
Abstract
Differentiation between adenocarcinomas is sometimes challenging. The promising avenue for discovering new biomarkers lies in bioinformatics using DNA methylation analysis. Utilizing a 2853-sample identification dataset and a 782-sample independent verification dataset, we have identified diagnostic DNA methylation biomarkers that are hypermethylated in cancer and differentiate between breast invasive carcinoma, cholangiocarcinoma, colorectal cancer, hepatocellular carcinoma, lung adenocarcinoma, pancreatic adenocarcinoma and stomach adenocarcinoma. The best panels for cancer type exhibit sensitivity of 77.8–95.9%, a specificity of 92.7–97.5% for tumors, a specificity of 91.5–97.7% for tumors and normal tissues and a diagnostic accuracy of 85.3–96.4%. We have shown that the results can be extended from the primary cancers to their liver metastases, as the best panels diagnose and differentiate between pancreatic adenocarcinoma liver metastases and breast invasive carcinoma liver metastases with a sensitivity and specificity of 83.3–100% and a diagnostic accuracy of 86.8–91.9%. Moreover, the panels could detect hypermethylation of selected regions in the cell-free DNA of patients with liver metastases. At the same time, these were unmethylated in the cell-free DNA of healthy donors, confirming their applicability for liquid biopsies.
Similar content being viewed by others


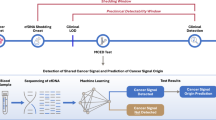
Introduction
Malignant liver tumors, which include primary liver tumors and liver metastases, are among the most common malignancies worldwide. Among primary malignant tumors, hepatocellular carcinoma is the most prevalent, followed by cholangiocarcinoma. Liver metastases include mostly carcinomas, the most common subtype being adenocarcinoma. The major sources of liver metastases are adenocarcinomas of the colon and rectum, followed by carcinomas of the pancreas, breast, lung and stomach. The disease has a poor prognosis and poor overall survival, especially with liver metastases1,2,3,4. Because of the variation in prognosis and treatment options, differentiation between malignant tumors of the liver and prediction of tumor origin in patients with carcinoma of unknown primary (CUP) in the liver are of vital importance. The correct diagnosis can be made using various methods; one of which is DNA methylation analysis.
DNA methylation plays an important role as an epigenetic mechanism of cancer initiation, maintenance and progression. Normally, knowledge of the methylation status of a single CpG site is of limited value unless it is related to the status of neighboring CpG sites. Therefore, efforts in the field of cancer epigenetics have primarily focused on the detection of differentially methylated regions (DMRs) comprising multiple consecutive methylated CpG sites. DMRs can occur throughout the genome but have been identified primarily in the promoter regions of genes, within the body of genes and in intergenic regulatory regions5,6,7,8. Clusters of hypermethylated CpG sites within a gene's promoter region are commonly associated with gene silencing, while coordinated hypermethylation in intragenic regions is associated with gene upregulation5,7. In cancer, hypermethylation contributes to the disease phenotype through genetic inactivation of tumor suppressor genes and DNA repair genes, thereby increasing the rate of mutagenesis. These genes are frequently associated with the cell cycle, apoptosis, cell division, DNA repair and DNA replication8,9,10.
DMRs and even single CpG sites with cancer-specific methylation changes have the potential to have clinical implications as diagnostic biomarkers. Epigenetic profiles inherently reflect tissue differentiation in normal and malignant tissues11. Alterations in methylation patterns are highly pervasive across a given tumor type. The unique methylation profile of cells can be used to distinguish cancer cells from healthy tissues and identify the tissue of origin of DNA11,12. In addition, a small number of selected CpG sites can be used to successfully differentiate between different cancer types10. Hypermethylation occurs early in cancer development and remains methylated across all stages of cancer progression11,13,14. Therefore, DNA methylation biomarkers can be used as potential diagnostic biomarkers to predict tumor origin in patient with metastatic cancer and CUP10,12,15,16,17. Additionally, DNA methylation markers can be extended from tissue samples to liquid biopsy, which is one of the most promising applications in the near future3.
Methylation array-based data from the Illumina Infinium HumanMethylation450 BeadChip (HM450) and lllumina MethylationEPIC BeadChip (EPIC) remain the most used platforms for genome wide methylation studies. They use hybridization of bisulfite-treated DNA with array probes in combination with single nucleotide extension, to measure methylation at the genomic hybridization site for a single CpG dinucleotide18,19,20,21. Because adjacent CpG sites are more likely to share the same methylation status, they often reflect the methylation status of a CpG-rich region22. Therefore, it is not surprising that the HM450 and EPIC arrays remain the most widely used assays for identifying DMRs to date. The chips enable simultaneous determination of the methylation status of more than 450,000/850,000 CpG sites in the human genome. To provide the most comprehensive overview of methylation status, they cover 96% of CpG islands, shelves, and shores, as well as gene regions18,19,20,21. The methylation values of the HM450 and EPIC arrays have been shown to be in excellent agreement with those of bisulfite sequencing, which further supports the credibility of those platforms18,23,24.
The aim of our research was to identify and verify novel cancer-specific methylation biomarkers that successfully differentiate between selected adenocarcinomas: breast invasive carcinoma (BRCA), cholangiocarcinoma (CHOL), colorectal cancer (CRC), hepatocellular carcinoma (LIHC), lung adenocarcinoma (LUAD), pancreatic adenocarcinoma (PAAD) and stomach adenocarcinoma (STAD). We used two different approaches for the identification dataset: a non-clustered approach (no sample clustering was performed) and a clustered approach (unsupervised sample clustering was performed within each project before probe selection). For each cancer type, we identified and verified multiple candidate methylation biomarkers in each approach and constructed panels that successfully differentiate between included adenocarcinoma and their liver metastases and can be detected in cell-free DNA (cfDNA). In addition, we were interested in the differences/similarities in the results of non-clustered and clustered approach.
Results
The bioinformatic analysis was performed on primary tumor samples and normal tissue samples from the BRCA, CHOL, COAD (colon adenocarcinoma), LIHC, LUAD, PAAD, READ (rectum adenocarcinoma) and STAD projects from The Cancer Genome Atlas (TCGA) dataset. The COAD and READ projects were merged and further addressed as CRC. After data preparation, a total of 2609 primary tumor samples and 244 normal tissue samples of selected projects were included. The number of primary tumor samples and normal samples per project included in our study is shown in Supplementary Table S1. The methylation data used in our study were collected through experiment with the HM450, the most comprehensive collection of methylation data available at TCGA. The chip provides information on the methylation status of more than 450,000 CpG sites in the human genome, which formed the starting point for our selection. In our results, methylation levels are quantified by the average beta value, which ranges from zero (unmethylated) to one (fully methylated)25. The range of beta values between zero and one can be interpreted as an approximation of the percentage of methylation of a selected CpG site or CpG sites in the studied region in the sample26. Using our bioinformatics analysis, we narrowed down and selected the best probe candidates for each cancer type to differentiate between the included cancer types. We focused on probes that were hypermethylated in the cancer types of interest and unmethylated in the comparator types. The results from the TCGA dataset were verified using an independent Gene Expression Omnibus (GEO) dataset with 823 samples (418 primary tumor samples, 364 normal tissue samples, 31 liver metastasis samples and 9 cfDNA samples) (Supplementary Table S2).
Clustering of methylation data
Unsupervised clustering was performed separately for each project in TCGA dataset. Each individual methylation cluster (MC) represent a group of samples within the project with similar methylation level, where calculated beta value represent the average methylation level of all HM450 probes in individual sample. Our analysis resulted in four to seven MCs per individual project. MC1 represent the group of samples within the project with the highest average methylation level, MC2 represent the group of samples with the second highest average methylation level, etc. The results of clustering analysis, the beta values and the number of tumor samples in each cluster are shown in Supplementary Table S1. DNA methylation heatmaps depicting the methylation pattern of the included adenocarcinomas are shown in Supplementary Fig. S1.
Selected hypermethylated probes
Non-clustered approach
For each cancer type, our bioinformatic analysis revealed a set of probes and associated CpG sites in human genome that are hypermethylated in that cancer and hypomethylated in the compared cancer types. The non-clustered approach resulted in two to twenty-one probes per cancer type. All probes and beta values across all cancer types and groups of normal tissue samples and distribution of hypermethylated samples across projects for every probe can be found in the Supplementary Table S3 and Supplementary Table S4. The best probes from non-clustered approach are listed in Supplementary Table S5. The individual probes beta values of included tumor samples and normal tissue samples are shown in Supplementary Fig. S2.
Clustered approach
Using a clustered approach, bioinformatic analyses revealed a number of probes and associated CpG sites in the human genome that were hypermethylated in the MC of interest and hypomethylated in the compared cancer types. More specifically, it reveals a set of probes that are hypermethylated in a subset of the included tumor samples (in MC of interest) and does not necessarily show up in the majority of samples as in the non-clustered approach. The number of probes varied from zero to 74 probes per MC. The absence of hypermethylated probes was most frequently observed in MCs with the lowest average methylation levels. All probes and beta values across all cancer types and groups of normal tissue samples and distribution of hypermethylated samples across projects for every probe can be found in the Supplementary Table S6 and Supplementary Table S7. For the selected probes the sensitivity and specificity of each probe to differentiate between cancer and paired normal tissue samples was calculated. In addition, the sensitivity and specificity of the probes to differentiate between all cancer types (all primary tumor samples) and all included samples (all primary tumor samples and normal tissue samples) were calculated. The best probes from non-clustered approach are listed in Supplementary Table S8. The distribution of beta values of individual probes over all included tumor clusters and normal tissue samples is shown in Supplementary Fig. S3. Some of the probes obtained with the clustered approach were the same as those obtained with the non-clustered approach. The majority of these probes were significantly hypermethylated in multiple MCs.
Panels
Hepatocellular carcinoma (LIHC)
In TCGA dataset LIHC resulted in highest number of hypermethylated probes among all cancers. Six probes included in the LIHC panel from the non-clustered approach differentiate LIHC from other cancers with 91.2% sensitivity, 94.8% specificity for all tumor samples, 95.2% specificity for all samples and 94.7% diagnostic accuracy (Table 1). The panel successfully differentiate LIHC from normal liver tissue with a specificity of 100%. In the clustered approach, eight probes were selected for the panel design. The panel showed slightly lower sensitivity and specificity for LIHC, but higher specificities and diagnostic accuracy than the panel from non-clustered approach (Table 1). The probe cg18485193 was used in both panels (Supplementary Fig. S2). This probe was hypermethylated in five of six LIHC clusters (LIHC MC2–MC6). The results of the GEO dataset show a high degree of agreement with the results of the TCGA dataset, with even higher LIHC sensitivity and similar specificities (Table 1). This can be seen on Fig. 1, which shows the distribution of the highest beta values of all included samples from the panels of both approaches and a comparison between the TCGA dataset and the GEO dataset.

Boxplots showing the distribution of the highest beta values of all included samples from the LIHC panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) LIHC panel clustered approach. (b) LIHC panel non-clustered approach.
Cholangiocarcinoma (CHOL)
Three probes from non-clustered approach were used in the CHOL panel and achieved a sensitivity of 77.8% and high specificities in TCGA dataset (Table 2). Although adding an additional probe would result in higher sensitivity, the CHOL specificity would decrease. Therefore, we decided to use fewer probes and maintain the high CHOL specificity. The panel with four probes from the clustered approach shows a slightly lower sensitivity (72.2%). Specificity for tumor samples (92.7%), specificity for all samples (93.1%) and diagnostic accuracy (92.8%) were slightly higher compared to the panel from non-clustered approach. Although probe cg02228804 was not included in either panel, it was obtained through both approaches (Supplementary Table S4, Supplementary Table S7 and Supplementary Fig. S2 and Supplementary Fig. S3). The results of the GEO dataset are similar to the results of the TCGA dataset, with slightly lower CHOL sensitivity and similar specificities (Table 2). Similarities can be seen in Fig. 2, which shows the distribution of the highest beta values of all included samples from the panels of both approaches and a comparison between the TCGA dataset and the GEO dataset.

Boxplots showing the distribution of the highest beta values of all included samples from the CHOL panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) CHOL panel clustered approach. (b) CHOL panel non-clustered approach.
Colorectal cancer (CRC)
For the CRC panel, four probes were selected from the non-clustered approach and three probes from the clustered approach (Table 3). Although both panels achieved a CRC specificity of 100%, the non-clustered panel yielded a much higher CRC sensitivity than the panel with the clustered approach (95.9% vs. 62.8%). In contrast, slightly higher specificity for all samples and higher diagnostic accuracy were observed with the clustered approach (Table 3). In the clustered approach, an additional probe can be added to achieve higher CRC sensitivity. While specificity for tumor samples and specificity for all samples would remain high, CRC specificity would decrease. Although not included in the final panel design, three identical probes were obtained from both approaches (Supplementary Table S4 and Supplementary Table S7). In the GEO dataset the panels resulted in slightly lower CRC sensitivity and CRC specificity, but achieved higher specificity for tumor samples, specificity for all samples and higher diagnostic accuracy (Table 3). The distribution of the highest beta values of all included samples from the panels of both approaches and a comparison between the TCGA dataset and the GEO dataset are shown in Fig. 3.

Boxplots showing the distribution of the highest beta values of all included samples from the CRC panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) CRC panel clustered approach. (b) CRC panel non-clustered approach.
Lung adenocarcinoma (LUAD)
LUAD was the cancer for which the fewest probes were obtained. The non-clustered approach yielded only two probes, cg21929771 is LUAD-specific and cg00907427 is hypermethylated in LUAD tumor samples and normal samples, but hypomethylated in all comparison groups. The panel consisting of these two probes yielded a LUAD sensitivity of 78.9%, a specificity of 89.8% for tumor samples, a specificity of 89.8% for all samples, and a diagnostic accuracy of 88.5% (Table 4). Although the panel is not LUAD specific, it can be used to differentiate between cancer types. To achieve 100% LUAD specificity, we recommend using only the cg21929771 probe, which successfully differentiate LUAD from other samples with a sensitivity of 65.2% and a specificity of 94.5% for all samples (Supplementary Fig. S2). For the non-clustered approach, significant probes were found only in LUAD MC1 (Supplementary Fig. S3). The panel developed from seven probes of the clustered approach resulted in lower LUAD sensitivity (51.8%), but higher specificities. Similar results were observed in the GEO dataset, which are shown graphically in Fig. 4 (Table 4).

Boxplots showing the distribution of the highest beta values of all included samples from the LUAD panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) LUAD panel clustered approach. (b) LUAD panel non-clustered approach.
Pancreas adenocarcinoma (PAAD)
Besides LUAD, PAAD was the one for which only a small number of probes were obtained. The non-clustered approach yielded only two probes, cg01237565 and cg00955911, which are hypermethylated not only in PAAD tumor samples but also in normal samples (Supplementary Table S5). The panel using these two probes detects PAAD with a sensitivity of 82.6% and a diagnostic accuracy of 85.3% (Table 5). The probe cg01237565 was obtained also in clustered approach (Supplementary Fig. S3). This probe was hypermethylated in four of five PAAD clusters. The four-probe PAAD panel developed using the clustered approach shows lower PAAD sensitivity (71.2%) but higher specificity and overall accuracy (94.5%) than the panel developed using the non-clustered approach. Similarly, it shows low PAAD specificity. Although the panels are not PAAD-specific and do not successfully differentiate between PAAD tumor samples and paired normal samples, they can be used to differentiate between included cancer types. Verification of the constructed panels in the GEO dataset confirmed that the panels do not differentiate between PAAD and the adjacent healthy pancreatic tissue, but successfully differentiate PAAD from other included tumors and healthy tissues (Table 5). This can be evident in Fig. 5. For successful differentiation between PAAD tumor samples and paired normal samples, we recommend the use of additional independent methylation biomarkers.

Boxplots showing the distribution of the highest beta values of all included samples from the PAAD panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) PAAD panel clustered approach. (b) PAAD panel non-clustered approach.
Stomach adenocarcinoma (STAD)
For the STAD panels, three probes were selected from the non-clustered approach and seven probes from the clustered approach (Table 6). Although both panels achieved a STAD specificity of 100%, the non-clustered panel yielded a much higher STAD sensitivity than the panel with the clustered approach (90.1% vs. 73.7%). Slightly higher specificities and higher diagnostic accuracy were observed with the non-clustered approach. The probe cg06622735 was used in both panels (Supplementary Fig. S2 and Supplementary Fig. S3). The results of the GEO dataset show a high degree of agreement with the results of the TCGA dataset, with even higher diagnostic accuracy (Table 6). This can also be seen in the graphic representation in Fig. 6.

Boxplots showing the distribution of the highest beta values of all included samples from the STAD panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) STAD panel clustered approach. (b) STAD panel non-clustered approach.
Breast invasive carcinoma (BRCA)
BRCA panels consisted of 7 and 10 selected probes from the non-clustered and clustered approaches, respectively. Both panels differentiate BRCA from other cancers with high sensitivity and specificity (Table 7). The panel from the clustered approach resulted in slightly higher BRCA sensitivity than the panel from the non-clustered approach (91.8% vs. 88.9%). In contrast, the latter resulted in higher BRCA specificity (96.9% vs. 94.8%), higher specificity for tumor samples (94.1% vs. 90.6%), higher specificity for all samples (94.7% vs. 91.4%), and higher diagnostic accuracy (93% vs. 91.5%). Both panels included probes cg17652435, cg02085210 and cg02435495. All those probes were hypermethylated in multiple BRCA clusters (Supplementary Table S8). The panels tested on GEO dataset also resulted in high sensitivities, specificities and diagnostic accuracies (Table 7). This can be seen in Fig. 7, which shows the distribution of the highest beta values of all included samples from the panels of both approaches and a comparison between the TCGA dataset and the GEO dataset.

Boxplots showing the distribution of the highest beta values of all included samples from the BRCA panels of both approaches and a comparison between the TCGA dataset and the GEO dataset. (a) BRCA panel clustered approach. (b) BRCA panel non-clustered approach.
Liver metastases
The designed PAAD and BRCA panels were tested in metastatic tumor samples. The PAAD panel from the non-clustered approach showed excellent 100% sensitivity for PAAD liver metastases and good specificities (Table 8). In contrast, the PAAD panel from the clustered approach showed a lower sensitivity but higher specificities between 92.4 and 94.9%. Both BRCA panels showed a sensitivity of 83.3% for BRCA liver metastases. Although the panel from the clustered approach achieved higher specificities than the panel from the non-clustered approach, both panels resulted in a high diagnostic accuracy (89.5% and 91.9%) (Table 8). The conservation of methylation from primary tumors to liver metastases and their cancer specificity is presented in Figs. 5 and 7.
Cell-free DNA
The design panels were tested on the available EPIC data from cfDNA samples from the GSE122126 dataset12. Three healthy individuals, three patients with CRC liver metastases and three patients with BRCA liver metastases, were included. Using our panels, we successfully detected cfDNA hypermethylation in two out of three patients with CRC liver metastases and in all three patients with BRCA liver metastases. All selected biomarkers were unmethylated in the cfDNA of healthy donors. The beta values for the selected biomarkers and the included cfDNA samples are listed in Supplementary Table S9.
Discussion
While a significant proportion of liver malignancies are primary tumors, the occurrence of liver metastases originating from adenocarcinomas is relatively common and frequently observed in clinical practice3,27. Sometimes the primary site of a metastatic tumor cannot be determined. These tumors, termed CUP, are frequently found in the liver4,28. The differential diagnosis and origin of metastatic adenocarcinoma are usually determined by histomorphologic examination and immunohistochemical studies3,27. However, in some cases, primary liver adenocarcinomas are poorly differentiated and indistinguishable from metastatic adenocarcinoma and the primary site of a metastatic tumor cannot be determined3,29. Therefore, the importance of genetics and epigenetics in differential diagnosis is increasing. Given the extensive research on epigenetic changes in cancer, DNA methylation is one of the most thoroughly studied. To identify new potential DNA methylation biomarkers, we focused on methylation data from the HM450, which includes approximately 450,000 CpGs in the human genome. This platform focuses on CpG islands and gene promoters that are typically unmethylated in healthy tissue and hypermethylated in cancer. This enabled the identification of hypermethylated regions, even though the majority of the cancer genome is typically hypomethylated30.
Although many DNA methylation biomarkers have been identified, most previous cancer research based on HM450 methylation array data mainly focused on the abnormal methylation patterns in a cancer or use a large number of probes for successful cancer differentiation. Some research groups have successfully identified potential DNA methylation markers that can differentiate and successfully diagnose various cancers31,32,33,34,35,36,37,38,39. Hao et al. successfully differentiate LUAD, LIHC, COAD, BRCA and adjacent normal tissues based on their DNA methylation profiles using machine learning on HM450 TCGA data. Moreover, they successfully identified majority of CRC liver metastases with a panel of 46 CpG biomarkers, which support the potential for using the DNA methylation signatures to improve the diagnosis of CUP in the liver35. Recent study accurately categorized samples of 19 tumor types (including BRCA, COAD, LUAD, LIHC and STAD) according to histology with diagnostic accuracy of 86%39. They used random forest model to derived 305-probe classifier set. Tang et al. achieve excellent performance using random forest models on 14 tumor types using between 9 and 738 CpG sites17. The results of these studies are not directly comparable with our results because the same cancer types were not included. Nevertheless, they show that high accuracies can be achieved, which is further confirmed by our study. The important difference is that significantly fewer methylation biomarkers were used in our study to achieve similar accuracies. Ding et al. conducted one of the most promising study on TCGA HM450 data. Group used machine learning to narrow down 12 CpG sites that could effectively differentiate between tumor samples for 26 main TCGA cancers. In addition, the group demonstrated that the proposed biomarkers can be extended to metastases and predict the origin of CUP10. Although the drawback of this study is that no clinical validation was performed, this study demonstrates that a small number of methylation biomarkers can be used to differentiate multiple cancer types. Despite the fact that the methods in our study are not consistent with theirs, our study supports their findings and shows that high diagnostic sensitivity and specificity can be achieved with a small number of methylation biomarkers. Furthermore, we have not come across any study that uses and compares the results of our two selected approaches.
In our study, we identified DMRs that are hypermethylated in the cancers of interest, whereas they are unmethylated in comparable cancers and the majority of normal tissue samples. Most identified DMRs can be used as methylation biomarkers that can successfully diagnose primary cancer and also differentiate it from adjacent healthy tissue. Furthermore, because hypermethylation of some otherwise methylation-resistant sites occurs early in cancer development and remains methylated at advanced stages, our biomarkers could be a valuable tool for differential diagnosis between primary and metastatic adenocarcinomas of the liver3,11,13. This positions them as a potentially invaluable resource for predicting tumor origin in patients with CUP, particularly in the liver, as selected cancers represent the two most common primary liver cancers and frequent sources of liver metastases1,2,3,4. Two different approaches were used to identify novel methylation biomarkers that were further used to design panels that successfully differentiate between included cancer types.
The first approach was a non-clustered approach in which no clustering of methylation data was performed. This approach resulted in much higher numbers of hypermethylated probes after the filtering process in some cancers, such as LIHC, STAD, BRCA, and CRC, than in others. The cancer-specific panels developed from these probes have the highest sensitivity, specificity and diagnostic accuracy (Tables 1, 3, 6 and 7). As expected, the panels for cancers with a low initial number of probes such as CHOL, LUAD and PAAD have lower sensitivity and specificity. Nevertheless, relatively high diagnostic accuracy is observed for these panels, ranging from 85.3 to 91.5% (Tables 2, 4 and 5).
In the second, clustered approach, unsupervised clustering was performed within each project prior to probe selection. It has been mainly used to identify methylation subtypes with distinct clinicopathologic, molecular and immunologic features, predictive and prognostic subtypes, and methylation-based classification40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59. In some studies, methylation clustering has been used as a preliminary step in diagnostic biomarker selection44,49. In our study, clustering allowed us to identify MCs within each cancer type based on their methylation patterns. Each MC is represented by a group of samples that, based on their methylation signatures, belong to a specific methylation subtype within each cancer type. Candidate probes were selected for each MC. Probes hypermethylated in multiple MCs generally resulted in higher overall cancer sensitivity than probes hypermethylated in only one MC. Probes selected from different MCs within a cancer type were combined into a cancer-specific panel. Because probes from different clusters detect specific subsets of samples within a cancer type, combining these probes should result in detection of the majority of tumor samples. Our results support this assumption. Panels that included probes from all tumor-related MCs showed high sensitivity. For example, the probes included in the LIHC panel from the clustered approach were selected from all six LIHC MCs. The combination of the selected probes resulted in a LIHC sensitivity of 89.1% (Table 1). In CRC, the significantly hypermethylated probes were obtained in all four MCs. Only three probes that were hypermethylated in CRC-MC1 to CRC-MC3 were included in the final panel design. They yielded a CRC sensitivity of 62.8%. Although inclusion of probe cg01655898, which is also hypermethylated in CRC-MC4 (Table 3), would result in higher CRC specificity (79%), high tumor samples specificity (97.6%) and all samples specificity (97.3%), we decided not to include it in the final panel because the CRC specificity would decrease dramatically. Probe cg01655898 is hypermethylated in CRC and adjacent healthy tissue samples and does not differentiate between them. Nevertheless, it can be used as an additional methylation biomarker that successfully differentiate between included cancers because it has a high specificity for CRC over other included cancers (99.8%). For some cancers, not all MCs resulted in significant probes. As expected, panels that did not contain probes from all MCs of a cancer type have lower sensitivity. The absence of probes hypermethylated in selected cancer types and hypomethylated in other cancer types was most frequently observed in MCs with the lowest average methylation levels (Supplementary Table S6). In PAAD, STAD and BRCA probes were not found in MCs with the lowest average methylation values (PAAD-MC5, STAD-MC5, STAD-MC6, and BRCA-MC7). In LUAD, only LUAD-MC1 resulted in significantly hypermethylated probes (Supplementary Table S6). Surprisingly, probes were obtained in CHOL clusters with lower average methylation, but not in CHOL-MC1. Using our cut-of criteria, we obtained probes that were hypomethylated in CHOL-MC1. However, when we removed LIHC from the probe selection criteria, the hypermethylated probes were identified. This observation leads us to suggest that the absence of hypermethylated probes may be due to the inherent similarities between different adenocarcinomas, particularly in this context between LIHC and CHOL. Since both tumors share the same tissue of origin—the liver—they naturally exhibit overlapping methylation features. Furthermore, cases of combined hepatocellular and cholangiocarcinomas further complicate the differentiation of primary liver malignancies, as such a primary liver tumor has features of both LIHC and CHOL60.
The results show that both approaches successfully identified several candidate probes that can be used as methylation biomarkers for the included cancer types. Although most of the probes obtained by the two approaches were different, some of the same candidate probes were found in all cancer types except LUAD. In the clustered approach, most of them were found in multiple MCs. This is not surprising since these probes are significant in a large number of tumor samples within the cancer of interest and therefore similar to the probes identified by the non-clustered approach. Some of these probes were used in cancer-specific panels from both approaches (e.g. LIHC, PAAD, STAD and BRCA panels). A trend was observed in the specificity and sensitivity of the panels. In general, as the sensitivity of the panels increased, the specificity for tumor samples and the specificity for all samples decreased (Tables 1, 2, 3, 4, 5, 6 and 7). The majority of panels from the non-clustered approach yielded higher sensitivity with still very high sensitivity than panels from the clustered approach (Tables 1, 2, 3, 4, 5, 6 and 7). In contrast, the clustered BRCA panel yielded higher BRCA sensitivity but lower specificity (Table 7). Given the relatively high sensitivity and specificity, both BRCA panels can be considered appropriate. The same is true for other cancer-specific panels (e.g. LIHC and CHOL).
To achieve greater credibility of the results and evaluate the performance of the designed panels, we perform a verification on an independent dataset from the GEO database. The 782 samples of primary tumors and normal tissues from the GEO database were used (Supplementary Table S2). The results obtained with the GEO dataset were very similar to those of the TCGA dataset and mostly achieved the same high sensitivities and high specificities for individual cancer types (Tables 1, 2, 3, 4, 5, 6 and 7). The high concordance of the results confirms the suitability of our approaches and ensures that the observed results are not specific to the features of the identification dataset (Figs. 1, 2, 3, 4, 5, 6 and 7).
To increase clinical significance of our results, the design panels were tested in metastatic tumor samples. EPIC methylation data from two primary adenocarcinomas that had metastasized to the liver were acquired from the GEO database (GSE217384 and GSE212375)14,61. The data included 31 liver metastases (13 PAAD liver metastases and 18 BRCA liver metastases). The best design panels show a sensitivity of 100% for PAAD liver metastases and a sensitivity of 83.3% for BRCA liver metastases. The design panels also show high specificity for liver metastases, all tumor samples and all samples included in the GEO dataset (Table 8). These results are consistent with studies suggesting that aberrant hypermethylation of CpG islands occurs early in cancer development and is maintained from the primary tumor to its metastases11,13,14. The recent study, whose samples were also included in our analysis, showed that the 5000 most variably methylated CpGs exhibited remarkable conservation of cancer-associated hypermethylation between the primary tumor and metastases14. Although a different set of probes was used, our results show the same trend. The conservation of methylation from primary tumors to liver metastases and their cancer specificity can be seen in Figs. 5 and 7.
To increase the clinical applicability of our results, we have shown that our biomarkers can be successfully extended to liquid biopsies from cancer patients with metastatic disease. Using our panels, we were able to successfully detect hypermethylation of selected regions in cfDNA from patients with CRC liver metastases and BRCA liver metastases, while these were unmethylated in cfDNA from healthy donors (Supplementary Table S9). All this strongly support that DNA methylation biomarkers can be used as potential diagnostic biomarkers to predict tumor origin in patients with metastatic cancer in cfDNA. In addition, the study from which our cfDNA data were derived showed how cfDNA methylation could be the basis for a non-invasive approach to identify the origin of CUP. They were able to successfully predict the origin of cfDNA in CUP patients with metastatic cancer.
To better understand the selected DMRs and their potential role in tumor biology, we performed an annotation of the selected probes (Supplementary Table S10). Most of the selected probes are located in promoter regions of genes and miRNAs or at CCTC binding factor (CTCF) binding sites. It is noteworthy that some of selected probes and their corresponding genes have already been associated with cancer. Hypermethylation of these regions has been associated with epigenetic reprogramming, tumorigenesis, metastasis and poor prognosis62,63,64,65,66. In addition, promoter regions have been associated with downregulation of the corresponding genes37,62,63,64,67,68,69,70,71,72. Some of the selected regions have already been identified as potential diagnostic methylation biomarkers that differentiate between primary tumors, adjacent normal tissue samples and other tumor types37,62,66,69,70,72,73,74,75,76,77. In addition, the aberrant methylation of annotated genes has been identified as a diagnostic methylation biomarker in liquid biopsies78,79.
To further evaluate the suitability of the proposed panels, the developed panels should be verified using additional data with tissue samples and cfDNA samples, including patients with primary tumors and liver metastases.
Conclusion
With this study, we have identified and verified novel DNA methylation biomarkers that successfully differentiate selected adenocarcinomas based on HM450 and EPIC DNA methylation data from TCGA and GEO. Two different approaches were used to identify hypermethylated probe candidates: a non-clustered approach (no clustering was performed) and a clustered approach (unsupervised clustering was performed within each project, followed by probe selection for each cluster). Two panels of selected methylation biomarkers from each approach were developed for each cancer type on the TCGA dataset. To demonstrate the robustness of our results, the panels were verified on an independent GEO dataset, which shows a high agreement with the TCGA dataset. The majority of the panels exhibit high sensitivity and specificity, suggesting that both approaches may be useful in the search for novel methylation biomarkers that differentiate primary cancers and adjacent normal tissues, differentiate between different cancer types and can be extended to liver metastases. To increase the clinical relevance of our findings, we have shown that our biomarkers can be detected in liquid biopsies from cancer patients with liver metastases. Using our panels, we were able to detect hypermethylation of selected regions in the cfDNA of patients with metastatic disease, while these were unmethylated in the cfDNA of healthy donors. We believe that the developed panels have potential for the diagnosis of selected primary adenocarcinomas, the characterization of liver metastases and the determination of cancer origin in CUP in the liver using tissue samples and cfDNA.
Methods
TCGA data download and preparation
For data collection and bioinformatics analysis software environment and language R were used80. HM450 array DNA methylation data for selected projects (BRCA, CHOL, COAD, LIHC, LUAD, PAAD, READ and STAD) were downloaded from the National Cancer Institute's Genomic Data Commons Data Portal (GDC), which is part of TCGA81. We used level three data, which represent beta value (level of methylation) for each individual probe, for primary tumor samples and normal tissue samples of each cancer project. All selected samples were fresh tissue samples. Formalin-fixed paraffin-embedded tissue samples, representing only a few samples in each project, were excluded from further analysis. For selected samples, probes on the X and Y chromosome were removed to avoid gender influence in downstream differential analyses. In addition, probes with missing data and duplicated measurement were removed. In the identification step, the data were analyzed using two different approaches: a non-clustered approach (no sample clustering was performed) and a clustered approach (unsupervised sample clustering was performed within each project). Separate results were obtained for each of these approaches. Simple study workflow is presented in Supplementary Fig. S4.
Clustering
Clustering was performed with recursively petitioned mixture model (RPMM), which has been applied extensively for clustering large-scale genomic data82. The RPMM is a model-based unsupervised clustering algorithm developed for beta-distributed DNA methylation measurement. RPMM clustering was performed on 5000 probes that showed the most variable methylation levels in tumor samples for each project. For initialization of a latent class model, a fanny algorithm (a fuzzy clustering algorithm) was used. A level-weighted version of the Bayesian information criterion (BIC) was used as a split criterion for an existing cluster. The MC were denoted according to the average methylation level per cluster: the cluster with the highest methylation value was defined as MC1, the cluster with the second highest methylation value as MC2, and so on. Although, the clustering was performed separately on each project, the exceptions were the COAD and READ projects, which were merged and further addressed as CRC. The normal tissue samples of the individual projects were not clustered (Supplementary Fig. S5).
Differentially methylated regions analysis
DMR analyses were performed in both, non-clustered and clustered approach (Supplementary Fig. S5). In the non-clustered approach, DMR analysis was performed on tumor samples of each project and normal tissue samples of each project, both representing an independent group. DMR analyses were performed between all groups of tumor samples and normal tissue samples. In the clustered approach, each cluster assigned to the corresponding tumor samples represented an independent group. The normal tissue samples of the individual projects were kept as independent groups. Similar to the non-clustered approach, DMR analyses were performed between all groups. The exception was groups of clusters assigned to the same cancer type. In total, we performed more than 700 DMR analyses.
DMR analysis was performed using TCGAbiolinks package80. The difference between the mean methylation (mean beta-values) of each group for each probe was calculated. The p-value was calculated using the Wilcoxon test using the Benjamini–Hochberg adjustment method (adjusted p-value). The cut-off parameters for DMR were set: minimum mean difference in methylation between compared groups had to be 0.2 and the adjusted p-value had to be 0.05 or smaller.
Selection of differentially methylated probes
According to the DMR analyses, the probes in each comparison were classified as significant (probes in which the minimum mean difference in methylation level between the group of interest and the comparison group was greater than 0.2 and the adjusted p-value was 0.05 or less) and not significant (probes that did not meet the cutoff criteria). The significant probes in each comparison were used as the basis for further selection.
In the non-clustered approach, the significant probes from DMR analyses comparing the cancer type of interest with other cancer types were intersected. For each cancer type, the probes that were hypermethylated in the cancer of interest and hypomethylated in the compared cancers were selected. As part of the clustered approach, the probe selection was performed for each cluster within each cancer type. Probe intersection was used to extract the probes that were differentially methylated in the MC of interest compared with all MCs from other cancer types. For the each MC, the probes that were hypermethylated in the MC of interest and hypomethylated in the compared MCs were selected.
The cutoff criteria for the probe selection in both approaches were that the difference in average methylation between the group of interest and the comparison groups had to be greater than 0.3 and the methylation in the comparison groups had to be less than 0.1. In cases where few or no significant probes were found, we introduced less stringent criteria: the difference in average methylation between the group of interest and the compared groups had to be greater than 0.2 and/or the methylation in the comparison groups had to be less than 0.15. The probes obtained were verified in normal tissue samples (Supplementary Fig. S5).
Panels design
To achieve better differentiation between selected cancer types, we designed a methylation biomarker panel for each cancer type. Where possible, we designed two panels for each cancer type: one with the probes obtained using a non-clustered approach and one with the probes obtained using a clustered approach. The probes with the highest average methylation in the investigated cancer were preferentially selected for the panel design. Probes detected in multiple clusters associated with the cancer type of interest were preferentially selected for panel design from the clustered dataset. Probes that were hypermethylated in cancer of interest and hypomethylated in normal tissue samples were preferentially selected in both approaches. The combination of the smallest possible number of hypermethylated probes that resulted in the highest sensitivity and highest specificity was selected for the final panel design.
Probes and panels testing
For selected probes and panels, experimental data (beta values) were checked for each sample in all investigated projects. The probes and panels were evaluated according to how many individual samples could be detected in investigated project and in the comparison projects based on their beta values. A beta value of 0.3 was chosen as the cut-off criterion. Sensitivity and specificity of the probes and panels to differentiate between cancer of interest and normal tissue samples were calculated. In addition, the sensitivity and specificity to differentiate between all cancer types (all primary tumor samples) and all included samples (all primary tumor samples and normal tissue samples) were calculated. For the panels, diagnostic accuracy was calculated83. The statistics was performed with R package EpiR84.
Verification of the results
The verification of the results was performed on an independent dataset from the GEO database (Fig. 1). HM450 and EPIC array DNA methylation data for selected projects comprising selected adenocarcinomas, available liver metastases and cfDNA (GSE75041, GSE11301785, GSE11301985, GSE21738461, GSE20124186, GSE4965687, GSE220160, GSE11952688, GSE14928289, GSE15989890, GSE6370491, GSE13421792, GSE20784693, GSE9955394, GSE10050395, GSE8888396, GSE21237514, GSE12212612) were downloaded. Where available, the raw data were downloaded and used to perform quality control, normalization and calculation of the beta value with the minfi package97. In this case, only samples that passed quality check were included. For projects for which no raw data were available, we used the project data provided by the authors for which quality check and normalization had already been performed. The data were downloaded and the beta values were extracted using the GEOquery package98. In the verification step, the experimental data (beta values) of the selected probes were checked for each sample in all projects. A beta value of 0.3 was selected as the cut-off criterion for a probe and thus for a sample to be labelled as hypermethylated. Panels were evaluated according to how many individual samples could be correctly classified based on their beta values. Sensitivity, specificity and diagnostic accuracy of the panels were calculated and compared with those from the TCGA dataset.
Annotation of selected probes
Annotation of selected probes were performed using Ensemble Release 11099.
Data availability
The datasets analyzed in this study are available from The Cancer Genome Atlas (https://portal.gdc.cancer.gov/) or Gene Expression Omnibus (https://www.ncbi.nlm.nih.gov/geo/). All data generated or analyzed during this study are included in this published article and its additional files.
References
Ananthakrishnan, A., Gogineni, V. & Saeian, K. Epidemiology of primary and secondary liver cancers. Semin. Interv. Radiol. 23, 47–63. https://doi.org/10.1055/s-2006-939841 (2006).
Tsilimigras, D. I. et al. Liver metastases. Nat. Rev. Dis. Primers 7, 27. https://doi.org/10.1038/s41572-021-00261-6 (2021).
Draškovič, T., Zidar, N. & Hauptman, N. Circulating tumor DNA methylation biomarkers for characterization and determination of the cancer origin in malignant liver tumors. Cancers (Basel) https://doi.org/10.3390/cancers15030859 (2023).
de Ridder, J. et al. Incidence and origin of histologically confirmed liver metastases: An explorative case-study of 23,154 patients. Oncotarget 7, 55368–55376. https://doi.org/10.18632/oncotarget.10552 (2016).
Aran, D., Toperoff, G., Rosenberg, M. & Hellman, A. Replication timing-related and gene body-specific methylation of active human genes. Hum. Mol. Genet. 20, 670–680. https://doi.org/10.1093/hmg/ddq513 (2011).
Bert, S. A. et al. Regional activation of the cancer genome by long-range epigenetic remodeling. Cancer Cell 23, 9–22. https://doi.org/10.1016/j.ccr.2012.11.006 (2013).
Jones, P. A. & Baylin, S. B. The fundamental role of epigenetic events in cancer. Nat. Rev. Genet. 3, 415–428. https://doi.org/10.1038/nrg816 (2002).
Suzuki, M. M. & Bird, A. DNA methylation landscapes: Provocative insights from epigenomics. Nat. Rev. Genet. 9, 465–476. https://doi.org/10.1038/nrg2341 (2008).
Lakshminarasimhan, R. & Liang, G. The role of DNA methylation in cancer. Adv. Exp. Med. Biol. 945, 151–172. https://doi.org/10.1007/978-3-319-43624-1_7 (2016).
Ding, W., Chen, G. & Shi, T. Integrative analysis identifies potential DNA methylation biomarkers for pan-cancer diagnosis and prognosis. Epigenetics 14, 67–80. https://doi.org/10.1080/15592294.2019.1568178 (2019).
Liu, M. C. et al. Sensitive and specific multi-cancer detection and localization using methylation signatures in cell-free DNA. Ann. Oncol. 31, 745–759. https://doi.org/10.1016/j.annonc.2020.02.011 (2020).
Moss, J. et al. Comprehensive human cell-type methylation atlas reveals origins of circulating cell-free DNA in health and disease. Nat. Commun. 9, 5068. https://doi.org/10.1038/s41467-018-07466-6 (2018).
Cheishvili, D. et al. <em>epi</em>Liver a novel tumor specific, high throughput and cost-effective blood test for specific detection of liver cancer (HCC). medRxiv, 2021.2002.2007.21251315, https://doi.org/10.1101/2021.02.07.21251315 (2021).
Garcia-Recio, S. et al. Multiomics in primary and metastatic breast tumors from the AURORA US network finds microenvironment and epigenetic drivers of metastasis. Nat. Cancer 4, 128–147. https://doi.org/10.1038/s43018-022-00491-x (2023).
Moran, S., Martinez-Cardús, A., Boussios, S. & Esteller, M. Precision medicine based on epigenomics: The paradigm of carcinoma of unknown primary. Nat. Rev. Clin. Oncol. 14, 682–694. https://doi.org/10.1038/nrclinonc.2017.97 (2017).
Moran, S. et al. Epigenetic profiling to classify cancer of unknown primary: A multicentre, retrospective analysis. Lancet Oncol. 17, 1386–1395. https://doi.org/10.1016/S1470-2045(16)30297-2 (2016).
Tang, W., Wan, S., Yang, Z., Teschendorff, A. E. & Zou, Q. Tumor origin detection with tissue-specific miRNA and DNA methylation markers. Bioinformatics 34, 398–406. https://doi.org/10.1093/bioinformatics/btx622 (2018).
Bibikova, M. et al. High density DNA methylation array with single CpG site resolution. Genomics 98, 288–295. https://doi.org/10.1016/j.ygeno.2011.07.007 (2011).
Dedeurwaerder, S. et al. Evaluation of the infinium methylation 450K technology. Epigenomics 3, 771–784. https://doi.org/10.2217/epi.11.105 (2011).
Peters, T. J. et al. De novo identification of differentially methylated regions in the human genome. Epigenetics Chromatin 8, 6. https://doi.org/10.1186/1756-8935-8-6 (2015).
Moran, S., Arribas, C. & Esteller, M. Validation of a DNA methylation microarray for 850,000 CpG sites of the human genome enriched in enhancer sequences. Epigenomics 8, 389–399. https://doi.org/10.2217/epi.15.114 (2016).
Affinito, O. et al. Nucleotide distance influences co-methylation between nearby CpG sites. Genomics 112, 144–150. https://doi.org/10.1016/j.ygeno.2019.05.007 (2020).
Roessler, J. et al. Quantitative cross-validation and content analysis of the 450k DNA methylation array from Illumina Inc. BMC Res. Notes 5, 210. https://doi.org/10.1186/1756-0500-5-210 (2012).
Pidsley, R. et al. Critical evaluation of the Illumina MethylationEPIC BeadChip microarray for whole-genome DNA methylation profiling. Genome Biol. 17, 208. https://doi.org/10.1186/s13059-016-1066-1 (2016).
Wilhelm-Benartzi, C. S. et al. Review of processing and analysis methods for DNA methylation array data. Br. J. Cancer 109, 1394–1402. https://doi.org/10.1038/bjc.2013.496 (2013).
Du, P. et al. Comparison of beta-value and M-value methods for quantifying methylation levels by microarray analysis. BMC Bioinform. 11, 587. https://doi.org/10.1186/1471-2105-11-587 (2010).
Park, J. H. & Kim, J. H. Pathologic differential diagnosis of metastatic carcinoma in the liver. Clin. Mol. Hepatol. 25, 12–20. https://doi.org/10.3350/cmh.2018.0067 (2019).
van de Wouw, A. J., Janssen-Heijnen, M. L., Coebergh, J. W. & Hillen, H. F. Epidemiology of unknown primary tumours; incidence and population-based survival of 1285 patients in Southeast Netherlands, 1984–1992. Eur. J. Cancer 38, 409–413. https://doi.org/10.1016/s0959-8049(01)00378-1 (2002).
Centeno, B. A. Pathology of liver metastases. Cancer Control 13, 13–26. https://doi.org/10.1177/107327480601300103 (2006).
Esteller, M. & Herman, J. G. Cancer as an epigenetic disease: DNA methylation and chromatin alterations in human tumours. J. Pathol. 196, 1–7. https://doi.org/10.1002/path.1024 (2002).
Liu, B. et al. DNA methylation markers for pan-cancer prediction by deep learning. Genes (Basel) https://doi.org/10.3390/genes10100778 (2019).
Zheng, C. & Xu, R. Predicting cancer origins with a DNA methylation-based deep neural network model. PLoS One 15, e0226461. https://doi.org/10.1371/journal.pone.0226461 (2020).
Eissa, N. S., Khairuddin, U. & Yusof, R. A hybrid metaheuristic-deep learning technique for the pan-classification of cancer based on DNA methylation. BMC Bioinform. 23, 273. https://doi.org/10.1186/s12859-022-04815-7 (2022).
Ibrahim, J., Op de Beeck, K., Fransen, E., Peeters, M. & Van Camp, G. Genome-wide DNA methylation profiling and identification of potential pan-cancer and tumor-specific biomarkers. Mol. Oncol. 16, 2432–2447. https://doi.org/10.1002/1878-0261.13176 (2022).
Hao, X. et al. DNA methylation markers for diagnosis and prognosis of common cancers. Proc. Natl. Acad. Sci. 114, 7414–7419. https://doi.org/10.1073/pnas.1703577114 (2017).
Vrba, L. & Futscher, B. W. A suite of DNA methylation markers that can detect most common human cancers. Epigenetics 13, 61–72. https://doi.org/10.1080/15592294.2017.1412907 (2018).
Liu, X., Peng, Y. & Wang, J. Integrative analysis of DNA methylation and gene expression profiles identified potential breast cancer-specific diagnostic markers. Biosci. Rep. https://doi.org/10.1042/bsr20201053 (2020).
Zhu, C. et al. A novel gene prognostic signature based on differential DNA methylation in breast cancer. Front. Genet. https://doi.org/10.3389/fgene.2021.742578 (2021).
Danilova, L., Wrangle, J., Herman, J. G. & Cope, L. DNA-methylation for the detection and distinction of 19 human malignancies. Epigenetics 17, 191–201. https://doi.org/10.1080/15592294.2021.1890885 (2022).
Amor, R. D., Colomer, A., Monteagudo, C. & Naranjo, V. A deep embedded refined clustering approach for breast cancer distinction based on DNA methylation. Neural Comput. Appl. 34, 10243–10255. https://doi.org/10.1007/s00521-021-06357-0 (2022).
Ang, P. W. et al. Comprehensive profiling of DNA methylation in colorectal cancer reveals subgroups with distinct clinicopathological and molecular features. BMC Cancer 10, 227. https://doi.org/10.1186/1471-2407-10-227 (2010).
Bernal, C. et al. DNA methylation profile in diffuse type gastric cancer: Evidence for hypermethylation of the BRCA1 promoter region in early-onset gastric carcinogenesis. Biol. Res. 41, 303–315 (2008).
Fackler, M. J. et al. Genome-wide methylation analysis identifies genes specific to breast cancer hormone receptor status and risk of recurrence. Cancer Res. 71, 6195–6207. https://doi.org/10.1158/0008-5472.Can-11-1630 (2011).
Hauptman, N., Jevsinek Skok, D., Spasovska, E., Bostjancic, E. & Glavac, D. Genes CEP55, FOXD3, FOXF2, GNAO1, GRIA4, and KCNA5 as potential diagnostic biomarkers in colorectal cancer. BMC Med. Genom. 12, 54. https://doi.org/10.1186/s12920-019-0501-z (2019).
Lamare, F. A. et al. Genome-wide DNA methylation profiling of stomach cancer in the ethnic population of Mizoram, North East India. Genomics 114, 110478. https://doi.org/10.1016/j.ygeno.2022.110478 (2022).
Li, T., Chen, X., Gu, M., Deng, A. & Qian, C. Identification of the subtypes of gastric cancer based on DNA methylation and the prediction of prognosis. Clin. Epigenetics 12, 161. https://doi.org/10.1186/s13148-020-00940-3 (2020).
Li, X. et al. Classification and prognosis analysis of pancreatic cancer based on DNA methylation profile and clinical information. Genes (Basel) 13, 2022. https://doi.org/10.3390/genes13101913 (1913).
Lian, Q. et al. DNA methylation data-based molecular subtype classification and prediction in patients with gastric cancer. Cancer Cell Int. 20, 349. https://doi.org/10.1186/s12935-020-01253-4 (2020).
McInnes, T. et al. Genome-wide methylation analysis identifies a core set of hypermethylated genes in CIMP-H colorectal cancer. BMC Cancer 17, 228. https://doi.org/10.1186/s12885-017-3226-4 (2017).
Roy, S., Singh, A. P. & Gupta, D. Unsupervised subtyping and methylation landscape of pancreatic ductal adenocarcinoma. Heliyon 7, e06000. https://doi.org/10.1016/j.heliyon.2021.e06000 (2021).
Xiang, R. & Fu, T. Gastrointestinal adenocarcinoma analysis identifies promoter methylation-based cancer subtypes and signatures. Sci. Rep. 10, 21234. https://doi.org/10.1038/s41598-020-78228-y (2020).
Yamanoi, K. et al. Epigenetic clustering of gastric carcinomas based on DNA methylation profiles at the precancerous stage: Its correlation with tumor aggressiveness and patient outcome. Carcinogenesis 36, 509–520. https://doi.org/10.1093/carcin/bgv013 (2015).
Zouridis, H. et al. Methylation subtypes and large-scale epigenetic alterations in gastric cancer. Sci. Transl. Med. 4, 156ra140. https://doi.org/10.1126/scitranslmed.3004504 (2012).
Qiu, Z. et al. Common DNA methylation changes in biliary tract cancers identify subtypes with different immune characteristics and clinical outcomes. BMC Med. 20, 64. https://doi.org/10.1186/s12916-021-02197-w (2022).
Loi, E. et al. HOXD8 hypermethylation as a fully sensitive and specific biomarker for biliary tract cancer detectable in tissue and bile samples. Br. J. Cancer 126, 1783–1794. https://doi.org/10.1038/s41416-022-01738-1 (2022).
Jusakul, A. et al. Whole-genome and epigenomic landscapes of etiologically distinct subtypes of cholangiocarcinoma. Cancer Discov. 7, 1116–1135. https://doi.org/10.1158/2159-8290.Cd-17-0368 (2017).
Gonçalves, E., Gonçalves-Reis, M., Pereira-Leal, J. B. & Cardoso, J. DNA methylation fingerprint of hepatocellular carcinoma from tissue and liquid biopsies. Sci. Rep. 12, 11512. https://doi.org/10.1038/s41598-022-15058-0 (2022).
Shen, J. et al. Genome-wide DNA methylation profiles in hepatocellular carcinoma. Hepatology 55, 1799–1808. https://doi.org/10.1002/hep.25569 (2012).
Wheeler, D. A., Roberts, L. R. & Cancer Genome Atlas Research Network. Comprehensive and integrative genomic characterization of hepatocellular carcinoma. Cell 169, 1327-1341.e1323. https://doi.org/10.1016/j.cell.2017.05.046 (2017).
Hamilton, S. R. & Aaltonen, L. A. IARC Press (2000).
Dragomir, M. P. et al. DNA methylation-based classifier differentiates intrahepatic pancreato-biliary tumours. EBioMedicine 93, 104657. https://doi.org/10.1016/j.ebiom.2023.104657 (2023).
Kim, G. C. et al. ETS1 suppresses tumorigenesis of human breast cancer via trans-activation of canonical tumor suppressor genes. Front. Oncol. 10, 642. https://doi.org/10.3389/fonc.2020.00642 (2020).
Song, P. et al. Genome-wide screening for differentially methylated long noncoding RNAs identifies LIFR-AS1 as an epigenetically regulated lncRNA that inhibits the progression of colorectal cancer. Clin. Epigenetics 14, 138. https://doi.org/10.1186/s13148-022-01361-0 (2022).
Wang, X. et al. RNF135 promoter methylation is associated with immune infiltration and prognosis in hepatocellular carcinoma. Front. Oncol. 11, 752511. https://doi.org/10.3389/fonc.2021.752511 (2021).
Gong, S., Ye, W., Liu, T., Jian, S. & Liu, W. The development of three-DNA methylation signature as a novel prognostic biomarker in patients with colorectal cancer. BioMed. Res. Int. 2020, 3497810. https://doi.org/10.1155/2020/3497810 (2020).
Hernandez-Meza, G. et al. DNA methylation profiling of human hepatocarcinogenesis. Hepatology 74, 183–199. https://doi.org/10.1002/hep.31659 (2021).
Erichsen, L. et al. Basic hallmarks of urothelial cancer unleashed in primary uroepithelium by interference with the epigenetic master regulator ODC1. Sci. Rep. https://doi.org/10.1038/s41598-020-60796-8 (2020).
Tommasi, S., Karm, D. L., Wu, X., Yen, Y. & Pfeifer, G. P. Methylation of homeobox genes is a frequent and early epigenetic event in breast cancer. Breast Cancer Res. 11, R14. https://doi.org/10.1186/bcr2233 (2009).
Cheng, J. et al. Integrative analysis of DNA methylation and gene expression reveals hepatocellular carcinoma-specific diagnostic biomarkers. Genome Med. 10, 42. https://doi.org/10.1186/s13073-018-0548-z (2018).
Matsumura, S. et al. Integrative array-based approach identifies MZB1 as a frequently methylated putative tumor suppressor in hepatocellular carcinoma. Clin. Cancer Res. 18, 3541–3551. https://doi.org/10.1158/1078-0432.Ccr-11-1007 (2012).
Moravcikova, E. et al. Down-regulated expression of apoptosis-associated genes APIP and UACA in non-small cell lung carcinoma. Int. J. Oncol. 40, 2111–2121. https://doi.org/10.3892/ijo.2012.1397 (2012).
Dihal, A. A. et al. The homeobox gene MEIS1 is methylated in BRAF (p.V600E) mutated colon tumors. PLoS One 8, e79898. https://doi.org/10.1371/journal.pone.0079898 (2013).
Revill, K. et al. Genome-wide methylation analysis and epigenetic unmasking identify tumor suppressor genes in hepatocellular carcinoma. Gastroenterology 145, 1424-1435.e1421-1425. https://doi.org/10.1053/j.gastro.2013.08.055 (2013).
Song, M. A. et al. Elucidating the landscape of aberrant DNA methylation in hepatocellular carcinoma. PLoS One 8, e55761. https://doi.org/10.1371/journal.pone.0055761 (2013).
Crujeiras, A. B. et al. Identification of an episignature of human colorectal cancer associated with obesity by genome-wide DNA methylation analysis. Int. J. Obes. (Lond) 43, 176–188. https://doi.org/10.1038/s41366-018-0065-6 (2019).
Zheng, Q., Min, S. & Zhou, Q. Identification of potential diagnostic and prognostic biomarkers for LUAD based on TCGA and GEO databases. Biosci. Rep. https://doi.org/10.1042/bsr20204370 (2021).
Yuan, P. et al. OSMR and SEPT9: Promising biomarkers for detection of colorectal cancer based on blood-based tests. Transl. Cancer Res. 5, 131–139 (2016).
Liang, W. et al. Circulating tumour cell combined with DNA methylation for early detection of hepatocellular carcinoma. Front. Genet. 13, 1065693. https://doi.org/10.3389/fgene.2022.1065693 (2022).
Kisiel, J. B. et al. Hepatocellular carcinoma detection by plasma methylated DNA: Discovery, phase I pilot, and phase II clinical validation. Hepatology (Baltimore, Md.) 69, 1180–1192. https://doi.org/10.1002/hep.30244 (2019).
Colaprico, A. et al. TCGAbiolinks: An R/Bioconductor package for integrative analysis of TCGA data. Nucleic Acids Res. 44, e71–e71. https://doi.org/10.1093/nar/gkv1507 (2015).
Hudson, T. J. et al. International network of cancer genome projects. Nature 464, 993–998. https://doi.org/10.1038/nature08987 (2010).
Houseman, E. A. et al. Model-based clustering of DNA methylation array data: A recursive-partitioning algorithm for high-dimensional data arising as a mixture of beta distributions. BMC Bioinform. 9, 365. https://doi.org/10.1186/1471-2105-9-365 (2008).
Alberg, A. J., Park, J. W., Hager, B. W., Brock, M. V. & Diener-West, M. The use of “overall accuracy” to evaluate the validity of screening or diagnostic tests. J. Gen. Intern. Med. 19, 460–465. https://doi.org/10.1111/j.1525-1497.2004.30091.x (2004).
Carstensen Bendix, Plummer Martyn , Laara Esa & Michael, H. (2022).
Shimada, S. et al. Comprehensive molecular and immunological characterization of hepatocellular carcinoma. EBioMedicine 40, 457–470. https://doi.org/10.1016/j.ebiom.2018.12.058 (2019).
Goeppert, B. et al. Integrative analysis defines distinct prognostic subgroups of intrahepatic cholangiocarcinoma. Hepatology 69, 2091–2106. https://doi.org/10.1002/hep.30493 (2019).
Chan-On, W. et al. Exome sequencing identifies distinct mutational patterns in liver fluke-related and non-infection-related bile duct cancers. Nat. Genet. 45, 1474–1478. https://doi.org/10.1038/ng.2806 (2013).
Yu, H. et al. DNA methylation profile in CpG-depleted regions uncovers a high-risk subtype of early-stage colorectal cancer. J. Natl. Cancer Inst. 115, 52–61. https://doi.org/10.1093/jnci/djac183 (2023).
Ishak, M. et al. Genome-wide open chromatin methylome profiles in colorectal cancer. Biomolecules 10, 719. https://doi.org/10.3390/biom10050719 (2020).
Li, M. et al. Genomic methylation variations predict the susceptibility of six chemotherapy related adverse effects and cancer development for Chinese colorectal cancer patients. Toxicol. Appl. Pharmacol. 427, 115657. https://doi.org/10.1016/j.taap.2021.115657 (2021).
Wielscher, M. et al. Diagnostic performance of plasma DNA methylation profiles in lung cancer. Pulmonary fibrosis and COPD. EBioMedicine 2, 929–936. https://doi.org/10.1016/j.ebiom.2015.06.025 (2015).
Espinet, E. et al. Aggressive PDACs show hypomethylation of repetitive elements and the execution of an intrinsic IFN program linked to a ductal cell of origin. Cancer Discov. 11, 638–659. https://doi.org/10.1158/2159-8290.Cd-20-1202 (2021).
Urabe, M. et al. Adenocarcinoma of the stomach and esophagogastric junction with low DNA methylation show poor prognoses. Gastric Cancer 26, 95–107. https://doi.org/10.1007/s10120-022-01344-3 (2023).
Woo, H. D. et al. Genome-wide profiling of normal gastric mucosa identifies Helicobacter pylori- and cancer-associated DNA methylome changes. Int. J. Cancer 143, 597–609. https://doi.org/10.1002/ijc.31381 (2018).
Chen, Y. et al. Concordance of DNA methylation profiles between breast core biopsy and surgical excision specimens containing ductal carcinoma in situ (DCIS). Exp. Mol. Pathol. 103, 78–83. https://doi.org/10.1016/j.yexmp.2017.07.001 (2017).
Johnson, K. C., Houseman, E. A., King, J. E. & Christensen, B. C. Normal breast tissue DNA methylation differences at regulatory elements are associated with the cancer risk factor age. Breast Cancer Res. 19, 81. https://doi.org/10.1186/s13058-017-0873-y (2017).
Aryee, M. J. et al. Minfi: A flexible and comprehensive Bioconductor package for the analysis of Infinium DNA methylation microarrays. Bioinformatics 30, 1363–1369. https://doi.org/10.1093/bioinformatics/btu049 (2014).
Davis, S. & Meltzer, P. S. GEOquery: A bridge between the gene expression omnibus (GEO) and BioConductor. Bioinformatics 23, 1846–1847. https://doi.org/10.1093/bioinformatics/btm254 (2007).
Martin, F. J. et al. Ensembl 2023. Nucleic Acids Res. 51, D933–D941. https://doi.org/10.1093/nar/gkac958 (2022).
Acknowledgements
This study was funded by the Slovenian Research and Innovation Agency (research core Funding No. P3-0054, Project Funding J3-3070 and PhD research funding).
Author information
Authors and Affiliations
Contributions
T.D.: data download, data processing, bioinformatics analysis, statistical analysis, writing; N.H.: study concept, bioinformatics analysis, writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Draškovič, T., Hauptman, N. Discovery of novel DNA methylation biomarker panels for the diagnosis and differentiation between common adenocarcinomas and their liver metastases. Sci Rep 14, 3095 (2024). https://doi.org/10.1038/s41598-024-53754-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-53754-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
