
Abstract
Streamflow (Qflow) prediction is one of the essential steps for the reliable and robust water resources planning and management. It is highly vital for hydropower operation, agricultural planning, and flood control. In this study, the convolution neural network (CNN) and Long-Short-term Memory network (LSTM) are combined to make a new integrated model called CNN-LSTM to predict the hourly Qflow (short-term) at Brisbane River and Teewah Creek, Australia. The CNN layers were used to extract the features of Qflow time-series, while the LSTM networks use these features from CNN for Qflow time series prediction. The proposed CNN-LSTM model is benchmarked against the standalone model CNN, LSTM, and Deep Neural Network models and several conventional artificial intelligence (AI) models. Qflow prediction is conducted for different time intervals with the length of 1-Week, 2-Weeks, 4-Weeks, and 9-Months, respectively. With the help of different performance metrics and graphical analysis visualization, the experimental results reveal that with small residual error between the actual and predicted Qflow, the CNN-LSTM model outperforms all the benchmarked conventional AI models as well as ensemble models for all the time intervals. With 84% of Qflow prediction error below the range of 0.05 m3 s−1, CNN-LSTM demonstrates a better performance compared to 80% and 66% for LSTM and DNN, respectively. In summary, the results reveal that the proposed CNN-LSTM model based on the novel framework yields more accurate predictions. Thus, CNN-LSTM has significant practical value in Qflow prediction.
Similar content being viewed by others
Introduction
Accurate streamflow (Qflow) prediction is crucial for efficient water management tasks, such as improving the efficiency of hydroelectricity generation, irrigation planning and flood management1. However, because of the nonlinear behaviour of the streamflow time series, streamflow prediction remains one of the very difficult matters in the field of hydrological sciences2,3. In addition, the accurate prediction of Qflow can contribute to several advantages for water resources project operation, efficient programming for flood monitoring, scheduling for reservoir operation, and several other hydrological processes. Therefore, the prediction of Qflow is essential in the field of hydrological engineering4.
Several models have been used in the past research for the development of Qflow prediction model in order to increase the accuracy in prediction. Stochastic models like, Auto Regressive (AR)5, Auto Regressive Moving Average (ARMA)6 and Autoregressive Moving Average with Exogenous Inputs (ARMAX)7, have been used for Qflow prediction based on the time series8. These statistical models analyze the time series dataset for the goal of developing a reliable technology for simulating the streamflow using classical statistics. However, those models have shown limitations to capture the nonlinear characteristics of the Qflow. On the other hand, Artificial Intelligence (AI) based data-driven models such as Artificial Neural Network (ANN)9,10, Support Vector Machine (SVM)11,12,13, Extreme Learning Machine (ELM)14,15, Fuzzy Neural Network (FNN)16,17 and Genetic Programming (GP)18,19,20, have proven superior in modelling processes compared to the stochastic model. These AI models have demonstrated an excellent capacity in the field of hydrology owing to their potential in solving the mimicking the associated non-linearity and non-stationarity in the hydrological processes and reported a successful implementation for Qflow process simulation21,22,23. For time series forecasting, it is important to abstract the correlated lagged Qflow for building any data driven predictive model24.
Among several massively employed AI models in the field of hydrology, ANN model is the one for streamflow prediction25, which imitates the operation of biological neuron and can solve the associated nonlinearity phenomenal time-series data. One of the earliest conducted studies, Zealand et al.26 utilized ANN model to simulate Qflow to a portion of the Winnipeg River system in Northwest Ontario, Canada. Authors concluded that the employed ANN model is superior to the conventional Winnipeg Flow Forecasting model (WIFFS) in term of the prediction capacity. Kerh and Lee27 predicted the Qflow at the downstream of catchment using the data of upstream historical data. The research was conducted on the basis of flood forecasting due to the data non-availability at the downstream. The research evidenced the potential of the ANN over the classical Muskingum model. In another study, Adamowski and Sun28 developed ANN model coupled with discrete wavelet transform (DWT-ANN) for Qflow prediction and found that DWT-ANN model outperformed the standalone ANN model. Demirel et al.29 studied the issue of flow prediction based on the soil and water assessment tool (SWAT) and ANN models; ANN shows better performance in peak flow prediction compared to SWAT.
Over the literature, several AI models introduced for the streamflow modelling such as support vector regression (SVR), adaptive neuro fuzzy inference system (ANFIS), extreme learning machine (ELM), random forest (RF), and their hybridized version with several optimization algorithms30. SVR model was used for long term (monthly) as well as short-term (hourly) Qflow prediction and shown a better performance than ANFIS and GP31,32. Atiquzzaman and Kandasamy33 employed ELM model for streamflow prediction for two different catchment sizes from two different climatic conditions and benchmarked it with SVR and GP. The results showed that the prediction accuracy was increased, and computational time was minimised. ELM has been further employed by34 to predict mean Qflow water level for three hydrological sites in eastern Queensland (Gowrie Creek, Albert, and Mary River).
Nevertheless, the implementation of AI models in the prediction of Qflow are not consistent and it is difficult to conclude which method is superior. Additionally, the AI model, like the ANN model, has some limitations such as learning divergence, shortcoming in the generalizing performance, trapping in the local minimum and over-fitting problems35. Whereas, SVR model seems to be overcoming some drawbacks of ANN, however, requires a long simulation time because of the kernel function (penalty factor and kernel width)13. Hence, if the data complexity is high, the AI models (e.g., ANN, SVR, ELM, ANFIS, etc.) may fail to learn all the conditions effectively. The motivation on the new discovery for new and robust machine learning models is still ongoing in the field of hydrology. In the recent research, new AI models represented by deep learning (DL) models have been developed for Qflow simulation. Various DL architectures (Deep Neural Network [DNN], Convolutional Neural Network [CNN] and Long Short-Term Memory [LSTM]) have been developed and widely used in the time-series prediction of solar radiation, wind, stock price etcetera36,37. These DL models such as the potential in handling highly stochastic datasets and abstracting the internal physical mechanism38. In more representative manner, Fig. 1 was generated using the VOSviewer software to exhibit the major keywords occurrence within Scopus database on the implementation of DL models in the field of hydrology in addition to the countries where the researches were adopted.

(a) The reported keywords occurrence (107 keywords) over the literature on the implementation of the deep learning models within the research domain of hydrology, (b) The investigated region around the globe.
This study offers a deep learning model based on the integration of CNN and LSTM, where the CNN model is applied to extract the intrinsic features of the Qflow time series while LSTM model utilizes the feature extracted by CNN for Qflow prediction. The reason to use the CNN-LSTM for the prediction of Qflow is to utilize the nonlinear processing capacity of CNN to obtain precise short-term Qflow prediction accuracy. Moreover, in CNN-LSTM model, CNN is used to remove noise and to take into account the correlation between lagged variables of Qflow, LSTM models temporal information and maps time series into separable spaces to generate predictions. This CNN-LSTM model has been used previously in various areas; in the field of natural language processing, emotions were analyzed using the CNN-LSTM model with text input39; in the field of speech processing, voice search tasks were done using the CLDNN model combining CNN, LSTM, and DNN40; in the field of video processing, a model combining CNN and Bi-directional LSTM was designed to recognize human action in video sequences41; in the field of medical field, CNN-LSTM was developed to accurately detect arrhythmias in the electrocardiogram (ECG)42; in the field of industrial area, convolutional bi-directional long short-term memory network was designed to predict tool wear43. Furthermore, in time series application CNN-LSTM model was developed for efficient prediction of residential energy consumption44,45, solar radiation forecasting46, wind speed prediction47 and stock price prediction48. In this study the prediction of Qflow is done on hourly basis for two hydrological catchments (Brisbane River:26.39° S 152 22° E and Teewah Creek: 26.16° S 153.03° E) in Australia. The main aim of the current research is to inspect the prediction capacity of several DL models in modelling hourly Qflow and compare the DL model performance (CNN-LSTM, LSTM, CNN, DNN) with other AI models (Multilayer Perceptron [MLP], ELM) as well as ensemble models (Decision Tree [DT], Gradient Boosting Regression [GBM], Extreme Gradient Boosting [XGB] and Multivariate Adaptive Regression Splines [MARS]). This investigation is considered one the earliest in the Australian region that is conducted on the examination of the deep learning, conventional AI models and ensemble models for the problem of streamflow prediction.
Theoretical overview
The theoretical overview of the deep learning model, CNN, LSTM, DNN and CNN-LSTM is presented in this section. The theoretical explanation of the MLP49, GBM50, ELM51, XGB52, DT53, MARS54 and RFR55 are all elucidated elsewhere since they are well-known conventional AI models (MLP, ELM) and ensemble methodologies (GBM, XGB, DT, MARS and RFR).
Convolutional neural network
CNN model56,57 differs from MLP by relying on the weight sharing concept. In literatures, three types of CNN networks are found, one-dimensional CNN (Conv1D), two-dimensional CNN (Conv2D) and three-dimensional CNN (Conv3D). In Conv1D, the convolution kernels move in one direction. The input and output data of Conv1D is 2-dimensional58. Mainly used for time series data59, the Conv1D has powerful capability of feature extraction: the non-linear features hidden in the raw data can be automatically extracted by the alternating convolutional layer and pooling layer in the Conv1D, and the adaptive feature learning is completed at the fully-connected layer. In this way, the Conv1D algorithm eliminates the manual process of feature extraction in traditional algorithms and end-to-end information processing is realized60. Conv2D is the first standard CNN introduced in the Lenet-5 architecture61. Conv2D is usually used for image data62. It is called Conv2D because the convolution kernels slide along the data in 2 dimensions. The input and output data of Conv2D is 3-dimensional, for instance, in image classifications CNN can detect edges, color distribution, etc. in an image, making these networks very powerful in image classification and other similar data containing spatial characteristics63,64. In Conv3D, the convolution kernels moves in 3 directions, the input and output data of Conv3D is 4-dimensional65. Conv3D is mainly used for 3D image data, for instance, magnetic resonance imaging (MRI) data. MRI data is widely used to examine the brain, spinal cord, internal organs, etc., computer tomography (CT) scans are also three-dimensional data, which is an example of the creation of a series of X-ray images taken from different angles around the body. Conv3D are used to classify the medical data or extract features from it66,67,68. Figure 2 shows a one-dimensional (1D) convolution operation, where \({x}_{1} \; to \; {x}_{6}\) represent the inputs while \({c}_{1} \; to \; {c}_{4}\) represent the feature maps after 1D convolution. The red, blue, and green connections are the links between the input layer and the convoluting layer and each connection is weighted while connections that have the same color have equivalent weight value. Thus, only 3 weight values are needed in Fig. 2 to implement the convolution operation. One major advantage of the CNN model lies in its easy training phase due to the fewer number of weights compared to the number of weights in a fully-connected architecture. Furthermore, it allows the effective extraction of important features. Each convolutional layer may be represented as follow69:

The 1-dimensional convolution operation. Symbol as per “Theoretical overview” section.
where \(f\) is the activation function, \({W}^{k}\) is weights of the kernel linked to the kth feature map, while \(*\) represents a convolution operator.
The considered CNN in this study has a fully connected layer and three convolutional layers; the selection of the convolutional layer channels was based on grid search. Furthermore, the activation function used is the rectified linear units (ReLU) while adaptive moment estimation (Adam) is used as the optimization algorithm. The ReLU can be expressed thus:
The one-dimensional (1D) convolution operator is used to ensure simplification of the modeling processes, as well as to ensure real-time Qflow prediction. The 1D convolution operator can make a direct prediction of the 1D Qflow data.
Long short-term memory
Recurrent neural network (RNN) are powerful and robust type of artificial neural networks that uses existing time-series data to predict the future data over a specified length of time70. However, the RNNs can only recollect the recent information but not the earlier information56. Though the RNNs can be trained by back-propagation, it will be very difficult to train them for long input sequences due to vanishing gradients. Hence, the main drawback of the RNN architecture is its shorter memory to remember the features, vanishing and exploding gradients71,72. In order to overcome the vanishing and exploding gradients problem LSTM model was proposed73, LSTMs are a special class of RNN that relies on special units called memory blocks in their hidden layers; these memory blocks perform the role of the normal neurons in the hidden layers73,74. There are also three gate units in the memory blocks called input, output, and forget gates; these gates help in updating and controlling the flow of information through the memory blocks75. The LSTM network is calculated as follows76: (i) if the input gate is activated, any new input information into the system will be accumulated to the cell; (ii) the status of the previous cell is forgotten if the forget gate is activated; (iii) the propagation of the output of the latest cell to the ultimate state is controlled by the output gate. Figure 3 depicts the LSTM architecture.

Topological structure of Long Short-Term Memory (LSTM) Network used in this study for the prediction of short-term (hourly) streamflow (Q, m3 s−1) at Brisbane River and Teewah Creek. Symbols as per “Theoretical overview” section.
Regarding streamflow prediction, the historical lagged input data is represented as \(x=({x}_{1},{x}_{2},\dots ,{x}_{T})\) while the predicted data is depicted as \(y=({y}_{1},{y}_{2},\dots ,{y}_{T})\). The computation of the predicted streamflow series is performed thus77:
where \({c}_{t}\): the activation vectors for cell, \({m}_{t}\): activation vectors for each memory block, \(W\): weight, \(b\): bias vectors, \(\circ\): scalar product, \(\sigma (.)\): gate activation function, \(g(.)\): input activation function, \(h(.)\): output activation function.
Proposed deep CNN-LSTM network
Figure 4 shows the proposed CNN-LSTM architecture in which the lagged hourly streamflow series serve as the inputs while the next hour streamflow is the output. In the proposed CNN-LSTM architecture, the first half is CNN that is used for feature extraction while the latter half is LSTM prediction that is for the analysis of the CNN-extracted features and for next-point streamflow prediction. There are three ID convolution layers in the CNN part of the proposed CNN-LSTM architecture.

Topological structure of Convolutional neural Network (CNN) integrated with Long Short-Term Memory (LSTM) Network used in this study for the prediction of short-term (hourly) streamflow (Q, m3 s−1) at Brisbane River and Teewah Creek.
Deep neural network
There is a close similarity between the DNN concept and artificial neural network with many hidden layers and nodes in each layer. It can be trained on a set of features which will be later used for the objective function approximation78. The naming of DNNs is based on the networks as they are typically a compilation of numerous functions. The notable application of DNN is the prediction of global solar radiation and wind speed79,80,81.
Study area and model development
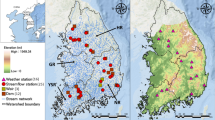
In order to develop a prediction model based on deep learning, conventional AI and ensemble models, this study has utilized lagged hourly data of streamflow (Qflow) from 01-January-2014 to 16-October-2017. Figure 5 plots a geographic map of the present study site, namely Brisbane River (Brisbane) and Teewah Creek (Noosa). The hourly streamflow (Qflow) data were acquired from the Water Monitoring Data Portal (Dept of Environment & Resource Management, http://watermonitoring.dnrm.qld.gov.au/host.htm). Figure 6 plots an average Qflow characteristics for Brisbane River and Teewah Creek by year, month, and day. It can be seen from the figure that the Qflow of the Brisbane river is more than that of Teewah creek, for Brisbane River the Qflow is minimum at June whereas for Teewah creek Qflow is significantly reduced at July, September and December. Similarly, the peak Qflow occurs in February for Brisbane river whereas for Teewah creek the peak Qflow occurs at March, June, August, and November. In addition, the time series plot of the Qflow for the year 2017 is shown in Fig. 7.

Location of Brisbane River and Teewah Creek study site in Australia, where experiments are carried out to validate the Deep Learning model for the prediction of hourly streamflow (Q, m3 s−1).

Variation of streamflow (Q, m3 s−1) by year, month and day for (a) Brisbane River and (b) Teewah Creek.

Hydrograph of streamflow during 2017 for (a) Brisbane River and (b) Teewah Creek, where the current study being done for hourly streamflow (Q, m3 s−1) prediction.
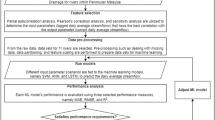
Model development
Data preparation
During data preparation, the first step is to determine the stationarity of the Qflow time series. To do this, the Dicky–Fuller (DF) test was used in this study. With the application of the DF test, it implies that the null-hypothesis which suggests that the Qflow time series is non-stationary, will be rejected. The next step is correlation analysis phase which aims at identifying the model order. The autocorrelation function (ACF) analysis was adopted in this study for the determination of the input of the Qflow prediction model; this implies the determination of the input values that correlates maximally with the prediction values (Fig. 8). The major aim of using the ACF analysis method is to perform prediction tasks82. Owing to the stationarity of the Qflow time series data, the computed 1-h interval autocorrelation function deteriorates at values < 0.27 as shown in Fig. 8 (the so-called correlation time (τc) in about 6-h (i.e., 6 lags of 1-h)). Qflow(t) is considered the time series variable while the vector (Qflow(t-6), Qflow(t-5), Qflow(t-4), Qflow(t-3), Qflow(t-2), Qflow(t-1), Qflow(t)) is used in the next step as the input for the prediction of the value Qflow(t+1).

Autocorrelation (ACF) and partial autocorrelation (PACF) plot of the streamflow (Q, m3 s−1) time series for Brisbane river with lag in hours in order to make the input matrix of lagged streamflow series for the model input.
Data normalization
Using Eq. (5), the modelled dataset was scaled between 0 and 1 to avoid the high values of variation in the dataset for easier simulation and converted to its original scale after modeling using Eq. (6)83,84, where Qflow, Qflow(min) and Qflow(max) represent the input data value and its overall minimum and maximum values, respectively
After normalization the data are segregated into training and testing sets as demonstrated in Table 1. The Qflow prediction was done for the year 2018 in the different range, spanning from 1-Week to 9-Months.
Main model development
This study developed a 3-layer CNN model, 6-layer LSTM model, 4-layer CNN-LSTM model, and 4-layer DNN model. Table 2 presents the hyperparameters of the respective models which are selected based on the trial-and-error method as presented in Table 3. Some of these hyperparameters are model specific.
Common hyperparameters
The DL modes share the following four common hyperparameters:
-
Activation function: All the network layers rely on the same activation function ReLU except for the output layer.
-
Dropout: This was considered a potential regularization technique for minimizing the issue of overfitting in order to improve the training performance84. Hence, dropout selects a fraction of the neurons (defined as a real hyperparameter in the range of 0 and 1) at each iteration and prevent them from training. This fraction of neurons was maintained at 0.1 in this study.
-
Two statistics regularizations including L1: least absolute deviation and L2: least square error was used together with dropout. The role of the L1 and L2 penalization parameters is to minimize the sum of the absolute differences and sum of the square of the differences between the predicted and the target Qflow values, respectively. The addition of a regularization term to the loss is believed to encourage smooth network mappings in a DL network by penalizing large values of the parameters; this will reduce the level of nonlinearity that the network models.
-
Early stopping: The problem of overfitting was further addressed by introducing the early stopping (ES) criteria from Kera’s work85; the mode was set to minimum while patience was set to 20. This is to ensure that the training will terminate when the validation loss has stopped decreasing for the number of patience-specified epochs.
CNN model hyperparameter
-
Filter size: The size of the convolution operation filter.
-
Number of convolutions: The number of convolutional layers in each CNN.
-
Padding: This study utilized the same padding in order to ensure that the dimensions of input feature map and output feature map are the same.
-
Pool-size: A pooling layer is used between each convolution layer to avoid overfitting; this pooling layer helps in decreasing the number of parameters and network complexity. This study utilized a pool-size of 2 between layer 1 and 2.
CNN-LSTM model development
The proposed CNN-LSTM in this study is comprised of three convolutional layers with pooling operations; the selection of the convolutional layers channels was based on grid search. In the architecture of the model, the outputs of the flattening layer serve as the inputs of the LSTM recurrent layer while the LSTM recurrent layer is directly linked to the final outputs. The inputs of networks are the lagged matrix of hourly Qflow. The input parameter is the hourly Qflow while the CNN-LSTM hyperparameters are deduced via the trial and error method as presented in Tables 2 and 3.
Benchmark models
Open source Python libraries such as Scikit-Learn, PyEarth86,87 and Keras deep learning library85,88 were used to implement the conventional AI (MLP, ELM) and ensemble models (Decision Tree [DT], Random Forest [RFR], Gradient Boosting Regression [GBM], Extreme Gradient Boosting [XGB] and Multivariate Adaptive Regression Splines [MARS]. The hyperparameters of the conventional AI models and ensemble models were deduced through the trial-and-error method which are outlined in Table 2.
All the simulations were performed in a computer with Intel core i7 @ 3.3 GHz and 16 GB of RAM memory. For the simulation of model Python89 programming language was used with deep learning library like Keras90 and TensorFlow91. Several other programming tools are also used, for instance MATLAB for plotting92, Minitab for statistical analysis93.
Performance metrics
In this section, the statistical metrics used for the model’s evaluation were reported. Following several machine learning models for hydrological process simulation, the following statistical metrics were used, including Correlation Coefficient (r), root mean square error (RMSE), mean absolute error (MAE), relative absolute error (RAE), Integral normalized root squared error (INRSE), Nash–Sutcliffe coefficient (ENS), Willmott’s index (WI), normalised root mean square error (NRMSE) and Legate and McCabe’s index (LM)94,95,96,97,98. Several researches found during their study that ENS and RMSE are the most commonly used reliable metrics for prediction problem99.
Additionally, for the comparison of different models, the promoting percentages of mean absolute error (PMAE) and promoting percentages of root mean square error (PRMSE) were computed. Furthermore, the absolute percentage bias (APB) and Kling Gupta efficiency (KGE) as key performance indicators for Qflow prediction, were calculated as well100.
The formulations of the metrics are:
-
i.
Correlation Coefficient (r):
$$r={\left(\frac{{\sum }_{i=1}^{N}\left({{Q}_{flow}}^{m}-<{{Q}_{flow}}^{m}>\right)\left({{Q}_{flow}}^{p}-<{{Q}_{flow}}^{p}>\right)}{\sqrt{{\sum }_{i=1}^{N}{\left({{Q}_{flow}}^{m}-<{{Q}_{flow}}^{m}>\right)}^{2}}\sqrt{{\sum }_{i=1}^{N}{\left({{Q}_{flow}}^{p}-<{{Q}_{flow}}^{p}>\right)}^{2}}}\right)}^{2}$$(6) -
ii.
Mean Absolute Error (MAE, m3 s−1):
$$MAE=\left(\sum^{\underset{t=1}{N}}|{{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}|\right)/N$$(7) -
iii.
Relative Root Mean Square Error (RMAE, %):
$$RMAE=\frac{1}{N}{\sum }_{i=1}^{N}\left|\frac{\left({{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}\right)}{{{Q}_{flow}}^{m}}\right|\times 100$$(8) -
iv.
Root Mean Square Error (RMSE, m3 s−1):
$$RMSE=\sqrt{\frac{1}{N}{\sum }_{i=1}^{N}{\left({{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}\right)}^{2}}$$(9) -
v.
Absolute Percentage Bias (APB, %):
$${\text{APB}}=\left[\frac{{\sum }_{i=1}^{N}({{Q}_{flow}}^{m}-{{Q}_{flow}}^{p})*100}{{\sum }_{i=1}^{N}{{Q}_{flow}}^{m}}\right]$$(10) -
vi.
Kling Gupta Efficiency (KGE):
$$KGE=1-\sqrt{(r-1{)}^{2}+{\left(\frac{<{{Q}_{flow}}^{p}{>}}{<{{Q}_{flow}}^{m}{>}}-1\right)}^{2}+{\left(\frac{C{V}_{p}}{C{V}_{s}}\right)}^{2}}$$(11) -
vii.
Integral Normalized Mean Square Error (INRSE):
$$INRSE=\sqrt{\frac{{\sum }_{i=1}^{N}({{Q}_{flow(i)}}^{m}-{{Q}_{flow(i)}}^{p}{)}^{2}}{{\sum }_{i}^{N}({{Q}_{flow(i)}}^{m}-<{{Q}_{flow(i)}}^{m}>{)}^{2}}}$$(12) -
viii.
Normalized Root Mean Square Error (NRMSE):
$$NRMSE=\frac{{\sum }_{i=1}^{N}({{Q}_{flow(i)}}^{m}-{{Q}_{flow(i)}}^{p}{)}^{2}}{{{Q}_{flow(i)}}^{m}}$$(13) -
ix.
Relative absolute error (RAE, %):
$$RAE=\frac{{\sum }_{i=1}^{N}\left|{{Q}_{flow}}^{m}-\left.{{Q}_{flow}}^{p}\right|\right.}{{\sum }_{i=1}^{N}\left|{{Q}_{flow}}^{m}-<{{Q}_{flow}}^{m}>\right|}*100$$(14) -
x.
Promoting Percentages of Mean Absolute Error (PMAE):
$${P}_{M{\text{AE}}}=|(MA{E}_{1}-MA{E}_{2})/MA{E}_{1}|$$(15) -
xi.
Promoting Percentages of Root Mean Square Error (PRMSE)
$${P}_{RM{\text{SE}}}=|(RMS{E}_{1}-RMS{E}_{2})/RMS{E}_{1}|$$(16) -
xii.
Nash–Sutcliffe coefficient (ENS):
$${E}_{NS}=1-\frac{{\sum }_{i=1}^{N}{\left[{{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}\right]}^{2}}{{\sum }_{i=1}^{N}{\left[{{Q}_{flow}}^{m}-\langle {{Q}_{flow}}^{p}\rangle \right]}^{2}}$$(17) -
xiii.
Willmott’s index (WI):
$$WI=1-\frac{{\sum }_{i=1}^{N}{\left[{{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}\right]}^{2}}{{\sum }_{i=1}^{N}{\left[|({{Q}_{flow}}^{p}-\langle {{Q}_{flow}}^{m}\rangle )|+|({{Q}_{flow}}^{m}-\langle {{Q}_{flow}}^{p}\rangle )|\right]}^{2}}$$(18) -
xiv.
Legate and McCabe’s index (LM):
$$LM=1-\frac{{\sum }_{i=1}^{N}|{{Q}_{flow}}^{m}-{{Q}_{flow}}^{p}|}{{\sum }_{i=1}^{N}|{{Q}_{flow}}^{m}-\langle {{Q}_{flow}}^{m}\rangle |}$$(19)where r: correlation coefficient, CV: coefficient of variation, \({{Q}_{flow}}^{m}\): measured Qflow, \({{Q}_{flow}}^{p}\): predicted Qflow,\(<{{Q}_{flow}}^{m}>\): average value of the Qflowm, \(<{{Q}_{flow}}^{p}>\): average value of the Qflowp, N: number of the dataset, \(MA{E}_{1}\) and \(RMS{E}_{1}\): mean model performance metrics (CNN = LSTM), \(MA{E}_{2}\) and \(RMS{E}_{2}\): benchmarked model performance (CNN, LSTM, DNN, MLP, etc.).
Applications results and analysis
In this section, the predictability performance of the proposed CNN-LSTM model and the comparable models for the four experimental tests are conducted for 1-Week, 2-Weeks, 4-Weeks, and 9-months [20% of total Streamflow data (Table 1)] for hourly Qflow prediction at Brisbane River and Teewah Creek. Each experiment consists of 10 Qflow prediction models, including the CNN-LSTM, CNN, LSTM, DNN, DT, ELM, GBM, MARS, MLP and XGB. The performance metrics of proposed CNN-LSTM, deep learning (CNN, LSTM, DNN), conventional AI and ensemble models in terms of r, RMSE, MAE, WI, LM and ENS are shown in Tables 4 and 5. The model prediction results over the testing phase represent the ability of the predictive models in simulating the streamflow data. Thus, the following sections will be focused on the model evaluation and assessment over the testing phase.
For both sites (Brisbane River and Teewah Creek), it can be seen that the \(1.00\le r\ge 0.88\) for all deep learning model, \(0.999\le r\ge 0.728\) for conventional AI and \(0.344\le r\ge 0.996\) ensemble model for all prediction interval. Since r is parametric and oversensitive to extreme values98, the conclusion of model performance based on this coefficient is not sufficient. Therefore, further assessment of model performance was done using MAE and RMSE. With low RMSE (CNN-LSTM/\(0.226\le RMSE\ge 0.155 \; \text{m}^{3}\;\text{s}^{-1} (Brisbane River))\) and MAE (CNN-LSTM/\(0.196\le MAE\ge 0.054 \; \text{m}^{3}\; \text{s}^{-1} (Tewah Creek) )\) the CNN-LSTM model outperform the all conventional data driven [e.g. ELM/\(0.182\le MAE\ge 0.701 \; \text{m}^{3} \text{s}^{-1}(Brisbane River)\)] as well as the ensemble model [e.g. DT/\(0.734\le MAE\ge 0.275 \; \text{m}^{3}\; \text{s}^{-1} (Teewah Creek) ]\) for all prediction interval of 1-Week, 2-Weeks, 4-Weeks and 9-Months (20% testing data).
Additionally, in hydrological model the ENS is a widely used metric for prediction of streamflow, water level, drought etcetera and is considered as an expertise score calculated as the reasonable capability100 that presents the mean values of the Qflow. However, ENS metric neglects the lower values and overestimates the larger ones98. In addition, Willmott's index (WI) metric is calculated due to its merits over the r and ENS. In the computation of the WI metric, errors and differences are given their appropriate weighting, which overcomes the insensitivity issues98. Further, WI and ENS do not take the absolute value into account and are oversensitive to peak residual values101, therefore LM was taken into consideration for further model assessment. The LM is not overestimated since it takes absolute values into account102. As shown in Table 5, with high magnitude of ENS, WI and LM, CNN-LSTM model [1.00 \(\le\) WI \(\ge\) 0.96, 0.989 \(\le\) LM \(\ge\) 0.868, 1.00 \(\le\) ENS \(\ge\) 0.955 (Brisbane River)] outperform all the models \([MLP: 0.994\le WI\ge 0.931, 0.901\le LM\ge 0.337, 0.973\le {E}_{Ns\cdot }\ge 0.739 \left(Brisbane River\right);DT: 0.952\le WI\ge 0.716, 0.982\le LM\ge 0.684, 0.983\le {E}_{Ns\cdot }\ge 0.467 \left(Brisbane River\right) ]\) for all the prediction levels for both sites.
Figures 9 and 10 show the hydrograph and the scatterplots (Fig. 11) of both the actual and predicted Qflow obtained by proposed CNN-LSTM model as well as conventional AI and ensemble models during the testing period. For the purpose of brevity, only the plots for prediction interval of 2-Weeks are shown. The hydrographs and the scatterplots demonstrate that the prediction of the CNN-LSTM model was closest to the observed Qflow values in comparison to the other models. The fit line formula (\(y=mx+c\)) presented in scatterplots where m and c are the model coefficients, respectively, closer to the 1 and 0 with a higher r value of 1.00 than ELM, MLP, LSTM, GBM and XGB models. Additionally, in hydrograph the relative error (RE) percentage are also shown, indicating that the RE of the CNN-LSTM model is comparatively smaller than that of other comparable models.

Hydrograph of predicted versus actual streamflow (Q, m3 s−1) from (a) CNN-LSTM model during test period (2-Weeks) compared with standalone model (b) Deep Neural Network (DNN), (c) Extreme Gradient Boosting Regression Model (XGB) , (d) Extreme Learning Machine (ELM) and (e) Multi-Layer Perceptron (MLP) for Brisbane River. The relative error are shown in blue color.

Hydrograph of predicted versus actual streamflow (Q, m3 s−1) from (a) CNN-LSTM model during test period (2 Weeks) compared with standalone model (b) Deep Neural Network (DNN), (c) Extreme Gradient Boosting Regression Model (XGB), (d) Extreme Learning Machine (ELM) and (e) Multi-Layer Perceptron (MLP) for Teewah Creek. The relative error are shown in blue color.

Scatterplot of predicted (Qpred) and actual (Qact) hourly streamflow (Q, m3 s−1) for (a) Brisbane River and (b) Teewah Creek using the CNN-LSTM, Extreme Learning Machine (ELM), Multi-Layer Perceptron (MLP), Long Short Term Memory Network (LSTM), Gradient Boosting Regression (GBM) and Extreme Gradient Boosting Regression Model (XGB) model. Least square regression equations of the form y = mx + C and the correlation coefficient (r) is inserted in each panel.
It is worthwhile highlighting that ELM, MLP, XGB models are able to achieve a good predictability performance with the limitation in maintaining the good prediction for the high Qflow values (Figs. 8 and 9). On the contrary, the CNN-LSTM model achieves a superior prediction result for the peak values compared to ELM, MLP and XGB models. The CNN-LSTM model only underestimates the peak values by 1.15% as opposed to 2.57%, 3.98% and 2.69% for the XGB, ELM and MLP, respectively for Brisbane River. This demonstrates the suitability of the CNN-LSTM for streamflow prediction.
To avoid the scale dependencies and impact of the outliers in the predicted streamflow, the RAE, NRMSE and INRSE were also recommended in some literatures103. Therefore, in this study further evaluation of model performance is conducted by using the RAE, NRMSE and INRSE (Table 6). For both sites, the CNN-LSTM model achieves a lower value of RAE, NRMSE and INRSE, outperforming the conventional AI and ensemble models. In line with the results presented in Tables 4 and 5, the integration of CNN and LSTM again has shown to enhance the prediction capability.
Furthermore, a comparison of the CNN-LSTM model without other models is performed in terms of the APB and KGE. The KGE and APB evaluation for the prediction of hourly Qflow reveals that the CNN-LSTM is the best performing model with KGE ≥ 0.991, APB ≤ 0.527 and KGE ≥ 0.991, APB ≤ 1.159 for Brisbane River and Teewah creek, respectively (Table 7), indicating a good model performance104 and making the CNN-LSTM model a reliable and powerful tool for the prediction of Qflow.
Figure 12 compares the boxplot of the proposed CNN-LSTM model with that of the standalone deep learning model as well as conventional AI and ensemble models. The ♦ markers in the figure demonstrate the outliers of the absolute prediction error (|PE|) of the testing data together with their upper quartile, median, and lower quartile. The distributions of the |PE| error acquired by the proposed CNN-LSTM model for all sites exhibit a much smaller quartile followed by the standalone deep learning models. By analysing Fig. 11, the accuracy of the proposed CNN-LSTM model for all sites is shown to be better than the comparative models.

Box plots of spread of prediction error (PE, m3 s−1) for proposed CNN-LSTM model during test period compared with standalone model Convolutional Neural Network (CNN) and Long Short Term Memory Network (LSTM) as well as the Deep Neural Network (DNN), Multi-Layer Perceptron (MLP), Extreme Learning Machine (ELM), Gradient Boosting Regression (GBM) and Extreme Gradient Boosting Regression (XGB) model.
The empirical cumulative distribution function (ECDF, Fig. 12) at each site depicts the prediction capacity of different models. The proposed CNN-LSTM model is shown to be superior to the conventional AI and ensemble models as well as the standalone models including LSTM and DNN. Based on the error (0 to ± 0.05 m3 s−1) for both Brisbane River and Teewah Creek, Fig. 13 depicts that the proposed CNN-LSTM model is the most precise model in streamflow prediction.

Empirical cumulative distribution function (ECDF) of absolute prediction error, |PE| (m3 s−1) of the testing data using CNN-LSTM vs. Deep Neural Network (DNN), Long Short Term Memory Network (LSTM), Multi-Layer Perceptron (MLP), and Extreme Gradient Boosting Regression (XGB) models in predicting streamflow (Q, m3 s−1) for Brisbane River (Left) and Teewah Creek (Right).
Figure 14 presents the frequency percentage distribution “histogram” of the predicted error (PE) based on the calculation of the error brackets with a 0.025 step size for Brisbane River. The presented graphical presentation can assist in a better understanding of model’s prediction performance83. The figure clearly reveals the outperformance of the CNN-LSTM model against the standalone models (DNN and LSTM), conventional AI models (MLP and ELM) and ensemble model (XGB), since its PE values are close to the zero frequency distribution. In a more quantitative term, the CNN-LSTM model shows the highest percentage of PE (56%) in the bin (0 < PE ≤ 0.025) followed by the ELM (49%), LSTM (44%), GBM (41%) DNN (40%), and finally the MLP model (0%). The accumulated PE percentages indicate that the PE of the CNN-LSTM model was below 0.15, while the conventional AI models yield a total of 97% and ensemble model yield a total of 89% of the PE in this band. This again supports the conclusion that CNN-LSTM is a superior technique for streamflow prediction.

Histogram illustrating the frequency (in percentages) of absolute Prediction errors (|PE|, m3 s−1) of the best performing CNNLSTM model during test period (4-weeks) compared with Long Short-Term Memory Network (LSTM), Deep Neural Network (DNN), Extreme Learning Machine (ELM), Gradient Boosting Regression (GBM) and Multi-Layer Perceptron (MLP) model. for the prediction of hourly streamflow (Q, m3 s−1) at Brisbane River.
To further investigate the prediction performance of the proposed CNN-LSTM model, the \({P}_{MAE} \; and \; {P}_{RMSE}\) of the experimental tests are employed to make the comparisons and analysis. Table 8 give the comparative analysis between the CNN-LSTM model and other involved models for the four experimental tests (1-Week, 2-Week, 4-Week and 9-Months). For instance, in 1-Week prediction, compared to LSTM model, the MAE and RMSE of CNN-LSTM model are reduced by 36.79% and 45.53% respectively for Brisbane River and 19.84% and 16.40% respectively for Teewah Creek. Similarly, reduction in MAE and RMSE of CNN-LSTM model compared to other model can be seen in 1-Week, 2-Weeks,4-Weeks, and 9-Months, hourly Qflow prediction. There are no negative values in promoting percentage error, which indicates that the integration of CNN and LSTM model can derive better prediction accuracy.
The model performance using Taylor diagram is presented in Fig. 15105. The main usage of this diagram is to present the closest predictive model with the observation in two-dimensional scale (standard deviation on the polar axis and correlation coefficient on the radial axis). Taylor diagram shows that the output of CNN-LSTM model is much closer to the actual observations compared to conventional AI and ensemble models.

Taylor diagram showing the correlation coefficient between observed and predicted streamflow (Q, m3s−1) and standard deviation of CNN-LSTM, Convolutional Neural Network (CNN), Deep Neural Network (DNN), Multi-Layer Perceptron (MLP), Gradient boosting regression (GBM), Extreme Gradient Boosting Regression (XGB) model, Decision Tree (DT) and Multivariate Adaptive Regression Splines (MARS) during testing period (4-Week) for Brisbane River.
Overall, the aforementioned evaluation results suggest that the CNN-LSTM model is superior to the standalone deep learning model as well as conventional AI and ensemble models. The proposed model CNN-LSTM is able to achieve a promising prediction performance and could be successfully applied to accurate and reliable hourly streamflow prediction. Furthermore, the averaged training time for the CNN-LSTM and the benchmarked models are listed in Table 2. Based on the results, DT followed by ELM, MARS and MLP requires the shortest training time but performs the worst in term of prediction accuracy. The proposed CNN-LSTM framework produces the most accurate prediction results with reasonable training time on various time horizons, including 1-Week, 2-Weeks, 4-Weeks and 9-Months.
Conclusions and possible future research directions
This research investigated a new AI model based on the integration CNN with LSTM for modelling hourly streamflow at two different catchments of Australia (Brisbane River and Teewah Creek). The CNN network is employed to abstract the essential streamflow (Qflow) features while the LSTM is used for the prediction process based on the abstracted time series features. To validate the proposed CNN-LSTM prediction model, nine different well-established AI models (i.e., CNN, LSTM, DNN, MLP, ELM, GBM, XGB, DT, MARS) were also implemented. The construction of the proposed predictive model (i.e., CNN-LSTM) is designed based on six antecedent values recognised through statistical autocorrelation analysis of the streamflow data time series. Prediction has been established at different time intervals: 1-Week, 2-Weeks, 4-Weeks and 9-Months, which were evaluated based on graphical and statistical metrics. According to the attained prediction results, it can be concluded that:
-
With low value of RMSE \(\left(0.226\le RMSE\ge 0.155 \; \text{m}^{3}\;\text{s}^{-1} \left(Brisbane River\right)\right)\) and MAE (\(0.196\le MAE\ge 0.054 \; \text {m}^{3}\; \text{s}^{-1} (Tewah Creek) )\) and high magnitude \([1.00\le WI\ge 0.996, 0.989\le LM\ge 0.868, 1.00\le {E}_{Ns\cdot }\ge 0.955 \left(Brisbane River\right) ]\) of the normalized index (WI, LM and ENS), CNN-LSTM model outperform the conventional AI as well as ensemble models;
-
The streamflow prediction during testing phase in terms of APB and KGE were compared with the standalone deep learning models, conventional AI and ensemble models. The results revealed that CNN-LSTM (KGE ≥ 0.991 and APB ≤ 0.527) model is able to accomplish accurately prediction capacity in comparison with LSTM, CNN, DNN, MLP, ELM, XGB, GBM, DT and MARS models for both Brisbane River and Teewah Creek for all prediction intervals;
-
With low normalized errors (\(0.007\le NRMSE\le 0.028, 0.050\le RAE\le 0.132, 0.017\le NRMSE\le 0.020\)), the CNN-LSTM model displays a better prediction accuracy against the comparative models in all the prediction intervals for both sites;
-
With no negative value in promoting percentage error, the CNN-LSTM model demonstrates the best prediction accuracy \({P}_{MAE}=92.55\% \; and \; P_{RMSE}=56.62\%\) for the MLP model (Brisbane River, 9-Months Qflow prediction);
-
The hydrograph and scatter plot reveal that the prediction from the CNN-LSTM model is closer to the corresponding actual values with a minimum relative error (\(RE\le 1.15 \; for \; CNN-LSTM, RE\le 2.69 \; for \; MLP)\) for peak flow values for both Brisbane River and Teewah Creek. In accordance to the error graphical presentation of boxplot, prediction error histogram and empirical cumulative distribution function confirmed the overall superior performance by the CNN-LSTM model with 84% of prediction error within 0–0.05 m3 s−1 range; Taylor plot of the compared models also reveals that the value of r for the CNN-LSTM model is closer to the actual Qflow and this is evidencing the predictability performance capacity of the proposed model. All the above visualization results suggest that the CNN-LSTM model is the best model for Qflow prediction in our comparison.
Future work could involve testing the CNN-LSTM model through integration of more casual hydrometeorological datasets (e.g., synoptic climate data or rainfall data) as an input predictor. During model development, the CNN-LSTM as well as other comparative models’ architecture that performed the best in the training period was determined as the optimal model (Table 2). However, the hyperparameter tuning methods like, Grid search106, Tree-structured Parzen estimators (Hyperopt)107, Population-based training108, Bayesian Optimization and HyperBand109 can also be used. These hyperparameter tuning methods can be time-consuming and resource-consuming, therefore separate study on the selection of best hyperparameter tuning methods can be conducted for Qflow prediction. In addition, data uncertainty and non-stationarity can be investigated for further insights on their influence on the modeling predictability performance. Furthermore, research could also include the application of the CNN-LSTM model as new computer aid for watershed monitoring and management by incorporating a wider range of climate scenarios.
References
Yaseen, Z. M., Sulaiman, S. O., Deo, R. C. & Chau, K.-W. An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 569, 387–408 (2018).
Senthil Kumar, A. R., Goyal, M. K., Ojha, C. S. P., Singh, R. D. & Swamee, P. K. Application of artificial neural network, fuzzy logic and decision tree algorithms for modelling of streamflow at Kasol in India. Water Sci. Technol. 68, 2521–2526 (2013).
Wang, W., Van Gelder, P. H. A. J. M., Vrijling, J. K. & Ma, J. Forecasting daily streamflow using hybrid ANN models. J. Hydrol. 324, 383–399 (2006).
Lange, H. & Sippel, S. Machine learning applications in hydrology. In Forest-Water Interactions 233–257 (Springer, 2020).
Chen, X., Mishra, N., Rohaninejad, M. & Abbeel, P. Pixelsnail: An improved autoregressive generative model. In International Conference on Machine Learning 864–872 (PMLR, 2018).
Prado, F., Minutolo, M. C. & Kristjanpoller, W. Forecasting based on an ensemble autoregressive moving average—adaptive neuro—fuzzy inference system—neural network—genetic algorithm framework. Energy 197, 117159 (2020).
Zhao, J., Gao, Y., Guo, Y. & Bai, Z. Travel time prediction of expressway based on multi-dimensional data and the particle swarm optimization–autoregressive moving average with exogenous input model. Adv. Mech. Eng. 10, 168781401876093 (2018).
Papacharalampous, G., Tyralis, H. & Koutsoyiannis, D. Predictability of monthly temperature and precipitation using automatic time series forecasting methods. Acta Geophys. 66, 807–831 (2018).
Marugán, A. P., Márquez, F. P. G., Perez, J. M. P. & Ruiz-Hernández, D. A survey of artificial neural network in wind energy systems. Appl. Energy 228, 1822–1836 (2018).
Zhang, Z. Artificial neural network. In Multivariate Time Series Analysis in Climate and Environmental Research 1–35 https://doi.org/10.1007/978-3-319-67340-0_1 (2017).
Ghimire, S., Deo, R. C., Downs, N. J. & Raj, N. Global solar radiation prediction by ANN integrated with European Centre for medium range weather forecast fields in solar rich cities of Queensland Australia. J. Clean. Prod. https://doi.org/10.1016/j.jclepro.2019.01.158 (2019).
Ehteram, M., Salih, S. Q. & Yaseen, Z. M. Efficiency evaluation of reverse osmosis desalination plant using hybridized multilayer perceptron with particle swarm optimization. Environ. Sci. Pollut. Res. https://doi.org/10.1007/s11356-020-08023-9 (2020).
Raghavendra, S. & Deka, P. C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. J. 19, 372–386 (2014).
Yousif, A. A. et al. Open channel sluice gate scouring parameters prediction: Different scenarios of dimensional and non-dimensional input parameters. Water https://doi.org/10.3390/w11020353 (2019).
Sanikhani, H., Deo, R. C., Yaseen, Z. M., Eray, O. & Kisi, O. Non-tuned data intelligent model for soil temperature estimation: A new approach. Geoderma 330, 52–64 (2018).
Li, H., Chen, C. L. P. & Huang, H.-P. Fuzzy Neural Intelligent Systems: Mathematical Foundation and the Applications in Engineering (CRC Press, 2018).
de Campos Souza, P. V. & Torres, L. C. B. Regularized fuzzy neural network based on or neuron for time series forecasting. In North American Fuzzy Information Processing Society Annual Conference 13–23 (Springer, 2018).
Danandeh Mehr, A. et al. Genetic programming in water resources engineering: A state-of-the-art review. J. Hydrol. https://doi.org/10.1016/j.jhydrol.2018.09.043 (2018).
Afan, H. A. et al. Input attributes optimization using the feasibility of genetic nature inspired algorithm: Application of river flow forecasting. Sci. Rep. 10, 1–15 (2020).
Deo, R. C., Ghimire, S., Downs, N. J. & Raj, N. Optimization of windspeed prediction using an artificial neural network compared with a genetic programming model. In Research Anthology on Multi-Industry Uses of Genetic Programming and Algorithms 116–147 (IGI Global, 2021).
Tao, H. et al. An intelligent evolutionary extreme gradient boosting algorithm development for modeling scour depths under submerged weir. Inf. Sci. 570, 172–184 (2021).
Yaseen, Z. M. An insight into machine learning models era in simulating soil, water bodies and adsorption heavy metals: Review, challenges and solutions. Chemosphere 130126 (2021).
Yaseen, Z. M. et al. Implementation of univariate paradigm for streamflow simulation using hybrid data-driven model: Case study in tropical region. IEEE Access 7, 74471–74481 (2019).
Akhtar, M. K., Corzo, G. A., van Andel, S. J. & Jonoski, A. River flow forecasting with artificial neural networks using satellite observed precipitation pre-processed with flow length and travel time information: Case study of the Ganges river basin. Hydrol. Earth Syst. Sci. 13, 1607–1618 (2009).
Kisi, O., Choubin, B., Deo, R. C. & Yaseen, Z. M. Incorporating synoptic-scale climate signals for streamflow modelling over the Mediterranean region using machine learning models. Hydrol. Sci. J. 64(10), 1240–1252 (2019).
Zealand, C. M., Burn, D. H. & Simonovic, S. P. Short term streamflow forecasting using artificial neural networks. J. Hydrol. 214, 32–48 (1999).
Kerh, T. & Lee, C. S. Neural networks forecasting of flood discharge at an unmeasured station using river upstream information. Adv. Eng. Softw. 37, 533–543 (2006).
Adamowski, J. & Sun, K. Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J. Hydrol. 390, 85–91 (2010).
Demirel, M. C., Venancio, A. & Kahya, E. Flow forecast by SWAT model and ANN in Pracana basin, Portugal. Adv. Eng. Softw. 40, 467–473 (2009).
Yaseen, Z. M., Faris, H. & Al-Ansari, N. Hybridized extreme learning machine model with salp swarm algorithm: A novel predictive model for hydrological application. Complexity 2020, (2020).
He, Z., Wen, X., Liu, H. & Du, J. A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region. J. Hydrol. 509, 379–386 (2014).
Wang, W. C., Chau, K. W., Cheng, C. T. & Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 374, 294–306 (2009).
Atiquzzaman, M. & Kandasamy, J. Robustness of extreme learning machine in the prediction of hydrological flow series. Comput. Geosci. 120, 105–114 (2018).
Deo, R. C. & Şahin, M. An extreme learning machine model for the simulation of monthly mean streamflow water level in eastern Queensland. Environ. Monit. Assess. 188(2), 90 (2016).
Ghimire, S., Deo, R. C., Downs, N. J. & Raj, N. Self-adaptive differential evolutionary extreme learning machines for long-term solar radiation prediction with remotely-sensed MODIS satellite and reanalysis atmospheric products in solar-rich cities. Remote Sens. Environ. 212, 176–198 (2018).
Ahmad, J., Farman, H. & Jan, Z. Deep learning methods and applications. SpringerBriefs Comput. Sci. https://doi.org/10.1007/978-981-13-3459-7_3 (2019).
Fu, M. et al. Deep learning data-intelligence model based on adjusted forecasting window scale: Application in daily streamflow simulation. IEEE Access 8, 32632–32651 (2020).
Hrnjica, B. & Mehr, A. D. Energy demand forecasting using deep learning. In Smart cities Performability, Cognition, & Security 71–104 (Springer, 2020).
Wang, J., Yu, L.-C., Lai, K. R. & Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) 225–230 (2016).
Sainath, T. N., Vinyals, O., Senior, A. & Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings https://doi.org/10.1109/ICASSP.2015.7178838 (2015).
Ullah, A., Ahmad, J., Muhammad, K., Sajjad, M. & Baik, S. W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 6, 1155–1166 (2017).
Oh, S. L., Ng, E. Y. K., San Tan, R. & Acharya, U. R. Automated diagnosis of arrhythmia using combination of CNN and LSTM techniques with variable length heart beats. Comput. Biol. Med. 102, 278–287 (2018).
Zhao, R., Yan, R., Wang, J. & Mao, K. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 17, 273 (2017).
Ullah, F. U. M., Ullah, A., Haq, I. U., Rho, S. & Baik, S. W. Short-term prediction of residential power energy consumption via CNN and multi-layer bi-directional LSTM networks. IEEE Access 8, 123369–123380 (2019).
Kim, T.-Y. & Cho, S.-B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 182, 72–81 (2019).
Ghimire, S., Deo, R. C., Raj, N. & Mi, J. Deep solar radiation forecasting with convolutional neural network and long short-term memory network algorithms. Appl. Energy 253, 113541 (2019).
Meka, R., Alaeddini, A. & Bhaganagar, K. A robust deep learning framework for short-term wind power forecast of a full-scale wind farm using atmospheric variables. Energy 221, 119759 (2021).
Vidal, A. & Kristjanpoller, W. Gold volatility prediction using a CNN-LSTM approach. Expert Syst. Appl. 157, 113481 (2020).
Deo, R. C. et al. Multi-layer perceptron hybrid model integrated with the firefly optimizer algorithm for windspeed prediction of target site using a limited set of neighboring reference station data. Renew. Energy 116, 309–323 (2018).
García Nieto, P. J. et al. Pressure drop modelling in sand filters in micro-irrigation using gradient boosted regression trees. Biosyst. Eng. 171, 41–51 (2018).
Huang, G.-B., Wang, D. H. & Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2, 107–122 (2011).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on knowledge Discovery and Data Mining 785–794 (ACM, 2016).
Li, W., Li, X., Li, H. & Xie, G. CutSplit: A decision-tree combining cutting and splitting for scalable packet classification. In IEEE INFOCOM 2018—IEEE Conference on Computer Communications https://doi.org/10.1109/infocom.2018.8485947 (2018).
Cristianini, N. & Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods (Cambridge University Press, 2000).
Breiman, L. Random Forrests. Machine learning (2001).
Canizo, M., Triguero, I., Conde, A. & Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 363, 246–260 (2019).
Zhao, B., Lu, H., Chen, S., Liu, J. & Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 28, 162–169 (2017).
Shen, X., Ni, Z., Liu, L., Yang, J. & Ahmed, K. WiPass: 1D-CNN-based smartphone keystroke recognition using WiFi signals. Pervasive Mobile Comput. 73, 101393 (2021).
Liu, S. et al. Data source authentication of synchrophasor measurement devices based on 1D-CNN and GRU. Electric Power Syst. Res. 196, 107207 (2021).
Yao, D., Li, B., Liu, H., Yang, J. & Jia, L. Remaining useful life prediction of roller bearings based on improved 1D-CNN and simple recurrent unit. Measurement 175, 109166 (2021).
Kuo, C.-C.J. Understanding convolutional neural networks with a mathematical model. J. Vis. Commun. Image Represent. 41, 406–413 (2016).
Zhao, Z. et al. Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-Based discrete speech emotion recognition. Neural Netw. 141, 52–60 (2021).
Eun, H., Kim, D., Jung, C. & Kim, C. Single-view 2D CNNs with fully automatic non-nodule categorization for false positive reduction in pulmonary nodule detection. Comput. Methods Programs Biomed. 165, 215–224 (2018).
Zhao, J., Mao, X. & Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 47, 312–323 (2019).
Rao, C. & Liu, Y. Three-dimensional convolutional neural network (3D-CNN) for heterogeneous material homogenization. Comput. Mater. Sci. 184, 109850 (2020).
Liu, Y. & Durlofsky, L. J. 3D CNN-PCA: A deep-learning-based parameterization for complex geomodels. Comput. Geosci. 148, 104676 (2021).
Chen, Y. et al. Multiple local 3D CNNs for region-based prediction in smart cities. Inf. Sci. 542, 476–491 (2021).
Ji, F., Zhang, H., Zhu, Z. & Dai, W. Blog text quality assessment using a 3D CNN-based statistical framework. Futur. Gener. Comput. Syst. 116, 365–370 (2021).
Núñez, J. C., Cabido, R., Pantrigo, J. J., Montemayor, A. S. & Vélez, J. F. Convolutional neural networks and long short-term memory for skeleton-based human activity and hand gesture recognition. Pattern Recogn. 76, 80–94 (2018).
ArunKumar, K. E., Kalaga, D. V., Kumar, C. M. S., Kawaji, M. & Brenza, T. M. Forecasting of COVID-19 using deep layer Recurrent Neural Networks (RNNs) with Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) cells. Chaos Solitons Fract. 146, 110861 (2021).
He, W. et al. Comparing SNNs and RNNs on neuromorphic vision datasets: Similarities and differences. Neural Netw. 132, 108–120 (2020).
Cinar, Y. G., Mirisaee, H., Goswami, P., Gaussier, E. & Aït-Bachir, A. Period-aware content attention RNNs for time series forecasting with missing values. Neurocomputing 312, 177–186 (2018).
Hochreiter, S. & Schmidhuber, J. J. Long short-term memory. Neural Comput. 9, 1–32 (1997).
Sainath, T. N., Vinyals, O., Senior, A. & Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) https://doi.org/10.1109/icassp.2015.7178838 (2015).
Chen, J., Zeng, G.-Q., Zhou, W., Du, W. & Lu, K.-D. Wind speed forecasting using nonlinear-learning ensemble of deep learning time series prediction and extremal optimization. Energy Convers. Manag. 165, 681–695 (2018).
Xingjian, S. H. I. et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems 802–810 (2015).
Liu, H., Tian, H., Liang, X. & Li, Y. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 157, 183–194 (2015).
Liu, W. et al. A survey of deep neural network architectures and their applications. Neurocomputing 234, 11–26 (2017).
Dalto, M., Matusko, J. & Vasak, M. Deep neural networks for ultra-short-term wind forecasting. In 2015 IEEE International Conference on Industrial Technology (ICIT) https://doi.org/10.1109/icit.2015.7125335 (2015).
Hu, Q., Zhang, R. & Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 85, 83–95 (2016).
Gensler, A., Henze, J., Sick, B. & Raabe, N. Deep Learning for solar power forecasting—An approach using AutoEncoder and LSTM Neural Networks. In 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC) https://doi.org/10.1109/smc.2016.7844673 (2016).
Yaseen, Z. M., Awadh, S. M., Sharafati, A. & Shahid, S. Complementary data-intelligence model for river flow simulation. J. Hydrol. 567, 180–190 (2018).
Deo, R. C., Wen, X. & Qi, F. A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl. Energy 168, 568–593 (2016).
Deo, R. C., Tiwari, M. K., Adamowski, J. F. & Quilty, J. M. Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stochastic Environ. Res. Risk Assess. https://doi.org/10.1007/s00477-016-1265-z (2016).
Chollet, F. keras. (2015).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Prettenhofer, P. & Louppe, G. Gradient boosted regression trees in scikit-learn. (2014).
Chollet, F. Keras: The python deep learning library. Astrophysics Source Code Library (2018).
Sanner, M. F. Python: A programming language for software integration and development. J. Mol. Graph. Model. 17, 57–61 (1999).
Ketkar, N. Introduction to Keras. Deep Learning with Python 97–111 https://doi.org/10.1007/978-1-4842-2766-4_7 (2017).
Abadi, M. et al. Tensorflow: A system for large-scale machine learning. In 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16) 265–283 (2016).
MathWorks, I. MATLAB: The Language of Technical Computing: Computation, Visualization, Programming. Installation Guide for UNIX Version 5. (Math Works Incorporated, 1996).
Ryan, B. F. & Joiner, B. L. Minitab Handbook (Duxbury Press, 2001).
Willmott, C. J. On the evaluation of model performance in physical geography. In Spatial Statistics and Models 443–446 (1984).
Willmott, C. J. & Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate Res. 30, 79–82 (2005).
Willmott, C. J. & Willmott, C. J. Some comments on the evaluation of model performance. Bull. Am. Meteor. Soc. https://doi.org/10.1175/1520-0477(1982)063%3c1309:SCOTEO%3e2.0.CO;2 (1982).
Shcherbakov, M. et al. An On-line and off-line pipeline-based architecture of the system for gaps and outlier detection in energy data stream. In 2013 3rd Eastern European Regional Conference on the Engineering of Computer Based Systems https://doi.org/10.1109/ecbs-eerc.2013.9 (2013).
Legates, D. R. & McCabe, G. J. Jr. Evaluating the use of ‘goodness-of-fit’ measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 35, 233–241 (1999).
Tung, T. M. & Yaseen, Z. M. A survey on river water quality modelling using artificial intelligence models: 2000–2020. J. Hydrol. https://doi.org/10.1016/j.jhydrol.2020.124670 (2020).
Gupta, H. V., Kling, H., Yilmaz, K. K. & Martinez, G. F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 377, 80–91 (2009).
Willems, P. A time series tool to support the multi-criteria performance evaluation of rainfall-runoff models. Environ. Model. Softw. 24, 311–321 (2009).
Danandeh Mehr, A., Kahya, E. & Olyaie, E. Streamflow prediction using linear genetic programming in comparison with a neuro-wavelet technique. J. Hydrol. 505, 240–249 (2013).
Shcherbakov, M. V. et al. A survey of forecast error measures. World Appl. Sci. J. 24, 171–176 (2013).
Moriasi, D. N. et al. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 50, 885–900 (2007).
Taylor, K. E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 106, 7183–7192 (2001).
LaValle, S. M., Branicky, M. S. & Lindemann, S. R. On the relationship between classical grid search and probabilistic roadmaps. Int. J. Robot. Res. 23, 673–692 (2004).
Bergstra, J., Yamins, D. & Cox, D. D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference, Vol. 13, 20 (Citeseer, 2013).
Jaderberg, M. et al. Population based training of neural networks. arXiv preprint arXiv:1711.09846 (2017).
Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A. & Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 18, 6765–6816 (2017).
Acknowledgements
The paper utilized hourly streamflow data from the Water Monitoring Data Portal (Dept of Environment & Resource Management) are duly acknowledged. The authors acknowledge the support provided by the University of Southern Queensland Research and Training Scheme (RTS).
Author information
Authors and Affiliations
Contributions
S.G.: concept, modeling, software, writing. Z.M.Y.: Project leader, writing, validation, formal analysis, visualization. A.A.F.: writing, validation, formal analysis, visualization, funding. R.C.D., J.Z., X.T.: supervision, Project leader, writing, validation, formal analysis, visualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghimire, S., Yaseen, Z.M., Farooque, A.A. et al. Streamflow prediction using an integrated methodology based on convolutional neural network and long short-term memory networks. Sci Rep 11, 17497 (2021). https://doi.org/10.1038/s41598-021-96751-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-96751-4
This article is cited by
-
An advanced hybrid deep learning model for predicting total dissolved solids and electrical conductivity (EC) in coastal aquifers
Environmental Sciences Europe (2024)
-
Comparative analysis of data-driven and conceptual streamflow forecasting models with uncertainty assessment in a major basin in Iran
International Journal of Energy and Water Resources (2024)
-
Developing a hybrid deep learning model with explainable artificial intelligence (XAI) for enhanced landslide susceptibility modeling and management
Natural Hazards (2024)
-
Assessment of machine learning models to predict daily streamflow in a semiarid river catchment
Neural Computing and Applications (2024)
-
Improved prediction of monthly streamflow in a mountainous region by Metaheuristic-Enhanced deep learning and machine learning models using hydroclimatic data
Theoretical and Applied Climatology (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
