
Abstract
The phase in which precipitation falls—rainfall, snowfall, or sleet—has a considerable impact on hydrology and surface runoff. However, many weather stations only provide information on the total amount of precipitation, at other stations series are short or incomplete. To address this issue, data from 40 meteorological stations in Poland spanning the years 1966–2020 were utilized in this study to classify precipitation. Three methods were used to differentiate between rainfall and snowfall: machine learning (i.e., Random Forest), daily mean threshold air temperature, and daily wet bulb threshold temperature. The key findings of this study are: (i) the Random Forest (RF) method demonstrated the highest accuracy in rainfall/snowfall classification among the used approaches, which spanned from 0.90 to 1.00 across all stations and months; (ii) the classification accuracy provided by the mean wet bulb temperature and daily mean threshold air temperature approaches were quite similar, which spanned from 0.86 to 1.00 across all stations and months; (iii) Values of optimized mean threshold temperature and optimized wet bulb threshold temperature were determined for each of the 40 meteorological stations; (iv) the inclusion of water vapor pressure has a noteworthy impact on the RF classification model, and the removal of mean wet bulb temperature from the input data set leads to an improvement in the classification accuracy of the RF model. Future research should be conducted to explore the variations in the effectiveness of precipitation classification for each station.
Similar content being viewed by others

Introduction
The ability to discriminate precipitation phase is important due to the different impacts of snowfall and rainfall on an array of environmental processes1,2,3 and several aspects of the industry, including transportation, agriculture, and farming4,5. The frequency and type of precipitation are just as important as their quantity and intensity in understanding the health of the ecosystem6,7,8 and the seasonality of hydrological and energy cycles1,2,3,9,10,11,12,13,14,15 which is crucial for decrease uncertainty in hydrological models16,17,18,19,20 and has a significant effect on water management7,8,21. A particular role belongs to the solid precipitation vital for snow cover development, which indirectly modifies radiation balance (increased albedo) and impacts large-scale climate dynamics22,23,24, stream flow and hydrological drought occurrences in spring and summer, snowmelt flooding25 and winter sports and recreation26. In Central Europe, seasonal variability in runoff and summer low flows are not only a function of low precipitation and high evapotranspiration, but they are also significantly affected by the previous winter snowpack27. Heavy snowfall can also be a serious risk to human health, life and property28,29,30,31,32 that can be significantly reduced when accurately forecasted. Winter precipitation forecasting relies heavily on the ability to precisely discriminate between winter precipitation types33,34,35 which is a challenging task due to the significant sensitivity of precipitation types to atmospheric conditions33. Therefore, evaluation of the role of particular atmospheric parameters (e.g. air temperature, humidity etc.) for forming particular precipitation phases is also useful for precipitation type forecasting. However, such a purpose requires high quality meteorological data for vertical profiles of the lower atmosphere which are available for a very sparse set of stations36,37,38.
Other precipitation phase discrimination attempts were based on single or several atmospheric parameters at the station level, using values averaged over the course of the day39,40,41,42. Daily data on precipitation phases recognized based on meteorological parameters are useful for climatological and environmental studies due to the lack of visual observations of precipitation phases at many stations. In South Korea out of 780 stations, 22 stations perform the manual observation of precipitation types43,44. Data on the precipitation phase, if available, usually covers shorter time periods compared to other meteorological parameters41—e.g. from 1979 in China, and from 1966 in Poland. In Poland, at most stations, the available time series of most meteorological elements began in 1951. The longest series of regular meteorological observations started at the end of the 18th or beginning of the 19th century. However such a long series exist for only a few stations and are not included in open databases. Moreover, traditional visual identification of precipitation types is massively replaced by automatic weather stations, which admittedly are able to recognize precipitation phases however with different accuracy and are differently coded, which can produce inhomogeneities in the chronological series45.
Novel approaches and procedures are still being developed to precisely identify precipitation phases based on novel data sources like remote sensing37,42,46,47 and new statistical tools like machine learning (ML)34,47,48. ML is an ideal solution for simulating the intricate interactions between many parameters and the precipitation phase because it does not require any distributional or modeling assumptions to handle multidimensional and complicated nonlinear relationships. However, ML is not without its limitations. There are a lot of distinct algorithms, thereby necessitating meticulous literature reviews and practical experience to align each model effectively with specific tasks. Moreover, the intricate nature of ML models introduces the requirement for parameter tuning, a meticulous process that consumes a substantial amount of time and, if not executed judiciously, can result in overfitting. Furthermore, the challenge of feature selection is also a significant consideration when deploying ML algorithms. Altogether, these procedural intricacies demand a substantial investment of time and the application of expert knowledge. Still, ML was extensively employed in the atmospheric sciences49,50,51,52,53,54. A multinomial logistic regression (MLR) model that used the NWP-driven variables beat the optimized Matsuo scheme and exhibited a 15% gain in accuracy relative to the NWP forecast44,55 tested the six following ML models—k-nearest neighbors, logistic regression, support vector machine (SVM), decision tree (DT), random forest (RF), and multi-layer perceptron and using thermodynamic and polarimetric variables, found that RF outperformed the operational technique and displayed the top score. When applying a ML model, optimizing and searching for an appropriate ML model is vital in order to assure both accuracy and computational efficiency in real-time operation55.
Accurate identification of the precipitation phase is still an important problem in atmospheric research, particularly climate change studies, and weather prediction that are both vital for society. The goal of this study is to use ML to discriminate snowfall from rainfall based on the lowest number of atmospheric parameters possible. Additionally, this study seeks to (i) identify the thresholds of daily mean air temperatures (Ta) and mean wet bulb temperatures (Tw) to differentiate between precipitation phases using both traditional and ML methods based on daily precipitation data collected from 40 best quality synoptic stations located across Poland between 1966 and 2020; (ii) explore the relationships between precipitation phases and various meteorological variables and select the optimal set of variables for accurate identification of precipitation phase based on ML; (iii) compare the accuracy of the threshold temperature and the Single Input Random Forest (SIRF) methods in determining precipitation phase to select the method that performs the best.
Although based on Polish data, this study delivers a universal method with respect to region, for identification of precipitation phases and contributes to the knowledge of the factors triggering the occurrence of precipitation phases. The results of this study can be useful for climate change environmental studies.
Dataset and methodology
Study area and dataset
Poland is located in Central Europe where the climate is moderate and transitional between oceanic and continental. Poland features varied landscapes, including the mountain ranges in the south with the highest peak reaching 1991 m asl, and lowlands and plains in the central regions, and a coastline along the Baltic Sea to the north. Average annual temperature varies between 7 and 8.5 °C and drops below 5 °C in mountain regions. In winter the warmest western and west-eastern edges of Poland experience air temperatures slightly above 0 °C while in the north-eastern part of the country air temperature drops to below – 3 °C. The record minimum daily air temperature was as low as − 41.0 °C.
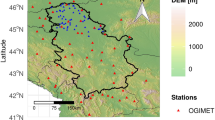
The present research utilizes daily meteorological data for the period 1966–2020 gathered from 40 synoptic stations located in Poland (Fig. 1). Synoptic stations of best quality are those operating according to WMO standards where manual observations were performed by qualified specialists, stations were not relocated, and data were complete with only single gaps permissible in the whole studied period of 1966–2020. Daily values were derived from synoptic data collected every three hours that comprise manual observations of weather phenomena (every 3 or 1 h), precipitation amount (every 6 or 12 h), air temperature, station level pressure and wind speed (every 3 h). Subsequently, the sub-daily data were used to calculate the daily values of the above mentioned parameters and additionally the mean wet bulb temperature, water vapor pressure, relative humidity, dew point temperature, minimum and maximum temperatures. The precipitation phase was identified based on the notation of weather phenomena coded according to standards in WMO Manual on codes (2019). Detailed information on the procedure of precipitation phase identification (solid, liquid, mixed) based on coded weather can be found in Łupikasza and Małarzewski (2023).

The distribution of the selected 40 synoptic stations in Poland, (based on data: https://egms.land.copernicus.eu/, modified in SURFER 25.2.259).
The quality of meteorological data used in this study underwent checking with Standard Normalised Homogenity Test (relative test) applied to daily and monthly values. Out of 60 synoptic stations we selected 40 stations with good quality data which were further checked with respect to outliers and extremes. Extreme precipitation totals were all verified and proved to be correct based on synoptic maps and known flood events. The data on precipitation phase from visual observations are less prone to inhomogeneities due to station relocations, however, a monthly number of days with precipitation phases were correlated between neighbouring stations. No evident inhomogeneities were detected. Data on the daily precipitation phase were utilized in the construction of classification models. In this study, the data used for classifying precipitation into rainfall and snowfall spans from November to April of the following year, as snowfall mainly occurs during this period, and the remaining months are not included in the analysis. In addition, the mixed precipitation was excluded from our analysis as its involvement exhibited poor classification performance in preliminary results. Trace precipitation was excluded from analysis due to its low environmental significance and higher susceptibility to erroneous identification of precipitation type45. At each station, the data was split into a training set (70%) and a test set (30%).
Random Forest
Random Forest (RF) (Breiman, 2001) is a machine-learning model increasingly used for classification. To apply the RF model for classifying precipitation phases, several procedural steps must be taken. Firstly, a dataset consisting of meteorological variables and precipitation phases needs to be collected. The meteorological variables included mean wet bulb temperature, water vapor pressure, relative humidity, dew point temperature, mean air temperature, minimum air temperature, maximum air temperature, precipitation amount, station level pressure, and wind speed, while the precipitation phases include no precipitation, rainfall, snowfall, and mixed phase. However, this study focused solely on the classification of rainfall and snowfall, thus only samples corresponding to rainfall and snowfall were retained. This dataset is then split into training (70%) and testing (30%) sets.
Next, the RF model is trained using the training set. This involves constructing multiple decision trees based on the meteorological variables and precipitation phases in the training set. Each decision tree splits the data based on a particular meteorological variable, and the final prediction is made based on the majority vote of the individual decision trees. After the model is trained, it is tested using the testing set. After making predictions on the testing set, the model's accuracy is determined by comparing its predicted precipitation phases with the actual precipitation phases. The evaluation metric for model performance, referred to as 'accuracy', is detailed in Section “Evaluation metric”.
In summary, the RF model can be used to classify precipitation types by training the model on a dataset of meteorological variables and precipitation phases, constructing decision trees based on the variables, and making predictions based on the majority vote of the decision trees.
In this study, the optimal values of mtry (number of variables randomly sampled at each split) and ntree (number of trees) for each selected meteorological station were determined using the grid search method. These parameters are hyperparameters in the RF model, which are used to control the behavior of the algorithm. Specifically, the value of mtry ranged from 1 to 10 with a step of 1, and the value of ntree ranged from 1 to 4000 with a step of 100. The default settings were used for other model parameters. In this study we chose RF due to its stability with reference to multicollinearity53.
Optimized threshold temperature approach
The daily mean threshold temperature approach is a method of classifying precipitation as either rainfall or snowfall based on the air temperature at which the precipitation falls. If the daily mean air temperature exceeds the local threshold temperature, then the amount of daily precipitation is categorized as liquid, and conversely, if the daily average air temperature is below or equal the threshold, the precipitation is classified as solid. This approach, which is also known as the scoring method, is commonly used in meteorology and weather forecasting to predict the precipitation type56,57.
In this study, we developed an R programming code to search for the optimal mean threshold temperature (optTa) for each of the 40 meteorological stations across Poland. This programming code automatically identifies the optTa for each station by analyzing the historical data on precipitation phase. The optTa was determined using the scoring method58 that identifies the lowest error of misclassified precipitation types. Specifically, the code searches for the best value of Ta (mean air temperature threshold) within the range of − 2.0 to 2.0 °C, with an increment of 0.1 °C. The optTa was selected based on the highest accuracy of the classification. We used an identical method to determine the optimal mean wet-bulb threshold temperature (optTw), however the range − 3.0 to 2.0 °C was established for Tw (mean wet-bulb temperature) because wet-bulb temperature is by definition lower or equal to air temperature. Wet-bulb temperature is closer to the surface air temperature of a falling hydrometeor than Ta59, therefore is considered to be a better parameter for discriminating precipitation phases41,42,56.
In this study, the aforementioned method has been formulated to compute optTa and optTw for individual weather stations. This approach is more advantageous compared to amalgamating stations into larger regions or entire countries, as previously seen in various reports.
Evaluation metric
In this study, we used the below metric to evaluate the accuracy of the classification model:
where TP—True Positive, the model correctly predicted that the instance belongs to the positive class (rainfall or snowfall), TN—True Negative, the model correctly predicted that the instance belongs to the negative class, FP—False Positive, the model incorrectly predicted that the instance belongs to the positive class, FN—False Negative, the model incorrectly predicted that the instance belongs to the negative class.
Results and discussion
Optimizing threshold temperatures using Ta and Tw
To determine the optimal threshold mean temperature (optTa), a search was conducted within the range of − 2.0 to 2.0 °C for each meteorological station. The search process for optTa values at Kołobrzeg station (WMO 12100) is pictured in Fig. 2. During the search, mean air temperature values between − 2.0 and 2.0 °C were examined sequentially, with an increment of 0.1 °C and, the accuracy of snowfall and rainfall classification (as defined in Section “Evaluation metric”) was calculated at every term and compared. The optTa value was selected as the Ta that yielded the highest accuracy for snowfall and rainfall classification. This procedure was repeated separately for each of the 40 synoptic stations, thus 40 corresponding optTa values were identified and are presented in Table 1.

An illustration of the process for searching threshold temperatures using Ta (the left figure) and Tw (the right figure) is demonstrated by selecting the Kołobrzeg meteorological station. All 40 meteorological stations were processed similarly to find the optTa and optTw.
Excluding the Śnieżka station, the optTa values ranged between 0.5 and 1.9 °C, and it reached (a minimum of) − 0.1 °C at the Śnieżka station, and (a maximum of) 1.9 °C, at both the Kasprowy Wierch and Aleksandrowice stations. According to Jennings et al. (2018), 95% of stations in the Northern Hemisphere had a threshold temperature ranging from − 0.4 to 2.4 °C. Regional or continental scale studies indicated the threshold temperature between − 1.0 and 2.5 °C39,40,60 thus the assessed optTa values for Poland fall into the hemisphere ranges. The optTw values varied between − 0.1 °C at the Słubice station and 0.8 °C at Kołobrzeg and Hel stations. The Tw thresholds were lower than Ta, as the wet-bulb temperature, by definition, is lower than the air temperature. Moreover, optTw range was narrower than optTa, indicating better performance than Ta, which was also found in41,42,56. The only exception is Śnieżka mountain station considered the station with most harsh climate conditions where both threshold temperatures are very low and optTa < optTw, although for single days wet-bulb was checked to be lower than air temperature. Noting that at this station, the classification accuracy at optTw = − 0.1 °C is 0.9551, which is only slightly different from the accuracy of 0.9562 at optTw = 0.1 °C.
Due to their close dependence on local atmospheric and geographical conditions, the optTa and optTw thresholds for distinguishing precipitation types demonstrated spatiotemporal variations61. Hynčica and Huth (2019) reported a significant variation in Ta values across northern Europe and even within a small area like the Czech Republic. The use of spatially uniform Ta values in land surface models may produce imprecise estimations of precipitation phases61, particularly in areas with variable topography. The temperature threshold for distinguishing between snowfall and rainfall over high-elevation regions has been observed to increase. In Poland, the optTa value for Kasprowy Wierch station located at 1991 m, is 1.9, while for Zakopane (857 m), Aleksandrowice (398 m), Kłodzko (356 m), and Jelenia Góra (342 m) are 1.9 °C, 1.5 °C, 1.2 °C, and 1.2 °C, respectively which indicated a 0.7 °C range of variability. This tendency can be explained by the lower air pressure at the higher elevations and thinner air, resulting in less resistance on the snow crystals. As a result, the crystals reach the ground faster, and absorb less heat from the ambient atmospheric environment, thereby allowing them to maintain their original state as snow at higher air temperatures at higher elevations41. However, there may be exceptions to this pattern, as precipitation type is also influenced by various other factors. The accurate optTa and optTw values for Polish synoptic stations are tabulated in Table 1 and can be used to discriminate between the liquid and solid phases. The range of variability in optimal air temperatures reached 1.9 °C for optTa and 0.8 °C for optTw. Such a wide range of variability indicates that a single threshold temperature used to discriminate snowfall from rainfall over the entire country can generate inaccurate classification.
Selection of meteorological variables best for discrimination of precipitation phases
Ten meteorological variables were selected to check their importance for discriminating precipitation phases with the Multiple Input Random Forest (MIRF) classification model.
Initially, all ten variables were used as input in the MIRF1 model (Table 2). Subsequently, to obtain a simpler and more effective model, the inputs were reduced if the classification performance did not deteriorate. The procedure was repeated as long as all variables that had no impact on modeling quality were eliminated. For example, at the first check wind speed was removed as an input variable to construct the MIRF2 model. The performance of MIRF2 was compared with that of MIRF1, and no significant difference was observed between the two models. Therefore, wind speed was considered not important in this classification model and was removed. A similar process was conducted to remove station level pressure in MIRF3 and precipitation amount in MIRF4. Figure 3a presents the classification performance after removing wind speed, station level pressure, and precipitation amount and shows no significant difference among the four models (MIRF1, MIRF2, MIRF3, and MIRF4).

Comparing the accuracy of various MIRF models in identifying the most effective meteorological factor for distinguishing between snowfall and rainfall. (a) Comparison performance of models MIRF1, MIRF2, MIRF3, and MIRF4; (b) Comparison performance of models MIRF1, MIRF8, and MIRF9; (c) Comparison performance of models MIRF1, MIRF5, MIRF6, and MIRF7; (d) Comparison performance of models MIRF1, MIRF10, and MIRF11.
Similarly, MIRF5 was built by excluding the maximum air temperature, but the model's performance decreased, particularly at the Mława (WMO#12270) and Kalisz (WMO#12435) stations (Fig. 3c). As a result, the maximum air temperature was retained, indicating that it is an important factor when discriminating snowfall from rainfall at the aforementioned stations. Next, in MIRF6 and MIRF7, the minimum air temperature and mean air temperature were removed, respectively, but the model's performance deteriorated. Therefore, it was decided to keep these variables.
Although several studies41,61 emphasized the importance of Tw in rainfall/snowfall classification, surprisingly, the MIRF8 performance was found to be better when the wet-bulb temperature (Tw) was removed (Fig. 3b). However, our results did not eliminate Tw as an efficient predictor of snowfall as indicated in Section “Optimizing threshold temperatures using Ta and Tw”. The negative effect of Tw on model performance can be explained by the fact that Tw was calculated based on air temperature, relative humidity, air pressure, and saturated vapor pressure, all of which were included in the set of input variables thus leading to the problem of multicollinearity which complicated the MIRF. In the further steps, dew point temperature in MIRF9 was eliminated.
Removing either water vapor pressure (in MIRF10) or relative humidity (in MIRF11) reduced the classification accuracy (Fig. 3d), and thus the two variables played an essential role in the model. Finally, five variables were retained as input variables for the classification model, including water vapor pressure, relative humidity, mean air temperature, maximum air temperature, and minimum air temperature. These results contribute to previous studies that found average air temperature and relative humidity or dew point temperature40,60,62,63 as crucial variables for the discrimination of snowfall from rainfall. Many studies suggest a better performance of wet-bulb temperature than other temperature-based methods41,42,61, however, it does not apply to the MIRF method.
The model that utilizes those 5 variables was referred to as MIRF and its performance was compared with the optTa and optTw methods (in Sub-section “The mean threshold temperature methods versus Single Input Random Forest Model (SIRF)”).
Comparison of threshold temperature methods and the Random Forest (RF)
The mean threshold temperature methods versus Single Input Random Forest Model (SIRF)
The performance of the mean threshold temperature method and the Single Input Random Forest (SIRF) method, which utilized only the mean air temperature as an input for the RF model were compared to assess the capability of the two methods when using the same input parameter. Figure 4a illustrates that the performance of the SIRF model was slightly worse than the mean threshold temperature method in both training and testing. This suggests that the benefits of machine learning methods such as RF are only effective and can be leveraged to their full potential when used for modelling complicated and non-obvious relationships between a set of variables. This is evidenced in Fig. 4b which shows that MIRF outperformed the threshold temperature methods, both temperature threshold method-based average temperature-TTM(Ta) and temperature threshold method-based wet bulb temperature-TTM(Tw).

Threshold temperature methods versus Single Input Random Forest Model (SIRF), and Multi Input Random Forest (MIRF); (a) Classification accuracy of TTM(Ta) and SIRF(Ta) in the train and test datasets; (b) Classification accuracy of TTM(Ta), TTM(Tw), and MIRF in the test dataset.
The process of precipitation formation is influenced by many meteorological factors, so it is reasonable that MIRF, which involves more variables, achieved better results in rainfall/snowfall classification. The issue is that MIRF needs to be properly constructed to find reasonable hyper-parameters and to avoid overfitting when used for prediction. At this point, the ability to handle the complicated relationship between rainfall/snowfall and predictors of the RF model can be fully harnessed. In the case of few meteorological variables available, the threshold temperature method is a better choice.
Additionally, it is evident that the threshold temperature method based on Ta (TTM(Ta)) demonstrated slightly superior performance compared to the temperature threshold method based on Tw (TTM(Tw)). Specifically, TTM(Ta) outperformed TTM(Tw) in 29 (72.5%) out of 40 meteorological stations. Overall, the classification accuracy of these two methods did not differ significantly.
Assessing the accuracy of the monthly-scale rainfall/snowfall classification model
The accuracy of the analyzed methods for discriminating snowfall and rainfall exhibited seasonal variations (Fig. 5). Multiple Input Random Forest (MIRF) outperforms the Threshold Temperature Method (TTM(Ta)) in terms of classification accuracy in December, January, February, and March. In November, TTM(Ta) and MIRF exhibited comparable classification performance, with TTM(Ta) even surpassing RF in April. The RF outperformed TTM(Ta) between December and March, i.e. in the months with low air temperature when the occurrence of snowfall strongly depends also on the set of other variables that, as recognized in Section “Selection of meteorological variables best for discrimination of precipitation phases”, include water vapor pressure, relative humidity, maximum air temperature, and minimum air temperature. In November, and April air temperature is relatively high in Poland thus probably having an enhanced influence on solid precipitation occurrence. Another possibility is that the atmosphere is more unstable in the shoulder seasons leading to more cumuliform (unstable) rather than stratiform (stable) conditions during precipitation events (this would change lapse rates which could affect the energy transfer for melting and refreezing while hydrometers fall from the cloud to ground at a given surface air temperature). In fact, these relationships are still not fully understood. Moreover, in April the number of snowfall events was much lower than the number of rainfall events. In this month, TTM(Ta) could be more efficient than MIRF because machine learning algorithms such as Random Forest require a large number of samples to be trained effectively and learn from past data. The above findings provide insights into selecting the appropriate model for each month with snowfall.

The spatial distribution of the accuracy of the TTM(Ta) (first row) and MIRF method (second row) for rainfall /snowfall classification, (software: SURFER 25.2.259).
Overall, RF demonstrated consistent classification performance across all months, with an average classification accuracy ranging only from 0.97 to 0.97. In contrast, the classification performance of TTM(Ta) exhibited wider variation, ranging from 0.92 to 0.98. On average, the classification performance of TTM(Ta) increases in the following order: December, January, February, March, November, and reaches its highest level in April (Fig. 6). It should be noted that the above results were extracted from only one model for all the data, rather than building a separate model for each month of the year. Constructing separate models for each month of the year may yield higher results but could be challenging for months with a low number of snowfalls, such as April and November. In this context, choosing MIRF remains a good option. The main text of the research paper only presents information about accuracy. Precision, recall, and F1_score can be found in the Supplementary.

Displays boxplots that depict the accuracy of rainfall/snowfall classification at 40 stations across Poland, presented by month. The boxplot on the left shows the results of the TTM(Ta), whereas the boxplot on the right shows the results of MIRF. The orange plus sign indicates the mean value.
Conclusion and outlook
Although precipitation phase is important for studying climate change, climate modelling and weather forecasting, discrimination between snowfall and rainfall is still a problem due to lack of observation, length of chronological series and reducing visual observations. The RF model developed in this study to classify the precipitation phases is based on daily values of selected meteorological variables measured at the station level and validated based on high-quality data from visual observations performed at 40 synoptic stations in Poland in the period 1966–2020. Additionally, we employed two other commonly used methods: the threshold mean temperature method and the threshold wet-bulb temperature method. Each of these methods relies solely on a single meteorological variable.
The results of the MIRF model are very promising and performed the best among the three methods. The accuracy of RF snowfall classification ranged from 91 to 100%. The mean threshold temperature and wet–bulb threshold temperatures showed similar classification performance.
Several experiments were also conducted to select the best predictors for the RF classification. The model revealed water vapor pressure as a crucial meteorological parameter for discriminating precipitation phase because it combines information on air temperature. Subsequently, the following variables also contributed to increasing the accuracy of the classification model: relative humidity, mean air temperature, minimum air temperature, and maximum air temperature. Surprisingly, wet–bulb temperature did not contribute to improving the performance of the MIRF classification model due to multicollinearity related to the method of Tw calculation. Furthermore, the MIRF model could be simplified without impacting accuracy by eliminating wind speed, station level pressure, precipitation amount, and dew point temperature. The findings are useful for future studies in selecting an appropriate model and predictors for classifying rainfall and snowfall.
A classification model based on RF has been developed and can be utilized to identify precipitation phases in meteorological stations located in Poland where information on precipitation phase is not available or visual observations are exchanged with automatic measurements. This model can be further extended to other European countries to detect precipitation phases.
Under climate change conditions, the processes triggering the formation of precipitation phases become more complex. Therefore, continuous observation and improvement of the classification models for precipitation types are necessary to enhance the effectiveness of the models in prediction.
In this study, the mixed precipitation phase exhibited poor classification performance in preliminary results. Therefore, it was excluded from our analysis, as no added value could be contributed to its classification. To improve the performance of the classification model and address the imbalance phenomena observed at some stations, techniques such as oversampling or undersampling can be employed in future research. However, due to the scope of this study, we did not implement these techniques. The poor predictive performance of sleet is attributed to its infrequent occurrence44 and the complexity of its formation process. The classification of mixed solid–liquid precipitation is known to be challenging and results in low forecast performance, as reported in several studies34,53,64.
Data availability
The data that support the findings of this study are available from the corresponding author, upon reasonable request.
References
Mackay, J. R. Some mechanical aspects of pingo growth and failure, Western Arctic Coast, Canada. Can. J. Earth Sci. 24, 1108–1119. https://doi.org/10.1139/e87-108 (1987).
Stieglitz, M. et al. The role of snow cover in the warming of Arctic permafrost. Geophys. Res. Lett. 30, 1721. https://doi.org/10.1029/2003GL017337 (2003).
Grab, S. Aspects of the geomorphology, genesis and environmental significance of Earth hummocks (thu´fur, pounus): Miniature cryogenic mounds. Prog. Phys. Geogr. 29, 139–155. https://doi.org/10.1191/0309133305pp440ra (2005).
Fathi, M., Haghi Kashani, M., Jameii, S. M. & Mahdipour, E. Big data analytics in weather forecasting: A systematic review. Arch. Comput. Methods Eng. 29(2), 1247–1275 (2022).
Hanlon, H. M., Bernie, D., Carigi, G. & Lowe, J. A. Future changes to high impact weather in the UK. Clim. Change 166(3–4), 50 (2021).
Ye, H. Changes in frequency of precipitation types associated with surface air temperature over northern Eurasia during 1936–90. J. Clim. 21, 5807–5819. https://doi.org/10.1175/2008JCLI2181.1 (2008).
Lone, S. A., Jeelani, G., Alam, A., Bhat, M. S. & Farooq, H. Effect of changing climate on the water resources of Upper Jhelum Basin (UJB), India. In Riverine Systems: Understanding the Hydrological, Hydrosocial and Hydro-heritage Dynamics (ed. Mukherjee, A.) 133–148 (Springer International Publishing, 2022).
Qiu, J., Shen, Z., Leng, G. & Wei, G. Synergistic effect of drought and rainfall events of different patterns on watershed systems. Sci. Rep. 11(1), 18957 (2021).
Loth, B., Graf, H. & Oberhuber, J. M. Snow cover model for global climate simulations. J. Geophys. Res. 98, 10451–10464. https://doi.org/10.1029/93JD00324 (1993).
Zhu, X. et al. Characteristics of the ratios of snow, rain and sleet to precipitation on the Qinghai-Tibet Plateau during 1961–2014. Quat. Int. 444, 137–150 (2017).
Huang, S. et al. Experimental study on the hydrological performance of green roofs in the application of novel biochar. Hydrol. Process. 34(23), 4512–4525 (2020).
Sehler, R., Li, J., Reager, J. T. & Ye, H. Investigating relationship between soil moisture and precipitation globally using remote sensing observations. J. Contemp. Water Res. Educ. 168(1), 106–118 (2019).
Fersch, B. et al. High-resolution fully coupled atmospheric–hydrological modeling: A cross-compartment regional water and energy cycle evaluation. Hydrol. Earth Syst. Sci. 24(5), 2457–2481 (2020).
Lafrenière, M. J. & Lamoureux, S. F. Effects of changing permafrost conditions on hydrological processes and fluvial fluxes. Earth-Sci. Rev. 191, 212–223 (2019).
Leach, J. A., Kelleher, C., Kurylyk, B. L., Moore, R. D. & Neilson, B. T. A primer on stream temperature processes. Wiley Interdiscip. Rev.: Water 10, e1643 (2023).
Amorim, J. D. S., Viola, M. R., Junqueira, R., Oliveira, V. A. D. & Mello, C. R. D. Evaluation of satellite precipitation products for hydrological modeling in the brazilian cerrado biome. Water 12(9), 2571 (2020).
Hu, Y. et al. Impacts of precipitation type variations on runoff changes in the source regions of the Yangtze and Yellow River Basins in the past 40 years. Water 14(24), 4115 (2022).
Aqnouy, M. et al. Comparison of hydrological platforms in assessing rainfall-runoff behavior in a mediterranean watershed of northern Morocco. Water 15(3), 447 (2023).
Blöschl, G. et al. Changing climate shifts timing of European floods. Science 357(6351), 588–590 (2017).
Xu, L., Chen, N., Yang, C., Yu, H. & Chen, Z. Quantifying the uncertainty of precipitation forecasting using probabilistic deep learning. Hydrol. Earth Syst. Sci. 26(11), 2923–2938 (2022).
Diodato, N. & Bellocchi, G. Climate control on snowfall days in peninsular Italy. Theor. Appl. Climatol. 140, 951–961. https://doi.org/10.1007/s00704-020-03136-0 (2020).
Barnett, T. P., Dumenil, L., Schlese, U., Roeckner, E. & Latif, M. The effect of Eurasian snow cover on regional and global climate variations. J. Atmos. Sci. 46, 661–685 (1989).
Cohen, J. & Entekhabi, D. The influence of snow cover on Northern Hemisphere climate variability. Atmos.-Ocean 39, 35–53. https://doi.org/10.1080/07055900.2001.9649665 (2001).
Gong, G., Entekhabi, D. & Cohen, J. A large-ensemble model study of the wintertime AO/NAO and the role of interannual snow perturbations. J. Clim. 15, 3488–3499. https://doi.org/10.1175/1520-0442(2002)015%3c3488:ALEMSO%3e2.0.CO (2002).
Feng, S. & Hu, Q. Changes in winter snowfall/precipitation ratio in the contiguous United States. J. Geoph. Res. 112, D15109. https://doi.org/10.1029/2007JD008397 (2007).
Scott, D., Dawson, J. & Jones, B. Climate change vulnerability of the US Northeast winter recreation–tourism sector. Mitig. Adapt. Strategies Glob. Change 13, 577–596 (2008).
Jenicek, M. & Ledvinka, O. Importance of snowmelt contribution to seasonal runoff and summer low flows in Czechia. Hydrol. Earth Syst. Sci. 24(7), 3475–3491 (2020).
Wild, R., O’Hare, G. & Wilby, R. A historical record of blizzards/major snow events in the British Isles, 1880–1989. Weather 51, 81–90 (1996).
Garcia, S. C. & Salvador F. F. Snowfall analysis in the Eastern Pyrenees. In Offenbach am Main: Proceedings 23rd Internacional Conference on Alpine Meteorology 303–307 (Selbstverlag Deutscher Wetterdienst, 1994).
Andersson, T. & Gustafsson, N. Coast of departure and coast of arrival: Two important concepts for the formation and structure of convective snow bands over sea and lakes. Mon. Weather Rev. 122, 1036–1049 (1994).
Spreitzhofer, G. Spatial, temporal and intensity characteristics of heavy snowfall events over Austria. Theor. Appl. Climatol. 62, 209–219 (1999).
Strasser, U. Snow loads in a changing climate: New risks?. Nat. Hazards Earth Syst. Sci. 8, 1–8 (2008).
Bhaga, T. D., Dube, T., Shekede, M. D. & Shoko, C. Impacts of climate variability and drought on surface water resources in Sub-Saharan Africa using remote sensing: A review. Remote Sens. 12(24), 4184 (2020).
Lang, Z., Wen, Q. H., Yu, B., Sang, L. & Wang, Y. Forecast of winter precipitation type based on machine learning method. Entropy 25(1), 138 (2023).
Shin, K., Kim, K., Song, J. J. & Lee, G. Classification of precipitation types based on machine learning using dual-polarization radar measurements and thermodynamic fields. Remote Sens. 14, 3820. https://doi.org/10.3390/rs14153820 (2022).
Bourgouin, P. A method to determine precipitation types. Weather Forecast. 15, 583–592 (2000).
Naseer, A., Koike, T., Rasmy, M., Ushiyama, T. & Shrestha, M. Distributed hydrological modeling framework for quantitative and spatial bias correction for rainfall, snowfall, and mixed-phase precipitation using vertical profile of temperature. J. Geophys. Res.: Atmos. 124, 4985–5009. https://doi.org/10.1029/2018JD029811 (2019).
Xu, L., Chen, N., Moradkhani, H., Zhang, X. & Hu, C. Improving global monthly and daily precipitation estimation by fusing gauge observations, remote sensing, and reanalysis data sets. Water Resour. Res. 56(3), e2019WR026444 (2020).
Kienzle, S. W. A new temperature based method to separate rain and snow. Hydrol. Process. 22, 5067–5085. https://doi.org/10.1002/hyp.7131 (2008).
Ye, H., Cohen, J. & Rawlins, M. Discrimination of solid from liquid precipitation over northern Eurasia using surface atmospheric conditions. J. Hydrometeor. 14, 1345–1355. https://doi.org/10.1175/JHM-D-12-0164.1 (2013).
Ding, B. et al. The dependence of precipitation types on surface elevation and meteorological conditions and its parameterization. J. Hydrol. 513, 154–163 (2014).
Sims, E. M. & Liu, G. A parameterization of the probability of snow-rain transition. J. Hydrometeorol. 16, 1466–1477. https://doi.org/10.1175/JHM-D-14-0211.1 (2015).
Liu, S. et al. Precipitation phase separation schemes in the Naqu river basin, eastern Tibetan plateau. Theor. Appl. Climatol. 131(1), 399–441 (2018).
Moon, S. H. & Kim, Y. H. An improved forecast of precipitation type using correlation-based feature selection and multinomial logistic regression. Atmos. Res. 240, 104928 (2020).
Łupikasza, B. E. & Małarzewski, Ł. Trends in the indices of precipitation phases under current warming in Poland, 1966–2020. Adv. Clim. Change Res. 14, 97–115 (2023).
Awaka, J. et al. Rain type classification algorithm module for GPM dual-frequency precipitation radar. J. Atmos. Ocean. Technol. 33(9), 1887–1898 (2016).
Ghada, W., Estrella, N. & Menzel, A. Machine learning approach to classify rain type based on Thies disdrometers and cloud observations. Atmosphere 10(5), 251 (2019).
Rahman, A. U. et al. Rainfall prediction system using machine learning fusion for smart cities. Sensors 22(9), 3504 (2022).
Dueben, P. D. et al. Challenges and benchmark datasets for machine learning in the atmospheric sciences: Definition, status, and outlook. Artif. Intell. Earth Syst. 1(3), e210002 (2022).
Jergensen, G. E., McGovern, A., Lagerquist, R. & Smith, T. Classifying convective storms using machine learning. Weather Forecast. 35(2), 537–559 (2020).
McGovern, A. et al. Using artificial intelligence to improve real-time decision-making for high-impact weather. Bull. Am. Meteorol. Soc. 98(10), 2073–2090 (2017).
Mostajabi, A., Finney, D. L., Rubinstein, M. & Rachidi, F. Nowcasting lightning occurrence from commonly available meteorological parameters using machine learning techniques. Npj Clim. Atmos. Sci. 2(1), 41 (2019).
Półrolniczak, M., Kolendowicz, L., Czernecki, B., Taszarek, M. & Tóth, G. Determination of surface precipitation type based on the data fusion approach. Adv. Atmos. Sci. 38, 387–399 (2021).
Shin, K., Song, J. J., Bang, W. & Lee, G. Quantitative precipitation estimates using machine learning approaches with operational dual-polarization radar data. Remote Sens. 13(4), 694 (2021).
Seo, B. C. A data-driven approach for winter precipitation classification using weather radar and nwp data. Atmosphere 11(7), 701 (2020).
Zhong, K., Zheng, F., Xu, X. & Qin, C. Discriminating the precipitation phase based on different temperature thresholds in the Songhua river basin, China. Atmos. Res. 205, 48–59 (2018).
Feiccabrino, J. M. Precipitation phase uncertainty in cold region conceptual models resulting from meteorological forcing time-step intervals. Hydrol. Res. 51(2), 180–187 (2020).
Grigg, L. D., Feiccabrino, J. & Sherenco, F. Testing the applicability of physiographic classification methods toward improving precipitation phase determination in conceptual models. Hydrol. Res. 51(2), 169–179 (2020).
Wang, Y.-H. et al. A wet-bulb temperature-based rain-snow partitioning scheme improves snowpack prediction over the drier western United States. Geophys. Res. Lett. 46, 13825–13835. https://doi.org/10.1029/2019GL085722 (2019).
Matsuo, T., Sasyo, Y. & Sato, Y. Relationship between types of precipitation on the ground and surface meteorological elements. J. Meteor. Soc. Japan 59(4), 462–476 (1981).
Su, B. et al. Estimated changes in different forms of precipitation (snow, sleet, and rain) across China: 1961–2016. Atmos. Res. 270, 106078 (2022).
Marks, D. G. & Winstral, A. H. Finding the rain/snow transition elevation during storm events in mountain basins. In Abstract in Joint Symposium JHW001: Interactions between snow, vegetation, and the atmosphere, the 24th General Assembly of the IUGG, Perugia, Italy, July 2–13 (2007).
Liu, J. & Chen, R. Discriminating types of precipitation in Qilian Mountains, Tibetan Plateau. J. Hydrol.: Reg. Stud. 5, 20–32 (2014).
Deng, H., Pepin, N. C. & Chen, Y. Changes of snowfall under warming in the Tibetan Plateau. J. Geophys. Res.: Atmos. 122(14), 7323–7341 (2017).
Acknowledgements
This research was supported by the National Science Centre, Poland, within the framework of research project no. 2017/27/B/ST10/00923, ‘Snowfall and rain response to current climate change and atmospheric circulation in Europe’. We would like to kindly thank the anonymous reviewers for their valuable comments, which enhanced the scientific quality of this paper as well as the Institute of Meteorology and Water Management—National Research Institute for making synoptic data available.
Author information
Authors and Affiliations
Contributions
Q.B.P. and E.Ł. did the formal analysis, and wrote the main manuscript text; M.Ł. prepared the data, and revised the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pham, Q.B., Łupikasza, E. & Łukasz, M. Classification of precipitation types in Poland using machine learning and threshold temperature methods. Sci Rep 13, 20750 (2023). https://doi.org/10.1038/s41598-023-48108-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-48108-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
