
Abstract
Solar flares are explosions on the Sun. They happen when energy stored in magnetic fields around solar active regions (ARs) is suddenly released. Solar flares and accompanied coronal mass ejections are sources of space weather, which negatively affects a variety of technologies at or near Earth, ranging from blocking high-frequency radio waves used for radio communication to degrading power grid operations. Monitoring and providing early and accurate prediction of solar flares is therefore crucial for preparedness and disaster risk management. In this article, we present a transformer-based framework, named SolarFlareNet, for predicting whether an AR would produce a \(\gamma\)-class flare within the next 24 to 72 h. We consider three \(\gamma\) classes, namely the \(\ge\)M5.0 class, the \(\ge\)M class and the \(\ge\)C class, and build three transformers separately, each corresponding to a \(\gamma\) class. Each transformer is used to make predictions of its corresponding \(\gamma\)-class flares. The crux of our approach is to model data samples in an AR as time series and to use transformers to capture the temporal dynamics of the data samples. Each data sample consists of magnetic parameters taken from Space-weather HMI Active Region Patches (SHARP) and related data products. We survey flare events that occurred from May 2010 to December 2022 using the Geostationary Operational Environmental Satellite X-ray flare catalogs provided by the National Centers for Environmental Information (NCEI), and build a database of flares with identified ARs in the NCEI flare catalogs. This flare database is used to construct labels of the data samples suitable for machine learning. We further extend the deterministic approach to a calibration-based probabilistic forecasting method. The SolarFlareNet system is fully operational and is capable of making near real-time predictions of solar flares on the Web.
Similar content being viewed by others

Introduction
Solar flares are sudden explosions of energy that occur on the Sun’s surface. They often occur in solar active regions (ARs), caused by strong magnetic fields typically associated with sunspot areas. Solar flares are categorized into five classes A, B, C, M, and X, with A-class flares having the lowest intensity and X-class flares having the highest intensity. Major flares are usually accompanied by coronal mass ejections and solar energetic particles1,2,3,4,5,6,7. These eruptive events can have significant and harmful effects on or near Earth, damaging technologies, power grids, space stations, and human life8,9,10,11. Therefore, providing accurate and early forecasts of solar flares is crucial for disaster risk management, risk mitigation, and preparedness.
Although a lot of effort has been devoted to flare prediction12,13,14,15, developing accurate, operational near-real-time flare forecasting systems remains a challenge. In the past, researchers designed statistical models for the prediction of flares based on the physical properties of active regions16,17,18. With the availability of large amounts of flare-related data14, researchers started using machine learning methods for flare forecasting3,19,20. More recently, deep learning, which is a subfield of machine learning, has emerged and showed promising results in predicting solar eruptions, including solar flares21,22.
For example, Nishizuka et al.23 developed deep neural networks to forecast M- and C-class flares that would occur within 24 h using data downloaded from the Solar Dynamics Observatory (SDO)24 and the Geostationary Operational Environmental Satellite (GOES). Sun et al.22 employed three-dimensional (3D) convolutional neural networks (CNNs) to forecast \(\ge\)M-class and \(\ge\)C-class flares using Space-weather HMI Active Region Patches (SHARP)25 magnetograms downloaded from the Joint Science Operations Center (JSOC) accessible at http://jsoc.stanford.edu/. Li et al.26 also adopted a CNN model to forecast \(\ge\)M-class and \(\ge\)C-class flares using SHARP magnetograms where the authors restructured the CNN layers in their neural network with different filter sizes. Deng et al.27 developed a hybrid CNN model to predict solar flares during the rising and declining phases of Solar Cycle 24.
Some researchers adopted SHARP magnetic parameters in time series for flare prediction. Static SHARP parameters quantitatively describe the properties of ARs, especially their ability to produce flares, at a given time. On the other hand, dynamic information, such as the magnetic helicity injection rate, sunspot motions, shear flows, and magnetic flux emergence/flux cancelation, is more important for flare forecasting. Using time series of SHARP parameters allows a model to capture the relationship between the evolution of magnetic fields of ARs and solar flares, hence achieving more accurate flare predictions 28,29. In an earlier study, Yu et al.30 added the evolutionary information of ARs to a predictive model for the prediction of short-term solar flares. More recently, Chen et al.31 designed a long short-term memory (LSTM) network to identify precursors of solar flare events using time series of SHARP parameters. LSTM is suitable for capturing the temporal dynamics of time series. Liu et al.9 developed another LSTM network with a customized attention mechanism to direct the network to focus on important patterns in time series of SHARP parameters. Sun et al.32 attempted to distinguish between ARs with strong flares (\(\ge\)M-class flares) and ARs with no flare at all. The authors showed that combining LSTM and CNN can better solve the “strong versus quiet” flare prediction problem, with data from both Solar Cycle 23 and Cycle 24. All of the aforementioned studies provided valuable models and algorithms in the field. However, the existing methods focused on short-term forecasts (usually within 24 h). Furthermore, the models were not used as operational systems.
In this paper, we propose a new deep learning approach to predicting solar flares using time series of SHARP parameters. Our approach employs a transformer-based framework, named SolarFlareNet, which predicts whether there would be a flare within 24 to 72 h, where the flare could be a \(\ge\)M5.0-, \(\ge\)M-, or \(\ge\)C-class flare. We further extend SolarFlareNet to produce probabilistic forecasts of flares and implement the probabilistic model into an operational, near real-time flare forecasting system. Experimental results demonstrate that SolarFlareNet generally performs better than, or is comparable to, related flare prediction methods.
Results
Deterministic prediction tasks
For any given active region (AR) and time point t, we predict whether there would be a \(\gamma\)-class flare within the next 24 h (48 h, 72 h, respectively) of t where \(\gamma\) can be \(\ge\)M5.0, \(\ge\)M, or \(\ge\)C. A \(\ge\)M5.0-class flare means the GOES X-ray flux value of the flare is above \(5 \times 10^{-5}\text{ Wm}^{-2}\). A \(\ge\)M-class flare refers to an X- or M-class flare. A \(\ge\)C-class flare refers to an X-class, M-class, or C-class flare. We focus on these three classes of flares due to their importance in space weather9,19,23,33. We developed three transformer models to tackle the three prediction tasks individually and separately. Notice that we did not consider \(\gamma\) to be \(\ge\)X due to the lack of samples for X-class flares. Instead, we use \(\ge\)M5.0 as the most significant class, which contains sufficient samples.
Comparison with previous methods
We conducted a series of experiments to compare the proposed SolarFlareNet framework with closely related methods. All these methods perform binary classifications/predictions as defined above. We adopt several performance metrics. Formally, given an AR and a data sample \(x_{t}\) observed at time point t, we define \(x_{t}\) to be a true positive (TP) if the \(\ge\)M5.0 (\(\ge\)M, \(\ge\)C, respectively) model predicts that \(x_{t}\) is positive, i.e., the AR will produce a \(\ge\)M5.0- (\(\ge\)M-, \(\ge\)C-, respectively) class flare within the next 24 h of t, and \(x_{t}\) is indeed positive. We define \(x_{t}\) as a false positive (FP) if the \(\ge\)M5.0 (\(\ge\)M, \(\ge\)C, respectively) model predicts that \(x_{t}\) is positive while \(x_{t}\) is actually negative, i.e., the AR will not produce a \(\ge\)M5.0- (\(\ge\)M-, \(\ge\)C-, respectively) class flare within the next 24 h of t. We say \(x_{t}\) is a true negative (TN) if the \(\ge\)M5.0 (\(\ge\)M, \(\ge\)C, respectively) model predicts \(x_{t}\) to be negative and \(x_{t}\) is indeed negative; \(x_{t}\) is a false negative (FN) if the \(\ge\)M5.0 (\(\ge\)M, \(\ge\)C, respectively) model predicts \(x_{t}\) to be negative while \(x_{t}\) is actually positive. We also use TP (FP, TN, and FN, respectively) to represent the total number of true positives (false positives, true negatives, and false negatives, respectively). The TP, FP, TN, and FN for the 48-h and 72-h ahead predictions are defined similarly. The performance metrics are calculated as follows:
Table 1 compares SolarFlareNet with related methods for 24-h ahead flare predictions. The performance metric values of SolarFlareNet are mean values obtained from 10-fold cross-validation9. The metric values of the highest performance models in the related studies are taken directly from those studies and are displayed in Table 1. The symbol ‘–’ means that a method does not produce the metric value for the corresponding prediction task. The best metric values are highlighted in boldface. TSS is the primary metric used in the literature on flare prediction. It can be seen from Table 1 that SolarFlareNet outperforms the state-of-the-art methods in terms of TSS except that Liu et al.9 perform better than SolarFlareNet in predicting \(\ge\)M5.0 class flares.
Table 2 presents the mean performance metric values with standard deviations enclosed in parentheses for the 48- and 72-h forecasts made by SolarFlareNet. None of the existing methods in Table 1 provides predictions in 48 or 72 h in advance and, therefore, they are not listed in Table 2. Overall, SolarFlareNet performs well for the 48- and 72-h forecasts. However, the metric values of the tool in Table 2 are lower than those in Table 1. This is understandable due to the longer range of predictions in Table 2.
Probabilistic forecasting with calibration
SolarFlareNet is essentially a probabilistic forecasting method, producing a probability between 0 and 1. The method compares the probability with a predetermined threshold, which is set to 0.5. Given an AR and a data sample \(x_{t}\) at time point t, if the predicted probability is greater than or equal to the threshold, then the AR will produce a flare within the next 24 (48, 72, respectively) hours of t (i.e., \(x_{t}\) belongs to the positive class); otherwise, the AR will not produce a flare within the next 24 (48, 72, respectively) hours of t (i.e., \(x_{t}\) belongs to the negative class). We can turn SolarFlareNet into a probabilistic forecasting method by directly outputting the predicted probability without comparing it with the threshold. Under this circumstance, the output is interpreted as a probabilistic estimate of how likely the AR will produce a flare within the next 24 (48, 72, respectively) hours of t. We employ a probability calibration technique with isotonic regression 36,37 to adjust the predicted probability and avoid the mismatch between the distributions of the predicted and expected probabilistic values 5. We add a suffix “-C” to SolarFlareNet to denote the network without calibration.
To evaluate the performance of a probabilistic forecasting method, we use the Brier score (BS) and Brier skill score (BSS), defined as follows4,5,38:
where N is the number of data samples in a test set; \(y_i\) denotes the observed probability and \(\hat{y}_i\) denotes the predicted probability of the ith test data sample, respectively; \(\bar{y} = \frac{1}{N}\sum _{i=1}^{N} y_i\) denotes the mean of all the observed probabilities. BS values range from 0 to 1, with 0 being a perfect score. BSS values range from \(-\infty\) to 1, with 1 being a perfect score.
Table 3 compares SolarFlareNet, used as a probabilistic forecasting method, with a closely related method9. The BS and BSS values in the table are mean values (with standard deviations enclosed in parentheses) obtained from 10-fold cross-validation. The metric values for the existing method are taken directly from the related work9. The best BS and BSS values are highlighted in bold. Notice that the existing method did not make 48-h or 72-h forecasts in advance. Table 3 shows that there is no definitive conclusion regarding the relative performance of SolarFlareNet and the existing method. The existing method is better in terms of BS, while SolarFlareNet is better in terms of BSS. On the other hand, the calibrated version of a model is better than the model without calibration. Notice also that the results of the 48-h and 72-h forecasts are worse than those of the 24-h forecasts. This is understandable since the longer the prediction window, the worse the performance a model achieves due to data deviation over time.
The SolarFlareNet system

The graphical user interface of the SolarFlareNet system.
We have implemented the probabilistic forecasting method described above into an operational, near real-time flare forecasting system. To access the system, visit the SolarDB website at https://nature.njit.edu/solardb/index.html. On the website, select and click the menu entry “Tools” and then select and click “Flare Forecasting System.” Figure 1 shows the graphical user interface (GUI) of the system. It displays a probabilistic estimate of how likely an AR will produce a flare within the next 24, 48, and 72 h of the time point at which the system is updated each day. No prediction is made for an AR marked with a special character *, #, or \(\sim\) where
-
* means the AR is near the limb,
-
# means the AR is spotless with the number of spots being zero,
-
\(\sim\) means no SHARP data is available for the AR.
The system provides daily predictions based on the data obtained from the previous day. When the user clicks the link to the previous day, the user is led to the SolarMonitor site that is accessible at https://www.solarmonitor.org/index.php where detailed AR information for that day is available. The system also provides previous forecasting results since the operational system came online. We compare the previous forecasting results with the true flare events in the GOES X-ray flare catalogs provided by NCEI. The SolarFlareNet system achieves 89% (76%, 71%, respectively) accuracy for 24-h (48-h, 72-h, respectively) ahead predictions.
Discussion and conclusion
In this article, we present a novel transformer-based framework to predict whether a solar active region (AR) would produce a \(\gamma\)-class flare within the next 24 to 72 h where \(\gamma\) is \(\ge\)M5.0, \(\ge\)M, or \(\ge\)C. We use three transform models to handle the three classes of flares individually and separately. All three transformer models perform binary predictions. We collect ARs with flares that occurred between 2010 and 2022 from the GOES X-ray flare catalogs provided by the National Centers for Environmental Information (NCEI). In addition, we downloaded SHARP magnetic parameters from the Joint Science Operations Center (JSOC). Each data sample contains SHARP parameters suitable for machine learning. We conducted experiments using 10-fold cross-validation9. Based on the experiments, our transformer-based framework generally performs better than closely related methods in terms of TSS (true skill statistics), as shown in Table 1. We further extend our framework to produce probabilistic forecasts of flares and implement the framework into an operational, near real-time flare forecasting system accessible on the Web. The probabilistic framework is comparable to a closely related method9 in terms of BS (Brier score) and BSS (Brier skill score) when making 24-h forecasts, as shown in Table 3, although the existing method did not make 48- or 72-h forecasts. Thus, we conclude that SolarFlareNet is a feasible tool for producing flare forecasts within 24 to 72 h.
Methods
Data collection
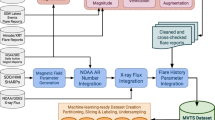
In this study we used SHARP magnetic parameters2,9,25 downloaded from the Joint Science Operations Center (JSOC) accessible at http://jsoc.stanford.edu/. Specifically, we collect data samples, composed of SHARP parameters, at a cadence of 12 minutes where the data samples are retrieved from the hmi.sharp_cea_720s data series on the JSOC website using the Python package SunPy39. We selected nine SHARP magnetic parameters as suggested in the literature2,3,4,9,19. These nine parameters include the total unsigned current helicity (TOTUSJH), total unsigned vertical current (TOTUSJZ), total unsigned flux (USFLUX), mean characteristic twist parameter (MEANALP), sum of flux near polarity inversion line (R_VALUE), total photospheric magnetic free energy density (TOTPOT), sum of the modulus of the net current per polarity (SAVNCPP), area of strong field pixels in the active region (AREA_ACR), and absolute value of the net current helicity (ABSNJZH). Table 4 presents an overview of the nine parameters. The SHARP parameters’ values are in different scales and units; therefore, we normalize each parameter’s values using the min-max normalization method4,5. Formally, let \(p^k_{i}\) be the original value of the ith parameter of the kth data sample. Let \(q^k_{i}\) be the normalized value of the ith parameter of the kth data sample. Let \(min_i\) be the minimum value of the ith parameter. Let \(max_i\) be the maximum value of the ith parameter. Then
We collected A-, B-, C-, M- and X-class flares that occurred between May 2010 and December 2022, and their associated active regions (ARs) from the GOES X-ray flare catalogs provided by the National Centers for Environmental Information (NCEI). Flares without identified ARs were excluded. This process yielded a database of 8 A-class flares, 6571 B-class flares, 8973 C-class flares, 895 M-class flares, and 58 X-class flares. Also, we collected 10 nonflaring ARs40. We collected data samples that were 24 (48, 72, respectively) hours before a flare. Furthermore, we collected data samples that were 24 (48, 72, respectively) hours after the start time of each nonflaring AR. The data was then cleaned as follows2,5,9.
We discard ARs that are outside ± 70\(^\circ\) of the central meridian. These ARs are near the limb and have projection effects that render the calculation of the ARs’ SHARP parameters incorrect. In addition, we discard a data sample if (i) its corresponding flare record has an absolute value of the radial velocity of SDO greater than 3500 m \(s^{-1}\), (ii) the HMI data have low quality41, or (iii) the data sample has missing values or incomplete SHARP parameters. Thus, we exclude low-quality data samples and keep qualified data samples of high quality in our study.
Data labeling
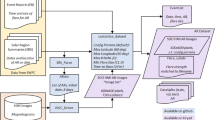
Data labeling is crucial in machine learning. To predict \(\ge\)C-class flares, suppose that a C-, M-, or X-class flare occurs at time point t on an AR (more precisely, the start time of the flare is t). Data samples between t and t − 24 h (48, 72 h, respectively) in the AR are labeled positive. If the flare occurs at time point t is an A-class or B-class flare, the data samples between t and t − 24 h (48, 72 h, respectively) in the AR are labeled negative. Figure 2 illustrates the labeling scheme to predict whether a \(\ge\)C-class flare would occur within 24 h. In predicting \(\ge\)M-class flares, we use \(\ge\)M-class flares to label positive data samples; use \(\le\)C-class flares to label negative data samples. In predicting \(\ge\)M5.0-class flares, we use \(\ge\)M5.0-class flares to label positive data samples; use \(\le\)C-class flares as well as M1.0- through M4.0-class flares to label negative data samples. If there are recurring flares whose corresponding data samples overlap, we give priority to the largest flare and label the overlapped data samples based on the largest flare. In all three prediction tasks, the data samples in the nonflaring ARs are labeled negative.
Table 5 shows the total numbers of positive and negative data samples in each class for 24-, 48-, and 72-h ahead flare predictions. The numbers in the table are lower than expected. This is because we discarded/removed many low-quality data samples as described above. If a gap occurs in the middle of a time series due to removal, we use a zero-padding strategy5,9 to create a synthetic data sample to fill the gap. The synthetic data sample has zero values for all nine SHARP parameters. The synthetic data sample is added after normalization of the values of the SHARP parameters, and therefore the synthetic data sample does not affect the normalization procedure.

Illustration of positive and negative data samples used in predicting \(\ge\)C-class flares. In the left panel, the red vertical line indicates the start time of a \(\ge\)C-class flare. The data samples collected in the 24 h prior to the red vertical line are labeled positive (in green color). In the right panel, the red vertical line indicates the start time of an A-class or B-class flare. The data samples collected in the 24 h prior to the red vertical line are labeled negative (in yellow color).
For each prediction task, we divide the corresponding data samples into 10 equal sized distinct partitions/folds that are used to perform 10-fold cross-validation experiments. In the run i, where \(1 \le i \le 10\), we use fold i as the test set and the union of the other nine folds as the training set. The data samples of the same AR are placed in the training set or the test set, but not both. This scheme ensures that a model is trained with data different from the test data and makes predictions on the test data that it has never seen during training. There are 10 folds and, consequently, 10 runs. The means and standard deviations of the performance metrics’ values over the 10 runs are calculated and recorded.
Data augmentation
The data sets used in this study to predict flares of the \(\ge\)M- and \(\ge\)M5.0-class are imbalanced as shown in Table 5 where negative data samples are much more than positive data samples. Imbalanced data pose a challenge in model training and often result in poor model performance. One may use data augmentation to combat the imbalanced data. Data augmentation is an important technique that enriches training data and increases the generalization of the model 42. Here, we adopt the Gaussian white noise (GWN) data augmentation scheme because it has shown a significant improvement in model performance43,44. GWN assumes that any two values are statistically independent, regardless of how close they are in time. The stationary random values of GWN are generated using the zero mean and 5\(\%\) of the standard deviation. During training, the data augmentation is applied to the minority (positive) class, leaving the majority (negative) class as is. During testing, the data are left without any augmentation so that the model predicts only on the actual test data to avoid any misleading performance assessment.
The SolarFlareNet architecture
Figure 3 presents the architecture of SolarFlareNet. It is a transformer-based framework that combines a one-dimensional convolutional neural network (Conv1D), long short-term memory (LSTM), transformer encoder blocks (TEBs), and additional layers that include batch normalization (BN) layers, dropout layers, and dense layers. The first layer is the input layer, which takes as input a time series of m consecutive data samples \(x_{t-m+1}\), \(x_{t-m+2}\) ...\(x_{t-1}\), \(x_{t}\) where \(x_{t}\) is the data sample at time point t5. (In the study presented here, m is set to 10.) The input layer is followed by a BN layer. BN is an additional mechanism to stabilize SolarFlareNet, make it faster, and help to avoid overfitting during training45. We applied BN after the input layer, the LSTM layer, and within the TEBs to make sure that SolarFlareNet is stable throughout the training process. The BN layer is followed by the Conv1D layer because time series generally have a strong 1D time locality that can be extracted by the Conv1D layers46. Then, the LSTM layer is used, which is equipped with regularization to also avoid overfitting. LSTM is suitable for handling time series data to capture the temporal correlation and dependency in the data. Adding an LSTM layer after a Conv1D layer has shown significant improvement in time series prediction47,48,49. The LSTM layer passes the learned features and patterns to a BN layer to stabilize the network before the data go to the TEBs.
We use transformer encoders without decoders because we process time series here, rather than performing natural language processing where the decoders are required to decode the words for sentence translation. The number of TEBs is set to 4. This number has a significant effect on the overall performance of the model50. When we use less than 4 TEBs, the model is not able to learn useful patterns and is under-fitted. When we use more than 4 TEBs, the large number of TEBs causes overhead on the encoder processing while the model tends to do excessive overfitting and lean toward the majority class (i.e., negative class) in the data, ignoring the minority class (i.e., positive class) entirely. Each TEB is configured with a dropout layer, multi-head attention (MHA) layer, a BN layer, a Conv1D layer, and an LSTM layer. The MHA layer is the most important layer in the encoder because it provides the transformation on the sequence values to obtain the different metrics. The MHA layer is configured with 4 heads and each attention head is also set to 4. The dropout layer is mainly used to overcome the overfitting caused by the imbalanced data. It drops a percentage of the neurons from the architecture, which causes the internal architecture of the model to change, allowing for better performance and stability. Finally, the softmax function is used as the final activation function, which produces a probabilistic estimate of how likely a flare will occur within the next 24 (48, 72, respectively) hours of t.

Architecture of SolarFlareNet.
Ablation study
We performed ablation tests to assess each component of SolarFlareNet. We consider four variants of SolarFlareNet, denoted SolarFlareNet-Conv, SolarFlareNet-L, SolarFlareNet-ConvL, and SolarFlareNet-T, respectively. Here, SolarFlareNet-Conv (SolarFlareNet-L, SolarFlareNet-ConvL, SolarFlareNet-T, respectively) represents the subnet of SolarFlareNet in which the Conv1D layer (LSTM layer, Conv1D and LSTM layers, transformer network with the 4 TEBs, respectively) is removed while keeping the remaining components of the SolarFlareNet framework. Table 6 compares the TSS values of the five models for the 24-, 48-, and 72-h ahead flare prediction. It can be seen from Table 6 that the full model, SolarFlareNet, outperforms the four subnets in terms of the TSS metric. This happens because the SolarFlareNet-Conv model captures the temporal correlation of the test data, but does not learn additional characteristics of the data to build a stronger relationship between the test data. SolarFlareNet-L captures the properties of the test data, but lacks knowledge of the temporal correlation patterns in the data to deeply analyze the sequential information in the test data. It can also be seen from Table 6 that the SolarFlareNet-ConvL model is not as good as the full model, indicating that the transformer network alone is not enough to produce the best results. Lastly, SolarFlareNet-T has the least performance among the four subnets, demonstrating the importance of the transformer network. In conclusion, our ablation study indicates that the performance of the proposed SolarFlareNet framework is not dominated by any single component. In fact, all components have made contributions to the overall performance of the proposed framework.
Data availability
The trained SolarFlareNet model and datasets used in this study can be downloaded from https://nature.njit.edu/solardb/solarflarenet.
References
Qahwaji, R., Colak, T., Al-Omari, M. & Ipson, S. Automated prediction of CMEs using machine learning of CME - flare associations. Sol. Phys. 248, 471–483 (2008).
Bobra, M. G. & Ilonidis, S. Predicting coronal mass ejections using machine learning methods. Astrophys. J. 821, 127 (2016).
Liu, C., Deng, N., Wang, J. T. L. & Wang, H. Predicting solar flares using SDO/HMI vector magnetic data products and the random forest algorithm. Astrophys. J. 843, 104 (2017).
Liu, H., Liu, C., Wang, J. T. L. & Wang, H. Predicting coronal mass ejections using SDO/HMI vector magnetic data products and recurrent neural networks. Astrophys. J. 890, 12 (2020).
Abduallah, Y. et al. Predicting solar energetic particles using SDO/HMI vector magnetic data products and a bidirectional LSTM network. Astrophys. J. Suppl. Ser. 260, 16 (2022).
Moreland, K. et al. A machine-learning oriented dataset for forecasting SEP occurrence and properties. In 44th COSPAR Scientific Assembly, vol. 44, 1151 (2022).
Singh, T., Benson, B., Raza, S., Kim, T. & Pogorelov, N. Improving the arrival time prediction of coronal mass ejections using magnetohydrodynamic ensemble modeling, heliospheric imager data and machine learning. In EGU General Assembly Conference Abstracts, EGU22–13167 (2022).
Daglis, I., Baker, D., Kappenman, J., Panasyuk, M. & Daly, E. Effects of space weather on technology infrastructure. Space Weather 2, S02004 (2004).
Liu, H., Liu, C., Wang, J. T. L. & Wang, H. Predicting solar flares using a long short-term memory network. Astrophys. J. 877, 121 (2019).
Zhang, H. et al. Solar flare index prediction using SDO/HMI vector magnetic data products with statistical and machine-learning methods. Astrophys. J. Suppl. Ser. 263, 28 (2022).
He, X.-R. et al. Solar flare short-term forecast model based on long and short-term memory neural network. Chin. Astron. Astrophys. 47, 108–126 (2023).
Huang, X., Zhang, L., Wang, H. & Li, L. Improving the performance of solar flare prediction using active longitudes information. Astron. Astrophys. 549, A127 (2013).
Panos, B. & Kleint, L. Real-time flare prediction based on distinctions between flaring and non-flaring active region spectra. Astrophys. J. 891, 17 (2020).
Georgoulis, M. K. et al. The flare likelihood and region eruption forecasting (FLARECAST) project: flare forecasting in the big data & machine learning era. J. Space Weather Space Clim. 11, 39 (2021).
Tang, R. et al. Solar flare prediction based on the fusion of multiple deep-learning models. Astrophys. J. Suppl. Ser. 257, 50 (2021).
Gallagher, P. T., Moon, Y. J. & Wang, H. Active-region monitoring and flare forecasting I. Data processing and first results. Solar Phys. 209, 171–183 (2002).
Leka, K. D. & Barnes, G. Photospheric magnetic field properties of flaring versus flare-quiet active regions. IV. A statistically significant sample. Astrophys. J. 656, 1173–1186 (2007).
Mason, J. P. & Hoeksema, J. T. Testing automated solar flare forecasting with 13 years of Michelson Doppler Imager magnetograms. Astrophys. J. 723, 634–640 (2010).
Bobra, M. G. & Couvidat, S. Solar flare prediction using SDO/HMI vector magnetic field data with a machine-learning algorithm. Astrophys. J. 798, 135 (2015).
Abduallah, Y., Wang, J. T. L., Nie, Y., Liu, C. & Wang, H. DeepSun: Machine-learning-as-a-service for solar flare prediction. Res. Astron. Astrophys. 21, 160 (2021).
Liu, S. et al. Deep learning based solar flare forecasting model. II. Influence of image resolution. Astrophys. J. 941, 20 (2022).
Sun, P. et al. Solar flare forecast using 3D convolutional neural networks. Astrophys. J. 941, 1 (2022).
Nishizuka, N., Sugiura, K., Kubo, Y., Den, M. & Ishii, M. Deep flare net (DeFN) model for solar flare prediction. Astrophys. J. 858, 113 (2018).
Pesnell, W. D. Solar Dynamics Observatory (SDO). In Handbook of Cosmic Hazards and Planetary Defense, 179–196 (Springer, 2015).
Bobra, M. G. et al. The Helioseismic and Magnetic Imager (HMI) vector magnetic field pipeline: SHARPs - Space-weather HMI Active Region Patches. Sol. Phys. 289, 3549–3578 (2014).
Li, X., Zheng, Y., Wang, X. & Wang, L. Predicting solar flares using a novel deep convolutional neural network. Astrophys. J. 891, 10 (2020).
Deng, Z. et al. Fine-grained solar flare forecasting based on the hybrid convolutional neural networks. Astrophys. J. 922, 232 (2021).
Tian, Y. Relationship between the evolution of solar magnetic field and flares in different active regions. J. Phys: Conf. Ser. 2282, 012025 (2022).
van Driel-Gesztelyi, L. & Green, L. M. Evolution of active regions. Living Rev. Sol. Phys. 12, 1 (2015).
Yu, D., Huang, X., Wang, H. & Cui, Y. Short-term solar flare prediction using a sequential supervised learning method. Sol. Phys. 255, 91–105 (2009).
Chen, Y. et al. Identifying solar flare precursors using time series of SDO/HMI images and SHARP parameters. Space Weather 17, 1404–1426 (2019).
Sun, Z. et al. Predicting solar flares using CNN and LSTM on two solar cycles of active region data. Astrophys. J. 931, 163 (2022).
Jonas, E., Bobra, M., Shankar, V., Todd Hoeksema, J. & Recht, B. Flare prediction using photospheric and coronal image data. Sol. Phys. 293, 48 (2018).
Huang, X. et al. Deep learning based solar flare forecasting model. I. Results for line-of-sight magnetograms. Astrophys. J. 856, 7 (2018).
Wang, X. et al. Predicting solar flares with machine learning: Investigating solar cycle dependence. Astrophys. J. 895, 3 (2020).
Kruskal, J. B. Nonmetric multidimensional scaling: A numerical method. Psychometrika 29, 115–129 (1964).
Sager, T. W. & Thisted, R. A. Maximum likelihood estimation of isotonic modal regression. Ann. Stat. 10, 690–707 (1982).
Wilks, D. S. Sampling distributions of the Brier score and Brier skill score under serial dependence. Q. J. R. Meteorol. Soc. 136, 2109–2118 (2010).
The SunPy Community et al. SunPy—Python for solar physics. Computational Science and Discovery8, 014009 (2015).
Hazra, S., Sardar, G. & Chowdhury, P. Distinguishing between flaring and nonflaring active regions. Astron. Astrophys. 639, A44 (2020).
Hoeksema, J. T. et al. The Helioseismic and Magnetic Imager (HMI) vector magnetic field pipeline: Overview and performance. Sol. Phys. 289, 3483–3530 (2014).
Deng, Y. et al. Deep transfer learning and data augmentation improve glucose levels prediction in type 2 diabetes patients. Nat. Portf. J. Digit. Med. 4, 1013345 (2021).
Um, T. T. et al. Data augmentation of wearable sensor data for Parkinson’s disease monitoring using convolutional neural networks. In Proceedings of the 19th Association for Computing Machinery International Conference on Multimodal Interaction (2017).
Li, K., Daniels, J., Liu, C., Herrero, P. & Georgiou, P. Convolutional recurrent neural networks for glucose prediction. IEEE J. Biomed. Health Inform. 24, 603–613 (2020).
Zerveas, G., Jayaraman, S., Patel, D., Bhamidipaty, A. & Eickhoff, C. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (2021).
Kravchik, M. & Shabtai, A. Detecting cyber attacks in industrial control systems using convolutional neural networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy (2018).
Abduallah, Y. et al. Reconstruction of total solar irradiance by deep learning. In Proceedings of the 34th International Florida Artificial Intelligence Research Society Conference (2021).
Abduallah, Y., Wang, J. T. L., Xu, C. & Wang, H. A transformer-based framework for geomagnetic activity prediction. In Proceedings of the 26th International Symposium on Methodologies for Intelligent Systems (2022).
Abduallah, Y. et al. Forecasting the disturbance storm time index with Bayesian deep learning. In Proceedings of the 35th International Florida Artificial Intelligence Research Society Conference (2022).
Vaswani, A. et al. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems (2017).
Acknowledgements
The authors thank members of the Institute for Space Weather Sciences for helpful discussions. We also thank the reviewers for valuable comments and suggestions.
Funding
This work was supported in part by US NSF grants AGS-1927578, AGS-2149748, and AGS-2228996.
Author information
Authors and Affiliations
Contributions
J.W. and H.W. conceived the study. Y.A. implemented the operational, near real-time flare forecasting system. Y.X. evaluated and tested the system. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abduallah, Y., Wang, J.T.L., Wang, H. et al. Operational prediction of solar flares using a transformer-based framework. Sci Rep 13, 13665 (2023). https://doi.org/10.1038/s41598-023-40884-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40884-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
