
Abstract
Two novel methods are being outlined that, when combined, can be used for spatiotemporal analysis of wind speeds and wave heights, thus contributing to global climate studies. First, the authors provide a unique reliability approach that is especially suited for multi-dimensional structural and environmental dynamic system responses that have been numerically simulated or observed over a substantial time range, yielding representative ergodic time series. Next, this work introduces a novel deconvolution extrapolation technique applicable to a wide range of environmental and engineering applications. Classical reliability approaches cannot cope with dynamic systems with high dimensionality and responses with complicated cross-correlation. The combined study of wind speed and wave height is notoriously difficult, since they comprise a very complex, multi-dimensional, non-linear environmental system. Additionally, global warming is a significant element influencing ocean waves throughout the years. Furthermore, the environmental system reliability method is crucial for structures working in any particular region of interest and facing actual and often harsh weather conditions. This research demonstrates the effectiveness of our approach by applying it to the concurrent prediction of wind speeds and wave heights from NOAA buoys in the North Pacific. This study aims to evaluate the state-of-the-art approach that extracts essential information about the extreme responses from observed time histories.
Similar content being viewed by others

Introduction
It is challenging to accurately assess multi-dimensional dynamic system reliability using conventional theoretical reliability methods1,2,3,4. Estimating the reliability of a complicated dynamic system is easy if sufficient system response data are available or if direct Monte Carlo simulations are performed5. However, experimental or computational costs may be expensive for many engineering dynamic systems with complicated dynamics. Motivated by this, the authors developed a new reliability method for dynamic systems that require significantly less measurement and computing costs.
It has been a challenge to how exactly one predicts the shape and characteristics of waves through wind speed variables, even though this has been started and partially solved in the works of6,7,8,9,10,11. Our work, however, deals with the general approach of extreme value theory in which no physical dynamics of the water waves are expected to play a significant role in driving the appearance of rare events, i.e. there is an expected universality of extreme events in a variety of different physical and natural systems12,13,14,15,16,17. Although beyond the scope of our work, there Some successful attempts have been to study extreme events in water waves (often called rogue or freak waves) with distributions uniquely determined by the dynamics of the physical system. For instance18,19, have shown that water waves departing from linear theory will modify their distribution from a Rayleigh type20,21,22 to a distribution dependent on the square root of the wave steepness. Similarly23,24, have shown that a Rayleigh distribution modified by a polynomial function of the ratio between height and water depth controls extreme events in Hurricane data. In addition, spectrum bandwidth seems to have different types of effects in extreme wave distribution depending on whether they are in deep25,26,27,28 or shallow water13. Furthermore, ocean processes such as shoaling or wave-current systems that drive wave trains out of equilibrium have been experimentally22,25,29,30,31,32,33,34,35,36,37 associated with increasing the occurrence of extreme waves by order of magnitude. However, it has been recently found that no established theoretical distribution to date, neither universal as Gumbel nor based on physical principles, can describe extreme wave statistics in a wide range of conditions6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37.
Note that methods introduced by authors here do not rely on Gumbel (or any other type) distribution type assumption, instead, Gumbel-based extrapolation was used just for comparison.
Method
Consider multi-degree of freedom (MDOF) jointly stationary dynamic environmental system with representative response vector process \({\varvec{R}}\left( t \right) = \left( {X\left( t \right), Y\left( t \right), Z\left( t \right), \ldots } \right)\), that has been either measured or simulated over a sufficiently long time span \(\left( {0,T} \right)\). Unidimensional global maxima over entire time span \(\left( {0,T} \right)\) is denoted as \(X_{T}^{{{\text{max}}}} = \mathop {\max }\limits_{0 \le t \le T} X\left( t \right)\), \(Y_{T}^{{{\text{max}}}} = \mathop {\max }\limits_{0 \le t \le T} Y\left( t \right)\), \(Z_{T}^{{{\text{max}}}} = \mathop {\max }\limits_{0 \le t \le T} Z\left( t \right), \ldots\).
By sufficiently long time span \(T\) authors mean large enough value of \(T\) with respect to the environmental dynamic system auto-correlation time. Let \(X_{1} , \ldots ,X_{{N_{X} }}\) be consequent temporal local maxima of the environmental process \(X\left( t \right)\) at discrete monotonously temporally increasing times \(t_{1}^{X} < \ldots < t_{{N_{X} }}^{X}\) within \(\left( {0,T} \right)\). Similar definition follows for other MDOF environmental response components \(Y\left( t \right), Z\left( t \right), \ldots\) with \(Y_{1} , \ldots ,Y_{{N_{Y} }} ;\) \(Z_{1} , \ldots ,Z_{{N_{Z} }}\) and so on. For simplicity, all \({\varvec{R}}\left( t \right)\) components, maxima are assumed to be non-negative. The target now is to accurately estimate environmental system failure probability, namely its probability of exceedance
where \(P = \iiint {_{{\left( {0, 0, 0, , \ldots } \right)}}^{{\left( {\eta_{X} , \eta_{Y} , \eta_{Z } , \ldots } \right)}} }p_{{X_{T}^{{{\text{max}}}} , Y_{T}^{{{\text{max}}}} , Z_{T}^{{{\text{max}}}} , \ldots }} \left( {X_{T}^{{{\text{max}}}} , Y_{T}^{{{\text{max}}}} , Z_{T}^{{{\text{max}}}} , \ldots } \right)dX_{T}^{{{\text{max}}}} dY_{{N_{Y} }}^{{{\text{max}}}} dZ_{{N_{z} }}^{{{\text{max}}}} \ldots\) being probability of non-exceedance for critical values of environmental response components \(\eta_{X}\), \(\eta_{Y}\), \(\eta_{Z}\),…; \(\cup\) denotes logical unity operation «or»; \(p_{{X_{T}^{{{\text{max}}}} , Y_{T}^{{{\text{max}}}} , Z_{T}^{{{\text{max}}}} , \ldots }}\) being joint probability density of the global maxima over the entire time span \(\left( {0,T} \right)\).In practice, however, it is not always feasible to estimate directly \(p_{{X_{T}^{{{\text{max}}}} , Y_{T}^{{{\text{max}}}} , Z_{T}^{{{\text{max}}}} , \ldots }}\) joint probability distribution due to its high dimensionality and limitations of the available data set. The moment when either \(X\left( t \right)\) exceeds \(\eta_{X}\), or \(Y\left( t \right)\) exceeds \(\eta_{Y}\), or \(Z\left( t \right)\) exceeds \(\eta_{Z}\), and so on, the environmental dynamic system being regarded as failed. Fixed failure levels \(\eta_{X}\), \(\eta_{Y}\), \(\eta_{Z}\),… being individual for each unidimensional response component of \({\varvec{R}}\left( t \right)\). \(X_{{N_{X} }}^{{{\text{max}}}} = {\text{max }}\{ X_{j} \,;j = 1, \ldots ,N_{X} \} = X_{T}^{{{\text{max}}}}\), \(Y_{{N_{Y} }}^{{{\text{max}}}} = {\text{max }}\{ Y_{j} \,;j = 1, \ldots ,N_{Y} \} = Y_{T}^{{{\text{max}}}}\),\(Z_{{N_{z} }}^{{{\text{max}}}} = {\text{max }}\{ Z_{j} \,;j = 1, \ldots ,N_{Z} \} = Z_{T}^{{{\text{max}}}}\), and so on.
Let sort local maxima time instants \(\left[ {t_{1}^{X} < \ldots < t_{{N_{X} }}^{X} ;{ }t_{1}^{Y} < \ldots < t_{{N_{Y} }}^{Y} ;{ }t_{1}^{Z} < \ldots < t_{{N_{Z} }}^{Z} } \right]\) recorded in temporally non-decreasing order into one single synthetic merged time vector \(t_{1} \le \ldots \le t_{N}\). Note that then \(t_{N} = {\text{max }}\{ t_{{N_{X} }}^{X} , t_{{N_{Y} }}^{Y} , t_{{N_{Z} }}^{Z} , \ldots \}\), \(N = N_{X} + N_{Y} + N_{Z} + \ldots\). In this case \(t_{j}\) represents local maxima of one of MDOF environmental dynamic structural response components either \(X\left( t \right)\) or \(Y\left( t \right)\), or \(Z\left( t \right)\) and so on. The latter means that having \({\varvec{R}}\left( t \right)\) time record, one only needs simultaneously and continuously screen for the system unidimensional response component local maxima and record its exceedance of MDOF limit vector \(\left( { \eta_{X} ,{ }\eta_{Y} ,{ }\eta_{Z} ,...} \right)\) in any of dynamic system components \(X, Y, Z, \ldots\) Local unidimensional response component maxima then merged into one synthetic temporal non-decreasing vector \(\vec{R} = \left( {R_{1} , R_{2} , \ldots ,R_{N} } \right)\) in accordance with merged time vector \(t_{1} \le \ldots \le t_{N}\). That is to say each local maxima \(R_{j}\) is in fact actual encountered local maxima corresponding to either \(X\left( t \right)\) or \(Y\left( t \right)\), or \(Z\left( t \right)\) and so on. Finally the unified limit vector \(\left( {\eta_{1} , \ldots ,\eta_{N} } \right)\) is introduced with each component \(\eta_{j}\) is either \(\eta_{X}\), \(\eta_{Y}\) or \(\eta_{Z}\) and so on, depending which of \(X\left( t \right)\) or \(Y\left( t \right)\), or \(Z\left( t \right)\) etc. corresponding to the current local maxima with running index \(j\).
Scaling parameter \(0 < \lambda \le 1\) being now introduced to artificially simultaneously decrease limit values for all system response components, i.e. new MDOF limit vector \(\left( { \eta_{X}^{\lambda } , \eta_{Y}^{\lambda } ,{ }\eta_{z}^{\lambda } ,...} \right)\) with \(\eta_{X}^{\lambda } \equiv \lambda \cdot \eta_{X}\), \(\equiv \lambda \cdot \eta_{Y}\), \(\eta_{z}^{\lambda } \equiv \lambda \cdot \eta_{Z}\), … being introduced. The unified limit vector \(\left( {\eta_{1}^{\lambda } , \ldots ,\eta_{N}^{\lambda } } \right)\) being introduced with each component \(\eta_{j}^{\lambda }\) being equal to either \(\eta_{X}^{\lambda }\), \(\eta_{Y}^{\lambda }\) or \(\eta_{z}^{\lambda }\) and so on The latter automatically defines the target probability \(P\left( \lambda \right)\) as a function of \(\lambda\), note that \(P \equiv P\left( 1 \right)\) from Eq. (1). Non-exceedance probability \(P\left( \lambda \right)\) can be now estimated as follows
In practice the dependence between neighbouring \(R_{j}\) is not always negligible, thus following one-step (will be called conditioning level \(k = 1\)) memory approximation being introduced
for \(2 \le j \le N\) (will be called conditioning level \(k = 2\)). Approximation introduced by Eq. (3) may be further expressed as
where \(3 \le j \le N\) (called here conditioning level \(k = 3\)), and so on38. Equation (4) presents series of subsequent refinements of statistical independence assumption. The latter type of approximations models statistical dependence effect between neighbouring maxima with an increased accuracy. Since original MDOF dynamic process \({\varvec{R}}\left( t \right)\) was assumed ergodic and therefore stationary, probability \(p_{k} \left( \lambda \right): = {\text{Prob}}\{ R_{j} > \eta_{j}^{\lambda } {|} R_{j - 1} \le \eta_{j - 1}^{\lambda } , R_{j - k + 1} \le \eta_{j - k + 1}^{\lambda } \}\) for \(j \ge k\) is independent of \(j\) but only dependent on conditioning level \(k\). Thus non-exceedance probability may be now approximated
Note that Eq. (5) follows from Eq. (1) by neglecting \({\text{ Prob}}\left( {R_{1} \le \eta_{1}^{\lambda } } \right) \approx 1\), as design failure probability must of a small order of magnitude, and N>>k. Equation (5) is similar to mean up-crossing rate equation for probability of exceedance39,40,41,42,43,44,45,46,47,48,49,50,51. There is convergence with respect to the conditioning parameter \(k\)
Note that Eq. (5) for \(k = 1\) turns into classic non-exceedance probability relationship with corresponding mean up-crossing rate function
where \(\nu^{ + } \left( \lambda \right)\) denotes the mean up-crossing rate of the response level \(\lambda\) for the above assembled non-dimensional vector \(R\left( t \right)\) assembled from scaled MDOF system response \(\left( {\frac{X}{{\eta_{X} }}, \frac{Y}{{\eta_{Y} }}, \frac{Z}{{\eta_{Z} }}, \ldots } \right)\). The mean up-crossing rate is given by the Rice's formula given in Eq. (7) with \(p_{{R\dot{R}}}\) being joint probability density for \(\left( {R, \dot{R}} \right)\) with \(\dot{R}\) being the time derivative \(R^{\prime}\left( t \right)\) 1. Equation (7) relies on the Poisson assumption, that is up-crossing events of high \(\lambda\) levels (in this paper it is \(\lambda \ge 1\)) may be assumed to be independent.
The proposed methodology may be used for nonstationary cases as well. Given environmental scattered diagram of \(m = 1,..,M\) sea states, each environmental short-term sea state having probability \(q_{m}\), so that \(\mathop \sum \limits_{m = 1}^{M} q_{m} = 1\). Next, let one introduce the long-term equation
with \(p_{k} \left( {\lambda ,m} \right)\) being the same function as in Eq. (6), but corresponding to a specific short-term sea state with number \(m\). The above introduced \(p_{k} \left( \lambda \right)\) as functions being often regular in the tail, specifically for values of \({ }\lambda\) approaching and exceeding \(1\). More specifically, for \(\lambda \ge \lambda_{0}\), the probability distribution tail behaves similar to \({\text{exp}}\left\{ { - \left( {a\lambda + b} \right)^{c} + d} \right\}\) with \(a, b, c, d\) being suitably fitted constants for suitable tail cut-on \(\lambda_{0}\) value. Therefore, one can write
By plotting \({\text{ln}}\left\{ {{\text{ln}}\left( {p_{k} \left( \lambda \right)} \right) - d_{k} } \right\}\) versus \({\text{ln}}\left( {a_{k} \lambda + b_{k} } \right)\), often nearly perfectly linear tail behaviour being observed. Optimal values of the parameters \(a_{k} , b_{k} , c_{k} ,p_{k} ,q_{k}\) may be determined using a sequential quadratic programming (SQP) method incorporated in the NAG Numerical Library52.
Let us consider stationary stochastic process \(X\left( t \right)\), being either simulated or measured over a certain time span \(0 \le t \le T\), and which is being represented as a sum of two independent identically distributed stationary environmental dynamic processes \(X_{1} \left( t \right)\) and \(X_{2} \left( t \right)\), namely
Denoting probability density function (PDF) of \(X\left( t \right)\) as \(p_{X}\) and PDF of \(X_{1} \left( t \right)\) and \(X_{2} \left( t \right)\) as \(p_{{X_{1} }}\), following convolution equation holds
In order to exemplify the latter idea regarding how to estimate unknown probability distribution robustly \(p_{{X_{1} }}\), subsequently improving given empirical distribution \(p_{X} .\) In the next, authors briefly discuss common knowledge regarding the discrete convolution of two vectors. The convolution of two vectors, \({\varvec{u}}\) and \({\varvec{v}}\), representing an area of overlap of vector components, as \({\varvec{v}}\) slides across \({\varvec{u}}\). Algebraically, convolution being the same operation as multiplying polynomials whose coefficients are the elements of, \({\varvec{u}}\) and \({\varvec{v}}\). Let \(m = {\text{length}}\left( {\varvec{u}} \right)\) and \(n = {\text{length}}\left( {\varvec{v}} \right)\). Then \({\varvec{w}}\) being the vector of length \(m + n - 1\), with \(k\)-th element being
The sum is over all the values of \(j\) that lead to legal subscripts for \(u\left( j \right)\) and \(v\left( {k - j + 1} \right)\), specifically \(j = {\text{max}}\left( {1,k + 1 - n} \right):1:{\text{min}}\left( {k,m} \right)\). When \(m = n\), as will be the main case in this study
From Eq. (12) one can also observe that having found \({\varvec{u}} = {\varvec{v}} = \left( {u\left( 1 \right),..,u\left( n \right)} \right)\), one can gradually obtain \({\varvec{w}}\)-components \(w\left( {n + 1} \right), \ldots ,w\left( {2n - 1} \right)\), as index increases from \(n + 1\) to \(2n - 1\). The latter clearly would extend vector \({\varvec{w}}\) into support domain that is twice longer than the original distribution support domain, i.e. doubling the \(p_{X}\) distribution support length \(\left( {2n - 1} \right) \cdot \Delta x \approx 2n \cdot \Delta x = 2X_{L}\), as compared to the original probability distribution support length \(n \cdot \Delta x = X_{L}\) with \(\Delta x\) being constant length of each descrete distribution bin. Note that \({\varvec{w}} = \left( {w\left( 1 \right), \ldots ,w\left( n \right)} \right)\) being discrete representation of the target empirical distribution \(p_{X}\), and \(n\) representing length of probability distribution support \(\left[ {0,X_{L} } \right]\), for simplicity in this paper one is limited to the case of one-sided positive valued random variables, namely \(X \ge 0\). As will be further discussed, a simple linear extrapolation of self deconvoluted vector \(\left( {u\left( 1 \right), \ldots ,u\left( n \right)} \right)\) towards \(\left( {u\left( {n + 1} \right), \ldots ,u\left( {2n - 1} \right)} \right)\) is suggested, with \(p_{{X_{1} }}\) having its tail linearly extrapolated within the range \(\left( {X_{L} ,2X_{L} } \right).\) Using Eq. (11) original vector \({\varvec{w}}\) will be extended and extrapolated into support domain being twice longer than original distribution support domain, namely doubling \(p_{X}\) distribution support length \(\left( {2n - 1} \right) \cdot \Delta x \approx 2n \cdot \Delta x = 2X_{L}\), as compared to original probability distribution support length \(n \cdot \Delta x = X_{L}\). To smoothen original distribution \(p_{X} \left( x \right)\) tail, authors have performed distribution \(p_{X}\) tail interpolation for high tail values \(x\), using Naess-Gaidai (NG) extrapolation method53. As has been discussed above, the proposed deconvolution extrapolation technique has an advantage of not presuming any specific extrapolation functional class needed to extrapolate distribution tail.
To validate the above-suggested extrapolation methodology, the «shorter» version of the original data set was used for extrapolation to compare with predictions based on a full «longer» data set.
Results
This section aims to demonstrate the efficiency of the previously described methodology by applying the new method to the National Oceanic and Atmospheric Administration buoy (NOAA) ten-minute average wind speed values and significant wave heights (calculated as the average of the highest one-third of all wave heights during the 20-min sampling period) in the North Pacific region near the Hawaiian Islands. For this study, the NOAA wind and wave measurement location Station 51003 (LLNR 28005.7)—WESTERN HAWAII—205 NM SW of Honolulu was selected, and its measured wind speed and wave height values were set as two environmental system components (dimensions) X, Y, thereby serving as an example of a two-dimensional (2D) environmental system. Unidimensional extreme response values were chosen as the whole analysed data set maximum wind speeds and wave heights respectively during observation period between years 2009–2014 for the chosen buoy in situ measurement location.
Figure 1 presents National Oceanic and Atmospheric Administration54, buoy locations in North Pacific, blue circle indicates area of interest. Figure 2 shows data buoy containing sensors used to monitor and collect atmospheric and oceanographic conditions, collected data is then converted into an electronic signal and transmitted to shore or logged in the onboard data unit. This 3-m foam buoy has following characteristics:

Wind and wave measurements location according to National Oceanic and Atmospheric Administration, blue circle indicates measurement station of interest. Figure taken from National Oceanic and Atmospheric Administration, https://www.ndbc.noaa.gov.

National Oceanic and Atmospheric Administration buoy54.
Site elevation: sea level.
Air temp height: 3.4 m above site elevation.
Anemometer height: 3.8 m above site elevation.
Barometer elevation: 2.4 m above mean sea level.
Sea temp depth: 2 m below water line.
Water depth: 1987 m.
Watch circle radius: 5004 yards.
In order to unify all two measured time series \(X, Y\) the following scaling was performed:
making all two responses non-dimensional and having the same failure limit equal to 1. Next, all local maxima from two measured time series were merged into one single time series by keeping them in time non-decreasing order: \(\vec{R} = \left( {{\text{max}}\left\{ {X_{1} ,Y_{1} } \right\}, \ldots ,{\text{max}}\left\{ {X_{N} ,Y_{N} } \right\}} \right)\) with the whole vector \(\vec{R}\) being sorted in temporally non-decreasing order of occurrence of these local maxima.
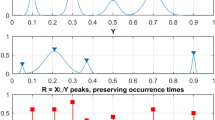
Figure 3 presents example of non-dimensional assembled vector \(\vec{R}\), consisting of assembled local maxima of raw daily largest highest daily windcast speed data. The failure probability distribution tail extrapolation was performed towards 100 years return period. Synthetic vector \(\vec{R}\) does not have physical meaning on its own, as it assembled of completely different response components. Index \(j\) is just a running index of local maxima encountered in non-decreasing time sequence. Index \(j\) being running index of local maxima encountered in non-decreasing time sequence. The «shorter» data record was generated by taking each tenth data point from the «longer» data record.

Scaled non-dimensional assembled 2D vector \(\vec{\user2{R}}\).
Figure 4 on the left presents the «shorter» data record \(f_{{X_{1} }}\) tail, obtained by deconvolution as in Eq. (13), and subsequently linearly extrapolated in the terminal tail section to cover the \(X_{1}\) range matching the «longer» data record. Figure 4 on the right presents final unscaled results of the proposed in this paper technique, namely the «shorter» decimal log scale \(f_{X}\) tail, extrapolated by deconvolution, along with «longer» data distribution tail and NG extrapolation.

Combined wind speed and wave height data. Left: scaled \(\user2{ f}_{{{\varvec{X}}_{1} }}\) tail on the decimal log scale for the «shorter» data (cyan), linearly extrapolated (dark blue). Right: unscaled raw «shorter» data (green) \(\user2{ f}_{{\varvec{X}}}\) tail on the decimal log scale, extrapolated by deconvolution method (dark blue), along with «longer» raw data (red) and NG extrapolation (cyan). Star indicates 100 years return period prediction.
It is seen that NG prediction does not agree with deconvolution approach, leading to non-conservative prediction, indicated by star in Fig. 4 on the right. It is seen from Fig. 4 on the right that the proposed method performs quite well, being based on the «shorter» data set, and delivering probability distribution close to the one based on the «longer» data set. Figure 4 on the right presents extrapolation according to Eq. (9) as well novel deconvolution method towards failure state with 100 year return period, which is 1, and somewhat beyond, \(\lambda = 0.05\) cut-on value was used. Dotted lines indicate extrapolated 95% confidence interval according to Eq. (10). According to Eq. (5) \(p\left( \lambda \right)\) is directly related to the target failure probability \(1 - P\) from Eq. (1). Therefore, in agreement with Eq. (5) system failure probability \(1 - P \approx 1 - P_{k} \left( 1 \right)\) may be now estimated. Note that in Eq. (5) \(N\) corresponds to a total number of local maxima in the unified response vector \(\vec{R}\).Conditioning parameter \(k = 6\) was found to be sufficient due to occurrence of convergence with respect to \(k\), see Eq. (6). The generalization potential of the proposed methods is extension to non-stationary systems with an underlying trend. If the underlying trend would be known, which is rarely the case, it may be subtracted to bring measurements to stationary state. Otherwise proper trend analysis would be needed in combination with advocated here methods. The main model assumptions subsequent limitation is the system quasi-stationarity as mentioned before.
Conclusions
The key advantage of introduced methodology is its ability to assess reliability of non-linear dynamic systems with high dimensionality.
This paper studied wind speeds and wave heights measured by National Oceanic and Atmospheric Administration buoys in North Pacific region, during years 2009–2014. Novel environmental reliability method has been applied to predict occurrence of extreme waves within time horizon of 100 years. Theoretical reasoning behind the proposed method has been given in detail.
Methods introduced in this paper, have been previously validated by application to range of dynamic environmental systems, but for only one-dimensional system responses. This study has aimed at further development of robust and simple general purpose multi-dimensional reliability method. Both measured and numerically simulated time series responses can be analyzed. In case of measured system response, as illustrated in this paper, an accurate prediction of environmental system failure probability is possible.
Finally, the suggested methodology can be used in wide range of modern engineering areas of applications. The presented environmental example does not limit applicability area of new method by any means.
Data availability
The datasets analyzed during the current study are available on request. Please contact Prof. Yihan Xing, email: yihan.xing@uis.no. See also54.
References
Rice, S. O. Mathematical analysis of random noise. Bell Syst. Tech. J. 23, 282–332 (1944).
Madsen, H. O., Krenk, S. & Lind, N. C. Methods of Structural Safety (Prentice-Hall Inc, 1986).
Ditlevsen, O. & Madsen, H. O. Structural Reliability Methods (Wiley, 1996).
Melchers, R. E. Structural Reliability Analysis and Prediction (Wiley, 1999).
Naess, A. & Gaidai, O. Estimation of extreme values from sampled time series. Struct. Saf. 31(4), 325–334 (2009).
Miles, J. On the generation of surface waves by shear flows. J. Fluid Mech. 3, 185–204 (1957).
Phillips, O. On the generation of waves by turbulent wind. J. Fluid Mech. 2, 417–445 (1957).
Phillips, O. The equilibrium range in the spectrum of wind-generated waves. J. Fluid Mech. 4, 426–434 (1958).
Phillips, O. Spectral and statistical properties of the equilibrium range in wind-generated gravity waves. J. Fluid Mech. 156, 505–531 (1985).
Pierson, W. J. & Marks, W. The power spectrum analysis of ocean-wave records. Trans. Am. Geophys. Union 33, 834–844 (1952).
Pierson, W. J. & Moskowitz, L. A proposed spectral form for fully developed wind seas based on the similarity theory of s. a. kitaigorodskii. J. Geophys. Res. 69, 5181–5190 (1964).
Christou, M. & Ewans, K. Field measurements of rogue water waves. J. Phys. Oceanogr. 9, 2317–2335 (2014).
Doeleman, M. W. Rogue waves in the Dutch North Sea. Master’s thesis, TU Delft (2021).
Ducrozet, G., Abdolahpour, M., Nelli, F. & Toffoli, A. Predicting the occurrence of rogue waves in the presence of opposing currents with a high-order spectral method. Phys. Rev. Fluids 6, 064803 (2021).
Forristall, G. On the distributions of wave heights in a storm. J. Geophys. Res. 83, 2353–2358 (1978).
Gaidai, O. et al. Novel methods for wind speeds prediction across multiple locations. Sci. Rep. 12, 1–9 (2022).
Glukhovskii, B. Investigation of Sea Wind Waves (in russian) (Gidrometeoizdat, 1966).
Tayfun, M. A. Narrow-band non-linear sea waves. J. Geophys. Res. 85, 1548–1552 (1980).
Tayfun, M. A. & Fedele, F. Wave-height distributions and non-linear effects. Ocean Eng. 34, 1631–1649 (2007).
Karmpadakis, I., Swan, C. & Christou, M. Assessment of wave height distributions using an extensive field database. Coast. Eng. 157, 103630 (2020).
Karmpadakis, I., Swan, C. & Christou, M. A new wave height distribution for intermediate and shallow water depths. Coast. Eng. 175, 104130 (2022).
Kimmoun, O., Hsu, H. C., Hoffmann, N. & Chabchoub, A. Experiments on uni-directional and non-linear wave group shoaling. Ocean Dyn. 71, 1105–1112 (2021).
Haring, R., Osborne, A. & Spencer, L. Extreme wave parameters based on continental shelf storm wave records. In Proc. 15th Int. Conf. on Coastal Engineering, 151–170 (1976).
Jahns, H. & Wheeler, J. Long-term wave probabilities based on hindcasting of severe storms. J. Pet. Technol. 25, 473–486 (1973).
Longuet-Higgins, M. On the statistical distribution of the heights of sea waves. J. Mar. Res. 11, 245–265 (1952).
Longuet-Higgins, M. S. On the distribution of the heights of sea waves: Some effects of nonlinearity and finite band width. J. Geophys. Res. 85, 1519–1523 (1980).
Zhang, J., Benoit, M., Kimmoun, O., Chabchoub, A. & Hsu, H. C. Statistics of extreme waves in coastal waters: Large scale experiments and advanced numerical simulations. Fluids 4, 99 (2019).
Zhang, H., Reynolds, R. & Bates, J. Blended and Gridded High Resolution Global Sea Surface Wind Speed and Climatology from Multiple Satellites: 1987 - Present (American Meteorological Society, 2006).
Kinsman, B. Surface waves at short fetches and low wind speed—a field study. Chesapeake Bay. Inst.,Tech. Rep (1960).
Li, Y., Draycott, S., Adcock, T. A. & Van Den Bremer, T. Surface wavepackets subject to an abrupt depth change: Part 2: Experimental analysis. J. Fluid Mech. 915, A72 (2021).
Li, Y. et al. Why rogue waves occur atop abrupt depth transitions. J. Fluid Mech. 919, R5 (2021).
Li, Y., Zheng, Y., Lin, Z., Adcock, T. A. & Van Den Bremer, T. Surface wavepackets subject to an abrupt depth change: Part 1: Second-order theory. J. Fluid Mech. 915, A71 (2021).
Majda, A., Moore, M. & Qi, D. Statistical dynamical model to predict extreme events and anomalous features in shallow water waves with abrupt depth change. Proc. Natl. Acad. Sci. U.S.A. 116, 3982–3987 (2019).
Mendes, S., Kasparian, J., 2022. Saturation of rogue wave amplification over steep shoals. Physical Review E - accepted for publication (https://journals.aps.org/pre/accepted/a2077KaaI041ec0626a21bd0ec4388c81ed896128). https://arxiv.org/abs/physics.flu-dyn/2207.13869.
Mendes, S. & Scotti, A. The rayleigh-haring-tayfun distribution of wave heights in deep water. Appl. Ocean Res. 113, 102739 (2021).
Mendes, S., Scotti, A., Brunetti, M. & Kasparian, J. Non-homogeneous model of rogue wave probability evolution over a shoal. J. Fluid Mech. 939, A25 (2022).
Mendes, S., Scotti, A. & Stansell, P. On the physical constraints for the exceeding probability of deep water rogue waves. Appl. Ocean Res. 108, 102402 (2021).
Naess, A., Leira, B. J. & Batsevych, O. System reliability analysis by enhanced Monte Carlo simulation. Struct. Saf. 31, 349–355 (2009).
Xing, Y., Gaidai, O., Ma, Y., Naess, A. & Wang, F. A novel design approach for estimation of extreme responses of a subsea shuttle tanker hovering in ocean current considering aft thruster failure. Appl. Ocean Res. https://doi.org/10.1016/j.apor.2022.103179 (2022).
Gaidai, O. et al. Offshore renewable energy site correlated wind-wave statistics. Probab. Eng. Mech. https://doi.org/10.1016/j.probengmech.2022.103207 (2022).
Sun, J. et al. Extreme riser experimental loads caused by sea currents in the Gulf of Eilat. Probab. Eng. Mech. https://doi.org/10.1016/j.probengmech.2022.103243 (2022).
Gaidai, O. & Naess, A. Extreme response statistics for drag dominated offshore structures. Probab. Eng. Mech. 23, 180–187 (2008).
Xu, X. et al. Bivariate statistics of floating offshore wind turbine dynamic response under operational conditions. Ocean Eng. https://doi.org/10.1016/j.oceaneng.2022.111657 (2022).
Gaidai, O. et al. Improving extreme anchor tension prediction of a 10-MW floating semi-submersible type wind turbine, using highly correlated surge motion record. Front. Mech. Eng. https://doi.org/10.3389/fmech.2022.888497 (2022).
Gaidai, O., Xing, Y. & Xu, X. COVID-19 epidemic forecast in USA East coast by novel reliability approach. Res. Square https://doi.org/10.21203/rs.3.rs-1573862/v1 (2022).
Xu, X. et al. A novel multi-dimensional reliability approach for floating wind turbines under power production conditions. Front. Mar. Sci. https://doi.org/10.3389/fmars.2022.970081 (2022).
Gaidai, O., Xing, Y. & Balakrishna, R. Improving extreme response prediction of a subsea shuttle tanker hovering in ocean current using an alternative highly correlated response signal. Results Eng. https://doi.org/10.1016/j.rineng.2022.100593 (2022).
Cheng, Y., Gaidai, O., Yurchenko, D., Xu, X. & Gao, S. Study on the dynamics of a payload influence in the polar ship. In The 32nd International Ocean and Polar Engineering Conference, Paper Number: ISOPE-I-22-342 (2022).
Gaidai, O., Storhaug, G., Wang, F., Yan, P., Naess, A., Wu, Y., Xing, Y. & Sun, J. On-board trend analysis for cargo vessel hull monitoring systems. In The 32nd International Ocean and Polar Engineering Conference, Paper Number:ISOPE-I-22-541 (2022).
Gaidai, O. et al. Offshore renewable energy site correlated wind-wave statistics. Probab. Eng. Mech. https://doi.org/10.1016/j.probengmech.2022.103207 (2022).
Gao, H., Gaidai, O., Naess, A., Storhaug, G. & Xu, X. Improving container ship panel stress prediction, based on another highly correlated panel stress measurement. Mar. Struct. 64, 138–145 (2018).
Numerical Algorithms Group. NAG Toolbox for Matlab (NAG Ltd, 2010).
Naess, A. & Moan, T. Stochastic Dynamics of Marine Structures (Cambridge University Press, 2013).
National Oceanic and Atmospheric Administration, https://www.ndbc.noaa.gov
Author information
Authors and Affiliations
Contributions
All authors contributed equally.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gaidai, O., Xing, Y. & Xu, X. Novel methods for coupled prediction of extreme wind speeds and wave heights. Sci Rep 13, 1119 (2023). https://doi.org/10.1038/s41598-023-28136-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-28136-8
This article is cited by
-
4400 TEU cargo ship dynamic analysis by Gaidai reliability method
Journal of Shipping and Trade (2024)
-
Gaidai reliability method for fixed offshore structures
Journal of the Brazilian Society of Mechanical Sciences and Engineering (2024)
-
Limit hypersurface state of art Gaidai reliability approach for oil tankers Arctic operational safety
Journal of Ocean Engineering and Marine Energy (2024)
-
Gaidai Multivariate Reliability Method for Energy Harvester Operational Safety, Given Manufacturing Imperfections
International Journal of Precision Engineering and Manufacturing (2024)
-
Dementia death rates prediction
BMC Psychiatry (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
