
Abstract
Spectrum sensing describes, whether the spectrum is occupied or empty. Main objective of cognitive radio network (CRN) is to increase probability of detection (Pd) and reduce probability of error (Pe) for energy consumption. To reduce energy consumption, probability of detection should be increased. In cooperative spectrum sensing (CSS), all secondary users (SU) transmit their data to fusion center (FC) for final measurement according to the status of primary user (PU). Cluster should be used to overcome this problem and improve performance. In the clustering technique, all SUs are grouped into clusters on the basis of their similarity. In cluster technique, SU transfers their data to cluster head (CH) and CH transfers their combined data to FC. This paper proposes the detection performance optimization of CRN with a machine learning-based metaheuristic algorithm using clustering CSS technique. This article presents a hybrid support vector machine (SVM) and Red Deer Algorithm (RDA) algorithm named Hybrid SVM–RDA to identify spectrum gaps. Algorithm proposed in this work outperforms the computational complexity, an issue reported with various conventional cluster techniques. The proposed algorithm increases the probability of detection (up to 99%) and decreases the probability of error (up to 1%) at different parameters.
Similar content being viewed by others
Introduction
The fast growth of wireless communications has resulted in many new sorts of services or applications for humans. The proliferation of various communication equipment causes the public frequency band to become increasingly congested1.In the 5G communication system, the role of cognitive radio is essential. Cognitive radio senses and detects free channels and enhances the radio spectrum through opportunistic and dynamic access. CRN has two types of users: PU means licensed users, and SU means unlicensed users2,3. SU senses radio spectrum and recognizes channels that primary licensed users do not occupy at a particular location and time4. SUs can use spectrum holes to avoid interference with PU. Many spectrum sensing techniques have been used to detect the spectrum. Examples are energy detection, matched filter, Euclidean distance, autocorrelation, and cyclostationary feature detection5,6,7,8. One of the essential technologies in the CR system based on channel prediction and radio spectrum distribution is spectrum sensing. If spectrum detection accuracy is low, it may cause significant interference to primary network users, limiting the development and use of cognitive radio technology.
Sensing performance is affected by noise, multipath fading or shadowing, uncertainty, and spatial diversity. SU receiver sensitivity should be high enough to detect weak and noisy PU signals. For this, complex and expensive hardware is required. Costly and complex hardware requirements are the problem9. The solutions to these problems are CSS. CSS discusses the sensing efficiency of each SU. SUs share their information and take a joint decision that is beneficial for all SUs. Decision accuracy and sensing efficiency are increased by exploiting links among SUs in the same environmental area10,11. Many CSS techniques have been proposed. First is the distributed CSS technique, in which every SU exchanges its results with sensing spectrum12. The problem with this technique is that it requires considerable processing time to get the final decision. Second, the centralized CSS technique was proposed to overcome this problem, requiring an FC to send and receive data to and from SUs13 The FC is a key component of cognitive radio networks. By fusing the local sensing decisions of the SUs, the FC can make more accurate decisions about the presence or absence of PUs. This can help to improve the overall performance of the cognitive radio network. The FC in a cognitive radio network is a central node that collects local sensing decisions from SUs and fuses them to make a global decision about the presence or absence of a PU. The FC can be formulated in a number of ways, but the most common approach is to use a decision fusion rule. A decision fusion rule is a mathematical function that takes as input the local sensing decisions of the SUs and outputs a global decision. There are many different decision fusion rules like AND rules, OR rules, and Majority rules. The choice of decision fusion rule depends on the application. For example, if the application requires a very low false alarm rate, then the AND rule may be a good choice. If the application is more tolerant of false alarms, then the OR rule or the majority rule may be a better choice. In addition to the decision fusion rule, the FC can also use a number of other parameters to fuse the local sensing decisions of the SUs. These parameters include are weights and threshold. The choice of weights and threshold depends on the application and the desired performance. In terms of detection rate, CSS is better than non-cooperative spectrum sensing. The disadvantages of CSS are extra power consumption, system overhead, more significant data exchange, and higher processing time. To overcome these problems, an advanced FC requires the processing of high-level computational signals. The channel state is determined based on sensing data forwarded by SUs to the FC. The requirement for an FC produces high computational capability. To overcome this problem, we use cluster-based spectrum sensing. In cluster, SUs transmit their data to cluster head. In the traditional energy detection method, SUs compare received signal results with the prior threshold and decide. If noise exists, the threshold is mismatched with the correct threshold, and the FC gets the wrong result. The author in14 discussed CSS based on dual-threshold to remove the limitation of threshold mismatch in energy detection. Here the author used credibility metric for sensing the results of SUs. These reliable sensing results lie in the decision zone. So, in14, the author discussed the dynamic dual-threshold CSS technique to enhance detection performance and remove sensing breakdown problems under noise power uncertainty. No detection occurs when energy falls between two thresholds, resulting in poor performance, such as a decrease Pd and a longer spectrum sensing time. To solve these issues, adaptive double threshold CSS using historical energy detection was suggested to solve them15. It is shown in16 that calculates the optimum threshold level value for improving spectrum sensing performance while maintaining the lowest possible error probability. To minimize the combined impacts of noise uncertainty and asynchronous primary user occurrences within the sensing period of the SU in a heterogeneous cognitive network, it is necessary first to identify the SU's sensing interval.
The article17 attempts to minimize the combined impacts of noise uncertainty and asynchronous primary user occurrences within the SU's sensing period in a heterogeneous cognitive network. So, as a result, an asymmetrical scale sampling criterion-based double threshold energy detection technique was suggested. A CRN suggested the greedy algorithm and particle swarm optimization to improve spectrum sensing18. In19, mathematical modelling and critical assessment of detection probability for energy detection-based spectrum sensing at low SNR in an uncertain, noisy environment are presented. A mathematical model has been suggested to calculate two thresholds for reliable sensing when measured energy is smaller than noise power uncertainty.
Here, a cluster-based CSS scheme is proposed. It depends on the cluster technique to increase performance of CRNs by increasing the probability of detection and decreasing probability of error with help of a machine learning-based metaheuristic algorithm. The probability of error is a combination of the probability of missed detection and the probability of false alarm. Clustering is a process of dividing a large network into smaller groups, or clusters, in order to improve performance and scalability. In CRNs, clustering is often used to form a virtual backbone, which can help to reduce communication overhead and improve the overall efficiency of the network. There are a number of different ways to create clusters in CRNs. One common approach is to use a centralized algorithm, in which a central node is responsible for assigning nodes to clusters. Another approach is to use a distributed algorithm, in which nodes themselves are responsible for selecting their own CHs.
Once clusters have been created, they need to be maintained in order to ensure that they continue to function properly. This involves tasks such as keeping track of the cluster members, electing new CH if necessary, and resolving conflicts between clusters. If the CH of a cluster becomes unavailable, then the cluster needs to be re-elected. This can be done using a number of different methods, such as a round-robin election or a voting algorithm. The key considerations for cluster creation, maintenance, and re-election in CRN are performance, scalability, robustness and security. Benefits of clustering in CRNs are scalability, efficiency and robustness. This paper proposed a novel combination of SVM and the RDA.
The organization of this paper is as follows: “Related work and problem formulation” Section provides related work regarding cluster-based CSS techniques and problem formulation. “Theoretical background” Section describes the theoretical foundation. “Proposed SVM–RDA Algorithm” Section describes conventional RDA and SVM algorithms. “Proposed methodology” Section describes methodology. “Results” Section discusses simulation results and compares the proposed technology with other technologies. “Performance analysis” Section describe performance analysis. Finally, the conclusion is part of “Conclusion” Section.
Related work and problem formulation
One of most challenging issues facing CRN is spectrum sensing20. An enormous amount of scientific interest has been generated. The literature has developed several narrowband spectrum sensing methods based on matched filtering, energy detection5, and cyclostationary feature detection8. To address the inaccuracies of the sensing technique, multiple detection thresholds should be used. For example,21 suggested energy detection with 2 thresholds to increase sensing decision accuracy. That is called CSS. CSS has two types, i.e., centralized and distributed. Forwarding sensing information to an FC is called centralized spectrum sensing21, and distributed spectrum sensing involves nodes sharing information among themselves to form a decentralized decision about spectrum holes22. Multiband joint detection23 and wavelet-based spectrum sensing24 are techniques to improve the performance of narrowband techniques across a broad bandwidth. Several methods have been suggested to reduce the need for such a high sample rate. As a result, several narrowband sensors detect the wideband at the same time.
In CRN, illegal SU access free permitted channels while there is less interference with PU and other SU25. The SUs are equipped with an unexpected and dynamic environment26. Energy detection methodology is considered due to its simplicity and low computational cost. For detection of PU, use proper energy threshold27. The author of28 investigates the impact of energy detection, CSS on CRN, and threshold selection in a fading atmosphere. Umebayashi29 presented a hierarchical CSS method using a dual-threshold energy detection mechanism. The author30 investigates a device to devise communication that combines 2 secondary links, 1 primary link, and a relay network and discusses the cluster relay selection method for secondary and primary transmission. Unfortunately, L1 norm minimization is unsuitable and mathematically expensive for many real-time applications. Threshold optimization matching pursuit (TOMP) is time-consuming due to the large number of projections. Cooperative sensing in a wireless environment reduces shadow and multipath fading effects31. In32, with help of TOMP algorithm, the sparse wideband spectrum signals are reconstructed33,34. With use of wavelet-based edge detector, boundaries between spectrum bands are estimated24 originally introduced in35. Fast matching pursuit (FMP) is an accurate and fast threshold-based greedy recovery algorithm for compressed sensing. The main aim of fast matching pursuit is to reconstruct a sparse signal from samples collected at a much lower rate than the Nyquist rate, as accurate and fast as possible, and apply it in a wide range of CRN applications. Unlike related works, FMP exploits the spectrum signal in the wavelet packet domains in which the spectrum is sparser. The L1 norm wavelet packet (WP) is also a greedy recovery algorithm36.
The author in37 describes the formation of a cluster of secondary users based on artificial intelligence based on machine learning and compares performance in terms of energy efficiency. The author in38 discussed CSS techniques with low complexity to get high cooperative gain and increase sensing results. The performance of existing techniques is good, and these techniques can remove uncertainty due to multipath fading and shadowing, and allowing for easy signal recovery with a satisfactory detection rate. The disadvantage is a low probability of detection and a high probability of error. In39, multiple reporting channels (MRC) for cluster-based cooperative CRN are proposed, which allows for greater use of the reporting time frame by increasing the sensing time of SU, thus reducing the overall cost.
Wideband spectrum sensing is available on several channels with several frequency bands. For wideband spectrum sensing, compressive spectrum sensing has been proposed40,41. In36, the author discussed centralized CSS, where autocorrelation results of SU’s signal are transferred to an FC for decision making. At the FC, these signals are recovered by a different matching pursuit recovery algorithm. These matching pursuits’ algorithms introduce fast and accurate spectrum sensing techniques.
Attributes of cooperative sensing are sensing, transmission and reporting42. When total number of SU increases in cooperative sensing, energy consumption also increases. So Probability of detection (Pd) reduces and probability of error (Pe) increases. To overcome this problem, SUs are grouped into different sets based on their sensing results. After that, Pd increases and Pe decreases at different parameters like signal to noise ratio, number of secondary users, and number of occupied bands. In earlier literature, SUs were grouped randomly or based on received signal strength. In earlier conventional clustering method, SU senses the result and CH is far from cluster and near to FC. Nodes in a cluster are close to each other but different from nodes of other clusters. Clustering is an unsupervised machine learning technique that groups data points together based on their similarity. Data points within the same cluster are more similar to each other than they are to data points in other clusters. So objective is to increase performance of clustering CSS with increase probability of detection and decrease probability of error by machine learning-based metaheuristic algorithm or learn heuristic algorithm. With learn heuristic algorithm, they select best SU from CRN, which saves energy consumption and partitions SUs into cluster. In spectrum sensing, Pd should be high to reduce disturbance due to PU and Pe should be low to increase spectrum utilization.
Theoretical background
In contrast to the cooperative SUs in the network, each SU conducts local spectrum sensing in isolation. The signal received by the jth SU is:
\(x_{j}\) is signal received by jth SU, \(h_{j}\) is channel gain between jth SU and PU, s is the signal of PU, and ni is noise. Hypothesis H1is existence of PU and hypothesis H0 is absence of PU. An FC performs the final spectrum sensing and coordination amongst collaborating SUs for large clusters of SU. It may be accomplished via the use of two methods. In first approach, collaborating SUs run local spectrum sensing independently to find results from the sensors. Consequently, they send their local findings to the FC, making the ultimate judgments through reporting channels. FC integrates incoming data and determines whether a PU signal is present in the detected channel. FC communicates absolute judgment to all SUs. According to second approach, cooperating SUs transmit their captured data to FC, responsible for performing spectrum sensing.
Individual spectrum sensing performance is used to calculate CSS performance. The probability of detection Pd, the probability of false alarm Pfa, and the probability of missed detection Pmd are the metrics that are being measured. Pd is the probability of detection, which means an SU announces existence of a PU signal while spectrum is occupied. The probability of detection is
H1 is a binary hypothesis linked to the existence of the PU signal. Individual Pfa, is defined as probability that SU reports existence of PU signal with clear spectrum. The probability of false alarm is.
H0 is a binary hypothesis linked to the absence of the PU signal. Pmd is probability that SU announces absence of PU signal while PU occupies spectrum. The probability of missed detection is
Cd is the cooperative probability of detection.
Pd is the probability of detection, and L is number of cooperating SU. Probability of error (Pe) is a combination of Pmd and Pfa.
CSS methods provide reasonable detection rates. However, CSS functions effectively with small SUs density. With a large density of cooperating SUs, these methods are complicated and slow to process. As a result43,44,45,46,47,48,49, suggested a clustering method based on CSS. SUs are clustered according to specific characteristics, (i) geographic region and (ii) distance between PU and SU. One SU serves as cluster head (CH) for each cluster, coordinating communications between its users and FC. At every cluster, SUs carry out their spectrum sensing individually and then transmit their findings to CH via a network of communication links. The findings are sent to the FC, where final decisions are made by the CH45. Individual spectrum sensing clustering performance metrics are also used for CSS47.Due to the analog to digital converter requirement, Nyquist sampling rate is not valuable for wideband spectrum sensing. So the author in50 reviews wideband spectrum sensing based on Nyquist sampling.
SUs in conventional energy detecting technologies often make decisions by comparing incoming signals to a previous threshold51. H0 or H1 is selected depending on whether received signal strength of PU is more than or less than threshold52. However, when SNR is low, detection effectiveness of conventional energy detection methods suffers significantly. An adaptive dual threshold energy detector was suggested as a solution to the issue of noise uncertainty, and it was developed using the best single threshold value. The author in53 describes CSS and non-CSS for full-duplex on a time-selective Nakagami-m fading channel.
Proposed SVM–RDA algorithm
Red deer algorithm
The RDA begins with a random population, similar to how other meta-heuristics work. A few of the finest RDs from among the population are chosen and designated as the ‘male RD,” while the other RDs are referred to as "hinds.' First and foremost, the male RD must roar. They are classified into two categories based on roaring power (i.e., stags and commanders). “After that, stags and each harem's commanders fight together to take control of their harem. Number of hinds in harems is proportional to commanders' fighting and roaring skills. As a result, commanders form harems where they mate with large numbers of hinds. Other male stags pair with their closest hinds regardless of the harem's size restriction. However, we only accept solutions that are better observed throughout the fighting between commanders and stags; in a similar way. Afterwards, harems are created and distributed among the commanders according to their degree of power. While doing the exploration phase, this step aids the algorithm. As a result, a harem commander mates with α percentage of hinds from his harem and β percentage of hinds from another harem. All stags should mate with closest hind during breeding season, i.e. they should only consider the distance between them and the hind and not the harem's restrictions. This stage considers both the exploration and exploitation phases at the same time”54.
Initialize red deer
Another critical stage of the RDA is the mating process, which results in the generation of RD progeny. The objective of enhancement is to develop a solution that is close to global in terms of problem’s variables. In machine learning, an array of RDA means red deer, and an array is:
To begin the process, we create an Npop starting population. We assign Nmale to a subset of the best RDs and Nhind to the remainder (Nhind = Npop − Nmale).
Roaring male RD
The male RD is attempting to enhance their elegance by screaming at this step. As a result, the roaring process may succeed or fail, just as it does in nature. Interestingly, in this methodology, male RDs come out on top regarding the available solution set. If the objective functions of neighbors are better than male RD, replace them with the prior ones. Permit every male RD to change their position. To update the position of males, the following equation is proposed:
UB is upper bounds of search space, and LB is lower bounds of search space. Maleold is present position of the male RD, and malenew is its new position. a1, a2 and a3 lie between 0 and 1.
Appoint γ percentage of the best male RDs as male commanders
There is a wide range of differences amongst male RDs in nature. Some of them are stronger, more enticing, or better at extending their area than the rest of them. In this way, RD is subdivided into commanders and stags, each serving a distinct purpose. The following formula is used to measure the number of commander males
NCom is a number of male commanders. Finally, stags are counted as follows:
NStag is the number of stags.
A battle between stags and male commanders
Assign stags to each commander at random. Two mathematical formulae for fighting are given by:
Suppose New1 and New2 are two newly produced solutions as a result of the fighting process. Com is commander, and the stag is stag. During the fight, a commander and a stag pursue one another. The result is the creation of two new solutions. One gets to choose the winner, while the other is out of the running.
Make harems
The commander creates harems here. A male commander captured a harem of hinds, and male commanders' strength determines harem size. To create the harems, we distribute hinds among commanders in a quantifiable way.
\(v_{n}\) is the power of the nth commander. \(V_{n}\) is a normalized value
Overall, more hinds go to the commander because of his higher fitness value.
Mate harem’s commander with \({\varvec{\alpha}}\) percentage of hinds in his harem
Deer reproduce in the same way that other animals do. A commander does this, and the parents make up a certain amount of the hinds in his harem.
\(N.harem_{n}^{male}\) is number of hinds from nth harem who mate with commander. Starting value of the RDA model's parameter is \(\alpha\), which lies between 0 and 1. The formula of the matting process is:
Offs is a new solution. Value of c lies between 0 and 1.
Pairing a harem’s commander in another harem with β % of hinds
In this case, male commander mates with β % of the hinds in his harem. To extend his area, the commander attacked another harem. An initial parameter is β, which lies between 0 and 1. The commander's harem has the following number of hinds:
\(N.harem_{k}^{male}\) is number of female red deer (hinds) from the kth harem who mate with the commander.
The stag pairs up with the closest hind
Each stag mates with its closest female red deer at this stage, and the male RD likes to track the female red deer during mating season. Without taking harem areas into account, this hind could be his favorites among all hinds. Stags were allowed to breed with hinds that were closest to them. People who are looking for a distance in j-dimension space should use the following formula to figure out which hind is closest:
\(d_{i}\) is the distance between ith hind and the stag.
Support vector machine
A supervised machine learning technique known as the SVM may be utilised for classification and regression problems. But it is mainly used in categorization. The SVM algorithm's objective is to construct the optimal decision boundary or line that can divide n-dimensional space into classes so that subsequent data points may be conveniently placed in the correct category. A hyperplane denotes the optimum decision boundary. After that, categorization is carried out by locating the hyper-plane that sharply defines the two groups. Hyperplane position and orientation are affected by support vectors that are near the hyperplane. Here, optimize the classifier's margin using these vectors. The location of the hyperplane varies if the support vectors are removed. These are the aspects that assist us in developing our SVM55.
Support vector machine-red deer algorithm
There are several meta-heuristic optimization algorithms developed that are inspired by nature. The efficiency of classification and prediction is improved by optimizing machine learning using the metaheuristic optimization algorithms56,57,58,59,60. Efforts have been made to improve SVM performance, but very few of these efforts have focused on SVM convergence. This study proposes a novel SVM–RDA algorithm. Flowchart of the proposed method is shown in Fig. 2. Proposed algorithm primarily comprises 2 procedures: (i) internal parameter optimization and the external classification performance evaluation. During the internal parameter optimization procedure, the SVM parameters are dynamically adjusted by the RDA method. The proposed SVM–RDA divides entire algorithm into two sub-sections. One section is demonstrated by SVM to initialize weight parameters and the other by RDA, in which the weight parameters are updated to find the best weight parameter value. The populations in RDA are randomly initialized. This proposed SVM–RDA included the benefits of a RDA for CH selection and energy-aware cluster formation. Machine learning, features extraction, regression, and classification operations are built on optimum parameters selection. In this paper, the RDA, a recent population-based meta-heuristic algorithm, is thoroughly reviewed. The RD algorithm combines the survival of the fittest principle from the evolutionary algorithms and the productivity and richness of heuristic search techniques.
The main steps conducted by the SVM–RDA are:
-
Step 1-Create a system model using PU, SU, and FC. Generate a full-duplex multiband signal.
-
Step 2-Check the availability of PUs in spectrums and collect FC, the energy value submitted by SUs in each round. Sense the availability of spectrum using the SVM algorithm.
-
Step 3-Initialise the parameters of SVM such as bias and weight vector (training).
-
Step 4: Make an SVM model that takes into account the energy level of the SU and the availability of the PU.
-
Step 5: Run a spectrum sensing test on the network after training it with a low starting weightand put it through a spectrum sensing test. If not correctly sense the spectrum and then update the weight of SVM using the RDO algorithm.
-
Step 6: Initialize the weight parameters of the red deer algorithm.
-
Step 7: Roar, male red deer.
-
Step 8: Select γ percentage of the best male red deer as the male commander.
-
Step 9: The battle between the male commander and the stag and the formation of haram.
-
Step 10: Mate commander with α and β % of hinds in another haram.
-
Step 11: Mating the stag with the nearest hind and calculating a new weight parameter.
-
Step 12: If this new weight parameter is not satisfied for spectrum sensing, then go to step 7.
-
Step 13: If end criteria are satisfied, then SVM classification is based on optimum weight value as testing set.
-
Step 14: It gives information about the spectrum that is available or not available.
-
Step 15: Assign SU to the available spectrum.
Proposed methodology
An FC and N SUs are considered in CSS, and the FC is in charge of all cooperative cognitive user channel allocation and monitoring. The suggested system acquires the SU received signal via a learn heuristic algorithm, a mix of machine and metaheuristic algorithms. Each SU transmits its signal to the CH, which recovers signal and senses spectrum from the data of the SUs. The CH then forwards their local choices to an FC, making the final decision on spectrum occupancy. All cooperating SUs transmit signal to CH for spectrum sensing. CH enables each SU to conduct its spectrum detection in the shortest amount of time possible, and then each SU sends its findings to the FC. As a result, our suggested method has a high Pd and a low Pe at different SNR and occupied bands. The FC in a cognitive radio network can be formulated for machine learning based metaheuristic algorithm in a number of ways. One approach is to use a decision fusion rule that is based on a machine learning algorithm. For example, a support vector machine (SVM) can be used to learn a decision boundary that separates the "busy" and "idle" states of the spectrum. The FC can then use this decision boundary to make a global decision about the presence or absence of a PU. Another approach is to use a metaheuristic algorithm to optimize the parameters of the fusion center. For example, RDA can be used to optimize the weights and threshold of the fusion center. The RDA can be used to search for a set of parameters that minimizes the false alarm rate and maximizes the detection rate.
System model
Consider a CRN with N SU and M PU and central FC that is subject to Rayleigh fading effect. Same set of SU is grouped in a cluster. The SNR of each SU measure is compared to the threshold. If evaluated SNR is less than predefined threshold of SNR, SU is not allowed for cooperative sensing. While SNR of SU is greater than threshold, SU is selected for cooperative sensing.
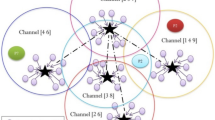
Assume N SUs are chosen for a particular sensing phase. So number of SU in single cluster is D = N/K. N is no. of SU that makes cluster. As shown in Fig. 1, CH is one of the SUs from the cluster. Clustering CSS has two types: inter-cluster CSS and intra-cluster CSS. In intra cluster CSS, SU detects the presence of PU information and transmits this information to the corresponding CH, then CH makes a final decision related to that cluster and forwards the information to FC. In inter-cluster CSS, all CH transmit their information to the FC, and FC make final decision related to data of CH. Intra cluster CSS occurs between two clusters. Cluster decisions may not be accurate at times due to a weak PU received signal. So there is uncertainty about a single cluster decision. So, inter cluster CSS can overcome this problem in which combined decision is taken by different clusters. The CH of each cluster is selected using a machine learning-based metaheuristic algorithm among set of selected SU. Sort the best SUs into clusters. If there are more than one licensed channel, apply hierarchical clustering methods to group them into cluster! based on high similarity between them61,62,63,64. These cluster can communicate outside of the cluster with the help of Improved Hierarchical Clustering Algorithm (IHCA).

System model of clustering cooperative spectrum sensing.
Flowchart
A flowchart describing workflow of proposed SVM–RDA algorithm is shown in Fig. 2.

Flow chart of SVM–RDA.
Pseudo code of SVM–RDA algorithm
-
1.
Define the parameters:
-
Number of clusters (K).
-
Clustering algorithm (e.g., k-means, hierarchical clustering).
-
SVM kernel (e.g., linear, radial basis function).
-
SVM regularization parameter (C).
-
SVM convergence criterion (e.g., maximum number of iterations).
-
Spectrum sensing threshold (T).
-
2.
Collect the spectrum data from the radio frequency (RF) sensors.
-
3.
Perform clustering on the spectrum data to identify the clusters:
-
Apply the chosen clustering algorithm to the spectrum data.
-
Determine the cluster centers and assign each data point to the nearest cluster.
-
4.
Initialize SVM for each cluster:
-
For each cluster, create an SVM model with the chosen kernel and regularization parameter.
-
5.
Train the SVM models:
-
For each cluster, use the data points belonging to that cluster to train the SVM model.
-
Set the class labels of the data points in the cluster to be 1 (occupied) if the signal strength is above the threshold T, and -1 (unoccupied) otherwise.
-
6.
Spectrum sensing:
-
Collect real-time spectrum data from the RF sensors.
-
For each data point, determine which cluster it belongs to based on its proximity to the cluster centers.
-
Use the corresponding SVM model for that cluster to classify the data point as occupied or unoccupied.
-
If the majority of SVM models classify the data point as occupied, then consider the spectrum as occupied; otherwise, consider it unoccupied.
-
7.
Repeat the spectrum sensing process periodically to adapt to dynamic spectrum usage.
-
8.
End.
RDA is a nature-inspired optimization algorithm inspired by the behavior of RD. It is used for feature selection and optimization. In the above pseudo-code, we are combining the RDA with SVM for spectrum sensing, but the specific implementation of the RDA might vary depending on the context and the problem you are trying to solve. Additionally, the choice of clustering algorithm, SVM parameters, and other settings may need to be tailored according to your specific application and data. RDA balance between exploration (global search) and exploitation (local search) of the solution space. Unlike traditional optimization methods, RDA often require minimal problem-specific knowledge or parameter tuning65.
Ethical approval
None of the authors’ experimented with human subjects or animals during this research.
Result
The suggested algorithm's performance is assessed using MATLAB R2014a on a 64-bit, core i5 processor, and 4 GB RAM system. The range of SNR is varied from − 20 to 20 dB. p(H0) = p(H1) = 0.5 are the probabilities of the PU being idle or busy state. The signal bandwidth is 7.56 MHz, and it is broadcast on the 720 MHz central radio frequency. The simulation results have been employed to show the dependency of Pd and Pe of CRN on SNR and occupied band. The probability of error is a combination of the Pfa and the Pmd. Here, analysis of the Pd and probability of error is based on SNR and the number of occupied bands using MATLAB. Improvements in the detection rates of CSS systems have shown acceptable results. However, they only need a small number of SUs to work effectively. This method is less effective because of the increased complexity and processing time required for many cooperating SUs. As a result, an FC solution based on CSS was suggested. SU is coordinated with the FC. As a result, SUs perform independent spectrum sensing and transmit their combined results to the FC for final decision. Figure 3 represents an FC-based CSS. Suppose that there is 1 PU and 90 SUs randomly dispersed in a square field with a length of 70 m. Here, PU uses the free-space path loss model. Figure 3 shows PU, SU, CH, and FC are distributed over 70 × 70 m.

shows the positions of the PU, SU, FC and CH.
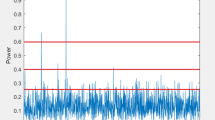
The performance of SVM–RDA algorithm is compared with DIsCOVER, Fuzzy-ED, Traditional-ED, and dynamic dual-threshold. Figure 4 represents the Pd versus Pfa with noise uncertainty under -12 dB SNR values. Because SUs have a low Pfa, they can easily reach approved bands that aren't being used. This means that more spectrum resources can be used by a lot. Decreasing Pd means PU is disturbed by SUs. Under low noise uncertainty, the detection performance of traditional-ED decreases. By comparing, the proposed algorithm can show strong performance in detection in the worst case. As a result, it can achieve a higher Pd than other methods under same Pfa. In our proposed method (SVM–RDA), the Pd is significant, and the Pe is less.

Probability of detection vs Probability of error.
Figure 5 describes Pd, versus number of cooperating SUs. As seen below, the Pd rises directly proportional to the number of collaborating SUs. So, detection rate rises as number of SUs grows, and detection performance improves means Pd will increase, that give good performance.

Probability of detection versus no. of cooperative SU.
For various SUs, Fig. 6 depicts the Pd related to the proposed algorithm (SVM–RDA) and dynamic dual-threshold model as an SNR function38. The SNR is between − 20 dB and 20 dB. As anticipated, Pd rises with SNR. Pd is less than 20% for SNR values below − 5 dB for 5 SUs and 10 SUs dynamic dual-threshold models. But, Pd is less than 70% for SNR values below − 5 dB for 5 SUs and 10 SUs for our proposed model (SVM–RDA). At SNR = 5 dB, the Pd is 100% for our proposed algorithm with 10 SU.

Probability of detection versus SNR at different cluster size.
Furthermore, in both instances, Pd of 10 SUs is greater than Pd of 5 SUs. The probability of detection related to dynamic dual-threshold with 5 SU and 10 SU becomes very close to 20 dB SNR, and for a proposed model, it is SNR = 13 dB. So, number of cooperating SUs grows and detection performance improves.
Figure 7 describes the Pe related to proposed algorithm (SVM–RDA) and dynamic dual-threshold model as an SNR function for different numbers of SUs. The probability of error reduces as the SNR increases. In addition, the Pe reduces as the number of cooperating SUs in cluster increases. Pe is high for 5 SUs and low for 10 SUs at high SNR, which can be explained by more cooperating users sensing the spectrum, resulting in lower Pe. Thus, CSS-based clustering scheme reduces Pe by detecting unused spectrum with many users.

Probability of error versus SNR at different cluster size.
Performance analysis
Table 1 demonstrates each optimization algorithm’s effectiveness [SVM–RDA, dynamic dual-threshold, Discover, Fuzzy energy detection, traditional energy detection, L1 Normalization for wavelet packet, Fast matching pursuit (for wavelet and wavelet packet domain) [FMP-W, FMP-WP] and threshold optimization matching pursuit for wavelet domain (TOMP-W)] in terms of Pd, Pfa, and different parameter values36,38.
At a − 5 dB SNR value, the proposed SVM–RDA has 46% and 9.8% more probability of detection than a dynamic dual-threshold for 5 SU and 10 SU, respectively. At 10 dB SNR, the proposed SVM–RDA has 24.24% and 14% higher detection probability than the dynamic dual-threshold for 5 SU and 10 SU, respectively. At the − 5 dB SNR value, the proposed SVM–RDA has 34.1% and 50% less probability of error than a dynamic dual-threshold for 5 SU and 10 SU, respectively. At a 10 dB SNR value, the proposed SVM–RDA has 79.16% and 18% less probability of error than a dynamic dual-threshold for 5 SU and 10 SU, respectively.
Compared to the current PSO-GSA, dynamic dual-threshold, Discover, Fuzzy energy detection, traditional energy detection, proposed algorithm is effective in spectrum sensing. It has obtained optimum energy consumption for spectrum sensing in CRN.
Conclusion
It has been suggested that CSS can improve the sensing performance of a system when many SUs are monitoring the same band of interest. This article proposes a new approach to CSS using clustering. The SVM–RDA is a machine learning-based metaheuristic algorithm that is presented in this article. The combination of SVM and RDA has significantly improved the performance of SVM. The SVM–RDA has a good balance of local and global search capabilities. The outputs of the proposed technique are described and compared to the results of CSS with a mathematical model. The performance of the proposed technique is evaluated using the Pd and Pe metrics. The simulations show that cooperative radio spectrum sensing achieves excellent detection and low error rates. The proposed method has a Pd of greater than 99% and a Pfa false alarm probability of less than 1%, which is better than similar algorithms. The SVM–RDA approach outperforms current techniques in terms of spectrum sensing performance. The proposed method improves the performance of CRNs compared to the current approach due to its efficiency in spectrum sensing. The proposed model will be improved in future research by incorporating co-headship in the cluster instead of a single CH. This method distributes the burden of a single CH across multiple CHs. In the future, it is important to study how nodes in cognitive wireless sensor networks (CWSNs) work together to ensure detection performance and design more energy-efficient spectrum sensing technologies based on this.
Data availability
All data generated or analyzed during this study are included in this article.
References
Ejaz, W., Shah, G. A., Hasan, N. U. & Kim, H. S. Energy and throughput efficient cooperative spectrum sensing in cognitive radio sensor networks. Trans. Emerg. Telecommun. Technol. 26(7), 1019–1030. https://doi.org/10.1002/ETT.2803 (2015).
Kaabouch, N. & Hu, W. C. Handbook of research on software-defined and cognitive radio technologies for dynamic spectrum management, vol. 1–2. 2014.
Sundar, S. Interference analysis and spectrum sensing of multiple cognitive radio systems. Int. J. Digit. Inf. Wirel. Commun. 4(2), 191–201. https://doi.org/10.17781/p001098 (2014).
Salahdine, F. Spectrum sensing techniques for cognitive radio networks. http://arxiv.org/abs/1710.02668. Accessed 27 Sep 2021.
Sun, H., Laurenson, D., C. W.-I. Communications, and undefined 2010. Computationally tractable model of energy detection performance over slow fading channels. ieeexplore.ieee.org. https://doi.org/10.1109/LCOMM.2010.090710.100934 (2010).
Manesh, M., Subramaniam, S., Reyes, H., N. K.-C. Networks, and undefined 2017. Real-time spectrum occupancy monitoring using a probabilistic model. Elsevier. https://www.sciencedirect.com/science/article/pii/S1389128617302463. Accessed 27 Sep 27 2021.
Akyildiz, I., Lo, B., R. B.-P. Communication, and undefined 2011. Cooperative spectrum sensing in cognitive radio networks: A survey. https://www.sciencedirect.com/science/article/pii/S187449071000039X. Accessed 27 Sep 2021.
Dandawate, A., G. G.-I. T. 1994 on signal, and undefined 1994. Statistical tests for presence of cyclostationarity. 42, 2355. https://ieeexplore.ieee.org/abstract/document/317857/. Accessed 30 Sep 2021.
Zeng, F., Tian, Z., C. L.-2010 I. I. C. on, and undefined 2010. Distributed compressive wideband spectrum sensing in cooperative multi-hop cognitive networks. https://ieeexplore.ieee.org/abstract/document/5502793/. Accessed 27 Sep 2021.
Dony Ariananda, D., Romero, D., & Leus, G. Cooperative compressive power spectrum estimation. 2014.
Kishore, R., Ramesha, C., K. A.-P. C. Science, and undefined 2016. Bayesian detector based superior selective reporting mechanism for cooperative spectrum sensing in cognitive radio networks. https://www.sciencedirect.com/science/article/pii/S1877050916314429. Accessed 27 Sep 2021.
Sun, H., D. L. 2009 F. U.-I., and undefined 2009. Cooperative compressive spectrum sensing by sub-Nyquist sampling. https://ieeexplore.ieee.org/abstract/document/5749398/. Accessed 27 Sep2021.
Ganesan, G. & Li, Y. Cooperative spectrum sensing in cognitive radio, part I: Two user networks. IEEE Trans. Wirel. Commun. https://doi.org/10.1109/TWC.2007.05775 (2007).
M. Ghaznavi, A. J.-I. Communications, and undefined 2017, “Defence against primary user emulation attack using statistical properties of the cognitive radio received power. https://ieeexplore.ieee.org/iel7/4105970/7973197/07973263.pdf. Accessed 28 Sep 2021.
Yu, S., Liu, J., Wang, J. & Ullah, I. Adaptive double-threshold cooperative spectrum sensing algorithm based on history energy detection. Wirel. Commun. Mob. Comput. https://doi.org/10.1155/2020/4794136 (2020).
Ostovar, A. Cooperative spectrum sensing optimal threshold selection in cognitive radio networks. Internet Technol. Lett. 3(5), 1–6. https://doi.org/10.1002/itl2.197 (2020).
Hassan, S. M., Eltholth, A. & Ammar, A. H. Double threshold weighted energy detection for asynchronous PU activities in the presence of noise uncertainty. IEEE Access 8, 177682–177692. https://doi.org/10.1109/ACCESS.2020.3024865 (2020).
Jayasri, C. A novel swarm intelligence optimized spectrum sensing approach for cognitive radio network. Turk. J. Comput. Math. Educ. 12(6), 136–143. https://doi.org/10.17762/turcomat.v12i6.1278 (2021).
Mahendru, G. A novel double threshold-based spectrum sensing technique at low SNR under noise uncertainty for Cognitive Radio Systems (2021).
Khattab, A., Perkins, D. & Bayoumi, M. Cognitive radio networks: from theory to practice. 2012. https://books.google.com/books?hl=hi&lr=&id=WyZshXf1d0UC&oi=fnd&pg=PR7&dq=+Khattab,+A.,+Perkins,+D.,+%26+Bayoumi,+M.+(2013).+Cognitive+radio+networks:+From+theory+to+practice.+Berlin:+Springer.&ots=OPQG99uJ_t&sig=4AbSexixUh5MMgyt9IZL3rMQKSA. Accessed 30 Sep 2021
Ariananda, D. G. L.-2012 C. R. of the Forty, and undefined 2012, Cooperative compressive wideband power spectrum sensing. https://ieeexplore.ieee.org/abstract/document/6489012/. Accessed 03 Oct 2021.
Bazerque, J., G. G.-I. T. On Signal, and undefined 2009. Distributed spectrum sensing for cognitive radio networks by exploiting sparsity. https://ieeexplore.ieee.org/abstract/document/5352337/. Accessed 03 Oct 03 2021.
Z. Quan, S. Cui, A. S.-I. transactions on signal, and undefined 2008, “Optimal multiband joint detection for spectrum sensing in cognitive radio networks. https://ieeexplore.ieee.org/abstract/document/4668431/. Accessed 03 Oct 03 2021.
Tian, Z. G. G.-2006 1st international conference on, and undefined 2006. A wavelet approach to wideband spectrum sensing for cognitive radios. https://ieeexplore.ieee.org/abstract/document/4211139/. Accessed 03 Oct 03 2021.
Zhang, D., Chen, Z., Ren, J., N., Z.-I. T., and undefined 2016. Energy-harvesting-aided spectrum sensing and data transmission in heterogeneous cognitive radio sensor network. https://ieeexplore.ieee.org/abstract/document/7448983/. Accessed 30 Sep 2021.
Maleki, S., Leus, G., Chatzinotas, S., & B., Ottersten. To AND or to OR: On energy-efficient distributed spectrum sensing with combined censoring and sleeping. https://ieeexplore.ieee.org/abstract/document/7086100/. Accessed 30 Sep 2021.
Gavrilovska, L. & Atanasovski, V. Spectrum sensing framework for cognitive radio networks. Wirel. Pers. Commun. 59(3), 447–469. https://doi.org/10.1007/S11277-011-0239-1 (2011).
Kumar, A., Thakur, P., Pandit, S. & Singh, G. Threshold selection and cooperation in fading environment of cognitive radio network: Consequences on spectrum sensing and throughput. AEU Int. J. Electron. Commun. https://doi.org/10.1016/j.aeue.2020.153101 (2020).
Umebayashi, K., K. H.-I. C., and undefined 2017. Threshold-setting for spectrum sensing based on statistical information. https://ieeexplore.ieee.org/abstract/document/7892973/. Accessed 30 Sep 2021.
Bakhsh, Z. M., Moghaddam, J. Z. & Ardebilipour, M. An interference management approach for CR-assisted cooperative D2D communication. AEU Int. J. Electron. Commun. 115, 1–10. https://doi.org/10.1016/j.aeue.2019.153026 (2020).
Hojjati, S., Ebrahimzadeh, A., S. A. Networks, and undefined 2017. Energy efficient cooperative spectrum sensing in wireless multi-antenna sensor network. https://doi.org/10.1007/s11276-015-1175-x.pdf. Accessed 30 Sep 2021.
Tian, Z., G. G. 2007 I. I. C. on, and undefined 2007. Compressed sensing for wideband cognitive radios. Accessed 30 Sep 2021.
La, C. M. D.-2006 I. C. on Image, and undefined 2006. Tree-based orthogonal matching pursuit algorithm for signal reconstruction. https://ieeexplore.ieee.org/abstract/document/4106770/. Accessed 17 Feb 2022.
Bui, H., La, C., M. D.-S. Processing, and undefined 2015. A fast tree-based algorithm for compressed sensing with sparse-tree prior. 108, 628–641, 2014. https://doi.org/10.1016/j.sigpro.2014.10.026.
Mallat, S., W. H.-I. Transactions on information theory, and undefined 1992. Singularity detection and processing with wavelets. https://ieeexplore.ieee.org/abstract/document/119727/. Accessed 17 Feb 2022.
Ahmed, M. M. A. & Mohamed, K. Fast matching pursuit for wideband spectrum sensing in cognitive radio networks. Wirel. Networks 25(1), 131–143. https://doi.org/10.1007/s11276-017-1545-7 (2019).
Bhatti, D. M. S., Ahmed, S., Chan, A. S. & Saleem, K. Clustering formation in cognitive radio networks using machine learning. AEU Int. J. Electron. Commun. https://doi.org/10.1016/j.aeue.2019.152994 (2020).
Wan, R., Ding, L., Xiong, N., Shu, W., L. Y.-H. C. and, and undefined 2019. Dynamic dual threshold cooperative spectrum sensing for cognitive radio under noise power uncertainty. https://doi.org/10.1186/s13673-019-0181-x. Accessed 27 Sep 2021.
Hossain, M. A., Schukat, M., & E., Barrett. 2020. Enhancing the spectrum sensing performance of cluster-based cooperative cognitive radio networks via sequential multiple reporting channels. Wirel Pers Commun. 116, 2411–2433. https://doi.org/10.1007/S11277-020-07802-4.
Salahdine, F., N. K.-I. J. of, and undefined 2017. A Bayesian recovery technique with Toeplitz matrix for compressive spectrum sensing in cognitive radio networks. https://doi.org/10.1002/dac.3314. Accessed 27 Sep 2021.
Salahdine, F., H. E. G.-2017 I. 8th A. Ubiquitous, and undefined 2017. A real time spectrum scanning technique based on compressive sensing for cognitive radio networks. https://ieeexplore.ieee.org/abstract/document/8249008/. Accessed 27 Sep 27 2021.
Bhatti, D., Shaikh, B., S. Z.-C. T., and U. 2017. Fuzzy c-means and spatial correlation based clustering for cooperative spectrum sensing. https://ieeexplore.ieee.org/abstract/document/8191025/. Accessed 17 Feb 2022.
Joshi, G., S. K. Sensors, and undefined 2016. A survey on node clustering in cognitive radio wireless sensor networks. https://www.mdpi.com/155848. Accessed 28 Sep 2021.
Wang, Y., Zhang, Y., Wan, P., S. Z.-W. C., and undefined 2018. A spectrum sensing method based on empirical mode decomposition and K-Means clustering algorithm. https://www.hindawi.com/journals/wcmc/2018/6104502/abs/. Accessed 28 Sep 2021.
Zhang, Y., Wan, P., Zhang, S., Wang, Y., N. L.-A. In Multimedia, and undefined 2017. A spectrum sensing method based on signal feature and clustering algorithm in cognitive wireless multimedia sensor networks. Accessed 28 Sep 2021.
Salah, I., Saad, W., M. S. 13th I., and undefined 2017. Cooperative spectrum sensing and clustering schemes in CRN: A survey. https://ieeexplore.ieee.org/abstract/document/8289806/. Accessed 28 Sep 2021.
Sharma, M., Chauhan, P. & Sarma, N. Probability of detection analysis in fading and nonfading scenario using cooperative sensing technique. Lect. Notes Netw. Syst. 24, 197–205. https://doi.org/10.1007/978-981-10-6890-4_18 (2018).
Wang, S., Liu, H. & Liu, K. An improved clustering cooperative spectrum sensing algorithm based on modified double-threshold energy detection and its optimization in cognitive wireless sensor networks. Int. J. Distrib. Sens. Netw. https://doi.org/10.1155/2015/136948 (2015).
Arjoune, Y., Kaabouch, N. Sensors, and undefined 2018. Wideband spectrum sensing: A Bayesian compressive sensing approach. Accessed 28 Sep 2021. https://www.mdpi.com/301696.
Aswathy, G. P. & Gopakumar, K. Sub-Nyquist wideband spectrum sensing techniques for cognitive radio: A review and proposed techniques. AEU - Int. J. Electron. Commun. 104, 44–57. https://doi.org/10.1016/j.aeue.2019.03.004 (2019).
Zhang, W., Mallik, R. K. & Letaief, K. B. Optimization of cooperative spectrum sensing with energy detection in cognitive radio networks. IEEE Trans. Wireless Commun. https://doi.org/10.1109/TWC.2009.12.081710 (2009).
Ahuja, B. & Kaur, G. Design of an improved spectrum sensing technique using dynamic double thresholds for cognitive radio networks. Wirel. Pers. Commun. 97(1), 821–844. https://doi.org/10.1007/S11277-017-4539-Y (2017).
Sabat, S., Sharma, P. K. & Gandhi, A. Full-duplex mobile cognitive radio network under Nakagami-m fading environment. AEU Int. J. Electron. Commun. 109, 136–145. https://doi.org/10.1016/j.aeue.2019.06.031 (2019).
Fathollahi-Fard, A. M., Hajiaghaei-Keshteli, M. & Tavakkoli-Moghaddam, R. Red deer algorithm (RDA): A new nature-inspired meta-heuristic. Soft Comput. 24(19), 14637–14665. https://doi.org/10.1007/S00500-020-04812-Z (2020).
Zhu, H., Song, T., Wu, J., Li, X. & Hu J. Cooperative spectrum sensing algorithm based on support vector machine against SSDF Attack. In 2018 IEEE International Conference on Communications Workshops, ICC Workshops 2018—Proceedings, pp. 1–6. https://doi.org/10.1109/ICCW.2018.8403653
Mahajan, S., Mittal, N. & Pandit, A. K. Image segmentation using multilevel thresholding based on type II fuzzy entropy and marine predators algorithm. Multimed. Tools Appl. 80(13), 19335–19359 (2021).
Mahajan, S., Abualigah, L., Pandit, A. K. & Altalhi, M. Hybrid Aquila optimizer with arithmetic optimization algorithm for global optimization tasks. Soft Comput. 26, 4863 (2022).
Mahajan, S. & Pandit, A. K. Hybrid method to supervise feature selection using signal processing and complex algebra techniques. Multimed. Tools Appl. https://doi.org/10.1007/s11042-021-11474-y (2021).
Mahajan, S. et al. An efficient adaptive salp swarm algorithm using type II fuzzy entropy for multilevel thresholding image segmentation. Comput. Math. Methods Med. https://doi.org/10.1155/2022/2794326 (2022).
Mahajan, S., & Pandit, A. K. Image Segmentation and Optimization Techniques: A Short Overview.
Pathak, S. & Jain, S. An optimized stable clustering algorithm for mobile ad hoc networks. EURASIP J. Wireless Commun. Netw. 2017, 51. https://doi.org/10.1186/s13638-017-0832-4,pp.1-11 (2017).
Pathak, S. & Jain, S. A novel weight based clustering algorithm for routing in MANET. Wireless Netw. 22, 2695–2704 (2016).
Pathak, S. & Jain, S. Comparative study of clustering algorithms for MANETs. J. Stat. Manag. Syst. 22(4), 653–664 (2019).
Pathak, S. & Jain, S. A priority-based weighted clustering algorithm for mobile ad hoc network. Int. J. Commun. Netw. Distrib. Syst. 22(3), 313–328 (2019).
Samuel, P., Subbaiyan, S., Balusamy, B., Doraikannan, S. & Gandomi, A. H. A technical survey on intelligent optimization grouping algorithms for finite state automata in deep packet inspection. Arch. Comput. Methods Eng. 28, 1371–1396 (2021).
Acknowledgements
Researchers Supporting Project number (RSPD2023R533), King Saud University, Riyadh, Saudi Arabia.
Funding
This project is funded by King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
All author contribute in this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Srivastava, V., Singh, P., Mahajan, S. et al. Performance enhancement in clustering cooperative spectrum sensing for cognitive radio network using metaheuristic algorithm. Sci Rep 13, 16827 (2023). https://doi.org/10.1038/s41598-023-44032-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-44032-7
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
