
Abstract
Differential evolution (DE) is a robust optimizer designed for solving complex domain research problems in the computational intelligence community. In the present work, a multi-hybrid DE (MHDE) is proposed for improving the overall working capability of the algorithm without compromising the solution quality. Adaptive parameters, enhanced mutation, enhanced crossover, reducing population, iterative division and Gaussian random sampling are some of the major characteristics of the proposed MHDE algorithm. Firstly, an iterative division for improved exploration and exploitation is used, then an adaptive proportional population size reduction mechanism is followed for reducing the computational complexity. It also incorporated Weibull distribution and Gaussian random sampling to mitigate premature convergence. The proposed framework is validated by using IEEE CEC benchmark suites (CEC 2005, CEC 2014 and CEC 2017). The algorithm is applied to four engineering design problems and for the weight minimization of three frame design problems. Experimental results are analysed and compared with recent hybrid algorithms such as laplacian biogeography based optimization, adaptive differential evolution with archive (JADE), success history based DE, self adaptive DE, LSHADE, MVMO, fractional-order calculus-based flower pollination algorithm, sine cosine crow search algorithm and others. Statistically, the Friedman and Wilcoxon rank sum tests prove that the proposed algorithm fares better than others.
Similar content being viewed by others
Introduction
The field of optimization research has experienced significant growth in recent decades, particularly with the widespread utilization of nature-inspired optimization algorithms (NIAs). These algorithms, derived from natural phenomena, are now employed across a multitude of research domains, including engineering design, management science, medical technology, social science, and others. While genetic algorithms (GA)1, differential evolution (DE)2, and particle swarm optimization (PSO)3 remain influential, the landscape has expanded with the introduction of numerous new algorithms inspired by different species and natural processes. This continuous innovation and the development of hybrid techniques underscore the dynamic nature of NIAs, showcasing their relevance and applicability in diverse problem-solving scenarios.
The fundamental domain is categorized into two main classes: evolutionary algorithms (EAs) and swarm intelligent algorithms (SIAs). EAs are rooted in fundamental natural processes, specifically drawing inspiration from Darwinian theory and natural selection. Notable examples include GA1, memetic algorithm (MA)4, scatter search (SS)5, stochastic fractal search (SFS)6, fire-hawk algorithm (FHA)7 among others, as prominent representatives.
On the other hand, SIAs are built upon the collective behavior observed in various species. This category encompasses algorithms such as red fox optimization algorithm (RFO)8, mud ring algorithm (MRA)9, sea horse optimizer (SHO)10, escaping bird search (EBS)11, golden eagle optimizer (GEO)12, clouded leopard optimization (CLO)13, hermit crab shell exchange (HCSE)14, honey badger algorithm (HBA)15, naked mole rat algorithm16 cuckoo search algorithm (CS)17, whale optimization algorithm (WOA)18, grey wolf optimization (GWO)19,20, equilibrium optimizer (EO)21, moth flame optimization (MFO)22 and others. These algorithms leverage the swarming behaviour of different species as a basis for their optimization strategies.
In real world, most of the practical engineering design problems are highly challenging and differential evolution (DE) has been applauded as an efficient problem solver by the evolutionary computing community, due to its simple linear structure, lesser known tuning parameters and versatile applicability23. The major reason for its popularity is because of its splendid performance and ranking in Congress on Evolutionary Computation (CEC) competitions by IEEE for various complex domain research scenarios and benchmark test suites (such as multi-modal, composite, single objective, dynamic, constrained, multi-objective, etc). Numerous efforts have been employed to improve the working efficiency, scalability, speed, robustness and accuracy of DE. Unlike traditional evolutionary programming (EP) and evolutionary strategies (ES), DE is based on the population members generated in the current generation with respect to randomly different members of the search space. Here, no probability based distribution (Gaussian distribution in case of EP and ES, Cauchy distribution in fast EPs) is required to generate new offspring. Numerous recent modifications have been added to DE as self-adaptive DE (SaDE)24, adaptive differential evolution with optional external archive (JADE)25, success-history based adaptive DE (SHADE)26, SHADE with population size reduction hybrid with semi-parameter adaptation of CMA-ES (LSHADE-SPACMA)27, hybrid ES-DE28 and others.
In this paper, a hypothesis of using a relatively new concept of iterative division to improve the exploration (expl) and exploitation (expt) operation and overcome the local optima stagnation is used29. Apart from this, four new modifications are added in the conventional DE to improve its overall performance. Firstly, an adaptive proportional population size reduction mechanism, inspired by GA30, is followed. Secondly, a reducing Weibull distributed31 crossover rate CR is introduced such that during the initial stages, the algorithm performs extensive expl whereas in final stages, expt is followed. The next modification follows the Gaussian sampling mechanism by hybridizing basic search equations to mitigate the problem of premature convergence and reinforce complementary searching capabilities32. Finally, instead of using a simple crossover and mutation operations, new hybridization based on grey wolf optimization (GWO)20 and cuckoo search (CS)29 are incorporated to improve the overall all performance of DE. The proposed algorithm has been named as multi-hybrid differential evolution (MHDE) algorithm. The resulting framework has been integrated with the basic DE and tested on IEEE CEC 200533, CEC 201434 and CEC 201735 test suites, four engineering design problems and three frame design problems. The results indicate that adding additional hybridization and self-adaptivity helps in providing reliable results.
The rest of the research article is given as, “Frame design problems” section provide details about the basics of frame optimization problems. “The proposed algorithm” section describes the proposed approach, its requirement and implementation. In “Numerical examples” section, numerical results on CEC 2005 test suite, CEC 2014 and CEC 2017 benchmark problems are presented whereas in “Real-world applications I: engineering design problems” section, four engineering design problems including pressure vessel design, rolling element bearing design, tension/compression spring design and cantilever beam design are discussed. In “Real-world applications II: frame design problems” section, design of 1-bay 8-story frame, 3-bay 15-story frame and 3-bay 24 story frames are presented. Finally, in “Conclusion” section, insightful conclusions and future recommendations are unearthed.
Frame design problems
Frame design problem is one among the most significant structural engineering design problem and has a diversified design flexibility36. The generalized equation for optimal frame design is given by
For W sections, X is the cross-sectional areas design vector, f(X) represents merit functions, ng is the number of design variables; g(X) is the objective function defined as the volume or weight of the frame structure; \(g_{penalty}(X)\) is defined as a penalty function and is a result of constraint violations on structural response.
The frame structure weight in the form of a function g(X) is given by
where mn is the total members making up the frame; \(L_i\) is the length of the \(i_{th}\) member within the frame; and \(\gamma _i\) density of the material in the \(i_{th}\) member.
The penalty function, \(g_{penalty}(X)\) is given by28:
where n is the number of constraints of the design problem, \(\epsilon _1\) and \(\epsilon _2\) are constants based on expl and expt, and \(o_i\) is the displacement or stress constraint. If \(o_i\) has a positive value, the corresponding value is added to the constraint functions. These constraints consist of
Element stresses
Maximum latent displacement
Inter-story displacements
where \(\sigma _i\) and \(\sigma _i^a\) is the stress and allowable stress in the ith member respectively; \(\Delta T\) is the maximum latent displacement; ns is the total number of stories; R and \(d_j\) is the maximum drift index and inter-story drift respectively; H and \(h_j\) is the height of the frame structure and story height of jth floor; \(R_I\) represents the inter-story drift index allowed by AISC 200128 and is set to 1/300. The constraints as per LRFD interactions formulas o AISC 2001 are given by
where \(P_u\) and \(P_n\) is the required and nominal tension or compression axial strength respectively, \(\phi _c =0.9\) and \(\phi _c=0.85\) are the resistance factor for tension and compression respectively, \(\phi _b=0.90\) is the flexural resistance reduction factor; \(M_{ux}\) and \(M_{uy}\), \(M_{nx}\) and \(M_{ny}\) are the flexural’s required strength and flexural nominal strengths respectively in the x end y direction. For a two-dimensional structure, the value of \(M_{ny}=0\).
In order to find the Euler and compression stresses, the effective length factor K is required. For bracing and beam members, \(K=1\) and for the column members, it is calculated by using SAP2000. For a generalized case, the approximate effective length within \(-1.0\%\) and \(+2.0\%\) accuracy are based on Dumonteil37 and are given by
where \(G_A\) and \(G_B\) at the two end joints A and B of the column section is the stiffness ratio of two columns and girders respectively.
The proposed algorithm
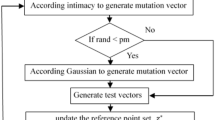
It is already known that even though a lot of new DE variants have been proposed, but it still suffers from various problems including poor expl, unbalanced expl versus expt operation and premature convergence23. Therefore, it becomes necessary to adopt changes, hybridize and add prospective modifications in the basic algorithm to overcome its inherent drawbacks and limitations. In the present work, the structure of DE is changed, and new adaptations are added in the crossover and mutation operation of the algorithm. Here GWO based equations20 are added in the crossover phase to improve the expl operation whereas mutation operation is enhanced by using CS based29 hybridization to enhance the expt operation. Apart from these modifications, the concept of iterative division is added so that considerable expl and exhaustive expt is performed towards the start whereas substantial expt and in-depth expl is performed with in certain sections towards the end29. The proposed MHDE is presented in the following steps:
Initialization
The first and the foremost step, like any other algorithm, in the MHDE algorithm is the initialization phase. Here new solutions are selected randomly within the search space. The general equation is thus given by
where \(n_{min,j}\) and \(n_{max,j}\) are the lower bounds and upper bounds and \(x_{i,j}\) is ith solution of a j dimensional problem (D), and U(0, 1) is a uniform random number distributed over [0, 1].
Mutation operation
At each generation, DE employs crossover operation, which is controlled by a scaling factor. The target solution is achieved by different mutation strategies. The most popular strategies are given by23
where \(x_i^t\) and \(x_j^t\) are the random solutions corresponding to the ith and jth member with D dimension, \(o_i^t\) is the velocity corresponding to the target solution, F is the scaling factor, \(x_{best}\) is the best solution and t is the current iteration. Here the equation derived from DE/rand/1 is more of an exploratory nature with increased diversity among the search agents whereas DE/best/1 has intensification properties, which promotes exploitative search around the best solution. In the proposed MHDE, both these equations are used in an adaptive manner and is explained as
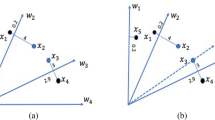
For the first half of the iterations, DE/rand/1 equation is used along with GWO based equations to perform the global search operation. The scaling factor uses Lévy distribution, as discussed in subsequent subsections. Here, GWO based equations are used to perform expt and expl. This is possible because of the presence of better expl capabilities of GWO20. The new solutions generated using modified equations is thus given by
where \(W_1, W_2, W_3\) and \(H_1,H_2,H_3\) are generated randomly from \(W=2a.e_1-a\) and \(H=2.e_2\), a is a linearly decreasing random number \(\in [0,2]\) whereas \(e_1\) and \(e_2\) lies between [0, 1]. The whole search process consists of DE/rand/1 equation and the new GWO inspired equations, which helps the algorithm in enhancing its expl properties.
For the other iterative half, the DE/best/1 equation along with Gaussian random sampling is used32. The general equation for this phase is the same as DE/best/1 equation with an additional advantage of the Gaussian mutation to deal with the local best solution. Here, m new solutions are spawned and compared in accordance with \(x_{best}\). If the new solution m is better than \(x_{best}\), \(x_{best}\) is replaced by the new solution. Also, it is only followed if the local best solution is not improving in a single iteration. For this strategy, the general equation is given by:
where G(0, 1) is a random number. Apart from this modification, the whole search operation is the same as the DE/best/1 equation. The main goal is to search for potential global best solution without getting trapped in local optimal solution. The search process is followed for consecutive iterations and over the course of time, the final best solution is updated. Thus, overall helps in reinforcing complementary searching capabilities32 to prevent the algorithm from local optima stagnation.
Crossover operation
Crossover (can be arithmetic, exponential or binomial) is the next step of DE and is meant for creating the final offspring vector \(x_i^t\). Here, the most commonly used binomial crossover operation is used. In this kind of crossover, each component of \(x_i^t\) either comes from the mutated vector \(o_i^t\) or \(x_i^t\) itself, and is given as
where \(rand_k[0,1] \in [0,1]\) and is continuously changed with respect to the jth part of the ith member of the population, CR is crossover rate and helps in controlling the extent of \(o_i^t\) and \(X_i^t\). This parameter is really important and helps in balancing expl as well as expt operation. In the proposed MHDE algorithm, modification has been added in the solution \(x_i^t\) (used in Eq. 18). Here the solution \(x_i^t\) is not the previous solution but is based on the local search equation of the CS algorithm and the general equation is given by
Here all the notations are the same as discussed in the mutation operation, apart from \(\epsilon \) which is a uniformly distributed random number generated using an adaptive strategy (discussed in subsequent subsections) and lies in the range of [0, 1]. The main aim is to equally balance the local and the global search without losing the diversity among the search agents. Here mutation is performed using Eq. (19), which helps the algorithm in providing extensive search capabilities and instead of using a previous solution, a new generalized solution is used for maintaining diversity among the search agent (intensive expt operation). The next step is selection operation.
Selection operation
For any minimization process, the fitness \(f(x_i^t)\) for the \(x_i^t\) solution is given by Eq. (20)
Here a generalized Roulette wheel selection mechanism is followed to find the final best solution. The next section deals with the various parameters of the proposed algorithm.
Parametric adaptation
In DE, a balanced expl and expt operation is achieved by optimizing F and CR. One among the earliest studies were conducted by38 where efficient values were \(0<\textit{CR}<0.2\) and \(0.4<\textit{F}<0.95\), while in39, values of \(0.1<\textit{CR}<1.0\) and \(0.15<\textit{F}<0.5\) were used and in24 self-adaptive F and CR provided better results. Overall, CR and \(F \in [0,1]\). The parameter F is meant for improving the expl properties of DE and in present work, Lévy flights are used to imitate this operation. The Lévy flight mechanism is highly efficient and generates larger step sizes, enhancing the expl properties. The step size based on Lévy flights is generated as
where \(\hspace{5pt} s=\frac{U}{|V|^1/\lambda }\hspace{2pt} U\sim N(0,\sigma ^2), \hspace{10pt}V\sim N(0,1)\) and \( \sigma ^2=\bigg \{\frac{\Gamma (1+\lambda )}{\lambda \Gamma [(1+\lambda )/2]}. \frac{\sin (\pi \lambda /2)}{2^{(\lambda -1)/2}}\). Here \(\lambda =1.5\) and \(\Gamma \) is the gamma function. The parameter N has mean 0 and variance \(\sigma ^2\) and is taken from a Gaussian distribution.
The second parameter CR is mainly meant for drifting the algorithm from expl to expt. Here based on CR, new solutions are kept if it is improved over subsequent iterations and if there is no improvement in the new generation solutions, the solutions are inspired by CS based hybridization. Though, work has been done for improving CR but it has been found that adding adaptive properties can provide more reliable results24. These conclusions pave the way for the requirement of a new distribution, which can help MHDE in a gradual transition from expl to expt without losing the global solution. Here, Weibull distribution has been used to overcome this drawback31. The probability distribution function is given by
where \(f(t)\ge 0\), \(\beta >0\), \(t\ge 0\hspace{5pt} or \hspace{5pt}\gamma \), \(\eta >0\), \(-\infty <\gamma >\infty \). It has three main parameters namely shape (\(\beta \)), scale (\(\eta \)) and location (\(\gamma \)) parameter. In most of the cases, \(\gamma =0\); \(\beta \) helps in switching between different distributions including L-shaped distribution for \(\beta \le 1\), normal distribution for \(\beta =3.602\), bell-shaped for \(\beta >1\) and others. For the present case, the two parameter Weibull distribution is used with \(\eta \) equals to the maximum iterations and \(\beta =2\). The values of Weibull distribution are taken from the literature31.
In the mutation phase, there is a new \(\epsilon \) parameter, inspired from CS, and is meant for improving the local search capabilities of an algorithm. The parameter is adapted in accordance with the scaling factor, as in case of35. The general equation is given by
Here freq, is a fixed function, t and \(t_{max}\) is the current and the maximum iterations. This parameter has been used only during the mutation operation and is intended for exploiting. Thus, three parameters are there to improve overall stability of the proposed MHDE algorithm.
Population adaptation
Population-based algorithms require an initial set of random solutions to start their search operation. Population decides three things, total spawned solutions, maximum function evaluations and complexity of an algorithm. A static population keeps the total function evaluations constant, whereas an adaptive decreasing population can reduce them significantly. The concept of adaptive population was formulated in40 and was extended to GA30. In40 with an increasing solution fitness, the population was decreased whereas for decreasing solution fitness, the population was increased. The major drawback of this formulation was the formation of new clones of existing solutions, paving the way for reduced performance. In30, an opposite adaptation was followed by reducing the population if the best fitness in increasing. For a multimodal problem, the algorithm should be able to optimize large landscapes. Initially, if there is a large population size, the fitness will be very high. The algorithm will explore the search space and, over the course of iterations, starts moving toward some random direction. Here because of the higher fitness, chances are there that new solutions are in the same direction and hence population size can be reduced30. This new population helps to find potential solutions without losing the final best solution. Also, with increase in the iterations, the variation in solution quality is marginal and hence using a smaller population provide many reliable results. This is because, each member in a small population has a higher probability of becoming the local best and eventually the global best solution. The mathematical equation deduced by30 is given as
Here N is the population for the \(t_{th}\) generation, \(\Delta f_t^{best}\) is given by \(\Big (\frac{f_{t-1}^{best}-f_{t-2}^{best}}{|f_{t-2}^{best}|}\Big )\) is change in the best fitness, \(\Delta f_{max}^{best}\) is the threshold value. It should be noted that a minimum fitness must be defined so that all the negative effects of minimal population are minimized.
Numerical examples
The proposed MHDE algorithm is analysed for numerical benchmark datasets and compared with respect to other recent hybrid algorithms. Two benchmark sets have been used, namely classical benchmark problems from CE C2005 test suite33 and CEC2014 test suite25. For comparison on CEC 2005, the major algorithms used are JADE25, Evolution strategy based on covariance adaptation (CMA-ES)21, SaDE41, a sine cosine crow search algorithm (SCCSA)42, extended GWO (GWO-E)20, fractional-order calculus-based FPA (FA-FPO)43, SHADE26 and LSHADE-SPACMA21. On the other hand for CEC 2014 benchmark problems, blended biogeography-based optimization (B-BBO)44, laplacian BBO (LX-BBO)44, random walk GWO (RW-GWO)44, population-based incremental learning (PBIL)45, improved symbiotic organisms search (ISOS)46, variable neighbourhood BA (VNBA)45, chaotic cuckoo search (CCS)45, and improved elephant herding optimization (IMEHO)45 are used.
For all test categories, the parametric details for all the algorithms under comparison is given in Table 1. Apart from the basic parameters, a \(population size = 50\), \(D = 30\) and total of 51 runs is used for evaluation. For CEC2005, the total function evaluations are taken as 15, 000 whereas for CEC2014, the maximum function evaluations are set34 as \(10^4\) \(\times \) D. The results for both the test cases are evaluated as mean error and standard deviation (std)34. It must be noted that the bold values in all the tables signifies the best algorithm corresponding to that particular problem.
For statistical testing, two statistical tests, namely Friedman rank (f-rank) and Wilcoxon’s rank-sum tests47 are used. The results are presented as ranks found by p-values at \(5\%\) level of significance. For every test function, the statistical results are presented as win(w)/loss(l)/tie(t). Here win(w) is the situation where the test algorithm is better than MHDE algorithm, the loss(l) scenario on the other hand, is the situation where the algorithm is worse than MHDE algorithm and “-” sign means tie(t) and it denotes that both the algorithms under consideration are either statistically similar or irrelevant in accordance to each other47. Apart from that, the f-rank is calculated for every function and an average of all the ranks is presented. In the next subsections, analysis on CEC 2005 benchmark problems is presented.
Classical benchmarks
A comparison of MHDE is performed with respect to the well-known variants of DE including JADE, SaDE, SHADE and LSHADE-SPACMA as well as some recently introduced algorithms including GWO-E, SCCSA, FA-FPO and CMA-ES as given by Table 2. Here \(G_1-G_7\) are unimodal functions (for testing expt capabilities), \(G_8-G_{12}\) are multi-modal functions (for a balanced expl and expt operation), and \(G_{13}-G_{15}\) are fixed dimension (convergence analysis), testing the effectiveness and consistency of the MHDE algorithm for finding the optimal solution. These test functions are defined in48 and are not explicitly discussed in the present paper.
The results are presented as mean and std values for 30 dimension size. For \(G_1\), \(G_3\), \(G_4\), \(G_5\), \(G_7\), \(G_{11}\), \(G_{12}\) and \(G_{13}\) functions, the algorithm performs better in comparison to others. For \(G_8\) and \(G_{10}\) functions, GWO-E, FA-FPO and the proposed MHDE performs equivalently whereas for function \(G_9\), SCCSA, FA-FPO have equivalent results with respect to MHDE. Apart from that, JADE is found to be better for \(G_{14}\) and SCCSA for \(G_{15}\) function. The statistical results show that MHDE converges to better solutions than JADE, SaDE, SHADE and LSHADE-SPACMA and others, which indicate that MHDE is an excellent algorithm.
Furthermore, the Friedman f-rank test and Wilcoxon rank sum tests are conducted to analyse the results of MHDE with respect to other algorithms for 51 individual trials for each function. Taking JADE versus MHDE as an example, w/l/t ratio and average f-rank of MHDE is better than JADE, it means that MHDE is significantly better than JADE at the 5% significance level or 95% level of confidence. Thus overall, ranking analysis results between DE variants, MHDE and other algorithms show that the proposed MHDE is significantly better.
Sensitivity analysis is done to check how the newly introduced parameters affect the performance and efficiency of MHDE. In Table 3, five different adjustments are made in the proposed modifications, and two statistical indicators (mean and std) are used to describe it. The same set of parameters and function evaluations are used as used for CEC 2005 benchmark testing. The improved crossover operation helps in performance enhancement for unimodal functions and hence leading to better expt properties. Addition of adaptive F helps in improving the global search capabilities and hence provides better expl. Adding adaptivity in CR and mutation operation helps in enhancing the accuracy for multi-modal functions, whereas adaptive population size N helps in reducing the function evaluations. Furthermore, the results of MHDE at different parameters are all better than JADE, SaDE and other hybrid versions of DE. To sum up, the performance of MHDE is robust and excellent. To further validate the superiority of MHDE with respect to some recently introduced algorithms, CEC 2014 benchmark test suite is used and has been explained in details in the next subsection.
CEC 2014 benchmarks
For CEC 2014 benchmarks, proposed MHDE algorithm and eight recently introduced hybrid algorithms have been selected for comparison. All of these algorithms are enhanced versions of new population-based algorithms and are B-BBO44, LX-BBO44, RW-GWO44, PBIL45, ISOS46, VNBA45, CCS45, and IMEHO45. The mean error and std values of all of these variants on 30 dimension problems are listed in Table 4.
Here, the results by comparing the difference between obtained solution and the desired best solution are found. If the difference becomes less than \(10^{-8}\), the error is treated as zero. From Table 4, it is found that MHDE performs better than all other algorithms under consideration. Here out of three uni-modal functions (\(G_1-G_3\)), MHDE performs better for two among all other algorithms showing superior capability in finding global solution. This further shows that the algorithm has better expl properties. Among multi-modal function (\(G_4-G_{10}\)), MHDE performs better for three functions among all the variants and for rest of the functions it is either ranked second or third. This again shows the superior performance of MHDE for local optima avoidance. For hybrid benchmarks (\(G_{11}-G_{20}\)) and composite benchmarks (\(G_{21}-G_{30}\)), MHDE is found to be the best among all other algorithms. This further proves the capability of MHDE in balancing the expl and expt operation to achieve global best solution. Overall, MHDE is ranked first, RW-GWO is ranked second and IMEHO is ranked third among all the other algorithms under comparison. In the next section, MHDE is used for design of frame structures.
CEC 2017 benchmarks
For a comprehensive evaluation of the proposed MHDE algorithm in comparison to MH algorithms, the SaDE35, SHADE52, JADE35, CV1.029, \(CV_{new}\)53, MVMO35, and CS17 algorithms have been utilized with 51 run and 100 population size. In order to have a fair comparison, a maximum function evaluations as \(10,000 \times D\) is used where \(D = 30\) is the dimension size. The algorithms used for comparison are highly competitive and have proved their worthiness for various CEC competitions. A rank-sum test (in terms of w/l/t) and f-test at 0.05 level of significance47 is done to evaluate the performance of MHDE, along with experimental mean error and standard deviation. The mean error is evaluated by calculating the difference between the obtained values and the global optimum of that problem. From the results in Table 5, the following observations are made. For the first case of unimodal problems, \(H_1\), \(H_2\) and \(H_3\), SHADE, JADE, SaDE, MVMO, and LSHADE give highly efficient results; \(CV_{new}\), CV1.0, CS and MHDE have similar performance and SHADE performed the best for these problems. For the multimodal problems, \(H_4\) to \(H_{10}\), SHADE, MVMO, JADE and SaDE have similar performance and LSHADE gave the best results. For hybrid problems, \(H_{11}\) to \(H_{20}\), CS, \(CV_{new}\), CV1.0, were better than the DE variants, and MHDE was found to be the best among others. For \(H_{21}\) to \(H_{30}\) composite problems, MHDE gives the best performance and is the most significant algorithm among all others under comparison. The results in the last line of Table 5, provides statistical p-values and f-rank, and it is found that with respect to MHDE, LSHADE gives better performance for 16 problems, SHADE for 14 problems, SaDE for 10 problems, JADE for 12 problems, MVMO for 15 problems, \(CV_{new}\) for 6 problems.
Overall comparison shows that MHDE is better than other algorithms for most of the hybrid and composite problems and has poor performance over unimodal and multimodal problems. This further proves the significance of MHDE over statistical and experimental results, for challenging optimization problems.
Real-world applications I: engineering design problems
Here, the effectiveness of the MHDE algorithm is assessed across a range of real-world optimization problems with diverse constraints. To handle constraints, a variety of techniques including decoder functions, repair algorithms, feasibility preservation and penalty functions are employed, as outlined in55. In this study, the focus is to opt for penalty functions due to their simplicity of implementation and widespread adoption. A common method for constraint management through penalty functions is detailed through a specific implementation, as illustrated in the equation below.
The equalities are described by \(g_i(\textbf{x})\) and the inequalities by \(h_j(\textbf{x})\). \(p\) and \(q\) count the number of equality and inequality constraints. Constants \(a_i\) and \(b_j\) are positive. \(n\) and \(\lambda \) are set as 1 or 2. Utilizing a penalty function results in an elevation of the objective function value when constraints are breached. This creates an incentive for the algorithm to steer clear of infeasible areas and prioritize the exploration of feasible regions within the search space.
For performance evaluation, four engineering design problems including, (1) pressure vessel design, (2) rolling element bearing design, (3) tension/compression spring design, and (4) cantilever beam design, are used. The MHDE algorithm is compared with respect to some of the well-known algorithms including, artificial rabbit optimization (ARO)55, taguchi search algorithm (TSA)56, multi-strategy chameleon algorithm (MCSA)56, hybrid particle swarm optimization (HPSO)57, equilibrium optimizer (EO)21, evolution strategies (ES)58, grasshopper optimization algorithm (GOA)59, (\(\mu + \lambda \)) evolutionary search (ES)60, harris hawk optimizer (HHO)56, cuckoo search (CS)55, GCAII55, ant colony optimization (ACO)55, co-evolutionary DE (CDE)60, bacterial foraging optimization algorithm (BFOA)61, symbiotic optimization search (SOS)62, passing vehicle search (PVS)63, meerkat optimization algorithm (MOA)64, red panda optimizer (RPO)65, mine blast algorithm (MBA)66, moth flame optimizer (MFO)56, thermal exchange optimization (TEO)67, GCAI55, co-evolutionary differential evolution (CDE)60, seagull optimization algorithm (SOA)68, co-evolutionary particle swarm optimization approach (CPSO)57, and dynamic opposition strategy taylor-based optimal neighbourhood strategy and crossover operator (DTCSMO)69.
Pressure vessel design
The optimization problem related to pressure vessels design is a widely acknowledged challenge in engineering. The fundamental objective is to minimize costs linked to material acquisition, welding, and the overall fabrication of pressure vessels, as discussed in57. This problem revolves around four key design variables: the thickness of the cylindrical shell represented as \(T_s\), the inside radius of the cylindrical shell denoted as R, the head thickness of the cylindrical shell indicated by \(T_h\), and the length of the cylindrical segment denoted as L. This problem has four constraints, as given by (29) and (30), as shown in Fig. 1.

Pressure vessel design problem.
Consider, \(\textbf{P}=\left[ L_1L_2L_3L_4\right] =\left[ T_sT_hRL\right] \)
Varying range, \(0\le L_1\le 99,\ 0\le L_2\le 99,\ 10\le L_3\le 200,\ 10\le L_4\le 200\)

Convergence of pressure vessel design.
The outcomes pertaining to this design problem are presented in Table 6, where the results are evaluated using different algorithms for comparative analysis. These algorithms encompass MCSA56, ARO55, CPSO75, HPSO57, (\(\mu + \lambda \))ES60, ACO55, CDE60, HHO56, MOA64, RPO65, MFO56, TSA55, MVO56, and others. The convergence patterns are shown in Fig. 2.
After optimization, the values of the variables obtained through MHDE are given by \(x = (0.7781695, 0.3846499, 40.32966, 199.9994)\). The corresponding optimal cost for this design problem is \(f = 5885.3353\). This result significantly outperforms the outcomes achieved by all other algorithms examined in our comparative analysis. The demonstration of such competitive performance serves to affirm the effectiveness of the proposed MHDE algorithm in comparison to the alternative algorithms that were evaluated.
Rolling elemet bearing design
This optimization problem is associated with the load-bearing capacity of rolling elements56, and is represented in Fig. 3. This design problem has ten variables and many constraints. It is mathematically given by
Consider \(\textbf{P} = [J_m, J_b, Z, f_i, f_o, K_{Dmin}, K_{Dmax}, \epsilon , e, \zeta ]\)
where
\(T = J-j-2J_b\), \(J =160\), \(j= 90\), \(B_w = 30\), \(r_i = r_o = 11.033\)
Variable range
\(0.5(J+j)\le J_m \le 0.6(J+j), 0.15(J-j)\le J_b \le 0.45(J-j), 4\le Z \le 50,\)
\(0.515\le f_i \le 0.6, 0.515\le f_o \le 0.6, 0.4 \le K_{Dmin}\le 0.5, 0.6 \le K_{Dmax} \le 0.7, 0.3 \le \epsilon \le 0.4,\)
\(0.02 \le e \le 0.1, 0.6 \zeta 0.85\)

Rolling element bearing design challenges.
In this design example, the algorithms used for comaprion are ARO55, GA263, MBA66, PVS63, TLBO76, SOA68, DTCSMO, PSO, and DE, and results are given in Table 7. The design variables obtained by MHDE for this particular scenario are determined as \( x = (125.7191, 21.2716, 11, 0.5150, 0.5150, 0.4195017, 0.6430438, 0.3000, 0.0310311, 0.6963122)\), and optimized cost is given as \(f = 85549.2391\). From the results in Table 7, it can be seen that the proposed algorithm is highly competitive with respect to other algorithms.
Tension/compression spring design
For a compression spring, there are three design variables, including the wire diameter (d), mean coil diameter (D), and the number of active coils (N). The design is given in Fig. 4. The mathematical formulation is as:
Consider, \(\textbf{P}=\left[ L_1L_2L_3\right] =\left[ dDN\right] \).
Limits, \(0.005\le L_1\le 2.0,\ 0.25\le L_2\le 1.30,\ 2.0\le L_3\le 15.0\)

Tension compression spring design challenge.
In this scenario, a comprehensive comparison is conducted, with respect to RPO, CDE, GCAII55, MMA79, CPSO, SI, ARO55, SOS62, CS55, MFO56, GCAI55, MFO, BFOA, HHO, GOA59, and others, as outlined in Table 9. For this particular case, the optimal design variables derived using the MHDE algorithm are given in Table 8 and Fig. 5, are specified as \(x = (0.0526768, 0.380935, 10)\). The resulting optimized cost is calculated as \(f = 0.012684\). These results prove the significance of the proposed algorithm for tension spring design problem.

Convergence of tension/compression spring design.
Cantilever beam design
This problem is meant for reducing the weight of a cantilever beam, having one constraint and five distinct blocks, representing several design variables, and is given by Fig. 6.
The design problem is mathematically given by Consider variable \(\textbf{P}= [L_1, L_2, L_3, L_4, L_5]\)
Minimize \(f_4(\textbf{P}= 0/0624(L_1+L_2+L_3+L_4+L_5))\)
Subject to \(g_1(\textbf{T})= \frac{61}{L_1^3}+\frac{37}{L_2^3}+\frac{19}{L_3^3}+\frac{7}{L_4^3}+\frac{1}{L_5^3}-1 \le 0\)
Variable range \(0.01 \le P_i \le 100, \hspace{5pt} i =1, \ldots , 5.\)

Cantilever beam design challenge.
A comparison is performed with respect to MFO56, ARO55, SOS62, CS55, GCAII55, GCAI55, MMA79, and GOA59. The results, in Table 9, show that design variables for this problem are \(x = (6.0140, 5.3128, 4.4914, 3.4993, 2.1563)\) and the optimized cost is \(f = 1.34000\). The convergence patterns are given in Fig. 7. Here also, the proposed algorithm is significant with respect to others.

Convergence of cantilever beam design.
Real-world applications II: frame design problems
Here, MHDE algorithm is used for weight minimization of 1-bay 8-story, 3-bay 15-story and 3-bay 24-story structures, respectively. The optimization results are compared with recently introduced hybrid algorithms to prove the significance of MHDE. Also, the frame structure benchmark problems are highly challenging to design due to higher level of difficulty in their implementation80. The figures of the three frames are taken from81.
Meta-heuristic algorithms (MHAs) have emerged as the core of modern optimization research and have set the trend for its use in almost every research domain. MHAs have been found to provide good solutions for frame design problems, and various algorithms have been presented in literature for optimal frame structure designing28,36,82. In the present work, the proposed MHDE is tested for optimizing weights in the frame structures. The termination criteria are based on maximum function evaluation and is inspired from36. The objective function is analysed 20,000 times for 1-bay 8-story frame and 30,000 for 3-bay 15-story frame whereas for 3-bay 24-story frame it is 50,000 respectively. For each problem, the population size used is 50 and a total of 20 independent runs have been performed. Apart from that, it has been kept in mind that there are no violations for a fair comparison among the algorithms. Here, a randomly generated initial population containing both feasible and infeasible solutions has been used to obtain statistically significant results.
Designing 1-bay 8-story frame
For this case, fabrication conditions from the initial foundation steps are achieved by using the same beam section and same column section for every two successive stories. The modulus of elasticity for the material is E = 200 GPa (29000 ksi) and 267 W-shaped sections must be used for choosing cross-sectional areas of all the elements. The only constraint is that the latent drift must be less than 5.08 cm. The design is shown in Fig. 8.
The comparison has been performed with respect to some of GA28, ACO28, DE28, ES-DE28, PSOACO82, HGAPSO82, PSOPC82 and SFLAIWO82. From the experimental results in Table 10, it has been found that MHDE has the minimum weight of 30.70 kN for the frame structure. The other best algorithms, ACO and SFLAIWO having 31.05 kN and 31.08 kN optimized weights respectively, are second and third best. Overall, MHDE provides more reliable results than most of the well-known algorithms reported in literature.

Design of 1-bay 8-story frame81.
Designing 3-bay 15-story frame
For a 3-bay 15-story frame design, the ASIC combined strength constraint and displacement constraint is included as an optimization constraint. The material properties of the frame include: E = 200 GPa (29000 ksi), yield stress \(F_y=248.2\) MPa and sway length on the top must be less than 23.5 cm. The length factor is calculated as \(k_x \ge 0\) for sway permitted frame and the length factor out-of-plane is \(k_y = 1.0\). The length of each beam is 1/5 span length and the design structure is given in Fig. 9.
Here, nine improved algorithms are used for comparison including HPSACO82, HBB-BC82, ICA-ACO36, DE28, ES-DE28, AWEO36, EVPS36, FHO7, SDE36 and SFLAIWO82. From the optimization results in Table 11, it is evident that the minimum weight is obtained by MHDE and is equal to 360.22 kN. The second-best algorithm is SFLAIWO having an optimized weight of 379.21 kN whereas for the third best SDE it is 387.89 kN. In comparison to second best and third-best algorithm, MHDE has a reduced weight of 18.99 kN and 27.67 kN respectively. The optimized average of 20 runs for this frame using MHDE is 364.73 kN with a 2.16 kN std. This further proves the superiority of MHDE algorithm in comparison to others.

Design of 3-bay 15-story frame81.
Designing 3-bay 24-story frame
This frame consists of 168 members28 and must be designed in accordance with LRFD specifications. This frame has a displacement constraint and properties of its material includes, \(E=205\) GPa and \(F_y=230.3\) MPa. The effective length is, \(K_x \ge 0\) and the out-of-plane length is \(K_y =1.0\). Here it should be noted that all the beams and columns are unbraced along the lengths and the design structure is shown in Fig. 10.

Design of 3-bay 24-story frame81.
For fabrication, the first and third bay of each floor uses the same beam section except the roof beam, and hence there are only 4 groups of beams. The initial stages of foundation, interior columns are grouped together over three consecutive stories. Overall, this frame consists of 4 groups of beams and 16 groups of columns, making the total number of design variables 20. The beam elements are chosen from 267 W-shapes, whereas column sections are restricted to W14 (37 W-shapes).
The optimized weights for this example are presented in Table 12. Here MHDE is compared with HBB-BC82, HS37, ICO28 ICA84, HBBPSO82, ES-DE28, AWEO36, FHA7, EVPS36 and SFLAIWO82. Here it has been found that among all the algorithms, MHDE achieved the minimum weight of 904.91 kN. The second and third best are EVPS and SFLAIWO algorithm and here the optimized weight is 905.67 kN and 911.78 kN respectively. The mean weight for 20 independent runs for MHDE is 910.23 kN with 3.78 kN deviation. The best values of results further prove the superiority of MHDE in contrast to other algorithms. Also, the function evaluations used for MHDE is much less than compared to other algorithms. For example, only, 50000 function evaluations are used for MHDE in contrast to SFLAIWO where 168,000 function evaluations have been utilized for weight optimization. Overall, it can be said that in this case also MHDE has superior performance and is easily able to enter the neighbourhood space of the global optimal solution.
Conclusion
This article presented a multi-hybrid algorithm by combing the concepts of iterative division along with adaptive mutation for improved expl, adaptive parameter for a balanced expl and exploitation, population size reduction, and Gaussian random sampling for mitigating the local optima stagnation problem. The new optimization strategy helps to carry out global search in a more efficient way by using GWO based equations. All the above-discussed features ensure good performance of MHDE.
MHDE was evaluated using CEC 2005 classical benchmarks, CEC 2014 and CEC 2017 benchmark datasets. The experimental and statistical results prove that MHDE is superior with respect to DE variants such as JADE, SaDE, SHADE and others. The algorithm was then applied for weight minimization of three frames design problems with discrete variables. Optimization results prove the superior performance and competitiveness of MHDE over other algorithms for frame design also. To summarize, it is concluded that MHDE is reliable and an efficient algorithm for solving complex structural design problems.
Further studies should aim at providing theoretical analysis of the sensitivity and performance of MHDE. More work can be done to find a suitable combination of adaptive parameters to make the algorithm suitable for most of the domain research problems. Another possibility is to introduce some of the recent algorithms instead of GWO or CS for equation modifications, in order to control the search operation for better accuracy. Apart from that, combination of multiple strategies might lead to negative interference in algorithm’s behavior. For example, changing F factor will lead to different expt/expl performance, however if a good step size is achieved, it might not be carried out due to lack of a changed crossover permission. In this sense, a careful sensitivity analysis should be performed in order to verify interference of the proposed strategies combined. Finally, work on the convergence analysis can be performed to provide more insights into the working capabilities of the proposed algorithm.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Holland, J. H. Genetic algorithms. Sci. Am. 267, 66–73 (1992).
Storn, R. & Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 11, 341–359 (1997).
Kennedy, J. & Eberhart, R. Particle swarm optimization, in Proceedings of ICNN’95—International Conference on Neural Networks, Vol. 4, 1942–1948 (IEEE, 1995).
Moscato, P. et al. On evolution, search, optimization, genetic algorithms and martial arts: Towards memetic algorithms. Caltech Concurr. Comput. Prog. C3P Rep.826, 1989 (1989).
Glover, F. A template for scatter search and path relinking, in European Conference on Artificial Evolution, 1–51 (Springer, 1997).
Salimi, H. Stochastic fractal search: A powerful metaheuristic algorithm. Knowl.-Based Syst. 75, 1–18 (2015).
Azizi, M., Talatahari, S. & Gandomi, A. H. Fire hawk optimizer: A novel metaheuristic algorithm. Artif. Intell. Rev. 56, 287–363 (2023).
Połap, D. & Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 166, 114107 (2021).
Desuky, A. S., Cifci, M. A., Kausar, S., Hussain, S. & El Bakrawy, L. M. Mud ring algorithm: A new meta-heuristic optimization algorithm for solving mathematical and engineering challenges. IEEE Access 10, 50448–50466 (2022).
Zhao, S., Zhang, T., Ma, S. & Wang, M. Sea-horse optimizer: A novel nature-inspired meta-heuristic for global optimization problems. Appl. Intell. 53, 1–28 (2022).
Shahrouzi, M. & Kaveh, A. An efficient derivative-free optimization algorithm inspired by avian life-saving manoeuvres. J. Comput. Sci. 57, 101483 (2022).
Mohammadi-Balani, A., Nayeri, M. D., Azar, A. & Taghizadeh-Yazdi, M. Golden eagle optimizer: A nature-inspired metaheuristic algorithm. Comput. Ind. Eng. 152, 107050 (2021).
Trojovská, E. & Dehghani, M. Clouded leopard optimization: A new nature-inspired optimization algorithm. IEEE Access 10, 102876–102906 (2022).
Sharma, A., Sharma, N. & Sharma, H. Hermit crab shell exchange algorithm: A new metaheuristic. Evol. Intell. 1–27 (2022).
Hashim, F. A., Houssein, E. H., Hussain, K., Mabrouk, M. S. & Al-Atabany, W. Honey badger algorithm: New metaheuristic algorithm for solving optimization problems. Math. Comput. Simul. 192, 84–110 (2022).
Salgotra, R. & Singh, U. The naked mole-rat algorithm. Neural Comput. Appl. 31, 8837–8857 (2019).
Salgotra, R., Singh, U., Saha, S. & Gandomi, A. H. Self adaptive cuckoo search: Analysis and experimentation. Swarm Evol. Comput. 60, 100751 (2021).
Salgotra, R., Singh, U. & Saha, S. On some improved versions of whale optimization algorithm. Arab. J. Sci. Eng. 44, 9653–9691 (2019).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Salgotra, R., Singh, U. & Sharma, S. On the improvement in grey wolf optimization. Neural Comput. Appl. 32, 1–40 (2019).
Faramarzi, A., Heidarinejad, M., Stephens, B. & Mirjalili, S. Equilibrium optimizer: A novel optimization algorithm. Knowl.-Based Syst. 191, 105190 (2020).
Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 89, 228–249 (2015).
Das, S., Mullick, S. S. & Suganthan, P. N. Recent advances in differential evolution—An updated survey. Swarm Evol. Comput. 27, 1–30 (2016).
Qin, A. K., Huang, V. L. & Suganthan, P. N. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans. Evol. Comput. 13, 398–417 (2008).
Zhang, J. & Sanderson, A. C. Jade: Adaptive differential evolution with optional external archive. IEEE Trans. Evol. Comput. 13, 945–958 (2009).
Tanabe, R. & Fukunaga, A. Success-history based parameter adaptation for differential evolution, in 2013 IEEE Congress on Evolutionary Computation, 71–78 (IEEE, 2013).
Mohamed, A. W., Hadi, A. A., Fattouh, A. M. & Jambi, K. M. Lshade with semi-parameter adaptation hybrid with CMA-ES for solving CEC 2017 benchmark problems, in 2017 IEEE Congress on Evolutionary Computation (CEC), 145–152 (IEEE, 2017).
Talatahari, S., Gandomi, A. H., Yang, X.-S. & Deb, S. Optimum design of frame structures using the eagle strategy with differential evolution. Eng. Struct. 91, 16–25 (2015).
Salgotra, R., Singh, U. & Saha, S. New cuckoo search algorithms with enhanced exploration and exploitation properties. Expert Syst. Appl. 95, 384–420 (2018).
Hallam, J. W., Akman, O. & Akman, F. Genetic algorithms with shrinking population size. Comput. Stat. 25, 691–705 (2010).
Scholz, F. Inference for the Weibull distribution. Stat 498B Ind. Stat. 632, 59 (2008).
Zhou, X., Wu, Z., Wang, H. & Rahnamayan, S. Gaussian bare-bones artificial bee colony algorithm. Soft. Comput. 20, 907–924 (2016).
Suganthan, P. N. et al. Problem definitions and evaluation criteria for the CEC 2005 special session on real-parameter optimization. KanGAL Rep. 2005005, 2005 (2005).
Liang, J., Qu, B. & Suganthan, P. Problem definitions and evaluation criteria for the cec 2014 special session and competition on single objective real-parameter numerical optimization. Computational Intelligence Laboratory, Zhengzhou University, Zhengzhou China and Technical Report, Nanyang Technological University, Singapore635 (2013).
Awad, N. H., Ali, M. Z. & Suganthan, P. N. Ensemble sinusoidal differential covariance matrix adaptation with Euclidean neighborhood for solving cec2017 benchmark problems, in 2017 IEEE Congress on Evolutionary Computation (CEC), 372–379 (IEEE, 2017).
Kaveh, A., Vaez, S. R. H. & Hosseini, P. Simplified dolphin echolocation algorithm for optimum design of frame. Smart Struct. Syst. 21, 321–333 (2018).
Degertekin, S. O. Optimum design of steel frames using harmony search algorithm. Struct. Multidiscip. Optim. 36, 393–401 (2008).
Rönkkönen, J., Kukkonen, S. & Price, K. V. Real-parameter optimization with differential evolution, in Congress on Evolutionary Computation, 506–513 (2005).
Omran, M. G., Salman, A. & Engelbrecht, A. P. Self-adaptive differential evolution, in International Conference on Computational and Information Science, 192–199 (Springer, 2005).
Eiben, A. E., Marchiori, E. & Valko, V. Evolutionary algorithms with on-the-fly population size adjustment, in International Conference on Parallel Problem Solving from Nature, 41–50 (Springer, 2004).
Brest, J., Zumer, V. & Maucec, M. S. Self-adaptive differential evolution algorithm in constrained real-parameter optimization, in 2006 IEEE International Conference on Evolutionary Computation, 215–222 (IEEE, 2006).
Khalilpourazari, S. & Pasandideh, S. H. R. Sine-cosine crow search algorithm: Theory and applications. Neural Comput. Appl. 32, 1–18 (2019).
Yousri, D., Abd Elaziz, M. & Mirjalili, S. Fractional-order calculus-based flower pollination algorithm with local search for global optimization and image segmentation. Knowl.-Based Syst. 197, 105889 (2020).
Gupta, S. & Deep, K. A novel random walk grey wolf optimizer. Swarm Evol. Comput. 44, 101–112 (2019).
Li, W., Wang, G.-G. & Alavi, A. H. Learning-based elephant herding optimization algorithm for solving numerical optimization problems. Knowl.-Based Syst. 195, 105675 (2020).
Tejani, G. G., Savsani, V. J., Patel, V. K. & Mirjalili, S. Truss optimization with natural frequency bounds using improved symbiotic organisms search. Knowl.-Based Syst. 143, 162–178 (2018).
Derrac, J., García, S., Molina, D. & Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1, 3–18 (2011).
Salgotra, R., Singh, U., Singh, S. & Mittal, N. A hybridized multi-algorithm strategy for engineering optimization problems. Knowl.-Based Syst. 217, 106790 (2021).
Garg, V. & Deep, K. Performance of Laplacian biogeography-based optimization algorithm on CEC 2014 continuous optimization benchmarks and camera calibration problem. Swarm Evol. Comput. 27, 132–144 (2016).
Wang, G.-G., Lu, M. & Zhao, X.-J. An improved bat algorithm with variable neighborhood search for global optimization, in 2016 IEEE Congress on Evolutionary Computation (CEC), 1773–1778 (IEEE, 2016).
Wang, G.-G., Guo, L., Gandomi, A. H., Hao, G.-S. & Wang, H. Chaotic krill herd algorithm. Inf. Sci. 274, 17–34 (2014).
Salgotra, R., Singh, U., Saha, S. & Nagar, A. New improved SALSHADE-cnEpSin algorithm with adaptive parameters, in 2019 IEEE Congress on Evolutionary Computation (CEC), 3150–3156 (IEEE, 2019).
Salgotra, R., Singh, U. & Saha, S. Improved cuckoo search with better search capabilities for solving cec2017 benchmark problems, in 2018 IEEE Congress on Evolutionary Computation (CEC), 1–7 (IEEE, 2018).
Salgotra, R., Singh, U. & Singh, G. Improving the adaptive properties of lshade algorithm for global optimization, in 2019 International Conference on Automation, Computational and Technology Management (ICACTM), 400–407 (IEEE, 2019).
Wang, L., Cao, Q., Zhang, Z., Mirjalili, S. & Zhao, W. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 114, 105082 (2022).
Hu, G., Yang, R., Qin, X. & Wei, G. MCSA: Multi-strategy boosted chameleon-inspired optimization algorithm for engineering applications. Comput. Methods Appl. Mech. Eng. 403, 115676 (2023).
He, Q. & Wang, L. An effective co-evolutionary particle swarm optimization for constrained engineering design problems. Eng. Appl. Artif. Intell. 20, 89–99 (2007).
Mezura-Montes, E. & Coello, C. A. C. An empirical study about the usefulness of evolution strategies to solve constrained optimization problems. Int. J. Gen. Syst. 37, 443–473 (2008).
Saremi, S., Mirjalili, S. & Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 105, 30–47 (2017).
Huang, F.-Z., Wang, L. & He, Q. An effective co-evolutionary differential evolution for constrained optimization. Appl. Math. Comput. 186, 340–356 (2007).
Mezura-Montes, E. & Hernández-Ocana, B. Bacterial foraging for engineering design problems: preliminary results, in Memorias del 4o Congreso Nacional de Computación Evolutiva (COMCEV’2008) (Centro de Investigación en Matemáticas Guanajuato, México, 2008).
Cheng, M.-Y. & Prayogo, D. Symbiotic organisms search: A new metaheuristic optimization algorithm. Comput. Struct. 139, 98–112 (2014).
Savsani, P. & Savsani, V. Passing vehicle search (PVS): A novel metaheuristic algorithm. Appl. Math. Model. 40, 3951–3978 (2016).
Xian, S. & Feng, X. Meerkat optimization algorithm: A new meta-heuristic optimization algorithm for solving constrained engineering problems. Expert Syst. Appl. 231, 120482 (2023).
Givi, H., Dehghani, M. & Hubálovskỳ, Š. Red panda optimization algorithm: An effective bio-inspired metaheuristic algorithm for solving engineering optimization problems. IEEE Access (2023).
Sadollah, A., Bahreininejad, A., Eskandar, H. & Hamdi, M. Mine blast algorithm: A new population based algorithm for solving constrained engineering optimization problems. Appl. Soft Comput. 13, 2592–2612 (2013).
Kaveh, A. & Dadras, A. A novel meta-heuristic optimization algorithm: Thermal exchange optimization. Adv. Eng. Softw. 110, 69–84 (2017).
Dhiman, G. & Kumar, V. Seagull optimization algorithm: Theory and its applications for large-scale industrial engineering problems. Knowl.-Based Syst. 165, 169–196 (2019).
Hu, G., Zhong, J., Wei, G. & Chang, C.-T. DTCSMO: An efficient hybrid starling murmuration optimizer for engineering applications. Comput. Methods Appl. Mech. Eng. 405, 115878 (2023).
Kaveh, A. & Talatahari, S. An improved ant colony optimization for the design of planar steel frames. Eng. Struct. 32, 864–873 (2010).
Garg, V., Deep, K. & Bansal, S. Improved teaching learning algorithm with Laplacian operator for solving nonlinear engineering optimization problems. Eng. Appl. Artif. Intell. 124, 106549 (2023).
Coello, C. A. C. & Cortés, N. C. Hybridizing a genetic algorithm with an artificial immune system for global optimization. Eng. Optim. 36, 607–634 (2004).
Bernardino, H. S., Barbosa, H. J., Lemonge, A. C. & Fonseca, L. A new hybrid AIS-GA for constrained optimization problems in mechanical engineering, in 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), 1455–1462 (IEEE, 2008).
Mezura-Montes, E. & Coello, C. A. C. Useful infeasible solutions in engineering optimization with evolutionary algorithms, in Mexican International Conference on Artificial Intelligence, 652–662 (Springer, 2005).
He, Q. & Wang, L. A hybrid particle swarm optimization with a feasibility-based rule for constrained optimization. Appl. Math. Comput. 186, 1407–1422 (2007).
Rao, R. V., Savsani, V. J. & Vakharia, D. Teaching-learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput. Aided Des. 43, 303–315 (2011).
Ray, T. & Saini, P. Engineering design optimization using a swarm with an intelligent information sharing among individuals. Eng. Optim. 33, 735–748 (2001).
Bernardino, H. S., Barbosa, H. J. & Lemonge, A. C. A hybrid genetic algorithm for constrained optimization problems in mechanical engineering, in 2007 IEEE Congress on Evolutionary Computation, 646–653 (IEEE, 2007).
Chickermane, H. & Gea, H. C. Structural optimization using a new local approximation method. Int. J. Numer. Methods Eng. 39, 829–846 (1996).
Kaveh, A. & Talatahari, S. Hybrid algorithm of harmony search, particle swarm and ant colony for structural design optimization, in Harmony Search Algorithms for Structural Design Optimization, 159–198 (Springer, 2009).
Gandomi, A. H., Deb, K., Averill, R. C., Rahnamayan, S. & Omidvar, M. N. Variable functioning and its application to large scale steel frame design optimization. Struct. Multidiscip. Optim. 66, 13 (2023).
Kaveh, A., Talatahari, S. & Khodadadi, N. The hybrid invasive weed optimization-shuffled frog-leaping algorithm applied to optimal design of frame structures. Period. Polytech. Civ. Eng. 63, 882–897 (2019).
Kaveh, A. & Talatahari, S. A discrete big bang-big crunchalgorithm for optimaldesign of skeletal structures. Asian J. Civ. Eng. (Build. Hous.) (2010).
Kaveh, A. & Talatahari, S. Optimum design of skeletal structures using imperialist competitive algorithm. Comput. Struct. 88, 1220–1229 (2010).
Funding
Open access funding provided by Óbuda University.
Author information
Authors and Affiliations
Contributions
R.S.Conceptualization, Methodology, Software, Data curation, Validation, Writing-Original draft preparation, Analysis and Experimentation Writing-Reviewing and Editing. A.H.G.: Supervision, Real world application, Analysis and Experimentation Writing-Reviewing and Editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salgotra, R., Gandomi, A.H. A novel multi-hybrid differential evolution algorithm for optimization of frame structures. Sci Rep 14, 4877 (2024). https://doi.org/10.1038/s41598-024-54384-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-54384-3
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
