive, feasible, and economical solution to early AD diagnosis which has been hindered by the lack of consistent clinical symptoms and the absence of clinically accessible neuroimaging and biological markers7. Among the retinal features, weakening and alterations of the retinal vasculature as an AD biomarker have recently emerged8. Clinical studies have focused on the time-consuming manual segmentation of the vasculature, propagating subjective error into the quantitative analysis. To counteract this problem, AI-based models have been introduced as more objective, repetitive, precise, and automated systems to aid the vasculature segmentation and the decision-making of ophthalmologists. Only a few AI-based models have investigated AD through the retina9,10,11 and no work has yet studied the retinal biomarkers for AD across the disease spectrum. Furthermore, these AI-based models have been used as black-box models without a clear understanding of why the model made such predictions.
Recent advances in Explainable-AI (XAI) have shed interpretability into AI models. Notable explainers are feature attributions (e.g., saliency maps12, SHAP13, LIME,14, and integrated gradients15). In particular, these explainers are effective at the macro-level (e.g., input-wise or layer-wise) highlighting the features that are most effective in decision-making. However, these explainers lack information attained at the micro-level of artificial neurons which influences different mechanisms of decision-making. We look to invoke this ideology into the perspective of AD, that is, a medical XAI framework to identify sub-types and progression stages of the disease.
We propose our XAI framework called Granu\(\underline{la}\)r Neuron-le\(\underline{v}\)el Expl\(\underline{a}\)iner (LAVA) for explainable diagnosis and assessment of the AD continuum. The intuition behind this approach is that analyzing the behavior of neurons generates rich information reflecting not only the correlation between biomarkers but also the interaction among biomarkers, thanks to inductive learning of deep neural network architectures. We thereby introduce latent representations of raw pixels reflected in the activation behavior of neurons as a resource to discover and reveal hierarchical taxonomies of potential biomarkers. LAVA is a systematic approach that probes into intermediate layers of the CNN model, inspects and leverages the activation patterns of neurons as auxiliary information to improve model Explainability and Diagnostic power jointly. Subsequently, we show how this new source of information during the learning process is used to predict coarse-to-fine class in a downstream classification task where only coarse-level target labels are available; such discovered knowledge can be linked to the domain of knowledge to gain new insights from experts in the application domain.
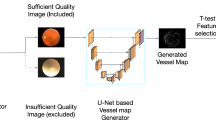
There are two core modules so-called Neuron Probing and Granularity Explanation that constitute the LAVA architecture, as shown in Fig. 1. The former identifies critical neurons and inspects their activation patterns. The latter clusters input sample images into distinctive groups emulated by the activation of critical neurons as independent random variables. LAVA is input size invariant, and model-agnostic in the sense that it can adapt to a broad class of CNN models and is adjustable to the granularity level of data in the application domain. It is notable that the activations of neurons are extracted during the test phase, hence CNN models that do not contain any dropout layers in their architectures are preferable in this framework in order to avoid randomized and non-reproducible results.

Overall architecture of LAVA framework. End-to-end learning process in LAVA framework is constituted by four main phases: (1) Data Acquisition where fundus images from the UK Biobank are collected along with quality selection and AutoMorph preprocessing to obtain retinal vasculature maps and morphological features, (2) Classification where a VGG-16 model is utilized for binary classification between AD and NC images supplemented with a feature attribution map, (3) Neuron-level XAI that consists of two modules of Neuron Probing to identify and extract critical neurons across the VGG-16 network and Granularity Explanation to identify sub-classes of labels hidden in data, and (4) AD Continuum Assessment where the diagnostic result of LAVA for an individual subject is summarized.
In this article, we present the development of a novel XAI framework, Granular Neuron-level Explainer (LAVA) to evaluate fundus images as a diagnostic modality of AD continuum assessment. We verify the effectiveness of LAVA through consistency checks using clinical measures of cognitive function and vascular integrity in the UK Biobank16. We employ feature attribution and pixel reconstruction methods to highlight regions of interest in the diagnosis of AD. The proposed framework supports the automation of an XAI diagnostic system which may be used for clinical intervention and advance the field’s mechanistic understanding of AD.
Results
Study design and participants
LAVA is developed to assess AD classification and to infer the disease continuum utilizing fundus images acquired from the UK Biobank16. The UK Biobank contains nearly 170,000 fundus images from over 500,000 participants. As a critical requirement in this approach, the image samples used in this study should meet several quality factors. Quality control is performed to exclude a large number of fundus images with artifacts and clarity issues using a pre-trained CNN module on the EyePacs-Q dataset. AD subjects with other additional sub-types of dementia (e.g., frontotemporal dementia (FTD) are excluded. We identify a total of 100 images from 61 unique AD subjects. To avoid potential confounding factors, we construct our binary-labeled dataset by matching each AD image with 80 unique age and gender-matched normal controls (NC) leading to a total number of 200 fundus images. The AutoMorph deep learning pipeline17 is used for preprocessing, vessel segmentation, and morphological vascular feature quantification.
Training and inference
A VGG-1618 binary classifier model is trained and evaluated under a subject-level five-fold stratified cross-validation setting on the segmented vessel maps where retinal images from each subject only appear in the same fold. This procedure is repeated with five repetitions with an optimal 5-fold accuracy of 75% and an average accuracy of 71.4% (SD = 0.03). The best-performing cross-validation model is utilized for post-hoc analysis.
Neuron probing
We probe into intermediate layers of the network at the neuron level to assess the AD continuum (see Fig. 1). In our setting, we choose Max-Pooling layers and the first two fully connected layers of the VGG-16 for critical neuron selection. Although our approach supports critical neuron extraction from early layers, we find our LAVA framework works effectively using a combination of Max-Pooling Layers. Owing to the Maximum Likelihood Estimation (MLE) algorithm to approximate the joint Mutual Information (MI) objective in the selection of critical neurons, the LAVA framework is reproducible, model agnostic, and input size invariant. We use Epsilon-support vector regression (\(\epsilon\)-SVR)19 with a linear kernel as a core algorithm to estimate the contribution coefficient of every single neuron at selected layers and wrap the output by Recursive Feature Elimination (RFE) to collectively realize our MLE-based critical feature selection objective.
We set two hyperparameters for the number of selected critical neurons at each layer to be 20 and the number of neurons pruned at each iteration to be 1000. This MLE-based feature selection procedure repeats to ensemble five sets of selected neurons at each layer by each of five cross-validation models into approximately 700 critical neurons, 100 from each layer, concatenated (with repetition) across the network. Supplementary Fig. S1 shows the Jaccard similarity index computed to compare overlapping between sets of neurons selected by five cross-validation models. Higher similarities suggest similar activation behavior at certain layers which can be interpreted as similar Region Of Interest (ROIs) used for the feature extraction.
Granularity explanation
Using the results obtained in neuron probing, we can distill the activation values of critical neurons across the network over all input samples as a new dataset that will be used for our knowledge discovery. Under a semi-supervised setting, LAVA employs the Adjacency-constrained Hierarchical Agglomerative Clustering (HAC) algorithm20 where an early constructed k nearest-neighbor graph (\(k-\)NNG) imposes connectivity constraints in the form of a 97.5% (\(k=5, N=200\)) sparse connectivity matrix of shape \(N\times N\) that links each input sample to its five nearest neighbors. This algorithm first creates a distance matrix for sample instances using the Euclidean metric and then reduces a chunk of distances to the k-nearest neighbors for each sample where the array of distances for that sample is partitioned by the element index \(k-1\) in the stable sorted order. k is a hyperparameter chosen based on experience and the number of target labels; \(k=3\) and \(k=5\) are common choices in the LAVA framework. The results show this approach is highly effective in using fundus biomarkers to identify latent sub-classes of the predicted label interpreted as AD continuum.
In this study, we make use of dendrogram diagram (Fig. 2) for two purposes: (1) Initial evaluation of the hardness of the clustering task, and (2) Decision on the appropriate number of clusters. The imaginary horizontal line traversing the dendrogram determines the distance between latent sub-clusters of individuals. The first largest breaking branch divides CN subjects from the rest of the subjects where each main branch contains sub-clusters of the same category in terms of the total variation. The second largest breaking branch categorizes AD and CN subjects into their sub-clusters within the AD continuum with the desired level of detail. The number of clusters is a hyperparameter in the LAVA framework normally chosen based on the granularity level of the data and the nature of the problem under study, which is set to 7 in this experiment. We use intrinsic metrics e.g., Calinski-Harabasz (CH) index (also known as the Variance Ratio Criterion)21 and Adjusted Mutual Information (AMI)22 to choose the appropriate clustering method by comparing their performances. The result of this clustering is summarized in Supplementary Table S1 including 3 purely AD groups, 3 purely NC groups, and 1 Mixed group of coarsely AD or NC-labeled subjects.
We further analyze the behavior of critical neurons of the trained network independent from the input data. First, we use t-SNE23 to project a high-dimensional space of critical neurons’ activation values at a certain layer down to two dimensions. Second, we apply the Kernel Density Estimation (KDE)24 method on top of t-SNE to estimate the probability density curve associated with each dimension of t-SNE embedding as shown in Fig. 3. Blue and orange curves at each layer can be interpreted as the distinctive behavior of the model in the prediction of coarse class labels (AD/NC), while the presence of multiple peaks at each curve reveals a mixture of multiple probability distributions corresponding to the different mechanisms of prediction or different activation patterns used in the prediction of each class of label. Our intuition is that each peak can potentially correspond to one distinctive sub-cluster of examined samples. This observation is an analogy to the previous dendrogram visualization of latent clustering structure within 200 input samples suggested by activation values of critical neurons in the network.
The choice of hierarchical clustering over other semi-supervised clustering methods e.g., KMeans25, Mean Shift Clustering26, Affinity Propagation19, etc. is made based on the behavior of critical neurons and how well each clustering algorithm can scale on our dataset. We use various statistical methods e.g., Variance Ratio Criterion, Adjusted Mutual Information, Rand index, V-measure, homogeneity score, and completeness score to evaluate and compare the performance of different clustering algorithms. We observe medical assessments reported on UK Biobank cognitive tests27 efficiently scale over a hierarchy and not a flat set of clusters. The primary results encourage our further investigation into finding an appropriate clustering algorithm in order to gain more insights into learning the connection between AD-related biomarkers in eye fundus images and the activation pattern of critical neurons in the network.

The results of the neuron-level hierarchical clustering. The dendrogram plot of agglomerative connectivity constraint clustering with ward’s linkage represents the similarity relationship among sub-clusters of patients colored by true labels in terms of the behavior of critical neurons. The imaginary horizontal line traversing the dendrogram determines the correspondent detail level of latent sub-clusters that characterize subjects within the continuum of disease.

Exploring activation pattern of critical neurons. Kernel density estimate (KDE) applied on top of two-dimensional embedded space (lower-dimensional representation of the critical neurons’ activation at different hidden layers) obtained by t-distributed stochastic neighbor embedding (t-SNE) and unveils multiple Gaussian distributions embedded in the activation pattern of critical neurons corresponding to distinctive sub-cluster(s) associated with AD or NC target class (blue and orange curves) of the disease.
Continuum assessment
Next, we showcase our LAVA-based hierarchical clustering is reflective of the AD continuum. Seeing that the UKB lacks a detailed assessment of activities of daily living, cognitive profile, or functional scores (e.g., the clinical dementia rating and the mini-mental state examination) and neither brain imaging data in our cohort, we use cognitive test measures from the UKB as proxy measures of cognitive ability28. These tests include two levels of memory from the UKB, the pairs matching and prospective memory, and an intellectual problem-solving measure, the fluid intelligence. We note that the clusters are extracted from retinal vasculature images, and thus, we hypothesize that image-level features should coincide with our continuum. Naturally, such image-level features live in an abstract space. To resolve this issue, we evaluate quantifiable morphological features, specifically, the fractal dimension and vessel density, that are representative of the image-level features and relate these to the cognitive ability of a subject.
We employ our analysis at the group-level (AD/NC) and the sub-group level. First, we verify that the cognitive measures are significantly different across groups, as shown in Supplementary Fig. S2. Next, as each metric is on a different scale, all of the scores are normalized on [0,1] for comparison. A normalized comparison across groups is illustrated in Fig. 4a through a visual radar plot. We demonstrate that such metrics form an increasing sequence of measures across clusters, supporting the idea that such latent clusters are indicative of the AD continuum. From this observation, we term our sub-groups in order ranging from the healthiest states of cognitive normal (CN) to the severity of AD [CN-1, CN-2, CN-3, Mixed, AD-1, AD-2, AD-3]. Notably, the Mixed Group contains a sub-cohort of AD and NC subjects suggesting similarities of AD subjects and potentially at-risk NC subjects. Furthermore, the reduction in morphological vascular features coincides with a decline in cognitive ability, thus supporting the retinal vasculature as indicative of the AD continuum, as shown in Fig. 4b. Last, taking from the observation of the sequence of our clusters, we look to assign a simplistic AD score of the continuum as illustrated in the gauge plot, Fig. 4c. To accomplish this, we average together the normalized cognitive metrics (pairs matching, prospective memory, and fluid intelligence). In this manner, the healthiest subject has a score of 0 and the severe subject has an upper bound score of 1. Therefore, for any new subject, we may apply our LAVA framework and assign a subject’s vessel to map a position in the AD continuum as a manner for assigning their risk and potential clinical intervention.

LAVA evaluation with clinical measures. The cognitive and vascular features are normalized onto [0,1] for scalable weighting. (a) The UK Biobank cognitive test measures vascular features between AD and NC groups. (b) The cognitive and vascular feature comparison in the continuum identified by the LAVA framework. (c) The AD score is defined by averaging the normalized cognitive features. Each sub-group block is not drawn to scale.
Visual model interpretation for clinical evaluation
We investigate the learning process by use of the guided backpropagation method, wherein we mask crucial input features and examine how the essential ROIs effective in the discovery of the AD continuum develop. With some modifications to the pruning objective, we use the method introduced in29 to reconstruct critical fragments effectively in the prediction of each latent sub-class using a sparse pathway limited to some percentile of critical neurons identified and scored in Neuron-level XAI phase. In this technique, the Integrated Gradients method15 is combined with Lucent objective30, and as shown in Fig. 5, biomarkers can be decoded at different levels of criticality to highlight the most determinant regions in the AD continuum prediction prioritized from the most specific to the most general.

Gaining insights into determinative biomarkers. The original CNN network is masked to include only a percentile of important neurons identified by LAVA, while Integrated Gradients computes the gradient of the model’s prediction output concerning its input features. The reconstructed pixels reflect the layout of biomarkers highly associated with the prediction of AD continuum progression. As the subnetwork becomes sparser for the most critical neurons, the reconstructed pixels reveal the most critical biomarkers effective in the diagnosis of each sub-cluster of the prediction.
Furthermore, we apply the prior technique in conjunction (and in comparison with) traditional attribution maps achieved by guided backpropagation31, to develop an effective method for searching relevant biomarkers at different scales. The guided backpropagation is repeated using the Noise Tunnel Algorithm32 averaging 10 times for robustness of relevance. To mimic a clinician’s diagnostic decision-making, we zoom into a \(70 \times 70\) crop of the image of highest feature attribution (see Fig. 6). Nevertheless, while the GBP visualization reveals where to place attention for clinical observers, a true understanding of visual biomarkers remains unclear and requires future research collaboration with domain experts in neuro-ophthalmology. For this reason, we hope that a combination of visual model interpretation and quantifiable morphological features can be used together for informed judgment.

Visualization of input features identified relevant to the prediction. The guided back-propagation method is employed to identify the region of interest. A sliding window is used to identify a crop of the image with the highest feature attribution. The reference fundus image (column 1) and the zoomed-crop (column 4) are shown for diagnostic visualisation that may help to explain the vascular biomarkers across the predicted continuum of AD progression.
Sanity check of the explanation
We evaluate the faithfulness of the LAVA in providing a true explanation of the model’s behaviors. We feed LAVA with a VGG-16 binary classifier where the parameters are randomized and examine how much the set of critical neurons in this model differs from that of the original model. We observe a significant change in the set of critical neurons identified by LAVA at each layer of the model after the weights of the network are replaced by random weights (Jaccard similarity index computed as at fc-3 layer is 0.008 and zero at every other layer). This suggests LAVA truly extracts neurons critical to the output of the model i.e., extracted neurons are correctly explaining the behavior of the network.
Discussion
We develop Granular Neuron-Level Explainer (LAVA), a novel explainability framework for AD classification from fundus imaging. Specifically, we equip a traditional VGG-16 CNN with a five-fold cross-validation binary classification accuracy of 75% with a neuron-level XAI framework to support the retinal vasculature as an efficient AD screening modality. Our explanations are generated through a two-phase procedure: (1) neuron probing and (2) granularity explanation. Notably, the utilization of a neuron-level-XAI model is valid, as the contribution of neurons is a better representation of the human imperceptible input features than the contribution of the raw input image pixels themselves29. The reason behind this argument is that the hidden (latent) variables constructed during the learning process by convolutional deep neural networks play a significant but underrated role in characterizing and fully describing the undergoing phenomenon in medical image processing.
Few prior studies using AI models have been approached using retinal fundus images9,10,11. However, these models do not consider the different stages of AD progression and thus do not offer a comprehensive evaluation of the risk severity. One of the primary contributions of this work is the projected inference of binary class labels (AD/NC) into latent sub-classes, which we claim to be indicative of the AD continuum. We support this argument through several approaches through comparisons of cognitive tests, morphological vascular features, and several visualization modules. The value of our findings is applicable in many biomedical applications to enhance the interpretation of classifier models, allowing enhanced diagnostic judgment and understanding of the underlying biological phenomena.
To demonstrate our claim of continuum assessment and allow various levels of enhanced interpretability, we compare the differences across cognitive level features (e.g., the pairs matching test, prospective memory, and fluid intelligence), morphological features (fractal dimension and vessel density), and visualization models. All designated cognitive and vascular measures are demonstrated to be reduced in the AD group compared to the normal controls at statistical significance (\(p < 0.01\)). We extend these differences from a group-level to a latent-sub-group level via visual gauge and radar plots to demonstrate a sequence of clusters, ranging from healthiest to strongest severity of AD. In particular, we are capable of arranging the latent-sub-groups identified by our LAVA framework into a seven-level continuum and designing a simplistic manner for assigning an AD-score to a subject. Guided backpropagation maps and critical neuron reconstruction techniques are used to determine diagnostic biomarkers, regions of interest, and differences amongst subgroups as deemed important by the model.
Although our study presents the ability to assess the AD continuum, the framework carries limitations. First, the amount of data is lacking, with only 100 images from 61 AD participants total, which hinders our model training and generalization to the real-world setting. Furthermore, we do not consider the effects of other confounding factors (demographics, genetics, etc.) or similarities in retinal biomarkers amongst other neurodegenerative diseases. While our work supports the reduction in cognitive performance and vessel structures6,33 in the retina, large individual variations between subjects could hinder the retina as a diagnostic site and need further validation. We also acknowledge the limitations of current cognitive variables and limited data assessing cognitive domains affected early and late in the disease like episodic memory and language. On the other hand, our XAI work supports clinical studies associating retinal degeneration to be linked to Alzheimer’s Disease, rather than normal aging, as well as connections with cerebral small vascular disease.
Overall, our study demonstrates an explainable and systematic framework to map subjects into the progression continuum of Alzheimer’s Disease using retinal vasculature from fundus images. Our method is effective in enhancing biological and diagnostic understanding and automating healthcare streamlining and preclinical screening. This study will help to examine how retinal pathology is connected to cognitive impairment neurodegeneration, with not only applications to AD but also other types of dementia and neurological/retinal diseases.
Methods
LAVA is a systematic method that leverages neuron-level explanation as auxiliary information during the learning process to predict coarse-to-fine class in a downstream classification task where only coarse-level target labels are available. In this section, the details of our proposed XAI framework are provided.
Neuron probing
In the first phase of the LAVA framework, we look to find a subset of critical neurons at each layer of the CNN model containing the most information concerning the prediction of class labels.
Let’s consider any CNNs classification model \(\Phi\) with a sequential structure consisting of L layers, where each layer l has \(K_{l}\) neurons and \(l=\{1,\ldots ,L\}\). Once any input sample \(x \in {\mathbb {R}}^n\) is fed into the model \(\Phi\) through the forwarding function \(y=f(x)\) where \(y \in {\mathbb {R}}^m\) is a logit, the activation of neurons at layer l denoted as \(Z_l\) is a random variable and also a function of the input \(Z_{l}=f_{l}(x)\) where \(f_l: {\mathbb {R}}^n\rightarrow {\mathbb {R}}^{k_l}\). The forwarding structure of the neural networks suggests the activation of neurons at each layer depends only on the activation of the neurons at the previous layer i.e., \(Z_l {\!\perp \!\!\!\perp } Z_i \vert Z_{l-1}, \forall i= 0,\ldots ,l-2\), where \({\!\perp \!\!\!\perp }\) denotes the independent relationship.
Our goal is to find a subset of critical neurons at each layer l containing the most information on the prediction of interest. Recently, the notion of criticality in neuron-level extraction and the objective of critical neurons identification subsequently is formulated with joint mutual-information (MI) function34 from probability and information theories35 to measure the mutual dependence between two variables.
Let \((Z_l,Z_{l+1})\) be two discrete random variables over the space \(\mathcal {Z}_l \times {\mathcal {Z}_{l+1}}\) to indicate activation of neurons for a pair of adjacent layers in CNN model. If \(P_{(Z_l,Z_{l+1})}\) denotes the joint distribution and \(P_{Z_l}\) and \(P_{Z_{l+1}}\) denote marginals, then the amount of information shared between those two adjacent layers can be measured by an MI objective that searches for the set of critical neurons at each layer on the set of critical neurons solved in the next layer34.
Thus, a sequence of MI objectives, starting from the last layer, can be optimized at any layer with respect to its preceding layer to identify the most critical neurons from each layer \(M_{l}\) through the network. This sparse sub-network of critical neurons conveys the most important information all the way from the input to the output of the model.
Directly solving Eq. (2) at each pair of adjacent layers in this sequential optimization formulation is in NP-hard36, because as proved in34, MIN-FEATURES37 problem can be reduced to this problem in polynomial time. On the other hand, the state of the Markov chain of L layers (\(Z_0\rightarrow Z_1\rightarrow \cdots \rightarrow Z_L\))38 suggests \(Z_l^{M_l}\) can determine Y, and consequently, \(M_l\) that contains \(M_l(Y)\). As a consequence, to overcome the the curse of dimensionality, an approximation solution can solve MI objective at each pair of a layer with the output \((Z_l^{M_l};Y )\) instead of solving that at each pair of adjacent layers \((Z_l^{M_l} ;Z_{l+1}^ {M_{l+1}})\) as follows:
The entropic (informational) correlation between a feature and class label in a high-dimensional scheme is a useful statistic measurement for feature selection. As the mutual information enlarges, the feature becomes more significant and distinguishable. Let \(z \in {Z_l}\) denote a feature (single neuron at layer l) and \(y \in Y\) denote a class of label, then the mutual information between them can be defined as follows:
where \(n=\{1,\ldots ,N\}\) and \(m=\{0,\ldots ,M\}\) are the number of different values for z and y respectively, \(p(z_i)\) and \(p(y_j)\) are marginals, and \(p(z_i,y_j)\) is the joint probability.
NeuCEPT34 uses Model-X Knockoffs as a statistical tool with false discovery rate control to approximate Markov Blanket39 as the smallest subset of neurons at each layer maximizing the MI; however, it imposes some limitations in our application: (1) The subtle differences among fundus images result in low variance in the distribution of neurons’ activation which makes it difficult for any neurons to be selected. (2) Selection of critical neurons from large-sized intermediate layers of our network is difficult due to the complexity of the matrix inversion operation involved. To overcome the aforementioned limitations, MI can be alternatively approximated using density estimates40 based on the Kernel Density Estimator (KDE)24 and thus Model-X Knockoffs can be replaced with any Maximum Likelihood Estimation (MLE)-based feature selection technique as an estimation of MI.
We adopt the same method used in41 for gene selection from expansive patterns of gene expression data in genetic diagnosis (or drug discovery) in LAVA to capture a very small and compact (non-redundant) multiset (i.e., an ensemble bag with repeated elements where multiplicity is allowed). of the most critical neurons at each selected layer through the network while evaluating the binary target labels (AD/NC) by cross-validation models in the different subsets of input images. This approach combines Epsilon Support Vector Regression with Recursive Feature Elimination algorithm (\(\epsilon\)-SVR+RFE) to satisfy the MLE objective in the selection of the critical neurons across all L layers each of \(K_l\)-dimensionality. Following the same objective of the Joint Mutual Information (MI) function, \(\epsilon\)-SVR42 maximizes likelihood estimation to identify critical neurons concerning the output of the model. More specifically, this feature scoring method constructs a coefficient vector with a logit link function and a regularized maximum likelihood score. Thus, as shown in43, this compact feature selection technique employed in LAVA assures that the neuron whose MI is larger is more likely to be selected as critical. In this technique, RFE is a wrapper-type statistical method that uses \(\epsilon\)-SVR algorithm in the core. It eliminates the least important features iteratively until the desired number of features is reached.
Epsilon-supported Support Vector Regression (\(\epsilon\)-SVR) attributes coefficients of contribution to each neuron under acceptable maximum error \(\epsilon\) (epsilon). First the activation value of M critical neurons at a selected layer for N sample inputs \(\{Z\}^{N \times M}\) maps in feature space \(U=\phi (Z\)), and then a hyperplane is constructed using a kernel function \(f(Z,W)=W^TZ+b\) that minimize its deviation from training data by minimizing the L2 norm of the coefficient vector \(\vert \vert W \vert \vert\). The setting of hyperparameters for \(\epsilon\)-SVR includes a kernel parameter (e.g, linear, sigmoid, radial basis function, and polynomial) and a regularization parameter. The latter is used to make a tradeoff between the complexity of the model and the accuracy of the training. The objective function of \(\epsilon\)-SVR is as follows:
constrained by \(\vert y_i - \sum _{j=1}^M w_j(z_{i,j})\vert \le \epsilon + \vert \xi _i \vert\).
Here \(w_j\) is the coefficient of the support vector in the decision function assigned to the j-th critical neuron and \(\epsilon\) denotes a margin for absolute distance value between actual and predicted values in the training loss function for which no penalty is associated. Penalties can be regularized by C as a measure of tolerance for the output of the i-th input sample to fall outside \(\xi _i\) deviation from true output variable \(y_i\) and still is acceptable within error margin \(\epsilon\). The implementation of \(\epsilon\)-SVR is from LIBSVM library44.
The results obtained by \(\epsilon\)-SVR+RFE feature selection technique at the Neuron Probing phase of the LAVA framework can be adjusted to the desired detail level that characterizes subpopulations within the target continuum. The pseudocode of this algorithm is provided in Supplementary Algorithm S1.
Granularity explanation
In the second phase of the LAVA framework, we search to answer this question“To what extent similarity between input samples in terms of the pattern of activation is consistent with that in terms of true labels in the multi-granularity deep local structure of the target domain?” To discern the division of AD subjects, our choice of agglomerative connectivity constraint clustering with ward’s linkage (also known as Minimum Variance) is rational to the intrinsic granularity of diagnostic biomarkers associated with the continuum of progressive nature of Alzheimer’s disease. We hypothesize that hierarchical representation levels hidden in the input image dataset can interpret biomedical features associated with progressive disease in this study. Although such artifacted dynamics biomarkers mapped to different levels of abstraction representation made by a convolutional deep neural model might not be visually descriptive and explicitly perceptible by humans.
We employ the Hierarchical Agglomerative Clustering (HAC) method with connectivity constraints (K-NNG graph)20 to partition entire eye fundus image samples into subgroups of data based on similar activation patterns of critical neurons during the evaluation of the image by the CNN model. The description and pseudocode of this algorithm are provided in Supplementary Algorithm S2 and Adjacency-constrained Hierarchical Agglomerative Clustering Supplementary Method S1.
The appropriate number of clusters can be visualized and heuristically determined on a hierarchical ward’s tree of the clustering learning process so-called dendrogram. The height of rectangles fit between different levels of hierarchy in the dendrogram representing the distinctiveness among clusters at that specific level. The number of vertical lines cut by an imaginary horizontal line traversing the dendrogram determines the corresponding number of clusters as a configurable parameter in the HAC learning algorithm.
Study population and baseline characteristics
This study is conducted on the UK Biobank. At the time of acquisition (Jun 2019) of our UKB basket, there are a total of 1005 AD subjects from approximately 500,000 total subjects. In particular, we investigate the incidence of AD, which is defined as subjects who are diagnosed with Alzheimer’s Disease after the baseline visit, in contrast to prevalent AD, which consists of subjects with a record of AD diagnosis before the baseline visit (as according to the UK public health records, ICD9 and ICD10 codes). From the 1005 AD subjects in the UKB, there are 111 AD subjects with fundus images. Next, we manually select an overall number of 100 images from 61 unique AD subjects images on the following criteria: (1) the incidence of AD, (2) sufficient visibility of the retinal vasculature in terms of the level of artifacts and clarity of the image, and (3) no record of other neurodegenerative diseases, excluding subjects with mixed dementia and/or forms of Parkinsonism. To prevent external bias in our analysis, we perform age and gender matching for each AD subject with one normal control (NC). We note that a normal control subject is taken with the understanding of no current label of dementia, regardless of whether a subject may be at risk, or develop dementia in the future. We identify 100 images from a total of 80 unique NC subjects, wherein an additional NC subject is substituted when the image quality for certain fundus image pairs for a matched AD subject is insufficient.
Supplementary Table S2 showcases the summary statistics of the study population including demographics (age, gender, and ethnicity), ophthalmic features, and covariates. The ophthalmic features include eye problems (e.g., glaucoma, cataratcs, etc.) and visual acuity (LogMAR). The covariates include townsend indices, obesity-diabetes status, smoking status, alcohol status, and history of stroke. Obesity-diabetes is defined as a BMI greater than 30 or a diagnosis of diabetes. All baseline characteristics are selected based on explored risk factors in AD studies45,46.
Data-preprocessing
A manual image quality selection is employed to ensure that each fundus image has sufficient retinal vascular visibility. We employ the AutoMorph pipeline for image pre-processing. In particular, the image undergoes thresh-holding, morphological image operations, and cropping to effectively remove the background of the fundus images. The images are passed into a Segan47 network for vessel segmentation pre-trained on a collection of labeled retinal vasculature datasets. The details of pre-training can be found in17. During the model training and evaluation of our classifiers, the vessel maps are resized to \(224 \times 224\) by ImageNet. The vascular morphological features are computed using the original image size.
Regarding the performance of AutoMorph pipeline, Bland-Altman plots in17 demonstrate an acceptable vascular feature agreement between expert annotation and AutoMorph segmentation. More specifically, they reported an intraclass-correlation coefficient (ICC) of 0.94 (0.88–0.97) and 0.94 (0.88–0.97) with a 95% confidence interval for the fractal dimension and vessel density respectively on the DR. HAGIS dataset.
Data partitioning, tuning, and evaluation
In the binary classification task, we apply nested subject-level stratified five-fold cross-validation. To avoid potential bias, each fold is split such that retinal images from the same subject all belong to the same fold and each fold is equivalent in number of images (n = 20 images). To optimize the performance of the model, we tune the hyper-parameters during training with a four-fold cross-validation loop and re-train the model over all training data with the best hyper-parameters. Our experiments suggest optimization over a small learning rate grid of [1e−4, 1e−5] and a maximal number of 50 epochs is sufficient. We use a cross-entropy loss, Adam optimizer48, and data augmentations (flipping and rotations) for fine-tuning an ImageNet pre-trained VGG-16 classifier18. The model is then re-trained over the optimal hyper-parameters using all of the training data and tested on the outer cross-validation fold.
Vascular morphological feature measurements
The AutoMorph pipeline is used to extract the vessel density and fractal dimension49 from the retinal vasculature. These measures are chosen based on hypothesized mechanisms concerning the reduction of vessel structures (e.g., small vessel disease) and structural complexity6,50,51. The vessel density is defined as the proportion of vessel pixels to the number of pixels in the image. The fractal dimension is defined here as the Minkowski-Bouligand dimension, also known as the box-counting dimension. Let X denote a (square) image, that is, the input vessel map. The Minkowski-Bouligand dimension is thus defined as follows:
Discretely, N is the input size of the image where \(\epsilon\) is taken such that the window size of the box is reduced by a factor of 2 until the window attains a box of the chosen size, \(16 \times 16\).
Cognitive tests
The UKB administers several cognitive tests for a subset of the UKB cohort27. The Pairs Matching Test (Field 399; Number of Incorrect Matches) contains a three-card and six-card variant. We select the six-card variant for analysis for simplicity, larger variance, as well as being used in other studies52. Moreover, we extract the prospective memory (Field 20018: Prospective Memory Result), and fluid intelligence (Field 20016: Fluid Intelligence Scores). Overall, these tests are chosen based on natural associations of reduction in AD subjects (symptomatic of the loss of memory and problem-solving) which have been investigated in prior clinical studies53,54. For the few subjects who do not have cognitive test measures, their values are interpolated using the average over their diagnostic class.
Participants
Participants with a clinical diagnosis of Alzheimer’s Disease (AD) are selected from the UK Biobank based on the availability and quality of the retinal vascular images. This study is approved by the ethics of the UK Biobank Ethics Advisory Committee (EAC) and the participants’ right to withdraw samples at any time. All patients gave written informed consent prior to participation.
Ethical approval
All methods in this study were conducted with the guidelines and regulations set forth by the UK Biobank and the associated research institutions.
Data availability
This research has been conducted using the UK Biobank Resource under application number 48388. The datasets are available to researchers through an open application via https://www.ukbiobank.ac.uk/register-apply/.
Code availability
The code related to the findings of this study is available for download at: https://github.com/NSH2022/LAVA..
References
Issue information. Alzheimers. Dement. 18(4), 545–550 (2022).
Aisen, P. S. et al. On the path to 2025: Understanding the Alzheimer’s disease continuum. Alzheimer’s Res. Ther. 9(1), 1–10 (2017).
Tábuas-Pereira, M., Baldeiras, I., Duro, D., Santiago, B., Ribeiro, M.H., Leitão, M.J., Oliveira, C., & Santana, I. Prognosis of early-onset vs. late-onset mild cognitive impairment: Comparison of conversion rates and its predictors. Geriatrics 1(2). https://doi.org/10.3390/geriatrics1020011 (2016).
Shi, H., Koronyo, Y., Rentsendorj, A., Fuchs, D.-T., Sheyn, J., Black, K.L., Mirzaei, N., & Koronyo-Hamaoui, M. Retinal vasculopathy in Alzheimer’s disease. Front. Neurosci. 1211 (2021).
Koronyo-Hamaoui, M. et al. Retinal vascular abnormalities and blood-retinal barrier breakdown in Alzheimer’s disease. Alzheimer’s Dementia 17, 056603 (2021).
Ong, Y.-T., Hilal, S. & Cheung, C.Y.-l., Xu, X., Chen, C., Venketasubramanian, N., Wong, T.Y., & Ikram, M.K. Retinal vascular fractals and cognitive impairment. Dementia Geriatr. Cogn. Disord. Extra4(2), 305–313 (2014).
Langella, S., Sadiq, M.U., Mucha, P.J., Giovanello, K.S., & Dayan, E. Lower functional hippocampal redundancy in mild cognitive impairment. Transl. Psychiatry11(61) (2021).
Zhang, Y., Wang, Y., Shi, C., Shen, M. & Lu, F. Advances in retina imaging as potential biomarkers for early diagnosis of Alzheimer’s disease. Transl. Neurodegen. 10(1), 1–9 (2021).
Wisely, C. E. et al. Convolutional neural network to identify symptomatic Alzheimer’s disease using multimodal retinal imaging. Br. J. Ophthalmol. 106(3), 388–395 (2022).
Tian, J. et al. Modular machine learning for Alzheimer’s disease classification from retinal vasculature. Nat. Sci. Rep. 11, 238. https://doi.org/10.1038/s41598-020-80312-2 (2021).
Zhang, Q. et al. Retinal imaging techniques based on machine learning models in recognition and prediction of mild cognitive impairment. Neuropsychiatr. Dis. Treat. 17, 3267–3281 (2021).
Simonyan, K., Vedaldi, A., & Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arxiv 2013. arXiv preprint arXiv:1312.6034 (2019).
Lundberg, S.M., & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 30 (2017).
Ribeiro, M.T., Singh, S., & Guestrin, C. “why should i trust you?”: Explaining the predictions of any classifier. In: NAACL 2016 (2016).
Sundararajan, M., Taly, A., & Yan, Q. Axiomatic attribution for deep networks. In International Conference on Machine Learning, pp. 3319–3328 (2017). PMLR
Sudlow, C. et al. Uk biobank: An open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 12(3), 1001779 (2015).
Zhou, Y. et al. Automorph: Automated retinal vascular morphology quantification via a deep learning pipeline. Transl. Vis. Sci. Technol. 11(7), 12–12 (2022).
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Frey, B. J. & Dueck, D. Clustering by passing messages between data points. Science 315, 972–976 (2007).
Ambroise, C., Dehman, A., Neuvial, P., Rigaill, G., Vialaneix, N.: Adjacency-constrained hierarchical clustering of a band similarity matrix with application to genomics. AMB 14 (2019).
Caliński, T. & Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 3(1), 1–27 (1974).
Nguyen, X.V., Epps, J., & Bailey, J. Information theoretic measures for clusterings comparison: is a correction for chance necessary? In: ICML ’09 (2009).
Van der Maaten, L., & Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res.9(11) (2008).
Chen, Y.-C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 1(1), 161–187 (2017).
Arthur, D., & Vassilvitskii, S. k-means++: The advantages of careful seeding. In: SODA ’07 (2007).
Comaniciu, D. & Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 24, 603–619 (2002).
Fawns-Ritchie, C., & Deary, I.J. Reliability and validity of the uk biobank cognitive tests. Am. J. Manag. Care15(4). https://doi.org/10.1371/journal.pone.0231627 (2020).
Spíndola, L. & Brucki, S. M. D. Prospective memory in Alzheimer’s disease and mild cognitive impairment. Dement. Neuropsychol. 5, 64–68 (2011).
Khakzar, A., Baselizadeh, S., Khanduja, S., Rupprecht, C., Kim, S.T., & Navab, N. Neural response interpretation through the lens of critical pathways. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 13523–13533 (2021).
Lucent. https://pypi.org/project/torch-lucent/. Accessed 2021-05-01.
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, pp. 618–626 (2017).
Smilkov, D., Thorat, N., Kim, B., Viégas, F.B., Wattenberg, M.: Smoothgrad: removing noise by adding noise. CoRR (2017). arXiv:1706.03825.
Luben, R. et al. Retinal fractal dimension in prevalent dementia: The alzeye study. Investig. Ophthalmol. Vis. Sci. 63(7), 244440–0119 (2022).
Vu, M.N., Nguyen, T.D., & Thai, M.T. Neucept: Locally discover neural networks’ mechanism via critical neurons identification with precision guarantee. arXiv preprint arXiv:2209.08448 (2022).
Cover, T. M. & Thomas, J. A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing) (Wiley-Interscience, USA, 2006).
Davies, S., & Russell, S. J. Np-completeness of searches for smallest possible feature sets. (1994)
Davies, S., & Russell, S. Np-completeness of searches for smallest possible feature sets. In AAAI Symposium on Intelligent Relevance, pp. 37–39 (1994). AAAI Press Menlo Park
Pearl, J. & Paz, A. Confounding equivalence in causal inference. J. Causal Inf. 2(1), 75–93 (2014).
Koller, D., & Friedman, N. Probabilistic Graphical Models: Principles and Techniques - Adaptive Computation and Machine Learning (The MIT Press, 2009).
Suzuki, T., Sugiyama, M., Sese, J., & Kanamori, T. Approximating mutual information by maximum likelihood density ratio estimation. In FSDM (2008).
Guyon, I., Weston, J., Barnhill, S. D. & Vapnik, V. N. Gene selection for cancer classification using support vector machines. Mach. Learn. 46, 389–422 (2004).
Platt, J., & Karampatziakis, N. Probabilistic outputs for svms and comparisons to regularized likelihood methods (2007).
Lin, X. et al. A support vector machine-recursive feature elimination feature selection method based on artificial contrast variables and mutual information. J. Chromatogr. B 910, 149–155 (2012).
Chang, C.-C. & Lin, C.-J. Libsvm: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 27–12727 (2011).
Gong, J., Harris, K., Peters, S. A. E., Woodward, M.: Sex differences in the association between major cardiovascular risk factors in midlife and dementia: A cohort study using data from the UK biobank. BMC Med.19(1) (2021). https://doi.org/10.1186/s12916-021-01980-z
Lumsden, A.L., Mulugeta, A., Zhou, A., & Hyppönen, E. Apolipoprotein e (APOE) genotype-associated disease risks: A phenome-wide, registry-based, case-control study utilising the UK biobank. eBioMedicine 59, 102954. https://doi.org/10.1016/j.ebiom.2020.102954 (2020).
Xue, Y., Xu, T., Zhang, H., Long, L. R. & Huang, X. Segan: Adversarial network with multi-scale l1 loss for medical image segmentation. Neuroinformatics 16(3), 383–392 (2018).
Kingma, D.P., & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Falconer, K. J. Cambridge Tracts in Mathematics: The Geometry of Fractal Sets Series Number 85 (Cambridge University Press, Cambridge, England, 2010).
Zhang, Y.S., Zhou, N., Knoll, B.M., Samra, S., Ward, M.R., Weintraub, S., & Fawzi, A.A.:Parafoveal vessel loss and correlation between peripapillary vessel density and cognitive performance in amnestic mild cognitive impairment and early Alzheimer’s disease on optical coherence tomography angiography. PloS One14(4). https://doi.org/10.1371/journal.pone.0214685 (2019).
Wardlaw, J. M., Sandercock, P. A., Dennis, M. S. & Starr, J. Is breakdown of the blood-brain barrier responsible for lacunar stroke, leukoaraiosis, and dementia?. Stroke 24(3), 806–812. https://doi.org/10.1161/01.STR.0000058480.77236.B3 (2014).
Lyall, D. M. et al. Cognitive test scores in uk biobank: Data reduction in 480,416 participants and longitudinal stability in 20,346 participants. PLoS ONE 11(4), 0154222 (2016).
Spíndola, L. & Brucki, S. M. D. Prospective memory in Alzheimer’s disease and mild cognitive impairment. Dement. Neuropsychol. 5, 64–68 (2011).
Raz, N. et al. Neuroanatomical correlates of fluid intelligence in healthy adults and persons with vascular risk factors. Cereb. Cortex 18(3), 718–726 (2008).
Acknowledgements
This material is based upon work supported by the National Science Foundation under Grant No. (NSF 2123809).
Author information
Authors and Affiliations
Contributions
N.Y., C.T., R.F., and M.T. conceptualized the manuscript and researched its contents. N.Y. developed the solution. N.Y. and C.T. developed the DL model. C.T., R.F., A.R.Z., and J.C. were involved in the quantitative analysis and evaluation of this study’s findings. All authors reviewed the manuscript and accepted the responsibility to submit it for publication.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yousefzadeh, N., Tran, C., Ramirez-Zamora, A. et al. Neuron-level explainable AI for Alzheimer’s Disease assessment from fundus images. Sci Rep 14, 7710 (2024). https://doi.org/10.1038/s41598-024-58121-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-58121-8
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
