
Abstract
Risk factors for pacemaker-induced cardiomyopathy (PICM) have been previously reported, including a high burden of right ventricular pacing, lower left ventricular ejection fraction, a wide QRS duration, and left bundle branch block before pacemaker implantation (PMI). However, predicting the development of PICM remains challenging. This study aimed to use a convolutional neural network (CNN) model, based on clinical findings before PMI, to predict the development of PICM. Out of a total of 561 patients with dual-chamber PMI, 165 (mean age 71.6 years, 89 men [53.9%]) who underwent echocardiography both before and after dual-chamber PMI were enrolled. During a mean follow-up period of 1.7 years, 47 patients developed PICM. A CNN algorithm for prediction of the development of PICM was constructed based on a dataset prior to PMI that included 31 variables such as age, sex, body mass index, left ventricular ejection fraction, left ventricular end-diastolic diameter, left ventricular end-systolic diameter, left atrial diameter, severity of mitral regurgitation, severity of tricuspid regurgitation, ischemic heart disease, diabetes mellitus, hypertension, heart failure, New York Heart Association class, atrial fibrillation, the etiology of bradycardia (sick sinus syndrome or atrioventricular block) , right ventricular (RV) lead tip position (apex, septum, left bundle, His bundle, RV outflow tract), left bundle branch block, QRS duration, white blood cell count, haemoglobin, platelet count, serum total protein, albumin, aspartate transaminase, alanine transaminase, estimated glomerular filtration rate, sodium, potassium, C-reactive protein, and brain natriuretic peptide. The accuracy, sensitivity, specificity, and area under the curve of the CNN model were 75.8%, 55.6%, 83.3% and 0.78 respectively. The CNN model could accurately predict the development of PICM using clinical findings before PMI. This model could be useful for screening patients at risk of developing PICM, ensuring timely upgrades to physiological pacing to avoid missing the optimal intervention window.
Similar content being viewed by others

Introduction
Pacemaker implantation (PMI) is an indispensable therapy for patients with sick sinus syndrome (SSS) and atrioventricular block (AVB)1, and the number of patients receiving PMI has been increasing, with approximately one million devices now being implanted annually worldwide2. PMI-related deterioration of left ventricular (LV) systolic function is known as pacemaker-induced cardiomyopathy (PICM)3. The following three definitions of PICM have been used in past clinical studies: (a) left ventricular ejection fraction (LVEF) ≤ 40% if the baseline value is ≥ 50% or an absolute reduction in LVEF ≥ 5% if the baseline value is < 50%; (b) LVEF ≤ 40% if the baseline value is ≥ 50% or an absolute reduction in LVEF ≥ 10% if the baseline value is < 50%; and (c) absolute reduction in LVEF ≥ 10% regardless of the baseline value4.
Previous studies have identified several risk factors for PICM, including older age5,6,7, male sex6, a history of ischemic heart disease (IHD)8,9, a history of atrial fibrillation (AF)5,10, a history of chronic kidney disease9, lower baseline LVEF11,12, wider intrinsic QRS duration6,13, left bundle branch block (LBBB)8, and a chronic higher right ventricular (RV) pacing burden14. Upgrade to cardiac resynchronization therapy is often required in patients with PICM15. However, predicting the development of PICM is still challenging because the risk factors for PICM have not been well established3. Recently, machine learning techniques have been used increasingly in the medical field and are considered useful tools in daily practice. The aim of the present study was to develop a CNN that can predict the development of PICM before PMI using clinical findings prior to PMI.
Methods
Definition of PICM
PICM was defined based on previous reports as follows: (a) exclusion of an alternative cause of cardiomyopathy, such as de novo myocardial ischemia, uncontrollable tachyarrhythmia, frequent premature contractions, or untreated hypertension; and (b) a > 10% reduction in LVEF measured by transthoracic echocardiography (TTE) after PMI. The patients underwent TTE within the 6 months before PMI and between 3 months and 3 years after PMI.
Data collection and study population
All data were retrospectively collected for the 561 patients identified to have undergone primary PMI for SSS or AVB at the University of Tokyo Hospital, Japan, between November 2006 and December 2021. The study inclusion criteria were as follows: age 20 years or over; primary PMI; and TTE data available both before and after PMI. The following exclusion criteria were applied: younger than 20 years; previous placement of a cardiac implantable electrical device; missing echocardiography data before and/or after PMI; history of heart transplantation; congenital heart disease; and an alternative cause of reduction in LVEF, such as de novo myocardial ischemia, uncontrollable tachyarrhythmia and frequent premature contractions, or untreated hypertension. Details of medical history and clinical data were retrospectively collected from all patients to identify variables that could predict the development of PICM. Their laboratory data were also obtained on admission to our hospital, and the results of follow-up TTE performed in the outpatient department.
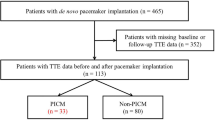
The clinical data for 165 patients (with PICM, n = 47; without PICM, n = 118) were divided into a training dataset (n = 99, 60%), a validation dataset (n = 33, 20%) and a test dataset (n = 33, 20%). The process used to collect the data for the study population is described in Fig. 1. Furthermore, due to the relatively small number of PICM patients in this study, we expanded the data using the Synthetic Minority Oversampling Technique (SMOTE) to ensure that PICM patients represented 50% of the total patient population.

Flow chart showing the process used to collect data for the study population. The study investigated patients who underwent primary pacemaker implantation between December 2006 and December 2021. A total of 165 patients who met the criteria were enrolled in the study. PMI, pacemaker implantation; TTE, transthoracic echocardiogram; PICM, pacing-induced cardiomyopathy.
Definition of clinical variables and creation of the dataset
The clinical data included the following variables: age, sex, body mass index (BMI), LVEF, left ventricular end-diastolic diameter (LVEDd), left ventricular end-systolic diameter (LVEDs), left atrial diameter (LAD), and severity of mitral and tricuspid regurgitation (MR and TR, respectively; classified into trivial, mild, moderate, or severe by TTE before PMI), history of ischaemic heart disease (IHD, diagnosed by angiography or scintigraphy), diabetes mellitus (DM, defined as use of oral hypoglycaemic agents or insulin or a glycosylated haemoglobin of ≥ 6.5%), hypertension (HT, defined as use of antihypertensive agents, systolic blood pressure ≥ 140 mmHg, or diastolic blood pressure ≥ 90 mmHg), and heart failure (HF, defined as New York Heart Association [NYHA] class ≥ 2), NYHA class (categorized based on symptoms and assessment of the medical examination on admission by the cardiologists), history of AF (diagnosed by electrocardiogram), SSS or AVB (binodal disease was included in AVB), presenting with LBBB, QRS duration on electrocardiogram, RV lead tip position (divided into apex and non-apex), and laboratory data. The laboratory data included the following parameters: white blood cell count (WBC), haemoglobin (Hb), platelet count (Plt), serum total protein (TP), albumin (Alb), aspartate transaminase (AST), alanine transaminase (ALT), estimated glomerular filtration rate (eGFR, calculated as: 194 × (serum creatinine)−1.094 × (age)−0.287 × [0.739 for female patients]16), sodium (Na), potassium (K), C-reactive protein (CRP), and brain natriuretic peptide (BNP). NYHA class and severity of MR and TR ware treated as ordinal numeric variables.
Three convolutional neural network (CNN) model were constructed for predicting the development of PICM. Dataset 1 included the following 31 variables: age, sex, BMI, LVEF, LVEDd, LVEDs, LAD, severity of MR and TR, history of IHD, DM, HT, and HF, NYHA class, history of AF, the etiology of bradycardia (sick sinus syndrome [SSS] or atrioventricular block [AVB]), presenting with LBBB, QRS duration, RV lead tip position, WBC, Hb, Plt, TP, Alb, AST, ALT, eGFR, Na, K, CRP, and BNP. Dataset 2 included the following 10 variables: age, sex, BMI, LVEF, severity of TR, history of IHD, NYHA class, the etiology of bradycardia, eGFR, and CRP. Dataset 3 included the following 11 variables: age, sex, BMI, LVEF, severity of TR, history of IHD, NYHA class, the etiology of bradycardia, RV lead tip position, eGFR, and CRP (Table 1). Three CNN models (Model 1, 2, and 3) were made based on these datasets, respectively.
Architecture of the CNN model
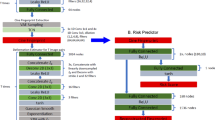
We employed Python programming language and the Neural Network Console provided by Sony Corporation (Minato, Tokyo, Japan) for the construction of the Convolutional Neural Network (CNN) model. A graphic representation of the architecture is shown in Fig. 2. The k-fold cross validation method was used to improve the evaluation of CNN model, and k = 4 in this setting (Fig. 3).

Neural network configuration. Construction of the convolutional neural network (CNN) consisted of the following layers: Input, Convolutional, Rectified Linear Unit (ReLU), Pooling, Fully Connected (Affine), Softmax, and Categorical Cross-Entropy. BMI, body mass index; BNP, brain natriuretic peptide; PICM, pacing-induced cardiomyopathy.

k-fold cross-validation. To mitigate overfitting, we designed a model that minimized the number of explanatory variables (regularization) and implemented k-fold cross-validation. We initially divided the training data into four subsets, conducting fourfold cross-validation. Each subset was used alternately as validation data, with the rest for training the model. This cycle was repeated to identify the training iteration count that minimized average loss across four trials. Using this optimal training iteration count, we retrained on the full training dataset and ultimately assessed the model's performance with test data.
Evaluation
To evaluate the CNN model, the number of true positive, true negative, false positive, and false negative results were counted, and accuracy, sensitivity and specificity were calculated. Sensitivity and specificity were calculated according to “the closest-to-(0, 1) criterion”17. The predictive ability of the CNN model was evaluated using receiver-operating characteristic curve (ROC) analysis and the area under the curve (AUC). The 95% confidence intervals (95% CI) of AUCs were described. The Net Reclassification Improvement (NRI) metric was employed to assess the predictive ability of the three CNN models. To evaluate the contribution of variables in predicting PICM onset in three CNN models, we calculated the SHAP (SHapley Additive exPlanations) values for each variable.
Statistical analysis
The patients were divided into a PICM group and a non-PICM group based on the previously described definition of PICM. Differences in baseline characteristics between the two groups were compared using Student’s t-test for continuous variables and the chi-squared test for categorical variables. DeLong's test was employed to compare the areas AUCs of three CNN models. All statistical analyses were performed using SPSS version 28.0 (IBM Corp., Armonk, NY, USA). A two-tailed P value < 0.05 was considered statistically significant.
Ethical approval
This study was approved by the University of Tokyo institutional ethics committee (approval number 2650-13). For the retrospective cohort, all patient information was deidentified and the requirement for written informed consent was waived by the University of Tokyo institutional ethics committee. The study protocol was conducted in accordance with the Declaration of Helsinki.
Results
Characteristics of the study population
One hundred and sixty-five patients (89 men, 53.9%) who underwent primary PMI and had both pre-PMI and post-PMI TTE data available were enrolled in the study. During a mean follow-up of 1.7 ± 1.1 years, 47 patients (28.5%) developed PICM. The patient characteristics are shown in Table 2. Information on NYHA class, severity of MR/TR, and RV lead tip position are summarized in Supplementary Table S1. Patients who developed PICM had a significantly higher preimplantation LVEF (68.7 ± 13.3% vs. 63.5 ± 11.0%, P = 0.01) and were significantly more likely to have a history of IHD (51.1% vs. 28.0%, P < 0.01) and a lower eGFR (47.9 ± 24.7 mL/min/1.73 m2 vs. 61.8 ± 24.5 mL/min/1.73 m2, P < 0.01). There were no other statistically significant differences in variables between patients with and without PICM.
No statistically significant difference in baseline characteristics was detected among patients in the training, validation, and test datasets (Supplementary Table S2). Moreover, there were no statistically significant differences between the four-fold cross-validation datasets and the test dataset (Supplementary Table S3).
Evaluation of the machine learning model for predicting the development of PICM
The accuracy, sensitivity, and specificity of each model are shown in Table 3. Receiver-operating characteristic curves are shown in Fig. 4, and the area under the curve for each model was 0.78 (0.59–0.95), 0.66 (0.45–0.86), and 0.62 (0.36–0.86), respectively. The variables selected to construct each three model and SHAP value of these are shown in Supplemental Figure S1. Based on the SHAP values, variables such as the etiology of bradycardia, eGFR and IHD were more important for predicting the onset of PICM in all CNN models. Conversely, factors previously identified as risk factors for the onset of PICM in cohort studies, such as LVEF, LBBB, and QRS duration, did not contribute significantly to Model 1, which demonstrated the highest accuracy in predicting the onset of PICM.

Receiver-operating characteristic curves for three models. A receiver-operating characteristic curve connects coordinate points with the false positive rate (1—specificity) on the x-axis and sensitivity on the y-axis, calculated from the test results at various cut-off values. Among the three models, Model 1 achieved the highest accuracy, with an AUC of 0.78. AUC, area under the curve.
Discussion
In this study, the prevalence of the development of PICM was consistent with that previously reported18. We developed a CNN for prediction of PICM using three types of datasets as described in Table 1. Variables in Dataset 1 included factors previously reported as risk factors for the onset of PICM5,6,7,8,9,10,11,12,14. Among the three models evaluated, Model 1, which incorporated the largest number of these variables, achieved the highest specificity.
In our study, our CNN algorithm exclusively employed numerical data as a contributing factor and did not incorporate image information. Consequently, there are situations where classical machine learning methods could offer certain advantages. Nevertheless, in our pursuit of greater precision, we selected to implement a CNN model. We conducted a comparative analysis with classical machine learning models, and the CNN model consistently demonstrated the highest accuracy. These results are presented in Table S4 within the Supplemental Data.
The variables used to construct Model 1, which showed the highest accuracy of all the models, are obtainable in daily practice. The CNN we have developed enabled us to predict the risk of PICM with some clinical information available before PMI, making it feasible for clinical practice. This CNN model has the potential to assist in identifying patients with PMI who require more intensive management, ensuring that timely upgrades to biventricular pacing/defibrillation systems are not overlooked.
However, this study suggests that although models incorporating multiple variables tend to yield higher prediction accuracy, obtaining comprehensive clinical information can be challenging in daily practice. Given this context, there is a need for predicting PICM using minimal clinical information. In this research, due to the limited patient sample size, the model encompassing the greatest number of variables demonstrated superior accuracy. Nonetheless, with an increase in patient numbers, it may become feasible to refine the model, potentially altering the significance of each variable. This could ultimately lead to a reduction in the required parameters, thereby facilitating the development of a more adaptable CNN model.
Our created model has a relatively lower sensitivity in diagnosing PICM, but the specificity is relatively high at 83.3%. In the context of predicting the onset of a condition, this specificity is not necessarily low. For instance, recently, other deep learning models predicting the onset of AF from electrocardiogram data have reported accuracies with AUC values ranging from 0.71 to 0.8219, and the best AUC in our study of 0.78 was comparable. Furthermore, it is important to consider that the role of our artificial intelligence (AI) model is not to identify patients who could develop the condition from the general population, but rather to differentiate patients at a lower risk of developing PICM. This is especially relevant for patients with implanted pacemakers who generally have normal cardiac function and primarily require periodic pacemaker interrogations. For these patients, if the AI assesses them as having a lower risk of developing PICM, their routine pacemaker check-ups will be continued as usual. On the other hands, for other patients, conducting regular examination, including consultations and TTE, annually or biannually can be recommended. This approach could encourage to eliminate unnecessary tests, while effectively identifying high-risk patients.
This study had several limitations. First, it was a retrospective analysis conducted at a single tertiary care centre, which may limit the generalizability of its findings. Some biases such as selection bias and observer bias should be considered. Some patients with PMI were excluded due to unmatched to inclusion criteria. Moreover, inter- and intra-observer variabilities in TTE were not assessed. Consequently, it remains unclear these variabilities could have influenced the results. Second, the procedural protocol for RV lead placement in our study was not standardized; that is, various pacing sites were used because of the recent prevailing conduction system pacing strategies. Therefore, further studies that include larger sample sizes and in-depth clinical studies are needed to improve the accuracy and confirm the feasibility of our CNN model. Finally, although our CNN model predicts for the occurrence of PICM based on pre-implantation information, our model is uncapable to predict the time of onset for the development of PICM. Previous reports on the occurring PICM ranges from 1 month20 to 16.9 years6 after PMI, showing significant variation, and there is currently no clear consensus of its onset. Therefore, it is challenging to determine when and how often postoperative TTE should be performed. In some patients, PICM may develop a long time after PMI, thus it is recommended to conduct regular examinations every six months to a year. The development of AI models capable of predicting the probability and time of PICM occurrence in patients with pacemaker could enable more accurate screening for those requiring regular examination.
In conclusion, we have demonstrated the potential of utilizing a CNN with available clinical information to predict development of PICM before PMI. Clinicians in daily practice can utilize a CNN to identify patients who are at risk of developing PICM, which has the potential to prevent overlooking timely upgrades to biventricular pacing systems.
Data availability
The datasets generated and analyzed during the current study are not publicly available due to privacy reasons but are available from the corresponding author on reasonable request.
References
Epstein, A. E. et al. 2012 ACCF/AHA/HRS focused update incorporated into the ACCF/AHA/HRS 2008 guidelines for device-based therapy of cardiac rhythm abnormalities: A report of the American College of Cardiology Foundation/American Heart Association Task Force on Practice Guidelines and the Heart Rhythm Society. J. Am. Coll. Cardiol. 61, e6-75. https://doi.org/10.1016/j.jacc.2012.11.007 (2013).
Mond, H. G. & Proclemer, A. The 11th world survey of cardiac pacing and implantable cardioverter-defibrillators: Calendar year 2009–a World Society of Arrhythmia’s project. Pacing Clin. Electrophysiol. 34, 1013–1027. https://doi.org/10.1111/j.1540-8159.2011.03150.x (2011).
Merchant, F. M. & Mittal, S. Pacing induced cardiomyopathy. J. Cardiovasc. Electrophysiol. 31, 286–292. https://doi.org/10.1111/jce.14277 (2020).
Kaye, G. et al. The prevalence of pacing-induced cardiomyopathy (PICM) in patients with long term right ventricular pacing—Is it a matter of definition?. Heart Lung Circ. 28, 1027–1033. https://doi.org/10.1016/j.hlc.2018.05.196 (2019).
Merchant, F. M. & Mittal, S. Pacing-induced cardiomyopathy. Card. Electrophysiol. Clin. 10, 437–445. https://doi.org/10.1016/j.ccep.2018.05.005 (2018).
Khurshid, S. et al. Incidence and predictors of right ventricular pacing-induced cardiomyopathy. Heart Rhythm. 11, 1619–1625. https://doi.org/10.1016/j.hrthm.2014.05.040 (2014).
Lee, S. A. et al. Paced QRS duration and myocardial scar amount: Predictors of long-term outcome of right ventricular apical pacing. Heart Vessels. 31, 1131–1139. https://doi.org/10.1007/s00380-015-0707-8 (2016).
Cho, S. W. et al. Clinical features, predictors, and long-term prognosis of pacing-induced cardiomyopathy. Eur. J. Heart Fail. 21, 643–651. https://doi.org/10.1002/ejhf.1427 (2019).
Oida, M. et al. The estimated glomerular filtration rate predicts pacemaker-induced cardiomyopathy. Sci. Rep. 13, 16514. https://doi.org/10.1038/s41598-023-43953-7 (2023).
Merchant, F. M. et al. Incidence and time course for developing heart failure with high-burden right ventricular pacing. Circ. Cardiovasc. Qual. Outcomes https://doi.org/10.1161/circoutcomes.117.003564 (2017).
Sharma, A. D. et al. Percent right ventricular pacing predicts outcomes in the DAVID trial. Heart Rhythm. 2, 830–834. https://doi.org/10.1016/j.hrthm.2005.05.015 (2005).
Curtis, A. B. et al. Improvement in clinical outcomes with biventricular versus right ventricular pacing: The BLOCK HF study. J. Am. Coll. Cardiol. 67, 2148–2157. https://doi.org/10.1016/j.jacc.2016.02.051 (2016).
Kim, J. H. et al. Major determinant of the occurrence of pacing-induced cardiomyopathy in complete atrioventricular block: A multicentre, retrospective analysis over a 15-year period in South Korea. BMJ Open 8, e019048. https://doi.org/10.1136/bmjopen-2017-019048 (2018).
Kiehl, E. L. et al. Incidence and predictors of right ventricular pacing-induced cardiomyopathy in patients with complete atrioventricular block and preserved left ventricular systolic function. Heart Rhythm. 13, 2272–2278. https://doi.org/10.1016/j.hrthm.2016.09.027 (2016).
Glikson, M. et al. 2021 ESC Guidelines on cardiac pacing and cardiac resynchronization therapy. Eur. Heart J. 42, 3427–3520. https://doi.org/10.1093/eurheartj/ehab364 (2021).
Matsuo, S. et al. Revised equations for estimated GFR from serum creatinine in Japan. Am. J. Kidney Dis. 53, 982–992. https://doi.org/10.1053/j.ajkd.2008.12.034 (2009).
Perkins, N. J. & Schisterman, E. F. The inconsistency of “optimal” cutpoints obtained using two criteria based on the receiver operating characteristic curve. Am. J. Epidemiol. 163, 670–675. https://doi.org/10.1093/aje/kwj063 (2006).
Abbas, J. et al. Incidence and predictors of pacemaker-induced cardiomyopathy with right ventricular pacing: a systematic review. Expert Rev. Cardiovasc. Ther. https://doi.org/10.1080/14779072.2022.2062323 (2022).
Khurshid, S. et al. ECG-based deep learning and clinical risk factors to predict atrial fibrillation. Circulation 145, 122–133. https://doi.org/10.1161/circulationaha.121.057480 (2022).
Li, D. L., Yoneda, Z. T., Issa, T. Z., Shoemaker, M. B. & Montgomery, J. A. Prevalence and predictors of pacing-induced cardiomyopathy in young adult patients (< 60 years) with pacemakers. J. Cardiovasc. Electrophysiol. 32, 1961–1968. https://doi.org/10.1111/jce.15029 (2021).
Author information
Authors and Affiliations
Contributions
M.O. contributed to the study design, data collection, data analysis and interpretation, and manuscript writing. E.H. and K.F. contributed to the data interpretation and writing of the manuscript. T.O., T.M., and Y.S. contributed to data collection. I.K was the senior supervisor on the study. All authors take responsibility for all aspects of the reliability and interpretation of the results as discussed.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Oida, M., Mizutani, T., Hasumi, E. et al. Prediction of pacemaker-induced cardiomyopathy using a convolutional neural network based on clinical findings prior to pacemaker implantation. Sci Rep 14, 6916 (2024). https://doi.org/10.1038/s41598-024-57418-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-57418-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
