
Abstract
Nowadays, a tremendous amount of human communications occur on Internet-based communication infrastructures, like social networks, email, forums, organizational communication platforms, etc. Indeed, the automatic prediction or assessment of individuals’ personalities through their written or exchanged text would be advantageous to ameliorate their relationships. To this end, this paper aims to propose KGrAt-Net, which is a Knowledge Graph Attention Network text classifier. For the first time, it applies the knowledge graph attention network to perform Automatic Personality Prediction (APP), according to the Big Five personality traits. After performing some preprocessing activities, it first tries to acquire a knowing-full representation of the knowledge behind the concepts in the input text by building its equivalent knowledge graph. A knowledge graph collects interlinked descriptions of concepts, entities, and relationships in a machine-readable form. Practically, it provides a machine-readable cognitive understanding of concepts and semantic relationships among them. Then, applying the attention mechanism, it attempts to pay attention to the most relevant parts of the graph to predict the personality traits of the input text. We used 2467 essays from the Essays Dataset. The results demonstrated that KGrAt-Net considerably improved personality prediction accuracies (up to 70.26% on average). Furthermore, KGrAt-Net also uses knowledge graph embedding to enrich the classification, which makes it even more accurate (on average, 72.41%) in APP.
Similar content being viewed by others

Introduction
Personality is the enduring set of traits and styles that an individual exhibits1. It surrounds people’s moods, attitudes, and opinions and it is explicitly expressed in their interactions with others2. Generally, it contains the comprehensive behavioural characteristics (both inherent and acquired) that can be observed in individuals’ social relations and even in their relations with the environment. The word personality stems from the Latin persona, which indicates a mask that an actor wore in theatrical plays in the ancient world to represent and project the particular personality traits of the role.
Undoubtedly, Internet-based communications (such as various instant messaging and social networks, email, forums, organizational communication platforms, etc.) is increasing daily. Regarding their advantages and new challenges facing humankind (like COVID-19), various types of Internet-based communications are becoming increasingly ubiquitous. Being aware of individuals’ personalities helps one perceive their thoughts, opinions, feelings, and responses to certain situations. It would be advantageous for everyone and may lead to better relationships, regardless of the type of relationship (the relationship between friends, the boss and employee, the seller and buyer, and others). Personality prediction or assessment has a broad spectrum of potential applications, for instance, different recommender systems, recruitment systems, online marketing, friend selection in social networks, personal counselling services, human resource management systems, etc.
Automatic Personality Prediction, which hereafter we shall call APP, is the assessment of human personality using computational approaches. It can be carried out based on the exchanged text among people as a representation of human language, which is the primary communication tool among humankind. Several studies involving text-based APP have exploited different methodologies for the purpose of APP in Internet-based communications. Preliminary studies of APP performed it using different linguistic features3,4,5,6,7 to capture more information about words and terms in the input texts, and finally use them as criteria to classify them. After a while, APP has received much attention and miscellaneous deep learning methods were utilized to acquire deeper information about text elements. Meanwhile, several attempts have been made to benefit the linguistic features and deep learning methods to improve the performance of APP8,9,10. In recent years, to achieve more knowledgeable representations, investigators have examined the effects of embedding the text elements on APP11,12,13,14,15,16,17.
In general, perusing the studies, one can find that all of them are essentially trying to acquire more knowings about the text elements, from linguistic feature-based methods to complex embedding-based deep learning approaches. That is to say, each of them by applying various methods, attempts to achieve a more knowledgeable representation of text elements to deal with rather than pure strings of characters. They are right since knowing is the basis of correct decisions and good performances for humans and machines. Besides, there is knowledge, and then there is knowing. Therefore, at first, we should discover the world behind the words. It will provide an excellent opportunity to promote the comprehension of text elements. This paper seeks to deal with this problem by acquiring a comprehensive, knowledgeable representation of the input text. Specifically, at first, it builds an equivalent graph for each text that entails all of the related knowledge of existing concepts in the input text. This graph (which we will refer to as knowledge graph) is a machine-readable representation and a competent knowing-full substitution of the input text. Additionally, to achieve the most determining parts of the graph, after aggregating individual knowledge graphs into one aggregated graph, it is suggested to pay attention to the most critical parts of the graph (using attention mechanism). Moreover, this paper suggests embedding the aggregated graph in another attempt to acquire an even more knowing-full representation of the graph elements. Finally, the resulting knowings will be utilized to build a classifier and perform APP.
Whilst, several researches have been carried out on text-based APP, no studies have been found that fundamentally are based on knowledge graph attention networks. This paper, for the first time (as far as we know), is focused on applying the attention mechanism over the knowledge graph in text-based APP. Indeed, a knowledge graph is a graph-based data model that formally represents the semantics of the existing concepts in the input text and models the knowledge behind them18. Like all graphs, it is made up of nodes and edges in which the nodes represent the entities of the real world, and the edges connect pairs of nodes according to their relationship. It practically provides a representation of the information about the world in a form that a computer system can exploit to solve different tasks19. Meanwhile, the graph attention mechanism is used to learn node representations which assign different importance to each neighbour’s contribution20. In practice, an attention mechanism allows the model to focus on task-relevant parts of the graph and assists it in making better decisions21. More specifically, applying the attention mechanism on graphs will yield some achievements, including it will adroitly allow the model to neglect and avoid the noisy parts of the graph22 which is a prevalent problem in knowledge graphs; it allows the model to assign a different relevance score to each node to pay attention to the most relevant information in current task20 (a comprehensive description about graph attention networks, can be found in Ref.21). To this end, this paper proposes KGrAt-Net, which is a knowledge graph attention network text classifier. It has a three-phase architecture including preprocessing, knowledge representation, and knowledge graph attention network classification. After cleaning up the input text and transforming it to a more digestible form for the machine in the first phase, in the second phase, KGrAt-Net attempts to represent the entire knowledge in each of the input texts and build their corresponding knowledge graphs, using DBpedia knowledge base. Finally, in the third phase, aggregating the individual knowledge graphs and applying an attention mechanism over the resulting graph, KGrAt-Net develops a model to classify the input text. To enrich the representation and improve classification, it also lets the users exploit knowledge graph embedding and graph attention network as an auxiliary representation.
This study aimed to address the following research questions:
- RQ.1:
-
How do the knowledge graph attention networks affect the performance of a text-based APP?
- RQ.2:
-
How does enriching the knowledge graph attention network by knowledge graph embedding affect the performance of a text-based APP?
- RQ.3:
-
Does classification using a knowledge graph attention network, affects equally the predictions in all personality traits? What about enriching it by knowledge graph embedding?
- RQ.4:
-
How does the knowledge graph, as a representation of input text, affect the text-based APP?
- RQ.5:
-
What obstacles stand in the way of APP when exploiting knowledge graph as the representation of input text?
This paper has been organized in the following way. The “Personality assessment in psychology” section second section deals with personality assessment in psychology. A brief overview of the recent history of text-based APP is presented in the “Literature review” section. The “Methods” section is concerned with the methodology used for developing KGrAt-Net. At first, it describes the architecture of KGrAt-Net as a classifier, and then it explains how to use KGrAt-Net for APP. The “Results” section presents the findings of the research, and the “Discussion” section includes a discussion of the implication of the findings as well as responses to the research questions. At last, some conclusions are drawn in the “Conclusion” section.
Personality assessment in psychology
Since the beginning of human interactions, people have likely been making personality assessments23. Indeed, the personality of people has a substantial influence on their lives. Several psychological investigations have been carried out to demonstrate the influence of personality on various aspects of human life; for instance decision making24, innovativeness and satisfaction with life25, good citizenship and civic duty26, romantic relationship27, forgiveness28, consumers’ behaviours29, job performance30, antisocial online behaviours31, suicidality32, getting a pandemic like COVID-1933, and many others. They are fundamentally established to understand and appraise individual personality differences that characterize people for a variety of purposes during receiving psychotherapy services.
Psychologists usually attempt to appraise the personality of people by asking them to respond to a self-report inventory or questionnaire (please refer to Ref.34 for more detailed information). There are several personality models such as Big Five model35, Myers–Briggs Type Indicator (MBTI)36, three trait personality model PEN37, the sixteen personality factor (16PF)38. Among them, the Big Five model is the most popular one which is widely used by both psychologists and computational researchers. It models human personality in five categories: Openness, Conscientiousness, Extroversion, Agreeableness, and Neuroticism, known as the acronym OCEAN, through assigning a binary value (true/false) to each of them. To clarify it, indicating some facets of each category may be helpful (please refer to Refs.39,40 for more details):
-
Openness (O) an inclination to embrace new ideas, arts, feelings, and behaviours; unconventional; focused on tackling new challenge; wide range of interests and so imaginative.
-
Conscientiousness (C) self-disciplined, well organized and dutiful; careful and hard-working; reliable, resourceful and on time.
-
Extroversion (E) outgoing, energetic, assertive and talkative; affectionate, sociable and articulate; enjoys being the centre of attention.
-
Agreeableness (A) an inclination to agree and accompany the others; altruist and unselfish; friendly, loyal and patient; modest, considerate and cheerful.
-
Neuroticism (N) an inclination to experience negative emotions like anxiety, anger, depression, sadness and envy; impulsive and moody; lack of confidence.
It also should be noted that the Big Five traits are mostly independent41. That is to say, being aware of someone’s one personality trait does not provide so much information on the remaining traits. All of the investigations in this study is relied on the Big Five personality model.
Literature review
During last years, by increasing the Internet-based infrastructures (like social networks), a large and growing body of literature has investigated the automatic personality prediction in miscellaneous contexts such as text, speech, image, video, and social media activities (likes, visits, mentions, digital footprints, profile interpretation and etc.). Among these, text as one of the most significant representations of human language, which is adroitly capable of reflecting the writer’s personality42, has achieved considerable attention.
Tracing the evolution of text-based APP systems, we can classify the previous studies into five categories: linguistic and statistical methods, hybrid methods (combination of linguistic methods and deep learning-based methods), embedding methods, ensemble modeling methods, and attention-based methods.
Linguistic and statistical methods
Several attempts have been made to perform text-based APP. APP’s first serious discussions and analyses emerged during the past two decades by exploiting linguistic and statistical knowledge of text elements. They primarily attempted to predict the personality of writers or speakers by assigning their words to pre-determined categories. Linguistic Inquiry and Word Count (LIWC)43 is one of the most widely used tools that counts the words in the input text and places them into several pre-defined linguistic and psychological categories. LIWC is a dictionary of words and word stems belonging to one or more pre-defined categories. Given a text, it simply computes the percentage of included words in each category. Since 2001, there have been different versions available until LIWC201544, which contains more than 89 categories. Mairesse features3, Medical Research Council (MRC)45, Structured Programming for Linguistic Cue Extraction (SPLICE)46, NRC Emotion Intensity Lexicon47, SenticNet48, etc. are other alternatives that provides linguistic features for words. Generally, the primary idea behind them is that the word usage in everyday language discloses individuals’ thoughts, personalities and feelings.
Several researchers have reported applying linguistic and lexical features in APP3,4,5,6,7. One study by Yuan et al.6 investigated the personality of the characters in vernacular novels. They assigned a vector for each dialogue using LIWC features, reflecting the characters’ personalities. They mapped the vectors with Big Five personality traits and determined the personality labels. Similarly, Mairesse et al.3 have utilized a variety of lexicon-based features in an effort to predict the personality traits from written text and spoken conversation. These features were also considered to predict the users’ personality from Facebook text contents4 and Twitter posts5. Besides, some authors have also called into question the relationship between various mentioned features and different personality traits through determining their correlations49,50,51.
Hybrid methods
Despite the previous superficial studies’ approximate success in APP, there was a great tendency among researchers to focus on deep learning approaches to enhance APP systems’ performance. Accordingly, a large and growing body of literature has investigated the combination of linguistic and statistical methods with deep learning methods8,10,52. Tandera et al.52 proposed a system to predict the personality of Facebook users in the Big Five model based on their information. They have combined several features like LIWC and SPLICE with a variety of traditional machine learning classification algorithms such as Naive Bayes, Support Vector Machine (SVM), Logistic Regression, Gradient Boosting, and Linear Discriminant Analysis (LDA), as well as some deep learning classification algorithms such as Long Short Term Memories (LSTMs), Gated Recurrent Unit (GRU), and 1-dimensional Convolutional Neural Network (CNN). They showed that applying deep learning methods can improve the performance of an APP system. In another study, Majumder et al.8 proposed a CNN in which the document-level Mairesse features (extracted directly from each text) were fed into it. They have trained five separate identical binary classifiers for each five personality traits in the Big Five model. Yuan et al.10 investigated the combination of the LIWC features with deeper features that have been extracted through a deep learning model from Facebook status content. At first, they extracted the language features via the LIWC tool. Then, they added these features into a CNN that automatically extracts the deep features from textual contents to perform predictions. Practically, combining linguistic features with robust deep learning classifiers has ameliorated the prediction performance, but the efforts to investigate different deep learning-based methods were continued.
Embedding methods
A wide diversity of contributions has been published on deep learning-based APP, each of which has a distinct methodology. In recent years, an increasing number of studies have investigated the application of embedding methods to transfer the text elements from a textual space to a real-valued vector space11,12,13,15. The authors in Ref.11 integrated traditional psycholinguistic features such as Mairesse, SenticNet, NRC Emotion Intensity Lexicon, and VAD Lexicon (a lexicon of over 20,000 English words annotated with their valence, arousal and dominance scores), with several language model embeddings, including Bidirectional Encoder Representation from Transformers (BERT), ALBERT (A Lite Biomedical BERT) and RoBERTa (A Robustly Biomedical BERT Approach) to predict personality from the Essays Dataset in Big Five model. To that end, they have three classification algorithms: logistic regression, SVM and multilayer perceptron (MLP). In their investigations, Ren et al.12 proposed a multi-label APP model which combines emotional and semantic features (SenticNet), specifically sentiment analysis-based features, with sentence-level embeddings (produced by BERT). They believed that the current deep learning-based approaches suffer two limitations; the lack of sentiment information as well as psycholinguistic features and the lack of context information (context-based meaning of words). At last, they used three different models (CNN, GRU and LSTM) to perform final predictions on MBTI and the Big Five model. In an attempt to predict users’ personalities in social media, Christian et al.13 proposed a multi-modal deep learning system based on multiple pre-trained language models, including BERT, RoBERTa, and XLNet as the features extraction methods. Similarly, they also believed that the existing algorithms suffer from the absence of context information. They fed the embeddings into three independent feed-forward neural networks and finally performed the predictions by averaging the outputs. As a matter of fact, totally transferring the text elements from textual space to real-valued space in embedding methods yields better performance.
Ensemble modeling methods
In the meantime, there have been a number of studies on how to take the advantages of several classifiers and benefit their prediction abilities simultaneously39,53,54,55. It was a great idea. The authors in Ref.39 proposed an ensemble modelling method that was made up of five independent APP models, comprising: term frequency (TF) vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and a Bi-directional LSTM. Afterwards, they ensembled all the classifiers through a Hierarchical Attention Network (HAN) to predict the Big Five personality traits using the Essays Dataset. Perusing their investigation, one can find that they have exploited the specific abilities of inherently different classifiers and have put them together towards APP objectives. Specifically, they have exploited statistical and superficial information (TF vector-based method), hierarchical semantic information (ontology-based methods), co-occurrence-based and context-based information (LSA-based method), and sequence analysis-based information (BiLSTM-based method) concurrently to perform final prediction. In a similar attempt to benefit ensemble modelling advantages, El-Demerdash et al.53 proposed a deep learning-based APP system that was based on data-level and classifier-level fusion. They believed that fusion could improve the performance of an APP system. Therefore, exploiting the Essays Dataset and MyPersonality dataset together, as well as the pre-trained language models’ embeddings like Elmo, ULMFiT, and BERT, they have performed the data-level fusion. Afterwards, for classifier-level fusion, they ensembled two multi-layer perceptrons (MLP) classifiers for BERT and Elmo along with Softmax classifier in the ULMFiT, to produce final predictions. Predictions were performed separately in each of the Big Five traits.
Attention-based methods
Besides, a few more recent evidences56,57,58 suggest the application attention mechanism in APP systems. Yang et al.56 investigated the multi-document personality prediction. The main idea behind their study was that most researchers in APP perform the predictions merely based on a single input document (or post) from an individual, whilst unifying them may conclude better predictions since some information appears when the documents are considered together rather than separately. To this end, they proposed a multi-document transformer that allows the encoder to access an individual’s information in other documents (posts). In their seminal study, they pinpointed that different personality traits truly demand different contexts to let them be expressed. Therefore, trying to predict different traits of an individual from a single document may inherently cause some miss-predictions. Finally, they used an attention mechanism on top of the transformer to perform predictions using Kaggel and Pandora MBTI datasets. Wang et al.57 proposed HMAttn-ECBiL, a hierarchical hybrid model based on a self-attention mechanism to acquire deep semantic information from input texts in MyPersonality dataset. HMAttn-ECBiL consists of two separate attention mechanisms: a CNN-based and a Bi-directional LSTM-based mechanism, respectively responsible for extracting the local features of text elements and sentence-level features. Their outputs, and the embeddings of the individual words were concatenated and then fed into a fully connected layer to perform predictions. They have attempted to improve the prediction performance through relying on diversity of features. In another study, Lynn et al.58 proposed a hierarchical attention mechanism to find the relative weight of users’ Facebook posts and then use them in predicting their personality in the Big Five model. To this end, they first used a GRU to acquire the message-level encodings. Then, a word-level attention mechanism was used to learn the weights of each word in the messages. Next, the message-level encodings and word-level attention were fed into a second GRU to yield user-level encodings. After that, a message-level attention mechanism acquires the weights of each user’s posts. Finally, the user encodings and the message-level attentions, were fed into two fully connected layers to perform the final prediction. Truthfully, considering the attention-based contributions provides evidence that could justify their competency in APP systems.
Detailed analysis of contributions to text-based APP systems reveals that most of them try to acquire a meaningful and knowledgeable representation of input text elements to perform their predictions. Ranging from superficial linguistic methods to miscellaneous deep learning-based methods. In the meantime, there is a competent option for representing the complete knowledge of and knowledge among existing concepts in the input text, namely the knowledge graph. Although miscellaneous researches have been carried out on APP, only one study has attempted to investigate the application of knowledge graphs in APP systems. The authors in Ref.59 proposed a knowledge graph-enabled text-based APP system, relying on the Big Five model. Specifically, they first tried to build the corresponding knowledge graph for a given text using DBpedia knowledge base. Then, they enriched the graph using some linguistic and semantic lexicon, such as MRC, NRC and DBpedia ontology. Afterwards, they embedded the knowledge graph to acquire an even more meaningful and knowledgeable representation. Finally, the graph embeddings were fed into several independent deep learning models, namely CNN, RNN, LSTM and BiLSTM to perform the predictions using the Essays Dataset. Their study provides additional support for the importance of competent representation of the input text in APP systems.
Overall, the studies presented thus far provide evidence that outlines the critical role of input text representation as well as an adroit method to utilize it towards achieving the objectives of an APP system. Despite all of the studies, no one as far as we know has investigated APP using knowledge graph attention networks. That is to say, what is not yet clear is what would the effect of applying an attention mechanism on a comprehensive and knowledgeable representation of input text, namely the knowledge graph.
Methods
In this section, to comprehend the proposed APP method, at first the architecture of KGrAt-Net as a knowledge graph attention network classifier is meticulously described. Then, automatic personality prediction using KGrAt-Net is explained thoroughly.
KGrAt-Net architecture
For the purpose of answering the research questions, which are stated in “Introduction” section, we suggested KGrAt-Net, a three-phase text classification approach which is basically founded on a knowledge graph attention network. Figure 1 depicts the general architecture of KGrAt-Net.

The general architecture of KGrAt-Net.
Phase-1: preprocessing
This traditionally popular and prominent phase in natural language processing strives to clean up the input text and transform it into a more digestible form for the machine. It practically facilitates and enhances the main processes in the subsequent phases. Depending on the task, it may consist of miscellaneous activities. What follows is a complete description of preprocessing activities which were carried out chronologically by KGrAt-Net, as presented in Fig. 1.
Tokenization
Tokenization is the process of chopping up a text into pieces called tokens which roughly correspond to words60. These pieces are considered the smallest semantic units in text processing. To this end, we used the tokenizer which is provided by Natural Language Toolkit (NLTK)61. The input of this step is the raw text, and the output is the list of its tokens.
Noise removal
For the purpose of acquiring more plain data, it is highly preferred to remove undesirable and interfering pieces of input text. In current study signs, punctuations and stop words were considered as undesirable pieces of text. To remove these pieces in the second step of preprocessing phase, we used NLTK.
Normalization
Normalization is the process of canonicalizing tokens to a more uniform sequence so that matches occur, despite superficial differences in the character sequences of the tokens60. In practice, it decreases the amount of information the machine has to deal with. Namely, the information that conceptually is similar but morphologically is different. In the third step of preprocessing phase, we performed lowercasing and lemmatization respectively, to normalize the input data.
Lemmatization is the morphological analysis of words that groups together their inflected forms and returns their bases or dictionary forms of them, which are called lemma. An alternative option to reduce the inflected forms of words is stemming which yields the words’ stems. It usually is fulfilled through chopping off the ending characters of the words, which often concludes the incorrect and misspelt forms of words. Therefore, it can be stated that the results of lemmatization (namely lemmas) are meaningful concepts rather than stems, in which we can find an equivalent match in the real world for them; what is really important in knowledge representation (as we will see in the second phase). This is why we preferred lemmatization to stemming. In the present study, the lemmatization was also carried out using NLTK.
Named entity recognition (NER)
Named entities refer to the “words” or “sequences of words”, which are the names of things such as organization, person, location, company, product, event and etc. Knowledge representation (and its result, namely knowledge graph), is actually the basis of KGrAt-Net’s decisions. During knowledge representation, one should query all of the existing entities in the input text in a knowledge base. Indeed, knowledge bases basically entail the knowledge about the entities of the real world. Hence, in an attempt to acquire the knowledge behind the words (or sequence of words) and represent them, it is absolutely critical to recognize the existing named entities in the input text. In this study, the spaCy NER62 was used to recognize named entities.
NER is the fourth step in preprocessing phase that yields a “list” of entities and concepts which convey the fundamental notions that have appeared in the input text.
Final preparations
Some further activities were performed in fifth step as the final preparations in preprocessing phase, including duplicate element removal, first letter capitalization and whitespace replacement. Duplicate elements (entities and concepts) will impose further unnecessary computations on the system during the main process. To avoid it, we removed duplicate elements from the resulted list in the fourth step and provided a “set” of entities and concepts. Furthermore, first letter capitalization, as well as whitespace replacement with an underscore for multi-word named entities, were done to prepare them to be matched with DBpedia knowledge base entries in the next phase.
A quick overview of the preprocessing phase, as can be seen in Fig. 1 can be concluded as follows:
-
(i)
input the raw input text;
-
(ii)
output a set of extracted entities and concepts from the input text;
-
(iii)
objective to prepare a more digestible form of input text for main processes in next phases.
Phase-2: knowledge representation
As explained in “Introduction” section, knowledge representation is the foundation of KGrAt-Net’s decisions. In practice, the result of such representation, namely the knowledge graph, establishes the needed infrastructure for main processes. KGrAt-Net in this phase, at the first step, tries to represent the input text throughout building the knowledge graph, and then in the next step, to reduce the computational complexity and remove unessential parts, attempts to prune the knowledge graph.
Knowledge graph building
Indisputably, the final output of the first phase, namely the set of entities and concepts, fundamentally arranges the presented notions in the input text. In this step, KGrAt-Net attempts to acquire the general knowledge organization, which is provided by the input text. There is always knowledge behind every entity and concept that carries valuable information. Besides, some semantic relations among entities and concepts evolve and expand the knowledge organization. For this purpose, KGrAt-Net relies on DBpedia knowledge base. In practice, it queries all of the elements of resulted set from the previous phase in DBpedia and extracts all the relevant knowledge of each entity and concept. In simple words, by querying each entity and concept, also known as resource, KGrAt-Net asks for a complete description of them from DBpedia.
In consequence of such queries, KGrAt-Net acquires any resources related to the queried one (for more information about how to query in such knowledge bases, please refer to Ref.63). More specifically, a set of RDFs is returned in response to each query. RDF stands for Resource Description Framework, which is basically a standard for representing information on the Web. An RDF is a triple which is made up of (subject, predicate, object). Both of the subject and object, denote the resources and the predicate denotes traits or aspects of the resource. In fact, a triple would be considered as a statement which declares the relationship (through the predicate) between two resources (subject and object). For instance, (the Mona Lisa, was created by Leonardo da Vinci) is a sample RDF. Visually, a triple is suitably equivalent to a directed edge in a graph from the subject toward the object, having the predicate as its label. More detailed information about RDFs is provided in Ref.64.
The resulting set of RDFs, also known as RDF graph, represents the knowledge of entities and concepts in a directed heterogeneous labelled multi-graph. RDF graph is wildly known as knowledge graph (KG). Therefore, at this step, we have a knowledgeable representation of the input text, namely the knowledge graph.
It has to be pointed out that KGrAt-Net applies two changes over the resulted knowledge graph to facilitate the main process in the next step, in particular: (i) it removes all of the labels (predicates) from the edges, (ii) it converts the multi-graph to a simple graph (through unifying multiple edges).
Knowledge graph pruning
The extensive coverage of knowledge by the knowledge graphs brings new challenges for knowledge graph-based systems65,66. Very high computational complexity (for both time and memory) always is a significant obstacle that makes working with knowledge graphs extremely cumbersome or even sometimes impossible (regarding hardware constraints). Moreover, the extensive coverage of knowledge of concepts will bring some unessential knowledge that in practice would deteriorate the performance of the system in the current task65,66. Therefore, pruning the knowledge graph would be so helpful.
To perform knowledge graph pruning, KGrAt-Net uses a simple strategy; it just keeps those edges (RDFs) in which their corresponding subjects and objects (namely the source and destination nodes) have appeared in the input text. Considering that the resulting graph plays a leading role in KGrAt-Net and generally all of the knowledge graph-based systems, pruning the knowledge graph would be an open question.
At last, a quick overview of the second phase, as it can be seen in Fig. 1 can be concluded as follows:
-
(i)
input the set of extracted entities and concepts from the input text;
-
(ii)
output pruned equivalent knowledge graph of the input text;
-
(iii)
objective acquiring a knowing-full representation of the input text, through building and pruning its equivalent knowledge graph.
Phase-3: knowledge graph attention network classification
The needed infrastructure to implement a knowledge graph-based attention network is available at this point. In this phase, KGrAt-Net at first aggregates all of the pruned knowledge graphs and acquires an aggregated knowledge graph. Then it focuses on preparing the aggregated knowledge graph for text classification and finally designs a classification model by applying an attention network over the aggregated knowledge graph. It also equipped the model to utilize the aggregated knowledge graph embedding to enrich the model and acquire more accurate predictions.
Pruned knowledge graphs aggregating
To perform text classification over the pruned knowledge graphs, we need to aggregate them and build an “aggregated knowledge graph”. In this step, all of the outputted pruned knowledge graphs from the second phase were aggregated, and a single aggregated knowledge graph was built. To avoid misunderstanding the concept of a knowledge graph, the term “aggregated knowledge graph” hereafter is referred to as “knowledge graph”.
Knowledge graph preparation
At this step, KGrAt-Net tries to make the final preparations for text classification over the knowledge graph. Let’s find out what kind of preparations are needed by KGrAt-Net at this point.
Perusing the research questions, KGrAt-Net developed a text classification model based on attention networks over the knowledge graph. Specifically, it attempts to develop a deep learning model over a graph. Hence, it is dealing with a Graph neural networks (GNNs) problem. GNNs are a general framework for defining deep neural networks on graph data67. In general, GNNs provide three types of prediction tasks on graphs68, including:
-
(a)
node-level task refer to those tasks associated with predicting some property of individual nodes in graph; such as node classification and node regression.
-
(b)
edge-level task refer to those tasks associated with predicting the property of a pair of nodes in the graph; a common example of an such task is link prediction.
-
(c)
graph-level task refer to those tasks associated with predicting some property of the whole graph; such as graph classification and graph property prediction.
A node classification task intends to train a model to predict the labels of the nodes69. KGrAt-Net figures out the text classification as a node classification problem. For this purpose, KGrAt-Net makes some changes to the knowledge graph. The current knowledge graph consists of a set of nodes as well as a set of edges; in which the nodes’ set is the collection of extracted entities from DBpedia, which will be called hereafter entity_nodes and the edges’ set is the collection of the semantic relationships among the extracted entities, that will be called hereafter entity_entity_edges. At this step, KGrAt-Net appends essay_nodes to the nodes’ set, each of which denotes an essay in the dataset. In fact, KGrAt-Net deals with essay_nodes to perform classification. Now we need to connect the essay_nodes to those related entity_nodes in knowledge graph. Hence, KGrAt-Net appends essay_entity_edges to the edge’s set, that relates the essay_nodes to entity_nodes. To do so, while appending an essay_node, KGrAt-Net checks out the occurrence of each entity_node in graph in current essay and then in case of finding an occurrence, it draws an essay_entity_edge between the essay_node and the entity_node. Now, KGrAt-Net is ready to perform node classification.
In simple terms, KGrAt-Net performs text-based automatic personality prediction as a node classification problem over the knowledge graph (acquired through aggregating all individual pruned knowledge graphs). After appending the essay_nodes to this knowledge graph (each of which corresponds to one essay in Essays Dataset) as well as the edges among them and entity_nodes, the knowledge graph is prepared for classification. Hence, it should be declared that KGrAt-Net classifies the essay_nodes to perform text (node) classification. Namely, it predicts the binary label of each essay_node for each of the five personality traits. Considering the essence of the attention mechanism over the graph, KGrAt-Net utilizes the overall structure of the knowledge graph to perform the classification.
Knowledge graph attention model
In the present step, KGrAt-Net efforts to develop an attention network to perform node classification. Our experimental set-up to perform the attention network, bears a close resemblance to that proposed by Veličković et al.20, but here the graph structure is different (since it is actually a knowledge graph and it encompasses essay_nodes as well as entity_nodes) besides that, it is used for text classification.
KGrAt-Net uses several graph attention layers, each of which with separate learnable weights. A set of node features \(h = \{\overrightarrow{h}_1, \overrightarrow{h}_2, ..., \overrightarrow{h}_N\}, \overrightarrow{h}_i \in \mathbb {R}^F,\) is the input of each single layer; where N stands for the number of nodes, and F stands for the number of features in each node. The output of the layer is a new set of node features, namely \(h^\prime = \{\overrightarrow{h}^\prime _1, \overrightarrow{h}^\prime _2, ..., \overrightarrow{h}^\prime _N\}, \overrightarrow{h}^\prime _i \in \mathbb {R}^{F^\prime }\). The following descriptions, explain what happen in each single layer.
Being more specific, at first via a feature transformation process the input features (\(\overrightarrow{h}_i\)) are encoded to a higher level and dense features (\(\overrightarrow{h}^\prime _i\)). For this purpose, simply a weight matrix of learnable parameters adopted for feature transformation, namely \({\textbf {W}} \in \mathbb {R}^{F^\prime \times F}\), is applied to each node (\({\textbf {W}}\overrightarrow{h}_i\)).
Next, the attention scores (\(e_{ij}\)) are calculated between all two neighbours using self-attention which is a shared attentional mechanism \(a : \mathbb {R}^{F^\prime } \times \mathbb {R}^{F^\prime } \rightarrow \mathbb {R}\), as revealed in Eq. (1). That is to say, the attention score (namely \(e_{ij}\)) is calculated for those j nodes, in which \(j \in \mathcal {N}_i\), where \(\mathcal {N}_i\) is the one-hop neighbours of the node i. In practice, it specifies the importance of the neighbours nodes (j-th node) for current node (i-th node).
Then for the purpose of normalizing the attention scores, softmax function is applied on each node’s incoming edges, as shown in Eq. (2). It causes the conversion of the output of the previous step into a probability distribution. Thus, the attention scores would be more comparable among other nodes.
Here, the attention mechanism (namely a) is a single-layer feedforward network which is parametrized by a weight vector \(\overrightarrow{{\textbf {a}}} \in \mathbb {R}^{2{F^\prime }}\), and followed by LeakyReLU activation function (with negative input slope \(\alpha = 0.2\)) to apply non-linearity in the transformation. The Eq. (3), expands out the computations of attention scores.
where, the \(\parallel \) denotes to concatenation process, and \(^T\) denotes the transpose of the vector.
Having the attention scores, the corresponding linear combination of features are calculated to provide the final output features (\(\overrightarrow{h}^\prime _i\)) of each node, as presented in Eq. (4). As it is theoretically based, the attention layer tries to assign different importance to each edge through the attention scores. The encodings from a neighbour are scaled by the attention scores and then aggregated together. This scaling practically leads to different contributions of neighbour nodes. After the aggregation, applying the \(\sigma \) as an activation function ensures the non-linearity.
Finally, to profit multi-head attention mechanism, L independent solitary attention mechanisms perform the presented transformation in Eq. (4). According to Eq. (5), averaging the results and finally applying a softmax yields the final prediction, which is produced by the multi-head attention network;
where \(\alpha _{ij}^l\) refers to the attention scores produced by l-th attention mechanism, namely \(a^l\); and \({\textbf {W}}^l\) refers to the corresponding weight matrix after the linear transformation. This was what happened in each layer.
Enriching the knowledge graph attention model by knowledge graph embedding
KGrAt-Net allows the users to profit from the embeddings of the knowledge graphs and the knowledge graph attention networks to carry out classification. It provides this supplementary option to enrich the classification and acquire another auxiliary representation of the pruned input graph. The graph is essentially made up of RDFs. In this step, the pruned knowledge graph will be transformed into a vector space, and an embedding matrix will be yielded, in which its rows denote the graph’s nodes and its columns, which denote the acquired dimensions after the embedding. In this investigation, the knowledge graph was embedded according to the procedure proposed by Ristoski et al.70. Their study proposed RDF2vec for embedding the RDF graphs and achieving the equivalent and more meaningful vector representation. In practice, RDF2vec efforts to maximally conserve the graph’s structure, albeit that it fulfils dimensionality reduction on it. RDF2vec is basically inspired by the word2vec71, a popular word embedding method that transforms words into a numerical vector space. It almost operates like word2vec. The sole difference is in their input sequence. Specifically, word2vec receives a set of sentences as the input sequence for training the model, whilst RDF2vec performs random walks on the graph to create sequences of RDF nodes to feed them into the learning model as the input sequence. As a result of such embedding, similar nodes locate close to each other in the final vector space and dissimilar ones do not. Exactly like what happens during word embedding in word2vec. Further details of RDF2vec are described in “Personality prediction” section.
At the end of the third phase, a quick overview of this phase would be helpful. As it can also be seen in Fig. 1 one can conclude that:
-
(i)
input pruned equivalent knowledge graph of the input text;
-
(ii)
output predicted label of input text;
-
(iii)
objective developing an attention network over the knowledge graph and enriching it by knowledge graph embedding to perform text classification.
Automatic personality prediction using KGrAt-Net
At the moment, a knowledge graph attention network text classifier, namely KGrAt-Net, is available. To answer the research questions, we performed automatic personality prediction using KGrAt-Net, as described below.
Dataset
In the current investigation, we used Essays Dataset72 for training and testing KGrAt-Net. It comprises 2467 essays written by psychology students. Afterwards, they were asked to fill out the Big Five Inventory Questionnaire. According to their responses, for each essay a binary label was assigned to each of five personality traits (OCEAN).
Figure 2 provides clear statistics for the distribution of labels in each personality trait in the dataset. The slight difference between the number of True and False labelled essays in each personality trait acknowledges that the dataset is balanced. Moreover, Table 1 declares that there is no correlations between personality traits in Essays Dataset.

The distribution of labels in each five personality traits in Essays Dataset.
Personality prediction
To train KGrAt-Net, one should iteratively perform the first and second phases for each sample in the dataset. Consequently, a concise knowledgeable equivalent (namely the corresponding pruned knowledge graph) will be available for each sample in the dataset. We did it for each essay in Essays Dataset and acquired the equivalent pruned knowledge graphs. In practice, KGrAt-Net will be trained and tested using the equivalent pruned knowledge graph of each sample in the Essays Dataset.
As described in “Knowledge graph preparation” section, KGrAt-Net performs the predictions as an essay_nodes classification problem. Each node was equipped with a feature vector (\(\overrightarrow{h}\)) and the target labels. More specifically, each essay_node contains:
-
(i)
A binary feature vector (\(\overrightarrow{h}\)) possessing the <entity_attributes> that demonstrates that each entity in the “entity vocabulary” (the collection of all the entities that appeared in the Essays Dataset) is present (indicated by 1), or absent (indicated by 0) in the corresponding essay.
-
(ii)
The <OCEAN_labels> a five-digit binary string that demonstrates personality traits’ target labels for each essay (1 and 0 declare each essay’s belonging and not belonging to each of the {O, C, E, A, and N} traits).
During learning and testing the model, the set of node features \(h = \{\overrightarrow{h}_1, \overrightarrow{h}_2, ..., \overrightarrow{h}_N\}, \overrightarrow{h}_i \in {\{0, 1\}}^F,\) were fed into the KGrAt-Net’s attention model. Subsequently, KGrAt-Net build the model following the computations described in “Knowledge graph attention model” section. Figure 3 presents the attention model which was used to perform the personality prediction.

The architecture of knowledge graph attention network classifier. The pruned knowledge graph is fed into the attention layers as a set of node features \(h = \{\overrightarrow{h}_1, \overrightarrow{h}_2, ..., \overrightarrow{h}_N\}\). Each layer, computes the corresponding set of features after applying attention mechanism, namely \(h^\prime = \{\overrightarrow{h}^\prime _1, \overrightarrow{h}^\prime _2, ..., \overrightarrow{h}^\prime _N\}\). Finally, the outputted set of node features from each layer (namely \(h^\prime _l , l \in \{1, 2, ..,5\}\)), are concatenated to produce the final prediction.
To provide more flexibility, KGrAt-Net allows the user to customize some settings for learning the model, including the number of final classes, number of attention layers, the number of hidden units in each attention layer, number of units (neurons) in starting dense layers, number of attention heads in each multi-head attention layer, optimizer (as well as the learning rate), loss function, train-test split ratio, number of epochs, batch size, the application of early stopping (as well as the patience value), and the validation split ratio in each epoch.
It should also be mentioned that, since the difference between single-label and multi-label APP models is not significant49, the prediction in each five personality traits was fulfilled individually and independently of the others. Namely, the prediction was performed individually in each of the five {O, C, E, A, and N} personality traits. The correlation matrix between five personality traits (Table 1), also justifies this.
Furthermore, to enrich the acquired representation, KGrAt-Net provides an option to benefit the pruned knowledge graph’s embedding along with the attention mechanism (as described in “Enriching the knowledge graph attention model by knowledge graph embedding” section). Selecting this option, KGrAt-Net will be enriched by knowledge graph embedding. That is to say, the graph embedding will be concatenated to the attention networks results and then will be fed into the softmax classifier, as shown in Fig. 4. KGrAt-Net, allows the user to configure the settings for RDF2vec. Specifying the maximum depth in each walk, the maximum number of walks per node to perform the random walks, and the embedding size is necessary. We set the maximum depth in each walk and the maximum number of walks per node, equal to 5, and the embedding size equal to 500.

The architecture of knowledge graph attention network classifier which is enriched by knowledge graph embedding. The predictions perform individually in each of the five {O, C, E, A, and N} personality traits.
Algorithm 1 details a step-by-step flow of KGrAt-Net’s classification method that would assist toward a better comprehension of its performance.

Results
Evaluation metrics
Conventionally, classification models are evaluated using some eminent evaluation metrics, namely precision, recall, f-measure, and accuracy. Their values are determined by matching the elements of two sets: the set of essays’ “actual labels” (which is sometimes referred to as gold standard) and the set of essays’ “system predicted labels”. Matching each essay’s actual binary label with its corresponding predicted label will lead us to one of the following situations:
-
(i)
the actual label is true and the system predicted label is also true (which is referred to as TP that indicates True Positive);
-
(ii)
the actual label is false and the system predicted label is also false (which is referred to as TN that indicates True Negative);
-
(iii)
the actual label is false while the system predicted label is true (which is referred to as FP that indicates False Positive);
-
(iv)
the actual label is true while the system predicted label is false (which is referred to as FN that indicates False Negative).
When evaluating an APP system, it is worth knowing what proportion of all predictions is predicted correctly. The system’s correct predictions just occur when the essay’s system predicted label is equal to its actual label. TP and TN specify this situation. Therefore, the system’s correct predictions are equal to TP + TN. Besides, the total number of system predictions is equal to TP + TN + FP + FN. In consequence the proportion of systems correct predictions, which is known as accuracy, is equal to \((TP + TN)/ (TP + TN + FP + FN)\).
What is more, some facets of the performance of a classification system reveal with precision, recall and their weighted harmonic mean, namely f-measure. If someone wants to know that, what proportion of system’s true labeled predictions (TP + FP), has actual true labels (TP), precision (P) exactly discloses it; in fact, \(P = TP/(TP + FP)\). Furthermore, If someone wants to know that, what proportion of the actual true labels (TP + FN), are predicted by the system (TP), recall (R) exactly discloses it; in fact \(R = TP/(TP + FN)\).
It should be noted that, despite their useful information, the precision and recall metrics can not be relied on individually to evaluate the performance of a classification system. Since there may be some cases with high values of precision and low values of recall simultaneously or contrariwise. It is basically due to their incomplete coverage of reports. Accordingly, f-measure \(= (2 \times P \times R)/(P + R)\) is proposed to combine their included reports and solve the problem. However, as can be seen from the precision and recall, since the f-measure ignores all of the correctly false labelled samples by the system (namely, TN), it loses the ground to accuracy while evaluating an APP system. Hence, accuracy is preferred to f-measure for system evaluation.
Evaluation results
We initiated this research to call into question the application of the attention mechanism over the corresponding knowledge graph for a given text in APP. To do so, we proposed KGrAt-Net, a three-phase text classifier. As discussed in the “Methods” section, receiving a text, in the first phase KGrAt-Net attempts to clean up the input text and transform it into a more digestible form for the machine by using some preprocessing activities. Next, in the second phase, it tries to represent the input text throughout building the corresponding knowledge graph. In this phase, it also attempts to prune unessential parts of the knowledge graph. Then finally, in the third phase, KGrAt-Net provides two ways to classify the input texts; one that includes a knowledge graph attention network and another that includes a knowledge graph attention network along with the knowledge graph’s embedding. Our findings are described below. The parameter settings which were applied in our proposed method, are presented in Table 2.
Some information about the final knowledge graph (which is acquired after the aggregation of all individual pruned knowledge graphs and knowledge graph preparation) may be useful. It contains 36,212 nodes (including 33,745 entity_nodes and 2467 essay_nodes). It also possesses 632,941 edges (including 133,250 entity_entity_edges and 499,691 essay_entity_edges). Since there are some entity_nodes that have appeared in each essay (refer to knowledge graph building and pruning in “Knowledge graph building” and “Knowledge graph pruning” sections), there are always some edges between each essay_nodes and some entity_nodes in the final knowledge graph.
Table 3 presents the results obtained from the evaluation of KGrAt-Net, when APP was just performed using knowledge graph attention network. It encompasses the values of four evaluation metrics, namely precision, recall, f-measure and accuracy for all of the OCEAN traits. As can be seen from the Table 3, an average value of 64.82% for precision indicates that, on average 64.82% of the KGrAt-Net’s true labelled predictions, were predicted correctly, while using knowledge graph attention network for APP. Furthermore, an average value of 81.44% for recall denotes that KGrAt-Net in average has recalled (predicted) 81.44% of the true labelled essays in the dataset correctly, in all of the five traits. On top of that, on average 70.26% of KGrAt-Net’s predictions in all of the five traits were accurate.
In a same manner, Table 4 presents the results obtained from the evaluation of KGrAt-Net, when APP was performed using knowledge graph attention networks along with the knowledge graphs’ embeddings. As can be seen from the Table 4, KGrAt-Net in average of 69.27%, predicted the personality traits of the input texts in all the five traits, precisely. In other words, as precision denotes, on average 69.27% of the KGrAt-Net’s true labelled predictions were predicted correctly. In addition, KGrAt-Net in average has recalled (predicted) 80.58% of the true labelled essays in the dataset correctly in all of the five traits. Besides, on average 72.41% of KGrAt-Net’s predictions in all of the five traits were accurate.
Baseline models
To validate the performance of KGrAt-Net effectively, we compare it with the following state-of-the-art baselines, which were performed on Essays Dataset:
-
Tighe et al.7 they have used LIWC features to perform APP on Essays Dataset using several classifiers (like SVM, Sequential Minimal Optimization, and Linear Logistic Regression). They concentrated on removing insignificant LIWC features during classification by applying Information Gain and Principal Components Analysis (PCA).
-
Majumder et al.8 they have proposed a CNN in which the document-level Mairesse features were fed into the model. They have trained five independent identical binary classifiers for OCEAN personality traits.
-
Yuan et al.10 they have exploited deep features extracted through a CNN and then combined them with LIWC features to improve APP.
-
El-Demerdash et al.15 they have proposed the application of Universal Language Model Fine-Tuning (ULMFiT) for APP, which is an effective transfer learning method that can be applied in different language processing tasks.
-
Jiang et al.16 they have exploited pre-trained contextual embeddings (BERT and RoBERTa) to achieve more accurate predictions in APP.
-
Kazameini et al.55 they have also suggested an APP system was based on BERT to extract contextualized word embeddings from textual data. Then, the embeddings and several psycholinguistic features, were fed into a Bagged-SVM classifier.
-
Wang et al.17 they have proposed a graph convolutional neural network that models users as well as their textual information (word-level and document-level) by a graph. Finally, the embeddings of this information were classified using a softmax classifier.
-
Ramezani et al.39 they have ensembled five inherently different classification models to profit their abilities in prediction simultaneously, including term frequency vector-based, ontology-based, enriched ontology-based, LSA-based, and BiLSTM-based methods.
-
Xue et al.73 they have proposed a semantic-enhanced APP system which acquires hierarchical semantic representations of the text elements.
-
El-Demerdash et al.53 they have proposed a deep learning-based APP system that was based on data-level and classifier-level fusion, which exploits various levels of information to improve the performance of an APP system.
-
Ramezani et al.59 they have proposed a knowledge graph-enabled APP system that classifies the input text by building, enriching, and embedding its corresponding knowledge graph.
The Table 5, provides an insight into the performance of baseline models in APP as well as the performance of proposed classification strategies by KGrAt-Net. As can be seen from the data in this table, KGrAt-Net’s enriched classifier has achieved the best results for accuracy and f-measure in all five personality traits. Meanwhile, the unenriched classifier has also outperformed all baseline models in accuracy and f-measure except Ramezani et al.59, in which it has just outperformed in O and N traits.
Discussion
This study was designed to assess the effect of the knowledge graph attention network in APP. To this end, we proposed KGrAt-Net, a knowledge graph attention network classifier that relies on applying an attention mechanism over the equivalent knowledge graph of text documents. Accordingly, it provides two classification strategies: the first performs APP by using a knowledge graph attention network classifier, and the second performs it by enriching the first strategy. More specifically, the second classification strategy uses a knowledge graph attention network along with knowledge graph embedding to perform classification.
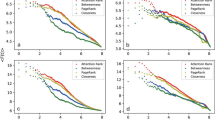
A comparison of four evaluation metrics, for both of the classification strategies proposed by KGrAt-Net, is shown in Fig. 5. From the accuracy chart (d) in this figure, and from the data in Tables 3 and 4 it is apparent that the second strategy, performs APP more accurate than the first strategy, in all of the Big Five personality traits. Enriching the knowledge graph attention network classifier with knowledge graph embedding concludes more accurate predictions than an unenriched classifier. That is to say, combining the nodes’ feature vectors with nodes’ embedding vectors leads to better results rather than when the nodes’ feature vectors are used solely. In the same manner, the second classification strategy has obtained better results than the first one, in all of the five traits for f-measure (c).
From another perspective, as discussed earlier, this study aimed to assess the importance of substituting text elements with more knowledgeable and knowing-full alternatives for the machine during APP computations. Considering these results, it was clearly confirmed that more knowledgeable and more knowing-full representations of the input text conclude more accurate results in APP. More specifically, paying different attentions to the neighbour concepts (nodes) in the knowledge graph during decision making in KGrAt-Net’s first classification strategy increases the effect of more prominent concepts during classification and concludes more accurate decisions. This idea was also confirmed by KGrAt-Net’s second classification strategy when the knowledge graph attention classifier was enriched by knowledge graph embedding. That is to say, enriching the attention mechanism’s feature vectors by knowledge graphs embedding vectors would cause even more accurate decisions. Indeed, since the embedding methods also try to increase the effect of more prominent concepts through dimensionality reduction during decision makings, they also attempt to utilize a more knowledgeable and more knowing-full representation of input text. To paraphrase, more knowings generally will bring more accurate predictions. What is more, each of these representations is capable of acquiring the knowings in certain aspects, and combining (enriching) them would cover more knowings during decision making and would diminish the effect of neglected information by each of the methods during decision making.
Comparing the accuracy of KGrAt-Net’s proposed classification strategies with the baseline models (as can be seen in Fig. 6), shows that KGrAt-Net has considerably enhanced the performance of APP. Simply put, classification using a knowledge graph attention network has significantly improved the accuracy of APP (as the average accuracies in Table 5 approves that). More precisely, KGrAt-Net’s first classification strategy has outperformed all of the state-of-the-art baseline models, except in some traits in Ramezani et al.59 (namely, C, E, and A). Their proposed APP system was basically based on knowledge graph embedding. An implication of this is the fact that, in spite of the knowledge graph attention network’s successes in predictions, text-based APP using knowledge graph embedding causes more accurate predictions in some traits. This is clearly acknowledged by KGrAt-Net’s enriched classification strategy when the knowledge graph attention network was enriched with knowledge graph embedding. The Fig. 6 clearly compares the accuracy of KGrAt-Net’s proposed strategies with the state of the art baseline models in APP.
Eventually, we are going to answer the research questions (as expressed in “Introduction” section) according to our findings as follows:
- RQ.1:
-
The results of our investigations revealed that the knowledge graph attention network has a significant positive effect on text-based APP. Comparing the average accuracies between the first classification strategy proposed by KGrAt-Net and baseline models in Table 5 clearly denotes the fact that there are considerable differences between the average accuracies in almost all baseline models (except Ramezani et al.59 in which it has outperformed to KGrAt-Net in C, E, and A). Comparing the accuracies in each of the OCEAN traits which are depicted in Fig. 6 also justifies the ability of knowledge graph attention network in text-based APP. In fact, it has empowered the model to pay attention to the most relevant parts of the knowledge graph and hence has aided in making better decisions. Specifically, regarding the nature of the attention mechanism, it should be stated that assigning different importance values for the neighbour concepts (nodes) in the knowledge graph during feature transformation causes better utilization of determining concepts during APP.
- RQ.2:
-
According to our findings (as can be seen in Table 5, Fig. 6), enriching the knowledge graph attention network by knowledge graph embedding, substantially enhances the text-based APP accuracies inasmuch as it concludes the best results among all baseline models. In fact, before the enrichment (as the results of KGrAt-Net’s first strategy illustrate), KGrAt-Net despite defeating all baseline models, failed to overcome one of the baseline models (Ramezani et al.59) in some traits (C, E, and A), which it is basically established on the basis of knowledge graph embedding. This obviously indicates that embedding the knowledge graph leads to benefit some neglected aspects of knowings that were missed by the attention mechanism. As a matter of fact, both the attention mechanism and embedding method over the knowledge graph remove certain parts of the graph, respectively, through paying attention to the most prominent parts of the graph and through dimensionality reduction. Hence, it should be stated that enriching the knowledge graph attention network by knowledge graph embedding brings some helpful knowings that improve APP’s accuracy.
- RQ.3:
-
Regarding the obtained results, applying the knowledge graph attention network generally enhances the performance of the text-based APP system in all of the OCEAN personality traits, although the enhancements are not quite equal. Being more specific, the knowledge graph attention network in practice has yielded the best results among the state-of-the-art baseline models in O and N, while in C, E, and A, defeating all other models, it has just fallen behind Ramezani et al.59 (as can be seen in Table 5, Fig. 6). Similarly, enriching it by the knowledge graph embedding totally has improved the performance of predictions in all of the OCEAN traits, inasmuch as KGrAt-Net definitely has achieved the best results among the state of the art baseline models. Generally, it can be concluded that applying knowledge graph attention as well as knowledge graph embedding in APP, capably improves the accuracy of APP, independent of each of the five personality traits. Regarding the essence of applied methods, it would be because acquiring the knowledge behind words through knowledge graphs brings more knowledgeable and knowing-full representations, which are eligible substitutions that lead to better predictions in all of the five traits.
- RQ.4:
-
The knowledge graph was the foundation of KGrAt-Net’s classifiers as the representation of input texts. Perusing the resulting values for applied evaluation metrics, we can claim that the knowledge graph as an alternative representation of the input text, adroitly encompasses the necessary information for the machine to perform text-based APP. This claim is clearly supported by both of the classification strategies proposed by KGrAt-Net. Actually, in practice representing the input text using its equivalent knowledge graph has provided the competent structure both for applying the attention mechanism and for embedding it to vector space. Furthermore, as can be seen from Table 5 among all of the text-based methods, those that are relied on knowledge graphs (namely,59 and the two proposed methods in the current study), have achieved the most striking results in accuracy and f-measure. This is an evident reason for the capability of knowledge graphs for representing the input text and providing eligible substitutions during APP.
- RQ.5:
-
According to our experience, basically when we represent the input text using knowledge graphs, we will face very large graphs, even for small pieces of text. Indeed, it is anticipated since the knowledge graph entails all of the existing information about each of the appeared concepts in the input text, as well as the relationship among them. The huge amount of information in the knowledge graph (both for nodes and edges), imposes a great deal of time and memory complexity on the system and even, most of the time, it would be impossible to proceed with the task. In fact, in practice not all of the existing information in the knowledge graph, take a positive role in the current task. Hence, it should be noted that while working with knowledge graphs, one should regard this concern and find an appropriate strategy to cope with it.

The comparison of four evaluation metrics for both classification techniques provided by KGrAt-Net, namely knowledge graph attention network classification (depicted by  ) and knowledge graph attention network along with knowledge graph embedding classification (depicted by
) and knowledge graph attention network along with knowledge graph embedding classification (depicted by  ). The values are rounded.
). The values are rounded.

Comparing the accuracy of baseline models in each OCEAN traits, with KGrAt-Net’s two proposed classifiers.
Conclusion
The present study was designed to determine the effect of the knowledge graph attention networks on text-based automatic personality prediction (APP). To this end, we proposed KGrAt-Net, which is a knowledge graph attention network classifier. It follows a three-phase approach to perform classification: it carries out some essential preprocessing activities in the first phase that makes the input text ready for main processes in the next phase; then, in the second phase, trying to achieve the knowledge behind the presented concepts in the input text, it represents the input text knowledgeably through building its equivalent knowledge graph; finally in the third phase, it designs a classification model through applying an attention network over the acquired knowledge graph.
This is the first time that a knowledge graph attention network has been used to perform a text-based APP. The findings from this study make several noteworthy contributions to the current literature. First, the knowledge graph attention network significantly improves the accuracy of a text-based APP system. Second, enriching the knowledge graph attention network classifier with knowledge graph embedding would considerably enhance the accuracy of predictions. Third, this study has gone some way towards enhancing our understanding of the efficacy of knowledge graphs in representing the knowledge behind the existing concepts in the input text and providing an eligible alternative for the input text that encompasses more comprehensive and digestible information for the machine, rather than the input string of characters. Finally, it also sheds some light on the importance of knowledge representation for the machine while performing human-like decision making.
Data availability
The datasets generated during the current study are available from the corresponding author on reasonable request.
References
Bergner, R. M. What is personality? Two myths and a definition. New Ideas Psychol. 57, 100759 (2020).
Peters, E. & Killcoyne, H. L. Psychology (The Britannica Guide to the Social Sciences) (Britannica Educational Pub, 2015).
Mairesse, F., Walker, M. A., Mehl, M. R. & Moore, R. K. Using linguistic cues for the automatic recognition of personality in conversation and text. J. Artif. Intell. Res. 30, 457–500 (2007).
Golbeck, J., Robles, C., Edmondson, M. & Turner, K. Predicting personality from twitter. In 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, 149–156. https://ieeexplore.ieee.org/abstract/document/6113107 (2011).
Sumner, C., Byers, A., Boochever, R. & Park, G. J. Predicting dark triad personality traits from twitter usage and a linguistic analysis of tweets. In 2012 11th International Conference on Machine Learning and Applications, Vol. 2, 386–393. https://ieeexplore.ieee.org/abstract/document/6406767 (2012).
Yuan, Y., Li, B., Jiao, D. & Zhu, T. The personality analysis of characters in vernacular novels by sc-liwc. In Human Centered Computing (eds Zu, Q. & Hu, B.) 400–409 (Springer, 2018).
Tighe, E. P., Ureta, J. C., Pollo, B. A. L., Cheng, C. K. & de Dios Bulos, R. Personality trait classification of essays with the application of feature reduction. In SAAIP@ IJCAI, 22–28. https://www.researchgate.net/profile/Nurendra-Choudhary/publication/305680463_Enhanced_Sentiment_Classification_of_Telugu_Text_using_ML_Techniques/links/5798da1908ae33e89fb0b276/Enhanced-Sentiment-Classification-of-Telugu-Text-using-ML-Techniques.pdf#page=34 (2016).
Majumder, N., Poria, S., Gelbukh, A. & Cambria, E. Deep learning-based document modeling for personality detection from text. IEEE Intell. Syst. 32, 74–79 (2017).
da Silva, B. B. C. & Paraboni, I. Personality recognition from facebook text. In Computational Processing of the Portuguese Language (eds Villavicencio, A. et al.) 107–114 (Springer, 2018).
Yuan, C., Wu, J., Li, H. & Wang, L. Personality recognition based on user generated content. In 2018 15th International Conference on Service Systems and Service Management (ICSSSM), 1–6. https://ieeexplore.ieee.org/abstract/document/8465006 (2018).
Mehta, Y. et al. Bottom-up and top-down: Predicting personality with psycholinguistic and language model features. In 2020 IEEE International Conference on Data Mining (ICDM), 1184–1189 (2020).
Ren, Z., Shen, Q., Diao, X. & Xu, H. A sentiment-aware deep learning approach for personality detection from text. Inf. Process. Manag. 58, 102532 (2021).
Christian, H., Suhartono, D., Chowanda, A. & Zamli, K. Z. Text based personality prediction from multiple social media data sources using pre-trained language model and model averaging. J. Big Data 8, 1–20. https://doi.org/10.1186/s40537-021-00459-1 (2021).
Jeremy, N. H. & Suhartono, D. Automatic personality prediction from Indonesian user on twitter using word embedding and neural networks. Procedia Comput. Sci. 179, 416–422 (2021).
El-Demerdash, K., El-Khoribi, R. A., Shoman, M. A. I. & Abdou, S. Psychological human traits detection based on universal language modeling. Egypt. Inform. J. 22, 239 (2020).
Jiang, H., Zhang, X. & Choi, J. D. Automatic text-based personality recognition on monologues and multiparty dialogues using attentive networks and contextual embeddings (student abstract). Proc. AAAI Conf. Artif. Intell. 34, 13821–13822 (2020).
Wang, Z., Wu, C.-H., Li, Q.-B., Yan, B. & Zheng, K.-F. Encoding text information with graph convolutional networks for personality recognition. Appl. Sci. 10, 4081 (2020).
Hogan, A. et al. Knowledge graphs. Synth. Lect. Data Semant. Knowl. 12, 1–257 (2021).
Bergman, M. K., Bergman, M. K. & Lagerstrom-Fife. Knowledge Representation Practionary (Springer, 2018).
Veličković, P. et al. Graph attention networks. In International Conference on Learning Representations. https://openreview.net/forum?id=rJXMpikCZ (2018). Accessed 08 March 2022.
Lee, J. B., Rossi, R. A., Kim, S., Ahmed, N. K. & Koh, E. Attention models in graphs: A survey. ACM Trans. Knowl. Discov. Data 13, 3363574. https://doi.org/10.1145/3363574 (2019).
Lee, J. B., Rossi, R. & Kong, X. Graph classification using structural attention. In Proc. 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’18, 1666–1674. https://doi.org/10.1145/3219819.3219980 (Association for Computing Machinery, 2018).
Butcher, J. N. Clinical personality assessment: History, evolution, contemporary models, and practical applications. In Oxford Handbook of Personality Assessment (ed. Butcher, J. N.) 5–21 (Oxford University Press, 2009).
Mendes, F. F., Mendes, E. & Salleh, N. The relationship between personality and decision-making: A systematic literature review. Inf. Softw. Technol. 111, 50–71 (2019).
Ali, I. Personality traits, individual innovativeness and satisfaction with life. J. Innov. Knowl. 4, 38–46 (2019).
Pruysers, S., Blais, J. & Chen, P. G. Who makes a good citizen? The role of personality. Pers. Individ. Differ. 146, 99–104 (2019).
Asselmann, E. & Specht, J. Taking the ups and downs at the rollercoaster of love: Associations between major life events in the domain of romantic relationships and the big five personality traits. Dev. Psychol. 56, 1803 (2020).
Walker, C. O. Exploring the contributions of grit and personality in the prediction of self-and other-forgiveness. J. Individ. Differ. 38, 196 (2017).
Liu, Z. et al. To Buy or Not to Buy? Understanding the Role of Personality Traits in Predicting Consumer Behaviors (SocInfo, 2016).
Tisu, L., Lupşa, D., Vîrgă, D. & Rusu, A. Personality characteristics, job performance and mental health: The mediating role of work engagement. Pers. Individ. Differ. 153, 109644 (2020).
Moor, L. & Anderson, J. R. A systematic literature review of the relationship between dark personality traits and antisocial online behaviours. Pers. Individ. Differ. 144, 40–55 (2019).
Moselli, M., Casini, M. P., Frattini, C. & Williams, R. Suicidality and personality pathology in adolescence: A systematic review. Child Psychiatry Hum. Dev. https://doi.org/10.1007/s10578-021-01239-x (2021).
Bacon, A. M. & Corr, P. J. Coronavirus (covid-19) in the United Kingdom: A personality-based perspective on concerns and intention to self-isolate. Br. J. Health. Psychol. 25, 839–848 (2020).
Vernon, P. E. Personality Assessment (Psychology Revivals): A Critical Survey (Routledge, 2014).
Soto, C. J. & Jackson, J. J. Five-factor model of personality. J. Res. Pers. 42, 1285–1302 (2013).
Furnham, A. Myers-Briggs Type Indicator (MBTI) 3059–3062 (Springer, 2020).
Ruch, W. et al. The long and winding road: A comprehensive analysis of 50 years of eysenck instruments for the assessment of personality. Pers. Individ. Differ. 169, 110070 (2021).
Cattell, H. E. & Mead, A. D. The sixteen personality factor questionnaire (16pf). SAGE Handb. Pers. Theory Assess. 2, 135 (2008).
Ramezani, M. et al. Automatic personality prediction: An enhanced method using ensemble modeling. Neural Comput. Appl. https://doi.org/10.1007/s00521-022-07444-6 (2022).
Feizi-Derakhshi, A.-R. et al. Text-based automatic personality prediction: A bibliographic review. J. Comput. Soc. Sci. https://doi.org/10.1007/s42001-022-00178-4 (2022).
Cummings, J. A. & Sanders, L. Introduction to Psychology (University of Saskatchewan Open Press, 2019).
Moreno, J. D., Martínez-Huertas, J. Á., Olmos, R., Jorge-Botana, G. & Botella, J. Can personality traits be measured analyzing written language? A meta-analytic study on computational methods. Pers. Individ. Differ. 177, 110818 (2021).
Pennebaker, J. W., Francis, M. E. & Booth, R. J. Linguistic Inquiry and Word Count: Liwc 2001 Vol. 71 (Lawrence Erlbaum Associates, 2001).
Pennebaker, J., Booth, R., Boyd, R. & Francis, M. Linguistic Inquiry and Word Count. www.LIWC.net (LIWC. net, 2015).
Wilson, M. Mrc psycholinguistic database: Machine-usable dictionary, version 20.0. Behav. Res. Methods Instrum. Comput. 20, 6–10. https://doi.org/10.3758/BF03202594 (1988).
Moffitt, K. et al. Structured programming for linguistic cue extraction (splice). In Proc. HICSS-45 Rapid Screening Technologies, Deception Detection and Credibility Assessment Symposium, 103–108. http://splice.cmi.arizona.edu (2012).
Mohammad, S. M. Word affect intensities. In Proc. 11th Edition of the Language Resources and Evaluation Conference (LREC-2018). http://saifmohammad.com/WebPages/AffectIntensity.htm (2018).
Cambria, E., Li, Y., Xing, F. Z., Poria, S. & Kwok, K. Senticnet 6: Ensemble application of symbolic and subsymbolic ai for sentiment analysis. In Proc. 29th ACM International Conference on Information and amp; Knowledge Management, CIKM’20, 105–114. https://doi.org/10.1145/3340531.3412003 (Association for Computing Machinery, 2020).
Farnadi, G. et al. Computational personality recognition in social media. User Model. User-Adapt. Interact. 26, 109–142. https://doi.org/10.1007/s11257-016-9171-0 (2016).
Park, G. et al. Automatic personality assessment through social media language. J. Pers. Soc. Psychol. 108, 934 (2015).
Schwartz, H. A. et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 8, 1–16. https://doi.org/10.1371/journal.pone.0073791 (2013).
Tandera, T., Hendro, S. D., Wongso, R. & Prasetio, Y. L. Personality prediction system from facebook users. Procedia Comput. Sci. 116, 604–611 (2017).
El-Demerdash, K., El-Khoribi, R. A., Ismail Shoman, M. A. & Abdou, S. Deep learning based fusion strategies for personality prediction. Egypt. Inform. J. 23, 47 (2021).
Kunte, A. & Panicker, S. Personality prediction of social network users using ensemble and xgboost. In Progress in Computing, Analytics and Networking (eds Das, H. et al.) 133–140 (Springer, 2020).
Kazameini, A., Fatehi, S., Mehta, Y., Eetemadi, S. & Cambria, E. Personality Trait Detection Using Bagged Svm Over Bert Word Embedding Ensembles (Association for Computational Linguistics, 2020).
Yang, F., Quan, X., Yang, Y. & Yu, J. Multi-document transformer for personality detection. Proc. AAAI Conf. Artif. Intell. 35, 14221–14229 (2021).
Wang, X., Sui, Y., Zheng, K., Shi, Y. & Cao, S. Personality classification of social users based on feature fusion. Sensors 21, 6758 (2021).
Lynn, V., Balasubramanian, N. & Schwartz, H. A. Hierarchical modeling for user personality prediction: The role of message-level attention. In Proc. 58th Annual Meeting of the Association for Computational Linguistics, 5306–5316. https://aclanthology.org/2020.acl-main.472 (Association for Computational Linguistics, Online, 2020).
Ramezani, M., Feizi-Derakhshi, M.-R. & Balafar, M.-A. Knowledge graph-enabled text-based automatic personality prediction. Comput. Intell. Neurosci. 2022, 3732351. https://doi.org/10.1155/2022/3732351 (2022).
Schütze, H., Manning, C. D. & Raghavan, P. Introduction to Information Retrieval Vol. 39 (Cambridge University Press, 2008).
Bird, S., Klein, E. & Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit (O’Reilly Media Inc., 2009).
Honnibal, M., Montani, I., Van Landeghem, S. & Boyd, A. spacy: Industrial-Strength Natural Language Processing in Python, Vol. 1212303. https://doi.org/10.5281/zenodo, https://spacy.io/ (2020).
Hogan, A. Sparql query language. In The Web of Data, 323–448 (Springer, 2020).
Consortium, W. W. W. Resource Description Framework (RDF) Model and Syntax Specification. https://www.w3.org/TR/PR-rdf-syntax/Overview.html (1999). Accessed 20 February 2022.
Faralli, S., Finocchi, I., Ponzetto, S. P. & Velardi, P. Efficient pruning of large knowledge graphs. In Proc. Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, 4055–4063. https://doi.org/10.24963/ijcai.2018/564 (International Joint Conferences on Artificial Intelligence Organization, 2018).
Mondal, S. & Mukherjee, N. A bfs-based pruning algorithm for disease-symptom knowledge graph database. In Information and Communication Technology for Intelligent Systems (eds Satapathy, S. C. & Joshi, A.) 417–426 (Springer, 2019).
Hamilton, W. L. Graph representation learning. Synth. Lect. Artif. Intell. Mach. Learn. 14, 1–159. https://doi.org/10.2200/S01045ED1V01Y202009AIM046 (2020).
Wu, L., Cui, P., Pei, J. & Zhao, L. Graph neural networks. In Graph Neural Networks: Foundations, Frontiers, and Applications (eds Pei, J. et al.) 27–37 (Springer, 2022).
Molokwu, B. C., Shuvo, S. B., Kar, N. C. & Kobti, Z. Node classification in complex social graphs via knowledge-graph embeddings and convolutional neural network. In Computational Science–ICCS 2020 (eds Krzhizhanovskaya, V. V. et al.) 183–198 (Springer, Cham, 2020).
Ristoski, P., Rosati, J., Di Noia, T., De Leone, R. & Paulheim, H. Rdf2vec: Rdf graph embeddings and their applications. Semant. Web 10, 721–752 (2019).
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space. In 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2–4, 2013, Workshop Track Proceedings (eds. Bengio, Y. & LeCun, Y.). https://iclr.cc/archive/2013/program-details/program.html (2013). Accessed 20 February 2022.
Pennebaker, J. W. & King, L. A. Linguistic styles: Language use as an individual difference. J. Pers. Soc. Psychol. 77, 1296 (1999).
Xue, X., Feng, J. & Sun, X. Semantic-enhanced sequential modeling for personality trait recognition from texts. Appl. Intell. 51, 1–13. https://doi.org/10.1007/s10489-021-02277-7 (2021).
Author information
Authors and Affiliations
Contributions
M.R. and M.R.F.D. contributed the following: designed and performed the experiments, formal analysis, writing, and investigations. M.R. and M.A.B. contributed the following: review and editing manuscript, data curation, supervision and the analytical methods verification.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ramezani, M., Feizi-Derakhshi, MR. & Balafar, MA. Text-based automatic personality prediction using KGrAt-Net: a knowledge graph attention network classifier. Sci Rep 12, 21453 (2022). https://doi.org/10.1038/s41598-022-25955-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-25955-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
