
Abstract
Birds are a kind of environmental indicator organism, which can reflect the changes in the ecological environment and biodiversity, and recognition of birdsongs can further help understand and protect birds and natural environment. Extreme learning machine (ELM) has the advantages of fast learning speed and good generalization ability, which is widely used in classification and recognition problems. Input layer weights and hidden layer thresholds are two key factors affecting ELM performance. As one of swarm intelligence optimization methods, differential evolution (DE) can be used to optimize the parameters of ELM. In order to enhance the diversity, convergence speed and global search ability of the DE population, and improve the accuracy and stability of the classification model, this paper proposes a multi-strategy differential evolution method (M-SDE) to optimize the parameters of the ELM. And the differential MFCC feature parameters, extracted from birdsongs, are applied to build classification models of M-SDE_ELM and an ensemble M-SDE_EnELM with optimized ELM for bird species recognition. In the experiments, the ELM models optimized by the swarm intelligence algorithms PSO and GOA are compared and analyzed by hypothesis tests with the M-SDE_ELM and M-SDE_EnELM. Results show that the M-SDE_ELM and M-SDE_EnELM can achieve a classification accuracy of 86.70% and 89.05% in the classification of nine species of birds respectively, and the recognition effect and stability of the M-SDE_EnELM model outperform other models.
Similar content being viewed by others


Introduction
Birds play an important role in nature. Knowing the birds in a specific area can help us understand the ecology of the area, and can effectively evaluate the environmental quality of the area's ecology, which is of great significance to the protection of the natural environment. Bird recognition helps us get along better with nature, and also provides a new perspective for researchers to maintain ecological balance and monitor ecology. As the language of birds, birdsongs is an important physiological feature of birds, and there are great differences in the birdsongs of different species of birds1,2. Therefore, birds recognition focuses on birdsongs. At present, many researchers have collected birdsongs signals and carried out a lot of research work. With adopting various feature parameters extraction techniques for birdsongs signals, machine learning algorithms are used to classify and recognize birdsongs. Extracting of the exact feature parameters and exploiting better learning algorithm will play a key role in the classification results.
Feature parameters commonly used in birdsongs recognition technology include MFCC, short-time energy (STE), linear predictive cepstral coding (LPCC) and linear predictive coding (LPC), etc. For example, Wang et al. took eight kinds of birds as the research object, and divided the birdsongs into bird tweet and bird sing to extract their MFCC feature parameters, and used the dual gaussian mixture model for training and recognition3. Xu et al. studied birdsongs recognition based on syllable length, MFCC, and DTW model based on LPC, combined with time–frequency texture feature and multi-label classifiers. With eleven kinds of birds as the research object, it selected the optimal feature parameters and classifiers to improve the recognition effect of a single classifier4.
Classical classifiers include random forest, decision tree, gaussian mixture model, neural network, ELM, etc. ELM is a randomized fast learning algorithm with good generalization ability5,6. Using ELM to study classification and recognition problems has become a research hotspot. For example, Xue et al. classify and recognize power quality events based on wavelet transform and ELM, which can effectively recognize eight kinds of disturbances and have strong robustness7. Lin et al. assisted in the diagnosis of Alzheimer's disease based on ELM, and the accuracy of this method in diagnosing Alzheimer's disease reached 87.62%8. Venkatalakshmi et al. extracted breast X-ray image feature set and combined ELM classifier to classify normal, malignant and benign breast cancer. The accuracy, sensitivity and specificity of the method are better than that of similar technology9. Kashif et al. proposed an ELM-based consonant phoneme recognition model for the accent recognition of different pronunciations of English consonant phonemes by native Arabic speakers, the accuracy of the model reached 88%10.
Because ELM generally randomly generates input layer weights and hidden layer thresholds, and then obtains output weights through calculations. There is no uniform form for the selection of parameters, and only a large amount of training and learning can be used to obtain the optimal parameter value. This method takes a long time because of calculation complexity. The final result may not be the optimal solution, and the performance of the classifier is unstable11. Therefore, it is necessary to use intelligent algorithm to optimize ELM parameters to make the classifier achieve better results. DE is a population-based random search algorithm12,13, which conducts intelligent search through mutation and crossover, and ensures that the best individual can be further utilized. With fast convergence speed and good global search performance, DE is one of the most powerful and universal evolutionary optimizers in continuous parameter space. For example, to reduce the prediction time of ELM and avoid falling into local optimality, Yang et al. proposed a differential evolution coral reef optimization algorithm with hybrid DE and metaheuristic coral reef optimization to balance exploration and development capabilities to achieve better performance14. Dahou et al. combined DE and convolutional neural networks (CNN) to solve the problem of Arabic sentiment classification, and used DE algorithm to optimize CNN parameters. Experiments show that DE-CNN has good performance in terms of accuracy and time consumption15. Li et al. used principal component analysis to reduce the dimensionality of the input feature and used the sequence floating backward algorithm to perform feature selection, and then input the optimal feature set into the differential evolution ELM to evaluate the transient stability of the power system. Compared with other ELMs, this model greatly improved its performance in transient stability classification evaluation16.
However, the standard DE algorithm often leads to premature convergence and search stagnation17. Therefore, many scholars conducted research on DE algorithm improvement. For example, Singh et al. used multi-objective DE to adjust the initial parameters of CNN and the optimized CNN can effectively classify chest CT images for COVID-1918. A memetic differential evolution algorithm was proposed to solve the problem of text clustering, improved the mutation strategy of DE and mixed it with the memetic algorithm, and was superior to other clustering algorithms based on AUC measurement, F-measure, statistical analysis and existing text clustering algorithms19. Vivekanandan et al. used “DE/rand/2/exp” as the differential strategy to select optimal feature of cardiovascular disease, using fuzzy analytic hierarchy process and feedforward neural network to predict heart disease, the accuracy of the model reached 83%20. Duan et al. combined “DE/best/2” mutation operator and “DE/rand/2” mutation operator to form a dual-strategy and dynamically adjusted control factor \(\uplambda\) during the evolution process, this algorithm can significantly improve the global optimization performance21. However, the mutation strategies adopted by these articles for DE are single strategy or dual strategy, and they all used a single classifier for classification. In order to improve population diversity, convergence speed and global search ability, this paper proposes a multi-strategy mutation of DE algorithm. And the classification model of ensemble multiple DE-optimized ELMs will be built to enhance the recognition effect and generalization ability.
This paper takes birdsongs as the research object. Firstly, the MFCC feature parameters of the birdsongs data are extracted, and in order to maintain the time domain continuity of the audio signal22, performing differential calculation on MFCC. Secondly, a multi-strategy mutation is formed by combination of three strategies, while using adaptive adjustment control parameters (scaling factor F and crossover probability CR) to improve the standard DE. The input layer weights and the hidden layer thresholds of ELM are adjusted through the DE. Finally, we ensemble optimized ELM model to classify birdsongs. This model can better solve the problems of unstable performance of ELM classifier and difficulty in determining the number of optimal hidden layer neurons in birdsongs recognition.
The main contributions of this paper can be summarized as follows:
-
(1)
Adopt the multi-strategy mutation in DE algorithm (M-SDE) to improve the population diversity and global search ability;
-
(2)
Use the M-SDE algorithm to optimize the hidden layer thresholds and input layer weights of the ELM model;
-
(3)
Extract the differential MFCC feature parameters of birdsongs, and build the ensemble optimized ELM (M-SDE_EnELM) to improve model stability and recognition accuracy for birdsongs.
The rest of this paper is organized as follows: Firstly, the ELM and differential evolution are described. Secondly, we propose multi-strategy differential evolution algorithm. Thirdly, we introduce the MFCC feature parameters extraction process of birdsongs and the birdsongs recognition model based on ensemble ELM with multi-strategy differential evolution algorithm. Fourthly, experimental results and limitations are discussed. Finally, we give the conclusions.
Extreme learning machine
ELM is an algorithm for training single layer feedforward neuron networks (SLFNs)23, which can effectively reduce the model runs time and produce good generalization performance. The topology of SLFNs is shown in Fig. 1.

Topological diagram of SLFNs.
SLFNs is composed of input layer, hidden layer and output layer. Assuming that the input layer has \(K\) nodes. \(K\) describes the number of features; the hidden layer has \(L\) nodes, and \(L\) describes the number of neurons in the hidden layer; the output layer has \(P\) nodes, \(P\) is the number of sample categories. SLFNs can be represented by triples \((K,L,P)\). Suppose training set:
Where \(N\) is the number of training samples, \({{x}_{i}=[{x}_{i1},{x}_{i2},\dots ,{x}_{iK}]}^{T}\in {R}^{K}\) is the feature of the sample, \({{y}_{i}=[{y}_{i1},{y}_{i2},\dots ,{y}_{iP}]}^{T}\in {R}^{P}\) is the category to which the sample \(i\) belongs to \(P\) categories and \({y}_{ip}\in \left\{\mathrm{0,1}\right\},p=1,\dots ,P\). Then the SLFNs with \(L\) hidden nodes can be expressed as
where \(h\left(x\right)\) is the feature mapping function, \(x\) is the input of the neural network, \({{w}_{j}=({w}_{j1},{w}_{j2},\dots ,{w}_{jK})}^{T}\) is the input weight, that is, the weight vector to connecting the input layer node and the jth node in the hidden layer, \({{\beta }_{j}=({\beta }_{j1},{\beta }_{j2},\dots ,{\beta }_{jK})}^{T}\) is the output weight, that is, the weight vector connecting the jth node of the hidden layer and the output layer node, \({b}_{j}\) is the threshold of the hidden layer, that is, the bias of the jth unit of the hidden layer. In ELM, the input weights and hidden layer thresholds are randomly initialized and generated, and the corresponding output weights are obtained. The goal of SLFNs learning is to minimize the output error, that is, \({\beta }_{j}\) satisfies Eq. (3)
It can be expressed as a matrix
where \(H\) is the output matrix of the hidden layer, \(\beta\) is the output weight, and \(Y\) is the expected output. ELM, a simple learning method for SLFNs, needs to search the optimal parameters \({\widehat{w}}_{j},{\widehat{b}}_{j},{\widehat{\beta }}_{j}\) to satisfy Eq. (8):
The least square solution of Eq. (8) can be expressed as
where \({H}^{+}\) is the Moore–Penrose pseudo-inverse matrix of matrix \(H\).

Differential evolution
Differential evolution is a swarm intelligent optimization method. It mainly works in four steps, initializing the population generation, mutation operation, crossover operation and selection operation. However, the individual in the population may cause the value of the individual to exceed the given maximum and minimum range after mutation and crossover, so boundary condition processing operation must be performed after the crossover operation.
-
(1)
Initialize the generated population
The individuals in the population can be expressed as: (the population size is \(NP\), the number of iterations is \(T\), and each individual is composed of a \(D\)-dimensional vector.)
$${x}_{i}\left(j\right)=\left({x}_{i,1}\left(j\right),{x}_{i,2}\left(j\right),{x}_{i,3}\left(j\right),\dots ,{x}_{i,D}\left(j\right)\right),1\le i\le NP,1\le j\le T$$(10)The initial population individuals are generally randomly generated within a given constraint boundary, as follows:
$${x}_{i,d}\left(j\right)=Xmin+rand\left(\mathrm{0,1}\right)\left(Xmax-Xmin\right),$$$$1\le i\le NP,1\le j\le T,1\le d\le D$$(11)\(Xmax\) and \(Xmin\) represent the upper and lower bounds of the individual values of the population respectively, and rand (0,1) refers the generation of a uniformly distributed random number between (0,1).
-
(2)
Mutation operation
The mutation vector is generated by the individual of its parent population through the mutation strategy. The mutation strategy is represented by “DE/x/y” and where x represents the vector such as random vector, best vector and current vector; y is the number of difference vectors. The commonly used mutation strategies are shown in Table 1.
Table 1 Mutation strategy. Where F is the scaling factor and 0 \(\le\) F \(\le\) 2; \(r1,\) \(r2, r3, r4\) and \(r5\) are randomly generated in the parent population and \(r1\ne r2\ne r3\ne r4\ne r5\); \({x}_{\mathrm{best}}\) is the best individual with the best fitness in the parent population; \({x}_{i}\) is the current corresponding parent population individual.
-
(3)
Crossover operation
$${u}_{i,d}(j)=\left\{\begin{array}{c}{v}_{i,d}\left(j\right), if \, rand\left(\mathrm{0,1}\right)<CR \, or \, randi\left(1,d\right)=j\\ {x}_{i,d}\left(j\right), if \, rand(\mathrm{0,1})>CR \, and \, randi\left(1,d\right)\ne j\end{array}\right.$$(12)where \(CR\) is the crossover probability and \(0\le CR\le 1\).
-
(4)
Boundary condition processing operation
$${u}_{i,d}(j)=\left\{\begin{array}{l}\left(Xmax-Xmin\right)*rand\left(\mathrm{0,1}\right)+Xmin, \, if \, {u}_{i,j}<Xmin \, or \, {u}_{i,j}>Xmax\\ {u}_{i,d}\left(j\right) , \, else\end{array}\right.$$(13) -
(5)
Selection operation
$${x}_{i}(j+1)=\left\{\begin{array}{l}{u}_{i}\left(j\right), \, if \, f\left({u}_{i}\left(j\right)\right)<f({x}_{i}\left(j\right))\\ {x}_{i}\left(j\right), \, else\end{array}\right.$$(14)With greedy criterion, the DE algorithm selects individuals from \(u\) as the individuals of the next generation population \(x\), \(f\left({u}_{i}\left(j\right)\right)\) represents the fitness of the jth generation individual in the crossover population \(u\), and \(f\left({x}_{i}\left(j\right)\right)\) represents the fitness of the jth generation individual in the parent population \(x\).
Multi-strategy differential evolution
Differential evolution performs intelligent search through mutation and crossover, and then selects the optimal individual. It has fast convergence speed and good global search performance. So, it can be used to optimize the parameters of the classifier. Because the input layer weights and hidden layer thresholds of ELM are generated randomly, the classifier becomes unstable due to the randomness of input layer weights and hidden layer thresholds. The method of running step by step to find the optimal input layer weights and hidden layer thresholds takes a long time, and the result may not be the optimal solution. Therefore, this paper uses differential evolution algorithm to optimize ELM parameters and improve the stability of the classifier, to make the classifier achieve better results.
In this study, we propose a multi-strategy differential evolution (M-SDE) to optimize parameters of ELM. Combination of three strategies forms a multi-strategy mutation. Three strategies are as follows.
-
(1)
“DE/rand/2” with strong global search performance and maintain population diversity;
-
(2)
“DE/best/2” with strong local development ability and fast convergence speed;
-
(3)
“DE/current to best/1” with the ability to maintain the diversity of the population and high convergence precision.
While using adaptive adjustment control parameters (scaling factor F and crossover probability CR) to improve the standard DE, Fig. 2 shows the process of DE optimizing ELM.


Optimized parameters of ELM with M-SDE.
Ensemble ELM with multi-strategy differential evolution
ELM classifier has a certain instability, so it is often necessary to improve the stability and accuracy of the classifier through ensemble methods. Therefore, this paper takes the value range of hidden layer neurons of ELM from four to ten times of the number of sample features, uses the majority voting algorithm to ensemble ten ELM models, and then uses the ensemble model to classify the test data.
This paper takes birds as the research object, collects birdsongs data, develops the study of birdsongs recognition based on M-SDE optimization ensemble ELM, and extracts the MFCC feature of birdsongs, establishes a birdsongs recognition model based on M-SDE optimized ensemble ELM.
MFCC feature extraction of birdsongs
The MFCC is proposed on the basis of auditory feature of the human ear that fully simulates the auditory feature of the human ear. It combines the human auditory feature and sound production, and is a sound feature parameter widely used at present24,25,26. Firstly, the input sound signal is performed denoising processing. Secondly, through endpoint detection, the effective voice segment is determined. Finally, the differential MFCC feature parameters of birdsongs signals are extracted to obtain its feature matrix. The process of extracting MFCC feature parameters is shown in Fig. 3.

Process of extracting MFCC feature parameters.
In this paper, the 13-dimensional MFCC feature parameters are extracted. In order to maintain the time domain continuity of the audio signal, the 13-dimensional ΔMFCC feature parameters and the 13-dimensional ΔΔMFCC feature parameters are obtained through the first-order difference and the second-order difference, respectively, and the three are fused (MFCC + ΔMFCC + ΔΔMFCC) to obtain the 39-dimensional differential MFCC feature parameters.
The differential formula is as follows:
Among them, \({C}_{t}\) is the tth feature parameter, \({C}_{t-1}\) is the t − 1th feature parameter, \({C}_{t+1}\) is the t + 1th feature parameter, \(Q\) is the dimension of the feature parameter, \({d}_{t}\) is the tth first order difference, and \(K\) is the time difference of the first order derivative is usually 1 or 2. In this paper, we take \(K\)=2. Substituting the first order difference calculated for the first time into Eq. (15) again can get the second order difference.
A birdsongs recognition model based on ensemble ELM with M-SDE
The birdsongs recognition model based on optimized ELM mainly includes four modules, namely, the establishment of training set and test set, training of M-SDE_ELM model, establishment of ensemble optimized ELM (M-SDE_EnELM) and prediction, details as follows:
-
(1)
Divide the differential MFCC feature data of birdsongs into training set and test set at a ratio of 7:3;
-
(2)
Generate optimized ELM (M-SDE_ELM) by optimizing the input layer weights and hidden layer thresholds of ELM through DE, where the mutation strategy of each iteration of DE is randomly generated by the three selected strategies (“DE/best/2”, “DE/rand/2”, “DE/current to best/1”);
-
(3)
Ensemble n (n = 10) M-SDE_ELM to form the M-SDE_EnELM ensemble model;
-
(4)
The majority voting algorithm are used in the trained M-SDE_EnELM ensemble model to classify and recognize birds.
Figures 4 and 5 show the process of constructing a birdsongs recognition model based on ensemble ELM with M-SDE. Figure 4 shows the extraction of birdsongs feature parameters. Figure 5 shows the M-SDE_EnELM model.

Extraction of birdsongs feature parameters.

Process of M-SDE_EnELM.
The majority voting algorithm is as follows.
where \(n\) is the number of ensemble model base classifiers, in this paper \(n\)=10. If the i-th base classifier classifies the sample \(x\) as class \(j\), then \({y}_{ij}(x)\)=1, otherwise \({y}_{ij}\left(x\right)\)=0.
Experiments and analysis
Data preprocessing
The collection of birdsongs data is mainly collected by the internet of things and crawler, supplemented by manual collection. Manual collection is to collect birdsongs through mobile phone or voice recorder; the internet of things collection is to collect birdsongs by designing the internet of things collection module; crawler collection is to crawl bird audios from the bird audios website27, the experimental data in this paper is obtained through web crawler.
This paper collected nine kinds of bird audios, namely Short-eared Owl, Whimbrel, Cormorant, Long-eared Owl, Sparrowhawk, Common Quail, Common Crane, Goshawk and Kestrel. The experimental bird audios are preprocessed and the unified data format is .wav format. The sound channel is mono, and the frequency is 16000HZ. After MFCC feature extraction, the feature matrix of birdsongs is obtained. The feature data is divided into training set and test set according to the ratio of 7:3, and four frames of audios data (each frame is 39d MFCC) are combined into one frame as a sample (156d MFCC). The training samples and test samples of each bird are shown in Table 2.
Experimental schemes
To verify the effectiveness of the proposed method, two groups of experiments are designed in this paper, and each group of experiment is run 10 times respectively, and the average result is taken as the final result. At the same time, in order to compare the difference and stability of the proposed method with other methods, hypothesis tests (t-test and F-test) analysis were performed on the 10 times run results of the two groups of experiments.
The first set of experiment is the single classifier comparison experiment. That is, original ELM model compared with the optimized ELM model by the heuristic algorithm. Grasshopper optimization algorithm (GOA)28 and particle swarm optimization algorithm (PSO)29 are population-based intelligent optimization algorithms which are widely used and have good results. To better compare the recognition effect of the M-SDE_ELM model, the GOA_ELM and PSO_ELM models (ELM is optimized by PSO and GOA, respectively.) are compared with it. The second set of experiment is the ensemble classifier comparison experiment. The ensemble original ELM model compares ensemble optimized ELM. The experimental process is shown in Fig. 6.

Experimental design process.
The parameters of the groups are as follows: the number of hidden layer neurons: n; population size: NP; max iteration: T; the feature dimension of the sample: df; the number of base classifiers: nc; linearly decrease parameter limit: c; velocity upper limit: vmax; target error: minerr; inertia weight limit: w; learning factor: C; cross probability: CR; fitness threshold: y; scaling factor: F0, F.
The experimental parameter settings of two groups are shown in Table 3.
In the second experimental scheme, ELM, GOA_ELM, PSO_ELM and M-SDE_ELM are used as the base classifiers of the four ensemble classifiers.
Analysis of experimental results
The experiment process in this paper is based on Matlab R2018b. After training the model in the experiment scheme with the training set, test it with the test set to analyze the recognition effect. Accuracy, F1_score and precision are calculated based on the confusion matrix, which are used as indicators to evaluate the classification model.
-
(1)
Single classifier
The classification performance of the four models established, including ELM, GOA_ELM, PSO_ELM, and M-SDE_ELM, on the test set are shown in Table 4.
Table 4 Performance of single classifier. The accuracy of ten runs of each classifier is shown in Fig. 7.
Figure 7 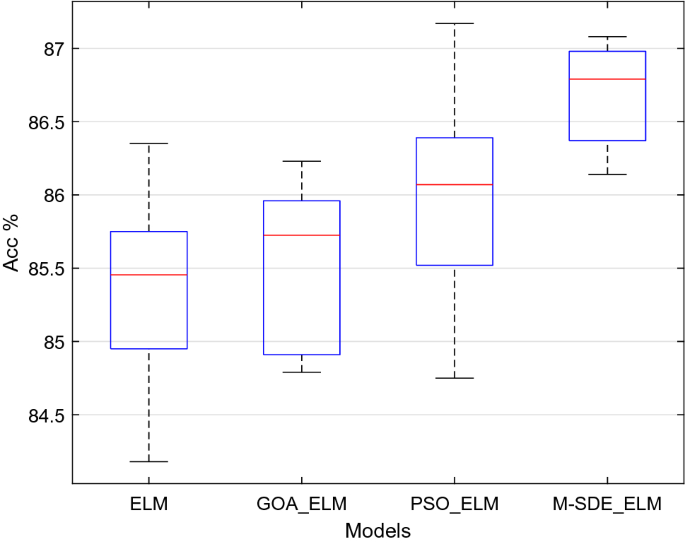
Single classifier experiments.
In Table 4 and Fig. 7, it shows that on the aspect of accuracy rate, M-SDE_ELM is superior to other three models, and the same as the F1_score and precision rank. On the aspect of standard deviation, the data of M-SDE_ELM is the lowest than other three models which reflects that it has a more stable performance among all the models.
Hypothesis tests (t-test and F-test) are performed on the 10-times recognition accuracy of M-SDE_ELM with the other three classification models, and the results are shown in Table 5.
Table 5 Hypothesis tests of single classifier. It can be seen from Table 5 that the t-tests are performed on M-SDE_ELM with the other three models, the p-values of the test results are all less than 0.05, indicating that the null hypotheses are rejected, that is, the mean of the recognition accuracy of M-SDE_ELM with the other three models have significant difference. F-tests for M-SDE_ELM with ELM and GOA_ELM, p-values are greater than 0.05, indicating acceptance of the null hypotheses, that is, the stability of M-SDE_ELM with ELM and GOA_ELM are consistent. While the p-value of F-test for M-SDE_ELM with PSO_ELM is less than 0.05, indicating that the null hypothesis is rejected, that is, the stability of M-SDE_ELM with PSO_ELM is different, and M-SDE_ELM is relatively stable. From the mean and standard deviation of M-SDE_ELM, the mean of M-SDE_ELM is the largest and the standard deviation is the smallest, so M-SDE_ELM outperforms the other three models.
It shows that the established M-SDE_ELM classifier has relatively good recognition effect and generalization performance.
To analyze and compare the efficiency of M-SDE_ELM, PSO_ELM, GOA_ELM three methods for birdsongs classification, the number of iterations and classification accuracy of the three methods are shown in Fig. 8.
Figure 8 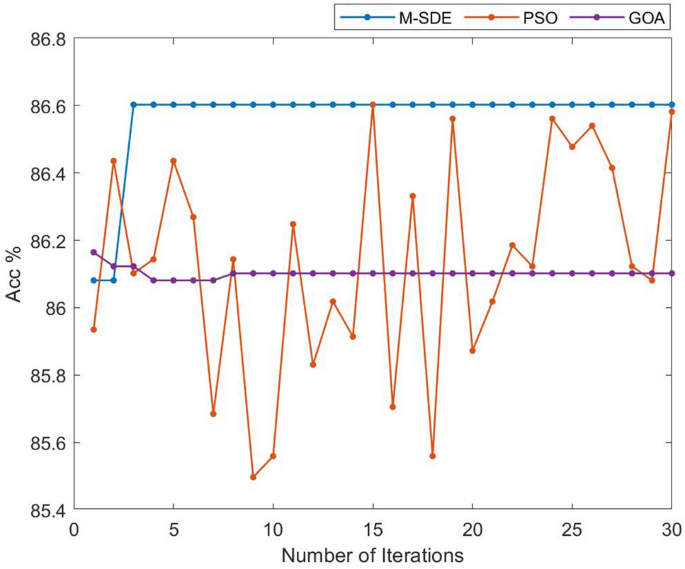
Comparison of iteration and accuracy of three methods.
It can be seen from Fig. 8 that compared with PSO and GOA, the M-SDE method can converge at the fastest speed and obtain higher classification accuracy, and at the same time, the accuracy fluctuates less and obtains relatively stable performance.
-
(2)
Ensemble classifier
The above four single classification models are used as the base classifiers to construct the ensemble classification models such as EnELM, GOA_EnELM, PSO_EnELM and M-SDE_EnELM, and the classification performance of the test set is shown in Table 6.
Table 6 Performance of ensemble classifier. The accuracy of ten runs of each classifier is shown in Fig. 9.
Figure 9 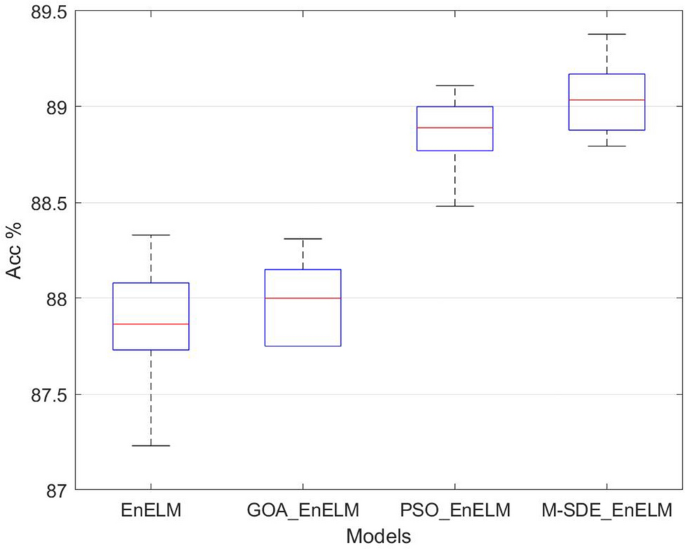
Ensemble classifier experiments.
From Table 6 the accuracy rate of M-SDE_EnELM is 89.05%, which is 1.17% higher than EnELM, 1.06% higher than GOA_EnELM, and 0.18% higher than PSO_EnELM. From the comparison of Table 4, Table 6 and Fig. 9, it can be seen that performance of M-SDE_EnELM are best among all classification models, and its accuracy is 0.18–3.65% higher than the other seven models. Its F1_score is 0.01–4.19% higher than the other seven models. And it has the same precision as PSO_EnELM and 1.26–4.18% higher than the other six models.
Hypothesis tests (t-test and F-test) are performed on the 10-time recognition accuracy of M-SDE_EnELM with the other three classification models, and the results are shown in Table 7.
Table 7 Hypothesis tests of ensemble classifier. From Table 7, the t-tests are performed on M-SDE_EnELM with the other three models respectively, and the p-values of the test results are all less than 0.05, indicating that the null hypotheses are rejected, that is, the mean of the recognition accuracy of M-SDE_EnELM with the three models have significant difference. F-tests are performed on M-SDE_EnELM with the other three models respectively, and p-values are greater than 0.05, indicating acceptance of the null hypotheses, that is, the stability of M-SDE_EnELM with the three models are consistent. From the mean and standard deviation of M-SDE_EnELM, the mean of M-SDE_EnELM is the largest and the standard deviation is the smallest, so M-SDE_EnELM outperforms the other three models.
The comparison of the experimental results of all models are shown in Fig. 10. It can be seen that the established M-SDE_EnELM classifier has better recognition effect and generalization performance for the birdsongs dataset. As a whole, the proposed M-SDE_EnELM model has better classification results than other models in the experimental schemes, and achieves better recognition results.
Figure 10 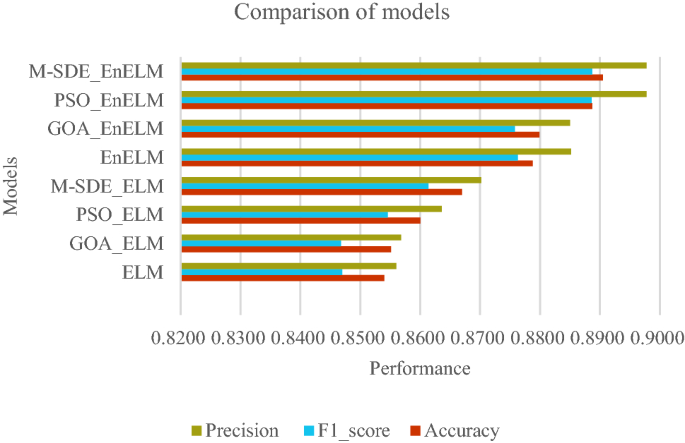
Comparison of models.




Model ablation
The M-SDE proposed in this paper adopts three different mutation strategies in the mutation stage. In order to further verify the advantages brought by the mixing of the three strategies, two groups of experiments are designed for comparison in this section, namely the single-strategy differential evolution algorithm optimization ELM experiment and the dual-strategy differential evolution algorithm optimization ELM experiment.
-
(1)
Single-strategy vs multi-strategy
The experimental settings of the single-strategy differential evolution algorithm are listed in Table 8. In this group of experiments, except for the different settings of the strategy and the M-SDE, other parameters are consistent with the M-SDE.
Table 8 Settings of the single-strategy models. In the experiment, each model was run independently for ten times, and the performance of each model is shown in Table 9.
Table 9 Performance comparison between single-strategy and multi-strategy of models. The accuracy of ten runs of each classifier is shown in Fig. 11.
Figure 11 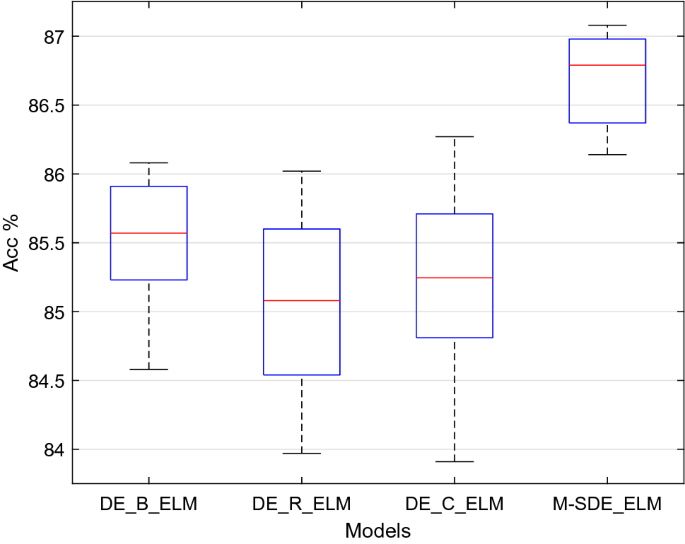
Comparison single-strategy models with multi-strategy models.
From Table 9, for the M-SDE_ELM model the accuracy is 86.70%, 1.17–1.62% higher than the other three single-strategy models, and its F1_score and precision are 1.12–1.75% and 1.25–1.89% higher than those of the three single-strategy models, respectively. In terms of the standard deviations, M-SDE_ELM has the least fluctuation. Combining with Fig. 11, M-SDE is more stable and has better performance than the three single-strategy models.
Therefore, we can conclude that M-SDE_ELM is better than DE_B_ELM, DE_R_ELM, DE_C_ELM three single-strategy models.
-
(2)
Dual-strategy vs multi-strategy
The experimental settings of the dual-strategy differential evolution algorithm are shown in Table 10. In this group of experiments, except for the different settings of the strategy and the M-SDE, other parameters are consistent with the M-SDE.
Table 10 Settings of the dual-strategy models. Similarly, each model was run independently for ten times, and the performance of each model is shown in Table 11.
Table 11 Performance comparison between dual-strategy and multi-strategy of models. The accuracy of ten runs of each classifier is shown in Fig. 12.
Figure 12 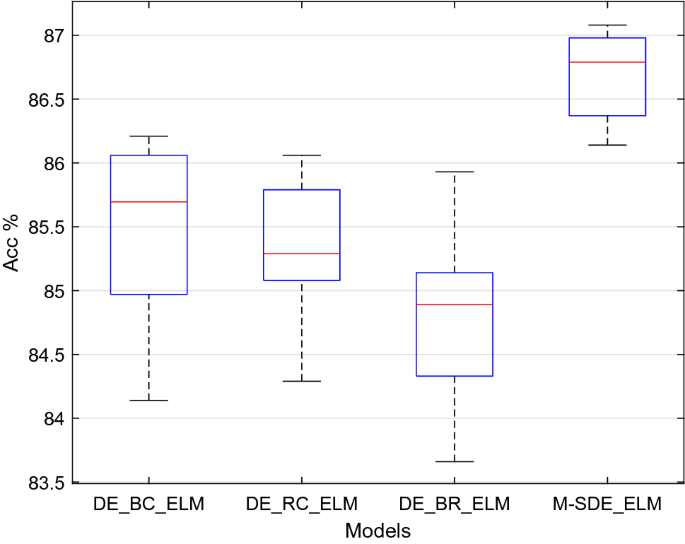
Comparison dual-strategy with multi-strategy models.
Seen from Table 11, the accuracy of M-SDE_ELM model is 86.70%, F1_score is 0.8614, and precision is 0.8702, respectively 1.23–1.88%, 1.39–1.96%, and 1.27–1.83% higher than the three dual-strategy models. In terms of the standard deviation of the three evaluation indicators, those of the M-SDE_ELM model are the smallest, and combining with Fig. 12, we can see that this model is more stable than other models, and its performance is better.
Therefore, we can conclude that M-SDE_ELM is better than DE_BC_ELM, DE_RC_ELM, DE_BR_ELM three dual-strategy models. Moreover, we can find that adding the “DE/current to best/1” strategy to the mutation strategy can effectively improve the performance of the model, and combining the three strategies can make the model performance better.
The above two sets of experimental results show that M-SDE_ELM adopts three mutation strategies, which can effectively improve the performance and stability of the model, and obtains good results.


Limitations and future scope
This paper proposes the M-SDE method based on the improved DE to optimize the ELM, and builds M-SDE_EnELM so as to carry out the research on birdsongs recognition. The study shows that more research is needed to expand the performance and feasibility of future work, and some of the most important points are listed below:
-
The M-SDE method needs to be further optimized to improve the ELM model performance and applicability.
-
The categories and sample sizes of birdsongs need to be expanded, and the M-SDE_EnELM model will be extended to more bird audios and other audios recognition.
-
Many feature parameter extraction methods are mentioned in30. At present, this study only uses MFCC as the feature parameter, and the method proposed in the literature can be tried to extract the features of multiple views for bird audios, and birdsongs recognition can be carried out by combining a variety of different feature parameters.
-
Both deep learning and traditional machine learning are now widely used for object recognition31,32,33. Deep learning can also extract low-level features of research objects while classifying. Handcrafted features can retain the characteristics of the research object itself, and combine the features extracted by deep learning with handcrafted features to better express the specific information of the object. Literature31 explored two methods of deep learning and machine learning, and combined traditional features and CNN features, and achieved good results. In the future, we will conduct feature fusion with the representation features extracted by deep learning and traditional hand-extracted features to improve the accuracy of of birdsongs recognition.
Conclusion
This study takes birdsongs as the research object, extracts the feature parameters of differential MFCC, and conducts classification research on birdsongs. The M-SDE method is proposed by improving the standard DE to optimize the ELM model with M-SDE. The ablation experiments show that the use of three strategies in the M-SDE algorithm can effectively improve the performance of the algorithm, so that the optimized ELM model can produce a better classification effect on birdsongs, which is better than the single-strategy models and the dual- strategy models.
Through comparative experiments on the ELM optimized by the three methods of M-SDE, PSO and GOA, the results show that the M-SDE_ELM and ensemble M-SDE_EnELM models proposed in this paper have a classification accuracy of 86.70% and 89.05% in nine species of birds, respectively, which is better than the ELM model optimized by PSO and GOA and the original ELM model. The M-SDE_EnELM model can better solve the problems of unstable performance of a single M-SDE_ELM classifier and difficult to determine the optimal number of neurons in the hidden layer, and has a good generalization ability.
Ethics declarations
In this paper, the experiments did not use live birds.
References
Shi, Q. H. Vocalization and Phylogenetic Classification of Seven Cranes in China. MA Thesis. (Northeast Forestry University, 2007).
Xiao, H. & Zhang, Y. Y. Birds chirp study. Bull. Biol. 44(03), 11–13 (2009).
Wang, E. Z. & He, D. J. Bird recognition based on MFCC and dual-GMM. Comput. Eng. Des. 35(05), 1868-1871+1881 (2014).
Xu, S. Z., Sun, Y. N., Huangfu, L. Y. & Fang, W. Q. Design of synthesized bird sounds classifier based on multi feature extraction classifiers and time-frequency chat. Res. Explor. Lab. 37(09), 81-86+91 (2018).
Zhai, J. H., Zang, L. G. & Zhou, Z. Y. An approach of integrating dropout extreme learning machine for data classification. J. Nanjing Norm. Univ. Nat. Sci. Ed. 40(03), 59–66 (2017).
Zhai, J. H., Zhou, Z. Y. & Zang, L. G. Ensemble of retrained extreme learning machine for data classification. J. Data Acquis. Process. 33(06), 962–970 (2018).
Xue, Z. A., Huang, C. R., Zhang, J. D., Zhi, H. & Gu, F. Classification of power quality disturbance based on wavelet transform and limit learning machine. Electr. Eng. 2020(15), 41–43 (2020).
Lin, W. M., Yuan, J. N., Feng, C. W. & Du, M. Computer-aided diagnosis of Alzheimer’s disease based on extreme learning machine. Chin. J. Biomed. Eng. 39(03), 288–294 (2020).
Venkatalakshmi, S. & Janet, J. ELM based cad system to classify mammograms by the combination of CLBP and contourlet. ICTACT J. Image Video Process. 7(4), 1 (2017).
Kashif, K., Wu, Y. Z. & Michael, A. Consonant phoneme based extreme learning machine (ELM) recognition model for foreign accent identification. World Symp. Softw. Eng. 2019, 69–73 (2019).
Yan, F. Quality Identification of Solder Joints Based on Optimized Limit Learning Machine Algorithm. MA thesis. (Yunnan University, 2018).
Storn, R. & Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11(4), 341 (1997).
Das, S., Mullick, S. S. & Suganthan, P. N. Recent advances in differential evolution—An updated survey. Swarm Evol. Comput. 2016, 1–30 (2016).
Yang, Z. Y., Zhang, T. H. & Zhang, D. Z. A novel algorithm with differential evolution and coral reef optimization for extreme learning machine training. Cogn. Neurodyn. 10(1), 73–83 (2016).
Dahou, A., Elaziz, M. A., Zhou, J. W. & Xiong, S. W. Arabic sentiment classification using convolutional neural network and differential evolution algorithm. Comput. Intell. Neurosc. 2019, 1–16 (2019).
Li, X. W., Liu, S. Y. & Gao, K. L. Assessment of power system transient stability based on differential evolution extreme learning machine. Sci. Technol. Eng. 20(01), 213–217 (2020).
Ding, Q. F. & Yin, X. Y. Research survey of differential evolution algorithms. CAAI Trans. Intell. Syst. 12(04), 431–442 (2017).
Singh, D., Kumar, V. & Vaishali, K. M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution-based convolutional neural networks. Eur. J. Clin. Microbiol. 39(7), 1379 (2020).
Mustafa, H., Ayob, M., Albashish, D. & Abu-Taleb, S. Solving text clustering problem using a memetic differential evolution algorithm. PLoS ONE 15(6), e0232816 (2020).
Vivekanandan, T. & Ch, S. Optimal feature selection using a modified differential evolution algorithm and its effectiveness for prediction of heart disease. Comput. Biol. Med. 90, 125–136 (2017).
Duan, M. J., Yang, H. Y., Wang, S. P. & Liu, Y. Self-adaptive dual-strategy differential evolution algorithm. PLoS ONE 14(10), 22706 (2019).
Cheng, L. & Zhang, H. Q. Research of birdsong recognition method based on improved MFCC. J. Commun. Univ. China Sci. Technol. 24(03), 41–46 (2017).
Huang, G. B., Zhu, Q. Y. & Siew, C. K. Extreme learning machine: Theory and applications. Neurocomputing 70(1–3), 489–501 (2006).
Wang, E. Z. Research of Birds Intelligent Recognition Method Based on Chirp. MA thesis. (Northwest A&F University, 2014).
Chen, S. S. Bird Sounds Recognition Using Time-Frequency Texture and Random Forest. MA thesis. (Fuzhou University, 2013).
Cao, Q. J. For Individual Recognition Technology Based on Chirp Crested Ibis Research. MA thesis. (Xi’an University of Architecture and Technology, 2016).
Liu, J., Liu, G. X., Zhang, Y. & Lv, D. J. Design and implementation of network crawling bird audio data acquisition system based on multithreading and translation. Mod. Comput. 30, 85-88+92 (2018).
Saremi, S., Mirjalili, S. & Lewis, A. Grasshopper optimization algorithm: theory and application. Adv. Eng. Softw. 105, 30–47 (2017).
Kennedy, J. & Eberhart, R. Particle Swarm Optimization (IEEE, 1995).
Chaturvedi, V., Kaur, A. B., Varshney, V., Garg, A. & Kumar, M. Music mood and human emotion recognition based on physiological signals: A systematic review. Multimed. Syst. 3, 1–24 (2021).
Bansal, M., Kumar, M., Sachdeva, M. & Mittal, A. Transfer learning for image classification using VGG19: Caltech-101 image data set. J. Ambient Intell. Hum. Comput. 2021, 1–12 (2021).
Singh, S., Ahuja, U., Kumar, M. & Kumar, K. Face mask detection using YOLOv3 and faster R-CNN models: COVID-19 environment. Multimed. Tools Appl. 80(13), 1–16 (2021).
Bansal, M., Kumar, M. & Kumar, M. 2D object recognition: a comparative analysis of SIFT, SURF and ORB feature descriptors. Multimed. Tools Appl. 80(12), 18839–18857 (2021).
Acknowledgements
This study was supported by the Yunnan Provincial Science and Technology Department under Grant no:202002AA10007, the National Natural Science Foundation of China under Grant no:6142078 and under Grant no:31860332, and the Yunnan Provincial Department of Education under Grant no:2021Y219.
Author information
Authors and Affiliations
Contributions
S.S.X. contributed to design of research methods, the establishment of model and the writing of the main part of the main manuscript. Y.Z. and D.J.L. has made important contributions in implementation of experiment, analyzing data and editing part of the manuscript. H.F.X., J.L. and Y.Y. plotted the graphs, collected data and participated in the investigation. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xie, S., Zhang, Y., Lv, D. et al. Birdsongs recognition based on ensemble ELM with multi-strategy differential evolution. Sci Rep 12, 9739 (2022). https://doi.org/10.1038/s41598-022-13957-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-13957-w
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
