
Abstract
Festuca ovina L. (sheep fescue), a perennial grass plant found in mountainous regions, is important from both an ecological and economic viewpoint. However, the variability of biological yield of sheep fescue due to its reliance on different characteristics makes it difficult to accurately prediction using classic modeling techniques. In this study, machine learning methods and multiple regression models (linear and non-linear) are used to investigate the interdependence of various morphological and physiological characteristics on accurate prediction of the biological yield (BY) of sheep fescue. Principal components analysis and stepwise regression were used to select six agronomic parameters i.e. thousand seed weight (TSW), relative water content (RWC), canopy cover (CC), leaf area index, number of florescence, and viability (VA), while the output variable was BY. To optimized the artificial neural network (ANN) structure, different transfer functions and training algorithms, different number of neurons in each layer, different number of hidden layers and training iteration were tested. The accuracy of the models and algorithms is analyzed by root mean square error (RMSE), mean absolute error (MAE), and determination coefficient (R2). According to the findings, ANN models were more accurate than regression models. The ANN model with two hidden layers (i.e. structure of 6–4–8–1) which had RMSE, MAE and R2 scores of 0.087, 0.065 and 0.96, respectively, was discovered as the best model for predicting the BY. In addition, result of the sensitivity analysis showed TSW, RWC and CC, in that order, were the variables most important for high-quality BY estimation in both models regardless of input combination. Finally, the paper concludes that early flowering sheep fescue genotypes with long maturation and great TSW must be regarded as the most suitable model for increasing BY in breeding projects.
Similar content being viewed by others
Introduction
Festuca ovina L. (sheep fescue) is a perennial grass plant with good quality for grazing1. The main F. ovina usage is for cultivation as forage in rangelands revegetation programs2. The plant is a densely tufted and is a drought-resistant grass3. Additionally, F. ovina has a strong capacity to improve water and nutrient absorption in poor soils due to mycorrhizal fungi4. According to the above, one of the most important goals for pasture managers is to enhance sheep fescue yield using appropriate farming practices However, timely and cost-effective evaluation of plant performance characteristics is essential for the management and exploitation of this valuable plant. It is difficult to estimate biological yield since it is a polygenetic trait that is highly influenced by the environment and has a low heritability. One technique for addressing this subject is to predict and model this trait through other tarits with higher heritability that affect biological production either directly or indirectly in a positive or negative way5.
For the analysis and prediction of biological yield, a variety of methods have been offered; these methods can be chosen depending on the objectives, type, and complexity of correlations between traits6.
According to literatures review, there are no modeling studies in sheep fescue to predict biological yield. In relation to other plant species, modeling studies have been performed for some plant species, with an emphasis on techniques based on linear relationships between parameters, such as path analysis (PA), multiple linear regression (MLR) and correlation7,8,9,10. These approaches, however, are limited to linear correlations and are unable to capture nonlinear and complex interactions between variables. In the presence of nonlinear effects, it appears that these approaches to be incapable of providing a complete and accurate illustration of the interactions between biological yield and its elements11,12.
Artificial intelligence techniques such as artificial neural networks (ANNs), genetic expression (GE), Bayesian classification (BC), adaptive neuro-fuzzy inference system (ANFIS), and other advanced modeling methods, in opposed to previous modelling techniques such as PA and MLR, have lately gotten a lot of attention from crop researchers, particularly when the relationship among parameters may well be nonlinear5,13,14,15. Artificial Neural Network (ANN) is a multi-networked (multilayer perceptron) system of logically arranged fundamental units that simulate the neuron activity in the human brain. It may model the complex and non-linear relationships without any prior assumptions of cause and effect relationships of the variables and comparatively advanced and competitive as compared to conventional regression and statistical models16. Neural network techniques are being effectively applied in many domains including agriculture, engineering, medical sciences, etc. In agriculture, ANN has been applied in predicting the biological yield for grass pea17. They found that the ANN models with the same input variables could predict the biological yield with a higher performance (R2≈ > 0.92) compared to the MLR models (R2≈ < 0.65). This advantage can be due to the nonlinear or complex relationships between variables and the high ability of nonlinear functions to find and capture them in ANN models. Mokarram and Bijanzadeh18 also compared MLR and ANN including multi-layer perceptron (MLP) and radial basis function (RBF) models to predicting biological yield of barely. Among the MLR, MLP and RBF models, MLP model had the highest R2 values for.
prediction of BY (R2 = 0.894).
Although, many researches have been performed to specify the best models for predicting biological process/plants yield using different types of data19,20. Abdipour et al.5 expressed ANN forecasted safflower seed performance with greater precision and effectiveness than the multi linear regression method. According to Ghodsi et al.21, the ANN model is an effective tool for predicting wheat production. Moreover, Mutlu et al.22 reported that NIR combined with the ANN, were able to accurately predict the characteristics of wheat flour. Safa et al.23 stated that Model ANN accomplished better than Model MLR in predicting CO2 emissions.
Based on the literatures there are various reports about the capability of the different modeling methods, and it has been reported that ANN always executed better than MLR or other models24. So, modeling the performance of sheep fescue based on its factors would be beneficial to understand the relationships between the most important organs of the plant in order to improve cultivation and harvesting programs.
Although in some studies the relationships between traits in this plant have been investigated with methods such as correlation25, modeling for biological function in this plant has not been done either by classical methods such as regression or by artificial intelligence methods. Therefore, determining the relationships between traits and an optimal model for predicting biological yield using strong modeling methods such as ANNs can greatly help breeders to improve the biological yield of this plant.
To the best knowledge of the authors, no research has performed a robust analysis on the interdependence of morphological and physiological attributes and biological yield in sheep fescue, and predicting of BY through the corresponding most suitable ANN algorithms.
According to the above, the purpose of the present study was to investigate and predict sheep fescue performance based on its morphological and physiological characteristics using ANN, MLR and non-linear regression models.
Materials and methods
Study area and climatic characteristics
The present research was performed under rain-fed conditions at two planting times in spring and autumn 2018 in the field of Balekhlichay watershed dry-farming lands in an area about 1058 km2, in Ardabil province, northwest of Iran (38°12′44″ N and 48°17′46″ E with altitude range from 1150 to 4811 m above sea level) (Fig. 1). The mean annual rainfall and mean temperature range at the low and high altitude are 299–766 mm and 3.9–7.9 °C, respectively and the study area slope is at the range of 12–60%. The dry-farming lands used in this research were among the lands of University of Mohaghegh Ardabili, Iran and because this research was supported by the Vice-Chancellor for Research and Technology of the University, did not need to obtain a permission.

The location of the study area.
The soil is characterized by a pH of 6.7–8.8, total mobile nitrogen of 2–36% and the electrical conductivity (EC) of 0.18–0.24 dS/m, available potassium of 170–217 ppm, available phosphorus of 20.58–33.61 ppm, C/N ratio of < 15, organic carbon (OC) of 0.07–3.8%, clay content of 17%, sand content of 69%, and silt content of 14%.
Field experiment, growing conditions and treatments
This study was done as a factorial experiment based on a randomized block design (RCBD) with three replications. The experimental factors were (1) planting time in two seasons (autumn and spring) and (2) facilitators in nine levels, including control, PSN (500 and 1000 mg/lit), EM (1 and 2%), Super absorbent (10 and 30 g/kg soil), Organic fertilizer (cattle manure) (100 and 200 g/kg soil). Table 1 shows the characteristics of the growth facilitators used in the present study. After determining the cultivation area, first, the ground plowed,the weeds were removed and the cultivation bed was prepared. Each plot was split into three subplots. Within each subplot, 15 holes were drilled, and 5 seeds were seeded. The seeds of the Festuca ovina L. were collected from its habitat in Sablan rangelands, Ardabil, Iran (47° 52′ E and 38° 12′ N). After harvesting from rangelands, seeds of Festuca ovina are stored in the herbarium of Faculty of Agriculture and Natural Resources, University fo Mohaghegh Ardabili with number 1342. It should be mentioned that harvesting the seeds of rangeland plants from the rangeland of Iran is free, however, the permission to harvest the seeds of the Festuca ovina from the Sabaland rangelands was obtained from the Department of Natural Resources and Watershed Management of Ardabil province, Iran. According to two planting seasons, 9 fertilizer combinations, dividing each plot into three plots and three replications, 162 data were collected, 18 outlier data were removed and 144 data were used for analysis.
Applying of treatments and maintenance
Powder of potassium silicate nanoparticles (PSN), effective microorganisms (EM) and Super absorbent (SA) were supplied by Sigma Aldrich Company (Fig. 2), Emkanpazir Pars Company (Shiraz, Iran), and Bojnourd Water Crystal Production Company, respectively. The morphological study of these nanoparticles was conducted by scanning electron microscope (SEM). The superabsorbent polymer used in this research was purchased from North Khorasan Bolour Ab Company (Shirvan, Iran). Organic fertilizer (cattle manure) was prepared from the green space of University of Mohaghegh Ardabili.

Scanning electron microscopy (SEM) image of potassium silicate nanoparticles.
When the plants had four primary leaves, PSN and EM, were added to the soil of each clump as solution. Treatments of PSN and EM in three steps and ten days apart were added to soil as solution. Super absorbent and Organic fertilizer were added to the soil. For the Super absorbent treatment, 10 and 30 g of Super absorbent separately were mixed with 1 kg soil and pits were filled with them. For the Organic fertilizer treatment, 100 and 200 g/kg of cow manure were combined with soil and were poured in the pits. During the growing season, weeds were removed mechanically, without the use of chemical pesticides.
Field sampling and measurement
Three randomly chosen plants from each plot were evaluated for harvest plant information using indicators including plant height (PH) (At the end of the growth period, the length of the shoots and roots of the plant were harvested and cleaned, then measured with a precise ruler), basal diameter (BD) (The basal diameter of harvested plants was measured with a precise ruler), canopy cover (CC) (First, the geometric shape of the circle or oval of the canopy was recognized, then they were calculated based on the formulas of the area of the circle and oval) and etc. Ten morpho-physiological traits including plant height (PH (, basal diameter (BD), canopy cover (CC), number of florescence (NI) (At the end of the vegetative period, the number of inflorescences was measured), thousand seed weight (TSW) (The thousand seeds of each species was considered randomly and accurately obtained using a digital scale), viability (VA) (It was considered based on the number of holes in which seed cultivation was done. Total Chlorophyll (TCh) (The amount of chlorophyll in plant leaves was measured by a chlorophyll meter)26, leaf area index (LFA) (leaf area index was measured based on ground based method)27, relative water content (RWC)28 and biological yield (BY)29 were evaluated in this study. For this purpose, in the end of growth stage, 3 plants from each plot were randomly selected30,31. Summary of statistical indices for estimated characteristics are shown in Table 2. The relative water content of leaf was specified by the following equation.
where FW: fresh leaf weight immediately after sampling, DW: dry weight of leaf after drying in oven and SW: saturated leaf weight after placing in distilled water.
Data preprocessing and statistical analysis
In order to avoid bias’s estimation due to differences in units of input variables, the following equation was used to normalization within in the ranges [0.1, 1] (Eq. 1).
where xi is the original value, xn is the normalized value, and xmax and xmin are the max and min values, respectively.
The nature and size of connections between BY and other qualities were investigated using a multiple linear regression (MLR) model and nonlinear regression models such as Exponential, Logistic, Quadratic, Gompertz, Asymptotic exponential, and Chapman-Richard. We chose the MLR model as the best regression model to characterize the correlations between variables based on model performance results (Table 5). As a result, the MLR model was used as a starting point for additional research. It should be noted that the most important hypotheses for selected MLR model including the existence of a linear relationship between the dependent and independent parameters, the independence of errors across the independent variables and homoscedasticity (Durbin-Watson value of 1.83), the absence of multicollinearity between the predictor factors (variance inflation factor (VIF value < 5) and tolerance (TOL value > 0.2) were evaluated (Table 6). SAS Institute Inc's statistical analysis system (SAS software) version 9.4 was used to assess the hypotheses and normalcy.
Input parameters selection
Input variable selection (IVS) is a crucial phase in the creation of a statistical model that has a significant impact on the model's performance. In general, when a high set of input parameters are utilized for a small sample size, researchers typically use models with the fewest input variables to answer their problems14,32. The simple correlation as an input variable selection method only shows the magnitude of the relationship among attributes and does not provide clear information about different kinds of direct or indirect effects among them. This drawback is important because the correlation coefficient between two variables can be affected by indirect effects of other variable(s) in a positive or negative way, reducing the chance of achieving a unique solution15. Because correlation analysis is ineffective as an IVS method, we employed principal component analysis (PCA) and stepwise regression (SWR), two more well-known and powerful IVS approaches (Tables 3 and 4). Both SWR and PCA are methods to separate the variables influencing the dependent variable for modeling to reduce the data volume. In the PCA, a linear combination of independent variables with the highest relationship with the dependent variable is determined, and usually this linear combination justifies a high percentage of changes in the dependent variable. In the SWR method, the variables with the highest correlation with dependent variable are entered into the model, and in the final stage, a model with a combination of the most influential variables is obtained.
Multiple linear regression
By proving the superiority of multiple linear regression over other regression models and the validity of multiple regression assumptions in the previous section, this regression model was calculated with the following equation (Eq. 2):
where yi is the biological yield, \(\beta_{0} - \beta_{n}\) are the regression coefficients, \({\text{x}}_{{1}} {\text{ - x}}_{{\text{n}}}\) are input factors, and \(\varepsilon\) is error associated with the observation.
Artificial neural network
A “Multi-Layer Perceptron (MLP)” model was constructed and the ANN model was calibrated with the help of MATLAB, R2018a, to build and analyze the efficacy of ANN to forecast the biological yield of sheep fescue33. The following equation represents the output of the ANN model in this research34:
where \(y_{{\text{t}}}\) is the network output (BY), \({\text{n}}\) is the number of hidden nodes, \({\text{m}}\) is the number of input nodes, \({\text{f}}\) is tangent sigmoid transfer function, \(\alpha_{j} \{ {\text{j = 0,1,}}...{\text{,n}}\}\) symbolize the weight vectors from the hidden to the output nodes, \(\beta_{{{\text{ij}}}} \{ {\text{i}} = 1,2,...,{\text{m}};{\text{j = 0,1,}}...{\text{,n}}\}\) are the input weights to the hidden nodes, and \(\alpha_{0}\) and \(\beta_{{0{\text{j}}}}\) are the arc weights that lead from the bias terms, which are always equal to one.
The initial fine-tuning of ANN topology was optimized by changing the hidden layers (1–3 layer), neurons in each hidden layer (1–30 neurons/layer), learning algorithms (Levenberg–Marquardt, Momentum and Conjugate gradient), transfer functions for hidden layer (Tansig, logsig and purelin), and the most effective network structure was created (Fig. 3).

Applied structure of MLP model to predict BY.
Each run on the training dataset was performed with a 2000 epoch size (training cycles) and a mean square error (MSE) cutoff value of 0.01 (based on normalized dataset scale). The mean of MSE values during the training, testing, and cross-validation stages in different epochs (1–2000) was explored to obtain an appropriate training procedure and avoid overtraining. Around 700 epochs are sufficient for convergence between training, testing, and cross-validation, as illustrated in Fig. 4. The entire dataset in this study was 144, which was randomly divided into three subsets: training (65 percent), testing (20 percent), and validation (15 percent)35. Due to the MATLAB software generates various random data for each run, the best ANN for each topology was chosen after a maximum of 40 runs.

The convergence of the average of MSE value during training and cross validation of the final ANN structure.
Model implementation and sensitivity analysis of input parameters
Three statistical quality indicators, namely mean absolute error (MAE), root mean square error (RMSE), and coefficient of determination (R2), were utilized to objectively examine the efficacy of ANN and MLR models to predict the biological yield of sheep fescue according to its variables.
where n is the number of data, Oi denotes the observed values, Pi denotes the anticipated values, and the bar represents the variable's mean.
A sensitivity analysis was used to examine the impact of several independent factors on the outcome. Sensitivity analysis reveals the usefulness of each variable, and can be used to identify the components that are most important for forecasting output36. For this, the dataset was run without any input variables (i.e., TSW, RWC, CC, LAI, NI, VA), and the models' implementation was assessed using R2, RMSE, and MAE.
Ethical approval
Experimental research and field studies on plants were approved by Review Board of Faculty of Agriculture and Natural Resources, University of Mohaghegh Ardabili, Ardabil, Iran. All methods were carried out in accordance with relevant guidelines and regulations. Harvesting the seeds of rangeland plants from the rangeland of Iran is free, however, the permission to harvest the seeds of the Festuca ovina from the Sabaland rangelands was obtained from the Department of Natural Resources and Watershed Management of Ardabil province, Iran.
Results and discussion
Input variables selection
To create an applicable model, two powerful methods were used: principal component analysis (PCA) and stepwise regression (SWR) (applied a model with a small number of input parameters to account for a large proportion of BY variance as an output). Based on SWR, the six attributes TSW, RWC, CC, LAI, NI, and VA were incorporated in the model (Table 3). The first two PCA components were chosen because their eigenvalues were > ≈ 1. Together, these two variables contributed for more than 86 percent of the variation (Table 4). According to PCA, the eigenvectors for the two initial components for the above six qualities were the largest (justifying over 86% of BY variation) (Table 4). Based on the same results achieved from both IVS techniques (SWR and PCA), these attributes (TSW, RWC, CC, LAI, NI, and VA) were chosen to be the most proper input parameters for both the ANN and MLR models (Table 5).
Multiple linear regression (MLR) model development
Although the convenience of linear regression models is the fundamental reason for their usage in research, these models can also accurately predict the output variable, particularly when there is a strong linear relationship between the input and output variables37,38. For this aim, six factors chosen among SWR and PCR (i.e., TSW, RWC, CC, LAI, NI, and VA), were included the MLR model (as independent parameters) to forecast the BY (as the dependent parameter) (Table 6). The following formulas were used to forecast BY for all, training, testing, and cross-validation data sets, respectively:
where y is the biological yield, \({x}_{1}\) is the thousand seed weight, \({x}_{2}\) is the relative water content of leaf, \({x}_{3}\) is the canopy cover, \({x}_{4}\) is the leaf area index, \({x}_{5}\) is the number of florescence, and \({x}_{6}\) is the viability.
According to above MLR equations (Eq. 7–10), the forecasted value of BY is a linear composition of TSW, RWC, CC, LAI, NI, and VA parameters, such that the sum of the squared deviations of the real and anticipated BY is minimum. These models show how BY changes with TSW, RWC, CC, LAI, NI, and VA, as well as what values of the model's parameters are required to acquire the desired BY value. However, the ability of these models to forecast the BY is contingent on the existence of a strong linear connection among the parameters. An overview of the statistical variables for regression models created using various types of data is shown in Table 6. As can be shown in Table 6, the MLR models were unable to accurately anticipate the BY. Linear regression models are unable to predict performance due to a small number of input parameters or the existence of complex/nonlinear interactions among components15. Despite the fact that there is no MLR modeling research with like attributes to estimate BY in this study, it is obvious that the MLR model (with R2 = 0.810) cannot accurately forecast BY.
Artificial neural network (ANN) model development
In order to create an appropriate ANN model with same input and output parameters which were used for the MLR models, ANN models with some of the most essential ANN architectural features were trained and optimized. As shown in Tables 7 and 8, the least amounts of RMSE and MAE and the highest R2 values were acquired by the ANN model with 6–7–3–1 structure, the Levenberg–Marquardt as learning algorithm, tansig as transfer function in hidden layers, and pureline transfer function in output layer. Although, Levenberg–Marquardt algorithm requires more memory compared other algorithms, it is a fast algorithm with high accuracy and efficiency, especially for small data samples (i.e. about 100)39. Various modeling studies have also concluded that Levenberg–Marquardt is the superior learning algorithm when compared to other algorithms like as Momentum and Conjugate gradient5,15,32,40. Tansig's superiority as a non-linear transfer function in our ANN models is most likely due to its characteristics in converting the analyzed input and afterwards conveying it to the output layer. It converts negative to positive infinity input values to a 0 to 1 output range41. On the other hand, linear transfer functions like "purelin" perform a basic linear conversion on the analyzed input before passing it to the output layer. However, the type of relationship between the input and output variables is critical in selecting the transfer function, and the higher implementation of nonlinear functions in the present research could be attributed to the nonlinear relationship between BY and input parameters. Nonlinear transfer functions, which cover non-linear fluctuations, have been used more than other transfer functions relying on the feature studied, particularly when there were non-linear correlations across qualities14,40,42,43,44.
Tables 7 and 8 demonstrate that the number of hidden layers and neurons within every layer, as well as the training algorithm and transfer function, all contributed significantly to the total variance in ANN efficiency. However, the complexity of the model depends on the nature of the subject, and an enhance in the number of hidden layers or the number of neurons in each layer does not always indicate an improvement in model efficiency5. In general, the ANN model we discovered in this research has a clean topology, which researchers prefer (with one or two hidden layers and a small number of neurons)5,12,40,45,46. The presence of significant nonlinear interactions between variables, as well as the creation of a model with an appropriate topology, can lead to such a high-performance forecast14,32,40. Mokarram and Bijanzadeh18 applied the MLR model in conjunction with two ANN models, the MLP and radial basis function (RBF) models, to estimate biological yield (BY) and stated that the MLP model had the highest R2 values for forecast of BY of Hordeum vulgare.
According to prior research, ANN modeling approaches are preferred over MLR modelling techniques15,40,47,48. This preference appears to be due to ANN modeling techniques' superior ability to capture the extremely nonlinear and complicated relationship between oil content and important parameters11,15,49. In predicting soybean yield, Kaul et al.50 stated that ANN produces better findings than traditional statistical procedures.
Comparing MLR and ANN models for forecasting BY
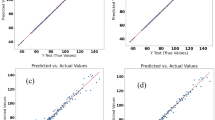
To give a more complete contrast between the two modelling techniques for forecasting BY, the models were tested using statistical qualitative metrics and also visual display on scatter plots based on numerous datasets (Figs. 5 and 6). As illustrated in Fig. 5a–d the elected ANN models had higher efficacy to forecast BY than the MLR models (Fig. 6a–d), and compared with MLR models could forecast BY for all, training, testing and cross validation dataset with a 18.52, 17.17, 19 and 20.48% enhance in R2 and a decrease of 30.49, 42.86, 37.35, and 32.22% in RMSE, respectively. The use of scatter plots to compare estimated and actual BY values for two models allows for a better understanding of the data distribution and the capability of the selection models to forecast the BY. The observed and forecasted values for the ANN model had the same distribution (with R2 = 0.962 and 0.958 for the training and testing datasets, respectively), and the measured values of BY through the ANN model tend to track the matching actual ones very closely (as shown in Fig. 5).

The scatter plot of measured and predicted values of biological yield in fitted multiple linear regression (MLR) model. (a) The scatter plot of measured versus predicted values of biological yield in training stage of MLR. (b) The scatter plot of measured versus predicted values of biological yield in testing stage of MLR. (c) The scatter plot of measured versus predicted values of callus induction percentage in cross-validation stage of MLR. (d) The scatter plot of all measured versus all predicted values of biological yield by MLR model.

The scatter plot of measured and predicted values of biological yield in fitted artificial neural network (ANN) model. (a) The scatter plot of measured versus predicted values biological yield in training stage of ANN. (b) The scatter plot of measured versus predicted values of biological yield in testing stage of ANN. (c) The scatter plot of measured versus predicted values of biological yield in cross-validation stage of ANN. (d) The scatter plot of all measured versus all predicted values of biological yield by ANN model.
On the other hand, the estimated and forecasted values for the MLR models, did not have a similar pattern as the ANN models, as demonstrated by the more dispersed distributions and outlines in Figs. 7 and 8. Also, there was no significant difference in statistical summaries (i.e. minimum of sample, lower quartile, median, upper quartile, and maximum of sample) between the observed and measured data by the ANN model, based on box plots (Fig. 7a and b). These characteristics, along with the absence of outliers (unusual data values) in box plots, are necessary modeling characteristics15,32. The presence of outlines and variations in the statistical summaries in the box plots generated by the MLR models demonstrated their poor efficacy for predicting BY, in contrast to the ANN models (Fig. 8a and b). It appears that displaying three datasets (the real dataset, data estimated by the ANN, and MLR for BY) on a graph is a better technique for evaluating the efficacy of the two models in forecasting BY. The predicted BY values by the ANN model exhibited a more similar trend to the BY actual values and were more accurate in forecasting BY than the MLR model, as shown in Fig. 9. In general, according to the findings, it can be concluded that ANN models with the same input parameters can forecast the BY (R2≈ > 0.95) more accurately than MLR models (R2≈ < 0.82). This benefit could be attributed to nonlinear or complicated interactions among variables, as well as nonlinear functions' improved ability to find and take them in ANN models. Contrasting two models in forecasting BY, on the other hand, demonstrated the importance of selecting a model that is appropriate for the subject matter being examined. Many forecasting researches have demonstrated the ANN's benefit in modeling due to its excellent capacity to take highly nonlinear and complex relationships among variables11,23,40,47,49.

Box plot of measured and predicted BY in the training and testing stages of ANN (a, b).

Box plot of measured and predicted BY in the training and testing stages of MLR (a, b).

Graphical representation of the measured and predicted values for BY in the training stage of ANN and MLR models.
Sensitivity analysis
In both ANN and MLR models, the sensitivity tests without a particular input parameter (i.e., TSW, RWC, CC, LAI, NI, and VA) were used to better understand the individual impacts of every input parameter and identify the most and slightest substantial inputs to anticipate BY, and the individual effects of input variables to forecast BY were arranged in Table 9 from highest to lowest. As illustrated in Table 9, both ANN and MLR models without STW had the lowest R2 (0.654, 0.504) and the highest RMSE (0.123, 0.142), and MAE (0.102, 0.119), respectively. When the ANN and MLR models are performed without TSW, their ability to predict BY appears to be severely reduced. Based on the sensitivity tests, TSW, RWC, and CC, in that order, were the most crucial variables for forecasting BY in both models. The sensitivity analysis provided a valuable insight of how different variables affected the yield. According to previous studies, TSW are still the most crucial factors having considerable impacts on BY51.
In addition to the three most important features to forecast BY, other qualities in the model (i.e. LAI, NI, and VA) explained roughly 28.2 percent and 23.1 percent of R2 in the ANN and MLR models, respectively. Based on the findings of the sensitivity testing, cultivars having early blooming, prolonged maturity, and a high TSW are excellent for enhancing BY when designing the proper structure. These early blooming cultivars are not likely to experience stress at this important phase, and if they are not exposed to drought and warm tension at the end of the growing season under rainfed conditions, they can continue their vegetative and reproductive growth.
Conclusion
In harsh environmental conditions, such as rainfed areas under heat and drought stress, the inheritance of quantitative polygenic features such BY is decreased significantly. In such circumstances, the genetic benefit of selection is decreased, and direct selection has a poor effect on the targeted feature. Applying modeling techniques to determine and combine indirect selection indications will help create a favorable design for the targeted feature, which is one way to overcome this difficulty. In order to achieve this, we created an ANN model as well as an MLR model to forecast BY using attributes chosen using PCA and SWR techniques (i.e. TSW, RWC, CC, LAI, NI, and VA). According to the findings, the ANN model with the Levenberg–Marquardt learning algorithm, tansig transfer function, and two hidden layers (i.e. structure 6–3–7–1) predicted the BY more accurately than the MLR. The capacity of the ANN model to detect complex and nonlinear effects, as opposed to the MLR model, may explain the advantage of the ANN model in forecasting BY. The ANN model could be a favorable alternative to classic modeling approaches like as path analysis, regression, and so on, due to the significant difference in efficacy of the two models in forecasting BY. Sensitivity analysis for both models revealed that STW was the most influential component in predicting BY, followed by RWC and CC, respectively. So, genotypes of sheep fescue with early flowering, long maturation, and high TSW are optimal for increasing BY. It appears that designing breeding strategies to produce plants with the above structure could open up a new window in the future evolution of this plant.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Change history
03 March 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-30816-4
References
Gullap, M. K., Erkovan, H. I. & Koc, A. The effect of bovine saliva on growth attributes and forage quality of two contrasting cool season perennial grasses grown in three soils of different fertility. Rangel. J. 33, 307–313 (2011).
Kwietniewski, H. Walory uzytkowe odmian gazonowych Festuca ovina wysiewanych w siewie czystym i mieszankach na trawnikach ozdobnych. Annales UMCS. Sec. E. 61, 389–396 (2006).
Ghorbani, A., Sharifi, J., Kavianpoor, A. H., Malekpour, B. & Gheshlagh, F. M. A. Investigation on ecological characteristics of Festuca ovina L. in south-eastern rangelands of Sabalan, Iranian. J. Range Desert Res. 20, 379–396 (2013).
Heijden, M. G. V. D., Boller, T., Wiemken, A. & Sanders, I. R. Different arbuscular mycorrhizal fungal species are potential determinants of plant community structure. Ecol. Soc. Am. 79, 2082–2091 (1998).
Abdipour, M., Younessi-Hmazekhanlu, M. & Ramazani, S. H. R. Artificial neural networks and multiple linear regression as potential methods for modeling seed yield of safflower (Carthamus tinctorius L.). Ind. Crop Prod. 127, 185–194 (2019).
Niazian, M., Sadat-Noori, S. A. & Abdipour, M. Artificial neural network and multiple regression analysis models to predict essential oil content of ajowan (Carum copticum L.). J. Appl. Res. Med. Aromat. Plants. 9, 124–131 (2018).
Ahmadi, J., Vaezi, B. & Pour-Aboughadareh, A. Assessment of heritability and relationships among agronomic characters in grass pea (Lathyrus sativus L.) under rainfed conditions. Biharean Biol. 9, 29–34 (2015).
Ghosh, A. & Khan, S. A. Determination of optimum sowing time of grass pea based on yield variation as affected by varied dates of sowing in new alluvial zone of West Bengal. Int. J. Agric. Environ. Biotechnol. 11, 11–15 (2018).
Kour, J. & Agarwal, N. Correlation and path coefficient analysis of yield components in advanced lines of Grasspea (Lathyrus sativus L.). Int. J. Stress Manag. 7, 682–686 (2016).
Sayar, M. S. Determining effect of seed yield components on seed yield by using path coefficient and correlation analysis in grass pea genotypes (Lathyrus sativus L.). Turkey 5th seed congress with international participation. 19–23 October 2014. 414 (2014).
Khairunniza-Bejo, S., Mustaffha, S. & Ismail, W. I. W. Application of artificial neural network in predicting crop yield: A review. J. Food Eng. 4, 1–9 (2014).
Niazian, M., Sadat-Noori, S. A. & Abdipour, M. Modeling the seed yield of Ajowan (Trachyspermum ammi L.) using artificial neural network and multiple linear regression models. Ind. Crop Prod. 117, 224–234 (2018).
Sabzalian, M. R., Khashei, M. & Ghaderian, M. Artificial and hybrid fuzzy linear neural network-based estimation of seed oil content of safflower. JAOCS J. Am. Oil Chem. Soc. 91, 2091–2099 (2014).
Mansouri, A., Fadavi, A. & Mortazavian, S. M. M. An artificial intelligence approach for modeling volume and fresh weight of callus–A case study of cumin (Cuminum cyminum L.). J. Theor. Biol. 397, 199–205 (2016).
Abdipour, M., Ramazani, S. H. R., Younessi-Hmazekhanlu, M. & Niazian, M. Modeling oil content of sesame (Sesamum indicum L.) using artificial neural network and multiple linear regression approaches. J. Am. Oil Chem. Soc. 95, 283–297 (2018).
Skawsang, S., Nagai, M., Tripathi, N. K. & Soni, P. Predicting rice pest population occurrence with satellite-derived crop phenology, ground meteorological observation, and machine learning: A case study for the central plain of Thailand. Appl. Sci. 9, 4846. https://doi.org/10.3390/app9224846 (2019).
Abdipour, M., Vaezi, B., Khademi, K. & Ghasemi, S. An optimized artificial intelligence approach and sensitivity analysis for predicting the biological yield of grass pea (Lathyrus sativus L.). Arch. Acker. Pel. Boden. 66, 1909–1924 (2020).
Mokarram, M. & Bijanzadeh, E. Prediction of biological and grain yield of barley using multiple regression and artificial neural network models. Aust. J. Crop Sci. 10, 895–903 (2016).
Kadir, M. K. A., Ayob, M. Z. & Miniappan, N. Wheat yield prediction: Artificial neural network based approach. In 2014 4th International Conference on Engineering Technology and Technopreneuship (ICE2T) (pp. 161–165). IEEE. (2014, August).
Niazian, M., Sadat-Noori, S. A., Abdipour, M., Tohidfar, M. & Mortazavian, S. M. M. Image processing and artificial neural network-based models to measure and predict physical properties of embryogenic callus and number of somatic embryos in ajowan (Trachyspermum ammi (L.) Sprague). In. Vitro Cell. Dev-PL. 54, 54–68 (2018).
Ghodsi, R., Yani, R. M., Jalali, R. & Ruzbahman, M. Predicting wheat production in Iran using an artificial neural networks approach. Int. J. Acad. Res. 2, 34–47 (2012).
Mutlu, A. C. et al. Prediction of wheat quality parameters using near-infrared spectroscopy and artificial neural networks. Eur. Food Res. Technol. 233, 267–274 (2011).
Safa, M., Nejat, M., Nuthall, P. L. & Greig, B. J. Predicting CO2 emissions from farm inputs in wheat production using artificial neural networks and linear regression models-Case study in Canterbury, New Zealand. Int. J. Adv. Comput. Sci. Appl. 7, 268–274 (2016).
Bocca, F. F. & Rodrigues, L. H. A. The effect of tuning, feature engineering, and feature selection in data mining applied to rainfed sugarcane yield modelling. Comput. Electron. Agr. 128, 67–76 (2016).
Movahed, F. B., Jafari, A. A. & Moradi, P. Investigation on variation and relationships among seed yield and its components in sheep fescue (Festuca ovina) under irrigation and dryland farming conditions, Zanjan, Iran. Iranian J. Range Desert Res. 20, 309–319 (2013).
Lichtenthaler, H. K. & Wellburn, A. R. Determination of total carotenoids and chlorophyll a and b of leaf extract in different solvents. Biochem. Soc. T. 11, 591–592 (1983).
Gower, S. T., Kucharik, C. J. & Norman, J. M. Direct and indirect estimation of leaf area index, fAPAR, and net primary production of terrestrial ecosystems. Remote Sens. Environ. 70, 29–51 (1999).
Ritchie, S. W. & Nguyen, H. T. Leaf water content and gas exchange parameters of two wheat genotypes differing in drought resistance. Crop Sci. 30, 105–111 (1990).
Mesdaghi, M. Plant ecology (Jahad Daneshgahi of Mashhad Press, 2014).
Moameri, M., Jafari, M., Motasharezadeh, B., Chahouki, M. A. Z. & Diaz, F. M. Investigating lead and zinc uptake and accumulation by Stipa hohenackeriana trin and rupr. in field and pot experiments. Biosci. J. 34, 138–150 (2018).
Gulluoglu, L., Arioglu, H., Bakal, H. & Bihter, O. N. A. T. Effect of high air and soil temperature on yield and some yield components of peanut (Arachis hypogaea L.). Turk. J. Field Crops 23, 62–71 (2018).
Emamgholizadeh, S., Parsaeian, M. & Baradaran, M. Seed yield prediction of sesame using artificial neural network. Eur. J. Agron. 68, 89–96 (2015).
Mathworks I. MATLAB and statistics toolbox release 2018a. Natick (Massachusetts, United States) (2018).
Azadeh, A., Ghaderi, S. & Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manage. 49, 2272–2278 (2008).
Farjam, A., Omid, M., Akram, A. & Fazel Niari, Z. A neural network based modeling and sensitivity analysis of energy inputs for predicting seed and grain corn yields. J. Agr. Sci. Tech-IRAN 16, 767–778 (2014).
Heidari, A., Arab, M. & Damari, B. Application of artificial neural network for modeling benefit to cost ratio of broiler farms in tropical regions of Iran. Res. J. Appl. Sci. 3, 546–552 (2011).
Colwell, J. D. Estimating Fertilizer Requirements: A Quantitative Approach (CAB International, 1994).
Parimala, K. & Mathur, R. Yield component analysis through multiple regression analysis in sesame. Int. J. Agric. Sci. 2, 338–340 (2006).
Xia, C., Yang, Z., Lei, B. & Zhou, Q. August. SCG and LM improved BP neural network load forecasting and programming network parameter settings and data preprocessing. In 2012 International Conference on Computer Science and Service System (pp. 38–42). IEEE. (2012).
Mansourian, S., Izadi Darbandi, E., Rashed Mohasse, M. H., Rastgoo, M. & Kanouni, H. Comparison of artificial neural networks and logistic regression as potential methods for predicting weed populations on dryland chickpea and winter wheat fields of Kurdistan province, Iran. Crop Prot. 93, 43–51 (2017).
Hagan, M. T., Demuth, H. B. & Jesús, O. D. An introduction to the use of neural networks in control systems. Int. J. Robust. Nonlin. 12, 959–985 (2002).
Ahmadi, S. H. et al. Modeling root length density of field grown potatoes under different irrigation strategies and soil textures using artificial neural networks. Field Crops Res. 162, 99–107 (2014).
Alvarez, R. Predicting average regional yield and production of wheat in the Argentine Pampas by an artificial neural network approach. Eur. J. Agron. 30, 70–77 (2009).
Elhami, B., Khanali, M. & Akram, A. Combined application of Artificial Neural Networks and life cycle assessment in lentil farming in Iran. Inf. Process. Agric. 4, 18–32 (2017).
McCulloch, W. S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5, 115–133 (1943).
Zeng, W., Xu, C., Wu, J. & Huang, J. Sunflower seed yield estimation under the interaction of soil salinity and nitrogen application. Field Crop Res. 198, 1–15 (2016).
Gholipour, M., Rohani, A. & Torani, S. Optimization of traits to increasing barley grain yield using an artificial neural network. Int. J. Plant Prod. 7, 1–18 (2013).
Ji, B., Sun, Y., Yang, S. & Wan, J. Artificial neural network for rice yield prediction in mountainous regions. J. Agr. Sci. 145, 249–261 (2007).
Singh, T., Kanchan, R., Verma, A. & Singh, S. An intelligent approach for prediction of triaxial properties using unconfined uniaxial strength. Min Eng J. 5, 12–16 (2003).
Kaul, M., Hill, R. L. & Walthall, C. Artificial neural networks for corn and soybean yield prediction. Agr. Sys. 85, 1–18 (2005).
Haghighi, A.R., Moghaddam, M., Valizadeh, M. & Javanshir, A. Path analysis of yield and related characteristics for Grass pea (Lathyrus sativus) landraces under rainfed and irrigated conditions. Proceedings of the Canadian journal of plant science; Agricultural INST Canada 280 Albert ST, Suite 900, Ottawa, Ontario K1P 5G8 (2006).
Acknowledgements
The authors would like to appreciate the University of Mohaghegh Ardabili for providing facilities during the research period.
Author information
Authors and Affiliations
Contributions
M. A. and A. GH Conceived the experiments and conducted field work. E.J and M.M. performed the experiments. M. A. analyzed the data. E. J. and M.M. wrote the manuscript. M. M., E. J., M.A., and M. A. provided editorial advice.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: In the original version of this Article, Moslem Abdipour was omitted as a corresponding author. Correspondence and requests for materials should also be addressed to abdipur.m@gmail.com.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khalaki, M.A., Jahantab, E., Abdipour, M. et al. An efficient estimation of crop performance in sheep fescue (Festuca ovina L.) using artificial neural network and regression models. Sci Rep 12, 20514 (2022). https://doi.org/10.1038/s41598-022-25110-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-25110-8
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
