
Abstract
In this research, for some different Schottky type structures with and without a nanocomposite interfacial layer, the current–voltage (I–V) characteristics have been investigated by using different Machine Learning (ML) algorithms to predict and analyze the structures’ principal electric parameters such as leakage current (I0), barrier height (\({\varphi }_{B0}\)), ideality factor (n), series resistance (Rs), shunt resistance (Rsh), rectifying ratio (RR), and interface states density (Nss). The interfacial nanocomposite layer is made by composing polyvinyl-pyrrolidone (PVP), zinc titanate (ZnTiO3), and graphene (Gr) nanostructures. The Gaussian Process Regression (GPR), Kernel Ridge Regression (KRR), Support Vector Regression (SVR), and Artificial Neural Network (ANN) are used as ML algorithms. The ML techniques training data are obtained using the thermionic emission method. Finally, by comparing the experimental and predicted results, the performance of the different ML algorithms in predicting the electrical parameters of Schottky diodes (SDs) has been compared to find the optimized ML algorithm. The ML predictions of basic electrical parameters by almost all algorithms are in good agreement with the actual values, while the SVR model has predicted closer values to the corresponding actual ones. The obtained results show that the quantity of the leakage current and Nss for MS type SD decreases, and φB0 increases with the interfacial layer usage, especially with graphene dopant.
Similar content being viewed by others

Introduction
Depending on the potential barrier height (BH) value, the metal/semiconductor (MS) structure or Schottky diode (SD) with/without an interfacial polymer layer has been known as a rectifying or non-rectifying device1. The contact is either Schottky or ohmic when the potential BH value is enough high or low, respectively2,3,4,5. According to Schottky and Mott theory, the back metal ohmic, front metal rectifier contacts, and the work functions of the semiconductor also determine the ohmic and rectifying behavior of these devices1,4,5. In p-type semiconductor, to get a rectifier, the work-function value of metal (Φm) value must be less than work-function of semiconductor (Φs), but to get an ohmic contact, Φm > Φs. In n-type semiconductor the situation was reversed the opposite is the case for an n-type semiconductor. These structures play an important role in all semiconductor devices such as SD with/without an interfacial polymer layer, capacitor, transistor, and solar cells 3. The essential scientific and technological difficulty in the MS structures is that their growing performance and cost-effective fabrication is depended on wielding the various suitable interfacial polymer/organic layers with metal/metal-oxide dopants and large-dielectric materials3,4,5,6,7. In other words, the main technological problem today is to both reduce the cost and increase the performance. Because polymers are usually cheap, flexible, easy to grow, have high mechanical and dynamic strength, but have low conductivity and dielectric values. However, this problem can be overcome by doping them with a low proportion of metal, metal oxide, and graphene. Therefore, it is worth to noting that, the prepared conventional insulator layers with the old-fashioned techniques inserted between metal and semiconductor layers have not been able to passivate the dangling bonds which activate on the semiconductor surface and reduce the leakage current6,7,8,9,10,11. In addition, sufficient flexibility, high surface space compared to volume rate, large capacity in charge/energy-storage, easy procedure techniques, weightlessness, and suitable stability of dielectric and mechanical characteristics are some of the reasons for improving the electric, dielectric, and optical features of these MS devices with an interfacial polymer/organic layer with/without metal, graphene, and metal-oxide dopants12,13,14,15. Therefore, controlling and manipulating potential BH is necessary to enhance the performance of the MS structure.
The electrical response of SDs varies depending on the operating environment, which affects its applicability in electronics technology. Moreover, the characterization of electric features of SDs is a long-time and high-cost process due to the sensitive laboratory requirement. So, engineering tools with high reliability are essential, enabling to predict the electrical properties of SDs. On the other hand, there are sometimes significant deviations from the ideal state between the electrical parameters obtained using thermionic emission theory as experimental and the theoretical methods. These deviations are generally due to the inhomogeneity of the barrier and the interfacial layer formed between the M/S interface, the series resistance (Rs) of the diode, and the interface states/traps (Nss) created between the interfacial layer and the semiconductor. Therefore, it is obvious to turn to alternative methods that can reduce part of the volume of experimental tests, leading to cost reduction and time-saving. Currently, the most prominent method to achieve this goal is the use of Machine Learning (ML), and scientific research has not only proven the applicability of ML in most branches of science and technology but also shows us the utility of this powerful scientific tool in the field of Schottky structures and predicting some of their electrical properties. ML is one of the subfields of artificial intelligence that is able to evaluate data samples and make some rules and patterns to extend a simulation model for predicting new data. It is a powerful predictive tool with high accuracy and no need for human decision and intermediation which is applied in many fields. ML consists of extensive types of modeling algorithms to learn the rules and then predict the new data13. Recently, the electrical parameters of SDs have been analyzed with the Machine Learning (ML) method in the literature.
Torun et al.14 analyzed the I–V characteristics of Au/Ni/n-GaN SD in the temperature range of 40–400 K with 4 algorithms of ML technique. They used Adaptive Neuro Fuzzy System (ANFS), Artificial Neural Network (ANN), Support Vector Regression (SVR), and Gaussian Process Regression (GPR) algorithms for modeling the experimental data of 5192 samples. After obtaining the model error and they compared their performance with each other, and they uncovered that the AFNS model has shown the best performance in both the train and test phases among the utilized models. Ali et al.15 modeled the electrical current of heterojunction SDs as a function of voltage and temperature by using an ANN based on the experimental data. They presented that the I–V results predicted by the ANN model are in good agreement with the experimental ones with a suitable accuracy. Güzel et al.16 reported the ANN system prediction of electric current of 6H-SiC/MEH-PPV SDs with an interfacial polymer layer in terms of the voltage and temperature. The experimental results were measured at the voltage and temperature ranges of − 3V to + 3V and 100–250 K, respectively. The results predicted by ANN system are incompatible with the experimental ones with a good accuracy and an average deviation of 0.15%. Çolak et al.17 used an ANN model with 15 neurons in 1 hidden layer to predict the electric current of a SD depending on the voltage of − 2 V to + 3 V and the temperature of 100–300 K. It was found that the predicted data are in good agreement with experimental results of SD. However, the investigation of ML techniques to determine the electrical parameters of SDs has been limited so far, and more research and investigations are needed, especially to identify and improve appropriate ML algorithms for Schottky structures. Therefore, it should be researched which algorithms have better predictive performance and under the influence of various factors on the characteristics of the input data, they still maintain this advantage, and in addition, how to increase their efficiency by improving and upgrading common algorithms.
In most studies conducted in the Schottky structures that have employed machine learning, the ANN algorithm has been utilized for training and prediction purposes. The obtained results demonstrate that the predicted data closely approximate the actual data with a negligible margin of error14,15,16,17. In this research, in addition to utilizing the ANN algorithm, we have employed three other algorithms, namely Gaussian Process Regression (GPR), Kernel Ridge Regression (KRR), and Support Vector Regression (SVR), for training and predicting the I–V characteristics of Schottky diodes. The purpose of employing these four algorithms is to examine their accuracy, prediction error, and overall performance by comparing the results of their predictions with each other and with the experimental data. Subsequently, if possible, we aim to identify an algorithm that exhibits the most negligible prediction error compared to the other algorithms employed in this study, thus demonstrating superior performance in most cases.
A perovskite-type ZnTiO3 and graphene could be considered as an interfacial layer grown between metal and semiconductor to get MIS type SD, capacitor, and solar cell aplications18,19,20. Therefore, in this study, zinc-titanate and graphene nanostructures have been doped into the PVP as interfacial layer between Al and p-Si layers to enhance the electrical performance of the MS-type SD. Five SDs with the structures of Al/p-Si (MS), Al/PVP/p-Si (MPS1), Al/PVP:Gr/p-Si (MPS2), Al/PVP:ZnTiO3/p-Si (MPS3), and Al/PVP:Gr-ZnTiO3/p-Si (MPS4) have been manufactured to study the effect of these interfacial polymer layers with/without dopants on the basic electric parameters of the MS type SD. The procedures of the material preparation and fabrication of the SDs have been concisely expressed. Next, the I–V characteristics of the SDs have been measured by the TE method to calculate and analyze the principal electric parameters of the SDs, such as n, BH, I0, Rsh, and Rs. After that using above mentioned ML algorithms, the I–V characteristics have been predicted, and then above and some other electrical parameters of SDs calculated. Comparing the experimental and predicted results, the performance of the different ML algorithms for accurately predicting the electrical parameters of SD have been evaluated to find the optimized ML algorithm.
Experimental details
Materials
The precursors of TiCl4, Zn(CH3COO)2.2H2O, and NaOH with a purity of more than 99% were provided by ROYALEX and Merck Companies, respectively. In order to rinse the Si wafer, the compounds of H2O2, HF, CH3COCH3, CH3OH, and C2H5OH have been used.
Moreover, the prepared nanocomposites were irradiated by a microwave device at a power range from 100 to 800 W and a fixed frequency of 2450 MHz produced by Samsung: model ME2040/ME201 (Korean company). To measure the I–V characteristics of the SDs have been carried out by KEITHLEY (Model 2450).
Synthesis of ZnTiO3 nanostructures
Figure 1 schematically illustrates the preparing procedures of ZnTiO3 nanostructures used as dopant in the interfacial polymer layer. In order to synthesize the ZnTiO3 nanostructures, at first, three beakers of Zn(CH3CO2)2, NaOH, and TiO2 solutions were prepared at 20cc volume. The nanostructures of TiO2 have already been provided by dropwise adding 22cc of TiCl4 (liquid phase) to 20cc of NaOH solution on a magnetic stirrer and then irradiating with an 800 W microwave for 10 min. The obtained white mixture was rinsed by deionized water and dried at 25 °C. Next, the prepared solutions of TiO2 and NaOH were dropwise added to the Zn(CH3CO2)2 solution under an ultrasonic irradiation. Next, the produced solution was exposed by an 800 W microwave radiation for 10 min. Then, the result was rinsed by a centrifugation process and dried at 25 °C. At last, the resulted nano-powder was annealed at a temperature of 700 °C for 2 h.

Preparing procedures of Zinc titanate nanostructure.
Washing process of Si wafer
In order to coat the interfacial polymer layer and make an MPS SD, the surface of the Si wafer needs to be cleaned from the pollutants as well as eliminate the SiO2 intrinsic layer on the surface. To this aim, different solutions have been used to wash the Si wafer in this work. First, it was rinsed by CH3COCH3 and CH3OH at a temperature of 55 °C for 5 minutes. Second, the Si wafer has been washed by a solution of H2O, NH4OH, and H2O2 at a temperature of 70 °C for 15 min. Finally, it was washed using a solution of H2O and HF acid at a temperature of 25 °C for 2 minutes.
Fabrication of SDs
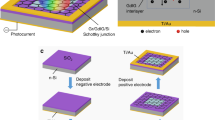
It is necessary to note that a 300 µm p-type Si wafer has been applied in this work. As an ohmic contact, an aluminum layer with a thickness of 100 nm was coated on the back side of silicon wafer at 10–6 Torr and then annealed at 500 °C. To make PVP:ZnTiO3 interfacial polymer layer, 10 mg of ZnTiO3 nanostructures was dispersed by ultrasonic technique after preparing a 5% solution of PVP with solvating 5 g of PVP nano-powders in 95cc water. The preparing steps of different interfacial polymer layers are schematically presented in Fig. 2.

Preparation procedures of different SDs.
Then, a soft layer of each prepared nanocomposites with a thickness of 100 nm has been deposited on the front side of the silicon wafer by using a spin coater system. At last, the 100 nm masks with 1.2 mm diameter were deposited on each prepared nanocomposite layers as the ohmic contacts. So, five SDs were manufactured by MS and MPS contacts without/with related interfacial nanocomposite layers. Figure 3 schematically shows these contacts with their corresponding energy-band diagrams.

Schematic of the manufactured (a) MS and (b) MPS3 type-SDs and their corresponding energy-band diagrams.
There is several information on the grown and crystalline size, surface morphology, bandgap energy of the ZnTiO3 and HOMO and LUMO contour maps of PVP molecule can be found in our previous study21.
ML algorithms
Machine learning, one of the substantial branches of artificial intelligence, is an interdisciplinary topic based on mathematics, statistics, computer science, and engineering, which optimized the computer programs' performance using data or former experiences. Several related research indicates that, the usage of machine learning is an effective method to get swiftly laws and trends from accessible data without needing the physical mechanism and also spending high experimental costs. Recent investigations demonstrated that machine learning has been utilized in various scientific and engineering problems such as biology, physics, chemistry, computer vision, medical care, industry, and even financial fields22,23,24,25,26,27,28,29,30,31,32. In this study, some machine learning techniques such as GPR, KRR, SVR, and ANN are used to model I–V diagram and predict some electrical and dielectric parameters of Schottky structures. Then the results obtained from the mentioned algorithms are compared with each other and with the experimental data.
In the following, we briefly explain the algorithms used in this research.
GPR algorithm
GPR algorithm is a non-parametric, supervised machine learning technique that utilizes a probabilistic approach to interpreting data33. In GPR models, it is assumed that the outputs have a joint Gaussian distribution, providing a powerful tool for predicting outcomes34. So, the GPR problem can be formulated by estimating the probability distribution of the predicted variables given in the training data. It is able to define the joint probability distribution of the outputs as:
with \(\mathcal{N}\) being the Gaussian distribution function with the mean value of 0 and the covariance matrix of δ. The mean value of the joint distribution will be assumed zero without loss of generality. It must be noted that the zero mean value can be deducted from the joint distribution to meet the assumption even if the output distribution is around some non-zero mean. The covariance matrix, δ, is given by;
where K, K∗, and K∗∗ refer to the single covariance matrices which are the combinations of the training and test data sets as: K = K(Xtrain; Xtrain), K∗ = K(Xtrain; Xtest), and K∗∗ = K(Xtest; Xtest). The covariance matrices, K, is described by a positive definite kernel function:
where σ and λ denote hyperparameters of the GPR model with x and \({\mathrm{x}}^{\mathrm{^{\prime}}}\) being the input pairs depending on the suitable data sets. In fact, the distance or similarity between the input pairs are measured by the kernel function. The GPR aims to predict the new distribution of the test data based on the training data. Therefore, the Bayes’ rule is applied respectively to acquire the expected value and covariance of this new distribution as follows33:
The predicted output distribution with the GPR is entirely defined by expressions (4) and (5). It is crucial that, unlike linear regression, GPR is not a parametric function. This non-parametric nature allows GPR to predict non-linear behaviors. Moreover, the GPR model not only indicates the expected value of the prediction but also provides an associated variance, giving confidence bounds on the model's predictions. Rather than relying solely on the training data, GP explicitly utilizes it to make predictions.
KKR algorithm
Ridge regression is one of the elementary algorithms that are able to be kernelized. For this, it is necessary to find a linear function modeling the dependency of both continuous covariates {xi} and response variable {yi}. Minimizing the quadratic cost is the classical method to do that as35:
The variable of xi should be replaced by ϕ(xi) when working in the feature space. However, it leads to the risk of facing overfit, which avoiding it needs to regularize. An effective approach to regularization is to penalize the magnitude of the weights (w). Cross-validation or leave-one-out estimates are among the most commonly employed algorithms. Therefore, the total cost function which must be minimized is as follows35.
The following expression is acquired by solving derivatives and setting them equal to zero yields.
It is clear that the regularization term results in numerically stabilizing the inverse by restricting the smallest eigenvalues from zero. When all data points replace by their feature vector, i.e. \({x}_{i}\to {\phi }_{i}=\phi ({{\varvec{x}}}_{i})\), the number of dimensions will be much larger than that of data points. It is able to use a clever technique to achieve the inverse in the most efficient way possible, either by reducing the dimensionality of the feature space or the number of data points. This technique is given by the following identity36:
By defining \(\phi ={\phi }_{ai}\) and \({\varvec{y}}={y}_{i}\), the solution is as follows:
This equation can be expressed in an alternate form as \({\varvec{w}}=\sum_{i}{\alpha }_{i}\phi ({{\varvec{x}}}_{i})\) by \(\alpha ={({\phi }^{T}\phi +\lambda {\mathbf{I}}_{\mathbf{n}})}^{-1}{\varvec{y}}\). It must be demonstrated that it does not actually require access to the feature vectors, which could potentially be infinitely long. Practically, we require the predicted value for a new test case, x, which is determined with its projection on the solution, w,
with \(K\left(b{x}_{i},b{x}_{j}\right)={\phi }^{T}({x}_{i})\phi ({x}_{j})\) and \({\varvec{\kappa}}\left({\varvec{x}}\right)=K({{\varvec{x}}}_{i},{\varvec{x}})\)32. So, it is only required access to the kernel K. There are various kernel functions such as linear, polynomial, sigmoid, and Radial Basis Function (RBF) which the last one has been selected in this work owing to the fewer factors and numerical complications of RBF37.
ANN algorithm
A multilayer perceptron (MLP) employs a supervised-learning technique known as backpropagation to train the network, allowing it to learn from its mistakes and adjust its parameters accordingly. A MLP is composed of multiple layers of interconnected nodes, where each node (except for the input nodes) is a neuron with a nonlinear activation function38. These nodes are connected by a directed graph, forming a powerful network of neurons. In a MLP, neurons in two adjacent layers are connected via the weighted edges to form a pair. A MLP consists of at least three layers of neurons, including an input layer, one or more hidden layers, and an output layer. These layers are interconnected, allowing information to flow from the input layer to the output layer, helping the MLP to learn and make predictions39. The perceptron takes a linear combination of weighted real-valued inputs and passes it through a nonlinear activation function to generate an output, y, as38:
where b, x, w, and ϕ refer to the bias, the input vector, weights vector, and the activation function, respectively. The MLP algorithms commonly select the hyperbolic tangent, the logistic sigmoid function, and ReLU function as the activation functions36. The MLP algorithm adjusts the weights of the hidden layer in order to minimize the output error. By considering the difference between actual (On(t)) and desired (Tn) values, the error function could be written as38;
In fact, minimizing the error function is the main propose of training procedure. By utilizing a learning parameter η (< 1), the convergence rate can be influenced and the step sizes at which weights are adapted can be reduced. The following rule can be used to update the ith weight connected to the jth output38:
Equations (1, 2, 3) illustrates an iterative weight adaptation process, in which a portion of the output error from the next iteration (t + 1) is added to the weight from the current iteration (t). MLPs are frequently employed for supervised-learning pattern recognition tasks. Interest in MLP backpropagation networks has been reignited due to the remarkable achievements of deep learning40. In this work, MLP was implemented with ten hidden layers and 100 neurons at each one. The input layer consists of applied voltage and different interfacial layers while the output layer includes the electric current.
SVR algorithm
The Support Vector Method (SVM) is one of the machine-learning techniques proposed by Vapnik41. This method is a supervised learning model based on statistical learning that is used for analyzing existing data for classification and regression analysis. SVM training algorithm using given training data that have been labeled as belonging to one of two different classes, designs a model that determines which classification class each new data belongs to.
SVM maps data to a feature space of high dimension to classify them. Of course, sometimes data may not be linearly separable. Anyway, a hyperplane is used as a separator between the categories and passes through as many data points as feasible within a specified distance so-called the margin42. Consequently, the error in the prediction can be reduced and the non-linear relevance between input and target variables can be handled by the SVR algorithm using a kernel function.
Consider a training data set \(T=\left\{\left({x}_{1},{y}_{1}\right), \dots , \left({x}_{N},{y}_{N}\right)\right\}\) including N ordered pairs of (xi,yi) for i = 1,2,…,N, where \({x}_{i}\) and \({y}_{i}\) imply the features and their corresponding values known as target values, respectively. For each feature (\({x}_{i}\)) a predicted value (\({y}_{p}\)) is considered to be fitted with \(f\left(x\right)\) in the SVR algorithm. So, finding a smooth regression profile \(f\left(x\right)\) with the minimum deviation ε value between the predicted and target values for all the data in the training set is the main proposal in implementing SVR. The estimation function of SVR algorithm, \(f\left(x\right)\), could be given by39:
where w, \(\varphi \left(x\right)\), and b are the weight vector, the feature function of input x, and a constant, respectively. In order to obtain the suitable regression function, it requires solving the convex optimization problem as follows:
It should be mentioned that such function \(f\left(x\right)\) satisfying these constraints for all points might not be found. The following positive and negative slack parameters \({\xi }_{i}\) and \({{\xi }_{i}}^{*}\) at every point can be presented to overcome to the infeasible constraints while the required conditions satisfy39:
where \(C\) is a predetermined penalty balancing the model complexity and the training set error and helping to prevent overfitting and \({\xi }_{i},{{\xi }_{i}}^{*}\ge 0\) for all i. The structural parameters of SVR algorithm are illustrated in Fig. 4.

The structural parameters of SVR algorithm.
This optimization problem can be solved by its converting to the dual problem at Karush–Kuhn–Tucker (KKT) condition39:
where \({\beta }_{i} ,{\beta }_{i}^{*}\in \left[0,C\right]\) are the Lagrange multipliers. Then, the SVR function could be expressed as follows after solving the dual problem:
where \(k\left({x}_{i},{x}_{j}\right)={\varphi \left({x}_{i}\right)}^{T}\varphi \left({x}_{j}\right)\) refers to the kernel function allowing us to linearly solve the non-linear problems40. It must be noted that the RBF is also chosen in implementing the SVR algorithm39,42. So, it is given by:
where \(\gamma\) denote the kernel width. The design of each ML models is carried out in three steps. The determination of hyper parameters forming the models is the first step. The analysis of training and predicting performance is the next step of the SVR model design. At last, the prediction data is obtained by the validated model.
All above algorithms have been used to compare their performance in predicting the electric current of the SDs with different interfacial layers.
Error and accuracy functions
As mentioned, a detailed study on the prediction proficiency is necessary after completing the design of ML models. Also, the calculation of performance factors and then their analysis help us to understand the prediction accuracy. So, the examination accuracy of ML models used in this work is specified by the parameters of mean absolute error (MAE) and mean squared error (MSE) which are defined as follow43:
Figure 5 show the MAE percentages of different algorithms applied for predicting the current value of the SD with and without interfacial layers. The values of MAE for each algorithm have been evaluated relative to 1. It is obvious that the MAE value of SVR model is lower than that of other models in the current prediction of all devices. Table 1 introduces the MSE value of each algorithm applied on the I–V characteristics of different MPS type-SDs to compare their accuracies in predicting the electric current with each other. The MSE value of the SVR model for all SDs is lower than that of the GPR, KRR, and ANN models. Although this value for the SVR algorithm is higher than that of the GPR and KRR ones at the MPS2 SD, the difference among them is small, and these values very close to each other.

The MAE percentage (relative to one) of different algorithms in the prediction of current values for the (a) MS, (b) MPS1, (c) MPS2, (d) MPS3, and (e) MPS4 SDs.
One of the other parameters that shows the accuracy of the used algorithm is the R2 score. Generally, the closer the value of the R2 score is to one, it means that the hyperparameters used in the algorithm are selected suitably and the more perfectly the model is trained, leading to predicting with less MSE. If the R2 score is equal to zero, the model would perform badly on an unseen dataset, originating from the bad selection of hyperparameters. The model is perfect provided that the value of the R2 score is equal to one. It is calculated as44:
where Xpred is the prediction value by the model, Xexp is the experimental value (actual value), and \({\overline{X} }_{exp}\) is the average value of the experimental data. In this work, the R2 score has only been determined for the SVR model due to its fewer MAE and MSE values among the used algorithms. Figure 6 shows the R2 score of the SVR model as a function of the hyperparameters used in this ML algorithm, i.e., C and γ. As seen, the value of the R2 score for all samples is becoming higher with increasing the values of C and γ in the SVR algorithm. The best value of these hyperparameter is C = 105 and γ = 102, resulting in the R2 score of 0.987 for MS, 0.995 for MPS1, 0.996 for MPS2, 0.997 for MPS3, and 0.998 for MPS4 SDs.

Variations of the R2 score vs the hyperparameters (C & γ) in the SVR model for the (a) MS, (b) MPS1, (c) MPS2, (d) MPS3, and (e) MPS4 SDs.
Results and discussion
Figure 7 logarithmically shows the I–V characteristics of the prepared SDs with different interfacial layers at the voltage range of ± 1 V by using the experimental data, SVR and ANN models. It should be mentioned that the test size of the used algorithms was 80, which is selected so that predictions are made in the voltage range of ± 1 V. Moreover, the thermionic emission (TE) technique is chosen to determine the I–V characteristics of the prepared SDs because the ML method needs relatively high numbers of data to accurately predict the new data, in contrary to other techniques such as Norde, dV/dlnI, and H(I). It is worth mentioning that TE theory is based on the idea that the BH must be much greater than kT, meaning that only electrons with enough energy to surpass the potential barrier are taken into account when calculating the current density. Additionally, thermal equilibrium is assumed to be established at the plane that determines emission, and the presence of a net current flow does not disrupt this equilibrium45. As seen, the ability of the SVR model to predict the electric current of SDs at distinct biases is more reliable than other algorithms, especially the ANN model in confirming their MSE values (see Table 1).

I–V characteristics of (a) MS, (b) MPS1, (c) MPS2, (d) MPS3, (e) MPS4 SDs and their analysis with the SVR and ANN models.
In order to compare the prediction performance of the SVR and ANN models with each other, the actual and predictive values for each SD with different interfacial layers are simultaneously illustrated in Fig. 8. The experimental and output data are located on the x- and y-axis, respectively. To introduce a more detailed understanding of prediction accuracy, it is necessary to estimate the locations of data points. For this aim, the zero-error line has been plotted in Fig. 8 for a better examination of the data points’ location. The location of data points of the SVR and ANN models concerning the zero-error line is able to be another confirmation of the capability of the SVR model in accurately predicting the electrical current. And so, the electrical parameters of SDs with different interfacial layers is higher than the ANN model.

The predictive values of the SVR and ANN models for (a) MS, (b) MPS1, (c) MPS2, (d) MPS3, (e) MPS4 SDs.
At the forward bias voltage and by considering a series resistance (Rs) for V ≥ 3kT/q, the current–voltage relation in a SD could be expressed as46:
where q is the electric charge (~ 1.60 × 10–19 C), k refers to the Boltzmann constant (~ 1.23 × 10–23 kg m2/K.s2), and T being the temperature (room temperature). The value of I0 is calculated by the linear part of ln(I)–V profile at V = 0 as47:
with A, A*, and \({\varphi }_{B0}\) being contact space, the Richardson constant, and BH at V = 0, respectively. Table 2 presents the values of I0 predicted by the ML algorithms for different prepared SDs in addition to their actual values. It is clear that the predicted value of I0 with the SVR model is the closest value to the actual one among other algorithms. Moreover, the values predicted by ANN algorithm are the farthest values from the actual ones for MPS1, MPS2, and MPS3 SDs. The GPR model has not predicted a suitable value for MS and MPS4 SDs compared to the actual value. It should be mentioned that the quantity of I0 for MS SD decreases with the interfacial layer usage, especially with graphene dopant. It implies the graphene nanoparticles doped in PVP polymer have a better influence in improving the electric features of MS SD.
The primary purpose of using a nanocomposite interfacial layer is to control and engineer the potential BH of the MS SD. So, it is one of the important electrical parameters of SDs that should be calculated at zero-bias voltage as48:
The BHs of various prepared SDs have been obtained and given in Table 3. Additionally, ML algorithms have been utilized to model the electric current used for calculating the BH of different SDs. In this case, the prediction of almost all algorithms is in good agreement with the actual value, while the SVR model has predicted an exact value corresponding to the actual one. From a physical point of view, the BH of MS contact has been raised when an interfacial polymer layer is put at the M/S interface. The highest increment is realized depending on the MPS2 SD, whose nanocomposite interfacial layer is doped by graphene nanoparticles.
The ideality factor is one of the other investigated electrical parameters of diodes in this research, which determines how the behavior of the diode follows the ideality diode. Its quantity (n) is unity at the ideal case although it generally deviated from the ideal conditions because of the presence of native or deposited interfacial layers such as polymer, insulator, and Ferro-electric materials at the M/S interface. Furthermore, the density of surface states formed at the interface of the interfacial layer and semiconductor, the thickness of the depletion layer (Wd = (2εsεoVi/qNa)0.5) related to the concentration of donor or acceptor atoms doped into the pure semiconductor, the thickness and dielectric value of the interfacial layer are the other effective parameters in determining the ideality factor as [n = 1 + di/\(\varepsilon\) i (\(\varepsilon\)i/Wd + qNss)]. With the use of the slope of ln(I)–V profile, the quantity of n is given by21,49:
It must be noted that other processes such as generation/recombination of electron–hole pairs, electrons tunneling via the potential barrier by the interface states, and barrier lowering owing to image-force influence on the ideality factor value and current-transport/conduction mechanisms in the MPS devices1,50. Table 4 shows the value of n calculated for the prepared SDs with and without different interfacial layers between the metal and semiconductor. Its reduction from 7.69 for MS to 3.31 for MPS4 implies that the existence of the interfacial layer leads to getting close the behavior of SD to the ideal case. Again, the ML algorithms have been applied to predict the n value for the considered SDs. It is obvious that the SVR model was able to calculate the ideality factor of SDs with high accuracy. Although other algorithms have suitable predictions in some cases, their deviation from the actual values is more than the SVR model. Among the ML algorithms considered in this work, the worst performance is related to the ANN model due to the highest deviation of prediction values from the corresponding actual ones.
Series resistance (Rs) is an electric parameter of diodes that affects the performance of SDs, especially the rectifying ratio (RR). It originated from several different sources such as the probe wires, the ohmic and rectifier contacts made on the back and front sides of the semiconductor bulk, the resistance of semiconductor, inhomogeneities of the dopant donor or acceptor atoms at the semiconductor, remaining impurities from the cleaning process between the contacts1,51,52,53. In spite of the fact that the series resistance is able to be neglected at the inversion and depletion regions, it will be more effective in the accumulation region1,2. In this work, the ohmic law is used to calculate the value of Rs and Rsh as follows52:
The quantity of Rs obtained for the prepared SDs with/without interfacial layer at the voltage of + 3 V is presented in Table 5. The ML algorithms are also applied to predict the Rs value of the considered SDs. As can be observed, the predictions of all algorithms are in good agreement with the actual values, however, the SVR model is able to predict the Rs quantity corresponding to the actual values with the minimum differences. Moreover, the prediction deviation of the KRR algorithm from the actual values is smaller than the GPR model and the ANN algorithm shows the most deviation from the actual value of Rs for different SDs.
There is a shunt resistance (Rsh) at the reverse bias voltage originating from the probe wire-ground patches, imperfections at the contact area, and leakage current across the interfacial layer53. Besides, the applied voltage (Va) will be shared across the MPS structure possessing Rs and Nss as Va = Vi + VRs + Vd + Vss, resulting in the deviation of lnI–V profile from the linearity form at sufficient large forward bias voltages54. Also, the value of Rsh for the various prepared SDs with/without interfacial layer is calculated at the reverse bias voltage of -3 V and room temperature represented in Table 6. Using the ML algorithms, the quantity of Rsh has been predicted with different accuracies to compare with the actual values.
The SVR predictions of the Rsh values for the considered SDs are closest to the actual ones while the ANN model shows the maximum deviation from the actual values among the applied ML algorithms. The GPR and KRR models are able to predict the Rsh value with the minimum deviation from the actual ones. From the physical point of view, the interfacial layer can drastically increase the shunt resistance from 3.89 kΩ for the MS type-SD to 495 kΩ for the MP3 type-SD, resulting in the leakage reduction of oxide/current ways at the interfacial layer and hence enhancement the performance of SDs.
The rectifying rate of the SD is determined by the quantity of RR which can be defined with the ratio of the electric current at the forward bias voltage (+ 3 V) to the reverse bias voltage (− 3 V) as RR = IF/IR55. Table 7 demonstrates the RR value of different prepared SDs in this work at room temperature. It is observable that the RR of the MS structure is significantly enhanced by inserting an interfacial layer between the metal and semiconductor, especially for MPS4-type SD whose interfacial layer has been doped by Gr and ZnTiO3 nanostructures. Since the ML algorithms have predicted the electric current of the considered SDs at the bias voltage range of ± 3 V, the predicted electric currents at the forward and reverse bias voltages are able to be used for calculating the RR values of different SDs. The RR values obtained based on the prediction values of the SVR model have the most agreement with the actual values. Besides, the lowest deviation in the calculation of RR quantities is related to the GPR and KRR predictions while the most deviation corresponds to the ANN prediction. Some experimental and theoretical studies on the structural, electrical, and optical features of these structures were also reported in the literature in the last years56,57,58,59,60.
One of the reasons of deviating the SD from the ideal behavior is the inhomogeneity distribution of metal/oxide dopants in the semiconductor along with the interface states. The following method could be used to understand how the importance of this flaw; the dependence of Nss on the voltage at the equilibrium condition is described as1,2:
with WD and δ being the depletion layer width and the thickness of the interfacial layer (~ 100 nm). Moreover, εi and εs refer to the interlayer/semiconductor permittivity, respectively. It must be noted that the energy difference of the Nss level and valance band for a p-type semiconductor is written as1,2,3:
By considering the relation among Rs, φe, and n(V) could be derived as3:
Using the Eqs. (13, 14, 15), the Nss values can be calculated for different prepared SDs represented in Table 8. It can be seen that inserting the interfacial layer with and without dopants between the metal and semiconductor leads to decreasing the density of interface states, especially for MPS2 where the PVP polymer layer is doped by the graphene nanostructures. Also, these graphene nanostructures significantly reduce the Nss of the MPS4 whose interfacial layer has been doped by the Gr-ZnTiO3 nanostructures compared with the MPS3 with the ZnTiO3 nanostructures doped in the PVP polymer layer. It is owing to the fact that the interfacial layer is led to a passivation at the semiconductor surface52. The energy-band diagrams representing the reduction of Nss in the MS and MPS3 SDs schematically show in Fig. 3. It should be mentioned that the creation of BH and native or deposited polymer layer at the M/S interface, their homogeneity distribution, and surface-states (Nss) lead to the conduction mechanisms (CMs) in the SDs3,4,5. Furthermore, the ML algorithms are used to predict the value of Nss for different SDs. The prediction values with the SVR model are the same as the actual values whereas the prediction of other algorithms is also in good agreement with the actual values. Therefore, almost all ML algorithms considered in this study are able to predict the density of interface states with high reliability.
Conclusions
In this research, five Schottky Diodes (SDs) with the structures of Al/p-Si (MS), Al/PVP/p-Si (MPS1), Al/PVP:Gr/p-Si (MPS2), Al/PVP:ZnTiO3/p-Si (MPS3), and Al/PVP:Gr-ZnTiO3/p-Si (MPS4) have been fabricated to investigate the effect of interfacial polymer layers with/without dopants on the basic electric parameters of the MS type SD. Then, the I–V features of the SDs have been studied by the TE method to calculate and analyze their principal electric parameters, such as I0, \({\varphi }_{B0}\), n, Rs, Rsh, RR, and Nss. All the above-mentioned parameters have been predicted by using some ML algorithms such as GPR, KRR, SVR, and ANN and compared each other. The obtained results show that the quantity of I0 or leakage current and Nss for MS type SD decreases, and \({\varphi }_{B0}\) increases with the interfacial layer usage, especially with graphene dopant. On the other hand, the BH of MS contact raises when an interfacial polymer layer is put at the M/S interface. The highest increase of BH occurred for the MPS2 structure due to the nanocomposite interfacial layer doping with graphene nanoparticles. Hence, the graphene nanoparticles doped in the PVP polymer have a better influence for the improvement of the electrical specifications of MS type SD. The reduction of the ideality factor (n) from 7.69 for MS SD to 3.31 for MPS4 structure depicts that the behavior of SD becomes closer to the ideal case due to the existence of the interfacial layer. Also, the RR of the MS structure is significantly enhanced by inserting an interfacial layer between the metal and semiconductor, especially for MPS4 SD whose interfacial layer has been doped by Gr and ZnTiO3 nanostructures. The interface states density decreases for MPS2, MPS4, and MPS3 structures due to the existence of the PVP polymer layer between the metal and semiconductor doped by the Gr, Gr-ZnTiO3, and ZnTiO3 nanostructures, respectively. Comparing the actual and predicted values of I0 by the ML algorithms for different SDs demonstrates that the values predicted by the ANN algorithm are the farthest values from the actual ones for MPS1, MPS2, and MPS3 SDs. This also has occurred for data predicted by the GPR model for MS and MPS4 SDs. On the contrary, for all structures, the data predicted by the SVR is closer to the real data.
The BH prediction values by almost all algorithms are in good agreement with the actual values, while the SVR model has predicted closer values to the corresponding actual ones. The prediction performance of all used algorithms for ideality factor n, Rs, and Rsh is almost suitable. Their deviation of prediction values from the actual ones, especially in the ANN model is more than the SVR model. The acquired RR values for different SDs are feasible with respect to the predicted electric currents at the forward and reverse biases because the electric current of the considered SDs has been predicted by the ML algorithms at the voltage range of ± 1 V. The predicted RR values by the SVR model have the most agreement with the actual values. Besides, the lowest deviation in the calculation of RR quantities is related to the GPR and KRR predictions while the most deviation corresponds to the ANN prediction. The deviation of Nss prediction values from actual ones is low enough for all used algorithms, especially SVR. In conclusion, almost all ML algorithms considered in this study are able to predict the density of interface states with high reliability. Considering the SDs electric current predictions due to the MSE values of ML algorithms, the prediction ability of the SVR model is more reliable than the other algorithms, especially the ANN model. Moreover, the hyperparameters used in GPR, KRR, and SVR algorithms are fewer than the ANN model. So, not only are these algorithms easier to use, but algorithm optimization is easier due to having fewer hyperparameters. As a results, this research can give researchers ideas to conduct more studies to identify other more suitable algorithms as well as improve and optimize them as much as possible.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Sze, S. M. & Ng, K. K. LEDs and lasers. Phys. Semicond. Devices 3, 601–657 (2006).
Nicollian, E. H., Brews, J. R. MOS (metal oxide semiconductor) Physics and Technology. 920 (John Wiley & Sons, 2002).
Card, H. C. & Rhoderick, E. H. Studies of tunnel MOS diodes I. Interface effects in silicon Schottky diodes. J. Phys. D Appl. Phys. 4(10), 1589 (1971).
Tung, R. T. The physics and chemistry of the Schottky barrier height. Appl. Phys. Rev. 1(1), 011304 (2014).
Al-Ahmadi, N. A. Metal oxide semiconductor-based Schottky diodes: A review of recent advances. Mater. Res. Express 7(3), 032001 (2020).
Altındal, Ş, Barkhordari, A., Azizian-Kalandaragh, Y., Çevrimli, B. S. & Mashayekhi, H. R. Dielectric properties and negative-capacitance/dielectric in Au/n-Si structures with PVC and (PVC: Sm2O3) interlayer. Mater. Sci. Semicond. Process. 15(147), 106754 (2022).
Al-Dharob, M. H. et al. The investigation of current-conduction mechanisms (CCMs) in Au/(0.07 Zn-PVA)/n-4H-SiC (MPS) Schottky diodes (SDs) by using (IVT) measurements. Mater. Sci. Semicond. Process. 85, 98–105 (2018).
Altındal Yerişkin, S., Balbaşı, M. & Orak, İ. The effects of (graphene doped-PVA) interlayer on the determinative electrical parameters of the Au/n-Si (MS) structures at room temperature. J. Mater. Sci. Mater. Electron. 28(18), 14040–14048 (2017).
Çiçek, O., Altındal, Ş & Azizian-Kalandaragh, Y. A highly sensitive temperature sensor based on Au/graphene-PVP/n-Si type Schottky diodes and the possible conduction mechanisms in the wide range temperatures. IEEE Sens. J. 20(23), 14081–14089 (2020).
Reddy, V. R. & Prasad, C. V. Surface chemical states, electrical and carrier transport properties of Au/ZrO2/n-GaN MIS junction with a high-k ZrO2 as an insulating layer. Mater. Sci. Eng., B 1(231), 74–80 (2018).
Ersöz, G., Yücedağ, İ, Azizian-Kalandaragh, Y., Orak, I. & Altındal, Ş. Investigation of electrical characteristics in Al/CdS-PVA/p-Si (MPS) structures using impedance spectroscopy method. IEEE Trans. Electron Devices 63(7), 2948–2955 (2016).
Azizian-Kalandaragh, Y. Dielectric properties of CdS-PVA nanocomposites prepared by ultrasound-assisted method. Optoelectron. Adv. Mater. Rapid Commun. 4(11), 1655–1658 (2010).
Houssein, E. H., Abohashima, Z., Elhoseny, M. & Mohamed, W. M. Machine learning in the quantum realm: The state-of-the-art, challenges, and future vision. Expert Syst. Appl. 21, 116512 (2022).
Torun, Y. & Doğan, H. Modeling of Schottky diode characteristic by machine learning techniques based on experimental data with wide temperature range. Superlattices Microstruct. 1(160), 107062 (2021).
Ali, H. A., El-Zaidia, E. F. & Mohamed, R. A. Experimental investigation and modeling of electrical properties for phenol red thin film deposited on silicon using back propagation artificial neural network. Chin. J. Phys. 1(67), 602–614 (2020).
Güzel, T. & Çolak, A. B. Artificial intelligence approach on predicting current values of polymer interface Schottky diode based on temperature and voltage: An experimental study. Superlattices Microstruct. 1(153), 106864 (2021).
Çolak, A. B., Güzel, T., Yıldız, O. & Özer, M. An experimental study on determination of the shottky diode current-voltage characteristic depending on temperature with artificial neural network. Phys. B 1(608), 412852 (2021).
Kim, H. T., Nahm, S., Byun, J. D. & Kim, Y. Low-fired (Zn, Mg) TiO3 microwave dielectrics. J. Am. Ceram. Soc. 82(12), 3476–3480 (1999).
Gui, Y., Li, S., Xu, J. & Li, C. Study on TiO2-doped ZnO thick film gas sensors enhanced by UV light at room temperature. Microelectron. J. 39(9), 1120–1125 (2008).
Durmus, Z., Durmus, A. & Kavas, H. Synthesis and characterization of structural and magnetic properties of graphene/hard ferrite nanocomposites as microwave-absorbing material. J. Mater. Sci. 50, 1201–1213 (2015).
Barkhordari, A., Mashayekhi, H. R., Amiri, P., Altındal, Ş & Azizian-Kalandaragh, Y. Role of graphene nanoparticles on the electrophysical processes in PVP and PVP: ZnTiO3 polymer layers at Schottky diode (SD). Semicond. Sci. Technol. 38(7), 075002 (2023).
Crampon, K., Giorkallos, A., Deldossi, M., Baud, S. & Steffenel, L. A. Machine-learning methods for ligand–protein molecular docking. Drug Discov. Today 27(1), 151–164 (2022).
Chan, C. H., Sun, M. & Huang, B. Application of machine learning for advanced material prediction and design. EcoMat. 4(4), e12194 (2022).
Xu, P., Chen, H., Li, M. & Lu, W. New opportunity: Machine learning for polymer materials design and discovery. Adv. Theory Simul. 5(5), 2100565 (2022).
Tao, Q., Xu, P., Li, M. & Lu, W. Machine learning for perovskite materials design and discovery. npj Comput. Mater. 7(1), 23 (2021).
Liu, X. et al. Material machine learning for alloys: Applications, challenges and perspectives. J. Alloy. Compd. 21, 165984 (2022).
Sabry, F., Eltaras, T., Labda, W., Alzoubi, K. & Malluhi, Q. Machine learning for healthcare wearable devices: The big picture. J. Healthc. Eng. 18, 2022 (2022).
Mueller, B., Kinoshita, T., Peebles, A., Graber, M. A. & Lee, S. Artificial intelligence and machine learning in emergency medicine: A narrative review. Acute Med. Surg. 9(1), e740 (2022).
Ivanciuc, O. Applications of support vector machines in chemistry. Rev. Comput. Chem. 25(23), 291 (2007).
Doğan, H. et al. Neural network estimations of annealed and non-annealed Schottky diode characteristics at wide temperatures range. Mater. Sci. Semicond. Process. 1(149), 106854 (2022).
Güzel, T. & Çolak, A. B. Investigation of the usability of machine learning algorithms in determining the specific electrical parameters of Schottky diodes. Mater. Today Commun. 1(33), 104175 (2022).
Ahmed, S., Alshater, M. M., El Ammari, A. & Hammami, H. Artificial intelligence and machine learning in finance: A bibliometric review. Res. Int. Bus. Financ. 1(61), 101646 (2022).
Rasmussen, C. E. & Williams, C. K. Gaussian Processes for Machine Learning (MIT press, 2006).
Murphy, K. P. Machine Learning (Springer-Verlag, 1991).
Mohri, M., Rostamizadeh, A. & Talwalkar, A. Foundations of Machine Learning (MIT Press, 2018).
Rupp, M., Tkatchenko, A., Müller, K. R. & Von Lilienfeld, O. A. Fast and accurate modeling of molecular atomization energies with machine learning. Phys. Rev. Lett. 108(5), 058301 (2012).
Zhang, R. & Wang, W. Facilitating the applications of support vector machine by using a new kernel. Expert Syst. Appl. 38(11), 14225–14230 (2011).
Ahmadloo, E. & Azizi, S. Prediction of thermal conductivity of various nanofluids using artificial neural network. Int. Commun. Heat Mass Transfer 1(74), 69–75 (2016).
Awad, M. & Khanna, R. Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers (Springer, 2015).
Ali, A., Abdulrahman, A., Garg, S., Maqsood, K. & Murshid, G. Application of artificial neural networks (ANN) for vapor-liquid-solid equilibrium prediction for CH4-CO2 binary mixture. Greenh. Gases Sci. Technol. 9(1), 67–78 (2019).
Vapnik, V. N. The Nature of Statistical Learning (1998).
Hsu, C. W., Chang, C. C., Lin, & C. J. A Practical Guide to Support Vector Classification 1396–1400 (2003).
Çolak, A. B., Yıldız, O., Bayrak, M. & Tezekici, B. S. Experimental study for predicting the specific heat of water based Cu-Al2O3 hybrid nanofluid using artificial neural network and proposing new correlation. Int. J. Energy Res. 44(9), 7198–7215 (2020).
Öcal, S., Gökçek, M., Çolak, A. B. & Korkanç, M. A comprehensive and comparative experimental analysis on thermal conductivity of TiO2-CaCO3/Water hybrid nanofluid: Proposing new correlation and artificial neural network optimization. Heat Transf. Res. 52(17), 55–79 (2021).
Potje-Kamloth, K. Chemical gas sensors based on organic semiconductor polypyrrole. Crit. Rev. Anal. Chem. 32(2), 121–140 (2002).
Durmus, Z., Durmus, A. & Kavas, H. Synthesis and characterization of structural and magnetic properties of graphene/hard ferrite nanocomposites as microwave-absorbing material. J. Mater. Sci. 50(3), 1201–1213 (2015).
Barkhordari, A. et al. The influence of PVC and (PVC: SnS) interfacial polymer layers on the electric and dielectric properties of Au/n-Si structure. Silicon 15, 1–1 (2022).
Altındal, Ş, Sevgili, Ö. & Azizian-Kalandaragh, Y. A comparison of electrical parameters of Au/n-Si and Au/(CoSO4–PVP)/n-Si structures (SBDs) to determine the effect of (CoSO4–PVP) organic interlayer at room temperature. J. Mater. Sci.: Mater. Electron. 30(10), 9273–9280 (2019).
Vargas, O., Caballero, Á. & Morales, J. Enhanced electrochemical performance of maghemite/graphene nanosheets composite as electrode in half and full Li–ion cells. Electrochim. Acta 1(130), 551–558 (2014).
Altındal, Ş et al. A comparison of electrical characteristics of Au/n-Si (MS) structures with PVC and (PVC: Sm2O3) polymer interlayer. Phys. Scr. 96(12), 125838 (2021).
Ashiri, R., Nemati, A., Ghamsari, M. S., Sanjabi, S. & Aalipour, M. A modified method for barium titanate nanoparticles synthesis. Mater. Res. Bull. 46(12), 2291–2295 (2011).
Barkhordari, A. et al. The effect of PVP: BaTiO3 interlayer on the conduction mechanism and electrical properties at MPS structures. Phys. Scr. 96(8), 085805 (2021).
Ansaree, J. & Upadhyay, S. Thermal analysis of formation of nano-crystalline BaTiO3 using Ba(NO3)2 and TiO2. Process. Appl. Ceram. 9(4), 181–185 (2015).
Yu, P., Cui, B. & Shi, Q. Preparation and characterization of BaTiO3 powders and ceramics by sol-gel process using oleic acid as surfactant. Mater. Sci. Eng., A 473(1–2), 34–41 (2008).
Altındal, Ş et al. Comparison of the electrical and impedance properties of Au/(ZnOMn: PVP)/n-Si (MPS) type Schottky-diodes (SDs) before and after gamma-irradiation. Phys. Scr. 96(12), 125881 (2021).
Rahman, N. et al. First principle study of structural, electronic, optical and mechanical properties of cubic fluoro-perovskites:(CdXF3, X= Y, Bi). Eur. Phys. J. Plus 136(3), 1–1 (2021).
Husain, M. et al. Structural, electronic, elastic, and magnetic properties of NaQF3 (Q= ag, Pb, Rh, and Ru) flouroperovskites: A first-principle outcomes. Int. J. Energy Res. 46(3), 2446–2453 (2022).
Husain, M. et al. Exploring the exemplary structural, electronic, optical, and elastic nature of inorganic ternary cubic XBaF3 (X= Al and Tl) employing the accurate TB-mBJ approach. Semicond. Sci. Technol. 37(7), 075004 (2022).
Saddique, J. et al. Modeling structural, elastic, electronic and optical properties of ternary cubic barium based fluoroperovskites MBaF3 (M= Ga and In) compounds based on DFT. Mater. Sci. Semicond. Process. 1(139), 106345 (2022).
Husain, M. et al. Examining computationally the structural, elastic, optical, and electronic properties of CaQCl 3 (Q= Li and K) chloroperovskites using DFT framework. RSC Adv. 12(50), 32338–32349 (2022).
Author information
Authors and Affiliations
Contributions
All authors contributed equally. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barkhordari, A., Mashayekhi, H.R., Amiri, P. et al. Machine learning approach for predicting electrical features of Schottky structures with graphene and ZnTiO3 nanostructures doped in PVP interfacial layer. Sci Rep 13, 13685 (2023). https://doi.org/10.1038/s41598-023-41000-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-41000-z
This article is cited by
-
Electrical properties of PVC:BN nanocomposite as interfacial layer in metal-semiconductor structure
Journal of Materials Science: Materials in Electronics (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
