
Abstract
Due to the lack of timely data on socioeconomic factors (SES), little research has evaluated if socially disadvantaged populations are disproportionately exposed to higher PM2.5 concentrations in India. We fill this gap by creating a rich dataset of SES parameters for 28,081 clusters (villages in rural India and census-blocks in urban India) from the National Family and Health Survey (NFHS-4) using a precision-weighted methodology that accounts for survey-design. We then evaluated associations between total, anthropogenic and source-specific PM2.5 exposures and SES variables using fully-adjusted multilevel models. We observed that SES factors such as caste, religion, poverty, education, and access to various household amenities are important risk factors for PM2.5 exposures. For example, we noted that a unit standard deviation increase in the cluster-prevalence of Scheduled Caste and Other Backward Class households was significantly associated with an increase in total-PM2.5 levels corresponding to 0.127 μg/m3 (95% CI 0.062 μg/m3, 0.192 μg/m3) and 0.199 μg/m3 (95% CI 0.116 μg/m3, 0.283 μg/m3, respectively. We noted substantial differences when evaluating such associations in urban/rural locations, and when considering source-specific PM2.5 exposures, pointing to the need for the conceptualization of a nuanced EJ framework for India that can account for these empirical differences. We also evaluated emerging axes of inequality in India, by reporting associations between recent changes in PM2.5 levels and different SES parameters.
Similar content being viewed by others

Main
Ambient air pollution is the world’s single largest environmental health risk and is estimated to have been responsible for 6.7 million premature deaths in 20191. Fine particulate matter (PM2.5) concentrations in India are among the highest in the world2,3,4. According to the 2019 Global Burden of Disease, PM2.5 was estimated to be responsible for 1.67 million deaths (0.98 million deaths from ambient pollution and 0.61 million deaths from household pollution), or 17.8% of the total deaths recorded in India, with economic losses alone corresponding to ~ 1.36% of the India’s Gross Domestic Product in 20175.
In the United States, and elsewhere, a rich body of environmental justice (EJ) research documents the substantial and persistent disparities in exposure to pollution by markers of privilege6,7,8,9,10. Such work has resulted in deliberate efforts to incorporate concerns of equity into environmental policymaking11. Little work has been done examining if socially disadvantaged and marginalized communities are also disproportionately burdened by particulate matter pollution in low- and middle-income countries like India12, although such work could inspire similar policy efforts.
In India, limited existing evidence has shown that pollution from coal fired power plants is higher among marginalized populations belonging to lower castes and among the poor13. Recent work has also found disparities in air pollution-related mortality from power generation plants, with poorer, coal-dependent states in eastern India bearing the brunt of PM2.5-mortality from electricity generation14. Other research has found that PM2.5 levels are higher in districts with a higher percentage of lower caste or Scheduled Caste (SC) residents, young children, and households in poor condition15. Scheduled Castes and Scheduled Tribes, and Other Backward Classes are officially designated groups of people who are among the most socioeconomically disadvantaged in India; and that the greatest increase in PM2.5 concentrations were in less urbanized districts with a high percentage of SCs, women, children, persons with disabilities, and households without toilets15.
The EJ studies described here draw on data for socioeconomic status (SES) from the Census as well as the Houselisting and Housing Census data of India13,15. As the Census is conducted once every 10 years, some of the variables, such as asset ownership, likely do not reflect the current distribution of wealth. In addition, the Census datasets contain limited information on SES information relevant to evaluating environmental justice concerns in India. For example, religion is typically not recorded. Finally, existing research that has utilized these datasets have been conducted at the district-level which may not be a fine-enough spatial scale to capture the substantial heterogeneity in PM2.5 and SES status in India. We aim to fill these gaps in the current study by evaluating how total (main analysis), anthropogenic PM2.5 levels, and source-specific PM2.5 concentrations (supplementary analyses) vary over a rich array of context-specific SES variables relating to caste, religion, income, education, household assets and wealth associated with social advantage in India, using data from the National Family and Health Survey (NFHS-4) conducted between 2015-2016.
The NFHS are nationally representative surveys measuring indicators of population, health and nutrition, with a focus on maternal and infant health. In the NFHS, women between 15 and 49 years of age from ~ 25-30 households, sampled randomly from each of 28,526 clusters (villages in rural areas and census enumeration blocks in urban areas), which were in turn randomly sampled from each district in India were interviewed in detail. Using a precision-weighted method (described in more detail in “Methods” Section) that accounts for the NFHS-4 survey design and sampling variability16,17, we estimated the prevalence of the following SES factors at the cluster-level from the survey responses for the time period 2010-2015: (1) Households that were in the lowest wealth quintile, (2) Households that had Below Poverty Line (BPL) ration cards, (3) Households that had electricity, (4) Households that had improved sanitation, (5) Households that used solid fuels for their energy needs, (6) Households that had access to safe drinking water, (7) Households headed by a Muslim, (8) Households headed by a college-educated individual, (9) Households headed by a woman, (10) Households headed by an individual belonging to a Scheduled Caste (SC), (11) Households headed by an individual belonging to a Scheduled Tribe (ST), (12) Households headed by an individual belonging to an Other Backward Class (OBC), (13) Mothers married young (< 18 years of age), and (14) Underweight mothers (BMI < 18.5 kg/m2), an indicator of food-access (Figs. S1–4). We also used population density available for each cluster in our analysis (Fig. S5).
Total-PM2.5 concentrations, averaged over the years 2010-2015 were obtained from a well-validated satellite-derived dataset18. The PM2.5 sources considered in this analysis are Agricultural Residue Burning (ARB), Domestic Burning (DOM), Industrial (IND), International (INT), OTH (other), POW (power), road dust (RD), and Transport (TRA). We derived anthropogenic PM2.5 values by deducting soil dust from natural sources from total PM2.5 levels. Source- and species- specific PM2.5 concentrations were obtained from the output of the Community Multiscale Air Quality (CMAQ) model, described elsewhere for the year 2016, alone19. We chose to consider anthropogenic concentrations, in addition to total levels, because policymakers have control over the former exposure.
We first visually examined relationships between the PM levels and SES variables considered by plotting mean PM concentrations for clusters categorized into deciles based on the prevalence of different SES variables. We used multilevel models to quantify the geographic variation of total, anthropogenic and source-specific PM2.5 across different spatial scales. We evaluated associations between each exposure of interest and the SES factors described in unadjusted and fully-adjusted multilevel models. We also evaluated how disparities in exposure to PM2.5 from power generation (POW) varied relative to the benefits consumers receive. We used average nighttime luminosity as a proxy for energy consumption from power generation. Finally, we evaluated associations between the change in PM2.5 levels between 2010 and 2015 with changes in different SES factors (for more details refer to “Methods” section).
Results
Descriptive statistics of the SES parameters and PM2.5 concentrations for the 28,072 clusters with non-missing SES and total PM2.5 levels are displayed in Table S1 in Supplementary Information. PM2.5 levels are high in India, with mean concentrations of 53.4 μg/m3 (median: 47 μg/m3; range: 3.5–131.7 μg/m3). Descriptive statistics for 27,534 clusters that have non-missing SES, anthropogenic, and source-specific PM2.5 levels are displayed in Table S2. Pair-wise Pearson correlation coefficients between the different parameters considered are displayed in Fig. S12.
Evaluating disparities in PM concentrations along different EJ dimensions
One-way ANOVA tests revealed that total-PM2.5 concentrations varied significantly over all clusters classified into deciles based on the prevalence of all SES parameters, considered. When repeating this analysis for urban clusters, alone, we generally observed similar results with one exception: total-PM2.5 levels did not vary significantly over urban clusters categorized into deciles based on the prevalence of poor residents.
Mean total-PM2.5 concentrations were on average higher in clusters corresponding to a high prevalence of SCs (Decile 10: 60.7 μg/m3, Decile 1: 21.2 μg/m3), OBCs (Decile 10: 54.1 μg/m3, Decile 1: 28.0 μg/m3), Muslims (Decile 10: 56.1 μg/m3, Decile 1: 38.3 μg/m3), poor households (Decile 10: 59.3 μg/m3, Decile 1: 58.8 μg/m3), households with no formal education (Decile 10: 56.5 μg/m3, Decile 1: 44.9 μg/m3), underweight mothers (Decile 10: 55.7 μg/m3, Decile 1: 35.4 μg/m3) and mothers who were married young (Decile 10: 59.1 μg/m3, Decile 1: 40.7 μg/m3). Mean total-PM2.5 levels were lower in clusters with a high percentage of STs (Decile 10: 31.6 μg/m3, Decile 1: 72.3 μg/m3), and electrified households (Decile 10: 58.1 μg/m3, Decile 1: 72.0 μg/m3). STs tend to live in remote rural areas20, which explains the trend observed in PM2.5 levels.
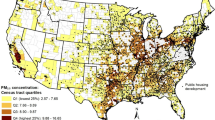
Contrary to expectations, total-PM2.5 levels were higher in clusters with a higher prevalence of households with safe drinking water (Decile 10: 76.7 μg/m3, Decile 1: 43.4 μg/m3), in clusters with a high prevalence of college-educated household heads (Decile 1: 49.3 μg/m3, Decile 10: 55.2 μg/m3), and in clusters with a lower prevalence of households headed by women (Decile 10: 51.2 μg/m3, Decile 1: 59.4 μg/m3). Total-PM2.5 concentrations were also lower in clusters with a higher prevalence of households living below the poverty line with ration cards (Decile 10: 39.7 μg/m3, Decile 1: 57.6 μg/m3). There is a negative correlation between the prevalence of poverty and households with safe drinking water (− 0.16), and almost no correlation (0.00) between the prevalence of households headed by women and poverty (Fig. S12). Although the prevalence of poverty and the prevalence of households living BPL with ration cards were correlated (0.37), not all households BPL can avail of a ration card due to limitations imposed by state quotas. The quotas rely on data from National Sample Survey (NSS) Household Consumption Survey for 2011–2012 which are outdated. Research has shown that it is often the most underprivileged who cannot access ration cards even though they are BPL21. Thus, the prevalence of households BPL, likely, does not capture the poorest of the poor in India. When we repeated this analysis, disaggregated by urban/rural designation, we observed similar trends among urban and rural clusters (Fig. 1).

Total-PM2.5 concentrations by decile of the different SES prevalence parameters considered, disaggregated by urban/rural clusters. Total-PM2.5 concentrations corresponding to the first and tenth decile are highlighted. The boxes correspond to the first and third quartiles of the distribution of Total-PM2.5 concentrations corresponding to each group.
We observed similar relationships between anthropogenic-PM2.5 levels and SES parameters (Fig. S13). One-way ANOVA tests revealed that anthropogenic-PM2.5 concentrations varied significantly over all clusters classified into deciles based on the prevalence of all SES parameters except college-educated household heads. The same was true for the variation of industrial-PM2.5, agricultural residue burning-PM2.5, and other-PM2.5 levels. Transport-PM2.5 varied significantly over all clusters categorized by the prevalence of all SES variables. The same was true for power-PM2.5 concentrations except over clusters classified into deciles on the basis of the prevalence of Muslim household and heads, and households with safe drinking water; And for domestic burning-PM2.5 levels except over clusters classified into deciles on the basis of the prevalence of households BPL; And for road dust-PM2.5 except for clusters classified into deciles on the basis of the prevalence households with a female head; And for international-PM2.5 except over clusters classified into deciles on the basis of the prevalence of households with underweight mothers. A full description of the variation of source-specific PM2.5 across clusters classified on the basis of the prevalence of different SES parameters can be found in section S2 in the SI.
When evaluating the distribution of SES parameters for different concentrations of total-PM2.5, we observed that at higher total-PM2.5 levels, there was a greater prevalence of SCs (prevalence at Decile 1: 0.10, Decile 10: 0.23), OBCs (Decile 1: 0.30, Decile 10: 0.48), Muslims (Decile 1: 0.10, Decile 10: 0.13), poor households (Decile 1: 0.10, Decile 10: 0.25), households that used solid fuels (Decile 1: 0.53, Decile 10: 0.59), households that were headed by someone with no formal education (Decile 1: 0.25, Decile 10: 0.30), households with a college educated head (Decile 1: 0.08, Decile 10: 0.11), underweight/thin mothers (Decile 1: 0.12, Decile 10: 0.21), and mothers who had married young (Decile 1: 0.30, Decile 10: 0.45).
The prevalence of the following SES parameters were lower for clusters experiencing high levels of total-PM2.5: household headed by an ST (Decile 1: 0.43, Decile 10: 0.01), households below the poverty line with ration cards (Decile 1: 0.39, Decile 10: 0.25), households with improved sanitation (Decile 1: 0.77, Decile 10: 0.51), and electrified households (Decile 1: 0.94, Decile 10: 0.79) (Fig. S22).
Evaluating variation in PM2.5 across multiple geographic scales
When we evaluated the partitioning of variation in total PM2.5 concentrations by the different geographic scales using multilevel models that only controlled for the logarithm of population density and urban/rural, we found that most of the variation (> 80%) was observed at the state-level, ~ 15% of the variation in total PM2.5 concentrations was observed at the district level, while the remaining was at the cluster-level (Table S2). Further adjusting for SES variables only explained a small proportion of variance (~ 1%) in PM2.5 concentrations at each spatial scale (Table S3). We found similar results when evaluating the partitioning of variation for anthropogenic PM2.5 levels (Table S4), and source-specific PM2.5 values (Table S5). The large variation of PM2.5 concentrations at the state-spatial scale indicates that tackling large regional sources should be a priority in tackling pollution in India. These results could also suggest that more detailed ground-based PM2.5 measurements and emission inventories are needed to capture fine-scale PM variations in India.
Evaluating associations between PM2.5 levels and different EJ dimensions
We used unadjusted and fully-adjusted multilevel models to evaluate associations between total PM exposures considered in this study and the various SES parameters. In order to compare associations across the different SES variables, we standardized each variable in the model using z-scores. More information can be found in “Methods” Section.
From the fully-adjusted multilevel models, we found that an increasing prevalence of SC, OBC households were associated with small but significant increases in total-PM2.5 concentrations. An increasing prevalence of poor, electrified, ST, Muslim households, households BPL with ration cards, underweight or thin mothers were associated with decreasing levels of total-PM2.5. Specifically, we observed that a 1 standard deviation (SD) increase in the prevalence of households with an OBC head was associated with the largest increase in total-PM2.5 concentrations of 0.199 μg/m3 (95% CI 0.116 μg/m3, 0.283 μg/m3). The next largest positive association was observed with the SES parameter: the prevalence of SC households: 0.127 μg/m3 (95% CI 0.062 μg/m3, 0.129 μg/m3), followed by the prevalence of mothers married young: 0.106 μg/m3 (95% CI − 0.003 μg/m3, 0.215 μg/m3).
The largest negative association was observed with the SES variable: the prevalence of ST households: − 0.383 μg/m3 (95% CI − 0.497 μg/m3, − 0.269 μg/m3) and the prevalence of households living in poverty: − 0.260 μg/m3 (95% CI − 0.376 μg/m3, − 0.144 μg/m3). The latter association diverges from our initial hypothesis that lower total-PM2.5 concentrations would be present in richer clusters (Table 1).
When evaluating these associations, disaggregated by urban/rural, we observed substantial differences. For instance, we observed positive associations between total-PM2.5 and the prevalence of SC: 0.198 μg/m3 (95% CI 0.114 μg/m3, 0.282 μg/m3) and OBC household heads: 0.245 μg/m3 (95% CI 0.139 μg/m3, 0.350 μg/m3) in rural clusters, respectively, but not urban clusters: − 0.030 μg/m3 (95% CI − 0.125 μg/m3, 0.065 μg/m3) and − 0.032 μg/m3 (95% CI − 0.231 μg/m3, 0.166 μg/m3), respectively. The negative association between total-PM2.5 levels and the prevalence of ST household heads was significant in rural clusters: − 0.371 μg/m3 (95% CI − 0.515 μg/m3, − 0.228 μg/m3), but not urban clusters: − 0.032 μg/m3 (95% CI − 0.231 μg/m3, 0.166 μg/m3), although the association in urban clusters demonstrated the same general trend observed in rural clusters.
We observed significant negative associations between total-PM2.5 levels in urban clusters with a higher prevalence of female-headed households: − 0.136 μg/m3 (95% CI − 0.268 μg/m3, − 0.003 μg/m3), but not in rural clusters: 0.056 μg/m3 (95% CI − 0.053 μg/m3, 0.165 μg/m3). We observed significant negative associations between total-PM2.5 levels in rural clusters with a higher prevalence of households living in poverty: − 0.298 (95% CI − 0.441, − 0.156), but not in urban areas: 0.081 (95% CI − 0.056, 0.219).
We noted significant associations between total-PM2.5 concentrations and the prevalence of households with improved sanitation : 0.123 μg/m3 (95% CI 0.010 μg/m3, 0.236 μg/m3) and households with safe drinking water: − 0.127 μg/m3 (95% CI − 0.216 μg/m3, − 0.039 μg/m3) in urban clusters, compared with − 0.137 μg/m3 (95% CI − 0.256 μg/m3, − 0.018 μg/m3) and 0.111 μg/m3 (95% CI 0.041 μg/m3, 0.181 μg/m3), respectively, in rural locations (Table 1). Our results suggest that different dimensions of inequality operate differently in urban and rural clusters.
When evaluating associations between the various SES parameters considered with anthropogenic-PM2.5 levels, we observed similar trends in associations to those estimated with total-PM2.5 levels (Table S6), with some differences. Namely, the general trend of associations between anthropogenic-PM2.5 concentrations and the prevalence of households with a Muslim head was positive: 0.010 μg/m3 (95% CI − 0.037 μg/m3, 0.056 μg/m3), whereas it was negative when considering total-PM2.5 levels. The same trend was observed when evaluating associations with the prevalence of households with improved sanitation: Associations with anthropogenic-PM2.5 were − 0.029 μg/m3 (95% CI − 0.089 μg/m3, 0.032 μg/m3), while those with total-PM2.5 were 0.112 μg/m3 (95% CI 0.037 μg/m3, 0.144 μg/m3).
We also reported associations with source-specific PM2.5 exposures using unadjusted (Table S7), fully-adjusted models (Table S8), and disaggregated by urban/rural designation (Table S9). We observed substantial differences in the magnitude and direction of associations observed with the different SES parameters considered. For example, PM2.5 from domestic burning is significantly lower in clusters with a higher prevalence of household heads with no formal education; However, we observed the opposite trend for PM2.5 from agricultural residue burning (for more details refer to section S4). The differences in associations are a result of the different distribution of sources (agricultural land, for example), as well as SES parameters (access to reliable electricity, among others). The latter is an environmental justice concern as research has shown that villages inhabited solely by SCs are significantly less likely to be electrified22 than other villages; while the former is not. Another possible reason for the difference in results is that so far, we assume a linear relationship between PM exposures and the different SES parameters considered. In future sections, we relax this assumption.
Evaluating associations between PM levels and different EJ dimensions after accounting for potential non-linearities
After accounting for potential non-linearities between the different SES parameters and total-PM2.5, there are several important nuances regarding associations between PM2.5 and the SES under consideration (Fig. 2). For example, when evaluating non-linear associations between total-PM2.5 and religion, caste, and gender-related SES, we find that although total-PM2.5 decreases on average with a unit increase in prevalence of ST households, total-PM2.5 concentrations increase in clusters with the highest prevalence of ST households. We observe a similar result in associations between totla-PM2.5 concentrations and clusters with a high prevalence of Muslim households (Fig. 2). Note that clusters with the highest prevalence of Muslim households have the lowest total-PM2.5 levels.

Partial response plot (red line) and 95% CI (between the blue dashed lines) for the association between total-PM2.5 and the prevalence of (A) SC households, (B) ST households, (C) OBC households, (D) Muslim households, (E) Households with a female head, (F) Mothers married young < 18 y of age), (G) Households BPL, (H) Poor Households, (I) Households with improved sanitation, (J) Electrified households, (K) Households using solid fuels, (L) Households with safe drinking water, (M) Underweight mothers, (N) Household head without formal education, (O) Household head with college-educated head, and (P) Population density in fully-adjusted models. We also display partial residual points and rug plots to provide readers with an understanding of the distribution of variables considered.
When evaluating associations between total-PM2.5 and the prevalence of poverty, we note that total-PM2.5 levels increase after initially decreasing for clusters corresponding to the highest prevalence of poverty (Fig. 2). We observed that the associations between total-PM2.5 and various household characteristics such as access to drinking water, access to improved sanitation, and access to electricity were fairly constant across different levels of these SES parameters. Total-PM2.5 concentrations first increased with the increasing prevalence of underweight mothers and then decreased (Fig. 2). Finally, we observed increases in total-PM2.5 in clusters with a higher prevalence of college-educated household heads (Fig. 2). These plots suggest that it is important to take into consideration non-linearity when evaluating associations between total-PM2.5 and SES in India. We note similar nonlinearities when evaluating associations between anthropogenic-PM2.5 levels and SES (Fig. S23), and between source-specific PM2.5 levels and SES (Figs. S24–S31) in supplementary analyses.
Evaluating associations between the ratio of power-PM levels and nighttime luminosity and different EJ dimensions
A higher prevalence of ST households in a cluster was significantly associated with a decrease in total-PM2.5 concentrations (Table 1); but was not significantly associated with changes in PM2.5 from power-generation (Table S8). However, we noticed significant disparities in exposure to PM2.5 from power generation relative to the benefits consumers receive (nighttime luminosity as a proxy for electricity use).
Specifically, the association between PM2.5 from power generation (burden) relative to nighttime luminosity (benefit) and the prevalence of ST households was significant: 15.187 (95% CI 3.829, 26.539) (Table 2). We observe similar results for clusters with a high prevalence of households in poverty: 15.970 (95% CI 3.459, 28.629). Unsurprisingly, we find that exposure relative to the benefits of PM2.5 from power generation is low in clusters with a high prevalence of electrified households, and safe drinking water (proxies of power consumption) (Table 2). Our analysis thus explores environmental justice concerns beyond looking at the distributional impacts of PM2.5, to the distributional impacts relative to the benefit from a key source of PM2.5.
Evaluating associations between the difference and percentage difference in PM2.5 concentrations in each cluster between 2015 and 2020 and different EJ dimensions
Overall, the mean difference in PM2.5 concentrations between 2010 and 2015 was 0.66 (min: − 24.4 μg/m3, max: 16.5 μg/m3, median: 0.8 μg/m3, standard deviation: 5.0 μg/m3). The mean percentage difference was 2.6% (min: − 22.3%, max: 24.9%, median: 1.9%, standard deviation: 9.5%).
We observed that there was a significant increase in PM2.5 increase levels 2015 relative to 2010 of 0.024 μg/m3 (95% CI 0.013 μg/m3, 0.047 μg/m3) for every standard deviation increase in the prevalence of Muslim households (Table 3). We observed the same general trend when evaluating associations between the percentage difference in PM2.5 levels between 2010 and 2015, relative to 2010 levels, instead of the absolute difference in PM2.5 levels in urban but not rural areas. In rural areas, there were significant decreases in PM2.5 levels in clusters with a higher prevalence of SC: − 0.040 μg/m3 (95% CI − 0.072 μg/m3, − 0.009 μg/m3), ST: − 0.054 μg/m3 (95% CI − 0.108 μg/m3, 0.000 μg/m3), OBC: − 0.042 μg/m3 (95% CI − 0.082 μg/m3, − 0.003 μg/m3), and mothers married < 18 years of age: − 0.062 μg/m3 (95% CI − 0.112 μg/m3, − 0.013 μg/m3); while we observed an increase in clusters with a higher prevalence of underweight mothers: 0.048 μg/m3 (95% CI 0.009 μg/m3, 0.088 μg/m3). We observed similar results in rural areas when evaluating associations between the percentage difference in PM2.5 levels, instead (Table 3). Our results that in recent years, overall, religion is becoming an increasingly important lens in India to evaluate EJ patterns.
We also noted a significant decrease in levels of − 0.051 μg/m3 (95% CI − 0.086 μg/m3, − 0.016 μg/m3) for every standard deviation increase in the prevalence of households BPL. We observed similar results when using the percentage difference in PM2.5 levels: − 0.071% (95% CI − 0.142%, − 0.001%) (Table 3). However, we noted a significant increase in the percentage difference in PM2.5 concentrations for every increase in the prevalence of poor households, overall: 0.135% (95% CI 0.044%, 0.226%), and in rural areas: 0.140% (95% CI 0.029%, 0.250%). We observed the opposite results in urban areas: − 0.146% (95% CI − 0.257%, − 0.034%) (Table 3). Our results suggest that villages in rural areas with a high prevalence of poorer residents, without access to services such as ration cards are vulnerable to increases in PM2.5 concentrations, relative to base levels.
Finally, we observed significant decreases in the percentage difference in PM2.5 levels for every increase in the prevalence of solid fuels, overall: − 0.131% (95% CI − 0.215%, − 0.048%) and in rural areas: − 0.150% (95% CI − 0.225%, − 0.075%), and opposite results in urban clusters: 0.236% (95% CI 0.132%, 0.341%) (Table 3).
Discussion
We curated a dataset of total, anthropogenic, and source-specific PM2.5 levels and SES variables associated with social advantage in India for a nationally representative set of clusters in India, which are villages in rural areas and census enumeration blocks in urban areas for the year 2015. Evaluating the variation in total-PM2.5 across multiple geographic scales, revealed that most variation occurred at the state-level, indicating that tackling large regional sources should be a priority in tackling pollution in India. This result could also suggest that more detailed ground-based PM2.5 measurements and emission inventories are needed to capture fine-scale PM variations in India.
In many regions of the world there is a growing understanding in EJ research that although identifying risk factors such as race, education and income is important, it is just as important to identify structural factors that result in such disparities23,24. Our research suggests that SES factors such as caste, religion, poverty, education, and access to various household amenities are important risk factors for PM2.5 exposures. Specifically, we observed that total-PM2.5 levels were significantly higher in clusters with a higher prevalence of SC, OBC households, and underweight and lower in clusters with a high prevalence of Muslim, ST, poor, and electrified households. However, different directions in associations were observed when disaggregating our analysis by urban/rural designation. For example, the general trend of associations between the prevalence of poor households and total-PM2.5 was positive in urban areas, but negative in rural locations. When considering other PM2.5 exposures, we also noted differences in the direction and magnitude of associations with different SES factors. Our results suggest that different dimensions of inequality operate differently in urban and rural areas, and for different sources. Future theoretical frameworks developed to conceptualize EJ in India, need to take these empirical differences into consideration.
Our relaxation of the assumption of linearity between the PM2.5 exposures considered and the different SES parameters can also potentially add nuance to the conceptualization of EJ in India. Specifically, we observed that total-PM2.5 levels were significantly lower, overall, in clusters with a higher prevalence of poor and Muslim households. However, when we accounted for potential non-linearities in the relationship between PM2.5 and the SES parameters considered, we observed that PM2.5 levels were highest in clusters with the highest prevalence of poverty and among the highest prevalence of Muslim households. Our analyses showed that clusters with a high prevalence of Muslim residents were observing significant increases in PM2.5 concentrations, suggesting that religion is becoming an important axis of inequality in India.
Although, most of this work conceptualized EJ in terms of evaluating disparities in exposure to PM2.5, we also considered a different definition of EJ; i.e. evaluating disparities in PM2.5 exposure from a key-source: power generation relative to the benefits received (using nighttime luminosity as a proxy). We observed that ST and poor households were exposed to significantly higher exposures from power-generation relative to the benefits they received. These results point to the urgency of expanding the theoretical discourse on EJ in India.
To summarize, this research presents a comprehensive overview of disparities in exposure to air pollution along several dimensions of environmental justice in India. Our approach has some limitations. Specifically, the PM2.5 exposures considered have several uncertainties. For example, previous work has shown that exposure estimates derived from satellite data diverge from each other, especially in rural areas where ground-based monitors are sparse4. In addition, we assigned ambient exposures to all individuals based on their cluster of residence. Due to the lack of data, we did not account for differences in housing characteristics, occupational exposures, activity patterns that could influence exposure to ambient PM2.5 concentrations.
Data and methods
Socioeconomic status (SES) and demographics
We drew data from the fourth round of National Family Health Survey (NFHS-4) of India (equivalent to Demographic and Health Survey) conducted between Jan 2015 and Nov 201625. NFHS are nationally representative household sample surveys measuring indicators of population, health and nutrition, with special emphasis on maternal and child health.
The NFHS-4 has a two-stage design, in which a number of clusters (villages in rural areas and census enumeration blocks in urban areas) are first selected from each of the 640 districts that existed at the time of the 2011 Census of India. Each of the 28,526 clusters was categorized as urban or rural. A household listing operation was then carried out by visiting each of the selected clusters and listing all residential households. Clusters with more than 300 households were divided into segments of 100–150 households. The resulting list of households served as a sampling frame for selection of households in the second stage. A fixed number of 22 households were selected from each cluster based on equal probability systematic sampling. Women aged 15–49 years were selected from these households for in-depth surveys. NFHS uses extensive interviewer training, standardized measurement methods, and an identical questionnaire to ensure standardization and comparability across diverse sites and times.
The GPS coordinates data for the NFHS-4 clusters were obtained via a special request. These survey cluster coordinates were collected in the field using GPS receivers, usually during the survey sample listing process. In general, the GPS readings for most clusters were accurate to less than 15 m. To ensure that respondent confidentiality was maintained, the GPS latitude/longitude positions were displaced for all clusters. The displacement was randomly carried out so that rural clusters contained a minimum of 0 and a maximum of 5 km of positional error. For 1% of the rural clusters, the displacement occurred up to 10 km. The displacement was restricted so that the points stayed within the second administrative level of the district.
We chose context-specific SES covariates to evaluate the EJ implications of pollution in India. In addition to choosing risk-factors related to income, education, household assets and wealth, which are commonly associated with social advantage, we also looked at caste- and religion-specific variables. Caste has a deep sociological history in Indian society. Lower castes now referred to as Schedule Caste (SCs), Scheduled Tribes (STs) and Other Backward Classes (OBCs) have historically been denied access to important public services. There is still strong evidence of discrimination against these groups in both the education sector and the labor market26,27,28. There is also evidence that religious minorities like Muslims have been marginalized in India29. We thus included these covariates as key EJ dimensions in India.
From Household Recode NFHS data, we extracted the following binary household-level covariates: (1) Poor: Household was in the lowest wealth quintile, (2) Household had a Below Poverty Line (BPL) ration card, (3) Household had electricity, (4) Household had improved sanitation, (5) Household used solid fuels for their energy needs, (6) Household had access to safe drinking water, (7) Household head was Muslim, (8) Household head had been to college, (9) Household head was uneducated, (10) Household head was female, (11) Household head belonged to a Scheduled Caste (SC), (12) Household head belonged to a Scheduled Tribe (ST), and (13) Household head belonged to an Other Backward Class (OBC).
From Individual-level NFHS-4 data from the women interviewed, we extracted the following binary level covariates: (1) Mother is uneducated, (2) Mother is literate, (3) Mother was married before 18 years of age, and (4) Mother is underweight (BMI < 18.5 kg/m2), an indicator of food-access.
NFHS-4 provides addition geospatial covariates for each cluster, on population density for the year 2015 (#/km2) within the 2 km (urban) or 10 km (rural) buffer surrounding the NFHS-4 survey cluster location. The estimate of population density is Population counts for each cluster used to produce these estimates were derived from the Gridded Population of the World, Version 4 (GPWv4). Although population density is traditionally measured as persons per square kilometer (or, square mile), a natural logarithmic transformation of this measure is used in our multivariate analysis to account for its skewed distribution, as recommended in previous EJ research. We also derived average nighttime luminosity in the form of a nightlight index (dimensionless) from the NFHS-4 geospatial data for the year 2015. (Figs. S1–S6 in Supplementary Information displays the spatial distribution of various SES parameters.)
We removed clusters for which we did not have information on context-specific SES covariates or population density and were left with 28,072 of a total of 28,526 clusters. Most of these clusters are in Jammu and Kashmir and Assam (Fig. S11).
Deriving cluster-specific SES covariates
To account for the complex survey design and sampling variability, we derived cluster-specific predicted probabilities of each variable from NFHS household and individual data described in “Evaluating Disparities in PM concentrations along different EJ dimensions” Section using four-level multilevel models16,30. The four levels of geographic units are individuals (or households) at level-1 (i), clusters at level-2 (j), districts at level-3 (k) and states at level-4 (l). The model is presented below:
\(\beta_{0}\) is the constant and represents the median log odds of each covariate across all of India; \(u_{0jkl}\), \(v_{0kl}\), and \(f_{0l}\) are the residuals at the cluster, district, and state levels, respectively. The residuals are assumed to be normally distributed with a mean 0 and a variance of \(\sigma_{u0}^{2}\), \(\sigma_{v0}^{2}\), and \(\sigma_{f0}^{2}\). These variance terms can be interpreted as within-district between-cluster variation (\(\sigma_{u0}^{2}\)), within-state between-district variation (\(\sigma_{v0}^{2}\)), and between-state variation (\(\sigma_{f0}^{2}\)).
From the model described in Eq. 1, the cluster-specific logit values were converted to probabilities by taking the average over the simulations, i.e.. \(exp \left( {\beta_{0} + u_{0jkl} + v_{0kl} + f_{0l} } \right) /\left( {1 + exp \left( {\beta_{0} + u_{0jkl} + v_{0kl} + f_{0l} } \right) } \right)\). For estimation, we used Monte Carlo Markov Chain (MCMC) methods with a burn-in of 5000 cycles, and monitoring of 50,000 iterations of chains. For all estimates, we used 2nd order penalized quasi-likelihood (PQL) for the estimation of starting values, but for few variables (Households with electricity, Poor households, Households with a Muslim head, Household with an ST head) the convergence failed, and we used 1st order marginalized quasi-likelihood (MQL) instead.
In this manner, cluster-specific predictions of the various covariates can be made by “shrunken” higher level residuals that consider the ratio of the between-state, between-district and between-cluster variance to the total variance, which includes the within-state, within-district and within-cluster sampling variance attributable to the sample size of districts with states, clusters within districts, and individuals within clusters. Hence, more shrinkage occurs i.e. cluster-specific means are pulled more towards district-means (and state-means) if there are fewer individuals within a cluster, and consequently higher sampling variances, and/or when the estimated variance of the clusters is small.
Total PM2.5 exposure
The main exposure variable in this study was long-term ambient PM2.5 between the years 2010–2015. Because India lacks surface PM2.5 monitoring sites at the spatial resolution required for the study, and the NFHS surveys do not record PM2.5 concentration in each cluster, we used satellite-derived annual averaged PM2.5 estimates derived by Hammer et al.18 as the main exposure of interest as this dataset has been validated and used in several global studies4,31. Satellite aerosol optical depths (AODs) were combined from multiple satellite products: MISR, MODIS Dark Target, MODIS and SeaWiFS Deep Blue, and MODIS MAIAC with simulation-based results based on their relative uncertainties. These AODs were related to near-surface monthly PM2.5 concentrations at a 0.01° × 0.01° (~ 1 km × 1 km at the equator) resolution over the globe using the ratio of simulated AOD and PM2.5 from the GEOS-Chem model. We clipped these estimates to India. On an annual scale the PM2.5 estimates are highly consistent with globally distributed ground monitors (R2 = 0.90–0.92). We previously evaluated this dataset based on ground-based monitors in India and found the India-specific R2 was 0.55 (RMSE: 27.5)4. We extracted mean PM2.5 levels in the 2 km/5 km buffer for urban and rural household clusters respectively (Fig. S7).
Note, we opted to use a satellite-derived exposure product for this analysis, instead of model-based products that we use to map source-specific and anthropogenic PM2.5 concentrations discussed below, as the model-based results are available for a single year, alone. We evaluate associations between the difference in PM2.5 concentrations between 2010 and 2015 and SES parameters in this paper. Moreover, the model-based PM2.5 exposure products are at a coarser resolution (36 km × 36 km), compared to the satellite-derived concentrations (1 km × 1 km). The spatial resolution of the satellite-derived concentrations is more well aligned with the spatial resolution of the NFHS clusters.
Anthropogenic and source-specific PM2.5 exposure
We estimated annual-averaged anthropogenic PM2.5 concentrations for the year 2016 using the Community Multiscale Air Quality (CMAQ) model19. The model set up WRF v.3.9.132 & CMAQ v.5.3.133 was used to estimate species-specific PM2.5 concentrations (elemental carbon: EC, ammonium: NH4, nitrate: NO3, organic carbon: OC, sulfate: SO4, soil, and others, including chloride (Cl), sodium (Na), magnesium (Mg), potassium (K), calcium (Ca), soil, and water molecules, and other unspecified species), as well as source-specific PM2.5 levels from agricultural residue burning (ARB), industry (IND), power (POW), transport (TRA), domestic burning (DOM), road dust (RDUST), international contributions (INT), others (OTH), that include refuse burning, construction, crematoria, NH3, biogenic emissions, refineries, and evaporative non-methane volatile organic compounds at a 36 km × 36 km scale19 (Fig. S9). We derived anthropogenic PM2.5 concentrations by subtracting soil dust levels from total PM2.5 concentrations derived from the speciated PM2.5 analysis. (Fig. S8). When conducting analyses involving anthropogenic PM2.5, and source-specific PM2.5 levels, we removed clusters for which we did not have information on these exposures due to issues with clipping the exposure dataset and were left with 27,535 clusters (Fig. S11). A coefficient of determination between ground-based observations and simulated monthly averaged PM2.5 concentrations of ~ 0.81 was reported. For more details refer to19. We also estimated the ratio of exposure to PM2.5 from power generation (POW) relative to the NFHS-4 nighttime luminosity index as a measure of inequalities of exposure to POW relative to the benefits that different consumers receive (Fig. S10).
Statistical methods
We evaluated disparities in exposure based on local demographic characteristics. To do so, we rank ordered all clusters based on the prevalence of the different SES parameters considered in this study. We compared the distribution of pollution levels in the top and bottom decile of clusters based on each SES parameter (Fig. 1). Note, we do not present population-weighted exposures because our prevalence parameters are based on the number of households or the number of mothers in each cluster, whereas we only have data on the total population in each cluster. We evaluated high-end exposure disparities to pollution by analyzing the distribution of demographic characteristics of clusters above the 90th percentiles of air pollution exposure among all clusters and comparing it to the national distribution (Fig. 2).
We analyzed the PM2.5 exposures as a continuous variable, with multilevel linear models including random effects for cluster, district and state-spatial scales. First, we used null models, only including fixed effects for urban/rural to estimate the crude variation in the pollutant exposures at each geographic level. The proportion of variance attributed to each level, z, was computed as follows: 100 × varz/(varcluster + vardistrict + varstate). We next added the logarithm of population density to our model and repeated this calculation.
We then used multilevel regression models, again only including urban/rural fixed effects and the logarithm of population density, using each of the PM exposures as the outcome and each SES variable as the exploratory parameters to evaluate associations between pollution and SES. We report the % variance change at each level from introducing the SES variables into the models.
We then ran fully adjusted models where we evaluated associations between the exposures of interest and SES factors after also adjusting for all other SES parameters. In all models, we scaled all independent variables by using z-scores to present effect estimates of linear associations per one standard deviation (SD) increase and facilitate comparability of estimates across all variables used. In the fully-adjusted models, we did not include the prevalence of literate mothers in the analysis, to ensure that the variance inflation factors of all coefficients included were less than four. We also report results from this analysis, disaggregated by urban/rural designation.
We tested for potential non-linearities between the exposures of interest and each SES under consideration and time of operation in the following manner: We used penalized splines (p-spline) to flexibly model the associations between the exposures of interest and the SES under consideration in the fully-adjusted model using a generalized additive model (GAM). We used the minimized generalized cross-validation score (GCV) criterion to select the optimal degrees of freedom (df). We plotted the relationships observed. The GAM fitting and analysis were conducted with the mgcv package in the programming language R.
We used fully-adjusted models to evaluate associations between the ratio of PM2.5 concentrations from power generation and the average nighttime luminosity (as a proxy for the benefits from power-generation) and each SES parameter. In this manner we evaluated the variation in exposure to concentrations from an important source, relative to benefits received across different SES levels. Finally, we evaluated associations between the difference in PM2.5 concentrations between the years 2015 and 2010, and the percentage difference with each SES parameter considered using fully-adjusted models. We repeated these analyses using data from urban and rural clusters, separately.
We mapped the geographic distribution of all analyzed variables. All models were run in R 4.2.1. Maps were plotted using QGIS 3.10.1.
Data availability
NFHS-4 data is available on submitting a request via the DHS website https://dhsprogram.com/.
Change history
09 November 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-46982-4
References
Home | State of Global Air. https://www.stateofglobalair.org/.
Balakrishnan, K. et al. The impact of air pollution on deaths, disease burden, and life expectancy across the states of India: The global burden of disease study 2017. Lancet Planet. Health 3, e26–e39 (2019).
Guttikunda, S. K., Nishadh, K. A. & Jawahar, P. Air pollution knowledge assessments (APnA) for 20 Indian cities. Urban Clim. 27, 124–141 (2019).
deSouza, P. N. et al. Robust relationship between ambient air pollution and infant mortality in India. Sci. Total Environ. 815, 152755 (2022).
Pandey, A. et al. Health and economic impact of air pollution in the states of India: The global burden of disease study 2019. Lancet Planet. Health 5, e25–e38 (2021).
Miranda, M. L., Edwards, S. E., Keating, M. H. & Paul, C. J. Making the environmental justice grade: The relative burden of air pollution exposure in the United States. Int. J. Environ. Res. Public. Health 8, 1755–1771 (2011).
Jbaily, A. et al. Air pollution exposure disparities across US population and income groups. Nature 601, 228–233 (2022).
Colmer, J., Hardman, I., Shimshack, J. & Voorheis, J. Disparities in PM2.5 air pollution in the United States. Science 369, 575–578 (2020).
Boing, A. F., deSouza, P., Boing, A. C., Kim, R. & Subramanian, S. V. Air pollution, socioeconomic status, and age-specific mortality risk in the United States. JAMA Netw. Open 5, e2213540 (2022).
deSouza, P. N. et al. Spatial variation of fine particulate matter levels in Nairobi before and during the COVID-19 curfew: Implications for environmental justice. Environ. Res. Commun. 3, 071003 (2021).
Mohai, P., Pellow, D. & Roberts, J. T. Environmental justice. Annu. Rev. Environ. Resour. 34, 405–430 (2009).
Hajat, A., Hsia, C. & O’Neill, M. S. Socioeconomic disparities and air pollution exposure: A global review. Curr. Environ. Health Rep. 2, 440–450 (2015).
Kopas, J. et al. Environmental justice in India: Incidence of air pollution from coal-fired power plants. Ecol. Econ. 176, 106711 (2020).
Sengupta, S. et al. Inequality in air pollution mortality from power generation in India. Environ. Res. Lett. 18, 014005 (2022).
Chakraborty, J. & Basu, P. Air quality and environmental injustice in India: Connecting particulate pollution to social disadvantages. Int. J. Environ. Res. Public. Health 18, 304 (2021).
Kim, R. et al. Precision mapping child undernutrition for nearly 600,000 inhabited census villages in India. Proc. Natl. Acad. Sci. 118, e2025865118 (2021).
Subramanian, S. V. et al. Progress on sustainable development goal indicators in 707 districts of India: a quantitative mid-line assessment using the National Family Health Surveys, 2016 and 2021. Lancet Reg: Health Southeast Asia 0, (2023).
Hammer, M. S. et al. Global estimates and long-term trends of fine particulate matter concentrations (1998–2018). Environ. Sci. Technol. https://doi.org/10.1021/acs.est.0c01764 (2020).
Singh, N., Agarwal, S., Sharma, S., Chatani, S. & Ramanathan, V. Air pollution over India: Causal factors for the high pollution with implications for mitigation. ACS Earth Space Chem. 5, 3297–3312 (2021).
Mohindra, K. & Labonté, R. A systematic review of population health interventions and Scheduled Tribes in India. BMC Public Health 10, 438 (2010).
Narayan, S. Time for universal public distribution system: Food mountains and pandemic hunger in India. Indian J. Hum. Dev. 15, 503–514 (2021).
Aklin, M., Cheng, C.-Y. & Urpelainen, J. Inequality in policy implementation: Caste and electrification in rural India. J. Public Policy 41, 331–359 (2021).
Tan, S. B., deSouza, P. & Raifman, M. Structural racism and COVID-19 in the USA: A county-level empirical analysis. J. Racial Ethn. Health Dispar. https://doi.org/10.1007/s40615-020-00948-8 (2021).
Van Horne, Y. O. et al. An applied environmental justice framework for exposure science. J. Expo. Sci. Environ. Epidemiol. https://doi.org/10.1038/s41370-022-00422-z (2022).
IIPS, O. National family health survey (NFHS-4): 2014–15: India. Mumbai Int. Inst. Popul. Sci. (2017).
Banerjee, A., Bertrand, M., Datta, S. & Mullainathan, S. Labor market discrimination in Delhi: Evidence from a field experiment. J. Comp. Econ. 37, 14–27 (2009).
Thorat, S. & Sadana, N. Discrimination and children’s nutritional status in India. IDS Bull. 40, 25–29 (2009).
Madheswaran, S. & Attewell, P. Caste discrimination in the Indian urban labour market: Evidence from the national sample survey. Econ. Polit. Wkly. 42, 4146–4153 (2007).
Robinson, R. Religion, socio-economic backwardness & discrimination: The case of Indian Muslims. Indian J. Ind. Relat. 44, 194–200 (2008).
Rajpal, S., Kim, J., Joe, W., Kim, R. & Subramanian, S. V. Small area variation in child undernutrition across 640 districts and 543 parliamentary constituencies in India. Sci. Rep. 11, 4558 (2021).
deSouza, P. N. et al. Impact of air pollution on stunting among children in Africa. Environ. Health 21, 128 (2022).
Skamarock, W. J. G. et al. A Description of the Advanced Research WRF Version 2 (NCAR Tech, 2005).
Appel, K. W. et al. The community multiscale air quality (CMAQ) model versions 5.3 and 5.3.1: System updates and evaluation. Geosci. Model Dev. 14, 2867–2897 (2021).
Funding
Dey acknowledges funding from IIT Delhi for Institute Chair Fellowship and from Clean Air Fund. Ko and Kim were supported by the National Research Foundation of Korea(NRF) grant No. RS-2023-00219289 funded by the Korea government (MSIT). Subramanian and Kim were supported by grant INV-002992 from the Bill & Melinda Gates Foundation.
Author information
Authors and Affiliations
Contributions
Conceptualization: P.D. Data curation: P.D., E.C., S.D., S.K., R.K. Methodology: P.D., R.K., S.V.S. Formal analysis: P.D. Investigation: All authors Writing-original draft: P.D. Writing- review and editing:
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the spelling of the author Sagnik Dey which was incorrectly given as Sagnk Dey.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
deSouza, P.N., Chaudhary, E., Dey, S. et al. An environmental justice analysis of air pollution in India. Sci Rep 13, 16690 (2023). https://doi.org/10.1038/s41598-023-43628-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-43628-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
