
Abstract
The reference evapotranspiration (ETo) is an essential component in hydrological and ecological processes. The objective of this research is to develop an explicit model to estimate ETo only using commonly measurable meteorological parameters such as relative humidity, air temperature, and wind speed, where the measurements corresponding to solar radiation are omitted. The model was generated using Genetic Programming (GP), evaluated, and validated with reference data ETo using FAO56-PM. This reference data was obtained from different climates (warm-temperate and arid-warm) and latitudes, acquired from CIMIS stations in the state of California, United States, and the El Porvenir station in the state of Coahuila, located in north-central Mexico. After applying the proposed methodology, a total of 3754 results were generated, demonstrating a significant improvement in the estimation of ETo compared to the Hargreaves–Samani model. A particularly noteworthy result revealed that our approach outperformed the Hargreaves–Samani model in the training phase by 27%, and in the testing phase by 16%, on average. In order to achieve a generalized model, a dataset encompassing meteorological stations in two different climates (warm-temperate and arid-warm) and various latitudes was utilized. The obtained outcome unveiled a highly effective model for estimating ETo in diverse climatic contexts, eliminating the need for local adjustments. This model significantly surpassed the Hargreaves–Samani model, exhibiting superior performance by 17% during the training phase and 18% during the testing phase. These results conclusively underscore the capability of our approach to provide more accurate and reliable ETo estimates. These results conclusively underscore the capability of our approach to provide more accurate and reliable ETo estimates. Finally, to validate the model, four different datasets with climates similar to those used for model creation (warm-temperate, warm-arid) and different latitudes were employed. The validation stage results clearly indicate the superiority of our reference evapotranspiration ETo11 model over the Hargreaves–Samani model by 51% in warm-temperate climates. For the dataset with arid-warm climate, our model continued to show satisfactory results, surpassing the Hargreaves–Samani model by 8%. GP emerges as an innovative and effective alternative for simplified model development. This approach introduces a novel paradigm that facilitates the efficient development of models, standing out for its simplicity and effectiveness in generating solutions.
Similar content being viewed by others

Introduction
Evapotranspiration (ET) is the combination of two separate processes, the first of which is the loss of water from the soil surface by evaporation and the second of which is crop transpiration. Evaporation and transpiration occur simultaneously, and there is no easy way to distinguish between these two phenomena. Since ET represents a vital component of the hydrological cycle, its precise estimation is necessary for the management of water resources, the hydrological balance of basins, and drainage system irrigation. The main climatic parameters that affect ET are solar radiation, temperature of the air, relative humidity, and wind speed.
In 1921, Cummings introduced an initial energy balance equation, which was later integrated by Penman in 1948 with a mass-transfer equation grounded in Dalton’s research, culminating in the formulation of the Penman equation. A crucial parameter in this equation was the Bowen ratio, first published in 1926. Subsequently, following Penman’s contributions, another significant advancement occurred in 1965 by Monteith. He refined Penman’s equation initially designed for a single leaf, giving rise to the Penman–Monteith model. This model, serving as the foundation for the FAO56-PM Reference Crop model, marked a pivotal milestone in the evolution of evaporation estimation techniques. McMahon and his collaborators provide a crucial discussion on the theory and fundamental definitions, along with a critical assessment of the models developed to date1.
The rate of evapotranspiration from a surface of reference, occurring without water constraints, is known as evapotranspiration of the reference crop, called ETo2.
However, it has significant limitations. Primarily, it requires a substantial amount of detailed data to obtain reliable results, which can be a challenge in situations of irregular data availability3. Additionally, the implementation of the model can be intricate, especially regarding the calculation of surface resistance, as indicated by previous studies4. These identified limitations underscore the imperative need to develop alternative models that streamline data collection and reduce computational complexity. On the other hand, the FAO recommends the Hargreaves–Samani model for places where only temperature data are available. Although it is true that the model only works with temperature differences, the calculation of daily ETo could be subject to errors due to the influence of the temperature range5.
A study conducted by6 provides a solution to the issue of the Hargreaves model by proposing an adjustment to suit the specific characteristics of semi-arid climates, typically Mediterranean, characterized by extremely hot and dry summers. This modification aims to enhance the accuracy of the original model by more appropriately accounting for the climatic peculiarities inherent in such environments, thereby enabling a more effective and reliable application in those contexts. However, it’s worth noting that the proposed solution is limited to a single climate type, and regional adjustments will be necessary for its implementation.
The estimation of ETo can be broadly grouped into three categories: (1) models entirely based on physical principles that incorporate the fundamentals of mass and energy conservation; (2) semi-physical models that specifically address mass or energy conservation; and (3) black-box models relying on artificial neural networks, empirical relationships, and fuzzy and genetic algorithms7. Currently, in addition to the mentioned models, remote sensing models have been developed and applied for ETo estimation. These models utilize data collected by remote sensors, such as satellite images, to assess and calculate ETo with greater precision8.
Some experts, as mentioned in the literature7,9, have delved into the application of genetic algorithms with the purpose of standardizing certain models to enhance estimation accuracy. These initiatives have placed particular emphasis on methods like Hargreaves and remote sensing technologies such as MODIS (Moderate Resolution Imaging Spectroradiometer). The primary goal of this approach is not only to refine the accuracy of estimations but also to ensure greater consistency and reliability in the results derived from these models and techniques. It is important to note that, despite these advancements, these models require specific adjustments to achieve a more precise adaptation to the particular conditions of the region under study. This recognition underscores the need to consider local factors in the application of these models to guarantee more accurate and contextually relevant estimations.
At present, evolutionary computation techniques such as GP, artificial neural networks, and neurofuzzy models have been used for modeling hydrological processes10,11,12,13,14. These techniques have the ability to model nonlinear complex processes and can estimate ETo accurately. However, their success depends on various factors such as the quantity and quality of the data, the selection of the model structure, and the required model parameters. In13, the authors estimated ETo using relative humidity and air temperature data. The authors used two strategies for handling data. The first strategy was clustering by climate type, and the second strategy used past meteorological data as input to the models. The techniques used in that study were a neural network and a support vector machine as well as six empirical equations; the latter showed the lowest performance. However, models generated through machine learning techniques such as artificial neural networks and support vector machines are perceived as black boxes due to their intrinsic complexity and internal algorithms involving multiple layers of interconnected nodes. This lack of transparency can lead to distrust and reluctance in their use, as they do not provide a clear explanation of the relationship between input variables and the obtained results. Additionally, the models were developed with clusters of data from weather stations with similar climates, which may result in inaccurate performance in regions with significantly different climatic conditions. ETo has also been addressed using genetic algorithms11 used daily climatic variables obtained from the California Irrigation Management Information System CIMIS15 of the Davis, Hasting, Suisun, Dixon, and Oakville stations. The authors evaluated the performance of genetic algorithms against various empirical models, such as Jensen–Haise, Hargreaves–Samani, Jones-Ritchie, the Turc method, and models based on solar radiation. However, despite the authors reporting good performance compared to other conventional methods, the new model uses the same input parameters as the FAO-PM reference model, limiting its applicability in areas where the necessary information is unavailable. Other authors, such as16, applied GP to estimate ETo in the Basque Country (northern Spain). The developed models used the meteorological parameters of relative humidity, solar radiation, air temperature, and wind speed. Although the models proposed by11,16 yield quite satisfactory results, it is important to note that they use the same parameters (air temperature, relative humidity, solar radiation, and wind speed) as the FAO-PM model. This similarity limits their implementation in locations where not all parameters are available. In17, the authors compared artificial neural networks using the standard Penman‒Monteith method. They worked with two datasets obtained from the Davis station of CIMIS. The variables used were solar radiation, maximum temperature, minimum temperature, maximum relative humidity, minimum relative humidity, wind speed and ETo obtained with the Penman‒Monteith standard method as the objective value. The results show that the artificial neural network model can be trained locally to predict ETo values better than the standard Penman‒Monteith method. However, despite the authors reporting positive performance, the new model uses the same input parameters as the Penman–Monteith reference model, limiting its applicability in areas where necessary information is not available. Additionally, being trained locally implies that, for use in another region, it will need to undergo a new training process.
Random forest models and generalized regression neural networks were used by18 to estimate ETo for the period 2009–2014 at two meteorological stations in China. The results show that the random forest model and the generalized regression network can be successfully applied to accurately estimate daily ETo. However, the random forest model may perform slightly better than the generalized regression neural network in estimating daily ETo. The presented models exhibit favorable performances; however, they are characterized as black-box models. Furthermore, it is worth noting that they were exclusively trained with a single type of climate, implying that if they are to be used in a region with different climatic conditions, they will need to undergo a new training process tailored to the specific conditions of the location.
The research conducted by19 compared different machine learning techniques for developing ETo models, achieving accurate results. On the other hand, the best-performing model presented involves variable net radiation, which often remains unavailable, limiting its implementation. Similarly, the models were generated for a humid climate. The extreme support machine in combination with genetic algorithms was employed by20 to develop models for estimating ETo. They found that the combination of these two techniques yielded accurate results using input variables such as Tmax, Tmin, u2, RH, and Rn/Rs, as well as Tmax, Tmin, and Rn/Rs. Nonetheless, these models were tailored for subtropical and plateau mountainous monsoon climates, and they utilize variables that are frequently unavailable, Such as solar radiation. Furthermore, these models are considered black-box models.
The models proposed by19,20 stand out for their higher accuracy compared to conventional models; however, their use of variables that are sometimes challenging to obtain, such as solar radiation, poses practical challenges. Additionally, these models were specifically designed for a particular climate, and their techniques, considered “black box,” present aforementioned disadvantages. The limitation in variable availability and climatic specialization may restrict the applicability of these models in different conditions or locations, emphasizing the importance of considering these limitations when assessing their suitability and applicability in broader contexts.
While some techniques found in the literature displayed in Table 1 demonstrate an accurate estimation of ETo, they face the challenge of being considered “black boxes,” complicating the interpretation of their results13,19. Furthermore, the findings presented involve the use of variables such as solar radiation and net radiation, the acquisition of which is hindered by the high costs associated with the necessary measurement equipment11,16. Additionally, a significant portion of the models has been designed to adapt to specific climates, posing complications in terms of generalization as they require a new training process when applied to climates different from those used during their development19. These challenges underscore the need to address the interpretability of the employed techniques and to develop more adaptable models that consider climatic variability to enhance their applicability in diverse contexts.
As evidenced in Table 1, the majority of the proposals under analysis share similarities in terms of the input variables used, aligning closely with the FAO-PM reference model. These proposals mostly adopt techniques considered as “black box.” However, an additional group of approaches stands out, aiming for the standardization of models such as Hargreaves and remote sensing techniques like MODIS through adjustments, employing genetic algorithms or kriging interpolation. It is important to note that some of these proposals are limited to the use of a single climatic dataset during their evaluation.
Within the scope of our research, we aim to develop an explicit model for easy evaluation. Our proposal is based on the use of commonly measurable variables, such as temperature, relative humidity, and wind speed. The primary objective is to achieve a precise approximation to the FAO-PM reference model. By opting for widely recorded variables, our intention is not only to simplify the model evaluation but also to enhance its practical applicability in environments where conventional meteorological data are available. This approach aims to contribute to the generation of more accessible and effective models in the field of evapotranspiration estimation.
In contrast, techniques like GP, by generating explicit models, offer advantages in terms of interpretability, facilitating the understanding, validation, and debugging of the model. The generalization capability and the incorporation of expert knowledge reinforce the utility of explicit models, highlighting their applicability in environments requiring a deep understanding of the domain. In this context, we have conceived a generalized and explicit model, enriched with expert knowledge in its formulation. This innovative approach utilizes easily measurable parameters such as temperature, relative humidity, and wind speed. It stands out for its ability to make accurate ETo estimations, surpassing the Hargreaves–Samani model. Furthermore, its versatility is evident in its applicability to two different climates: arid-warm and warm-temperate. This model not only optimizes result interpretation but also emerges as a valuable and adaptable tool for various climatic conditions, enhancing its utility in heterogeneous environments.
GP has emerged as an evolution of traditional genetic algorithms, maintaining the same principle of natural selection. What is now intended is to solve problems through the induction of programs and algorithms. It is in this possibility where all the potential of GP resides, as it allows the automated development of programs, understood in a broad sense, that is, as algorithms in which, based on a series of inputs, a series of outputs is generated. In this way, for example, a mathematical equation could be induced using GP.
Throughout history, extensive research has been conducted with the purpose of estimating Reference ETo using standard meteorological data. In this context, sustained efforts have been focused on reducing the number of variables and, consequently, the meteorological data required for the estimation of ETo1.
In our research, the FAO Penman‒Monteith method (FAO56-PM) is considered to be the knowledge expert since it is based on robust physical bases and explicitly incorporates physiological parameters and aerodynamics. The objective of this research is to generate an explicit model to estimate the ETo in at least two different climates without local adjustment using meteorological variables such as relative humidity, air temperature, and wind speed. The estimation of ETo was performed for arid-warm and warm-temperate climates. In this case, commonly measurable climatic parameters (relative humidity, air temperature, and wind speed) are used, disregarding solar radiation. For the development and validation of our model, we used databases obtained from CIMIS and a database of the El Porvenir station in the state of Coahuila, located in north-central Mexico. In our model performance evaluation, we utilize statistical indicators such as the root mean square error (RMSE) and the coefficient of determination R2, comparing the obtained results with the Hargreaves–Samani models and the reference model.
The implementation of our ETo model based solely on temperature, relative humidity, and wind speed data will offer significant benefits to the community. By simplifying the process and reducing dependence on complex meteorological data, this approach becomes more accessible and economically viable, especially valuable in areas with limited resources or less developed meteorological infrastructure. The widespread application of the model, adaptable to at least two different climates (warm temperate, warm arid), will enable efficient irrigation management in agriculture. This will result in water use optimization, significantly contributing to environmental sustainability. The positive impact of this approach will be notably reflected in agricultural planning and water resource management, generating tangible benefits for local communities in terms of sustainability and efficiency. The successful implementation of our model will not only improve water efficiency in agriculture but also result in lower production costs, thus strengthening the economic viability of agricultural communities.
The main contributions of this research are the following:
-
The generation of an analytical model using GP, climatic parameters (relative humidity, air temperature, and wind velocity) and the use of expert knowledge to estimate the daily ETo.
-
A generalized model to be used in at least two types of climate (arid and temperate) with results that are comparable to the state of the art.
-
A methodology that could be employed to discover a function that estimate the ETo under specific restrictions
The article is organized as follows: “Materials and methods” section shows the materials and methods; “Results” section. In “Discussion” section presents the results, “Discussion” section presents the discussion, and “Conclusions and future work” section presents the conclusions and future work.
Materials and methods
In this section, we provide a detailed explanation of the FAO56-PM reference model and the Hargreaves–Samani model, along with some generalities about GP. Subsequently, we elaborate on the model development process, addressing aspects ranging from data acquisition, organization, and preprocessing to the execution of the evolutionary algorithm, as illustrated in Fig. 1. This comprehensive approach aims to offer a complete and understandable view of the methodological framework used in constructing our model, highlighting key stages and the sequence of actions that led to its final formulation.

Source: Author and collaborators’ work.
Flowchart of the evolutionary process. From a training dataset, the GP proposes various types of models with the aim of identifying the one that best fits the behavior of ETo within a specific time range.
The FAO56-PM reference method
The FAO Penman‒Monteith method called (FAO56-PM), Eq. (1), is recommended as the standard method for estimating ETo. However, this estimation poses a challenge when the availability of meteorological data is limited. The FAO56-PM method requires parameters for its application, such as the slope of the vapor pressure curve, ∆ [kPa/°C]; the net surface solar radiation, Rn [MJ m2 dia−1]; the thermal flux density of the soil, G [MJ m2 dia−1]; the psychrometric constant, γ [kPa°C−1]; the mean air temperature, Tmean [°C]; the speed of the wind, u2 [M/s]; the saturation vapor pressure, es [kPa]; and the actual vapor pressure, ea [kPa]. These parameters are a function of air temperature, soil temperature, relative humidity, solar radiation, atmospheric pressure, wind speed, etc.2.
In this study, the FAO56-PM method Eq. (1) has been used as a reference to evaluate the results of the investigation due to the absence of experimental values for ETo.
The Hargreaves–Samani method
The FAO currently recommends the Hargreaves–Samani Eq. (2) in cases where only temperature data are available21. This is the result of seeking a standardization of the different existing empirical methods to estimate ETo with reduced data22,23,24.
where Tmax represents the maximum temperature [°C]; Tmin represents the minimum temperature [°C]; and Ra represents the extraterrestrial radiation [MJ m2dia−1]. However, the Hargreaves–Samani equation underestimates the ETo value2.
Genetic programming
Genetic programming (GP) is a domain-independent technique in which computer programs evolve to solve problems. GP is based on the Darwinian principle of survival of the fittest as well as analogies to natural genetic operations such as reproduction and mutation25. GP builds a population of individuals (mathematical models) from different combinations of a set of mathematical expressions randomly. Once the population is initialized, the fitness of each individual is evaluated on the basis of some objective function. Fitness is a numerical value that is assigned to each individual based on its performance. The better the fitness of an individual is, the higher the probability of passing to the next generation or having offspring. In each generation, the models are modified by applying genetic operators: selection, crossover, and mutation25. Each individual is represented in the form of a syntactic tree. The crossover operator generates new models so that the search space of the problem is thoroughly sampled. The crossover is performed by selecting two parents from the population and exchanging the corresponding subtree structures in a corresponding random area through a randomly chosen point. The crossover operator produces two offspring with different characteristics. The crossover point between Parents 1 and 2 is shown in Fig. 2 with a dotted line; the structures of the corresponding subtrees are swapped, giving rise to Children 1 and 2. The number of models that intersect depends on the probability set in the parameters of the evolutionary algorithm. Mutation involves the random alteration of the syntax tree at the branch or node level. This alteration is made based on the established mutation probability. The mutation introduces new offspring into the population and thus avoids falling into a local optimum. Figure 3 shows the mutation operator. These new models form the basis for the next generation. Each model of the population can be considered to be a potential solution to the problem. Figure 4 shows the flowchart of GP. In GP the coding of individuals is performed in the form of a tree, where the interior nodes represent the functions and the terminal nodes represent the variables and constants (See Fig. 5).

Source: Author and collaborators’ work.
Crossover operator.

Source: Author and collaborators’ work.
Mutation operator.

Source: Author and collaborators’ work.
Genetic programming flowchart.

Source: Author and collaborators’ work.
Syntax tree solution.
The GP technique has the ability to work with limited data Pioneering research, such as that conducted by26,27, has underscored the intrinsic ability of GP to adapt and evolve solutions in environments with small datasets. Specific strategies for handling limited data, including genetic operators and diversity control techniques, have been proposed to enhance the effectiveness of GP in extracting patterns under these conditions. Furthermore, studies such as28 have explored GP’s adaptability to problem complexity, enabling the effective representation of patterns even in situations with sparse data.
Genetic programming to estimate reference evapotranspiration
Database
The direct measurement of ETo is complex and is usually estimated indirectly through measurements of climatic parameters.
The databases used in the development of our model were obtained from CIMIS, which houses various weather stations located in different regions of the state of California, United States. A noteworthy feature of CIMIS is that it provides the necessary variables to calculate ETo using the FAO-PM reference model. Additionally, it is important to highlight that CIMIS is an open database, facilitating access and availability of information for the scientific and academic community and one from the state of Coahuila in north-central Mexico. Information on the CIMIS database can be acquired free of charge, from www.cimis.water.ca.gov. Data are available in the database at hourly and daily time scales, and includes solar radiation, air temperature, soil temperature, relative humidity, vapor pressure, wind speed, wind direction and precipitation. The total incoming solar radiation is measured by employing pyranometers at a height of 2.0 m above the ground. Air temperature is measured at a height of 1.5 m above the ground by using a thermistor. Soil temperature is measured at 15 cm (6 inches) below the soil surface. The relative humidity sensor is sheltered in the same enclosure with the air temperature sensor at 1.5 m above the ground. Wind speed is measured by utilizing three-cup anemometers at 2.0 m above the ground. Wind direction is measured by using a wind vane at 2.0 m above the ground. Wind direction values range from 0 to 3608 (both being true north) and are adjusted for declination of the Earth’s axis. Rainfall is measured by employing tipping bucket rain gauges.
The databases for the construction of the model cover a period from 2011 to 2015 and 2019 on a daily scale. The selection of these periods is due to having fewer missing data.
GP, as an evolutionary computational approach, has a remarkable ability to work efficiently with small datasets compared to artificial neural networks, which require a large amount of data. In line with this characteristic, we have decided to use small datasets from CIMIS. This choice does not imply a restriction derived from the availability of the database, as we acknowledge that it is accessible. Instead, it is based on the inherent suitability of GP to extract patterns and generate effective solutions in data-constrained environments. This approach allows us to explore and leverage the capability of GP to address complex problems and extract meaningful knowledge even when the amount of available data is limited. Since an analytical model is obtained, it can be easily verified across different time intervals. In this context, the main objective of the work is to present the methodology for estimating an ETo model. The type of climate was defined based on the climatic classification of29. To choose the training and testing databases, geographical diversity and climatic variability were considered as criteria. The databases used for training and testing consist of 4 weather stations located in different geographic locations, with 2 stations having arid-warm climate and the other two with warm-temperate climate, as detailed in Table 2. As for the selection of databases for validation, different stations were chosen compared to those used in the training and testing phases but with similar climates. To validate the model, 4 different weather stations were used, with 3 of them having warm-temperate climate and 1 with arid-warm climate, as shown in Table 3. The attributes of the databases used are: maximum temperature (Tmax [°C]), minimum temperature (Tmin [°C]), maximum relative humidity (HRmax [%]), minimum relative humidity (HRmin [%]), and daily mean wind speed (u2 [m/s]).
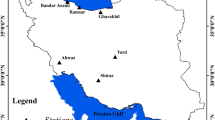
Figures 6 and 7 were extracted from Google Maps30 and subsequently customized following the guidelines published in31. The figures display the geographical locations of the weather stations used in the training, testing, and validation phases of our model.

Weather stations used for training and testing.

Weather stations used for validation.
Data preprocessing
An exploratory analysis of the databases was conducted to identify potential incorrect, missing, or improperly recorded data. During this analysis, it was observed that the CIMIS databases contained records with missing data In accordance with32, a strategy to address this situation is to use the standard method for imputing missing data, as proposed by33. This approach involves replacing missing values with the average under similar meteorological conditions within a time window of ± 7 days.
As a result, 334 records were collected from the El Porvenir station during the period from February to December 2019. Additionally, 1826 records were obtained from each of the CIMIS stations, spanning from January 2011 to December 2015, as shown in Table 2.
Subsequently, a preprocessing operation was carried out to standardize the units in which the original data were registered: the temperature was recorded in [°F] and covered to [°C]; the wind speed data were recorded in [mph] and then converted to [m/s]; and solar radiation was initially recorded in [Ly/day] and then converted to [W/m2] using the conversion factor Ly/day/2.065 = [W/m2] provided by CIMIS.
The databases from El Porvenir, Davis, Calipatria, and McArthur were used to create three different datasets (DS01, DS02, and DS03), as shown in Table 4. These datasets were utilized in both the training and testing phases.
The datasets were consolidated as follows: DS01 incorporates data from the El Porvenir station, representing an arid-warm climate (BWh); DS02 includes data from the Davis station with a warm-temperate climate (Csa); and DS03 is formed by integrating data from four meteorological stations (El Porvenir, Davis, Calipatria y McArthur) covering at least two different climates [arid-warm (BWh) and warm-temperate (Csa)]. Table 4 shows the three datasets and their characteristics.
Each daily dataset shown in Table 4 was divided into 80% for training and 20% for testing. Uniform sampling was performed to obtain the test data (i.e., one out of every five data items was taken for the test set, and the remainder was used for the training set). The structure of the daily training and test datasets is shown in Table 5.
To validate the results, four meteorological stations with different geographical locations than those used in the training and testing phases were included, as detailed in Table 3. These stations were used to create four distinct datasets: DS04, associated with the Modesto station; DS05, linked to the Oakville station; DS06, corresponding to the Meloland station; and DS07, related to the Ferndale station. Table 6 presents the characteristics of the datasets used in the validation process. This approach ensures the robustness of the model by assessing its performance under varied geographical conditions.
The choice of the ETo11 model was based on the simplicity of its structure, the number of input parameters, and the accuracy it demonstrated during the training and testing stages, as observed in Table 12. While there are other models available, due to space constraints, we exclusively utilized the ETo11 Model.
Construction of the proposed model with genetic programming
For the development of the model, the GPLab library was used in the MatLab environment. This tool proved to be essential for designing and analyzing our model, providing advanced functionalities and facilitating the implementation of specific algorithms needed for our research objectives. The choice of the GPLab library was based on its versatility, effectiveness, and ability to address the particular challenges of our project, enabling us to achieve accurate and meaningful results within the scope of our study.
GP has provided a new way of analyzing and optimizing water resources due to its ability to solve complex problems with one or more objectives. These problems were classified as intractable with traditional methods since their models can be discontinuous and nondifferential, with mixed and integral variables and with a high dimensionality34.
Before applying GP to a problem, five preparatory steps must be performed according to John25. These five steps consist of determining the set of terminals, the set of functions, the fitness function, the parameters to control the execution, and the method to designate a result.
Determining the set of terminals
The set of terminals represents the independent variables of the model not yet discovered. The set of terminals (along with the set of functions) are the elements from which GP attemps to build a model to solve the problem posed. In our research, during the process of selecting the set of functions and terminals, we conducted various experiments using genetic programming. This methodology enables the evolutionary algorithm to discriminate functions and terminals that are not relevant in model construction, preserving only those elements that have a higher degree of utility. Additionally, we relied on the valuable expert knowledge provided by the Penman–Monteith reference model. Since evaluating the Penman–Monteith model involves a series of essential steps, we based our procedures on these, integrating them into the evolutionary algorithm to enhance the robustness and precision of our approach. This combined approach of genetic programming and expert knowledge from Penman–Monteith has proven to be integral in selecting functions and terminals, improving the quality and effectiveness of our models. Table 7 shows the set of terminals chosen for the evolutionary algorithm.
Determining the set of functions
Functions are the mathematical operators that are applied to the different terminals. In our research, the basic operators +, −, * and / were used in conjunction with √x, √x, x2, x3, ln(x), exp(x), sin(x), cos(x), and arctan(x) functions used in hydrological studies35,36. The set of functions included the hyperbolic functions normally used to discover physical phenomena37. The set of functions is presented in Table 8.
Determining the fitness functions
The evolutionary process is governed by the measure of fitness. Each individual in the population is run and then evaluated using the fitness function to determine its performance. The aptitude function (along with the functions and terminals) establishes the search space and allows the quality of the individuals to be evaluated. In this case, it must take positive real values. In our investigation, we chose to apply the RMSE Eq. (3) Use a fitness function to evaluate the difference between the predicted value and the target value. Therefore, the fitness function is defined as follows:
where n is the total number of data points and Pi and Oi are the predicted and target ETo values, respectively. The better the fitness of an individual is, the higher the probability of passing to the next generation.
Determining the parameters of the evolutionary algorithm
The main parameters for controlling the execution of the evolutionary algorithm are the population size, the maximum number of generations in the initialization method, the selection method, the crossover probability, and the mutation probability. In our research, the values assigned to the parameters are observed in Table 9.
Determining the method to designate a result
Each execution requires the specification of a termination criterion to decide when to terminate and a method of designating results. The solutions were obtained by taking an RMSE < 1 in training. To stop the evolutionary algorithm, we use the maximum number of generations established in the algorithm parameters as the stop criterion.
In our research, three datasets from different climates based on29 classification were tested as input for the formulation of models with GP see Table 4. After exploratory testing, it was necessary to adjust the configuration of the process. The evolutionary algorithm was run fifty times for the DS01 and DS02 datasets, obtaining 2076 and 1408 solutions, respectively. For the DS03 dataset, the evolutionary algorithm was executed 30 times using the same parameters established, resulting in 270 solutions. In total, the evolutionary process obtained 3754 solutions (see Table 10).
The evaluation of the models was carried out with 20% of the data reserved for testing of the DS01, DS02, and DS03 datasets. The evaluation was carried out by calculating the RMSE and the coefficient of determination R2; this last measure was not considered as part of the optimization of the model. RMSE and R2 are two metrics commonly used in the context of predictions and regression models to assess the performance of a model compared to actual values.
The RMSE and R2 metrics are commonly used in forecasting to assess both the accuracy and the quality of fit of the model. RMSE provides a measure of how close the model’s predictions are to the actual values, while R2 provides information about the proportion of variability that the model is capturing compared to the total variability in the data. Together, these metrics offer a comprehensive view of the model’s performance in terms of accuracy and ability to explain variability in the data. RMSE and R2 are calculated using Eqs. (3) and (4), respectively.
where n is the total number of data points, and Pi and Oi are the predicted ETo and, and \({\overline{O}}_{i}\) and \({\overline{P}}_{i}\) target ETo values, respectively.
Ethical approval and consent to participate
In the course of our investigation, no experimental procedures involving human subjects were undertaken.
Results
Evolution Statistics
This section presents a statistical analysis of the evolutionary process for the DS01, DS02, and DS03 datasets. The objective is to show the convergence rate of the proposed algorithm. Figure 8 shows the best fit, the average of the best fits, and the standard deviation of the 50 runs for the DS01 and DS02 datasets and the 30 runs for the DS03 dataset.

Best fit, the average of the best fits, and the standard deviation of the 50 runs for the DS01 and DS02 datasets and the 30 runs for the DS03 dataset.
Note that, on average, solutions with a fitness measure less than one were found in the 15th, 65th, and 174th generations. The minimum fitness was reached for the three datasets around the 200th generation, and the average fitness converged to 0.9036, 0.9734 and 0.9668 from the 1st, 3st and 44th generations for the DS01, DS02 and DS03 datasets, respectively.
Experimental results
The number of solutions found with GP was 3754, from which the fourteen best solutions were selected. Priority was given to those with the best aptitude, an RMSE less than one, the least structural complexity, and the lowest number of input parameters. The selected models are shown in Table 11. The models were labeled EToi (where i represents a consecutive number).
The structure of the ETo1 and ETo4 models is a function of temperature; the structure of the ETo2, ETo6, ETo7, ETo9, ETo10, ETo12, ETo13, and ETo14 models is a function of temperature and wind speed; and the structure of the ETo3, ETo5, ETo8 and ETo11 models is a function of relative humidity, temperature, and wind speed.
In this case, simple models such as ETo1 were obtained, which is a function of saturation vapor pressure, but the results outperform the Hargreaves–Samani model in the DS01 dataset, which corresponds to arid-warm climate. Similarly, some models include parameters such as solar declination, which are expressed solely in terms of the day of the year.
Evaluation of the models
Table 12 summarizes the performance of the models measured by RMSE and R2 for all the datasets shown in Table 4 used to develop the model. It can be observed that the evolutionary approach with GP is capable of learning complex and nonlinear relationships that are difficult to model with conventional techniques. For example, the models have a range of RMSE between 0.639 and 2.054, and R2 between 0.521 and 0.925 with 20% of the datasets used for model development.
The structural analysis of the models provides interesting insight into the strategies identified by the evolutionary process to combine functions and terminals.
In Table 12, the results show that the ETo6 model with input parameters of temperature and wind speed was the best model with the test data of the DS01 dataset, with RMSE = 0.882 and R2 = 0.838. The scatter plots and time series in Fig. 9 show that the ETo6 model outperformed the Hargreaves–Samani model. For example, in Fig. 9a, the ETo6 model obtained an RMSE = 0.882, while the Hargreaves–Samani model obtained an RMSE = 2.374. On the other hand, in Fig. 9b, the ETo6 model obtained R2 = 0.8387, and the Hargreaves–Samani model presented in Fig. 9c reached R2 = 0.631. This may be because the model was developed using the DS01 dataset.

Comparison of the ETo6 and Hargreaves–Samani models with the FAO56-PM reference model using test data from the DS01 dataset. (a) RMSE ETo6 and Hargreaves–Samani, (b) R2 ETo6, and (c) R2 Hargreaves–Samani.
The ETo8 model that uses relative humidity, temperature, and wind speed input parameters obtained more accurate results in estimating the ETo with the DS02 and DS03 datasets than the Hargreaves–Samani model. For the DS02 dataset, Fig. 10a shows a value of RMSE = 0.639 for the ETo8 model, outperforming the Hargreaves–Samani model, which reached a value of RMSE = 1.177. Figure 10b shows a value of R2 = 0.925 for the ETo8 model, while Fig. 10c shows a value of R2 = 0.741 obtained with the Hargreaves–Samani model. Likewise, for the DS03 dataset, Fig. 10d shows an RMSE = 0.761 for the ETo8 model, while the Hargreaves–Samani model shows an RMSE = 0.979. Figure 10e shows a value of R2 = 0.910 for the ETo8 model, and Fig. 10f shows a value of R2 = 0.844 for the Hargreaves–Samani model.

Comparison of the ETo8 model and the Hargreaves–Samani model with the FAO56-PM model using the datasets DS02 and DS03. (a) RMSE ETo8 and Hargreaves–Samani for DS02, (b) R2 ETo8 for DS02, (c) R2 Hargreaves–Samani for DS02, (d) RMSE ETo8 and Hargreaves–Samani for DS03, (e) R2 ETo8 for DS03, and (f) R2 Hargreaves–Samani for DS03.
According to the results presented in Fig. 10, the model developed with GP ETo8 considerably outperforms the Hargreaves–Samani model. However, the model has a complex structure.
On the other hand, the model ETo11 Eq. (5) presents a relatively simple structural formulation with a range of results in the evaluation stage with an RMSE between 0.693 and 1.756 and R2 between 0.759 and 0.910 for the three datasets. Therefore, even though the ETo11 model was not the best model found, it was selected for the validation stage. It presents important characteristics to consider since only input parameters that depend on relative humidity, temperature and wind speed and its results outperform the Hargreaves–Samani model on all three datasets used for testing.
Model validation
To validate the ETo11 model, Eq. (5) Developed with GP, the DS04, DS05, DS06, and DS07 datasets were used with arid-warm and warm-temperate climates obtained from locations other than those used for their training. Their characteristics are shown in Table 6. The Hargreaves–Samani model was included to compare the performance between these two models. Table 13 shows the values of RMSE and R2 obtained with the ETo11 and Hargreaves–Samani models.
The scatter and time series plots in Figs. 11 and 12 show that the ETo11 model has greater accuracy than the Hargreaves–Samani model with respect to the FAO56-PM model of reference for the four datasets used for validation. For example, Fig. 11a shows greater precision by the ETo11 model with a value of RMSE = 0.314 than the Hargreaves–Samani model with a value of RMSE = 0.635. Similarly, by means of a linear regression analysis, it can be observed in Fig. 11b,c that our model is a better fit than the Hargreaves–Samani model, with R2 = 0.978 against R2 = 0.916 with the DS04 dataset.

Comparison of the ETo11 model and the Hargreaves–Samani model with the FAO56-PM model using the datasets DS04 and DS05. (a) RMSE ETo11 and Hargreaves–Samani for DS04, (b) R2 ETo11 for DS04, (c) R2 Hargreaves–Samani for DS04, (d) RMSE ETo11 and Hargreaves–Samani for DS05, (e) R2 ETo11 for DS05, and (f) R2 Hargreaves–Samani for DS05.

Comparison of the ETo11 model and the Hargreaves–Samani model with the FAO56-PM model using the datasets DS06 and DS07. (a) RMSE ETo11 and Hargreaves–Samani for DS06, (b) R2 ETo11 for DS06, (c) R2 Hargreaves–Samani for DS06, (d) RMSE ETo11 and Hargreaves–Samani for DS07, (e) R2 ETo11 for DS07, and (f) R2 Hargreaves–Samani for DS07.
For the DS05 dataset, the results continue to be favorable for the ETo11 model, as shown in Fig. 11d. Our model has an RMSE = 0.682 compared to an RMSE = 0.710 from the Hargreaves–Samani model. On the other hand, Fig. 11e,f show the results of the linear regression analysis, where it can be seen that the models obtain similar results in the statistical index R2, with a value of 0.918 for the two models. For the DS06 dataset, it can also be observed that the ETo11 model outperforms the Hargreaves–Samani model. Figure 12a shows values of RMSE = 1.483 obtained with our model compared to the Hargreaves–Samani model with RMSE = 1.616. Figure 12b,c show the results of R2 with values of 0.818 and 0.767 for the ETo11 and Hargreaves–Samani models, respectively, with the ETo11 model showing greater precision. As a result, our model aims to adhere to the reference data in the different validation datasets, making its behavior similar in Figs. 11 and 12.
These results were obtained for an arid-warm climate. However, to validate our ETo11 model in a different climate, we used the DS07 dataset with a warm-temperate climate. Similarly, the time series plots in Fig. 12d show that our model outperforms the Hargreaves–Samani model by a lower magnitude with values of RMSE = 0.292 compared to RMSE = 0.400. The scatter plot of Fig. 12e also shows an index of R2 = 0.937 compared to the values of R2 = 0.8672 of Fig. 12f, and it becomes clear that our model outperforms the Hargreaves–Samani model.
The structural analysis of the ETo models presented in Table 11 offers an intriguing perspective into the strategies identified by the evolutionary process to combine the primitive set (functions and terminals). In this study, we employed a frequency of use unit, representing how often an element is utilized to generate a new model. Figures 13 and 14 depict the occurrence frequency of the function and terminal sets. The function and terminal numbers correspond to those assigned in the description provided in Tables 4 and 5.

Frequency of occurrence of the terminal set.

Frequency of occurrence of the function set.
Regarding the elements belonging to the terminal set, it can be observed that ws (solar radiation angle at sunset) has the highest occurrence frequency, being used in 59.8% of the generated models. It is followed by e°Tmax (saturation vapor pressure at max. temp.), which has an occurrence frequency of 54.62%, and finally, the saturation vapor pressure has a frequency of 54.47%. It is noted that the GP process did not utilize the majority of provided terminals, indicating that the GP algorithm identified them as not strictly necessary for estimating ETo. Moreover, it is important to highlight that the presented ETogp models do not directly employ the basic climatic parameters. However, they are implicitly used in variables representing expert knowledge, such as saturation vapor pressure (es), solar declination (ds), vapor pressure deficit (ea), and vapor pressure at minimum and maximum temperature (e°Tmax, e°Tmin), all of which belong to the Terminal set. For instance, saturation vapor pressure (es) is derived from vapor pressure at minimum temperature (e°Tmin) and vapor pressure at maximum temperature (e°Tmax), both of which are functions of minimum and maximum temperatures. Similarly, the vapor pressure deficit (ea) is derived from the vapor pressure at minimum temperature (e°Tmin), vapor pressure at maximum temperature (e°Tmax), minimum relative humidity (HRmin), and maximum relative humidity (HRmax). This is intriguing since only temperature and relative humidity climatic parameters are used, suggesting that GP can identify fundamental climatic parameters for estimating ETo.
In the case of the function set, the importance of each operator was more evenly distributed. The addition operator was used in 92.61% of cases, while the sine operator was the least used at 11.36%. This is intriguing as GP can construct structurally simple models for estimating ETo. This finding suggests that the GP algorithm recognized the relationship between fundamental yet effective climatic parameters in estimating the ETo phenomenon.
Statistical significance
In order to assess the statistical significance of the data, Student’s t-tests were conducted for each of the datasets used in the validation, as detailed in Table 14.
The results obtained with a 5% tolerance conclusively indicate that there is no significant difference between the means of the two models, ETo11 and FAO-PM. In this context, it cannot be stated that the models differ significantly in terms of their performance; therefore, both could be considered statistically equivalent based on the data analysis. This finding supports the consistency and reliability of both models in estimating ETo.
Discussion
In this study, a methodology was presented for developing analytical models of ETo using GP. Unlike genetic algorithms that optimize the parameters of a given model, GP allows for obtaining a new formulation that fits the acquired data. Thus, the advantage of the GP approach lies in its open-box or white-box characteristic. If we were to use a black-box approach (e.g., neural networks, fuzzy logic, and most statistical approaches), we would hardly be able to explicitly uncover the relationship among the climatic variables considered in the ETo phenomenon.
The proposed methodology offers great flexibility, as it can adapt to data from various climate types and account for constraints on these data. Thus, this study aimed to construct an ETo model that only takes into account climatic variables commonly measurable at a meteorological station, such as temperature, relative humidity, and wind speed.
By implementing the proposed methodology, a total of 3754 models were successfully generated, all of which demonstrated a substantial improvement in ETo estimation compared to the Hargreaves–Samani model. However, a meticulous selection process was carried out, choosing only fourteen of these models based on criteria such as their accuracy, input parameters, and structural complexity. During the training phase, a noticeable superiority was evident, reaching up to 27% compared to the Hargreaves–Samani model, while in the testing phase, this improvement remained significant at 16%. In pursuit of achieving a generalized model, a dataset from meteorological stations located at various latitudes and featuring diverse climates was employed, spanning from warm-temperate regions to warm-arid zones.
Initially, only an arid climate was considered, and this methodology enabled the construction of models with a simple structure that allows for straightforward implementation. This has led us to address three main questions: Are models obtained for one region applicable to regions with slightly different conditions? Can models developed for the climate of one region be applied to another region with a different climate? For example, can a model created for an arid region be applicable to a temperate region? Is it feasible to generate a model for different climates, in this case, for arid and temperate climates, while restricting the input to measurements of temperature, relative humidity, and wind speed? To answer these questions, experiments and results were developed as described in the preceding section, demonstrating how models initially discovered for the Porvenir region in Coahuila, Mexico, were successfully applied to regions in southern California. It was also possible to identify models initially developed for an arid climate and subsequently model ETo in temperate climates. In general, models proposed in other research studies, such as those by16,17,19 have been developed with a specific regional focus. The need to reapply the methodology for their extension to different geographical areas underscores the limitation in their generalizability. These models, designed for particular climatic and geographical conditions, necessitate additional adjustments and validations when applied in different environments. The adaptability and transferability of these approaches to various locations and climatic contexts require careful consideration of environmental variations and the potential need for methodological adjustments to ensure accurate and effective application.
Finally, to validate the performance of the generalized model, four datasets from different latitudes with climatic characteristics similar to those used in the model development process (warm-temperate, warm-arid) were employed. The results obtained in the validation phase clearly highlight the superiority of our model designated as ETo11 over the Hargreaves–Samani model, achieving an increase of 51% in warm-temperate climates. In the case of the dataset associated with warm-arid climates, our model continued to exhibit satisfactory results by surpassing the Hargreaves–Samani model by 8%. These robust results underscore the effectiveness and versatility of our methodological approach, consolidating its suitability for addressing climatic variability and geographic heterogeneity in ETo estimation. It is important to note that in this study, the Penman‒Monteith formulation has been taken as the reference standard due to its adoption by the FAO. This standard was developed using the definition of the reference crop, which is a hypothetical crop with an assumed height of 12 cm, a surface resistance of 70 s m−1, and an albedo of 0.23, representing ETo from an extensively covered surface of actively growing, uniformly tall green grass that is adequately irrigated21. However, in dry and desert regions where local environments experience aridity effects due to insufficient ETo, the FAO56-PM model tends to overestimate ETo. A promising approach is the use of boundary layer theory in meteorological data conditioning, which allows quantification of the effects of aridity on the surface38. Nonetheless, its implementation poses challenges due to its complexity. The intricacy of the meteorological data conditioning method makes it impractical for widespread use in practical applications. Nevertheless, the methodology proposed in this study can easily be adapted to other reference metrics, such as measurements from a precision instrument or any other estimations.
Various studies10,13,14,19,20 have explored the use of machine learning models and methods such as GP to estimate ETo. The effectiveness of these approaches has been highlighted, but concerns have been raised about the inclusion of variables like solar radiation and the limitation to a single climate type, impacting the generalization of results. “Black-box” models have also shown strong but limited interpretability in their outcomes. In our case, we have developed a model addressing these concerns by training and validating it with data from two different climates (arid-warm and warm-temperate), enhancing its generalization capacity. Moreover, by employing GP as a “white-box” approach, we achieved greater transparency and understanding of key variables influencing ET0. This analytical focus improves result interpretation and underscores the importance of considering climatic diversity for a more robust and applicable model in various environmental conditions.
On the other hand, from the point of view of39 the annual ETo at the global level is highly correlated with solar radiation and the average annual temperature, especially when considering power or exponential regression functions. Annual ETo exhibits the expected negative correlation with average relative humidity, while it appears to be uncorrelated with wind speed. As solar radiation and temperature increase, the variability of ETo also increases significantly. It is recommended to consider at least two explanatory variables to reduce the effects of heteroscedasticity in the empirical modeling of ETo. However, GP stands out for its effectiveness in solving complex and nonlinear problems that prove challenging to model using traditional approaches. The capability of GP to explore extensive search spaces, coupled with an adaptable representation of solutions in the form of trees or graphs, enables it to address the intrinsic complexity of systems characterized by multiple variables and nonlinear relationships. In our research, we aimed to use commonly measurable meteorological parameters, opting to forego the measurement of solar radiation due to the costly equipment required for its acquisition.
Currently, the methodology has been tested using data representing specific climates. However, in our ongoing effort to enhance and broaden its applicability, we are considering the implementation of the methodology in a wider range of climates, aiming to achieve a more robust generalization. This step towards climatic diversification will allow us to assess and validate the effectiveness of the methodology in diverse environments, encompassing a variety of atmospheric and geographic conditions. This approach will not only extend the utility of the methodology but also reinforce its validity and applicability in a broader context, ensuring effective use in various locations and climatic scenarios. This process of expansion into diverse climates is regarded as a key direction for the future development of the methodology, aiming for a more solid and widespread application.
Conclusions and future work
Accurate estimation of ETo is essential for calculating irrigation requirements and, overall, for water resource management. GP represents a powerful tool capable of developing new models to accurately estimate ETo.
This study presents an evolutionary approach using GP techniques to develop an explicit model to estimate Eto. The proposed model uses the daily climatic parameters of relative humidity, temperature, and wind speed obtained from CIMIS stations and the El Porvenir farm. The model also takes advantage of the expert knowledge provided by the FAO56-PM model. The results surpassed those of the Hargreaves–Samani model in the testing and validation stages. GP techniques have been shown to be a good tool for hydrological studies and can serve as a robust approach that can open a new field for the development of explicit formulations for many hydrological problems.
The model obtained can be used in arid-warm and warm-temperate climates and can be an alternative to the FAO-56-PM reference model in regions where only relative humidity, air temperature, and wind speed data are available. This methodology can be applied by taking other types of climates into account or limiting it to specific hydrological basins.
In future work, the consideration is to work with lysimeter data from arid areas with the aim of developing more accurate models based on measurements rather than estimations, aiming for broader model generalization. On the other hand, there is a plan to expand the data sample for training and validation to include 10, 15, and 20 years of data.
On the other hand, specific research will be conducted in sub-tropical climates, as they pose a significant challenge for ETo models. Choosing to work in this specific climatic context will allow us to test the robustness and applicability of the developed model under more complex and variable conditions. This approach will contribute to a more comprehensive understanding of the model’s effectiveness, enhancing its generalization capability and utility across diverse climatic conditions.
Data availability
The datasets analyzed during the current study are available upon registration in the California Irrigation Management Information System (CIMIS) repository, https://cimis.water.ca.gov/.
Code availability
Not applicable for that section.
References
McMahon, T., Finlayson, B. & Peel, M. Historical developments of models for estimating evaporation using standard meteorological data. Wiley Interdiscip. Rev. Water 3(6), 788–818 (2016).
Allen, R. G., Pereira, L. S., Raes, D. & Smith, M. Evapotranspiración del Cultivo: Guías Para la Determinación de los Requerimientos de Agua de Los Cultivos Vol. 298 (FAO, 2006).
Wanniarachchi, S. & Sarukkalige, R. J. H. A review on evapotranspiration estimation in agricultural water management: Past, present, and future. Hydrology 9(7), 123 (2022).
Meraz-Maldonado, N. & Flores-Magdaleno, H. J. W. Maize evapotranspiration estimation using Penman–Monteith equation and modeling the bulk canopy resistance. Water 11(12), 2650 (2019).
Hargreaves, G. H. & Allen, R. G. History and evaluation of Hargreaves evapotranspiration equation. J. Irrig. Drain. Eng. 129, 53–63 (2003).
Gavilán, P., Lorite, I., Tornero, S. & Berengena, J. J. Regional calibration of Hargreaves equation for estimating reference ET in a semiarid environment. Agric. Water Manag. 81(3), 257–281 (2006).
Ankur Srivastava, A. S. et al. Modelling the dynamics of evapotranspiration using Variable Infiltration Capacity model and regionally calibrated Hargreaves approach. Irrig. Sci. 36, 289 (2018).
Zhang, Z., Gong, Y. & Wang, Z. J. Accessible remote sensing data based reference evapotranspiration estimation modelling. Agric. Water Manag. 210, 59–69 (2018).
Srivastava, A. et al. Evaluation of variable-infiltration capacity model and MODIS-terra satellite-derived grid-scale evapotranspiration estimates in a River Basin with Tropical Monsoon-Type climatology. J. Irrig. Drain. Eng. 143(8), 04017028 (2017).
Jovic, S., Nedeljkovic, B., Golubovic, Z. & Kostic, N. Evolutionary algorithm for reference evapotranspiration analysis. Comput. Electron. Agric. 150, 1–4 (2018).
Guven, A., Aytek, A., Yuce, M. I. & Aksoy, H. Genetic programming-based empirical model for daily reference evapotranspiration estimation. Clean-Soil Air Water 36, 905–912 (2008).
Shiri, J. et al. Generalizability of gene expression programming-based approaches for estimating daily reference evapotranspiration in coastal stations of Iran. J. Hydrol. 508, 1–11 (2014).
Ferreira, L. B., da Cunha, F. F., de Oliveira, R. A. & Fernandes Filho, E. I. Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM—A new approach. J. Hydrol. 572, 556–570 (2019).
Trajkovic, S., Todorovic, B. & Stankovic, M. Forecasting of reference evapotranspiration by artificial neural networks. J. Irrig. Drain. Eng. 129, 454–457 (2003).
(CIMIS)®. The California irrigation management information system, accessed March 2022; https://cimis.water.ca.gov/Default.aspx (2022).
Shiri, J. et al. Daily reference evapotranspiration modeling by using genetic programming approach in the Basque country (northern Spain). J. Hydrol. 414, 302–316 (2012).
Kumar, M., Raghuwanshi, N., Singh, R., Wallender, W. & Pruitt, W. Estimating evapotranspiration using artificial neural network. J. Irrig. Drain. Eng. 128, 224–233 (2002).
Feng, Y., Cui, N., Gong, D., Zhang, Q. & Zhao, L. Evaluation of random forests and generalized regression neural networks for daily reference evapotranspiration modeling. Agric. Water Manag. 193, 163–173 (2017).
Granata, F. J. Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric. Water Manag. 217, 303–315 (2019).
Liu, Q. et al. Genetic algorithm-optimized extreme learning machine model for estimating daily reference evapotranspiration in Southwest China. Atmosphere 13(6), 971 (2022).
Allen, R. G. et al. Crop Evapotranspiration-Guidelines for Computing Crop Water Requirements-FAO Irrigation and Drainage Paper 56 Vol. 300, D05109 (FAO, 1998).
Hargreaves, G. H. & Samani, Z. A. Reference crop evapotranspiration from temperature. Appl. Eng. Agric. 1, 96–99 (1985).
Ahooghalandari, M., Khiadani, M. & Jahromi, M. E. Developing equations for estimating reference evapotranspiration in Australia. Water Resour. Manag. 30, 3815–3828 (2016).
Oudin, L. et al. Which potential evapotranspiration input for a lumped rainfall–runoff model?: Part 2—Toward a simple and efficient potential evapotranspiration model for rainfall–runoff modeling. J. Hydrol. 303, 290–306 (2005).
Koza, J. Genetic Programming: On the Programming of Computers by Means of Natural Selection (The MIT Press, 1992).
Koza, J. R., Bennett III, F. H., & Stiffelman, O. Genetic programming as a Darwinian invention machine. Paper presented at the European Conference on Genetic Programming (1999).
Banzhaf, W., Nordin, P., Keller, R. E. & Francone, F. D. Genetic Programming: An Introduction: On the Automatic Evolution of Computer Programs and Its Applications (Morgan Kaufmann Publishers Inc, 1998).
Angeline, P. J., & Pollack, J. Evolutionary module acquisition. Paper presented at the Proceedings of the second annual conference on evolutionary programming (1993).
Köppen, W., & Geiger, G. Handbuch der klimatologie-gebrüder borntraeger (1930).
Google Maps. Geographical location of weather stations, consulted 24 September 2022; https://www.google.com.mx/maps (2022).
Google. Brand Resource Center. Geographic guidelines, consulted 24 September 2022; https://about.google/brand-resource-center/products-and-services/geo-guidelines/ (2022).
Mobilia, M. & Longobardi, A. Prediction of potential and actual evapotranspiration fluxes using six meteorological data-based approaches for a range of climate and land cover types. ISPRS Int. J Geo-inf. 10(3), 192 (2021).
Papale, D. et al. Towards a standardized processing of Net Ecosystem Exchange measured with eddy covariance technique: Algorithms and uncertainty estimation. Biogeosciences 3(4), 571–583 (2006).
Sreekanth, J. & Datta, B. Multiobjective management of saltwater intrusion in coastal aquifers using genetic programming and modular neural network based surrogate models. J. Hydrol. 393, 245–256 (2010).
Mehdizadeh, S., Behmanesh, J. & Khalili, K. Using MARS, SVM, GEP and empirical equations for estimation of monthly mean reference evapotranspiration. Comput. Electron. Agric. 139, 103–114 (2017).
Mattar, M. A. Using gene expression programming in monthly reference evapotranspiration modeling: A case study in Egypt. Agric. Water Manag. 198, 28–38 (2018).
Pandir, Y. & Ulusoy, H. New generalized hyperbolic functions to find new exact solutions of the nonlinear partial differential equations. J. Math. https://doi.org/10.1155/2013/201276 (2013).
Allen, R. G. et al. Conditioning point and gridded weather data under aridity conditions for calculation of reference evapotranspiration. Agric. Water Manag. 245, 106531 (2021).
Tegos, A. et al. Parametric modelling of potential evapotranspiration: A global survey. Water 9(10), 795 (2017).
Acknowledgements
The authors would like to thank TecNM project 14813.22-P and CONACYT for the support of the doctoral scholarship.
Funding
The authors declare that they received no funds, grants, or other support during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
F.J.R. worked on the conceptualization of the research, on the implementation of the methodology used, on the development of the research, on the processing and standardization of the data, and on the original preparation of the paper and was one of the main contributors to the manuscript. A.M. worked in the research conceptualization process, in the validation and formal analysis of results, in the development of the research, in the review, translation and editing of the manuscript, and in the supervision of the research. E.C. worked on the conceptualization of the research, on the implementation of the methodology used in the research and was one of the main contributors to the technique used in the research. He also collaborated in the formal analysis of results, in obtaining and processing the data, in reviewing and editing the manuscript, and in supervising the research. J.J.F. His contribution was in the validation and formal analysis of the results, in the development of the research, in the review and editing of the manuscript, and in the supervision of the manuscript. In the course of our investigation, no experimental procedures involving human subjects were undertaken.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ruiz-Ortega, F.J., Clemente, E., Martínez-Rebollar, A. et al. An evolutionary parsimonious approach to estimate daily reference evapotranspiration. Sci Rep 14, 6736 (2024). https://doi.org/10.1038/s41598-024-56770-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-56770-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
