
Abstract
Concrete-filled steel tubular (CFST) columns have extensive applications in structural engineering due to their exceptional load-bearing capability and ductility. However, existing design code standards often yield different design capacities for the same column properties, introducing uncertainty for engineering designers. Moreover, conventional regression analysis fails to accurately predict the intricate relationship between column properties and compressive strength. To address these issues, this study proposes the use of two machine learning (ML) models—Gaussian process regression (GPR) and symbolic regression (SR). These models accept a variety of input variables, encompassing geometric and material properties of stub CFST columns, to estimate their strength. An experimental database of 1316 specimens was compiled from various research papers, including circular, rectangular, and double-skin stub CFST columns. In addition, a dimensionless output variable, referred to as the strength index, is introduced to enhance model performance. To validate the efficiency of the introduced models, predictions from these models are compared with those from two established standard codes and various ML algorithms, including support vector regression optimized with particle swarm optimization (PSVR), artificial neural networks, XGBoost (XGB), CatBoost (CATB), Random Forest, and LightGBM models. Through performance metrics, the CATB, GPR, PSVR and XGB models emerge as the most accurate and reliable models from the evaluation results. In addition, simple and practical design equations for the different types of CFST columns have been proposed based on the SR model. The developed ML models and proposed equations can predict the compressive strength of stub CFST columns with reliable and accurate results, making them valuable tools for structural engineering. Furthermore, the Shapley additive interpretation (SHAP) technique is employed for feature analysis. The results of the feature analysis reveal that section slenderness ratio and concrete strength parameters negatively impact the compressive strength index.
Similar content being viewed by others

Introduction
Concrete-filled steel tube (CFST) members are composite structures of hollow steel tubes filled with concrete. They offer advantages over steel and traditional reinforced concrete columns, including improved structural performance, strength, and ductility1. The steel tube provides confinement to the concrete core, delaying or preventing its failure or lateral expansion, and the concrete core constrains the inward local buckling of the outer steel tube1,2. CFST columns also exhibit enhanced fire and seismic resistance and act as permanent formwork for concrete, reducing construction time.
CFST columns are available in different types based on loading patterns and geometry, such as concrete-filled steel tube columns and concrete-filled double-skin steel tubular columns (CFDSTs), which have an additional hollow inner steel tube arrangement. Different cross-sectional shapes can be used for CFST columns3,4,5,6, including circular, square, rectangular, octagonal, hexagonal, or elliptic sections. Circular CFST columns are preferred for their uniform confinement on the concrete core, providing higher load-bearing capacity and ductility. In contrast, rectangular-shaped columns are preferred for the ease of construction and connection erection.
In addition, CFST columns are classified in terms of global buckling as stub and long columns. Stub columns, also known as short columns, are designed to resist axial compressive loads and have relatively short heights compared to their cross-section dimensions7,8. The design considerations for stub and long columns differ due to their distinct structural behaviors, i.e., stub columns need to investigate the interaction between confined concrete and the steel tube and local outward buckling. On the other hand, long columns may need more attention to factors such as effective length, global buckling, and lateral bracing to consider stability issues.
Experimental investigations are commonly used to investigate the behavior of CFST columns. However, experimental studies are often limited by the range of parameters and can be costly and time-consuming. Machine learning (ML) techniques can complement experimental studies, as they have proven effective in predicting structural element behaviors. ML algorithms such as support vector regression (SVR)9, Gaussian process (GPR)10,11, gene expression programming (GEP)12, and artificial neural network (ANN)13,14,15,16,17,18 have been developed and successfully used by researchers in developing empirical formulas and statistical models for predicting material properties such as strength and elastic modulus, as well as the performance of structural members.
ML methods find numerous applications in predicting the ultimate capacity of CFST columns, with artificial neural networks (ANNs) commonly employed. For example, Ahmadi et al.13,14 utilized ANN to predict the ultimate strength of short CFST columns. Du et al.15 employed ANN models to calculate the axial concentric strength of stub rectangular CFST columns using 305 column specimens. Le et al.16 used an ANN to predict the axial capacity of square and rectangular CFST columns using 880 specimens. Tran et al.17 gathered a database of 300 samples under uniaxial loading to drive ML models for calculating the axial strength of the squared CFT column. In addition, Zarringol et al.18 utilized four distinct databases, totaling 3091 CFST columns, encompassing rectangular and circular columns with and without eccentricity. They developed four separate ANN models for the axial capacities of each category and incorporated strength reduction factors to enhance practical design applications.
Gaussian process regression (GPR) is another ML technique applied in computing the ultimate capacity of CFST columns. Le19 proposed a GPR-based ML model for estimating the ultimate strength of square CFSTs, demonstrating a considerably high prediction accuracy. Furthermore, Hou and Zhou20 optimized ML models, including the backpropagation ANN, GPR model, genetic algorithm, radial basis function neural network (RBFNN), and multiple linear regression (MLR) models, to predict the axial compressive strength of stub and long circular CFST columns.
Furthermore, gene expression programming (GEP) and genetic algorithms (GAs)12 are valuable tools in predicting empirical formulas for the ultimate strength of CFST columns. Guneyisi et al.21,22 utilized gene expression programming to generate empirical formulations for the axial strength of circular CFST and CFDST stub columns. Javed et al.23 implemented GEP to predict the load-bearing strength of circular CFST long columns. Furthermore, Jiang et al.24 compared GEP results and finite element analysis outcomes for circular CFST columns. Naser et al.25 employed GA and GEP to develop predictive models for the axial ultimate load of rectangular and circular CFST columns. Table 1 summarizes previous ML models in predicting CFST stub column strength.
Research significance
ML models can offer a robust and innovative approach to predicting the axial capacity of CFST columns. Although some existing ML models and simplified design equations have been introduced for CFST column predictions17,18,26,27, further work is necessary, primarily for the following reasons:
-
1.
Many researchers directly used axial strength as the output parameter even when its statistical distribution is skewed and biased, without further manipulation or considering its impact on model performance.
-
2.
Existing studies often utilize the entire global database consisting of short and long columns for training/testing ML models. However, the distinct failure mechanisms of long and stub CFST columns can affect the relationships between inputs and strengths. Ipek et al.28 conducted a sensitivity analysis to evaluate the performance of the developed ML models using a global database. It was observed that the performance of these models deteriorates for length-to-depth ratios between 2 and 4 while consistently performing well for larger ratios. Additionally, as highlighted by Hou and Zhou20, the division of databases into long-column and stub-column subsets significantly enhanced the accuracy of ML methods instead of using the global database. Therefore, this study focuses only on predicting the axial capacity of short columns.
-
3.
While most studies focus on using ANN to predict the axial compression strength of CFST columns, other supervised ML algorithms, such as SVR, GPR, symbolic regression, and tree-based ML algorithms, are less commonly employed.
-
4.
Although the ANN model can introduce design formulas, the resulting formulas include numerous weights, biases, and transfer functions, which are not suitable for engineering practice16.
-
5.
As reported in the literature in Table 1, the predicted formulas for designing CFST columns using GA and GEP are efficient and compatible with experimental results. However, a significant drawback is that many of the provided formulas are complicated, unit-dependent, and lack explanations. This paper introduces a novel model to derive simple, practical, unit-independent expressions for predicting the axial compression of CFST columns.
This research collects an extensive experimental database of 1316 specimens from diverse research papers, including circular, rectangular, and double-skin stub CFST columns under axial load without eccentricity. Eight data-driven models are developed, including Gaussian process regression (GPR), symbolic regression (SR), support vector regression optimized with particle swarm optimization (PSVR), artificial neural networks (ANN), XGBoost (XGB), CatBoost (CATB), Random Forest (RF), and LightGBM (LGBM) models. The axial loads reported from the experimental results are normalized to enhance the performance of the ML models. In addition, the proposed formulas are introduced for designing each column type. The hyperparameter tuning of the introduced ML models is performed using the Bayesian Optimization (BO) technique.
Dataset description
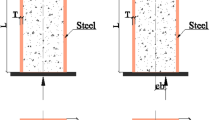
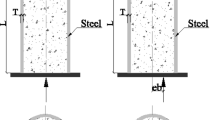
In this section, a comprehensive experimental database containing 1316 column specimens has been carefully selected from research papers focusing on axially loaded stub CFST columns without eccentricity. The loading and geometric configuration of the specimens are illustrated in Fig. 1. All collected tests were conducted on CFST short columns (with length-to-width ratios smaller than or equal to 4.07,8,18) under monotonic loading and without internal rebar reinforcement. Only samples loaded uniformly across the entire cross-section are considered in the dataset. The database gathered includes the following: (1) Dataset 1 comprises 674 observations with five input parameters related to circular CFST (CCFST) columns; (2) Dataset 2 involves 396 observations with six input parameters relevant to rectangular CFST (RCFST) columns; and (3) Dataset 3 contains 246 observations and involves seven input parameters associated with double-skin CFST (CFDST) columns.

The dimensions of CFST columns.
The information presented in Table 2 summarizes the details of the collected specimens, including the outer steel tube diameter (D in mm) for circular CFST and CFDST columns, the outside diameter of the inner steel tube (Di in mm) for CFDST columns, the outer steel tube width (B in mm) and outer steel tube depth (H in mm) for rectangular CFST columns, the thickness of the outer steel tube (t in mm), the thickness of the inner steel tube (ti in mm), the compressive strength of the core concrete (f′c in MPa), the yield strength of the outer steel tube (fy in MPa), the yield strength of the inner steel tube (fyi in MPa), and the column length (L in mm). These parameters are assumed to directly influence the axial capacity (Pu) of CFST columns of 1316 observations. Naser et al.25 suggested that the remaining material properties of concrete and steel, i.e., Young’s modulus of steel (Es) and concrete (Ec) and the ultimate strength of steel (fu), have no significant influence on the training of data-driven models. Table 2 illustrates the statistical distributions of the collected datasets.
Generally, using approximately normally distributed data for machine learning algorithms results in more stable and reliable models. As shown in Fig. 2a, the axial capacity distribution is not normally distributed with extreme skewness for CCFST columns, deteriorating the performance of machine learning models. Therefore, the authors proposed a dimensionless strength index, denoted by psi, as the main output parameter, extracted from normalizing the axial load by dividing the column capacity by the sum of the individual strengths of its components: the steel tubes and core concrete, as defined in Eq. (1).
where As and Ac are the outer steel tube and concrete areas, respectively. Note that for CFDST columns, the contribution of the inner tube, \({A}_{si}{f}_{yi}\) is added to the nominal column capacity, \({N}_{pl}\), in the above equation, where \({A}_{si}\) is the area of the inner steel tube for CFDST columns. The strength index can reflect the confinement efficiency of the CFST column, i.e., a relatively high value of the strength index (psi > 1.0) indicates high confinement exerted by the outer tube. High confinement exerted by the outer steel tube enhances the actual triaxial strength of inner concrete compared to its uniaxial strength fc′. As depicted in Fig. 2b and Table 2, the statistical distribution of the strength index closely resembles a normal distribution. The proximity of strength index values to 1.0 and its physical and dimensionless nature make it easily predictable and interpretable.

Frequency histogram of the axial load output and strength index for CCFST columns.
The most critical parameter that controls stub column stability is the local slenderness coefficient, λ, defined in Eq. (2) for circular and rectangular tubes29, as follows:
As shown in Table 2, the database covers a wide range of steel section slenderness, including all compact (λ ≤ 0.15 for circular tubes, λ ≤ 2.26 for rectangular tubes), noncompact (0.15 ≤ λ ≤ 0.19 for circular tubes, 2.26 ≤ λ ≤ 3.0 for rectangular tubes) and slender (λ > 0.19 for circular tubes, λ > 3.0 for rectangular tubes) columns, as recommended by AISC360-2229. In addition, the database encompasses a wide range of concrete and steel strengths. As shown in Table 2, the database includes both traditional materials (with fc′ values below 70 MPa and fy values below 460 MPa, as suggested in AISC 360-2229) and higher strength classes (with fc′ up to 190 MPa and fy up to 1153 MPa). It should be noted that most design codes of practice impose limits within their scope of application29,30. These restrictions are related to the strengths of steel and concrete materials and the slenderness of steel sections.
Furthermore, Fig. 3 visually presents the correlation matrices of both the input and output variables. As displayed in Fig. 3, the correlation coefficient between any pair of input variables is relatively weak (ρ < 0.5), except for the correlations between the outer dimensions of the tube and the column length. In addition, there is a strong relationship between the dimensions of the columns and their axial capacity, which may reduce the performance of the ML training process. However, the correlation between the dimensions and the strength index, psi, is less significant, nearly positive for tube thickness and negative for outer dimensions of the columns and section slenderness, as decreasing the outer dimensions-to-thickness ratio enhances the confinement behavior of stub columns. The yielding strength of the outer steel tube has a negligible impact on the strength index. In contrast, concrete compressive strength is inversely correlated to the strength index for circular and CFDST columns and has a negligible effect on rectangular columns. The high observed correlation for circular sections refers to the ductile behavior of using low-strength concrete. In contrast, the low correlation for rectangular sections refers to the general low confinement provided by the steel tube with a rectangular shape compared to the circular-shaped sections.

Correlation matrix for the CFST columns database.
Gaussian process
Gaussian processes (GPRs)10 are an ML method based on Bayesian learning principles. GPR constructs a Gaussian distribution over functions, as defined in Eq. (3), and observed data points inform this distribution. This technique can effectively handle uncertainty, adapt to noise and complexity levels, and prevent overfitting.
where \(f\left(x\right)\) is the function distribution at input \(x\), \(m\left(x\right)\) is the mean function, and \(K\left( {x,x^{\prime}} \right)\) is the covariance (kernel) function determining the covariance between any inputs x and \(x^{\prime}\). A combination of kernels, including the Gaussian kernel, Matern kernel, and periodic kernel, are utilized together to capture the different aspects of the data, such as the overall level, smoothness, noise, and variations. The kernel parameters are optimized by maximizing the log-marginal-likelihood10. Given observed input‒output pairs, GPR allows predictions for new inputs by inferring a Gaussian distribution over functions as follows:
where the posterior distribution \(p\left(f\left(x\right)|X,y\right)\) is also a Gaussian distribution with a posterior mean function \({\mu }_{p}\left(X\right)\) and a posterior covariance function \({\Sigma }_{p}\left(X\right)\) defined as follows:
where \({\mu }_{p}\left(x\right)\) and \({\Sigma }_{p}\left(x\right)\) define the mean prediction of the new input point x and the uncertainty (variance) associated with each prediction. The flow chart of the GPR model is illustrated in Fig. 4a.

Flow charts of the introduced ML models.
The GPR model can introduce confidence intervals for prediction outcomes, as illustrated in Fig. 5. This direct quantification of uncertainty enhances its applicability in guiding practical design considerations. The even distribution of the predicted column strength around the measured strength, as depicted in Fig. 5, further substantiates GPR's accurate predictive capabilities for stub CFST column strength.

Gaussian process regression on a semilog scale on the y-axis for CCFST columnss.
Symbolic regression and proposed equations
Symbolic regression (SR)31,32 is a supervised learning task and a genetic programming technique12 aiming to discover simple and interpretable mathematical expressions that best fit a given dataset by exploring a predefined space of analytic expressions and mathematical functions. SR problems are solved as multi-objective optimization problems, balancing prediction accuracy and model complexity. SR algorithms often use techniques such as genetic programming to improve candidate mathematical expressions by applying the principles of natural selection and evolution to refine the expressions until satisfactory models are found iteratively. In this study, a recent Python library called PySR33 is employed to predict mathematical expressions for the axial capacity of stub columns.
The SR algorithm starts building an initial population with a random combination of operational symbols or functions (e.g., \(+ , - ,/,{*}\), ^ etc.) and terminals, such as input variables and constants, to generate a tree-liked expression for each individual in the population. Individuals are selected in a probabilistic way, giving more possibilities to the best and making it possible for the worst to be selected. Otherwise, if only the best expressions were selected, the algorithm would converge prematurely, making all the populations equal. Consequently, a great part of the search space would be stopped from being explored, and the search would be intensively carried on in a small region only. The selected individuals are mutated or crossed over to produce a new generation of populations, using the fitness function to choose the best individuals in each population generation. The mutation process consists of varying a node at random by replacing a function (Fig. 6a), a terminal (Fig. 6b), or an entire subtree with another random node or subtree, while the crossover operation performs cross-swapping of two subtrees selected randomly in a pair of individuals (Fig. 6c).

Mutation and crossover operations in SR model.
In SR modeling, error minimization, and simplicity are key objectives of the fitness function. The fitness function is defined as33
where \({l}_{pred}\left(E\right)\) is the prediction loss (chosen as the Mean Absolute Error), \(C\left(E\right)\) is the complexity of the expression E, defined as the total number of nodes in the expression, and frecency[C(E)] is a combined measure of frequency and recency of the expression occurring at complexity C(E) in the population, which is used to avoid excessive growth and redundancies in expressions produced by the SR model. Table 3 specifies the parameters of the SR model used in generating expressions. The main procedures of the SR are introduced in Fig. 4b.
The process of selecting the optimal equation requires many iterations and a thorough exploration of each iteration. These iterations involve trying various custom functions, a wide range of operators, and exhaustive combinations of unitless input variables, which have a potential influence on stub column strength, such as the confinement factor ξ, local slenderness ratio λ, global slenderness ratio \(\overline{\lambda }\), and cross-section dimension ratios (L/D, L/B, H/B, Di/D). Unlike the approach commonly found in the literature22, where unit-dependent inputs were used for axial strength prediction using Gene Expression Programming (GEP), the previously mentioned inputs are unitless to enhance the robustness and interpretability of column behavior by avoiding any potential issues related to unit dependencies. The equation derived from each iteration has undergone comprehensive evaluation, simplification and refinement to achieve a concise, understandable, and accurate function. The selection criteria carefully balance various aspects, including equation complexity, accuracy, interpretability, and the sensitivity of its output to variable changes. For circular CFST columns, the following equation is extracted:
where \(\lambda\) and \(\overline{\lambda }\) are the local slenderness and global slenderness ratios, respectively, defined as follows:
where \({E}_{s}{I}_{s}\) and \({E}_{c}{I}_{c}\) are the flexural stiffness of steel and concrete parts.
Regarding the rectangular CFST columns, the proposed equation is:
Here, \(\xi =\frac{{A}_{s}{f}_{y}}{{A}_{c}{f}_{c}^{\mathrm{^{\prime}}}}, \beta =\frac{H}{B} ,\) and \(\lambda =\frac{B}{t}\sqrt{\frac{{f}_{y}}{{E}_{s}}}\)
For double-skin CFST circular columns, the equation is:
Here, \(\xi =\frac{{A}_{s}{f}_{y}}{{A}_{c}{f}_{c}^{\mathrm{^{\prime}}}}, \alpha =\frac{{D}_{i}}{D},\) and \(0.2\le \alpha \le 0.85\).
The proposed equations establish a comprehensive and simple framework with meaningful physical interpretations for predicting the axial capacity of various CFST columns. In the context of the circular column formula in Eq. (8), it is evident that increasing the square of global slenderness \(\overline{\lambda }\), local slenderness λ or the fc′/fy ratio reduces axial capacity. Concerning the rectangular section equation in Eq. (9), the axial strength of the composite column decreases with increasing local slenderness λ or H/B ratio; for the double-skin CFST columns formula in Eq. (10), an increase in the confinement ratio reduces the column capacity. These observations align with the experimental behavior of CFST columns. In addition, the provided equations are simple and unit-independent and have physical meaning compared to the previous studies in Table 1.
Data preprocessing and hyperparameter optimization technique
The min–max scaling technique is employed for data normalization to reduce the negative impact of multidimensionality. The grid searching technique is utilized for tuning the models’ hyperparameters during the training phase, and fivefold cross-validation is employed to mitigate the overfitting issues. After normalization, datasets were divided into two distinct training and testing subsets. The objective of segregating testing subsets was to assess how well the trained models perform on the new unseen datasets. As widely reported by many studies13,14,34, eighty percent of the original dataset is allocated randomly for training, leaving the remaining 20% for testing. To compare and evaluate the effectiveness and reliability of the introduced models, six different ML models, including the support vector machine integrated with particle swarm optimized (PSVR)35, Artificial Neural Network (ANN), XGBoost (XGB), CatBoost (CATB), Random Forest (RF), and LightGBM (LGBM) models, were introduced. All the introduced ML models were constructed and evaluated using the same training and testing subsets for a fair comparison.
The performance of most ML algorithms largely depends on their hyperparameters, which are predefined before model training. Properly tuning these hyperparameters is necessary to guarantee the optimum prediction performance. Searching for the optimum hyperparameters involves trying out different values for each and selecting the combination that introduces the best performance on the validation data. Using traditional techniques, i.e., grid search (GS) and random search (RS), is time-consuming, especially for large search spaces with numerous hyperparameters. In contrast, Bayesian Optimization (BO) models using the surrogate function, i.e., Gaussian process, random forest, and tree-structured Parzen estimators models (TPE)36, guide the selection of the next hyperparameter value based on the previous results from tested hyperparameter values. This approach minimizes unnecessary evaluations, enabling BO to identify the optimal hyperparameter combination in fewer iterations than the GS and RS methods37. In this study, we adopted the TPE model36 to optimize the introduced ML models due to their robustness compared to other surrogate functions37. Mean Absolute Percentage Error, MAPE is chosen as the objective function in the validation dataset. The expected improvement (EI) of TPE, defined in Eq. (11), builds a probability model of the objective function and uses it to select the most promising hyperparameters to evaluate in the true objective function36:
where z is the hyperparameter combination chosen from the search space, and s* is a threshold chosen to be some quantile γ of the observed s values, so that \(p\left(s<{s}^{*}\right)=\gamma\). Additionally, \(l\left(z\right)\) and \(g\left(z\right)\) correspond to two distinct distributions: one where the objective function values are below the threshold, l(z), and another where the values exceed the threshold, g(z). To maximize EI, TPE focuses on drawing samples of hyperparameters with the maximum l(z)/g(z) ratios, from Eq. (11). Finally, cross-validation was applied to assess the introduced models' effectiveness, avoid overfitting, and obtain accurate predictions for the testing data.
Performance and results of ML models
The scatter plots in Fig. 7 illustrate the relationship between experimental and predicted outcomes for various ML models applied to training and testing datasets for columns with different cross-section shapes. It can be observed that the data points tightly gather around the diagonal line for most of ML models, signifying a strong alignment between the model predictions and experimental results. This alignment signifies the reliability and prediction accuracy of the developed models. Table 4 introduces evolution metrics to assess the performance of the established ML models, including the mean (μ), coefficient of variance (CoV), coefficient of determination (R2), root mean squared error (RMSE), the mean absolute percentage error (MAPE), and a20-index, defined as follows:
where \({y}_{i}\) and \({\widehat{y}}_{i}\) are the actual and predicted output values of the i-th sample, respectively, \(\overline{y }\) is the mean value of experimental observations, and n is the number of specimens in the database. The a20-index16,38 measures the percentage of samples with actual to prediction ratio, \({\widehat{y}}_{i}/{y}_{i}\), falling within the range of 0.80–1.20. All data generated and algorithms introduced in this study are included in the supplementary file.

Comparison between proposed equations and ML models for training and testing datasets.
As shown in Table 4, all introduced ML models display mean μ, R2, and a20-index values close to 1.0 and small values for CoV, MAPE%, and RMSE for different cross sections. The prediction results of all introduced models exhibit CoV less than 0.076, MAPE% lower than 6%, and RMSE less than 552 kN, indicating minimized scattering in the prediction results compared to the experimental results. Table 4 reveals that the CATB, GPR, and XGB models introduce the best evaluation metrics for the testing subsets, with MAPE% values equal to 1.394%, 1.518%, and 2.135% for CCFST, RCFST, and CFDST column datasets, respectively. In addition, PSVR can accurately predict the capacity of stub CFST columns with MAPE% values equal to 2.497 and 5.151 for CCFST and RCFST columns, respectively. The superior predictive capability of PSVR demonstrates that the SVR model, incorporating the metaheuristic optimization methods39 like the PSO algorithm, can significantly enhance the performance of the SVR model.
Furthermore, the evolution metrics of the testing resemble those of the training set, except for the GPR and CATB models. However, the performance of GPR and CATB models in the testing set is comparable to that of the remaining data-driven models and even better than that of other ML models. In addition, when examining the R2 value and a20-index for the entire dataset, it was found that they are nearly identical to those of the test and training subdatasets. Such robust and stable alignment between the performance of sub-datasets signifies a minimal occurrence of overfitting during the training process of the models.
Although the GPR, CATB, XGB models stands out with significantly superior results compared to other models, extracting an explicit design formula from these models is a challenging task. In contrast, the proposed equations extracted from the SR algorithm offer a distinct advantage by providing simple and practical explicit design formulas, making them more accessible and easier to interpret, even with slightly lower accuracy than the introduced ML models. Although ANN could provide accurate and explicit formulas for strength prediction, utilizing the network in engineering design might not be practical due to the lengthy formulas of the ANN model.
The compressive strength predictions of CFST columns by the proposed equations were compared with the existing code formulas, including EC430 and AISC36029 for different types of columns. As observed in Table 4, for all types of CFST columns, the proposed equations attain a mean, R2, and a20-index nearly equal to 1.0 with CoV less than 0.076 and MAPE% less than 5.9, while EC4 and AISC360 show CoV larger than 0.091, 0.168 with MAPE% larger than 7.1% and 15%, respectively. In addition, the AISC360 predictions, compared to EC4 predictions, appear to overestimate the axial capacity for different cross sections with a higher mean approaching 1.20, lower a20-index, and relatively high error indices. The RMSE and MAPE of AISC36029 predictions are approximately two to six times those of EC430, indicating the better performance of EC4 compared to AISC360. In addition, AISC360 introduces an a20-index with a value approximately 50% lower than that obtained from the EC4 results. This discrepancy could stem from the absence of confinement effect calculations in AISC36029. Although all cited codes’ standards display a safe design, the error indices introduced by the ML models and proposed equation are significantly small compared to these standards. Specifically, the proposed equations demonstrate superior performance compared to these standards across all evaluation criteria.
Figure 8 displays the prediction errors of the design standards and the developed ML models for different cross sections. It indicates that most of the introduced ML models are more accurate than the design standards, especially for the GPR, CATB, and PSVR models, implying the superiority of these ML methods in estimating the axial capacity of stub CFST columns. In the case of CCFST columns, the CATB, GPR, and PSVR models display more than 95% of test samples within the 10% error range, while the proposed equation, EC4, and AISC360 show 83%, 75%, and 7% of test samples, respectively, within the same range. For RCFST columns, all ML models exhibit accuracy, with over 75% of test samples falling within a 10% error range, while the corresponding proportions for the proposed equation, EC4, and AISC360 are 85%, 73%, and 42%, respectively. Regarding CFDST columns, all ML models, excluding the RF and LGBM models, correctly predict 90% of the specimens within a 10% range error, while the proposed equation, EC4, and AISC360 attain nearly 83%, 68%, and 17% accuracy for the test samples, respectively, within the same error range. Thus, the introduced ML models can be considered valuable tools alongside the design standards in estimating the axial capacity of stub CFST columns.

Prediction errors of design standards and established ML models.
Feature importance analysis
Evaluating the influence of input parameters on axial compressive strength is a critical aspect of designing CFST columns. This study employs the Shapley Additive Explanation (SHAP) method to analyze the impact of input parameters on the strength index40. As illustrated in Fig. 9, the summary plot provides the impact of each feature on a model's predictions and defines the relative importance of each feature on the axial strength. Figure 10 displays the SHAP feature importance for each input feature. A feature importance value greater than zero indicates a positive correlation between the variable and the strength index, while a value less than zero signifies a negative impact on the strength index. The SHAP decision plots in Fig. 11 reveal the complex decision-making process of ML models and to observe how the summary plot works globally in predicting axial compressive strength for CFST columns. The compressive concrete strength and the slenderness ratio stand out as the most influential design parameters within the dataset, especially for CCFST and CFDST columns. The remaining variables' feature importance is ranked in descending order. Additionally, it is observed that, except for yield strength fy and steel tube thickness, t, all other input variables negatively influence or have a mixed impact on the strength index. This suggests that an increase in the outer tube yield strength and thickness will enhance the performance of stub columns, while increasing the section slenderness ratio and concrete strength will negatively impact the compressive strength index.

Summary plot for stub CFST column database.

SHAP feature importance for stub CFST column database.

SHAP decision plots for stub CFST column database.
Conclusion
In conclusion, this study compiled a comprehensive experimental database of 1316 datasets from various research papers, including circular, rectangular, and double-skin CFST short columns under axial loading without eccentricity. The datasets were carefully selected to ensure reliable and consistent results. Normalization of the axial load was performed to enhance the performance of the data-driven models using a unitless variable termed the strength index. Various data-driven models, including Gaussian process regression (GPR), symbolic regression (SR), support vector regression optimized with particle swarm optimization (PSVR), and artificial neural networks (ANN), XGBoost (XGB), CatBoost (CATB), Random Forest (RF), and LightGBM (LGBM) models, were developed and evaluated. In addition, the proposed formulas are presented for designing circular, rectangular, double-skin CFST columns. The following conclusions can be drawn:
-
The proposed normalization approach of the axial load yields a nearly normal distribution, which improves model performance and robustness. In addition, using the strength index as an output parameter reflects the insights into the level of confinement provided by the outer tube for different column types.
-
The CATB, GPR, and XGB models stood out as the most accurate and reliable models for strength predictions of CCFST, RCFST, and CFDST column datasets, respectively, while the proposed equations offered simple and practical expressions with acceptable accuracy.
-
Symbolic regression emerges as a promising methodology for extracting empirical equations endowed with practical applicability and meaningful physical interpretations.
-
The proposed equations demonstrated their reliability and robustness compared to existing design code standards.
-
SHAP analysis revealed that an increase in the outer tube yield strength and thickness will enhance the performance of stub columns, while increasing the section slenderness ratio and concrete strength will negatively impact the compressive strength index.
In summary, the proposed data-driven models can extract the axial compression capacity of CFST stub columns with reliable and accurate results, making them valuable tools for structural engineers.
Data availability
All data generated or analyzed during this study are included in this published article and available in a public repository https://github.com/kmegahed/Stub-CFST-Machine-learning.
References
Liew, J. Y. R., Xiong, M. & Xiong, D. Design of concrete filled tubular beam-columns with high strength steel and concrete. Structures 8, 213–226. https://doi.org/10.1016/j.istruc.2016.05.005 (2016).
Liu, D., Gho, W. M. & Yuan, J. Ultimate capacity of high-strength rectangular concrete-filled steel hollow section stub columns. J. Constr. Steel Res. 59(12), 1499–1515. https://doi.org/10.1016/S0143-974X(03)00106-8 (2003).
Ding, F., Luo, L., Zhu, J., Wang, L. & Yu, Z. Mechanical behavior of stirrup-confined rectangular CFT stub columns under axial compression. Thin-Walled Struct. 124(June 2017), 136–150. https://doi.org/10.1016/j.tws.2017.12.007 (2018).
Han, L. H. Tests on stub columns of concrete-filled RHS sections. J. Constr. Steel Res. 58(3), 353–372. https://doi.org/10.1016/S0143-974X(01)00059-1 (2002).
Sakino, K., Nakahara, H., Morino, S. & Nishiyama, I. Behavior of centrally loaded concrete-filled steel-tube short columns. J. Struct. Eng. 130(2), 180–188. https://doi.org/10.1061/(asce)0733-9445(2004)130:2(180) (2004).
Ibañez, C., Hernández-Figueirido, D. & Piquer, A. Shape effect on axially loaded high strength CFST stub columns. J. Constr. Steel Res. 147, 247–256. https://doi.org/10.1016/j.jcsr.2018.04.005 (2018).
Zhao, X. L. & Hancock, G. J. Tests to determine plate slenderness limits for cold-formed rectangular hollow sections of grade C450. Steel Constr. 25(4), 2–16 (1991).
Lai, M. H. & Ho, J. C. M. A theoretical axial stress-strain model for circular concrete-filled-steel-tube columns. Eng. Struct. 125, 124–143. https://doi.org/10.1016/j.engstruct.2016.06.048 (2016).
Suykens, J. A. K. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9(3), 293–300. https://doi.org/10.1023/A:1018628609742 (1999).
Rasmussen, C. E. et al. Gaussian processes for machine learning Vol. 1 (Springer, Berlin, 2006).
Megahed, K., Mahmoud, N. S. & Abd-Rabou, S. E. M. Application of machine learning models in the capacity prediction of RCFST columns. Sci. Rep. 13(1), 20878. https://doi.org/10.1038/s41598-023-48044-1 (2023).
Goldberg, D. E. & Holland, J. H. Genetic algorithms and machine learning. Mach. Learn. 3(2), 95–99. https://doi.org/10.1023/A:1022602019183 (1988).
Ahmadi, M., Naderpour, H. & Kheyroddin, A. Utilization of artificial neural networks to prediction of the capacity of CCFT short columns subject to short term axial load. Arch. Civ. Mech. Eng. 14(3), 510–517. https://doi.org/10.1016/j.acme.2014.01.006 (2014).
Ahmadi, M., Naderpour, H. & Kheyroddin, A. ANN model for predicting the compressive strength of circular steel-confined concrete. Int. J. Civ. Eng. 15(2), 213–221. https://doi.org/10.1007/s40999-016-0096-0 (2017).
Du, Y., Chen, Z., Zhang, C. & Cao, X. Research on axial bearing capacity of rectangular concrete-filled steel tubular columns based on artificial neural networks. Front. Comput. Sci. 11(5), 863–873. https://doi.org/10.1007/s11704-016-5113-6 (2017).
Le, T.-T., Asteris, P. G. & Lemonis, M. E. Prediction of axial load capacity of rectangular concrete-filled steel tube columns using machine learning techniques. Eng. Comput. 38(4), 3283–3316. https://doi.org/10.1007/s00366-021-01461-0 (2022).
Tran, V.-L., Thai, D.-K. & Kim, S.-E. Application of ANN in predicting ACC of SCFST column. Compos. Struct. 228, 111332. https://doi.org/10.1016/j.compstruct.2019.111332 (2019).
Zarringol, M., Thai, H.-T., Thai, S. & Patel, V. Application of ANN to the design of CFST columns. Structures 28, 2203–2220. https://doi.org/10.1016/j.istruc.2020.10.048 (2020).
Le, T.-T. Practical machine learning-based prediction model for axial capacity of square CFST columns. Mech. Adv. Mater. Struct. 29(12), 1782–1797. https://doi.org/10.1080/15376494.2020.1839608 (2022).
Hou, C. & Zhou, X. G. Strength prediction of circular CFST columns through advanced machine learning methods. J. Build. Eng. 51(November 2021), 104289. https://doi.org/10.1016/j.jobe.2022.104289 (2022).
Güneyisi, E. M., Gültekin, A. & Mermerdaş, K. Ultimate capacity prediction of axially loaded CFST short columns. Int. J. Steel Struct. 16(1), 99–114. https://doi.org/10.1007/s13296-016-3009-9 (2016).
İpek, S. & Güneyisi, E. M. Ultimate axial strength of concrete-filled double skin steel tubular column sections. Adv. Civ. Eng. 2019, 6493037. https://doi.org/10.1155/2019/6493037 (2019).
Javed, M. F. et al. New prediction model for the ultimate axial capacity of concrete-filled steel tubes: An evolutionary approach. Crystals https://doi.org/10.3390/cryst10090741 (2020).
Jiang, H., Mohammed, A. S., Kazeroon, R. A. & Sarir, P. Use of the gene-expression programming equation and FEM for the high-strength CFST columns. Appl. Sci. https://doi.org/10.3390/app112110468 (2021).
Naser, M. Z., Thai, S. & Thai, H.-T. Evaluating structural response of concrete-filled steel tubular columns through machine learning. J. Build. Eng. 34, 101888. https://doi.org/10.1016/j.jobe.2020.101888 (2021).
Tran, V.-L., Thai, D.-K. & Nguyen, D.-D. Practical artificial neural network tool for predicting the axial compression capacity of circular concrete-filled steel tube columns with ultra-high-strength concrete. Thin-Walled Struct. 151, 106720. https://doi.org/10.1016/j.tws.2020.106720 (2020).
Xu, J., Wang, Y., Ren, R., Wu, Z. & Ozbakkaloglu, T. Performance evaluation of recycled aggregate concrete-filled steel tubes under different loading conditions: Database analysis and modelling. J. Build. Eng. 30, 101308. https://doi.org/10.1016/j.jobe.2020.101308 (2020).
İpek, S., Güneyisi, E. M., Mermerdaş, K. & Algın, Z. Optimization and modeling of axial strength of concrete-filled double skin steel tubular columns using response surface and neural-network methods. J. Build. Eng. https://doi.org/10.1016/j.jobe.2021.103128 (2021).
AISC, AISC 360-22 Specification for Structural Steel Buildings. Am. Inst. Steel Constr., p. 780, 2022.
BEng, S. H. & Park, S. EN 1994-Eurocode 4: Design of composite steel and concrete structures. Retrieved May, vol. 10, 2022 (1994).
Koza, J. R. Genetic programming as a means for programming computers by natural selection. Stat. Comput. 4(2), 87–112. https://doi.org/10.1007/BF00175355 (1994).
Udrescu, S.-M. & Tegmark, M. AI Feynman: A physics-inspired method for symbolic regression. Sci. Adv. 6(16), eaay2631 (2020).
Cranmer, M. Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl,” 2023, [Online]. Available: http://arxiv.org/abs/2305.01582.
Nguyen, M. S. T., Trinh, M. C. & Kim, S. E. Uncertainty quantification of ultimate compressive strength of CCFST columns using hybrid machine learning model. Eng. Comput. 38(0123456789), 2719–2738. https://doi.org/10.1007/s00366-021-01339-1 (2022).
Ren, Q., Li, M., Zhang, M., Shen, Y. & Si, W. Prediction of ultimate axial capacity of square concrete-filled steel tubular short columns using a hybrid intelligent algorithm. Appl. Sci. https://doi.org/10.3390/app9142802 (2019).
Bergstra, J., Bardenet, R., Bengio, Y. & Kégl, B. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems, 2011, vol. 24, [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf.
Yang, L. & Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 415, 295–316. https://doi.org/10.1016/j.neucom.2020.07.061 (2020).
Asteris, P. G. & Mokos, V. G. Concrete compressive strength using artificial neural networks. Neural Comput. Appl. 32(15), 11807–11826. https://doi.org/10.1007/s00521-019-04663-2 (2020).
Bianchi, L., Dorigo, M., Gambardella, L. M. & Gutjahr, W. J. A survey on metaheuristics for stochastic combinatorial optimization. Nat. Comput. An Int. J. 8(2), 239–287. https://doi.org/10.1007/s11047-008-9098-4 (2009).
Wang, J., Lu, R. & Cheng, M. Application of ensemble model in capacity prediction of the CCFST columns under axial and eccentric loading. Sci. Rep. 13(1), 9488. https://doi.org/10.1038/s41598-023-36576-5 (2023).
Tran, V.-L., Kim, S.-E. & Thai, D.-K. A new empirical formula for prediction of the axial compression capacity of CCFT columns. Steel Compos. Struct. 33, 181–194. https://doi.org/10.12989/scs.2019.33.2.181 (2019).
Memarzadeh, A., Sabetifar, H. & Nematzadeh, M. A comprehensive and reliable investigation of axial capacity of Sy-CFST columns using machine learning-based models. Eng. Struct. 284(January), 115956. https://doi.org/10.1016/j.engstruct.2023.115956 (2023).
Acknowledgements
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
K.M. is responsible for analysis and preparing the figures. N.M. is responsible for material preparation and data collection. S.A. wrote the first draft of the manuscript. All authors contributed to the study conception and design, reviewed all previous versions of the manuscript, and read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Megahed, K., Mahmoud, N.S. & Abd-Rabou, S.E.M. Prediction of the axial compression capacity of stub CFST columns using machine learning techniques. Sci Rep 14, 2885 (2024). https://doi.org/10.1038/s41598-024-53352-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-53352-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
