
Abstract
Minnesota Multiphasic Personality Inventory-2 (MMPI-2) is a widely used tool for early detection of psychological maladjustment and assessing the level of adaptation for a large group in clinical settings, schools, and corporations. This study aims to evaluate the utility of MMPI-2 in assessing suicidal risk using the results of MMPI-2 and suicidal risk evaluation. A total of 7,824 datasets collected from college students were analyzed. The MMPI-2-Resturcutred Clinical Scales (MMPI-2-RF) and the response results for each question of the Mini International Neuropsychiatric Interview (MINI) suicidality module were used. For statistical analysis, random forest and K-Nearest Neighbors (KNN) techniques were used with suicidal ideation and suicide attempt as dependent variables and 50 MMPI-2 scale scores as predictors. On applying the random forest method to suicidal ideation and suicidal attempts, the accuracy was 92.9% and 95%, respectively, and the Area Under the Curves (AUCs) were 0.844 and 0.851, respectively. When the KNN method was applied, the accuracy was 91.6% and 94.7%, respectively, and the AUCs were 0.722 and 0.639, respectively. The study confirmed that machine learning using MMPI-2 for a large group provides reliable accuracy in classifying and predicting the subject's suicidal ideation and past suicidal attempts.
Similar content being viewed by others

Introduction
Machine learning (ML) is defined as a computational strategy that automatically determines methods and parameters to arrive at an optimal solution to a problem, rather than preprogramming by humans to present a fixed solution1. Moreover, machine learning algorithms are integrated into everyday life as internet searches and product recommendations, translation services, speech recognition services, and autonomous vehicles2.
Machine learning is the study and application of algorithms and systems that can improve knowledge or performance through experience. The basic premise of machine learning is the assumption that a machine can learn from data, recognize patterns in data, and understand data with minimal human intervention. By making the data understandable from the start, machines can detect complex and meaningful data patterns, which may be difficult or impossible for humans to derive. Furthermore, machine learning algorithms can be changed and improved when exposed to new data, so these detection patterns have the advantages of efficiency, complexity, and flexibility3.
In psychiatry, machine learning applications have been proposed to improve diagnostic and prognostic accuracy and determine treatment options4. In recent studies, machine learning is applied to big data in medical and health fields for disease diagnosis, treatment, and prevention5. Machine learning is specifically useful in predicting human behavior, including high-risk behavior. It can be applied to improve the effectiveness and goals of prevention programs and interventions1.
Some studies apply machine learning to differentiate between various types of psychopathology. For example, some studies use machine learning, the Structured Inventory of Malingered Symptomatology (SIMS) scale6, and the Minnesota Multiphasic Personality Inventory-2 (MMPI-2) scale to discriminate malingering to obtain external benefits7. Several studies have been conducted on MMPI-2 in particular as it is useful and expandable8. Regarding prediction, machine learning technology has advantages in accuracy and scalability compared to conventional statistical approaches3. Hence, various machine learning studies are focused on suicide prediction3,5,9,10,11,12.
Suicide results from a combination of factors derived from genetic, neurobiological, psychological, and social factors13,14,15. Suicidal behavior, attempt and completion are closely related to impulsivity and aggression16. And they share many neurobiological correlates14,17,18,19, comorbidity of psychiatric disorders such as mood disorder, borderline personality disorder, and substance use disorder (SUD)20,21,22,23,24,25,26,27,28. Therefore, it will be important to screen various risk factors and psychopathology to determine suicide risk.
Methods of screening for suicide may include unsystematic interviews, systematically structured or semi-structured interviews, and the use of self-report tests. The screening scale used by a clinician may be appropriate in a clinical environment, such as inpatient or outpatient situations. However, there are many limitations to the amount of time spent on screening tests for a large number of groups. Moreover, the self-report test is suitable for screening as it can be performed with ease, but the test validity may be a problem depending on the examinee’s attitude.
Among the self-report tests, MMPI-2 is one of the most widely used objective personality tests worldwide and is the most frequently used scale for evaluating psychopathology and emotional function29,30. MMPI-2 is very useful in distinguishing psychiatric disorders. It is frequently used for assessing clinical conditions related to suicidal risk31. Specifically, it has a validity scale to detect inappropriate examinee attitudes and judge the interpretability test data.
Many studies have been conducted to screen suicidal risk using MMPI-2. Studies report that some clinical scales are associated with suicidal ideation and behaviors, but elevated clinical scale scores show inconsistent results32,33,34,35,36.
The authors examined the difference in suicidal risk using the MMPI-2 reconstructed clinical scale, beyond the inconsistent results in previous studies on suicidal risk and clinical scales37. Compared with the control group, all of the suicidal risk group showed an overall increase in the Minnesota Multiphasic Personality Inventory-2-Restructured Clinical (MMPI-2-RC) scale, which confirmed that various psychopathological characteristics were overlapped with suicidal risk. However, this rise only confirms the tendency, and there is still insufficient evidence on the predictability of suicide-related pathology.
The MMPI-2, which is widely used in medical fields (psychiatric treatment sites and health check-ups) and employee selection, can assist in suicide prevention by classifying and predicting high suicidal risk. Therefore, this study aimed to distinguish people with suicidal risk by applying the latest machine learning algorithms using MMPI-2 results.
Results
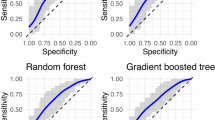
Among the 7824 participants, 3685 (47.1%) were male, a total of 673 (8.6%) participants classified as a suicidal ideation group, and 404 (5.4%) were classified as a suicidal attempt group (Table 1). Of the total datasets, 5008 were used as train data, 1252 as validation data, and 1564 as test data. Prediction accuracy of the random forest method was 92.9% for suicidal ideation and 95% for suicidal attempts; k-Nearest Neighbors (KNN) accurately predicted 91.6% of suicidal ideation and 94.7% of suicidal attempts (Table 2). Table 3 shows all parameters for suicidal ideation and suicidal attempts. When using the Suicidal/Death Ideation (SUI) scale t score to predict suicidal ideation and suicidal attempts, the area under the curve (AUCs) were 0.769 and 0.815. And using the random forest method to predict suicidal ideation and suicidal attempts, the AUCs were 0.844 and 0.851, which were more accurate than 0.722 and 0.639 when KNN was applied (Table 3, Figs. 1, 2). The F1 score was highest when using the random forest method of suicide attempt (92.6%) and lowest when applying KNN for suicide ideation (88.4%, Table 3).

ROC curve plots for suicidal ideation.

ROC curve plots for suicidal attempt.
Discussion
This study attempted to predict and report suicide-related risk with the ML technique using 50 scales of MMPI-2, the most commonly used self-report evaluation tool. Although differences exist depending on the ML technique used, it was confirmed that each predicted suicidal ideation and past suicidal attempts at an excellent level. In particular, in the case of the random forest method, AUC of 0.844 for suicidal ideation and 0.851 for suicidal attempts represent good performance values, indicating the potential for prediction using machine learning techniques without directly checking suicidal ideation and suicidal attempts. Research studies that predicted suicide accidents using public health data along with recent machine learning algorithms (AUC = 0.85)5 or predicted suicide accidents using various self-reporting tools and socio-demographic statistics data (AUC = 0.87–0.91)10, and AUC in this study show similar performance.
Machine learning technology for suicide prediction has an edge in accuracy and scalability compared to conventional statistical approaches3. Despite these advantages, there is a limitation that it has not yet been able to produce accurate predictions repeatedly due to the potential complexity of suicidal ideation and actions3,12. In a recent study investigating the probability of death due to suicide using insurance data and general characteristics of the National Health Insurance Service cohort in Korea, the machine learning model predicting death due to suicide showed a low-performance value (AUC = 0.68)38.
Previous suicidal attempts are the strongest predictor of future suicidal attempts12,39, but the AUC values vary depending on the time and measurement of past suicidal attempts (AUC 65–91%)10,11, and so previous study decided to conduct a machine learning study by setting suicidal ideation as a better potential predictor of suicidal risk than suicidal attempts5. Therefore, this paper has the advantage of applying machine learning predictions by setting both suicidal attempts and suicidal ideation as parameters, which are potential predictors of suicidal risk, and verified the prediction of machine learning by comparing various techniques.
Currently, machine learning risk algorithms can predict who will attempt or die by suicide but cannot tell when a person at risk can act. If the risk of suicide is considered high enough to threaten the individual's safety, clinicians must take steps to intervene, which in many cases may include involuntary hospitalization. This decision is one of the most difficult predictions, and clinicians are responsible for determining the risk level, given the limitations of existing algorithms12. Therefore, more information and knowledge will be required from the clinician about the influence level of various variables on suicidal risk, the timing of risk level, and intervention. For example, indirect tools such as ERQ, ARS, and SWLS represent better predictions of actual suicidal attempts than direct measures of suicidal ideation10. In many suicide accidents and suicidal attempts, the patients experience mood disorders or anxiety disorders40,41,42,43. The stress associated with academics, job, and life events is also related to suicide44,45. Traditional approaches to preventing and assessing suicide are generally expensive and time-consuming. As individuals at high suicidal risk often refuse to seek experts46,47, machine learning algorithms to predict suicide risk can be an effective alternative.
Accurate risk detection is necessary for suicide prevention, but studies to date have not yet verified the suitability of various risk management strategies in consideration of the suicidal risk level presented by the algorithm. Further, the most effective intervention for suicidal risk levels should be considered. However, no study has investigated the effect of intervention at the suicidal risk level suggested by the algorithm3. Further research is necessary for suicidal risk assessment and intervention by clinicians.
The random forest technique, which showed an excellent level of accuracy in this study, belongs to the unsupervised learning algorithm and has the advantage of being relatively easy to use because it only needs to determine the number of trees and the number of conditions that enter the branch points when creating a model48,49. However, a limitation is that one cannot obtain information other than the prediction result because the inside of the generated decision tree cannot be observed48,50. Moreover, machine learning cannot accurately describe the relationship between input and output51. Therefore, it is difficult to determine the complex effect of the selected characteristics on determining classification.
The limitations of this study are as follows. First, these results are not representative of the entire population, as the survey was conducted at one university. Second, as a self-reported study, there is a limit to fully trusting subject responses. Self-report tests are more open to suicide-related content than to standardized interviews. However, it seems necessary to analyze suicidal tendencies and psychopathological factors through various tools. Third, this study was conducted for a non-clinical group, and there was no clinical diagnosis and no information on the subject's psychiatric treatment history. This study was a retrospective analysis using data from part of a school project, and hence, it was difficult to obtain information. Fourth, there was no detailed suicide information on the fatality, method, and frequency of suicide. Fifth, because it is a cross-sectional study, the causal relationship between related factors and suicidal risk could not be clearly defined. In the future, it will be necessary to confirm through follow-up studies that continuously evaluate suicidal risk in various population groups, including clinical patients.
Nevertheless, this study was conducted on a large-scale, with consistent evaluation and multi-faceted analysis on the same group of college students, which may be its strongest point. There are many studies using MMPI-2, but this study verified its accuracy via additional evaluations related to suicide in a large group and confirmed the prediction potential with the subsequent use of MMPI-2 alone. In particular, it is possible to present the possibility of indirectly predicting and assessing the risk in a situation where it is difficult to directly ask questions on sensitive issues when evaluating the selection process of companies or schools or military enlistment. Moreover, as a study conducted at a single university, it is possible to identify risk factors through a long-term cohort group analysis through additional research projects.
The assessment of various types of psychopathology affecting suicide cannot be replaced by MMPI-2 alone. However, using MMPI-2, it is possible to obtain test results with secured validity for various aspects of psychopathology, and if used well together with clinical interviews, it may serve as an auxiliary tool. Furthermore, through the clinical characteristics of MMPI-2, this study uncovered various variables related to suicidal risk and various psychopathological factors influencing suicidal ideation and suicide accidents. If further analyzed, the possibility of using MMPI-2 in suicidal risk assessment is expected to increase.
Conclusion
This study confirmed that ML using MMPI-2 provides reliable accuracy in classifying and predicting the subject's suicidal ideation and past suicidal attempts. Based on these findings, we believe that it will help clinicians detect and treat high-risk suicide groups early in practice.
Methods
Participants
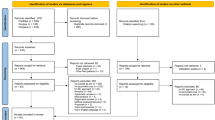
This study used part of the questionnaire dataset from a student health check-up conducted at Kongju National University37. Written consent was obtained after explaining the purpose of the research to all subjects. The study analyzed the answers given by 7824 (3685 males, 4139 females) participants out of a total of 8772, excluding 948 participants (919 participants that did not take the MINI suicidality, 8 participants with 10 or more cannot say scores in MMPI-2, 21 participants have invalid VRIN score, Fig. 3). This study was approved by the National Kongju University Ethics Committee. The participants were informed that the information they provide would be kept strictly confidential and used for research purposes only, and written consent was obtained. This research involving human research participants must have been performed in accordance with the Declaration of Helsinki.

Flow chart of participants inclusion and exclusion.
Measurements
Minnesota multiphasic personality inventory-2-restructured form
For Minnesota Multiphasic Personality Inventory-2 Restructured Form (MMPI-2-RF), a total of 50 scales that could effectively measure the clinical significance of MMPI-2 questions were developed and consisted of 8 validity scales and 42 major scales (Table 4). In this study, the Korean version of MMPI-2-RF was used, whose reliability and validity were verified52.
Suicide risk assessment
To evaluate suicidal risk, we used the MINI (Mini International Neuropsychiatric Interview, MINI) suicidality module. MINI is a structured interview tool developed in 1998 for diagnosing Diagnostic and Statistical Manual of Mental Disorders, fourth edition (DSM-IV) and the 10th revision of the International Statistical Classification of Diseases (ICD-10) Axis I mental illness. This study used the standardized version of Korean version 5.053. Among these, suicide evaluation consisted of a total of 6 questions related to suicide, with weights for each question and the total score distributed from 0 to 29; the higher the score, the higher the suicidal risk. In this study, a subject was assigned to the suicide thought group on answering any one of the questions 1 to 3 related to suicidal ideation, and categorized in the suicide attempt group if the answer was yes to the sixth question on the case of a lifelong suicide attempt.
Statistical analysis
To this end, MMPI-2-RF and suicide thought-related scales were used as inputs into the artificial neural network algorithm for student mental health check-up data to determine the factors affecting actual suicidal ideation. Among the machine learning techniques, Random forest classification and the KNN method were used.
There are two major importance indicators to measure the importance of explanatory variables in the random forest54. First, the Mean Decrease Gini (MDG) value is used as the average value from all trees by measuring the amount of impurity reduction of the selected variables each time each tree forming a random forest extends its branch. Therefore, a high MDG value for a specific variable means that classifying individuals with that variable helps to reduce impurity, that is, to group the same categories. Moreover, the importance of variables can be determined by the concept of accuracy, which is defined as Mean Decrease Accuracy (MDA). MDA is the average of the difference by variable between the accuracy of the constructed tree and the accuracy that decreases when reconstructed after removing a specific variable. The higher the influence of a variable in improving the classification accuracy, the greater is the amount of reduction in the accuracy on removing the variable. Thus, as the values of both indicators measuring the importance of variables in the random forest increase, the variable importance increases. The KNN algorithm has the same properties as the training data but extracts k data located closest to the training data using Euclidean distance from unclassified data and specifies the category of unclassified data through the class of the extracted data55.
The result variables were analyzed by suicidal ideation and suicidal attempts, using 50 scales of MMPI-2-RF as explanatory variables (Table 4). The AUC of receiver operating characteristic (ROC) curve was measured. The closer the AUC is to 1, the better is the model. The AUC 0.5 ~ 0.6 was evaluated as a coincidence level; 0.6 ~ 0.7 was not good, 0.7 ~ 0.8 was worthless, 0.8 ~ 0.9 was good, and 0.9 ~ 1.0 was excellent56.
A total 20% of the sample was used as test data, and 20% of the remaining 80% as validation data; each training data set and testing data set were randomly separated. All statistical analyses were performed using JASP v0.14.4 (Amsterdam, Netherland).
References
Dwyer, D. B., Falkai, P. & Koutsouleris, N. Machine learning approaches for clinical psychology and psychiatry. Annu. Rev. Clin. Psychol. 14, 91–118. https://doi.org/10.1146/annurev-clinpsy-032816-045037 (2018).
Jordan, M. I. & Mitchell, T. M. Machine learning: Trends, perspectives, and prospects. Science 349, 255–260. https://doi.org/10.1126/science.aaa8415 (2015).
Linthicum, K. P., Schafer, K. M. & Ribeiro, J. D. Machine learning in suicide science: Applications and ethics. Behav. Sci. Law 37, 214–222. https://doi.org/10.1002/bsl.2392 (2019).
Fazel, S. & O’Reilly, L. Machine learning for suicide research-can it improve risk factor identification?. JAMA Psychiat. 77, 13–14. https://doi.org/10.1001/jamapsychiatry.2019.2896 (2020).
Ryu, S., Lee, H., Lee, D. K. & Park, K. Use of a machine learning algorithm to predict individuals with suicide ideation in the general population. Psychiat. Invest. 15, 1030–1036. https://doi.org/10.30773/pi.2018.08.27 (2018).
Orrù, G. et al. The development of a short version of the SIMS using machine learning to detect feigning in forensic assessment. Psychol. Injury Law 1, 1–12 (2020).
Mazza, C. et al. Introducing machine learning to detect personality faking-good in a male sample: A new model based on minnesota multiphasic personality inventory-2 restructured form scales and reaction times. Front. Psychiatry 10, 389. https://doi.org/10.3389/fpsyt.2019.00389 (2019).
Menton, W. H. Generalizability of statistical prediction from psychological assessment data: An investigation with the MMPI-2-RF. Psychol. Assess. 32, 473–492. https://doi.org/10.1037/pas0000808 (2020).
Gradus, J. L., King, M. W., Galatzer-Levy, I. & Street, A. E. Gender differences in machine learning models of trauma and suicidal ideation in veterans of the Iraq and Afghanistan Wars. J. Trauma Stress 30, 362–371. https://doi.org/10.1002/jts.22210 (2017).
Oh, J., Yun, K., Hwang, J. H. & Chae, J. H. Classification of suicide attempts through a machine learning algorithm based on multiple systemic psychiatric scales. Front. Psychiatry 8, 192. https://doi.org/10.3389/fpsyt.2017.00192 (2017).
Passos, I. C. et al. Identifying a clinical signature of suicidality among patients with mood disorders: A pilot study using a machine learning approach. J Affect. Disord. 193, 109–116. https://doi.org/10.1016/j.jad.2015.12.066 (2016).
Walsh, C. G., Ribeiro, J. D. & Franklin, J. C. Predicting risk of suicide attempts over time through machine learning. Clin. Psychol. Sci. 5, 457–469. https://doi.org/10.1177/2167702617691560 (2017).
Cheng, A. T., Chen, T. H., Chen, C. C. & Jenkins, R. Psychosocial and psychiatric risk factors for suicide: Case-control psychological autopsy study. Br. J. Psychiatry 177, 360–365. https://doi.org/10.1192/bjp.177.4.360 (2000).
van Heeringen, K. & Mann, J. J. The neurobiology of suicide. Lancet Psychiatry 1, 63–72. https://doi.org/10.1016/S2215-0366(14)70220-2 (2014).
O’Connor, R. C. & Nock, M. K. The psychology of suicidal behaviour. Lancet Psychiatry 1, 73–85. https://doi.org/10.1016/S2215-0366(14)70222-6 (2014).
Oquendo, M. A. & Mann, J. J. The biology of impulsivity and suicidality. Psychiatr. Clin. N. Am. 23, 11–25. https://doi.org/10.1016/s0193-953x(05)70140-4 (2000).
Courtet, P., Gottesman, I. I., Jollant, F. & Gould, T. The neuroscience of suicidal behaviors: What can we expect from endophenotype strategies?. Transl. Psychiatry 1, e7–e7 (2011).
Mann, J. J. Neurobiology of suicidal behaviour. Nat. Rev. Neurosci. 4, 819–828. https://doi.org/10.1038/nrn1220 (2003).
Mann, J. J. Psychobiologic predictors of suicide. J. Clin. Psychiatry 48(Suppl), 39–43 (1987).
Beautrais, A. L. et al. Prevalence and comorbidity of mental disorders in persons making serious suicide attempts: A case-control study. Am. J. Psychiatry 153, 1009–1014 (1996).
Runeson, B. Mental disorder in youth suicide: DSM-III-R Axes I and II. Acta Psychiatr. Scand. 79, 490–497. https://doi.org/10.1111/j.1600-0447.1989.tb10292.x (1989).
Marttunen, M. J., Aro, H. M., Henriksson, M. M. & Lönnqvist, J. K. Mental disorders in adolescent suicide: DSM-III-R axes I and II diagnoses in suicides among 13-to 19-year-olds in Finland. Arch. Gen. Psychiatry 48, 834–839 (1991).
Brent, D. A. et al. Psychiatric risk factors for adolescent suicide: A case-control study. J. Am. Acad. Child Adolesc. Psychiatry 32, 521–529. https://doi.org/10.1097/00004583-199305000-00006 (1993).
Henriksson, M. M. et al. Mental disorders and comorbidity in suicide. Am. J. Psychiatry 150, 935–940. https://doi.org/10.1176/ajp.150.6.935 (1993).
Lesage, A. D. et al. Suicide and mental disorders: A case-control study of young men. Am. J. Psychiatry 151, 1063–1068. https://doi.org/10.1176/ajp.151.7.1063 (1994).
Trautman, P. D., Rotheram-Borus, M. J., Dopkins, S. & Lewin, N. Psychiatric diagnoses in minority female adolescent suicide attempters. J. Am. Acad. Child Adolesc. Psychiatry 30, 617–622. https://doi.org/10.1097/00004583-199107000-00014 (1991).
Rudd, M. D., Dahm, P. F. & Rajab, M. H. Diagnostic comorbidity in persons with suicidal ideation and behavior. Am. J. Psychiatry 150, 928–934. https://doi.org/10.1176/ajp.150.6.928 (1993).
Yen, S. et al. Association of borderline personality disorder criteria with suicide attempts: Findings from the collaborative longitudinal study of personality disorders over 10 years of follow-up. JAMA Psychiat. 78, 187–194. https://doi.org/10.1001/jamapsychiatry.2020.3598 (2021).
Greene, R. L. The MMPI-2: An Interpretive Manual (Allyn & Bacon, 2000).
Watkins, C. E., Campbell, V. L., Nieberding, R. & Hallmark, R. Contemporary practice of psychological assessment by clinical psychologists. Prof. Psychol. Res. Pract. 26, 54–60. https://doi.org/10.1037/0735-7028.26.1.54 (1995).
Butcher, J. N., Graham, J. R., Ben-Porath, Y. S., Tellegen, A. & Dahlstrom, W. G. MMPI-2: Minnesota multiphasic personality inventory-2 (University of Minnesota Press, 2001).
Kopper, B. A., Osman, A. & Barrios, F. X. Assessment of suicidal ideation in young men and women: The incremental validity of the MMPI-2 content scales. Death Stud. 25, 593–607. https://doi.org/10.1080/07481180126578 (2001).
Kopper, B. A., Osman, A., Osman, J. R. & Hoffman, J. Clinical utility of the MMPI-A content scales and Harris-Lingoes subscales in the assessment of suicidal risk factors in psychiatric adolescents. J. Clin. Psychol. 54, 191–200. https://doi.org/10.1002/(sici)1097-4679(199802)54:2%3c191::aid-jclp8%3e3.0.co;2-v (1998).
Lee, J. Y., Moon, K. J. & Heo, J. Y. The relationship between suicidal ideation and MMPI-2 profile among college students. J. Hum. Understand. Counsel. 33, 53–69 (2012).
Lee, K., Lee, H. K., Kim, S. H., Jang, E.-Y. & Kim, D. Suicide risk and the MMPI-2 findings among college students. Anxiety Mood 11, 120–128 (2015).
Sepaher, I., Bongar, B. & Greene, R. L. Codetype base rates for the “I Mean Business” suicide items on the MMPI-2. J. Clin. Psychol. 55, 1167–1173. https://doi.org/10.1002/(sici)1097-4679(199909)55:9%3c1167::aid-jclp13%3e3.0.co;2-6 (1999).
Kim, S., Lee, H. K. & Lee, K. Assessment of suicidal risk using Minnesota multiphasic personality inventory-2 restructured form. BMC Psychiatry 20, 81. https://doi.org/10.1186/s12888-020-02495-2 (2020).
Choi, S. B., Lee, W., Yoon, J. H., Won, J. U. & Kim, D. W. Ten-year prediction of suicide death using Cox regression and machine learning in a nationwide retrospective cohort study in South Korea. J. Affect Disord. 231, 8–14. https://doi.org/10.1016/j.jad.2018.01.019 (2018).
Luby, J. L. et al. Early childhood depression and alterations in the trajectory of gray matter maturation in middle childhood and early adolescence. JAMA Psychiat. 73, 31–38. https://doi.org/10.1001/jamapsychiatry.2015.2356 (2016).
Inskip, H. M., Harris, E. C. & Barraclough, B. Lifetime risk of suicide for affective disorder, alcoholism and schizophrenia. Br. J. Psychiatry 172, 35–37. https://doi.org/10.1192/bjp.172.1.35 (1998).
Beck, A. T., Steer, R. A., Kovacs, M. & Garrison, B. Hopelessness and eventual suicide: A 10-year prospective study of patients hospitalized with suicidal ideation. Am. J. Psychiatry 142, 559–563. https://doi.org/10.1176/ajp.142.5.559 (1985).
Oquendo, M. A. et al. Prospective study of clinical predictors of suicidal acts after a major depressive episode in patients with major depressive disorder or bipolar disorder. Am J Psychiatry 161, 1433–1441. https://doi.org/10.1176/appi.ajp.161.8.1433 (2004).
Sareen, J. et al. Anxiety disorders and risk for suicidal ideation and suicide attempts: A population-based longitudinal study of adults. Arch. Gen. Psychiatry 62, 1249–1257. https://doi.org/10.1001/archpsyc.62.11.1249 (2005).
Grover, K. E. et al. Problem solving moderates the effects of life event stress and chronic stress on suicidal behaviors in adolescence. J. Clin. Psychol. 65, 1281–1290. https://doi.org/10.1002/jclp.20632 (2009).
Tsutsumi, A. et al. Low control at work and the risk of suicide in Japanese men: a prospective cohort study. Psychother. Psychosom. 76, 177–185. https://doi.org/10.1159/000099845 (2007).
Chan, W. I., Batterham, P., Christensen, H. & Galletly, C. Suicide literacy, suicide stigma and help-seeking intentions in Australian medical students. Australas Psychiatry 22, 132–139. https://doi.org/10.1177/1039856214522528 (2014).
Shen, Y. et al. Detecting risk of suicide attempts among Chinese medical college students using a machine learning algorithm. J. Affect. Disord. 273, 18–23. https://doi.org/10.1016/j.jad.2020.04.057 (2020).
Hsieh, C. H. et al. Novel solutions for an old disease: Diagnosis of acute appendicitis with random forest, support vector machines, and artificial neural networks. Surgery 149, 87–93. https://doi.org/10.1016/j.surg.2010.03.023 (2011).
Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling (Packt Publishing Ltd, 2019).
Díaz-Uriarte, R. & De Andres, S. A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 7, 3 (2006).
Singh, Y., Bhatia, P. K. & Sangwan, O. A review of studies on machine learning techniques. Int. J. Comput. Sci. Secur. 1, 70–84 (2007).
Han, K. H., Moon, K. J., Lim, J. Y. & Kim, J. S. MMPI-2-RF: Manual for Korean version of MMPI-2-RF (Maumsarang Ltd., 2011).
Yoo, S. et al. Validity of Korean version of the mini-international neuropsychiatric interview. Anxiety Mood 2, 50–55 (2006).
Archer, K. J. & Kimes, R. V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 52, 2249–2260. https://doi.org/10.1016/j.csda.2007.08.015 (2008).
Islam, M. J., Wu, Q. J., Ahmadi, M. & Sid-Ahmed, M. A. in 2007 International Conference on Convergence Information Technology (ICCIT 2007). 1541–1546 (IEEE).
Zhu, W., Zeng, N. & Wang, N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS implementations. NESUG Proc. 19, 67 (2010).
Funding
This research was supported by the Basic Science Research Program of the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2018R1D1A1B07050245), and the Technology Innovation Program (20012931) funded by the Ministry of Trade, Industry and Energy (MOTIE, Korea). This funding source had no role in the design of this study and will not have any role during its execution, analyses, interpretation of the data, or decision to submit results.
Author information
Authors and Affiliations
Contributions
K.L. and S.K. contributed to the design of the study, interpretation of the results, and preparation of the manuscript. K.L., H.-K.L. coordinated the data acquisition. K.L. and S.K. wrote the draft manuscript. K.L., H.-K.L., and S.K. contributed to the critical revision of the article for important intellectual content. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kim, S., Lee, HK. & Lee, K. Detecting suicidal risk using MMPI-2 based on machine learning algorithm. Sci Rep 11, 15310 (2021). https://doi.org/10.1038/s41598-021-94839-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-94839-5
This article is cited by
-
Role of machine learning algorithms in suicide risk prediction: a systematic review-meta analysis of clinical studies
BMC Medical Informatics and Decision Making (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
