
Abstract
According to the statistics of 160 typical fire and explosion accidents in oil storage areas at home and abroad nearly 50 years, 122 of them occurred the secondary accidents in the emergency responses. Based on 122 accident cases, 21 causal factors leading to secondary accidents are summarized. In order to quantify the influencing degree of these causal factors on the accident consequences, a multiple linear regression model was established between them. In the modeling process, these factors are decomposed into the criterion layer, variable layer, and bottom layer. The improved analytic hierarchy process (IAHP) was used to establish the relationship between the bottom factors and variable factors, and the regression analysis method was used to establish the relational model between variable layer and criterion layer. For 122 cases of the secondary accidents, this study took the year as a statistical dimension, and obtained 40 groups of sample data. The first 34 groups of sample data were used to build the causal factors model, and the last 6 groups of sample data were tested the generalization ability of the model by using the established regression model combined with grey prediction model. The results show that the prediction ability of the established model was better than that of the grey prediction model alone. Moreover, the relative contribution and change trend of the causal factors were evaluated using the mutation progression method, and corresponding preventive countermeasures were proposed. It was found that human professional skills, knowledge and literacy, environmental issues, and firefighting facilities are the main influencing factors that lead to the secondary accidents. These three kinds of factors show a gradual improvement trend, and the existing prevention measures should be maintained and further improved. The problem of inherent objects or equipment factors has not been effectively improved and has a worsening trend, which is the focus of prevention in the future, and the prevention and control efforts need to be moderately increased. The research results have important guiding significance for understanding the quantitative influences of causal factors on the accident consequences, improving emergency response capabilities, reducing accident losses, and avoiding secondary accidents.
Similar content being viewed by others

Introduction
Safe oil storage system is important to ensure the safety of people's livelihoods and the healthy development of the economy. Once a fire or explosion accident occurs during oil storage system, it may cause serious consequences such as casualties, economic losses, and environmental pollution. However, much can be learned from real-world data. For example, secondary accidents caused by improper emergency responses have sometimes occurred, which have increased the casualties, expanded the accident situation, and increased environmental pollution. According to the statistics, just in China in 20171, there were more than eight accidents with increased casualties (41 people were killed and 16 injured) as a result of inappropriate emergency disposal in the petrochemical industry. It can be seen that there are potential causal factors in the emergency responses to accidents and post-reconstruction process. These causal factors and their interactions are the keys to secondary accidents and serious consequences. Determining these potential causal factors and establishing the relationships between them and the consequences of an accident could quantitatively determine their effects on the consequences of the accident, which could provide a scientific basis for more targeted active protection beforehand.
At present, analyses of the causal factors for fire accidents in oil storage systems are mainly based on the factors influencing the initial accident, and the analysis methods mainly adopt qualitative or quantitative methods. For example, in a qualitative analysis method, the fishbone diagram analysis method is used to determine the factors influencing oil and static electricity accidents, and the analytic hierarchy process (AHP) is used to determine the importance of each influencing factor2. Feng et al.3 used the interpretative structural modeling (ISM) theory to establish an explanatory structure model for the causes of third-party damage to oil and gas pipelines, constructed a six-layer hierarchical structure integrated system, and calculated the weights of the factors at each level of the hierarchical system using the optimal order comparison method to find the key factors. Huang et al.4 took the Qingdao oil and gas pipeline leakage and explosion accident as an example and used the AHP to analyze the human factors influencing the oil and gas pipeline leakage and explosion and determine the weight of each influencing factor. Qualitative analysis methods can better describe the relationships between the factors and the relative importance of each factor. However because of human subjectivity, it is difficult to accurately determine the quantitative influence and relative contribution of each factor to the accident.
In the quantitative analysis methods, on one hand, the causal factors are analyzed using some quantitative methods, such as, the fault tree analysis (FTA) method, a Bayesian network (BN), or a combination of the two often used. For example, FTA5,6,7,8 is used to quantitatively analyze the factors influencing fire and explosion accidents involving oil storage tanks, and to calculate and sort the structural importance of each factor. The BN method9,10 was used to analyze the probabilities of the causal factors in a natural gas explosion accident. Some scholars11 have used the FTA and BN methods to analyze the causal factors of leakage in submarine oil and gas pipelines. Ma et al.12 analyzed the causal factors and their degree of influence for fire and explosion accidents at a gas station based on fault trees and improved Bayesian network methods.
On the other hand, quantitative analysis is carried out by establishing a correlation between the causal factors and the consequences of the accident. Cui et al.13 introduced the fuzzy bow-tie model in quantitative risk analysis to quantitatively analyze the possibility and consequences of oil spill accidents, and then proposed specific risk prevention and control measures. Yu et al.14 applied the protection layer analysis method, established an independent protection layer model, found the root cause of an accident, used the protection layer model to analyze the occurrence probability of the consequence event, and proposed a complete semi-quantitative analysis method for urban gas pipeline failure and risk assessment. Zhao et al.15 used PHAST software to quantitatively analyze the influences of factors such as the wind speed and blowout pressure on the consequences of an accident. Shang et al.16 analyzed the leakage and diffusion law for urban LPG pipelines and their influencing factors, and used the RNGk-ε model to analyze the impact of the environmental wind speed, obstacles, and urban topographical conditions on the consequences of LPG leakage accidents using LPG pipelines in a certain city.
In summary, the current research on the causal factors of fire accidents involving oil storage system focuses primarily on the initial accident. It mainly uses qualitative or quantitative analysis methods, or existing risk assessment models, to analyze the effects of the causal factors on the consequences of accidents. However, from the current literature, there is no public report on the establishment of a quantitative impact model from the perspective of the relationship between the causal factors of a secondary accident and the consequences of the accident. Therefore, based on a statistical analysis of 160 typical fire and explosion accidents in oil storage areas publicly reported at home and abroad over the past 50 years, this paper summarizes 21 causal factors leading to secondary accidents and their frequencies. A multiple linear regression model between the causal factors of a secondary accident and the accident consequences was established through the multi-level decomposition of the causal factors and the establishment of the correlation between layers. Moreover, the relative contribution of each causal factor was evaluated, and the main influencing factors affecting the accident consequences were determined by analyzing the change trend. This made it possible to propose corresponding proactive preventive measures.
Statistical analyses of causal factors
According to the statistics for 160 typical fire and explosion accidents in oil storage areas at home and abroad from 1971 to 202017,18,19, 122 (including 75 in China and 47 in foreign countries) secondary accidents occurred. The 160 accident cases collected in this paper are the statistical data of fire and explosion accidents occurred in the oil reservoir area and involving the oil storage tank and its accessories (such as oil pipeline, discharge pipe, fire cooling sprinkler system, fire foam system, etc.), which are recorded in public reports and literature. Based on 122 accident cases, the classified risk source identification method20 is adopted to identify the major influencing factors that occur frequently in emergency responses. From four aspects: humans, materials, environment, and management21, 21 main causal factors leading to secondary accidents are obtained. The labels for these causal factors and their frequencies are listed in Table 1.
Modeling and analysis of causal factors
Modeling idea of causal factors model
As can be seen from Table 1, there are 21 main causal factors that lead to secondary accidents in the emergency processes. Taking these factors directly as variables would undoubtedly be the best way to reflect the corresponding relationships between the causal factors and the accident consequences. However, because of the large number of causal factors, this would lead to too many independent variables in the model, and the modeling accuracy would be difficult to guarantee. Therefore, based on the layered construction principle (namely, layer-by-layer modeling principle) of the model, these causal factors are decomposed by multiple layers, and the corresponding relationship between the bottom layer and the dependent variables is indirectly found by establishing the direct relationship between factors at adjacent layers. In this study, the causal factors were decomposed into three levels, which were called the "criterion layer (first level)," "variable layer (second level)," and "bottom layer (third level)" from top to bottom. Among these, the criterion layer included human, material, and environmental factors. The management factors previously counted were incorporated into the human factors based on the three types of hazard sources22. Because the implementation and operation of management factors are inseparable from human behavior, they can be controlled and implemented by human factors. Moreover, a large number of accident statistics show that human factors (including human operation, organization management, plan design, decision-making errors) are the most important causes of accidents. The variable layer factors were subdivisions of the criterion layer factors. Among these, the material factors were divided into inherent objects or equipment (such as storage tanks and oil pipelines) and firefighting facilities based on the different equipment failures. The bottom layer included 21 causal factors derived from the statistics. Table 2 shows the hierarchical decomposition of the causal factors in the emergency responses to fire accidents involving oil storage system.
Modeling method of causal factors model
Preprocessing of input and output variables in causal factors model
The relationships between the consequences of an accident and the causal factors have significant randomness. The construction process for the causal factors model needs to decrease the randomness of the accident system to obtain the overall characteristics of a certain type of accident, so that it has more reference significance. Therefore, time is required as a statistical dimension when modeling the causal factors obtained from multiple case accident statistics. The output of the model is the accumulation of the severity values of all the major accidents (the severity of the accident is reflected in the number of deaths) within a certain period of time t, and the input variable of the model is the overall characteristic value of the accident factors within time t.
Based on this, for 122 statistical accident cases, this study took the year as a statistical dimension, and obtained 40 groups of sample data. The last six groups of sample data were reserved for prediction testing, and the first 34 groups of sample data were used to build the causal factors model, which was established using the regression analysis method. The form of this model is shown in Eq. (1):
where \({\mathrm{y}}\left({\mathrm{j}}\right)\) is the cumulative value of the accident consequences of all the accidents in the \({j}\)th group, \({f}_{i}(j)\) is the eigenvalue of the \({i}\)th influencing factor in the \({j}\)th group, \({a}_{i}\) is the characteristic constant of the \({i}\)th influencing factor, and \({a}_{0}\) is the characteristic constant.
Determination of eigenvalues in variable layer factors
According to Eq. (1), in order to establish the causal factors model, it is necessary to determine the eigenvalues of the variable layer factors. According to the layer-by-layer modeling principle, there must be a certain linear relationship between the eigenvalues at the variable layer factors and those at the bottom layer factors, and the relationship between them could be obtained by Eq. (2).
where \({\beta }_{ik}\) is the weight of bottom layer factor \({x}_{ik}(j)\), \({f}_{i}(j)\) is the eigenvalue of the \({i}\)th variable layer factor in the \({j}\)th group, and \({x}_{ik}(j)\) is the cumulative eigenvalue of the \({k}\)th bottom layer factor under the \({i}\)th variable layer factor in the \({j}\)th group.
The eigenvalues of the bottom layer factors were represented by binary numbers, where "0" indicated that the causal factor did not appear in the accident, and "1" indicated that the causal factor did appear in the accident. Among the 40 pieces of sample data, the cumulative eigenvalues of the bottom layer factors (that is, the values of \({x}_{ik}(j)\)) are listed in Table 3.
Determining weight coefficients of bottom factors
According to Eq. (2), the eigenvalues at the variable factors are the linear combination of the cumulative eigenvalues of the bottom factors and their corresponding weight values. Because the influences of the bottom factors on the corresponding variable factors and their contributions to the occurrence and evolution of accidents are different, weight coefficients were used to distinguish the contributions of the bottom factors to the corresponding variable factors. These weight coefficients could be divided into subjective and objective weight coefficients. This study adopted the improved analytic hierarchy process (IAHP) method to determine the subjective weight coefficients of the bottom factors. By optimizing the order, IAHP can self-harmoniously modify the original judgment matrix and obtain a completely consistent ordering result without any consistency checking process23,24,25. The calculation process of the weight coefficient is as follows.
-
(1)
Compare and score the relative importance of bottom pairwise factors
The magnitude rule of Eq. (3) is adopted to evaluate the relative importance of the pair comparison of the bottom factors.
$${({\mathrm{r}}_{\mathrm{i}})}_{\mathrm{jk}}=\left\{\begin{array}{l}0 \quad ({\mathrm{X}}_{\mathrm{ij}} \; \text{is} \; \text{not} \; \text{as} \; \text{important} \;\text{as} \;{\mathrm{X}}_{\mathrm{ik}})\\ 1 \quad ({\mathrm{X}}_{\mathrm{ij}} \; \text{is} \; \text{as} \; \text{important} \; \text{as} \; {\mathrm{X}}_{\mathrm{ik}})\\ 2 \quad ({\mathrm{X}}_{\mathrm{ij}}\; \text{is} \; \text{more} \; \text{important} \; \text{than} \; {\mathrm{X}}_{\mathrm{ik}})\end{array}\right.$$(3)where \({({\mathrm{r}}_{\mathrm{i}})}_{\mathrm{jk}}\) represents the relative importance score of the bottom factors \({\mathrm{X}}_{\mathrm{ij}}\) and \({\mathrm{X}}_{\mathrm{ik}}\); i is the \({i}\)th variable layer factor (i = 1,2,3,4) ; \({\mathrm{X}}_{\mathrm{ij}}\) is the \({j}\)th bottom factor under the \({i}\)th variable layer factor; \({\mathrm{X}}_{\mathrm{ik}}\) is the \({k}\)th bottom factor under the \({i}\)th variable layer factor. The relative importance of the bottom factors is measured by the statistical frequency in Table 1. Frequency is more greater, and the relative importance is more greater. The probability that the frequency of two bottom factors is exactly the same is very small, so it is unreasonable to think that the importance of both factors is the same only when the frequency is strictly equal. Therefore, in this paper, when the difference in the frequencies of two bottom factors was not more than 10%, they were considered to have the same importance. That is, it means that \({\mathrm{X}}_{\mathrm{ij}}\) has the same importance with \({\mathrm{X}}_{\mathrm{ik}}\) as long as \(\left|\frac{{{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{j}}-{{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{k}}}{\mathrm{min}\{{{({\mathrm{m}}}_{{\mathrm{i}})}}_{\mathrm{j}},{{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{k}}\}}\right|\times 100{\%}\le 10{\%}\). Where \({{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{j}}\) is the frequency of \({\mathrm{X}}_{\mathrm{ij}}\); \({{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{k}}\) is the frequency of \({\mathrm{X}}_{\mathrm{ik}}\). \({{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{j}}\), \({{({\mathrm{m}}}_{\mathrm{i}})}_{\mathrm{k}}\) are the "total" values in the last row of Table 3, for example, \({{({\mathrm{m}}}_{1})}_{1}=2\), \({{({\mathrm{m}}}_{1})}_{2}=6\), \({{({\mathrm{m}}}_{1})}_{3}=3\).
-
(2)
Calculate the importance ranking index and judgment matrix Ai
By pair comparison of the frequencies of bottom factors in the same group (i.e., calculation of \({({\mathrm{r}}_{\mathrm{i}})}_{\mathrm{jk}}\)), Eq. (4) can be used to calculate the importance ranking index \({{({\mathrm{s}}}_{\mathrm{i}})}_{\mathrm{j}}\) of any bottom factors.
$${{({\mathrm{s}}}_{\mathrm{i}})}_{\mathrm{j}}=\sum_{\mathrm{k}=1}^{\mathrm{p}}{{({\mathrm{r}}}_{\mathrm{i}})}_{\mathrm{jk}}$$(4)The judgment matrix is calculated as shown in Eq. (5).
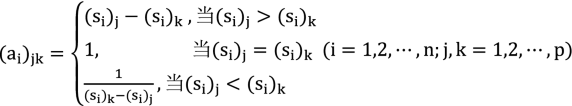 (5)
(5)where \({{({\mathrm{a}}}_{\mathrm{i}})}_{\mathrm{jk}}\) is the corresponding element in the judgment matrix Ai; n is the order of judgment matrix Ai; p is the number of bottom factors obtained by the decomposition of the \({i}\)th variable layer factor.
-
(3)
Calculate the optimal matrix Bi of judgment matrix Ai.
Element \({{({\mathrm{b}}}_{\mathrm{i}})}_{\mathrm{jk}}\) of the optimization matrix Bi is calculated by Eq. (6).
$${({{\text{b}}_{\text{i}}})_{{\text{jk}}}} = {\raise0.7ex\hbox{${\sqrt[{\text{p}}]{{\mathop \prod \nolimits_{{\text{q}} = 1}^{\text{p}} {{({{\text{a}}_{\text{i}}})}_{{\text{jq}}}}}}}$} \!\mathord{\left/ {\vphantom {{\sqrt[{\text{p}}]{{\mathop \prod \nolimits_{{\text{q}} = 1}^{\text{p}} {{({{\text{a}}_{\text{i}}})}_{{\text{jq}}}}}}} {\sqrt[{\text{p}}]{{\mathop \prod \nolimits_{{\text{q}} = 1}^{\text{p}} {{({{\text{a}}_{\text{i}}})}_{{\text{kq}}}}}}}}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${\sqrt[{\text{p}}]{{\mathop \prod \nolimits_{{\text{q}} = 1}^{\text{p}} {{({{\text{a}}_{\text{i}}})}_{{\text{kq}}}}}}}$}}~~~\left( {{\text{q}} = 1,2, \ldots ,{\text{p}}} \right)$$(6)Then, the optimization matrix \({\mathrm{B}}_{\mathrm{i}}={[{{({\mathrm{b}}}_{\mathrm{i}})}_{\mathrm{jk}}]}_{{\mathrm{p}}\times {\mathrm{p}}}\)
-
(4)
Compute the weight value of the bottom factor.
The weight value of the bottom factor \({\mathrm{X}}_{\mathrm{ij}}\) is calculated as shown in Eq. (7).
$${{(\upomega }_{\mathrm{i}})}_{\mathrm{j}}={\upomega }_{\mathrm{ij}}=\sqrt[{\mathrm{p}}]{\prod_{{\mathrm{q}}=1}^{\mathrm{p}}{{({\mathrm{b}}}_{{\mathrm{i}}})}_{\mathrm{jq}}}$$(7)After normalization, the normalized weight coefficient is calculated by Eq. (8).
$${{(\upbeta }_{\mathrm{i}})}_{\mathrm{j}}={\upbeta }_{\mathrm{ij}}=\frac{{\upomega }_{\mathrm{ij}}}{\sum_{\mathrm{j}=1}^{\mathrm{p}}{\upomega }_{\mathrm{ij}}}$$(8)According to Eqs. (3)–(8) and the data results in Table 3, the weight coefficients of the bottom factors were calculated by Matlab programming and listed in Table 4.
Table 4 Weight coefficients of bottom causal factors.
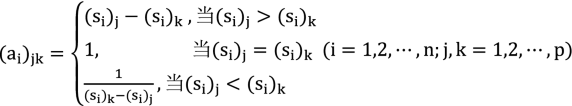
Establishment of causal factors model
According to “Modeling method of causal factors model” section, the mapping relationship between the variable layer factors and the bottom factors had been established, and eigenvalues of variable layer factors had been obtained. On this basis, the influence model between causal factors and accident consequences could be established only by determining the eigenvalue coefficient of each variable layer factor in Eq. (1) and the constant of the model. These eigenvalue coefficients and constant are actually the regression coefficient \({a}_{i}\) and characteristic constant \({a}_{0}\) in Eq. (1). Therefore, in the paper, 34 sample data sets were used as the output values, \(y(j)\), and input values, \({f}_{i}(j)\), and regression coefficients \({a}_{i}\) and characteristic constant \({a}_{0}\) could be calculated using the least squares method. Through Excel and Matlab programming, the respective variables were subjected to multiple regression analyses to obtain fitted value \(\widehat{y}\left(j\right)\) of dependent variable \(y(j)\) and characteristic value \({f}_{i}(j)\) of the variable layer factors, as listed in Table 5. The residual error is shown in Fig. 1.

Residual analysis graph of fitting data.
As can be seen from Fig. 1, the residual value of the eighth data point exceeded expectations and could be regarded as an abnormal point. Thus, the eighth data point was dropped, and the regression analysis was repeated. By analogy, fitted value \(\widehat{y}\left(j\right)\) of dependent variable \(y(j)\) obtained by the regression analysis after discarding the four sets of data is listed in Table 6. Under a 95% confidence level, the significance test results for the regression coefficients of the respective variables are listed in Table 7, with the analysis of variance results shown in Tables 8 and 9.
Therefore, according to Table 7, the multiple regression equation of the causal factors in the emergency response process can be established as shown in Eq. (9).
Tables 8 and 9 show that the regression equation has a good fitting effect and is representative, and the linear relationships between the regression coefficients and regression variables are significant.
Generalization test of causal factors model
In order to verify the generalization ability of the established causal factors model, the last six groups of sample data (2015–2020) were used for predictions. Considering the strong randomness of accident system, incompleteness of statistical data and less sample data, and focusing on medium and short term data prediction, so the grey prediction method with strong versatility was selected26. Firstly, the GM(1,1) grey prediction method was used to calculate the eigenvalue of each variable layer in each group of data, and these eigenvalues were used as the input data of the established regression model and substituted into Eq. (3) to predict the number of possible deaths in each group of data. The prediction results are listed in Table 10. Moreover, the predicted values calculated by the regression model of the causal factors established in this study were compared with the values predicted by the GM(1,1) model alone, as listed in Table 11. It can be seen that the average data prediction error of the established model was smaller than that of the direct prediction by GM(1,1), and the prediction effect was better than that of the GM(1,1) model alone.
Model error analysis
The main factors affecting the accuracy of the established causal factor model for emergency responses in this study were the randomness and uncertainty of the accident itself. The randomness of accidents was manifested in the fact that the causal factors of accidents appeared randomly, and the evolution of an accident was affected by the interaction of the internal causal factors of the accident system and the random influence of the external environment. This made the relationships between accident consequences and causal factors more uncertain. The main sources of errors in the model constructed in this study included the following three aspects.
-
(1)
Sample size. This study collected and sorted fire and explosion accident cases involving typical oil depots at home and abroad over the past 50 years by conducting a literature review, consulting online public reports, and performing enterprise research. Because of data acquisition limitations, there may be incomplete statistics on accident cases.
-
(2)
Sample reliability. Because of the incomplete disclosure of some accident case data, there may be incomplete data and uncertain reliability in the accident cases investigated in this study. This may have affected the accuracy of the eigenvalues in the bottom factors, thereby affecting the accuracy of the model.
-
(3)
Weight coefficients. The weight distribution of the bottom factors of the model was one of the important factors affecting the accuracy of the model. A more reasonable weight distribution could make the model more inclined to the objective law of the accident evolution process. However, because the relationship between the evolution of accidents and the causal factors has not yet been accurately described, the subjective weighting method was selected to determine the weights, which introduced errors in the calculation of the weights.
Therefore, in order to improve the accuracy and generalization ability of the model, statistical methods (such as an analysis of variance and cross validation) could be further considered to reduce the randomness and uncertainty between the causal factors and the consequences of the accident, thereby reducing the error of the model.
Causal factor evaluation and corresponding preventive measures
Causal factor evaluation based on mutation progression method
Effective accident prevention countermeasures can be formulated only when hidden dangers are found from the causal factors. Therefore, it was necessary to evaluate the relative contributions of the causal factors and determine their changing trends so as to provide more targeted and prioritized prevention measures for the causal factors. There are many methods to evaluate the relative contributions of causal factors, such as the fuzzy evaluation method, analytic hierarchy process, mutation progression method, and expert evaluation method. Among these, the mutation progression method does not need to consider the index weight, but considers the relative importance of each evaluation index, overcomes the subjectivity in the weight distribution process, and is suitable for solving multi-objective decision-making problems27. Therefore, the mutation progression method was used to evaluate the relative contributions of the causal factors in this study. There were four variables in the regression model of the causal factors in this study. Therefore, the butterfly mutation model was used to evaluate the causal factors. The normalization formula of the butterfly mutation model is shown in Eq. (10):
where \({F}_{1}\), \({F}_{2}\), \({F}_{3}\), and \({F}_{4}\) are the variable layer factors; and \({x}_{{F}_{i}}\) is the evaluation value of the mutation progression of the \({i}\)th variable layer factor.
The sum of the evaluation values of the mutation progression of each causal factor in the variable layer is the relative dangerous state parameter \({D}_{h}\), as shown in Eq. (11).
The specific calculation steps for the butterfly mutation are detailed in the literature28. Taking the annual cumulative value of the bottom factors in the 40 groups of sample data as the measured value of the evaluation factor, according to Eqs. (10) and (11), and the data in Table 3, the evaluation values (\({x}_{{F}_{i}}\)) of the mutation progression of each group were calculated. The change trends of these evaluation values are shown in Figs. 2, 3, 4, 5, 6.

Change trend graph for \({x}_{{F}_{1}}\).

Change trend graph for \({x}_{{F}_{2}}\).

Change trend graph for \({x}_{{F}_{3}}\).

Change trend graph for \({x}_{{F}_{4}}\).

Change trend graph for \({D}_{h}\).
It can be seen from these figures that \({x}_{{F}_{1}}\), \({x}_{{F}_{4}}\), and \({x}_{{F}_{3}}\) generally show a downward trend; \({x}_{{F}_{2}}\) has a deteriorating trend; and \({D}_{h}\) has a general downward trend. The changing trends of \({x}_{{F}_{1}}\), \({x}_{{F}_{4}}\), and \({x}_{{F}_{3}}\) are similar to those of \({D}_{h}\). Although \({x}_{{F}_{1}}\), \({x}_{{F}_{4}}\), and \({x}_{{F}_{3}}\) can be considered to be the main factors affecting \({D}_{h}\), \({x}_{{F}_{2}}\) has a deteriorating trend and needs to be considered. From the 39 and 40 sets of data, \({x}_{{F}_{1}}\),\({x}_{{F}_{2}}\),\({x}_{{F}_{4}}\), and \({D}_{h}\) all show a deteriorating trend, which indicates that the fire safety situation is not optimistic, and the consequences of a secondary accident during oil storage system may rebound.
Analysis of preventive measures
People's professional skills, knowledge and literacy, environmental issues, and firefighting facilities are the main factors leading to secondary accidents in oil storage system. These three types of factors generally show a trend of gradual improvement. However, according to the last two sets of data (groups 39 and 40), the mutation progression values of people's professional skills, knowledge, and literacy show an upward trend, which requires close attention. Inherent objects or equipment are generally deteriorating, but according to the last two sets of data (groups 39 and 40), their mutation progression values have dropped significantly. Therefore, from a macro point of view, inherent objects or equipment are the focus of prevention, but the other three types of factors have not completely improved and cannot be ignored. Therefore, based on the evaluation results for each influencing factor, the following preventive measures are proposed.
-
(1)
Inherent objects or equipment: Strengthen regular inspections of tanks, valves, and other inherent facilities, with the timely elimination of potential safety hazards such as corrosion and cracks in oil tanks. Closely monitor whether the tank body stress and settlement deformation exceed the safety requirements. Regularly inspect oil depots to prevent oil leakage.
-
(2)
People's professional skills, knowledge, and accomplishments: Strengthen fire safety training for employees and ensure that they are familiar with operating procedures and precautions. Enhance awareness of safety laws, enact strict management mechanisms, and prevent illegal operations.
-
(3)
Environmental aspects: Design the structures and layouts of factory buildings in accordance with relevant national regulations, and ensure fire separation between buildings in a reservoir area.
-
(4)
Firefighting facilities: It is necessary to perform regular maintenance, inspections, and renewal work to ensure that these can be put into use at any time to prevent long-term disrepair and failure. Carry out practice exercises to ensure that employees are skilled and conduct appropriate operations.
Conclusion
This study focused on emergency safety by modeling and evaluating the causal factors in the emergency responses to fire accidents involving oil storage system. Consequently, the following conclusions can be drawn from the research reported in this paper.
-
(1)
Based on the principle of multi-factor hierarchical modeling, the causal factors in the emergency response processes were decomposed into criterion, variable, and bottom layers. The corresponding relationships between the bottom layer factors and variable layer factors were established using the mapping rule, and a multiple linear regression model between the variable layer factors and accident consequences was established using the regression analysis method. This made it possible to finally establish a quantitative model between the causal factors in the emergency response processes and the accident consequences.
-
(2)
By combining the established regression model of the causal factors in the emergency response processes with the GM(1,1) grey prediction method, the severity of accident consequences was predicted, and it was found that the prediction result was more accurate than that when using the GM(1,1) model alone and more in line with the actual accident results.
-
(3)
The mutation progression evaluation values for the causal factors and their change trends were calculated using the butterfly mutation model. The relative importance and degree of influence of the causal factors on the accident consequences were obtained, and targeted preventive countermeasures were proposed.
-
4)
Through the establishment of a quantitative model between the causal factors in the emergency response processes and the consequences of fire accidents involving oil storage system, and the quantitative evaluation of the degrees of influence of the causal factors on the accident consequences, this study provided an important theoretical basis for revealing the occurrence and evolution mechanism of secondary accidents during emergency response processes and realizing proactive protection beforehand.
References
Department of hazardous chemicals safety supervision and administration of the ministry of emergency management and China association for chemical safety. Collection of typical cases of chemical and hazardous chemicals accidents in China (2017). https://www.sohu.com/a/298178913_100012850 (Accessed 12 Oct 2019).
Hu, Y. Q. et al. Analysis on influence factors of electrostatic accidents in oil industry based on fishbone diagram and AHP. J. Saf. Sci. Technol. 11(1), 133–137 (2015).
Feng, M. Y., Xiao, G. Q. & Zhang, H. B. Analysis on the causes of third-party damage to oil-gas pipelines based on ISM and optimal sequence method. Saf. Environ. Eng. 22(6), 90–94 (2015).
Huang, P. et al. Human factors analysis of leakage explosion of oil and gas pipeline based on HFACS and AHP. Saf. Environ. Eng. 23(6), 114–118 (2016).
Sheng, Y. Z., Tang, F. & Wu, P. P. Fault tree analysis of oil tank fire explosion. Saf. Health Environ. 16(4), 47–49 (2016).
Li, W. D. Study on fire and explosive accidents of oil depots based on fault tree analysis. Contemp. Chem. Ind. 44(7), 1609–1611 (2015).
Ao, H. G. Fault tree analysis of the storage tanks in the chemical industry. In Fourth International Conference on Instrumentation & Measurement, 928–931 (2014).
Wang, D. Q., Zhang, P. & Chen, L. Q. Fuzzy fault tree analysis for fire and explosion of crude oil tanks. J. Loss Prev. Process Ind. 26(6), 1390–1398 (2013).
Wu, J. S. et al. Probabilistic analysis of natural gas pipeline network accident based on Bayesian network. J. Loss Prev. Process Ind. 46, 126–136 (2017).
Huang, Y. M., Ma, G. W. & Li, J. D. Grid-based risk mapping for gas explosion accidents by using Bayesian network method. J. Loss Prev. Process Ind. 48, 223–232 (2017).
Li, X. H., Chen, G. M. & Zhu, H. W. Quantitative risk analysis on leakage failure of submarine oil and gas pipelines using Bayesian network. Process Saf. Environ. Prot. 103, 163–173 (2016).
Ma, Q. C., Zhang, J. W. & Zhang, L. B. Accident analysis of fire and explosion in gas station based on improved Bayesian Network. J. Saf. Sci. Technol. 10(6), 176–182 (2014).
Cui, W. G. et al. Risk analysis on oil spill in berthing and handling operation of oil tanker based on fuzzy Bow-tie model. J. Saf. Sci. Technol. 12(12), 92–98 (2016).
Yu, H. H. et al. Layers of protection analysis for typical accidents of urban gas pipelines. Oil Gas Storage Transport. 35(3), 254–258 (2016).
Zhao, M. et al. Analysis of the influencing factors of the consequences of blowout accidents in natural gas wells containing hydrogen sulfide. Safety 39(2), 20–23 (2018).
Shang, R. X. et al. Analysis on the leakage consequences and influencing factors of urban LPG pipeline by fluent. J. Guangxi Univ. 44(01), 298–303 (2019).
Fan, J. Y. Statistical analysis of 1050 safety accidents data in oil depots. Oil Depot Gas Station 6, 19–21 (2003).
Zhang, Q. L. Analysis of Typical Fire Cases of Oil Storage Tanks at Home and Abroad (Tianjin University Press, 2014).
Yang, Y., Liu, J. Z. & Fu, S. G. Safety Evaluation and Emergency Rescue Technology of Oil Depot (China Petrochemical Press, 2009).
Yuan, C. F. et al. The Classification risk source identification method on essential safety of the emergency process for oil reservoir system fire accident. Ind. Saf. Environ. Protect. 43(11), 49–53 (2017).
Tian, S. C., Zhang, L. H. & Wang, L. SD of 3 types of hazard source system of coal mine gas explosion. J. Xi’an Univ. Sci. Technol. 31(6), 689–692 (2011).
Zhao, N. G., Yan, Q. H. & Miao, L. X. et al. The cause of fire and explosion accidents in oil depots based on three types of hazard sources. Oil & Gas Storage and Transportation. 37(1), 24–28 (2018).
Mu, B., Wang, T. C. & Ding, X. G. Application of IAHP law in environmental factors evaluation in construction enterprises. Saf. Health Environ. 10(8), 8–11 (2010).
Chen, R. J. & Hu, Y. F. Study on the application of the IAHP method in environmental influence comprehensive evaluation in highway construction. Ind. Saf. Environ. Protect. 31(11), 28–30 (2005).
Zeng, H. Study on quantitative analysis of effect factors and prevention intervention of major industrial accident. Master thesis: South China University of Technology (2012).
Zheng, X. P., Liu, M. T. & Li, W. Review on the accident-forecasting research methods. J. Saf. Environ. 3, 162–169 (2008).
Zhang, T. J. et al. Application of the catastrophe progression method in predicting coal and gas outburst. Mining Sci. Technol. 19(4), 430–434 (2009).
Liu, P. C. et al. Application of butterfly catastrophe theory in stability of slope with weak interlayer. J. Guizhou Univ. 36(2), 109–112 (2019).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (51404052), Scientific Research Fund Project of Liaoning Educational Department in 2021 (LJKZ0049), and the Humanities and Social Science Foundation of the Ministry of Education of China (17YJAZH115).
Author information
Authors and Affiliations
Contributions
C.Y. put forward the overall research ideas and methods, and modified the logical structure and literal expression of the article. Y.Z. built and developed the model and wrote the main parts of the manuscript. J.W. and Y.T. collected accident cases and statistics and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, C., Zhang, Y., Wang, J. et al. Modeling and evaluation of causal factors in emergency responses to fire accidents involving oil storage system. Sci Rep 11, 19018 (2021). https://doi.org/10.1038/s41598-021-97785-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-97785-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
