
Abstract
Predicting out-of-hospital cardiac arrest (OHCA) events might improve outcomes of OHCA patients. We hypothesized that machine learning algorithms using meteorological information would predict OHCA incidences. We used the Japanese population-based repository database of OHCA and weather information. The Tokyo data (2005–2012) was used as the training cohort and datasets of the top six populated prefectures (2013–2015) as the test. Eight various algorithms were evaluated to predict the high-incidence OHCA days, defined as the daily events exceeding 75% tile of our dataset, using meteorological and chronological values: temperature, humidity, air pressure, months, days, national holidays, the day before the holidays, the day after the holidays, and New Year’s holidays. Additionally, we evaluated the contribution of each feature by Shapley Additive exPlanations (SHAP) values. The training cohort included 96,597 OHCA patients. The eXtreme Gradient Boosting (XGBoost) had the highest area under the receiver operating curve (AUROC) of 0.906 (95% confidence interval; 0.868–0.944). In the test cohorts, the XGBoost algorithms also had high AUROC (0.862–0.923). The SHAP values indicated that the “mean temperature on the previous day” impacted the most on the model. Algorithms using machine learning with meteorological and chronological information could predict OHCA events accurately.
Similar content being viewed by others


Introduction
Out-of-hospital cardiac arrest (OHCA) is a public health issue worldwide, and survival after OHCA remains unsatisfactory1. Prevention or early recognition using scoring systems has been emphasized in in-hospital cardiac arrest (IHCA) and pediatric cardiac arrest guidelines2, 3. Accordingly, prevention and early recognition of OHCA in adult patients are important; prediction algorithms for OHCA events may improve OHCA outcomes through prevention or early recognition.
Baseline characteristics, which are known as risk factors for OHCA, include older age, male sex, past medical history or family history of coronary heart disease, sudden cardiac arrest, high blood pressure, and dyslipidemia4,5,6. In addition, external factors such as weather conditions and human chronological behaviour patterns are also known risk factors for OHCA incidence. Specifically, OHCA incidence tends to increase in winter, on days with cold ambient temperatures and large diurnal temperature ranges7, or in the early morning, on weekends8. Although these external risk factors of OHCA incidence have been elucidated, few studies have used prediction algorithms for OHCA using both meteorological and chronological data.
In recent years, machine learning techniques have rapidly developed as diagnostic and prognostic tools. A machine learning algorithm can assist in the quick and automatic learning of data patterns, even from complex data. Machine learning approaches have shed new light on resuscitation science.
Thus, we hypothesized that machine learning algorithms using meteorological and chronological information can be used to accurately predict high OHCA incidence and help clinicians identify “high-risk” days for OHCA incidence. We used a large sample size of the OHCA cohort (> 136,000 patients) from the Japanese population-based repository database and tested the accuracy of our algorithms. Because machine learning approaches can identify key factors, we performed a deeper analysis of the association of these factors.
Methods
Study setting and patients
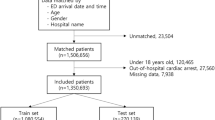
The nationwide, population-based OHCA registry by the Fire and Disaster Management Agency of the Ministry of Internal Affairs and Communications, in the form of the internationally standardized Utstein style, Japan9, between January 2005 and December 2015, was collated. Despite their etiologies (e.g., presumed cardiac diseases, respiratory diseases and trauma), all OHCA events were included. In this database, patients who were not transported to the hospital due to distinct postmortem changes were excluded from registration. The definition of the distinct postmortem change for patients with non-transportation after a cardiac arrest based on the Japanese law satisfies all of the followings: (1) pupil dilation, (2) loss of reflection to the light of pupils, (3) loss of body temperature, (4) appearance of rigour mortis or postmortem lividity. Of the 1,296,802 patients, 1,277,126 patients aged 18 years and older were included in the study. Since we assume that urban areas of mainland Japan have similar baseline characteristics of population composition and weather, we chose datasets from the top six populated prefectures, including Tokyo, Kanagawa, Aichi, Osaka, Saitama, and Chiba. (Supplementary Fig. 1). In the training cohort, we included 96,597 patients in Tokyo from January 2005 to December 2012. We included 143,168 patients in the top six populated prefectures (37,778 in Tokyo and 105,390 in the other five cities) from January 2013 to December 2015 as test cohorts (Fig. 1).

Flowchart of study enrollment.
The Chiba University Hospital Certified Clinical Research Review Board approved this study (No. 4042) and waived the need for written informed consent in accordance with the Ethical Guidelines for Medical and Health Research Involving Human Subjects in Japan.
Definition and data collection
We had to determine the accurate time of OHCA to clarify OHCA incidence. However, the exact time of the OHCA incidence was uncertain in not witnessed patients, and the OHCA incidence may be the OHCA recognition. In this study, the patients with distinct postmortem changes were excluded. As the changes would be found a half day after CA, almost all OHCA patients in this study must be recognized at least half a day after CA. Therefore, we focused on day of the OHCA incidence and identify “high risk” days for OHCA incidence.
The OHCA incidence per one million people was calculated for each prefectural population using annual population data from the e-Stat Portal Site of Official Statistics of Japan from 2004 to 2016 (https://www.e-survey.go.jp/en). We defined the OHCA high-incidence days as those exceeding the number of OHCA events greater than 75% tile of the Tokyo data between 2005 and 2015. In addition, we examined the number exceeding 95% tile of the OHCA events in the Tokyo data.
For the prediction of high-incidence days of OHCA, explainable features such as the percentage of the elderly population (per prefecture), date of the emergency call, meteorological conditions and chronological features were used to train the machine learning models. The meteorological data included temperature, humidity, and air pressure. For the chronological features, we included months, days, national holidays, the day before the holidays, the day after the holidays, and New Year's holidays (between 29th December and 3rd January) in the final model, according to previous studies10.
Weather data were obtained from the Japan Meteorological Agency and are available to the public (http://www.data.jma.go.jp/gmd/risk/obsdl/index.php). The weather data at the meteorological observatory located in the city with the largest population in each prefecture was chosen as the representative weather data for each prefecture.
Feature selection
The meteorological predictors considered in this study were the daily average, minimum, maximum, and diurnal changes in ambient temperature, relative humidity, and air pressure. Our strategy for feature selection is to identify the best combination of meteorological features that predict daily OHCA incidence and then to use those features to predict high-incident OHCA days in the final classification model. As weather conditions are expected to affect human health with a time lag, we also estimated the best time lags for each meteorological feature.
For the selection of the meteorological features, we took multiple steps to identify the features that correlate with OHCA occurrence by building a Poisson univariate model by combining each meteorological feature with an estimated time lag and the number of OHCA occurrences per day (Supplementary Methods for details). Finally, the following two meteorological variables were selected as the best predictive features: the average and diurnal temperature of the previous day. We then used these features with all the chronological features mentioned above, as well as the percentage of the elderly population, as input features of the machine learning models.
Statistical analysis
The primary outcome variable was the number of high-incidence OHCA days. Various machine learning algorithms were used to conduct the primary analysis of OHCA prediction in the Tokyo training cohort. The eight algorithms included XGBoost, RF, LDA, LR, SVM, NB, MLP, and KNN as a representative of a gradient boosting algorithm, tree algorithm, dimension reduction technique, linear algorithm, Bayes theorem-based algorithm, neural network algorithms and k-nearest neighbours algorithm, respectively. These algorithms were selected based on their ability to identify different combinations of features, including linear and nonlinear combinations. For example, XGBoost and MLP can identify linear and nonlinear combinations of features, while LDA and LR can identify linear combinations of features. RF, NB, SVM and KNN can identify nonlinear combinations. By utilizing these algorithms, we aimed to carefully select the most effective model for predicting OHCA using a combination of meteorological and demographic information.
We built these eight classification models with fine-tuned parameters using the training data and evaluated the performance of the eight models based on AUROC values, which were estimated from sixfold cross-validation. In cross-validation, the folds are split into chronological sets as a standard procedure when handling time-series data. Each fold for the training and test data has a fixed time interval of five years and one year, respectively. Of the eight machine-learning algorithms in the training cohort, the best machine-learning algorithm, XGBoost, was used in the test cohort. Additionally, we investigated whether the XGBoost model could predict the OHCA events even if the value of 95% tile was used as the threshold. A sub-group analysis was conducted in patients with OHCA presumably caused by cardiac diseases in the most predictive model, the XGBoost model.
The performance of the models was measured in terms of the AUROC as a superior metric as well as the accuracy, sensitivity, specificity, and F1 score. We used the SHAP algorithm of the XGBoost model to interpret the contribution of each feature to the predictive model. In the algorithm, the SHAP value was computed by the difference in the model output resulting from including a feature in the algorithm, providing information about the impact of each feature on the output. In the SHAP summary plots, every violin plot is composed of all the data points from each feature, with a higher value being redder and a lower value being bluer. The violin plots were aligned with the SHAP values along the x-axis. Thus, a redder/bluer violin plot on the right side (i.e., a higher positive SHAP value) suggests that the higher/lower the value of the feature, the more the model predicts a positive/negative impact.
Since the SHAP analysis revealed important factors, including temperature, percentage of the elderly population, onset day, and month, we investigated the incidence of daily OHCA between elderly and non-elderly patients as a secondary analysis using Tokyo data from 2005 to 2015. The elderly population was defined as people aged 65 and over in this study based on the popular age for retirement to compare the influence of chronological behaviour differences.
In this study, we used the nationwide, population-based OHCA registry, which collects OHCA data from the entire population under investigation. We used all the data that is available, therefore sample size calculation was not applicable. Data are expressed as medians (interquartile ranges) for continuous values and absolute numbers and percentages for categorical values. We employed the Mann–Whitney U test for numerical variables, and the Chi-square test for categorical variables. Statistical significance was set at p < 0.05.
Analyses were performed using Python 3.7.6 packages (Scikit-learn 0.23.2, XGBoost 1.1.1, Pandas 1.1.5, and NumPy 1.19.2) to construct machine learning models. Python packages, including Scikit-learn, XGBoost, Pandas, Numpy, Matplotlib, and the SHAP package are all open-source packages. Permission to use these packages is granted free of charge to any person (Python License: https://docs.python.org/3/license.html, SHAP: https://github.com/slundberg/shap/blob/master/LICENSE). All the figures in this study were created using the visualization package in Python Matplotlib (3.3.4)11, 12.
Results
Baseline characteristics and meteorological features
From January 2005 to December 2015, the number of patients of OHCA in Japan was 1,296,802, of which 1,277,126 were above 18 years old. The etiologies were presumed cardiac diseases (730,585, 57%), respiratory diseases (83,299, 6%), exogeneous (184,521, 34%), traffic accident and so on. The training cohort included 96,597 OHCA patients (Tokyo, 2005–2012) (Table 1); the median daily incidence of OHCA was 2.5 cases per one million. In the test cohorts (six prefectures, 2013–2015), the median daily incidence of OHCA ranged from 2.3 to 2.5 cases per one million. The percentage of the elderly (65 years or older) population in the six cities ranged from 19.8 to 24.5%, and the percentages of elderly OHCA patients ranged from 71.9 to 80.5% in the six cities. There were no statistically significant differences in the annual average temperature, humidity, or air pressure between the six prefectures.
The OHCA high-incidence days, which was defined as the number exceeding 75% tile of daily OHCA incidence in the Tokyo data, was 3.1 per one million population. The other five prefectures had a similar 75% tile of OHCA incidence, which ranged from 2.7 to 3.1 per one million population. High-incidence days had decreased temperature, humidity, and increased air pressure compared to low-incident days; “Month” and “Day” were statistically different in a training cohort (Table 2). In addition, the number exceeding 95% tile was 4.0, which was similar to the 75% tile figure.
Prediction of OHCA high-incidence days
In the primary analysis of OHCA prediction in the Tokyo training cohort using eXtreme Gradient Boosting (XGBoost), random forest (RF), linear discriminant analysis (LDA), logistic regression (LR), multilayer perceptron (MLP), Naïve Bayes (NB), support vector machine with radial basis function kernel (SVM), and k-Nearest Neighbors (kNN), all classification models achieved the mean area under the receiver operating characteristic curve (AUROC) over 0.89 (Table 3). XGBoost had the highest predictive value (AUROC 0.906 [confidence interval; CI 0.868–0.944]), which was chosen for further validation. The developed prediction algorithm demonstrated a high predictive value by repeating the analysis in the test cohorts. The AUROC were similarly high and 0.923, 0.882, 0.888, 0.889, 0.879, and 0.862, respectively in the top six populated prefectures (Table 4). Furthermore, the XGBoost model developed a highly accurate prediction model even if the value of 95% tile was used as the threshold: the AUROC of the training cohort was 0.941, and that of the test cohort was 0.958. In the presumed cardiac diseases of OHCA, the prediction algorithm with the XGBoost model had a high predictive value (the AUROC 0.891, and 0.790–0.859 respectively in training and test cohort) (Supplementary Table 1).
In the analysis to search for important features using the SHapley Additive exPlanations (SHAP), the following five major features contributed significantly to the predictive model of OHCA: “mean temperature on the previous day,” “month,” “percentage of the elderly population,” “diurnal temperature on the previous day,” and “days of the week” (Fig. 2a). The violin plot of SHAP showed that a lower mean temperature on the previous day was associated with a higher risk of OHCA (Fig. 2b). Contrary to this, several redder points of “mean temperature” are on the positive SHAP value side; we observed that the higher mean temperature raised the possibility of OHCA high-incidence days and found that those data were in the summer season (June, July, August, and September). This reflects the non-linear correlation between the mean temperature and OHCA incidence. The SHAP values of the monthly variables (with November coded as the reference) show that the bluer points positively impact the model output. This implies that the winter season (December, January, and February) is an OHCA high-incidence time. The bluer on the right side of the “days of the week” variable results from the fact that OHCA occurrence on Sunday and Monday is frequent in our data.

The SHAP value of OHCA prediction in the Tokyo training cohort. (a) Important predictive factors calculated by the SHAP values. (b) The summary plots of each SHAP values. A higher value of the feature value indicates a redder data point, and a lower value indicates a bluer data point. SHAP; SHapley Additive explanation, OHCA; out-of-hospital cardiac arrest.
Comparison of OHCA incidence between elderly and non-elderly patients
Since the SHAP analysis revealed that “mean temperature on the previous day” and “percentage of the elderly population” were important factors, we divided the Tokyo data from 2005 to 2015 into elderly and non-elderly patients and plotted OHCA incidence per one million by temperature on the previous day (Supplementary Fig. 2a). In the elderly group, the non-linear (“U-shape”) correlation drastically changed with temperature changes, while the little effect of temperature on OHCA incidence was observed in the non-elderly group (Supplementary Fig. 2a, Supplementary results). According to the analysis of OHCA incidence on days of the week in each group, the OHCA incidence was high on Sundays and Mondays in the elderly group. At the same time, it was high only on Mondays in the non-elderly group (p < 0.01) (Supplementary Fig. 2b). There was no difference in the OHCA incidence in the months between the groups (Supplementary Fig. 3).
Discussion
In this study, we developed a machine learning model to predict “risky” days for OHCA events using the meteorological and chronological data with a combination of nationwide OHCA repository data. Our algorithms were able to accurately predict high OHCA incidence days using XGBoost, which demonstrated that the incidence of OHCA was affected by weather conditions, the percentage of the elderly population, and calendar dates. In addition, the atmospheric temperature had a more substantial influence on OHCA events in the elderly than in the non-elderly population. Sunday and Monday were predicted to be the highest incidence days of OHCA for elderly people, while for the non-elderly, that was only Monday.
The benefit of using machine learning models in resuscitation was well established in literature: the deep learning model was developed to predict cardiac arrest and acute respiratory failure occurring in intensive care units more accurately13 than the National Early Warning Score (NEWS) and the Modified Early Warning Score (MEWS)14. Similarly, the machine learning model for predicting the daily OHCA incidence from meteorological and chronological data has also been proposed15. However, these studies used only a few algorithms for the accurate prediction of OHCA incidence and did not evaluate the high-incidence days of OHCA. Because the population and industry of each Japanese prefecture differ, and the Japanese climate has subpolar, temperate, and subtropical zones, there are some chronological changes and meteorological differences in each prefecture that need to be considered. We selected data from Japanese metropolitan areas, the weather conditions of which are not extremely different from Tokyo, and developed a prediction model based on the collected Tokyo data and verified its validity by applying it to the OHCA data of Tokyo and five other prefectures in Japan, which resulted in high accuracy of AUROC > 0.86. The XGBoost model also maintained high predictive accuracy for a higher occurrence of OHCA high-incidence days and high-incidence days in presumed patients of cardiac diseases. Therefore, our prediction algorithms are expected to aid in the identification of a high OHCA risk patient with various characteristics; including witness, not witness, and a variety of etiology. If an OHCA forecasting system based on machine learning algorithms could be established, it could alert local citizens, public utilities, and emergency services the day with a high risk of OHCA occurrences, and this could lead to strengthened monitoring of latent patients and prompt recognition and treatment indications for OHCA. This can be similar to hay fever and heat stroke forecasts.
Our SHAP analysis revealed that the major factors affecting OHCA incidence were low mean ambient temperature, the diurnal temperature of the previous day, the month, the percentage of the elderly population, and the day of the week. The result showing the link between low average temperature in the winter season and high OHCA incidence is in line with that reported in previous studies16,17,18. Even though exposure to cold weather was a major factor in the seasonality of OHCA incidence, the incidence peaked in January rather than February, in which the average temperature was the lowest of the year. It can be inferred that this may be related to seasonal changes in social activities and the new year holiday in January, which strongly influences OHCA occurrence, for example, holiday drinking8. A previous study showed that a large change in ambient temperature could be related to an increased sympathetic tone and blood viscosity, which may lead to an increased number of OHCA events15, 19. Changes in behaviour may explain circaseptan variability in OHCA incidence during weekdays and seasons8.
We focused on the elderly and non-elderly patients to clarify the influence of age on OHCA incidence. The comparison of the incidence of OHCA between the elderly and non-elderly groups demonstrated that the average temperature of the previous day more severely impacted OHCA incidence in the elderly than in the non-elderly group. This result is consistent with previous studies. Yoshinaga et al. reported that the number of cardiogenic OHCA cases in the elderly population increased after exposure to cold temperatures17.
The OHCA incidence was highest on Mondays for both the elderly and non-elderly populations, as well as on Sundays only for the elderly population. The reason for the increase in Mondays could be a change in the human behaviour pattern from weekends to weekdays, especially for workers, for example, “Mondays are depressing”17, 20, 21. Therefore, the reason for the high OHCA incidence on Sundays in the elderly group may be different from that in the non-working group.
Our study has several limitations. First, this was a nationwide OHCA study conducted in a single urban region of Japan. Therefore, whether the algorithm has a high predictive value in different areas with different backgrounds and meteorological data remains unclear. Second, detailed data on OHCA patients are unavailable, including the history of a medical condition, working, and behaviour patterns before OHCA. Third, some patients recognized more than half a day after the occurrence of cardiac arrest might be enrolled in this study because the judgements of transportation of the patients were dependent on the personnel of emergency medical personnel at the pre-hospital site. Finally, we excluded pediatric patients; hence, the model cannot be applied to children. Further studies including wider regions or detailed data on patient characteristics may strengthen the findings for the prediction of OHCA using machine learning.
In conclusion, we successfully predicted the days of the high incidence of OHCA from climate data using machine learning. Predicting the occurrence of OHCA may lead to the prevention or early detection of OHCA and therefore potentially improve its prognosis.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Yan, S. et al. The global survival rate among adult out-of-hospital cardiac arrest patients who received cardiopulmonary resuscitation: A systematic review and meta-analysis. Crit. Care https://doi.org/10.1186/s13054-020-2773-2 (2020).
Berg, K. M. et al. Part 7: Systems of care: 2020 American Heart Association guidelines for cardiopulmonary resuscitation and emergency cardiovascular care. Circulation 142, S580–S604 (2020).
Topjian, A. A. et al. Part 4: Pediatric basic and advanced life support: 2020 American Heart Association guidelines for cardiopulmonary resuscitation and emergency cardiovascular care. Circulation 142, S469–S523 (2020).
Safdar, B. et al. Differential survival for men and women from out-of-hospital cardiac arrest varies by age: Results from the OPALS study. Acad. Emerg. Med. 21, 1503–1511 (2014).
Friedlander, Y. et al. Family history as a risk factor for primary cardiac arrest. Circulation 97, 155–160 (1998).
Jouven, X., Desnos, M., Guerot, C. & Ducimetière, P. Predicting sudden death in the population: The Paris Prospective Study I. Circulation 99, 1978–1983 (1999).
Onozuka, D. & Hagihara, A. Associations of day-to-day temperature change and diurnal temperature range with out-of-hospital cardiac arrest. Eur. J. Prev. Cardiol. 24, 204–212 (2017).
Bagai, A. et al. Temporal differences in out-of-hospital cardiac arrest incidence and survival. Circulation 128, 2595–2602 (2013).
Perkins, G. D. et al. Cardiac arrest and cardiopulmonary resuscitation outcome reports: Update of the utstein resuscitation registry templates for out-of-hospital cardiac arrest. Resuscitation 96, 328–340 (2015).
Takahashi, K. & Shimadzu, H. The daily incidence of out-of-hospital cardiac arrest unexpectedly increases around New Year’s Day in Japan. Resuscitation 96, 156–162 (2015).
Caswell, T. A. et al. Matplotlib/Matplotlib v3.3.4. Zenodo. (2020).
Hunter, J. D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 9, 90–95 (2007).
Kwon, J.-M., Lee, Y., Lee, Y., Lee, S. & Park, J. An algorithm based on deep learning for predicting in-hospital cardiac arrest. J. Am. Heart Assoc. https://doi.org/10.1161/JAHA.118.008678 (2018).
Kim, J., Chae, M., Chang, H.-J., Kim, Y.-A. & Park, E. Predicting cardiac arrest and respiratory failure using feasible artificial intelligence with simple trajectories of patient data. J. Clin. Med. 8, 1336 (2019).
Nakashima, T. et al. Machine learning model for predicting out-of-hospital cardiac arrests using meteorological and chronological data. Heart 107, 1084–1091 (2021).
Widiger, T. A. PDTRT special section: Methodological issues in personality disorder research. Pers. Disord. Theory Res. Treat. 8, 2–13 (2017).
Yoshinaga, T. et al. Risk of out-of-hospital cardiac arrest in aged individuals in relation to cold ambient temperature: A report from north tochigi experience. Circ. J. 84, 69–75 (2019).
Gasparrini, A. et al. Mortality risk attributable to high and low ambient temperature: A multicountry observational study. The Lancet 386, 369–375 (2015).
Keatinge, W. R. et al. Increases in platelet and red cell counts, blood viscosity, and arterial pressure during mild surface cooling: Factors in mortality from coronary and cerebral thrombosis in winter. Br. Med. J. (Clin. Res. Ed.) 289, 1405–1408 (1984).
Han, K. T. & Kim, S. J. Instability in daily life and depression: The impact of sleep variance between weekday and weekend in South Korean workers. Health Soc. Care Community 28, 874–882 (2020).
Alexander, W., Coghlan, P. & Greenwood, J. E. A 365-day view of the difficult patients treated in an Australian Adult Burn Center. J. Burn Care Res. 36, e146–e152 (2015).
Author information
Authors and Affiliations
Contributions
Study concept and design: T.N., K.S.-S., R.M., R.K., and Y.Y. Acquisition of data: T.N., K.S.-S., R.K. Drafting of the manuscript: T.N., K.S.-S., T.S., R.M., and R.K. Critical revision of the manuscript for important intellectual content: K.S.-S., T.S., R.M., R.K., Y.Y., T.O. (Oshima), T.O. (Oami), K.T., K.S., and T.N. Statistical analysis: T.N., K.S.-S., T.S., R.M., R.K., and Y.Y. Supervision: T.N. All authors gave final approval of the version to be published.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shimada-Sammori, K., Shimada, T., Miura, R.E. et al. Machine learning algorithms for predicting days of high incidence for out-of-hospital cardiac arrest. Sci Rep 13, 9950 (2023). https://doi.org/10.1038/s41598-023-36270-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36270-6
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
