
Abstract
In this paper, a new class of distributions called the T-X\(^\theta\) family of distributions for bounded—(0,1)—and unbounded—\((0,\infty )\)—supported random variables is suggested. Some special sub-models of the proposed family are utilized. A new sub-model is selected to be studied in details. The statistical properties of the suggested family including quantile function, moments, moment generating function, order statistics and Rényi entropy are discussed. The maximum likelihood method is provided to estimate the parameters of the distribution and a Monte Carlo simulation study is used. The discretized T-X\(^\theta\) family provided many sub-families and sub-models. In addition, eight real data sets are utilized to demonstrate the flexibility of the proposed continuous and discrete family’s multiple sub models.
Similar content being viewed by others
Introduction
Data and their distributions are the consequences of generating models. One can imagine that real generating methods are unlimited and therefore we are met with quite a few of models. Statisticians try to choose a mathematical model to fit a given data set. The more data we have, the larger our repertoire of models should be. The existence of a huge variety of data in many problems, requires numerous changes in the classical distributions producing new families of distributions. The newly found distributions may have new properties beside inheriting some advantages of the classical ones which often are special cases of the new generated distribution. This adds additional flexibility to the produced distribution, which it is hoped that it will be of benefit and provides accurate prediction. As a result, comparisons with the classical distributions were frequently in favor of the newly produced ones. Several approaches have been suggested on how to find new flexible distributions. Many alternatives have been employed; sometimes they realized there purpose through adding one or more parameters to a baseline distribution in different ways, some used transformation forms while others merged more than one distribution to obtain a new one. Reference1 proposed the transformed transformer’s family (T-X family). This method is derived from three functions (R, F, and W), where R and F are the cdfs of two random variables, T and X, respectively, and the W(.) function is used to connect T’s support to the range of X. The cdf and the pdf of the T-X family are given by
and
where r(t) and R(t) are the pdf and cdf of the random variable T\(\in [a,b]\), where \(-\infty \le a<b\le \infty .\) The W(.) is monotonically and non decreasing function with rang of W = [a, b].
-
1.
\(W(F(x))\in [a,b]\).
-
2.
W(F(x)) is differentiable and monotonically non decreasing.
-
3.
\(W(F(x))\longrightarrow\) a, as \(x\longrightarrow -\infty \;\) and \(\;W(F(x))\longrightarrow\) b, as \(x\longrightarrow \infty .\)
Several new types of distributions using various W(.) functions were introduced in the literature. Table 1 includes some members of the T-X family depends on different examples of the W(.) functions for non negative continuous random variable T.
The aim of this research is to introduce a new family of distributions called the T-X\(^{\theta }\) family of distributions. The cdf, pdf, Survival and hazard functions of the new family are proposed, also some T-X\(^{\theta }\) families based on different T distributions are introduced. Using different T and X functions some new models are introduced, the statistical properties of the E-X\(^\theta\)E distribution including Survival and hazard rate functions, the quantile function, moments, order statistics and Rényi entropy are derived. The maximum likelihood method is used for estimating the parameters and a simulation study on a variety of sample sizes for the E-X\(^\theta\)E distributions is investigated. The performance of several members of the discretized and continuous T-X\(^\theta\) families of distributions are performed using eight different types of lifetime data sets. Finally the conclusion is provided.
The new family
Here a new way of defining the W(x) function in the T-X family of distributions is proposed. Let T and X be non-negative random variables with cdf R(t) and F(x) and assumed the random variable T\(\in (a,b)\) and X\(\in (a,b)\), for \(0\le a< b\le \infty\) then the cdf and the pdf of the new T-X\(^{\theta }\) family of distributions can be defined as follows
and
where \(\theta >0\) is an additional shape parameter.
The new W(.) function is a generalization that can be defined for both of ranges (0,1) and \((0,\infty )\). One can see that the random variables T, and X should have the same range.
The Survival and hazard functions of a random variable X with T-X\(^{\theta }\) family are, respectively given, by
and
When \(\theta\) = 0, and T is distributed as beta or Kumaraswamy distribution, then this family is the beta-generated or the Kumaraswamy-generated family of distributions as defined in Table 1.
Based on different T distributions Table 2 displays some members of T-X\(^{\theta }\) family with the same X function.
Special models
This section introduces various new T-X\(^\theta\) family models based on different X random variables. The Exponential-X\(^\theta\)Exponential distribution is studied in details and Some of its features are provided. In Table 3, several new models derived from the T-X\(^{\theta }\) family of distributions are provided.
The Uniform-X\(^\theta\)Beta distribution in Table 3 is the McDonald distribution defined by Ref.8 with \(\theta +1 = c\)
The Exponential-X\(^{\theta }\)Exponential
Let the random variable T follows the Exponential distribution with parameter \(\lambda = 1\), and F(x) is the cdf of the Exponential distribution with parameter \(\alpha\), then the cdf and the pdf of the Exponential-\(X^{\theta }\)Exponential(E-\(X^{\theta }\)E) distribution are defined as
and
where the survival and the hazard functions are
and
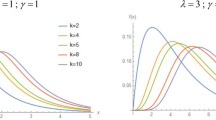
For different values of \(\alpha\) and \(\theta\) the pdf and the hazard function of the E-\(X^{\theta }E\) distribution are plotted in Fig. 1.

The pdf and the hazard function of the EX\(^\theta\)E distribution for different parameter values.
Properties of the E-X\(^{\theta }\)E distribution
In this subsection the E-X\(^{\theta }\)E distribution is studied in details. Some properties of the E-X\(^{\theta }\)E distribution including quantile function, moments, moment generating function, order statistics and entropy are provided.
The quantile function
The quantile function (qf) of the E-X\(^{\theta }\)E distribution can be obtained by equating the cdf (G(x)) in (3) to u, \(0<u<1,\) and solve it for x, then
There is no closed form for the quantile function and it can be obtained numerically. Butting u = 0.5, in (5), the median (M) of the E-\(X^{\theta }E\) distribution can be calculated.
pdf expansion
Here we need to expand the pdf which will be useful in calculating some properties of the E-X\(^{\theta }\)E distribution such as moments and moment generating function. To obtain the pdf expansion one needs to use the following expansion
then the pdf in (4) can be expressed as
The moments
If X is a random variable distributed as E-X\(^{\theta }E (\alpha ,\theta )\), then the nth ordinary moment of E-X\(^{\theta }E\) distribution using the pdf in (6) will be
The central moments can be obtained from the moments by
Therefore, the mean and the variance of the E-\(x^{\theta }E\) distribution are given by
and
The numerical values of mean (\(\mu\)) and variance (\(\sigma ^2\)) of the E-X\(^{\theta }\)E distribution are listed in Table 4 for selected values of \(\alpha\) and \(\theta\).
From Table 4 one can notes that; the mean and the variance of the E-X\(^{\theta }E\) distribution decreases as \(\theta\) or \(\alpha\) increases. For fixed value of \(\alpha\) or \(\theta\) the mean and variance decreases as the other parameter increases.
The skewness and kurtosis based on moments
The measure of skewness (Sk) describes the degree of symmetry of the distribution while the kurtosis (Ku) is the peakedness of the distribution. They associated with the E-X\(^{\theta }\)E distribution using the moments by
and
Table 5 shows numerical values for the skewness (Sk), and kurtosis (Ku) of the E-\(X^{\theta }E\) distribution for some values of \(\alpha\) and \(\theta\).
From the results provided in Table 5, it’s observed that the E-X\(^{\theta }\)E distribution covered different shapes of pdf.
For different values of \(\alpha\), one can notes that; the distribution is right skew \((Sk>0)\) for \(\theta <3\). For \(\theta = 3\), the distribution is approximately symmetric \((Sk = 0)\), and for \(\theta >3\) the distribution is left skew \((Sk<0)\).
For fixed value of \(\alpha\), the kurtosis of the E-X\(^{\theta }\)E distribution is high peak (leptokurtic) for values of \(3<\theta <5\), but the distribution is neither too high peak nor too flat topped for \(3<\theta <10\) (mesokurtic).
The moment generating function
The moment generating function of the E-X\(^{\theta }\)E distribution can be obtained using the expansion in (6), as follows
Thus we can find the nth moment by differentiating the \(M_{X}(t)\) n times, and then setting t = 0 in the result; that is,
Order statistics
Let \(X_{1}, \dots , X_{k}\) be k independent random variables from distribution with pdf g(x) and cdf G(x). According to Ref.9, the pdf of rth order statistics, is given by
Using the binomial expansion for te quantity
Inserting (8), (3) and (4) in (7), then the pdf of the rth order statistic from the T-X\(^{\theta }\) family of distributions is given by
Let \(X_{1}, \ldots , X_{k}\) be a random sample from the E-X\(^{\theta }\)E distribution. The pdf of rth order statistic, \(X_{r:k}\), for the E-X\(^{\theta }\)E distribution is defined by
where \(\omega _{i,j,l} = \dfrac{k!(-1)^j(l+k-r+1)^{i+j}}{(r-1-l)!(k-r)!l!i! j!}\).
Proof
The pdf of rth order statistic, \(X_{r:k}\), for the E-X\(^{\theta }\)E distribution can be written as
where \(v = l+k-r+1\). Using the Exponential expansion for \(e^{-vx^{\theta }+vx^{\theta } e^{-\alpha x}}\), then the Form in (9) is obtained. \(\square\)
Entropy
In information theory entropy can be regarded as a measure of a system’s degree of uncertainty. It has a widely applications in economics, physics, weather science and sociology. in this section the Rényi entropy measurements is evaluated for the E-X\(^{\theta }\)E distribution.
Rényi entropy
10 defined the Rényi entropy which considered as a generalization of the Hartley, Shannon, collision and min entropy. The Rényi entropy of a random variable X is defined by
The Rényi entropy of the T-\(X^\theta\) family of distributions is given by
This form is easy to be shown by applying the following binomial expansion
The Rényi entropy of of a random variable X following the E-\(X^{\theta }\)E distribution is
Proof
Applying result in (10), then the Rényi entropy of the E-X\(^{\theta }\)E can be written as
Since \(e^{-\rho x^{\theta }(1- e^{-\alpha x})} = \sum _{k = 0}^{\infty }\dfrac{\left( -\rho x^{\theta }(1- e^{-\alpha x})\right) ^{k}}{k!}\) , then the Rényi entropy will be
Since \(\left( 1- e^{-\alpha x}\right) ^{m+k} = \sum _{r = 0}^{m+k}\left( {\begin{array}{c}m+k\\ r\end{array}}\right) (-1 )^{r}e^{-r\alpha x}.\) Then
Assuming the exchange between summation and integration is possible, then the last form will be
The result in Eq. (11) obtained from the last form by using the gamma function as
\(\square\)
Parameter estimation and simulation study
In the first subsection, the maximum likelihood estimation (MLEs) of the parameters of the E-X\(^{\theta }\)E distribution is discussed. In the second subsection, a simulation study is obtained.
Maximum likelihood (MLE)
Let \(X_{1}, X_{2},..., X_{n}\) be a random sample from E-X\(^{\theta }\)E distribution. The log-likelihood function corresponding to (4) is
The partial derivatives of \(\alpha\) and \(\theta\) corresponding to (12), are given by
and
Therefore, the MLE for \({\hat{\alpha }}\) and \({\hat{\theta }}\) are achieved by setting (13) and (14) to zero and then numerically solving them using a simulation technique such as Newton Rahbson.
Interval estimation
the second derivatives of the log likelihood function for \(\alpha\) and \(\theta\) are
and
The hessian matrix H can be obtained as follows by using Eqs. (13), (16) and (17) .
where, \({\Theta } = (\alpha , \theta )\), \(\hat{{\Theta }}\sim N_{2}({\Theta },-H(\hat{{\Theta }}|x)^{-1})\) and the information matrix \(I( {\Theta }|x) = -E(H({\Theta }|x))\) , The EX\(^{\theta }\)E distribution’s MLEs for parameters \(\alpha\) and \(\theta\) only exist if the Hessian matrix is negative definite then the likelihood has a unique root. Consequently, the matrix -H(\(\hat{{\Theta }}\)) can be used to calculate asymptotic confidence intervals for the parameters \(\alpha\) and \(\theta\).
Simulation study
In this subsection a Monte Carlo simulation study is presented to demonstrate the effectiveness of the ML approach for estimating the E-X\(^{\theta }E\) distribution parameters (\(\alpha\) and \(\theta\)). The following are the steps of the simulation procedure:
-
1.
Set the parameter values for (\(\alpha\) and \(\theta\)) as (2,0.1), (0.1,2), (0.5,1.5), (1.2,1.5), (1,0.2), (0.3,0.2), (0.6,0.5), (0.1,0.2), (1,2), and (0.2,1).
-
2.
Using the E-\(X^{\theta }\)E distribution’s quantile function, which is defined in (5), to generate a random sample of size n, where n = 20, 45, 60, 90, 120, 150, and 200.
-
3.
Using the generated data obtained in step 2, the MLE of the parameters \(\alpha\) and \(\theta\) is calculated.
-
4.
The biases and the root mean squared errors (RMSE) were determined using the provided formulas,
$$\begin{aligned} \text {bias}(\gamma ) = \dfrac{1}{1000}\sum _{i = 1}^{1000}({\hat{\gamma }}_{i}-\gamma )\quad \text {and} \quad \text {RMSE}(\gamma ) = \sqrt{\dfrac{1}{1000}\sum _{i = 1}^{1000}({\hat{\gamma }}_{i}-\gamma )^{2}}. \end{aligned}$$
The biases, root mean squared errors and variances of \({\hat{\alpha }}\) and \({\hat{\theta }}\) are reported in Table 6. In general, as predicted, the results in this table showed a decrease in the values of the biases RMSE and variance as sample size increases, indicating that the MLE is a reliable approach for estimating the E-X\(^{\theta }\)E parameters as it is unbiased, the variance is minimum and it realizes the consistence.
Discrete T-X\(^{\theta }\) family
Statistical literature contains many techniques that can be used to discretize the continuous family of distributions. One of these techniques is the one that depends on the survival function. Following11, the survival function for a discrete life time distribution is defined as \(S(x) = P(X\ge x), x = 1,2,...\) and \(S(0) = 1\), then the probability mass function (pmf) is:
The new family is generated by discretizing the continuous cdf function in (1) using the form in (18). The pmf of the T-X\(^{\theta }\) family is given by
Based on this pmf, with different T distributions, Table 7 contains some new discrete sub-families of the discrete T-X\(^{\theta }\) family.
From Table 7 for the DW-X\(^{\theta }\) family, we notes that;
-
When the shape parameter \(\lambda = 1,\) the DW-X\(^{\theta }\) family reduces to the discrete Exponential family of distributions (DE-X\(^{\theta }\)) with parameters \(1/\beta\) and \(\theta\).
-
When \(\lambda = 2,\) the DW-X\(^{\theta }\) family reduces to the discrete Rayleigh family of distributions (DR-X\(^{\theta }\)) with parameters \(\beta ^2\) and \(2\theta\).
-
The DW-X\(^{\theta }\) family can be considered as The DE-X\(^{\theta }\) family with exponentiation F(x), ie \(\theta ^{\lambda } = \theta ^{\star },\) \({\beta }^{\lambda } = {\beta }^{\star }\)and \(\lambda\) is the exponentiation parameter.
The discrete exponetial-X\(^{\theta }\), DE-X\(^{\theta }\) family
The cumulative distribution function (cdf), survival function and probability mass function (pmf) of the DE-X\(^{\theta }\) family of distributions are
The survival and the hazard rate functions of the DE-X\(^{\theta }\) family of distributions are
With different X random variables, many distributions can be generated as members of the DE-X\(^{\theta }\) family as shown in Table 8.
The DE-Exponential\(^{\varvec{\theta }}\)(DEE) distribution
The DEE distribution is derived here as an example from Table 8. Substituting F(x) in (20) and (21) by the Exponential distribution with parameter \(\beta\), then The pmf of the DEE distribution with three parameters are given by;
while the survival and the hazard functions are given by
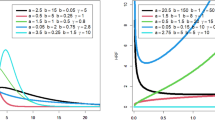
Figure 2 displays some possible pmf shapes of the DEE distribution. The hazard rate function may has an increasing or decreasing shape as shown in Fig. 3.

The pmf of the DEE distribution for different parameter values.

The hazard function of the DEE distribution for different parameter values.
Applications to real data
The applications in this section are derived into two subsections, the first subsection contains applications of the continuous distributions displayed in Table 3. While, the second subsection deals with count data that matched the discrete distributions presented in Table 8.
Using continuous data
In this subsection multiple models of the T-X\(^\theta\) family are fitted to four different data sets. These examples are provided to demonstrate the flexibility of the new family members when compared against a variety of distributions. The estimation of each model parameters is obtained using the maximum likelihood method. To compare the distributions, three criteria are calculated, including: the Akaike information criterion (AIC), the Bayesian information criterion (BIC) and the corrected Akaike information criterion (AICc).
where \(L(\theta ; x)\) denotes the log likelihood for the model, k is the number of parameters and n is the sample size. In general the model that best fits the data is the one with the highest log L and p values and the lowest AIC, AICc, BIC, and Ks values. The Mathematica package was used to assess all of the required computations and figures. Table 9 shows the distributions that have been fitted to the data for comparison considerations.
Data set I
The data set provides the wait times (in min) before service for 100 Bank clients, which were evaluated and assessed by16 for fitting the Lindley distribution. The data are: 0.8, 0.8, 1.3, 1.5, 1.8, 1.9, 1.9, 2.1, 2.6, 2.7, 2.9, 3.1,3.2, 3.3, 3.5, 3.6, 4.0, 4.1, 4.2, 4.2, 4.3, 4.3, 4.4, 4.4, 4.6, 4.7, 4.7, 4.8, 4.9 ,4.9, 5.0, 5.3, 5.5, 5.7, 5.7, 6.1, 6.2, 6.2, 6.2, 6.3, 6.7 ,6.9 ,7.1, 7.1, 7.1, 7.1, 7.4, 7.6, 7.7, 8.0, 8.2, 8.6, 8.6, 8.6, 8.8, 8.8, 8.9, 8.9, 9.5, 9.6,9.7, 9.8, 10.7, 10.9, 11, 11, 11.1, 11.2, 11.2, 11.5, 11.9, 12.4,12.5, 12.9, 13, 13.1, 13.3, 13.6, 13.7, 13.9, 14.1, 15.4, 15.4, 17.3,17.3, 18.1, 18.2, 18.4, 18.9, 19, 19.9, 20.6, 21.3, 21.4, 21.9, 23,27, 31.6, 33.1, 38.5.
The estimated parameter values and the goodness of fit measures for this data are presented in Table 10. According to the results in this table, the G-X\(^\theta\)L, E-X\(^\theta\)E, G-X\(^\theta\)E, E-X\(^\theta\)G, and L-G{F} distributions are fitted to this data. The G-X\(^\theta\)L distribution is the best option among other competitive models, as shown by the findings in Table 10, as it has the greatest p-value, and the smallest other goodness of fit statistics. These findings are also supported by Fig. 4 which represents the empirical cdf and the observed density (histogram) for data set I together with the competitive models.

(a) The empirical and the estimated cdf for data set I. (b) The histogram and estimated pdf for data set I.
Data set II
The data set comes from Ref.17 and represents the time between failures for repairable components. The data are provided as shown below:
-
1.43, 0.11, 0.71, 0.77, 2.63, 1.49, 3.46, 2.46, 0.59, 0.74, 1.23, 0.94, 4.36, 0.40, 1.74, 4.73, 2.23, 0.45, 0.70, 1.06, 1.46, 0.30, 1.82, 2.37, 0.63, 1.23, 1.24, 1.97, 1.86, 1.17.
The parameter estimates and the goodness-of-fit statistics for E-X\(^{\theta }\)E, G-X\(^{\theta }\)L,G-X\(^{\theta }\)E, Bu-X\(^{\theta }\)E, CIR and PIL distributions are listed in Table 11. All competitive distributions are fitted and perform well when examining these data with a p-value greater than 0.05. However, the optimal model to acquire the best assessment of the data is the E-X\(^{\theta }\)E model, which has the smallest values of -ll, AIC, BIC, AICc and k-s statistics, as well as the highest p-value of all the examined models. Figure 5 supports the results in Table 11.

(a) The empirical and the estimated cdf for data set II. (b) The histogram and estimated pdf for data set II.
Data set III
The data set was acquired from Ref.18and consists of 30 successive values of March precipitation (in inches) in Minneapolis/St Paul. The data is as follows:
-
0.77, 1.74, 0.81, 1.2, 1.95, 1.2, 0.47, 1.43, 3.37, 2.2, 3, 3.09, 1.51, 2.1, 0.52, 1.62, 1.31, 0.32, 0.59, 0.81, 2.81, 1.87, 1.18, 1.35, 4.75, 2.48, 0.96, 1.89, 0.9, 2.05.
Figure 6 depicts the empirical cdf and observed density (histogram) for Data set III, compared with the cdf’s and pdf’s of E-X\(^{\theta }\)E, E-X\(^{\theta }\)G, G-X\(^{\theta }\)E, Bu-X\(^{\theta }\)E and CIR distributions. Table 12 displays the calculated parameters as well as the goodness-of-fit values. As seen in Table 12 and Fig. 6, the G-X\(\theta\)E distribution was chosen as the best model for this data because it had the lowest goodness-of-fit statistics and the greatest p-value, which = 1, of all the competitive distributions.

(a) The empirical and the estimated cdf for data set III. (b) The histogram and estimated pdf for data set III.
Data set IV
The data shows the remission times (in months) of 128 bladder cancer patients. Reference15 have made use of this data. The following are the data set values:
-
0.08, 2.09, 3.48, 4.87, 6.94, 8.66, 13.11, 23.63, 0.20, 2.23, 3.52, 4.98, 6.97, 9.02, 13.29, 0.40, 2.26, 3.57, 5.06, 7.09, 9.22, 13.80, 25.74, 0.50, 2.46, 3.64, 5.09, 7.26, 9.47, 14.24, 25.82, 0.51, 2.54, 3.70, 5.17, 7.28, 9.74, 14.76, 26.31, 0.81, 2.62, 3.82, 5.32, 7.32, 10.06, 14.77, 32.15, 2.64, 3.88, 5.32, 7.39, 10.34, 14.83, 34.26, 0.90, 2.69, 4.18, 5.34, 7.59, 10.66, 15.96, 36.66, 1.05, 2.69, 4.23, 5.41, 7.62, 10.75, 16.62, 43.01, 1.19, 2.75, 4.26, 5.41, 7.63, 17.12, 46.12, 1.26, 2.83, 4.33, 5.49, 7.66, 11.25, 17.14, 79.05, 1.35, 2.87, 5.62, 7.87, 11.64, 17.36, 1.40, 3.02, 4.34, 5.71, 7.93, 11.79, 18.10, 1.46, 4.40, 5.85, 8.26, 11.98, 19.13, 1.76, 3.25, 4.50, 6.25, 8.37, 12.02, 2.02, 3.31, 4.51, 6.54, 8.53, 12.03, 20.28, 2.02, 3.36, 6.76, 12.07, 21.73, 2.07, 3.36, 6.93, 8.65, 12.63, 22.69.
Plots of the fitted cdf’s and pdf’s for this data set are shown in Fig. 7. The calculated parameter values and goodness of fit measures are shown in Table 13. This table shows that, E-X\(^{\theta }\)E, G-X\(^{\theta }\)E, G-X\(^{\theta }\)L distributions are Fitted and perform well when examining this data set with a p-value greater than 0.05. While the NW-L distribution isn’t fitted to this data. However, the optimal model to acquire the best assessment of the data is the E-X\(^{\theta }\)E model, which has the smallest values of -ll, AIC, BIC, AICc and K-S statistics, as well as the highest p-value of all the examined models. Figure 7 supports the results in Table 13

(a) The empirical and the estimated cdf for data set IV. (b) The histogram and estimated pdf for data set IV.
Using discrete data
Applications to count data sets from different fields are examined to demonstrate the practical applicability of the proposed models presented in Table 8. The R software is used to acquire the statistical results. MLE’s, Akaike Information Criteria (AIC), Bayesian Information Criteria(BIC), \(\chi ^{2}\) test with associated p-values are performed to compare the flexibility of distributions. For competitive considerations, the data were also fitted to the Gamma distribution and some other discrete competitive distribution shown in Table 14.
Data set V
This data set represents the survival times of 44 patients suffering from head and neck cancer who retreated using a combination of radiotherapy. This data is taken from Ref.24. The data are:
12 32 37 24 24 74 81 26 41 58 63 68 78 47 55 84 155 159 92 94 110 127 130 133 140 112 119 146 173 179 194 195 339 432 209 249 281 319 469 725 817 519 633 1776
Figure 8 illustrates the empirical and estimated cdf of this data. Table 15 displays the calculated parameters as well as the goodness-of-fit values. From the outcomes of this Table, we conclude that the DEE, DEW, DEB, DEL, DEFr, DEG, DEETE, INH, DEOWE, DBiEXII, PMiD and Geometric distributions are Fitted and perform quite well for evaluating this data. The DEE distribution is selected as the best model for the data because it has the smallest values of the goodness-of-fit statistics and the highest p-value among all the competitive distributions.

The empirical cdf’s of some fitted distributions for data set V.
Data set VI
These data show the time intervals in days between coal mine explosions from March 15, 1851 to March 22, 1962, inclusive. This time range is 40,550 days long. So the data consists of 190 numbers totaling 40,549. The 0 occurs because two incidents occurred on June 6, 1875. These findings are presented in Ref.25. The data set is; 0 1 1 2 2 3 4 4 4 6 7 10 11 12 12 12 13 15 15 16 16 16 17 17 18 19 19 19 20 20 22 23 24 25 27 28 29 29 29 31 31 32 34 34 36 36 37 40 41 41 42 43 45 47 48 49 50 53 54 54 55 56 59 59 61 61 65 66 66 70 72 75 78 78 78 80 80 81 88 91 92 93 93 95 95 96 96 97 99 101 108 110 112 113 114 120 120 123 123 124 124 125 127 129 131 134 137 139 143 144 145 151 154 156 176 182 186 187 188 189 190 193 194 197 202 203 208 215 216 217 217 217 218 224 225 228 232 233 250 255 275 275 275 276 286 292 307 307 312 312 315 324 326 326 329 330 336 345 348 354 361 364 368 378 388 420 431 456 462 467 498 517 536 538 566 632 644 745 806 826 871 952 1205 1312 1358 1630 1643 2366
The summary statistics for this data is shown in Table 16. Figure 9 depicts the fitted cdf plots of the proposed models compared with the DEETE, INH, DEOWE, DBiEXII, PMiD and Geometric distributions for the data set VI. The estimated parameter values and the goodness of fit measures are presented in Table 16. According to the results in this table, the DEE, DEW, DEB, DEL, DEFr, DEG and DEOWE distributions are fitted to the data. The DEE distribution is the best option among other competitive models as it has the greatest p-value, while the DEG has the smallest other goodness of fit statistics, as shown by the findings in Table 16.

The empirical cdf’s of some fitted distributions for data set VI.
Data set VII
This data derived from a study performed in the lab on male mice who were given a 300 roentgen radiation exposure and were 5–6 weeks old. This information describes additional causes of death than the two primary causes: Thymic lymphoma and reticulum cell sarcoma. This data were examined by Ref.26. The data are:
40 42 51 62 163 179 206 222 228 252 249 282 324 333 341 366 385 407 420 431 441 461 462 482 517 517 524 564 567 586 619 620 621 622 647 651 686 761 763
Figure 10 shows the fitted cdf plots of the suggested models compared with the DEETE, INH, DWMOE, DBiEXII, PMiD and Geometric distributions to this data set. Table 17, shows the estimated values of parameters as well as the goodness of fit statistics.
This table shows that, with the exception of the INH and Geometric distributions, all distributions are fitted and performed well when examining these data with p-values greater than 0.05. However, The PMiD distribution is the best option among other competitive models as it has the greatest p-value, as shown by the findings in Table 17.

The empirical cdf’s of some fitted distributions for data set VII.
Data set VIII
These data are the yields from 70 consecutive runs of a batch chemical process (see25). The data are 23 23 25 34 35 35 36 37 38 38 38 39 40 40 41 41 43 44 44 45 45 45 45 45 48 48 49 50 50 50 50 50 50 51 51 51 51 51 52 53 54 54 54 54 55 55 55 55 56 57 58 58 59 59 59 59 60 60 62 64 64 64 68 71 71 71 74 74 80.
The empirical and estimated cdf for the this data is shown in Fig. 11. The estimated parameters and goodness-of-fit measurements are also included in Table 18.
This Table shows that, the DEE, DEW, DEB, DEL, DEFr, DEG, DEETE, and DEOWE distributions are Fitted and perform quite well for evaluating this data with p-values larger than 0.05. The DEOWE distribution is selected as the best model for these data because it has the smallest -ll, AIC, BIC, and \(\chi 2\) values and the highest p-value.

The empirical cdf’s of some fitted distributions for data set VIII.
Summary and conclusion
In this research, a new way for generating distributions is developed with high degree of flexibility that would be very useful in modeling real data in various fields. The new family of distributions is called the T-X\(^{\theta }\) family suggested with extra shape parameters \(\theta\) for bounded and positive unbounded random variables. Several specific sub-families and sub-models of the proposed family are presented including the Exponential-X\(^{\theta }\) Exponential distribution which was selected and studied in details. The parameters of this distribution were estimated using the MLE method. A simulation study was also conducted to investigate the efficiency as well as behavior of estimates. The discretized T-X\(^{\theta }\) family of distributions has been proposed and some discrete models of the family were defined. As an example, the discrete Exponential Exponential, DEE, distribution, a three-parameter discrete distribution derived, various alternative graphs of the DEE’s pmf and hazard functions were shown. Eight different actual data sets were used to demonstrate the effectiveness of some members of the suggested continuous and discrete members of the family vs some other distributions. In general, the results indicate that the proposed distributions are highly flexible, provide accurate results and can fit various types of data. The new models achieved a closer match for all data sets.
References
Alzaatreh, A., Lee, C. & Famoye, F. A new method for generating families of continuous distributions. Metron 71, 63–79. https://doi.org/10.1007/s40300-013-0007-y (2013).
Eugene, N., Lee, C. & Famoye, F. Beta normal distribution and its applications. Commun. Stat. Theory Methods 31, 497–512 (2002).
Cordeiro, G. M. & de Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 81, 883–898 (2011).
Alzaghal, A., Famoye, F. & Lee, C. Exponentiated tx family of distributions with some applications. Int. J. Stat. Probab. 2, 31 (2013).
Ahmad, Z., Elgarhy, M. & Hamedani, G. A new Weibull-x family of distributions: Properties, characterizations and applications. J. Stat. Distrib. Appl. 5, 1–18 (2018).
Jamal, F. & Nasir, M. A. Some new members of the tx family of distributions. In 17th International Conference on Statistical Sciences, Vol. 33 (2019).
Ahmad, Z., Mahmoudi, E., Dey, S. & Khosa, S. K. Modeling vehicle insurance loss data using a new member of tx family of distributions. J. Stat. Theory Appl. 19, 133–147 (2020).
McDonald, J. B. et al. Some generalized functions for the size distribution of income. Econometrica 52, 647–663 (1984).
David, H. A. & Nagaraja, H. N. Order Statistics (Wiley, 2004).
Rényi, A. On measures of entropy and information. In Proc. Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, Vol. 4, 547–562 (University of California Press, 1961).
Kemp, A. W. Classes of discrete lifetime distributions. Commun. Stat. Theory Methods 33, 3069–3093 (2004).
Mahmoud, M. R., Mandouh, R. M. & Abdelatty, R. E. Lomax–Gumbel Frechet a new distribution. J. Adv. Math. Comput. Sci. 31, 1–19 (2019).
Mahdy, M., Ahmed, B. & Ahmad, M. Elicitation inverse Rayleigh distribution and its properties. J. ISOSS 5, 30–49 (2019).
Hassan, A. S., Al-Omar, A. I., Ismail, D. M. & Al-Anzi, A. A new generalization of the inverse Lomax distribution with statistical properties and applications. Int. J. Adv. Appl. Sci. 8, 89–97 (2021).
Alshanbari, H. M., Ijaz, M., Asim, S. M., Hosni El-Bagoury, A.A.-A. & Dar, J. G. New weighted Lomax (NWL) distribution with applications to real and simulated data. Math. Probl. Eng. 2021, 1–12 (2021).
Ghitany, M. E., Atieh, B. & Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 78, 493–506 (2008).
Murthy, D. P., Xie, M. & Jiang, R. Weibull Models (Wiley, 2004).
Hinkley, D. On quick choice of power transformation. J. R. Stat. Soc. Ser. C (Appl. Stat.) 26, 67–69 (1977).
Alaa, R. & Eledum, H. Discrete extended erlang-truncated Exponential distribution and its applications. Appl. Math. 16, 127–138 (2022).
Singh, B., Singh, R. P., Nayal, A. S. & Tyagi, A. Discrete inverted Nadarajah–Haghighi distribution: Properties and classical estimation with application to complete and censored data. Stat. Optim. Inf. Comput. 10, 1293–1313 (2022).
Nagy, M. et al. The new novel discrete distribution with application on covid-19 mortality numbers in Kingdom of Saudi Arabia and Latvia. Complexity 2021, 1–20 (2021).
Eliwa, M. S., Tyagi, A., Almohaimeed, B. & El-Morshedy, M. Modelling coronavirus and larvae pyrausta data: A discrete binomial Exponential II distribution with properties, classical and bayesian estimation. Axioms 11, 646 (2022).
Maya, R., Irshad, M. R., Chesneau, C., Nitin, S. L. & Shibu, D. S. On discrete Poisson–Mirra distribution: Regression, inar (1) process and applications. Axioms 11, 193 (2022).
Afify, A. Z., Elmorshedy, M. & Eliwa, M. A new skewed discrete model: Properties, inference, and applications. Pak. J. Stat. Oper. Res. 17, 799–816 (2021).
Hand, D. J., Daly, F., McConway, K., Lunn, D. & Ostrowski, E. A Handbook of Small Data Sets (CRC Press, 1993).
Hoel, D. G. A representation of mortality data by competing risks. Biometrics 28, 475–488 (1972).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors contributed to this work equally. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mandouh, R.M., Mahmoud, M.R. & Abdelatty, R.E. A new (T-X\(^\theta\)) family of distributions: properties, discretization and estimation with applications. Sci Rep 14, 1613 (2024). https://doi.org/10.1038/s41598-023-49425-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-49425-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
