
Abstract
Emergency departments (ED) are complex, triage is a main task in the ED to prioritize patient with limited medical resources who need them most. Machine learning (ML) based ED triage tool, Score for Emergency Risk Prediction (SERP), was previously developed using an interpretable ML framework with single center. We aimed to develop SERP with 3 Korean multicenter cohorts based on common data model (CDM) without data sharing and compare performance with inter-hospital validation design. This retrospective cohort study included all adult emergency visit patients of 3 hospitals in Korea from 2016 to 2017. We adopted CDM for the standardized multicenter research. The outcome of interest was 2-day mortality after the patients’ ED visit. We developed each hospital SERP using interpretable ML framework and validated inter-hospital wisely. We accessed the performance of each hospital’s score based on some metrics considering data imbalance strategy. The study population for each hospital included 87,670, 83,363 and 54,423 ED visits from 2016 to 2017. The 2-day mortality rate were 0.51%, 0.56% and 0.65%. Validation results showed accurate for inter hospital validation which has at least AUROC of 0.899 (0.858–0.940). We developed multicenter based Interpretable ML model using CDM for 2-day mortality prediction and executed Inter-hospital external validation which showed enough high accuracy.
Similar content being viewed by others

Introduction
Emergency department (ED) is complex and need urgent judgement for the better triage1,2. In order to determine the patient’s condition quickly, Korea Triage Acuity Scale (KTAS), New Early Warning Score and Modified Early Warning Score have been developed by expertise3,4. However, although most scores require complicated process to make, they are fixed score and have low reliability and poor outcome due to subjective assessment5. To solve this problem, data and machine learning (ML) based objective score has emerged6,7.
Those ML based models have problems of black box and external validation8,9. There has been some studies for interpretable triage in ED which utilized framework for interpretable scoring system called Autoscore10,11,12. However it was only conducted with limited population and specific for ER admission patients11. Each hospital have different population and characteristics, so we need to develop each hospital based unique score for the application.
Another tricky part for the external validation in ML research is data protection law and policy13,14. It is impossible to transfer the data into other hospital for preserving privacy. To solve this challenge, common data model (CDM) can be adopted for each hospital15. Through the CDM format, multicenter research could be done without data transfer. Standardized format of terminology and structure can be made for each hospital’s different electronic medical records format and policy. There has been some CDM based research regarding the ML16,17, there was no CDM based interpretable machine learning research in Korea.
The aim of the study is to develop, and inter-hospital external validate the interpretable ML score among the 3 big hospitals in Korea using novel framework using CDM.
Results
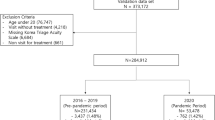
During the same study period for each hospital from 2016 to 2017 145,371, 169,896 and 96,369 patients visited ED in A, B and C respectively as shown in Fig. 1. Among them, totally 57,511, 86,533 and 41,946 patients were excluded due to age under 18, DOA, and trauma patient. Finally, 86,670, 83,363 and 54,423 patients were used for developing models. The mortality rate was from 0.51%, 0.55% and 0.65% for 2 days.

Flow chart for each hospital from 2016 to 2017 emergency department visits. Age under 18, traumatic and death on arrival patient were excluded.
The distribution of ED patients’ demographics for each hospital is shown in Table 1. Each cohort included 445, 464 and 379 of events. (67.2 (14.3), 72.8 (14.4) and 72.5 (13.5) for age; 265 (59.6.%), 245 (52.8%) and 218 (57.5%) for male). Regarding the mortality patient, there were quite differences between hospitals, especially in patient conciseness of Alert at hospital A (70.8%) have higher than others (44.0 and 28.2%). Moreover, patient with severe (KTAS1 or KTAS2) at scene in hospital C (87.4%) was higher than other hospitals. (49.7% and 71.3%). Regarding the vital sign all hospital have different patterns, especially in SPO2 and BP. In terms of comorbidities history, Hospital A have much higher cancer related patients (73.9%) compared to B and C (9.5 and 5%). Whereas Hospital B and C have higher chronic disease including diabetes (28.2 and 28%). Synthetic minority over-sampling technique (SMOTE) based distribution and significance of difference for each variable were provided with standardized mean difference (SMD) were shown in Supplementary Tables 1–3.
Based on the variable importance from the Autoscore framework shown in Table 2 and parsimonious plot shown in Supplementary Fig. 1, we selected top 8 variables for score generations. Common feature for three hospitals were vital sign, age, patient consciousness. Vital sign such as systolic blood pressure (SBP) and heart rate (HR) were important in hospital A and B, whereas Consciousness was most important in hospital C. SBP, HR, Temperature were top 3 contributed variables in overall rank.
Scores for each hospital were presented in Table 3. The developed score for each hospital had different patterns. Among the included variables, Temperature and SpO2 were the highest effect in hospital A (17), patient consciousness for hospital B (27) and C (33). In hospital B, Age (13) was also high scored variables. Whereas Systolic blood pressure (14) was dominant at hospital C. Overall score was calculated with weighted score of number of patients and performance for each institutions. Score based on SMOTE was provided at Supplementary Table 4.
We evaluated each score to the other hospital for the intra-institutional external validation. We used the testing cohort to evaluate the performance of each score. Table 4 depicts the AUROC with CI for the external validation which showed the best internal validation (0.913, 0.919 and 0.930) and dropped a little for the external results. Overall evaluation results show the quite good classification results from 0.904 to 0.933. Other metrics for original and SMOTE were shown in Supplementary Table 5.
Discussion
In this study, we developed interpretable score based on CDM Autoscore for ED and evaluated with 3 tertiary hospitals in Korea for inferring the 2-day mortality for ED visit patients. Although each hospitals have different characteristics, scores were accurate for their external validation results for other institutions which has at least of 0.885 (0.842–0.942) AUROC. Moreover, it was interpretable score, so it can be integrated easily into clinical practice. We found each scores from their own hospital, which is the internal validation results were accurate from 0.913 to 0.930 AUROC. We also identified the extent of lack of accuracy and acceptance when we apply the score to other institute.
To the best of our knowledge, this is the first study for interpretable machine learning using CDM framework in ED. Many policies or laws regarding the data protection or leak was published for the protection of private patient information18,19. For solving these problems, our framework can share the result without any transferring patient data. CDM is designed to standardize the structure and vocabulary of observational health data that can produce reliable evidence without sharing data. This approach creates a unique opportunity of implementing several existing data exploration and evidence generation tools and participating in world-wide distributed research network studies without raw data leakage20,21,22. Extensibility and generatability can be obtained based on our framework. More institutions can be added to analysis cohort for further development and validation because of the developed semi-automated ETL process enables CDM conversion for all institution’s NEDIS data in Korea.
Interpretable point-based score can be easily utilized for the real practice. A paper published from Netherlands in 2023 also developed international early warning score for predicting mortality in ED23. The score was consistent with our interpretable score in terms of having high impact on consciousness, systolic blood pressure and temperature and Spo2. Whereas old age was most impact factor in international score.
Another novelty for this study is it conducted the cross-external validation for identifying the generalizability. Patient distribution is different for each institution. In case of hospital C, almost mortality patients had severe KTAS level and consciousness was most important for predicting mortality. We need to develop each score for institution. Many previous study emphasized the importance of external validation for the generality of model14,24,25. Most of the studies conducted one model from one site to other sites26,27, but in this study all institutions made their one score and we can compare the results for each one.
There are some limitations for this study, first it was a retrospective, the score needs to be evaluated in prospectively for the checking the applicability. However, this score-based model development is easy to apply to EMR integration because of advantages of point-based score. Second, we need to consider the representative score for Korea. We can develop with national emergency department information system data which is data from 403 ED data for developing national level score for Korea.
In summary, we developed the K-SERP score for 3 hospitals in Korea using CDM Autoscore for ED and showed good cross-external validation results which were at least 0.899 of AUROC. We can expand the result with other emergency department site based on CDM framework. Each score could be interpreted and applied to clinical process easily.
Method
Study design and setting
This retrospective and validation study was executed across from 3 ED in Korea (A, B and C). A, B and C are tertiary hospitals located in a metropolitan city in Korea. Respectively, the hospital has approximately 2000, 1000, and 1000 inpatient beds. Approximately more than 80,000, 90,000 and 50,000 patients visit the ED annually. There are 16, 20 and 7 specialists working at each institution, respectively. All data were mapped to the Observational Medical Outcome Partnership Common Data Model (OMOP-CDM) for the multicenter study. This study was approved by the Samsung Medical Center Institutional Review Board (2023-02-036), and a waiver of informed consent was granted for EHR data collection and analysis because of the retrospective and de-identified nature of the data. All methods were performed in accordance with the relevant guidelines and regulations.
Selection of participants
Initially, ED patients from 2016 to 2017 were included for each hospital. Patient older than 18 with disease patients were included. We also excluded patient with left without being seen or death on arrival/cardiopulmonary resuscitation patients. We split into two cohort: development (70%) cohort for training the interpretable ML model and test (30%) for evaluation from each hospital.
Candidate predictors
We extracted data from each hospital’s electronic medical records system which all patient information was deidentified. Candidate input variables were considered with available features at the stage of ED triage including demographic characteristics such as age, gender, administrative variables including time of ED visit and clinical variables such as severity index, consciousness, and initial vital sign. Comorbidities were also obtained from hospital diagnosis records in the preceding 5 years before patients’ emergency visit and compared for each hospital. They were extracted from International Statistical Classification of Diseases and Related Health Problems, Tenth Revision (ICD-10). The list and description of candidate predictors and comorbidities are given in the supplementary Tables 6 and 7.
Outcomes
Emergency patients with semi-acute conditions typically undergo surgical procedure or are admitted to Intensive care unit (ICU) following emergency room treatment and given the imperative for patients to survive. Our primary outcome was 2-day mortality which was the target feature for analysis to build the interpretable ML model for each hospital.
Common data model (CDM)
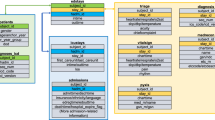
For the multicenter study, we adopted OMOP CDM from the research network Observational Health Data Sciences and Informatics (OHDSI)28 for standardized structure and vocabularies to map emergency department data based on Systematized Nomenclature of Medicine–Clinical Terms (SNOMED-CT) and Logical Observation Identifiers Names and Codes (LOINC) as example shown Supplementary Fig. 1. Extract, Transformation and Load (ETL) process was performed with structured query language. Each ED care and diagnosis related information was mapped into proper CDM tables as shown in Fig. 2. For example, patient demographics and vital sign are mapped to Person and Measurement table, respectively. After transformation was completed into CDM format, all hospital can get the same structure and vocabularies, for executing same research query. All details of transformation and code are accessible on Gitgub29.

Table mapping for converting clinical to common data model tables. CDM: common data model; ED: Emergency department.
CDM autoscore for ED framework
AutoScore Framework is a machine learning-based clinical score generator, consisting of six modules developed from Singapore12. Module 1 uses a random forest for ranking variables according to their importance. Module 2 transforms variables by categorizing continuous variables to improve interpretation with quantile information. Module 3 makes scores for each variable based on a logistic regression coefficient. Module 4 selects which variables could be included in the scoring model. In Module 5, clinical domain knowledge is incorporated to the score and cutoff points can be defined when categorizing continuous variables. Module 6 evaluates the performance of the score in a separate test dataset. The AutoScore framework provides a systematic and automated approach to develop score automatically, combining of advantage of machine learning for discriminating and the strength of logistic regression in its interpretability. For the overall score generation, We considered weighted average scores across all institutions. For each institutions i, a weight \({w}_{i}\) was formulated as \({w}_{i}\) = \(\left(\sqrt{{(AUC}_{i})} \times {N}_{i}^{3}\right)\)/\({\sum }_{i=1}^{M}\sqrt{{(AUC}_{i})} \times {N}_{i}^{3})\) × 100% where \({N}_{i}\) was the sample size, \({AUC}_{i}\) was the AUC value obtained based on the validation set, and M was the total number of institutions. Overall score was calculated with weighted score based on \({w}_{i}\).
We defined our new novel framework “CDM Autoscore for ED”, combination of CDM based standardized format and autoscore based interpretable framework shown in Fig. 3. The analysis and preparation code using CDM format was also shared on GitHub29.

Overall process of “CDM Autoscore for ED”. Each Institutions conducted Extract, Transformation and Load process for converting local data into CDM format. Algorithms from each of institution were derived using interpretable machine learning framework and validated inter-and intra- institutionally. EMR: Electronic medical records; ETL: Extract, transformation and Load; OMOP CDM: Observational Medical Outcome Partnership Common Data Model.
Statistical analysis
Categorical features were expressed as frequency and percentages and continuous features were expressed as means and standard deviations. Comparison tests for each hospital were performed with analysis of variance and chi-square tests at 5% significance levels. Standardized mean difference (SMD) was also calculated for comparing each hospital. Two types of validations for this study were conducted. First, we executed internal-institutional validation for each hospital’s score. We also performed intra-institutional validation pair-wisely for the external validation. Area under the curve in the receiver operating characteristic (AUROC) and 95% confidence interval (CI) with 1000 times of bootstrap was reported. Other metrics including accuracy, sensitivity, specificity, positive predictive value (PPV) and negative predictive value (NPV) were also reported. SMOTE was conducted for handling the imbalance problem. Twice of minority was oversampled and same number of majorities according to the number of minority was sampled with fixed seed number.
Data availability
Data was available in study site clinical data warehouse. The datasets generated and analyzed during the current study are not publicly available due dataset includes although is de-identifed, part of patient information, but are available from the corresponding author on reasonable request.
Abbreviations
- ED:
-
Emergency department
- ML:
-
Machine learning
- SERP:
-
Score for emergency risk prediction
- CDM:
-
Common data model
- AUROC:
-
Area under receiver operating curve
- KTAS:
-
Korea triage acuity scale
- SMOTE:
-
Synthetic minority over-sampling technique
- SMD:
-
Standardized mean difference
- OMOP-CDM:
-
Observational medical outcome partnership common data model
- OHDSI:
-
Observational health data sciences and informatics
- SNOMED-CT:
-
Systematized nomenclature of medicine–clinical terms
- LOINC:
-
Logical observation identifiers names and codes
- ETL:
-
Extract transformation load
- EMR:
-
Electronic medical records
- CI:
-
Confidence interval
- SD:
-
Standard deviation
References
Hoot, N. R. & Aronsky, D. Systematic review of emergency department crowding: Causes, effects, and solutions. Ann. Emerg. Med. 52, 126–136 (2008).
Petrie, D. A. & Comber, S. Emergency department access and flow: Complex systems need complex approaches. J. Eval. Clin. Pract. 26, 1552–1558 (2020).
Mitsunaga, T. et al. Comparison of the National Early Warning Score (NEWS) and the Modified Early Warning Score (MEWS) for predicting admission and in-hospital mortality in elderly patients in the pre-hospital setting and in the emergency department. PeerJ 7, e6947 (2019).
Kwon, H. et al. The Korean triage and acuity scale: Associations with admission, disposition, mortality and length of stay in the emergency department. Int. J. Qual. Health Care 31, 449–455 (2019).
Choi, H., Ok, J. S. & An, S. Y. Evaluation of validity of the Korean triage and acuity scale. J. Korean Acad. Nurs. 49, 26–35 (2019).
Liu, Y. et al. Development and validation of a practical machine-learning triage algorithm for the detection of patients in need of critical care in the emergency department. Sci. Rep. 11, 24044 (2021).
Yu, J. Y., Jeong, G. Y., Jeong, O. S., Chang, D. K. & Cha, W. C. Machine learning and initial nursing assessment-based triage system for emergency department. Healthc. Inform. Res. 26, 13–19 (2020).
Mueller, B. et al. Artificial intelligence and machine learning in emergency medicine: A narrative review. Acute Med. Surg. 9, e740 (2022).
Dugas, A. F. et al. An electronic emergency triage system to improve patient distribution by critical outcomes. J. Emerg. Med. 50, 910–918 (2016).
Yun, H., Choi, J. & Park, J. H. Prediction of critical care outcome for adult patients presenting to emergency department using initial triage information: An XGBoost algorithm analysis. JMIR Med. Inform. 9, e30770 (2021).
Xie, F. et al. Development and assessment of an interpretable machine learning triage tool for estimating mortality after emergency admissions. JAMA Netw. Open. 4, e2118467 (2021).
Xie, F., Chakraborty, B., Ong, M. E. H., Goldstein, B. A. & Liu, N. AutoScore: A machine learning-based automatic clinical score generator and its application to mortality prediction using electronic health records. JMIR Med. Inform. 8, e21798 (2020).
Ramspek, C. L., Jager, K. J., Dekker, F. W., Zoccali, C. & van Diepen, M. External validation of prognostic models: What, why, how, when and where?. Clin. Kidney J. 14, 49–58 (2020).
Riley, R. D. et al. External validation of clinical prediction models using big datasets from e-health records or IPD meta-analysis: Opportunities and challenges. BMJ 353, i3140 (2016).
Reps, J. M. et al. Feasibility and evaluation of a large-scale external validation approach for patient-level prediction in an international data network: Validation of models predicting stroke in female patients newly diagnosed with atrial fibrillation. BMC Med. Res. Methodol. 20, 102 (2020).
Choi, Y. I. et al. Development of machine learning model to predict the 5-year risk of starting biologic agents in patients with inflammatory bowel disease (IBD): K-CDM network study. J. Clin. Med. 9, 3427 (2020).
Ryu, B., Yoo, S., Kim, S. & Choi, J. Development of prediction models for unplanned hospital readmission within 30 days based on common data model: A feasibility study. Methods Inf. Med. 60, e65–e75 (2021).
Kim, Y. Uncertain future of privacy protection under the Korean public health emergency preparedness governance amid the COVID-19 pandemic. Cogent Soc. Sci. 8, 2006393 (2022).
Lee, D., Park, M., Chang, S. & Ko, H. Protecting and utilizing health and medical big data: Policy perspectives from Korea. Healthc. Inform. Res. 25, 239–247 (2019).
You, S. C. et al. Association of ticagrelor vs clopidogrel with net adverse clinical events in patients with acute coronary syndrome undergoing percutaneous coronary intervention. JAMA 324(16), 1640–1650 (2020).
Schuemie, M. J. et al. Principles of large-scale evidence generation and evaluation across a network of databases (LEGEND). J. Am. Med. Inform. Assoc. 27(8), 1331–1337 (2020).
Burn, E. et al. Deep phenotyping of 34,128 adult patients hospitalised with COVID-19 in an international network study. Nat. Commun. 11(1), 5009 (2020).
Candel, B. G. J. et al. Development and external validation of the international early warning score for improved age- and sex-adjusted in-hospital mortality prediction in the emergency department. Crit. Care Med. 51, 881–891 (2023).
Bleeker, S. E. et al. External validation is necessary in prediction research: a clinical example. J. Clin. Epidemiol. 56, 826–832 (2003).
Collins, G. S. et al. External validation of multivariable prediction models: A systematic review of methodological conduct and reporting. BMC Med. Res. Methodol. 14, 40 (2014).
Lee, Y. J. et al. A multicentre validation study of the deep learning-based early warning score for predicting in-hospital cardiac arrest in patients admitted to general wards. Resuscitation 163, 78–85 (2021).
Kwon, J. M. et al. Development and validation of deep-learning algorithm for electrocardiography-based heart failure identification. Korean Circ. J. 49, 629–639 (2019).
Hripcsak, G. et al. Observational health data sciences and informatics (OHDSI): Opportunities for observational researchers. Stud. Health Technol. Inform. 216, 574–578 (2015).
Kim DY. NEDIS CDM github GitHub. https://github.com/OHDSI/ETL---Korean-NEDIS.
Funding
This research was supported by a grant of Korea Health Technology R&D Project throught the Korea Health Industry Development Institute (KHIDI) and the Medical data-driven hospital support project through the Korea Health Information Service (KHIS), funded by the Ministry of Health & Welfare, Republic of Korea (Grant Number: HI19C1328).
Author information
Authors and Affiliations
Contributions
Conceptualization: W.C.C.; data curation: J.Y.Y., S.Y.; formal analysis: J.Y.Y. D.Y.K; investigation: X.F.; methodology: X.F., M.E.H.O.; visualization: J.Y.Y.; writing—original Draft: J.Y.Y., writing—review and editing: J.Y.Y., H.J.J., K.W.J., R.W.P., J.M.G.,G.S.H., X.F., M.E.H.O., Y.Y.N., W.C.C.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, J.Y., Kim, D., Yoon, S. et al. Inter hospital external validation of interpretable machine learning based triage score for the emergency department using common data model. Sci Rep 14, 6666 (2024). https://doi.org/10.1038/s41598-024-54364-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-54364-7
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
