
Abstract
Renal clear cell carcinoma (KIRC) is one of the most common tumors worldwide and has a high mortality rate. Ferroptosis is a major mechanism of tumor occurrence and development, as well as important for prognosis and treatment of KIRC. Here, we conducted bioinformatics analysis to identify KIRC hub genes that target ferroptosis. By Weighted gene co-expression network analysis (WGCNA), 11 co-expression-related genes were screened out. According to Kaplan Meier's survival analysis of the data from the gene expression profile interactive analysis database, it was identified that the expression levels of two genes, PROM2 and PLIN2, are respectively related to prognosis. In conclusion, our findings indicate that PROM2 and PLIN2 may be effective new targets for the treatment and prognosis of KIRC.
Similar content being viewed by others

Introduction
Renal cell carcinoma (RCC) is known to account for more than 90% of all adult kidney tumors1. Its predominant histological subtype is renal clear cell carcinoma (also called kidney renal clear cell carcinoma; KIRC), which accounts for ~ 80% of RCC2, the prognostic risk assessment of KIRC varies according to TNM staging, age, and gender. The five-year survival of patients is closely related to the pathological grade, depending on whether the tumor is early, intermediate, or advanced. If the patient is in the early stage of the disease, i.e., a pathological grade of I or II, the patient will have a better treatment effect and a longer survival period after surgical resection, with a five-year survival rate as high as 80–90%. If the patient is in the middle and advanced stages of KIRC, with a pathological grade of III or IV, the prognosis of the patient is relatively poor, tumor malignancy and the probability of metastasis and recurrence high, and the survival period shortened to five years. In these instances, the survival rate is ~ 20%3,4,5. Therefore, it is recommended that patients must be detected and treated early. However, only ~ 10% of patients with KIRC show characteristic clinical symptoms, and 20–30% of patients have metastases already detected at the first visit. In ~ 30% of patients with localized KIRC, recurrence occurs twice after surgical resection, whereas conventional radiotherapy and chemotherapy are furthermore largely ineffective in curing KIRC6. Although the mechanism of its occurrence and development has been studied in-depth, its pathogenesis and carcinogenesis are still unclear, and specific sensitive tumor markers are still lacking7. Therefore, it is imperative to improve our understanding of the molecular mechanism of KIRC to identify prognostic biomarkers and treatment targets that can guide the existing clinical phenotypic staging systems.
Modern high-throughput sequencing technologies include DNA sequencing, RNA sequencing (RNA-seq), and epigenome research. Bioinformatics analysis of the results of these technologies, especially network analysis, allows us to obtain genome assembly, genome annotation, and gene function annotation8,9,10. Bioinformatics provides a new perspective by efficient integration of multiple large-scale datasets for various human diseases. However, most bioinformatics research only focuses on identifying differentially expressed genes (DEGs)11, which neglects the functional relationship and high correlation between genes with similar expression patterns12,13. Weighted gene co-expression network analysis (WGCNA) explores the correlation between different genomes or between samples and clinical features by constructing a free-scale gene co-expression network14,15,16. This method is widely used to identify related clinical modules and hub genes of different types of cancer17. For example, Yuan et al. used WGCNA as early as 2017 to discover that the expression of six pivotal genes is closely related to the progression and prognosis of KIRC18. Lastly, Zhang et al. used WGCNA to verify the six hub genes of colorectal cancer19.
Ferroptosis is a cell death pathway, first proposed by Professor Brent Stockwell of Columbia University in 201220, which is caused by an increase in iron ion load driving a large amount of lipid peroxidation. It primarily involves three major metabolic mechanisms, including iron metabolism, lipid metabolism, and amino acid metabolism21. Among these, lipid metabolism induces tumor development and treatment resistance by enhancing lipid synthesis, storage, and catabolism. In general, the membrane fatty acid composition, such as the ratio of saturated fatty acids, monounsaturated fatty acids, and polyunsaturated fatty acids, promotes cell growth. However, tumor cells show plasticity in fatty acid metabolism which has resulted in a shift in research focus to limit fat toxicity and ferroptosis as a means to improve overall survival (OS) in patients with cancer22,23.
Studies have shown that ferroptosis is closely related to the occurrence and development, as well as prognosis and treatment of tumors—with KIRC as a tumor type sensitive to ferroptosis24. In KIRC and normal tissues, ferroptosis regulators are related to PD-L1 expression which affects the tumor immune microenvironment promoting tumorigenesis25. Furthermore, Wu et al. showed that ferroptosis is related to the clinicopathological characteristics of patients with KIRC and constructed five KIRC and ferroptosis-related prognostic models26. Another study found that 11 ferroptosis genes (CARS, CD44, DPP4, GCLC, HMGCR, HSPB1, NCOA4, SAT1, PHKG2, GOT1, HMOX1) were significantly related to the OS of patients with KIRC27. Moreover, CHAC128, Acyl-CoA Thioesterase 8 and 1129, and SUV39H130 may be effective prognostic indicators of KIRC. Lastly, Gao et al. found that the TAZ/WNT10B axis may serve as biomarkers and therapeutic targets for KIRC immunotherapy31. Taken together, there are many studies on KIRC, but the current understanding of its pathogenesis, tumor progression, and metastasis is still imperfect, with many of its characteristics differing from other cancers32,33,34. Therefore, finding novel ferroptosis-related targets or pathways for the treatment of KIRC would two-fold curb the high recurrence rate and growing drug resistance of KIRC.
In this study, we downloaded the RNA-seq data of KIRC samples from The Cancer Genome Atlas (TCGA), used WGCNA to determine the genes and modules related to the clinical characteristics of patients with KIRC, and aimed to identify the co-expression of genes related to clinical characteristics and ferroptosis. Then, through survival analysis of the co-expressed genes, we determined hub genes with the highest prognostic potential. Our study aims to find a link between KIRC-related genes with ferroptosis that may be used for the prognosis of KIRC. This could be insightful for the development of potential biomarkers and treatment targets, providing a new perspective for future research into KIRC.
Materials and methods
Data sources and study design
RNA-seq data and clinical information on patients were downloaded on October 17th, 2021 from the ‘Colon and Rectal Cancer’ cohort of the TCGA database (https://www.cancer.gov/about-nci/organization/ccg/research/structural genomics/tcga), hosted at the Xena website of the University of California at Santa Cruz35 (http://xena.ucsc.edu/; Table 1 and Supplementary Tables S1–S2). The RNA-seq data contained 538 tumor samples and 407 normal tissue samples from 945 patients with KIRC. Data on the clinical information, including the OS of patients with KIRC, were also obtained from the TCGA database (http://xena.ucsc.edu/; Supplementary Tables S3). In addition, data on genes related to induction and inhibition of ferroptosis were downloaded from the FerrDB database (http://www.zhounan.org/ferrdb/; Supplementary Table S4). Using principal component analysis (PCA), we excluded samples if the first two principal components identified were unable to distinguish tumor tissue from normal tissue. The study process is shown in Fig. 1.

Work-flow of this study.
PCA analysis
The theoretical basis for realizing high-dimensional data visualization is based on dimensionality reduction algorithms. UMAP, tSNE, and PCA are several common dimensionality reduction methods used in our study.
For UMAP, we used the R software package UMAP v0.2.7.0 for analysis. The Z-score was first performed on the expression spectrum, followed by the UMAP function for dimension reduction analysis to obtain the matrix. For PCA, the R software package STATS v3.6.0 was used for analysis. After obtaining the Z-score, the prCOMP function was used for dimension reduction analysis to obtain the matrix. For tSNE, the R software package Rtsne v0.15 was used for analysis. Similarly, the Z-Score was first performed on the expression spectrum, and then the Rtsne function was used for dimension reduction analysis to obtain the matrix36,37. Of these three methods, UMAP proved to be better than the rest. UMAP uses a very efficient visualization and scalable dimensionality reduction algorithm. In terms of visualization quality, the UMAP algorithm has a competitive advantage over t-SNE, but also retains more global structure, has superior running performance, and better scalability. Furthermore, UMAP has no computational limit on the embedding dimension, which makes it useful as a general-purpose dimension reduction technique for machine learning. UMAP also provides useful and intuitive properties that preserve more global structure, especially the continuity of cell subsets. Therefore, we used UMAP to exclude samples by distinguishing tumors from normal tissue.
Identification of KIRC DEGs
To obtain the DEGs for differential analysis between different groups, we used the R software package-Limma (Linear Models for Microarray Data, DOI:https://doi.org/10.1093/NAR/GKV007, v3.40.6), which is a DEG screening method based on generalized linear models. Specifically, we obtained the expression spectrum dataset and used the ‘lmFit’ function to perform multiple linear regression. Furthermore, we used the ‘eBays’ function to compute moderated t-statistics, moderated f-statistic, and log-odds of DEGs by empirical Bayes moderation of the standard errors towards a common value to finally obtain the DEG significance of each gene. DEGs were defined as those showing |log2(fold-change)|> 1 and P < 0.01. Volcano plots of DEGs were plotted using the R function 'ggplot2'.
WGCNA
At first, the Pearson's correlation matrices and average linkage method were both performed for all pair-wise genes, and then a weighted adjacency matrix was constructed using a power function Amn =|Cmn|β (Cmn = Pearson's correlation between genes m and n; Amn = adjacency between genes m and n)17,38; and β was a soft-thresholding parameter that could emphasize strong correlations between genes and penalize weak correlations. After choosing the power of 6, the adjacency was transformed into a topological overlap matrix (TOM)39, which could measure the network connectivity of a gene defined as the sum of its adjacency with all other genes for network generation, and the corresponding dissimilarity (1-TOM) was calculated. To classify genes with similar expression profiles into gene modules, average linkage hierarchical clustering was conducted according to the TOM-based dissimilarity measure with a minimum size (gene group) of 100 for the genes dendrogram, with the sensitivity set to 4. To further analyze the module, we calculated the dissimilarity of module eigengenes, chose a cut line for module dendrogram and merged some modules40. In addition, we also merged modules with a distance of less than 0.25, and finally obtained nine co-expression modules. It is worth noting that the grey module is considered to be a gene set that cannot be assigned to any module.
Correlation analysis of clinical features and modules for identification of KIRC hub genes
Using clinical features as input, we performed correlation analysis between the modules and clinical features, as well as between MM (module membership) and GS (gene significance). Based on the weighted correlation, a hierarchical clustering analysis was performed, and the clustering results were segmented according to set criteria to obtain different gene modules—represented by the branches and different colors of the clustering tree. The relationship between models was studied and an interaction network of different models was constructed on the system level. We used the “Venn” R package to draw a Venn map of ferroptosis-related DEGs and prognostic genes, while also preserving information related to the intersection genes.
Functional enrichment analysis by gene set enrichment analysis (GSEA)
The GSEA v3.0 software was obtained from the GSEA (http://software.broadinstitute.org/gsea/index.jsp) website36, whereas the c2.cp.kegg.v7.4.symbols.gmt subset was downloaded from the Molecular Signatures Database41 (http://www.gsea-msigdb.org/gsea/downloads.jsp) to evaluate related pathways and molecular mechanisms based on gene expression profiles and phenotypes. The minimum gene set function was set to 5 and the maximum gene set to 5,000 resamplings (5 × 1,000 resamplings). P < 0.05 and a false discovery rate (FDR) < 0.25 were considered statistically significant.
Functional enrichment of DEGs
We used the GO annotation of genes in the ‘org.hs.eg.db’ v3.1.0 R software package as the background, then mapped genes into the background set, and used ‘clusterProfiler’ v3.14.3 for enrichment analysis to obtain the result of gene accumulation. The minimum gene set function was 5 and the maximum gene set was 5,000. P < 0.05 and an FDR < 0.25 were considered statistically significant.
Bioinformatics validation of hub genes
The survival prediction of hub genes was assessed using Kaplan–Meier analysis with the ‘survival’ v3.2–7 R package. First, we obtained the DEG profile and prognostic data of 578 KIRC tumor samples from the TCGA and then determined the median expression value of each gene. Depending on whether the expression of a given gene was above or below the median, samples were assigned to either the "high expression" or "low expression" group. The log-rank test was used to evaluate the significance of the difference in survival between the high and low expression groups. If the test correlated with P < 0.05, we considered the gene to be a verified pivot gene.
Verifying that a gene is a DEG in most tumors is part of the broad-spectrum analysis. If gene is differentially expressed in most tumors, it means that it is broad-spectrum. Thereafter, a single gene is analyzed for its expression in tumors based on its differential expression in each tumor. We downloaded a unified standardized pan-cancer dataset from the UCSC (https://xenabrowser.net/) database: TCGA TARGET GTEx (PANCAN, N = 19,131, G = 60,499), and further extracted ENSG00000155066 (prominin-2; PROM2) and ENSG00000147872 (perilipin-2; PLIN2) gene expression data in each sample. We screened samples from the datasets for Solid Tissue Normal, Primary Solid Tumor, Primary Tumor, Normal Tissue, Primary Blood-Derived Cancer-Bone Marrow, and Primary Blood-Derived Cancer-Peripheral Blood. Thereafter, we performed log2(x + 0.001) transformation on each expression value. Lastly, we eliminated cancer types with less than 3 samples to obtain the expression data of 34 cancer types. We used R software (version 3.6.4) to calculate the expression difference between normal and tumor samples for each tumor and used the unpaired Wilcoxon Rank Sum and Signed Rank Tests to analyze the significance of the difference36,41.
Statistical analysis
In this study, all statistical analyses were performed using R language (version 4.0.2). A two-sided P value of < 0.05 was considered as statistically significant. The adjusted P value was determined by the Benjamini–Hochberg method. All methods were carried out in accordance with relevant guidelines and regulations.
Human and animal rights
This article only collected data from existing databases without any direct involvement of human participants.
Results
Data pre-processing
The KIRC gene expression profile dataset downloaded from the TCGA database contains 72 normal samples and 534 tumor samples (Supplementary Table S1). Based on PCA, the first two principal components differentiated well between tumors and normal samples, forming two distinct clusters. In grouping tumor and normal samples, those with close distances had similar properties, and samples that deviated significantly from the population were removed. In total, 27 tumor tissues and 1 normal tissue were excluded (Fig. 2A,B). The gene expression profiles of the remaining 578 samples (Fig. 2C) and 259 ferroptosis-related genes were used for subsequent analysis.

Identification of 71 normal and 507 KIRC samples by PCA. (A) Principal component analysis. Red dots represent tumor samples; blue dots represent normal samples. (B) Exclusion of 26 tumors and 1 normal sample after PCA. (C) Principal component analysis result.
Identification of DEGs
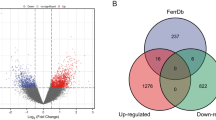
The data set after excluding outliers was analyzed by limma analysis. From the results of the volcano plot and heatmap (Fig. 3A,B), we found 5,151 DEGs with obvious differences after analysis, of which 2,522 genes were up-regulated and 2,629 genes down-regulated.

Identification of DEGs between 71 normal and 507 KIRC samples. (A) The volcano plot. Red dots represent down-regulated genes, black dots not-significant genes, and yellow dots up-regulated genes. (B) The heat map shows the expression difference of differentially expressed genes (DEGs).
GSEA
GSEA is used to evaluate the distribution trend of genes in a predefined gene set ranked by phenotype correlation (based on its contribution to phenotype). As expected, several ferroptosis-related functions were involved, including pyruvate metabolism, propanoate metabolism, fatty acid metabolism, bladder cancer, butanoate metabolism proximal tubule bicarbonate reclamation steroid biosynthesis aminoacyl T-RNA biosynthesis, arginine and proline metabolism, etc. (Fig. 4) (www.kegg.jp/kegg/kegg1.html) 42,43,44.

Gene set enrichment analysis.
WGCNA and identification of critical modules
We performed a cluster analysis according to the expression matrix of 5,151 DEGs and the network of clinical data of 578 KIRC samples. It can be seen that all samples in the cluster were within the cut-off threshold (height < 200) which means that all values were normal (Fig. 5D). Four clinical variables were used in WGCNA (Fig. 5D): tumor-normal, gender, age, and stage. The 578 samples were divided into two clusters: tumor and normal. To build a scale-free network, we set the soft threshold power β to 6, the independence to 0.83, and the average connectivity to 36.36 (Fig. 5A,B). The DEGs with similar expression patterns were gathered into the same module, and the modules showing the cutting height difference < 0.25 were merged. This process produced nine co-expression modules: blue, green, green-yellow, grey, magenta, purple, turquoise, black and yellow (Fig. 5C). The characteristic genes of the turquoise module (r = 0.96) and blue module(r = 0.81) are highly correlated with KIRC (Fig. 6C,D). These results were also confirmed by analysis of hierarchical clustering, heatmap, and adjacency relationship (Fig. 6A,B). Taken together, these results indicate that turquoise and blue modules may be closely related to KIRC. Therefore, the central genes of the turquoise and blue modules were further analyzed.

WGCNA of DEGs and identification of hub genes. (A) Scale independence. (B) Average connectivity. (C) Numbers of genes in the nine modules. (D) Clustering dendrogram of 578 samples. Black color represents ‘tumor’ for the variable ‘tumor-normal’; ‘Female’ or ‘Male’ for the variable ‘gender’; and ‘Stage I’, ‘Stage II’, ‘Stage III’, and ‘Stage IV’ for the variable ‘stage’. (E) Dendrogram. Each branch represents a gene, and each color represents a co-expression module.

WGCNA of DEGs and identification of hub genes. (A) Module eigengene (MEs) heatmap. (B) Heatmap of the correlation between module eigengenes (MEs) and clinical characteristics of patients with KIRC. Each cell contains the correlation coefficient and P-value. (C, D) Scatter plots of GS score and MM (see the ‘Materials and methods’ section) for genes in the (C) blue and (D) turquoise modules.
Identifying candidate hub genes from the most relevant modules
As shown in Fig. 6C,D, the MM and GS scores were strongly correlated with each other in the turquoise and blue modules. The criteria for selecting pivot genes were relatively lower than the standard cut-off threshold (MM > 0.79). Under the unified threshold of "cor. gene Module Membership" > 0.6 and "cor. gene Trait Significance" > 0.6, a total of 708 genes were determined to be satisfied in the turquoise module and 357 genes in the blue module.
Screening of co-expressed genes of ferroptosis-related genes and KIRC DEGs
By analyzing the ferroptosis genes contained in the DEGs, we found that there were a total of 11 KIRC DEGs related to ferroptosis (Fig. 7). As shown in Fig. 8, the GO enrichment analysis of these 11 genes was all related to lipid metabolism. It is well known that abnormal lipid metabolism is an important factor inducing ferroptosis. In other words, ferroptosis plays a vital role in KIRC.

The Venn diagram demonstrating the relationship between ferroptosis genes and DEGs.

GO analysis of 11 co-expressed genes between ferroptosis-related genes and KIRC DEGs.
Hub gene expression and correlation with survival
The Wald test method was used to analyze the hub genes with ACSF2, PROM2, and PLIN2 confirmed as possible prognostic-related genes (Fig. 9A). By examining the potential correlation between the expression of candidate central genes and patient survival, we found that PROM2 and PLIN2 were significantly related to prognosis (Fig. 9C,D), while no significance was found for ACSF2 (Fig. 9B). Therefore, we defined the PROM2 and PLIN2 genes as the "final" pivotal genes.

Survival analysis and validation of hub genes. (A) Wald Test. (B) Kaplan–Meier survival curves of patients with KIRC stratified by low or high expression of PLIN2. (C, D) Kaplan–Meier survival curves of patients with KIRC stratified by low or high expression of PLIN2 (C) and PROM2 (D). (E–F) Differences in expression of the PLIN2 (C) and PROM2 (D) genes between normal and tumor tissues. *P < 0.01.
We also confirmed that the expression of PROM2 and PLIN2 were significantly different between the normal and KIRC tissues (Fig. 9E,F). PLIN2 was down-regulated in KIRC, while PROM2 was up-regulated.
As seen from Fig. 10A,B, the expression of PROM2 and PLIN2 were significantly different between multiple tumors. Furthermore, the protein–protein interaction network analysis chart is shown in Fig. 11A,B.

Validation of hub genes in various tumors. (A, B) Differences in expression of the PLIN2 (A) and PROM2 (B) genes in various tumors. *P < 0.01.

Protein–protein interaction of PROM2 (A) and PLIN2 (B).
Discussion
KIRC is one of the most serious malignant tumors worldwide. Various studies have used WGCNA to explore molecular markers for diagnosis and prognosis. Specifically, Zou et al. showed that KIRC has a unique metabolic state more prone to ferroptosis in response to the hypoxia-inducible factor pathway45. On the therapeutic front, they indicated GPX4 as an effective therapeutic target for KIRC. However, their research only focused on specific genes in KIRC, and the mechanism of ferroptosis in KIRC remained uncertain.
In this study, we found 5,151 DEGs between normal and KIRC tissues using limma analysis, indicating that the occurrence and development of KIRC are regulated by a complex genetic network. By using WGCNA, we identified that genes of the turquoise and blue modules were most closely related to KIRC, with 1,066 relevant genes. By analyzing these 1,066 KIRC-related genes and 259 ferroptosis genes, a total of 11 ferroptosis co-expression hub genes were found. Then, GO function enrichment analysis showed these genes were mainly involved in abnormal fatty acid metabolism pathways which regulate ferroptosis in KIRC—consistent with previous related studies. These findings on the importance of fatty acid metabolism pathways in ferroptosis may be helpful to understand the tumorigenic mechanism and treatment options of KIRC. Finally, our survival analysis of these 11 hub genes showed that PROM2 and PLIN2 expression are closely related to the poor prognosis of patients with KIRC. Therefore, PROM2 and PLIN2 may be promising prognostic indicators for patients with KIRC.
PLIN2, also known as adipose differentiation-related protein, wraps lipid droplets and phospholipids, as well as participates in the storage of neutral lipids in lipid droplets46,47. Ma et al. showed that the expression of PLIN2 decreased significantly in the iron overload group, iron overload caused ferroptosis in the liver of mice with a decrease in GPX4 expression and an increase in Ptgs2 expression, resulting in a high level of lipid peroxidation, 79% decrease in the protein level of Perilipin-2 (PLIN2)48. Another study showed that PLIN2 promotes the proliferation and apoptosis of gastric cancer cells by modifying the ferroptosis pathway, such as regulating various ferroptosis-related genes, including acyl-CoA synthase long-chain family member 3, etc. PLIN2 has also been shown to be an indispensable factors for inhibiting ferroptosis caused by abnormal fat metabolism in gastric cancer49. However, no research has been done on PLIN2 in KIRC. In line with previous studies, our findings confirm the critical role of PLIN2 in ferroptosis inhibition caused by abnormal fat metabolism and further indicate PLIN2 as a potential prognostic risk factor of KIRC.
Studies have shown that PROM2 participates in the composition of the plasma membrane microstructure where it mainly participates in biological processes such as promoting cell growth, migration, and perception by interacting with membrane cholesterol50. PROM2 expression may be closely related to both prostate and breast cancer51. PROM2 is also a candidate gene marker for distinguishing renal chromophobe cell carcinoma and benign renal eosinophiloma52. Nevertheless, no research had been done on the role of PROM2 in KIRC before our study.
A variety of signaling pathways are involved in the regulation of tumor proliferation, migration, and invasion, including the JAK-STAT, NF-κB, Ras-Raf-MAPK, and Notch signaling pathways amongst others. Specifically, the phosphatidylinositol 3-kinase/protein kinase B (PI3K/AKT) signaling pathway is most commonly dysregulated in human tumors53,54,55,56,57, which plays an important role in a series of cell biological processes such as cell growth, proliferation, and angiogenesis58,59,60,61,62. In this regard, studies have shown that PROM2 can promote the proliferation, migration, and invasion of breast cancer by activating the PI3K/AKT pathway. Furthermore, ferroptosis plays an important role in triggering inflammation by activating the PI3K/AKT signaling pathway63,64,65,66,67. In our study, we found that PROM2 is an independent risk factor for KIRC and may have potential as a prognostic indicator. Moreover, we propose that PROM2 regulates ferroptosis via the PI3K/AKT signaling pathway in KIRK.
Conclusion
In this study, we combined bioinformatics analysis and data set cross-validation to study the prognostic genes related to ferroptosis in KIRC and obtained two new hub genes (PLIN2 and PROM2) that may be related to the prognosis of KIRC. We specifically elucidated the role of ferroptosis in KIRC, provided new insight into the molecular mechanism of KIRC, as well as revealed prognostic indicators and novel therapeutic targets for KIRC.
Abbreviations
- DEGs:
-
Differentially expressed genes
- FDR:
-
False discovery rate
- GSEA:
-
Gene set enrichment analysis
- KIRC:
-
Kidney renal clear cell carcinoma
- OS:
-
Overall survival
- PCA:
-
Principal component analysis
- PI3K/AKT:
-
Phosphatidylinositol 3-kinase/protein kinase B
- PLIN2:
-
Perilipin-2
- PROM2:
-
Prominin-2
- RCC:
-
Renal cell carcinoma
- RNA-seq:
-
RNA sequencing
- TCGA:
-
The Cancer Genome Atlas
- TOM:
-
Topological overlap matrix
- WGCNA:
-
Weighted gene co-expression network analysis
References
Ferlay, J. et al. Cancer incidence and mortality worldwide: Sources, methods and major patterns in GLOBOCAN 2012. Int. J. Cancer 136, E359–E386. https://doi.org/10.1002/ijc.29210 (2015).
Yossepowitch, O. et al. Renal cell carcinoma recurrence after nephrectomy for localized disease: predicting survival from time of recurrence. J. Clin. Oncol. 24(19), 8280. https://doi.org/10.1200/JCO.2005.04.8280 (2006).
Nguyen, M. M., Gill, I. S. & Ellison, L. M. The evolving presentation of renal carcinoma in the United States: trends from the Surveillance, Epidemiology, and End Results program. J. Urol. 176, 144. https://doi.org/10.1016/j.juro.2006.07.144 (2006).
Hollingsworth, J. M., Miller, D. C., Daignault, S. & Hollenbeck, B. K. Five-year survival after surgical treatment for kidney cancer: A population-based competing risk analysis. Cancer https://doi.org/10.1002/cncr.22600 (2007).
Jonasch, E., Gao, J. & Rathmell, W. K. Renal cell carcinoma. BMJ 10, 349. https://doi.org/10.1136/bmj.g4797 (2014).
Makhov, P. et al. Resistance to systemic therapies in clear cell renal cell carcinoma: Mechanisms and management strategies. Mol. Cancer Ther. 17(7), 1355–1364. https://doi.org/10.1158/1535-7163.MCT-17-1299 (2018).
Xu, W. H. et al. Prognostic value and immune infiltration of novel signatures in clear cell renal cell carcinoma microenvironment. Aging (Albany NY) 11(17), 6999–7020. https://doi.org/10.18632/aging.102233 (2019).
Kuenzi, B. M. & Ideker, T. A census of pathway maps in cancer systems biology. Nat. Rev. Cancer 20(4), 233–246. https://doi.org/10.1038/s41568-020-0240-7 (2020).
Barabasi, A. L., Gulbahce, N. & Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 12, 56–68. https://doi.org/10.1038/nrg2918 (2011).
Tian, Y. et al. Integration of network biology and imaging to study cancer phenotypes and responses. IEEE-ACM Trans. Comput. Biol. Bioinform. 11, 1009–1019. https://doi.org/10.1109/Tcbb.2014.2338304 (2014).
Wei, J. H. et al. Predictive value of single-nucleotide polymorphism signature for recurrence in localised renal cell carcinoma: A retrospective analysis and multicentre validation study. Lancet Oncol. 20, 591–600. https://doi.org/10.1016/S1470-2045(18)30932-x (2019).
Shi, K. et al. Identify the signature genes for diagnose of uveal melanoma by weight gene co-expression network analysis. Int. J. Ophthalmol. 8, 269–274. https://doi.org/10.3980/j.issn.2222-3959.2015.02.10 (2015).
Wang, Q. L., Chen, X., Zhang, M. H., Shen, Q. H. & Qin, Z. M. Identification of hub genes and pathways associated with retinoblastoma based on co-expression network analysis. Genet. Mol. Res. 14, 16151–16161. https://doi.org/10.4238/2015.December.8.4 (2015).
van Dam, S., Vosa, U., van der Graaf, A., Franke, L. & de Magalhaes, J. P. Gene co-expression analysis for functional classification and gene-disease predictions. Brief. Bioinform. 19, 575–592. https://doi.org/10.1093/bib/bbw139 (2018).
Wan, Q., Tang, J., Han, Y. & Wang, D. Co-expression modules construction by WGCNA and identify potential prognostic markers of uveal melanoma. Exp. Eye Res. 166, 13–20. https://doi.org/10.1016/j.exer.2017.10.007 (2018).
Review of Weighted Gene Coexpression__Network Analysis, doi:https://doi.org/10.1007/978-3-642-16345-6
Langfelder, P. & Horvath, S. WGCNA: An R package for weighted correlation network analysis. BMC Bioinform. 9, 559. https://doi.org/10.1186/1471-2105-9-559 (2008).
Yuan, L. et al. Co-expression network analysis identified six hub genes in association with progression and prognosis in human clear cell renal cell carcinoma (ccRCC). Genom. Data 14, 132–140. https://doi.org/10.1016/j.gdata.2017.10.006 (2017).
Zhang, Y. et al. Identification of hub genes in colorectal cancer based on weighted gene co-expression network analysis and clinical data from The Cancer Genome Atlas. Biosci. Rep. 41, 20211280. https://doi.org/10.1042/Bsr20211280 (2021).
Dixon, S. J. et al. Ferroptosis: An iron-dependent form of nonapoptotic cell death. Cell 149, 1060–1072. https://doi.org/10.1016/j.cell.2012.03.042 (2012).
Li, S. X. & Huang, Y. Ferroptosis: An iron dependent cell death form linking metabolism, diseases, immune cell and targeted therapy. Clin. Transl. Oncol. https://doi.org/10.1007/s12094-021-02669-8 (2021).
Jiang, X. J., Stockwell, B. R. & Conrad, M. Ferroptosis: mechanisms, biology and role in disease. Nat. Rev. Mol. Cell Biol. 22, 266–282. https://doi.org/10.1038/s41580-020-00324-8 (2021).
Hoy, A. J., Nagarajan, S. R. & Butler, L. M. Tumour fatty acid metabolism in the context of therapy resistance and obesity. Nat. Rev. Cancer 21, 753–766. https://doi.org/10.1038/s41568-021-00388-4 (2021).
Chen, J. et al. A new prognostic risk signature of eight ferroptosis-related genes in the clear cell renal cell carcinoma. Front. Oncol. 11, 700084. https://doi.org/10.3389/fonc.2021.700084 (2021).
Wang, S. et al. Comprehensive analysis of ferroptosis regulators with regard to PD-L1 and immune infiltration in clear cell renal cell carcinoma. Front. Cell Dev. Biol. 9, 676142. https://doi.org/10.3389/fcell.2021.676142 (2021).
Wu, G. Z., Wang, Q. F., Xu, Y. K., Li, Q. L. & Cheng, L. A new survival model based on ferroptosis-related genes for prognostic prediction in clear cell renal cell carcinoma. Aging-US 12, 14933–14948. https://doi.org/10.18632/aging.103553 (2020).
Chang, K. L., Yuan, C. & Liu, X. G. Ferroptosis-related gene signature accurately predicts survival outcomes in patients with clear-cell renal cell carcinoma. Front. Oncol. 11, 649347. https://doi.org/10.3389/fonc.2021.649347 (2021).
Li, D. et al. Ferroptosis-related gene CHAC1 is a valid indicator for the poor prognosis of kidney renal clear cell carcinoma. J. Cell Mol. Med. 25, 3610–3621. https://doi.org/10.1111/jcmm.16458 (2021).
Xu, C. L. et al. Acyl-CoA thioesterase 8 and 11 as novel biomarkers for clear cell renal cell carcinoma. Front. Genet. 11, 594969. https://doi.org/10.3389/fgene.2020.594969 (2020).
Wang, J. F. et al. SUV39H1 deficiency suppresses clear cell renal cell carcinoma growth by inducing ferroptosis. Acta Pharma. Sin. B 11, 406–419. https://doi.org/10.1016/j.apsb.2020.09.015 (2021).
Gao, S. et al. A novel ferroptosis-related pathway for regulating immune checkpoints in clear cell renal cell carcinoma. Front. Oncol. 11, 678694. https://doi.org/10.3389/fonc.2021.678694 (2021).
Qi, X. C., Li, Q. L., Che, X. Y., Wang, Q. F. & Wu, G. Z. The uniqueness of clear cell renal cell carcinoma: Summary of the process and abnormality of glucose metabolism and lipid metabolism in ccRCC. Front. Oncol. 11, 727778. https://doi.org/10.3389/fonc.2021.727778 (2021).
Ma, S. J. et al. Analysis of ferroptosis-related gene expression and prognostic factors of renal clear cell carcinoma based on TCGA database. Int. J. Gen. Med. 14, 5969–5980. https://doi.org/10.2147/Ijgm.S323511 (2021).
Bai, D. et al. Genomic analysis uncovers prognostic and immunogenic characteristics of ferroptosis for clear cell renal cell carcinoma. Mol. Ther. Nucleic Acids 25, 186–197. https://doi.org/10.1016/j.omtn.2021.05.009 (2021).
Goldman, M. J. et al. Visualizing and interpreting cancer genomics data via the Xena platform. Nat. Biotechnol. 38, 675–678. https://doi.org/10.1038/s41587-020-0546-8 (2020).
Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47. https://doi.org/10.1093/nar/gkv007 (2015).
G.K. Smyth, limma: Linear Models for__Microarray Data
Chen, L. et al. Co-expression network analysis identified FCER1G in association with progression and prognosis in human clear cell renal cell carcinoma. Int. J. Biol. Sci. 13, 1361–1372. https://doi.org/10.7150/ijbs.21657 (2017).
Nakamura, H. et al. Identification of key modules and hub genes for small-cell lung carcinoma and large-cell neuroendocrine lung carcinoma by weighted gene co-expression network analysis of clinical tissue-proteomes. PLoS ONE 14, e0217105. https://doi.org/10.1371/journal.pone.0217105 (2019).
Chen, X., Hu, L. L., Wang, Y., Sun, W. J. & Yang, C. Single cell gene co-expression network reveals FECH/CROT signature as a prognostic marker. Cells 8, 698. https://doi.org/10.3390/cells8070698 (2019).
Wettenhall, J. M. & Smyth, G. K. limmaGUI: A graphical user interface for linear modeling of microarray data. Bioinformatics 20, 3705–3706. https://doi.org/10.1093/bioinformatics/bth449 (2004).
Kanehisa, M. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 28(1), 27–30. https://doi.org/10.1093/nar/28.1.27 (2000).
Kanehisa, M. Toward understanding the origin and evolution of cellular organisms. Protein Sci. 28(11), 1947–1951. https://doi.org/10.1002/pro.3715 (2019).
Kanehisa, M., Furumichi, M., Sato, Y., Ishiguro-Watanabe, M. & Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 49, D545–D551. https://doi.org/10.1093/nar/gkaa970 (2021).
Zou, Y. et al. A GPX4-dependent cancer cell state underlies the clear-cell morphology and confers sensitivity to ferroptosis. Nat. Commun. 10, 1617. https://doi.org/10.1038/s41467-019-09277-9 (2019).
Conte, M., Franceschi, C., Sandri, M. & Salvioli, S. Perilipin 2 and age-related metabolic diseases: A new perspective. Trends Endocrinol. Metab. 27(12), 893–903. https://doi.org/10.1016/j.tem.2016.09.001 (2016).
Ma, W., Jia, L., Xiong, Q., Feng, Y. & Du, H. The role of iron homeostasis in adipocyte metabolism. Food Funct. 12(10), 4246–4253. https://doi.org/10.1039/d0fo03442h (2021).
Ma, W., Jia, L., Xiong, Q. & Du, H. Iron overload protects from obesity by ferroptosis. Foods 10(8), 1787. https://doi.org/10.3390/foods10081787 (2021).
Sun, X. et al. The modification of ferroptosis and abnormal lipometabolism through overexpression and knockdown of potential prognostic biomarker perilipin2 in gastric carcinoma. Gastric Cancer 23(2), 241–259. https://doi.org/10.1007/s10120-019-01004-z (2020).
Florek, M. et al. Prominin-2 is a cholesterol-binding protein associated with apical and basolateral plasmalemmal protrusions in polarized epithelial cells and released into urine. Cell Tissue Res. 328(1), 31–47. https://doi.org/10.1007/s00441-006-0324-z (2007).
Fargeas, C. A., Florek, M., Huttner, W. B. & Corbeil, D. Characterization of prominin-2, a new member of the prominin family of pentaspan membrane glycoproteins. J. Biol. Chem. 278(10), 8586–8596. https://doi.org/10.1074/jbc.M210640200 (2003).
Rohan, S. et al. Gene expression profiling separates chromophobe renal cell carcinoma from oncocytoma and identifies vesicular transport and cell junction proteins as differentially expressed genes. Clin. Cancer Res. 12(23), 6937–6945. https://doi.org/10.1158/1078-0432.CCR-06-1268 (2006).
Campbell, R. A. et al. Phosphatidylinositol 3-kinase_AKT-mediated activation of estrogen receptor alpha_ a new model for anti-estrogen resistance. J. Biol. Chem. 276(13), 9817–9824. https://doi.org/10.1074/jbc.M010840200 (2001).
Clark, A. S., West, K., Streicher, S. & Dennis, P. A. Constitutive and inducible Akt activity promotes resistance to chemotherapy, trastuzumab, or tamoxifen in breast cancer cells. Mol. Cancer Ther. 1(9), 707–717 (2002).
Frogne, T. et al. Antiestrogen-resistant human breast cancer cells require activated protein kinase B_Akt for growth. Endocr. Relat. Cancer 12(3), 599–614. https://doi.org/10.1677/erc.1.00946 (2005).
Kim, D. et al. AKT-PKB signaling mechanisms in cancer and chemoresistance. Front. Biosci. 10, 975. https://doi.org/10.2741/1592 (2005).
Tokunaga, E. et al. The association between Akt activation and resistance to hormone therapy in metastatic breast cancer. Eur. J. Cancer 42(5), 629–635. https://doi.org/10.1016/j.ejca.2005.11.025 (2006).
Katso, R. et al. Cellular function of phosphoinositide 3-kinases: implications for development, homeostasis, and cancer. Annu. Rev. Cell Dev. Biol. 17, 615–675. https://doi.org/10.1146/annurev.cellbio.17.1.615 (2001).
Vivanco, I. & Sawyers, C. The phosphatidylinositol 3-Kinase AKT pathway in human cancer. Nat. Rev. Cancer 2(7), 489–501. https://doi.org/10.1038/nrc839 (2002).
Testa, J. R. & Tsichlis, P. AKT signaling in normal and malignant cell. Oncogene 24(50), 7391–7393. https://doi.org/10.1038/sj.onc.1209100 (2005).
Kim, D. et al. Targeting PI3K signalling in cancer_opportunities, challenges and limitations. Nat. Rev. Cancer 9(8), 550–562. https://doi.org/10.1038/nrc2664 (2009).
Fruman, D. A. & Rommel, C. PI3K and cancer_lessons, challenges and opportunities. Nat. Rev. Drug Discov. 13(2), 140–156. https://doi.org/10.1038/nrd4204 (2014).
Li, S., Li, Y., Wu, Z., Wu, Z. & Fang, H. Diabetic ferroptosis plays an important role in triggering on inflammation in diabetic wound. Am. J. Physiol. Endocrinol. Metab. 321, E509–E521. https://doi.org/10.1152/ajpendo.00042.2021 (2021).
Brown, C. W. et al. Prominin2 drives ferroptosis resistance by stimulating iron export. Dev. Cell 51, 575. https://doi.org/10.1016/j.devcel.2019.10.007 (2019).
Liu, L., Yang, S. & Wang, H. α-Lipoic acid alleviates ferroptosis in the MPP-induced PC12 cells via activating the PI3K/Akt/Nrf2 pathway. Cell Biol. Int. 45(2), 422–431. https://doi.org/10.1002/cbin.11505 (2021).
Yi, J. M., Zhu, J. J., Wu, J., Thompson, C. B. & Jiang, X. J. Oncogenic activation of PI3K-AKT-mTOR signaling suppresses ferroptosis via SREBP-mediated lipogenesis. Proc. Natl. Acad. Sci. USA 117, 31189–31197. https://doi.org/10.1073/pnas.2017152117 (2020).
Manning, B. D. & Toker, A. AKT/PKB signaling: Navigating the network. Cell 169(3), 381–405. https://doi.org/10.1016/j.cell.2017.04.001 (2017).
Funding
This study was supported by the Scientific and Technological Innovation Major Base of Guangxi (No. 2018-15-Z04), the State Project for Essential Drug Research and Development (No.2019ZX09301132), Guangxi Key Research and Development Project (No. AB20117001).
Author information
Authors and Affiliations
Contributions
All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, S., Xu, X., Zhang, R. et al. Identification of co-expression hub genes for ferroptosis in kidney renal clear cell carcinoma based on weighted gene co-expression network analysis and The Cancer Genome Atlas clinical data. Sci Rep 12, 4821 (2022). https://doi.org/10.1038/s41598-022-08950-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-08950-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
