
Abstract
Recognizing human actions in video sequences, known as Human Action Recognition (HAR), is a challenging task in pattern recognition. While Convolutional Neural Networks (ConvNets) have shown remarkable success in image recognition, they are not always directly applicable to HAR, as temporal features are critical for accurate classification. In this paper, we propose a novel dynamic PSO-ConvNet model for learning actions in videos, building on our recent work in image recognition. Our approach leverages a framework where the weight vector of each neural network represents the position of a particle in phase space, and particles share their current weight vectors and gradient estimates of the Loss function. To extend our approach to video, we integrate ConvNets with state-of-the-art temporal methods such as Transformer and Recurrent Neural Networks. Our experimental results on the UCF-101 dataset demonstrate substantial improvements of up to 9% in accuracy, which confirms the effectiveness of our proposed method. In addition, we conducted experiments on larger and more variety of datasets including Kinetics-400 and HMDB-51 and obtained preference for Collaborative Learning in comparison with Non-Collaborative Learning (Individual Learning). Overall, our dynamic PSO-ConvNet model provides a promising direction for improving HAR by better capturing the spatio-temporal dynamics of human actions in videos. The code is available at https://github.com/leonlha/Video-Action-Recognition-Collaborative-Learning-with-Dynamics-via-PSO-ConvNet-Transformer.
Similar content being viewed by others


Introduction
Human action recognition plays a vital role for distinguishing a particular behavior of interest in the video. It has critical applications including visual surveillance for detection of suspicious human activities to prevent the fatal accidents1,2, automation-based driving to sense and predict human behavior for safe navigation3,4. In addition, there are large amount of non-trivial applications such as human–machine interaction5,6, video retrieval7, crowd scene analysis8 and identity recognition9.
In the early days, the majority of research in Human Activity Recognition was conducted using hand-crafted methods10,11,12. However, as deep learning technology evolved and gained increasing recognition in the research community, a multitude of new techniques have been proposed, achieving remarkable results.
Action recognition preserves a similar property of image recognition since both of the fields handle visual contents. In addition, action recognition classifies not only still images but also dynamics temporal information from the sequence of images. Built on these intrinsic characteristics, action recognition’s methods can be grouped into two main approaches namely recurrent neural networks (RNN) based approach and 3-D ConvNet based approach. Besides of the main ones, there are other methods that utilize the content from both spatial and temporal and coined the name two-stream 2-D ConvNet based approach13.
Initially, action recognition was viewed as a natural extension of image recognition, and spatial features from still frames could be extracted using ConvNet, which is one of the most efficient techniques in the image recognition field. However, traditional ConvNets are only capable of processing a single 2-D image at a time. To expand to multiple 2-D images, the neural network architecture needs to be re-designed, including adding an extra dimension to operations such as convolution and pooling to accommodate 3-D images. Examples of such techniques include C3D14, I3D15, R3D16, S3D17, T3D18, LTC19, among others
Similarly, since a video primarily consists of a temporal sequence, techniques for sequential data, such as Recurrent Neural Networks and specifically Long Short Term Memory, can be utilized to analyze the temporal information. Despite the larger size of images, feature extraction is often employed. Long-term Recurrent Convolutional Networks (LRCN)20 and Beyond-Short-Snippets21 were among the first attempts to extract feature maps from 2-D ConvNets and integrate them with LSTMs to make video predictions. Other works have adopted bi-directional LSTMs22,23, which are composed of two separate LSTMs, to explore both forward and backward temporal information.
To further improve performance, other researchers argue that videos usually contain repetitive frames or even hard-to-classify ones which makes the computation expensive. By selecting relevant frames, it can help to improve action recognition performance both in terms of efficiency and accuracy24. A similar concept based on attention mechanisms is the main focus in recent researches to boost overall performance of the ConvNet-LSTM frameworks25,26.
While RNNs are superior in the field, they process data sequentially, meaning that information flows from one state to the next, hindering the ability to speed up training in parallel and causing the architectures to become larger in size. These issues limit the application of RNNs to longer sequences. In light of these challenges, a new approach, the Transformer, emerged27,28,29,30,31.
There has been a rapid advancement in action recognition in recent years, from 3-D ConvNets to 2-D ConvNets-LSTM, two-stream ConvNets, and more recently, Transformers. While these advancements have brought many benefits, they have also created a critical issue as previous techniques are unable to keep up with the rapidly changing pace. Although techniques such as evolutionary computation offer a crucial mechanism for architecture search in image recognition, and swarm intelligence provides a straightforward method to improve performance, they remain largely unexplored in the realm of action recognition.
In our recent research32, we developed a dynamic Particle Swarm Optimization (PSO) framework for image classification. In this framework, each particle navigates the landscape, exchanging information with neighboring particles about its current estimate of the geometry (such as the gradient of the Loss function) and its position. The overall goal of this framework is to create a distributed, collaborative algorithm that improves the optimization performance by guiding some of the particles up to the best minimum of the loss function. We extend this framework to action recognition by incorporating state-of-the-art methods for temporal data (Transformer and RNN) with the ConvNet module in an end-to-end training setup.
In detail, we have made the following improvements compared to our previous publication.
We have supplemented a more comprehensive review of the literature on Human Action Recognition. We have implemented the following enhancements and additions to our work:
-
(1)
We have introduced an improved and novel network architecture that extends a PSO-ConvNet to a PSO-ConvNet Transformer (or PSO-ConvNet RNN) in an end-to-end fashion.
-
(2)
We have expanded the scope of Collaborative Learning as a broader concept beyond its original application in image classification to include action recognition.
-
(3)
We have conducted additional experiments on challenging datasets to validate the effectiveness of the modified model.
These improvements and additions contribute significantly to the overall strength and novelty of our research.
The rest of the article is organized as follows: In Sect. 2, we discuss relevant approaches in applying Deep Learning and Swarm Intelligence to HAR. In addition, the proposed methods including Collaborative Learning with Dynamic Neural Networks and ConvNet Transformer architecture as well as ConvNet RNN model are introduced in Sects. 3.1, 3.2 and 3.3, respectively. The results of experiments, the extension of the experiments and discussions are presented in Sects. 4, 5 and 6. Finally, we conclude our work in Sect. 7.
Related works
In recent years, deep learning (DL) has greatly succeed in computer vision fields, e.g., object detection, image classification and action recognition24,30,33. One consequence of this success has been a sharp increase in the number of investments in searching for good neural network architectures. An emerging promising approach is changing from the manual design to automatic Neural Architecture Search (NAS). As an essential part of automated machine learning, NAS automatically generates neural networks which have led to state-of-the-art results34,35,36. Among various approaches for NAS already present in the literature, evolutionary search stands out as one of the most remarkable methods. For example, beginning with just one layer of neural network, the model develops into a competitive architecture that outperforms contemporary counterparts34. As a result, the efficacy of the their proposed classification system for HAR on UCF-50 dataset was demonstrated33 by initializing the weights of a convolutional neural network classifier based on solutions generated from genetic algorithms (GA).
In addition to Genetic Algorithms, Particle Swarm Optimization—a population-based stochastic search method influenced by the social behavior of flocking birds and schooling fish—has proven to be an efficient technique for feature selection37,38. A novel approach that combines a modified Particle Swarm Optimization with Back-Propagation was put forth for image recognition, by adjusting the inertia weight, acceleration parameters, and velocity39. This fusion allows for dynamic and adaptive tuning of the parameters between global and local search capability, and promotes diversity within the swarm. In catfish particle swarm optimization, the particle with the worst fitness is introduced into the search space when the fitness of the global best particle has not improved after a number of consecutive iterations40. Moreover, a PSO based multi-objective for discriminative feature selection was introduced to enhance classification problems41.
There have been several efforts to apply swarm intelligence to action recognition from video. One such approach employs a combination of binary histogram, Harris corner points, and wavelet coefficients as features extracted from the spatiotemporal volume of the video sequence42. To minimize computational complexity, the feature space is reduced through the use of PSO with a multi-objective fitness function.
Furthermore, another approach combining Deep Learning and swarm intelligence-based metaheuristics for Human Action Recognition was proposed43. Here, four different types of features extracted from skeletal data—Distance, Distance Velocity, Angle, and Angle Velocity—are optimized using the nature-inspired Ant Lion Optimizer metaheuristic to eliminate non-informative or misleading features and decrease the size of the feature set.
The ideas of applying pure techniques of Natural Language Processing to Computer Vision have been seen in recent years29,30,44. By using the sequences of image patches with Transformer, the models29 can perform specially well on image classification tasks. Similarly, the approach was extended to HAR with sequence of frames30. In “Video Swin Transformer”31, the image was divided into regular shaped windows and utilize a Transformer block to each one. The approach was found to outperform the factorized models in efficiency by taking advantage of the inherent spatiotemporal locality of videos where pixels that are closer to each other in spatiotemporal distance are more likely to be relevant. In our study, we adopt a different approach by utilizing extracted features from a ConvNet rather than using original images. This choice allows us to reduce computational expenses without compromising efficiency, as detailed in Sect. 3.2.
Temporal Correlation Module (TCM)45 utilizes fast-tempo and slow-tempo information and adaptively enhances the expressive features, and a Temporal Segment Network (TSN) is introduced to further improve the results of the two-stream architecture46. Spatiotemporal vector of locally aggregated descriptor (ActionS-ST-VLAD) approach designs to aggregate relevant deep features during the entire video based on adaptive video feature segmentation and adaptive segment feature sampling (AVFS-ASFS) in which the key-frame features are selected47. Moreover, the concept of using temporal difference can be found in the works48,49,50. Temporal Difference Networks (TDN) approach proposes for both finer local and long-range global motion information, i.e., for local motion modeling, temporal difference over consecutive frames is utilized whereas for global motion modeling, temporal difference across segments is integrated to capture long-range structure48. SpatioTemporal and Motion Encoding (STM) approach proposes an STM block, which contains a Channel-wise SpatioTemporal Module (CSTM) to present the spatiotemporal features and a Channel-wise Motion Module (CMM) to efficiently encode motion features in which a 2D channel-wise convolution is applied to two consecutive frames and then subtracts to obtain the approximate motion representation49.
Other related approaches that can be mentioned include Zero-Shot Learning, Few-Shot Learning, and Knowledge Distillation Learning51,52,53. Zero-Shot Learning and Few-Shot Learning provide techniques for understanding domains with limited data availability. Similar to humans, who can identify similar objects within a category after seeing only a few examples, these approaches enable the model to generalize and recognize unseen or scarce classes. In our proposed approach, we introduce the concept of Collaborative Learning, where particles collaboratively train in a distributed manner.
Despite these advances, the field remains largely uncharted, especially with respect to recent and emerging techniques.
Proposed methods
Collaborative dynamic neural networks
Define \(\mathscr {N}(n,t)\) as the set of k nearest neighbor particles of particle n at time t, where \(k\in \mathbb {N}\) is some predefined number. In particular,
where \(i_1\), \(i_2, \ldots i_k\) are the k closest particles to n and \(x^{(i_k)}(t)\) and \(v^{(i_k)}(t)\in \mathbb {R}^D\) represent the position and velocity of particle \(i_k\) at time t. Figure 1 illustrates this concept for \(k=4\) particles.

A demonstration of the \(\mathscr {N}(n,t)\) neighborhood, consisting of the positions of four closest particles and particle n itself, is shown. The velocities of the particles are depicted by arrows.
Given a (continuous) function \(L\,:\,\mathbb {R}^D\longrightarrow \mathbb {R}\) and a (compact) subset \(S\subset \mathbb {R}^D\), define
as the subset of points that minimize L in S, i.e., \(L(z)\le L(w)\) for any \(z\in \mathscr {Y}\subset S\) and \(w\in S\).
Dynamic 1 We investigate a set of neural networks that work together in a decentralized manner to minimize a Loss function L. The training process is comprised of two phases: (1) individual training of each neural network using (stochastic) gradient descent, and (2) a combined phase of SGD and PSO-based cooperation. The weight vector of each neural network is represented as the position of a particle in a D-dimensional phase space, where D is the number of weights. The evolution of the particles (or neural networks) is governed by Eq. (3), with the update rule specified by the following dynamics:
where \(v^{(n)}(t)\in \mathbb {R}^{D}\) is the velocity vector of particle n at time t; \(\psi ^{(n)}(t)\) is an intermediate velocity computed from the gradient of the Loss function at \(x^{(n)}(t)\); \(\phi ^{(n)}(t)\) is the intermediate position computed from the intermediate velocity \(\psi ^{(n)}(t)\); \(r(t)\overset{i.i.d.}{\sim }\textsf{Uniform}\left( \left[ 0,1\right] \right)\) is randomly drawn from the interval \(\left[ 0,1\right]\) and we assume that the sequence r(0), r(1), r(2), \(\ldots\) is i.i.d.; \(P^{(n)}(t)\in \mathbb {R}^D\) represents the best position visited up until time t by particle n, i.e., the position with the minimum value of the Loss function over all previous positions \(x^{(n)}(0),\,x^{(n)}(1),\,\ldots ,\,x^{(n)}(t)\); \(P_{g}^{(n)}(t)\) represents its nearest-neighbors’ counterpart, i.e., the best position across all previous positions of the particle n jointly with its corresponding nearest-neighbors \(\bigcup _{s\le t} \mathscr {N}\left( n,s\right)\) up until time t:
The weights \(w_{n\ell }\) are defined as
with \(\left| \left| \cdot \right| \right|\) being the Euclidean norm and \(f:\,\mathbb {R}\rightarrow \mathbb {R}\) being a decreasing (or at least non-increasing) function. In Dynamic 1, we assume that
for some constants \(M,\beta >0\). This strengthens the collaboration learning between any of two particles by pushing each particle against each other.
Dynamic 2 An alternative to Eq. (3) is to pull back a particle instead of pushing it in the direction of the gradient. In the previous section, the assumption was that all particles were located on the same side of a valley in the loss function. However, if one particle is on the opposite side of the valley relative to the rest of the particles, it will be pulled further away from the minimum using the first dynamic. To address this issue, we introduce a second dynamic (Dynamic 2) that pulls the particle back. The formula for this dynamics is as follows:
where \(x_{(i)}(t)\in \mathbb {R}^{D}\) is the position of particle i at time t; M, \(\beta\) and c are constants set up by experiments with \(\left| \left| \cdot \right| \right|\) being the Euclidean norm; \(r(t)\overset{i.i.d.}{\sim }\textsf{Uniform}\left( \left[ 0,1\right] \right)\) randomly drawn from the interval \(\left[ 0,1\right]\) and we assume that the sequence r(0), r(1), r(2), \(\ldots\) is i.i.d.; \(P_{nbest(i)}(t)\in \mathbb {R}^D\) represents nearest-neighbors’ best , i.e., the best position across all previous positions of the particle n jointly with its corresponding nearest-neighbors \(\bigcup _{s\le t} \mathscr {N}\left( n,s\right)\) up until time t.
ConvNet transformer architecture for action recognition
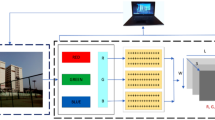
In this section, we discuss a hybrid ConvNet-Transformer architecture that replaces the traditional ConvNet-RNN block for temporal input to classify human action in videos. The architecture is composed of several components, including a feature extraction module using ConvNet, a position embedding layer, multiple transformer encoder blocks, and classification and aggregation modules. The overall diagram of the architecture can be seen in Fig. 2. The goal of the architecture is to effectively capture the temporal information present in the video sequences, in order to perform accurate human action recognition. The hybrid ConvNet-Transformer design leverages the strengths of both ConvNets and Transformers, offering a powerful solution for this challenging task.
Features extraction via ConvNet and position embedding
In the early days of using Transformer for visual classification, especially for images, the frames were typically divided into smaller patches and used as the primary input31,54,55. However, these features were often quite large, leading to high computational requirements for the Transformer. To balance efficiency and accuracy, ConvNet can be utilized to extract crucial features from images, reducing the size of the input without sacrificing performance.
We assume that, for each frame, the extracted features from ConNet have a size of (w, h, c) where w and h are the width and height of a 2D feature and c is the number of filters. To further reduce the size of the features, global average pooling is applied, reducing the size from \(w \times h \times c\) to c.
The position encoding mechanism in Transformer is used to encode the position of each frame in the sequence. The position encoding vector, which has the same size as the feature, is summed with the feature and its values are computed using the following formulas. This differs from the sequential processing of data in the RNN block, allowing for parallel handling of all entities in the sequence.
where pos, i and PE are the time step index of the input vector, the dimension and the positional encoding matrix; \(d_{model}\) refers to the length of the position encoding vector.

Rendering end-to-end ConvNet-Transformer architecture.
Transformer encoder
The Transformer Encoder is a key component of the hybrid ConvNet-Transformer architecture. It consists of a stack of N identical layers, each comprising multi-head self-attention and position-wise fully connected feed-forward network sub-layers. To ensure the retention of important input information, residual connections are employed before each operation, followed by layer normalization.
The core of the module is the multi-head self-attention mechanism, which is composed of several self-attention blocks. This mechanism is similar to RNN, as it encodes sequential data by determining the relevance between each element in the sequence. It leverages the inherent relationships between frames in a video to provide a more accurate representation. Furthermore, the self-attention operates on the entire sequence at once, resulting in significant improvements in runtime, as the computation can be parallelized using modern GPUs.
Our architecture employs only the encoder component of a full transformer, as the goal is to obtain a classification label for the video action rather than a sequence. The full transformer consists of both encoder and decoder modules, however, in our case, the use of only the encoder module suffices to achieve the desired result.
Assuming the input sequence (\(X={x_1,x_2, \ldots ,x_n}\)) is first projected onto these weight matrices \(Q = XW_Q\), \(K = XW_K\), \(V = XW_V\) with \(W_Q\),\(W_K\) and \(W_V\) are three trainable weights, the query (\(Q = q_1,q_2, \ldots ,q_n\)), key (\(K = k_1,k_2, \ldots ,k_n\)) of dimension \(d_k\), and value (\(V = v_1,v_2, \ldots ,v_n\)) of dimension \(d_v\), the output of self-attention is computed as follows:
As the name suggested, multi-head attention is composed of several heads and all are concatenated and fed into another linear projection to produce the final outputs as follows:
where parameter matrices \(W^Q_i\in \mathbb {R}^{d_{model} \times d_k}\), \(W^K_i\in \mathbb {R}^{d_{model} \times d_k}\), \(W^V_i\in \mathbb {R}^{d_{model} \times d_v}\) and \(W^O\in \mathbb {R}^{hd_v \times d_{model}}\), \(i=1,2, \ldots ,h\) with h denotes the number of heads.
Frame selection and data pre-processing
Input videos with varying number of frames can pose a challenge for the model which requires a fixed number of inputs. Put simply, to process a video sequence, we incorporated a time distributed layer that requires a predetermined number of frames. To address this issue, we employ several strategies for selecting a smaller subset of frames.
One approach is the “shadow method,” where a maximum sequence length is established for each video. While this method is straightforward, it can result in the cutting of longer videos and the loss of information, particularly when the desired length is not reached. In the second method, we utilize a step size to skip some frames, allowing us to achieve the full length of the video while reducing the number of frames used. Additionally, the images are center-cropped to create square images. The efficacy of each method will be evaluated in our experiments.
Layers for classification
Assuming, we have a set of videos \(S(S_1,S_2, \ldots ,S_m)\) with corresponding labels \(y(y_1,y_2, \ldots ,y_m)\) where m is the number of samples. We select l frames from the videos and obtain g features from the global average pooling 2-D layer. Each transformer encoder generates a set of representations by consuming the output from the previous block. After N transformer encoder blocks, we can obtain the multi-level representation \(H^N(h^N_1,h^N_2, \ldots ,h^N_l)\) where each representation is 1-D vector with the length of g (see Fig. 2 block (A) \(\rightarrow\) (D)).
The classification module incorporates traditional layers, such as fully connected and softmax, and also employs global max pooling to reduce network size. To prevent overfitting, we include Gaussian noise and dropout layers in the design. The ConvNet-Transformer model is trained using stochastic gradient descent and the categorical cross entropy loss is used as the optimization criterion.
ConvNet-RNN
Recent studies have explored the combination of ConvNets and RNNs, particularly LSTMs, to take into account temporal data of frame features for action recognition in videos20,21,22,23,56,57.
To provide a clear understanding of the mathematical operations performed by ConvNets, the following is a summary of the relevant formulations:
where X represents the input image; \(O_{i}\) is the output for layer \(i\textrm{th}\); \(W_{i}\) indicates the weights of the layer; \(f_{i}(\cdot )\) denotes weight operation for convolution, pooling or FC layers; \(g_{i}(\cdot )\) is an activation function, for example, sigmoid, tanh and rectified linear (ReLU) or more recently Leaky ReLU58; The symbol (\(\circledast\)) acts as a convolution operation which uses shared weights to reduce expensive matrix computation59; Window (\(\boxplus _{n,m}\)) shows an average or a max pooling operation which computes average or max values over neighbor region of size \(n \times m\) in each feature map. Matrix multiplication of weights between layer \(i\textrm{th}\) and the layer \((i-1)\textrm{th}\) in FC is represented as (\(*\)).
The last layer in the ConvNet (FC layer) acts as a classifier and is usually discarded for the purpose of using transfer learning. Thereafter, the outputs of the ConvNet from frames in the video sequences are fed as inputs to the RNN layer.
Considering a standard RNN with a given input sequence \({x_1, x_2, \ldots ,x_T}\), the hidden cell state is updated at a time step t as follows:
where \(W_h\) and \(W_x\) denote weight matrices, b represents the bias, and \(\sigma\) is a sigmoid function that outputs values between 0 and 1.
The output of a cell, for ease of notation, is defined as
but can also be shown using the softmax function, in which \(\hat{y}_t\) is the output and \(y_t\) is the target:
A more sophisticated RNN or LSTM that includes the concept of a forget gate can be expressed as shown in the following equations:
where the \(\odot\) operation represents an elementwise vector product, and f, i, o and c are the forget gate, input gate, output gate and cell state, respectively. Information is retained when the forget gate \(f_t\) becomes 1 and eliminated when \(f_t\) is set to 0.
For optimization purposes, an alternative to LSTMs, the gated recurrent unit (GRU), can be utilized due to its lower computational demands. The GRU merges the input gate and forget gate into a single update gate, and the mathematical representation is given by the following equations:
Finally, it’s worth noting that while traditional RNNs only consider previous information, bidirectional RNNs incorporate both past and future information in their computations:
where \(h_{t-1}\) and \(h_{t+1}\) indicate hidden cell states at the previous time step (\(t-1\)) and the future time step (\(t+1\)).
Results
Benchmark datasets
The UCF-101 dataset, introduced in 2012, is one of the largest annotated video datasets available60, and an expansion of the UCF-50 dataset. It comprises 13,320 realistic video clips collected from YouTube and covers 101 categories of human actions, such as punching, boxing, and walking. The dataset has three distinct official splits (rather than a pre-divided training set and testing set), and the final accuracy in our experiments is calculated as the arithmetic average of the results across all three splits.
HMDB-5161 was released around the same time as UCF-101. The dataset contains roughly 5k videos belonging to 51 distinct action classes. Each class in the dataset holds at least 100 videos. The videos are collected from a multiple sources, for example, movies and online videos.
Kinetics-40062 was recently made available in 2017. The dataset consists of 400 human action classes with at least 400 video clips for each action. The videos were assembled from realistic YouTube in which each clip lasts around 10s. In total, the dataset contains about 240k training videos and 20k validation videos and is one of the largest well-labeled video datasets utilized for action recognition.
Downloading individual videos from the Kinetics-400 dataset poses a significant challenge due to the large number of videos and the fact that the dataset only provides links to YouTube videos. Therefore, we utilize Fiftyone63, an open-source tool specifically designed for constructing high-quality datasets, to address this challenge. In our experiment, we collected top-20 most accuracy categories according to the work62 including “riding mechanical bull”, “presenting weather forecast”, “sled dog racing”, etc. Eventually, we obtained 7114 files for training and 773 files for validation with a significant number of files were not collected because the videos were deleted or changed to private, etc. In the same manner, we gathered all categories from HMDB-51 and obtained 3570 files for training and 1530 files for validation. The tool provides one-split for the HMDB-51, but the document does not specify which split.
Our experiments were conducted using Tensorflow-2.8.264, Keras-2.6.0, and a powerful 4-GPU system (GeForce® GTX 1080 Ti). We used Hiplot65 for data visualization. Figure 3 provides snapshot of samples from each of the action categories.

A snapshot of samples of all actions from UCF-101 dataset60.
Evaluation metric
For evaluating our results, we employ the standard classification accuracy metric, which is defined as follows:
Implementation
Training our collaborative models for action recognition involves building a new, dedicated system, as these models require real-time information exchange. To the best of our knowledge, this is the first such system ever built for this purpose. To accommodate the large hardware resources required, each model is trained in a separate environment. After one training epoch, each model updates its current location, previous location, estimate of the gradient of the loss function, and other relevant information, which is then broadcast to neighboring models. To clarify the concept, we provide a diagram of the collaborative system and provide a brief description in this subsection.
Our system for distributed PSO-ConvNets is designed based on a web client-server architecture, as depicted in Fig. 4. The system consists of two main components: the client side, which is any computer with a web browser interface, and the server side, which comprises three essential services: cloud services, app services, and data services.
The cloud services host the models in virtual machines, while the app services run the ConvNet RNN or ConvNet Transformer models. The information generated by each model is managed by the data services and stored in a data storage. In order to calculate the next positions of particles, each particle must wait for all other particles to finish the training cycle in order to obtain the current information.
The system is designed to be operated through a web-based interface, which facilitates the advanced development process and allows for easy interactions between users and the system.

Dynamic PSO-ConvNets System Design. The system is divided into two main components, client and server. The client side is accessed through web browser interface while the server side comprises of cloud, app, and data services. The cloud stores virtual machine environments where the models reside. The app service is where the ConvNet-RNN or ConvNet-Transformer runs, and the information generated by each model is managed and saved by the data service. The particles in the system update their positions based on shared information, including current and previous locations, after completing a training cycle.
Effectiveness of the proposed method
Table 1 presents the results of Dynamic 1 and Dynamic 2 on action recognition models. The experiment settings are consistent with our previous research for a fair comparison. As shown in Fig. 2, we consider two different ConvNet architectures, namely DenseNet-201 and ResNet-152, and select eight models from the Inception66, EfficientNet67, DenseNet68, and ResNet69 families. In the baseline action recognition methods (DenseNet-201 RNN, ResNet-152 RNN, DenseNet-201 Transformer, and ResNet-152 Transformer), features are first extracted from ConvNets using transfer learning and then fine-tuned. However, in our proposed method, the models are retrained in an end-to-end fashion. Pretrained weights from the ImageNet dataset70 are utilized to enhance the training speed. Our results show an improvement in accuracy between \(1.58\%\) and \(8.72\%\). Notably, the Dynamics 2 for DenseNet-201 Transformer achieves the best result. We also report the time taken to run each method. Fine-tuning takes less time, but the technique can lead to overfitting after a few epochs.
The experiments described above were conducted using the settings outlined in Tables 2 and 3. The batch size, input image size, and number of frames were adjusted to maximize GPU memory utilization. However, it is worth noting that in Human Activity Recognition (HAR), the batch size is significantly reduced compared to image classification, as each video consists of multiple frames. Regarding the gradient weight M, a higher value indicates a stronger attractive force between particles.
Comparison with state-of-the-art methods
The comparison between our method (Dynamic 2 for ConvNet Transformer) and the previous approaches is shown in Table 4. The second method (Transfer Learning and Fusions) trains the models on a Sports-1M Youtube dataset and uses the features for UCF-101 recognition. However, the transfer learning procedure is slightly different as their ConvNet architectures were designed specifically for action recognition. While it may have been better to use a pretrained weight for action recognition datasets, such weights are not readily available as the models differ. Also, training the video dataset with millions of samples within a reasonable time is a real challenge for most research centers. Despite these limitations, the use of Transformer and RNN seem to provide a better understanding of temporal characteristics compared to fusion methods. Shuffle &Learn tries with two distinct models using 2-D images (AlexNet) and 3-D images (C3D) which essentially is series of 2-D images. The accuracy is improved, though, 3-D ConvNets require much more power of computing than the 2-D counterparts. There are also attempts to redesign well-known 2-D ConvNet for 3-D data (C3D is built from scratch of a typical ConvNet14), e.g., DPC approach and/or pretrained on larger datasets, e.g., 3D ST-puzzle approach. Besides, VideoMoCo utilizes Contrastive Self-supervised Learning (CSL) based approaches to tackle with unlabeled images. The method extends image-based MoCo framework for video representation by empowering temporal robustness of the encoder as well as modeling temporal decay of the keys. Our Dynamic 2 method outperforms VideoMoCo by roughly \(9\%\). SVT is a self-supervised method based on the TimeSformer model that employs various self-attention schemes79. On pre-trained of the entire Kinetics-400 dataset and inference on UCF-101, the SVT achieves 90.8% and 93.7% for linear evaluation and fine-tuning settings, respectively. When pre-trained on a subset of Kinetics-400 with 60,000 videos, the accuracy reduces to 84.8%. Moreover, the TSN methods apply ConvNet and achieves an accuracy of 84.5% using RGB images (2% less than our method) and 92.3% using a combination of three networks (RGB, Optical Flow and Warped Flow). Similarly, the STM approach employs two-stream networks and pre-trained on Kinetics that enhances the performance significantly. Designing a two-stream networks or multi-stream networks would require a larger resource, due to the limitations, we have not pursued this approach at this time. Furthermore, using optical flow80 and pose estimation81 on original images may improve performance, but these techniques are computationally intensive and time consuming, especially during end-to-end training. The concept of Collaborative Learning, on the other hand, is based on a general formula of the gradient of the loss function and could be used as a plug-and-play module for any approach. Finally, the bag of words method was originally used as a baseline for the dataset and achieved the lowest recognition accuracy (\(44.5\%\)).
Hyperparameter optimization
In these experiments, we aimed to find the optimal settings for each model. Table 5 presents the results of the DenseNet-201 Transformer and ResNet-152 Transformer using transfer learning, where we varied the maximum sequence length, number of frames, number of attention heads, and dense size. The number of frames represents the amount of frames extracted from the sequence, calculated by \(step=\text{(maximum } \text{ sequence } \text{ length)/(number } \text{ of } \text{ frames) }\). The results indicate that longer sequences of frames lead to better accuracy, but having a large number of frames is not necessarily the best strategy; a balanced approach yields higher accuracy. Furthermore, we discovered that models performed best with 6 attention heads and a dense size of either 32 or 64 neurons.
Figures 5 and 6 show the results for ConvNet RNN models using transfer learning. In the experiments, we first evaluated the performance of eight ConvNets (Inception-v3, ResNet-101, ResNet-152, DenseNet-121, DenseNet-201, EfficientNet-B0, EfficientNet-B4, and EfficientNet-B7). The two best performers, DenseNet-121 and ResNet-152 ConvNet architectures, were selected for further experimentation. The results of varying the number of frames showed a preference for longer maximum sequence lengths.

Hyperparameter optimization results for ConvNet RNN models with transfer learning. the models are numbered as follows: 1. Inception-v3, 2. ResNet-101, 3. ResNet-152, 4. DenseNet-121, 5. DenseNet-201, 6. EfficientNet-B0, 7. EfficientNet-B4, 8. EfficientNet-B7. The abbreviations acc, gn, and lr stand for accuracy, Gaussian noise, and learning rate, respectively.

Impact of varying the number of frames on the three-fold accuracy of DenseNet-201 RNN and ResNet-152 RNN using transfer learning on the UCF-101 benchmark dataset.
Extension
In this Section, we extend our experiments to perform on more challenge datasets, i.e., Kinetics-400 and HMDB-51. In our methods, ConvNets are retrained to improve accuracy performance when compared to Transfer Learning32,44, but these processes can take a long time on the entire Kinetics-400 dataset. As a result, we decided to obtain only a portion of the entire dataset in order to demonstrate our concept. As shown in Table 6, our main focus in this study is to compare Non-Collaborative Learning (or Individual Learning) and Collaborative Learning approaches. In each experiment, we conduct two repetitions and record both the mean accuracy and the best accuracy (Max) achieved. All settings are the same as in the experiments with UCF-101 dataset. The learning rate range is obtained by running a scan from a low to a high learning rate. As a consequence, the learning rates of particles PSO-1, PSO-2 and PSO-3 are set at \(10^{-2}\), \(10^{-3}\) and \(10^{-4}\), respectively, whereas the learning rates of the wilder particle PSO-4 has a range of \([10^{-5},10^{-1}]\). The results show a preference for the Collaborative Learning methods as the Dynamic 1 and Dynamic 2 outperform the Individual Learning through both datasets, e.g., an improvement of 0.7% can be seen on Kinetics-400 using DenseNet-201 Transformer. The results obtained in our experiments clearly demonstrate the superiority of our proposed Collaborative Learning approach for video action recognition.
Discussion
The performance of action recognition methods such as ConvNet Transformer and ConvNet RNN is largely dependent on various factors, including the number of attention heads, the number of dense neurons, the number of units in RNN, and the learning rate, among others. Collaborative learning is an effective approach to improve the training of neural networks, where multiple models are trained simultaneously and both their positions and directions, as determined by the gradients of the loss function, are shared. In our previous research, we applied dynamics to ConvNets for image classification and in this study, we extend the concept to hybrid ConvNet Transformer and ConvNet RNN models for human action recognition in sequences of images. We first aim to identify the optimal settings that lead to the highest accuracy for the baseline models. As seen in Table 1, the ConvNet Transformer models did not perform as well as the ConvNet RNN models with transfer learning, which could be due to the limited data available for training, as transformers typically require more data than RNN-based models. However, our proposed method, incorporating dynamics and end-to-end training, not only outperforms the baseline models, but also results in the ConvNet Transformer models outperforming their ConvNet RNN counterparts. This can be attributed to the additional data provided to the transformer models through data augmentation and additional noise.
Conclusion
Recognizing human actions in videos is a fascinating problem in the art of recognition, and while Convolutional Neural Networks provide a powerful method for image classification, their application to HAR can be complex, as temporal features play a critical role.
In this study, we present a novel video action recognition framework that leverages collaborative learning with dynamics. Our approach explores the hybridization of ConvNet RNN and the recent advanced method Transformer, which has been adapted from Natural Language Processing for video sequences. The experiments include the exploration of two dynamics models, Dynamic 1 and Dynamic 2. The results demonstrate a round improvement of 2–9% in accuracy over baseline methods, such as an \(8.72\%\) increase in accuracy for the DenseNet-201 Transformer using Dynamic 2 and a \(7.26\%\) increase in accuracy for the ResNet-152 Transformer using Dynamic 1. Our approach outperforms the previous methods, offering significant improvements in video action recognition.
In summary, our work makes three key contributions: (1) We incorporate Dynamic 1 and Dynamic 2 into a hybrid model that combines ConvNet with two popular sequence modeling techniques—RNN and Transformer. (2) We extend the distributed collaborative learning framework to address the task of human action recognition. (3) We conducted extensive experiments on the challenging datasets including UCF-101, Dynamics-400 and HMDB-51 over a period of 2–3 months to thoroughly evaluate our approach. To validate its effectiveness, we compared our method against state-of-the-art approaches in the field.
Data availability
The datasets generated and/or analysed during the current study are available in the UCF101 repository, https://www.crcv.ucf.edu/data/UCF101.php. All data generated or analysed during this study are included in this published article [and its supplementary information files].
Abbreviations
- \(X\) :
-
Input frame in video sequences for ConvNet
- \(O_{i}\) :
-
Output for layer ith
- \(f_{i}\) :
-
Weight operation for convolution, pooling or fully connected layers at layer ith
- \(g_{i}\) :
-
Activation function at layer ith
- \(x_{t}\) :
-
Input sequence of RNN at time step t
- \(W_{h},W_{x},b,\sigma\) :
-
Weight matrices, bias, sigmoid function
- \(h_{t}\) :
-
Hidden cell state at time step t
- \(y_{t},\hat{y}_t\) :
-
Output of a cell at time step t
- \(f_{t},i_{t},o_{t},c_{t},c^{'}_{t}\) :
-
Forget gate, input gate, output gate and cell states at time step t
- \(x^{n}(t),v^{n}(t)\) :
-
Position and velocity vector of particle n at time t
- \(\phi ^{(n)}(t),\psi ^{(n)}(t)\) :
-
Intermediate position and intermediate velocity of particle n at time t
- \(P^{n}(t)\) :
-
Best position visited up until time t by particle n
- \(P_{g}^{n}(t)\) :
-
Best position across all previous positions of the particle n jointly with its nearest-neighbors up until time t
- \(L\) :
-
Loss function
- \(c,c_{1},c_{2}\) :
-
Accelerator coefficients
- \(r(t)\) :
-
Random uniform within the interval [0,1]
- \(M,\beta\) :
-
Constants
References
Sultani, W., Chen, C. & Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 6479–6488 (2018).
Li, A. et al. Abnormal event detection in surveillance videos based on low-rank and compact coefficient dictionary learning. Pattern Recognit. 108, 107355 (2020).
Razali, H., Mordan, T. & Alahi, A. Pedestrian intention prediction: A convolutional bottom-up multi-task approach. Transp. Res. Part C Emerg. Technol. 130, 103259 (2021).
Yang, H., Liu, L., Min, W., Yang, X. & Xiong, X. Driver yawning detection based on subtle facial action recognition. IEEE Trans. Multimed. 23, 572–583 (2020).
Presti, L. L. & La Cascia, M. 3d skeleton-based human action classification: A survey. Pattern Recognit. 53, 130–147 (2016).
Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 28, 976–990 (2010).
Zhu, H., Vial, R. & Lu, S. Tornado: A spatio-temporal convolutional regression network for video action proposal. In Proceedings of the IEEE International Conference on Computer Vision 5813–5821 (2017).
Curtis, S., Zafar, B., Gutub, A. & Manocha, D. Right of way. Vis. Comput. 29, 1277–1292 (2013).
Paul, S. N. & Singh, Y. J. Survey on video analysis of human walking motion. Int. J. Signal Process. Image Process. Pattern Recognit. 7, 99–122 (2014).
Wang, H., Kläser, A., Schmid, C. & Liu, C.-L. Action recognition by dense trajectories. In CVPR 2011 3169–3176 (2011). https://doi.org/10.1109/CVPR.2011.5995407.
Wang, H. & Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision 3551–3558 (2013).
Gorelick, L., Blank, M., Shechtman, E., Irani, M. & Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 29, 2247–2253 (2007).
Simonyan, K. & Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 27 (2014).
Tran, D., Bourdev, L., Fergus, R., Torresani, L. & Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision 4489–4497 (2015).
Carreira, J. & Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 6299–6308 (2017).
Hara, K., Kataoka, H. & Satoh, Y. Can spatiotemporal 3d CNNS retrace the history of 2D CNNS and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition 6546–6555 (2018).
Xie, S., Sun, C., Huang, J., Tu, Z. & Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV) 305–321 (2018).
Diba, A. et al. Temporal 3d convnets: New architecture and transfer learning for video classification (2017). arXiv:1711.08200.
Varol, G., Laptev, I. & Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 40, 1510–1517 (2017).
Donahue, J. et al. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2625–2634 (2015).
Yue-Hei Ng, J. et al. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 4694–4702 (2015).
Ullah, A., Ahmad, J., Muhammad, K., Sajjad, M. & Baik, S. W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 6, 1155–1166 (2017).
He, J.-Y., Wu, X., Cheng, Z.-Q., Yuan, Z. & Jiang, Y.-G. DB-LSTM: Densely-connected bi-directional LSTM for human action recognition. Neurocomputing 444, 319–331 (2021).
Gowda, S. N., Rohrbach, M. & Sevilla-Lara, L. Smart frame selection for action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence 1451–1459 (2021).
Ge, H., Yan, Z., Yu, W. & Sun, L. An attention mechanism based convolutional LSTM network for video action recognition. Multimed. Tools Appl. 78, 20533–20556 (2019).
Wu, Z., Xiong, C., Ma, C.-Y., Socher, R. & Davis, L. S. Adaframe: Adaptive frame selection for fast video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1278–1287 (2019).
Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems 5998–6008 (2017).
Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G. & Jégou, H. Going deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision 32–42 (2021).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale (2020). arXiv:2010.11929.
Arnab, A. et al. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision 6836–6846 (2021).
Liu, Z. et al. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 3202–3211 (2022).
Phong, N. H., Santos, A. & Ribeiro, B. PSO-convolutional neural networks with heterogeneous learning rate. IEEE Access 10, 89970–89988. https://doi.org/10.1109/ACCESS.2022.3201142 (2022).
Ijjina, E. P. & Chalavadi, K. M. Human action recognition using genetic algorithms and convolutional neural networks. Pattern Recognit. 59, 199–212 (2016).
Real, E. et al. Large-scale evolution of image classifiers. In International Conference on Machine Learning 2902–2911 (PMLR, 2017).
Nayman, N. et al. Xnas: Neural architecture search with expert advice. Adv. Neural Inf. Process. Syst. 32 (2019).
Noy, A. et al. Asap: Architecture search, anneal and prune. In International Conference on Artificial Intelligence and Statistics 493–503 (PMLR, 2020).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In: Proceedings of ICNN’95-International Conference on Neural Networks, vol. 4, 1942–1948 (IEEE, 1995).
Shi, Y. & Eberhart, R. A modified particle swarm optimizer. In: 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360) 69–73 (IEEE, 1998).
Tu, S. et al. ModPSO-CNN: An evolutionary convolution neural network with application to visual recognition. Soft Comput. 25, 2165–2176 (2021).
Chuang, L.-Y., Tsai, S.-W. & Yang, C.-H. Improved binary particle swarm optimization using catfish effect for feature selection. Expert Syst. Appl. 38, 12699–12707 (2011).
Xue, B., Zhang, M. & Browne, W. N. Particle swarm optimization for feature selection in classification: A multi-objective approach. IEEE Trans. Cybern. 43, 1656–1671 (2012).
Zhang, R. Sports action recognition based on particle swarm optimization neural networks. Wirel. Commun. Mob. Comput. 2022, 1–8 (2022).
Basak, H. et al. A union of deep learning and swarm-based optimization for 3d human action recognition. Sci. Rep. 12, 1–17 (2022).
Phong, N. H. & Ribeiro, B. Rethinking recurrent neural networks and other improvements for image classification (2020). arXiv:2007.15161.
Liu, Y., Yuan, J. & Tu, Z. Motion-driven visual tempo learning for video-based action recognition. IEEE Trans. Image Process. 31, 4104–4116 (2022).
Wang, L. et al. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision 20–36 (Springer, 2016).
Tu, Z. et al. Action-stage emphasized spatiotemporal VLAD for video action recognition. IEEE Trans. Image Process. 28, 2799–2812 (2019).
Wang, L., Tong, Z., Ji, B. & Wu, G. TDN: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1895–1904 (2021).
Jiang, B., Wang, M., Gan, W., Wu, W. & Yan, J. STM: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2000–2009 (2019).
Phong, N. H. & Ribeiro, B. Action recognition for American sign language (2018). arXiv:2205.12261.
Zhang, L. et al. Tn-zstad: Transferable network for zero-shot temporal activity detection. IEEE Trans. Pattern Anal. Mach. Intell. 45, 3848–3861 (2022).
Gao, Z. et al. A pairwise attentive adversarial spatiotemporal network for cross-domain few-shot action recognition-r2. IEEE Trans. Image Process. 30, 767–782 (2020).
Tu, Z., Liu, X. & Xiao, X. A general dynamic knowledge distillation method for visual analytics. IEEE Trans. Image Process. 31, 6517–6531 (2022).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision 10012–10022 (2021).
Zhang, Y. et al. Vidtr: Video transformer without convolutions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision 13577–13587 (2021).
Ullah, A., Ahmad, J., Muhammad, K., Sajjad, M. & Baik, S. W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 6, 1155–1166. https://doi.org/10.1109/ACCESS.2017.2778011 (2018).
Chen, J., Samuel, R. D. J. & Poovendran, P. LSTM with bio inspired algorithm for action recognition in sports videos. Image Vis. Comput. 112, 104214. https://doi.org/10.1016/j.imavis.2021.104214 (2021).
Maas, A. L., Hannun, A. Y., Ng, A. Y. et al. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml 3 (Citeseer, 2013).
LeCun, Y., Kavukcuoglu, K. & Farabet, C. Convolutional networks and applications in vision. In Proceedings of 2010 IEEE International Symposium on Circuits and Systems 253–256 (IEEE, 2010).
Soomro, K., Zamir, A. R. & Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild (2012). arXiv:1212.0402.
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T. & Serre, T. Hmdb: A large video database for human motion recognition. In 2011 International Conference on Computer Vision 2556–2563 (IEEE, 2011).
Kay, W. et al. The kinetics human action video dataset (2017). arXiv:1705.06950.
Voxel51. The open-source tool for building high-quality datasets and computer vision models (2023). https://github.com/voxel51/fiftyone.
Abadi, M. et al. Tensorflow: Large-scale machine learning on heterogeneous systems, software available from tensorflow.org (2015). https://www.tensorflow.org.
Haziza, D., Rapin, J. & Synnaeve, G. Hiplot, interactive high-dimensionality plots (2020). https://github.com/facebookresearch/hiplot.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2818–2826 (2016).
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning 6105–6114 (PMLR, 2019).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 4700–4708 (2017).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 770–778 (2016).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 1097–1105 (2012).
Karpathy, A. et al. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1725–1732 (2014).
Noroozi, M. & Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VI 69–84 (Springer, 2016).
Han, T., Xie, W. & Zisserman, A. Video representation learning by dense predictive coding. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 0–0 (2019).
Xu, D. et al. Self-supervised spatiotemporal learning via video clip order prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10334–10343 (2019).
Kim, D., Cho, D. & Kweon, I. S. Self-supervised video representation learning with space-time cubic puzzles. In: Proceedings of the AAAI Conference on Artificial Intelligence 8545–8552 (2019).
Shu, Y., Shi, Y., Wang, Y., Huang, T. & Tian, Y. P-odn: Prototype-based open deep network for open set recognition. Sci. Rep. 10, 1–13 (2020).
Pan, T., Song, Y., Yang, T., Jiang, W. & Liu, W. Videomoco: Contrastive video representation learning with temporally adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 11205–11214 (2021).
Ranasinghe, K., Naseer, M., Khan, S., Khan, F. S. & Ryoo, M. S. Self-supervised video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2874–2884 (2022).
Bertasius, G., Wang, H. & Torresani, L. Is space-time attention all you need for video understanding? In ICML 4 (2021).
Zhao, S., Zhao, L., Zhang, Z., Zhou, E. & Metaxas, D. Global matching with overlapping attention for optical flow estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 17592–17601 (2022).
Fang, H.-S. et al. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 45, 7157–7173. https://doi.org/10.1109/TPAMI.2022.3222784 (2023).
Acknowledgements
This research is sponsored by FEDER funds through the programs COMPETE—“Programa Operacional Factores de Competitividade” and Centro2020—“Centro Portugal Regional Operational Programme”, and by national funds through FCT—“Fundação para a Ciência e a Tecnologia”, under the Project UIDB/00326/2020 and UIDP/00326/2020. The support is gratefully acknowledged.
Author information
Authors and Affiliations
Contributions
N.H.P.: conceptualization, methodology, coding, experiments, validation, formal analysis, investigation, writing—original draft, writing—review and editing; B.R.: writing—review and editing, supervision. All authors have reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nguyen, H.P., Ribeiro, B. Video action recognition collaborative learning with dynamics via PSO-ConvNet Transformer. Sci Rep 13, 14624 (2023). https://doi.org/10.1038/s41598-023-39744-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-39744-9
This article is cited by
-
Modeling transformer architecture with attention layer for human activity recognition
Neural Computing and Applications (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
