
Abstract
Childhood obesity is a complex disorder that appears to be influenced by an interacting system of many factors. Taking this complexity into account, we aim to investigate the causal structure underlying childhood obesity. Our focus is on identifying potential early, direct or indirect, causes of obesity which may be promising targets for prevention strategies. Using a causal discovery algorithm, we estimate a cohort causal graph (CCG) over the life course from childhood to adolescence. We adapt a popular method, the so-called PC-algorithm, to deal with missing values by multiple imputation, with mixed discrete and continuous variables, and that takes background knowledge such as the time-structure of cohort data into account. The algorithm is then applied to learn the causal structure among 51 variables including obesity, early life factors, diet, lifestyle, insulin resistance, puberty stage and cultural background of 5112 children from the European IDEFICS/I.Family cohort across three waves (2007–2014). The robustness of the learned causal structure is addressed in a series of alternative and sensitivity analyses; in particular, we use bootstrap resamples to assess the stability of aspects of the learned CCG. Our results suggest some but only indirect possible causal paths from early modifiable risk factors, such as audio-visual media consumption and physical activity, to obesity (measured by age- and sex-adjusted BMI z-scores) 6 years later.
Similar content being viewed by others

Introduction
Childhood obesity is a serious public health problem in many countries1 leading to severe co-morbidities in later life such as type 2 diabetes, cardiovascular diseases, certain types of cancer, depression and other psychosocial problems2,3,4. Prevention of obesity in children and adolescents seems to be the “only feasible solution” to tackle the obesity epidemic5. But prevention strategies need promising targets to achieve any public health effect. However, childhood obesity is a complex disorder that appears to be influenced by an interacting system of individual behaviour, group and societal settings such as family, school or the country-specific infrastructure (e.g. public health system, built environment)6.
While most investigations focus on single exposure-outcome associations, our approach is to assess the complex interplay of obesity-related factors over the transition from childhood to adolescence by estimating a “cohort causal graph” (CCG), i.e. a causal graph that allows for the longitudinal structure of cohort data, including early life, individual, familial and social aspects using data from the European IDEFICS/I.Family cohort7. Causal discovery is still rarely used in medicine8, epidemiology9,10, with the most of them in the field of genetics11,12. This might be because the available methodologies and available software were previously limited to handling simple data structures. For the first time, our analysis infers a causal graph from observational data in which we simultaneously account for the temporal order of the covariates13,14, mixed variable scales and missing values11. The main aim is to identify plausible causal paths from early modifiable risk factors, such as diet, physical activity (PA), media consumption, subjective well-being and sleep, to body mass index (BMI) 6 years later. These may suggest or rule out potential targets for future obesity prevention strategies.
Methods
Study population
The IDEFICS/I.Family cohort7,15 is a European cohort study initiated with the overall aims to identify and prevent dietary and lifestyle induced health effects in infants, children and adolescents. The baseline survey (B) was conducted in 2007/08 in eight European countries (Belgium, Cyprus, Estonia, Germany, Hungary, Italy, Spain and Sweden) with 16,229 participating children (2 to 9.9 years old). The first follow-up examinations (FU1, conducted in 2009/10) included 13,596 children and applied the same standardised assessments. The second follow-up examinations (FU2, conducted in 2013/14) enrolled 7105 children who already participated at B or FU1.
Ethical approval was obtained from the responsible ethics committees in each country and all research was performed in accordance with the Declaration of Helsinki principles (Belgium: Ethics Committee of the University Hospital Ghent (EC UZG 2007/243, B670201316342); Cyprus: National Bioethics Committee (EEBK/EM/2007/16, EEBK/ETI/2012/33); Estonia: Tallinn Medical Research Ethics Committee of the National Institutes for Health Development (1093, 128); Germany: Ethics Committee of the University Bremen (16/01/2007, 11/12/2012); Hungary: Scientific and Research Ethics Committee of the Medical Research Council Budapest (22-156/2007-1018EKU, 4536/2013/EKU); Italy: Ethics Committee of the Health Office Avellino (2/CE, 12/12); Spain: Ethics Committee for Clinical Research of Aragon (PI07/13, PI13/0012); Sweden: Regional Ethical Review Board of Gothenburg (264-07, 927-12). All children and their parents provided oral and written informed consent, respectively, before examinations and/or the collection of samples, subsequent analysis and storage of personal data and collected samples. Teens older than 12 years were asked to provide their written consent using a simplified version of the consent form. Study subjects and their parents could opt out of each single study component.
Covariates
We included variables reflecting eating behaviour, lifestyle, social, cultural and environmental factors that are assumed to be related to overweight and obesity across the early life course. A detailed description of all measurements and their units used in our analysis is provided in Table 1 and in the supplement. Some of these variables are time-invariant and would not be targeted by any intervention programme in later childhood, such as region of residence or migration background. Other time-invariant variables might impact a child’s development during pregnancy and as an infant, such as mother’s age at birth or breastfeeding duration; we will refer to these as early life factors. All other variables are time-varying and were measured repeatedly. Age- and sex-specific BMI z-scores (BMI) for children and adolescents were calculated according to the extended IOTF criteria16; for simplicity we refer to these as BMI. Mother’s BMI was assessed at each survey in kg/m2. The homeostatic model assessment (HOMA-IR, short HOMA) index17 served as a marker for insulin resistance. The diet of the child was measured by a validated FFQ18 and was classified by an adapted version of the Youth Healthy Eating Index (YHEI)19. The YHEI assesses the consumption frequencies of both healthy and unhealthy food as well as eating behaviours, where a higher score indicates a healthier diet20. PA was measured by questionnaire, and an audio-visual media consumption score (AVM) was used as proxy for sedentary behaviour. Total sleep duration including nocturnal sleep was estimated based on 24-h dietary recall data at baseline21 and quantified by self-reports at the two follow-ups. Multiple dimensions of psychosocial well-being were assessed by questionnaire which was developed for parents’ response on behalf of children and adolescents22. Children above the age of 12 completed the questionnaires for themselves. Further details on the study population and used covariates are given in the supplement.
Statistical analysis
For our analyses, only children who participated in all three surveys were considered. Multiple imputation (MI) was applied to avoid loss of study subjects and to reduce potential bias due to missing values23; specifically we used tenfold imputation with random forests as implemented in the R-package mice24. MI assumes that values were missing at random (MAR). To strengthen the plausibility of the MAR assumption, the imputation models were fitted on a larger dataset containing additional variables that contribute to the various scores such as AVM or well-being23.
To estimate the cohort causal graph (CCG), we applied a method of causal discovery known as PC-algorithm25,26. The algorithm outputs empirically plausible causal directed acyclic graphs (causal DAGs) suggesting direct and indirect causal relations, as shown by directed edges or directed paths. We chose this particular algorithm because other, especially likelihood-based approaches typically make more implicit or explicit distributional assumptions which would seem highly implausible for the given cohort data. While the PC-algorithm also makes assumptions, there is some more robustness of our approach, e.g. in the context of multiple imputation27. As a DAG represents certain conditional (in)dependencies between variables28, the PC-algorithm proceeds by investigating conditional independencies in the data using statistical tests, and then determines all DAGs that agree with these independencies. The result is not unique since different DAGs can represent the same conditional independencies, i.e. certain causal structures are indistinguishable. Instead, the algorithm outputs the equivalence class of all DAGs that represent the detected conditional independencies. This class is represented by a so-called completed partially directed acyclic graph (CPDAG)29 containing directed and undirected edges, where an undirected edge means that both causal directions occur in the equivalence class. The validity of the PC-algorithm relies on the assumptions of causal sufficiency, i.e. absence of latent confounding, and of faithfulness, under which the PC-algorithm consistently selects the true CPDAG25. Of note, while the causal interpretation of directed edges or paths in the output of causal discovery algorithms relies on causal sufficiency, which may often be implausible, the absence of such edges and paths can still be interpreted as absence of causal relations even without causal sufficiency.
The PC-algorithm had to be modified for application to multiply imputed cohort data11,27,30. Further, to account for the cohort structure we used the tiered PC-algorithm tPC31. This was then combined with functions from micd32 to deal with multiply imputed data containing a mix of categorical and continuous variables. The R packages micd and tPC are both extensions of pcalg33. The tPC-algorithm outputs a maximally oriented partially directed acyclic graph (MPDAG), which is similar to a CPDAG but can contain more directed edges due to background knowledge13,34. tPC determines an MPDAG under the restriction that edges are prohibited from pointing backwards in time which also reduces the number of required statistical tests for conditional independencies. In our analysis we pre-specified the following ordering: region, sex and migration → ISCED and income at baseline → all early life factors → baseline variables → ISCED and income at FU1 → remaining FU1 variables → ISCED and income at FU2 → remaining FU2 variables. Additionally, specific orientations between certain pairs of variables were prohibited, for example from breastfeeding to birth weight. We carried out a number of alternative and sensitivity analyses to check the robustness of the estimated MPDAG against specific analytical choices: (a) while the main analysis used a nominal level of 0.05 for the conditional independence tests, we compared this with a nominal level of 0.1 (MI-0.1); (b) using test-wise deletion (TWD) instead of MI and (c) applying a different, likelihood-based, causal discovery algorithm which uses the EM algorithm for missing values35. Moreover, to assess the general stability of the output we drew 100 bootstrap samples from the analysis data, applied to each a single random forest imputation using the same imputation model as in the main analysis, and then estimated 100 bootstrap graphs (BGs). Thus, we can take the frequencies of interesting causal structures in the bootstrap samples as indication of their stability, e.g. specific edges (direct causal links) or indirect links via (partially) directed paths between exposures and outcome. In a directed path, all edges between two nodes are directed, while in a partially directed path, at least one edge between two nodes is undirected. More background on causal graphs and other graph characteristics are described in the supplement.
Results
Study sample
The study sample included 5,112 children who participated in all three surveys. Table 2 shows that children were on average aged 5.9 years at baseline and 11.7 years at FU2. At baseline, 12.6% of the children have overweight and 6.7% suffer from obesity. BMI z-scores increased on average by approx. 0.2 standard deviations (SD) over the years (0.32 to 0.55). The overall number of missing values was 15% with some variables exhibiting very large numbers of missings such as PA at FU2 (50.1%) (see Figure S1 and Table S1 characteristics after imputation). Diagnostic plots of the multiply imputed data were satisfactory (see Figure S2).
Cohort causal graph
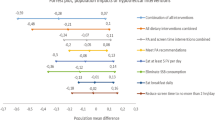
The CCG resulting from our main analysis is shown in Fig. 1 (see also https://bips-hb.github.io/ccg-childhood-obesity for an interactive graph). Overall the graph had 104 edges linking 51 variables, of which 12 could not be oriented. Focusing on BMI as outcome, there were direct links from region, familial educational level, birthweight and mother’s BMI (B) to BMI (B); in contrast, there were no paths from any of the modifiable risk factors to BMI (B). However, all of these modifiable baseline factors (sleep, AVM, YHEI, PA, well-being) were possible ancestors and hence possible causes of BMI in both follow-ups (cf. Table 3), i.e. they had partially directed paths to BMI. These included paths from all five modifiable baseline risk factors to BMI six years later. For instance, there were five partially directed paths from YHEI (B) to BMI (FU2) (Fig. 2). Almost all paths between exposures and BMI (FU2) went through AVM (FU1) and HOMA (FU1, FU2), many also through well-being (FU1) and some through YHEI (B). In the CCG we also see that the exposures themselves were moderately interconnected within the same tier and across time, with many orientations of edges among the exposures at FU1 being undecidable. Note also that most repeated measurements were linked by edges with the exception of BMI.

Causal graph of childhood obesity based on N = 5112 European children and adolescents born between 1997 and 2006 estimated by the tiered PC-algorithm for multiple imputed datasets. The nodes colours correspond to the different stages of the life course. Edges without arrowheads could not be orientated by the algorithm. An overlap of nodes and edges was unavoidable. We advise to look at the interactive graphs here: https://bips-hb.github.io/ccg-childhood-obesity/. AVM audio-visual media consumption, B baseline, FU1 first follow-up, FU2 second follow-up, HH diet: month when the child was introduced into the household's diet, HOMA homeostatic model assessment-insulin resistance, ISCED highest parental education (International Standard Classification of Education), PA physical activity, YHEI youth healthy eating index, zBMI body mass index z-score.

All five possible causal paths between the Youth Healthy Eating Index (YHEI) at baseline and zBMI at the second follow-up (AVM audio-visual media consumption, PA physical activity). AVM audio-visual media consumption, B baseline, FU1 first follow-up, FU2 second follow-up, HH diet month when the child was introduced into the household's diet, HOMA homeostatic model assessment-insulin resistance, ISCED highest parental education (International Standard Classification of Education), PA physical activity, YHEI youth healthy eating index, zBMI body mass index z-score.
Bootstrap analysis
We assessed the stability of selected features of the main CCG based on 100 BGs. Of the 104 edges in the main CCG, 36 were found in more than 80% of BGs, with a further six edges in more than 70% of BGs (see Table S2). Of these edges, 16 were between repeated measures of the same variable, e.g. HOMA.FU1-HOMA.FU2, and 13 emanated from modifiable risk factors. In contrast, 50 edges occurred in 50% or fewer of the BGs. The presence of any paths from exposures to BMI was rather stable. Specifically, we considered directed or partially directed paths from baseline modifiable exposures to later BMI (FU2) (see Table 4). The most frequent were paths from YHEI to BMI (84% of BGs), while paths from sleep duration to BMI were in 75% of the BGs; paths from the other three baseline exposures (well-being, AVM, PA) to BMI occurred in 80% of the BGs. There were mostly multiple causal paths found between an exposure and the outcome. For instance, the median number of different (partially) directed paths from AVM (B) to BMI (FU2) found in each BG was 20. No BGs ever contained a direct edge from a baseline modifiable exposure to BMI at FU2. Table 5 shows patterns between repeated measurements in the main CCG and the BGs. It can be seen for BMI that in 95 BGs the paths B → FU1 → FU2 or B → FU1 → FU2 ← B were found despite not being contained in the main CCG.
The BGs contained on average 22 edges more than the CCG in the main analysis. For comparison with this main CCG, we constructed a graph containing the same number of edges based on the most frequent edges; this resulted in the inclusion of all edges that occurred in more than 44 of BGs (see Fig. S6). The (structural) Hamming distance between main CCG and BG44 was 56 (73), indicating that about half of the edges between the two graphs are the same.
Sensitivity analyses
Using a larger nominal significance level of 10% (CCG MI-0.1) essentially confirmed the core results from the main graph with only few more edges (Table 6, Fig. S3). The CCGs estimated with two alternative methods for missing values (TWD and EM) were with 40 to 50% more edges less sparse than the main graph (cf. Figs. S4, S5), where only 20% of the edges in the main analysis were also found in the TWD graph. This was also reflected by the Hamming distances, which was large with 205 for TWD compared to the main CCG. The structural Hamming distance, which additionally counts directional changes, indicated for the MI-0.1 graph that the increase of the nominal level resulted in some undirected edges being directed (e.g., well-being (FU2) → YHEI (FU2)), or vice versa, and others to be re-directed (e.g., the edge between PA (B) and YHEI (B)).
Discussion
The estimated CCG suggested rather sparse causal relationships between various variables around childhood obesity, with dependencies of repeated measures across time being the strongest and most stable as one might expect. All the individually modifiable risk factors diet, PA, sleep duration, subjective well-being and audio-visual media consumption at baseline were stably found to be possible indirect, but not direct, causes of BMI 6 years later, mostly via the HOMA index which was closely linked to BMI. Associations between media exposure36,37,38,39, sleep40,41,42, PA40, diet40, well-being41 and insulin resistance measured by HOMA were previously found by others and in the IDEFICS/I.Family cohort, partly in smaller subsets and using different variables such as objective accelerometer-based measurements of PA43,44,45. Insulin resistance is strongly associated with obesity, which is reflected by an undirected edge in the CCG. Excess adipose tissue is a known risk factor for insulin resistance; however, normal-weight children may also be affected46. From the early life factors, birthweight was a (possible) ancestor of BMI (B, FU1, FU2) and formula milk feeding for BMI (FU1, FU2). High birth weight is known to be associated with childhood obesity47; and a recent systematic review describes that there is moderate evidence that breast milk consumption reduces the risk of overweight and obesity at age 2 years and older48.
Overall, our results suggested that early life interventions targeting health behaviours of the child will have some, but only indirect effects on BMI49. Hence, cultural, perinatal and familial variables are potentially more immediate causal influences on obesity. Based on the selected CCG, we might therefore hypothesise that early life interventions alone may be insufficient to prevent childhood obesity. Indeed, Börnhorst et al.49 found that even sustained (over 13 years) and joint hypothetical interventions on multiple modifiable behaviours only reduced the risk of obesity in children from 31 to 25%. Thus, our finding is compatible with the view that the causal structure governing childhood health behaviours and outcomes should be considered from a complex adaptive system's perspective50,51,52. Lee et al.50 emphasize that obesity is shaped by multiple factors which act at different scales such as individual behaviour and physiology, but also genetics, social dynamics, the built environment, and societal forces. As a way forward, Maitland et al.53, for example, describe the practical implementation of a “whole of systems” approach.
Using sensitivity analyses we investigated the robustness of the CCG regarding the handling of missing values and used bootstrap samples to assess the stability of learned graph structures. The method for handling missing values is not negligible as more complex and quite different graphs were estimated using TWD or the EM-algorithm instead of MI. Moreover, it was noticeable that the TWD graph, unlike the CCG, was not able to detect edges between repeated measurements. Witte et al.27 showed that TWD can fail in recovering certain causal structures regardless of the underlying missingness mechanism (MCAR, MAR or MNAR). Further, MI was usually more efficient than TWD, although datasets including variables with mixed measurement scales were more problematic.
We used bootstrap resamples to account for the uncertainty in the selection of the CCG54,55,56. In interpreting the results, it has to be kept in mind that the BGs tended to have more edges than the main CCG, due to spurious dependences induced by sampling with replacement from the given data56,57. We therefore considered the BGs purely as a measure of the stability rather than, say, for estimating edge probabilities. Thus, edge and path frequencies indicate the stability of presence and absence of certain graph structures. While about a third of the learned edges in the main analysis were quite stable, we also found that half of the edges were rather unstable. Similarly, we found that the existence of some paths from early modifiable risk factors to later BMI was quite stable, but the actual paths themselves were very variable, i.e. a particular path may not be selected in more than 20% of BGs. In contrast, the absence of direct links from early modifiable risk factors to later BMI was very stable as these occurred in no BGs. This can be interpreted as the absence of direct causal influences even when the assumption of causal sufficiency is violated.
The main analysis was able to find the expected paths for repeated measurements of HOMA and all modifiable risk factors, but not for BMI, and only partly for daily family meals and mother’s BMI. The BGs runs revealed that missing edges between the repeated measurements of BMI are very rare. The CCG is therefore difficult to explain in this respect. In contrast, the learned CCG suggests the plausible relationship that BMI is conditionally independent of modifiable risk factors given the child's insulin resistance status (HOMA).
The instabilities that we found through the bootstrap analysis might partly be explained by the rather low sample size for the perhaps rather weak associations, the extra uncertainty due to the high proportion of missing values, and the large intervals between follow-ups. Especially the confidence in specific paths might be rather low which is critical. A greater stability would, for instance, be desirable for subsequent analyses that use a learned causal graph to determine adjustment sets to estimate causal effects8. Some graphical rules for identifying adjustment sets just take the adjacent nodes of the exposure into account and others require also the mediators between exposure and outcome, for which reliable knowledge on causal paths is required58,59.
Recently, Peterson, Osler & Ekstrom14 also proposed an extension of the PC-algorithm to include temporal information for inferring a graph from observational data. However, our extensions of the PC-algorithm allows the first application of causal discovery to real-world cohort data accounting jointly for missing values, mixed discrete and continuous variables, and background knowledge such as time-ordering. The required theory and software have only recently been developed11,27.
The IDEFICS/I.Family cohort provides a rich source of phenotypes capturing different dimensions of dietary and lifestyle related health aspects repeatedly measured over the early life course. However, a challenge was the choice of variables included in the analysis; these needed to be sufficiently different (i.e. not measuring the same underlying construct) to find meaningful dependencies between the different dimensions of obesity. The further sensitivity analyses (see web page) showed that different choices yielded slightly different selected CCGs, but the overall message remained the same: adolescents’ BMI was not directly affected by earlier behavioural variables, but had indirect, potentially causal, links through AVM (FU1) and HOMA (FU1, FU2).
Further general sources of bias with observational data could also affect our results, such as reporting or selection bias. However, all participating countries adhered to a harmonised protocol and to quality control procedures ensuring high data quality.
Conclusion
Causal graphs represent causal relationships between variables. An extended version of the PC algorithm now allows learning causal graphs from tiered data including missing values. Such a causal graph discovery analysis was performed on the IDEFICS/I.Family cohort investigating (causal) dependencies underlying childhood and adolescent obesity in 2 to 16-year-old Europeans.
The resulting CCG suggested that cultural, perinatal and familial factors and insulin resistance (HOMA-IR) potentially played a more immediate causal role than individually modifiable risk factors which had stable but only indirect relations with adolescents’ BMI.
Data availability
All CCGs are available as interactive graphs at https://bips-hb.github.io/ccg-childhood-obesity/. The R analysis code is available at https://github.com/bips-hb/ccg-childhood-obesity. All data analyzed within the paper were obtained from the IDEFICS/I.Family cohort and is available from the I.Family consortium (http://www.ifamilystudy.eu) on reasonable request.
References
NCD Risk Factor Collaboration (NCD-RisC) in Collaboration with Pigeot I. Worldwide trends in body-mass index, underweight, overweight, and obesity from 1975 to 2016: A pooled analysis of 2416 population-based measurement studies in 128.9 million children, adolescents, and adults. Lancet 390, 2627–2642 https://doi.org/10.1016/S0140-6736(17)32129-3 (2017).
Ahrens, W. et al. Metabolic syndrome in young children: Definitions and results of the IDEFICS study. Int. J. Obes. 38, S4–S14. https://doi.org/10.1038/ijo.2014.130 (2014).
Skinner, A. C., Perrin, E. M., Moss, L. A. & Skelton, J. A. Cardiometabolic risks and severity of obesity in children and young adults. New. Engl. J. Med. 373, 1307–1317. https://doi.org/10.1056/NEJMoa1502821 (2015).
Weihrauch-Blüher, S. & Wiegand, S. Risk factors and implications of childhood obesity. Curr. Obes. Rep. 7, 254–259. https://doi.org/10.1007/s13679-018-0320-0 (2018).
Lobstein, T., Baur, L. & Uauy, R. Obesity in children and young people: A crisis in public health. Obes. Rev. 5, 4–85. https://doi.org/10.1111/j.1467-789X.2004.00133.x (2004).
Reisch, L. A. & Gwozdz, W. The impact of consumer behavior on the development of overweight in children. An overview. Bundesgesundheitsbla 53, 725–732. https://doi.org/10.1007/s00103-010-1077-0 (2010).
Ahrens, W. et al. Cohort Profile: The transition from childhood to adolescence in European children—How I.Family extends the IDEFICS cohort. Int. J. Epidemiol. 46, 1394–1395 https://doi.org/10.1093/ije/dyw317 (2017).
Lee, J. J. R. et al. Causal determinants of postoperative length of stay in cardiac surgery using causal graphical learning. J. Thorac. Cardiovasc. Surg. https://doi.org/10.1016/j.jtcvs.2022.08.012 (2022).
Anker, J. J., Kummerfeld, E., Rix, A., Burwell, S. J. & Kushner, M. G. Causal network modeling of the determinants of drinking behavior in comorbid alcohol use and anxiety disorder. Alcohol. Clin. Exp. Res. 43, 91–97 https://doi.org/10.1111/acer.13914 (2019).
Miley, K. et al. Causal pathways to social and occupational functioning in the first episode of schizophrenia: Uncovering unmet treatment needs. Psychol. Med. 53, 2041–2049. https://doi.org/10.1017/S0033291721003780 (2023).
Foraita, R. et al. Causal discovery of gene regulation with incomplete data. J. R. Stat. Soc. Ser. A Stat. Soc. 183, 1747–1775. https://doi.org/10.1111/rssa.12565 (2020).
Triantafillou, S. et al. Predicting causal relationships from biological data: Applying automated causal discovery on mass cytometry data of human immune cells. Sci. Rep. 7, 12724. https://doi.org/10.1038/s41598-017-08582-x (2017).
Bang, C. W. & Didelez, V. Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence. Vol. 216 (eds. Evans Robin, J. & Ilya, S.). 119--129 (PMLR, Proceedings of Machine Learning Research, 2023).
Petersen, A. H., Osler, M. & Ekstrøm, C. T. Data-driven model building for life-course epidemiology. Am. J. Epidemiol. 190, 1898–1907. https://doi.org/10.1093/aje/kwab087 (2021).
Ahrens, W. et al. The IDEFICS cohort: Design, characteristics and participation in the baseline survey. Int. J. Obes. 35, S3–S15. https://doi.org/10.1038/ijo.2011.30 (2011).
Cole, T. J. & Lobstein, T. Extended international (IOTF) body mass index cut-offs for thinness, overweight and obesity. Pediatr. Obes. 7, 284–294. https://doi.org/10.1111/j.2047-6310.2012.000064.x (2012).
Peplies, J. et al. Percentiles of fasting serum insulin, glucose, HbA1c and HOMA-IR in pre-pubertal normal weight European children from the IDEFICS cohort. Int. J. Obes. 38, S39–S47. https://doi.org/10.1038/ijo.2014.134 (2014).
Huybrechts, I. et al. Evaluation of the Children’s Eating Habits Questionnaire used in the IDEFICS study by relating urinary calcium and potassium to milk consumption frequencies among European children. Int. J. Obes. 35, S69–S78. https://doi.org/10.1038/ijo.2011.37 (2011).
Feskanich, D., Rockett, H. R. H. & Colditz, G. A. Modifying the Healthy Eating Index to assess diet quality in children and adolescents. J. Am. Diet Assoc. 104, 1375–1383. https://doi.org/10.1016/j.jada.2004.06.020 (2004).
Gwozdz, W. et al. Maternal employment and childhood obesity—A European perspective. J. Health Econ. 32, 728–742. https://doi.org/10.1016/j.jhealeco.2013.04.003 (2013).
Hense, S. et al. Factors that influence weekday sleep duration in European children. Sleep 34, 633–639. https://doi.org/10.1093/sleep/34.5.633 (2011).
Bammann, K., Reisch, L. A., Pohlabeln, H., Williams, G. & Wolters, M. Core questionnaires. In Instruments for Health Surveys in Children and Adolescents (eds. Bammann, K., Lissner, L., Pigeot, I. & Ahrens, W.) (Springer, 2019).
van Buuren, S. Flexible Imputation of Missing Data. 2 edn. (Chapman and Hall/CRC, 2018).
van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 45, 1–67. https://doi.org/10.18637/jss.v045.i03 (2011).
Spirtes, P., Glymour, C. & Scheines, R. Causation, Prediction, and Search. 2 edn (The MIT Press, 2001).
Foraita, R., Spallek, J. & Zeeb, H. Causal directed acylic graphs. In Handbook of Epidemiology (eds. Ahrens, W. & Pigeot, I.) (Springer, 2024) (in press).
Witte, J., Foraita, R. & Didelez, V. Multiple imputation and test-wise deletion for causal discovery with incomplete cohort data. Stat. Med. 41, 4716–4743. https://doi.org/10.1002/sim.9535 (2022).
Didelez, V. Causal concepts and graphical models. In Handbook of Graphical Models (eds. Maathuis, M.H., Drton, M., Lauritzen, S. & Wainwright, M.). Chap. 15 (CRC Press, 2018).
Andersson, S. A., Madigan, D. & Perlman, M. D. A characterization of Markov equivalence classes for acyclic dsigraphs. Ann. Stat. 25, 505–541. https://doi.org/10.1214/aos/1031833662 (1997).
Andrews, R. M., Foraita, R., Didelez, V. & Witte, J. A Practical Guide to Causal Discovery with Cohort Data. arXiv: https://arxiv.org/abs/2108.13395 (2021).
Witte, J. & Foraita, R. Tired PC Algorithm (tPC). R Package v. 1.0.0. https://CRAN.R-project.org/package=tpc (2022).
Foraita, R. & Witte, J. Multiple Imputation in Causal Graph Discovery (MICD). R Package v. 1.1.1. https://CRAN.R-project.org/package=micd (2022).
Kalisch, M., Mächler, M., Colombo, D., Maathuis, M. H. & Bühlmann, P. Causal inference using graphical models with the R package pcalg. J. Stat. Softw. 47, 26. https://doi.org/10.18637/jss.v047.i11 (2012).
Kalisch, M. & Bühlmann, P. Estimating high-dimensional directed acyclic graphs with the PC-algorithm. JMLR 8, 613–636 (2007).
Friedman, N. Proceedings of the Fourteenth International Conference on Machine Learning. 125–133 (Morgan Kaufmann Publishers Inc., 1997).
Barker, A. R. et al. Physical activity, sedentary time, TV viewing, physical fitness and cardiovascular disease risk in adolescents: The HELENA study. Int. J. Cardiol. 254, 303–309. https://doi.org/10.1016/j.ijcard.2017.11.080 (2018).
Guzmán, V. et al. Associations of sleep duration and screen time with incidence of overweight in European children: The IDEFICS/I.Family Cohort. Obes. Facts 15, 55–61 https://doi.org/10.1159/000519418 (2021).
Carson, V. et al. Systematic review of sedentary behaviour and health indicators in school-aged children and youth: An update. Appl. Physiol. Nutr. Med. 41, S240–S265. https://doi.org/10.1139/apnm-2015-0630 (2016).
Sayin, F. K. & Buyukinan, M. Sleep duration and media time have a major impact on insulin resistance and metabolic risk factors in obese children and adolescents. Child Obes. 12, 272–278. https://doi.org/10.1089/chi.2015.0126 (2016).
Peplies, J. et al. Longitudinal associations of lifestyle factors and weight status with insulin resistance (HOMA-IR) in preadolescent children: The large prospective cohort study IDEFICS. Int. J. Behav. Nutr. Phys. Act 13, 97. https://doi.org/10.1186/s12966-016-0424-4 (2016).
Thumann, B. F. et al. Associations between sleep duration and insulin resistance in European children and adolescents considering the mediating role of abdominal obesity. PLoS One 15, e0235049. https://doi.org/10.1371/journal.pone.0235049 (2020).
Fobian, A. D., Elliott, L. & Louie, T. A systematic review of sleep, hypertension, and cardiovascular risk in children and adolescents. Curr. Hypertens. Rep. https://doi.org/10.1007/s11906-018-0841-7 (2018).
Pala, V. et al. Dietary patterns and longitudinal change in body mass in European children: A follow-up study on the IDEFICS multicenter cohort. Eur. J. Clin. Nutr. 67, 1042–1049. https://doi.org/10.1038/ejcn.2013.145 (2013).
Sprengeler, O. et al. Trajectories of objectively measured physical activity and childhood overweight: Longitudinal analysis of the IDEFICS/I.Family cohort. Int. J. Behav. Nutr. Phys. Act 18, 103. https://doi.org/10.1186/s12966-021-01171-2 (2021).
Thumann, B. F. et al. Cross-sectional and longitudinal associations between psychosocial well-being and cardiometabolic markers in European children and adolescents. Psychosom. Med. 82, 764–773. https://doi.org/10.1097/psy.0000000000000845 (2020).
Tagi, V. M., Giannini, C. & Chiarelli, F. Insulin resistance in children. Front. Endocrinol. https://doi.org/10.3389/fendo.2019.00342 (2019).
Yu, Z. B. et al. Birth weight and subsequent risk of obesity: A systematic review and meta-analysis. Obes. Rev. 12, 525–542. https://doi.org/10.1111/j.1467-789X.2011.00867.x (2011).
Dewey, K. et al. USDA nutrition evidence systematic reviews. In The Duration, Frequency, and Volume of Exclusive Human Milk and/or Infant Formula Consumption and Overweight and Obesity: A Systematic Review (USDA Nutrition Evidence Systematic Review, 2020).
Börnhorst, C. et al. The effects of hypothetical behavioral interventions on the 13-year incidence of overweight/obesity in children and adolescents. Int. J. Behav. Nutr. Phys. Act 20, 100. https://doi.org/10.1186/s12966-023-01501-6 (2023).
Lee, B. Y. et al. A systems approach to obesity. Nutr. Rev. 75, 94–106. https://doi.org/10.1093/nutrit/nuw049 (2017).
Rutter, H. et al. The need for a complex systems model of evidence for public health. Lancet 390, 2602–2604. https://doi.org/10.1016/S0140-6736(17)31267-9 (2017).
Swinburn, B. A. et al. The global syndemic of obesity, undernutrition, and climate change: The Lancet Commission report. Lancet 393, 791–846. https://doi.org/10.1016/S0140-6736(18)32822-8 (2019).
Maitland, N. et al. Tracking implementation within a community-led whole of system approach to address childhood overweight and obesity in south west Sydney, Australia. BMC Public Health 21, 1233. https://doi.org/10.1186/s12889-021-11288-5 (2021).
Pigeot, I., Sobotka, F., Kreiner, S. & Foraita, R. The uncertainty of a selected graphical model. J. Appl. Stat. 42, 2335–2352. https://doi.org/10.1080/02664763.2015.1030368 (2015).
Scutari, M. Learning Bayesian networks with the bnlearn R package. J. Stat. Softw. 35, 1–22 (2010).
Steck, H. & Jaakkola, T. Advances in Neural Information Processing Systems (eds. Thrun, S., Saul, L. K. & Schölkopf, B.) (MIT, 2023).
Janitza, S., Binder, H. & Boulesteix, A.-L. Pitfalls of hypothesis tests and model selection on bootstrap samples: Causes and consequences in biometrical applications. Biom. J. 58, 447–473. https://doi.org/10.1002/bimj.201400246 (2016).
Witte, J. & Didelez, V. Covariate selection strategies for causal inference: Classification and comparison. Biom. J. 61, 1270–1289. https://doi.org/10.1002/bimj.201700294 (2019).
Witte, J., Henckel, L., Maathuis, M. H. & Didelez, V. On efficient adjustment in causal graphs. JMLR 21, 1–45 (2020).
Bammann, K. et al. Socioeconomic factors and childhood overweight in Europe: Results from the multi-centre IDEFICS study. Pediatr. Obes. 8, 1–12. https://doi.org/10.1111/j.2047-6310.2012.00075.x (2013).
UNESCO Institute for Statistics (UIS). International Standard Classification of Education: ISCED 2011. (UIS, 2012).
Vanaelst, B. et al. Prevalence of psychosomatic and emotional symptoms in European school-aged children and its relationship with childhood adversities: Results from the IDEFICS study. Eur. Child Adolesc. Psy. 21, 253–265. https://doi.org/10.1007/s00787-012-0258-9 (2012).
Marshall, W. A. & Tanner, J. M. Variations in pattern of pubertal changes in girls. Arch. Dis. Child. 44, 291–303. https://doi.org/10.1136/adc.44.235.291 (1969).
Hamming, R. W. Error detecting and error correcting codes. Bell Syst. Tech. J. 29, 147–160. https://doi.org/10.1002/j.1538-7305.1950.tb00463.x (1950).
Tsamardinos, I., Brown, L. E. & Aliferis, C. F. The max–min hill-climbing Bayesian network structure learning algorithm. Mach. Learn. 65, 31–78. https://doi.org/10.1007/s10994-006-6889-7 (2006).
Acknowledgements
This work was done as part of the I.Family Study (http://www.ifamilystudy.eu/) and GrowH! (https://www.growh.eu) and is published on behalf of its consortia. We thank the IDEFICS and I.Family children and their parents for taking the time to participate in this extensive examination programme. We are grateful for the support provided by school boards, headmasters, teachers, school staff and communities, and for the effort of all study nurses and our data managers, especially Claudia Brünings-Kuppe, Sandra Israel-Georgii and Ramona Siebels. We especially thank our colleagues Antje Hebestreit, Maike Wolters, Christoph Buck, Timm Intemann and Heide Busse for their valuable input to realise this interdisciplinary research.
Funding
Open Access funding enabled and organized by Projekt DEAL. We gratefully acknowledge financial support by the German Research Foundation (DFG, DI 2372/1-1). The IDEFICS study was financially supported by the European Commission within the Sixth RTD Framework Programme Contract No. 016181 (FOOD); the I.Family study was funded by the European Commission within the Seventh RTD Framework Programme Contract No. 266044 (KBBE 2010-14). The GrowH! project is funded by the Joint Programming Initiative “A Healthy Diet for a Healthy Life” (JPI HDHL), a research and innovation initiative of EU member states and associated countries. The funding agencies supporting this work are (in alphabetical order of participating countries): Belgium: Research Foundation—Flanders (FWO); Germany: Federal Ministry of Education and Research (BMBF; grant no. 01EA2102A); Spain: Spanish State Research Agency (AEI); The Netherlands: The Netherlands Organisation for Health Research and Development (ZonMw). This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the ERA-NET Cofund action No. 727565.
Author information
Authors and Affiliations
Contributions
RF, JW, IP, VD conceived and designed the study. RF performed the analysis and interpreted the data. RF and VD drafted the manuscript. VD supervised the work. JW, CB, WG, VP, LR, IP and VD made substantial contributions to the analysis and the interpretation of the data. SDH, LL, FL, DM, LM, TV, MT, IP contributed data. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Foraita, R., Witte, J., Börnhorst, C. et al. A longitudinal causal graph analysis investigating modifiable risk factors and obesity in a European cohort of children and adolescents. Sci Rep 14, 6822 (2024). https://doi.org/10.1038/s41598-024-56721-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-56721-y
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
