
Abstract
Disulfidptosis, a new type of regulated cell death associated with the actin cytoskeleton, provides a new therapeutic tool for cancers. The direct relationship between disulfidptosis-related lncRNAs(DRLs) in liver hepatocellular carcinoma(HCC) remains unclear. We acquired transcriptomic data, corresponding clinical data, and tumor mutation data of HCC from the TCGA database. First of all, DRLs were determined through correlation analysis. Then, a prognostic model containing six DRLs was created by adopting univariate Cox regression, LASSO algorithm and multivariate Cox regression analysis. Based on the model, 424 HCC patients were divided into high- and low-risk groups. Next, we structured ROC curves and PCA through combining the model and clinical data. Enrichment analysis and immune infiltration analysis were adopted to further explore the relationship between the model and prognosis. In addition, we explored the relationship between the model and tumor mutation burden (TMB). There were significant differences between high- and low- risk groups, and patients in the high-risk group showed poor prognosis. Enrichment analysis suggested that metabolic progress was obviously different between the two groups. According to the analysis of immune infiltration, there were several differences in immune cells, function, and checkpoints. Patients with high-risk and high TMB demonstrated the least favorable prognosis. The two risk groups both manifested visiblly in chemotherapy drug sensitivity. To sum up, we set up a DRL-based signature and that may provide a predictable value for the prognosis and use of chemotherapy drugs for HCC patients.
Similar content being viewed by others


Introduction
Liver cancer is one of the most malignant cancers in the world and has an extremely poor prognosis. According to recent global cancer statistics, liver cancer ranks third in terms of cancer associated mortality, although it ranks only sixth in cancer related incidence1. Moreover, the number of deaths from liver cancer ranks second among all cancers in China2. Among all pathological types, HCC is the most predominant type. Surgical resection is the main treatment method for patients with early-stage disease. Without obvious symptoms, patients often become unsuitable for surgical treatment when first diagnosed with liver cancer. While interventional therapy (including transcatheter arterial chemoembolization (TACE), microwave ablation, and particle implantation), targeted therapy, and immunotherapy have been proven effective for most patients with advanced HCC, such methods can only prolong the survival period and the prognosis remains unsatisfactory in most cases3. Even though it is widely known that hepatitis B virus (HBV) is associated with HCC, hepatocarcinogenesis is a complex process in which many signal pathway transductions are altered4. Mutation is the most common molecular pathogenesis, which may lead to different types of treatments5.
Disulfidptosis, a novel metabolic-related regulated cell death (RCD), is of peculiar value in the area of cancer metabolic therapy6. High expression of solute carrier family 7 member 11 (SLC7A11) could result in the accumulation of cysteine which would contribute to disulfide stress in cell metabolism7. When anomalous disulfide bonds form between actin cytoskeleton proteins, a lack of glucose and high expression of SLC7A11 would cause the excessive accumulation of disulfides, which could eventually lead to cell shrinkage and death8. It is worth mentioning that disulfidptosis would not be suppressed by diverse kinds of cell death inhibitors, even though genes related to cell death had been knocked out9. Based on this discovery, disulfidptosis may serve as a novel measure for tumor treatment. A small portion of regulatory mechanisms had been identified recently9. However, further exploration and identification of disulfidptosis are urgently needed and it is necessary to discover the underlying mechanism.
Long noncoding RNAs (lncRNAs), a group of non-protein-coding transcripts with at least 200 nucleotides, are now well recognized to regulate energy metabolism in cancer10. An increasing number of studies have revealed that lncRNAs are closely associated with the occurrence and development of tumors and have a dual effect on promoting and inhibiting cancer11. For instance, downregulating the expression of LINC01060 could inhibit tumor growth and metastasis in osteosarcoma through PI3K/AKT signaling12. Similarly, silencing HOTAIR significantly reduces the migration ability of cells and induces cell apoptosis in cervical cancer13. Liu et al. found that LIN01268 can promote pancreatic cancer through PI3K/AKT aixs14. In human hepatocellular carcinoma, Guo et al. found the high expression of LNC02870 which could result in migration and invasion of cancer15. TPA has been shown to promote the progression of breast cancer via the TGF-β signaling pathway16.
In this study, we extracted transcriptome data of patients with HCC from The Cancer Genome Atlas (TCGA) database. We identified 746 lncRNAs that were significantly correlated with disulfdptosis-related genes (|Cor|> 0.4 and P < 0.001). Then, we constructed a prognostic model containing 6 disulfdptosis-related lncRNAs, including AC007406.2, AL049840.3, AC138696.2, MKLN1-AS, AC069307.1 and TMCC1-AS1. Subsequently, we investigated the predictive ability through combining the risk score and clinical data. We also evaluated the biological properties, immune infiltration, TMB, and drug responsiveness of the model. The aim of this study was to offer new perspectives and approaches for clinical immunotherapy and potential chemotherapeutic drugs for HCC.
Materials and methods
Data collection
Transcriptomic data, corresponding clinical data and simple nucleotide variation(SNV) of patients with HCC (374 tumor tissues and 50 normal tissues) from The Cancer Genome Atlas (TCGA) database (https://www.cancer.gov/). The Perl programming language (version 5.30.0.1) was used to arrange data including transcriptomic and clinical information for subsequent analysis.
Collection of the disulfdptosis-related genes and lncRNAs
The disulfdptosis-related genes list was gathered from the previous study of Liu and their colleagues17. Correlation analysis was used to assess the relationship between disulfdptosis-related genes and lncRNAs and Sankey diagram was plotted to visualize the results. The standards for the correaltion are |Cor|> 0.4 and P < 0.001.
Construction of the prognosis model
All patients were randomly separated into a training cohort and a test cohort at a ratio of 1:1. Univariate regression analysis was applied to screen genes associated with prognosis (P < 0.05). The least absolute shrinkage and selection operator (LASSO) and multivariate Cox regression were used to further filter the lncRNAs for model establishment. The final formula of the model was as follows.
Characterization of the model
Datas were classified by the median risk score threshold in train group as high- or low-risk groups. To estimate the predictive value of the model, we used a series of methods. The R packages "survminer" and "survival" were utilized to depict overall survival (OS) and progression-free survival (PFS). Scatter plots, risk curves, and heatmaps were portrayed to valuate the differences between high- and low-risk groups. Such methods were taken in the training cohort, test cohort and TCGA cohort.
Validation of the prognostic model
Univariate and multivariate Cox regression analyses were implemented to confirm the independence of the prognostic model with other clinical characteristics (age, gender, grade stage, Alpha-fetoprotein (AFP), Prothrombin Time (PT), Total Bilirubin (TB), Albumin (Alb), Platelet). Receiver operating characteristic (ROC) curves were drawn to evaluate the sensitivity and specificity of the prognostic model compared with other clinical characteristics. In addition, an external cohort from GEO database(https://www.ncbi.nlm.nih.gov/geo/) was used to validate the stability and generalization ability of the model.
PCA and nomogram construction
Principal component analysis (PCA) was applied to investigate whether the risk score could be a meaningful signature to classify patients. A nomogram was created through integrating the risk score and other prognostic characteristics to predict the 1-, 3- and 5-year OS of HCC patients by using the R package "regplot". Meanwhile, a calibration curve was made to examine whether the nomogram had a high accuracy of survival prediction.
Biological enrichment analysis
Genes which P < 0.05 and the false discovery rate (FDR) q < 0.05 would be set as differentially expressed genes. The Gene Ontology (GO) function18 and Kyoto Encyclopedia of Genes and Genomes (KEGG)19 were used to analyze the differential pathway enrichment according to differentially expressed genes through the "clusterProfiler" R package. In addition, gene set enrichment analysis (GSEA) was utilized to identify the primary pathways in the two groups20.
Immune infiltration of the model
The R package "GSEABase" was operated to find the differences between the high- and low- risk groups in immune function. Moreover, a histogram and a boxplot were drawn to visualize the differences in immune cell infiltration between the two groups.
Tumor mutation burden and chemotherapy drug sensitivity
We employed waterfall plots to investigate the discrepancies in tumor mutation burden (TMB) between the two groups. Furthermore, we identified mutant genes and types of mutations which were occurred most frequently. According to the TMB score we calculated, we used a survival curve to analysis the differences in prognosis between the high- and low- TMB groups. In addition, we incorporated the TMB score and risk score to analyze the survival conditions of the HCC patients.
For further exploration of the clinical value of the model and drug sensitivity prediction, "oncoPredict" package was operated to calculate chemotherapy drug sensitivity. We downloaded data from Drug Sensitivity in Cancer (GDSC) and combined the data with transcriptomics data to estimate the differences in sensitivity between the high- and low- risk groups.
Statistical analysis
All statistical analyses were performed using R 4.3.1 software and Perl packages were applied to deal with the data. Of all the processes, P < 0.05 was considered statistically significant.
Ethical approval and consent to participate
The study complied with the principles of the Declaration of Helsinki. Access to the de-identifed linked dataset was obtained from the TCGA databases in accordance with the database policy. For analyses of de-identifed data from the TCGA databases, institutional review board approval and informed consent were not required.
Results
The overall study progress is shown in Fig. 1.

The overall study progress.
Identification of disulfidptosis-related LncRNAs (DRLs) in HCC
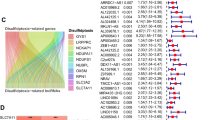
The genes GYS1, NDUFS1, OXSM, LRPPRC, NDUFA11, NUBPL, NCKAP1, RPN1, SLC3A2 and SLC7A11 were regarded as disulfdptosis-related genes according to pervious study. All the genes were highly expressed in tumor samples and except for the genes NDUFS1 and NUBPL, other genes showed apparent differences between the two groups (Fig. 2). A Sankey diagram was constructed to visualize the correlation between disulfdptosis-related genes and lncRNAs(Fig. 3a). As seen in the figure, NCKAP1 and GYS1 have the most connections with lncRNAs.

Differences in the expression of disulfdptosis-related genes between tumor tissues and normal tissues.

Identification of the signature of DRLs. (a) Sankey diagram of lncRNAs co-expressed with disulfdptosis-related genes. (b) Co-expression relationships between disulfdptosis-related lncRNA and disulfdptosis-related genes.
Prognostic model and characterization of model
After combining transcriptomic and clinical data from TCGA, we randomly divided the samples into training and validation groups at a ratio of 1:1 and there was no significant difference in clinical characteristics between the two groups (Table 1). 88 DRLs were screened by using univariate Cox regression analysis. After that, the LASSO regression analysis was applied to find candidate DRLs. Finally, 6 DRLs were filtered to construct a prognostic model, including AC007406.2, AL049840.3, AC138696.2, MKLN1-AS, AC069307.1 and TMCC1-AS1. Among all the genes, AC007406.2, AL049840.3, AC138696.2, MKLN1-AS and TMCC1-AS1 were considered as positive factors for prognosis while AC069307.1 was considered as negative factor. The calculation formula of risk score was as follows: Risk-Score = [Expression level of AC007406.2 ∗ (0.17) + Expression level of AL049840.3 ∗ (0.63) + Expression level of AC138696.2 ∗ (0.27) + Expression level of MKLN1-AS ∗ (0.74)- Expression level of AC069307.1 ∗ (0.80) + Expression level of TMCC1-AS1 ∗ (0.79)]. In addition, co-expression analysis was performed between disulfdptosis-related genes and DRLs and the results are shown in Fig. 3b. Based on the formula, we divided the patients into high- and low- risk groups by the median risk score threshold (The median risk score threshold was 0.834941555). We used several prognostic analyses to assess the predictive value of the model. According to the OS and PFS curves, we identified that patients in high-risk group had a worse prognosis than those in the low-risk group (Fig. 4a–c,g). Meanwhile, survival curves were used to evaluate the risk of death between the two groups (Fig. 4d–f). As shown in the figures, the high-risk group had a superior risk of death compared to the low-risk group.

Characterizations of the DRLs model. (a–c) The OS of TCGA cohort, the training cohort, and the test cohort. (d–f) Survival curves between high- and low- risk groups in TCGA cohort, the training cohort and the test cohort. (g) The PFS survival analysis in TCGA cohort.
Model predictive value assessment
By integrating clinical characteristics (including age, sex, tumor grade, tumor stage, AFP, TB, Alb, platelet and PT), we adopted univariate and multivariate Cox regression analyses to assess the independence of the model (Fig. 5a,b). The results suggested that risk score could serve as an independent prognostic factor in univariate Cox regression analysis and was also independent of other clinical traits according to multivariate Cox regression. Moreover, the ROC curve indicated that the model had a more accurate predictive ability than other clinical characteristics, with an area under curve (AUC) of 0.712 (Fig. 5c). As for the predictive value of survival, the AUCs of 1-year, 3-year and 5-year survival were 0.726, 0.712 and 0.738 (Fig. 5d). A c-index curve was plotted to further verify the predictive value, with c-index values greater than those of other traits (Fig. 5i). Furthermore, we drew a nomogram to provide a convenient and visualizable tool for prediction (Fig. 5j). With the growth of the nomscore, the survival rates of patients gradually decreased and the consistency of the predictions and actual measured results of the nomogram was validated by a calibration curve (Fig. 5k). Through dividing the clinical characteristics stage and the value of AFP into two groups, we found that whether in the early and advanced stage or low and high value of AFP, the low-risk group showed a better prognosis than high-risk group (Fig. 5e–h). As for the validation cohort, the AUC is 0.622 (Fig. 5l). The outcomes of PCA indicated that the DRL model had a better ability of risk cutoff compared with other gene sets (Fig. 6 a-d).

Validation of the disulfdptosis-related lncRNA signature. (a, b) Assessment of the independency of the model by univariate and multivariate Cox regression analyses (c) The AUC showed that risk score was an independent predictor compared with other clinical characteristics. (d) The predictive value in the OS of 1-, 3-, 5 years. (e, f) Survival curves of patients with early stage or advanced stage. (g, h) Survival curves of patients with Low and high value of AFP. (i) The C-Index of risk score was higher than other clinicopathological signatures. (j) The nomogram of DRLs model combined with other clinical features. (k) The calibration curve of the nomogram. (l) The ROC curve of validation cohort.

The outcomes of PCA in different gene sets.
Biological functional analysis
According to a standard of fdr < 0.5, we investigated the differentially expressed genes between high- and low- risk groups. We operated GO and KEGG analyses and the results revealed the genes were primarily enriched in organic anion transport and motor proteins (Fig. 7a–c). In addition, GSEA analysis showed that the genes in the high-risk group were enriched mainly in pentose and glucuronate interconversions and ascorbate and aldarate metabolism (Fig. 7d). While in the low-risk group, they were functionally enriched mainly in glycine and theronine metabolism and fatty acid metabolism (Fig. 7e).

GO, KEGG and GSEA analysis. (a) The circle diagram of GO analysis. (b) The bubble diagram of GO analysis. (c) The barplot diagram of KEGG analysis. (d) GSEA analysis of the high-risk group. (e) GSEA analysis of the low-risk group.
Immune cells infiltration analysis
Based on the TIME analysis, patients in high-risk group showed higher stromal and ESTIMATE scores than those in the low-risk group which indicating that tumor invasion and metastasis would be more likely to appear in the high-risk group(Fig. 8a).We evaluated the immune function between high- and low-risk groups and the results were presented in Fig. 8b. R package "Cibersoft" was used to analyze the difference in immune cell infiltration between two groups (Fig. 8c). The specific quantization of the difference was shown in Fig. 8d, suggesting that the low-risk group was enriched in several immune functions (B-cells, Neutrophils, NK-cells, T-helper cells, Type-I IFN response and Type-II IFN response) while the high-risk group was enriched mainly in MHC class-I and Macrophages.

Immune infiltration analysis of the signature. (a) Stromal, immune, and ESTIMATE scores comparison between high- and low-risk group. (b) Differences in immune function between high- and low-risk groups. (c) Differences in immune cells infiltration between high- and low-risk group. (d) The barplot of differences in immune function between high- and low-risk groups.
Tumor mutational burden
Of all the samples, 20 genes including TP53, CTNNB1, TNN, MUC16, ALB, PCLO et al. were mutated most frequently (Fig. 9a). We operated the same analysis in both training cohort and validation cohort (Fig. 9b,c). In addition, we conducted a correlation analysis among the genes which mutated most (Fig. 9d). As for the gene TP53, we drew a lollipop to explore the frequency of mutation, the genetic locus which mutated most and the type of mutations (Fig. 9e). Results showed TP53 had a probability of 29% to mutate and missense mutation was the type of mutation occurred most frequently. Moreover, of all the classifications of mutations, missense mutation occurred most often, and single nucleotide polymorphisms (SNVs) were the most frequent type. Among all the types of SNV, transitions occurred more frequently than transversions, and conversion of cytosine to thymine had the most frequent occurrence (Fig. 9f,g). To assess the predictive value of the TMB score, we plotted a survival curve and the results showed that patients with low-TMB would have a better prognosis (Fig. 9h). The same results appeared in the survival curve when incorporating TMB and risk score. The low-TMB and low-risk groups had the best prognosis among all the groups (Fig. 9i).

Relationship between DRLs model and tumor mutation burden. (a–c) Waterfall plots of somatic mutation characteristics in TCGA cohort, the training cohort and the test cohort. (d) Correlation analysis among the genes which mutated most. (e)The lollipop of gene TP53. (f, g) The identifications of the classifications of mutation. (h)The survival curve between high- and low-TMB groups. (i) K–M survival curves between the four groups.
Prediction of chemotherapy drug sensitivity
Chemotherapy is one of the most considerable treatments for patients with HCC. We calculated the sensitivity of a series of chemotherapy drugs in high- and low- risk groups by using GDSC database. According to the results, epirubicin, gemcitabine and oxaliplatin were more sensitive to patients in high-risk group while vinblastine, paclitaxel and 5-fluorouracil seemed to be sensitive to low-risk group patients (Fig. 10a–f).

Chemotherapy drug sensitivity prediction for DRLs model. (a–c) Drugs which were more sensitive to patients in high-risk group. (d–f) Drugs which were more sensitive to patients in low-risk group.
Discussion
Liver cancer had been a major public health problem for many years all over the worlds. There are a large number of patients with hepatitis B, which causes HCC most in China. In the past 10 to 20 years, more and more researches had focused on the mechanisms of cancer occurrence and development. Therefore, targeted therapy and immunotherapy had become increasingly important with the development of molecular biology. In recent years, several prognostic models based on autophagy-related genes21, ferroptosis-related genes22, cuproptosis-related genes23, pyroptosis-related genes24 have been constructed to predict the prognosis of different cancers. Not only mRNAs but also lncRNAs had been used to establish prognostic models for predicting prognosis25,26,27,28. Disulfidptosis is a novel type of cell death. Rather than other types of regulated cell death, disulfidptosis would not be suppressed by cell death inhibitors, which would provide a new thread for cancer therapy.
To the best of our knowledge, there is no research on constructing disulfdptosis-related lncRNAs in HCC at present. In the present study, we discovered 746 lncRNAs, which had apparently correlationships with disulfdptosis-related genes. After a series of processes of dimensionality reduction, 6 disulfdptosis-related lncRNAs had been screened to construct a prognostic model, including AC007406.2, AL049840.3, AC138696.2, MKLN1-AS, AC069307.1 and TMCC1-AS. The DRL prognostic model showed an excellent ability of prognosis prediction according to the C-index and ROC curves. Among the six lncRNAs, several genes have been identified to be associated with tumor progression. For example, MKLN1-AS is upregulated in HCC tissues and promotes the proliferation and epithelial-mesenchymal transition (EMT) of HCC29. Chen found that TMCC1-AS could promote cell proliferation and migration in HCC30. Both articles showed the same results as our study. On the basis of the algorithm of the model, the risk score was calculated to separate the patients into two groups and the low-risk group had a better prognosis according to the OS and PFS curves. Further validation was conducted to evaluate the accuracy, independence, sensitivity, and specificity of the model’s value of prediction. Independent prognostic analysis suggested that the model was an independent prognostic factor for HCC patients. The ROC and C-index curves identified that the accuracy, sensitivity and specificity of the model were superior to other clinical characteristics. Such results demonstrated that the model could be a novel method for prognostic prediction of HCC. The results of PCA showed that the model had an excellent ability to distinguish low- and high-risk patients. GSEA showed that in high-risk group, the genes were mainly enriched in glycometabolism steroid metabolism. While in the low-risk group, they were mainly enriched in amino acid metabolism and lipid metabolism.
The immune environment is of vital importance to the tumor microenvironment. Our findings revealed that the immune functions of high-risk group were enriched mainly in MHC class-I and Macrophages. As for the immune cells infiltration, there was a better enrichment of CD4 + T cells and CD8 + T cells in low-risk group and the results were the same as a previous study in which CD8 + T cells may be related to superior prognosis31.
TMB, which is related to immune checkpoint inhibitors (ICIs) and prognosis, has become more and more important for cancer therapy. Our study showed that there was no significant difference between high- and low-risk groups in TMB. However, by integrating TMB and risk-score, we found patients with low-TMB and low-risk had the best prognosis while the prognosis of patients with high-TMB and high-risk was worst. Gene TP53 showed the highest frequency of mutation in both groups, with a proportion of 29% of all the patients. TP53 was identified to be related to colorectal cancer liver metastasis32. Similarly, Tornesello33 found the mutation of TP53 could promote the progress of liver cancer. In addition, we calculated the sensitivity of several chemotherapy drugs. Epirubicin, gemcitabine, oxaliplatin, vinblastine, paclitaxel and 5-fluorouracil are common chemotherapy drugs for patients with HCC. In our study, we found epirubicin, gemcitabine and oxaliplatin were sensitive to patients in high-risk group and in contrast, vinblastine, paclitaxel and 5-fluorouracil were sensitive to patients in low-risk group.
There are several deficiencies that need to be mentioned. First, this study is theoretically feasible because we only analyzed the data from TCGA and we did not verify it in vivo or vitro. Second, disulfidptosis is a new type of RCD which means there are not enough researches on it and the biological significance of six long stranded non coding RNAs is not yet clear, and it is possible that they affect prognosis through a mechanism completely unrelated to disulfide deficiency. Therefore, the disulfidptosis-related we used may not contain all genes which would lead to imprecise results. Third, external validation may be taken to further evaluate the prognostic value of the 6-DRLs model. Thus, further studies and more experiments should be carried out to validate the model and biomarker.
Conclusion
We constructed a 6 disulfidptosis -related lncRNAs prognostic model and based on the model, we separated HCC patients into two groups. There were significant differences between two groups in survival outcomes. In addition, the independence, accuracy, and specificity of the model had been validated. In summary, this model could be a therapeutic biomarker for the treatment and prognosis of HCC patients.
Data availability
Data used to support the fndings of this study are available from the corresponding authors upon request.
References
Hyuna, S. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71, 209–249. https://doi.org/10.3322/caac.21660 (2021).
Zheng, R. S. et al. Cancer statistics in China, 2016. Zhonghua zhong liu za zhi [Chinese journal of oncology] 45(3), 212–220. https://doi.org/10.3760/CMA.J.CN112152-20220922-00647 (2023).
Alejandro, F., María, R. & Jordi, B. Hepatocellular carcinoma. Lancet 391, 1301–1314. https://doi.org/10.1016/S0140-6736(18)30010-2 (2018).
Farazi, P. A. & DePinho, R. A. Hepatocellular carcinoma pathogenesis: from genes to environment. Nat. Rev. Cancer 6, 674–687. https://doi.org/10.1038/nrc1934 (2006).
Villanueva, A., Newell, P., Chiang, D. Y., Friedman, S. L. & Llovet, J. M. Genomics and signaling pathways in hepatocellular carcinoma. Semin. Liver Dis. 27, 55–76. https://doi.org/10.1055/s-2006-960171 (2007).
Zheng, P., Zhou, C., Ding, Y. & Duan, S. Disulfidptosis: a new target for metabolic cancer therapy. J. Exp. Clin. Cancer Res. 42(1), 103. https://doi.org/10.1186/s13046-023-02675-4 (2023).
Koppula, P., Zhuang, L. & Gan, B. Cystine transporter SLC7A11/xCT in cancer: ferroptosis, nutrient dependency, and cancer therapy. Protein Cell 12(8), 599–620. https://doi.org/10.1007/s13238-020-00789-5 (2021).
Zheng, T., Liu, Q., Xing, F., Zeng, C. & Wang, W. Disulfidptosis: a new form of programmed cell death. J. Exp. Clin. Cancer Res. 42(1), 137. https://doi.org/10.1186/s13046-023-02712-2 (2023).
Liu, X. et al. Actin cytoskeleton vulnerability to disulfide stress mediates disulfidptosis. Nat. Cell Biol. 25(3), 404–414. https://doi.org/10.1038/s41556-023-01091-2 (2023).
Nair, L., Chung, H. & Basu, U. Regulation of long non-coding RNAs and genome dynamics by the RNA surveillance machinery. Nat. Rev. Mol. Cell Biol. 21(3), 123–136. https://doi.org/10.1038/s41580-019-0209-0 (2020).
Guttman, M. et al. Chromatin signature reveals over a thousand highly conserved large non-coding RNAs in mammals. Nature 458(7235), 223–227. https://doi.org/10.1038/nature07672 (2009).
Qiang, Z. et al. LINC01060 knockdown inhibits osteosarcoma cell malignant behaviors and tumor growth and metastasis in vivo through the PI3K/Akt signaling. Cancer Biol. Ther. 24(1), 2198904. https://doi.org/10.1080/15384047.2023.2198904 (2023).
Lei, S. et al. HOTAIR knockdown impairs metastasis of cervical cancer cells by down-regulating metastasis-related genes. J. Obstet. Gynaecol. 43, 2181060. https://doi.org/10.1080/01443615.2023.2181060 (2023).
Shanshan, L. et al. Exosomal lncRNA LINC01268 promotes pancreatic cancer progression via the miR-217-KIF2A-PI3K/AKT axis. Genes Dis. 10(5), 1799–1801. https://doi.org/10.1016/j.gendis.2022.12.018 (2023).
Mengya, G. et al. LINC02870 facilitates SNAIL translation to promote hepatocellular carcinoma progression. Mol. Cell Biochem. 478(9), 1899–1914. https://doi.org/10.1007/s11010-022-04575-1 (2023).
Qinglin, Li. et al. Study of lncRNA TPA in promoting invasion and metastasis of breast cancer mediated by TGF-β signaling pathway. Front. Cell Dev. Biol. 9, 688751. https://doi.org/10.3389/fcell.2021.688751 (2021).
Liu, X. et al. Actin cytoskeleton vulnerability to disulfide stress mediates disulfdptosis. Nat. Cell Biol. 25(3), 404–414. https://doi.org/10.1038/s41556-023-01091-2 (2023).
Jinhui, L. et al. Identification of a prognostic signature of epithelial ovarian cancer based on tumor immune microenvironment exploration. Genomics 112(6), 4827–4841. https://doi.org/10.1016/j.ygeno.2020.08.027 (2020).
Kanehisa, M., Sato, Y., Furumichi, M., Morishima, K. & Tanabe, M. New approach for understanding genome variations in KEGG. Nucleic Acids Res. 47(D1), D590–D595. https://doi.org/10.1093/nar/gky962 (2019).
Subramanian, A. et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl. Acad. Sci. USA 102(43), 15545–15550. https://doi.org/10.1073/pnas.0506580102 (2005).
Deli, M. et al. Autophagy-related genes prognosis signature as potential predictive markers for immunotherapy in hepatocellular carcinoma. PeerJ 8, e8383. https://doi.org/10.7717/peerj.8383 (2020).
Ying, G. et al. A ferroptosis-related lncRNAs signature predicts prognosis of colon adenocarcinoma. Life (Basel) 13(7), 1557. https://doi.org/10.3390/life13071557 (2023).
Fengjiao, He. et al. Identification and validation of a novel cuproptosis-related genes signature associated with prognosis, clinical implications and immunotherapy of hepatocellular carcinoma. Front. Pharmacol. 14, 1088993. https://doi.org/10.3389/fphar.2023.1088993 (2023).
Jingmin, Xu. et al. Constructing and validating a pyroptosis-related genes prognostic signature for stomach adenocarcinoma and immune infiltration: Potential biomarkers for predicting the overall survival. J. Oncol. 2022, 3102743. https://doi.org/10.1155/2022/3102743 (2022).
Yuan, Q. et al. Construction of a ferroptosis-related five-lncRNA signature for predicting prognosis and immune response in thyroid carcinoma. Cancer Cell Int. 22(1), 296. https://doi.org/10.1186/s12935-022-02674-z (2022).
Yang Liuqing, Yu. et al. Cuproptosis-related lncRNAs are biomarkers of prognosis and immune microenvironment in head and neck squamous cell carcinoma. Front. Genet. 13, 947551. https://doi.org/10.3389/fgene.2022.947551 (2022).
Xiaoying, Li., Feng, J. & Yang, Li. A novel autophagy-related lncRNA prognostic risk model for breast cancer. J. Cell Mol. Med. 25(1), 4–14. https://doi.org/10.1111/jcmm.15980 (2021).
Jinhui, L. et al. Pyroptosis-related lncRNAs are potential biomarkers for predicting prognoses and immune responses in patients with UCEC. Mol. Ther. Nucleic Acids 27, 1036–1055. https://doi.org/10.1016/j.omtn.2022.01.018 (2022).
Chao, G. et al. SOX9/MKLN1-AS axis induces hepatocellular carcinoma proliferation and epithelial-mesenchymal transition. Biochem. Genet. 60(6), 1914–1933. https://doi.org/10.1007/s10528-022-10196-6 (2022).
Chen Cheng, Su. et al. Long non-coding RNA TMCC1-AS1 predicts poor prognosis and accelerates epithelial-mesenchymal transition in liver cancer. Oncol. Lett. 22(5), 773. https://doi.org/10.3892/ol.2021.13034 (2021).
Stine, Z. E., Schug, Z. T., Salvino, J. M. & Dang, C. V. Targeting cancer metabolism in the era of precision oncology. Nat. Rev. Drug Discov. 21(2), 141–162. https://doi.org/10.1038/s41573-021-00339-6 (2022).
Wenjie, S. et al. TP53 mutation is enriched in colorectal cancer liver metastasis in the context of polyclonal seeding. Pathol. Res. Pract. 236, 153958. https://doi.org/10.1016/j.prp.2022.153958 (2022).
Lina, T. M. et al. Mutations in TP53, CTNNB1 and PIK3CA genes in hepatocellular carcinoma associated with hepatitis B and hepatitis C virus infections. Genomics 102(2), 74–83. https://doi.org/10.1016/j.ygeno.2013.04.001 (2013).
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Data collection was performed by Yi Li. and Shanshan Jiang. Data analysis were performed by Chao Chen.The first draft of the manuscript was written by Chen Chao. Chaoyang Wang. and Ningjun Yu. amended the manuscript and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript. Chao Chen, Chaoyang Wang, Yi Li, Shanshan Jiang, NingJun Yu. prepared Figs. 1–10 and Table 1. All authors have read the manuscript and agreed to publish.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, C., Wang, C., Li, Y. et al. Prognosis and chemotherapy drug sensitivity in liver hepatocellular carcinoma through a disulfidptosis-related lncRNA signature. Sci Rep 14, 7157 (2024). https://doi.org/10.1038/s41598-024-57954-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-57954-7
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
