
Abstract
Although the belief rule base (BRB) expert system has many advantages, such as the effective use of semi-quantitative information, objective description of uncertainty, and efficient nonlinear modeling capability, it is always limited by the problem of combinatorial explosion. The main reason is that the optimization of a BRB with many rules will consume many computing resources, which makes it unable to meet the real-time requirements in some complex systems. Another reason is that the optimization process will destroy the interpretability of those parameters that belong to the inadequately activated rules given by experts. To solve these problems, a novel optimization method for BRB is proposed in this paper. Through the activation rate, the rules that have never been activated or inadequately activated are pruned during the optimization process. Furthermore, even if there is a complete data set and all rules are activated, the activation rate can also be used in the parallel optimization process of the BRB expert system, where the training data set is divided into some subprocesses. The proposed method effectively solves the combinatorial explosion problem of BRB and can make full use of quantitative data without destroying the original interpretability provided by experts. Case studies prove the advantages and effectiveness of the proposed method, which greatly expands the application fields of the BRB expert system.
Similar content being viewed by others


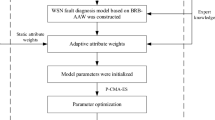
Introduction
Expert systems are one of the most traditional artificial intelligence methods and have been used in many fields, including finance, industry, medicine, and education1. It can express extensive knowledge and experience of a complex system and obtain the final results by the inference engine. However, in the era of big data, an expert system cannot effectively utilize multisource data from complex environments and internal systems, which limits its applications. Data-driven approaches can make up for this defect, such as neural networks2,3, dynamic Bayesian networks4, and deep learning methods5. However, they cannot use expert experience and domain knowledge to guide the setting of initial parameters, which brings much uncertainty and pressure to the model optimization. A semiquantitative model can combine the advantages of the above two types of models, such as the hidden Markov model (HMM)6 and fuzzy neural network7. Although the above methods have been applied in many cases, they all lack the ability to process various types of uncertainty, including randomness, fuzziness and ignorance, and lack the interpretability and credibility of the results. As an intelligent expert system and interpretable artificial intelligence method, the belief rule base (BRB) expert system8,9,10 can effectively utilize semiquantitative information, including qualitative knowledge and quantitative data, and objectively express uncertain information. Currently, increasing attention is being paid to BRBs, and many variants have been developed11,12,13,14,15.
Although BRB has many advantages, as an expert system, it will also face the problem of combinatorial explosion when the number of attributes is increased. The main reason is that the number of rules in the BRB will increase exponentially with the increase in attributes and reference levels. There are many problems to be solved for BRBs, and the most important problem is model optimization. Because of the increasing parameters in the BRB, the optimization process will expend considerable time and computing resources. For example, there are 8 attributes in distinguishing diabetes. Assuming that each attribute has 3 reference levels, the number of rules in BRB is 38 = 6561. In the following sections, we will see that each rule of BRB has 12 parameters, including rule weights, attribute weights, and belief degrees of consequents. Thus, the number of parameters of the BRB is 6561 × 12 = 78,732, which means that searching for optimal parameters will run in a very high-dimensional solution space. In addition, the objective function of BRB optimization is a nonconvex, highly nonlinear, and existing equality constraint problem. Therefore, the optimization process of BRBs with a large number of parameters is very difficult to solve. On the other hand, it is also unreasonable to optimize all the parameters of the BRB because some rules may not be activated or only activated a few times by incomplete quantitative data. It is not only meaningless to optimize those rules but will also destroy the original interpretability provided by experts.
Based on the above descriptions, it is necessary to develop an effective method to solve the optimization problem of BRBs. Currently, there are 2 types of methods for this problem: (1) Dimension reduction methods, which can reduce the number of attributes, such as principal component analysis (PCA)16 and linear discriminant analysis (LDA)17. For example, Hu used PCA to reduce the characteristics of attacks in network security situation prediction by using BRB18. (2) Structure reduction methods, which can reduce the number of rules. For example, Zhou proposed an automatic adding and deleting criterion for belief rules in BRBs based on statistical utility19. Chang proposed a structure learning method for BRBs based on gray targets (GTs) and multidimensional scaling (MDS)16.
Although the above methods can relieve the pressure of BRB optimization to a certain extent, some shortcomings still exist. Dimension reduction methods cannot keep the original meaning of the attribute, which weakens the advantage that the BRB expert system can effectively utilize domain knowledge. Structure reduction methods are not always efficient and reach practical optimization speeds at the expense of precision. Obviously, from the view of scale reduction, the optimization problem of BRBs with a large number of parameters cannot be effectively solved. Therefore, a novel optimization method for BRBs with activation rates is proposed in this paper, where the activation rate is used to determine which rules should be optimized in a process, and then the whole optimization process of BRBs can be simplified without losing accuracy. Furthermore, in the situation that most of the rules are activated, the activation rate can also be used in the parallel process of BRB optimization, where the training data set is divided into some subprocesses. The proposed method in this paper can reduce the unnecessary optimization of those unactivated rules of the BRB expert system, which ensures that the quantitative data can be utilized as much as possible without destroying the original interpretability provided by experts.
The remainder of this paper is organized as follows. In “The basic description of the BRB expert system” section, the basic description of the BRB expert system is introduced, and the optimization problem of BRBs is analysed. In “Optimization method for BRBs” section, the novel optimization method with activation rate is proposed, and the parallelized process is constructed. In “Case studies” section, two case studies are designed to verify the effectiveness of the proposed method. The paper is concluded in “Conclusion” section.
The basic description of the BRB expert system
The structure of the BRB expert system
BRB is an intelligence expert system that can effectively use qualitative knowledge and quantitative data and can express most uncertainty information. The basic construction of the BRB expert system is as follows8.
where \(R_{k}\) denotes the \(kth\) rule in the belief rule base, and \(a_{i} (i = 1, \ldots ,M)\) denotes the \(ith\) antecedent attribute, whose referential value is \(A_{i}^{k}\), \(A_{i}^{k} = \left( {A_{i,1}^{k} ,A_{i,2}^{k} , \ldots A_{{i,J_{i} }}^{k} } \right)\), where \(J_{i}\) denotes the number of referential levels of the \(ith\) attribute. \(M\) denotes the number of antecedent attributes. To simplify the problem, we assume that the number of attributes in each rule is the same. \(D_{j} \left( {j = 1, \ldots ,N} \right)\) denotes the \(jth\) output result, whose belief degree can be expressed by \(\beta_{j,k}\). \(D\) is the set that includes all the results, so the belief degree \(\beta_{D,k}\) assigned to \(D\) denotes the remaining belief degree. Because \(\beta\) denotes the probabilities of the results, the sum of those belief degrees must equal 1, which is the constraint condition in training BRB.
The BRB expert system uses the above belief rules to construct the nonlinear relationship between the input and output of a complex system, and as a general probability, the belief degree can express various types of uncertain information in an objective world.
The reasoning process of the BRB expert system
When data are imported into BRB, some rules are activated. The principle of the activation is that when attributes of the data match the corresponding reference levels, the transformation method is used to generate a matching degree of the attribute value relative to the reference value. The transformation method depends on the form of the attributes. If the attributes are quantitative, the matching degrees can be obtained by the equivalence transformation technique20,21. If the attributes are qualitative, the matching degrees can be obtained by the subjective judgment of experts22. All the matching degrees will construct \(M\) matching degree vectors, denoted by \(v_{i}\), where each vector includes \(J_{i}\) matching degrees. Then a matching degree matrix \(V\) can be obtained. \(V\) includes an element \(V_{k,i} \, \left( {k = 1, \ldots L; \, \,i = 1, \ldots M} \right)\) that is selected from \(v_{i}\) according to the rules arranged by reference level. Thus the activation weight of the \(kth\) rule \(\omega_{k}\) can be calculated by
If the activation weight is not equal to 0, the corresponding rule is activated. Then, the following evidential reasoning (ER) rule is utilized to fuse the activated rules and finally obtain the distribution of belief degrees \(\widehat{\beta }_{j}\) assigned to the results, as shown in Eq.
Optimization of the BRB expert system
It can be seen from the above descriptions that BRB includes many parameters, of which the initial values are usually given by experts. These initial parameters constitute a rough BRB, which cannot produce accurate results. Therefore, parameter optimization for BRBs is necessary. The first step is to establish an optimization objective, shown as follows.
where \(F\left( \Omega \right)\) denotes the objective function, which can be defined through the mean square deviation between the real values and testing results of the BRB. \(\Omega\) denotes the parameters to be optimized.
Equation (3) is a highly nonlinear, highly dimensional, strongly constrained optimization problem. Therefore, the second step is to select an appropriate optimization algorithm to solve the optimization objective of the BRB23 used the sequential quadratic programming (SQP) algorithm to obtain the optimal parameters of BRBs24 proposed the projection covariance matrix adaptation evolution strategy (P-CMA-ES) algorithm, which achieves a good optimization effect.
Although the accuracy of BBR can be improved by the parameter optimization process, when the attributes and reference levels are increased, BRB has to face the problem of combinatorial explosion. As described in “Introduction” section, a large number of parameters will not only reduce the speed of optimization, which will lead to failure in the scene with high real-time requirements but also lead to a decrease in accuracy because of the difficulty of optimal solution search in high-dimensional space. The above limitation greatly restricts the application of BRBs in more complex and wide fields. Therefore, an efficient optimization method for BRBs is proposed in this paper.
Optimization method for BRBs
A novel optimization method for BRBs with activation rates is proposed in this section. The method can be used in two different application scenarios: (1) BRBs with incomplete samples or patterns, which means that a part of the rules will never be activated or only activated a few times. By pruning these rules by using the activation rate and threshold, the optimization dimension will be greatly reduced. (2) Fully activated BRB, where all rules are activated many times. Through parallel operation by using the activation rate and threshold, optimization will be separated into many child processes, which will fundamentally solve the problem of BRB optimization. Next, the basic principles of the proposed optimization method will be introduced in two different scenarios.
BRB optimization method with activation rate
After an in-depth analysis of the combination explosion problem, we found that when samples are incomplete or the actual system does not cover all patterns, a part of the rules will never be activated or only activated very few times in the whole training process, which is called inadequate-activated rules. However, in the traditional optimization process of BRBs, the parameters of all rules are involved in optimization, which is unreasonable. The initial parameters of the BRB are given by experts based on experience and domain knowledge. If the parameters of these nonactivated or inadequate-activated rules are optimized, then we give up expert knowledge without enough quantitative data to provide information for model learning. To solve the above problem, the activation rate for the BRB is first proposed, as follows.
where \(ar_{k}\) denotes the activation rate of the \(kth\) rule and \(an_{k}\) denotes the number of activation times of the \(kth\) rule.
To prune the nonactivated and inadequate-activated rules, a threshold \(h\) of the activation rate must be given. When the activation rate is greater than the threshold \(h\), the parameters of the corresponding rules can be optimized, and the remaining rules still keep the initial values given by experts.
Remark 1
Note that ank can be obtained only after all samples are input into the initial BRB, which cannot affect the efficiency of optimization because the initial BRB is without a training process and can quickly obtain output results.
Parallel optimization method of BRBs
The scale of the BRB can only be reduced to a certain extent through the activation rate, but when the data set is relatively complete, the scale reduction will be limited, which cannot solve the optimization problem of BRBs with a large number of parameters in essence. With the development of computer technology, parallel optimization provides a good solution, which can greatly reduce the optimization time. Theoretically, if we have enough computing units, the optimization time will surely meet the requirements of the actual system. Thus, a parallel optimization method for BRBs is proposed in this section.
Inspired by the activation rate and pruning rules, the parallelization of BRB optimization can be achieved by partitioning the data set, which can be denoted as
where \(S\) denotes the original data set, \(sn\) denotes the number of samples, and \(M\) denotes the number of attributes of each sample \(s_{i,1} ,s_{i,2} , \cdots ,s_{i,M}\).
The parallelization steps of BRB optimization are shown as follows:
-
Step 1 First, the initial parameter values of the BRB are set according to expert knowledge.
-
Step 2 Assuming that the number of optimization subprocesses is pn, the training data set can be divided into pn parts, each of which is an average sampled from sn samples of the original data set.
-
Step 3 Input every sub data set into the initial BRB, and calculate the activation rate \(AR_{n} = \left( {ar_{1}^{n} ,ar_{2}^{n} , \ldots ,ar_{k}^{n} } \right);\left( {n = 1,2, \ldots pn} \right)\) of each sub data set, where \(AR_{i}\) denotes the activation rate set of the \(ith\) sub data set. \(ar_{k}^{n}\) denotes the activation rate of the \(kth\) rule activated by the \(nth\) sub data set.
-
Step 4 Set the threshold for the activation rate, which can decide which rules to participate in each optimization subprocess. Then, the BRB can be divided into pn sub-BRB models, denoted as \(BRB_{n}\).
-
Step 5 The corresponding sub-BRB is assigned to different computing units and optimized independently according to the corresponding training sub data set. The optimization algorithm is P-CMA-ES, which is used to minimize the objective function shown in Eq. (3). Please refer to algorithm 1 for pseudo code of P-CMA-ES algorithm.
-
Step 6 After the above steps, we obtain pn groups of belief degree distributions, and each group has \(sn\) belief degree distributions for the output results of \(sn\) samples in the BRB. The belief degree distribution generated by the \(nth\) optimization subprocess of the \(ith\) testing sample can be denoted as \(B_{n,i} = \left( {\hat{\beta }_{n,i}^{1} ,\hat{\beta }_{n,i}^{2} , \ldots ,\hat{\beta }_{n,i}^{N} } \right)\). To obtain the final belief degree distribution, the weighted average method is utilized, and the weight of the \(nth\) distribution can be determined by \(pw_{n}\)
where \(an_{k}^{n}\) denotes the number of activation times of the \(kth\) rule in \(BRB_{n}\). Then, the final belief degrees distribution of \(ith\) sample \(B_{f}^{i}\) can be obtained by Eq. (8), the final results of the BRB can be obtained by Eq. (9).
Remark 2
The above optimization subprocesses are independent of each other. The weighted average operation for the final belief degree distribution is executed only when the optimization is completed.

Case studies
To verify the superiority of the proposed method, two cases, “Health status assessment of laser gyro” and “Leak size estimation of oil pipeline”, were used for verification.
Health status assessment of laser gyro
Problem formulation
A laser gyro is a precision instrument in the navigation control system. Its state parameters are zero-order drift coefficient, first-order drift coefficient, X-axis gyroscope light intensity voltage. When these parameters exceed the calibration threshold, it means that the laser gyro has failed, and the navigation control system will fail at this time. However, when these parameters are within the threshold, the laser gyro will also show different states. At this time, evaluating their health is also a necessary means to measure whether the laser gyro meets the navigation accuracy. Therefore, this case studies the health assessment of laser gyro, using the following data sets.
In this case, the data set of the laser gyro is used to prove the advantages of the proposed method. This data set contains a zero-order drift coefficient, first-order drift coefficient, X-axis gyroscope light intensity voltage, and expected utility value. The data set has 2000 samples, as shown in Figs. 1, 2, 3 and 4.

The zero-order drift coefficient of the laser gyro.

The first-order drift coefficient of the laser gyro.

The X-axis gyroscope light intensity voltage of the laser gyro.

The expected utility value of the laser gyro.
First, we can establish a BRB expert system according to expert experience or domain knowledge. The reference values of the zero-term drift coefficient, first-term drift coefficient, and X-axis gyroscope light intensity voltage are shown in Tables 1, 2 and 3. Thus the BRB expert system of laser gyroscope health status detection can be described
where \(H,SH,UH\) denote the reference values of the laser gyroscope health status, as shown in Table 4. The other parameters of the BRB expert system are shown in Table 5.
As described in the above sections, the data set may not cover all patterns about the zero-order drift coefficient, first-order drift coefficient and X-axis gyroscope light intensity voltage, which means that perhaps only a part of the rules shown in Table 6 can be activated. To prove this point, the laser gyro data samples are input into the above BRB expert system. The samples are divided into a training data set and a testing data set. The training data set includes 500 samples, which are regularly selected from the 2000 samples, and the remaining 1500 samples are used as a testing data set. The P-CMA-ES algorithm is utilized as an optimization tool of the BRB expert system, and to ensure the fairness of the optimization process, the parameters and iterations are the same for different conditions.
Case 1-optimization process of a BRB using activation rates
Figure 5 shows the activation rates of 64 rules in the BRB expert system when the training data set is entered. It can be seen that the activation rates of different rules are not the same, and the activation rates of some rules are even very small and will hardly be activated.

The activation rates of 64 rules in the BRB expert system.
Four BRBs with different activation rate thresholds are established for comparison with the traditional BRB. In these BRBs, the rule whose activation rate is larger than the threshold value will be selected to participate in the optimization process. Thus, the different threshold values will retain different numbers of rules. The optimization algorithm is P-CMA-ES, and the iteration time is 100. Table 6 shows the details and testing results generated by different BRBs. Where BRB stands for traditional BRB, BRB_1 to BRB_4 represents four BRBs with different activation thresholds, BRB_SQP stands for BRB using Sequential Quadratic Programming optimization algorithm, BRB_PSO stands for BRB using Particle Swarm Optimization algorithm, BRB_S stands for BRB using only the selected rules. Table 7 shows the health status distribution of different laser gyros under different BRBs.
It can be seen that BRB_1 with fewer rules generates the best result. The mean square error (MSE) of BRB_1 with 243 optimization parameters is even smaller than that of the traditional BRB with 259 optimization parameters.
Figures 6, 7 and 8 can better demonstrate the results of comparative experiments, where 1500 samples are divided into three parts.

The 1–500 comparative results generated by different BRBs.

The 501–1000 comparative results generated by different BRBs.

The 1001–1500 comparative results generated by different BRBs.
Remark 3
Note that the number of selected rules shown in Table 6 does not mean that the BRB expert system only has these rules; the remaining rules are also included. They do not participate in the optimization process.
Remark 4
As seen from the above experimental results, although BRB_1 achieves the best accuracy with minimum rules in the optimization process, the accuracy is not sufficient because of the few iterations of the P-CMA-ES algorithm. It is obvious that, in theory, further optimization will not have an obvious effect.
Case 2-parallel processing for BRBs using activation rates
In this section, all samples are treated as training data to activate more rules in the BRB to start up the parallel optimization process of the BRB. Figure 9 shows the activation rates generated by training data. The activation rates of 64 rules are more balanced than the activation rates shown in Fig. 5 of case 4.1.2. In Fig. 9, most rules have been activated, although some rules are activated less frequently. When more rules participate in the optimization process, the number of parameters to be optimized will increase dramatically. Therefore, the method of decomposing the data set is proposed to generate independent optimization subprocesses.

The activation rates of 64 rules generated by all samples.
Remark 5
Note that the training data set of optimization subprocesses is divided into some independent parts, and each part is average sampled from all samples in the original data set. The number of parts of the training data set is equal to the number of optimization subprocesses whose parameters are the same as those in case 4.1.2.
By using the parallel optimization method described in “Parallel optimization method of BRBs” section, the training data sets are divided into 6 parts, each of which belongs to the corresponding 6 sub-BBR models, denoted as sub.1–6. Thus, the parallel optimization processes can also be divided into 6 parts. The operating environment uses the MATLAB parallel toolkit with an Intel Core i7-8750H 2.2 GHz CPU and 16 GB memory. The optimization algorithm is P-CMA-ES, and the iteration time is 100. The activation rates of 64 rules generated by subs.1–6 are shown in Fig. 10.

The activation rates of 64 rules generated by sub.1–6.
In this case, the activation rate threshold of the parallel optimization is 0.001; then, the number of rules involved in the optimization of each sub-BRB are shown in Table 8.
Thus, the 6 sub-BRBs are assigned to 6 optimization subprocesses and optimized independently. The comparison results between the original BRB without using the activation rate and optimization parallelization, the BRB with the activation rate but without optimization parallelization (nonparallelization BRB_a), and the BRB with the activation rate and optimization parallelization (parallelization BRB_a) are shown in Table 9.
In Table 9, parallelization BRB_a uses the least time to obtain the best results. Its running time is approximately one-third that of other models. It can be predicted that with the increase in the number of processors, the running time will decrease without affecting the accuracy.
The experimental results show that the BRB expert system with activation rate has higher accuracy than the initial BRB or other BRB optimization algorithms in the process of laser gyro health state assessment, and the time spent is also very little. It effectively solves the problem of BRB expert system combination explosion.
Leak size estimation of oil pipeline
Problem formulation
In this case, an actual data set of an oil pipeline leak in Britain is used to prove the advantage of the proposed method1. This oil pipeline is a hundred kilometers long, and when the pipeline leaks, the flow rate and pressure of the oil in the pipeline will change according to a certain mode. The data set has 2007 samples which include flow difference, average pressure difference, and leak size, as shown in Figs. 11, 12 and 13.

The flow difference of the oil pipeline.

The average pressure difference of the oil pipeline.

The leak size of the oil pipeline.
The reference values of flow difference and pressure difference are shown in Tables 10, 11. Thus, the BRB expert system of pipeline leak detection can be described as
where Z, VS, M, H, VH denote the reference values of leak size, as shown in Table 12. The other parameters of the BRB expert system are shown in Table 13.
As described in the above sections, the data set may not cover all patterns about flow difference and pressure difference, which means that perhaps only a part of the rules shown in Table 13 can be activated. To prove this point, the samples of oil pipeline leaks are entered into the above BRB expert system. The samples are divided into training data set and testing data set. The training data set includes 510 samples, which are selected from the 2007 samples regularly, and the remaining 1497 samples are used as a testing data set. P-CMA-ES algorithm is utilized as an optimization tool of the BRB expert system, and to ensure the fairness of the optimization process, the parameters and iterations are the same for different conditions.
Case 1-optimization process of BRB using activation rates
Figure 14 shows the activation rates of 56 rules in the BRB expert system when the training data set are entered. It can be seen that only a few rules are activated and their activation times of them are different.

The activation rates of 56 rules in the BRB expert system.
Four BRBs with different activation thresholds were established to compare with traditional BRBs. In these BRBs, rules with activation rates greater than the threshold are selected to participate in the optimization process. Therefore, different thresholds preserve different numbers of rules. The optimization algorithm is P-CMA-ES with an iteration time of 100. Table 14 shows the details and test results for different BRBs. Where BRB stands for traditional BRB, BRB_1 to BRB_4 represents four BRBs with different activation thresholds, BRB_SQP stands for BRB using Sequential Quadratic Programming optimization algorithm, BRB_PSO stands for BRB using Particle Swarm Optimization algorithm, BRB_S stands for BRB using only the selected rules.
It can be seen that BRB_4 with minimum rules generates the best result. The mean square error (MSE) of BRB_4 with 26 optimization parameters is even smaller than traditional BRB with 338 optimization parameters.
Figures 15, 16 and 17 can better demonstrate the results of comparative experiments, where 1497 samples are divided into three parts.

The 1–500 comparative results generated by different BRBs.

The 501–1000 comparative results generated by different BRBs.

The 1001–1497 comparative results generated by different BRBs.
Case 2-parallel processing for BRB using activation rates
In this section, all samples are treated as training data to activate more rules in BRB, which is to start up the parallel optimization process of BRB. Figure 18 shows the activation rates generated by training data. It can be seen that the activation rates of 56 rules are more balanced than activation rates shown in Fig. 14 of case 4.2.1. In Fig. 18, most rules have been activated, although some rules are activated less frequently. When more rules participate in the optimization process, the number of parameters to be optimized will increase dramatically. Therefore, the method of the decomposing data set is proposed to generate independent optimization sub-processes.

The activation rates of 56 rules generated by all samples.
By using the parallel optimization method described in “Parallel optimization method of BRBs” section, the training data sets are divided into 6 parts, each of which belongs to the corresponding 6 sub-BBR models, denoted as sub.1–6. Thus, the parallel optimization processes can be also divided into 6 parts. The operating environment uses MATLAB parallel toolkit with Intel Core i7-8750H 2.2 GHz CPU, 16 GB memory. The optimization algorithm is P-CMA-ES, and the iteration time is 100. The activation rates of 56 rules generated by sub.1–6 are shown in Fig. 19.

The activation rates of 56 rules generated by sub.1–6.
In this case, the activation rate threshold of the parallel optimization is 0.002, then the number of the rules involved in optimization of each sub-BRB are shown in Table 15.
Thus, the 6 sub-BRBs are assigned to 6 optimization sub-processes and optimized independently. The comparison results between original BRB without using activation rate and optimization parallelization, BRB with activation rate but without optimization parallelization (non-parallelization BRB_a), and BRB with activation rate and optimization parallelization (parallelization BRB_a) are shown in Table 16.
In Table 16, parallelization BRB_a uses the least time to get the best results. Its running time is about one-fourth of other models. It can be predicted that with the increase of the number of processors, the running time will decrease without affecting the accuracy.
The experimental results show that the BRB expert system with activation rate has higher accuracy than the initial BRB or other BRB optimization algorithms in the process of oil pipeline leakage size assessment, and it takes less time. It effectively solves the problem of BRB expert system combination explosion.
Conclusion
To solve the combinatorial explosion problem of the BRB expert system, a novel optimization method is proposed in this paper. The proposed method can be applied in two situations: (1) Only a few rules in BRB are activated. In this case, activation rate is used to prune the rules that have never been activated or are inadequately activated. The initial parameters of these removed rules are given by experts, which will not only keeps the role of expert experience but also enhance the credibility of the results. (2) Most rules in BRB are activated. In this case, parallel optimization is proposed by decomposing training data, and activation rate is utilized in each parallel optimization sub-process. The final results of BRB can be obtained by the weighted average method. The proposed optimization method for the BRB expert system can be applied to all kinds of BRB models and can increase the accuracy while reducing the calculation pressure by reducing the parameters and using parallel operation.
Data availability
The datasets generated and/or analysed during the current study are not publicly available due Laboratory requirements but are available from the corresponding author on reasonable request.
References
Duda, R. O. & Shortliffe, E. H. Expert systems research. Science 220(4594), 261 (1983).
Ebadzadeh, M. M. & Salimi-Badr, A. IC-FNN: A novel fuzzy neural network with interpretable intuitive and correlated-contours fuzzy rules for function approximation. IEEE Trans. Fuzzy Syst. 26(3), 1288–1302 (2018).
He, W., Chen, Y. & Yin, Z. Adaptive neural network control of an uncertain robot with full-state constraints. IEEE Trans. Cybern. 46(3), 620–629 (2017).
Ghahramani, Z. An introduction to hidden Markov models and Bayesian networks. Int. J. Pattern Recognit. Artif. Intell. 15(1), 9–42 (2001).
Greenspan, H., Ginneken, B. & Summers, R. M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med. Imaging 35(5), 1153–1159 (2016).
Zhou, Z. J., Hu, C. H. & Xu, D. L. A model for real-time failure prognosis based on hidden Markov model and belief rule base. Eur. J. Oper. Res. 207(1), 269–283 (2010).
Juang, C. F. & Chen, C. Y. Data-driven interval type-2 neural fuzzy system with high learning accuracy and improved model interpretability. IEEE Trans. Cybern. 43(6), 1781–1795 (2013).
Zhou, Z. J., Hu, G. Y., Hu, C. H., Wen, C. L. & Chang, L. L. A survey of belief rule base expert system. IEEE Trans. Syst. Man Cybern. Syst. https://doi.org/10.1109/TSMC.2019.2944893 (2019).
Yang, J. B., Liu, J. & Wang, J. Belief rule-base inference methodology using the evidential reasoning approach-RIMER. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 36(2), 266–285 (2006).
Zhou, Z. J., Hu, C. H., Yang, J. B., Xu, D. L. & Zhou, D. H. Online updating belief-rule-based systems using the RIMER approach. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 41(6), 1225–1243 (2011).
Hu, G. Y. et al. A method for predicting the network security situation based on hidden BRB model and revised CMA-ES algorithm. Appl. Soft Comput. 48, 404–418 (2016).
Hu, G. Y. & Qiao, P. L. Cloud belief rule base model for network security situation prediction. IEEE Commun. Lett. 20(5), 914–917 (2016).
Yang, J. B., Wang, Y. M., Xu, D. L., Chin, K. S. & Chatton, L. Belief rule-based methodology for mapping consumer preferences and setting product targets. Expert Syst. Appl. 39, 4749–4759 (2012).
Feng, Z. C. et al. Fault diagnosis based on belief rule base with considering attribute correlation. IEEE Access 6, 1–1 (2017).
Zhou, Z. G. et al. A bilevel belief rule-based decision support system for diagnosis of lymph node metastasis in gastric cancer. Knowl.-Based Syst. 54, 128–136 (2013).
Chang, L. L., Zhou, Y., Jiang, J., Li, M. J. & Zhang, X. H. Structure learning for belief rule base expert system: A comparative study. Knowl.-Based Syst. 39, 159–172 (2013).
Kim, T. K. & Kittler, J. Locally linear discriminant analysis for multimodally distributed classes for face recognition with a single model image. IEEE Trans. Pattern Anal. Mach. Intell. 27(3), 318–327 (2005).
Zhang, B. C. et al. Network intrusion detection based on directed acyclic graph and belief rule base. ETRI J. 39(4), 592–604 (2017).
Zhou, Z. J. et al. Online updating belief rule based system for pipeline leak detection under expert intervention. Expert Syst. Appl. 36(4), 7700–7709 (2009).
Bustince, H. & Burillo, P. Mathematical analysis of interval-valued fuzzy relations: Application to approximate reasoning. Fuzzy Sets Syst. 113(2), 205–219 (2000).
Chen, S. M. & Hsiao, W. H. Bidirectional approximate reasoning for rule-based systems using interval-valued fuzzy sets. Fuzzy Sets Syst. 113(2), 185–203 (2000).
Zimmermann, H. J. An application-oriented view of modeling uncertainty. Eur. J. Oper. Res. 122(2), 190–199 (2000).
Jian, J. B. A superlinearly and quadratically convergent SQP type feasible method for constrained optimization. Appl. Math.-A J. Chin. Univ. (B) 15(3), 319–332 (2000).
Zhou, Z. J. et al. A model for hidden behavior prediction of complex systems based on belief rule base and power set. IEEE Trans. Syst. Man Cybern. Syst. 88(PP), 1–7 (2017).
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62273113, China Postdoctoral Science Foundation under Grant 2020M673668, and Guangxi Key Laboratory of Trusted Software under Grant KX202050, and National Defense Science and Technology Key Laboratory fund under grant 6142101210309, and basic scientific research items of equipment under Grant 514010203-214.
Author information
Authors and Affiliations
Contributions
Conceptualization, G.X., J.W. and G.H.; methodology, G.X., G.H.; software, J.W.; validation, G.X., J.W. and G.H.; formal analysis, G.X.; investigation, X.H.; data curation S.T.; writing—original draft preparation, J.W.; writing—review and editing, G.X. and G.H.; visualization, J.W. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiang, G., Wang, J., Han, X. et al. A novel optimization method for belief rule base expert system with activation rate. Sci Rep 13, 584 (2023). https://doi.org/10.1038/s41598-023-27498-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-27498-3
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
