
Abstract
We evaluated the effectiveness of automated segmentation of the liver and its vessels with a convolutional neural network on non-contrast T1 vibe Dixon acquisitions. A dataset of non-contrast T1 vibe Dixon liver magnetic resonance images was labelled slice-by-slice for the outer liver border, portal, and hepatic veins by an expert. A 3D U-Net convolutional neural network was trained with different combinations of Dixon in-phase, opposed-phase, water, and fat reconstructions. The neural network trained with the single-modal in-phase reconstructions achieved a high performance for liver parenchyma (Dice 0.936 ± 0.02), portal veins (0.634 ± 0.09), and hepatic veins (0.532 ± 0.12) segmentation. No benefit of using multi-modal input was observed (p = 1.0 for all experiments), combining in-phase, opposed-phase, fat, and water reconstruction. Accuracy for differentiation between portal and hepatic veins was 99% for portal veins and 97% for hepatic veins in the central region and slightly lower in the peripheral region (91% for portal veins, 80% for hepatic veins). In conclusion, deep learning-based automated segmentation of the liver and its vessels on non-contrast T1 vibe Dixon was highly effective. The single-modal in-phase input achieved the best performance in segmentation and differentiation between portal and hepatic veins.
Similar content being viewed by others

Introduction
Medical imaging data is rapidly growing and already constitutes an estimated 90 percent of all healthcare data today1. Without technical support, such an overwhelming amount of data cannot be handled by medical experts to provide fast and accurate clinical information about the patient’s health status. In recent years, deep learning (DL) technologies have become the standard for computer vision and imaging tasks2. DL technologies with magnetic resonance imaging (MRI) have been used in neuroimaging3, but may be used as well in other organs such as the liver, with its complex macro- and microstructure. Besides better image reconstruction algorithms and the detection of focal liver lesions, segmentation tasks of 3D volumetric MRI data represent one of the most promising applications for DL algorithms, notably in diffuse liver disease.
Liver segmentation is fundamental in numerous downstream applications. Focal liver lesions characterization requires exact lesion localization for baseline and follow-up exams. The combination of multiparametric MRI sequences with liver parenchymal and vascular morphology and volumes allows to generate numerous novel quantitative non-invasive MR-biomarkers4, 5. Such quantitative biomarkers may improve phenotyping of macro- and microstructural liver remodeling in chronic liver disease, as well as the planning and follow-up of endovascular and surgical liver interventions, including the calculation of the postoperative remnant liver volume (RLV)6, 7. However, manual delineation of liver parenchyma, portal, and hepatic veins is time-consuming. An automated method would be needed to perform this task routinely in a reliable and efficient way.
As computed tomography (CT) provides millimetric 3D datasets, it is not surprising that many studies that use DL in abdominal imaging have predominantly been performed using publicly accessible CT images1, 8. Due to superior contrast-to-noise ratio, DL algorithms were mostly trained on contrast-enhanced scans9, 10. However, many liver imaging studies are nowadays performed by MRI, with advantages in characterizing focal and diffuse liver diseases. Due to its inherent higher contrast-to-noise ratio, an examination without intravenous contrast administration is possible11.
Recent studies showed good results with a U-Net-based learning framework on T1 weighted images for automated segmentation of the liver and other abdominal organs 12. However, these segmentations only considered the outer liver borders and not the liver veins13, 14. For liver vessel segmentation, several results were published using non-DL-based multi-step segmentation approaches on CT images15, contrast-enhanced T1 weighted images16, non-contrast Fast Imaging with Steady-state Precession (FISP)17, and T1 weighted images18. The delineation of different veins in the liver and separation of hepatic and portal veins remains a difficult task.
Since pre-contrast T1 weighted acquisitions of the liver are often performed with the Dixon technique, the generated in-phase, and opposed-phase images, including fat- and water-reconstructions, may represent a promising approach as an input for a DL-algorithm. To the best of our knowledge no DL-algorithm for liver parenchyma and vessel segmentation has yet been published on non-contrast T1 weighted Dixon sequences.
The purpose of this study was to evaluate the effectiveness of automated liver parenchyma, portal veins, and hepatic veins segmentation on non-contrast T1 vibe Dixon acquisitions with a convolutional neural network.
Methods
The workflow of our study is illustrated in Fig. 1.

Workflow of our study of automated MRI liver and vessels segmentation with a convolutional neural network (nnU-Net) on non-contrast T1 vibe Dixon acquisitions. The MRI sequences were extracted from a pre-existing picture archiving and communication system (PACS) and manually labelled slice-by-slice. Segmentation experiments with single-modal and multi-modal inputs were defined. In-phase (In), water (W), and opposed-phase (Opp) constituted single-modal inputs. In-phase, water (In-W); in-phase, opposed-phase (In-Opp); in-phase, opposed-phase, water (In-Opp-W); and in-phase, opposed-phase, fat, water (In-Opp-F-W) constituted multi-modal inputs. For each experiment, the nnU-Net was trained and evaluated separately. Lastly, the segmentation results were analyzed quantitatively and statistically compared.
Study population
In this single-institution study, datasets of liver MRIs with a non-contrast 3 mm T1 vibe Dixon sequence were included from a pre-existing database of liver MRIs prospectively acquired in patients with suspected liver disease between 16/03/2016 and 08/02/2018, as previously published19,20,21. The following patients were excluded: those < 18 years of age, those denying consent, and those with prior focal liver lesions > 2 cm, prior liver resection or interventions, as well as patients with cholestatic liver disease. Clinical information was collected from the patients, including sex, age, body mass index (BMI), and etiology of chronic liver disease (CLD). The study was approved by the local ethics committee (Bern cantonal ethics committee, Bern, Switzerland) and was carried out in accordance with the principles of the Declaration of Helsinki. All patients gave written informed consent to participate in the study. The authors had full access to and take full responsibility for the integrity of the data.
Magnetic resonance imaging
All MRI datasets were acquired on a Siemens MAGNETOM Prismafit 3T scanner (Siemens Healthineers, Erlangen, Germany), using a 6-channel body coil. A standard non-contrast T1 vibe Dixon sequence was acquired, covering the whole liver by generating in-phase, opposed-phase, water, and fat reconstructions (Fig. 2). Images were acquired with a slice thickness of 3 mm, axial dimensions ranging from 210 × 320 to 270 × 320 pixels with pixel spacings ranging from 1.09375 × 1.09375 mm2 to 1.5625 × 1.5625 mm2 and 60 to 80 axial slices (Table 1). Cases with severe fat–water swaps (Dixon artifacts) were excluded. Cases with slight breathing artifacts were not excluded to obtain results that are comparable with real life clinical routine liver MRI acquisitions.

Example of a patient with a standard non-contrast T1 vibe Dixon acquisition of the liver. Please note the signal drop between (a) in-phase and (b) opposed-phase in this patient with severe steatosis, which can also be seen in (d) the fat and (e) water reconstructions. On the right-hand side, manual segmentation of (c) liver parenchyma (red) and (f) portal veins (purple) and hepatic veins (blue) on the in-phase.
Manual segmentation
The liver MRI datasets were manually labelled slice-by-slice for the outer liver border and the portal and hepatic veins by a trained reader with two years of experience in liver MRI (D.C.). The manual segmentation was performed using the medical software ITK-SNAP22 (version 3.8.0) on the in-phase images in the axial plane, as shown in Fig. 2. The results were reviewed by a board-certified abdominal radiologist with > 10 years’ experience with liver MRI (A.T.H.).
Deep learning-based segmentation
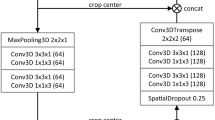
The automated delineation of the liver and veins was implemented as a 3D voxel-wise multi-label classification task. Specifically, the nnU-Net23 framework was used as it offers a fully automated machine learning pipeline including data preprocessing, data augmentation, U-Net12-based neural network architecture optimization and data post-processing. To comply with the network input file format, all T1 vibe Dixon sequences in Digital Imaging and Communications in Medicine (DICOM) protocol were converted to the Neuroimaging Informatics Technology Initiative (NIfTI) format. The nnU-Net framework expects one or more 3D images as input and outputs a 3D segmentation mask of the same dimension (Fig. 3).

Processing of single-modal (top row) and multi-modal (bottom row) MRI sequence data at the input level of the 3D U-Net in use (nnU-Net23). The implementation uses 2D kernels at the first convolutional layer #1 since it treats the MRI sequences as anisotropic data.
Training and evaluation
The four T1 vibe Dixon in-phase, opposed-phase, water, and fat reconstruction imaging were used as isolated single-modal, as well as multi-modal inputs. A single-modal input referred to the case when only one reconstruction was used as an input to the neural network, whereas a multi-modal input referred to the case when two or more reconstructions were stacked together as an input to the neural network. We evaluated the impact of each type of input on the performance of the network model for the liver and vessel segmentation task. As for the neural network technique of processing multi-modal input, we used input-level fusion as in the work of Zhou et al.24. Figure 3 illustrates how the nnU-Net processed single-modal and multi-modal input at the first convolutional layer of the network.
The nnU-Net network was trained with the default setup as published by Isensee, Jager, et al.23. This included as loss function the combination of Dice loss and cross-entropy loss, the Adam optimizer with an initial learning rate of 3 × 10–4, and a learning rate scheduler that reduced the learning rate to at least 10–6 depending on the moving average of the training loss and the validation loss. For data augmentation, the following techniques were applied during training: random rotations, random scaling, random elastic deformations, gamma correction augmentation and mirroring. We did not make any changes to the architecture of the nnU-Net.
Nested cross-validation (NCV) was used to obtain a robust performance estimate on unseen test data. For each experiment, nnU-Net was trained 10 times on the liver MRI dataset with a leave-out test set of three different patients in every iteration (NCV outer loop). Performances on the test liver MRI datasets were averaged. For each training, the network was optimized on a NVIDIA GeForce RTX 3090 GPU for 150 epochs with a batch size of two using fivefold cross validation (NCV inner loop) following the approach by Isensee, Jaeger, et al.23.
Quantitative analysis
The performance of the neural network to segment liver parenchyma, portal, and hepatic veins was compared between single- and multi-modal inputs. Dice similarity coefficient (DSC) was used to quantify the segmentation performance of the model. In addition, the average precision (AP) metric was calculated, as it ignores true negatives (negative background outside of the liver in the MRI field-of-view) and focuses on precision and recall. Kruskal–Wallis test with Dunn’s multiple comparison post hoc test was used to compare DSC between single- and multi-modal inputs. Significance level was chosen to be α = 0.05. All statistical analysis was performed with the Python ecosystem (Python 3.6.12, SciPy 1.5.4, scikit-learn 0.24.2, SimpleITK 2.0.2, Matplotlib 3.3.3). For the analysis of the segmentation performance in the central region versus the peripheral region of the liver, two points at the portal vein bifurcation and the hepatic vein confluence were manually set by a board-certified abdominal radiologist (A.T.H.). A sphere was defined with the center point being the midpoint of the two points and a radius of 75% of their distance. The region inside the sphere was considered as central region, the region outside the sphere was considered as peripheral region. The accuracy of the segmentation of portal veins, hepatic veins, and liver parenchyma was compared between the central and peripheral region.
Results
Patients
Liver MRI datasets from twenty female and ten male patients without fat–water swaps (Dixon artifacts) were included. Fifteen datasets were used from patients with chronic liver disease (50%) and fifteen from patients with no chronic liver disease (Table 2). Median patient age was 58.5 years (range 34–80 years) with a median weight of 80 kg (range 40–114) and a median BMI of 26.6 kg/m2 (range 15–45). Etiology of chronic liver disease was non-alcoholic fatty liver disease in eight patients, alcohol-related liver disease in three patients, and viral hepatitis in four patients. From the 15 patients with chronic liver disease, 9 patients had a liver cirrhosis. Median liver proton density fat fraction was 8%, ranging from 1.5–33.7%. Three datasets (10%) presented ghosting artifacts, in line with a realistic setting of routine abdominal MRI scans in a radiology department.
Training runtime
The training of the network took roughly 4 h per dataset and fold, repeated in 10 iterations in 7 different single- and multi-modal experiments. Each iteration included 5 training folds following the fivefold cross validation training approach by nnU-Net. This resulted in a total of 70 different training datasets with a total training duration of 1400 h. Once a model was trained, liver parenchyma and vessel segmentation inference in one test liver MRI dataset was performed in 50 s using a NVIDIA GeForce RTX 3090 GPU, an AMD EPYC 7302 16-Core Processor CPU, and an IBM Spectrum Scale-based file system.
Quantitative evaluation
Quantitative segmentation results from manual segmentation and neural network segmentation are illustrated in a representative case in Fig. 4, showing an excellent performance of liver parenchymal segmentation and a good delineation and differentiation between the portal and hepatic veins. The neural network trained with the single-modal in-phase reconstruction achieved the highest overall performance with an average DSC of 0.936 ± 0.02 for liver parenchyma, 0.634 ± 0.09 for portal veins, and 0.532 ± 0.12 for hepatic veins, as shown in Table 3. All single- and multi-modal inputs yielded comparable liver parenchyma segmentations without statistically significant differences (p = 0.09). In contrast, performance of the portal and hepatic veins segmentation was significantly lower when using the opposed-phase, as compared to the in-phase single-modal input (p < 0.001), while there was no significant difference between the in-phase and water-reconstruction input for portal (p = 0.331) and hepatic veins (p = 1.0) in the post hoc comparison (Table 4). There was no significant difference for liver, portal, and hepatic vessel segmentation between the in-phase single-modal input and the multi-modal input combining in-phase with opposed phase, fat, and water reconstructions (Fig. 5). Similar results were obtained by using the average precision metric, ignoring the true negative background outside of the liver in the MRI field of view, as demonstrated by the precision-recall curves in Fig. 6.

Example of an expert (first column) and automated (second column) segmentation of liver parenchyma (red), portal veins (purple), and hepatic veins (blue). The third column shows a visualization of the correct segmentation, as well as under-segmentation (cyan), and over-segmentation (yellow), as performed by the model with an in-phase sequence.

Comparison of liver segmentation performance with different model inputs: (1) single-modal in-phase (In) in the first column, (2) multimodal in-phase and water reconstruction in the second column (In-W), (3) multi-modal in-phase, opposed-phase, fat, and water reconstructions in the third column (In-Opp-F-W) and (4) single-modal opposed-phase (Opp) in the last column. The correct segmentation is shown in red for the liver parenchyma, purple for the portal veins, and blue for the hepatic veins. Under-segmentation is shown in cyan and over-segmentation in yellow, as performed by the model with an in-phase sequence.

Precision-recall curves and average precision (AP) of automated liver parenchyma, portal veins, and hepatic veins segmentation on single- and multi-modal inputs. In-phase (In), water (W), and opposed-phase (Opp) constituted single-modal inputs. In-phase, water (In-W); in-phase, opposed-phase, water (In-Opp-W); in-phase, opposed-phase (In-Opp); and in-phase, opposed-phase, fat, water (In-Opp-F-W) constituted multi-modal inputs. Best viewed in screen.
The accuracy of parenchymal segmentation with the single-modal in-phase reconstruction was 93% in the central region and 94% in the peripheral region. The accuracy of portal veins segmentation was 64% in the central region and 55% in the peripheral region. The accuracy of hepatic veins segmentation was 52% in the central region and 43% in the peripheral region, as shown in Fig. 7. If only the vascular voxels were analyzed, without the liver parenchyma, accuracy for differentiation between portal and hepatic veins was 99% for portal veins and 97% for hepatic veins in the central region and slightly lower in the peripheral region (91% for portal veins and 80% for the hepatic veins).

Model segmentation accuracy and misclassification rate for liver parenchyma segmentation (left), portal veins segmentation (middle), and hepatic veins segmentation (right). The results are shown for the central region of the liver (upper row) and the peripheral region of the liver (bottom row). In-phase (In), water (W), and opposed-phase (Opp) constituted single-modal inputs. In-phase, water (In-W); in-phase, opposed-phase, water (In-Opp-W); in-phase, opposed-phase (In-Opp); and in-phase, opposed-phase, fat, water (In-Opp-F-W) constituted multi-modal inputs. Liver parenchyma segmentation is shown in red, portal veins segmentation in purple, hepatic veins segmentation in blue, and background segmentation in black. The colors are identical to Figs. 4 and 5. Best viewed in screen.
Discussion
To the best of our knowledge, this is the first study that uses a 3D neural network (nnU-Net23) for automated liver parenchyma, portal veins, and hepatic veins segmentation on non-contrast T1 vibe Dixon liver MRIs. The performance of liver parenchyma segmentation was excellent, when compared with a manual slice-by-slice segmentation as the gold standard. The delineation of hepatic and portal veins was highly accurate, and voxels were rarely classified to the incorrect venous system. Based on this convolutional neural network, segmentation of liver parenchyma, portal, and hepatic veins was possible on a standard non-contrast T1 vibe Dixon sequence in less than one minute.
Our liver parenchyma results are comparable with existing literature, as shown in Table 5. Kavur et al.14 presented an nnU-Net-based evaluation for liver parenchyma segmentation with a DSC of 0.95, which is very similar to our DSC of 0.94 for the single-modal in-phase input. However, Kavur et al. did not separate the liver veins from the parenchyma, so their algorithm only segmented the outer liver by ignoring the hepatic and portal veins. Kart et al.13 achieved even slightly higher DSCs of 0.97–0.98 on non-contrast T1 weighted images but analyzed in healthy volunteers and not in patients with chronic liver disease and by ignoring the liver veins as well. Ivashchenko et al.25 proposed a liver segmentation workflow based on contrast-enhanced multi-phase MRIs, resulting in a DSC of 0.95 for liver parenchyma. Ivashchenko et al.26 also studied the feasibility of liver vessel segmentation on contrast enhanced MRIs using a DL-based method, resulting in a median DSC of 0.60 for portal veins and 0.65 for hepatic veins. While our result for portal veins is slightly better (0.66), the results for the hepatic veins was slightly lower (0.55), which may be explained by the fact that we used non-contrast T1 vibe Dixon sequences and our manual segmentation labelled even the small peripheral hepatic veins, which were difficult to detect for the neural network. Other groups tried to segment liver veins on T1 weighted images with a non-DL-based approach using thresholding and filtering, but without separating between portal and liver veins18. Other non-DL-based approaches were published for liver vessel segmentation on CT and MRI images15, contrast-enhanced T1 weighted images16, and Fast Imaging with Steady-state Precession (FISP) sequences17, some without differentiation between portal and liver veins.
A multi-modal input from combined T1, T2, and FA sequences27 or the combination of FLAIR, T1, T1c, and T228 increased the performance of neural network models for neuro-imaging segmentations. However, the use of different MRI sequences needs spatial co-registration24, 27, which is easier to perform on neuro-imaging studies, whereas liver MRIs commonly contain more motion artefacts. The T1 vibe Dixon sequence used for this study has an optimal fat–water separation29 without the need for spatial co-registration and provides a high level of contrast between veins and liver parenchyma. However, the combination of in-phase, opposed-phase, fat, and water inputs did not increase the performance of the liver and veins segmentation. While the best performance was achieved with a single-modal in-phase input, the lowest performance was achieved with a single-modal opposed-phase input. A possible explanation for this observation is the occurrence of chemical shift artifacts (India ink artifacts) on opposed-phase images, occurring at fat–water boundaries, such as the outer liver border or the vessel-parenchyma interfaces. Combination of in- and opposed-phase images as a multi-modal input therefore showed a lower performance than the isolated single-modal in-phase input. As fat and water reconstructions are calculated based on the in- an opposed-phase images, it is no surprise that the addition of those reconstructions did not increase the model performance. In patients with significant liver steatosis, the contrast between the liver parenchyma and liver veins will be inverted, as compared to the in-phase acquisition. The median proton density fat fraction of the MRI liver datasets in this study was 8.0% and ranged from 1.5% to 33.7%. A training on a dataset including more patients with liver steatosis should be performed to test whether the convolutional neural network would profit of a multi-modal in- and opposed-phase input in those patients.
This study has several limitations. The used dataset was relatively small, and a larger dataset may result in better portal and hepatic veins segmentation. However, the performance of the hepatic parenchyma segmentation was comparable to the performance of DL-algorithms trained on larger datasets13. Another inherent limitation is the slice thickness of 3 mm of the used standard T1 vibe Dixon MRI sequences. The performance of the DL-algorithm may improve when using 3D T1 sequences with a smaller slice thickness. However, the T1 vibe Dixon sequences are very robust, fast, and widely available. Finally, another limitation is that MRI acquisitions were all performed on 3T MRI scanners from a single manufacturer. This resulted in a relatively homogeneous data set and the study should be extended and validated on different scanners with different field strengths.
In conclusion, neural network segmentation of liver veins and parenchyma on non-contrast T1 vibe Dixon is highly effective. The best performance was achieved with a single-modal in-phase input for automated liver parenchyma segmentation and good differentiation between portal and hepatic veins.
Data availability
Data generated or analyzed during the study are available from the corresponding author by request.
References
Zhou, S. K. et al. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proc. IEEE https://doi.org/10.1109/JPROC.2021.3054390 (2020).
Feng, X., Jiang, Y., Yang, X., Du, M. & Li, X. Computer vision algorithms and hardware implementations: A survey. Integration 69, 309–320. https://doi.org/10.1016/j.vlsi.2019.07.005 (2019).
Zhu, G. et al. Applications of deep learning to neuro-imaging techniques. Front. Neurol. 10, 1 (2019).
Catucci, D. et al. Noninvasive assessment of clinically significant portal hypertension using ΔT1 of the liver and spleen and ECV of the spleen on routine Gd-EOB-DTPA liver MRI. Eur. J. Radiol. 144, 1 (2021).
Zaman, S., Gilani, S. A., Bacha, R., Manzoor, I. & Hasan, Z. U. Correlation between portal vein diameter and craniocaudal length of the spleen. J. Ultrason. 19, 276–281 (2019).
Watanabe, Y. et al. A new proposal of criteria for the future remnant liver volume in older patients undergoing major hepatectomy for biliary tract cancer. Ann. Surg. 267, 338–345 (2018).
Inoue, Y. et al. Volumetric and functional regeneration of remnant liver after hepatectomy. J. Gastrointest. Surg. 23, 914–921 (2019).
Ciecholewski, M. & Kassjański, M. Computational methods for liver vessel segmentation in medical imaging: A review. Sensors 21, 1–21. https://doi.org/10.3390/s21062027 (2021).
Hu, P., Wu, F., Peng, J., Liang, P. & Kong, D. Automatic 3D liver segmentation based on deep learning and globally optimized surface evolution. Phys. Med. Biol. 61, 8676–8698 (2016).
Qayyum, A., Lalande, A. & Meriaudeau, F. Automatic segmentation of tumors and affected organs in the abdomen using a 3D hybrid model for computed tomography imaging. Comput. Biol. Med. 127, 1 (2020).
Whang, S. et al. Comparison of diagnostic performance of non-contrast MRI and abbreviated MRI using gadoxetic acid in initially diagnosed hepatocellular carcinoma patients: a simulation study of surveillance for hepatocellular carcinomas. Eur. Radiol. 1, 1. https://doi.org/10.1007/s00330-020-06754-4/Published (2020).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. (2015).
Kart, T. et al. Deep learning-based automated abdominal organ segmentation in the UK Biobank and German National Cohort Magnetic Resonance Imaging Studies. Invest Radiol 56, 401–408 (2021).
Kavur, A. E. et al. CHAOS Challenge - combined (CT-MR) healthy abdominal organ segmentation. Med Image Anal. 69, 1 (2021).
Lebre, M. A. et al. Automatic segmentation methods for liver and hepatic vessels from CT and MRI volumes, applied to the Couinaud scheme. Comput. Biol. Med. 110, 42–51 (2019).
Lu, S., Huang, H., Liang, P., Chen, G. & Xiao, L. Hepatic vessel segmentation using variational level set combined with non-local robust statistics. Magn. Reson. Imaging 36, 180–186 (2017).
Goceri, E., Shah, Z. K. & Gurcan, M. N. Vessel segmentation from abdominal magnetic resonance images: adaptive and reconstructive approach. Int. J. Numer. Method Biomed. Eng 33, 1 (2017).
Marcan, M. et al. Segmentation of hepatic vessels from MRI images for planning of electroporation-based treatments in the liver. Radiol. Oncol. 48, 267–281 (2014).
Obmann, V. C. et al. Liver MR relaxometry at 3T—Segmental normal T1 and T2* values in patients without focal or diffuse liver disease and in patients with increased liver fat and elevated liver stiffness. Sci. Rep. 9, 1 (2019).
Obmann, V. C. et al. Liver MRI susceptibility-weighted imaging (SWI) compared to T2* mapping in the presence of steatosis and fibrosis. Eur. J. Radiol. 118, 66–74 (2019).
Obmann, V. C. et al. T1 mapping of the liver and the spleen in patients with liver fibrosis-does normalization to the blood pool increase the predictive value? Chronic liver disease GGT Gamma-glutamyl-transpeptidase HVPG Hepatic venous pressure gradient IVC Inferior vena cava MOLLI Modified Look-Locker inversion recovery sequence MRE Magnetic resonance elastography MRI Magnetic resonance imaging. https://doi.org/10.1007/s00330-020-07447-8/Published.
Yushkevich, P. A. et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. Neuroimage 31, 1116–1128 (2006).
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier-Hein, K. H. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211 (2021).
Zhou, T., Ruan, S. & Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array https://doi.org/10.1016/j.array.2019.100004 (2020).
Ivashchenko, O. V. et al. A workflow for automated segmentation of the liver surface, hepatic vasculature and biliary tree anatomy from multiphase MR images. Magn. Reson. Imaging 68, 53–65 (2020).
Ivashchenko, O. V., Zhai, Z., Stoel, B. & Ruers, T. J. M. Optimization of hepatic vasculature segmentation from contrast-enhanced MRI, exploring two 3D Unet modifications and various loss functions. SPIE-Intl. Soc. Opt. Eng. 1, 1. https://doi.org/10.1117/12.2574267 (2021).
Zhang, W. et al. Deep convolutional neural networks for multi-modality isointense infant brain image segmentation. Neuroimage 108, 214–224 (2015).
Cui, S., Mao, L., Jiang, J., Liu, C. & Xiong, S. Automatic semantic segmentation of brain gliomas from MRI images using a deep cascaded neural network. J. Healthc. Eng. 2018, 1 (2018).
Dixon, W. T. Simple proton spectroscopic imaging. Radiology 153, 189–194 (1984).
Acknowledgements
This project was funded by the Swiss National Science Foundation (SNSF), grant number #188591. Calculations were performed on UBELIX (http://www.id.unibe.ch/hpc), the HPC cluster at the University of Bern.
Funding
This project was funded by the Swiss National Science Foundation (SNSF), grant number #188591. There are no relevant author disclosures. The authors declare no competing interests. A.T.H. has received research grants from the Swiss National Science Foundation, the Swiss Academy of Medical Sciences, the Helmut-Hartweg Foundation and the Foundation to Fight against Cancer, all for work outside the submitted study. He has received speaker/consulting honoraria or travel support from Bayer, Bracco, and Siemens, all for work outside the submitted study.
Author information
Authors and Affiliations
Contributions
L.Z. and A.T.H. designed the study, conducted literature review, performed the experiments, analyzed the data, and wrote the manuscript. L.Z. and Y.S. programmed and managed required software. D.C., A.B., L.E., A.C., V.O., A.T.H. acquired the data. D.C. and A.T.H. annotated the data. A.B., L.E., A.C., V.O., R.S. and A.T.H. secured project funding. All authors reviewed the experimental design and assisted in manuscript writing. All authors discussed the results and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zbinden, L., Catucci, D., Suter, Y. et al. Convolutional neural network for automated segmentation of the liver and its vessels on non-contrast T1 vibe Dixon acquisitions. Sci Rep 12, 22059 (2022). https://doi.org/10.1038/s41598-022-26328-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-26328-2
This article is cited by
-
Signal Intensity Trajectories Clustering for Liver Vasculature Segmentation and Labeling (LiVaS) on Contrast-Enhanced MR Images: A Feasibility Pilot Study
Journal of Imaging Informatics in Medicine (2024)
-
Large scale crowdsourced radiotherapy segmentations across a variety of cancer anatomic sites
Scientific Data (2023)
-
Automated 3D liver segmentation from hepatobiliary phase MRI for enhanced preoperative planning
Scientific Reports (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
