
Abstract
Decoding the factors behind odor perception has long been a challenge in the field of human neuroscience, olfactory research, perfumery, psychology, biology and chemistry. The new wave of data-driven and machine learning approaches to predicting molecular properties are a growing area of research interest and provide for significant improvement over conventional statistical methods. We look at these approaches in the context of predicting molecular odor, specifically focusing on multi-label classification strategies employed for the same. Namely binary relevance, classifier chains, and random forests adapted to deal with such a task. This challenge, termed quantitative structure–odor relationship, remains an unsolved task in the field of sensory perception in machine learning, and we hope to emulate the results achieved in the field of vision and auditory perception in olfaction over time.
Similar content being viewed by others

Introduction
For decades, scientists from various disciplines have been searching for an olfactory classification system on a psychological or physiochemical basis1. A robust model that can accurately predict odor would cut down significantly on the time and capital spent in formulation, extraction, and production of new odors for which there is substantial commercial demand. There is also an incentive to find substitutes for odorants that are environmentally hazardous or very scarce. For example, sandalwood scent is derived from santalol, and in an effort to synthetically reproduce the scent, chemist Jacques Vailliant spent more than a year creating structural variations of santalol by changing the ring and branch structures with very little success2.
The biological process of olfaction is characterized by the odorant molecules entering the nasal cavity where odor perception is due to the interaction of volatile compounds with the olfactory receptor neurons (ORNs) that lie in the olfactory epithelium, which occupies a 3.7 cm zone in the upper part of the nasal cavity3. Humans have around 12 million ORNs in each epithelium (right and left); as the olfaction system is bilateral, there are two of each structure3.
Broadly there are two general approaches to odor classification: -
-
1.
By featurizing of the molecular properties/Structure of odorous compound-This approach tries to establish a link between the molecular/structural properties like molecular vibration, molecular weight, molecule shape, electron donor, acid–base, and other physicochemical parameters and perceived odor on the principle of capturing some global relation between a set of features and target variable4. For example, it is common knowledge that molecules with an ester functional group usually have a fruity and floral smell. The vibrational spectrum can also serve as a proxy for the structure of a molecule and form the feature space5.
-
2.
As features of the sensory percept- This school of thought argues that odor is merely a psychological construct and therefore entirely subjective. The basis for classification then becomes the verbal odor descriptions used by subjects to describe a particular odor. A review of a large body of research reported that many of the proposed perception-based classification systems are vague or even contradictory6.This can be attributed to differences in subjects’ vocabulary, sensitivity to odor with age, cultural experience, etc. It is now, therefore, rarely used in scientific literature and is more or less obsolete.
Another less frequently used approach focuses on mouse olfactory sensory neurons (OSNs) where receptor activity through a calcium signal forms the basis for odor instead of subjective descriptors from human subjects7.
QSOR modelling in the past
As a subdomain of the molecular property prediction problem (also called QSAR or quantitative structure–activity relationships)8, interest has been revived in QSOR over the last decade, with machine learning algorithms becoming more and more complex, and especially with breakthroughs in the field of deep learning and neural networks9.
Early implementations of neural networks for QSOR were very shallow and modelled on overly small odor and sample spaces (rarely more than 100 molecules were used and categories of odor to classify numbered between one and 10)10,11,12.While the exact structure of odor space and its dimensions is still an area of active research, it is well established that the magnitude of a global odor space, if it exists, is at least in the100s.
Challenges in QSOR
The main hurdle in QSOR is the drastic change in odor caused by very small changes in the structure or functional group of a molecule. Early attempts at generating a set of rigid empirical odor rules on the basis of molecular substituent, intramolecular distances, and other molecular properties for odor prediction were immediately broken any time a new odorant molecule was discovered and thus were full of exceptions. Here are some of the examples which defied the odor rules:
-
1.
Enantiomeric compounds, also known as optical isomers, have the same chemical functions and are structurally close, but only as few as 5% of enantiomer couples have a similar smell. Two such examples are shown in Fig. 113.
-
2.
Structurally different organic compounds having a similar smell, for example, musk-related odors shown in Fig. 214.
-
3.
Besides changing the odor, a small structural change to a molecule may also cause a decrease in odor intensity as shown in Fig. 3.

Examples of enantiomeric compounds with dissimilar odors.

Examples of odorants with different structures but similar odor (musk).

Example of the changing odorant character of a compound with slight structural modification.
Methods
Forming an integrated dataset
Two separate expertly labeled odor datasets were used during the course of this study, namely Leffingwell PMP 2001 and the training data made available during the “learning to smell challenge” by Firmenich. The Leffingwell dataset was originally curated for researching olfaction and all the odorant molecules in it were labeled with one or more odor descriptors, hand-picked by olfactory experts (usually a practicing perfumer). In order to come up with an integrated dataset that could be directly fed to our model, merging of the aforementioned datasets using a common schema was required along with the filtering of duplicate odorous molecules.
Firmenich's dataset had a total of 4704 molecules and a vocabulary of 109 unique odor descriptors, while the PMP dataset contained 3523 molecules and 113 unique odor descriptors. We observed that 61 odor descriptors were common in both the datasets and upon closer inspection, it was found that some odor descriptors were identical semantically but different syntactically ('black currant' vs. 'blackcurrant,' 'leafy' vs. 'leaf' etc.). A similarity-based string search using the fuzzywuzzy module was done to make a list of such odor descriptors; we manually removed any pairs which were not deemed to be referring to the same odor. Further transformation of the pair of odor descriptors to fit in with Firmenich's vocabulary was done which resulted in a total of 75 intersecting odor descriptors. The final dataset formed by merging both the datasets had a total of 7374 molecule samples and 109 unique odor classes with varying sample counts (Fig. 4).The highest number of samples were associated with the fruity class at a count of 2050 samples, while the fennel class had the lowest associated sample count with 9 samples. A standard training/test split of 80:20 percent was set for our model evaluation and a five-fold cross-validation was conducted on the training set.

A scatter plot representing the number of samples in each of the 109 unique odor classes.The size of each point in the plot is proportional to the magnitude of the number of samples in that odor class.
Exploring label imbalance
Multi-label datasets (MLDs) typically have heavy label imbalance. To verify this a couple of label imbalance metrics by the name of MeanIR and IRLbl were computed along with plotting a histogram of odor labels to visually infer if any such imbalances remained. Further, class_weight hyper parameter for the models was set to “balanced” to tackle class imbalances within our dataset.
Exploring label correlation
Where a multi-class task would have only one odor label associated with the molecule out of 109 unique odors in the dataset, a multi-label task has one or more than one odor labels associated with a molecule out of 109 unique odors.
For example.
Multi-class | Multi-label | ||
Molecule | Odor | Molecule | Odor |
CSC#N | ['alliaceous'] | CCC(=O)O | ['pungent', 'sour', 'dairy'] |
Generally, complete independence between the labels is assumed. However, most researchers highlight the importance to take into account label dependency information15. For example, a ‘fruity’ label may be more likely to occur with the label ‘apple’ based on linguistic similarity. A co-occurrence matrix (109 × 109, for 109 unique odors in the integrated dataset) where i’th row and j’th column represents the frequency of the co-occurrence of the two labels was built to gauge label dependency up to second degree. To get a more global knowledge of any such label correlation, we ran the Louvain community detection algorithm on the odor labels which attempts to optimize modularity; a measure for the quality of partition between communities of nodes.
Featurizing molecules
To get a meaningful numerical representation of odor molecules which to be fed to our model, we used three traditional featurization techniques:- Mordred, Morgan, and daylight fingerprinting. The first of the three was generated using Mordred descriptor calculator16 while Rdkit was used for the other two.
Pre-processing
Some columns from the feature space were dropped due to a large percentage of missing values. The remaining missing values were imputed using a KNN Imputer. Furthermore, each label set was converted into a 109-length bit vector; 1 denoting the presence of the label and 0 denoting its absence with the associated molecule.
Training machine learning models
We used a random forest classifier with multi-label support17 in the scikit-learn library as our baseline model. Further, we use two different model approaches for chaining random forest models together:- Binary Relevance and Classifier chains18.
Using evaluation metrics to validate model performance
To measure multi-label classifiers, we averaged the classes. We used the micro-averaging method where the individual true positives, false positives, and false negatives of the system for different label sets were averaged. The micro-averaged F1-Score represented the harmonic mean of micro averaged recall and micro averaged precision.
Results and discussion
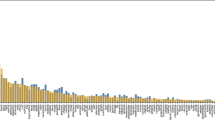
A preliminary histogram plot (Fig. 5) revealed that fennel has the least occurrence in our dataset while fruity is the highest occurring label. As apparent, the distribution is highly skewed implying a heavy label imbalance. This imbalance was further verified by computing the MeanIR (29.169). The disparity between the absolute frequency of the top 10 most frequently occurring and least frequently occurring odor labels make the skewness more apparent in Table 1.

Label imbalance with the fruity label occurring approximately 27% of the time as opposed to fennel occurring less than 1% times in our data.
To ensure that the training and test dataset have a general representation of the data, we used iterative stratified sampling instead of random sampling while splitting our dataset by importing the iterative_train_test_split class from the scikit-multilearn library as the random sampling resulted in completely omitting the fennel odor descriptor adding to the already skewed label imbalance (Fig. 6).

Random split versus a stratified split respectively on the data. The difference in the height of blue and orange bars represents the relative difference in the occurrence of a particular label in the test and training set. It is clearly visible that stratified sampling produces a much more representative training and test set.
The construction of the co-occurrence matrix whose heatmap is shown in Fig. 7, revealed that green and fruity labels co-occurring 518 times and sweet and fruity labels co-occurring 433 times are the top 2 frequently occurring label pairs (Table 2). That means of all the molecules having a fruity odor 25% of them also have a green odor. Conversely, 40% of all molecules having a green odor also have a fruity odor. This follows suit with the general observation with MLDs that there usually exists some label correlation.

Heat map of our co-occurrence matrix truncated to top 80 odor.
Louvain community detection reveals the correlation between larger length label sets and it was observed that some of the groupings obtained by running the algorithm can be corroborated by common sense; for example, medicinal, phenolic, and chemical being in the same community intuitively seems right. The same is true for odor labels like fruity, apple, pear, banana, tropical fruit, melon, and grape. At the same time, some odor labels occur in communities one would not expect them to, for example, food with plastic, honey with lemon, etc. The network graph confirms that there exists some global correlation between labels. As seen in Fig. 8 the algorithm uncovered 4 clusters among a total of 109 odor labels. This approach was based on a measure called modularity, which tries to maximize the difference between the actual number of edges in a community and the expected number of edges in the community.

Graph constructed on the basis of Louvain method for community detection in networks. Nodes with the same colour belong to the same community.
The cardinality of our dataset (mean number of labels per sample) is three, suggesting the multilabel-ness of our data is typical (most MLDs are in the {1, 5} interval) and the label density (cardinality divided by the number of labels) is 0.02846 (most MLDs have density values below 0.1). This value is useful to know how sparse is the labels sets in the MLD. Higher density values denote label sets with more active labels than the lower ones.
Figure 9 shows the feature importance which was generated with random forests to get an idea of the features which contribute most significantly to the odor prediction task. Centered moreau-broto autocorrelation of lag 5 weighted by van der Waals volume (ATSC5v) and Geary coefficient of lag 5 weighted by ionization potential (GATS5i) are the top two Mordred features of importance, and further study into these might provide us with some insight into the kind of structural fragments or their relative spatial positions that result in imparting a particular odor to molecules.

Feature importance based on closeness to the root node of decision trees in the forest computed on mordred featurization.
Both of these two descriptors are spatial autocorrelation descriptors which in general explain how the considered property is distributed along the topological structure of the molecule. Representing the molecule as a graph with atoms at the vertices and bonds as the edges, both the auto descriptors consider a certain molecular property (e.g. atomic masses, atomic van der Waals volumes, atomic Sanderson electronegativities, atomic polarizabilities, etc.) distribution between pair wise atoms in the molecule at a certain topological distance (smallest number of interconnecting bonds between the two atoms).
Our model performance evaluated on micro averaged scores for each featurization revealed that the binary relevance model trained on Daylight fingeprints yielded the best F1_score. It is also worth mentioning that Binary relevance produced somewhat comparable F1_scores for mordred and Morgan featurizations with classifier chains and superior F1_scores with random forest models.
It is worthwhile noting that although there is a label correlation between our odor labels, we got better model performance from binary relevance which discards these correlations as opposed to classifier chains which take them into account, as evident from Table 3. Fivefold cross validation was carried out on the training set in order to further authenticate the scores shown in Table 4. One possible explanation for this contradiction might lie in the ordering of target labels which we have taken to be random. Because the models in each chain are arranged randomly there is significant variation in performance among the chains. Presumably, there is an optimal ordering of the classes in a chain that will yield the best performance. However, we do not know that ordering a priori.
We also computed label-wise scores (Table 5) and observed that the top 15 F1_scores generally belonged to labels that had a higher percentage of associated samples in our dataset (mean percentage of samples associated with top 15 labels = 3.553), although there were exceptions to it like fennel (0.122 percentage) and ammoniac (0.176 percentage).
In contrast, the bottom 15 F1_scores generally belonged to labels that had a lower percentage of associated samples (mean percentage of samples associated with bottom 15 labels = 1.027).From this, it is inferred that our model performs better on frequent labels than infrequent labels.
Conclusion
We assembled a novel and large dataset of expertly labelled odorants and applied multi-label classification techniques to predict the relationship between a molecule’s structure and its smell. We achieved close to state-of-the-art results obtained using GNN’s y4 on this QSOR task, employing multi-label classification techniques, and further demonstrated the label correlations that occur in our label space. Finally, we evaluated labels for which our best performing model is a weak learner and others for which it performs well.
Data availability
All data generated or analysed during this study are included in this published article and its supplementary information files.
References
Kaeppler, K. & Müller, F. Odor classification: A review of factors influencing perception-based odor arrangements. Chem. Senses https://doi.org/10.1093/chemse/bjs141 (2013).
Barwich, A.-S. Making sense of smell: Classifications and model thinking in olfaction theory (2013).
Sela, L. & Sobel, N. Human olfaction: A constant state of change-blindness. Exp. Brain Res. 205(1), 13–29 (2010).
Sanchez, B., et al. (2019). Machine learning for scent: Learning generalizable perceptual representations of small molecules.
Pandey, N. et al. Vibration-based biomimetic odor classification. Sci. Rep. 11, 11389. https://doi.org/10.1038/s41598-021-90592-x (2021).
Chastrette, M., Elmouaffek, A. & Sauvegrain, P. A multidimensional statistical study of similarities between 74 notes used in perfumery. Chem. Senses 13, 295–305 (1988).
Poivet, E. et al. Functional odor classification through a medicinal chemistry approach. Sci. Adv. 4(2), 6086. https://doi.org/10.1126/sciadv.aao6086 (2018).
Peter, S. C., et al. Quantitative Structure-Activity Relationship (QSAR): Modeling Approaches to Biological Applications (2018). https://doi.org/10.1016/B978-0-12-809633-8.20197-0.
Sharma, A., Kumar, R., Ranjta, S. & Varadwaj, P. K. SMILES to smell: Decoding the structure–odor relationship of chemical compounds using the deep neural network approach. J Chem Inf Model 61(2), 676–688. https://doi.org/10.1021/acs.jcim.0c01288 (2021).
Chastrette, M., Cretin, D. & Aïdi, E. Structure−Odor relationships: using neural networks in the estimation of camphoraceous or fruity odors and olfactory thresholds of aliphatic alcohols. J. Chem. Inf. Comput. Sci. 36(1), 108–113 (1996).
Chastrette, M., El Aïdi, C. & Crétin, D. Structure-odour relationships for bell-pepper, green and nutty notes in pyrazines and thiazoles. Comparison between neural networks and similarity searching. SAR QSAR Environ. Res. 7(1–4), 233–258. https://doi.org/10.1080/10629369708039132 (1997).
Zakarya, D., Cherqaoui, D. Esseffar, M. H., Villemin, D. & Cense, J.-M. Application of neural networks to structure-sandalwood odour relationships. J. Phys. Organ. Chem. 10(8), 612–622 (1997).
Brookes, J. C., Horsfield, A. P. & Stoneham, A. M. Odour character differences for enantiomers correlate with molecular flexibility. J. R. Soc. Interface 6(30), 75–86 (2009).
Boelens, M. H. & van Gemert L. J. Volatile character-impact sulfur compounds and their sensory properties. Perfum. Flavorist. 18, 30–39 (1983).
Alvares-Cherman, E., Metz, J. & Monard, M. C. Incorporating label dependency into the binary relevance framework for multi-label classification. Expert Syst. Appl. 39(2), 1647–1655 (2012).
Moriwaki, H., Tian, Y.-S., Kawashita, N. & Takagi, T. Mordred: a molecular descriptor calculator. J. Cheminform. 10(1), 4 (2018).
Clare, A. & King, R. D. Knowledge discovery in multi-label phenotype data. In Proceedings of the 5th European Conference Principles on Data Mining and Knowledge Discovery, PKDD’01, Vol. 2168 42–53 (Springer, 2001).
Read, J., Pfahringer, B., Holmes, G. & Frank, E. Classifier chains for multi-label classification. Mach. Learn. 85, 333–359 (2011).
Acknowledgements
We thank Leffingwell and Associates and Firmenich for their generosity in sharing their data for research use.
Author information
Authors and Affiliations
Contributions
K.S. and V.R. conceived the idea. K.S. carried out the work. K.S. and V.R. wrote and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Saini, K., Ramanathan, V. Predicting odor from molecular structure: a multi-label classification approach. Sci Rep 12, 13863 (2022). https://doi.org/10.1038/s41598-022-18086-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-18086-y
This article is cited by
-
Predicting odor from vibrational spectra: a data-driven approach
Scientific Reports (2024)
-
OWSum: algorithmic odor prediction and insight into structure-odor relationships
Journal of Cheminformatics (2023)
-
Adaptable “bubble particles” prepared by green aqueous phase reshaping for completely removing odor
Nano Research (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
