
Abstract
Determination of self-organized criticality (SOC) is crucial in evaluating the dynamical behavior of a time series. Here, we apply the complex network approach to assess the SOC characteristics in synthesis and real-world data sets. For this purpose, we employ the horizontal visibility graph (HVG) method and construct the relevant networks for two numerical avalanche-based samples (i.e., sand-pile models), several financial markets, and a solar nano-flare emission model. These series are shown to have long-temporal correlations via the detrended fluctuation analysis. We compute the degree distribution, maximum eigenvalue, and average clustering coefficient of the constructed HVGs and compare them with the values obtained for random and chaotic processes. The results manifest a perceptible deviation between these parameters in random and SOC time series. We conclude that the mentioned HVG’s features can distinguish between SOC and random systems.
Similar content being viewed by others

Introduction
One of the most important parts of studying natural phenomena is classifying them into groups with the same characteristics. This could provide important information about forecasting capabilities and appropriate computational techniques required for further studies. Even though it seems straightforward at first sight, it is not, and it requires scientists to follow certain processes and strategies1. The problem becomes more intricate when there isn’t a comprehensive description of the subject system or the phenomenon encompasses a wide range of fields. Complex systems seem to confront both, because on the one hand there is no all-inclusive interpretation of these systems2,3,4, and on the other hand, they include everything from brain structure to insect colonies, price fluctuations in financial markets, condensate matter, Internet, Plasma and Solar physics, and even all human societies3,5,6,7,8,9,10. Given the breadth and intricacy mentioned, classifying complex systems is an outstanding issue that has attracted vast research interests11,12,13,14.
One of the most familiar aspects of complexity science is the nonlinear response of a system to small variations in its initial condition, usually referred to as chaotic behavior15,16,17. This behavior has been repeatedly reported in the literature across various fields including astronomy, biology, chemistry, economy, engineering, geology, etc.18,19. Considering the high sensitivity to initial conditions, identification of chaotic behavior in real-world data is more challenging than in artificial data sets20. Another aspect is the theory of SOC, in which a gradual energy supply leads the system to a critical state. Then, the system relaxes through a sequence (avalanche) of nonlinear energy-dissipative events that manifests a power-law-like behavior5,21,22,23,24,25. Here, “energy” corresponds to any interaction that could impose a phase transition from an original meta-stable state to another26, in contrast to the chaotic systems for which no stable state can be considered27.
Conventionally, a system with a slow driving rate and instant relaxations is most likely a SOC system if it could produce a wide range of avalanches with inverse dependence of frequencies on the event sizes. However, some variations from this interpretations have been discussed in the literature28,29. The chaotic and SOC systems along with significant differences exhibit some character resemblances and might even behave similarly30.
To this date, several algorithms have been developed to characterize complex systems31,32. One of the most popular techniques is the measure of Lyapunov’s exponent33,34, which determines how fast a very small distance between two originally close trajectories grow (or decrease) over time35. Another technique is to perform a cyclical analysis on time series (TS) and investigate whether the frequency spectrum exhibits a periodic pattern36,37,38. Furthermore, fractal dimension39,40, Kolmogorov-Sinai entropy41, and the network approach42,43 have been widely used in the identification and analysis of complex systems. The complex network theory could provide more convenient and manageable tools to conduct TS analysis44,45,46,47.
In the present study, we first validate the complexity of several observational and synthesis TS applying the detrended fluctuation analysis (DFA). Then, we construct the HVGs of these TS and calculate some of the graphs’ properties such as the degree distribution, maximum eigenvalue, and average clustering coefficient. Finally, we assess whether it is possible to distinguish between different categories of complex systems using these features. The remainder of this paper is organized as follows: in “DFA as a test for the complexity of a TS”, we explain the performed DFA. In “The classifier indicator”, we explain how the network theory could practically provide an indicator for random TS and discuss the possibility of determining random processes from other types (i.e., chaotic and SOC processes). In “HVGs of SOC systems” we first introduce several data sets and argue their complexity in applying the DFA. Then, we investigate the utility of the HVG approach in their identification. Finally, we present the conclusion in “Discussion”.
DFA as a test for the complexity of a TS
A common point of most studies on complex systems is the extraction of patterns that govern the system’s dynamic and complexity testing is one of the first steps in such analyses48. Diagnosing the complexity of a system could be accomplished using a variety of methods mainly classified into three categories: nonlinear dynamic methods (based on the evaluation of the attractor properties in the phase space), the entropy-based methods (relevant to the disorder in a system) and fractality49. The fractal analysis gives an estimate of the complexity by measuring self-similarity (long-term persistence) in a TS. This analysis describes the global structures of a TS by means of a scaling coefficient \(\alpha\), and a detrending estimator which corresponds to the fluctuations in the TS50. Hurst51 introduced the Hurst exponent as a scaling fractal analysis, and ever since, several methods have been developed to determine this exponent52,53,54,55.
Peng et al.56 established the DFA to determine the central trend and fluctuations of a TS via a polynomial fit. In this methodology, the time profile of a given data sample x(i) for \(i=1, 2 .. N\) is defined:
where \(\bar{x}\) is the average of the sample. The profile is divided into l equally spaced segments (blocks) with a total number of \(N_{l}=(N/l)\) data points in each segment. The corresponding profile of each block is then fitted with a polynomial function which represents its local trend, \(y_{l}(j)\). Subtracting the local trend from the original profile in each segment gives the characterization of the fluctuation:
Repetition of this procedure for various choices of l gives F(l) which follows \(F(l)\propto l^{\alpha }\). To put it simply, the scaling coefficient is the slope of F(l) in a logarithmic presentation. An \(\alpha\) between (0, 0.5) indicates a long-term anti-persistence characteristic, namely, the TS is anti-correlated. If this parameter takes values between 0.5 and 1, the TS is correlated, and its long-term persistence behavior can be studied. \(1<\alpha <1.5\) implies a non-stationarity57,58. Besides, an \(\alpha\) approximately equal to 1.5, 1 and 0.5 refers to Brownian, 1/f (pink), and white noise, respectively. The last corresponds to purely uncorrelated TS such as a random walk or an i.i.d. process59,60.
We performed the DFA on all the studied TS and verified their long-term correlations. The results are presented in “HVGs of SOC systems”.
The classifier indicator
Applying the complex network approach, Lacasa et al.61 introduced the visibility graph (VG) method which converts a given TS into a graph. According to this algorithm, the sample data points are regarded as nodes (vertices), and an edge (link) is considered between nodes i and j if the following condition is met:
where \((t_{c}, y_{c})\) is a data value placed in between i and j. Further to this algorithm, Luque et al.62 presented the HVG which to a great extent is analogous to the VG method except for the visibility condition:
A major advantage of the HVG method is that it provides the analytical capability to calculate the degree distribution of random series. Therefore, the degree distribution of any random process regardless of the generator type follows a specific distribution:
where P and k denote the probability distribution function (PDF) and the degree of nodes, respectively. The probability distribution of Eq. (5) could be regarded as an indicator for random series. In other words, if the degree distribution of a given sample follows Eq. (5) the underlying mechanism is most likely specified as a random process.
The question is how the degree distribution of other processes behaves in comparison with random TS. Luque et al.62 tried to address this question by performing a study on chaotic systems. They found that the degree distribution of chaotic processes deviate from the random indicator as they have higher probabilities at high degrees. Here, we go one step further and investigate the degree distribution of the total energy of SOC systems and examine their behavior against the random indicator. Moreover, we calculate the maximum eigenvalues and average clustering coefficients of several SOC systems and evaluate their utility in distinguishing between SOC and random systems. The details of the analysis and the achieved results are discussed in the next section.
HVGs of SOC systems
The main idea of the present study is to investigate the SOC characteristics of data samples using the network approach. For this purpose, we construct the HVGs of various SOC systems and compare some of their networks’ properties (e.g., degree distribution) with random processes. But, we first need to validate the complexity of the subject TS.
In order to measure the possible deviations between the degree distributions of SOC and random TS, we calculate both the orthogonal regression and the Kolmogorov-Smirnov test (KS-test). Considering the random indicator as the reference, degrees with higher (lower) probabilities than the indicator are assigned with positive (negative) distances. Therefore, the sum of all distances specifies whether the subject system behaves randomly (approximate zero deviation), chaotically (positive deviation), or it represents SOC (negative deviation). Further to the degree distribution, we measure each network’s maximum eigenvalue which has been acknowledged as an efficient method to distinguish between chaotic and random TS63,64. Here, we appraise its capability in determining SOC systems. We also compute the average clustering coefficients6,7,10,65,66 of the HVGs and compare the outcomes with random processes.
We start our survey with the most celebrated SOC system, namely the sand-pile model67. This model employs a grid over which sand grains are initially randomly distributed. At each time step, a grain falls into a randomly selected square. The whole system is conned to a stability criterion that depends on the heights of nearest neighbors. Whenever a square does not contain enough capacity to accommodate the new grain (the height exceeds a pre-xed threshold), the grain ows into neighboring squares or ejects from the corners of the grid to locally relax the system.
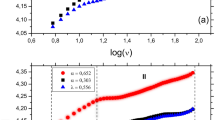
We reproduce the sand-pile model using both the original Bak redistribution rules and those introduced by Manna (Fig. 1)68. The result of the performed DFA on both sand-pile models are presented in Fig. 2. The measured scaling coefficient of two random TS are also shown in the figure. According to the results, the scaling coefficients obtained with the DFA method for both Bak and Manna sand-pile models lies between 0.5 and 1. This indicates a long-term memory in these TS and confirms the complexity of the sand-pile systems.

The HVG for the Manna sand-pile model with 9000 grains.

The scaling coefficient of the DFA for: the Bak sand-pile model (top left panel), Manna sand-pile model (top right panel), uniformly distributed random series (bottom left panel), and a normally distributed random series (bottom right panel).
The degree distribution of both sand-pile models’ HVGs together with the theoretical distribution of random systems (Eq. 5) are shown in Fig. 3. The HVGs are constructed using the total energy of the SOC systems. As seen in the figure, most of the degrees (especially the high degrees) have less probabilities than the random indicator. The total deviation between the Bak and Manna sand-pile models and the indicator are \(-5.9417\) and \(-5.7680\), respectively. The orthogonal distances are measured in the logarithmic scale.

Semi-logarithmic presentation of degree distributions for: any random process (solid black line) which follows Eq. (5), the Bak (blue line), and Manna (red line) sand-pile models.
Figure 4 displays the maximum eigenvalues of both sand-pile models together with the relevant values for some random and chaotic processes. The random TS are constructed using the uniform and normal generators whilst the chaotic TS correspond to a logistic map \(x_{t+1}=\mu x_{t}(1-x_{t})\) and the Hénon map \((x_{t+1},y_{t+1})=(y_{t+1}-a x_{t}^{2},b x_{t})\) in a fully chaotic region with \(\mu =4, a=1.4,\) and \(b=0.3\). As shown in the figure, the maximum eigenvalues slightly increase with respect to the network’s size. For a convenient network with a total number of nodes greater than 2500, the maximum eigenvalues of a random and chaotic TS lie approximately in the ranges of 7–7.7 and 7.8–8.7, respectively. Whilst, the maximum eigenvalues of Bak and Manna sand-pile models are in the range of 5.5–6.3. The average clustering coefficients6,7,10,65,66 of mentioned TS are also presented in Fig. 5. Likewise, the maximum eigenvalues, and the average clustering coefficients of both sand-pile models are distinguishable from the random and chaotic processes.

The maximum eigenvalues against the number of nodes for the constructed network for different TS.

The average clustering coefficient for the Bak (solid blue line) and Manna (solid red line) models, several random TS (dotted colored lines), and two chaotic TS (dashed colored line).
So far, we have obtained that the HVGs of individual categories, random and SOC, seem to have distinctive characteristics. This raises the question of whether these properties (i.e., degree distribution, maximum eigenvalue, and average clustering coefficient) could practically be used as an indicator to identify SOC systems. To address this question, we examine several other SOC systems in the following.
Inspired by the power-law-like behavior of the solar flare energies, Tajfirouze and Safari69 presented a SOC model to investigate the complex evolution of nano-flare emissions in the quiet Sun and active regions. The nano-flare emission model is controlled by three free parameters, namely the power index \(\alpha\), damping time \(\tau _{d}\), and the occurrence probability of flaring events \(p_{f}\)70,71,72. The parameter \(\alpha\) is the power index in the frequency-size distribution of flare energies (E):
The reported values for this parameter in solar and stellar flares lies between 1.5 and 2.923,24,70,72,73,74,75,76,77,78,79,80,81. \(\tau _{d}\) corresponds to the flare damping time and various choices of \(\tau _{d}\) could affect the overall shape of the flares’ frequency-size distribution. For example, the adoption of large values for this parameter leads to a Gaussian frequency-size distribution rather than a power law. The parameter \(p_{f}\) corresponds to the likelihood of a flare taking place and can take all values between 0 and 1. Figure 6 displays the simulated light curves of the nano-flare emission model for different sets of parameters (\(\alpha \in\) [1.4 3.2], \(\tau _{d} = 10,\) and \(p_{f} < 0.2\)).

Simulated light curves of the nano-are emission model for \(\tau _d=10\), \(p_f =0.2\), and different \(\alpha\) values.
Figures 7 and 8 present the result of the performed DFA and the degree distributions of the simulated light curves, respectively. The calculated scaling coefficients confirm the complexity of the simulated TS. All degree distributions exhibit a negative orthogonal regression from the random indicator. The deviation between each degree distribution and the indicator together with the maximum eigenvalues, and average clustering coefficients of each simulation are listed in Table 1. The results are compatible with the sand-pile models. The reported values are obtained by taking the average and standard deviations of each parameter for various sets of runs. Note that the procedure of repeating the calculations is not generally applicable to the real-world data sets except for conveniently large data samples.

The scaling coefficient of the DFA for the simulated light curves of the nano-flare emission model with \(\alpha\) =1.4, 1.6, 1.8, 2, 2.2, 2.4.

Semi-logarithmic presentation of degree distributions for: any random process (solid black line) which follows Eq. (5), and various runs of simulation of the nano-flare emission model with \(\alpha \in\)[1.4 3.2], \(\tau _{d} = 10\), and \(p_f =0.2\)
We continue our survey by performing the same analysis on various financial data sets as other examples of SOC systems22,82. The dynamics of price movements or other indices of the financial markets are determined by the behavior of individuals who act based on their information82. Here, we investigate the historical price of several assets (such as gold, different company stocks, and commodities), as well as several economic indices (such as the Nasdaq 100, S &P 500, and U.S. dollar index). This information is registered in the Stooq Database and is online available at https://stooq.com/. We construct the HVGs for the maximum amounts of available data and the daily frequencies. Figure 9 exhibits the result of the DFA for the financial TS. The scaling coefficient of the subject series manifest the complex nature of these systems. Figure 10 displays the relevant degree distributions. The obtained orthogonal distances, maximum eigenvalues, and the average clustering coefficients of each HVG are presented in Table 2. Similar to previous SOC systems, the estimated parameters are less than the relevant values of random systems. However, the departures between the financial HVG’s clustering coefficients and the random systems are less significant compared to the sand-pile and nano-flare emission models.

The scaling coefficient of the DFA for the exchange rate for euros to dollars (Euro/U.S. Dollar 1:1), gold price per ozt (Gold (ozt)/U.S. Dollar 1:1), Microsoft corp stock price, NASDAQ 100 index , S &P 500 index, U.S. dollar index.

Semi-logarithmic presentation of PDFs of the degree of nodes for: any random process (solid black line) which follows Eq. (5), the exchange rate for euros to dollars (Euro/U.S. Dollar 1:1) from 04 January 1971 till 23 July 2021, gold price per ozt (Gold (ozt)/U.S. Dollar 1:1) from 01 March 1793 till 23 July 2021, Microsoft corp stock price from 13 March 1986 till 23 July 2021, NASDAQ 100 index from 1 October 1985 till 23 July 2021, S& P 500 index from 2 January 1952 till 23 July 2021, U.S. dollar index from 4 January 1971 till 23 July 2021.
Further to the calculation of orthogonal distances, we apply the KS-test to compare the degree distribution of the HVGs with the random indicator (null hypothesis). The KS-test returns the test statistic (t-stat, the ratio of the departure between a specific model and the indicator to its standard deviation) and the p value (p)83,84,85. \(p>0.1\) (threshold) rejects the null hypothesis and indicates that a degree distribution for a specific model may not obey the random indicator. Table 3 presents the obtained t-tests and p values for various random and SOC TS. As expected, the t-test values for both degree distributions of the normal and power-law random models satisfy the random indicator that are not rejected by p values (\(p>0.1\)). We observed that the degree distribution of the SOC TS deviates from the random indicator that is also rejected with the null hypothesis via the small p values (\(p<0.1\)).
Discussion
Determination of SOC has been always a challenge for the community. Although some evidence such as power-law frequency-size distribution of released energies usually inspires the idea of SOC, an extended knowledge of the underlying mechanism is required. In the present study, we argued the possibility of distinguishing SOC from random processes using their TS and appraised the capability of the complex network approach in this scheme. Particularly, we investigated the utility of the HVG in identifying the SOC characteristics of artificial and real-world data sets. We first constructed the HVGs of the Bak and Manna sand-pile models, the nano-flare emission model, and financial markets. Then, we validated the complexity of each TS by performing a DFA. Based on the obtained scaling coefficients, we confirmed that all studied TS differed from any uncorrelated random TS. We also computed the degree distribution, maximum eigenvalue, and the average clustering coefficient of each HVG and compared them with the relevant values for random processes.

A HVG plot for a sample of 150 data points generated by the Manna sand-pile model (top panel), and a HVG of the same size TS generated by a uniform random algorithm (bottom panel).
Considering Eq. (5) as an indicator for any random process, we obtained the degree distributions of several SOC systems’ HVGs and evaluated their deviations from the random indicator. In all the studied TS, we found a negative orthogonal distance between the degree distribution of the subject system and the indicator (see e.g., Figs. 3 , 8, 10). In other words, we found that higher degrees are less probable in SOC systems rather than random processes. Therefore, an increase in the probability of high degrees indicates a transition from SOC to randomness or even chaos.
One may ask why the HVG’s degree distribution of a SOC TS lies below the random TS? To address this question, we compare a SOC TS generated via an avalanche mechanism (Fig. 11) with a randomly generated one. The first fluctuates slowly and it is called the load and unload mechanism. More specifically, due to the fact that it takes several consecutive steps for the system to experience either a growth or decay in its values, the variations appear slowly in the TS. However, in a random TS, a faster fluctuation is observed as after each kick or an extensive value the system holds to a minimal value due to the true nature of any random process. In practice, the time that it takes for a SOC system to build-up (or release) its energy controls the connectivity of the HVG’s network as it prevents having nodes with extensive connectivity. As shown in Fig. 11, the probability of having nodes with smaller degrees (e.g., \(k=2,3\)) in a SOC system is far greater than in a random TS. This, which has occurred due to the underlying generative mechanism of SOC, consequently leads to lower probabilities for higher degrees as \(sum P(k) =1\). In other words, the probability function \(P(k)=1/3(2/3)^{k-2}\) which is a baseline for random TS lies below the degree distribution of SOC TS at \(k=3\). Also in a random TS, having the central nodes (nodes with large values) after some small values can provide high connectivity (the tail of degree distribution).
Furthermore, we found that the HVG’s maximum eigenvalues of any random process with at least 2500 data samples lie in the range of 7–7.8. However, the maximum eigenvalues of all the studied SOC systems are between 5.5 and 6.5. Similar departures are found between the average clustering coefficients of SOC and random processes.
We conclude that the obtained differences between the HVGs’ properties (degree distribution, maximum eigenvalue, and average clustering coefficient) of SOC and random systems originate in their generative mechanism and the HVG might be a useful tool in identifying SOC systems.
Data availability
The data for sand-pile and nano-flare emission models that support the findings of this study are available from the authors upon request [bardia.kaki@znu.ac.ir and safari@znu.ac.ir]. The financial markets data that support the findings of this study are available from [https://stooq.com/].
References
Szostak, R. Classifying Science—Phenomena, Data, Theory, Method, Practice, Vol 7 of Information Science and Knowledge Management (Springer, 2004).
Solé, R. V., Manrubia, S. C., Luque, B., Delgado, J. & Bascompte, J. Phase transitions and complex systems: Simple, nonlinear models capture complex systems at the edge of chaos. Complexity 1, 13–26. https://doi.org/10.1002/cplx.6130010405 (1996).
Newman, M. E. J. Resource letter CS-1: Complex systems. Am. J. Phys. 79, 800. https://doi.org/10.1119/1.3590372 (2011).
Siegelmann, H. Complex systems science and brain dynamics. Front. Comput. Neurosci.https://doi.org/10.3389/fncom.2010.00007 (2010).
Pinto, C. M., Mendes Lopes, A. & Machado, J. T. A review of power laws in real life phenomena. Commun. Nonlinear Sci. Numer. Simul. 17, 3558–3578. https://doi.org/10.1016/j.cnsns.2012.01.013 (2012).
Gheibi, A., Safari, H. & Javaherian, M. The solar flare complex network. Astrophys. J. 847, 115. https://doi.org/10.3847/1538-4357/aa8951 (2017).
Daei, F., Safari, H. & Dadashi, N. Complex network for solar active regions. Astrophys. J. 845, 36. https://doi.org/10.3847/1538-4357/aa7ddf (2017).
Caldarelli, G. Review of ‘Introduction to the Theory of Complex Systems’ by Stefan Thurner, Rudolf Hanel and Peter Klimek. J. Complex Netw.https://doi.org/10.1093/comnet/cnz038 (2019).
Lotfi, N., Javaherian, M., Kaki, B., Darooneh, A. H. & Safari, H. Ultraviolet solar flare signatures in the framework of complex network. Chaos 30, 043124. https://doi.org/10.1063/1.5129433 (2020).
Mohammadi, Z., Alipour, N., Safari, H. & Zamani, F. Complex network for solar protons and correlations with flares. J. Geophys. Res. Sp. Phys. 126, e2020JA028868. https://doi.org/10.1029/2020JA028868 (2021).
Crosby, R. W. Toward a classification of complex systems. Eur. J. Oper. Res. 30, 291–293. https://doi.org/10.1016/0377-2217(87)90073-7 (1987).
Meyer, M. H. & Curley, K. F. An applied framework for classifying the complexity of knowledge-based systems. MIS Q. 15, 455–472. https://doi.org/10.2307/249450 (1991).
Korbel, J., Hanel, R. & Thurner, S. Classification of complex systems by their sample-space scaling exponents. New J. Phys. 20, 093007. https://doi.org/10.1088/1367-2630/aadcbe (2018).
Hudcová, B. & Mikolov, T. Classification of complex systems based on transients. In Classification of Complex Systems Based on Transients, 367–375. https://doi.org/10.1162/isal_a_00260 (2020).
Lorenz, E. N. Deterministic nonperiodic flow. J. Atmos. Sci. 20, 130–141. https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2 (1963).
Cencini, M., Cecconi, F. & Vulpiani, A. Chaos: From Simple Models to Complex Systems. Series on Advances in Statistical Mechanics (World Scientific, 2010).
Icha, A. Book review: Chaos in nature, by christophe letellier, world scientific series on nonlinear science, series a, vol. 81, series editor leon o. chua, world scientific, 2013; isbn: 978-981-4374-42-2. Pure Appl. Geophys. 171, 1593–1595. https://doi.org/10.1007/s00024-013-0700-z (2014).
Strogatz, S. H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering (Westview Press, 2000).
Rutherford, A. Systems Thinking and Chaos: Simple Scientific Analysis on How Chaos and Unpredictability Shape Our World (and How to Find Order in It) (Independently Published, 2019).
Toker, D., Sommer, F. T. & D’Esposito, M. A simple method for detecting chaos in nature. Commun. Biol. 3, 1–13. https://doi.org/10.1038/s42003-019-0715-9 (2020).
Bak, P. How Nature Works: The Science of Self-Organized Criticality Vol. 1 (Copernicus, 1996).
Bartolozzi, M., Leinweber, D. & Thomas, A. Self-organized criticality and stock market dynamics: An empirical study. Phys. A 350, 451–465. https://doi.org/10.1016/j.physa.2004.11.061 (2005).
Farhang, N., Safari, H. & Wheatland, M. S. Principle of minimum energy in magnetic reconnection in a self-organized critical model for solar flares. Astrophys. J. 859, 41. https://doi.org/10.3847/1538-4357/aac01b (2018).
Farhang, N., Wheatland, M. S. & Safari, H. Energy balance in avalanche models for solar flares. Astrophys. J. Lett. 883, L20. https://doi.org/10.3847/2041-8213/ab40c3 (2019).
Tebaldi, C. Self-organized criticality in economic fluctuations: The age of maturity. Front. Phys. 8, 658. https://doi.org/10.3389/fphy.2020.616408 (2021).
Bak, P. & Chen, K. Self-organized criticality. Sci. Am. 264, 46–53 (1991).
Gang, H. & Zhilin, Q. Controlling spatiotemporal chaos in coupled map lattice systems. Phys. Rev. Lett. 72, 68–71. https://doi.org/10.1103/PhysRevLett.72.68 (1994).
Jeldtoft, J. H. Self-Organized Criticality: Emergent Complex Behavior in Physical and Biological Systems. Cambridge Lecture Notes in Physics (Cambridge University Press, 1998).
Sornette, D. Critical Phenomena in Natural Sciences: Chaos, Fractals, Selforganization and Disorder: Concepts and Tools. Springer Series in Synergetics (Springer, 2006).
Turcotte, D. L. Self-organized criticality: Does it have anything to do with criticality and is it useful?. Nonlinear Process. Geophys. 8, 193–196. https://doi.org/10.5194/npg-8-193-2001 (2001).
Aguirre, L. A. & Letellier, C. Modeling nonlinear dynamics and chaos: A review. Math. Probl. Eng. 1–35, 2009. https://doi.org/10.1155/2009/238960 (2009).
Uthamacumaran, A. A review of dynamical systems approaches for the detection of chaotic attractors in cancer networks. Patterns 2, 100226. https://doi.org/10.1016/j.patter.2021.100226 (2021).
Wolf, A., Swift, J. B., Swinney, H. L. & Vastano, J. A. Determining lyapunov exponents from a time series. Phys. D 16, 285–317. https://doi.org/10.1016/0167-2789(85)90011-9 (1985).
Shi, W. Lyapunov exponent analysis to chaotic phenomena of marine power system. In Fault Detection, Supervision and Safety of Technical Processes 2006 (ed. Zhang, H.-Y.) 1497–1502 (Elsevier Science Ltd, 2007). https://doi.org/10.1016/B978-008044485-7/50251-7.
Eckhardt, B. & Yao, D. Local lyapunov exponents in chaotic systems. Phys. D 65, 100–108. https://doi.org/10.1016/0167-2789(93)90007-N (1993).
Dumont, R. S. & Brumer, P. Characteristics of power spectra for regular and chaotic systems. J. Chem. Phys. 88, 1481–1496. https://doi.org/10.1063/1.454126 (1988).
Valsakumar, M. C., Satyanarayana, S. V. M. & Sridhar, V. Signature of chaos in power spectrum. Pramana 48, 69–85. https://doi.org/10.1007/BF02845623 (1997).
Jiang, W., Kong, X. & Zhang, Q. Chaotic signal pattern recognition using orthogonal wavelet packet method. SAE Trans. 111, 256–261 (2002).
Theiler, J. Estimating fractal dimension. J. Opt. Soc. Am. A 7, 1055–1073. https://doi.org/10.1364/JOSAA.7.001055 (1990).
Freistetter, F. Fractal dimensions as chaos indicators. Celest. Mech. Dyn. Astron. 78, 211–225 (2000).
Frigg, R. In what sense is the Kolmogorov–Sinai entropy a measure for chaotic behaviour?-bridging the gap between dynamical systems theory and communication theory. Brit. J. Philos. Sci.https://doi.org/10.1093/bjps/55.3.411 (2004).
Zhang, J. & Small, M. Complex network from pseudoperiodic time series: Topology versus dynamics. Phys. Rev. Lett. 96, 238701. https://doi.org/10.1103/PhysRevLett.96.238701 (2006).
Li, C., Lu, J. & Chen, G. Network analysis of chaotic dynamics in fixed-precision digital domain. In 2019 IEEE International Symposium on Circuits and Systems (ISCAS), 1–5. https://doi.org/10.1109/ISCAS.2019.8702232 (2019).
Yang, Y. & Yang, H. Complex network-based time series analysis. Phys. A 387, 1381–1386. https://doi.org/10.1016/j.physa.2007.10.055 (2008).
Barabási, A.-L. The network takeover. Nat. Phys. 8, 14–16. https://doi.org/10.1038/nphys2188 (2012).
Manshour, P. Complex network approach to fractional time series. Chaos 25, 103105. https://doi.org/10.1063/1.4930839 (2015).
Mata, A. S. Complex networks: A mini-review. Braz. J. Phys. 50, 658–672. https://doi.org/10.1007/s13538-020-00772-9 (2020).
Ribeiro, H. V., Jauregui, M., Zunino, L. & Lenzi, E. K. Characterizing time series via complexity-entropy curves. Phys. Rev. E 95, 062106. https://doi.org/10.1103/PhysRevE.95.062106 (2017).
Jebb, A. T., Tay, L., Wang, W. & Huang, Q. Time series analysis for psychological research: Examining and forecasting change. Front. Psychol.https://doi.org/10.3389/fpsyg.2015.00727 (2015).
Complexity testing techniques for time series data. A comprehensive literature review. Chaos Solitons Fractals 81, 117–135. https://doi.org/10.1016/j.chaos.2015.09.002 (2015).
Hurst, H. E. Long-term storage capacity of reservoirs. Trans. Am. Soc. Civ. Eng. 116, 770–799. https://doi.org/10.1061/TACEAT.0006518 (1951).
Kiyono, K., Struzik, Z. R., Aoyagi, N., Togo, F. & Yamamoto, Y. Phase transition in a healthy human heart rate. Phys. Rev. Lett. 95, 058101. https://doi.org/10.1103/PhysRevLett.95.058101 (2005).
Chianca, C., Ticona, A. & Penna, T. Fourier-detrended fluctuation analysis. Phys. A 357, 447–454. https://doi.org/10.1016/j.physa.2005.03.047 (2005).
Rodriguez, E., Carlos Echeverría, J. & Alvarez-Ramirez, J. Detrending fluctuation analysis based on high-pass filtering. Phys. A Stat. Mech. Appl. 375, 699–708. https://doi.org/10.1016/j.physa.2006.10.038 (2007).
Alvarez-Ramirez, J., Rodriguez, E. & Carlos Echeverria, J. A dfa approach for assessing asymmetric correlations. Phys. A 388, 2263–2270. https://doi.org/10.1016/j.physa.2009.03.007 (2009).
Peng, C.-K. et al. Mosaic organization of dna nucleotides. Phys. Rev. E 49, 1685–1689. https://doi.org/10.1103/PhysRevE.49.1685 (1994).
Wang, Y. et al. Traffic Flow Volume Fluctuation Analysis using MF-DFA, 4184–4191 (2009).
Kantelhardt, J. W., Koscielny-Bunde, E., Rego, H. H. A., Havlin, S. & Bunde, A. Detecting long-range correlations with detrended fluctuation analysis. Phys. A 295, 441–454. https://doi.org/10.1016/S0378-4371(01)00144-3 (2001).
Absil, P.-A., Sepulchre, R., Bilge, A. & Gérard, P. Nonlinear analysis of cardiac rhythm fluctuations using dfa method. Phys. A 272, 235–244. https://doi.org/10.1016/S0378-4371(99)00295-2 (1999).
Alipour, N. & Safari, H. Statistical properties of solar coronal bright points. Astrophys. J. 807, 175. https://doi.org/10.1088/0004-637X/807/2/175 (2015).
Lacasa, L., Luque, B., Ballesteros, F., Luque, J. & Nuño, J. C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. 105, 4972–4975. https://doi.org/10.1073/pnas.0709247105 (2008).
Luque, B., Lacasa, L., Ballesteros, F. & Luque, J. Horizontal visibility graphs: Exact results for random time series. Phys. Rev. E 80, 046103. https://doi.org/10.1103/PhysRevE.80.046103 (2009).
Fioriti, V., Tofani, A. & Pietro, A. D. Discriminating chaotic time series with visibility graph eigenvalues. Complex Syst.https://doi.org/10.25088/complexsystems.21.3.193 (2012).
Flanagan, R., Lacasa, L. & Nicosia, V. On the spectral properties of feigenbaum graphs. J. Phys. A Math. Theor. 53, 025702. https://doi.org/10.1088/1751-8121/ab587f (2019).
Barabási, A.-L. & Bonabeau, E. Scale-free networks. Sci. Am. 288, 60–69. https://doi.org/10.2307/26060284 (2003).
Najafi, A., Darooneh, A. H., Gheibi, A. & Farhang, N. Solar flare modified complex network. Astrophys. J. 894, 66. https://doi.org/10.3847/1538-4357/ab8301 (2020).
Bak, P., Tang, C. & Wiesenfeld, K. Self-organized criticality: An explanation of the 1/f noise. Phys. Rev. Lett. 59, 381–384. https://doi.org/10.1103/PhysRevLett.59.381 (1987).
Manna, S. S. Two-state model of self-organized criticality. J. Phys. A Math. Gener. 24, L363–L369. https://doi.org/10.1088/0305-4470/24/7/009 (1991).
Tajfirouze, E. & Safari, H. Can a nanoflare model of extreme-ultraviolet irradiances describe the heating of the solar corona?. Astrophys. J. 744, 113. https://doi.org/10.1088/0004-637x/744/2/113 (2011).
Pauluhn, A. & Solanki, S. K. A nanoflare model of quiet Sun EUV emission. Astron. Astrophys. 462, 311–322. https://doi.org/10.1051/0004-6361:20065152 (2007).
Safari, H., Innes, D. E., Solanki, S. K. & Pauluhn, A. Nanoflare model of emission line radiance distributions in active region coronae. In Modern Solar Facilities—Advanced Solar Science (Kneer, F., Puschmann, K. G. & Wittmann, A. D., eds.), 359 (2007).
Bazarghan, M., Safari, H., Innes, D. E., Karami, E. & Solanki, S. K. A nanoflare model for active region radiance: Application of artificial neural networks. Astron. Astrophys. 492, L13–L16. https://doi.org/10.1051/0004-6361:200810911 (2008).
Hudson, H. S. Solar flares, microflares, nanoflares, and coronal heating. Sol. Phys. 133, 357–369. https://doi.org/10.1007/BF00149894 (1991).
Crosby, N. B., Aschwanden, M. J. & Dennis, B. R. Frequency distributions and correlations of solar X-ray flare parameters. Sol. Phys. 143, 275–299. https://doi.org/10.1007/BF00646488 (1993).
Krucker, S. & Benz, A. O. Energy distribution of heating processes in the quiet solar corona. Astrophys. J. 501, L213–L216. https://doi.org/10.1086/311474 (1998).
Parnell, C. E. & Jupp, P. E. Statistical analysis of the energy distribution of nanoflares in the quiet sun. Astrophys. J. 529, 554–569. https://doi.org/10.1086/308271 (2000).
Wheatland, M. S. & Litvinenko, Y. E. Energy balance in the flaring solar corona. Astrophys. J. 557, 332–336. https://doi.org/10.1086/321655 (2001).
Klimchuk, J. A., Reale, F., Testa, P. & Parenti, S. Observations of nanoflare produced hot (10 Mk) plasma. In AAS/Solar Physics Division Meeting #40, vol. 40 of AAS/Solar Physics Division Meeting, 12.14 (2009).
Fletcher, L. et al. An observational overview of solar flares. Sp. Sci. Rev. 159, 19–106. https://doi.org/10.1007/s11214-010-9701-8 (2011).
Reale, F. Coronal loops: Observations and modeling of confined plasma. Liv. Rev. Solar Phys. 11, 4. https://doi.org/10.12942/lrsp-2014-4 (2014).
Hosseini Rad, S., Alipour, N. & Safari, H. Energetics of solar coronal bright points. Astrophys. J. 906, 59. https://doi.org/10.3847/1538-4357/abc8e8 (2021).
Biondo, A. E., Pluchino, A. & Rapisarda, A. Modeling financial markets by self-organized criticality. Phys. Rev. E 92, 042814. https://doi.org/10.1103/PhysRevE.92.042814 (2015).
Massey, F. J. Jr. The Kolmogorov–Smirnov test for goodness of fit. J. Am. Stat. Assoc. 46, 68–78. https://doi.org/10.1080/01621459.1951.10500769 (1951).
Miller, L. H. Table of percentage points of kolmogorov statistics. J. Am. Stat. Assoc. 51, 111–121. https://doi.org/10.1080/01621459.1956.10501314 (1956).
Marsaglia, G., Tsang, W. W. & Wang, J. Evaluating Kolmogorov’s distribution. J. Stat. Softw. 8, 1–4. https://doi.org/10.18637/jss.v008.i18 (2003).
Acknowledgements
Authors would like to thank the United States Geological Survey archive and the Stooq Database for sharing their information. Nastaran Farhang express her gratitude to the Iran National Science Foundation (INSF) for supporting this research under Grant No. 99012824. The authors also gratefully acknowledge the anonymous reviewers for their constructive suggestions.
Author information
Authors and Affiliations
Contributions
B.K. conceived of the presented idea. H.S. and N.F. were involved in designing the study and supervised the work. B.K. worked out almost all of the computations. All authors contributed to the analysis of the results and the writing of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kaki, B., Farhang, N. & Safari, H. Evidence of self-organized criticality in time series by the horizontal visibility graph approach. Sci Rep 12, 16835 (2022). https://doi.org/10.1038/s41598-022-20473-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-20473-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
