
Abstract
This study explores the integration of artificial intelligence (AI) teaching assistants in sports tennis instruction to enhance the intelligent teaching system. Firstly, the applicability of AI technology to tennis teaching in schools is investigated. The intelligent teaching system comprises an expert system, an image acquisition system, and an intelligent language system. Secondly, employing compressed sensing theory, a framework for learning the large-scale fuzzy cognitive map (FCM) from time series data, termed compressed sensing-FCM (CS-FCM), is devised to address challenges associated with automatic learning methods in the designed AI teaching assistant system. Finally, a high-order FCM-based time series prediction framework is proposed. According to experimental simulations, CS-FCM demonstrates robust convergence and stability, achieving a stable point with a reconstruction error below 0.001 after 15 iterations for FCM with various data lengths and a density of 20%. The proposed intelligent system based on high-order complex networks significantly improves upon the limitations of the current FCM model. The advantages of its teaching assistant system can be effectively leveraged for tennis instruction in sports.
Similar content being viewed by others

Introduction
An increasing number of educational disciplines are incorporating artificial intelligence (AI) technology to enhance teaching effectiveness, driven by the continuous advancement of this technology. In the realm of physical education, AI sports technology is widely utilized, rendering physical education more intelligent and individualized to better cater to the diverse needs and traits of students1,2,3. An emerging sports training approach rooted in AI is referred to as the intelligent sports training system. These systems can formulate customized training schedules for students based on their physical characteristics, athletic abilities, and training requirements. Additionally, they can monitor students’ sporting progress in real-time, offering timely advice and insights. The integration of AI technology into sports equipment gives rise to intelligent sports equipment4. By tracking and analyzing students’ sporting activities in real-time, these systems provide individualized and scientifically informed sports advice and training plans.
AI in the educational landscape has the potential to automate grading processes and offer feedback to students through AI teaching assistant systems, thereby enabling educators to allocate their time to other responsibilities5,6. However, as AI applications expand, expert systems encounter challenges in handling complexities. Presently, artificial neural networks (ANNs) are confined to shallow models, limiting their efficacy in addressing intricate issues and utilizing vast datasets for learning and training efficiently. Managing and operating complex AI systems pose difficulties for traditional big data or massive network systems, as well as conventional analysis and optimization techniques. The extensive search space and complex spatial patterns of optimization problems further complicate the modeling of vast and intricate systems. In this context, the fuzzy cognitive map (FCM), as an intelligent computing tool, stands out for its advantages in abstractness, flexibility, and fuzzy reasoning, making it an ideal choice for system modeling and reasoning when compared to standard techniques like expert systems and neural networks7. In recent years, researchers have explored the application of AI techniques, such as neural networks and Bayesian networks, in education. For instance, neural networks are utilized to develop intelligent teaching systems that adapt to students’ needs autonomously. Juan et al.8 (2021) emphasized that neural network models could self-learn and adjust based on student performance and feedback, thereby offering a more personalized teaching experience. Additionally, Bayesian networks have found application in education, particularly in knowledge reasoning and decision-making. Nyberg et al.9 (2022) asserted that Bayesian networks were employed to analyze common fallacies in informal logic, study and evaluate various arguments, and expose common errors in evidence reasoning. Despite these advancements, the application of these techniques to physical education has received limited attention, with existing studies primarily focusing on theoretical exploration and model design. The challenges associated with large-scale complex system modeling and real-time stream data modeling remain unresolved using current FCM learning methodologies. Addressing these critical issues is paramount to enhancing the effectiveness of FCM in modeling complex systems.
In current educational technology, intelligent teaching systems predominantly rely on preset teaching plans and models, lacking the flexibility to adapt to individual differences and specific needs of students. This limitation arises from the systems’ emphasis on predetermined teaching strategies, overlooking the dynamic progress and distinct needs of students. Moreover, these systems often lack adaptability in responding to the intricate dynamics of the teaching process, hindering timely adjustments based on student performance and feedback. In addressing these challenges and recognizing the individual differences in students and the unique context of physical education, this study proposes an intelligent-assisted physical education teaching model based on high-order complex networks to enhance existing technology. The landscape of intelligent technology is evolving, particularly with the increasing integration of AI technology in sports. This evolution encompasses various aspects of computer vision, such as the introduction of eagle-eye technology in tennis. Complex networks are crucial tools and techniques for comprehending intricate systems, especially when seeking explanations for complex real-world scenarios. In the realm of advancing AI technology in tennis, this study endeavors to analyze the incorporation of AI technology into sports tennis instruction. Additionally, an intelligent modeling model is implemented to tackle real-world challenges. FCM serves as a modeling tool for complex systems in developing AI helper systems, and a more precise and reliable FCM model is proposed. The compressed sensing theory establishes a framework for learning large-scale FCM from time series data, and a framework for time series prediction based on high-order FCM is introduced.
This study makes a significant contribution by advancing the sophistication of physical education teaching models through the integration of AI assistance guided by high-order complex networks. Firstly, the research centers on the application of AI technology in school tennis instruction, constructing an intelligent teaching system comprising an expert system, an image acquisition system, and an intelligent language system. The design of this system is expected to elevate the intelligence level of tennis instruction. Secondly, the study employs compressive sensing theory to formulate a learning framework for a large-scale FCM, known as Compressive Sensing-FCM (CS-FCM). This framework aims to address challenges associated with automatic learning methods in the designed AI-assisted teaching system. This innovative approach provides a novel avenue for learning large-scale FCMs from time series data, offering theoretical support for the intelligence of teaching assistant systems. Lastly, the research proposes a time series prediction framework based on a high-order FCM. Through experimental simulations, CS-FCM demonstrates robust convergence and stability, providing crucial support for the development of intelligent systems and significantly improving the limitations of current FCM models. In summary, this study introduces AI-assisted teaching by incorporating guidance from high-order complex networks, presenting novel perspectives and methods for enhancing the intelligence of physical education teaching models. The positive results obtained in experimental simulations validate the effectiveness of the proposed model, laying the foundation for its broader application in future physical education teaching. This research contributes valuable experiences and references for the future integration of artificial intelligence in the field of education.
Materials and methods
AI technology in sports tennis teaching mode
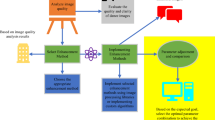
The market for AI in sports is projected to reach approximately 1.4 billion USD by 2020, with expectations for significant growth to 19.2 billion USD by 2030 at a compound annual growth rate of 30.3%10. The role of AI technology in sports continues to evolve, providing innovative and valuable contributions to sporting events. Two fundamental aspects of sports competitions are adherence to rules and engaging in competitive activities. The integration of AI technology with competitive events enhances training and facilitates advancements in the competition landscape. A critical challenge in competitive sports training lies in analyzing whether athletes’ training activities, including speed, angle, and strength, align with the project regulations promptly11,12. Figure 1 illustrates the intelligent application of AI-based sports events.

Intelligent application of sports events based on AI.
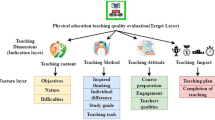
An increasing number of tennis teams and coaches are embracing the use of AI technology to enhance player training and management. Prominent teams, such as the French tennis team, leverage AI systems for analyzing game data and devising comprehensive training plans. Across various clubs, coaches, and teams, there is a growing trend of integrating AI technology to optimize training methods and analyze data for performance enhancement. However, as this technology continues to evolve, the specific details and applications are undergoing continuous refinement and updates, with no current unified standard. The integration of AI into competitive sports training involves utilizing cameras to capture athletes’ data, analyzing and assessing them through video-based human motion recognition algorithms, and drawing informed conclusions13,14,15. This approach allows athletes to gain intuitive insights into their training shortcomings and deficiencies, enabling them to receive higher-quality training plans through coach guidance and analysis. The four primary applications of AI in physical education are illustrated in Fig. 2. The intelligent AI sports teaching assistant system incorporates machine vision, AI cloud computing, and other technical means to generate personalized exercise prescriptions, provide targeted exercise suggestions, and establish a digital exercise space, creating an integrated closed loop of “learning, practicing, competing, and testing.”

Four typical services of AI in physical education.
In the realm of competitive sports, the construction of prediction models for athletes’ conduct often relies on extensive game films. Stanford University researchers have notably contributed to this domain by developing a statistical model of athletes’ behavior. Utilizing the marked hitting cycle database, encompassing a sequence of actions from preparation through hitting to recovery, the researchers generated players’ hitting and return decisions. This study introduces a mechanism for constructing actual video segment datasets, instrumental in creating controllable video systems that produce high-quality videos based on diverse real data16. The procedure employs the technique of neural image migration to mitigate variations in an athlete’s appearance (clothing, hairstyles, etc.) on different competition days or at various competition periods. Additionally, the algorithm addresses the challenge of missing pixel data when a player is only partially visible, ensuring the new video’s stability and coherence, such as the player’s stance in response to assessing the ball. The integration of data-efficient online optimization introduces an agent-assisted method that fosters a novel interaction between AI and athletes. Within the interactive cycle, athletes can select customized models with AI, establishing a feedback loop where training data and results can be iteratively incorporated into the model. This iterative process enhances the synergy between AI technology and athletes, contributing to a dynamic and adaptive training environment.
Tennis instruction enhanced by an AI assistant system
In the contemporary era marked by the proliferation of AI technologies, encompassing 5G and big data, the education sector is compelled to seamlessly integrate education with AI technology. The deployment of AI as a teaching assistant has significantly amplified the efficacy of teaching methodologies, propelling the frontier of equitable education. Table 1 illustrates the specific applications of AI teaching assistant systems within the educational domain. AI assistant technology engages in analyzing and grading actions, concurrently providing technical support to students throughout their learning trajectories. Moreover, AI addresses the challenges faced by educators in thoroughly observing, providing nuanced feedback, and facilitating a profound understanding of the content. At the core of AI’s capabilities lies pattern recognition, a technique wherein computers emulate human senses to perceive and interpret data from the external environment. Propelled by the rapid evolution of digital information theory and computer technology, endeavors persist to evaluate natural information and convert it into digital signals. This evaluation enables the analysis and processing of digital signals through computational intelligence. A pivotal contribution of AI in education is the construction of virtual learning environments and data resources for educators. This project empowers teachers to meticulously plan lessons, organize classrooms, and prepare instructional materials in advance. By leveraging intelligent teaching tools and software, teachers can amass data on their students’ learning endeavors, facilitating sophisticated analyses at the teaching level to garner profound insights into the academic progress of their pupils.
The AI assistant application’s visual recording feature enhances the training process’s clarity. This capability allows students and instructors to jointly review training videos, facilitating in-person discussions about areas that may need improvement in technical actions. Moreover, students can more effectively identify their shortcomings. Actively correcting errors becomes possible for students as they watch videos and follow the guidance provided by AI teaching assistants. An AI teaching assistant system utilizes video and image data from the world’s top professional players to analyze and compare their serves. The system visually examines the results, highlighting similarities and differences between players17,18,19. Figure 3 displays the real-time monitoring of the service training process assisted by AI. Students can observe the technical maneuvers of elite players on the screen, while experienced players can oversee the landing point of the service. AI teaching assistants resolve these queries through big data analysis, presenting the information to students on a large screen in an accessible manner. Simultaneously, the intricate technical procedures can be accelerated and magnified.

(Source: AccuTennis official website).
Real-time monitoring of serve training
AI teaching assistants excel in refining and computing sports indicators, assessing risks and errors in sports information, and collecting real-time sports data during student training. Specialized training sessions undergo continuous monitoring by AI teaching assistants, which involves scrutinizing and comparing the recorded outcomes of each activity with predetermined indicators. In instances where students’ action data deviates from the anticipated indicators, the AI teaching assistants guide corrections through the feedback system. The AI assistant system accurately computes sports technical indicators and promptly communicates them to students. This function enables students to comprehend the shortcomings in their actions and make timely corrections using the sports technical data acquired through sensors and the visual capture system.
CS-FCM framework based on compressed sensing
While AI has shown success in addressing general issues, it still grapples with overcoming developmental barriers such as interpretability and generalization, particularly in dealing with complex matters. The current limitations of AI include a lack of comprehensive understanding of complexity, and its mathematical foundation faces challenges related to nonlinear issues, resulting in unforeseen outcomes. This uncertainty manifests in the non-uniqueness and instability of complex system learning outcomes and the non-repeatability and unpredictability of system dynamic behavior discovery20,21. The primary challenges arising from nonlinear issues in complexity include the scientific description complexity of big data, structural complexity induced by the nonlinear correlation of primary components in complex systems, and evolutionary complexity stemming from the unpredictable regulation of these systems’ behaviors22,23,24. Multi-collinearity is observed in a set of independent variables when, although these variables are not precisely equal to zero when linearly combined with other independent variables, there exists a significant degree of inter-correlation among them. The regression coefficient’s variation is relatively high due to numerous collinearities. Even though the coefficient remains an unbiased estimate, a result with considerable volatility often deviates from reality.
As a tool for knowledge representation and reasoning, FCM depicts a system in a manner akin to human thought processes. Expert knowledge and practical information distilled from data are amalgamated through rule-based structures, emphasizing causal links and graph structures to express knowledge. The predominant focus of FCM researchers lies in implementing and learning techniques, structure expansion methods, and analysis techniques to facilitate decision support across various domains. The framework introduced in this study, CS-FCM, is founded on compressed sensing principles and is applied to the learning of large-scale FCM from time series data.
Compressed sensing, a signal processing technique, adeptly acquires and reconstructs signals by resolving linear systems with limited information. Specifically, compressed sensing aims to reconstruct the vector \(X \in R^{N}\) from the linear measurement \(Y\) about \(X\):
The more general form can be expressed as Eq. (2).
In Eq. (2), \(\phi\) indicates the \(M \times N\) matrix, and \(\varepsilon\) denotes the noise. This problem can be formulated as an \(L_{0}\)-regularization problem described as Eq. (3).
Here, \(\left\| X \right\|_{0}\) signifies the \(L_{0}\) norm, and \(X\) means the number of non-zero elements in v.
\(L_{1}\) regularization poses a convex optimization problem, and precise signal reconstruction can be attained by solving the following convex optimization problem:
To apply compressed sensing to FCM learning tasks, the problem is initially decomposed into learning local connections for each node. Node i can be obtained by:
Here, \(\psi^{ - 1}\) refers to the inverse function of \(\psi\). \(\phi\) is determined by the state \(C_{j} \left( t \right)\) of the node; \(W_{i}\) signifies the weight vector between the ith node and all nodes.
To learn the sparse structure from all nodes to node i, the following \(L_{1}\) regularization problem can be established according to Eq. (7).
To solve Eq. (7), a compressed sensing algorithm based on \(L_{1}\) regularization optimization is adopted, and the problem can be defined as Eq. (8).
The solution to Eq. (8) involves the use of the primal–dual path tracing interior point method. Initially, it is essential to set dual variables corresponding to \(\lambda_{{u_{1} ;j}}\) and \(\lambda_{{u_{2} ;j}}\) in Eqs. (9) and (10):
The Newton iteration is iterated through the primal–dual algorithm until the proxy dual gap, denoted as \(\eta = - f^{T} \lambda\) is reduced below the given tolerance. The maximum iteration is set to 10,000, and the implementation process of CS-FCM unfolds as follows: (1) Initialize \(i \leftarrow 1\), and obtain \(\phi\) and \(Y\). (2) Formulate an objective function for node i. (3) Resolve Eq. (1) using the standard interior point method. (4) Update \(i \leftarrow i + 1\) n. (5) If (\(i > N\)), the algorithm halts; otherwise, proceed to step 2.
The least square method and L1 regulation are incorporated into the FCM weight learning problem. The weight matrix of the FCM is derived by minimizing the error through the least square method, effectively minimizing noise interference. Simultaneously, the minimization of the L1 regulation of the weight addresses the challenge of ensuring sparsity in the weight matrix, a limitation in the current learning methods. The nonlinear Hebbian algorithm, a widely employed unsupervised learning method in system weight learning, is utilized. To enhance learning efficiency and model accuracy, the connection weight is adjusted by taking the product of the state values of the causal node and the outcome node linked with the weight without employing additional constraints. As the number of layers updated by Hebb increases, the classification accuracy of the network gradually diminishes, although the accuracy remains superior to the untrained random initialization state. Anti-Hebb plasticity learning diminishes the weight of asynchronously activated neuron connections, with softmax assigning values based on the asynchronous activation value. Consequently, the neuron connections exhibiting poorer synchronization experience higher updating weights.
Time series prediction framework based on high-order FCM
Neural networks, graph theory, and other topics related to FCM have been extensively applied across various industries, evolving into a prominent research area in the field of AI due to their robust intuitive expression and reasoning capabilities25,26,27. The Fuzzy C-means clustering, also integral to the process of information granulation, typically facilitates the acquisition of core representations by concept nodes. Subsequently, the FCM’s training transforms into an optimization problem for the weight matrix28.
In the self-encoder’s output, the middle hidden layer is extracted from feature X, and this extracted feature can effectively reconstruct the original feature. In essence, the middle layer accomplishes the abstraction of the original data, serving as an alternative representation. Two structural aspects define the hidden layer in the middle: (1) Dimension reduction, characterized by fewer hidden layer nodes than input layer nodes. (2) Sparsity, involving the addition of sparsity constraints to neurons within the hidden layer.
This study uses a Sparse Autoencoder (SAE) to reconstruct the input from its coding representation. The unsupervised learning algorithm is applied to train SAE, addressing the limitation of the prediction model framework based on FCM falling into local optimization. The structure of SAE is depicted in Fig. 4, with each map containing k feature nodes. The SAE output is denoted by \(X^{o}\), while \(W_{S} = \left\{ {W_{1} ,W_{1}^{o} } \right\}\) and \(b_{S} = \left\{ {b_{1} ,b_{1}^{o} } \right\}\) respectively represent the weight and bias in SAE29,30,31. Initially, the input data undergoes precise mapping by SAE to obtain a concealed representation. The predicted value of the original time series is then calculated by combining the learned features with the output of the High-order Fuzzy Cognitive Map (HFCM). Granular time series are incorporated to construct the HFCM model, capturing the fundamental properties of time series and ensuring the model’s interpretability.

Structure of SAE.
Each SAE characteristic node is considered a node in the HFCM, ensuring an equal count of characteristic nodes and nodes in the HFCM. The calculation of the node state value in HFCM is elucidated in Eq. (11):
Here, \(\left[ {.\left| . \right.} \right]\) stands for vertical vector connection. \(Z\) and \(H\) are used to calculate the output of SAE-FCM using Eq. (12):
In Eq. (12), \(W_{3} \in R^{2k \times 1}\), and the training of \(W_{3}\) is a linear task, and its calculation can be completed by ridge regression:
In Eq. (13), \(\lambda\) and \(I\) represent a constant and an identity matrix, respectively.
For enhanced prediction accuracy of the SAE-HFCM model, fine-tuning is employed to adjust the model parameters. Should the targeted training accuracy remain elusive post fine-tuning, the process is reiterated. The training algorithm flow of the SAE-HFCM model is delineated in Table 2.
This study assesses the effectiveness of the SAE-HFCM model using four datasets—Sunspot, S&P500, Radio, and Lake—each exhibiting diverse features. The Sunspot dataset, tracking sunspot counts from 1700 to 1987, demonstrates strong temporal correlation and periodicity, posing a challenge for time series predictions. The S&P500 dataset, encompassing the daily starting prices of the S&P 500 index from June 1, 2016, to June 1, 2017, is marked by complexity and nonlinearity due to various influencing factors in the stock market. The Radio dataset, spanning radio broadcasts in Washington, DC, from May 1934 to April 1954, is characterized by significant nonlinearity and complexity, making traditional linear models less effective. The Lake dataset covers monthly water level measurements of Lake Erie from 1921 to 1970, containing multivariate information and spatial correlation, necessitating using geographic information system (GIS) models for predictions. For statistical significance testing of datasets, the Lake dataset is exemplified. It includes geographical location, depth, water temperature, and weather information. Four models are established to explore the impact of these factors on lake water quality: a full variable model and three univariate models (each containing only one independent variable). Initially, the statistical significance of the full variable model is tested using the F-test and P value. Results indicate that all independent variables in the full variable model significantly influence lake water quality (P values are all less than 0.05). Subsequently, the coefficient significance test is conducted, affirming the reliability of all coefficient estimates (p values of the T test are less than 0.05). Following this, three univariate models are tested for statistical significance through univariate regression analysis and P value assessment, revealing that independent variables in all univariate models significantly impact lake water quality (P values are less than 0.05).
The model selection process employs the grid search approach, segmenting the standard time series data into three subsets: the training set (70% of the total data), validation set (10%), and test set (20%). During training, the model learns historical data patterns from the time series to inform future predictions. The validation set is utilized to fine-tune model parameters and select the optimal model. Finally, the test set evaluates the model’s overall performance. The optimal prediction model is chosen, and prediction accuracy is assessed using both the validation set and the test set. SAE processes the training data to derive time series characteristics, with the number of nodes in HFCM aligning with the hidden units in SAE. To gauge performance, a comparative analysis is conducted between SAE-HFCM and the Autoregressive Model Per Scale (AR)32 and ANN33. The difference in performance on the Root Mean Square Error (RMSE) index is specifically examined.
Results and discussion
Convergence and stability analysis of CS-FCM
In this study, the convergence and stability of CS-FCM are examined, and the outcomes of experiments conducted on FCM with densities of 20% and 40% are depicted in Figs. 5 and 6. The experiments involve 100 nodes, with varying N1 values set at 0.2, 0.4, 0.6, 0.8, and 1.0, where N1 represents the total data length divided by the number of nodes. As illustrated in Fig. 5, for FCM with a 20% density and different data lengths, CS-FCM demonstrates remarkable efficiency by converging to a stable point with a reconstruction error below 10–3 in just 15 iterations. Figure 6 further reveals that, for FCM with a 40% density, CS-FCM achieves stability after 17 iterations. Hence, CS-FCM exhibits robust convergence and stability across varying densities and data lengths. Furthermore, the study explores the scalability of CS-FCM by testing it on an FCM with 1000 nodes. Despite a decrease in accuracy with an increased number of nodes, CS-FCM demonstrates its capability to learn large-scale FCM structures.

Convergence and stability of CS-FCM with data density of 20%.

Convergence and stability of CS-FCM with data density of 40%.
As the number of nodes within the FCM increases while maintaining the same density, the algorithm is required to establish more connections between them. Despite a decrease in accuracy with an expanding number of nodes, CS-FCM can effectively learn large-scale FCM structures. This underscores the model’s proficiency in connection learning, enabling it to navigate complex network structures. It is noteworthy that these findings, although derived from a specific dataset, highlight the model’s adaptive learning strategy, allowing the model to autonomously adjust to diverse problem scenarios. Moreover, leveraging compressed sensing technology empowers the model to handle large-scale data efficiently without additional data annotation. This emphasizes the model’s robust generalization capability, making it applicable across multiple problem scenarios. Comparative analysis of FCM performance under varied density conditions enhances comprehension of the algorithm’s limitations and potential and opens avenues for refining and optimizing the FCM algorithm to better suit diverse and intricate data network environments.
Performance evaluation of the SAE-HFCM model in a complex system
The hyperparameters of the comparative models are determined through rigorous experimentation. The RMSE results for the SAE-HFCM model and other methodologies proposed here are ultimately obtained through extensive trials and summarized in Table 3 across four datasets. Notably, the results indicate that, across all datasets, the SAE-HFCM model introduced in this study surpasses both AR and ANN. The prediction curve and error curve of the SAE-HFCM model are illustrated on the test set to provide a visual representation. Figure 7, utilizing the time series of the S&P500 dataset as an example, showcases that the SAE-HFCM model has achieved remarkable accuracy. It is noteworthy that the primary source of current errors is the sudden changes in the time series. This observation aligns with the conclusions of Stefenon et al. (2021)34, corroborating the validity and effectiveness of this study.

Prediction curve and error curve based on SAE-HFCM model on S&P500 data set.
Conclusion
This study endeavors to investigate a sports education teaching model guided by high-order complex networks, wherein an AI assistant delivers intelligent assistance in tennis instruction through CS-FCM. CS-FCM, a pivotal component of this system, is integrated into the AI assistant, employing compressed sensing principles. This innovative approach encompasses a large-scale FCM learning framework, specifically named CS-FCM. The framework is scrutinized using experimental data with FCM densities of 20% and 40%, providing valuable insights into the efficacy of the system. The SAE is trained utilizing unsupervised learning techniques to address the deficiency in the architecture of the FCM-based prediction model, which is susceptible to local optimization. Utilizing the acquired features in conjunction with the output from HFCM, the predicted values of the original time series are determined. The research findings reveal that, for an FCM density of 20%, CS-FCM attains a stable point within 15 iterations, with a reconstruction error below 10–3. In the case of an FCM density of 40%, stability is achieved after 17 iterations. These results unequivocally demonstrate the superior performance of CS-FCM in large-scale FCM learning. Despite a decline in accuracy with an increase in node quantity, CS-FCM remains effective in learning large-scale FCM, showcasing the model’s robust capacity in connection learning. Particularly noteworthy is its excellent performance in handling complex network structure data. Moreover, the RMSE results of the SAE-HFCM model on four datasets significantly surpass those of traditional AR and ANN models. The experiments, illustrated by the time series of the S&P500 dataset, highlight the exceptional predictive accuracy of the SAE-HFCM model on the test set. It demonstrates notable adaptability to abrupt changes in time series. In conclusion, this study validates the feasibility and effectiveness of CS-FCM in an intelligent sports education system. Furthermore, with the introduction of the SAE-HFCM model, the performance of the FCM algorithm in time series prediction is enhanced. The research results provide robust support for intelligent teaching systems and offer valuable insights for intelligent-assisted teaching in various domains. The approach delineated in this study exhibits certain limitations, primarily rooted in its dependence on automatic feature extraction and representation learning. This reliance may potentially constrain its performance under specific circumstances. Subsequent research endeavors could delve into the exploration of more sophisticated techniques in data processing and feature engineering. This exploration aims to effectively capture the intricate and nuanced properties inherent in physical training data, thereby advancing the robustness and versatility of the proposed methodology.
Data availability
All data generated or analyzed during this study are included in this published article (and its Supplementary Information files).
References
Liu, Q. & Ding, H. Application of table tennis ball trajectory and rotation-oriented prediction algorithm using artificial intelligence. Front. Neurorobot. 16, 46 (2022).
Gao, Y. et al. Remote sensing scene classification based on high-order graph convolutional network. Eur. J. Remote Sens. 54(sup1), 141–155 (2021).
Liu, J., Wang, L. & Zhou, H. The application of human–computer interaction technology fused with artificial intelligence in sports moving target detection education for college athlete. Front. Psychol. 12, 677590 (2021).
Yang, J., Tang, L. & Li, X. W. Research on face recognition sports intelligence training platform based on artificial intelligence. Int. J. Artif. Intell. Tools 30(06n08), 2140015 (2021).
Wang, Y. Physical education teaching in colleges and universities assisted by virtual reality technology based on artificial intelligence. Math. Probl. Eng. 2021, 1–11 (2021).
Huang, X., Huang, X. & Wang, X. Construction of the teaching quality monitoring system of physical education courses in colleges and universities based on the construction of smart campus with artificial intelligence. Math. Probl. Eng. 2021, 1–11 (2021).
Hao, L. & Zhou, L. M. Evaluation index of school sports resources based on artificial intelligence and edge computing. Mob. Inf. Syst. 2022, 1–9 (2022).
Juan, D. & Hong, W. Y. Particle swarm optimization neural network for research on artificial intelligence college English classroom teaching framework. J. Intell. Fuzzy Syst. 40(2), 3655–3667 (2021).
Nyberg, E. P. et al. BARD: A structured technique for group elicitation of Bayesian networks to support analytic reasoning. Risk Anal. 42(6), 1155–1178 (2022).
Huang, W. et al. Technical and tactical diagnosis model of table tennis matches based on BP neural network. BMC Sports Sci. Med. Rehabil. 13(1), 1–11 (2021).
YanRu, L. An artificial intelligence and machine vision based evaluation of physical education teaching. J. Intell. Fuzzy Syst. 40(2), 3559–3569 (2021).
Xu, Z. & Zhang, S. Special issue on artificial intelligence technologies in sports and art data applications. Neural Comput. Appl. 35(6), 4199–4200 (2023).
Bamunif, A. O. A. Sports information & discussion forum using artificial intelligence techniques: A new approach. Turk. J. Comput. Math. Educ. (TURCOMAT) 12(11), 2847–2854 (2021).
Qiao, F. Application of deep learning in automatic detection of technical and tactical indicators of table tennis. PLoS ONE 16(3), e0245259 (2021).
Zhou, Y. et al. Triboelectric nanogenerator based self-powered sensor for artificial intelligence. Nano Energy 84, 105887 (2021).
Wei, S., Wang, K. & Li, X. Design and implementation of college sports training system based on artificial intelligence. Int. J. Syst. Assur. Eng. Manag. 13(Suppl 3), 971–977 (2022).
Giles, B., Kovalchik, S. & Reid, M. A machine learning approach for automatic detection and classification of changes of direction from player tracking data in professional tennis. J. Sports Sci. 38(1), 106–113 (2020).
Latifinavid, M. & Azizi, A. Development of a vision-based unmanned ground vehicle for mapping and tennis ball collection: A fuzzy logic approach. Future Internet 15(2), 84 (2023).
Huan Nan, C. & Zhen, Z. L. An artificial intelligence fuzzy system for improvement of physical education teaching method. J. Intell. Fuzzy Syst. 40(2), 3595–3604 (2021).
Wang, H. & Fei, W. Failure recognition method of rolling bearings based on the characteristic parameters of compressed data and FCM clustering. J. Intell. Fuzzy Syst. 38(2), 1477–1485 (2020).
Wang, H., Hou, Y. & Yu, H. Analysis of integrated energy-load characteristics based on sparse clustering and compressed sensing. IET Energy Syst. Integr. 1(3), 194–201 (2019).
Tian, B. et al. Fast bayesian compressed sensing algorithm via relevance vector machine for LASAR 3D imaging. Remote Sens. 13(9), 1751 (2021).
Wang, H., Wu, Y. & Xie, H. Secure and efficient image transmission scheme for smart cities using sparse signal transformation and parallel compressive sensing. Math. Probl. Eng. 2021, 1–13 (2021).
Osamy, W., Aziz, A. & Khedr, A. M. Deterministic clustering based compressive sensing scheme for fog-supported heterogeneous wireless sensor networks. PeerJ Comput. Sci. 7, e463 (2021).
Tang, Y. & Xiao, Y. Learning hierarchical concepts based on higher-order fuzzy semantic cell models through the feed-upward mechanism and the self-organizing strategy. Knowl. Based Syst. 194, 105506 (2020).
Tatarkanov, A. A. et al. A fuzzy approach to the synthesis of cognitive maps for modeling decision making in complex systems. Emerg. Sci. J. 6(2), 368–381 (2022).
Lopez-Bernabe, E., Foudi, S. & Galarraga, I. Mind the map? Mapping the academic, citizen and professional stakeholder views on buildings and heating behaviour in Spain. Energy Res. Soc. Sci. 69, 101587 (2020).
Selvanambi, R. et al. Lung cancer prediction using higher-order recurrent neural network based on glowworm swarm optimization. Neural Comput. Appl. 32, 4373–4386 (2020).
Cook, L. G., Caulkins, N. N. & Chapman, S. B. A strategic memory advanced reasoning training approach for enhancing higher order cognitive functioning following sports-and recreation-related mild traumatic brain injury in youth using telepractice. Perspect. ASHA Spec. Interest Groups 5(1), 67–80 (2020).
Chiu, M. S. et al. The interplay of affect and cognition in the mathematics grounding activity: Forming an affective teaching model. EURASIA J. Math. Sci. Technol. Educ. 18(12), em2187 (2022).
Millroth, P. Toward a richer understanding of human cognition: Unleashing the full potential of the concurrent information-processing paradigm. New Ideas Psychol. 63, 100873 (2021).
Schaffer, A. L., Dobbins, T. A. & Pearson, S. A. Interrupted time series analysis using autoregressive integrated moving average (ARIMA) models: A guide for evaluating large-scale health interventions. BMC Med. Res. Methodol. 21(1), 1–12 (2021).
Abiodun, O. I. et al. Comprehensive review of artificial neural network applications to pattern recognition. IEEE Access 7, 158820–158846 (2019).
Stefenon, S. F. et al. Photovoltaic power forecasting using wavelet Neuro-Fuzzy for active solar trackers. J. Intell. Fuzzy Syst. 40(1), 1083–1096 (2021).
Funding
Funding was provided by The 2022 regular project of Shaanxi Sports Bureau, "Exploring and Studying the Mode and Method of Sports and Education Integration in Shaanxi Province (Grant No. NO:2022473).
Author information
Authors and Affiliations
Contributions
X.S. contributed to conception and design of the study. X.S. organized the database and performed the statistical analysis. X.S. wrote the first draft of the manuscript. What's more, he wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Song, X. Physical education teaching mode assisted by artificial intelligence assistant under the guidance of high-order complex network. Sci Rep 14, 4104 (2024). https://doi.org/10.1038/s41598-024-53964-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-53964-7
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
