
Abstract
Patient safety reporting systems give healthcare provider staff the ability to report medication related safety events and errors; however, many of these reports go unanalyzed and safety hazards go undetected. The objective of this study is to examine whether natural language processing can be used to better categorize medication related patient safety event reports. 3,861 medication related patient safety event reports that were previously annotated using a consolidated medication error taxonomy were used to develop three models using the following algorithms: (1) logistic regression, (2) elastic net, and (3) XGBoost. After development, models were tested, and model performance was analyzed. We found the XGBoost model performed best across all medication error categories. ‘Wrong Drug’, ‘Wrong Dosage Form or Technique or Route’, and ‘Improper Dose/Dose Omission’ categories performed best across the three models. In addition, we identified five words most closely associated with each medication error category and which medication error categories were most likely to co-occur. Machine learning techniques offer a semi-automated method for identifying specific medication error types from the free text of patient safety event reports. These algorithms have the potential to improve the categorization of medication related patient safety event reports which may lead to better identification of important medication safety patterns and trends.
Similar content being viewed by others

Introduction
Patient safety reporting systems provide a mechanism for healthcare provider staff, including frontline clinicians, nurses, and technicians to report patient safety errors and concerns1. While there are several categorization schemes for defining the types of errors that are reported, patient safety errors range from events where no harm occurs to the patient (e.g., “near misses” or “close calls”) to events in which patients are harmed (e.g., adverse events)2. Reporting systems vary by site; however, reports are typically composed of “structured data” and a free text description of the actual safety issue.
The promise of reporting systems is that they have the potential to dramatically improve the safety and quality of care by exposing possible vulnerabilities in the care process by documenting information on near miss and adverse events. Many provider organizations have promoted use of these systems, and while there are still barriers to reporting, many clinicians enter reports and provider organizations are amassing large databases1,3,4,5,6,7. Effectively analyzing these events has the potential for new insight as to where safety hazards reside8. There is also the opportunity to combine data across different provider organizations to identify patterns that may not be visible by looking at data from a single organization. Patient safety organizations (PSOs), which are legally secure environments for analyzing safety data, provide an opportunity to identify these broader trends.
While most organizations manually review their most significant cases that involve patient harm and conduct a root cause analysis or other review technique, this makes up a very small percent of the total number of reports9. For many organizations the number of reports has grown to tens of thousands and even hundreds of thousands, and for PSOs, the number of reports can be in the millions. The majority of safety reports are unanalyzed and recognized safety hazards that have not yet reached the level of patient harm go undetected by patient safety and risk analysts because they are buried in the large number of patient safety event (PSE) reports. This is a major shortcoming given that clinicians are taking the time to report, and the data are available.
There is an opportunity to apply machine learning techniques to improve the analysis of PSE reports so that these data can be used more effectively to identify patient safety patterns and trends so that interventions can be developed to address these trends. The objective of this study is to examine whether natural language processing (NLP) can be used to better categorize PSE reports, with a focus on medication related reports and categorization of these reports by medication error type.
Background
Medication safety event reports
When looking at the composition of PSE report databases, medication safety events are often the most frequently reported patient safety report type and are often associated with the greatest harm to patients10. Consequently, improving the analysis of these reports through a semi-automated approach will likely have significant impact given the volume of reports that may need to be reviewed and acted upon. A first step in analyzing medication related PSE reports is to determine the type of medication error described in the report. Semi-automatically categorizing medication related reports into the appropriate medication error type is a natural place to apply computational techniques given the importance of understanding the type of medication error and that well-defined medication error categories already exist.
Natural language processing (NLP) as an automatic method to categorize reports
At a high level, NLP is a probability based method to detect patterns in text and to categorize based on these patterns11. NLP has been used extensively in healthcare to analyze clinical documents to identify specific healthcare conditions, identifying drugs, mining the electronic health records, as well as several other applications12,13,14,15,16. To realize the tremendous value of NLP to the analysis of PSE reports it is important to understand the nature of a PSE report. Each report generally contains structured information such as the time and site of occurrence (e.g., emergency department, blood bank), role of the participants (e.g., physician, nurse, technician), patient demographics (e.g., age, gender), as well as a classification of the severity and type of event (e.g., death, harm, near-miss). The type of event is a general category label such as “fall”, “medication”, “lab”, etc. These event categories can vary by institution and can even vary within institution depending on whether the same reporting system is being used. In addition to the structured data elements, the reports also include an unstructured free-text field in which the reporter can provide a narrative describing the safety event in greater detail. Here, reporters can contextualize safety events and near misses by documenting contributing factors, the circumstances surrounding the event, and other information not captured in the structured fields. These free-text fields provide incredible value to organizations looking to minimize system-based risks. Given that the PSE reports generally have rich free text responses, various NLP techniques to extract health and medical concepts, relationships, negations, tense, and causation lend themselves for expediting the analysis of large numbers of reports by removing the need for analysts to read all reports17,18. Previous work has demonstrated how NLP techniques can be implemented into workflows to improve patient safety19. With the growing focus on medication safety20, it is important to understand how similar techniques can be used to understand and prevent medication errors.
Medication error type categories
A commonly used taxonomy to describe medication errors is the National Coordinating Council for Medication Error Reporting and Prevention (NCC MERP) taxonomy21. The taxonomy is composed of several different categories and the specific type of medication error (e.g., wrong drug, wrong rate, etc.) is one of the most commonly used parts of the taxonomy. Nearly all medication related PSE reports are categorized into these medication error types somewhere in the reporting and analysis process. This categorization may be performed by the reporter when entering the port and/or by the analyst when reviewing reports and attempting to make sense of the reports. We sought to semi-automatically categorize PSE reports into the appropriate medication error type to improve the analysis process.
Methods
Data source
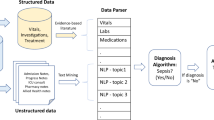
This paper uses 3,861 PSE reports from a ten-hospital healthcare system in the mid-Atlantic region of the United States. Hospitals from this system range from large, academic hospitals found in urban centers to smaller community hospitals in rural settings. The patient population is diverse in terms of race/ethnicity, gender, age, and health condition resulting in a generalizable data set. Structured fields in the reporting system include department, general event type, specific event type, and severity level. These reports were previously annotated by subject matter experts (a pharmacist and patient safety analysts) using a consolidated MERP framework22. We use these annotations for our model training and testing, Fig. 1.

Flow diagram for how models were developed and tested to classify PSE reports in MERP categories.
MERP categories
For this study, the original 14 subcategories of “Error Type” found in the standard taxonomy of medication errors from the NCC MERP were modified into eight categories. During manual review of the reports, we determined limitations in the free text of some reports made it impossible to distinguish some of the similar and related categories without making too many assumptions (e.g., wrong strength and wrong concentration). This led to our use of a consolidated MERP framework and highlights the challenges with overlapping concepts in MERP categories, especially for complex free text narratives. Each report could fall into zero, one, or multiple MERP categories including: (1) wrong drug, (2) wrong time, (3) wrong strength or concentration, (4) wrong dosage form or technique or route, (5) improper dose/dose omission, (6) wrong rate, (7) wrong patient, and (8) monitoring error, defined in Table 1. Most reports were categorized into one or two MERP categories but could be categorized into as many as six, Table 2.
Experimental pipeline
Text preprocessing and feature selection
One researcher automated the preprocessing of the free text from the 3,861 PSE reports. The goal of this preprocessing step is to reduce noise and make the text ready to feed into our natural language processing models. Numbers and punctuations were removed, and all the free text was lower-cased using an automated computer program. We used unigrams (i.e., single words like “patient”, “medication”, or “prescription”), bigrams (i.e., consecutive word pairs like “patient allergy”, “medication dose”, or “prescription written”), and trigrams (i.e., consecutive word triplets like “patient allergy overlooked”, “medication dose incorrect”, or “prescription written late”) terms to ensure we were capturing strings of words that were particularly meaningful. We excluded terms that appeared in greater than 99 percent and less than one percent of reports. Words that appear in 99 percent of reports are often context specific stop words, such as ‘the’, ‘a’, and ‘patient’ and do not help model performance. Words that appear in less than one percent (often times proper names) typically will introduce more noise into the modeling process. This filtering process is a common step in text preprocessing to improve model performance23. Term frequency-inverse document frequency (TFIDF) was used to create a ngram (unigram, bigram, and trigram) feature vector for each report.
Model development and testing
For each MERP category, we evaluated three algorithms to predict whether a report did or did not fall into the category based on the report’s free text. The algorithms used for each MERP category were: (1) Logistic regression, (2) Elastic net, and (3) XGBoost. Logistic regression was chosen as an interpretable model for binary dependent variables. Elastic net was chosen as it expands upon logistic regression by combining the L1 and L2 penalties of lasso and ridge regression methods and minimizing the loss24. XGBoost was selected because it implements the gradient boosting decision tree algorithm which sequentially adds new models together to make predictions while minimizing loss25.
A One-vs-rest (OvR) approach was taken for each MERP category. OvR is a common heuristic method used when multiple classes (e.g., multiple MERP categories) are present in a classification problem. Using OvR, we can change our multi-class classification problem into multiple binary classification problems allowing the use of algorithms like logistic regression and more interpretable models.
The models were trained and validated on 70 percent of the original 3,861 reports using fivefold cross validation. While there is no hard rule for the percentage and number of CV folds, 80 percent for training and validation and using fivefold CV is a common practice when building machine learning models26,27,28. We choose a slightly lower percentage for training and validation because of the data imbalance and to avoid overfitting while reserving enough data to test. The hyperparameters of the elastic net model were tuned with cross-validation. Bayesian optimization was utilized to optimize the hyperparameters of the XGBoost. Each model was then tested on the held-out testing dataset (i.e., the remaining 30 percent of reports). Our metrics included a confusion matrix, precision, recall, specificity, F1 score, area under the curve—receiver operating characteristic curve (AUC-ROC), precision-recall and receiver operating characteristic curve (PR-ROC), and accuracy.
A confusion matrix describes the complete performance of the model by outputting (from left to right, top to bottom): true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). Precision measures the number of correct positive predictions by dividing the number of positive results predicted by the classifier calculated as: (TP)/(TP + FP). Recall (ie sensitivity) measures the number of actual positives that were correctly identified by calculating: (TP)/(FN + TP). Specificity measures the number of actual negatives that were correctly identified by calculating: (TN)/(TN + FP). F1 score is the harmonic mean between precision and recall calculated as: 2 * (1/((1/precision) + (1/recall)). AUC-ROC is a measurement that represents how well the model distinguishes between classes. PR-ROC is a measurement that represents the trade-off between the true positive rate (precision) and the positive predictive value (recall). Lastly, accuracy is the percentage of correct predictions.
Lastly, we used the gain metric to identify the five most important features in the best performing model for each MERP category. Gain implies the relative contribution of the corresponding feature to the model calculated by taking each feature’s contribution for each tree in the model. A higher value of this metric when compared to another feature implies it is more important for generating a prediction.
The study presented no risk to animal and/or animal subjects and was reviewed by the Institutional Review Board at MedStar Health Research Institute. All experimental protocols were approved by the Institutional Review Board at MedStar Health Research Institute. This research was performed in accordance with relevant guidelines and regulations.
Results
Model performance
Model performances for the three different algorithms are shown in Table 3. Performance scores were generally lowest when using logistic regression and highest when using XGBoost. When using logistic regression, the average F1 score across MERP categories was 0.54 (standard deviation of 0.26). For elastic net, the average F1 score across MERP categories was 0.59 (standard deviation of 0.23). The average F1 score across MERP categories was 0.72 (standard deviation of 0.15) when using XGBoost. Performance across MERP categories is also shown in Table 3. The ‘Wrong Drug’ category performed best across all three algorithms while the ‘Wrong Patient’ category generally had the lowest performance metrics.
Co-occurrence of MERP categories
754 out of 1,159 (65.1%) reports in our testing dataset were manually categorized into two or more MERP categories. In over 75 percent of reports categorized as ‘Wrong Drug’, the reports were also categorized as ‘Improper Dose/Dose Omission’ or ‘Wrong Time’. In addition, reports categorized as ‘Wrong Time’ co-occurred with ‘Improper Dose/Dose Omission’ or ‘Wrong Drug’ over two-thirds of the time, Table 4.
Most important features within MERP categories
We used the gain metric to evaluate the five most important features (i.e., words) from each XGBoost model, Table 5. XGBoost models had on average the highest F1 score for each MERP category. The features for ‘Wrong Drug’, ‘Wrong Time’, and ‘Improper Dose/Dose Omission’ were generally verb or action words such as entered and ordered. ‘Wrong Strength or Concentration’ and ‘Wrong Rate’ were often measurement or units. ‘Wrong Dosage Form or Technique or Route’ forms like tablet and extended release. ‘Wrong Patient’ was about workflow actions and nouns around patient while ‘Monitoring Errors’ were around allergies and other monitoring of symptoms.
Discussion
Algorithm application in medication safety workflows
This study categorizes patient safety event reports into medication error categories and compares model performance in this large dataset across three different algorithms (e.g., logistic regression, elastic net, and XGBoost). Like previous work29, we find that our method saves time by programmatically processing reports and making themes in medication errors easier to uncover compared to manually reading through each report to group into MERP categories. In addition, the structured categories available to reporters are limited, and reporters do not always select the most appropriate categories. Our method bypasses the unreliability of the structured categories and groups reports by their free text.
Building off previous work, our analysis of the co-occurrence of MERP categories highlights the higher level of complexity when assigning multiple MERP categories to a report. Future work should develop a belief network to fully understand the correlation between MERP categories. Using the gain metric to determine feature importance allows a better understanding of the unique aspects of each type of medication errors.
There are several opportunities to apply natural language processing and machine learning techniques to improve medication safety. First, these algorithms could be integrated into reporting systems to guide the person entering the report to select a structured category that best aligns with the appropriate MERP category. This would serve to reduce inappropriate classifications and the labor-intensive recoding of reports. Second, the algorithms could be applied across all PSE reports, even non-medication reports, to identify patterns and trends in PSE report data. This is especially important for patient safety organizations and other stakeholders that are analyzing large datasets of safety event reports. Finally, patient safety committees that are looking for different patterns and trends in PSE report data may want to apply these algorithms to identify whether specific actions should be taken based on the emerging patterns.
MERP categories could be integrated with other structured categories in the reporting system such as medication names mentioned, departments, event date, etc. With the MERP categories identified, patient safety analysts could quickly identify specific medication errors related to a medication, hospital, or site. MERP categories could also be tracked and monitored over time. Future work should formally implement similar models into quality and safety workflow or develop more complex models to determine the benefit of these and similar models.
Challenges and limitations
The voluntary nature of PSE reports often led to under reporting and should be used primarily to identify general themes but often cannot conclude causality. In addition, working with free text is difficult–especially the free text found in PSE reports. Often these reports include abbreviations, medical jargon, and misspellings that present challenges for analysis. These challenges can be seen in the MERP categories that performed poorly across the three algorithms. The two MERP categories that performed the worst also had the smallest sample sizes suggesting that training these models with limited datasets can also lead to poor performance in certain categories. Though difficult with datasets such as PSE reports, future work should strive to work with more balanced datasets with equal representation across all MERP categories to ensure consistent model performance.
Further in complicated cases, incident reporters and human annotators could categorize error types based on their clinical experience, reflection of occupational responsibilities, and expectation. However, such human or personal perceptions were not always expressed in sentences that our current model can use to categorize the error types. This presents an opportunity for more sophisticated machine learning techniques to be used in future analyses of medication errors in PSE reports. Future work should consider leveraging large language models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) and comparing performance to the three algorithms used in this study. Because of the previously noted abbreviations, medical jargon, and misspellings commonly found in these reports, a hybrid or human in the loop approach to developing machine learning-based models should also be considered to mitigate model shortcomings. Furthermore, integrating these models into an interactive visualization allows the clinical staff to gain insights as well as provide feedback and corrections to update the model results in near-real time.
Conclusion
NLP techniques may offer a semi-automated method for identifying specific medication error types from the free text of PSE reports. The analysis and categorization of patient safety event reports often require expert review and can be a time-consuming process. In this case report, we applied various NLP techniques to recategorize medication patient safety events into specific workflow related categories. These categories provide insights into system and workflow processes that might require additional attention.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available because they contain sensitive patient health information. However, deidentified data are available from the corresponding author on reasonable request.
References
Clarke, J. R. How a system for reporting medical errors can and cannot improve patient safety. Am. Surg. 72(11), 1088–1091 (2006).
Chang, A., Schyve, P. M., Croteau, R. J., O’Leary, D. S. & Loeb, J. M. The JCAHO patient safety event taxonomy: a standardized terminology and classification schema for near misses and adverse events. Int. J. Qual. Health Care 17(2), 95–105 (2005).
Kostopoulou, O. & Delaney, B. Confidential reporting of patient safety events in primary care: Results from a multilevel classification of cognitive and system factors. BMJ Qual. Saf. 16(2), 95–100 (2007).
Leape, L. L. Reporting of adverse events. N. Engl. J. Med. 347(20), 1633–1638. https://doi.org/10.1056/NEJMNEJMhpr011493 (2002).
Pronovost, P. J., Morlock, L. L., Sexton, J. B. et al. Improving the value of patient safety reporting systems. Advances in Patient Safety: New Directions and Alternative Approaches (Vol 1: Assessment). 2008;
Pronovost, P. J. et al. Toward learning from patient safety reporting systems. J. Crit. Care 21(4), 305–315 (2006).
Tighe, C. M., Woloshynowych, M., Brown, R., Wears, B. & Vincent, C. Incident reporting in one UK accident and emergency department. Accid. Emerg. Nurs. 14(1), 27–37 (2006).
Fong, A., Hettinger, A. Z. & Ratwani, R. M. Exploring methods for identifying related patient safety events using structured and unstructured data. J. Biomed. Inform. 58, 89–95 (2015).
Pham, J. C. et al. Establishing a global learning community for incident-reporting systems. BMJ Qual. Saf. 19(5), 446–451 (2010).
Tamuz, M., Thomas, E. & Franchois, K. Defining and classifying medical error: Lessons for patient safety reporting systems. BMJ Qual. Saf. 13(1), 13–20 (2004).
Bates, M. Models of natural language understanding. Proc. Natl. Acad. Sci. 92(22), 9977–9982 (1995).
Demner-Fushman, D., Chapman, W. W. & McDonald, C. J. What can natural language processing do for clinical decision support?. J. Biomed. Inform. 42(5), 760–772 (2009).
Kelahan, L. C., Fong, A., Ratwani, R. M. & Filice, R. W. Call case dashboard: Tracking R1 exposure to high-acuity cases using natural language processing. J. Am. College Radiol. 13(8), 988–991 (2016).
Melton, G. B. & Hripcsak, G. Automated detection of adverse events using natural language processing of discharge summaries. J. Am. Med. Inform. Assoc. 12(4), 448–457 (2005).
Sevenster, M., Bozeman, J., Cowhy, A. & Trost, W. A natural language processing pipeline for pairing measurements uniquely across free-text CT reports. J. Biomed. Inform. 53, 36–48 (2015).
Wang, X., Hripcsak, G., Markatou, M. & Friedman, C. Active computerized pharmacovigilance using natural language processing, statistics, and electronic health records: A feasibility study. J. Am. Med. Inform. Assoc. 16(3), 328–337 (2009).
Fong, A. et al. Integrating natural language processing expertise with patient safety event review committees to improve the analysis of medication events. Int. J. Med. Inform. 104, 120–125 (2017).
Cohan A, Fong A, Goharian N, Ratwani R. A neural attention model for categorizing patient safety events. Springer; 720–726 (2017).
Wang, R. et al. Integration of the Extreme Gradient Boosting model with electronic health records to enable the early diagnosis of multiple sclerosis. Mult. Scler. Relat, Disord. 47, 102632 (2021).
Agrawal, A. Medication errors: Prevention using information technology systems. Br. J. Clin. Pharmacol. 67(6), 681 (2009).
https://www.nccmerp.org/sites/default/files/taxonomy2001-07-31.pdf.
Adams, K. T. et al. Identifying health information technology usability issues contributing to medication errors across medication process stages. J. Patient Saf. 17(8), e988–e994 (2021).
Nadkarni, P. M., Ohno-Machado, L. & Chapman, W. W. Natural language processing: an introduction. J. Am. Med. Inform. Assoc. 18(5), 544–551 (2011).
Zou, H. & Hastie, T. Regularization and variable selection via the elastic net. J. Royal Stat. Soc. Series B (Stat. Methodol.) 67(2), 301–320 (2005).
Chen, T., Guestrin, C. Xgboost: A scalable tree boosting system. 785–794 (2016).
Kohavi R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Montreal, Canada; 1137–1145 (1995).
Allen, D. M. The relationship between variable selection and data agumentation and a method for prediction. Technometrics 16(1), 125–127 (1974).
Dhillon, A. & Singh, A. Machine learning in healthcare data analysis: A survey. J. Biol. Today’s World 8(6), 1–10 (2019).
Zhou, S., Kang, H., Yao, B. & Gong, Y. An automated pipeline for analyzing medication event reports in clinical settings. BMC Med. Inform. Decis. Mak. 18(5), 1–11 (2018).
Funding
This Grant-funded work is sponsored by the Agency for Healthcare Research and Quality. Study sponsors had no further involvement in the submission of this work.
Author information
Authors and Affiliations
Contributions
C.B., M.F., R.R., and A.F. contributed to the design of the study, implementation of the work, analysis of the results, and writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. All authors contributed to the study design, data collection and analysis, interpretation, and writing for this submission.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Boxley, C., Fujimoto, M., Ratwani, R.M. et al. A text mining approach to categorize patient safety event reports by medication error type. Sci Rep 13, 18354 (2023). https://doi.org/10.1038/s41598-023-45152-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-45152-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
