
Abstract
There is broad interest in discovering quantifiable physiological biomarkers for psychiatric disorders to aid diagnostic assessment. However, finding biomarkers for autism spectrum disorder (ASD) has proven particularly difficult, partly due to high heterogeneity. Here, we recorded five minutes eyes-closed rest electroencephalography (EEG) from 186 adults (51% with ASD and 49% without ASD) and investigated the potential of EEG biomarkers to classify ASD using three conventional machine learning models with two-layer cross-validation. Comprehensive characterization of spectral, temporal and spatial dimensions of source-modelled EEG resulted in 3443 biomarkers per recording. We found no significant group-mean or group-variance differences for any of the EEG features. Interestingly, we obtained validation accuracies above 80%; however, the best machine learning model merely distinguished ASD from the non-autistic comparison group with a mean balanced test accuracy of 56% on the entirely unseen test set. The large drop in model performance between validation and testing, stress the importance of rigorous model evaluation, and further highlights the high heterogeneity in ASD. Overall, the lack of significant differences and weak classification indicates that, at the group level, intellectually able adults with ASD show remarkably typical resting-state EEG.
Similar content being viewed by others

Introduction
Autism spectrum disorder (ASD) is defined by persistent differences in social interactions, atypical sensory reactivity, and restricted and repetitive behavior1. High heterogeneity exists among individuals receiving the diagnosis, since the criteria allow a broad spectrum of symptoms, and the neural mechanisms underlying ASD remain unclear. To elucidate the neurobiological mechanisms behind ASD, many studies have used neuroimaging2,3,4. Discovery of biomarkers for ASD has the potential to support diagnosis and might disentangle the heterogeneity5. Recently, there has been a growing interest in discovering resting-state electroencephalographic (EEG) biomarkers for various neuropsychiatric conditions, as EEG has good clinical practicality, due to being non-invasive, portable, widely available, and low cost.
Many different resting-state EEG features have been investigated in regards to ASD, with spectral power being the most commonly used feature. Decreased theta power6, alpha power7,8,9,10 and gamma power have been observed in ASD11,12. However, increased alpha power13 and gamma power have also been reported in ASD14. Other spectral features, e.g., peak alpha frequency15, theta/beta ratio16 and asymmetry17 have also been associated with ASD. Besides spectral features, abnormal functional connectivity18, microstates19, and measurements of criticality20,21 have also been found in ASD. The role of each individual feature and their implications on ASD are outside the scope of this paper (for reviews, see2,3,22).
In addition to identifying group mean differences of resting-state EEG features in ASD, many recent studies also investigated the potential of classifying ASD with predictive machine learning models. The advantages of predictive modelling is that it is optimized for predicting new subjects or future outcomes, which aligns with the goal of diagnostic/prognostic tools23. Different models and features have been employed, e.g., discriminant function analysis using spectral power have yielded 90% accuracy16 and using coherence 87% balanced accuracy was obtained24. K-nearest neighbor using alpha power resulted in 96.4% accuracy, and support vector machines (SVM) have also been utilized with alpha power and peak alpha frequency and achieved 93% accuracy15. SVM have also been employed on recurrence quantification analysis features, which resulted in 92.9% accuracy25, and on 20 features consisting of some descriptive statistics (e.g. mean and variance), spectral power, Hjorth parameters and entropy features, which resulted in 93.8% accuracy26. Besides conventional machine learning models, artificial neural networks have also been used for classification of ASD and obtained 94.8%27, 97.2%28 and 100%29,30,31 accuracy. However, not all studies have reported such promising results, one study using discriminant function analysis with spectral power obtained 64.5% balanced accuracy32, and another study using SVM with spectral power obtained 68% accuracy33. A recently published paper using SVM on spectral power and coherence in over 400 subjects also reported around 57% accuracy34. The differences in classification performances may relate to the heterogeneity and complexity of ASD5; however, other sources of uncertainty about the exact classification performance include low sample sizes, imbalanced datasets, and lack of an unseen test dataset. Specifically, some of the machine learning studies did not use an independent test set or cross-validation to split the data10,25,33 or only used a single layer of cross-validation for training, hyperparameter tuning and testing26,27,29,31,35. Both of these situations are problematic due to the evaluated classification performances being likely to be overestimated due to overfitting (reviewed in36,37,38,39). Additionally, only five of the resting-state EEG studies classifying ASD investigated more than 100 subjects15,16,24,32,34, thus currently there is no clear consensus about the physiological resting-state EEG correlates of ASD.
To disentangle the potential role of resting-state EEG biomarkers for characterization of ASD, the present study estimated many of the commonly used resting-state EEG features that have shown promising results. Specifically, we source-modelled the EEG time series and computed spectral features (power, asymmetry, theta/beta ratio, peak alpha frequency and 1/f exponent), measures of criticality (long-range temporal correlations [DFA exponent] and functional excitation inhibition ratio [fEI]) and functional connectivity (coherence [Coh], imaginary part of coherence [Imcoh], phase locking value [PLV], weighted phase lag index [wPLI] and power envelope correlations [PEC]). A relatively large sample size of 186 participants were recruited and feature selection methods and machine learning models were applied to evaluate the biomarker potential of the selected EEG features in distinguishing between individuals with and without ASD. To not have our results be dependent on one particular machine learning model, we trained variations of three commonly used classifiers, namely support vector machine (SVM), logistic regression with L1 and L2 norm and random forest. Additionally, to obtain a robust evaluation of the model performances, we employed repeated two-layer cross-validation, in order to train the models on a training set, estimate hyperparameters on a validation set and finally evaluate the generalization performance on an unseen separate test set (see Fig. 1 for overall analysis framework). To our knowledge, no studies aiming to predict ASD using resting-state EEG with machine learning have employed such a comprehensive EEG biomarker set, and stringent repeated cross-validation scheme for evaluating their models.

Overview of the EEG analysis framework. The EEG data was preprocessed and source modelled, followed by estimation of commonly used EEG biomarkers. Repeated 10-by-10 two-layer cross-validation was performed to split the data. Feature selection, model training and hyperparameter tuning were performed on the inner fold training and validation set, while the generalization performance was evaluated on the entirely unseen test set. Logistic regression, random forest, and support vector machine were employed to classify ASD.
Results
Multiple EEG features exhibited correlation with age
For each EEG feature type, we computed how many features were significantly correlated with age after false discovery rate (FDR) correction (Pearson’s correlations, \(p<\) 0.05) and observed that spectral power, theta/beta ratio, 1/f exponents and PEC had greater than chance-level correlations with age. Table 1 shows the percentage of all features within each feature type that were significantly correlated with age.
Further investigation revealed that the correlations between power, PEC and age were frequency-band dependent. Specifically, absolute delta, theta and alpha power, relative beta and gamma power, and delta PEC exhibited high correlations with age. To take into account the difference in age between the ASD and non-autistic comparison groups, we removed the linear trend for 1/f exponents, theta/beta ratio, and power and PEC in the above-mentioned frequency bands. Figure 2 show examples of the strongest correlations with age for each of the highlighted feature types prior to age-effect correction.

Several EEG features exhibit age dependence. Scatter plots illustrating correlations between age and (a) Absolute Power, (b) Theta/Beta Ratio, (c) 1/f exponent, and (d) PEC of source-modelled signals.
The importance of correcting for age-related effects can be observed when evaluating the mean differences in 1/f exponents between the ASD and non-autistic comparison group before and after age correction. Without age-effect correction, the 1/f exponents were significantly lower in the ASD group (Fig. 3a,c). However, this effect was confounded by the negative correlation between age and 1/f exponents (Fig. 2c), which becomes apparent after age-effect correction, where no significant effects were observed in 1/f exponents between the ASD and non-autistic comparison group (Fig. 3b,d).

The effect of age on 1/f exponents. (a,c) Prior to age-effect correction of 1/f exponents, we observed a significant difference in group-means. (b,d) However, this effect was confounded by age, as evident by the lack of significant effects after we corrected for the age-effect. Mean with 95% confidence intervals are shown.
The ASD and non-autistic comparison group did not differ in group-mean or group-variability
No EEG features differed significantly between the ASD and non-autistic comparison group after age-effect correction (Figs. 4 and 5). We performed permutation tests with FDR correction for each feature type separately, but did not observe any significant difference between the two groups (\(p>\) 0.05 for all features).
Considering the large variation in symptomatology in ASD, it is plausible that the ASD and non-autistic comparison groups would show differences in variability in spite of the lack of mean differences. However, using Levene’s test with FDR correction for each feature type separately, we did not observe any significant difference in variability between the two groups (\(p>\) 0.05).

The ASD and non-autistic comparison groups have similar quantitative EEG features. Representative examples of computed EEG feature values averaged across the brain regions for: (a) Absolute Alpha Power, (b) Alpha Asymmetry, (c) Peak Alpha Frequency, (d) Theta/Beta Ratio, (e) Alpha DFA exponents, and (f) Alpha fEI. Mean with 95% confidence intervals are shown.

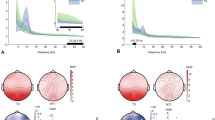
The ASD and non-autistic comparison groups have similar connectivity patterns. Examples of the mean (a) Coherence, (b) Phase Locking Value, (c) Imaginary Coherence, (d) Weighted Phase Lag Index, and (e) Power Envelope Correlations for the ASD and non-autistic comparison group, their difference, and correlation in the alpha band. The closer the points are to the diagonal line in the correlation plots, the better the correlation between the group-mean connectivities. Self-connectivity was excluded, hence the insular regions, which only contain one patch in each hemisphere, are colored black to reflect the missing value (see “Methods”). Pearson’s correlation was used to compute r. MAE, mean absolute error.
Machine learning models based on EEG features predicted ASD around chance-level
The statistical tests indicated that each individual EEG feature was not significantly different between the two groups. To investigate whether combinations of features could potentially serve as biomarkers for prediction of ASD, we employed multivariate machine learning models. To estimate how well the models would potentially predict on new unseen subjects, we trained and tested using two-layer cross-validation. The data was divided into a training set, which the model was trained on, a validation set, which was used to tune the hyperparameters, and a test set, which was the unseen data that was used to estimate the generalization performance of the models. Although we obtained decent training and validation accuracies, the performance dropped to around chance-level for most of the models when tested on completely unseen data. The best full classifier, which had access to all the features, was logistic regression with L1 regularization with a balanced test accuracy of 50.0%. None of the four full classifiers performed better than chance.
We also tested each feature type separately, i.e., the same four classifiers were applied, but the feature selection was limited to each individual feature type. Here, the best classification performance was obtained by logistic regression with L1 regularization using peak alpha frequency with a balanced test accuracy of 55.8% (Fig. 6), followed by PLV with a balanced test accuracy of 55.1% and fEI with a balanced test accuracy of 53.7%. All three feature types performed significantly better than chance (one-sided Wilcoxon signed-rank test \(p<\) 0.05), albeit the effects were small. Additionally, the performance of both peak alpha frequency and PLV was significantly better than chance-level in three out of the four classifiers, while fEI performed better than chance-level in two out of the four classifiers (See Supplementary Table S1 for the performance of all combinations of features and classifiers).

Performance of each feature type with logistic regression with L1 regularization. The logistic regression with all features are shown on the left, followed by the performances of each individual feature type, sorted according to average balanced test accuracy (green points). The dashed line indicates chance-level performance. Most of the feature types displayed significant training (red points) and validation (blue points) accuracies, which did not survive when tested on completely unseen data (cf. Fig. 7). Mean with 95% confidence intervals are shown.
Mean-level predictions of AQ and SPQ
Besides classifying ASD, we also investigated if combinations of EEG features would be able to predict the autism-spectrum quotient short questionnaire (AQ) score and the visual and auditory scores of the sensory perception quotient short questionnaire (SPQvis and SPQaud) using linear regression. The best full model was linear regression with L1 regularization, which obtained a normalized mean absolute error (nMAE) of 1.051 for AQ. None of the models with access to all features obtained a nMAE below 1, hence they did not perform better than predicting the mean on any of the questionnaire scales. We also tested each feature type separately and found the best performance for linear regression with L1 norm using fEI, which obtained a test nMAE of 0.960 for prediction of AQ. This result was significantly better than mean prediction (one-sided Wilcoxon signed-rank test p < 0.05), suggesting that fEI variability may be related to autism severity. However, no significant correlations between fEI and AQ were found after FDR correction, and the prediction was merely 4% better than the mean prediction MAE. The only other feature type with better than mean-level predictions was the theta/beta ratio, which obtained a test nMAE of 0.993 using linear regression with L1 regularization, and a test nMAE of 0.979 using linear regression with L2 regularization for AQ prediction. All other features did not perform better than predicting the mean on any of the questionnaire scales (see Supplementary Table S2 for the performance of all combinations of features, regression models, and target variables).
Discussion
In spite of many attempts to identify EEG correlates of ASD, there is a lack of consistency of measures used and findings reported (for reviews, see2,3,22). With the aim of finding something more robust, we recruited, to our knowledge, one of the largest single-center adult ASD cohorts, and tested a comprehensive set of EEG features and machine learning models using two-layer cross-validation. This approach reinforced the picture that intellectually able adults with ASD show remarkably typical resting-state EEG. No significant group-mean or group-variance differences were observed between the ASD and non-autistic comparison group across the 3443 features investigated after FDR correction within biomarker types, which is in agreement with the visual inspection of biomarkers showing only minute differences in means (Fig. 4). Correspondingly, our machine learning models only performed slightly better than chance-level.
One caveat with an exploratory analysis involving many different features is the need for multiple testing correction, which might have resulted in a relatively lower statistical power compared to studies conducted in a hypothesis-driven paradigm. However, to not be too conservative and be more relatable to the other resting-state EEG studies, we only corrected for the number of features within each feature type separately, and even with this consideration, we still did not achieve any significant group-mean or group-variance differences. Visual inspection of distributions of EEG feature values (e.g. Fig. 4) also did not invoke the impression that the lack of significance is due to harsh multiple comparison correction.
Furthermore, the primary aim of our study was not to identify group-mean differences within single features, but to combine the many different features, and utilize machine learning to infer which combinations of features might have potential value as biomarkers for ASD. Even if each individual feature has small effect sizes, they might still provide relevant predictive information if they are combined in a multivariate model40. However, our machine learning models were unable to find an EEG pattern characteristic for the ASD group.
This is inconsistent with some of the studies using machine learning on resting-state EEG in ASD which reported classification accuracies above 87%15,16,24,25,26,27,28,29,30,31. However, the evaluation of the model performances were problematic in some of the studies. Two studies10,33 did not perform any cross-validation, which means they trained and tested on the same data and this has the caveat of the models overfitting to the data, which would result in the models being unable to generalize to new data36,37,38,39. Thus the reported performance of their models would correspond to the high training accuracies we observed (e.g. the red points in Fig. 6). The other studies employed cross-validation, but some performed feature selection on the whole data before splitting the data30,31, which means information leakage might have occurred, and the reported classification performances might be over-estimated. Another potential information leakage problem was observed in a study that split the data based on epochs, hence the same subjects might occur in both the training and test sets25. Some studies also only employed a single layer of cross-validation, despite having hyperparameters that should be tuned26,27,29,31,35. If a single layer of cross-validation is used for training and tuning, then there is no test set to estimate how well the model would generalize to new unseen subjects (reviewed in37). It would correspond to the validation accuracies we observed, where we obtained more than 80% accuracy in multiple folds using the model with all features (e.g. the blue points in Fig. 6).
Nonetheless, it is also important to stress that a single layer of cross-validation is enough if no hyperparameters are tuned, e.g., if the models do not have hyperparameters16,24,32, or if default values for hyperparameters are selected a priori (reviewed in37). Since our models had hyperparameters, we employed two-layer cross-validation to obtain a robust estimation of the predictive performance of our machine learning models. The hyperparameters and number of features were tuned in the inner layer, and we tested the generalization performance in the outer layer. Surprisingly, although we obtained decent validation performances with some models achieving above 80% validation accuracies, there was a large drop in performance when we evaluated on entirely unseen data, to the point where our best models merely performed slightly better than chance-level, further highlighting the importance of rigorous model evaluation. This finding is consistent with a recently published EEG study on ASD that obtained up to 57% balanced accuracy for ASD, when testing on unseen data using a nested cross-validation scheme34. Interestingly, we observed a high variance in test accuracies, reflecting how big an impact the exact split of the data could have on our machine learning models.
One of the most common arguments for inconsistent results across different studies is that methodological differences confound the results. However, the high variation we observed in test accuracies suggest that even if the facilities, equipment, preprocessing steps, algorithms, and researchers are the same, the results can still vary substantially based on the specific participants in the sample. Specifically, we obtained performance values ranging from not better than chance-level up to around 80% balanced test accuracy on classifying ASD. This clearly highlights the highly heterogeneous nature of ASD, and combined with differing recruitment methods, facilities, analysis methods and relatively small sample sizes in clinical ASD EEG studies, it is not surprising that inconsistent findings occur, and that robust neural biomarkers have not yet been found for ASD. The high variance in test accuracies also stress the importance of rigorous model evaluation schemes, e.g. two-layer cross-validation for models with hyperparameters37, for identification of robust biomarkers.
The problem with small sample sizes not being representative of the clinical population is also clearly illustrated by the paradox that machine learning models seem to perform worse on more neuroimaging data23,41. This negative correlation with sample sizes does not mean that the models trained on more data are worse, but instead that with few samples the models are more likely to overfit to bias within the sample, that is not reflective for the whole clinical population. Thus, subtle within group differences might be misinterpreted as between group differences. Additionally, this issue might be further inflated by publication bias42.
Apart from methodological differences, there are theoretical considerations that should be taken into account as well. The definition of ASD has become a topic of interest recently for three reasons: Firstly, ASD prevalence has more than tripled in recent years, from 0.67% in the year 2000 to 2.3% in 201843. Secondly, the criteria for ASD according to the DSM has changed considerably in the past decades, most prominently between its fourth and fifth edition where multiple previously distinct conditions have been merged into the current condition “Autism Spectrum Disorder”. Thirdly, it has been shown that psychological and neurological effect sizes in ASD research have been continually decreasing in the past decades while no such effect was shown for schizophrenia research44. While the increase in ASD prevalence could be attributed to an increased public awareness or other external factors such as pollution45, it can also partly be attributed to ASD being used for a broader spectrum of symptoms and disorders. The increased heterogeneity could partly explain the decreased effect sizes in ASD research, since higher heterogeneity would result in increased within group variance46. Our results also support the notion of high heterogeneity in ASD.
We acknowledge that the present study has limitations. The machine learning models were trained on commonly used EEG features and are thus dependent on these specific feature types. We developed a comprehensive framework to encompass a broad number of feature types to investigate whether each feature or combinations of features could characterize ASD, but other combinations of EEG features remain unexplored, e.g., graph theory based network metrics, entropy, and microstates have also been associated with ASD47,48,49.
Another limitation to the present study is the experimental paradigm. We investigated the EEG activity during 5 min eyes-closed rest, which might be different from eyes-open rest or task-based paradigms50. One previous study found group differences in alpha power and coherence during eyes-open EEG in adults with ASD, but not in the eyes-closed condition13.
The study sample should also be highlighted. The ASD group is comprised of adults with average or above average intelligence, often employed, late-diagnosed and well educated, while many previous ASD EEG studies focused on children. Therefore, discrepancies between our results and studies investigating children with ASD might occur; e.g., in a previous study, we observed that children with ASD had greater group-mean DFA and higher variability in DFA and fEI20, but this result was not observed in the sample investigated in this study. One might argue that because many individuals in the ASD group were not diagnosed at an early age, they might have less pronounced autistic traits or been better at compensatory strategies, however, we did not see an association between AQ score and age of diagnosis (Supplementary Fig. S1). AQ is a self-report measure of autistic trait, but the only quantitative measure of autism severity available uniformly from all participants.
It should also be highlighted that both our ASD and non-autistic comparison group included 57% and 54% females, respectively. This is higher than the general autistic population, which has a strong male bias. The participants in this study were recruited based on voluntary sign-up and, historically, females volunteer more readily for such activities. Although our female bias might make the results less relatable to other studies with a strong male bias, there were also benefits of having a relatively gender balanced dataset. The machine learning models that we trained would be less likely to be better at classifying males relatively to females due to discrepancies in number of training samples.
Overall, our results indicate that intellectually able adults with ASD have eyes-closed resting-state EEG activity within the typical range. This does not necessarily mean that resting-state EEG traces contain no meaningful information about ASD, however, the electrophysiological effects were likely too subtle to be picked up by our models relative to the high heterogeneity in ASD, even with a sample size of close to 200 participants. Future studies should try to increase effect sizes or mitigate the effect of heterogeneity by increasing sample sizes to better represent the whole ASD population and/or look for prototypes46,51 or distinct subtypes within ASD. Identification of subtypes might improve diagnosis and enable better tailored treatment on an individual/subgroup level23,41,52. Differences might also be more prominent during specific tasks targeted at the autistic traits, e.g. crucial differences could be picked up by employing interactive paradigms, and studying interpersonal mechanisms in ASD53,54,55,56,57,58. Encompassing longitudinal data or data from multiple modalities might also increase effect sizes40, e.g., combining genetics (heritability was estimated to be around 83% for ASD59), neuroimaging, psychological, and social information. The analysis framework we developed can be readily expanded to integrate with all of these modalities and support the development of a biopsychosocial model for ASD60,61.
Methods
Participants
The participants were part of a larger project investigating mechanisms underlying ASD in adults and recruited through the Netherlands Autism Register (NAR62). Upon registration, autistic adult participants of the NAR confirmed that they have a clinical diagnosis of autism spectrum disorder (ASD) as established by an authorized professional (e.g., psychiatrist/psychologist) based on Diagnostic and Statistical Manual of Mental Disorders (DSM-IV63 or DSM-51). Specifically, inclusion criteria for the ASD cohort were a clinical diagnosis of ASD (according to DSM-5), Asperger’s syndrome, pervasive developmental disorder-not otherwise specified, autism (according to DSM-IV), and age between 18 and 55 years. Exclusion criteria for the non-autistic comparison group was a diagnosis of ASD or a diagnosis of ASD in a direct family member. The clinical professionals worked independently from the authors, and who were unaware of the goals and outcomes of this study. The diagnostic process included anamneses, proxy reports, and psychiatric and neuropsychological examinations. Individuals have to confirm their autism diagnosis and disclose additional information on when, where, and by whom (psychiatrist/psychologist) the diagnosis was determined, as well as the measure used (ADOS or ADI-R)64. Moreover, official proof of autism diagnoses could be obtained for a subsample of individuals in the NAR. Patterns of functioning in this group were similar to the rest of the sample64. Additionally, previous findings on the validity of parent-reported autism diagnosis to a web-based register supports the validity of the register diagnosis65. Of the autistic participants, 53% had paid employment, 41% were married or in a relationship (7% were divorced), 7% lived with their parents or in residential care. A more detailed description of the adult participants of the NAR can be found in Scheeren et al. 202266. Table 2 presents the characteristics of the included participants. The protocol of this study was approved by the ethics committee of the VU University Medical Center (approval number 2013/45). The study was conducted in accordance with the guidelines and regulations approved by the respective ethical committee and in compliance with the provisions of the declaration of Helsinki. All participants provided informed consent and were financially reimbursed. Data and scripts from this study are available upon request.
Clinical measures
Autism-spectrum quotient short questionnaire
The autism-spectrum quotient short questionnaire (AQ67) is an abridged version of the autism-spectrum quotient68. It consists of 28 self-report items, which can be clustered into two main factors: Social Behavior, and Numbers and Patterns. The items under Social Behavior can further be divided into the subfactors: Social Skills, Routine, Attention Switching, and Imagination. All items are scored on a four-point Likert scale and range from “Definitely agree” to “Definitely disagree”. The items are summed to obtain total AQ scores. Higher AQ score suggest more autistic traits.
Sensory perception quotient short questionnaire
The sensory perception quotient short questionnaire (SPQ69,70) is a 35-item self-report assessing sensory perception of touch, smell, vision, hearing, and taste. We only used the items pertaining to the factors vision (6 items) and hearing (5 items). All items are scored on a four-point Likert scale and range from “Strongly agree” to “Strongly disagree”. The items are summed to obtain factor scores (SPQvis and SPQaud). Lower scores on the SPQ suggest a lower sensory threshold, thus higher sensory sensitivity.
EEG acquisition
Resting-state EEG was recorded during 5 min of eyes-closed rest with a 64-channel BioSemi system sampled at 2048 Hz. The participants received the instructions: “Please keep your eyes closed, relax, and try not to fall asleep”. Impedance across all electrodes was kept below 5 k\(\Omega\). Additionally, four electrodes were placed at the left and right outer canthi to capture horizontal eye movements, and an electrode underneath each eye for vertical eye movements and blinking.
EEG pre-processing
The EEG data were processed using MNE-Python 0.24.371. First, the data were band-pass filtered at 1–100 Hz, notch filtered at 50 Hz, downsampled to 500 Hz, and divided into 4 s epochs without overlap. Bad epochs and channels with gross non-ocular artefacts were rejected by visual inspection. The data were re-referenced to the common average and ocular and ECG artefacts were removed using Piccard independent component analysis72 with the number of components set to 32. Autoreject 0.2.273 was employed to catch any remaining artefacts, which guided a final visual inspection. Subjects with less than 2 min of clean signal were excluded from further analysis (n = 3), resulting in a total sample size of 95 ASD and 91 non-autistic participants. The EEG features were estimated in the five canonical frequency bands: delta (1.25–4 Hz), theta (4–8 Hz), alpha (8–13 Hz), beta (13–30 Hz), and gamma (30–48 Hz), unless otherwise stated.
EEG source localization
We used L2 minimum norm estimation, as implemented by MNE-Python, to obtain cortical current estimates from our sensor level data. The FreeSurfer average brain template from FreeSurfer 674 was used to construct the boundary element head model and forward operator for the source modelling. The regularization parameter was set to \(\lambda ^2=1/9\). A diagonal matrix with 0.2 V values was used for the covariance matrix, which was the default values for EEG provided by MNE-Python. Unconstrained orientations were allowed, and principal component analysis was employed on the whole source time series at each vertex to reduce the three-dimensional signals to one-dimensional time series of the dominant principal component. The time series of the 20484 source vertices were further collapsed into 68 cortical patches based on the Desikan Killiany atlas, by first aligning the dipole orientations by shifting vertices with opposite polarity to the majority of vertices by \(\pi\), followed by averaging the amplitudes of all vertices within a patch. The phase shifting prevents the vertices with opposite polarities from canceling each other out during the averaging operation. Some of the estimated EEG features were computed across cortical brain regions, i.e., patches within frontal, parietal, temporal, occipital, cingulate, and insular regions were averaged. The individual patches were mapped to the brain regions according to the appendix in Klein et al., 201275.
EEG feature estimation
A brief description of each EEG feature type is provided (see Fig. 1 for overview of all features), as all the estimated features are already well-established. More detailed information and equations can be found in the supplementary information.
Spectral analysis
Multitaper spectral estimation76 was employed to estimate absolute and relative power in the five canonical frequency bands. EEG power asymmetry was calculated by subtracting each left hemispheric patch from the corresponding patch in the right hemisphere77, followed by averaging across the brain regions. Theta/beta ratio was computed by dividing theta power by beta power and averaged in brain regions. Peak alpha frequency and 1/f exponent was estimated using the FOOOF algorithm78. In total we estimated 680 power features, 6 theta/beta ratios, 30 asymmetry features, 69 peak alpha frequency features, and 68 1/f exponents.
Criticality
Long-range temporal correlations79 were estimated following the detrended fluctuation analysis (DFA) procedure described in Hardstone et al., 201280 to obtain DFA exponents. Functional excitation/inhibition ratio (fEI) was estimated according to Bruining et al., 202020. In total we estimated 345 DFA and fEI features, one for each brain patch and a global averaged value in each of the five frequency bands.
Functional connectivity
All functional connectivity measurements were computed for all pairwise combinations of the 68 brain patches. This yields 2346 connections, which results in 56,950 features when taking into account all connections are calculated for every frequency bands and five different connectivity measurements. This vast number is many times higher than the number of subjects we have, which can lead to overfitting for the machine learning models (also known as curse of dimensionality81). To reduce the number of dimensions, we averaged the connectivity measurements across patches within brain regions and for each hemisphere, e.g., the connectivity between the frontal-lh and parietal-rh brain regions were computed as the average connectivity between all the brain patches located in the frontal-lh with all the brain patches located in the parietal-rh. When computing intra-regional connectivity, e.g., frontal-lh with frontal-lh, we again computed the average connectivity between all the brain patches located with the frontal-lh, but excluded self-connectivity for patches, i.e., the same brain patch with itself was not considered. Specifically for the insular regions, which only contained one brain patch, no intra-regional connectivity was estimated. In total we reduced the number of connections to 76, which across the five frequency bands amount to 380 features for each of the five connectivity feature types, resulting in a total of 1900 features.
Coherence (Coh) was calculated as the magnitude of the cross spectrum between two signals divided with the square root of the product of each signal’s power spectrum for normalization82. The imaginary part of coherence (Imcoh) was also used as a standalone feature, due to its lower sensitivity towards volume conduction83. We also computed the phase locking value (PLV), which measures connectivity as a function of phase difference variability84, and weighted phase lag index (wPLI), which also measures phase synchronization but is less sensitive towards volume conduction85. Lastly, power envelope correlations (PEC) were estimated following Toll et al., 202086.
Prediction
All the EEG features were combined and turned into a data matrix of number of subjects by 3443 features. Given that there were more features than samples, and in order to decrease the dimensionality and reduce overfitting81, we applied multiple dimensionality-reduction methods. First, minimal-redundancy-maximum-relevance (mRMR87) was applied to each EEG feature type to attenuate the effect of imbalance in the number of features between each of the EEG feature types. To not have our results be dependent on one particular machine learning model, we trained variations of three commonly used machine learning models to predict ASD: (1) support vector machine (SVM) with recursive feature elimination, (2) logistic regression with Ridge regularization (L2) and sequential forward selection, (3) logistic regression with Lasso regularization (L1) and (4) random forest. For prediction of questionnaire scores, we employed linear regression with either L1 or L2 norm. Model training, hyperparameter tuning and evaluation of the models were conducted in a stratified 10-by-10 fold two-layer cross-validation scheme repeated 10 times to take into account the effect of random splits, resulting in 100 final models (10 repetitions of 10-fold outer cross-validation; Fig. 7). The stratification ensured the proportion of people with ASD were balanced across folds. Balanced accuracy, the mean of sensitivity and specificity, was estimated for the classifier performances. A balanced accuracy around 50% indicates chance-level prediction for a two-class classification. Normalized mean absolute error (nMAE), the ratio of MAE of the model to the MAE obtained when predicting the mean value of the training set, was computed for evaluation of the regression models. A nMAE = 1 indicates prediction around the level of just predicting the mean, while a lower nMAE indicates superior performance compared to predicting the mean value.
All model hyperparameters were tuned in the inner cross-validation fold on the validation set with grid search. Specifically, we tested the performance of using 10, 20, 30 or 40 features in mRMR, 16 values on a logarithmic scale from 0.01 to 1000 for the regularization parameter C for logistic regression, 13 values on a logarithmic scale from 0.001 to 1 for SVM, and 10, 50, 100, 500 or 1000 trees with depths 1 or 2 in random forest. The range of the hyperparameters were determined during preliminary analysis of when the models started to overfit and the step sizes were designed with the computational time in mind. We used mlxtend 0.19.088 for sequential forward selection, scikit-learn 1.0.189 for the implementation of cross-validation and the machine learning models, and a python implementation of mRMR90.

Schematic of the repeated two-layer cross-validation scheme. In order to obtain robust and reliable estimations of how well the machine learning models would perform on unseen data, we employed 10 repetitions of 10-by-10 two-layer cross-validation. The outer fold split ensured we tested on unseen data, while the inner fold split alleviates overfitting when we optimized model hyperparameters, i.e., regularization strength for logistic regression and SVM, number of trees and depth for random forest, and the number of features used by the models after feature selection.
Age-effect correction
It is well-established that some EEG features have an age-dependent effect. Both peak alpha frequency91, theta/beta ratio92 and 1/f exponents have been found to be lower in old compared to young adults78,93,94,95. DFA exponents have also been found to increase from childhood into early adulthood before it stabilizes96. Although the age range of both groups fell between 19 and 55 years, the ASD group was, on average, 11 years older than the non-autistic comparison group (Permutation test, \(p =\) 0.0001). We investigated the linear correlations between each EEG feature type and age. For all the features that showed more significant Pearson’s correlations than chance-level after false-discovery rate (FDR) correction, we corrected for the age-effect by removing the linear trend. The FDR correction was applied to each feature type separately and the detrending was performed for the whole cohort.
Statistical analysis
Results are shown as mean with 95% confidence intervals. A non-parametric permutation test with FDR correction was used to test for group mean differences. Levene’s test with FDR correction was used to assess equality of variances. The FDR correction was applied to each feature type separately. Pearson’s correlation coefficient and Student’s t-distribution was used to test for significant linear correlations. Non-parametric Wilcoxon signed-rank test was used to test differences between classifiers. One-sided tests were used for baseline comparisons (chance-level for the classifiers or mean prediction for the regressors). A p-value < 0.05 was considered significant for rejection of the null hypothesis.
Data availability
Data are available from SB and the code is available from QL on request.
References
American Psychiatric Association. The Diagnostic and Statistical Manual of Mental Disorders (DSM-5) (American Psychiatric Association, 2013).
Wang, J. et al. Resting state EEG abnormalities in autism spectrum disorders. J. Neurodev. Disord. 5, 1. https://doi.org/10.1186/1866-1955-5-24 (2013).
O’Reilly, C., Lewis, J. D. & Elsabbagh, M. Is functional brain connectivity atypical in autism? A systematic review of EEG and MEG studies. PLoS One 12, e0175870. https://doi.org/10.1371/journal.pone.0175870 (2017).
Holiga, S. et al. Patients with autism spectrum disorders display reproducible functional connectivity alterations. Sci. Transl. Med. https://doi.org/10.1126/scitranslmed.aat9223 (2019).
Horien, C. et al. Functional connectome-based predictive modelling in autism. Biol. Psychiatry. https://doi.org/10.1016/J.BIOPSYCH.2022.04.008 (2022).
Hornung, T., Chan, W. H., Müller, R. A., Townsend, J. & Keehn, B. Dopaminergic hypo-activity and reduced theta-band power in autism spectrum disorder: A resting-state EEG study. Int. J. Psychophysiol. 146, 101–106. https://doi.org/10.1016/J.IJPSYCHO.2019.08.012 (2019).
Pierce, S. et al. Associations between sensory processing and electrophysiological and neurochemical measures in children with ASD: An EEG-MRS study. J. Neurodev. Disord. https://doi.org/10.1186/s11689-020-09351-0 (2021).
Mash, L. E. et al. Atypical relationships between spontaneous EEG and fMRI activity in Autism. Brain Connect. 10, 18–28. https://doi.org/10.1089/brain.2019.0693 (2020).
Keehn, B., Westerfield, M., Müller, R. A. & Townsend, J. Autism, attention, and alpha oscillations: An electrophysiological study of attentional capture. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2, 528–536. https://doi.org/10.1016/j.bpsc.2017.06.006 (2017).
Sheikhani, A., Behnam, H., Mohammadi, M. R., Noroozian, M. & Mohammadi, M. Detection of abnormalities for diagnosing of children with autism disorders using of quantitative electroencephalography analysis. J. Med. Syst. 36, 957–963. https://doi.org/10.1007/s10916-010-9560-6 (2012).
Romeo, R. R. et al. Parental language input predicts neuroscillatory patterns associated with language development in toddlers at risk of autism. J. Autism Dev. Disord. https://doi.org/10.1007/s10803-021-05024-6 (2021).
Maxwell, C. R. et al. Atypical laterality of resting gamma oscillations in autism spectrum disorders. J. Autism Dev. Disord. 45, 292–297. https://doi.org/10.1007/s10803-013-1842-7 (2015).
Mathewson, K. J. et al. Regional EEG alpha power, coherence, and behavioral symptomatology in autism spectrum disorder. Clin. Neurophysiol. 123, 1798–1809. https://doi.org/10.1016/j.clinph.2012.02.061 (2012).
van Diessen, E., Senders, J., Jansen, F. E., Boersma, M. & Bruining, H. Increased power of resting-state gamma oscillations in autism spectrum disorder detected by routine electroencephalography. Eur. Arch. Psychiatry Clin. Neurosci. 265, 537–540. https://doi.org/10.1007/s00406-014-0527-3 (2015).
Zhao, J., Song, J., Li, X. & Kang, J. A study on EEG feature extraction and classification in autistic children based on singular spectrum analysis method. Brain Behav. 10, e01721. https://doi.org/10.1002/brb3.1721 (2020).
Chan, A. S. & Leung, W. W. Differentiating autistic children with quantitative encephalography: A 3-month longitudinal study. J. Child Neurol. 21, 391–399. https://doi.org/10.1177/08830738060210050501 (2006).
Burnette, C. P. et al. Anterior EEG asymmetry and the modifier model of autism. J. Autism Dev. Disord. 41, 1113–1124. https://doi.org/10.1007/s10803-010-1138-0 (2011).
Zhou, T., Kang, J., Cong, F. & Li, D. . X. Early childhood developmental functional connectivity of autistic brains with non-negative matrix factorization. NeuroImage Clin. 26, 102251. https://doi.org/10.1016/j.nicl.2020.102251 (2020).
Dcroz-Baron, D. F., Baker, M., Michel, C. M. & Karp, T. EEG microstates analysis in young adults with autism spectrum disorder during resting-state. Front. Hum. Neurosci. https://doi.org/10.3389/FNHUM.2019.00173 (2019).
Bruining, H. et al. Measurement of excitation-inhibition ratio in autism spectrum disorder using critical brain dynamics. Sci. Rep. 10, 1–15. https://doi.org/10.1038/s41598-020-65500-4 (2020).
Jia, H. & Yu, D. Attenuated long-range temporal correlations of electrocortical oscillations in patients with autism spectrum disorder. Dev. Cogn. Neurosci. 39, 100687. https://doi.org/10.1016/j.dcn.2019.100687 (2019).
Newson, J. J. & Thiagarajan, T. C. EEG frequency bands in psychiatric disorders: A review of resting state studies. Front. Hum. Neurosci. 12, 521. https://doi.org/10.3389/fnhum.2018.00521 (2019).
Arbabshirani, M. R., Plis, S., Sui, J. & Calhoun, V. D. Single subject prediction of brain disorders in neuroimaging: Promises and pitfalls. NeuroImage 145, 137–165. https://doi.org/10.1016/j.neuroimage.2016.02.079 (2017).
Duffy, F. H. & Als, H. A stable pattern of EEG spectral coherence distinguishes children with autism from neuro-typical controls—A large case control study. BMC Med. 10, 1–19. https://doi.org/10.1186/1741-7015-10-64 (2012).
Heunis, T. et al. Recurrence quantification analysis of resting state EEG signals in autism spectrum disorder—a systematic methodological exploration of technical and demographic confounders in the search for biomarkers. BMC Med. 16, 1–17. https://doi.org/10.1186/s12916-018-1086-7 (2018).
Peng, S. et al. Early screening of children with autism spectrum disorder based on electroencephalogram signal feature selection with L1-norm regularization. Front. Hum. Neurosci. 15, 656578. https://doi.org/10.3389/fnhum.2021.656578 (2021).
Djemal, R., Alsharabi, K., Ibrahim, S. & Alsuwailem, A. EEG-based computer aided diagnosis of autism spectrum disorder using wavelet, entropy, and ANN. BioMed Res. Int. https://doi.org/10.1155/2017/9816591 (2017).
Hadoush, H., Alafeef, M. & Abdulhay, E. Automated identification for autism severity level: EEG analysis using empirical mode decomposition and second order difference plot. Behav. Brain Res. 362, 240–248. https://doi.org/10.1016/j.bbr.2019.01.018 (2019).
Grossi, E., Olivieri, C. & Buscema, M. Diagnosis of autism through EEG processed by advanced computational algorithms: A pilot study. Comput. Methods Prog. Biomed. 142, 73–79. https://doi.org/10.1016/j.cmpb.2017.02.002 (2017).
Grossi, E., Buscema, M., Della Torre, F. & Swatzyna, R. J. The, “MS-ROM/IFAST’’ model, a novel parallel nonlinear EEG analysis technique, distinguishes ASD subjects from children affected with other neuropsychiatric disorders with high degree of accuracy. Clin. EEG Neurosci. 50, 319–331. https://doi.org/10.1177/1550059419861007 (2019).
Grossi, E., Valbusa, G. & Buscema, M. Detection of an autism EEG signature from only two EEG channels through features extraction and advanced machine learning analysis. Clin. EEG Neurosci. 52, 330–337. https://doi.org/10.1177/1550059420982424 (2021).
Chan, A. S., Sze, S. L. & Cheung, M. C. Quantitative electroencephalographic profiles for children with autistic spectrum disorder. Neuropsychology 21, 74–81. https://doi.org/10.1037/0894-4105.21.1.74 (2007).
Kang, J., Han, X., Song, J., Niu, Z. & Li, X. The identification of children with autism spectrum disorder by SVM approach on EEG and eye-tracking data. Comput. Biol. Med. https://doi.org/10.1016/j.compbiomed.2020.103722 (2020).
Garcés, P. et al. Resting state EEG power spectrum and functional connectivity in autism: A cross-sectional analysis. Mol. Autism 13, 1–16. https://doi.org/10.1186/s13229-022-00500-x (2022).
Zhang, S., Chen, D., Tang, Y. & Zhang, L. Children ASD evaluation through joint analysis of EEG and eye-tracking recordings with graph convolution network. Front. Hum. Neurosci. 15, 651349. https://doi.org/10.3389/fnhum.2021.651349 (2021).
Lemm, S., Blankertz, B., Dickhaus, T. & Müller, K. R. Introduction to machine learning for brain imaging. NeuroImage 56, 387–399. https://doi.org/10.1016/j.neuroimage.2010.11.004 (2011).
Hosseini, M. et al. I tried a bunch of things: The dangers of unexpected overfitting in classification of brain data. Neurosci. Biobehav. Rev. 119, 456–467. https://doi.org/10.1016/j.neubiorev.2020.09.036 (2020).
Poldrack, R. A., Huckins, G. & Varoquaux, G. Establishment of best practices for evidence for prediction: A review. JAMA Psychiatry https://doi.org/10.1001/jamapsychiatry.2019.3671 (2020).
Rashid, B. & Calhoun, V. Towards a brain-based predictome of mental illness. Hum. Brain Mapp. 41, 3468–3535. https://doi.org/10.1002/hbm.25013 (2020).
Loth, E. et al. The meaning of significant mean group differences for biomarker discovery. PLoS Comput. Biol. 17, e1009477. https://doi.org/10.1371/journal.pcbi.1009477 (2021).
Woo, C. W., Chang, L. J., Lindquist, M. A. & Wager, T. D. Building better biomarkers: Brain models in translational neuroimaging. Nat. Neurosci. 20, 365–377. https://doi.org/10.1038/nn.4478 (2017).
Easterbrook, P. J., Gopalan, R., Berlin, J. A. & Matthews, D. R. Publication bias in clinical research. Lancet 337, 867–872. https://doi.org/10.1016/0140-6736(91)90201-Y (1991).
CDC. Data & Statistics on Autism Spectrum Disorder (2022).
Rødgaard, E. M., Jensen, K., Vergnes, J. N., Soulières, I. & Mottron, L. Temporal changes in effect sizes of studies comparing individuals with and without autism: A meta-analysis. JAMA Psychiatry 76, 1124–1132. https://doi.org/10.1001/jamapsychiatry.2019.1956 (2019).
Imbriani, G. et al. Early-life exposure to environmental air pollution and autism spectrum disorder: A review of available evidence. Int. J. Environ. Res. Public Health 18, 1–24. https://doi.org/10.3390/ijerph18031204 (2021).
Mottron, L. A radical change in our autism research strategy is needed: Back to prototypes. Autism Res. 14, 2213–2220. https://doi.org/10.1002/AUR.2494 (2021).
Barttfeld, P. et al. Organization of brain networks governed by long-range connections index autistic traits in the general population. J. Neurodev. Disord. 5, 1–9. https://doi.org/10.1186/1866-1955-5-16 (2013).
Bosl, W., Tierney, A., Tager-Flusberg, H. & Nelson, C. EEG complexity as a biomarker for autism spectrum disorder risk. BMC Med. 9, 1–16. https://doi.org/10.1186/1741-7015-9-18 (2011).
Jia, H. & Yu, D. Aberrant intrinsic brain activity in patients with autism spectrum disorder: Insights from EEG microstates. Brain Topogr. 32, 295–303. https://doi.org/10.1007/s10548-018-0685-0 (2019).
Modi, M. E. & Sahin, M. Translational use of event-related potentials to assess circuit integrity in ASD. Nat. Rev. Neurol. 13, 160–170. https://doi.org/10.1038/nrneurol.2017.15 (2017).
Lombardo, M. V. Prototyping as subtyping strategy for studying heterogeneity in autism. Autism Res. 14, 2224–2227. https://doi.org/10.1002/AUR.2535 (2021).
Hong, S. J. et al. Toward neurosubtypes in autism. Biol. Psychiatry 88, 111–128. https://doi.org/10.1016/j.biopsych.2020.03.022 (2020).
Tanabe, H. C. et al. Hard to “tune in’’: Neural mechanisms of live face-to-face interaction with high-functioning autistic spectrum disorder. Front. Hum. Neurosci. 6, 268. https://doi.org/10.3389/fnhum.2012.00268 (2012).
Schilbach, L. et al. Toward a second-person neuroscience. Behav. Brain Sci. 36, 393–414. https://doi.org/10.1017/S0140525X12000660 (2013).
Leong, V. & Schilbach, L. The promise of two-person neuroscience for developmental psychiatry: Using interaction-based sociometrics to identify disorders of social interaction. Br. J. Psychiatry 215, 636–638. https://doi.org/10.1192/BJP.2019.73 (2019).
Pan, Y. & Cheng, X. Two-person approaches to studying social interaction in psychiatry: Uses and clinical relevance. Front. Psychiatry 11, 301. https://doi.org/10.3389/FPSYT.2020.00301/BIBTEX (2020).
Kruppa, J. A. et al. Brain and motor synchrony in children and adolescents with ASD—A fNIRS hyperscanning study. Soc. Cogn. Affect. Neurosci. 16, 103–116. https://doi.org/10.1093/scan/nsaa092 (2021).
Schilbach, L. Autism and other disorders of social interaction: Where we are and where to go from here. Eur. Arch. Psychiatry Clin. Neurosci. 272, 173–175. https://doi.org/10.1007/S00406-022-01391-Y (2022).
Sandin, S. et al. The heritability of autism spectrum disorder. JAMA J. Am. Med. Assoc. 318, 1182–1184. https://doi.org/10.1001/jama.2017.12141 (2017).
Doyle, N. Neurodiversity at work: A biopsychosocial model and the impact on working adults. Br. Med. Bull. 135, 108. https://doi.org/10.1093/BMB/LDAA021 (2020).
Panisi, C. & Marini, M. Dynamic and systemic perspective in autism spectrum disorders: A change of gaze in research opens to a new landscape of needs and solutions. Brain Sci. https://doi.org/10.3390/BRAINSCI12020250 (2022).
Register, N. A. Netherlands Autism Register (2022).
American Psychiatric Association. The Diagnostic and Statistical Manual of Mental Disorders (DSM-IV) (American Psychiatric Association, 1994).
Deserno, M. K. et al. Sleep determines quality of life in autistic adults: A longitudinal study. Autism Res. 12, 794–801. https://doi.org/10.1002/aur.2103 (2019).
Daniels, A. M. et al. Verification of parent-report of child autism spectrum disorder diagnosis to a web-based autism registry. J. Autism Dev. Disord. 42, 257–265. https://doi.org/10.1007/s10803-011-1236-7 (2012).
Scheeren, A. M., Buil, J. M., Howlin, P., Bartels, M. & Begeer, S. Objective and subjective psychosocial outcomes in adults with autism spectrum disorder: A 6-year longitudinal study. Autism 26, 243–255. https://doi.org/10.1177/13623613211027673 (2022).
Hoekstra, R. A. et al. The construction and validation of an abridged version of the autism-spectrum quotient (AQ-short). J. Autism Dev. Disord. 41, 589–596. https://doi.org/10.1007/s10803-010-1073-0 (2011).
Baron-Cohen, S., Wheelwright, S., Skinner, R., Martin, J. & Clubley, E. The Autism-Spectrum Quotient (AQ): Evidence from asperger syndrome/high-functioning autism, males and females, scientists and mathematicians. J. Autism Dev. Disord. 31, 5–17 (2001) (0005074v1.).
Tavassoli, T., Hoekstra, R. A. & Baron-Cohen, S. The Sensory Perception Quotient (SPQ): Development and validation of a new sensory questionnaire for adults with and without autism. Mol. Autism 5, 1–10. https://doi.org/10.1186/2040-2392-5-29 (2014).
Weiland, R. F., Polderman, T. J., Hoekstra, R. A., Smit, D. J. & Begeer, S. The Dutch Sensory Perception Quotient-Short in adults with and without autism. Autism 24, 2071–2080. https://doi.org/10.1177/1362361320942085 (2020).
Gramfort, A. et al. MEG and EEG data analysis with MNE-Python. Front. Neurosci. 7, 1–13. https://doi.org/10.3389/fnins.2013.00267 (2013).
Ablin, P., Cardoso, J. F. & Gramfort, A. Faster independent component analysis by preconditioning with hessian approximations. IEEE Trans. Signal Process. 66, 4040–4049. https://doi.org/10.1109/TSP.2018.2844203 (2018).
Jas, M., Engemann, D. A., Bekhti, Y., Raimondo, F. & Gramfort, A. Autoreject: Automated artifact rejection for MEG and EEG data. NeuroImage 159, 417–429. https://doi.org/10.1016/j.neuroimage.2017.06.030 (2017).
Fischl, B. FreeSurfer. NeuroImage 62, 774–781. https://doi.org/10.1016/j.neuroimage.2012.01.021 (2012).
Klein, A. & Tourville, J. 101 labeled brain images and a consistent human cortical labeling protocol. Front. Neurosci. https://doi.org/10.3389/FNINS.2012.00171/ABSTRACT (2012).
Babadi, B. & Brown, E. N. A review of multitaper spectral analysis. IEEE Trans. Biomed. Eng. 61, 1555–1564. https://doi.org/10.1109/TBME.2014.2311996 (2014).
Sutton, S. K. & Davidson, R. J. Prefrontal brain asymmetry: A biological substrate of the behavioral approach and inhibition systems. Psychol. Sci. 8, 204–210 (1997).
Donoghue, T. et al. Parameterizing neural power spectra into periodic and aperiodic components. Nat. Neurosci. 23, 1655–1665. https://doi.org/10.1038/s41593-020-00744-x (2020).
Linkenkaer-Hansen, K., Nikouline, V. V., Palva, J. M. & Ilmoniemi, R. J. Long-range temporal correlations and scaling behavior in human brain oscillations. J. Neurosci. 21, 1370–1377. https://doi.org/10.1523/jneurosci.21-04-01370.2001 (2001).
Hardstone, R. et al. Detrended fluctuation analysis: A scale-free view on neuronal oscillations. Front. Physiol. https://doi.org/10.3389/fphys.2012.00450 (2012).
Altman, N. & Krzywinski, M. The curse(s) of dimensionality. Nat. Methods 15, 399–400. https://doi.org/10.1038/s41592-018-0019-x (2018).
Nunez, P. L. et al. EEG coherency I: Statistics, reference electrode, volume conduction, Laplacians, cortical imaging, and interpretation at multiple scales. Electroencephalogr. Clin. Neurophysiol. 103, 499–515. https://doi.org/10.1016/S0013-4694(97)00066-7 (1997).
Nolte, G. et al. Identifying true brain interaction from EEG data using the imaginary part of coherency. Clin. Neurophysiol. 115, 2292–2307. https://doi.org/10.1016/j.clinph.2004.04.029 (2004).
Lachaux, J. P., Rodriguez, E., Martinerie, J. & Varela, F. J. Measuring phase synchrony in brain signals. Hum. Brain Mapp. 8, 194–208. https://doi.org/10.1002/(SICI)1097-0193(1999)8:4<194::AID-HBM4>3.0.CO;2-C (1999).
Stam, C. J., Nolte, G. & Daffertshofer, A. Phase lag index: Assessment of functional connectivity from multi channel EEG and MEG with diminished bias from common sources. Hum. Brain Mapp. 28, 1178–1193. https://doi.org/10.1002/hbm.20346 (2007).
Toll, R. T. et al. An electroencephalography connectomic profile of posttraumatic stress disorder. Am. J. Psychiatry 177, 233–243. https://doi.org/10.1176/appi.ajp.2019.18080911 (2020).
Peng, H., Long, F. & Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 27, 1226–1238. https://doi.org/10.1109/TPAMI.2005.159 (2005).
Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 3, 638. https://doi.org/10.21105/joss.00638 (2018).
Pedrogosa, F. et al. Scikit-learn: Machine learning in python fabian. J. Mach. Learn. Res. 12, 2825–2830. https://doi.org/10.1289/EHP4713 (2011).
Mazzanti, S. mRMR Python Implementation (2021).
Grandy, T. H. et al. Peak individual alpha frequency qualifies as a stable neurophysiological trait marker in healthy younger and older adults. Psychophysiology 50, 570–582. https://doi.org/10.1111/psyp.12043 (2013).
Finley, A. J., Angus, D. J., Reekum, C. M. V., Davidson, R. J. & Schaefer, S. M. Periodic and aperiodic contributions to theta-beta ratios across adulthood. Psychophysiology. https://doi.org/10.1111/psyp.14113 (2022).
Voytek, B. et al. Age-related changes in 1/f neural electrophysiological noise. J. Neurosci. 35, 13257–13265. https://doi.org/10.1523/JNEUROSCI.2332-14.2015 (2015).
Tröndle, M. et al. Decomposing age effects in EEG alpha power. bioRxiv https://doi.org/10.1101/2021.05.26.445765 (2021).
Merkin, A. et al. Age differences in aperiodic neural activity measured with resting EEG. bioRxiv 1–30 (2021).
Smit, D. J. et al. Scale-free modulation of resting-state neuronal oscillations reflects prolonged brain maturation in humans. Journal of Neuroscience 31, 13128–13136. https://doi.org/10.1523/JNEUROSCI.1678-11.2011 (2011).
Acknowledgements
This research was supported and funded by NWO ZonMW Top grant (2017/02015/ZONMW and 2017/02186/ZONMW).
Author information
Authors and Affiliations
Contributions
R.F.W., D.J.A.S., K.L.H. and S.B. conceived and conducted the experiments. Q.L., I.K., T.S.A., and K.L.H. designed the analysis. Q.L. implemented the code and generated the first draft of the manuscript. R.F.W., H.D.M., D.J.A.S., S.B. and K.L.H. contributed to interpretation of the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Q., Weiland, R.F., Konvalinka, I. et al. Intellectually able adults with autism spectrum disorder show typical resting-state EEG activity. Sci Rep 12, 19016 (2022). https://doi.org/10.1038/s41598-022-22597-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-22597-z
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
